Dark Matter of Primate Genomes: Satellite DNA Repeats and Their Evolutionary Dynamics




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Satellite DNA Abundance in Different Primate Lineages

3. General and Primate-Specific satDNA Types
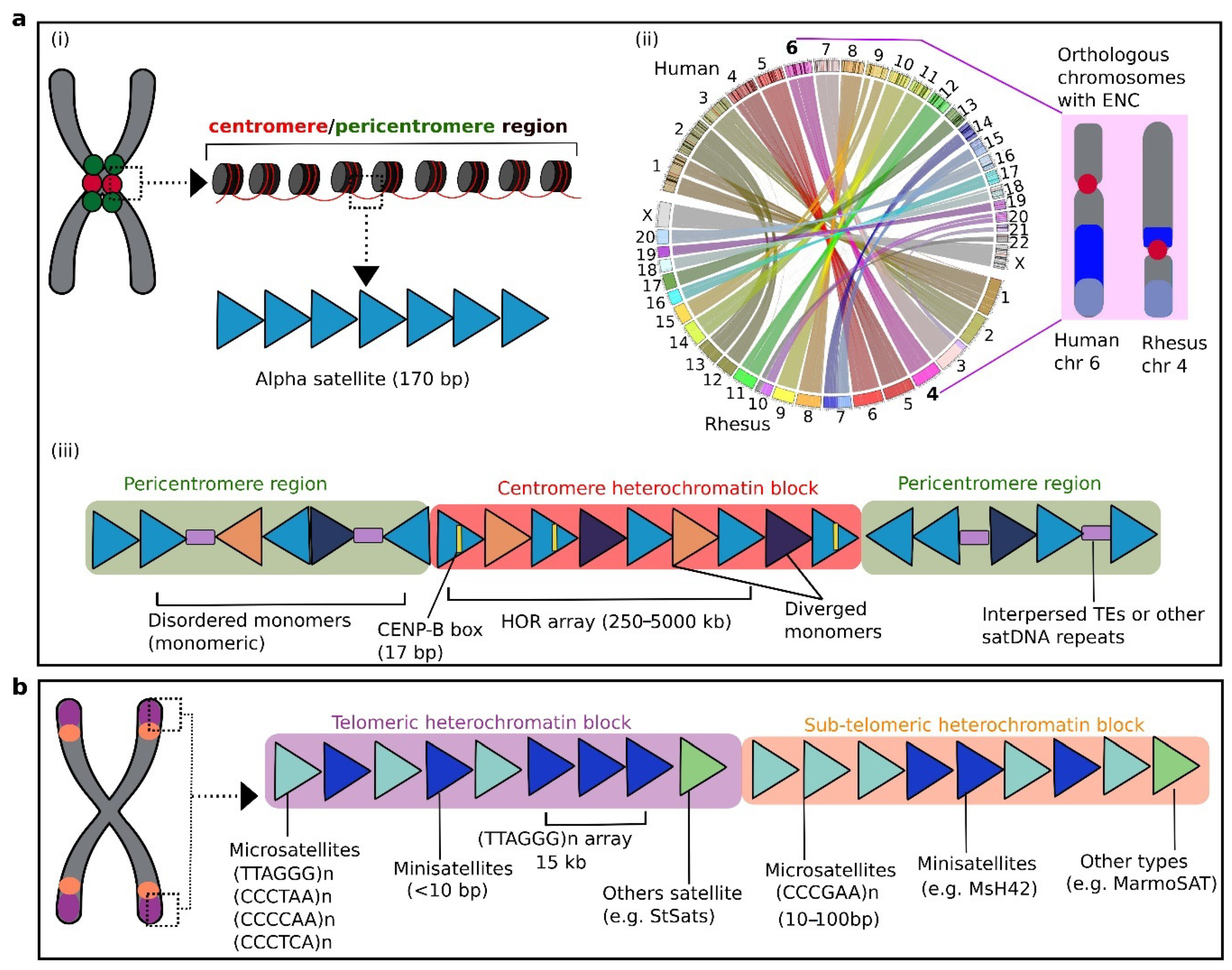
3.1. Centromeric and Pericentromeric satDNA: Primate-Specific Alpha Satellites and HORS
3.2. Telomeric and Subtelomeric satDNA

4. Sex Chromosomes: A High-Impact Arena for satDNA
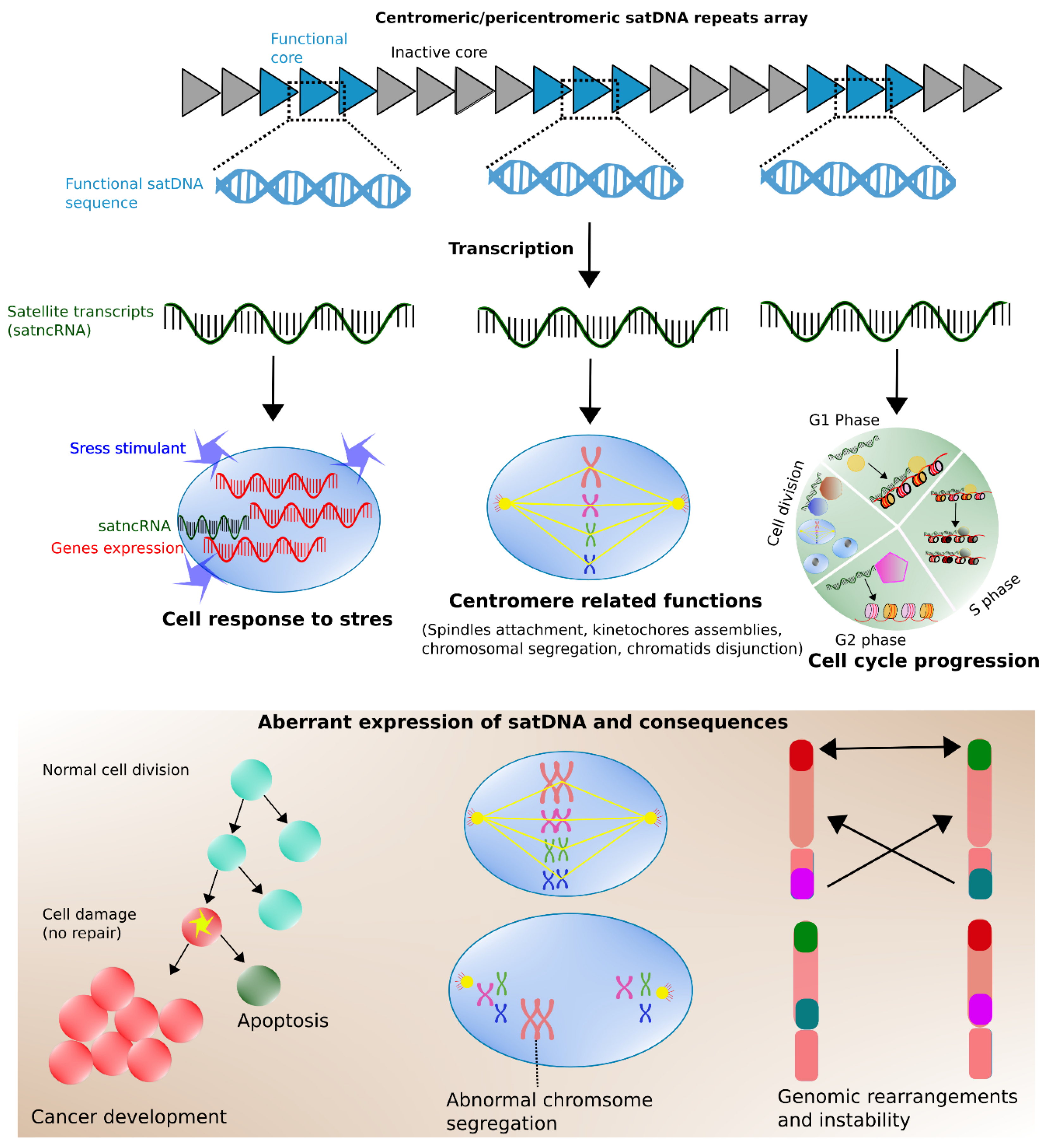
5. Transcription of Satellite Repeats: Hidden Switches for Dialing Gene Expression Up and Down
6. Species and Population-Specific Variation: An Auspicious satDNA Feature for Genome Evolution
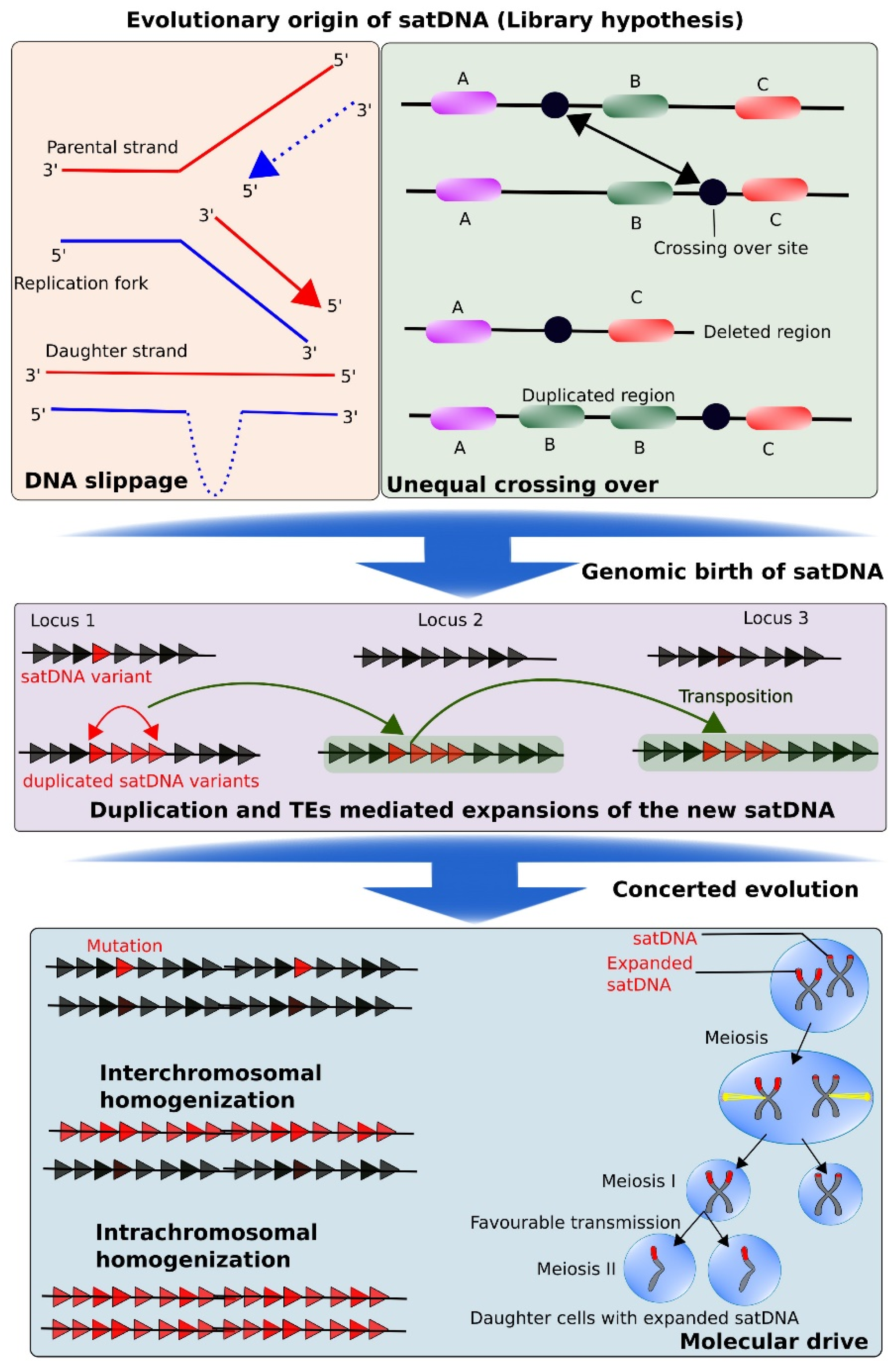
7. Evolutionary Birth and Expansion of Satellite DNA
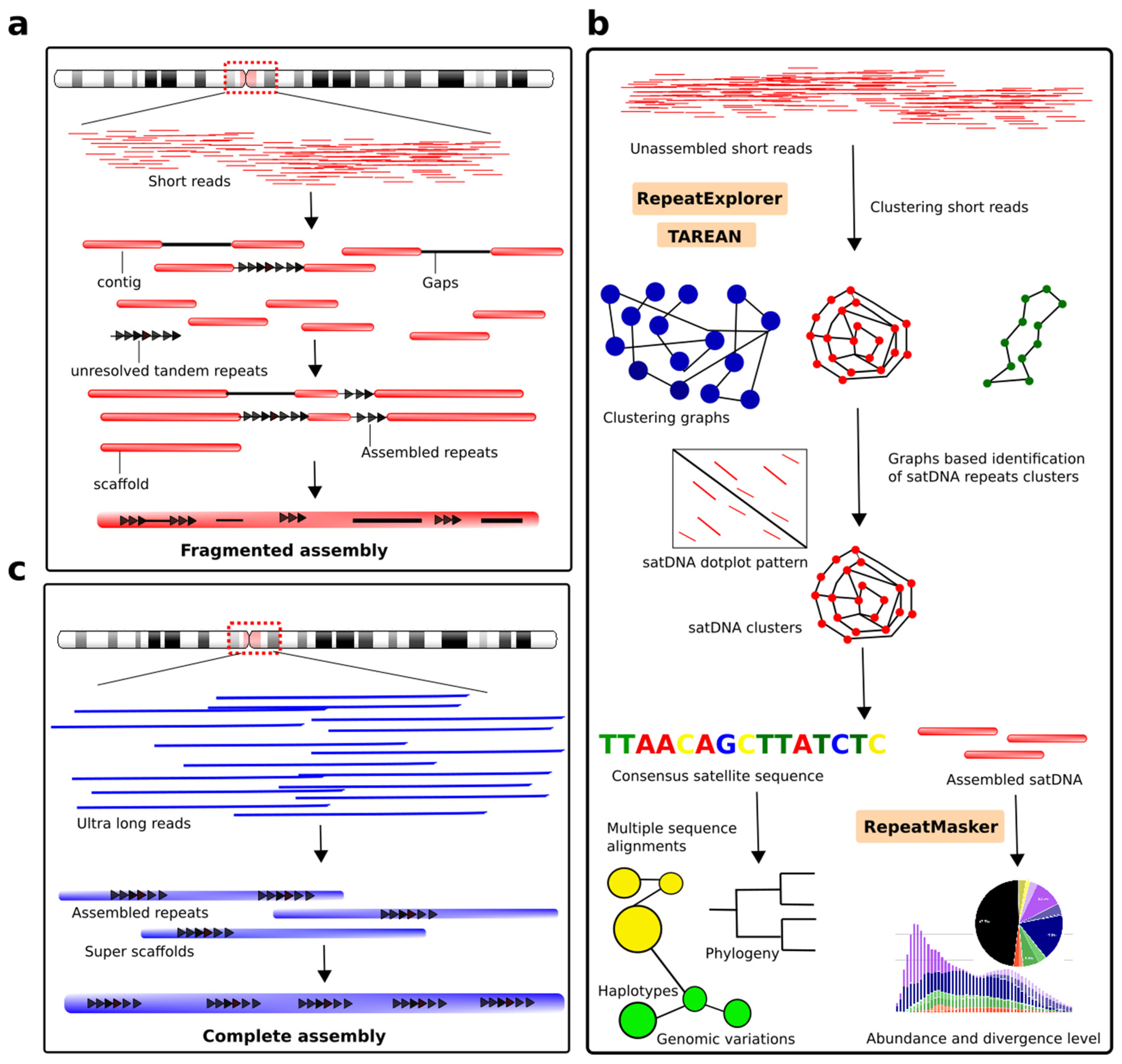
8. Enlightening the Dark Matter of the Genome: Modern Approaches and Challenges in Detecting satDNA Repeats
9. Concluding Remarks
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Rogers, J.; Gibbs, R.A. Comparative primate genomics: Emerging patterns of genome content and dynamics. Nat. Rev. Genet. 2014, 15, 347–359. [Google Scholar] [CrossRef] [PubMed]
- Enard, W.; Pääbo, S. Comparative primate genomics. Annu. Rev. Genom. Hum. Genet. 2004, 5, 351–378. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mikkelsen, T.S.; Hillier, L.W.; Eichler, E.E.; Zody, M.C.; Jaffe, D.B.; Yang, S.P.; Enard, W.; Hellmann, I.; Lindblad-Toh, K.; Altheide, T.K.; et al. Initial sequence of the chimpanzee genome and comparison with the human genome. Nature 2005, 437, 69–87. [Google Scholar] [CrossRef]
- Gibbs, R.A.; Rogers, J.; Katze, M.G.; Bumgarner, R.; Weinstock, G.M.; Mardis, E.R.; Remington, K.A.; Strausberg, R.L.; Venter, J.C.; Wilson, R.K.; et al. Evolutionary and biomedical insights from the rhesus macaque genome. Science 2007, 316, 222–234. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alföldi, J.; Lindblad-Toh, K. Comparative genomics as a tool to understand evolution and disease. Genome Res. 2013, 23, 1063–1068. [Google Scholar] [CrossRef] [Green Version]
- Little, P.F.R. Structure and function of the human genome. Genome Res. 2005, 15, 1759–1765. [Google Scholar] [CrossRef] [Green Version]
- Chi, K.R. The dark side of the human genome. Nature 2016, 538, 275–277. [Google Scholar] [CrossRef]
- Miga, K.H.; Koren, S.; Rhie, A.; Vollger, M.R.; Gershman, A.; Bzikadze, A.; Brooks, S.; Howe, E.; Porubsky, D.; Logsdon, G.A.; et al. Telomere-to-telomere assembly of a complete human X chromosome. Nature 2020, 585, 79–84. [Google Scholar] [CrossRef]
- Biémont, C. Genome size evolution: Within-species variation in genome size. Heredity (Edinb) 2008, 101, 297–298. [Google Scholar] [CrossRef]
- Srikulnath, K.; Uno, Y.; Matsubara, K.; Thongpan, A.; Suputtitada, S.; Apisitwanich, S.; Nishida, C.; Matsuda, Y. Chromosomal localization of the 18S–28S and 5s rRNA genes and (TTAGGG)n sequences of butterfly lizards (Leiolepis belliana belliana and Leiolepis boehmei, Agamidae, Squamata). Genet. Mol. Biol. 2011, 34, 582–586. [Google Scholar] [CrossRef]
- Ambrožová, K.; Mandáková, T.; Bureš, P.; Neumann, P.; Leitch, I.J.; Koblížková, A.; Macas, J.; Lysak, M.A. Diverse retrotransposon families and an AT-rich satellite DNA revealed in giant genomes of Fritillaria lilies. Ann. Bot. 2011, 107, 255–268. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Scalvenzi, T.; Pollet, N. Insights on genome size evolution from a miniature inverted repeat transposon driving a satellite DNA. Mol. Phylogenet. Evol. 2014, 81, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Ahmad, S.F.; Singchat, W.; Jehangir, M.; Panthum, T.; Srikulnath, K. Consequence of paradigm shift with repeat landscapes in reptiles: Powerful facilitators of chromosomal rearrangements for diversity and evolution (running title: Genomic impact of repeats on chromosomal dynamics in reptiles). Genes 2020, 11, 827. [Google Scholar] [CrossRef] [PubMed]
- Gregory, T.R.; Nicol, J.A.; Tamm, H.; Kullman, B.; Kullman, K.; Leitch, I.J.; Murray, B.G.; Kapraun, D.F.; Greilhuber, J.; Bennett, M.D. Eukaryotic genome size databases. Nucleic Acids Res. 2007, 35, D332–D338. [Google Scholar] [CrossRef] [Green Version]
- Kidwell, M.G. Transposable elements and the evolution of genome size in eukaryotes. Genetica 2002, 115, 49–63. [Google Scholar] [CrossRef]
- Hancock, J.M. Genome size and the accumulation of simple sequence repeats: Implications of new data from genome sequencing projects. Genetica 2002, 115, 93–103. [Google Scholar] [CrossRef]
- Liu, G.; Thomas, J.; Touchman, J.; Blakesley, B.; Bouffard, G.; Beckstrom-Sternberg, S.; McDowell, J.; Maskeri, B.; Thomas, P.; Zhao, S.; et al. Analysis of primate genomic variation reveals a repeat-driven expansion of the human genome. Genome Res. 2003, 13, 358–368. [Google Scholar] [CrossRef] [Green Version]
- Marques-Bonet, T.; Ryder, O.A.; Eichler, E.E. Sequencing primate genomes: What have we learned? Annu. Rev. Genomics Hum. Genet. 2009, 10, 355–386. [Google Scholar] [CrossRef] [Green Version]
- Treangen, T.J.; Salzberg, S.L. Repetitive DNA and next-generation sequencing: Computational challenges and solutions. Nat. Rev. Genet. 2012, 13, 36–46. [Google Scholar] [CrossRef]
- Melters, D.P.; Bradnam, K.R.; Young, H.A.; Telis, N.; May, M.R.; Ruby, J.G.; Sebra, R.; Peluso, P.; Eid, J.; Rank, D.; et al. Comparative analysis of tandem repeats from hundreds of species reveals unique insights into centromere evolution. Genome Biol. 2013, 14, R10. [Google Scholar] [CrossRef]
- Charlesworth, B.; Jarne, P.; Assimacopoulos, S. The distribution of transposable elements within and between chromosomes in a population of Drosophila melanogaster. III. Element abundances in heterochromatin. Genet. Res. 1994, 64, 183–197. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prakhongcheep, O.; Hirai, Y.; Hara, T.; Srikulnath, K.; Hirai, H.; Koga, A. Two types of alpha satellite DNA in distinct chromosomal locations in Azara’s owl monkey. DNA Res. 2013, 20, 235–240. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prakhongcheep, O.; Chaiprasertsri, N.; Terada, S.; Hirai, Y.; Srikulnath, K.; Hirai, H.; Koga, A. Heterochromatin blocks constituting the entire short arms of acrocentric chromosomes of Azara’s owl monkey: Formation processes inferred from chromosomal locations. DNA Res. 2013, 20, 461–470. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prakhongcheep, O.; Thapana, W.; Suntronpong, A.; Singchat, W.; Pattanatanang, K.; Phatcharakullawarawat, R.; Muangmai, N.; Peyachoknagul, S.; Matsubara, K.; Ezaz, T.; et al. Lack of satellite DNA species-specific homogenization and relationship to chromosomal rearrangements in monitor lizards (Varanidae, Squamata). BMC Evol. Biol. 2017, 17, 193. [Google Scholar] [CrossRef] [Green Version]
- Thongchum, R.; Singchat, W.; Laopichienpong, N.; Tawichasri, P.; Kraichak, E.; Prakhongcheep, O.; Sillapaprayoon, S.; Muangmai, N.; Baicharoen, S.; Suntrarachun, S.; et al. Diversity of PBI-DdeI satellite DNA in snakes correlates with rapid independent evolution and different functional roles. Sci. Rep. 2019, 9, 15459. [Google Scholar] [CrossRef] [Green Version]
- Suntronpong, A.; Singchat, W.; Kruasuwan, W.; Prakhongcheep, O.; Sillapaprayoon, S.; Muangmai, N.; Somyong, S.; Indananda, C.; Kraichak, E.; Peyachoknagul, S.; et al. Characterization of centromeric satellite DNAs (MALREP) in the Asian swamp eel (Monopterus albus) suggests the possible origin of repeats from transposable elements. Genomics 2020, 112, 3097–3107. [Google Scholar] [CrossRef]
- Nakagawa, T.; Okita, A.K. Transcriptional silencing of centromere repeats by heterochromatin safeguards chromosome integrity. Curr. Genet. 2019, 65, 1089–1098. [Google Scholar] [CrossRef]
- Kim, J.H.; Ebersole, T.; Kouprina, N.; Noskov, V.N.; Ohzeki, J.I.; Masumoto, H.; Mravinac, B.; Sullivan, B.A.; Pavlicek, A.; Dovat, S.; et al. Human gamma-satellite DNA maintains open chromatin structure and protects a transgene from epigenetic silencing. Genome Res. 2009, 19, 533–544. [Google Scholar] [CrossRef] [Green Version]
- Schueler, M.G.; Higgins, A.W.; Rudd, M.K.; Gustashaw, K.; Willard, H.F. Genomic and genetic definition of a functional human centromere. Science 2001, 294, 109–115. [Google Scholar] [CrossRef] [Green Version]
- Schueler, M.G.; Sullivan, B.A. Structural and functional dynamics of human centromeric chromatin. Annu. Rev. Genom. Hum. Genet. 2006, 7, 301–313. [Google Scholar] [CrossRef]
- Aldrup-MacDonald, M.E.; Sullivan, B.A. The past, present, and future of human centromere genomics. Genes 2014, 5, 33–50. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fachinetti, D.; Han, J.S.; McMahon, M.A.; Ly, P.; Abdullah, A.; Wong, A.J.; Cleveland, D.W. DNA Sequence-Specific Binding of CENP-B Enhances the Fidelity of Human Centromere Function. Dev. Cell 2015, 33, 314–327. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McNulty, S.M.; Sullivan, B.A. Alpha satellite DNA biology: Finding function in the recesses of the genome. Chromosom. Res. 2018, 26, 115–138. [Google Scholar] [CrossRef]
- Jagannathan, M.; Warsinger-Pepe, N.; Watase, G.J.; Yamashita, Y.M. Comparative analysis of satellite DNA in the drosophila melanogaster species complex. G3 Genes Genomes Genet. 2017, 7, 693–704. [Google Scholar] [CrossRef] [Green Version]
- Lower, S.S.; McGurk, M.P.; Clark, A.G.; Barbash, D.A. Satellite DNA evolution: Old ideas, new approaches. Curr. Opin. Genet. Dev. 2018, 49, 70–78. [Google Scholar] [CrossRef] [PubMed]
- Garrido-Ramos, M.A. Satellite DNA: An evolving topic. Genes 2017, 8, 230. [Google Scholar] [CrossRef]
- Hartley, G.; O’neill, R.J. Centromere repeats: Hidden gems of the genome. Genes 2019, 10, 223. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hedges, D.J.; Callinan, P.A.; Cordaux, R.; Xing, J.; Barnes, E.; Batzer, M.A. Differential Alu mobilization and polymorphism among the human and chimpanzee lineages. Genome Res. 2004, 14, 1068–1075. [Google Scholar] [CrossRef] [Green Version]
- Han, K.; Sen, S.K.; Wang, J.; Callinan, P.A.; Lee, J.; Cordaux, R.; Liang, P.; Batzer, M.A. Genomic rearrangements by LINE-1 insertion-mediated deletion in the human and chimpanzee lineages. Nucleic Acids Res. 2005, 33, 4040–4052. [Google Scholar] [CrossRef] [Green Version]
- Cordaux, R.; Batzer, M.A. The impact of retrotransposons on human genome evolution. Nat. Rev. Genet. 2009, 10, 691–703. [Google Scholar] [CrossRef] [Green Version]
- Cordaux, R.; Sen, S.K.; Konkel, M.K.; Batzer, M.A. Computational methods for the analysis of primate mobile elements. Methods Mol. Biol. 2010, 628, 137–151. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Trizzino, M.; Park, Y.S.; Holsbach-Beltrame, M.; Aracena, K.; Mika, K.; Caliskan, M.; Perry, G.H.; Lynch, V.J.; Brown, C.D. Transposable elements are the primary source of novelty in primate gene regulation. Genome Res. 2017, 27, 1623–1633. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jurka, J.; Krnjajic, M.; Kapitonov, V.V.; Stenger, J.E.; Kokhanyy, O. Active Alu in Paternal Germlines>Active Alu Elements Are Passed Primarily through Paternal Germlines. Theor. Popul. Biol. 2002, 61, 519–530. [Google Scholar] [CrossRef]
- Tørresen, O.K.; Star, B.; Mier, P.; Andrade-Navarro, M.A.; Bateman, A.; Jarnot, P.; Gruca, A.; Grynberg, M.; Kajava, A.V.; Promponas, V.J.; et al. Tandem repeats lead to sequence assembly errors and impose multi-level challenges for genome and protein databases. Nucleic Acids Res. 2019, 47, 10994–11006. [Google Scholar] [CrossRef]
- Lee, H.E.; Eo, J.; Kim, H.S. Composition and evolutionary importance of transposable elements in humans and primates. Genes Genom. 2014, 37, 135–140. [Google Scholar] [CrossRef]
- Lee, H.R.; Hayden, K.E.; Willard, H.F. Organization and molecular evolution of CENP-A-associated satellite DNA families in a basal primate genome. Genome Biol. Evol. 2011, 3, 1136–1149. [Google Scholar] [CrossRef] [Green Version]
- Cechova, M.; Harris, R.S.; Tomaszkiewicz, M.; Arbeithuber, B.; Chiaromonte, F.; Makova, K.D. High Satellite Repeat Turnover in Great Apes Studied with Short- And Long-Read Technologies. Mol. Biol. Evol. 2019, 36, 2415–2431. [Google Scholar] [CrossRef] [Green Version]
- Cacheux, L.; Ponger, L.; Gerbault-Seureau, M.; Richard, F.A.; Escudé, C. Diversity and distribution of alpha satellite DNA in the genome of an Old World monkey: Cercopithecus solatus. BMC Genom. 2016, 17, 916. [Google Scholar] [CrossRef] [Green Version]
- Cacheux, L.; Ponger, L.; Gerbault-Seureau, M.; Loll, F.; Gey, D.; Richard, F.A.; Escudé, C. The targeted sequencing of alpha satellite DNA in Cercopithecus pogonias provides new insight into the diversity and dynamics of centromeric repeats in old world monkeys. Genome Biol. Evol. 2018, 10, 1837–1851. [Google Scholar] [CrossRef]
- Sullivan, L.L.; Chew, K.; Sullivan, B.A. α satellite DNA variation and function of the human centromere. Nucleus 2017, 8, 331–339. [Google Scholar] [CrossRef] [Green Version]
- Sullivan, L.L.; Sullivan, B.A. Genomic and functional variation of human centromeres. Exp. Cell Res. 2020, 389, 111896. [Google Scholar] [CrossRef]
- Smit, A.; Hubley, R.; Grenn, P. RepeatMasker Open-4.0. 2015. Available online: http://www.repeatmasker.org/ (accessed on 1 August 2020).
- 10KTrees Website. Available online: https://10ktrees.nunn-lab.org/Primates/dataset.html (accessed on 27 July 2020).
- Letunic, I.; Bork, P. Interactive Tree of Life (iTOL) v4: Recent updates and new developments. Nucleic Acids Res. 2019, 47, W256–W259. [Google Scholar] [CrossRef] [Green Version]
- Miga, K.H. Completing the human genome: The progress and challenge of satellite DNA assembly. Chromosom. Res. 2015, 23, 421–426. [Google Scholar] [CrossRef] [PubMed]
- Waring, M.; Britten, R.J. Nucleotide sequence repetition: A rapidly reassociating fraction of mouse DNA. Science 1966, 154, 791–794. [Google Scholar] [CrossRef] [PubMed]
- López-Flores, I.; Garrido-Ramos, M.A. The repetitive DNA content of eukaryotic genomes. Genome Dyn. 2012, 7, 1–28. [Google Scholar] [CrossRef] [PubMed]
- Biscotti, M.A.; Canapa, A.; Forconi, M.; Olmo, E.; Barucca, M. Transcription of tandemly repetitive DNA: Functional roles. Chromosom. Res. 2015, 23, 463–477. [Google Scholar] [CrossRef] [PubMed]
- Rogers, J.; Mahaney, M.C.; Witte, S.M.; Nair, S.; Newman, D.; Wedel, S.; Rodriguez, L.A.; Rice, K.S.; Slifer, S.H.; Perelygin, A.; et al. A genetic linkage map of the baboon (Papio hamadryas) genome based on human microsatellite polymorphisms. Genomics 2000, 67, 237–247. [Google Scholar] [CrossRef]
- Catacchio, C.R.; Ragone, R.; Chiatante, G.; Ventura, M. Organization and evolution of Gorilla centromeric DNA from old strategies to new approaches. Sci. Rep. 2015, 5, 14189. [Google Scholar] [CrossRef] [Green Version]
- Bersani, F.; Lee, E.; Kharchenko, P.V.; Xu, A.W.; Liu, M.; Xega, K.; MacKenzie, O.C.; Brannigan, B.W.; Wittner, B.S.; Jung, H.; et al. Pericentromeric satellite repeat expansions through RNA-derived DNA intermediates in cancer. Proc. Natl. Acad. Sci. USA 2015, 112, 15148–15153. [Google Scholar] [CrossRef] [Green Version]
- Miga, K.H.; Newton, Y.; Jain, M.; Altemose, N.; Willard, H.F.; Kent, E.J. Centromere reference models for human chromosomes X and y satellite arrays. Genome Res. 2014, 24, 697–707. [Google Scholar] [CrossRef] [Green Version]
- Sujiwattanarat, P.; Thapana, W.; Srikulnath, K.; Hirai, Y.; Hirai, H.; Koga, A. Higher-order repeat structure in alpha satellite DNA occurs in New World monkeys and is not confined to hominoids. Sci. Rep. 2015, 5, 10315. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Richard, G.F.; Pâques, F. Mini- and microsatellite expansions: The recombination connection. EMBO Rep. 2000, 1, 122–126. [Google Scholar] [CrossRef] [PubMed]
- Subramanian, S.; Mishra, R.K.; Singh, L. Genome-wide analysis of microsatellite repeats in humans: Their abundance and density in specific genomic regions. Genome Biol. 2003, 4, R13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ramel, C. Mini- and microsatellites. EHP 1997, 105, 781–789. [Google Scholar] [CrossRef] [PubMed]
- Näslund, K.; Saetre, P.; Von Salomé, J.; Bergström, T.F.; Jareborg, N.; Jazin, E. Genome-wide prediction of human VNTRs. Genomics 2005, 85, 24–35. [Google Scholar] [CrossRef] [PubMed]
- Blanquer-Maumont, A.; Crouau-Roy, B. Polymorphism, monomorphism, and sequences in conserved microsatellites in primate species. J. Mol. Evol. 1995, 41, 492–497. [Google Scholar] [CrossRef] [PubMed]
- Garza, J.C.; Slatkin, M.; Freimer, N.B. Microsatellite allele frequencies in humans and chimpanzees, with implications for constraints on allele size. Mol. Biol. Evol. 1995, 12, 594–603. [Google Scholar] [CrossRef] [Green Version]
- Coote, T.; Bruford, M.W. Human Microsatellites Applicable for Analysis of Genetic Variation in Apes and Old World Monkeys. J. Hered. 1996, 87, 406–410. [Google Scholar] [CrossRef] [Green Version]
- Kayser, M.; Caglià, A.; Corach, D.; Fretwell, N.; Gehrig, C.; Graziosi, G.; Heidorn, F.; Herrmann, S.; Herzog, B.; Hidding, M.; et al. Evaluation of Y-chromosomal STRs: A multicenter study. Int. J. Legal Med. 1997, 110, 125–133. [Google Scholar] [CrossRef]
- Goossens, B.; Chikhi, L.; Utami, S.S.; De Ruiter, J.; Bruford, M.W. A multi-samples, multi-extracts approach for microsatellite analysis of faecal samples in an arboreal ape. Conserv. Genet. 2000, 1, 157–162. [Google Scholar] [CrossRef]
- Nair, S.; Ha, J.; Rogers, J. Nineteen new microsatellite DNA polymorphisms in pigtailed macaques (Macaca nemestrina). Primates 2000, 41, 343–350. [Google Scholar] [CrossRef] [PubMed]
- Winkler, L.A.; Zhang, X.; Ferrell, R.; Wagner, R.; Dahl, J.; Peter, G.; Sohn, R. Geographic Microsatellite Variability in Central American Howling Monkeys. Int. J. Primatol. 2004, 25, 197–210. [Google Scholar] [CrossRef]
- Clisson, I.; Lathuilliere, M.; Crouau-Roy, B. Conservation and evolution of microsatellite loci in primate taxa. Am. J. Primatol. 2000, 50, 205–214. [Google Scholar] [CrossRef]
- Buschiazzo, E.; Gemmell, N.J. Conservation of human microsatellites across 450 million years of evolution. Genome Biol. Evol. 2010, 2, 153–165. [Google Scholar] [CrossRef] [Green Version]
- Oklander, L.I.; Steinberg, E.R.; Mudry, M.D. A new world monkey microsatellite (AP74) higly conserved in primates. Acta Biol. Colomb. 2012, 17, 93–101. [Google Scholar]
- Boán, F.; Blanco, M.G.; Quinteiro, J.; Mouriño, S.; Gómez-Márquez, J. Birth and Evolutionary History of a Human Minisatellite. Mol. Biol. Evol. 2004, 21, 228–235. [Google Scholar] [CrossRef]
- Moyzis, R.K.; Buckingham, J.M.; Cram, L.S.; Dani, M.; Deaven, L.L.; Jones, M.D.; Meyne, J.; Ratliff, R.L.; Wu, J.R. A highly conserved repetitive DNA sequence, (TTAGGG)(n), present at the telomeres of human chromosomes. Proc. Natl. Acad. Sci. USA 1988, 85, 6622–6626. [Google Scholar] [CrossRef] [Green Version]
- O’Sullivan, R.J.; Karlseder, J. Telomeres: Protecting chromosomes against genome instability. Nat. Rev. Mol. Cell Biol. 2010, 11, 171–181. [Google Scholar] [CrossRef] [Green Version]
- Bandaria, J.N.; Qin, P.; Berk, V.; Chu, S.; Yildiz, A. Shelterin protects chromosome ends by compacting telomeric chromatin. Cell 2016, 164, 735–746. [Google Scholar] [CrossRef] [Green Version]
- Wyatt, H.D.M.; West, S.C.; Beattie, T.L. InTERTpreting telomerase structure and function. Nucleic Acids Res. 2010, 38, 5609–5622. [Google Scholar] [CrossRef] [Green Version]
- Maddar, H.; Ratzkovsky, N.; Krauskopf, A. Role for telomere cap structure in meiosis. Mol. Biol. Cell 2001, 12, 3191–3203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Boán, F.; Rodríguez, J.M.; Gómez-Márquez, J. A non-hypervariable human minisatellite strongly stimulates in vitro intramolecular homologous recombination. J. Mol. Biol. 1998, 278, 499–505. [Google Scholar] [CrossRef] [PubMed]
- Boán, F.; Rodríguez, J.M.; Mouriño, S.; Blanco, M.G.; Viñas, A.; Sánchez, L.; Gómez-Márquez, J. Recombination analysis of the human minisatellite MsH42 suggests the existence of two distinct pathways for initiation and resolution of recombination at MsH42 in rat testes nuclear extracts. Biochemistry 2002, 41, 2166–2176. [Google Scholar] [CrossRef] [PubMed]
- Nergadze, S.G.; Rocchi, M.; Azzalin, C.M.; Mondello, C.; Giulotto, E. Insertion of telomeric repeats at intrachromosomal break sites during primate evolution. Genome Res. 2004, 14, 1704–1710. [Google Scholar] [CrossRef] [Green Version]
- Plohl, M.; Meštrović, N.; Mravinac, B. Satellite DNA evolution. Genome Dyn. 2012, 7, 126–152. [Google Scholar] [CrossRef]
- Kazakov, A.E.; Shepelev, V.A.; Tumeneva, I.G.; Alexandrov, A.A.; Yurov, Y.B.; Alexandrov, I.A. Interspersed repeats are found predominantly in the “old” α satellite families. Genomics 2003, 82, 619–627. [Google Scholar] [CrossRef]
- Steiner, F.A.; Henikoff, S. Diversity in the organization of centromeric chromatin. Curr. Opin. Genet. Dev. 2015, 31, 28–35. [Google Scholar] [CrossRef]
- Plohl, M.; Luchetti, A.; Meštrović, N.; Mantovani, B. Satellite DNAs between selfishness and functionality: Structure, genomics and evolution of tandem repeats in centromeric (hetero)chromatin. Gene 2008, 409, 72–82. [Google Scholar] [CrossRef]
- Verdaasdonk, J.S.; Bloom, K. Centromeres: Unique chromatin structures that drive chromosome segregation. Nat. Rev. Mol. Cell Biol. 2011, 12, 320–332. [Google Scholar] [CrossRef] [Green Version]
- Fukagawa, T.; Earnshaw, W.C. The centromere: Chromatin foundation for the kinetochore machinery. Dev. Cell 2014, 30, 496–508. [Google Scholar] [CrossRef] [Green Version]
- Maio, J.J. DNA strand reassociation and polyribonucleotide binding in the African green monkey, Cercopithecus aethiops. J. Mol. Biol. 1971, 56, 579–595. [Google Scholar] [CrossRef]
- Manuelidis, L.; Wu, J.C. Homology between human and simian repeated DNA. Nature 1978, 276, 92–94. [Google Scholar] [CrossRef] [PubMed]
- Vissel, B.; Andy Choo, K.H. Evolutionary relationships of multiple alpha satellite subfamilies in the centromeres of human chromosomes 13, 14, and 21. J. Mol. Evol. 1992, 35, 137–146. [Google Scholar] [CrossRef] [PubMed]
- Musich, P.R.; Brown, F.L.; Maio, J.J. Highly repetitive component α and related alphoid DNAs in man and monkeys. Chromosoma 1980, 80, 331–348. [Google Scholar] [CrossRef] [PubMed]
- Willard, H.F.; Waye, J.S. Hierarchical order in chromosome-specific human alpha satellite DNA. Trends Genet. 1987, 3, 192–198. [Google Scholar] [CrossRef]
- Alves, G.; Seuánez, H.N.; Fanning, T. Alpha satellite DNA in neotropical primates (Platyrrhini). Chromosoma 1994, 103, 262–267. [Google Scholar] [CrossRef]
- Alves, G.; Canavez, F.; Seuánez, H.; Fanning, T. Recently amplified satellite DNA in Callithrix argentata (Primates, Platyrrhini). Chromosom. Res. 1995, 3, 207–213. [Google Scholar] [CrossRef]
- Alexandrov, I.; Kazakov, A.; Tumeneva, I.; Shepelev, V.; Yurov, Y. Alpha-satellite DNA of primates: Old and new families. Chromosoma 2001, 110, 253–266. [Google Scholar] [CrossRef]
- Cellamare, A.; Catacchio, C.R.; Alkan, C.; Giannuzzi, G.; Antonacci, F.; Cardone, M.F.; Della Valle, G.; Malig, M.; Rocchi, M.; Eichler, E.E.; et al. New insights into centromere organization and evolution from the white-cheeked Gibbon and marmoset. Mol. Biol. Evol. 2009, 26, 1889–1900. [Google Scholar] [CrossRef] [Green Version]
- Akihiko, K.; Yuriko, H.; Shoko, T.; Israt, J.; Sudarath, B.; Visit, A.; Hirohisa, H. Evolutionary origin of higher-order repeat structure in alpha-satellite DNA of primate centromeres. DNA Res. 2014, 21, 407–415. [Google Scholar] [CrossRef] [Green Version]
- Plohl, M.; Meštrović, N.; Mravinac, B. Centromere identity from the DNA point of view. Chromosoma 2014, 123, 313–325. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pita, M.; Gosálvez, J.; Gosálvez, A.; Nieddu, M.; López-Fernández, C.; Mezzanotte, R. A highly conserved pericentromeric domain in human and gorilla chromosomes. Cytogenet. Genome Res. 2010, 126, 253–258. [Google Scholar] [CrossRef] [PubMed]
- Jarmuz, M.; Glotzbach, C.D.; Bailey, K.A.; Bandyopadhyay, R.; Shaffer, L.G. The evolution of satellite III DNA subfamilies among primates. Am. J. Hum. Genet. 2007, 80, 495–501. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alkan, C.; Ventura, M.; Archidiacono, N.; Rocchi, M.; Sahinalp, S.C.; Eichler, E.E. Organization and evolution of primate centromeric DNA from whole-genome shotgun sequence data. PLoS Comput. Biol. 2007, 3, 1807–1818. [Google Scholar] [CrossRef] [PubMed]
- Miller, D.A. Evolution of primate chromosomes. Science 1977, 198, 1116–1124. [Google Scholar] [CrossRef] [PubMed]
- Montefalcone, G.; Tempesta, S.; Rocchi, M.; Archidiacono, N. Centromere repositioning. Genome Res. 1999, 9, 1184–1188. [Google Scholar] [CrossRef] [Green Version]
- Ventura, M.; Antonacci, F.; Cardone, M.F.; Stanyon, R.; D’Addabbo, P.; Cellamare, A.; Sprague, L.J.; Eichler, E.E.; Archidiacono, N.; Rocchi, M. Evolutionary formation of new centromeres in macaque. Science 2007, 316, 243–246. [Google Scholar] [CrossRef] [Green Version]
- Stanyon, R.; Rocchi, M.; Capozzi, O.; Roberto, R.; Misceo, D.; Ventura, M.; Cardone, M.F.; Bigoni, F.; Archidiacono, N. Primate chromosome evolution: Ancestral karyotypes, marker order and neocentromeres. Chromosom. Res. 2008, 16, 17–39. [Google Scholar] [CrossRef]
- Amor, D.J.; Andy Choo, K.H. Neocentromeres: Role in human disease, evolution, and centromere study. Am. J. Hum. Genet. 2002, 71, 695–714. [Google Scholar] [CrossRef] [Green Version]
- Wade, C.M.; Giulotto, E.; Sigurdsson, S.; Zoli, M.; Gnerre, S.; Imsland, F.; Lear, T.L.; Adelson, D.L.; Bailey, E.; Bellone, R.R.; et al. Genome sequence, comparative analysis, and population genetics of the domestic horse. Science 2009, 326, 865–867. [Google Scholar] [CrossRef] [Green Version]
- Shang, W.H.; Hori, T.; Toyoda, A.; Kato, J.; Popendorf, K.; Sakakibara, Y.; Fujiyama, A.; Fukagawa, T. Chickens possess centromeres with both extended tandem repeats and short non-tandem-repetitive sequences. Genome Res. 2010, 20, 1219–1228. [Google Scholar] [CrossRef] [Green Version]
- Maio, J.J.; Brown, F.L.; Musich, P.R. Toward a molecular paleontology of primate genomes—I. The HindIII and EcoRI dimer families of alphoid DNAs. Chromosoma 1981, 83, 103–125. [Google Scholar] [CrossRef]
- Kalitsis, P.; Choo, K.H.A. The evolutionary life cycle of the resilient centromere. Chromosoma 2012, 121, 327–340. [Google Scholar] [CrossRef] [PubMed]
- McKinley, K.L.; Cheeseman, I.M. The molecular basis for centromere identity and function. Nat. Rev. Mol. Cell Biol. 2016, 17, 16–29. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Hong, W.Y.; Cho, M.; Sim, M.; Lee, D.; Ko, Y.; Kim, J. Synteny Portal: A web-based application portal for synteny block analysis. Nucleic Acids Res. 2016, 44, W35–W40. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schneider, V.A.; Graves-Lindsay, T.; Howe, K.; Bouk, N.; Chen, H.C.; Kitts, P.A.; Murphy, T.D.; Pruitt, K.D.; Thibaud-Nissen, F.; Albracht, D.; et al. Evaluation of GRCh38 and de novo haploid genome assemblies demonstrates the enduring quality of the reference assembly. Genome Res. 2017, 27, 849–864. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Klein, S.J.; O’Neill, R.J. Transposable elements: Genome innovation, chromosome diversity, and centromere conflict. Chromosom. Res. 2018, 26, 5–23. [Google Scholar] [CrossRef] [Green Version]
- Prosser, J.; Frommer, M.; Paul, C.; Vincent, P.C. Sequence relationships of three human satellite DNAs. J. Mol. Biol. 1986, 187, 145–155. [Google Scholar] [CrossRef]
- Willard, H.F. Chromosome-specific organization of human alpha satellite DNA. Am. J. Hum. Genet. 1985, 37, 524–532. [Google Scholar]
- Warburton, P.E.; Willard, H.F. Genomic analysis of sequence variation in tandemly repeated DNA. Evidence for localized homogeneous sequence domains within arrays of α-satellite DNA. J. Mol. Biol. 1990, 216, 3–16. [Google Scholar] [CrossRef]
- Paar, V.; Basar, I.; Rosandic, M.; Gluncic, M. Consensus Higher Order Repeats and Frequency of String Distributions in Human Genome. Curr. Genom. 2007, 8, 93–111. [Google Scholar] [CrossRef] [Green Version]
- Aldrup-MacDonald, M.E.; Kuo, M.E.; Sullivan, L.L.; Chew, K.; Sullivan, B.A. Genomic variation within alpha satellite DNA influences centromere location on human chromosomes with metastable epialleles. Genom. Res. 2016, 26, 1301–1311. [Google Scholar] [CrossRef] [Green Version]
- Willard, H.F. Evolution of alpha satellite. Curr. Opin. Genet. Dev. 1991, 1, 509–514. [Google Scholar] [CrossRef]
- Haaf, T.; Warburton, P.E.; Willard, H.F. Integration of human α-satellite DNA into simian chromosomes: Centromere protein binding and disruption of normal chromosome segregation. Cell 1992, 70, 681–696. [Google Scholar] [CrossRef]
- Warburton, P.E.; Haaf, T.; Gosden, J.; Lawson, D.; Willard, H.F. Characterization of a chromosome-specific chimpanzee alpha satellite subset: Evolutionary relationship to subsets on human chromosomes. Genomics 1996, 33, 220–228. [Google Scholar] [CrossRef] [PubMed]
- Haaf, T.; Willard, H.F. Chromosome-specific α-satellite DNA from the centromere of chimpanzee chromosome 4. Chromosoma 1997, 106, 226–232. [Google Scholar] [CrossRef] [PubMed]
- Terada, S.; Hirai, Y.; Hirai, H.; Koga, A. Higher-order repeat structure in alpha satellite DNA is an attribute of hominoids rather than hominids. J. Hum. Genet. 2013, 58, 752–754. [Google Scholar] [CrossRef] [Green Version]
- Alkan, C.; Cardone, M.F.; Catacchio, C.R.; Antonacci, F.; O’Brien, S.J.; Ryder, O.A.; Purgato, S.; Zoli, M.; Della Valle, G.; Eichler, E.E.; et al. Genome-wide characterization of centromeric satellites from multiple mammalian genomes. Genom. Res. 2011, 21, 137–145. [Google Scholar] [CrossRef] [Green Version]
- Koga, A.; Tanabe, H.; Hirai, Y.; Imai, H.; Imamura, M.; Oishi, T.; Stanyon, R.; Hirai, H. Co-opted megasatellite DNA drives evolution of secondary night vision in Azara’s Owl monkey. Genome Biol. Evol. 2017, 9, 1963–1970. [Google Scholar] [CrossRef]
- Nishihara, H.; Stanyon, R.; Kusumi, J.; Hirai, H.; Koga, A. Evolutionary origin of OwlRep, a megasatellite DNA associated with adaptation of owl monkeys to nocturnal lifestyle. Genome Biol. Evol. 2018, 10, 157–165. [Google Scholar] [CrossRef]
- Waye, J.S.; Willard, H.F. Human β satellite DNA: Genomic organization and sequence definition of a class of highly repetitive tandem DNA. Proc. Natl. Acad. Sci. USA 1989, 86, 6250–6254. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Greig, G.M.; Willard, H.F. β satellite DNA: Characterization and localization of two subfamilies from the distal and proximal short arms of the human acrocentric chromosomes. Genomics 1992, 12, 573–580. [Google Scholar] [CrossRef]
- Cardone, M.F.; Ballarati, L.; Ventura, M.; Rocchi, M.; Marozzi, A.; Ginelli, E.; Meneveri, R. Evolution of beta satellite DNA sequences: Evidence for duplication-mediated repeat amplification and spreading. Mol. Biol. Evol. 2004, 21, 1792–1799. [Google Scholar] [CrossRef] [PubMed]
- Meneveri, R.; Agresti, A.; Valle, G.D.; Talarico, D.; Siccardi, A.G.; Ginelli, E. Identification of a human clustered G + C-rich DNA family of repeats (Sau3A family). J. Mol. Biol. 1985, 186, 483–489. [Google Scholar] [CrossRef]
- Meneveri, R.; Agresti, A.; Marozzi, A.; Saccone, S.; Rocchi, M.; Archidiacono, N.; Corneo, G.; Valle, G.D.; Ginelli, E. Molecular organization and chromosomal location of human GC-rich heterochromatic blocks. Gene 1993, 123, 227–234. [Google Scholar] [CrossRef]
- Agresti, A.; Rainaldi, G.; Lobbiani, A.; Magnani, I.; Di Lernia, R.; Meneveri, R.; Siccardi, A.G.; Ginelli, E. Chromosomal location by in situ hybridization of the human Sau3A family of DNA repeats. Hum. Genet. 1987, 75, 326–332. [Google Scholar] [CrossRef]
- Agresti, A.; Meneveri, R.; Siccardi, A.G.; Marozzi, A.; Corneo, G.; Gaudi, S.; Ginelli, E. Linkage in human heterochromatin between highly divergent Sau3A repeats and a new family of repeated DNA sequences (HaeIII family). J. Mol. Biol. 1989, 205, 625–631. [Google Scholar] [CrossRef]
- Bakker, E.; Wijmenga, C.; Vossen, R.H.A.M.; Padberg, G.W.; Hewitt, J.; van Der Wielen, M.; Rasmussen, K.; Frants, R.R. The FSHD-linked locus D4F104S1 (p13E-11) ON 4q35 has a homologue on 10qter. Muscle Nerve 1995, 18, S39–S44. [Google Scholar] [CrossRef] [Green Version]
- Lemmers, R.J.F.L.; Wohlgemuth, M.; Frants, R.R.; Padberg, G.W.; Morava, E.; Van Der Maarel, S.M. Contractions of D4Z4 on 4qB subtelomeres do not cause facioscapulohumeral muscular dystrophy. Am. J. Hum. Genet. 2004, 75, 1124–1130. [Google Scholar] [CrossRef] [Green Version]
- Clark, L.N.; Koehler, U.; Ward, D.C.; Wienberg, J.; Hewitt, J.E. Analysis of the organisation and localisation of the FSHD-associated tandem array in primates: Implications for the origin and evolution of the 3.3 kb repeat family. Chromosoma 1996, 105, 180–189. [Google Scholar] [CrossRef]
- Winokur, S.T.; Bengtsson, U.; Vargas, J.C.; Wasmuth, J.J.; Altherr, M.R. The evolutionary distribution and structural organization of the homeobox-containing repeat D4Z4 indicates a functional role for the ancestral copy in the FSHD region. Hum. Mol. Genet. 1996, 5, 1567–1575. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ballarati, L.; Piccini, I.; Carbone, L.; Archidiacono, N.; Rollier, A.; Marozzi, A.; Meneveri, R.; Ginelli, E. Human genome dispersal and evolution of 4q35 duplications and interspersed LSau repeats. Gene 2002, 296, 21–27. [Google Scholar] [CrossRef]
- Meneveri, R.; Agresti, A.; Rocchi, M.; Marozzi, A.; Ginellil, E. Analysis of GC-rich repetitive nucleotide sequences in great apes. J. Mol. Evol. 1995, 40, 405–412. [Google Scholar] [CrossRef] [PubMed]
- Hirai, H.; Taguchi, T.; Godwin, A.K. Genomic differentiation of 18S ribosomal DNA and β-satellite DNA in the hominoid and its evolutionary aspects. Chromosom. Res. 1999, 7, 531–540. [Google Scholar] [CrossRef] [PubMed]
- McLaughlin, C.R.; Chadwick, B.P. Characterization of DXZ4 conservation in primates implies important functional roles for CTCF binding, array expression and tandem repeat organization on the X chromosome. Genome Biol. 2011, 12, R37. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mitchell, A.R.; Gosden, J.R.; Ryder, O.A. Satellite DNA relationships in man and the primates. Nucleic Acids Res. 1981, 9, 3235–3249. [Google Scholar] [CrossRef] [Green Version]
- Fowler, J.C.S.; Burgoyne, L.A.; Baker, E.G.; Riugenbergs, M.L.; Callen, D.F. Human Satellite III DNA: Genomic location and sequence homogeneity of the TaqI-deficient polymorphic sequences. Chromosoma 1989, 98, 266–272. [Google Scholar] [CrossRef]
- Hu, H.; Li, B.; Duan, S. The alteration of subtelomeric DNA methylation in aging-related diseases. Front. Genet. 2019, 10, 697. [Google Scholar] [CrossRef] [Green Version]
- Vergnaud, G.; Denoeud, F. Minisatellites: Mutability and genome architecture. Genome Res. 2000, 10, 899–907. [Google Scholar] [CrossRef] [Green Version]
- Riethman, H. Human subtelomeric copy number variations. Cytogenet. Genome Res. 2009, 123, 244–252. [Google Scholar] [CrossRef] [Green Version]
- Louis, E.J.; Vershinin, A.V. Chromosome ends: Different sequences may provide conserved functions. BioEssays 2005, 27, 685–697. [Google Scholar] [CrossRef]
- Cuadrado, A.; Jouve, N. Mapping and organization of highly-repeated DNA sequences by means of simultaneous and sequential FISH and C-banding in 6×-triticale. Chromosom. Res. 1994, 2, 331–338. [Google Scholar] [CrossRef] [PubMed]
- Brown, W.R.A.; MacKinnon, P.J.; Villasanté, A.; Spurr, N.; Buckle, V.J.; Dobson, M.J. Structure and polymorphism of human telomere-associated DNA. Cell 1990, 63, 119–132. [Google Scholar] [CrossRef]
- Jurka, J.; Pethiyagoda, C. Simple repetitive DNA sequences from primates: Compilation and analysis. J. Mol. Evol. 1995, 40, 120–126. [Google Scholar] [CrossRef]
- Araujo, N.P.; De Lima, L.G.; Dias, G.B.; Kuhn, G.C.S.; De Melo, A.L.; Yonenaga-Yassuda, Y.; Stanyon, R.; Svartman, M. Identification and characterization of a subtelomeric satellite DNA in Callitrichini monkeys. DNA Res. 2017, 24, 377–385. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Royle, N.J.; Baird, D.M.; Jeffreys, A.J. A subterminal satellite located adjacent to telomeres in chimpanzees is absent from the human genome. Nat. Genet. 1994, 6, 52–56. [Google Scholar] [CrossRef] [PubMed]
- Koga, A.; Hirai, Y.; Hara, T.; Hirai, H. Repetitive sequences originating from the centromere constitute large-scale heterochromatin in the telomere region in the siamang, a small ape. Heredity (Edinb) 2012, 109, 180–187. [Google Scholar] [CrossRef] [Green Version]
- Ventura, M.; Catacchio, C.R.; Sajjadian, S.; Vives, L.; Sudmant, P.H.; Marques-Bonet, T.; Graves, T.A.; Wilson, R.K.; Eichler, E.E. The evolution of African great ape subtelomeric heterochromatin and the fusion of human chromosome 2. Genome Res. 2012, 22, 1036–1049. [Google Scholar] [CrossRef] [Green Version]
- Fanning, T.G.; Seuánez, H.N.; Forman, L. Satellite DNA sequences in the New World primate Cebus apella (Platyrrhini, Primates). Chromosoma 1993, 102, 306–311. [Google Scholar] [CrossRef]
- Nishibuchi, G.; Déjardin, J. The molecular basis of the organization of repetitive DNA-containing constitutive heterochromatin in mammals. Chromosom. Res. 2017, 25, 77–87. [Google Scholar] [CrossRef]
- Riethman, H.; Ambrosini, A.; Paul, S. Human subtelomere structure and variation. Chromosom. Res. 2005, 13, 505–515. [Google Scholar] [CrossRef] [PubMed]
- Kehrer-Sawatzki, H.; Cooper, D.N. Molecular mechanisms of chromosomal rearrangement during primate evolution. Chromosom. Res. 2008, 16, 41–56. [Google Scholar] [CrossRef] [PubMed]
- Stankiewicz, P.; Park, S.S.; Inoue, K.; Lupski, J.R. The evolutionary chromosome translocation 4;19 in Gorilla gorilla is associated with microduplication of the chromosome fragment syntenic to sequences surrounding the human proximal CMT1A-REP. Genome Res. 2001, 11, 1205–1210. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carbone, L.; Alan Harris, R.; Gnerre, S.; Veeramah, K.R.; Lorente-Galdos, B.; Huddleston, J.; Meyer, T.J.; Herrero, J.; Roos, C.; Aken, B.; et al. Gibbon genome and the fast karyotype evolution of small apes. Nature 2014, 513, 195–201. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Koehler, U.; Bigoni, F.; Wienberg, J.; Stanyon, R. Genomic reorganization in the concolor gibbon (hylobates concolor) revealed by chromosome painting. Genomics 1995, 30, 287–292. [Google Scholar] [CrossRef]
- Wienberg, J.; Jauch, A.; Lüdecke, H.J.; Senger, G.; Horsthemke, B.; Claussen, U.; Cremer, T.; Arnold, N.; Lengauer, C. The origin of human chromosome 2 analyzed by comparative chromosome mapping with a DNA microlibrary. Chromosom. Res. 1994, 2, 405–410. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Z.; Ventura, M.; She, X.; Khaitovich, P.; Graves, T.; Osoegawa, K.; Church, D.; DeJong, P.; Wilson, R.K.; Pääbo, S.; et al. A genome-wide comparison of recent chimpanzee and human segmental duplications. Nature 2005, 437, 88–93. [Google Scholar] [CrossRef]
- Ahmad, S.; Martins, C. The Modern View of B Chromosomes under the Impact of High Scale Omics Analyses. Cells 2019, 8, 156. [Google Scholar] [CrossRef] [Green Version]
- Singh, L.; Purdom, I.F.; Jones, K.W. Sex chromosome associated satellite DNA: Evolution and conservation. Chromosoma 1980, 79, 137–157. [Google Scholar] [CrossRef]
- Hughes, J.F.; Rozen, S. Genomics and genetics of human and primate y chromosomes. Annu. Rev. Genom. Hum. Genet. 2012, 13, 83–108. [Google Scholar] [CrossRef] [Green Version]
- Steinemann, S.; Steinemann, M. Y chromosomes: Born to be destroyed. BioEssays 2005, 27, 1076–1083. [Google Scholar] [CrossRef] [PubMed]
- Filatov, D.A.; Monéger, F.; Negrutlu, I.; Charlesworth, D. Low variability in a Y-linked plant gene and its implications for Y- chromosome evolution. Nature 2000, 404, 388–390. [Google Scholar] [CrossRef] [PubMed]
- Charlesworth, B.; Charlesworth, D. The degeneration of Y chromosomes. Philos. Trans. R. Soc. B Biol. Sci. 2000, 355, 1563–1572. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Skaletsky, H.; Kuroda-Kawaguchl, T.; Minx, P.J.; Cordum, H.S.; Hlllier, L.D.; Brown, L.G.; Repplng, S.; Pyntikova, T.; All, J.; Blerl, T.; et al. The male-specific region of the human Y chromosome is a mosaic of discrete sequence classes. Nature 2003, 423, 825–837. [Google Scholar] [CrossRef] [PubMed]
- Blackmon, H.; Brandvain, Y. Long-term fragility of Y chromosomes is dominated by short-term resolution of sexual antagonism. Genetics 2017, 207, 1621–1629. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, C.; Li, X.; Jabs, E.W.; Court, D.; Lin, C.C. Human gamma X satellite DNA: An X chromosome specific centromeric DNA sequence. Chromosoma 1995, 104, 103–112. [Google Scholar] [CrossRef]
- Lee, C.; Stanyon, R.; Lin, C.C.; Ferguson-Smith, M.A. Conservation of human gamma-X centromeric satellite DNA among primates with an autosomal localization in certain Old World monkeys. Chromosom. Res. 1999, 7, 43–47. [Google Scholar] [CrossRef]
- Schueler, M.G.; Dunn, J.M.; Bird, C.P.; Ross, M.T.; Viggiano, L.; Rocchi, M.; Willard, H.F.; Green, E.D. Progressive proximal expansion of the primate X chromosome centromere. Proc. Natl. Acad. Sci. USA 2005, 102, 10563–10568. [Google Scholar] [CrossRef] [Green Version]
- Babcock, M.; Yatsenko, S.; Stankiewicz, P.; Lupski, J.R.; Morrow, B.E. AT-rich repeats associated with chromosome 22q11.2 rearrangement disorders shape human genome architecture on Yq12. Genome Res. 2007, 17, 451–460. [Google Scholar] [CrossRef] [Green Version]
- Hughes, J.F.; Skaletsky, H.; Pyntikova, T.; Graves, T.A.; Van Daalen, S.K.M.; Minx, P.J.; Fulton, R.S.; McGrath, S.D.; Locke, D.P.; Friedman, C.; et al. Chimpanzee and human y chromosomes are remarkably divergent in structure and gene content. Nature 2010, 463, 536–539. [Google Scholar] [CrossRef] [Green Version]
- Tomaszkiewicz, M.; Rangavittal, S.; Cechova, M.; Sanchez, R.C.; Fescemyer, H.W.; Harris, R.; Ye, D.; O’Brien, P.C.M.; Chikhi, R.; Ryder, O.A.; et al. A time- and cost-effective strategy to sequence mammalian Y chromosomes: An application to the de novo assembly of gorilla Y. Genome Res. 2016, 26, 530–540. [Google Scholar] [CrossRef] [PubMed]
- Bernardo Carvalho, A.; Clark, A.G. Efficient identification of y chromosome sequences in the human and drosophila genomes. Genome Res. 2013, 23, 1894–1907. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brutlag, D.L. Molecular arrangement and evolution of heterochromatic DNA. Annu. Rev. Genet. 1980, 14, 121–144. [Google Scholar] [CrossRef]
- Nei, M. Accumulation of Nonfunctional Genes on Sheltered Chromosomes. Am. Nat. 1970, 104, 311–322. [Google Scholar] [CrossRef]
- Bachtrog, D. Y-chromosome evolution: Emerging insights into processes of Y-chromosome degeneration. Nat. Rev. Genet. 2013, 14, 113–124. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Floridia, G.; Zatterale, A.; Zuffardi, O.; Tyler-Smith, C. Mapping of a human centromere onto the DNA by topoisomerase II cleavage. EMBO Rep. 2000, 1, 489–493. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Andersen, C.L.; Wandall, A.; Kjeldsen, E.; Mielke, C.; Koch, J. Active, but not inactive, human centromeres display topoisomerase II activity in vivo. Chromosom. Res. 2002, 10, 305–312. [Google Scholar] [CrossRef]
- Spence, J.M.; Critcher, R.; Ebersole, T.A.; Valdivia, M.M.; Earnshaw, W.C.; Fukagawa, T.; Farr, C.J. Co-localization of centromere activity, proteins and topoisomerase II within a subdomain of the major human X α-satellite array. EMBO J. 2002, 21, 5269–5280. [Google Scholar] [CrossRef] [Green Version]
- Giacalone, J.; Friedes, J.; Francke, U. A novel GC–rich human macrosatellite VNTR in Xq24 is differentially methylated on active and inactive X chromosomes. Nat. Genet. 1992, 1, 137–143. [Google Scholar] [CrossRef]
- Samonte, R.V.; Conte, R.A.; Verma, R.S. Physical mapping of human 7q and 14q subtelomeric DNA sequences in the great apes. DNA Res. 1997, 4, 249–252. [Google Scholar] [CrossRef] [Green Version]
- Graur, D.; Zheng, Y.; Azevedo, R.B.R. An evolutionary classification of genomic function. Genome Biol. Evol. 2015, 7, 642–645. [Google Scholar] [CrossRef] [Green Version]
- Palacios-Gimenez, O.M.; Bardella, V.B.; Lemos, B.; Cabral-De-Mello, D.C. Satellite DNAs are conserved and differentially transcribed among Gryllus cricket species. DNA Res. 2018, 25, 137–147. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferreira, D.; Meles, S.; Escudeiro, A.; Mendes-da-Silva, A.; Adega, F.; Chaves, R. Satellite non-coding RNAs: The emerging players in cells, cellular pathways and cancer. Chromosom. Res. 2015, 23, 479–493. [Google Scholar] [CrossRef] [PubMed]
- Louzada, S.; Lopes, M.; Ferreira, D.; Adega, F.; Escudeiro, A.; Gama-carvalho, M.; Chaves, R. Decoding the role of satellite DNA in genome architecture and plasticity—An evolutionary and clinical affair. Genes 2020, 11, 72. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Quénet, D.; Dalal, Y. A long non-coding RNA is required for targeting centromeric protein A to the human centromere. eLife 2014, 3, e26016. [Google Scholar] [CrossRef]
- Johnson, W.L.; Yewdell, W.T.; Bell, J.C.; McNulty, S.M.; Duda, Z.; O’Neill, R.J.; Sullivan, B.A.; Straight, A.F. RNA-dependent stabilization of SUV39H1 at constitutive heterochromatin. eLife 2017, 6, e25299. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Qu, Q.; Warrington, R.; Rice, A.; Cheng, N.; Yu, H. Mitotic Transcription Installs Sgo1 at Centromeres to Coordinate Chromosome Segregation. Mol. Cell 2015, 59, 426–436. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Camacho, O.V.; Galan, C.; Swist-Rosowska, K.; Ching, R.; Gamalinda, M.; Karabiber, F.; De La Rosa-Velazquez, I.; Engist, B.; Koschorz, B.; Shukeir, N.; et al. Major satellite repeat RNA stabilize heterochromatin retention of Suv39h enzymes by RNA-nucleosome association and RNA:DNA hybrid formation. eLife 2017, 6, e25293. [Google Scholar] [CrossRef]
- McNulty, S.M.; Sullivan, L.L.; Sullivan, B.A. Human Centromeres Produce Chromosome-Specific and Array-Specific Alpha Satellite Transcripts that Are Complexed with CENP-A and CENP-C. Dev. Cell 2017, 42, 226–240.e6. [Google Scholar] [CrossRef]
- Shirai, A.; Kawaguchi, T.; Shimojo, H.; Muramatsu, D.; Ishida-Yonetani, M.; Nishimura, Y.; Kimura, H.; Nakayama, J.I.; Shinkai, Y. Impact of nucleic acid and methylated H3K9 binding activities of Suv39h1 on its heterochromatin assembly. eLife 2017, 6, e25317. [Google Scholar] [CrossRef]
- Chan, F.L.; Marshall, O.J.; Saffery, R.; Kim, B.W.; Earle, E.; Choo, K.H.A.; Wong, L.H. Active transcription and essential role of RNA polymerase II at the centromere during mitosis. Proc. Natl. Acad. Sci. USA 2012, 109, 1979–1984. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lyn Chan, F.; Wong, L.H. Transcription in the maintenance of centromere chromatin identity. Nucleic Acids Res. 2012, 40, 11178–11188. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grenfell, A.W.; Heald, R.; Strzelecka, M. Mitotic noncoding RNA processing promotes kinetochore and spindle assembly in Xenopus. J. Cell Biol. 2016, 214, 133–141. [Google Scholar] [CrossRef] [PubMed]
- Smurova, K.; De Wulf, P. Centromere and Pericentromere Transcription: Roles and Regulation … in Sickness and in Health. Front. Genet. 2018, 9, 674. [Google Scholar] [CrossRef] [Green Version]
- Jolly, C.; Metz, A.; Govin, J.; Vigneron, M.; Turner, B.M.; Khochbin, S.; Vourc’h, C. Stress-induced transcription of satellite III repeats. J. Cell Biol. 2004, 164, 25–33. [Google Scholar] [CrossRef] [Green Version]
- Rizzi, N.; Denegri, M.; Chiodi, I.; Corioni, M.; Valgardsdottir, R.; Cobianchi, F.; Riva, S.; Biamonti, G. Transcriptional Activation of a Constitutive Heterochromatic Domain of the Human Genome in Response to Heat Shock. Mol. Biol. Cell 2004, 15, 543–551. [Google Scholar] [CrossRef] [Green Version]
- Biamonti, G. Nuclear stress bodies: A heterochromatin affair? Nat. Rev. Mol. Cell Biol. 2004, 5, 493–498. [Google Scholar] [CrossRef]
- Goenka, A.; Sengupta, S.; Pandey, R.; Parihar, R.; Mohanta, G.C.; Mukerji, M.; Ganesh, S. Human satellite-III non-coding RNAs modulate heat-shockinduced transcriptional repression. J. Cell Sci. 2016, 129, 3541–3552. [Google Scholar] [CrossRef] [Green Version]
- Valgardsdottir, R.; Chiodi, I.; Giordano, M.; Rossi, A.; Bazzini, S.; Ghigna, C.; Riva, S.; Biamonti, G. Transcription of Satellite III non-coding RNAs is a general stress response in human cells. Nucleic Acids Res. 2008, 36, 423–434. [Google Scholar] [CrossRef]
- Pezer, Ž.; Brajković, J.; Feliciello, I.; Ugarković, D. Satellite DNA-mediated effects on genome regulation. Genome Dyn. 2012, 7, 153–169. [Google Scholar] [CrossRef]
- Lanza, R.P.; Cibelli, J.B.; Blackwell, C.; Cristofalo, V.J.; Francis, M.K.; Baerlocher, G.M.; Mak, J.; Schertzer, M.; Chavez, E.A.; Sawyer, N.; et al. Extension of cell life-span and telomere length in animals cloned from senescent somatic cells. Science 2000, 288, 665–669. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rizvi, S.; Raza, S.T.; Mahdi, F. Telomere Length Variations in Aging and Age-Related Diseases. Curr. Aging Sci. 2015, 7, 161–167. [Google Scholar] [CrossRef] [PubMed]
- Bass, H.W.; Riera-Lizarazu, O.; Ananiev, E.V.; Bordoli, S.J.; Rines, H.W.; Phillips, R.L.; Sedat, J.W.; Agard, D.A.; Cande, W.Z. Evidence for the coincident initiation of homolog pairing and synapsis during the telomere-clustering (bouquet) stage of meiotic prophase. J. Cell Sci. 2000, 113, 1033–1042. [Google Scholar] [PubMed]
- Koga, A.; Notohara, M.; Hirai, H. Evolution of subterminal satellite (StSat) repeats in hominids. Genetica 2011, 139, 167–175. [Google Scholar] [CrossRef] [PubMed]
- Novo, C.; Arnoult, N.; Bordes, W.Y.; Castro-Vega, L.; Gibaud, A.; Dutrillaux, B.; Bacchetti, S.; Londoño-Vallejo, A. The heterochromatic chromosome caps in great apes impact telomere metabolism. Nucleic Acids Res. 2013, 41, 4792–4801. [Google Scholar] [CrossRef] [PubMed]
- Calderón, M.D.C.; Rey, M.D.; Cabrera, A.; Prieto, P. The subtelomeric region is important for chromosome recognition and pairing during meiosis. Sci. Rep. 2014, 4, 6488. [Google Scholar] [CrossRef] [Green Version]
- Eymery, A.; Horard, B.; el Atifi-Borel, M.; Fourel, G.; Berger, F.; Vitte, A.L.; Van den Broeck, A.; Brambilla, E.; Fournier, A.; Callanan, M.; et al. A transcriptomic analysis of human centromeric and pericentric sequences in normal and tumor cells. Nucleic Acids Res. 2009, 37, 6340–6354. [Google Scholar] [CrossRef] [Green Version]
- Ting, D.T.; Lipson, D.; Paul, S.; Brannigan, B.W.; Akhavanfard, S.; Coffman, E.J.; Contino, G.; Deshpande, V.; Iafrate, A.J.; Letovsky, S.; et al. Aberrant overexpression of satellite repeats in pancreatic and other epithelial cancers. Science 2011, 331, 593–596. [Google Scholar] [CrossRef] [Green Version]
- Ugarković, D.; Plohl, M. Variation in satellite DNA profiles—Causes and effects. EMBO J. 2002, 21, 5955–5959. [Google Scholar] [CrossRef] [Green Version]
- Gläser, B.; Grützner, F.; Willmann, U.; Stanyon, R.; Arnold, N.; Taylor, K.; Rietschel, W.; Zeitler, S.; Toder, R.; Schempp, W. Simian Y Chromosomes: Species-specific rearrangements of DAZ, RBM, and TSPY versus contiguity of PAR and SRY. Mamm. Genome 1998, 9, 226–231. [Google Scholar] [CrossRef]
- Altemose, N.; Miga, K.H.; Maggioni, M.; Willard, H.F. Genomic Characterization of Large Heterochromatic Gaps in the Human Genome Assembly. PLoS Comput. Biol. 2014, 10, e1003628. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alonso, A.; Hasson, D.; Cheung, F.; Warburton, P.E. A paucity of heterochromatin at functional human neocentromeres. Epigenetics Chromatin 2010, 3, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Miga, K.H. Centromeric satellite DNAs: Hidden sequence variation in the human population. Genes 2019, 10, 352. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Waye, J.S.; Willard, H.F. Structure, organization, and sequence of alpha satellite DNA from human chromosome 17: Evidence for evolution by unequal crossing-over and an ancestral pentamer repeat shared with the human X chromosome. Mol. Cell. Biol. 1986, 6, 3156–3165. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Warburton, P.E.; Willard, H.F. Interhomologue sequence variation of alpha satellite DNA from human chromosome 17: Evidence for concerted evolution along haplotypic lineages. J. Mol. Evol. 1995, 41, 1006–1015. [Google Scholar] [CrossRef] [PubMed]
- Rudd, M.K.; Wray, G.A.; Willard, H.F. The evolutionary dynamics of α-satellite. Genome Res. 2006, 16, 88–96. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shepelev, V.A.; Alexandrov, A.A.; Yurov, Y.B.; Alexandrov, I.A. The evolutionary origin of man can be traced in the layers of defunct ancestral alpha satellites flanking the active centromeres of human chromosomes. PLoS Genet. 2009, 5, e1000641. [Google Scholar] [CrossRef]
- Maloney, K.A.; Sullivan, L.L.; Matheny, J.E.; Strome, E.D.; Merrett, S.L.; Ferris, A.; Sullivan, B.A. Functional epialleles at an endogenous human centromere. Proc. Natl. Acad. Sci. USA 2012, 109, 13704–13709. [Google Scholar] [CrossRef] [Green Version]
- Durfy, S.J.; Willard, H.F. Molecular analysis of a polymorphic domain of alpha satellite from the human X chromosome. Am. J. Hum. Genet. 1987, 41, 391–401. [Google Scholar]
- Schindelhauer, D.; Schwarz, T. Evidence for a fast, intrachromosomal conversion mechanism from mapping of nucleotide variants within a homogeneous α-satellite DNA array. Genome Res. 2002, 12, 1815–1826. [Google Scholar] [CrossRef] [Green Version]
- Goldberg, I.G.; Sawhney, H.; Pluta, A.F.; Warburton, P.E.; Earnshaw, W.C. Surprising deficiency of CENP-B binding sites in African green monkey alpha-satellite DNA: Implications for CENP-B function at centromeres. Mol. Cell. Biol. 1996, 16, 5156–5168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yoda, K.; Ando, S.; Okuda, A.; Kikuchi, A.; Okazaki, T. In vitro assembly of the CENP-B/α-satellite DNA/core histone complex: CENP-B causes nucleosome positioning. Genes Cells 1998, 3, 533–548. [Google Scholar] [CrossRef] [PubMed]
- Donehower, L.; Furlong, C.; Gillespie, D.; Kurnit, D. DNA sequence of baboon highly repeated DNA: Evidence for evolution by nonrandom unequal crossovers. Proc. Natl. Acad. Sci. USA 1980, 77, 2129–2133. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rubin, C.M.; Deininger, P.L.; Houck, C.M.; Schmid, C.W. A dimer satellite sequence in bonnet monkey DNA consists of distinct monomer subunits. J. Mol. Biol. 1980, 136, 151–167. [Google Scholar] [CrossRef]
- Pike, L.M.; Carlisle, A.; Newell, C.; Hong, S.B.; Musich, P.R. Sequence and evolution of rhesus monkey alphoid DNA. J. Mol. Evol. 1986, 23, 127–137. [Google Scholar] [CrossRef]
- Prassolov, V.S.; Kuchino, Y.; Nemoto, K.; Nishimura, S. Nucleotide sequence of the BamHI repetitive sequence, including the hindIII fundamental unit, as a possible mobile element from the Japanese monkey Macaca fuscata. J. Mol. Evol. 1986, 23, 200–204. [Google Scholar] [CrossRef]
- Alves, G.; Seuánez, H.N.; Fanning, T. A Clade of New World Primates with Distinctive Alphoid Satellite DNAs. Mol. Phylogenet. Evol. 1998, 9, 220–224. [Google Scholar] [CrossRef]
- Willard, H.F.; Waye, J.S. Chromosome-specific subsets of human alpha satellite DNA: Analysis of sequence divergence within and between chromosomal subsets and evidence for an ancestral pentameric repeat. J. Mol. Evol. 1987, 25, 207–214. [Google Scholar] [CrossRef]
- Alexandrov, I.A.; Mitkevich, S.P.; Yurov, Y.B. The phylogeny of human chromosome specific alpha satellites. Chromosoma 1988, 96, 443–453. [Google Scholar] [CrossRef]
- Romanova, L.Y.; Deriagin, G.V.; Mashkova, T.D.; Tumeneva, I.G.; Mushegian, A.R.; Kisselev, L.L.; Alexandrov, I.A. Evidence for selection in evolution of alpha satellite DNA: The central role of CENP-B/pJα binding region. J. Mol. Biol. 1996, 261, 334–340. [Google Scholar] [CrossRef]
- Greig, G.M.; Warburton, P.E.; Willard, H.F. Organization and evolution of an alpha satellite DNA subset shared by human chromosomes 13 and 21. J. Mol. Evol. 1993, 37, 464–475. [Google Scholar] [CrossRef] [PubMed]
- Kugou, K.; Hirai, H.; Masumoto, H.; Koga, A. Formation of functional CENP-B boxes at diverse locations in repeat units of centromeric DNA in New World monkeys. Sci. Rep. 2016, 6, 27833. [Google Scholar] [CrossRef] [PubMed]
- Nishihara, H.; Kobayashi, N.; Kimura-Yoshida, C.; Yan, K.; Bormuth, O.; Ding, Q.; Nakanishi, A.; Sasaki, T.; Hirakawa, M.; Sumiyama, K.; et al. Coordinately Co-opted Multiple Transposable Elements Constitute an Enhancer for wnt5a Expression in the Mammalian Secondary Palate. PLoS Genet. 2016, 12, e1006380. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Raskina, O.; Barber, J.C.; Nevo, E.; Belyayev, A. Repetitive DNA and chromosomal rearrangements: Speciation-related events in plant genomes. Cytogenet. Genome Res. 2008, 120, 351–357. [Google Scholar] [CrossRef] [PubMed]
- Emadzade, K.; Jang, T.S.; Macas, J.; Kovařík, A.; Novák, P.; Parker, J.; Weiss-Schneeweiss, H. Differential amplification of satellite PaB6 in chromosomally hypervariable Prospero autumnale complex (Hyacinthaceae). Ann. Bot. 2014, 114, 1597–1608. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ershova, E.S.; Malinovskaya, E.M.; Konkova, M.S.; Veiko, R.V.; Umriukhin, P.E.; Martynov, A.V.; Kutsev, S.I.; Veiko, N.N.; Kostyuk, S.V. Copy number variation of human satellite III (1q12) with Aging. Front. Genet. 2019, 10, 704. [Google Scholar] [CrossRef] [Green Version]
- Wevrick, R.; Willard, H.F. Long-range organization of tandem arrays of α satellite DNA at the centromeres of human chromosomes: High-frequency array-length polymorphism and meiotic stability. Proc. Natl. Acad. Sci. USA 1989, 86, 9394–9398. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wei, K.H.C.; Grenier, J.K.; Barbash, D.A.; Clark, A.G. Correlated variation and population differentiation in satellite DNA abundance among lines of Drosophila melanogaster. Proc. Natl. Acad. Sci. USA 2014, 111, 18793–18798. [Google Scholar] [CrossRef] [Green Version]
- Kursel, L.E.; Malik, H.S. The cellular mechanisms and consequences of centromere drive. Curr. Opin. Cell Biol. 2018, 52, 58–65. [Google Scholar] [CrossRef]
- Ruiz-Ruano, F.J.; López-León, M.D.; Cabrero, J.; Camacho, J.P.M. High-throughput analysis of the satellitome illuminates satellite DNA evolution. Sci. Rep. 2016, 6, 28333. [Google Scholar] [CrossRef] [Green Version]
- Navajas-Pérez, R.; Schwarzacher, T.; De La Herrán, R.; Ruiz Rejón, C.; Ruiz Rejón, M.; Garrido-Ramos, M.A. The origin and evolution of the variability in a Y-specific satellite-DNA of Rumex acetosa and its relatives. Gene 2006, 368, 61–71. [Google Scholar] [CrossRef] [PubMed]
- De La Herrán, R.; Robles, F.; Navas, J.I.; López-Flores, I.; Herrera, M.; Hachero, I.; Garrido-Ramos, M.A.; Ruiz Rejón, C.; Ruiz Rejón, M. The centromeric satellite of the wedge sole (Dicologoglossa cuneata, Pleuronectiformes) is composed mainly of a sequence motif conserved in other vertebrate centromeric DNAs. Cytogenet. Genome Res. 2008, 121, 271–276. [Google Scholar] [CrossRef] [PubMed]
- Fry, K.; Salser, W. Nucleotide sequences of HS-α satellite DNA from kangaroo rat dipodomys ordii and characterization of similar sequences in other rodents. Cell 1977, 12, 1069–1084. [Google Scholar] [CrossRef]
- Meštrović, N.; Mravinac, B.; Juan, C.; Ugarković, D.; Plohl, M. Comparative study of satellite sequences and phylogeny of five species from the genus Palorus (Insecta, Coleoptera). Genome 2000, 43, 776–785. [Google Scholar] [CrossRef]
- Pons, J.; Gillespie, R.G. Evolution of satellite DNAs in a radiation of endemic Hawaiian spiders: Does concerted evolution of highly repetitive sequences reflect evolutionary history? J. Mol. Evol. 2004, 59, 632–641. [Google Scholar] [CrossRef]
- Meštrović, N.; Mravinac, B.; Pavlek, M.; Vojvoda-Zeljko, T.; Šatović, E.; Plohl, M. Structural and functional liaisons between transposable elements and satellite DNAs. Chromosom. Res. 2015, 23, 583–596. [Google Scholar] [CrossRef]
- Cohen, S.; Agmon, N.; Yacobi, K.; Mislovati, M.; Segal, D. Evidence for rolling circle replication of tandem genes in Drosophila. Nucleic Acids Res. 2005, 33, 4519–4526. [Google Scholar] [CrossRef] [Green Version]
- Cohen, S.; Agmon, N.; Sobol, O.; Segal, D. Extrachromosomal circles of satellite repeats and 5S ribosomal DNA in human cells. Mob. DNA 2010, 1, 11. [Google Scholar] [CrossRef] [Green Version]
- Satović, E.; Vojvoda Zeljko, T.; Luchetti, A.; Mantovani, B.; Plohl, M. Adjacent sequences disclose potential for intra-genomic dispersal of satellite DNA repeats and suggest a complex network with transposable elements. BMC Genom. 2016, 17, 997. [Google Scholar] [CrossRef] [Green Version]
- McGurk, M.P.; Barbash, D.A. Double insertion of transposable elements provides a substrate for the evolution of satellite DNA. Genome Res. 2018, 28, 714–725. [Google Scholar] [CrossRef] [Green Version]
- Elder, J.F.; Turner, B.J. Concerted evolution of repetitive DNA sequences in eukaryotes. Q. Rev. Biol. 1995, 70, 297–320. [Google Scholar] [CrossRef] [PubMed]
- Dover, G. Molecular drive: A cohesive mode of species evolution. Nature 1982, 299, 111–117. [Google Scholar] [CrossRef] [PubMed]
- Dover, G. Concerted evolution, molecular drive and natural selection. Curr. Biol. 1994, 4, 1165–1166. [Google Scholar] [CrossRef]
- Feliciello, I.; Akrap, I.; Brajkovi, J.; Zlatar, I.; Ugarkovic, D. Satellite DNA as a driver of population divergence in the red flour beetle tribolium castaneum. Genome Biol. Evol. 2014, 7, 228–239. [Google Scholar] [CrossRef]
- Rogers, J. In transition: Primate genomics at a time of rapid change. ILAR J. 2013, 54, 224–233. [Google Scholar] [CrossRef] [Green Version]
- Conesa, A.; Madrigal, P.; Tarazona, S.; Gomez-Cabrero, D.; Cervera, A.; McPherson, A.; Szcześniak, M.W.; Gaffney, D.J.; Elo, L.L.; Zhang, X.; et al. A survey of best practices for RNA-seq data analysis. Genome Biol. 2016, 17, 406–410. [Google Scholar] [CrossRef] [Green Version]
- Jurka, J.; Walichiewicz, J.; Milosavljevic, A. Prototypic sequences for human repetitive DNA. J. Mol. Evol. 1992, 35, 286–291. [Google Scholar] [CrossRef]
- Jurka, J.; Kapitonov, V.V.; Pavlicek, A.; Klonowski, P.; Kohany, O.; Walichiewicz, J. Repbase Update, a database of eukaryotic repetitive elements. Cytogenet. Genome Res. 2005, 110, 462–467. [Google Scholar] [CrossRef]
- Kent, W.J.; Sugnet, C.W.; Furey, T.S.; Roskin, K.M.; Pringle, T.H.; Zahler, A.M.; Haussler, A.D. The Human Genome Browser at UCSC. Genome Res. 2002, 12, 996–1006. [Google Scholar] [CrossRef] [Green Version]
- Gelfand, Y.; Rodriguez, A.; Benson, G. TRDB—The Tandem Repeats Database. Nucleic Acids Res. 2007, 35, D80–D87. [Google Scholar] [CrossRef]
- Hubley, R.; Finn, R.D.; Clements, J.; Eddy, S.R.; Jones, T.A.; Bao, W.; Smit, A.F.A.; Wheeler, T.J. The Dfam database of repetitive DNA families. Nucleic Acids Res. 2016, 44, D81–D89. [Google Scholar] [CrossRef] [Green Version]
- Ruitberg, C.M.; Reeder, D.J.; Butler, J.M. STRBase: A short tandem repeat DNA database for the human identity testing community. Nucleic Acids Res. 2001, 29, 320–322. [Google Scholar] [CrossRef]
- Benson, G. Tandem repeats finder: A program to analyze DNA sequences. Nucleic Acids Res. 1999, 27, 573–580. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schaper, E.; Korsunsky, A.; Pečerska, J.; Messina, A.; Murri, R.; Stockinger, H.; Zoller, S.; Xenarios, I.; Anisimova, M. TRAL: Tandem repeat annotation library. Bioinformatics 2015, 31, 3051–3053. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jain, M.; Koren, S.; Miga, K.H.; Quick, J.; Rand, A.C.; Sasani, T.A.; Tyson, J.R.; Beggs, A.D.; Dilthey, A.T.; Fiddes, I.T.; et al. Nanopore sequencing and assembly of a human genome with ultra-long reads. Nat. Biotechnol. 2018, 36, 338–345. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Novák, P.; Neumann, P.; Macas, J. Graph-based clustering and characterization of repetitive sequences in next-generation sequencing data. BMC Bioinform. 2010, 11, 378. [Google Scholar] [CrossRef] [Green Version]
- Novák, P.; Neumann, P.; Pech, J.; Steinhaisl, J.; MacAs, J. RepeatExplorer: A Galaxy-based web server for genome-wide characterization of eukaryotic repetitive elements from next-generation sequence reads. Bioinformatics 2013, 29, 792–793. [Google Scholar] [CrossRef] [Green Version]
- Novák, P.; Robledillo, L.Á.; Koblížková, A.; Vrbová, I.; Neumann, P.; Macas, J. TAREAN: A computational tool for identification and characterization of satellite DNA from unassembled short reads. Nucleic Acids Res. 2017, 45, e111. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmad, S.F.; Singchat, W.; Jehangir, M.; Suntronpong, A.; Panthum, T.; Malaivijitnond, S.; Srikulnath, K. Dark Matter of Primate Genomes: Satellite DNA Repeats and Their Evolutionary Dynamics. Cells 2020, 9, 2714. https://doi.org/10.3390/cells9122714
Ahmad SF, Singchat W, Jehangir M, Suntronpong A, Panthum T, Malaivijitnond S, Srikulnath K. Dark Matter of Primate Genomes: Satellite DNA Repeats and Their Evolutionary Dynamics. Cells. 2020; 9(12):2714. https://doi.org/10.3390/cells9122714
Chicago/Turabian StyleAhmad, Syed Farhan, Worapong Singchat, Maryam Jehangir, Aorarat Suntronpong, Thitipong Panthum, Suchinda Malaivijitnond, and Kornsorn Srikulnath. 2020. "Dark Matter of Primate Genomes: Satellite DNA Repeats and Their Evolutionary Dynamics" Cells 9, no. 12: 2714. https://doi.org/10.3390/cells9122714
APA StyleAhmad, S. F., Singchat, W., Jehangir, M., Suntronpong, A., Panthum, T., Malaivijitnond, S., & Srikulnath, K. (2020). Dark Matter of Primate Genomes: Satellite DNA Repeats and Their Evolutionary Dynamics. Cells, 9(12), 2714. https://doi.org/10.3390/cells9122714