1. Introduction
Peanuts are a significant source of plant oils and proteins and are widely cultivated worldwide [
1]. However, leaf spot disease caused by Cercosporidium personatum is destructive and can cause up to 70% yield loss in severe cases [
2]. Therefore, timely, accurate, and efficient detection of peanut leaf spot disease in the field and understanding of its severity can provide technical support and scientific guidance for accurate field management. This approach can improve peanut yields, ensure peanut quality, and reduce the use of agricultural chemicals and residues [
3,
4]. As a result, it is critical to develop effective methods for detecting and managing peanut leaf spot disease.
Traditional field disease detection methods rely on field sampling by plant protection personnel to determine disease severity. However, this method has several disadvantages, including subjectivity, low efficiency, and high cost. Serological detection techniques [
5,
6] and pathogen isolation techniques [
7] are the most commonly used methods in disease detection. However, their detection processes are time consuming, labor intensive, and destructive, making them unsuitable for efficient and non-destructive crop disease detection [
8]. These methods also fail to meet the need for scientific monitoring and control of crop diseases. Therefore, there is a need to develop more efficient, accurate, and non-destructive methods for detecting crop diseases.
Remote sensing technology has advantages such as objectivity, non-destructiveness, and repeatability and has become an important means of monitoring in recent years [
9]. Hyperspectral technology has characteristics such as multiple bands and high detection accuracy and has been widely used in agriculture [
10,
11,
12,
13]. However, there is some invalid interference information in the full-spectrum data, which can easily reduce the generalization ability and overall accuracy of the model. The high collinearity of hyperspectral data also increases the complexity of the model and computing time. Therefore, many scholars obtain spectral feature wavelengths through feature selection methods to improve the detection efficiency and accuracy of the model. The authors of [
14] utilized a continuous projection algorithm (SPA), boosted regression trees (BRTs), and a genetic algorithm (GA) for feature wavelength selection and employed various machine learning techniques for non-destructive detection of tomato spotted wilt virus (TSWV) in tobacco. They found that the SPA–BRT combination produced the best results, with an average overall accuracy of 85.2%. The authors of [
15] used RELIEF-F to select feature wavelengths for hyperspectral reflectance of southern corn rust (SCR) at varying levels of severity. To detect disease severity, they developed a vegetation index based on the normalized difference between two wavelengths. The results indicated an overall accuracy of 87% for SCR detection and severity classification accuracy of 70%. The authors of [
16] collected hyperspectral data of healthy, anthracnose, and gray mold strawberry leaves. The competitive adaptive reweighted sampling (CARS) and random frog (RF) pairs were used for feature selection. They evaluated and compared the classification performance of the feature wavelengths using six classification models, and the majority of the models achieved high accuracy (100%) and robust performance.
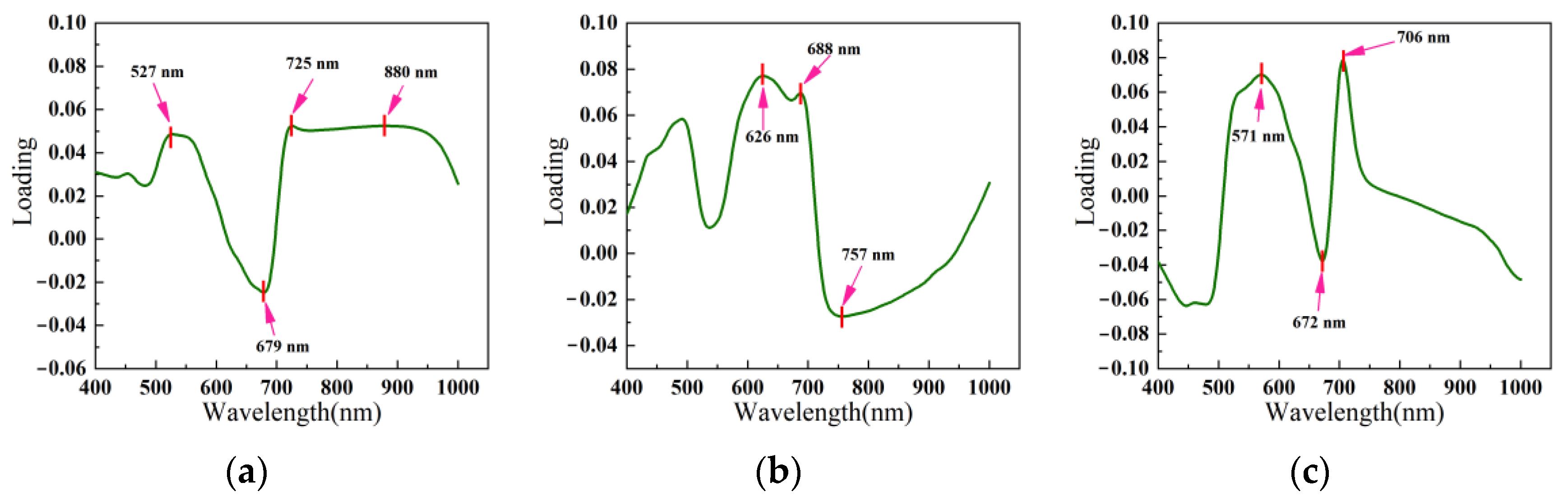
The feature selection methods mentioned above primarily employ candidate subsets and evaluation functions to select feature wavelengths, and these methods can achieve greater accuracy through training. However, these methods are sensitive to the selection criteria of candidate subsets and the use of evaluation functions and require substantial manual labeling. In contrast, spectral information methods can select features by assessing feature importance. Among these, principal component analysis loading (PCA loading) is one of the more commonly used feature selection methods. The authors of [
17] used the PCA loading method to select feature wavelengths for spectra of healthy and diseased wheat ear tissues. The study showed that the head blight index (HBI) constructed from feature wavelengths of 665–675 nm and 550–560 nm could be a detection indicator for identifying head blight. The authors of [
18] used second-order derivative spectroscopy and PCA to select optimal wavelengths for detecting oilseed rape stalk bunt. Partial least squares discriminant analysis (PLS-DA), a radial basis function (RBF) neural network, a support vector machine (SVM), and an extreme learning machine (ELM) were used for modeling. The results showed that the best classification accuracy of both calibration and prediction sets was above 90%. The authors of [
19] used PCA to identify more effective spectral regions and PC vectors to distinguish healthy and decayed tissues. The loadings of PCs corresponding to each wavelength were analyzed to extract key wavelength images from raw hyperspectral data. The authors of [
20] used common peaks and valleys in the loading curves of PCA’s first and second principal components to select feature wavelengths of maize seed maturity hyperspectral data. The authors of [
21] performed PCA loading, second-order derivative spectroscopy, CARS, and used an SPA to select feature wavelengths for different hyperspectral sample sets of infected oilseed rape. The results showed that the PCA loading method is insensitive to the data set’s composition and can produce more stable results across different data sets.
The above literature shows that feature wavelengths of the full spectrum can be effectively extracted using PCA loading. However, as the method selects the wavelengths corresponding to the peaks and troughs of each principal component as feature wavelengths, it often results in an excessive selection of feature wavelengths, which may not be conducive to practical applications and cost reduction. Therefore, this study proposes a novel PCA loading feature selection method based on assigning contribution weights. The specific objectives are as follows: (1) Obtain hyperspectral reflectance of leaf spot disease of different severity using collection equipment and determine the wavelength range with high variability through data analysis. (2) Determine the feature wavelengths for detecting leaf spot disease of peanuts using a PCA loading feature selection method based on the contribution weight assignment proposed in this study. (3) Evaluate the ability of the feature wavelengths to detect the severity of leaf spot disease using different classifiers.
5. Discussion
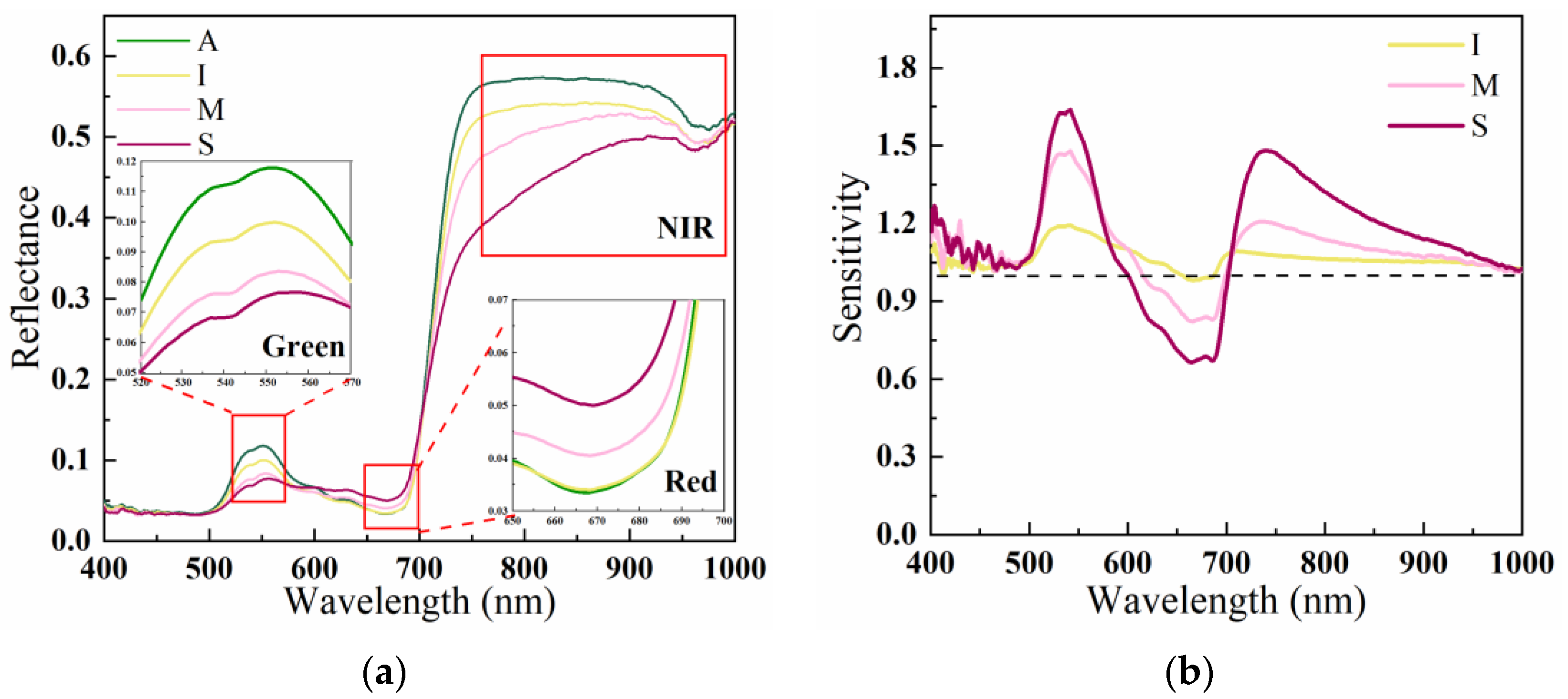
In this study, we evaluated the variability in wavelengths by analyzing the average spectral features and sensitivity of different disease levels. Our findings indicate that the wavelengths with the highest variability are primarily located in the green, red, and near-infrared bands. These results are consistent with those reported in [
35]. Specifically, The authors of [
36] proposed that the decline in reflectance in the green band could be attributed to the breakdown of chlorophyll. In addition, the variation in reflectance in the red band might be related to changes in carotenoid and lutein pigments. On the other hand, the authors of [
37,
38] suggested that the decline in reflectance in the NIR region is mainly influenced by changes in leaf structure and water content.
The studies of [
39,
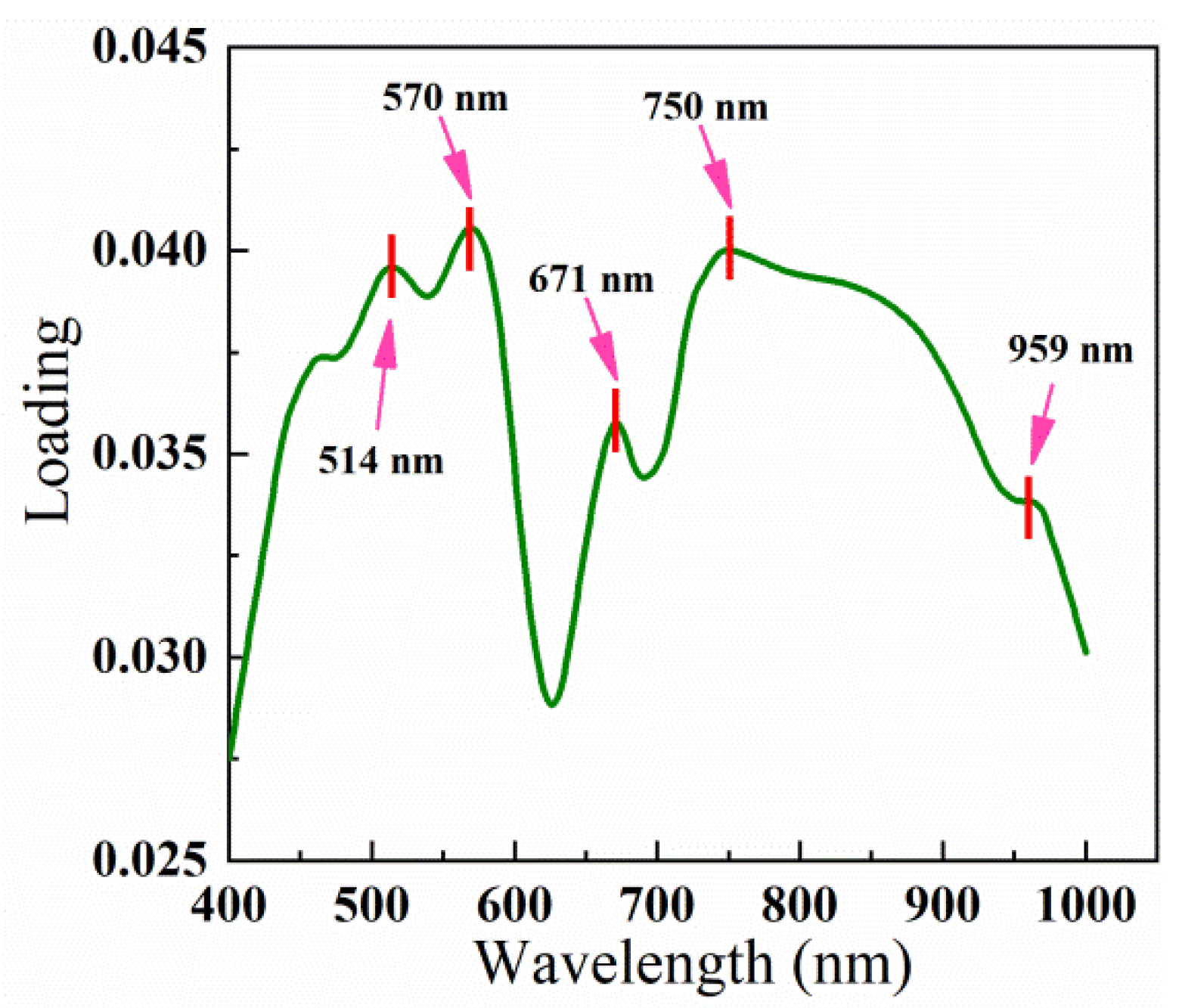
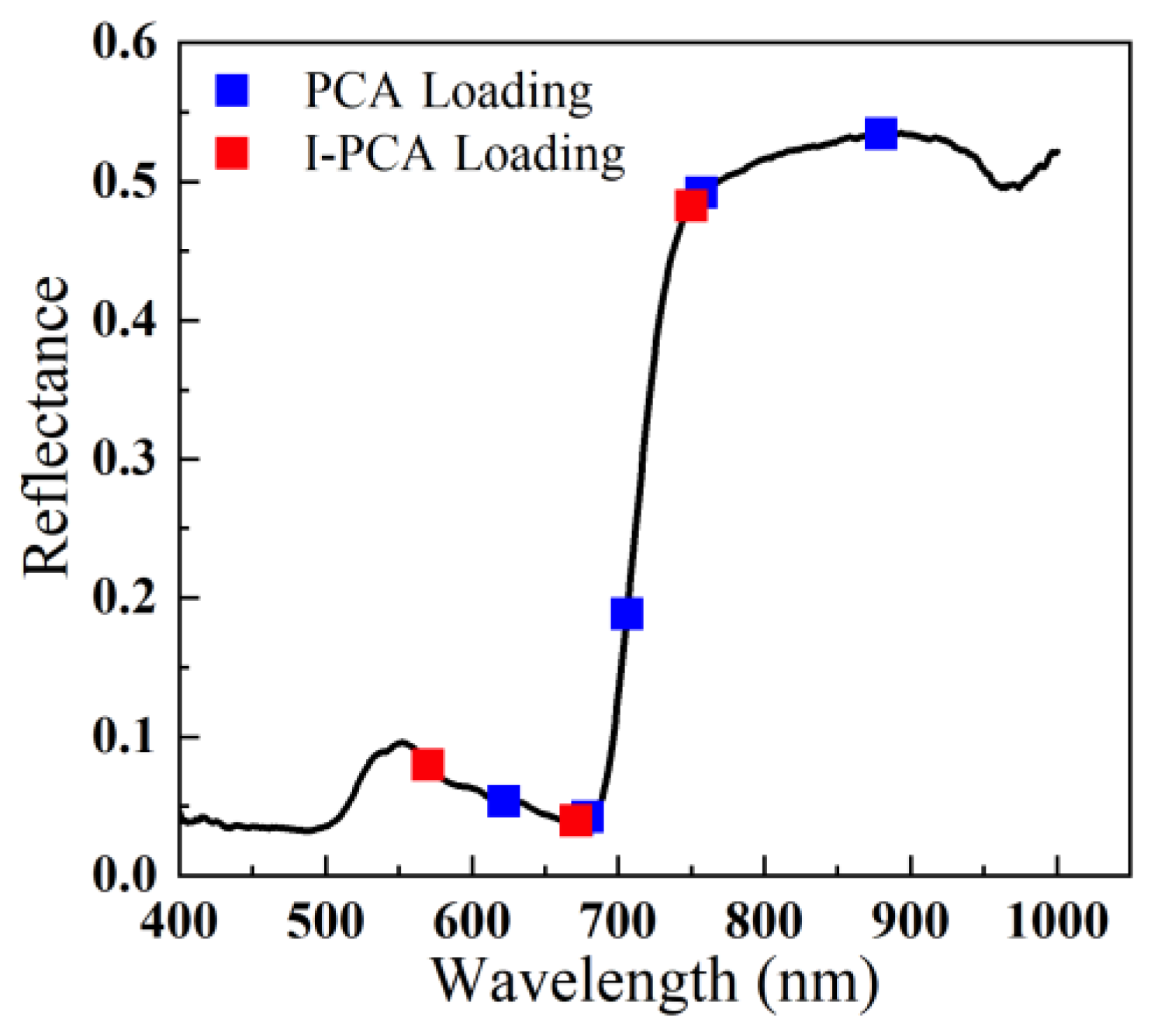
40] have shown that different crops and diseases have distinct spectral responses, and identifying specific feature wavelengths is crucial for accurate disease detection. Therefore, in this study, we used the proposed I-PCA loading method to assign weights to each wavelength, and we obtained high weight values in the ranges of 500–570 nm, 650–700 nm, and 760–1000 nm. We then used the local peak and correlation optimization method to select 570 nm, 671 nm, and 750 nm as feature wavelengths. Notably, 570 nm was in the green band, 671 nm was in the red band, and 750 nm was in the near-infrared band. These findings align with our analysis of spectral variability among disease levels.
Other studies have also used the feature wavelengths identified in this study. For example, the authors of [
41] used 570 nm to detect FHB in late flowering, and the authors of [
42] identified it as a crucial feature wavelength for detecting apple blasts. Additionally, 670 nm is commonly used to estimate leaf chlorophyll content and is a feature wavelength widely used in vegetation indices such as the NDVI [
43], MSR [
44], MCARI [
45], TCARI [
46], and OSAVI [
47]. Additionally, 750 nm was identified by [
48] as the most distinguishable part of the lesion detection spectrum. Our findings suggest that diseases cause changes in crops’ physiological and biochemical parameters, leading to distinct spectral responses. Identifying and utilizing specific feature wavelengths can greatly enhance disease detection accuracy.
This study employed eight feature selection methods to identify feature wavelengths, including CARS, LSMI, RF, Relief-F, the SPA, UVE, PCA loading, and I-PCA loading. We found that different methods produced different feature wavelengths, which can be attributed to the different evaluation criteria of the methods. Similar findings were reported by the Zhang [
49] and Balabin [
50], who used 10 and 16 optimal wavelength selection methods, respectively. Notably, the feature wavelengths identified by all methods were mostly concentrated in the green, red, red-edge, and near-infrared bands, consistent with variability in wavelengths. When we evaluated the feature wavelengths using KNNs, SVMs, and BP, we found that all models achieved satisfactory accuracy, with OA and Kappa exceeding 85% and 80%, respectively. Although different methods selected different feature wavelengths, these features were still concentrated in similar regions, demonstrating their ability to enhance detection capability. There were often cases of excessive and repetitive selection in methods with a larger number of selected feature wavelengths. For example, CARS and UVE selected 10 and 9 feature wavelengths, respectively. However, some of their selected feature wavelengths were concentrated between 400 and 420 nm and 980 and 1000 nm, which did not correspond with the results of wavelength difference analysis. Therefore, selecting too many feature wavelengths may not improve disease detection accuracy. In addition, the LSMI, SPA, and I-PCA loading methods were used for feature selection, and the results show that only three feature wavelengths were selected. The KNN, SVM, and BP algorithms were used to evaluate the disease detection ability of different feature wavelengths. The results showed that LSMI achieved an OA and Kappa of over 90% and 87%, respectively, with all classifiers. In comparison, the SPA achieved an OA and Kappa of over 87% and 83%, respectively, with all classifiers. Other studies have also demonstrated the effectiveness of the LSMI and SPA methods in feature selection [
30,
33]. Therefore, selecting fewer feature wavelengths can achieve higher disease detection accuracy. Similar to the LSMI and SPA methods, the three feature wavelengths selected in this study were located in the green, red, and near-infrared bands and detected with high a degree of accuracy. Furthermore, it can be seen from analysis of wavelength difference that the feature wavelengths selected in this study are better than those selected by the LSMI and SPA methods, which may be the reason why the selected feature wavelengths performed better in disease detection in this study.
In this study, various feature selection methods were evaluated using different classifiers, with I-PCA loading identified as the best-performing method. Specifically, the SVM classification results using feature wavelengths selected by I-PCA loading achieved high OA and Kappa scores of 96.88% and 95.81%, respectively. Further analysis of disease severity detection using the selected feature wavelengths, and the results are shown in
Table 6. The results revealed that the HM values for all categories exceeded 96%, with the highest HM of 98.55% achieved for level S. More samples incorrectly predicted A levels as I levels, and fewer samples incorrectly predicted I levels as A levels, resulting in a PA below 95% and a UA above 98% for A levels. These results suggest that the model can accurately predict healthy areas, which can aid in the timely detection and control of crop diseases in real-world production settings.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}