
Why Were [GADV]-amino Acids and GNC Codons Selected and How Was GNC Primeval Genetic Code Established?

Highlights
- The reason why four GNC codons and four [GADV] amino acids were selected to form the first genetic code is explained.
- The corresponding relationship between GNC codons and [GADV] amino acids was accidentally frozen.
- The process of establishing the first genetic code has been revealed.
Abstract
:1. Introduction
- From what code did the genetic code originate?
- How were amino acids and codons selected for the first genetic code and how was the first genetic code established?
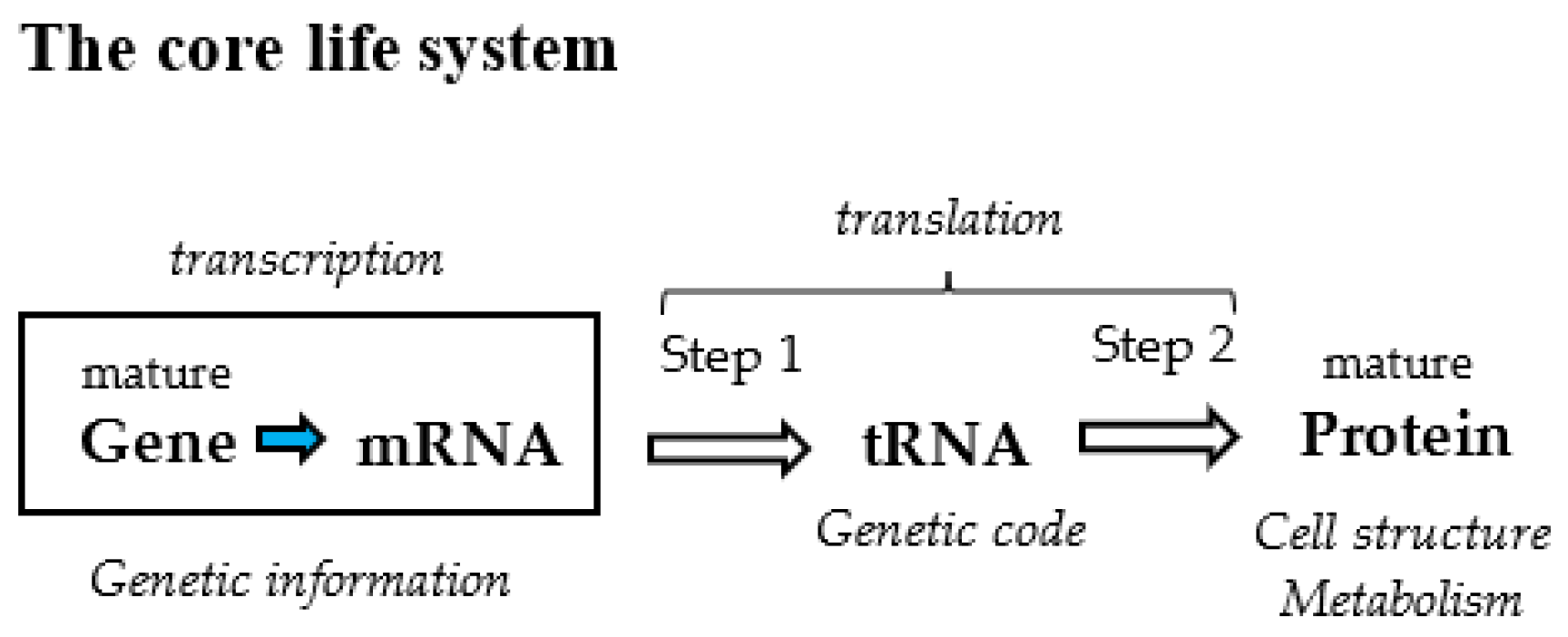
2. GNC-SNS Primitive Genetic Code Hypothesis
2.1. GC-NSF(a) Hypothesis for Formation of Entirely New Genes
2.2. SNS Primitive Genetic Code Hypothesis
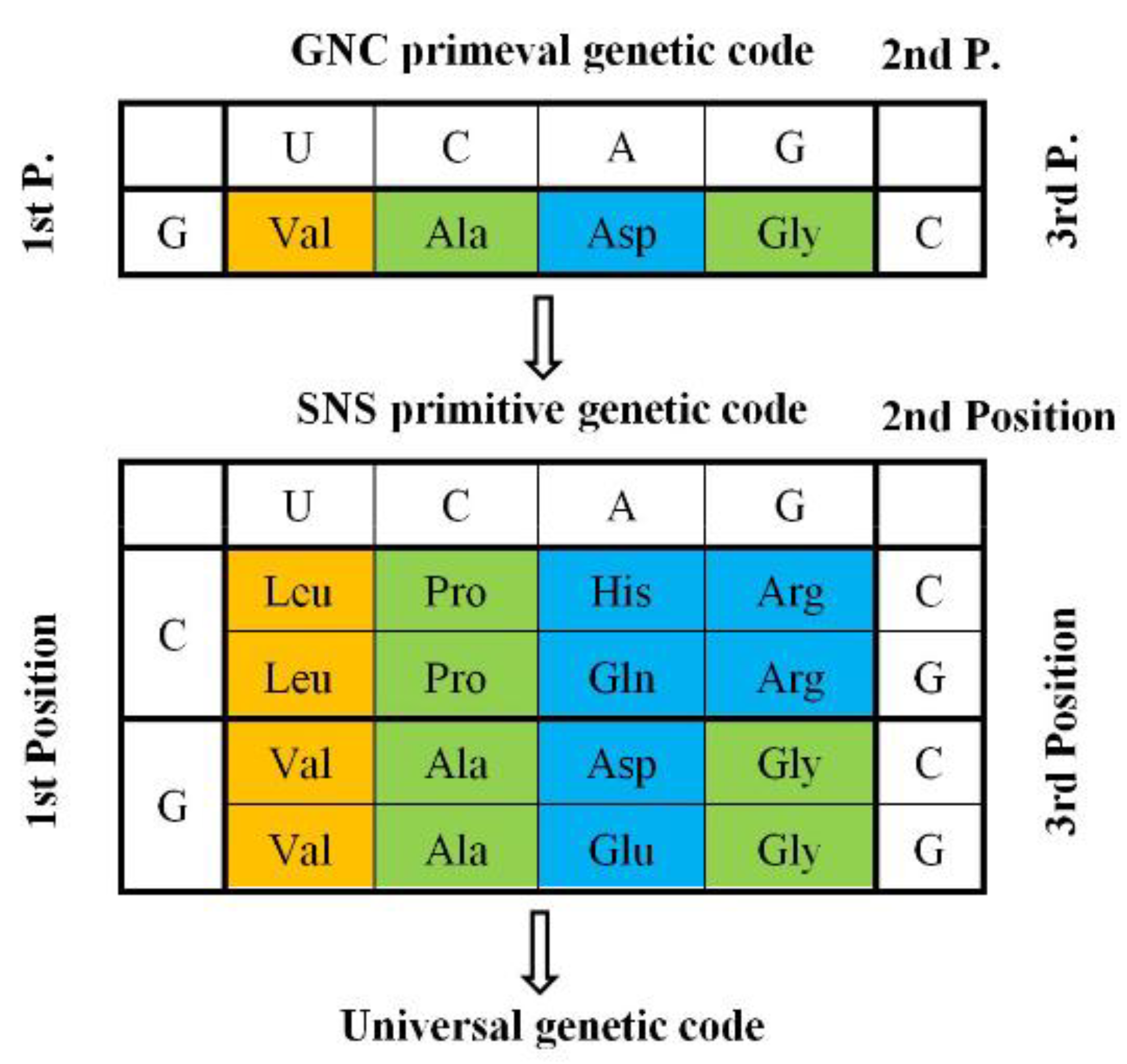
2.3. GNC Primeval Genetic Code Hypothesis
3. Why Were [GADV]-amino Acids and GNC Codons Selected?
3.1. How Were Four [GADV]-amino Acids Selected?
3.1.1. Why Are Only α-amino Acids Used in Proteins?
3.1.2. Why Are Twenty Natural Amino Acids Used in Proteins?
3.1.3. Why Are Only L-Amino Acids Used in Proteins?

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Gly [G] | Ala [A] | Asp [D] | Val [V] | |
|---|---|---|---|---|
| Hydropathy | 1 | 1.6 | −9.2 | 2.6 |
| α-Helix | 0.56 | 1.29 | 1.04 | 0.91 |
| β-Sheet | 0.92 | 0.9 | 0.72 | 1.49 |
| Turn/coil | 1.64 | 0.78 | 1.41 | 0.47 |
3.1.4. Why Are Hydrophobic Val and Hydrophilic Asp Encoded in the GNC Code?
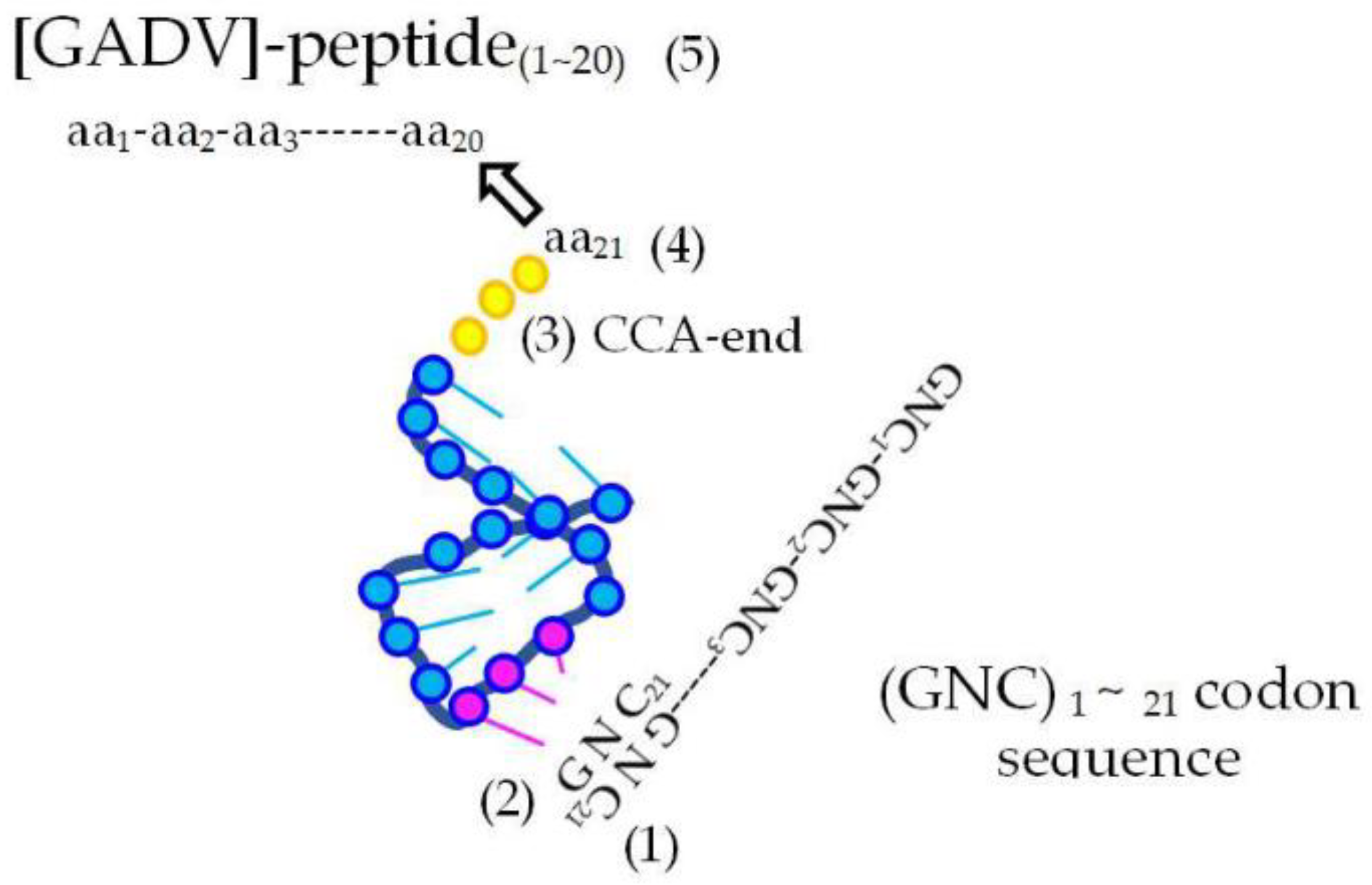
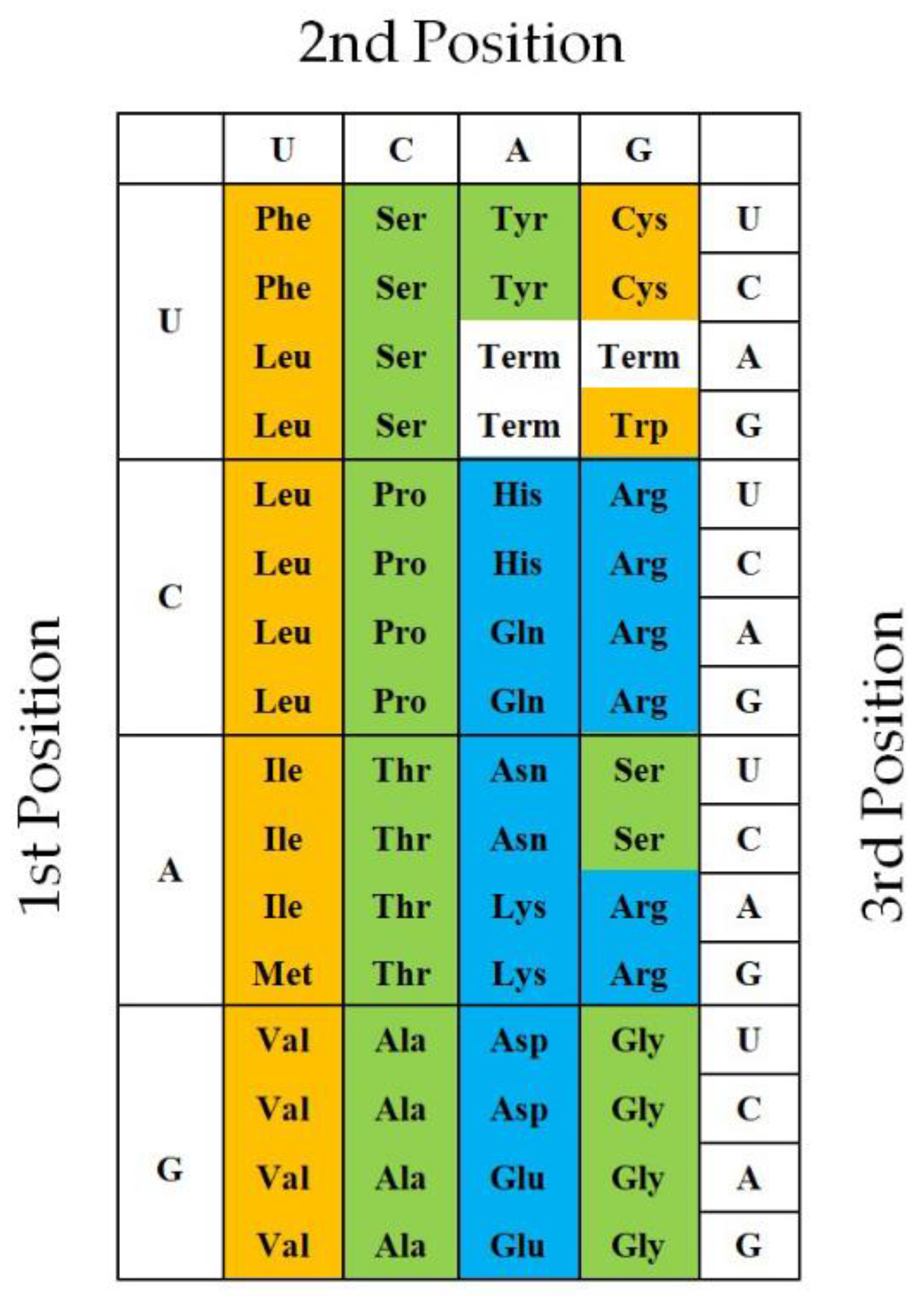
3.2. How Were Four GNC Codons Selected for the First Genetic Code?
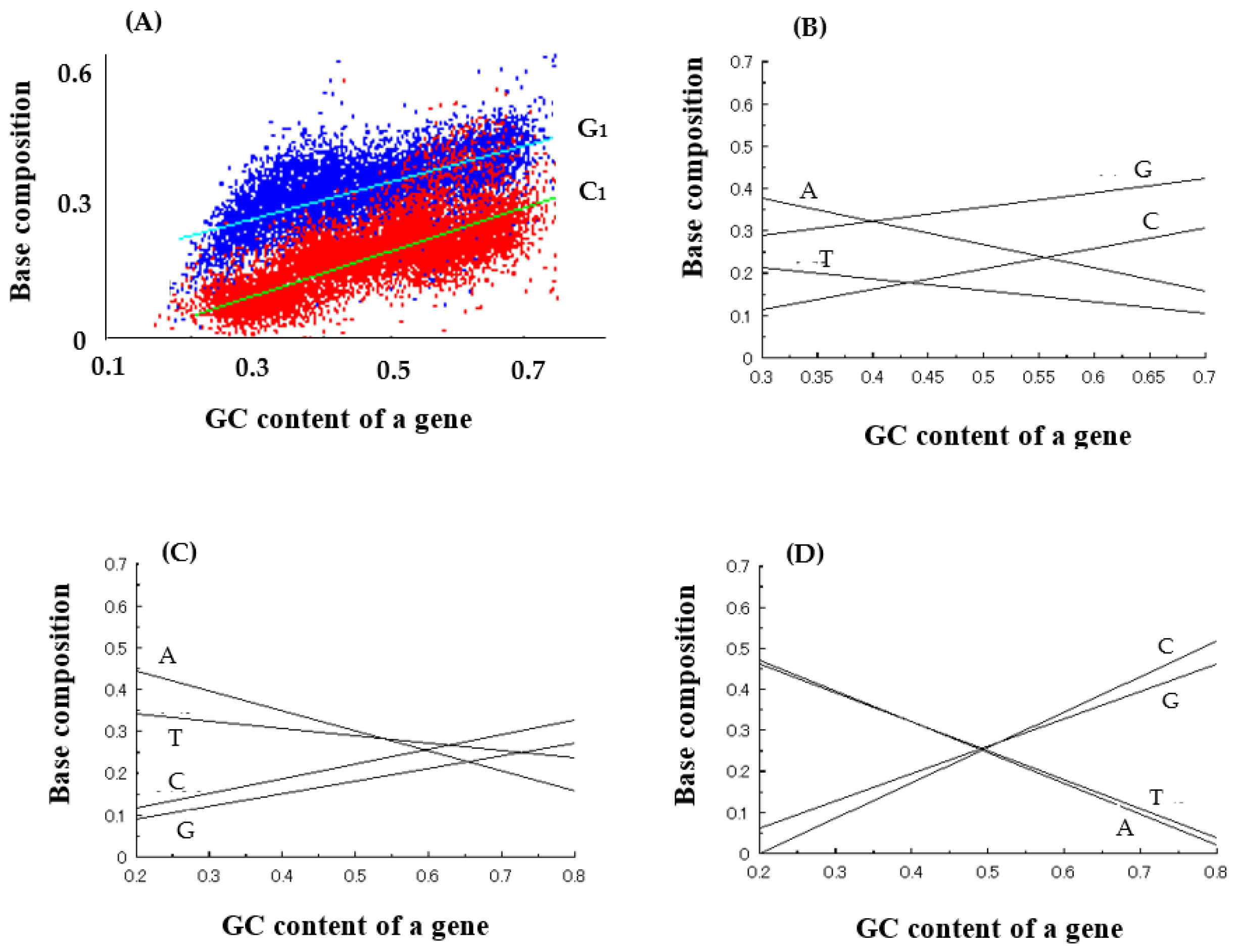
3.2.1. Grounds Showing That GNC Codons Were Used in the First Genetic Code
3.2.2. Strong Binding of a Triplet, GNC, with the Complementary Triplet, GNC
4. How Were the Correspondence Relations between GNC Codons and [GADV]-amino Acids Established?
4.1. Direct Complex Formation between GNC Anticodons/Codons and [GADV]-amino Acids Is Impossible
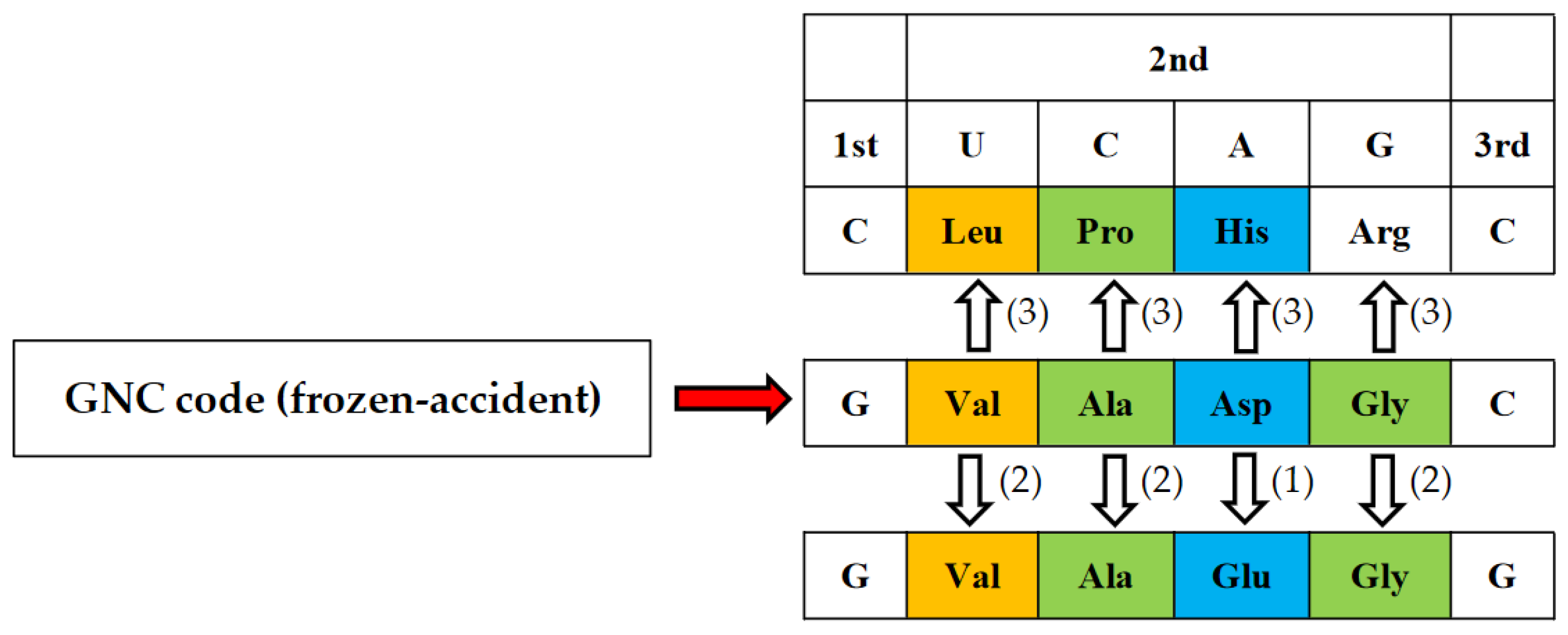
4.2. GNC Code Frozen-Accident Theory on the Origin of the Genetic Code
4.3. How Was the First GNC Code Established?
5. Discussion
- From what code did the genetic code originate?
- How was the correspondence relations between codons and amino acids determined?
- How were the four [GADV]-amino acids selected among messy amino acids which accumulated on primitive Earth?
- Why were the four GNC codons selected through random processes?
- Hydrophobic property of an amino acid does not change largely by base substitution at the first base position of codon.
- Hydrophobic property of an amino acid changes largely by base substitution at the second base position of codon.
- In many cases, the same amino acid is used in a codon box, even if a base is substituted at the third codon position, because of degeneracy of the genetic code. Degeneracy can contribute to the formation of entirely new genes [25].
- Amino acids were arranged randomly or neutrally, using aaRSs and tRNAs, which were produced by the introduction of a small number of base substitutions into previously existing aaRS genes and tRNAs into the genetic code table after the establishment of the GNC primeval genetic code, as assumed by neutral theory [26].
- Amino acids, which were synthesized upon formation of a new metabolic pathway and accumulated in a cell at a high amount as assumed by the coevolution theory [23,24], were used and assigned into the genetic code table when the use of the amino acid was beneficial for cell growth as deduced by adaptive theory [27].
- 1.
- That is supported by the fact that 2-ABA (α-amino-n-butylate), which has a simpler structure than Val and therefore should be synthesized with prebiotic means more easily than Val (Table 1), was not used in GNC code. Note that the reason why not only 2-ABA but also norvaline were not assigned into the code could not be reasonably explained.
- 2.
- An amino acid newly synthesized through a new metabolic pathway should be assigned as a new amino acid into a previously existing genetic code table when productive power of primitive cells increased by use of the new amino acid. Inversely, if the amino acid inhibited cell growth, the amino acid should not take root as a new amino acid in the genetic code table.
- The reason why Glu was used after Asp is because Glu was synthesized with 2-oxoglutarate as a substrate, which was synthesized upon elongation of the metabolic pathway as a starting point of 2-oxyaloacetate, which is a substrate for Asp synthesis (Figure 8: step (1)).
- The use of Glu [E] induced the duplicated use of codons for three amino acids, Val, Ala, and Gly (Figure 8: step (2)), in order to suppress excess hydrophilicity of [GADVE]-protein upon the use of Glu.
- Three amino acids, Leu, Pro, and His, were selected and arranged as piling up onto the GNS code one by one after completion of the GNS code encoding five [GADVE]-amino acids (Figure 8: step (3)). The reason why a hydrophobic and α-helix forming Leu, a weakly hydrophobic and turn/coil forming Pro, and a weakly hydrophilic and α-helix forming His were used in a new genetic code table is because insufficient properties of GNS-encoding three amino acids, a hydrophobic and β-sheet forming Val, a weakly hydrophobic and α-helix forming Ala, and a hydrophilic and turn/coli forming Asp, could be complemented by capture of the three amino acids, Leu, Pro, and His.
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ikehara, K. Towards Revealing the Origin of Life—Presenting the GADV Hypothesis; Springer Nature, Gewerbestrasse: Cham, Switzerland, 2021. [Google Scholar]
- Trifonov, E.N.; Bettecken, T. Sequence fossils, triplet expansion, and reconstruction of earliest codons. Gene 1997, 205, 1–6. [Google Scholar] [CrossRef]
- Hartman, H.; Smith, T.F. Origin of the genetic code is found at the transition between a thioester world of peptides and the phosphoester world of polynucleotides. Life 2019, 9, 69. [Google Scholar] [CrossRef] [Green Version]
- Higgs, P.G. A four-column theory for the origin of the genetic code: Tracing the evolutionary pathways that gave rise to an optimized code. Biol. Direct. 2009, 24, 4–16. [Google Scholar] [CrossRef] [Green Version]
- Watson, J.D.; Hopkins, N.H.; Roberts, J.W.; Steitz, J.A.; Weiner, A.M. Molecular Biology of the Gene, 4th ed.; The Benjamin/Cummings Publishing Company, Inc.: Menlo Park, CA, USA, 1987; p. 94025. [Google Scholar]
- Shepherd, J.C.W. Fossil remnants of a primeval genetic code in all forms of life? Trends Biochem. Sci. 1984, 9, 8–10. [Google Scholar] [CrossRef]
- Ikehara, K.; Omori, Y.; Arai, R.; Hirose, A. A novel theory on the origin of the genetic code: A GNC-SNS hypothesis. J. Mol. Evol. 2002, 54, 530–538. [Google Scholar] [CrossRef]
- Ikehara, K.; Yoshida, S. SNS hypothesis on the origin of the genetic code. Viva Orig. 1996, 26, 301–310. [Google Scholar]
- Ikehara, K.; Amada, F.; Yoshida, S.; Mikata, Y.; Tanaka, A. A possible origin of newly-born bacterial genes: Significance of GC-rich nonstop frame on antisense strand. Nucl. Acids Res. 1996, 24, 4249–4255. [Google Scholar] [CrossRef] [Green Version]
- Miller, S.L.; Orgel, L.E. The Origins of Life on the Earth; Prentice-Hall: Englewood Cliffs, NJ, USA, 1974. [Google Scholar]
- Cleaves, H.J.; Chalmers, J.H.; Lazcano, A.; Miller, S.L.; Bada, J.L. A reassessment of prebiotic organic synthesis in neutral planetary atmosphere. Orig. Life Evol. Biosph. 2008, 38, 105–115. [Google Scholar] [CrossRef]
- Kojo, K. Origin of homochirality of amino acids in the biosphere. Symmetry 2010, 2, 1022–1032. [Google Scholar] [CrossRef] [Green Version]
- Breslow, R.; Levine, M.S. Amplification of enantiomeric concentrations under credible prebiotic conditions. Proc. Natl. Acad. Sci. USA 2006, 103, 12979–12980. [Google Scholar] [CrossRef] [Green Version]
- Berg, J.M.; Tymoczko, J.L.; Stryer, L. Biochemistry, 5th ed.; W.H. Freeman and Company: New York, NY, USA, 2002. [Google Scholar]
- Ikehara, K. Origins of gene, genetic code, protein and life: Comprehensive view of life system from a GNC-SNS primitive genetic code hypothesis. J. Biosci. 2002, 27, 165–186. [Google Scholar] [CrossRef]
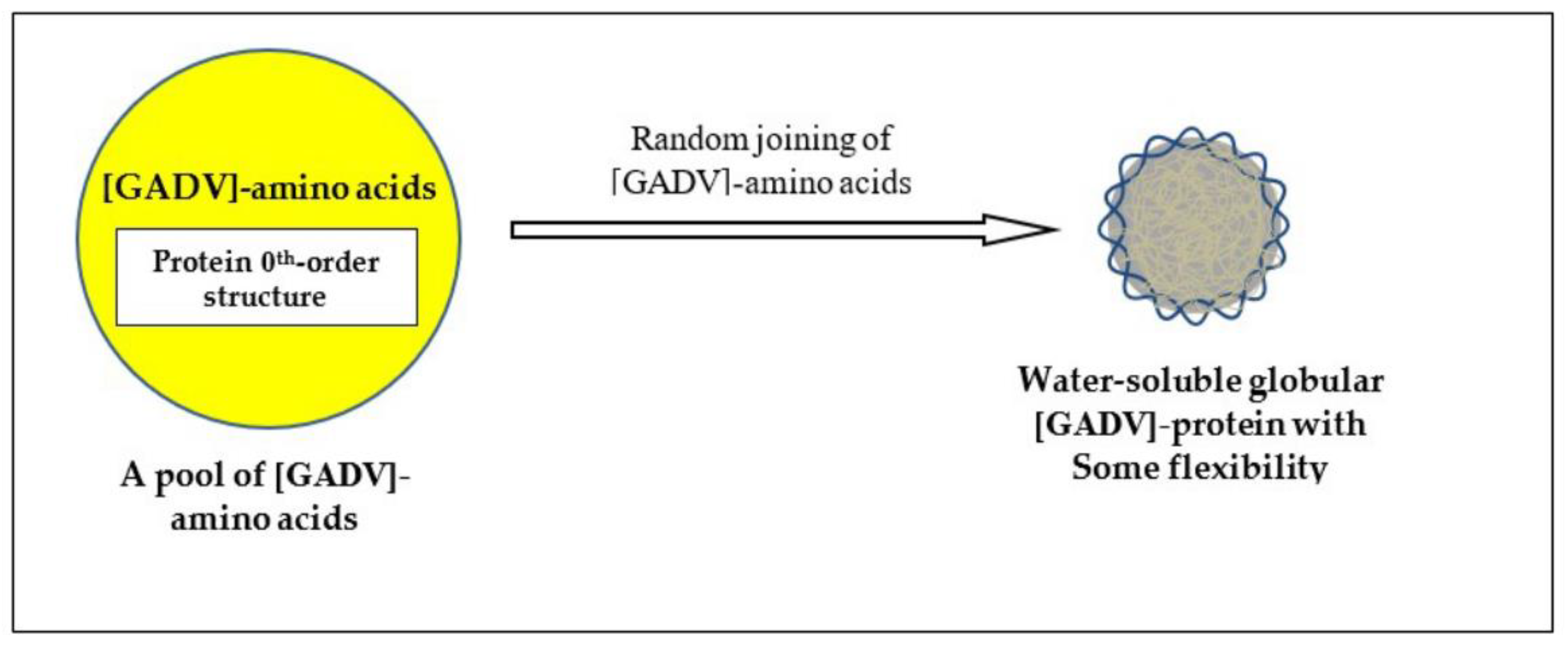
- Ikehara, K. Protein ordered sequences are formed by random joining of amino acids in protein 0th-order structure, followed by evolutionary process. Orig. Life Evol. Biosph. 2014, 44, 279–281. [Google Scholar] [CrossRef]
- Van der Gulik, P.; Massar, S.; Gilis, D.; Buhrman, H.; Rooman, M. The First peptides: The evolutionary transition between prebiotic amino acids and early proteins. J. Theor. Biol. 2009, 261, 531–539. [Google Scholar] [CrossRef] [Green Version]
- Ikehara, K. The origin of tRNA deduced from Pseudomonas aeruginosa 5′ anticodon-stem sequence: Anticodon stemloop hypothesis. Orig. Life Evol. Biosph. 2019, 49, 61–75. [Google Scholar] [CrossRef]
- Transfer RNA Database (Universitat Leipzig). Available online: http//trnadb.bioinf.uni-leipzig.de (accessed on 25 October 2021).
- Taghavi, A.; van der Schoot, P.; Berryman, J.T. DNA partitions into triplets under tension in the presence of organic cations, with sequence evolutionary age predicting the stability of the triplet phase. Q. Rev. Biophys. 2017, 50, e15. [Google Scholar] [CrossRef] [Green Version]
- Shimizu, M. Molecular basis for the genetic code. J. Mol. Evol. 1982, 18, 297–303. [Google Scholar] [CrossRef]
- Yarus, M. The genetic code and RNA-amino acid affinities. Life 2017, 7, 13. [Google Scholar] [CrossRef] [Green Version]
- Wong, J.T.F. A co-evolution theory of the genetic code. Proc. Natl. Acad. Sci. USA 1975, 72, 1909–1912. [Google Scholar] [CrossRef] [Green Version]
- Di Giulio, M. An extension of the coevolution theory of the origin of the genetic code. Biol. Direct. 2008, 3, 37. [Google Scholar] [CrossRef] [Green Version]
- Ikehara, K. Degeneracy of the Genetic Code has Played an Important Role in Evolution of Organisms. SOJ Genet. Sci. 2016, 3, 1–3. [Google Scholar] [CrossRef]
- Massey, S.E. How to ‘find’ an error minimized genetic code: Neutral emergence as an alternative to direct Darwinian selection for evolutionary optimization. Nat. Comput. 2018, 18, 203–212. [Google Scholar] [CrossRef]
- Knight, R.D.; Freeland, S.J.; Landweber, L.F. Adaptive evolution of the genetic code. In The Genetic Code and the Origin of Life; .de Pouplana, L.R., Ed.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 201–220. [Google Scholar]








| Compounds | Yield (mmol) | Compounds | Yield (mmol) |
|---|---|---|---|
| Gly | 440 | α-amino-n-butylate | 270 |
| Ala | 790 | α,γ-diaminobutylate | ~30 |
| Asp | 34 | β-amino-n-butylate | ~0.3 |
| Val | 19.5 | β-aminoisobutylate | ~0.3 |
| Glu | 7.7 | γ-aminobutylate | 2.4 |
| Leu | 11.3 | Norvaline | 61 |
| Ile | 4.8 | Norleucine | 6 |
| Pro | 1.5 | β-alanine | 18.8 |
| Ser | 5 | Alloisoleucine | 5.1 |
| Thr | ~0.8 | Isoserine | 5.5 |
| 5′-AntiC-Stem | AntiC-Loop | 3′-AntiC-Stem | |
| Gly | CGACC | UUGCCAA | GGUCG |
| Ala | CUUGC | AUGGCAU | GCAAG |
| Asp | CCUGC | CUQUC/C | GCAGG |
| Val | CCACC | UUGACAU | GGUGG |
| Glu | CCGCC | AUGGCAU | GGCGG |
| 5′-AntiC-Stem | AntiC-Loop | 3′-AntiC-Stem | |
| Leu | CUAGC | UUCAG;P | GPUAG |
| Pro | CUUCG | JUCGGKA | CGAAG |
| His | CUGGA | UUQUG/P | PCCAG |
| Gln | CCGGA | JUCUG/P | PCCGG |
| Arg | CUCGG | UUCAG;P | GPUAG |
| Amino Acid | Codon/Anticodon | ΔGt/kBT |
|---|---|---|
| Gly [G] | GGC/GCC | 1.71 |
| Ala [A] | GCC/GGC | 1.71 |
| Ser | AGC/GCT | 1.86 |
| Val [V] | GTC/GAC | 2.01 |
| Asp [D] | GAC/GTC | 2.02 |
| Thr | ACC/GGT | 2.07 |
| Arg | AGA/TCT | 2.18 |
| Phe | TTC/GGT | 2.2 |
| Glu | GAA/TTC | 2.2 |
| Asn | AAC/GTT | 2.25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ikehara, K. Why Were [GADV]-amino Acids and GNC Codons Selected and How Was GNC Primeval Genetic Code Established? Genes 2023, 14, 375. https://doi.org/10.3390/genes14020375
Ikehara K. Why Were [GADV]-amino Acids and GNC Codons Selected and How Was GNC Primeval Genetic Code Established? Genes. 2023; 14(2):375. https://doi.org/10.3390/genes14020375
Chicago/Turabian StyleIkehara, Kenji. 2023. "Why Were [GADV]-amino Acids and GNC Codons Selected and How Was GNC Primeval Genetic Code Established?" Genes 14, no. 2: 375. https://doi.org/10.3390/genes14020375
APA StyleIkehara, K. (2023). Why Were [GADV]-amino Acids and GNC Codons Selected and How Was GNC Primeval Genetic Code Established? Genes, 14(2), 375. https://doi.org/10.3390/genes14020375