

Integrated Pleiotropic Gene Set Unveils Comorbidity Insights across Digestive Cancers and Other Diseases



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Sources
2.2. Data Analysis Methods
2.2.1. Identification of Comorbid Diseases in Five Digestive Cancers
2.2.2. Pleiotropic Gene Set Construction
- (1)
- MalaCards Database: We initiated the process by searching for the disease name on the MalaCards website (refer to URLs) and clicking on the ‘show all’ button for related sections, including ‘Genes’, ‘ClinVar’, and ‘UniProtKB/Swiss-Prot’. We retrieved relevant information that contained in each of these URLs
- (2)
- GWAS Catalog: First, we searched each disease’s name on the GWAS Catalog website (see URLs) and downloaded the relevant GWAS Catalog files for each disease (see Table S1). Second, we extracted the genes associated with each disease from these downloaded files. Our selection criteria included a significance threshold and manual inspection (excluding unrelated diseases, such as those labelled as ‘measurement’ in the ‘MAPPED TRAIT’ column).
- (3)
- UKB GWAS Data: This dataset was curated following GWAS analysis of 7221 phenotypes across six continental ancestry groups in the UKB [22]. Our approach was based on the ‘UKBB GWAS Imputed v3-File Manifest Release 20180731.xlsx’ file (see URLs). Firstly, we queried each disease name in the ‘Description Lookup’ sheet to obtain the ‘phenotype code’ for each disease (see Table S1). Secondly, we downloaded ‘variants.tsv.bgz’ and each ‘<phenotype code>.gwas.imputed v3.both sexes.tsv.bgz’ using the provided commands in the ‘Manifest 201807’ sheet. We then converted variant locations to variant rsids, beta coefficients to odds ratios (OR = exp(beta)) and so on in order to obtain the GWAS summary statistics file in the required FUMA format [23]. Thirdly, we uploaded these GWAS summary statistics to the FUMA ‘SNP2GENE’ website, setting default parameters (such as ), except for specific configurations: Reference panel population: UKB release2b; Minimum Minor Allele Frequency (≥): 0.001; eQTL mapping → Tissue types: Select all; Gene types → Gene type: Protein coding; MAGMA gene expression analysis: Select ‘GTEx v8:54 tissue types’ and ‘GTEx v8:30 general tissue types’. Subsequently, we downloaded the ‘Gene table (mapped genes)’ files, which provided us with the list of genes.
2.2.3. Dendrogram Analyses
2.2.4. Definition of Pleiotropic Structure and Hub Genes/Proteins in Disease Pairs
2.2.5. Functional Enrichment Analysis
2.3. URLs
3. Results
3.1. Developing a Workflow to Collect Potential Susceptibility Genes for Five Digestive Cancers and Other Diseases
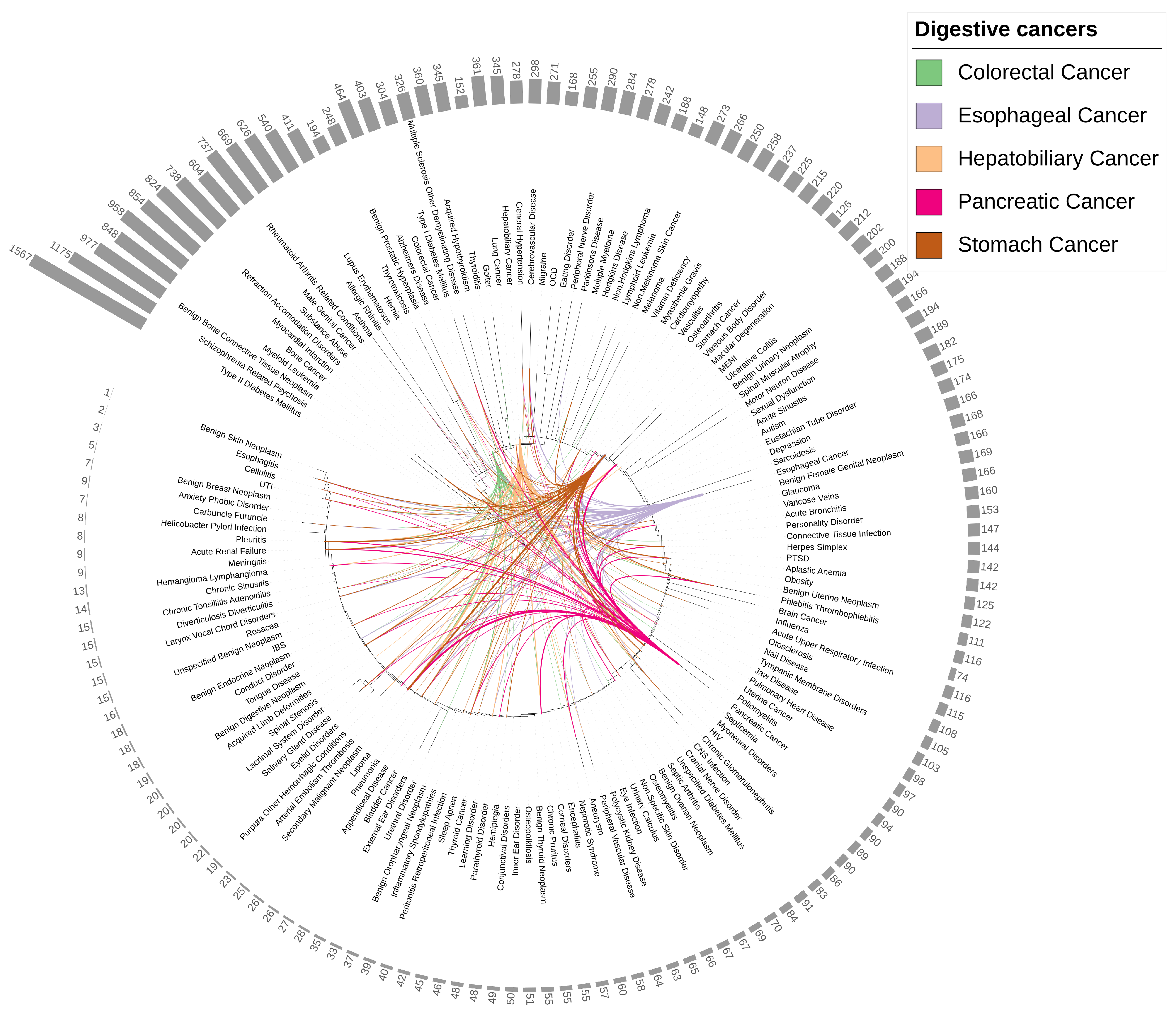
3.2. Establishing a Catalogue of Comorbidities for Five Digestive Cancers from EHRs
3.3. Identifying Integrated Pleiotropic Genes and Pleiotropic Structures between Five Digestive Cancers and 145 Diseases
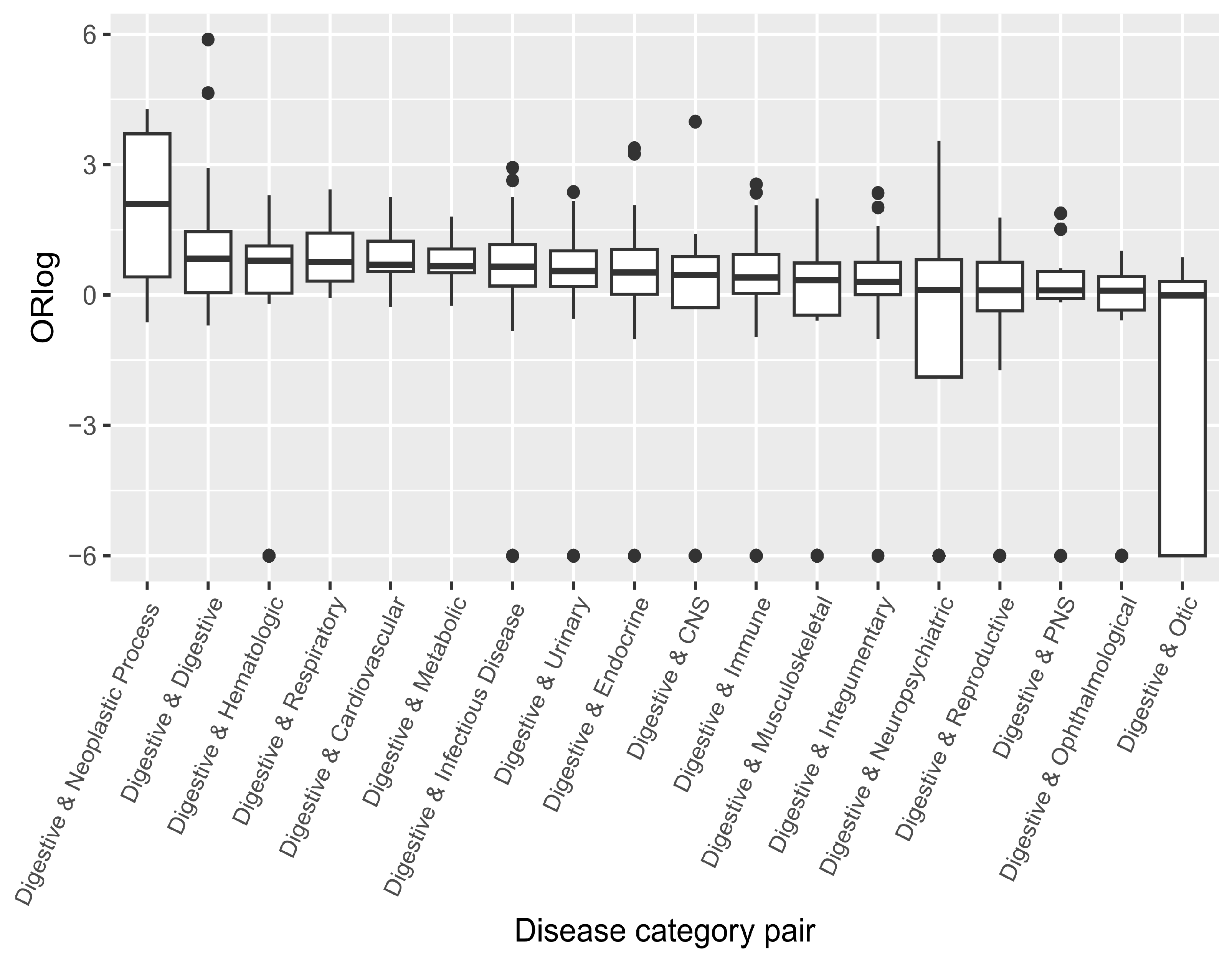
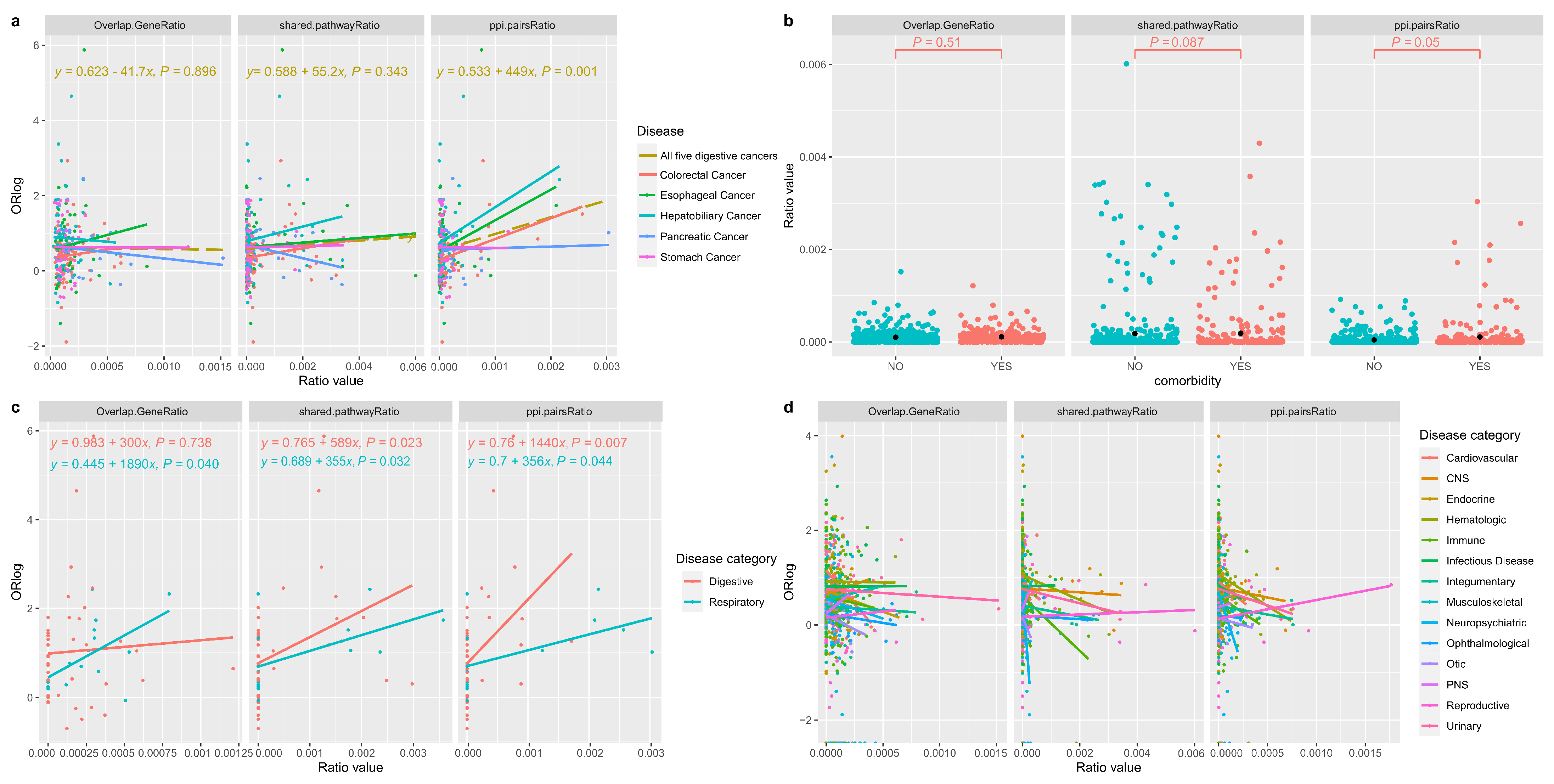
3.4. Correlating the Likelihood of Co-Occurrence and Shared Genetic Factors for Disease Pairs
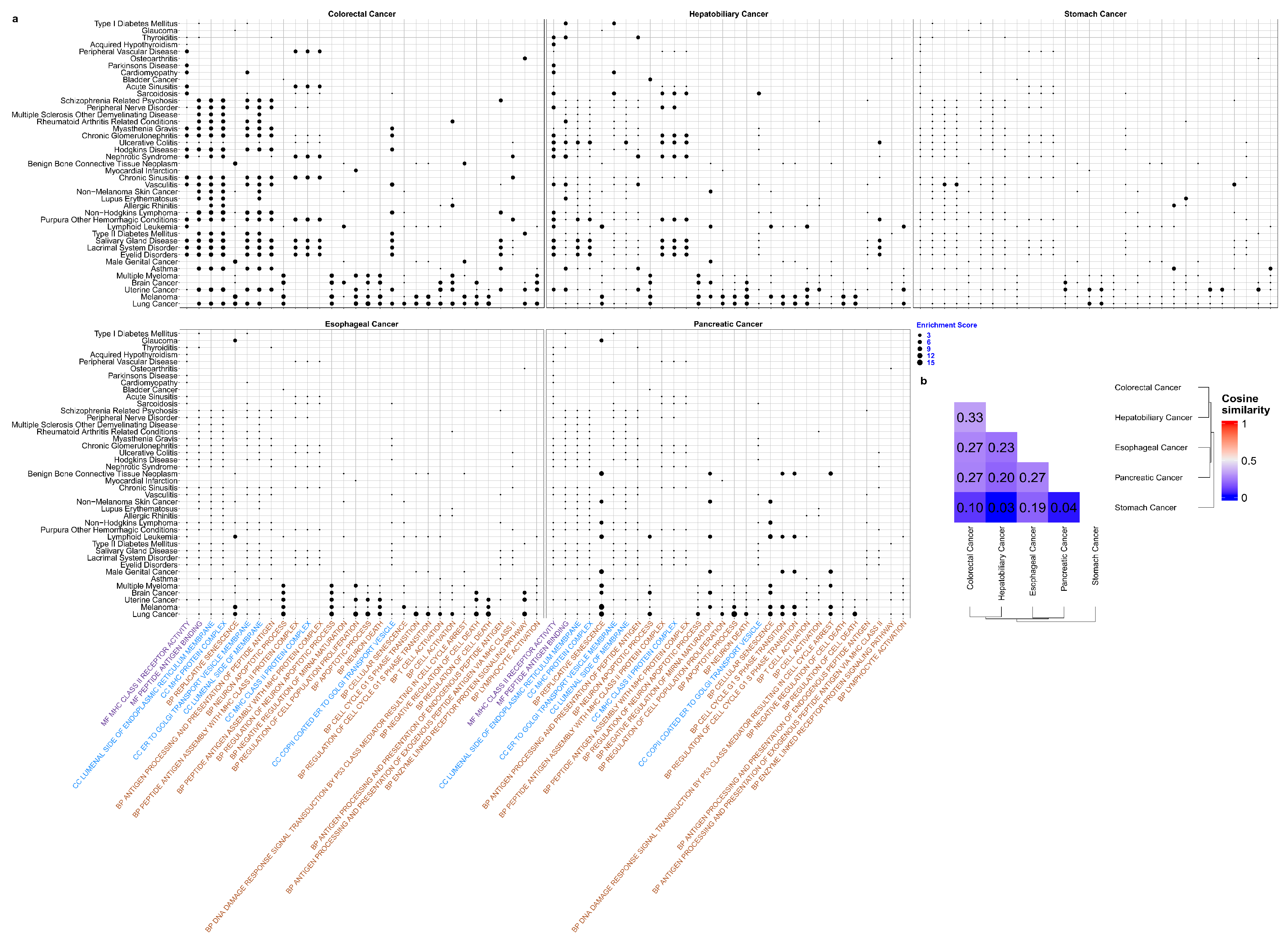
3.5. Unravelling Functional Pathways for Pleiotropic Genes in Disease Pairs between Five Digestive Cancers and 145 Diseases
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Code Availability
References
- Bray, F.; Laversanne, M.; Weiderpass, E.; Soerjomataram, I. The ever-increasing importance of cancer as a leading cause of premature death worldwide. Cancer 2021, 127, 3029–3030. [Google Scholar] [CrossRef]
- Arnold, M.; Abnet, C.C.; Neale, R.E.; Vignat, J.; Giovannucci, E.L.; McGlynn, K.A.; Bray, F. Global burden of 5 major types of gastrointestinal cancer. Gastroenterology 2020, 159, 335–349. [Google Scholar] [CrossRef]
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA A Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef]
- Starfield, B. Threads and yarns: Weaving the tapestry of comorbidity. Ann. Fam. Med. 2006, 4, 101–103. [Google Scholar] [CrossRef]
- Camilleri, M.; Malhi, H.; Acosta, A. Gastrointestinal complications of obesity. Gastroenterology 2017, 152, 1656–1670. [Google Scholar] [CrossRef]
- Hemminki, K.; Sundquist, K.; Sundquist, J.; Försti, A.; Liska, V.; Hemminki, A.; Li, X. Population-Attributable Fractions of Personal Comorbidities for Liver, Gallbladder, and Bile Duct Cancers. Cancers 2023, 15, 3092. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, X.; Zhong, Y.; Wei, S.; Li, L.; Wei, W.; Liu, F.; Li, Y.; Wang, S. Clinical characteristics and changing trajectories of esophageal cancer and gastric cancer in China from 2010 to 2019: An analysis of a hospital-based database of 24,327 patients. Front. Oncol. 2023, 13, 928. [Google Scholar] [CrossRef]
- Hang, J.; Cai, B.; Xue, P.; Wang, L.; Hu, H.; Zhou, Y.; Ren, S.; Wu, J.; Zhu, M.; Chen, D.; et al. The joint effects of lifestyle factors and comorbidities on the risk of colorectal cancer: A large Chinese retrospective case-control study. PLoS ONE 2015, 10, e0143696. [Google Scholar] [CrossRef]
- Nakai, Y.; Isayama, H.; Sasaki, T.; Sasahira, N.; Tsujino, T.; Kogure, H.; Yagioka, H.; Yashima, Y.; Togawa, O.; Arizumi, T.; et al. Comorbidity, not age, is prognostic in patients with advanced pancreatic cancer receiving gemcitabine-based chemotherapy. Crit. Rev. Oncol. 2011, 78, 252–259. [Google Scholar] [CrossRef]
- Emran, T.B.; Shahriar, A.; Mahmud, A.R.; Rahman, T.; Abir, M.H.; Siddiquee, M.; Ahmed, H.; Rahman, N.; Nainu, F.; Wahyudin, E.; et al. Multidrug resistance in cancer: Understanding molecular mechanisms, immunoprevention and therapeutic approaches. Front. Oncol. 2022, 12, 891652. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Yang, C.; Pei, Y.F. Genetic Pleiotropy in Complex Traits and Diseases. Front. Genet. 2022, 13, 897383. [Google Scholar] [CrossRef] [PubMed]
- Watanabe, K.; Stringer, S.; Frei, O.; Umićević Mirkov, M.; de Leeuw, C.; Polderman, T.J.; van der Sluis, S.; Andreassen, O.A.; Neale, B.M.; Posthuma, D. A global overview of pleiotropy and genetic architecture in complex traits. Nat. Genet. 2019, 51, 1339–1348. [Google Scholar] [CrossRef] [PubMed]
- Davey Smith, G.; Hemani, G. Mendelian randomization: Genetic anchors for causal inference in epidemiological studies. Hum. Mol. Genet. 2014, 23, R89–R98. [Google Scholar] [CrossRef] [PubMed]
- Rappaport, N.; Twik, M.; Plaschkes, I.; Nudel, R.; Iny Stein, T.; Levitt, J.; Gershoni, M.; Morrey, C.P.; Safran, M.; Lancet, D. MalaCards: An amalgamated human disease compendium with diverse clinical and genetic annotation and structured search. Nucleic Acids Res. 2017, 45, D877–D887. [Google Scholar] [CrossRef] [PubMed]
- Landrum, M.J.; Lee, J.M.; Riley, G.R.; Jang, W.; Rubinstein, W.S.; Church, D.M.; Maglott, D.R. ClinVar: Public archive of relationships among sequence variation and human phenotype. Nucleic Acids Res. 2014, 42, D980–D985. [Google Scholar] [CrossRef] [PubMed]
- The UniProt Consortium. UniProt: The universal protein knowledgebase in 2023. Nucleic Acids Res. 2023, 51, D523–D531. [Google Scholar] [CrossRef] [PubMed]
- Sollis, E.; Mosaku, A.; Abid, A.; Buniello, A.; Cerezo, M.; Gil, L.; Groza, T.; Güneş, O.; Hall, P.; Hayhurst, J.; et al. The NHGRI-EBI GWAS Catalog: Knowledgebase and deposition resource. Nucleic Acids Res. 2023, 51, D977–D985. [Google Scholar] [CrossRef] [PubMed]
- Sudlow, C.; Gallacher, J.; Allen, N.; Beral, V.; Burton, P.; Danesh, J.; Downey, P.; Elliott, P.; Green, J.; Landray, M.; et al. UK biobank: An open access resource for identifying the causes of a wide range of complex diseases of middle and old age. PLoS Med. 2015, 12, e1001779. [Google Scholar] [CrossRef] [PubMed]
- Watanabe, K.; Taskesen, E.; Van Bochoven, A.; Posthuma, D. Functional mapping and annotation of genetic associations with FUMA. Nat. Commun. 2017, 8, 1826. [Google Scholar] [CrossRef]
- Liu, Y.; Elsworth, B.; Erola, P.; Haberland, V.; Hemani, G.; Lyon, M.; Zheng, J.; Lloyd, O.; Vabistsevits, M.; Gaunt, T.R. EpiGraphDB: A database and data mining platform for health data science. Bioinformatics 2021, 37, 1304–1311. [Google Scholar] [CrossRef]
- Jia, G.; Zhong, X.; Im, H.K.; Schoettler, N.; Pividori, M.; Hogarth, D.K.; Sperling, A.I.; White, S.R.; Naureckas, E.T.; Lyttle, C.S.; et al. Discerning asthma endotypes through comorbidity mapping. Nat. Commun. 2022, 13, 6712. [Google Scholar] [CrossRef] [PubMed]
- Strawbridge, R.J.; Ward, J.; Cullen, B.; Tunbridge, E.M.; Hartz, S.; Bierut, L.; Horton, A.; Bailey, M.E.; Graham, N.; Ferguson, A.; et al. Genome-wide analysis of self-reported risk-taking behaviour and cross-disorder genetic correlations in the UK Biobank cohort. Transl. Psychiatry 2018, 8, 39. [Google Scholar] [CrossRef] [PubMed]
- Watanabe, K.; Taskesen, E.; van Bochoven, A.; Posthuma, D. FUMA: Functional mapping and annotation of genetic associations. Eur. Neuropsychopharmacol. 2019, 29, S789–S790. [Google Scholar] [CrossRef]
- Letunic, I.; Bork, P. Interactive Tree Of Life (iTOL) v5: An online tool for phylogenetic tree display and annotation. Nucleic Acids Res. 2021, 49, W293–W296. [Google Scholar] [CrossRef]
- Zheng, J.; Haberland, V.; Baird, D.; Walker, V.; Haycock, P.C.; Hurle, M.R.; Gutteridge, A.; Erola, P.; Liu, Y.; Luo, S.; et al. Phenome-wide Mendelian randomization mapping the influence of the plasma proteome on complex diseases. Nat. Genet. 2020, 52, 1122–1131. [Google Scholar] [CrossRef]
- Gillespie, M.; Jassal, B.; Stephan, R.; Milacic, M.; Rothfels, K.; Senff-Ribeiro, A.; Griss, J.; Sevilla, C.; Matthews, L.; Gong, C.; et al. The reactome pathway knowledgebase 2022. Nucleic Acids Res. 2022, 50, D687–D692. [Google Scholar] [CrossRef]
- Hu, J.X.; Thomas, C.E.; Brunak, S. Network biology concepts in complex disease comorbidities. Nat. Rev. Genet. 2016, 17, 615–629. [Google Scholar] [CrossRef]
- Rubio-Perez, C.; Guney, E.; Aguilar, D.; Piñero, J.; Garcia-Garcia, J.; Iadarola, B.; Sanz, F.; Fernandez-Fuentes, N.; Furlong, L.I.; Oliva, B. Genetic and functional characterization of disease associations explains comorbidity. Sci. Rep. 2017, 7, 6207. [Google Scholar] [CrossRef]
- Cooper, G.S.; Xu, F.; Schluchter, M.D.; Koroukian, S.M.; Barnholtz Sloan, J.S. Diverticulosis and the risk of interval colorectal cancer. Dig. Dis. Sci. 2014, 59, 2765–2772. [Google Scholar] [CrossRef]
- Schlottmann, F.; Dreifuss, N.H.; Patti, M.G. Obesity and esophageal cancer: GERD, Barrett s esophagus, and molecular carcinogenic pathways. Expert Rev. Gastroenterol. Hepatol. 2020, 14, 425–433. [Google Scholar] [CrossRef]
- Hu, J.; Liu, K.; Luo, J. HIV–HBV and HIV–HCV coinfection and liver cancer development. In HIV/AIDS-Associated Viral Oncogenesis; Springer: Cham, Switzerland, 2019; pp. 231–250. [Google Scholar]
- Hu, Y.; Zeng, N.; Ge, Y.; Wang, D.; Qin, X.; Zhang, W.; Jiang, F.; Liu, Y. Identification of the shared gene signatures and biological mechanism in type 2 diabetes and pancreatic cancer. Front. Endocrinol. 2022, 13, 847760. [Google Scholar] [CrossRef] [PubMed]
- Whelton, P.K.; Goldblatt, P. An investigation of the relationship between stomach cancer and cerebrovascular disease: Evidence for and against the salt hypothesis. Am. J. Epidemiol. 1982, 115, 418–427. [Google Scholar] [CrossRef]
- Itano, S. Early gastric cancer and its complications: Bleeding, perforation and pyloric stenosis. Acta Medica Okayama 1983, 37, 431–440. [Google Scholar] [PubMed]
- Stilidi, I.; Sigua, B.; Zemlyanoy, V.; Kurkov, A.; Gubkov, I. Gastric cancer complicated by bleeding: A systematic review. Khirurgiia 2022, 3, 101–114. [Google Scholar]
- Kim, S.W.; Shin, H.C.; Kim, I.Y.; Kim, Y.T.; Kim, C.J. CT findings of colonic complications associated with colon cancer. Korean J. Radiol. 2010, 11, 211–221. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.H.; Lo, E.Y.J.; Lee, K.F.; Chong, C.C.N.; San Lai, P.B. An unusual cause of upper gastrointestinal bleeding due to recurrent hepatocellular carcinoma: A case report. Int. J. Surg. Case Rep. 2020, 70, 83–86. [Google Scholar] [CrossRef]
- Sahu, S.K.; Chawla, Y.K.; Dhiman, R.K.; Singh, V.; Duseja, A.; Taneja, S.; Kalra, N.; Gorsi, U. Rupture of hepatocellular carcinoma: A review of literature. J. Clin. Exp. Hepatol. 2019, 9, 245–256. [Google Scholar] [CrossRef] [PubMed]
- Yeh, H.; Chiang, C.C.; Yen, T.H. Hepatocellular carcinoma in patients with renal dysfunction: Pathophysiology, prognosis, and treatment challenges. World J. Gastroenterol. 2021, 27, 4104. [Google Scholar] [CrossRef]
- Coveler, A.L.; Mizrahi, J.; Eastman, B.; Apisarnthanarax, S.J.; Dalal, S.; McNearney, T.; Pant, S. Pancreas cancer-associated pain management. Oncologist 2021, 26, e971–e982. [Google Scholar] [CrossRef]
- Gullo, L.; Pezzilli, R.; Morselli-Labate, A.M.; Italian Pancreatic Cancer Study Group. Diabetes and the risk of pancreatic cancer. N. Engl. J. Med. 1994, 331, 81–84. [Google Scholar] [CrossRef]
- Oki, E.; Zhao, Y.; Yoshida, R.; Egashira, A.; Ohgaki, K.; Morita, M.; Kakeji, Y.; Maehara, Y. The difference in p53 mutations between cancers of the upper and lower gastrointestinal tract. Digestion 2009, 79, 33–39. [Google Scholar] [CrossRef] [PubMed]
- Dinu, D.; Dobre, M.; Panaitescu, E.; Bîrlă, R.; Iosif, C.; Hoara, P.; Caragui, A.; Boeriu, M.; Constantinoiu, S.; Ardeleanu, C. Prognostic significance of KRAS gene mutations in colorectal cancer-preliminary study. J. Med. Life 2014, 7, 581. [Google Scholar] [PubMed]
- Chiurillo, M.A. Role of the Wnt/β-catenin pathway in gastric cancer: An in-depth literature review. World J. Exp. Med. 2015, 5, 84. [Google Scholar] [CrossRef] [PubMed]
- Cancer Genome Atlas Research Network. Comprehensive molecular characterization of gastric adenocarcinoma. Nature 2014, 513, 202. [Google Scholar] [CrossRef]
- Rzhetsky, A.; Wajngurt, D.; Park, N.; Zheng, T. Probing genetic overlap among complex human phenotypes. Proc. Natl. Acad. Sci. USA 2007, 104, 11694–11699. [Google Scholar] [CrossRef]
- Matakidou, A.; Eisen, T.; Houlston, R. Systematic review of the relationship between family history and lung cancer risk. Br. J. Cancer 2005, 93, 825–833. [Google Scholar] [CrossRef] [PubMed]
- Mukherjee, S.; Saxena, R.; Palmer, L.J. The genetics of obstructive sleep apnoea. Respirology 2018, 23, 18–27. [Google Scholar] [CrossRef]
- Zhang, X.; Miao, X.; Guo, Y.; Tan, W.; Zhou, Y.; Sun, T.; Wang, Y.; Lin, D. Genetic polymorphisms in cell cycle regulatory genes MDM2 and TP53 are associated with susceptibility to lung cancer. Hum. Mutat. 2006, 27, 110–117. [Google Scholar] [CrossRef]
- Park, J.; Lee, D.S.; Christakis, N.A.; Barabási, A.L. The impact of cellular networks on disease comorbidity. Mol. Syst. Biol. 2009, 5, 262. [Google Scholar] [CrossRef]
- Fang, X.; Wei, J.; He, X.; An, P.; Wang, H.; Jiang, L.; Shao, D.; Liang, H.; Li, Y.; Wang, F.; et al. Landscape of dietary factors associated with risk of gastric cancer: A systematic review and dose-response meta-analysis of prospective cohort studies. Eur. J. Cancer 2015, 51, 2820–2832. [Google Scholar] [CrossRef]
- O’Sullivan, D.E.; Sutherland, R.L.; Town, S.; Chow, K.; Fan, J.; Forbes, N.; Heitman, S.J.; Hilsden, R.J.; Brenner, D.R. Risk factors for early-onset colorectal cancer: A systematic review and meta-analysis. Clin. Gastroenterol. Hepatol. 2022, 20, 1229–1240. [Google Scholar] [CrossRef]
- Laviano, A. High protein diet in digestive cancers. Curr. Opin. Clin. Nutr. Metab. Care 2022, 25, 348–353. [Google Scholar] [CrossRef] [PubMed]
- Goh, K.I.; Cusick, M.E.; Valle, D.; Childs, B.; Vidal, M.; Barabási, A.L. The human disease network. Proc. Natl. Acad. Sci. USA 2007, 104, 8685–8690. [Google Scholar] [CrossRef]
- Lee, D.S.; Park, J.; Kay, K.; Christakis, N.A.; Oltvai, Z.N.; Barabási, A.L. The implications of human metabolic network topology for disease comorbidity. Proc. Natl. Acad. Sci. USA 2008, 105, 9880–9885. [Google Scholar] [CrossRef]
- Menche, J.; Sharma, A.; Kitsak, M.; Ghiassian, S.D.; Vidal, M.; Loscalzo, J.; Barabási, A.L. Uncovering disease-disease relationships through the incomplete interactome. Science 2015, 347, 1257601. [Google Scholar] [CrossRef]
- Li, L.; Cheng, W.Y.; Glicksberg, B.S.; Gottesman, O.; Tamler, R.; Chen, R.; Bottinger, E.P.; Dudley, J.T. Identification of type 2 diabetes subgroups through topological analysis of patient similarity. Sci. Transl. Med. 2015, 7, 311ra174. [Google Scholar] [CrossRef] [PubMed]
- Dagliati, A.; Geifman, N.; Peek, N.; Holmes, J.H.; Sacchi, L.; Bellazzi, R.; Sajjadi, S.E.; Tucker, A. Using topological data analysis and pseudo time series to infer temporal phenotypes from electronic health records. Artif. Intell. Med. 2020, 108, 101930. [Google Scholar] [CrossRef]
- Hidalgo, C.A.; Blumm, N.; Barabási, A.L.; Christakis, N.A. A dynamic network approach for the study of human phenotypes. PLoS Comput. Biol. 2009, 5, e1000353. [Google Scholar] [CrossRef] [PubMed]
- Jensen, A.B.; Moseley, P.L.; Oprea, T.I.; Ellesøe, S.G.; Eriksson, R.; Schmock, H.; Jensen, P.B.; Jensen, L.J.; Brunak, S. Temporal disease trajectories condensed from population-wide registry data covering 6.2 million patients. Nat. Commun. 2014, 5, 4022. [Google Scholar] [CrossRef]
- Manolio, T.A.; Collins, F.S.; Cox, N.J.; Goldstein, D.B.; Hindorff, L.A.; Hunter, D.J.; McCarthy, M.I.; Ramos, E.M.; Cardon, L.R.; Chakravarti, A.; et al. Finding the missing heritability of complex diseases. Nature 2009, 461, 747–753. [Google Scholar] [CrossRef]
- Choudhary, G.I.; Fränti, P. Predicting Onset of Disease Progression Using Temporal Disease Occurrence Networks. Int. J. Med. Inform. 2023, 175, 105068. [Google Scholar] [CrossRef] [PubMed]
- Ye, Y.; Doak, T.G. A parsimony approach to biological pathway reconstruction/inference for genomes and metagenomes. PLoS Comput. Biol. 2009, 5, e1000465. [Google Scholar] [CrossRef] [PubMed]
- Devkota, P.; Wuchty, S. Controllability analysis of molecular pathways points to proteins that control the entire interaction network. Sci. Rep. 2020, 10, 2943. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.R.; Islam, F.; Nafady, M.H.; Akter, M.; Mitra, S.; Das, R.; Urmee, H.; Shohag, S.; Akter, A.; Chidambaram, K.; et al. Natural small molecules in breast cancer treatment: Understandings from a therapeutic viewpoint. Molecules 2022, 27, 2165. [Google Scholar] [CrossRef] [PubMed]
- Rauf, A.; Abu-Izneid, T.; Khalil, A.A.; Imran, M.; Shah, Z.A.; Emran, T.B.; Mitra, S.; Khan, Z.; Alhumaydhi, F.A.; Aljohani, A.S.M.; et al. Berberine as a potential anticancer agent: A comprehensive review. Molecules 2021, 26, 7368. [Google Scholar] [CrossRef]
- Clyburne-Sherin, A.; Fei, X.; Green, S.A. Computational reproducibility via containers in psychology. Meta-Psychol. 2019, 3, MP.2018.892. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Luo, G.; Dong, Z.; Zheng, W.; Jia, G. Integrated Pleiotropic Gene Set Unveils Comorbidity Insights across Digestive Cancers and Other Diseases. Genes 2024, 15, 478. https://doi.org/10.3390/genes15040478
Wu X, Luo G, Dong Z, Zheng W, Jia G. Integrated Pleiotropic Gene Set Unveils Comorbidity Insights across Digestive Cancers and Other Diseases. Genes. 2024; 15(4):478. https://doi.org/10.3390/genes15040478
Chicago/Turabian StyleWu, Xinnan, Guangwen Luo, Zhaonian Dong, Wen Zheng, and Gengjie Jia. 2024. "Integrated Pleiotropic Gene Set Unveils Comorbidity Insights across Digestive Cancers and Other Diseases" Genes 15, no. 4: 478. https://doi.org/10.3390/genes15040478
APA StyleWu, X., Luo, G., Dong, Z., Zheng, W., & Jia, G. (2024). Integrated Pleiotropic Gene Set Unveils Comorbidity Insights across Digestive Cancers and Other Diseases. Genes, 15(4), 478. https://doi.org/10.3390/genes15040478