4.1. YOLOV7 Model Experiment
The model version uses YOLOV7-X for training, because YOLOV7-X has a greater width and depth than the secondary version of YOLOV7, which means that YOLOV7-X can extract richer features and have better recognition effects. During the training phase, the results obtained by each epoch are validated on the validation set, resulting in a group of precision and recall rates based on thresholds. Multiple sets of precision and recall rates can be obtained when different thresholds are set for the model, allowing the P-R curve, or AP (average precision), to be plotted. There were three input scales used for training, which are 416 × 416, 512 × 512, and 640 × 640. The epoch of the training was set to 300. The best weight of AP was used as the best weight of the model. The performances of the three different input sizes were compared, where the IoU threshold was set to 0.5, and the confidence threshold was set to 0.001.
Table 3 shows the final training results.
The AP was used to determine the comprehensive performance of the model. The precision and recall of the model with the best weights were evaluated. In
Table 3, it is seen that the model’s AP and recall increased as the input image resolution increased. The highest AP and recall of the model were obtained when the model input resolution was 640 × 640. All the model indexes were improved in the results of input resolution 416 × 416 and input resolution 512 × 512. When the input resolution of the model was 640 × 640, the precision decreases from 81.06% to 80.12%, compared to the input resolution of 512 × 512. The decrease in precision might be due to the increase in the model’s false detection of objects, but the model’s recall rate improved significantly. The accuracy results also reflect the difficulty of identifying banana pseudostems in complex scenarios in one aspect. Furthermore, the evaluation indicators for the three training processes in 300 epochs were analyzed.
Figure 4 shows the changes in the metrics during the training.
As can be seen in
Figure 4, the model fit quickly in the early epochs of training, due to the use of loaded pre-training weights. The model metrics then increased slowly from the 50th epoch to the 100th epoch, and are relatively stable from the 100th epoch to the 300th epoch. The AP performance of the model was better for the input resolution of 640 × 640 compared to the input resolutions of 512 × 512 and 416 × 416. Therefore, in the subsequent comparison experiments, the 640 × 640 model input was used as the basis for model improvement and comparison experiments.
The banana pseudostem dataset contains a very dense setting, and includes small and occluded objects. These factors posed a significant challenge to the performance of the model. An example is given in
Figure 1b, to demonstrate these situations.
A scale differential experimental analysis was performed on the model, to analyze the detection effect of banana pseudostems in more detail. Specifically, the object area in the test set was divided into small, medium, and large-scale objects. Small objects, were those smaller than 32 square pixels. Medium objects, referred to objects larger than 32 square pixels and smaller than 96 square pixels. Large objects, referred to objects larger than 96 square pixels.
Table 3 gives the results of the scale differentiation of YOLOV7 (input resolution of 640 × 640).
In
Table 4, the AP of the model was low for small and medium objects. The AP of small object detection was only 32.5%. The objects of other scales easily sheltered small and medium objects, which contained fewer pixels. The features available were fewer compared to the objects of other scales. Among them, small object detection was one of the difficulties in deep learning object detection and was the main reason for the low accuracy of the object detection model. Two ideas were proposed to solve the problem of low accuracy for small and medium-sized objects in banana pseudostem detection.
- 1.
Using Focal loss to improve the loss function allows the model to focus on training hard samples, as training for the occlusion of small- and medium-sized objects was challenging;
- 2.
In the complex orchard environment, some specific banana pseudostems could not be identified, or were identified with low accuracy. Mixup data enhancement could be used to try to improve the generalization ability of the model.
4.2. Improved Experiments
Focal loss. The authors of [
1] experimented with the effect of multiple sets of
and
on the COCO dataset. The results showed that AP performed best at
,
. Without fine-tuning it, this study simply used hyperparameters
,
. The
of Equation (
12) was set to 2.0, and the
of Equation (
14) was set to 0.25, to balance the loss.
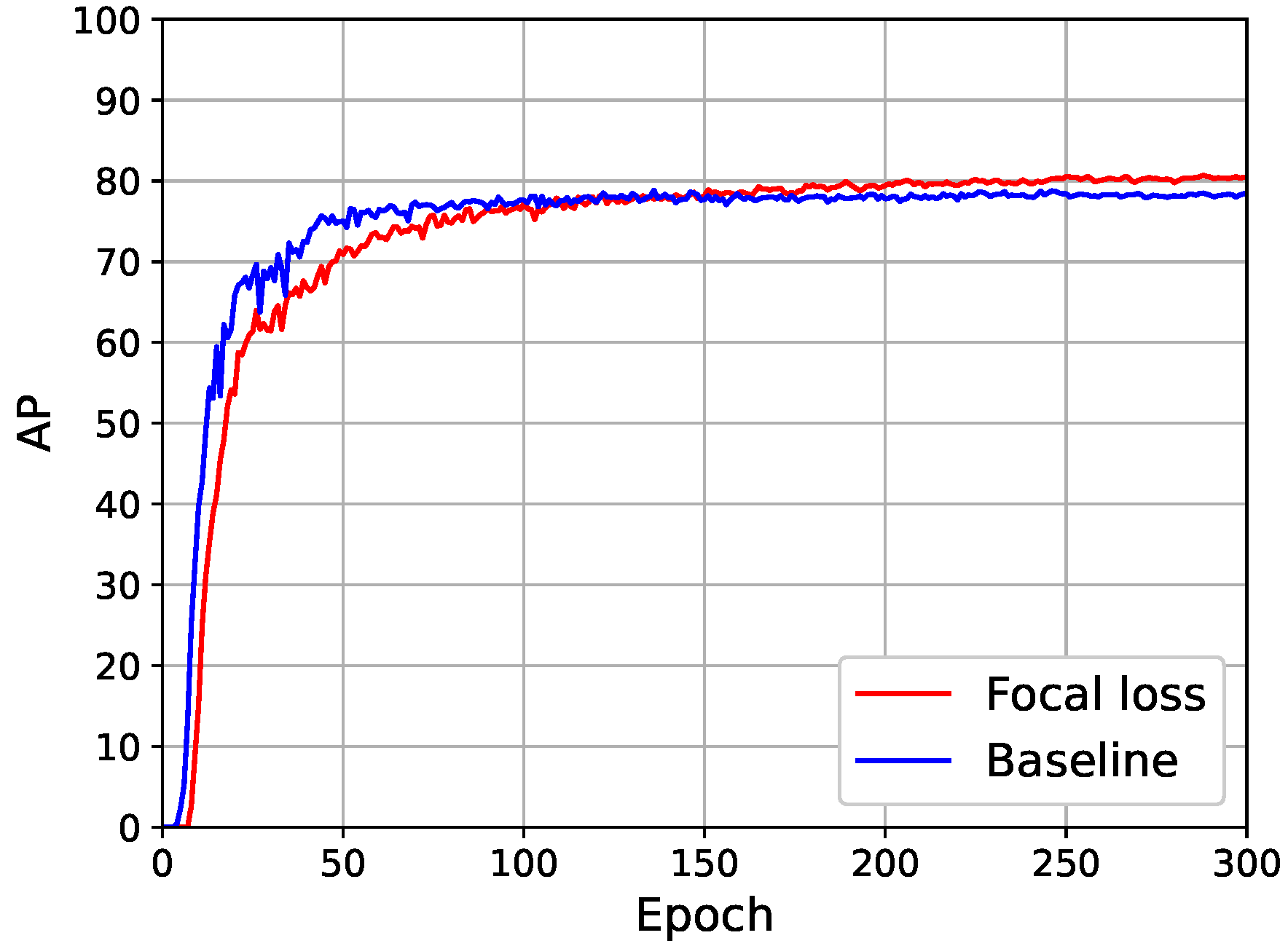
Figure 5 shows the AP iteration curve of the model after the Focal loss improvement. Due to pre-training weights, the improved model fit quickly in the epochs in the early training period. The AP curve of the model improved by Focal loss was lower than the baseline in the first 100 epochs of training. The reason was that Focal loss increases the weight of hard samples in the loss, and the model slows down the fit of standard samples. In the later stage of model training, from the 150th epoch to the end of the training, the AP curve of the model improved by Focal loss gradually exceeded the baseline.
Focal loss improved the model. No. 5 in
Figure 6b was a pseudostem heavily obscured by plantain leaves. No. 6 was a pseudostem that was more similar to lichen. Both no. 5 and no. 6 were hard samples. Pseudostems no. 5 and no. 6 were not detected in baseline, but they both could be detected after the Focal loss improvement. However, pseudostems no. 1 and no. 7, which were not detected in baseline, were also not identified after the Focal loss improvement. No. 1 was a partially obscured pseudostem, and the image features resembled the bamboo in the pseudostem environment. No. 7 was a small pseudostem, which was more heavily obscured and could provide fewer features. No. 4 was also a small pseudostem and was not labeled in the dataset, which could be interpreted as an unlabeled sample. The baseline model did not recognize this no. 4 pseudostem. After the improvement of Focal loss, the no. 4 pseudostem could be identified, even though it was unlabeled. Pseudostems no. 1 and no. 7 were still not detected. Although the Focal loss slightly reduced the confidence in identifying some normal samples, it improved the ability of the model to identify hard samples.
Mixup. The Mixup paper tested a set of alpha experiments on CIFAR-10 data, when 20% of the data were replaced by random noise. The conclusion showed that the test error was lowest when
. The
parameter could be fine-tuned, but this study did not do so. The hyperparameter
was used in the experiment. In the Mixup experiment, the
in Equations (
15) and (
16) are randomly taken as beta distribution
. Mixup data enhancement was performed on 40% of the training samples for each epoch, when training the network. The data enhancement strategy was to start during the training, not before the training. Therefore, the above data enhancement was not through increasing the number of training datasets but through dynamic data enhancement during training.
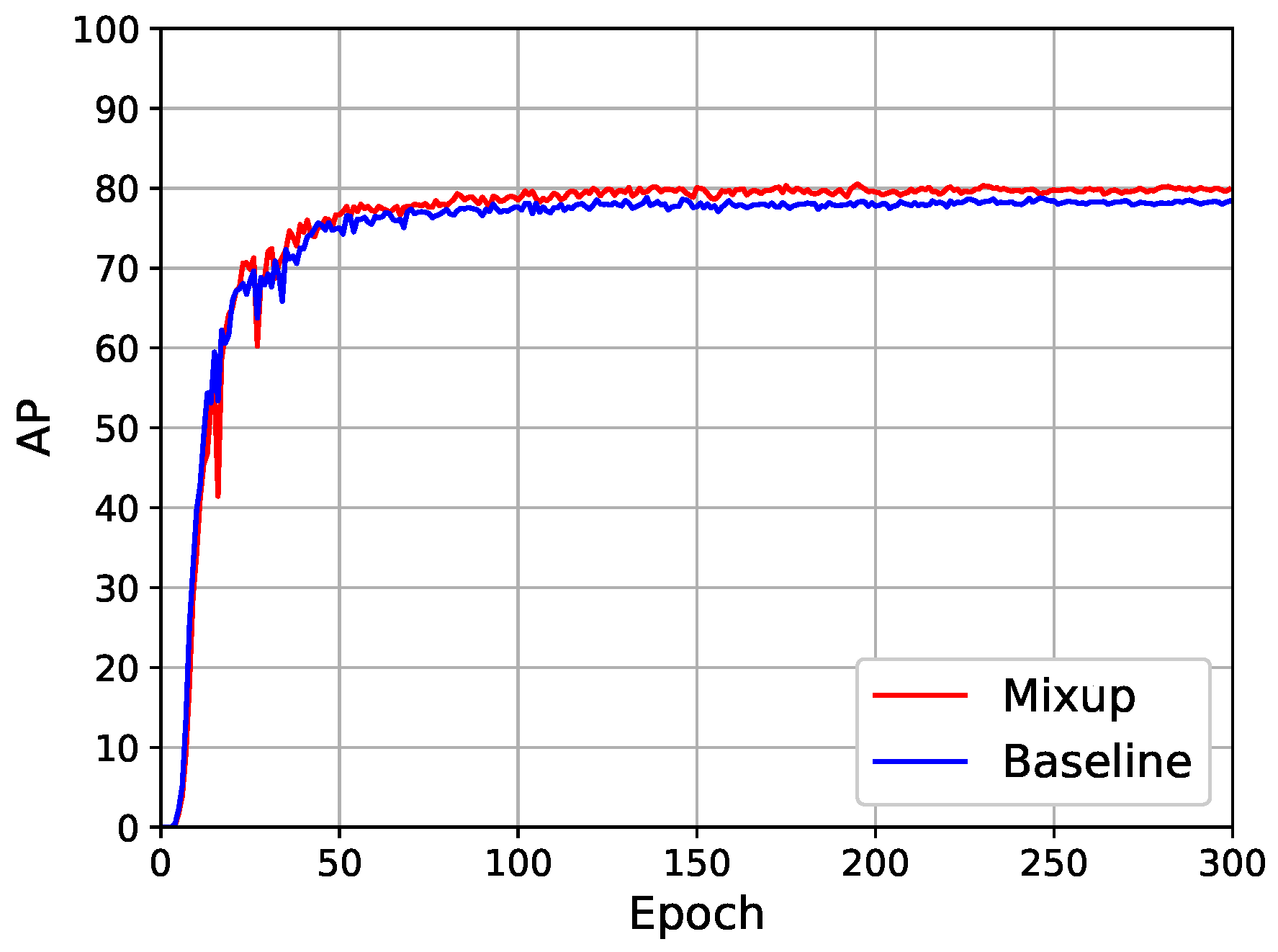
Figure 7 shows the AP iteration curves of the model after the Mixup data enhancement. The model was fitted quickly in the first dozen epochs early in training. The AP curves of baseline and Mixup in the first 50 epochs were very similar. The Mixup curve gradually exceeded baseline from the 50th epoch.
Mixup improved the robustness and generalization ability of the model. The detection box regression of the small pseudostem of no. 3 in
Figure 6c matched better with baseline. After the improvement of Mixup, the model was able to identify pseudostem no. 4 and pseudostem no. 7. However, the pseudostems of no. 1, no. 5, and no. 6 were still not identified. These two improvement ideas (i.e., Focal loss and Mixup) were combined, to improve the recognition ability of the model.
Comprehensive improvement. A mixed experiment of Focal loss and Mixup was attempted in this experiment. Compared with the Focal Loss and Mixup experiments, the mixed experiment achieved the best results.
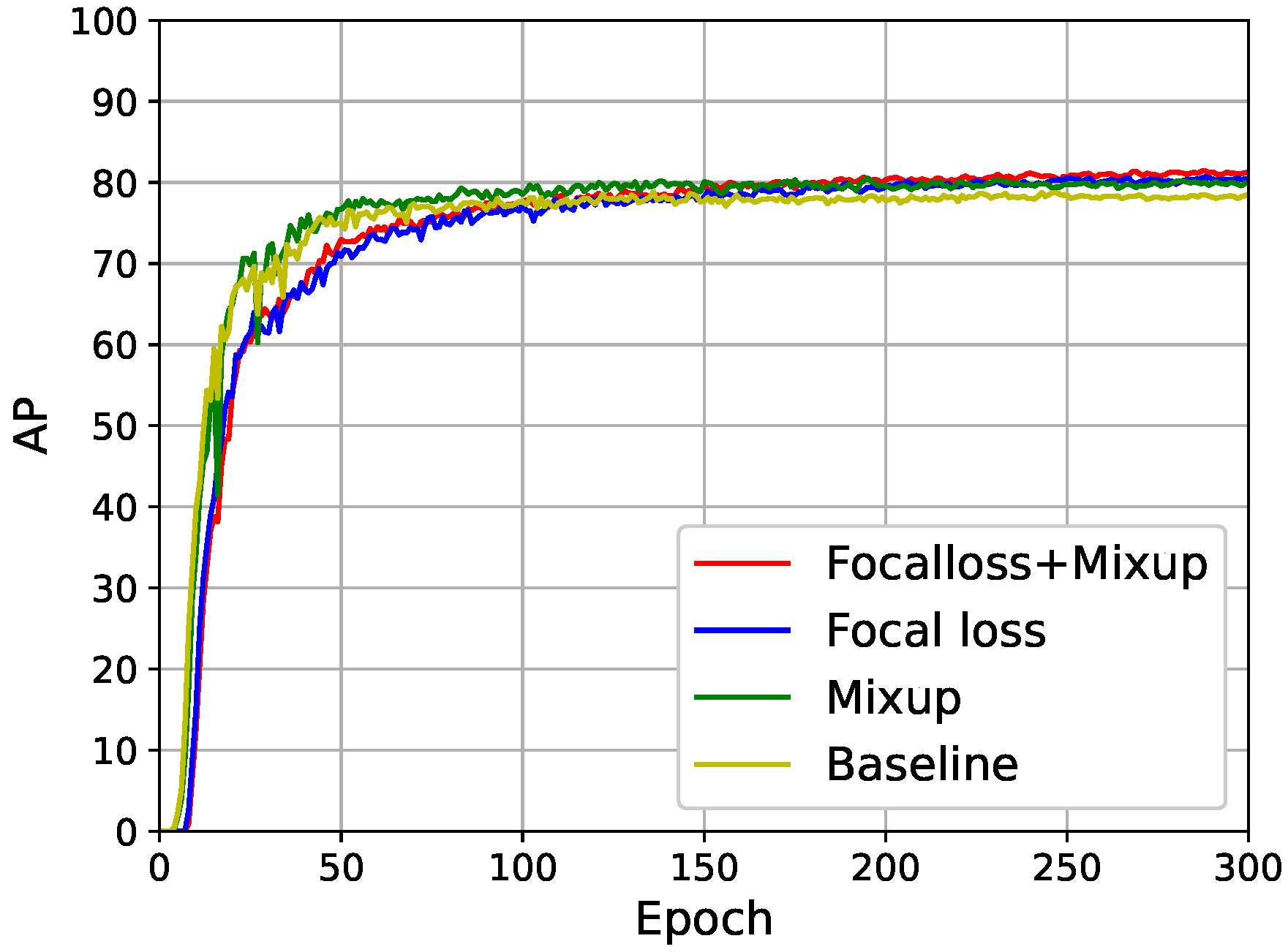
Figure 8 shows the AP iteration curve of the model training. In
Figure 8, the best curve (red curve) fit at a similar speed to the one improved by Focal loss only (blue curve). The best curve (red curve) slowed the fit to normal samples early in training, as the model focused on training hard samples. The combined improved model fit slower than the one fit by Mixup and baseline only. The AP curves of the best model gradually fit in the first 150 epochs and level off and increased slightly from the 150th epoch to the end of training. The AP of the best model was higher than Focal loss, Mixup, and baseline.
The best model achieved results beyond Focal loss and Mixup.
Figure 6d shows that the best model could detect the previously undetected pseudostem no. 1. Although the regression of pseudostem no. 1 was not a good match, it was much better than not being detected. The regression of the detection box of pseudostem no. 3 was better than that of Mixup in
Figure 6c. The banana leaves of other pseudostems obscured the upper part of pseudostem no. 3. Because of the obscuration, it was debatable whether the top part, above pseudostem no. 3, belonged to no. 3. Therefore, the return of the test box of pseudostem no. 3 was not important here. The best model can detect pseudostem no. 5, which was heavily obscured. Pseudostem no. 6, similar to lichens, could also be detected. Unfortunately, small pseudostems no. 2 and no. 7 were not detected. The detection of small pseudostems was still a great challenge for the model.
To better analyze the detection effect of the pseudostems, this work analyzed the object scales of detection for the models with the Focal loss improvement, Mixup improvement, and combined improvement. This work evaluated the detection at three scales: large, medium, and small in the dataset.
Table 5 shows the results of the experiment.
All experiments showed improved AP values for object detection at all three scales. Among all the improved experiments, small objects had the largest AP gain, followed by medium objects, and finally large objects. Among them, the best model had the largest AP gain. The best model, improved by Focal loss and Mixup, achieved 81.45% AP, among which large object AP achieved 93.4%, medium object AP reached 73.9%, and small object AP achieved 38.7%Ṫhe AP of the three scales of the best model exceeded the AP of the baseline, and the models improved by Focal loss only and Mixup only. In
Table 5, both Focal loss and Mixup improved the detection accuracy for different scales of objects, especially for small and medium objects, proving the experiment’s validity.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}