1. Introduction
Rice, as one of the most crucial food crops globally, serves as a staple food for over 60% of the world’s population [
1]. As a key reproductive and nutritional organ of rice, the accurate detection of rice spikes plays an important role in various field management applications, such as yield prediction [
2], pest and disease detection [
3], nutritional diagnosis [
4], and growth stage identification [
5]. However, conventional manual sampling and counting techniques fall short in meeting the escalating demand for rice spike detection in the field. To efficiently acquire rice spike images, accurately detect rice spikes, and alleviate labor costs, there is an urgent need for a convenient, rapid, and precise method of rice spike detection.
Over the past two decades, numerous researchers have explored the use of computer vision techniques for identifying rice spikes. Traditional machine learning methods depend on manual feature engineering and classification for spike detection [
6,
7,
8]. However, the generalization ability of these methods drops significantly when the application domain or environment changes [
9,
10]. With the rapid development of artificial intelligence technology, deep learning-based object detection methods have demonstrated excellent performance in the agricultural field, introducing innovative possibilities for detecting various crops, including wheat [
11], maize [
12], sorghum [
13], rice [
14], and others [
15]. These methods are mainly classified into two categories: pixel-based semantic segmentation and target-based detection.
Pixel-based semantic segmentation is a method that utilizes complex deep learning models for the detailed analysis of pixel-level features, accurately classifying each pixel in an image into predefined categories. This approach is exemplified by the use of models such as FCN [
16], U-Net [
17], and Mask-RCNN [
18]. Hong et al. [
19] presented an enhanced Mask R-CNN for rice spike detection, integrating Otsu preprocessing of rice images under field conditions to improve rice spike detection efficiency. Target-based deep learning models fall into two categories, namely two-stage detection models and single-stage detection models. The first category is two-stage detection methods, known for their high detection accuracy but slower speed, such as Faster RCNN [
20], Cascade RCNN [
21], etc. Zhou et al. [
22] developed and implemented a spike detection and counting system based on improved region-based fully convolutional networks. By generating a series of bounding boxes containing the detected rice spikes and comparing the number of spikes in each box with manually labeled results, they demonstrated the accuracy of their system in rice detection and counting in the field. Tan et al. [
23] proposed a new architecture, RiceRes2Net, based on an enhanced Cascade RCNN, to enhance the efficiency of rice spike detection and to classify rice spike images captured by smart phones in the field. The utilization of deep learning models for spike detection in the above study showcases its effectiveness. The single-stage detection methods are well-known algorithms, such as SSD [
24], RetinaNet [
25], YOLOv5, YOLOv7 [
26], YOLOv8, etc. Sun et al. [
27] proposed an enhanced YOLOv4 method for detecting curved rice spikes, which utilized MobileNetv2 as a backbone network and combined focal point loss and attention mechanisms to enhance the detection of various types of rice spikes. Wang et al. [
28] introduced a novel extreme value suppression method based on the YOLOv5 network, demonstrating higher robustness and accuracy in recognizing rice spike images captured by smart phones.
However, these studies primarily focus on detecting rice within small regions, with the results often used for close-range field photography and counting of rice. In such scenarios, where rice sizes are normal, modifying the loss function (Wang) and utilizing lightweight modules (Sun) are applicable. In contrast, drone-captured field rice spike images present challenges such as a larger capture range, minor spikes, and severe occlusion issues at the image edges. Research on drone-based detection has provided valuable insights [
29,
30,
31]. Lyu et al. [
32] used a drone equipped with a high-resolution camera to capture rice spike images at a height of 1.2 m, and then employed Mask R-CNN for rice spike detection. The experimental results demonstrated that this method achieved an average precision of 79.46% and is suitable for field detection of rice spikes. Teng et al. [
33] enhanced the YOLOv5 model by incorporating a feature extraction module and integrating the SE attention mechanism. They developed an online rice spike detection platform based on this improved algorithm, demonstrating the feasibility of accurately detecting rice spikes in the field using drone. However, the abovementioned studies failed to consider the small size and prominent edge features of drone-captured rice spikes, making the proposed methods inadequate for accurate drone-based rice spike detection.
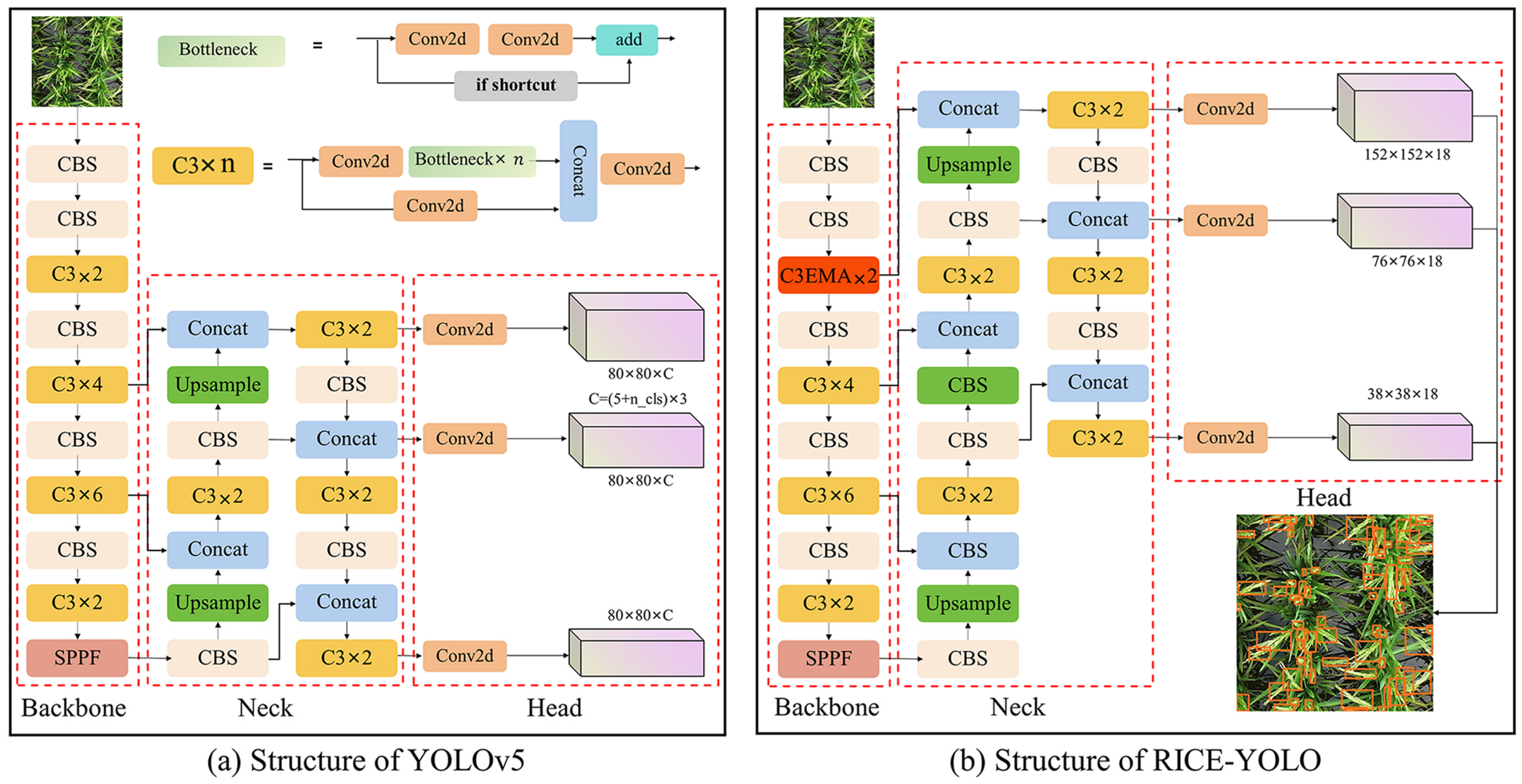
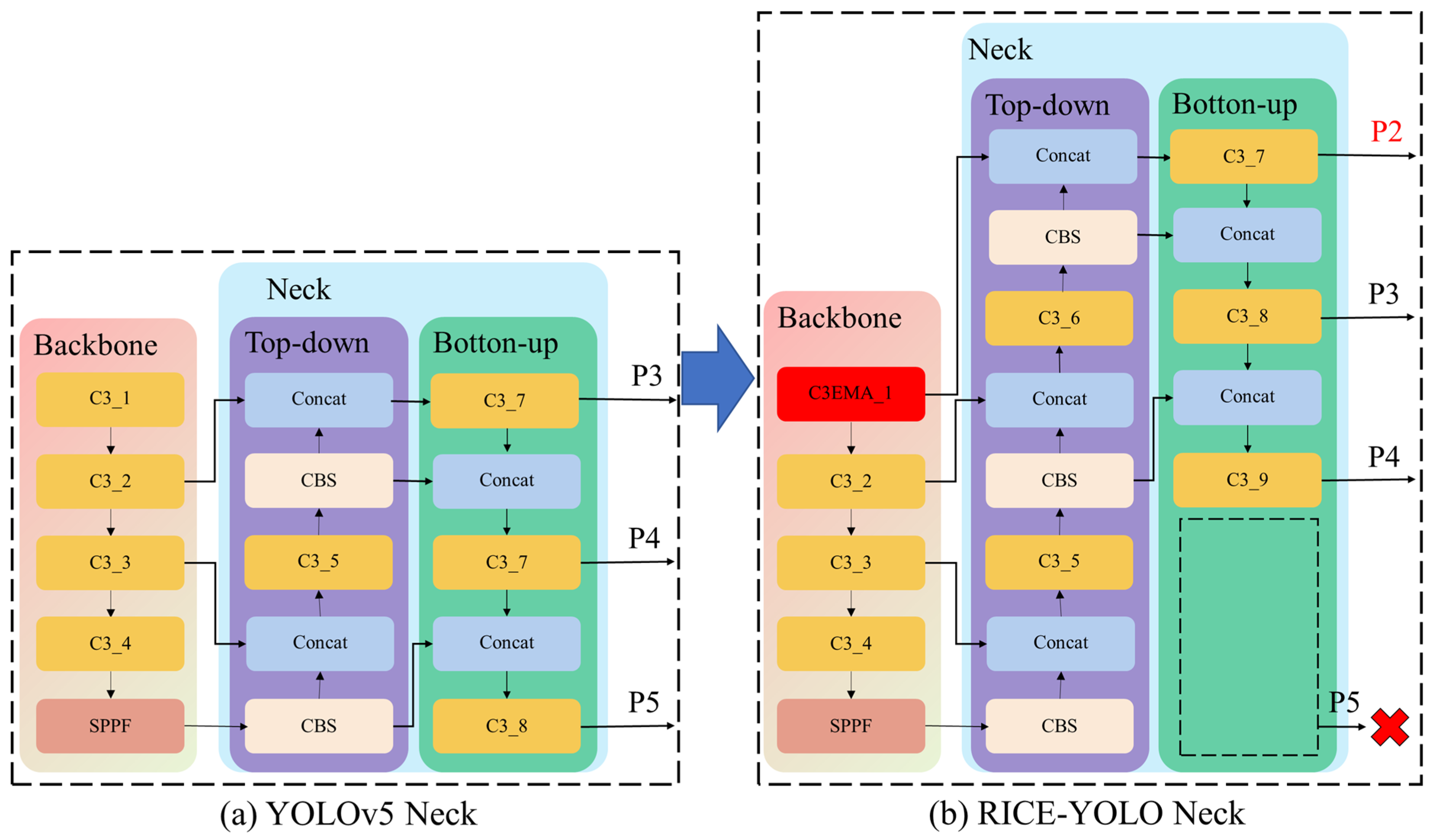
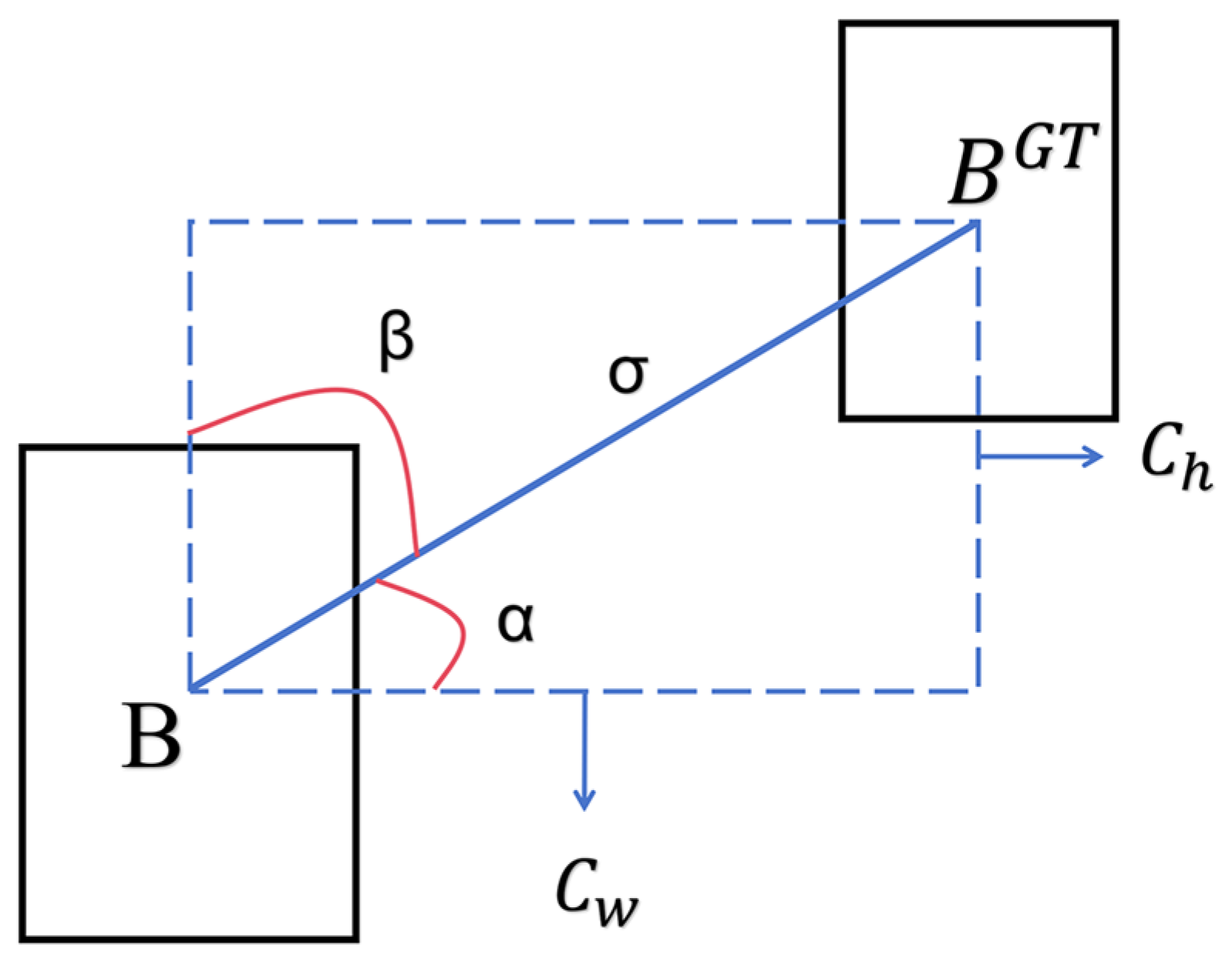
Therefore, in response to occlusion, dense distribution, and small targets in drone-captured rice spike images, a novel detection method was proposed, which can be deployed on drone platform for real-time detection of rice spikes in the field for future application. Given the requirement for a compact model size, YOLOv5 from the single-stage network was selected as the baseline model. Compared to existing studies, our research focuses on the challenging identification of rice spikes in the field with unique texture features. An EMA (efficient multiscale attention) attention mechanism emphasizing the width and height directions was introduced to enhance the model’s feature extraction capabilities for rice spike edges. Additionally, a novel neck network design was proposed, indicating that in the drone’s perspective, not only can small object detection layers be added but also detection heads for large objects can be removed. Furthermore, addressing edge deformation distortion, the incorporation of the SIOU (SCYLLA intersection over union) loss function may lead to favorable outcomes. Finally, the detection accuracy and practical applicability of the improved model are comprehensively evaluated via experimental analysis.
3. Results
3.1. Analysis Performance of C3-EMA Modules
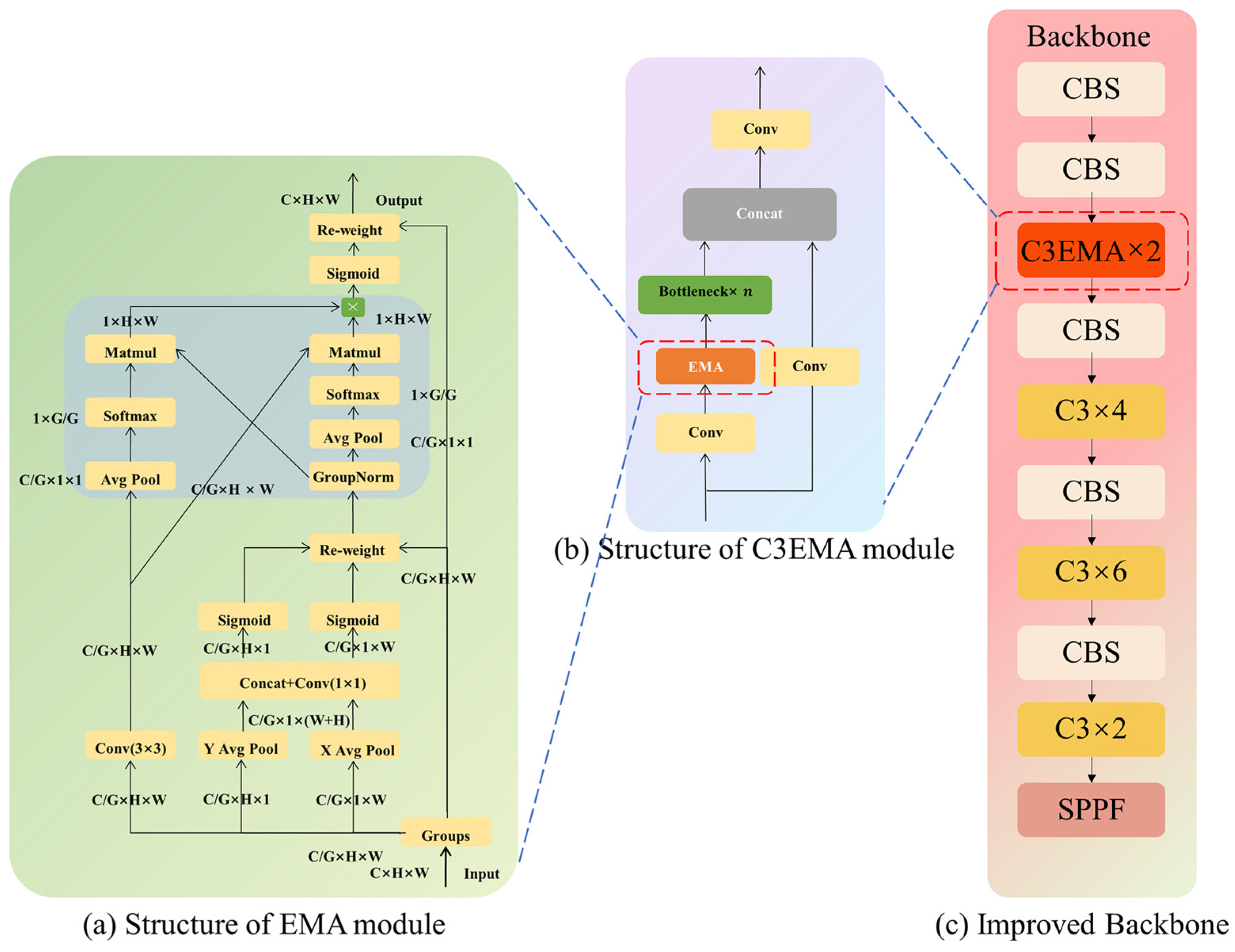
The C3 module adopts the CSPNet [
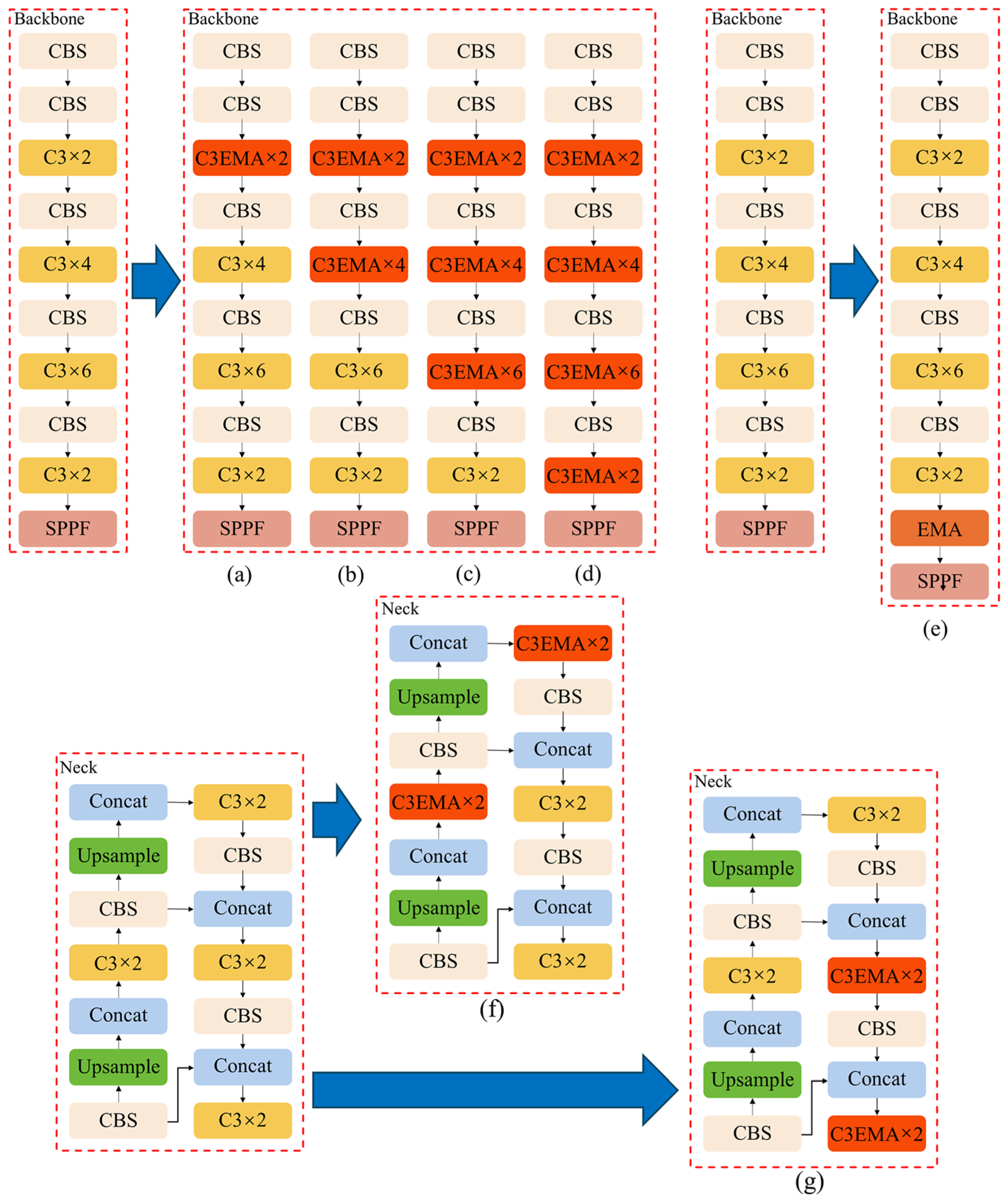
38] architecture, comprising a CSP Bottleneck with three convolutional layers. The C3 module splits the base layer’s feature maps into two segments, facilitating feature reintegration across layers, which is instrumental in augmenting the network’s depth and receptive field, thus enhancing feature extraction efficiency. In our study, the EMA modules were integrated into different C3 modules of YOLOv5, such as backbone network, neck network, and SPPF layer. Then, the detection performance was evaluated by experiment results.
The results are shown in
Table 3, the original YOLOv5 model yielded an
[email protected] accuracy of 92.7%. Substituting the backbone network’s C3 module with the C3-EMA module resulted in a notable augmentation of model accuracy, as shown in
Figure 10a,b compared with the YOLOv5, the integration of the EMA module in the first C3 of the backbone network led to a
[email protected] increase of 1.4% with
[email protected] value of 94.1%, while integration of the EMA module in the first two C3 of the backbone network led to a
[email protected] increase of 1.5%. However, in
Figure 10c,d, the further the EMA module was integrated in C3 module of the backbone network, the less the
[email protected] values increased. The application of the C3-EMA module within the neck network, specifically replaced the C3 module in the top-down and bottom-up components, as shown in
Figure 10f,g, yield only 0.1% and 0.2% increase in
[email protected] value, compared with YOLOv5. Furthermore, adding the EMA module between the CBS module and the SPPF module (
Figure 10e) in the backbone, achieved in a model accuracy of 93.1%, a modest uplift of 0.4% relative to the YOLOv5 model.
Upon analysis, EMA module integrated in C3 of backbone network performed better than that of Neck networks and SPPF module. In multilayer network models, as information traversed deeper layers, target features become fuzzy at deeper levels. Therefore, the introduction of the C3-EMA module at the outset of the backbone network is suggested to preserve the clarity and integrity of target features, facilitating the network in capturing key features more effectively and enhancing detection accuracy. Conversely, in deeper layers, such as the top-down components and bottom-up components in the neck network and similar positions within the backbone network, the network’s depth and complexity may introduce interference and blurring of target features, leading to the degradation of semantic information. In these instances, attention modules may struggle to focus effectively on target features due to the complexity of feature maps, potentially obscuring critical details. Hence, when designing network architectures, the consideration of target feature extraction at various layers is crucial to fully exploit attention mechanisms for enhancing feature extraction and detection performance.
In addition, to visualize the feature extraction capability of backbone network of YOLOv5 and RICE-YOLO, grad-class activation mapping (Grad-CAM) was adopted. In
Figure 11, the Grad-CAM used the gradient information of the feature map from different layers of YOLOv5 and RICE-YOLO, presented separately, to understand the importance of each feature point to the target decision. Each pixel of Grad-CAM contributes uniquely to the final classification result, with varying colors indicating the level of impact on the detection outcome: darker colors denote significant influence, while lighter colors suggest lesser impact. In
Figure 11b, four orange arrows point to rice spikes that were correctly identified by the YOLOv5 C3-EMA model but missed by the YOLOv5 model. This indicates that the introduction of the C3-EMA module enhances feature extraction, as the EMA module’s two subnetworks improve the model’s spatial and channel feature extraction capabilities, thereby enhancing rice spike detection performance. At the deeper layer of network, as shown in
Figure 11d, four red arrows pointing out four bright areas showed that the feature network of RICE-YOLO model can clearly distinguish four small-scale rice spikes, while the
Figure 11b,c fails to make this distinction The results indicated that the improved backbone network bolstered the model’s proficiency in extracting both global and local features.
3.2. Ablation Study
To comprehensively evaluate the effectiveness of the EMA attention mechanism, small object detection layer, and SIoU loss function proposed in this study, YOLOv5 was chosen as the baseline model for conducting comprehensive ablation experiments. The experimental results are summarized in
Table 4.
The results presented in
Table 4 demonstrated the significant impact of the proposed enhancement modules and methods on enhancing the accuracy of rice spike detection on drone image in field environment. In Model B, the integration of the C3-EMA module resulted in a 1.4% improvement in
[email protected] value, demonstrating the efficacy of the EMA attention mechanism in enhancing the model’s ability to integrate channel information. In Model C, addition of microscale detection layer (MDL) and elimination of detection layer for large targets in the PAN network, revealed a 1.8% enhancement in
[email protected] value, indicating the effectiveness of improvement in addressing the imbalance of target sizes in drone rice spike images. Model D exhibited a 0.5% performance increase upon incorporating the SIoU loss function, underscoring its advantage in mitigating errors associated with angular deformations at image edges and enhancing detection accuracy. The combined utilization of the three modules in model E, F, and G further improved model accuracy. Model G, the proposed RICE-YOLO with YOLOv5 incorporating C3-EMA, MDL, and SIoU loss function, achieved the best performance with
[email protected] value of 94.8% which showed a 2.1% performance enhancement while reducing parameters comparing with YOLOv5.
3.3. Detection Performance of RICE-YOLO at Different Growth Stages
To rigorously assess the rice spike detection performance of the proposed model across two critical growth stages, rice spike detection experiments were performed at heading stage and filling stage. Results are shown in
Table 5.
At heading stage, the RICE-YOLO model demonstrated remarkable precision, achieving a
[email protected] of 96.1% and a recall rate of 93.1%, outperforming the YOLOv5 model which posted metrics of 94.9% and 86.8%, respectively. In the subsequent filling stage, the performance of RICE-YOLO remained robust, with a
[email protected] of 86.2% and a recall rate of 82.6%, thereby exceeding the outcomes of YOLOv5, which recorded a
[email protected] of 83.2% and a recall rate of 77.2%.
Upon conducting a comparative analysis of detection performance at the two stages, it was observed that RICE-YOLO experienced a notable reduction in detection accuracy, from 96.1% during the heading stage to 86.2% in the filling stage. This phenomenon suggests a reduced complexity in detection tasks during the heading stage relative to the filling stage, likely due to the distinct phenotypic characteristics of the rice spikes at these growth stages, which in turn impacts the algorithm’s efficiency in the latter stage.
Overall,
Table 5 indicated that the RICE-YOLO model, in comparison to the original YOLOv5 model, not only achieved performance improvements of 2.1% in
[email protected] and 3.2% in recall but also showed better performance at two growth stage with an increase of 1.2% and 6.3% during the heading stage, and 3% and 5.4% during the filling stage, respectively. These results validate the capability of the RICE-YOLO model to effectively execute detection tasks for rice spikes captured via drones in field environment.
3.4. Performance Comparison with Other Deep Learning Models
To evaluate the RICE-YOLO more comprehensively, the RICE-YOLO was compared with other four classic deep learning models, including two single-stage models (YOLOv7 and YOLOv8) and two two-stage models (Faster R-CNN and Cascade R-CNN). YOLOv7 and YOLOv8 are newer versions in the YOLO series gaining significant attention. Fast R-CNN demonstrates stable performance as a traditional two-stage method, while Cascade R-CNN enhances detection with its cascading structure, serving as a widely adopted improved model. The rice spike dataset in
Section 2.1 was used, and
[email protected], Recall, FPS, Params and FLOPs were adopted as evaluation metrics. The comparative results are presented in
Table 6.
According to
Table 6, the proposed RICE-YOLO model achieves a
[email protected] of 94.8% and a Recall of 87.6%, meeting the real-time detection requirements for rice spike images in field conditions. Compared to the YOLOv8 model introduced in 2023 within the YOLO series, the RICE-YOLO model outperforms in
[email protected] and Recall, increasing by 4.7% and 5.5%, respectively. RICE-YOLO model was also superior to the YOLOv7 in all aspects except for FPS, exhibiting improvements of 2% in
[email protected] and 2.8% in recall. Notably, it achieves a reduction of 20.46 in parameter count and 48.5 in FLOPs. Furthermore, the RICE-YOLO and YOLOv7 perform better than the two-stage models in both the
[email protected] and Recall.
In addition,
Figure 12 demonstrates the rice spike detection results obtained from six different models. RICE-YOLO shows superior detection performance when it comes to identifying small, aligned, and partially obscured rice spikes that are commonly found during the rice growth stages. By introducing a small target detection layer and removing the large target detection head, this model ensures accurate detection of small-scale rice spikes. In the scenario depicted in
Figure 12a, most rice spikes are small in scale. RICE-YOLO successfully detects all spikes, while YOLOv8, YOLOv5, Faster RCNN, and Cascade RCNN falsely detected the leaves as rice spikes. In
Figure 12b, YOLOv8, YOLOv7, YOLOv5, and Faster RCNN all missed detected a small rice spike. In field environments, rice spikes often grow densely, forming aligned spikes or spikes overlapped by spikes, stems, and leaves. These situations can make it challenging for deep learning models to accurately detect spikes, leading to missed or false detection. In
Figure 12c, two spikes grow side by side, with the purple arrows highlighting the repeated detections of these spikes by YOLOv5 and YOLOv8. In
Figure 12d, the blue arrows show instances where those models struggled to detect closely arranged rice spikes, and the purple arrows point to the prediction boxes where Faster RCNN and Cascade RCNN repeat detections due to closely arranged multiple rice spikes, whereas RICE-YOLO effectively detect the spikes in both situations. In
Figure 12e,f, rice spikes are overlapped by leaves, the RICE-YOLO precisely detection the whole rice spikes, however, the YOLOv8, YOLOv7, YOLOv5, Faster RCNN, and Cascade RCNN recognized the whole spike as two separated spikes, causing repeated detection.
To further evaluate the rice spike detection performance of the RICE-YOLO, models above were tested under complex field environment, such as excessive light, strong shade, and water reflections.
Figure 13 presents the detection results of six models under these complex field conditions. In
Figure 13a, several rice spikes were missed detected by YOLOv5, YOLOv7, and YOLOv8, which can be attributed to spikes with overexposure from strong lighting, but RICE-YOLO can successfully detect these rice spikes. In
Figure 13b, some leaves in strong light exposure were falsely detected as rice spikes by YOLOv5, YOLOv7, YOLOv8, and two two-stage models, whereas RICE-YOLO avoided this situation. In
Figure 13c, a leaf in shade is falsely detected as rice spike by YOLOv5 and YOLOv8. In addition, a rice spike in shade, as shown in
Figure 13d, is missed detected by YOLOv5 and YOLOv8, and caused repeated detection by YOLOv7, with the two two-stage models misclassifying the background as spikes. In case of water surface reflections and dark light, as shown in
Figure 13e,f, YOLOv5, YOLOv7, and YOLOv8 falsely detected background as rice spikes. These results demonstrate that the proposed RICE-YOLO model effectively identifies rice spikes in various field environments.
In the aspect of computational complexity, all the single-stage models were faster than the two-stage models. The FPS of Faster RCNN and Cascade RCNN were 14 and 12, respectively. Meanwhile, the FPS of RICE-YOLO, YOLOv7, and YOLOv8 were 36, 45, and 82, respectively; the proposed RICE-YOLO had a lower FPS than YOLOv8 and YOLOv7.
The presented results showed that the RICE-YOLO model proposed in this paper can learn a more representative set of features which helped better locate the rice spikes at different growth stages, thus met the requirements of high recognition accuracy. However, while RICE-YOLO demonstrates superior recognition accuracy, it was at the expense of the time consumption, compared to other YOLO series models, indicating room for improvement.
4. Discussion
This study provides significant insights into the detection of rice spikes in drone-captured images in agricultural fields, with a focus on optimizing rice spike detection and local drone perspective detection.
To improve detection precision, RICE-YOLO was proposed for rice spike detection by designing three new scale detection branches, introducing EMA attention mechanism, and integrating the SIoU loss function. Compared with YOLOV5m, RICE-YOLO increased by 2.1% on
[email protected], and with improvements of 1.2% and 3.0% in
[email protected] during the heading and the filling stages, respectively. Finally, RICE-YOLO achieved a
[email protected] of 94.8% on our in-field rice spike dataset, ranking highest among five representative object detection models in comparison. In comparison to the research conducted by Wang [
28], which also centered on the detection of rice spikes, our proposed model demonstrates robust performance in more intricate drone perspectives and natural field lighting conditions, despite both studies utilize the YOLO series as a baseline. Secondly, Wang’s study employed cameras at close range to capture rice spike images in limited paddy field areas, whereas our model, trained to detect rice spikes from drone angles, enhances robustness to viewpoint variations and practicality in field operations. Furthermore, our research includes separate optimizations for small targets and occluded rice spikes, enhancing the model’s applicability in complex field aerial scenarios with dense rice spikes and occluded targets. It is noteworthy that Wang conducted preliminary research on eliminating duplicate detections, which warrants further investigation in future studies. In summary, our model effectively meets the requirements in practical field applications, exhibiting outstanding performance in both detection speed and accuracy.
Our model demonstrates commendable detection results, primarily attributed to our targeted optimization strategies. Firstly, a novel detection branch with three scales guided the network to focus on rice spike targets ranging from medium to small scales, enabling the network to effectively capture features of targets with corresponding sizes. While the common practice for improvement in drone perspectives is to add more detection branches, occasionally reducing redundant scale detection branches can enhance efficiency. This not only simplifies the network structure but also has the potential to boost network performance by eliminating unnecessary gradients and promoting targeted feature learning. This concept holds promise for extension to other detection tasks involving medium and small targets. Secondly, the EMA module introduced in our model directs more attention to the spatial width and height features of rice spikes, enhancing the model’s detection capability for spikes with prominent edge features, which are crucial for identifying occluded rice spikes and improves our model’s detection performance in challenging scenarios.
In our study, RICE-YOLO effectively mitigated incorrect detections of occluded and small rice spikes.
Figure 11 illustrates the capacity of RICE-YOLO to rectify false detections, duplication detections and missed detections of small, densely arranged, and occluded rice spikes. In particular, as shown in
Figure 13, RICE-YOLO demonstrates robust performance in identifying rice spikes under field conditions with lighting shadows, while other well-performing models failed to do so. Thus, RICE-YOLO could effectively detect small, occluded, and rice spikes under varying lighting conditions. However, similarly to other advanced target detection models, RICE–YOLO has limitations in detecting highly occluded or excessive light. The detection of these targets in two-dimensional images remains a challenging task.
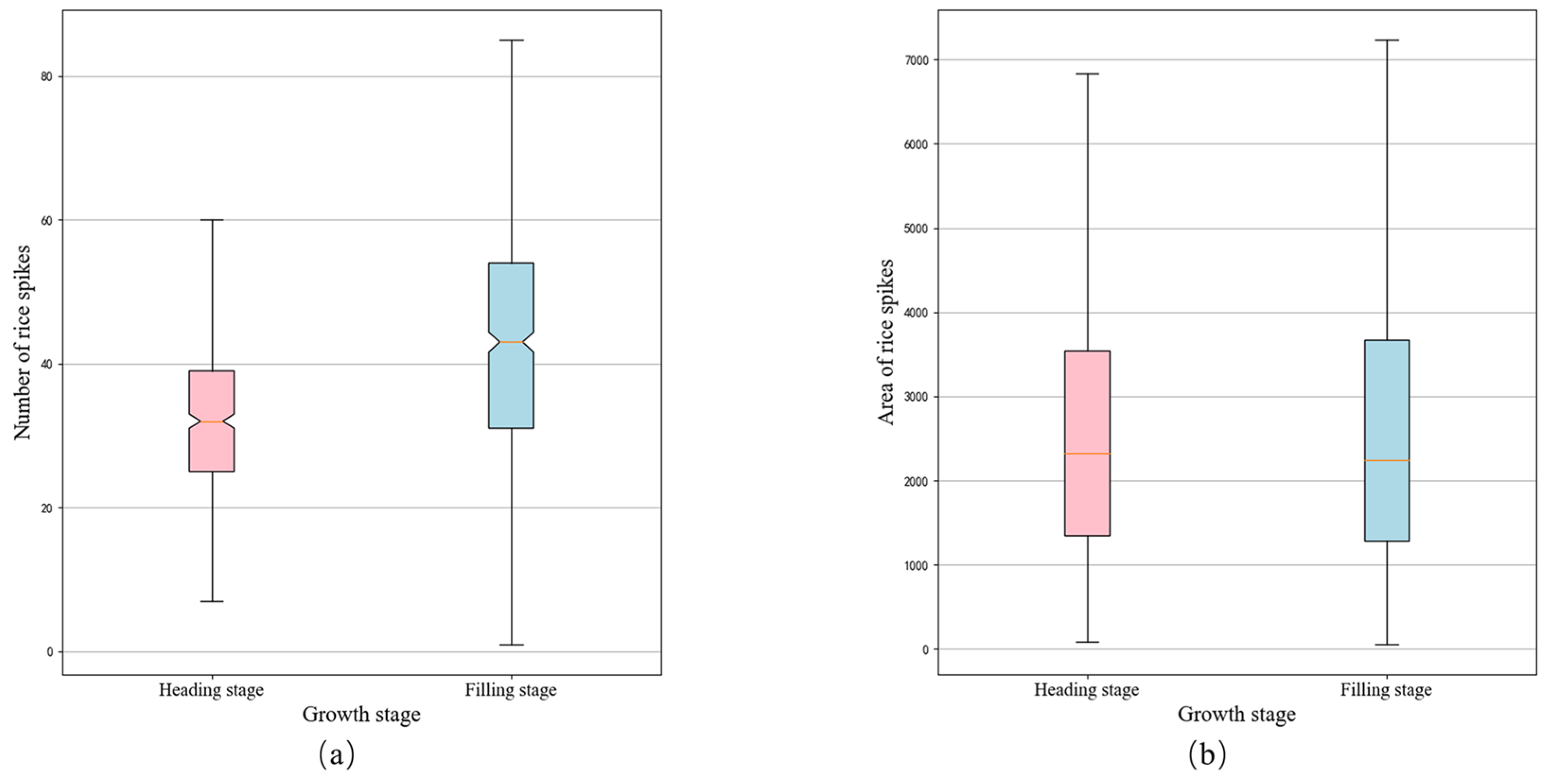
The filling stage of the rice spikes contains instances of significant occlusion and excessive lighting conditions. A detailed analysis of the model’s reduced accuracy across the two stages was conducted. The box plots in
Figure 14 depict the distribution characteristics of spikes in images from the two rice growth stages. Observing
Figure 14a,b, it is evident that the median number of rice spikes per image increased from 31 during the heading stage to 43 during the grain filling stage, with similar in area. This observation suggests a significant increase in spike density within a single image as rice plants mature. Furthermore, visual representation of the datasets from the two stages in
Figure 15 reveals distinct characteristics during the grain filling stage, with noticeable bending of spikes, common occurrences of occlusion, and dense arrangements. Additionally, to enhance the algorithm’s capacity against excessed light, some images were captured closer to noon during the filling stage. All these factors together led to a decline in the accuracy and recall of the filling stage.
The performance of the YOLO Series varied. As an advanced version in the YOLO series, YOLOv7 has made significant improvements by incorporating technologies like E-ELAN (extended-efficient layer attention network), RepConv [
39], and an auxiliary head. These enhancements have increased its parameter count and computational complexity, measured in FLOPS, while also leading to a slight accuracy boost of 0.2%. This incremental improvement aligns with the expected outcomes considering the model’s enhanced capabilities. On the other hand, YOLOv8, another Ultralytics product [
34], has shown a noticeable drop in accuracy to 90.2% on the same dataset. This decrease can be mainly attributed to YOLOv8′s architecture, which was specifically optimized for the COCO dataset, potentially limiting its adaptability to the dataset used in this study. The architectural changes and optimizations with YOLOv5 to YOLOv8 are outlined in
Figure 16.
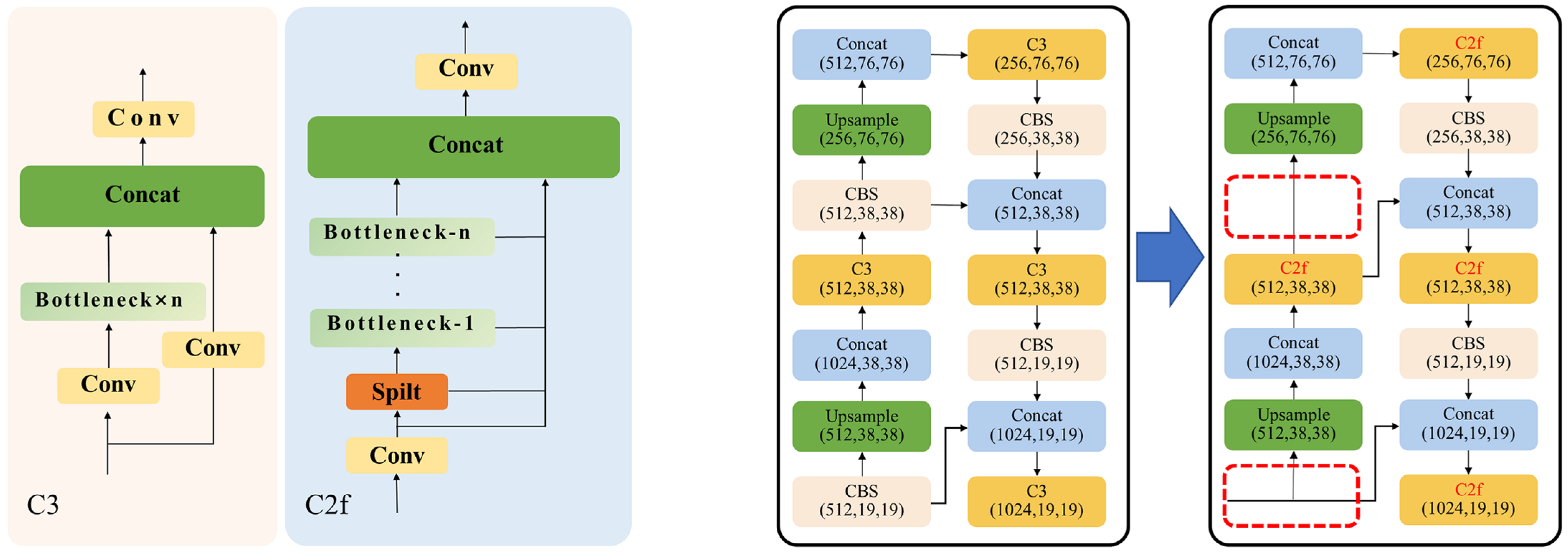
To enhance its performance in detecting larger objects within the COCO dataset, YOLOv8 has replaced the C3 module used in YOLOv5 with the C2f (CSP bottleneck with two convolutions) module.
Figure 16a details the differences between the two modules. The C2f module adds an extra path between each bottleneck, merging with other modules, while removing the important shortcut connection between the first Conv module and the output in the C3 module. This architectural change shifts the model’s focus towards deeper, convolutionally processed features, enhancing its capacity to detect larger objects. However, the elimination of shortcut connections leads to a loss of shallow information from the initial input features, which is not reconcatenated in later stages, resulting in reduced accuracy in detecting smaller objects. Additionally, as depicted in
Figure 16b, YOLOv8 has eliminated the convolutional layer in the upsample phase of the top-down components in the neck network featured in YOLOv5. This further reduces YOLOv8′s feature extraction capability, negatively impacting its performance in more intricate detection tasks.
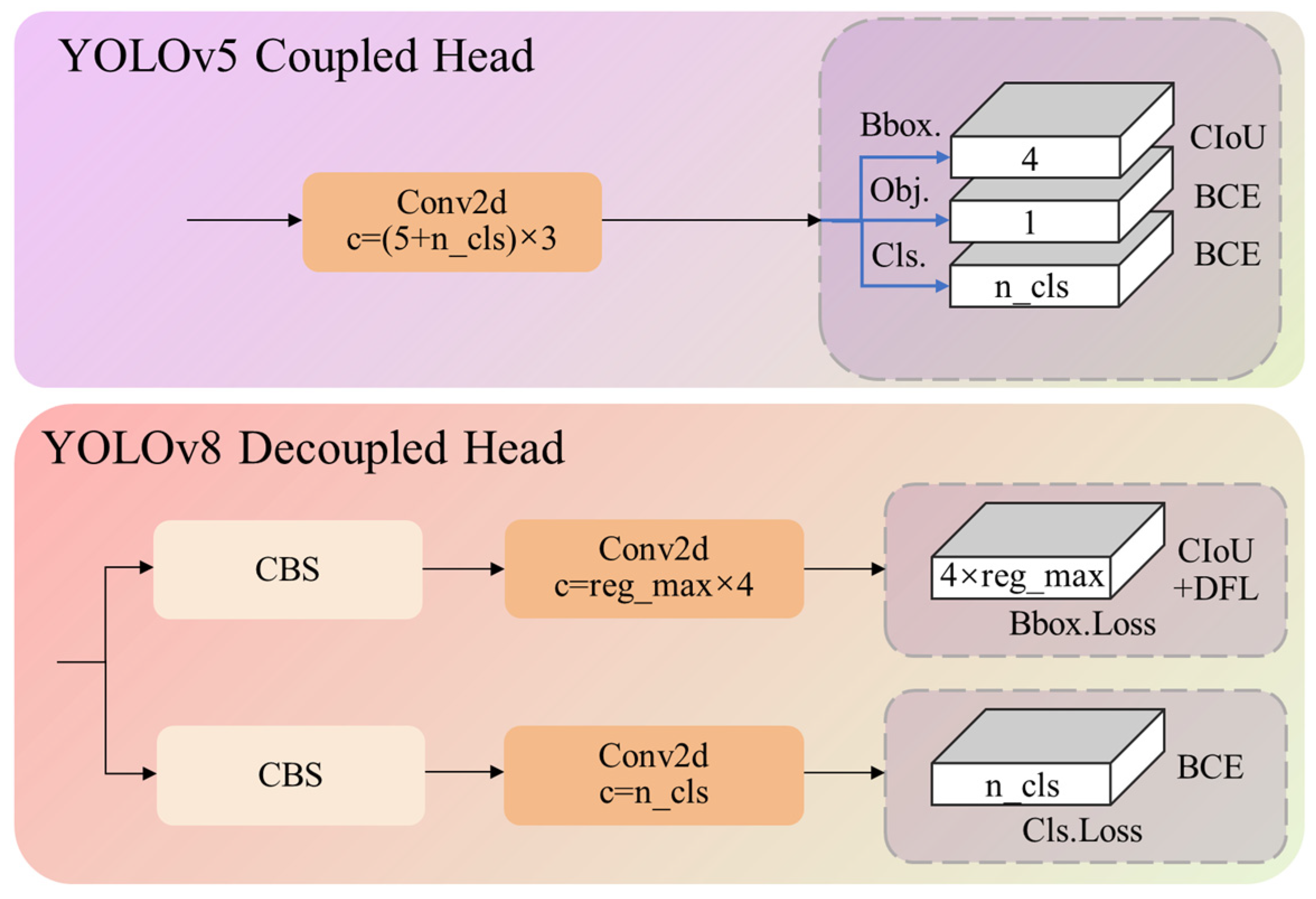
Moreover, YOLOv8 brings a significant refinement to its architecture by implementing a decoupled-head structure, as shown in
Figure 17. This signifies a departure from the original YOLOv5, which utilized a unified detection head sharing parameters for classification and regression tasks. In contrast, YOLOv8 distinctively separates the classification and regression functions, abolishing the shared-parameter mechanism. This architectural advancement aims to enhance the model’s accuracy and efficiency by assigning dedicated pathways for the distinct tasks of object classification and bounding box regression.
The processes of classification and localization have distinct objectives in object detection. Classification focuses on identifying the most similar category among predefined classes, while localization adjusts bounding box parameters to match ground truth (GT) box coordinates closely [
40]. Implementing these tasks allows for faster model convergence. However, in this study, focusing on only the single rice spike category and considering the challenges of their dense and diminutive nature, this approach does not improve precision. Therefore, it is crucial to evaluate the model’s design against the specific requirements of the object detection task to choose an architecture that ensures the highest detection efficacy.
While the effectiveness of RICE-YOLO in detecting rice spikes in the field has been validated, there is still room for improvement. Firstly, due to the complexity condition in the field and the significant occlusion with the growth of rice, this model has inevitable occurrences of false detections, duplication detections and missed detections. One potential solution is to use the generative adversarial networks to connect separated rice spikes, enhancing the training of better performance detection models. Secondly, in our dataset, one image is captured for one rice field plot. Since the drone’s field of view (FOV) is relatively large, the rice plants in the center of the image appear more upright, where occlusion phenomenon for rice spikes is occurring less. However, the further away the rice plants are from the center of the FOV, the more inclined they will be in the image, and the more the occlusion phenomenon will be occurring. In practical applications, a possible approach to reduce such phenomenon is to capture additional images for the rice spikes that are originally at the edges of the image. Moreover, excessive lighting conditions significantly impact detection accuracy. While the current improvement algorithm assumes extreme sampling conditions at noon, intense lighting can still adversely affect detection accuracy in practical scenarios. A viable approach would be to conduct sampling in the morning or afternoon to achieve better precision for rice spike detection.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}