1. Introduction
Apples are a vital agricultural commodity worldwide and a significant contributor to economic development in the agricultural sector. In the United States, Washington State alone accounts for 67% of the entire apple production [
1]. Apples are not only delicious but are also packed with a variety of nutrients, including vitamins C and E. These nutritional benefits have made apples a popular choice among consumers. [
2,
3]. The majority of orchard management today is performed by human labor, which is not only physically taxing but also ineffective, expensive, and prone to error [
4].
The integration of intelligence in orchards, driven by the advancement of smart agriculture [
5], has emerged as a crucial factor in obtaining precise product information. Nonetheless, detecting fruits accurately in natural environments presents significant challenges. Issues such as fluctuating lighting conditions, overlapping shading, and the resemblance between distant small fruits and the background can lead to inaccuracies in fruit detection [
4,
6,
7]. Accurate fruit detection holds great research value and practical significance for the development of automated harvesting and yield estimation in orchards. Therefore, it is an important area of focus for researchers in this field.
In recent years, there have been some notable advancements in the automated detection and management of orchards, which can be categorized into two main approaches: traditional methods and deep learning algorithms. Traditional image processing methods have primarily focused on extracting information such as color, shape, and basic features from images [
8]. These extracted features are then classified using techniques such as support vector machines or artificial neural networks [
9], forming the basis for fruit detection and segmentation [
10]. Tian et al. [
11] proposed a localization technique based on image depth information to find the circle center, fit the contour, and improve recognition accuracy with a recognition rate of 96.61%. Lin et al. [
12] developed a support vector machine-based segmentation algorithm for citrus detection using density clustering to reduce the effect of the environment with excellent performance. Wang et al. [
13] used the Retinex image enhancement algorithm, and two-dimensional discrete wavelet transform to apply it to fruit detection based on color features and texture features, with a final accuracy of 85.6%. Wang et al. [
14] proposed an algorithm for identifying and locating obscured apples based on K-mean clustering, with a higher localization rate and 89% recognition accuracy than Hough transform and contour curvature methods. Zhang et al. [
15] proposed an insulator profile detection method based on an edge detection algorithm. The Canny algorithm was selected as the main algorithm for insulator profile detection, which provides an efficient, accurate, and reliable way for the automated detection of insulator profiles with some practical value.
This paper has selected a deep learning algorithm with strong autonomous learning and feature extraction abilities to address these challenges. These algorithms demonstrate strong robustness and generalization capabilities in fruit detection, making them highly effective for automating orchard processes. Li et al. [
16] proposed a target detection algorithm based on YOLOv4-tiny detection of green peppers, combining attention mechanism and multi-scale prediction ideas, with an average accuracy of 95.11%, model size of 30.9 MB, and FPS of 89. Tian et al. [
4] presented an enhanced YOLOv3 model for detecting apples at various growth stages. They incorporated DenseNet feature enhancement propagation and enhanced feature reuse techniques to enhance the feature layers at low and medium resolutions. Their model achieved an average detection time that can handle a resolution of 3000 × 3000 per frame, outperforming the original model and Faster-R-CNN. Zhang et al. [
17] proposed a YOLOv4-tiny-based apple detection model with the backbone introducing GhostNet feature extraction network with a CA attention mechanism, introducing depth-separable convolution in the neck and YOLO head for reconstruction, and FPN adding CA attention module to enhance the feature extraction of small targets with an average accuracy of 95.72%. The model has a 37.9 MB model size and a 45.2 FPS. Tu et al. [
18] proposed an improved method based on Multi-Scale Fast Region Convolutional Neural Networks (MS-FRCNN) to detect lower-level features by merging feature maps from shallower convolutional feature maps, used in the region of interest pooling, effectively improving the detection of small passionfruit. Uddhav Bhattarai and Manoj Karkee [
19] proposed CountNet, a weakly supervised flower/fruit counting network based on deep learning, to learn the number of objects from image-level annotations as input, yielding good MAE and EMSE in an orchard setting. Qian et al. [
20] proposed HOG+SVM and an improved YOLOv5-based method for fast recognition of multiple apples in complex environments with parameter reconstruction, the inclusion of an attention mechanism module and fine-tuning of the loss function to better extract the features of different apples and improve the recognition ability of the model. Jan Weyler et al. [
21] proposed a method to predict the bounding boxes of crops and weeds automatically, as well as the key points of leaves, with a good ability to estimate leaf numbers, and this method achieved excellent performance in complex scenarios with overlapping plants at different growth stages compared to Mask R-CNN. Chen et al. [
22] proposed a Citrus-YOLOv7 model to detect citrus, introducing a small target detection layer, lightweight convolution, and CBAM attention mechanism to achieve multi-scale feature extraction and fusion with an average accuracy of 97.29%, an average detection time of 69.38 ms, and a model size of 24.26 MB. Sun et al. [
23] proposed an optimized Retinanet-PVTv2 that introduced a gradient coordination mechanism to detect small green fruits/begonia in a nocturnal environment and showed APs of 85.2% and 61.0% on the NightFruit and Gala datasets, respectively. Yonis Gulzar [
24] proposed a TL-MobileNetV2 model used to classify 40 fruits, removing the classification layers present in the MobileNetV2 architecture, adding five different layers, and also using different pre-processing and model adjustments, effectively improving the efficiency and accuracy of the model with an accuracy of 99%. Normaisharah Mamat et al. [
25] proposed an automatic image annotation advancement method using repetitive annotation tasks for the automatic annotation of objects, which was evaluated on different YOLO networks, and the results showed that the proposed method is fast and highly accurate in fruit classification, providing great value in image annotation. Yasir Hamid [
26] proposed a deep convolutional neural network model using MobileNetV2 architecture and data augmentation techniques to implement an intelligent seed classification system, and the results show that it has high accuracy and is important for the sustainability of seed analysis. Sonam Aggarwal [
27] proposed an artificial intelligence-based stacked integration approach to predict protein subcellular localization, which combines the three powerful pre-trained models, and the results showed that combining different weak convolutional neural networks gave better predictions than individual models with better network performance.
This study proposes an improved YOLOv7-tiny detection and counting network for small target apples to better cope with the inevitable realities of natural environments, complex backgrounds, and complex weather. The dataset was enriched with data enhancement techniques, adding three innovations to the backbone and neck of the model, improving detection accuracy for small target apples, and reducing the number of parameters in the model. The results show that the model has high robustness and generalization performance in detection and counting and can be deployed to mobile applications to facilitate automated orchard management.
The following are the contributions of the authors’ work in this study:
(1) Construction of an Apple dataset with complex weather using the MinneApple public dataset, cropping and marking this, and simulating rain and fog scenarios using data augmentation techniques;
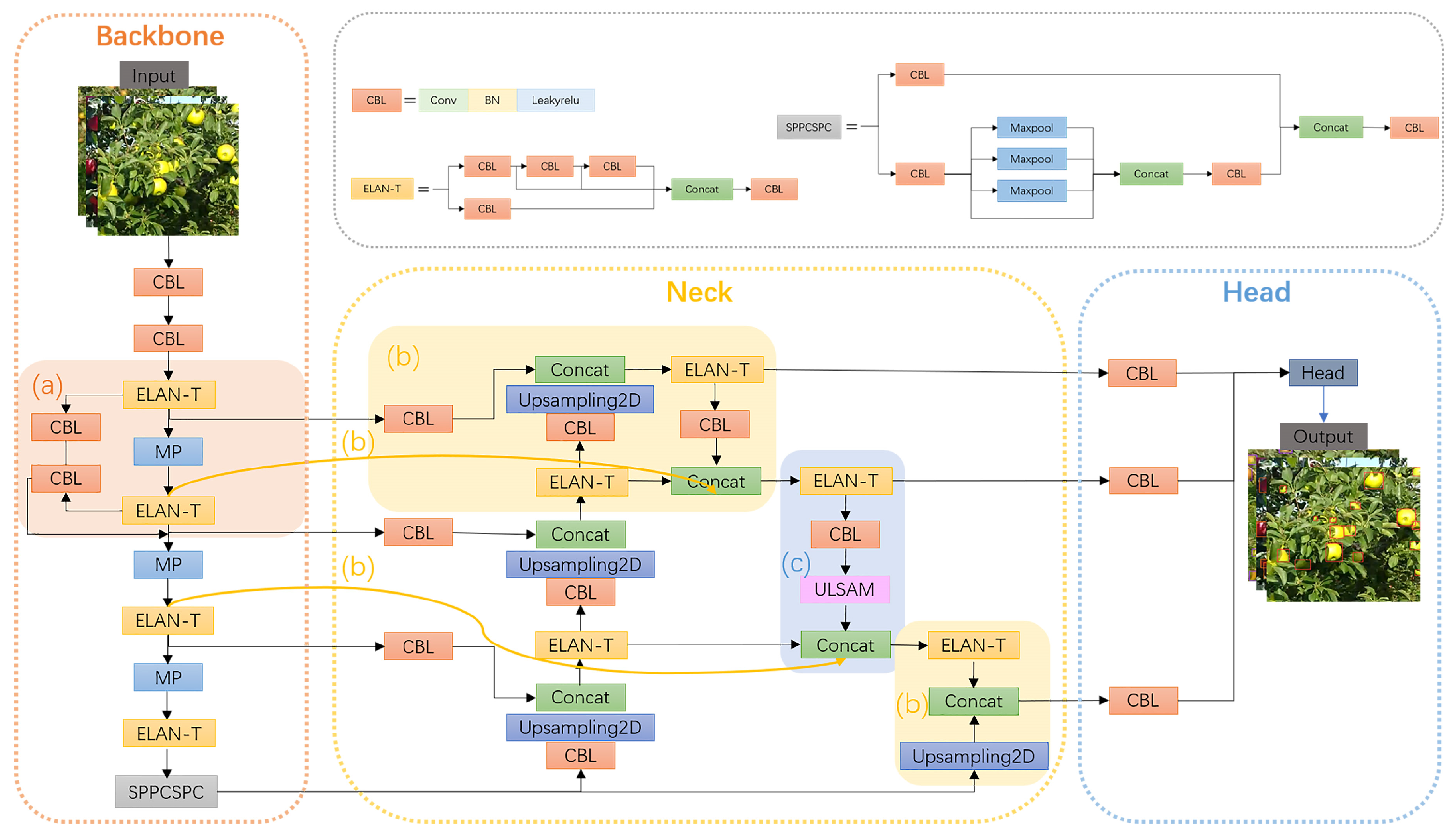
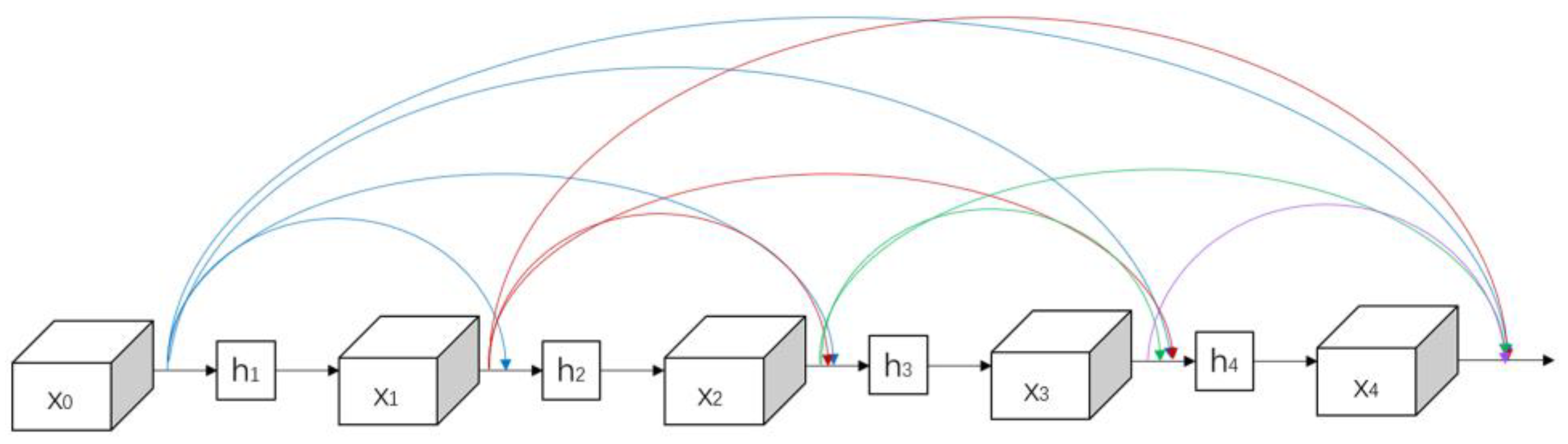
(2) Borrowing from DenseNet idea to construct a backbone network by adding to shallow features through skip connections to reduce the loss of small target features;
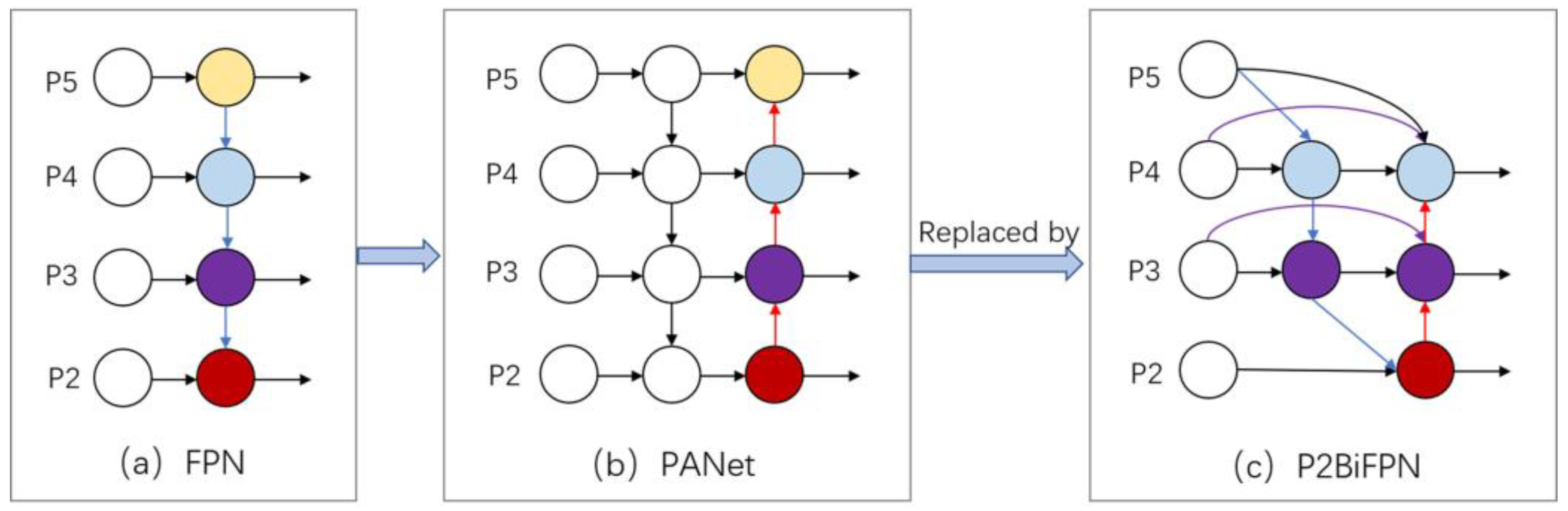
(3) Multi-scale fusion using P2BiFPN to detect small fruits with low resolution at a distance;
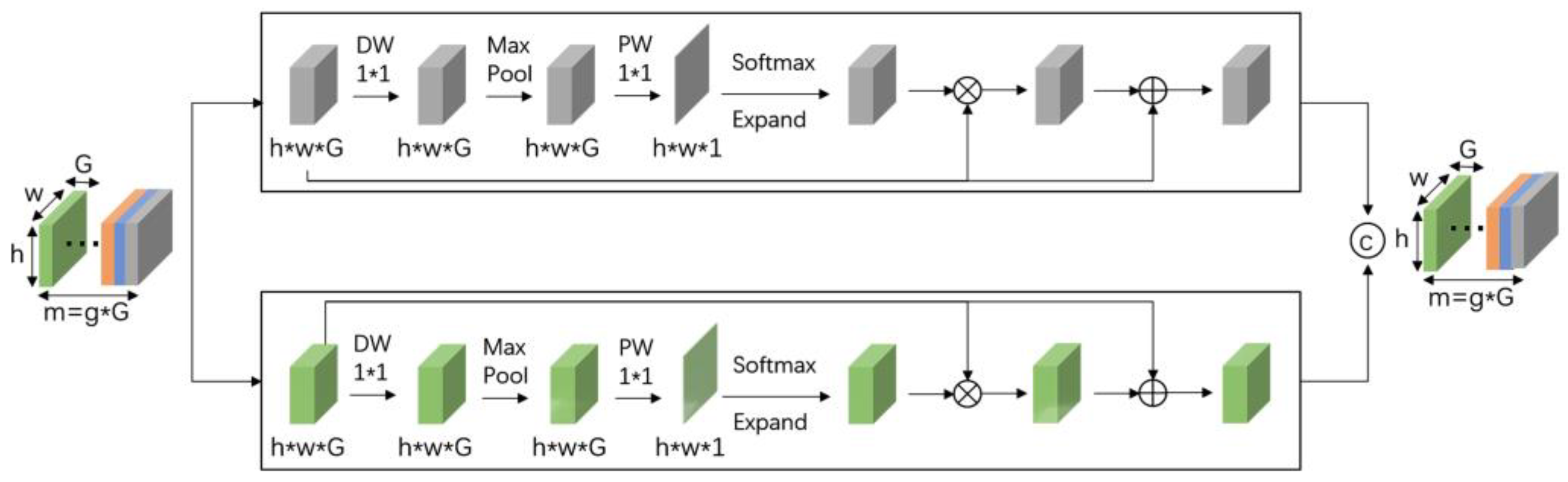
(4) A lightweight ULSAM attention mechanism is used to discard redundant features without increasing the model volume.
This study aims to enhance the model’s ability to detect and count small target apples with complex backgrounds in natural environments and to adapt to complex weather conditions.
3. Results
3.1. Training Process
In this study, the same initial training parameters are set for each group of experiments. We input an image size of 416 × 416, an epoch value of 300, a learning rate of 0.01, a momentum of 0.937, and a weight_decay of 0.0005, and the optimizer chosen is Adam, as shown in
Table 3. The data is recorded using Tensorboard during the training process, and the training set loss is written for each iteration; the validation set loss is written for each training round, and the model weights are saved.
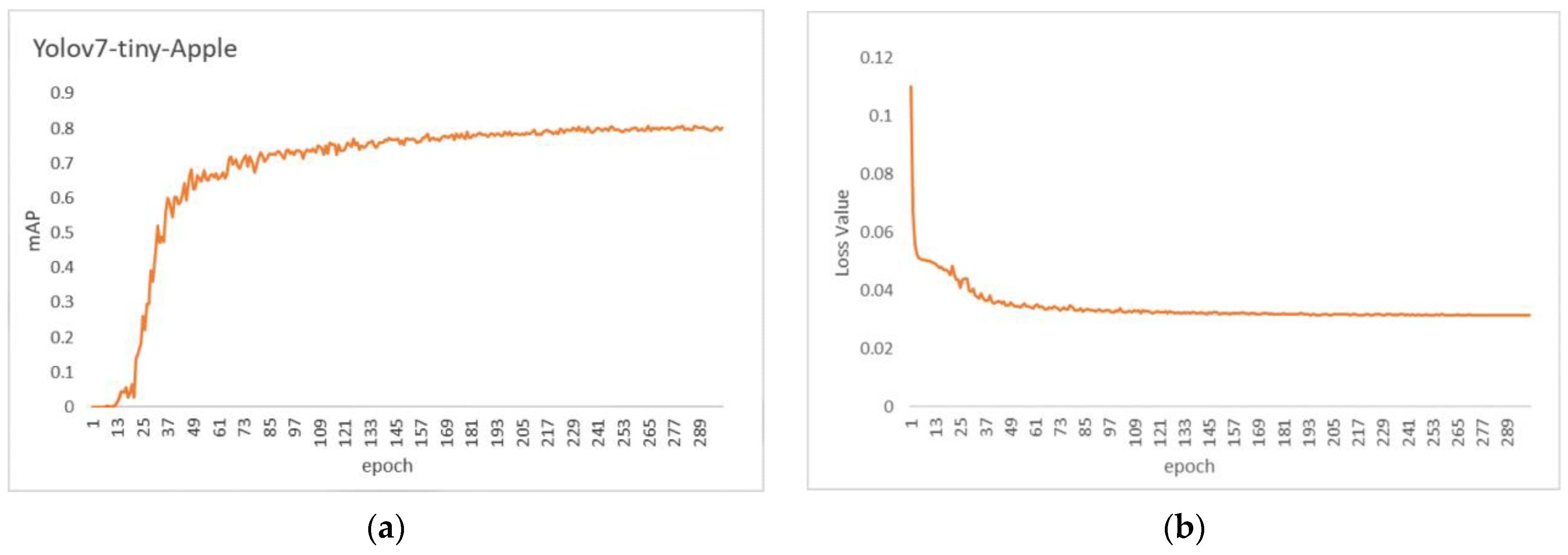
As shown in
Figure 7, the model’s detection accuracy values and training loss values vary with the number of iterations during the training process. Gradually converging from 50 rounds onwards, the detection accuracy gradually increases, and the loss of the model gradually decreases, and finally, the 250 rounds level off, and the accuracy and loss values no longer change. It can be seen that the YOLOv7-tiny-Apple model does not suffer from over- and under-fitting and gradient disappearance [
41] and can be applied to the detection and counting of small target fruits.
3.2. Ablation Experiments
In this experiment, ablation experiments verify each improvement point’s effectiveness. We propose a total of three innovation points, and the results of the ablation experiment are shown in
Table 4.
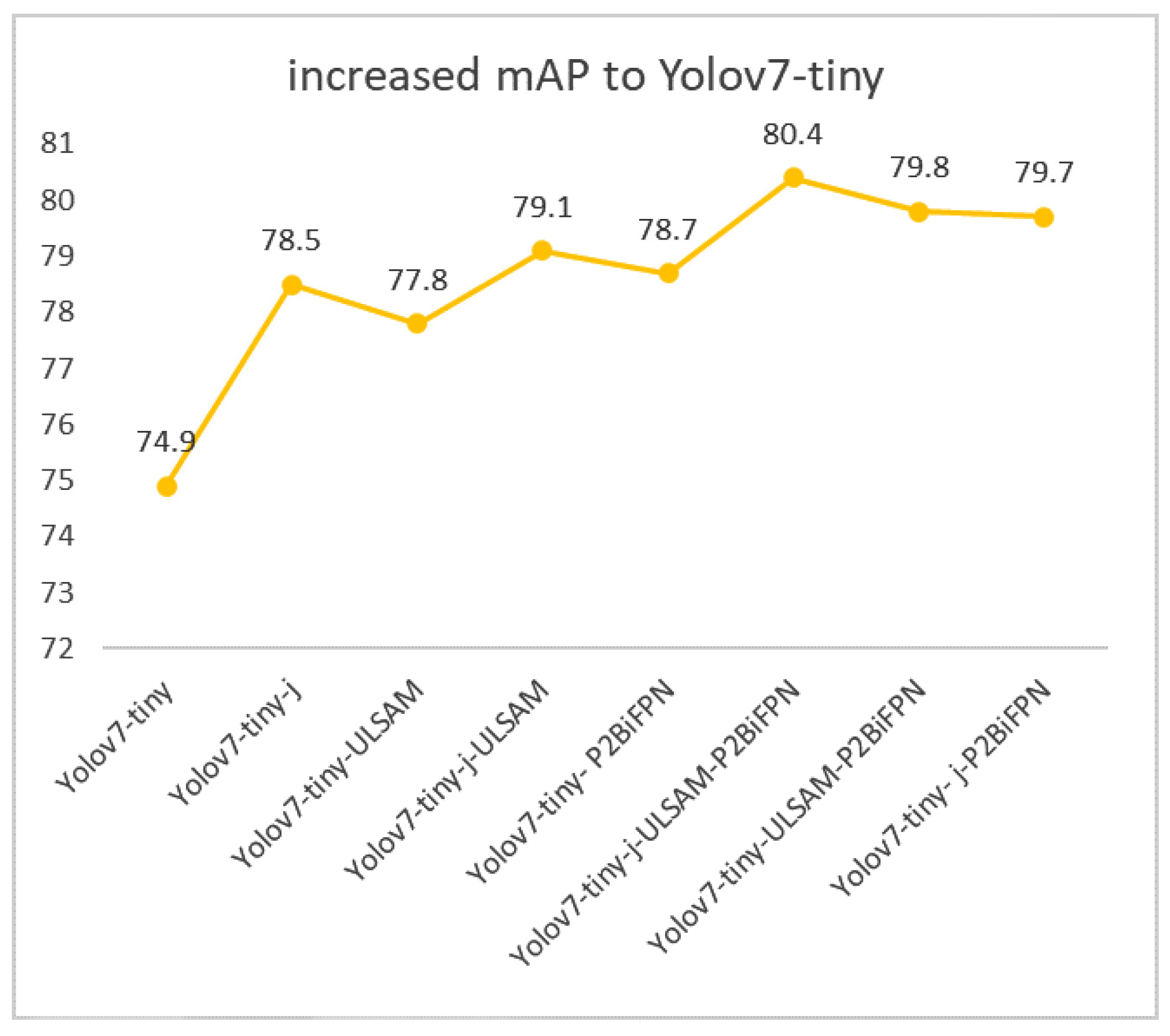
After improving the first skip connection j, it is clear that the network adding the skip connection improves mAP by 3.6%, mF1, Precision, and Recall by 3.1%, 2.6%, and 3.5%, respectively, on the original base network, and the number of parameters of the model increases by 0.16 M. The second improvement point, P2BiFPN, improves mAP by 3.8%, mF1, Precision, and Recall by 3.5%, 1.8%, and 4.8%, respectively, compared with the base network, and the amount of parameters of the model is reduced by 1.11 MB, which greatly reduces the complexity of the model. The third improvement point is that the ULSAM attention mechanism increases the detection accuracy while the number of parameters of the model does not change, satisfying the detection model of the lightweight network. Compared with the base network, mAP improved by 2.9%, mF1, Precision, and Recall improved by 2.3%, 1.4%, and 3.3%, respectively; the number of parameters of the model did not change, while FPS was reduced but could meet the fast detection of the model.
All three improvement points significantly enhanced the accuracy of the base model in this experiment. We systematically combined them in pairs, as shown in
Figure 8, demonstrating the feasibility of the model’s detection accuracy after each combination. Finally, by integrating all three improvements, we achieved an mAP (mean Average Precision) value of 80.4%, Precision, Recall, and mF1 values of 80.1%, 74.1%, and 76.8%, respectively. Moreover, the resulting model has a compact size of 5.06 MB. This shows that the improvement of this experiment is more effective in feature extraction in the complex background of the natural environment, largely discarding the redundant interference and having superior detection performance.
For counting, this study uses the images in the test set for testing, and the counting results are shown in
Table 5. From the results, it can be seen that for the first innovation point j skip connection, RMSE is reduced by 0.281, and MAE is slightly higher by 0.006; for the second innovation point, P2BiFPN, RMSE is reduced by 0.285, and MAE is slightly higher by 0.091; for the third innovation point, the ULSAM attention mechanism, RMSE is reduced by 0.32, and MAE is reduced by 0.043. The counting metrics of this experiment, RMSE reduced by 0.416 and MAE reduced by 0.165, are also effective in terms of counting and have performance improvement.
3.3. Comparison Experiments
The more classical and popular Faster Rcnn-VGG, SSD-MobileNetV2, CenterNet-ResNet50, the newer and prominent lightweight networks YOLOv5s [
42], YOLOx-tiny [
43], YOLOv6t [
44], and YOLOv7 were selected for comparison with the seven models of YOLOv7-tiny-Apple in this study, and the detection results are shown in
Table 6.
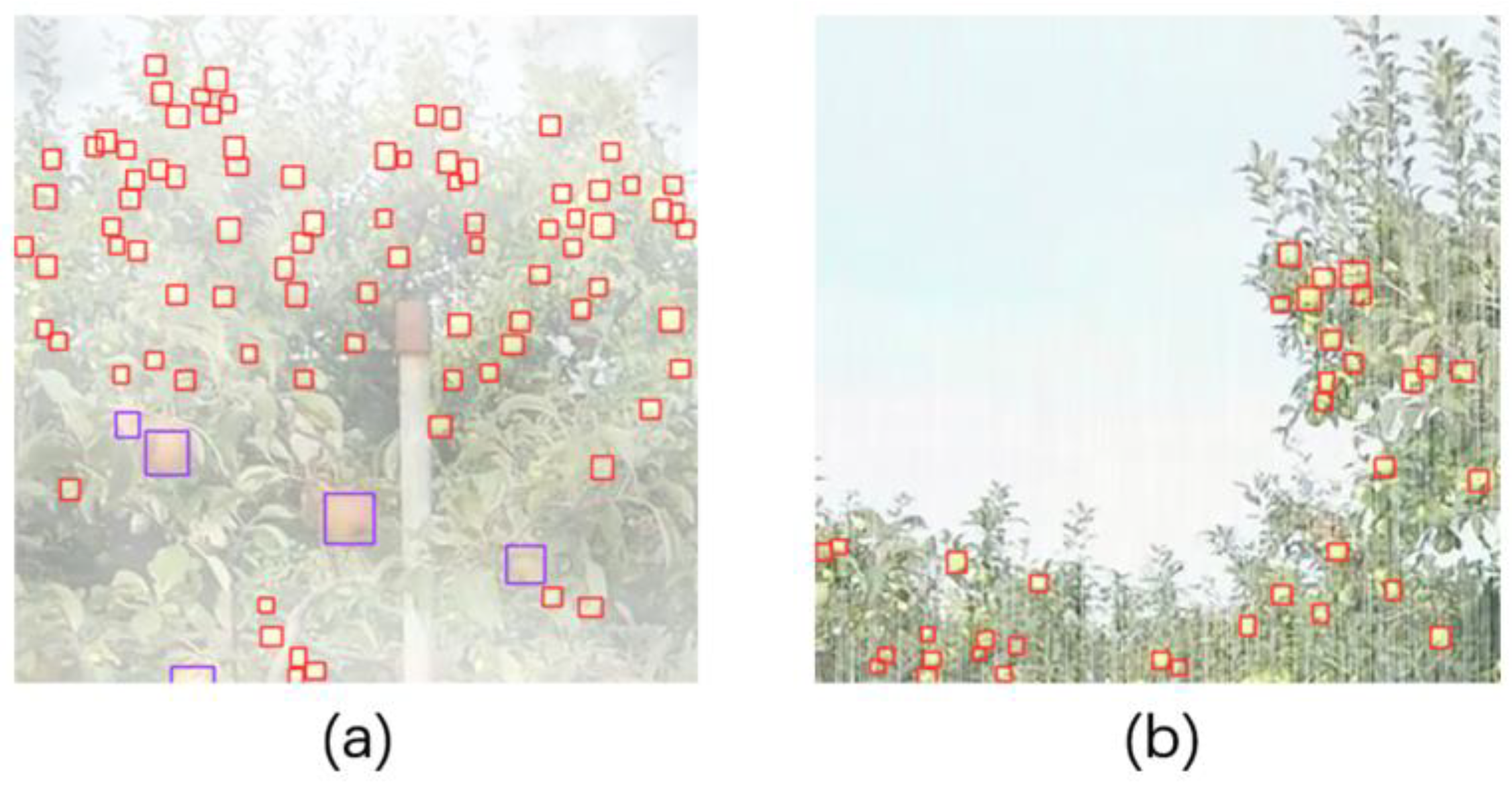
By comparing the experimental tests, it was found that the mAP of YOLOv7-tiny-Apple was the highest among the models, reaching 80.4%, which was 2% higher than that of YOLOv5, the best-performing model, ensuring the detection accuracy, while the number of parameters was also the smallest. Compared with Recall, the model sensitivity of YOLOv7-tiny-Apple is 6%, 5.1%, 3.6%, 8.9%, and 3.1% higher than the other models, respectively. When comparing Precision, SSD-MobileNetV2, and CenterNet-ResNet50 stand out more but have no advantage in the remaining areas. The value of mF1 was compared with several models and found that the value of this model was the highest and had better detection accuracy for detecting different classes of fruits. Relative to the FPS, the FPS of YOLOv7-tiny-Apple was 101.01Hz, which was higher than Faster Rcnn-VGG, SSD-MobileNetV2, CenterNet-ResNet50, YOLOv7, and YOLOx-tiny and lower than the other three models, but it is sufficient for fast detection of fruits. This shows the superiority of the present model compared to other models, and compared with other current YOLO small model series, we can see that the present model has higher detection accuracy while the model is also the smallest, which is sufficient to achieve lightweight, small target detection in the complex background of a natural environment, illustrating the superiority of the present experimental model.
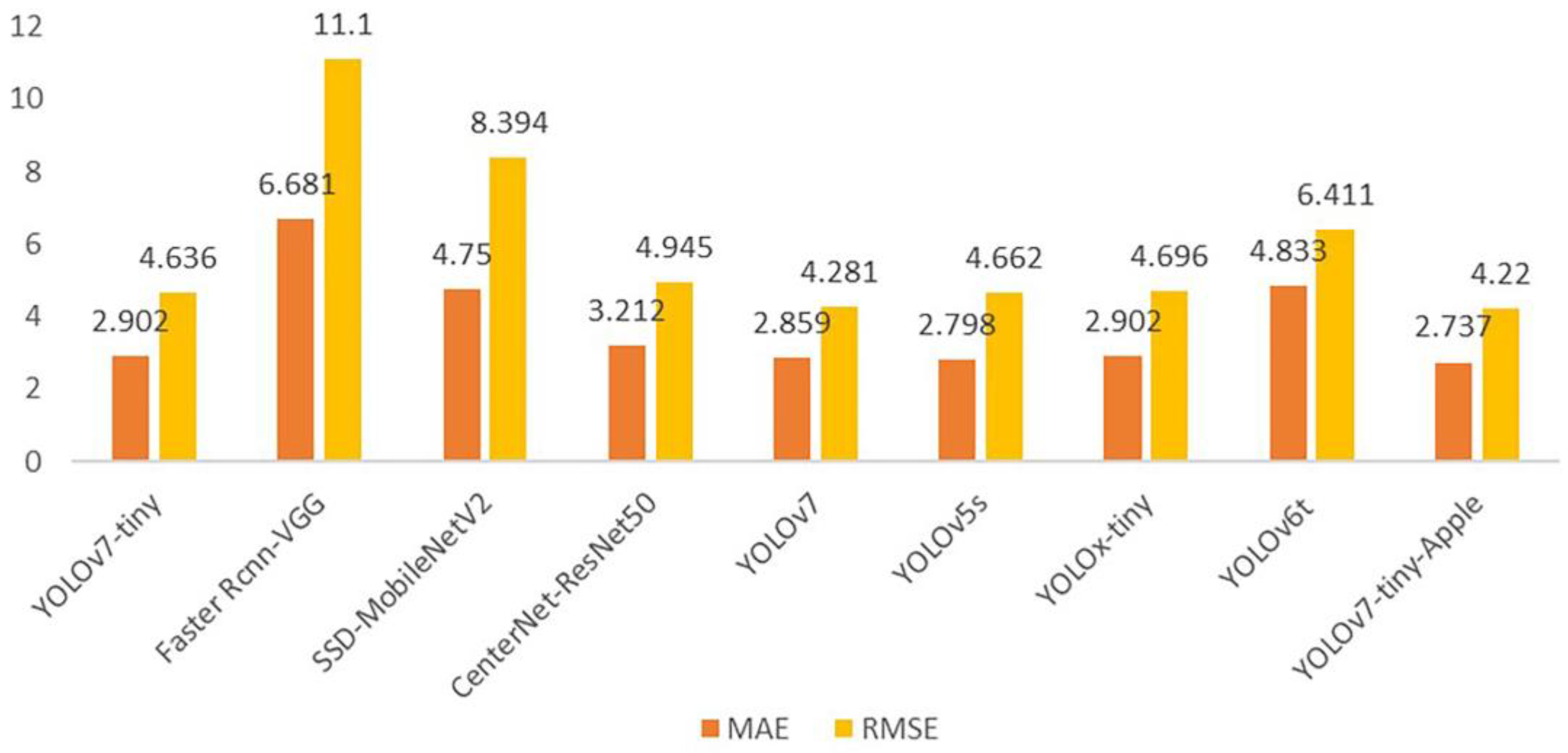
The test set photos were also used to detect the counting images from the comparison trials. To examine the efficacy of this experimental approach,
Figure 9 displays the MAE and RMSE counting impacts of the evaluation model. It is evident that the YOLOv7-tiny-Apple model’s MAE and RMSE, which are 2.737 and 4.220, respectively, better than the counting effects of other models and are the best counting effects. As shown in
Table 7.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}