1. Introduction
The vegetable soybean (
Glycine Max (L.) Merrill) is a soybean harvested at approximately 80% maturity. The soybean is popular in China, South Korea, Japan, and other countries because of its high protein, fat, calcium, vitamins, and dietary fiber content [
1]. In recent years, with the improvement of human health awareness and the understanding of the health function of natural products, the vegetable soybean has gradually attracted wide attention in the world. The production and trade of vegetable soybean have been rising for years [
2]. In order to meet the increasing production and trade demand, it is of great significance to cultivate high-quality and high-yield vegetable soybean varieties.
As part of the soybean phenotype, the soybean pod number and seed number are powerful indicators for improving crop yield and biological research [
3]. Simpson and Wilcox [
4] showed that seed number and pod number are closely related to seed yield. Wang et al. [
5] analyzed the variation trend of soybean varieties in 25 soybean variety areas in the Yellow-huai-hai river basin. The results showed that seeds per pod (SPPOD) and seed weight were the main reasons for the increase in yield. Liu et al. [
6] identified QTLS for six yield-related traits using simple sequence repeat markers, and proposed yield-related traits including plant height, number of main stem nodes, pod number per plant, number of seeds per pod, 100 seed weight, and number of seeds per plant. Therefore, it is necessary to develop a method to obtain pod number and seed number quickly and accurately.
At present, most of the traditional manual detection methods are time-consuming, laborious, costly, and prone to subjective errors [
7]. With the development of imaging technology, image-processing technology has been widely used in crop phenotype detection [
8,
9]. Many scholars have achieved good results in using image-processing techniques to detect soybean phenotypes, such as screening the quantitative values of soybean seed color and various morphological characteristics [
10], obtaining phenotypic information such as the length of vegetable soybeans [
11], and extracting parameters related to pod color and size [
12]. However, the above research requires image acquisition in a specific capture environment and sparse placement of crops without overlapping. In addition, classical image-processing technology is sensitive to texture features and the illumination conditions of objects, and has problems such as insufficient robustness and generalization ability [
13,
14], so it cannot carry out recognition tasks stably and effectively.
Deep learning has grown rapidly in recent years and is making a significant impact across all industries [
15]. Compared with traditional digital image-processing technology, the advantage of deep learning is that the network automatically learns and extracts relevant features, which can effectively solve the problems mentioned above. Due to its powerful performance and accuracy, deep learning has become more and more popular in the field of agriculture [
16], such as in fruit classification [
17], crop grain recognition [
18], pest and disease recognition [
19], weed recognition [
20], etc. In the context of smart agriculture, it is expected to use deep learning methods to classify and count soybean pods. Uzal et al. [
21] proposed a classical method based on cut-clipping feature extraction (FE), the support vector machine (SVM) classification model, and Convolutional Neural Network (CNN). This method is able to estimate the pod number based on the number of soybean seeds. Riera et al. [
22] used the VGG19 network model [
23] to identify, isolate, and detect regions of interest in complex environments, and used tracking technology to count the number of pods in the whole plot. Yan et al. [
24] used deep learning to transfer five different network models for the classification and identification of soybean pods, and the model with the highest accuracy rate reached 98.41%.
However, the traditional convolutional neural classification network can only detect a single object in a single image, which cannot meet the needs of high-throughput detection. Compared with the traditional classification network, the object-detection algorithm based on deep learning can classify and identify multiple pods in a single image, which is more suitable for high-throughput counting tasks of pods and seeds. For example, Guo Rui et al. [
25] divided pods (into empty pods, one-seed pod, two-seed pod, three-seed pod, four-seed pod, and five-seed pod) and used the improved YOLOv4 [
26] object-detection algorithm to achieve an average accuracy of 84.37% for these six types of pods. Xiang Yun [
27] used a deep learning target-detection network and machine vision to realize the classification of vegetable soybeans and the rapid acquisition of pod length and width. Through experiment and comparison, it was found that YOLOv5 [
28] was superior to the previous classification network in both single-image single-pod and single-image multi-pod classification. Zhu Ring-sheng et al. [
29] compared various deep learning algorithms for identifying and counting soybean flowers and pods, and further improved and optimized the Faster R-CNN model [
30] based on the characteristics of soybean flowers and pods, and the final accuracy of the model for identifying flowers and pods was improved to 94.36% and 91%, respectively. In a word, the object-detection algorithm has great potential in pod recognition.
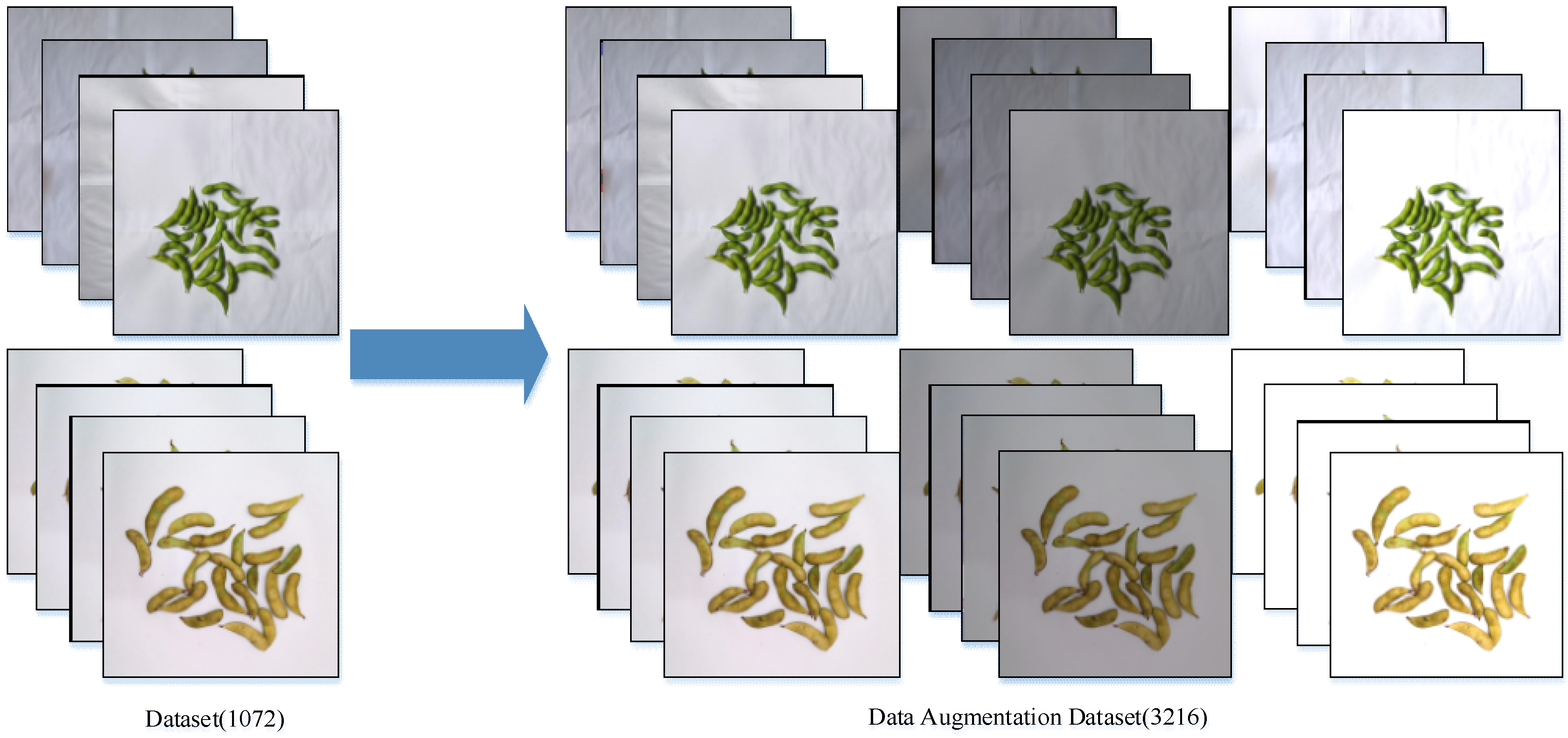
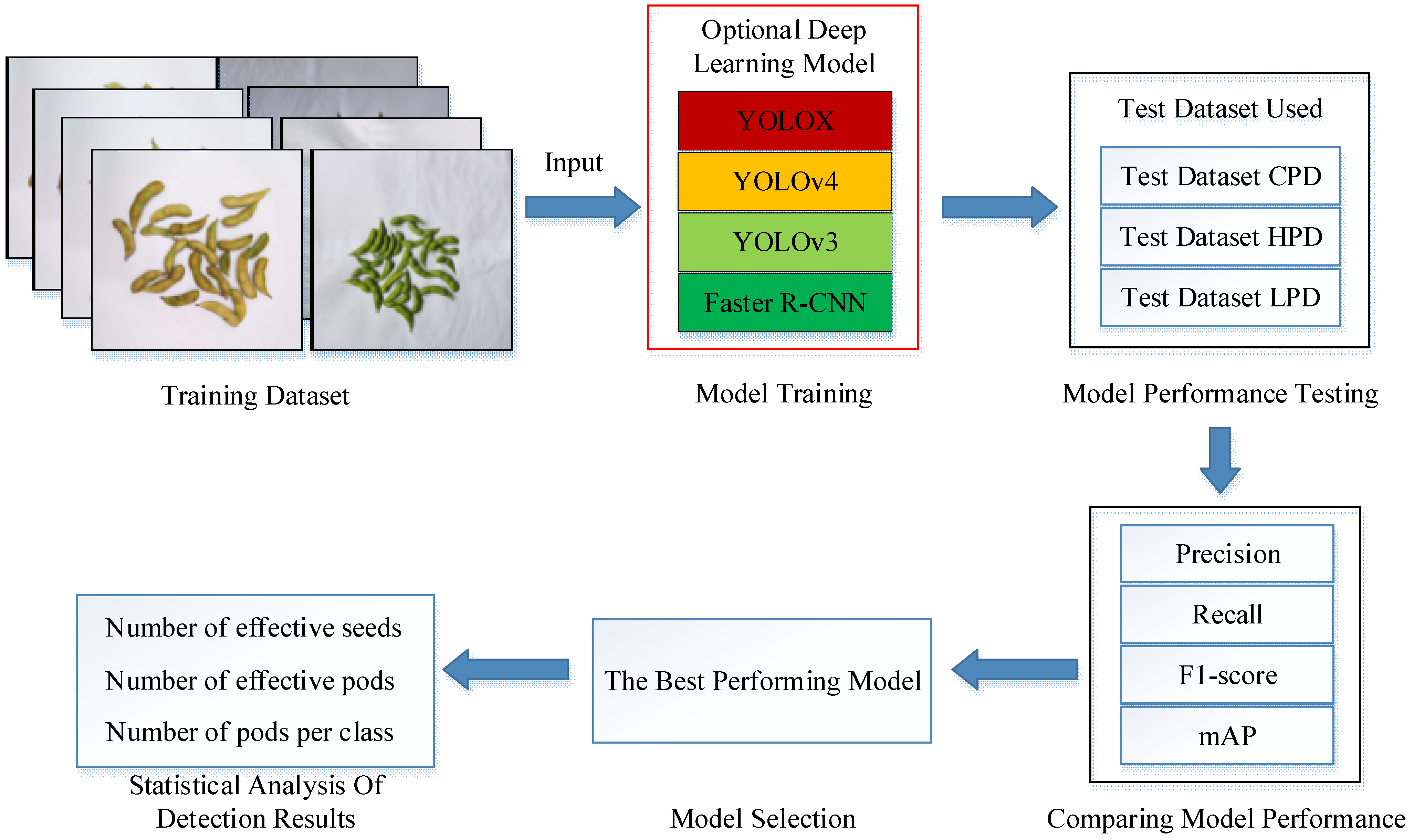
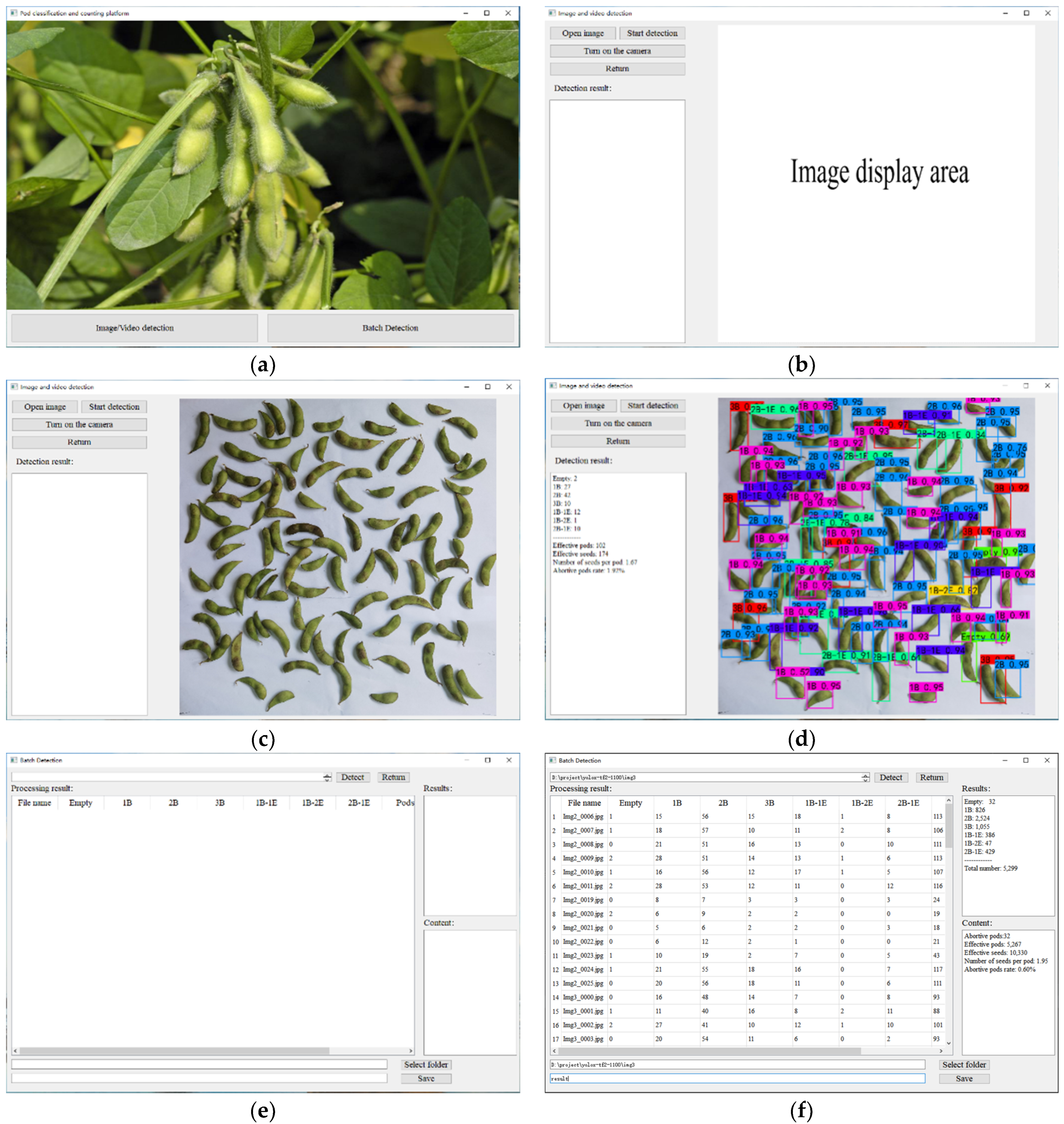
The aim of this paper was to propose a fast and accurate pod-detection method which could solve the problem of counting pods and seeds in a soybean indoor planting test. This method can not only realize the classification and counting of pods, but also distinguish the effective grains and abortive grains inside the pod and count the effective grains separately. In this study, we first established a training dataset with 3216 images, and also made a distorted image test dataset, a high-density pods image test dataset, and a low-pixel image test dataset, containing 90 images each. Then, four object detection models, Faster R-CNN, YOLOv3 [
31], YOLOv4, and YOLOX [
32], were trained on the training dataset, and the performance were compared on the three test datasets to select the best model. Finally, our pod classification and counting method was validated.
The main contribution of this study are as follows:
- (1)
We propose a new method for fine classification of pods based on the number of effective seeds and abortive seeds in pods. This method can obtain the number of effective seeds more accurately. To the best of our knowledge, this is the first work that can distinguish the effective seeds from the abortive seeds in soybean pods.
- (2)
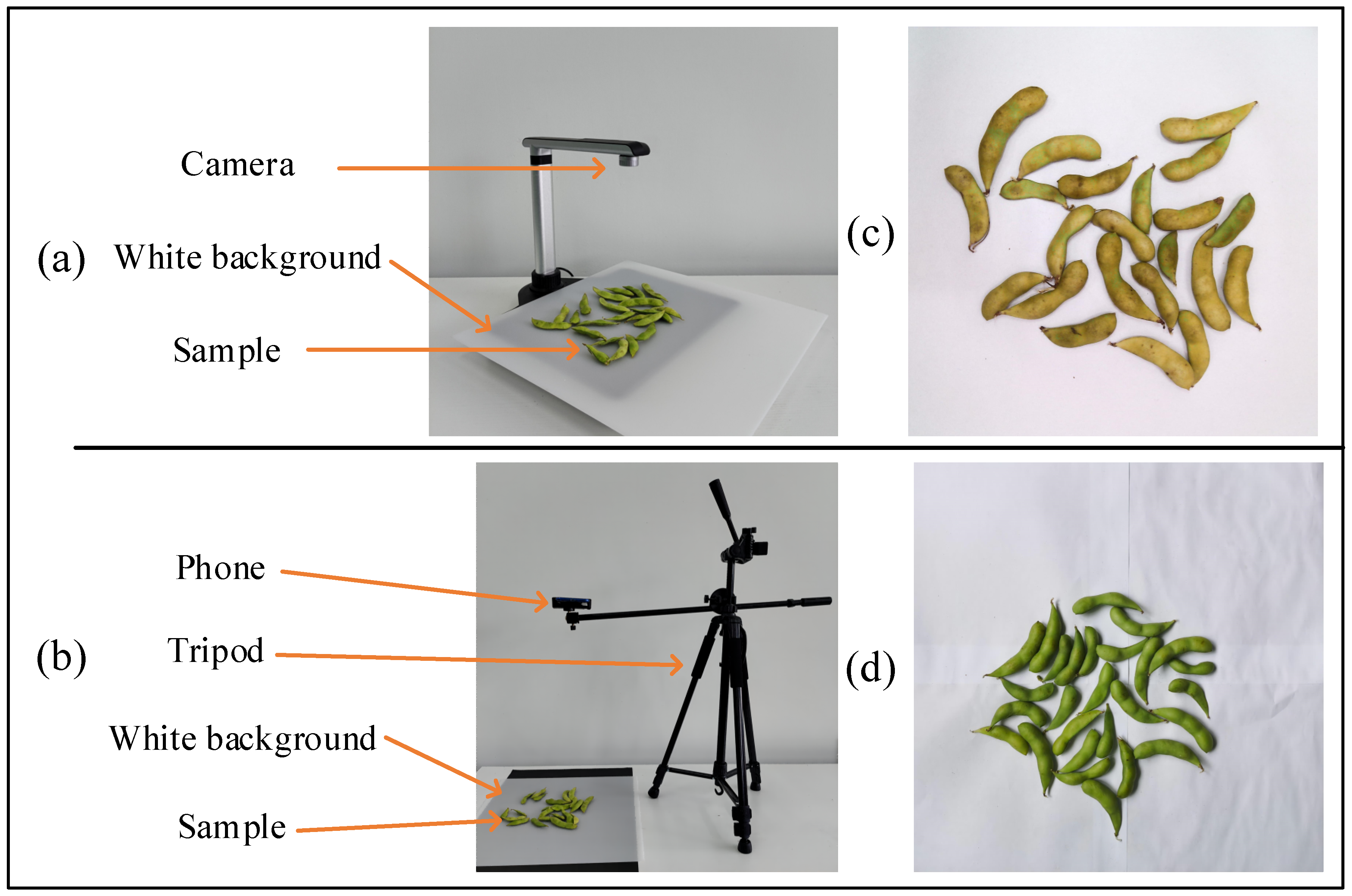
A soybean pod dataset based on multiple devices is designed to simulate the problems of high pod density, image distortion, and low resolution encountered in image acquisition in reality.
- (3)
The proposed object-detection network achieves good performance when processing densely sampled soybean pods, and can effectively identify distorted images and low-pixel images.
The other parts of this paper are as follows. The second part mainly includes the production of soybean pod dataset, the selection of object-detection algorithm, and the improved pod classification and counting method. In the third section, the training and testing process and analysis results are given. The last section concludes the research.
4. Conclusions
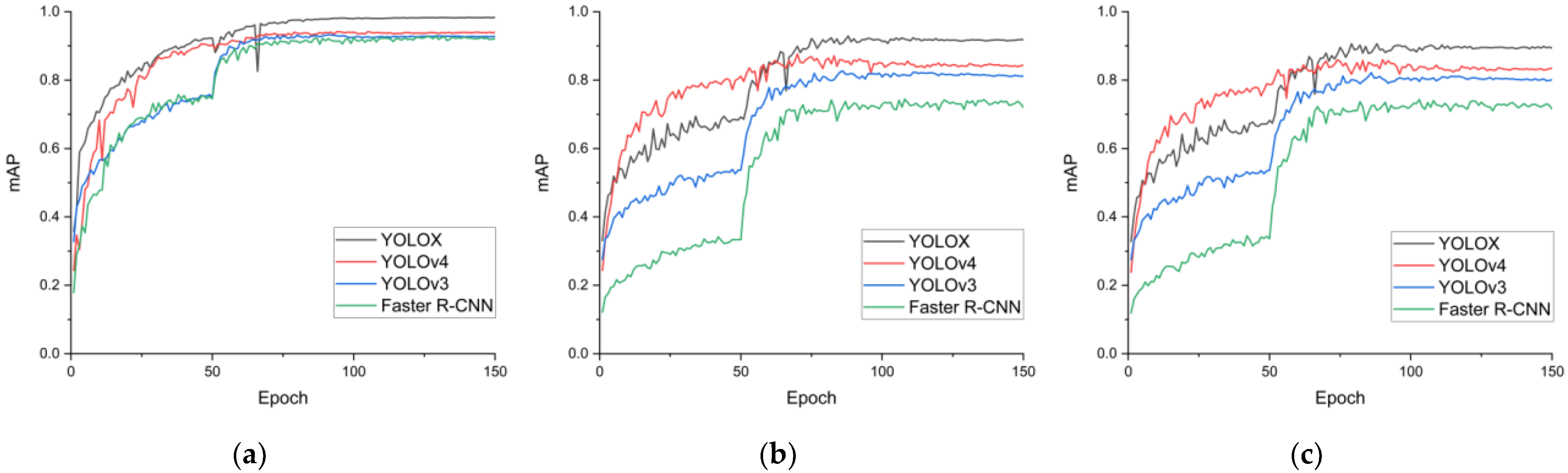
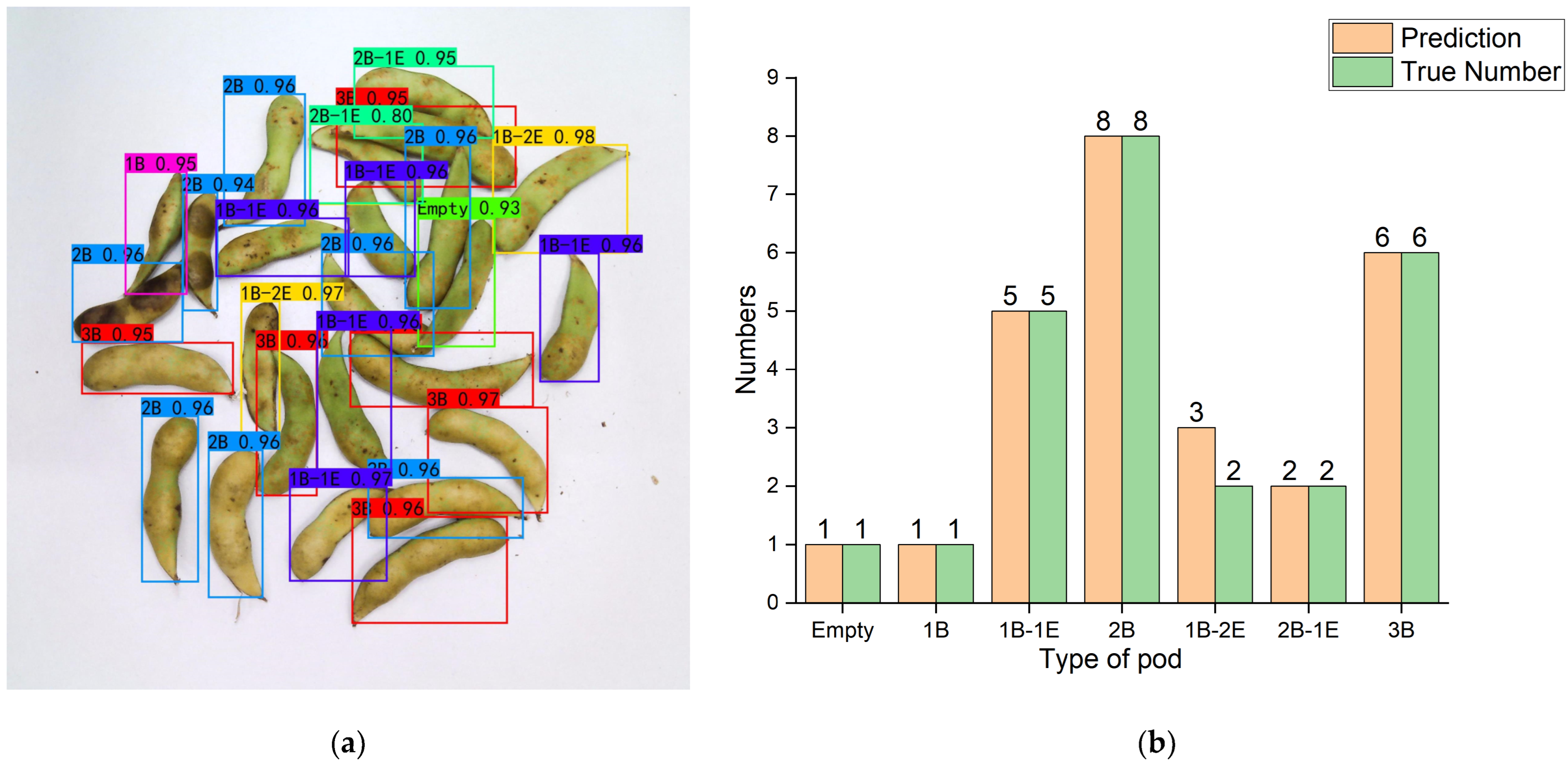
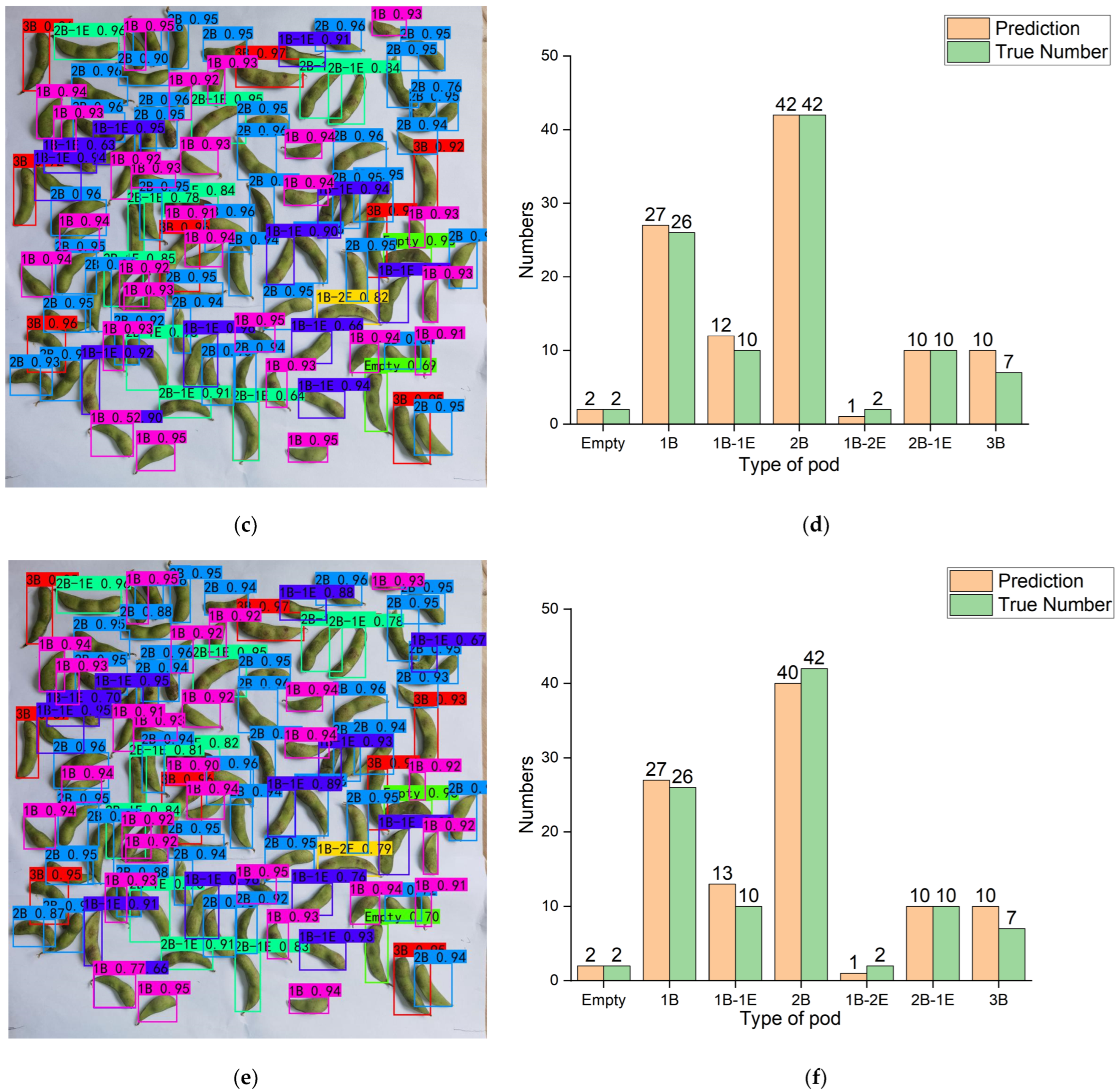
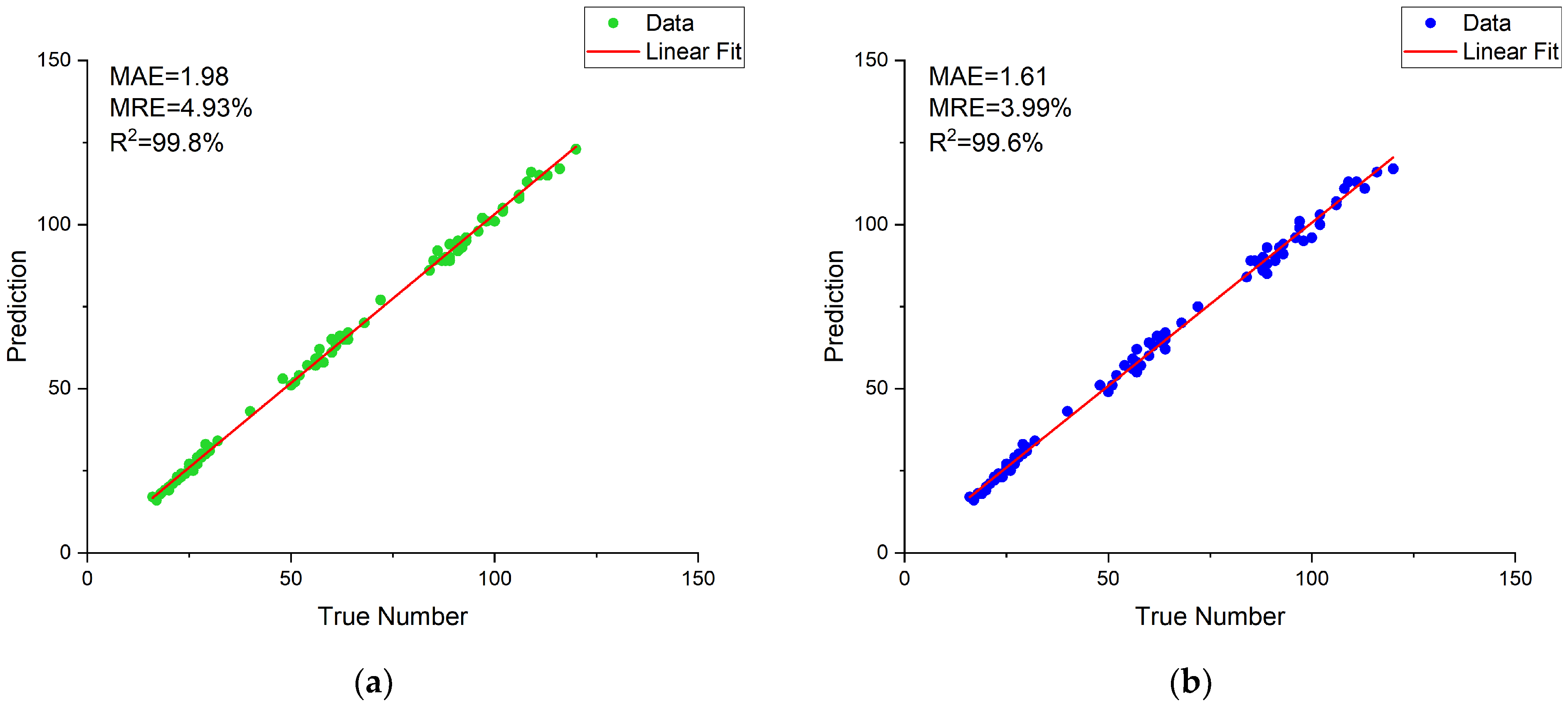
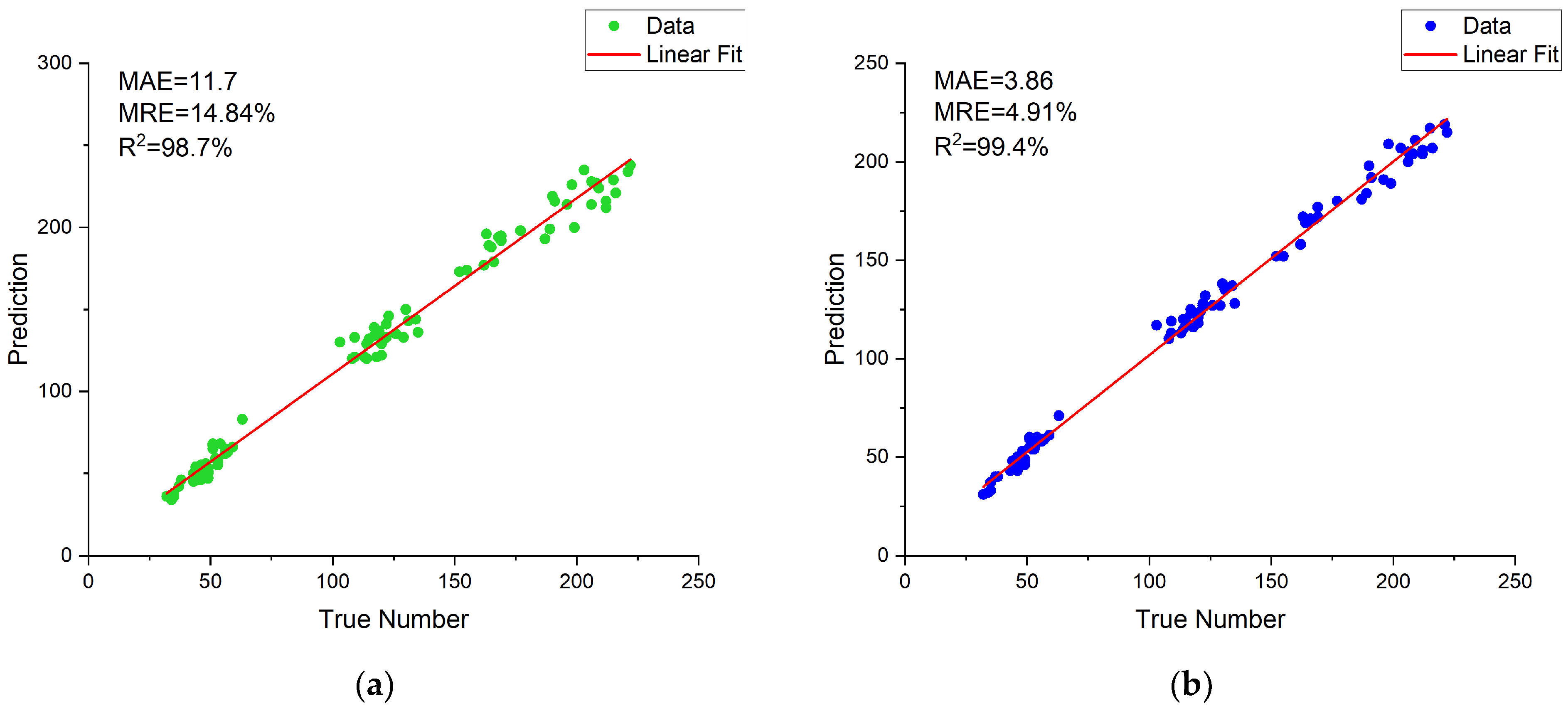
The purpose of this work was to study the method of high-throughput classification and identification of soybean pods, and finally realize the accurate count of soybean seed number and soybean pod number. In order to reduce the error of seed counting caused by empty pods and abortive seeds in pods, a classification method based on the number of available seeds and aborted seeds in soybean pods was first proposed. The non-maximum suppression parameters were adjusted to reduce the pod count error. At the same time, we built a training dataset containing 3216 images, and built a distorted image test dataset, a high-density pod image test dataset, and a low-pixel image test dataset (each containing 90 images). Then, four target detection models (Faster R-CNN, YOLOv3, YOLOv4, and YOLOX) were trained on the training dataset, and the performance on the three test datasets was compared. Among them, YOLOX has the best overall performance, with mAP of 98.24%, 91.80%, and 90.27% in test dataset CPD, test dataset HPD, and test dataset LPD, respectively. Finally, the number of pods and seeds obtained by the proposed classification and counting method was analyzed with the results obtained by common classification methods. The MRE of pod and seed count of the method was 3.99% and 4.91%, which is 0.94% and 9.93% lower than that of the common method. Experimental data show that our high-throughput pod classification and counting method speed up the laboratory testing of soybeans, solves the problem of pod and seed counting in the laboratory testing of soybeans, and reduces the errors of pod and seed counting, which is helpful to improve current and future breeding programs.
Although our method can complete pod classification and counting well, there are still some limitations at present. Firstly, pods need to be manually picked from the plant, resulting in excessive labor time. Secondly, this study focuses on indoor seed testing, which is specifically reflected in the need to randomly place pods on a white background board. In the future research, we intend to further explore a more accurate and convenient method to directly detect the complete soybean plant outdoors to obtain the category and number of pods.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}