1. Introduction
The growth and development of organisms and the ability to respond to environmental conditions are controlled by an intrinsic regulation mechanism, which spans multiple molecular levels [
1]. Gene regulatory networks (GRNs) depict this complex mechanism at the level of genes and provide an intuitive understanding of how these interactions determine the characteristics of organisms [
2]. The structure of GRN reflects the interactions between the regulatory elements in biological systems, such as genes and proteins [
3,
4,
5]. Therefore, the reconstruction of gene regulatory network from gene expression data, also known as reverse engineering, is the most fascinating task in system biology and bioinformatics. More importantly, these predicted networks can generate valuable hypotheses to promote further biological research. This has led to the fast development of computational approaches for the reconstruction of GRNs [
6].
At the simplest level, clustering methods can be applied to find genes sharing the same expression pattern, which are likely to be involved in the same regulatory processes [
7]. Pearson correlation coefficient and mutual information [
8,
9,
10] are commonly used metrics for measuring the similarity of expression profiles. This idea was developed further to construct relevance networks by using such metrics [
11,
12,
13]. These correlation-based methods are highly efficient, but cannot identify the directions or model system dynamics.
The explosion of expression data, promoted by novel and high-throughput technologies, has thus propelled the evolution of GRN analysis from clustering method to systematic or model-based methods. Systematic methods can provide researchers with deeper insights into the holistic regulatory mechanism at a network level [
4,
14,
15]. Taking this one step further, biologists can put forward valuable clues or ideas in real life scenarios, such as disease gene discovery [
5], seed oil [
16], yield character location [
17].
However, due to the small sample size of expression data and the exponential solution space, it would be a big challenge. The large amount of data from high-throughput technologies offers an opportunity for seeking systematic approaches to understanding the structure of gene regulatory networks [
4]. The main mathematical models include Boolean network [
18,
19,
20], Bayesian Network [
21,
22,
23,
24], and differential equation [
25,
26,
27]. These mathematical models can vary from the very simplified, such as Boolean network, to the very complex, such as differential equations in computing complexity aspect. Each has its own characteristics and fits different applicable scenes. With the gradual increase of computing complexity, the data size they can process rapidly goes down. Using the assumption that genes are simple binary switches in genetic regulation, the Boolean network approach uses the Boolean functions to model gene regulatory networks. The probabilistic Boolean network extends Boolean network methods by integrating rule-based dependencies between variables [
28]. Although these assumptions make the Boolean network the most mathematically tractable, these crude simplifications cannot reflect the genetic reality. At the opposite end, the differential equation approach quantitatively describes the dynamics of change of each gene’s expression level on its regulatory genes. Obviously, differential equation approach can capture more detail about genes’ activities, but it is only suited for some concrete and very small systems, generally ascribed to computational complexity.
Bayesian network is another popular model for the reconstruction of GRNs, which uses Directed Acyclic Graph (DAG) to represent GRNs. Between these three approaches, the Bayesian network is a combination of probability and graph theory and of medium complexity and scale. More importantly, due to its inherent probabilistic nature, the Bayesian network can deal with noisy data and cope with uncertainty. Yet, the Bayesian network model has its limitations. Due to its NP-hard nature of structure learning with respect to the number of genes, the exact Bayesian network structure can be learned only for relatively small networks [
29].
Typically, two main approaches, search-and-score approach and constraint-based approach, are used to learn the structure of BN. The constraint-based approach [
30,
31,
32,
33] tries to use statistical or information measures to test the conditional independence (CI) between variables. These methods rely heavily on the threshold selected for CI tests. High-order CI tests using large condition sets may be unreliable with the limitation of data size. Recently, the recursive autonomy identification (RAI) algorithm [
31] reduces the number of high-order CI tests using sequentialization and recursion techniques and, hence, requires fewer data. However, the requirements of computational capabilities and data size to perform reliable tests are still problems of constraint-based approaches, which limits their application in biological network reconstruction.
The search-and-score approach [
34,
35,
36] attempts to traverse all possible structures using certain search algorithms to find the optimal one that maximizes the scoring function. In addition, prior knowledge can be easily incorporated into the model through the prior probability term in the scoring function. The search methods are heuristic and do not guarantee global optimal in most cases in consideration of large search space.
Hence, a typical way to accelerate the learning phase of search-and-score algorithms is to reduce the search space of possible structures. Specific methods include Sparse candidate (SC) [
21], maximum number of parents limitation [
37] (also called maxP technique), Max-Min Hill-Climbing (MMHC) [
38], and the Candidate auto selection method (CAS) [
39] etc.
The sparse candidate algorithm applies a restrict-search iteration strategy to speed up the search process. It heuristically estimates the parents of each node, and then perform a search-and-score procedure. The algorithm constraints the size of the parent set per node to a user-defined upper limit
k and repeatedly execute the above two steps. The maxP technique restricts the search space in a more simple way, by only limiting the maximum number of parents for each node without a heuristic estimation step. Nevertheless, the two methods ignore the biological fact and suffer from the problem of tuning parameter. The fact that they actually do not generate candidate sets for each node results in wasting much of the time on examining unreasonable candidates due to the scale and the sparsity of biological networks [
39].
Actually, the MMHC algorithm should be called a hybrid method. It first applies a constraint-based algorithm, called Max-Min Parents and Children (MMPC), to learn the neighbors of each node and then uses hill-climbing search to orient the edges [
38]. The combination of constraint-based approach and search-and-score approach seems to be a trend. So far, MMHC outperforms all other methods in the field of search-and-score approach, given enough samples.
However, as mentioned in the analysis of constraint-based approach, the exponential data dependence to accurately estimate the strength of conditional independence in MMPC step cannot be satisfied in a biological sense. The lack of data leads to a failure in candidate sets identification and then makes the behavior of MMHC algorithm similar to typical greedy search. So, we can see that the situation, typically known as “large p, small n” problem, greatly limits the use of the MMHC method for biological network reconstruction. Moreover, users also need to define a p-value as the threshold of conditional independence. Hence, the MMHC algorithm does not work well on small datasets and may lead to a huge amount of false positives.
Recently, in our previous work, the CAS algorithm was proposed to infer GRN [
39]. It uses a method based on mutual information and breakpoint detection to separate related nodes and unrelated nodes. However, the overestimation of the strength between genes and its neighbors results in the problem of false positives.
In this paper, we propose the Flooding-pruning Hill-Climbing algorithm (FPHC) on the basis of our previous work in order to further improve its performance for GRN reconstruction. FPHC also follows the idea of hybrid methods for learning structure of BN and aims at reducing the false discovery rate of neighbor node identification. FPHC tries to alleviate these problems listed above with less data, that is, to infer the directed network with less false-positive edges and with high computational efficiency. By learning the skeleton of BN, FPHC estimates the candidate neighbor set of each node: a neighbor set of node X is all the nodes Y that shares an edge with X. The difference from existing methods is that the algorithm needs smaller sample size and is highly effective and deterministic.
FPHC works in a sound manner and solves the problems in SC and MMHC methods. To find the candidate set, the FPHC method employs a two-phase algorithm to identify the neighbors of each node, called the flooding phase and pruning phase. This is very different with MMHC, which uses a heuristic constraint-based algorithm to identify the skeleton. The flooding phase aims at finding the propagation boundary of mutual information in a DAG through a breakpoint detection method, which is the same as our previous work. In this step, the related nodes of each node will be selected. In the pruning phase, the concept of data processing level (DPI Level) is introduced to filter out indirect regulations (false positives). To infer the structure, we apply the greedy search-and-score methods to learn the network structure based on the neighbor sets of each node.
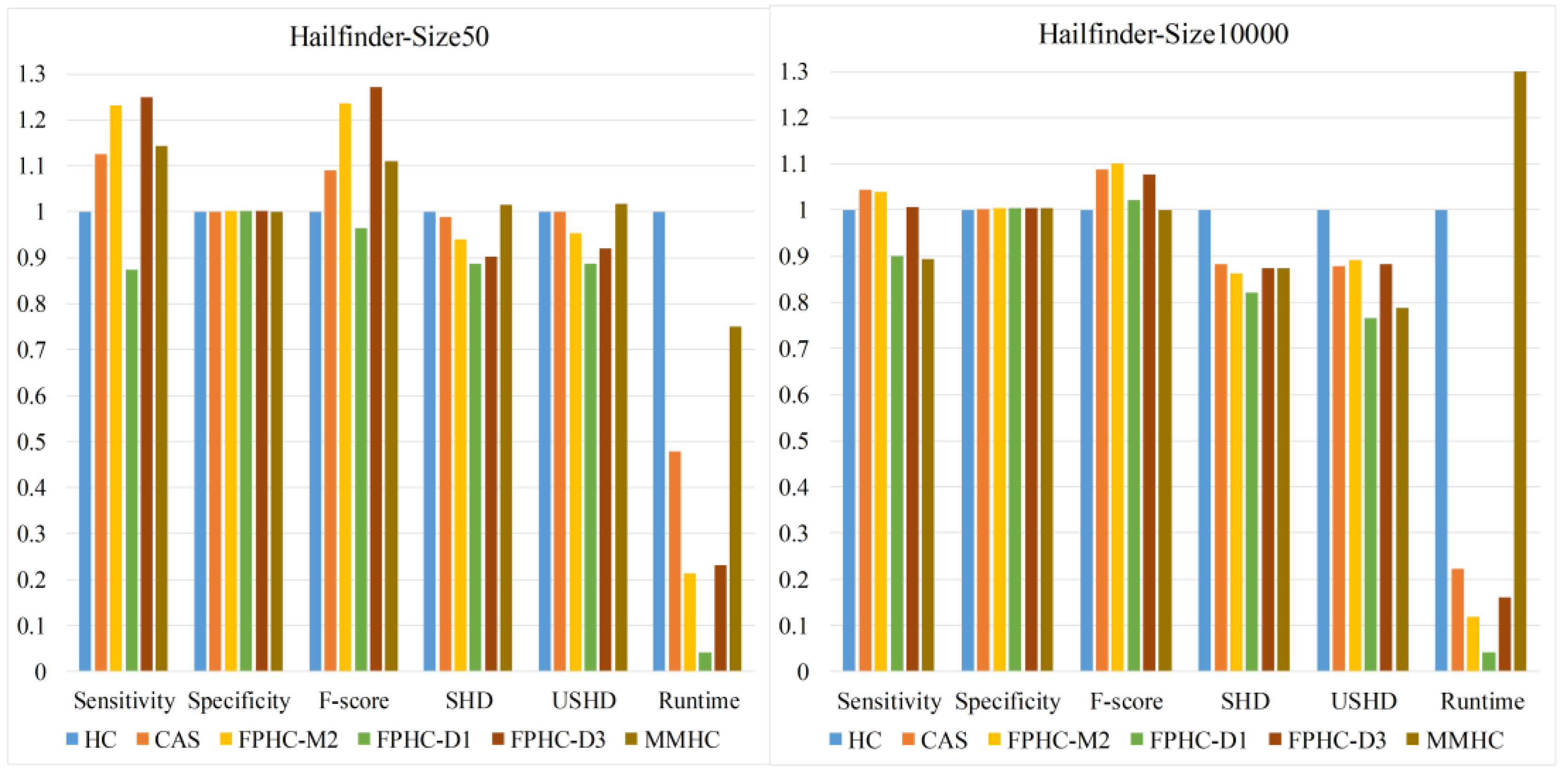
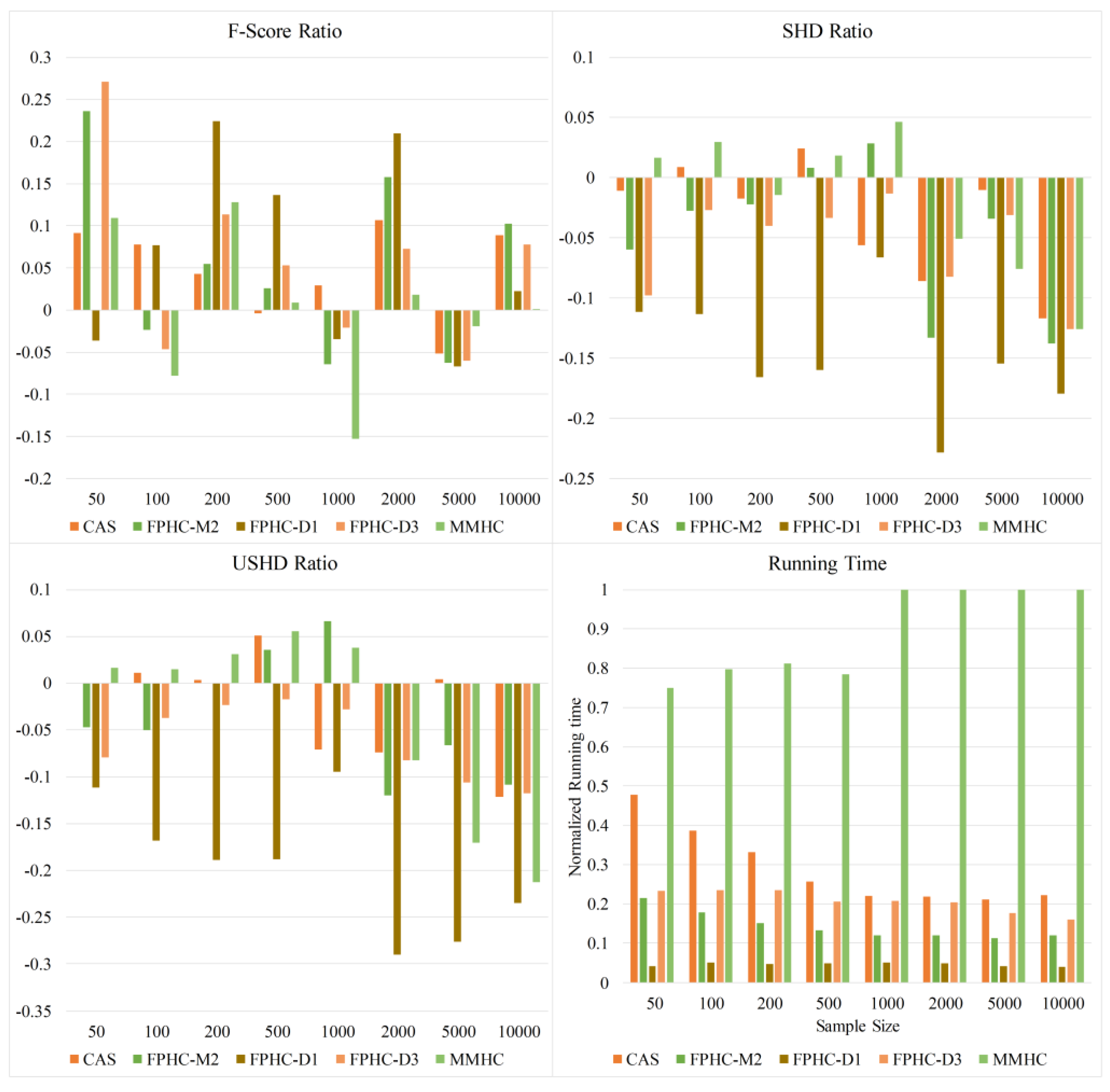
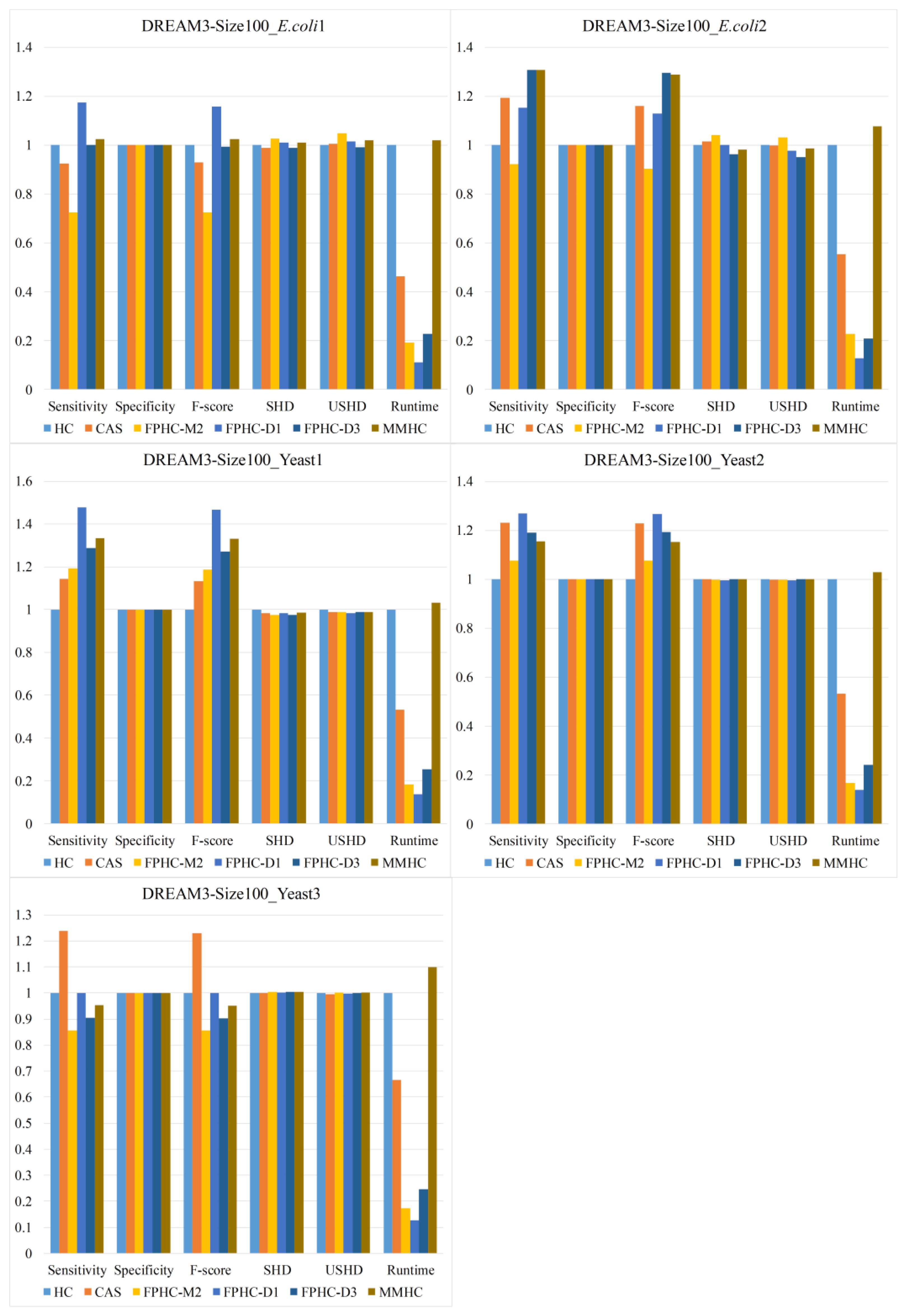
To evaluate the proposed methods, comparison experiments against several typical methods are carried out on various networks and sample sizes. Our study also provides a theoretical analysis and comparison of existing candidate selection algorithms.
2. Materials and Methods
A Bayesian network consists of two parts. A DAG
represents the network structure, where
represents the variables (or genes),
is the total number of variables or genes and
, the edge set, consists of ordered pairs (for example,
) of distinct nodes in
An uppercase letter (for example,
) and
represents a variable or gene and the corresponding expression vector. A Conditional Probability Table (CPT) represents the corresponding joint probability of this structure. Under the decomposable assumption, the joint probability can be represented in a product form:
Then some scoring functions are derived for learning Bayesian network structures in a search-and-score scheme. In our study, the widely used BDeu score [
36] (Bayesian Dirichlet with uniform priors) with an equivalent sample size of one is selected. The learning aim is to recover the parents
of all nodes that maximize the joint probability, given dataset
D.
2.1. Mutual Information
Mutual information (MI) is a powerful and fair metric for measuring the non-linear dependency between gene pairs. In this article, mutual information is adopted as a similarity measure between the expression profiles of two genes. The mutual information of two discrete variables (genes)
is defined as:
where
is the joint probability of variable
X and
Y, and
are the marginal probabilities of variable
X and
Y, respectively. The MI indicates the relationship between two genes without considering other variables. Hence, MI tends to overestimate the regulation strengths between genes. High MI value indicates that there may be a close relationship between the variables (genes)
X and
Y, while low MI value implies their independence. We use
to represent the interaction of gene
i and gene
j, if
, gene
i and gene
j do not interact directly. This notation includes the gene pairs that are statistically independent (MI = 0) and the gene pairs that are not statistically independent and indirectly interact.
2.2. Data Processing Inequality and the Concept of DPI Level
The data processing inequality (DPI) states that if gene
and gene
interact only through a third gene
, and no alternative path exists between gene
and gene
, then the following conclusion will be obtained [
40,
41]:
That is, only the least of the three MIs can come from indirect interactions, and check the DPI may identify those indirect interacted gene pairs. Taking this one step further, we put forward the idea of DPI Level. Given target node , suppose there are l nodes on the path from to . Hence, for node , this inequation can be tested l times. This concept uses the number of times that satisfied the inequation to indicate the distance between and . Thus, the bigger the DPI Level, the more distantly related of the two nodes. Specifically, in a tree structure, the DPI Level is the jumps from to , and all the nodes with DPI Level = 1 are the neighbors.
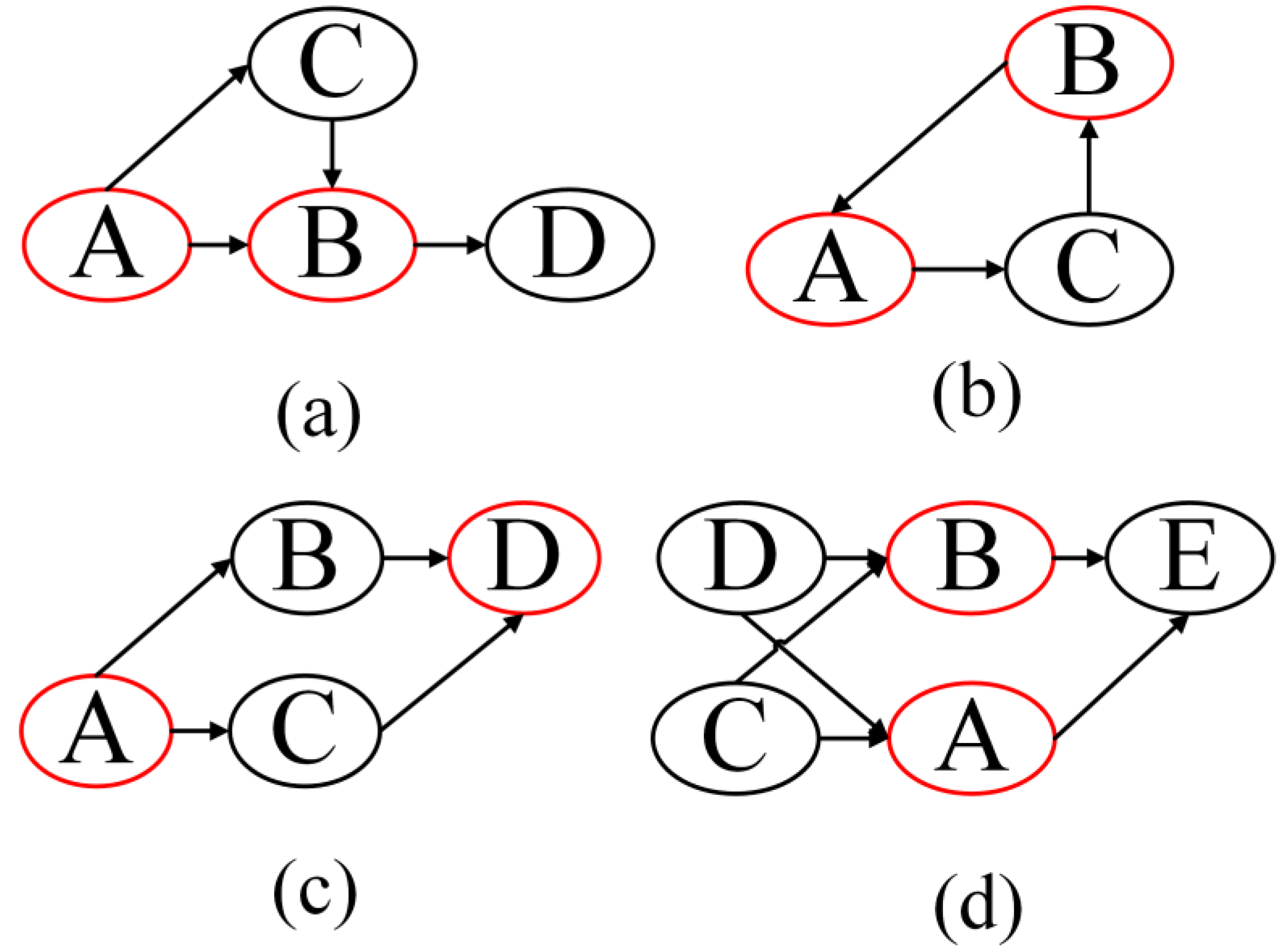
However, feed-forward control and feedback loops, called triples, are commonly observed in a common biological network. In
Figure 1, the nodes with red cycles around it are the pairs affected by duplicate paths. They are feed forward (
Figure 1a), feedback (
Figure 1b), parallel control channel (
Figure 1c), and duplicate parents (
Figure 1d), respectively. In this situation, the computation of DPI Level is not exactly the distance between
and
. The DPI Level of
will be affected if there are triples or parallel regulations in the path from
to
, as shown in
Figure 1. The DPI Level will increase, according to the nodes involved in triples. The detailed algorithm for calculating the DPI Level is the Pruning Phase section.
2.3. The Flooding-Pruning Neighbor Selection Algorithm
The Bayesian network learning algorithm FPHC presented in this work is based on the local neighbor selection algorithm called Flooding-Pruning Neighbor Selection (FPNS). FPNS provided a way to exactly identify the neighbors of target node T, that is, the edges to and from node T, and is used by FPHC to select the neighbors of each node. Although we use the break-point detection algorithm of our previous work, the idea of FPNS is different with CAS. The idea of FPNS algorithm comes from the information spreading process on a DAG. The FPNS simulates the propagation, truncation, and attenuation processes of signals. This makes the two phases of FPNS tightly coupled. FPNS consists of two phases: the flooding phase and pruning phase. The name “flooding phase” means that we will include all the nodes that can be reached when signals travel along the active paths in a flooding manner. The name “pruning phase” means that we will prune the rambling branches to remain a more precise candidate set for each target node.
We describe the idea of FPNS briefly and then state the specific algorithm.
For selected target node T, we represent the set of candidate neighbors of T as and the set of related nodes as . Given dataset D, FPNS will output the candidate neighbor set , provided there is an underlying true network. includes the parent nodes and child nodes of target node T. Firstly, FPNS will identify the propagation boundary of target node T in the flooding phase, that is, to generate related node set . All the statistically related nodes will be included in . Then, candidate neighbor set is generated by cutting off the indirect nodes based on the concept of DPI Level in pruning phase. This simulates the attenuation process of signals. By invoking FPNS on all nodes, we will obtain the reduced search space, which consists of neighbor sets of all nodes. Finally, one has to get the orientation of each edge to learn the structure of BN. This will be discussed in the structure learning section.
2.3.1. Flooding Phase
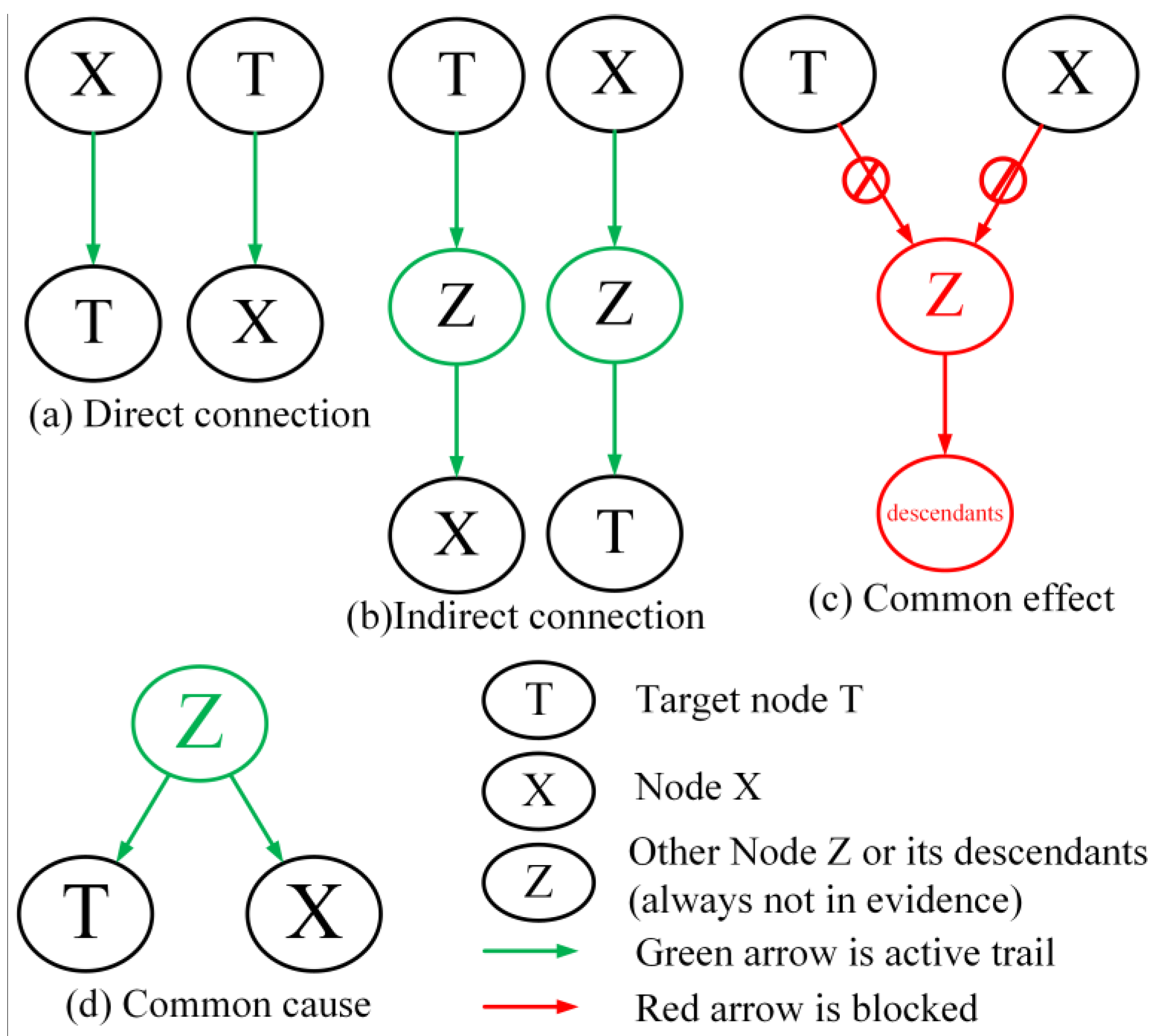
We know that distant relatives with lower MI give little information for target variable T, and close relatives (neighbors) with higher MI can help to understand the target T. The aim of this phase is to identify the related nodes
of target node T. All the possible relations between target node T and other nodes are shown in
Figure 2.
For the task of BN structure reconstruction, Node Z and its descendants are always not in evidence. Therefore, the related nodes that can be reached to or from target node T are in two categories: (i) direct connection and indirect connection situation as shown in
Figure 2a,b, in which these nodes are its descendants and ancestors; (ii) common cause situation as shown in
Figure 2d, in which these nodes are its brothers. As for the first type, the information from target node T can flow from its ancestors or to its descendants, furthermore, this information decreases with their genetic relationship. As for type ii, target T and its brothers share some information inherited from their parents.
The nodes that cannot be reached from Target node T are the nodes separated by a V-Structure or the nodes are not in the same connected-component, as shown in
Figure 2c. These nodes are independent to target node T. That means the information is truncated from these nodes. Thus the target node T and unrelated nodes are statistically independent, which means that these MIs are zero. However, they are actually measurement noises. From what has been discussed above, we can safely draw the conclusion that the MIs of target node T and the related nodes are distributed differently with the MIs of target node T and separated nodes. So, based on the analysis and mentioned research [
9,
42], we can further assume that there is a breakpoint in the MIs of target T that can be used to distinguish the related nodes and separated nodes.
At this point, the problem of identifying the related node set of target T (contains all the node in the propagation boundary) is translated into a breakpoint detection problem, which can be solved by hypothesis testing. At this point, the main idea of the flooding phase is the same as with our previous work. The idea is described as follows on target node T.
The MI vector of target node T and all the other nodes is given and all the MIs are sorted into ascending order. According to the above analysis, the null hypothesis and the alternative hypothesis are stated as follows:
- H0:
Null hypothesis—no breakpoint exists
- H1:
Alternative hypothesis—one significant breakpoint exists
That is, there is a position in vector that divided the nodes into two parts: related nodes and others.
Under the null hypothesis, if all the MIs are from the same distribution, then the probability is
. Under the alternative hypothesis, there is a breakpoint at position
k in
of target node T. Thus, the two types of nodes come from different distributions. The maximum likelihood can be defined as in Equation (4).
where
in Equation (4) are the probability density function, and
are the corresponding parameter.
To detect if there is a breakpoint in
, the testing statistic
Q can be constructed as (5):
For calculating these probabilities, we should make reasonable assumptions about their probability distributions. As mentioned above, the MIs of target node T and unrelated nodes are actually noises. Therefore, a normal distribution is reasonable to model these MIs. We have learned from experience, however, that a normal distribution is a good choice to model unknown distributions. With this in mind, all the mentioned possibilities can be calculated correctly.
Usually, a constant
c should be selected as a threshold to complete the hypothesis testing. Actually, to achieve the goal of identifying the best candidate of related nodes, we just need to locate the position
k in relation to maximum
Q. At this point, it becomes to an optimization problem, as in Equation (6):
The nodes on the right side of position
k are added into
. The nodes in set
are processed one by one.
Theorem 1. If MIs can be estimated with no errors, the Flooding Phase can identify the related nodes exactly.
Proof of Theorem 1. If the MIs are estimated with no errors, the MIs of target node T and the statistically dependent nodes (the nodes separated by a V-structure and the nodes in the disconnected part) will be zero. One can just add all the nodes with non-zeros MI to the set. ☐
In reality, especially in biological scenes, MIs cannot be estimated exactly due to the noise and the limitation of data. According to the experiment, the Flooding phase works in practice.
2.3.2. Pruning Phase
So far, we have generated the related node set , which contains neighbors and indirect nodes (false positives). That is to say, we get a high Type I Error and a low Type II Error. Hence, we designed a pruning step to reduce the Type I error by removing the indirect nodes.
Recent studies [
11,
40] indicate that data processing inequality can help to distinguish indirect regulation relationships. However, it has some potential limitations. Based on this concept, we put forward the concept of DPI Level to rank all the related nodes of Target T that are identified in the flooding phase. The pruning phase using DPI Level to prune the false positives of target node T. The definition of DPI Level for related nodes of target T is shown as follows:
Definition 1. Given target node T and its related node set, in which the nodes are sorted according to MI, the DPI Level of nodeis defined as follows:
If
is the first node in , the DPI Level of is defined as 1.
If is not the first node in , for each node in front of , triplet is constructed and tested using inequation (3). The DPI Level of is defined as the maximum DPI Level of that satisfies inequation (3) plus 1.
The DPI Level reflects the affinity between the related nodes and target node T.
According to the concept of DPI Level, we designed a pruning phase to prune the related node set and then generate the neighbor set .
For target node T, the pruning phase begins from the identified related nodes set which consists of ordered related nodes. Starting from the second node in , the pruning phase calculates the DPI Level of each related node in turn until we have traversed the set . Then, we apply this procedure to all nodes in V to get the hierarchical structure of each node.
By definition, the smaller the DPI Level, the closer the relationship is between target node T and node
. Obviously, the threshold of DPI Level greatly affects the result of pruning phase. Hence, the key problem is how to select the threshold of DPI Level to determine the nodes, which are the direct neighbors.
Theorem 2. Given target node T and its related node set, if the subnetwork defined byis a tree, the pruning algorithm will construct the underlying structure correctly, provided there is enough data to estimate MI correctly.
Proof. According to Theorem 1 in ARACNE [
11], the underlying undirected network can be reconstructed exactly, provided the network is a tree and has only pairwise interactions. At this point, if there is no feed forward control and feedback control in this subnetwork, the underlying subnetwork defined by
is a tree. Hence, we will reconstruct the structure of this subnet. ☐
Based on Theorem 2, we derive lemma 1 for the threshold of DPI Level.
Lemma 1 If target node T is not involved in any feed forward or feedback loops, the DPI Level of the directed neighbors of target node T is 1.
Proof . If target node T is not involved in any feed forward or feedback loops, there are no duplicate paths from the neighbors to target node T. That is, no triplet satisfies Equation (3). Hence, the DPI Level of neighbors is 1. ☐
Theorem 1 and Lemma 1 give a solution under ideal circumstances. However, gene regulatory networks are not restricted to tree structures and feed forward and feedback control schemas are often observed in GRNs. At this point, applying inequation (3) will break the triples of feedback or feedforward loops. The DPI Level of neighbors will change with the number of nodes involved in loops. As mentioned above, a different threshold leads to a different depth of pruning. Moreover, the sample size and complexity of the network will affect the estimation of MI and then the calculation of DPI Levels. Details of how to select the threshold will be discussed in the next section.
So far, we have described the whole procedure of FPNS. The pseudo code of FPNS is shown in Algorithm 1. Here, we use threshold to denote the pruning depth in pruning phase. If the DPI Level of the node is less than this threshold, this node is selected as the neighbor node. If the DPI Level of the node is bigger than this threshold, this node is pruned.
The full algorithm is as follows.
| Algorithm 1. The Flooding-Pruning Neighbor Selection algorithm (FPNS) |
Input: Node Set , Discrete Expression data , threshold for pruning depth
Output: Neighbor Set of each node in , denoted by |
Initialize the neighbor set of each node with null set.
For
// Flooding phase.
Candidate set .
Calculate MI of and all nodes in .
Store the n 1 MIs into M in ascending order.
//locate position k that maximizes statistic Q
For every node in
End For
// Pruning phase.
Calculate the DPI Level of each node in
For every node in
End for
End for
Return |
2.4. Choice of Tuning Parameter
The major factors that affect the selection of tuning parameter are the sample size and the complexity and size of the network.
- (a)
Sample size has a significant effect on the estimation of MI.
- (b)
Network size will affect the power of statistics in the flooding phase.
- (c)
Network complexity directly affects the calculation and selection of .
Moreover, we do not forget that the aim of FPNS is generating the candidate neighbor set for the following structure learning. As we know, due to the factors mentioned above, the pruning depth will affect the result of the candidate neighbors. This will directly influence the recall of true neighbors. The smaller the threshold, the more false positives are excluded. Obviously, if the DPI Level is set to one, all the false positives will be avoided. However, some true neighbors involved in feedback or feed forward loops will also be excluded from the true neighbor set.
According to the above analysis, we give some guidance on how to select that balances Type I and Type II errors.
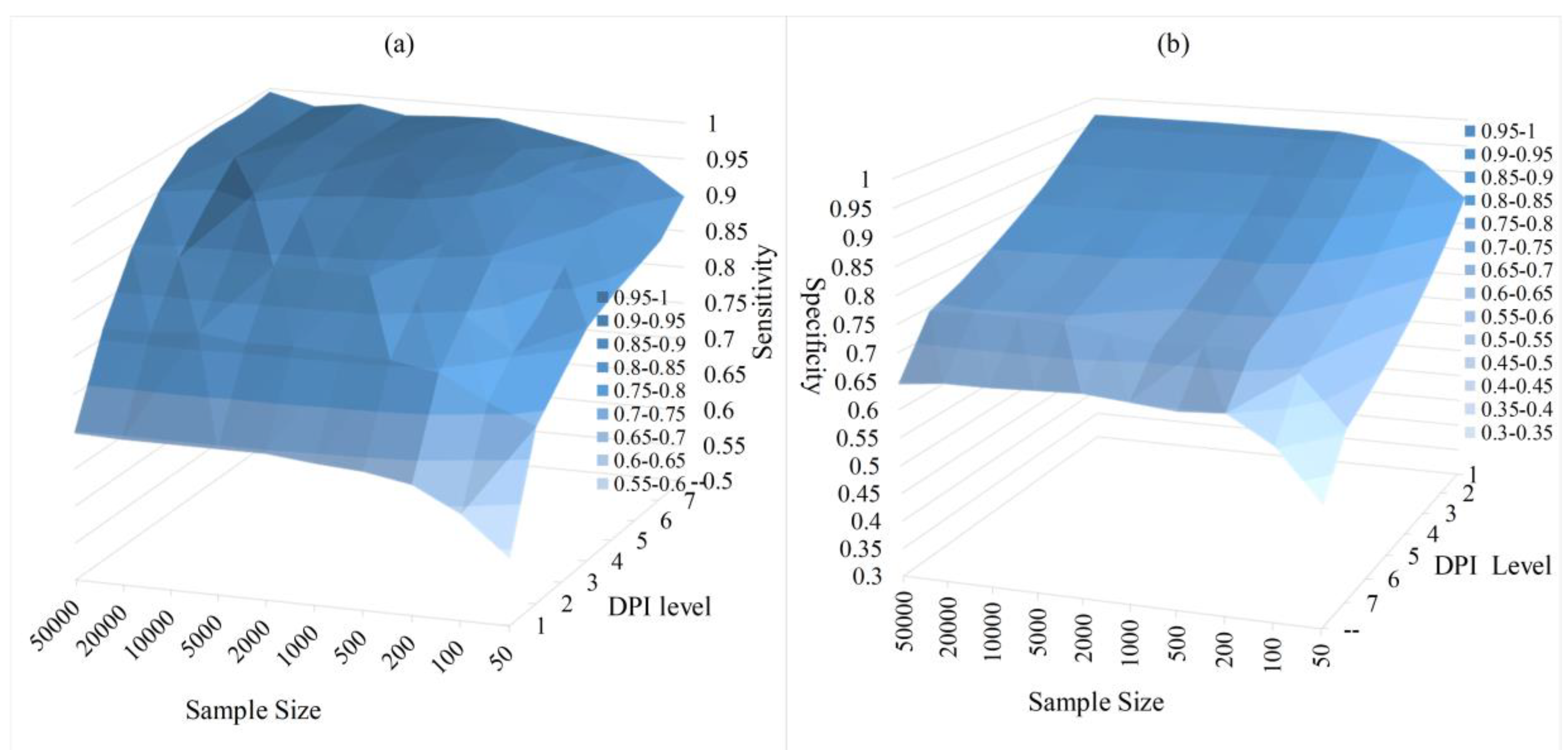
For the same network, having enough data means an accurate estimation of MI. Hence, if only limited data are available, should be appropriately increased to get a reasonable sensitivity. For the target network of high complexity, should be appropriately increased because feedback or feed-forward loops in a network will affect the DPI calculation of related nodes. For the target network, one could roughly estimate its complexity according to the possible function to be studied. According to our experiment results on different networks and different sample sizes, are suitable in most cases. For larger networks with limited data, may be more suitable. These suggested settings are drawn on the above analysis and in our experiment results.
Do we have a more general strategy for instead? Here, we give a general setting for . Set as the mode of the calculated DPI Levels of nodes in but no less than 2. Since MI decreases rapidly as the signals travel along an active path, we find that the distant relatives on rambling branches will be ignored. Hence, spindle-shaped shrinkage will occur during the flooding phase. This makes the reconstructed structure of (the distribution of the DPI Levels) like a spindle. Hence, the mode is selected in a natural way to cut this spindle. The setting “no less than 2” is a small trick to increase the sensitivity due to the complexity of real distribution and the situation of Theorem 1. The results with this setting are also included in this work.
2.5. Example Trace
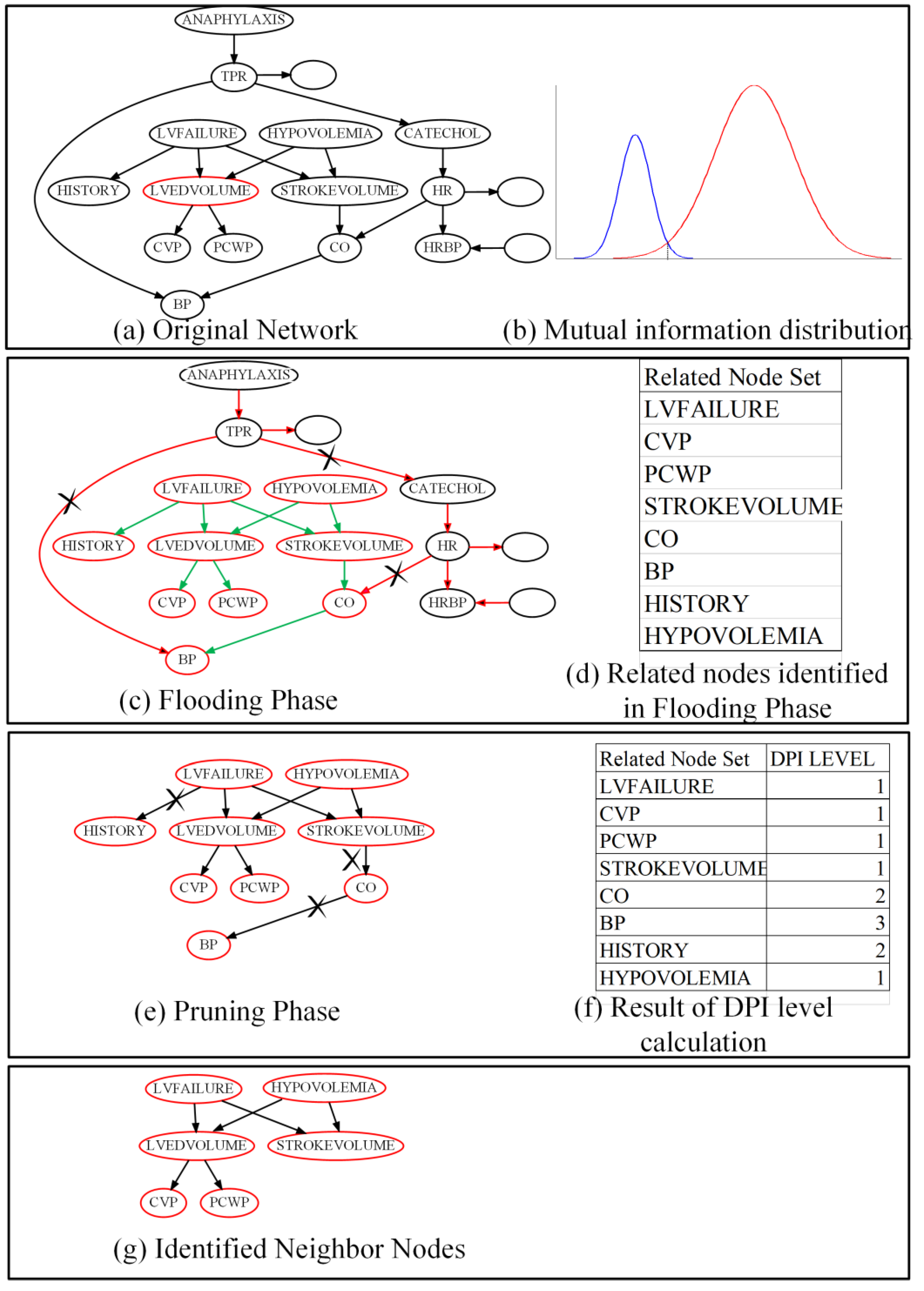
We will further illustrate that FPNS runs on target node T by using an example trace shown in
Figure 3. This running example is part of the alarm network with sample size = 200. In this case, we consider that the data is nearly enough for estimating the MIs correctly. The original network, part of the alarm network, is shown in
Figure 3a. Target node T (LVEDVOLUME) is denoted with a red circle around it. The circles without node names indicate the rest of the alarm network.
Figure 3b is a schematic diagram in order to denote that MI distribution of T and related nodes are different from the MI distribution of T and unrelated nodes. In addition, this diagram shows that we cannot decrease the Type I error and Type II error at the same time without increasing the sample size. According to the MIs distribution, we do a hypothesis test as described in the flooding phase. That is, to identify all the nodes that can be reached from target node T, as shown in
Figure 2. In
Figure 3c, the red arrow means blocked trails by V-structure, and the green arrow means active trails through which target node T can reach the other nodes the same as in
Figure 2a,b,d. Here, nodes with a red circle around them are the identified related nodes which can be reached through the active trails. Nodes with black circles in
Figure 3c means these nodes are separated by a V-structure and will be eliminated in the step.
Figure 3d lists the related nodes identified in the flooding phase. Next, as shown in
Figure 3e,f, FPNS will prune the related nodes according to the DPI Level of each node. Here, the pruning depth is set to 1. This means that all the nodes with a DPI Level bigger than 1 will be cut off. Finally, the identified neighbors are shown in
Figure 3g. As we can see from
Figure 3g, a sibling node (STROKEVOLUME) is identified as a neighbor of target node T by mistake. The correlation is over-estimated incorrectly because of the duplicate path (they share two common cause nodes) from STROKEVOLUME to target node T, as described in
Figure 2 (parallel regulation).
2.6. Flooding-Pruning Hill-Climbing-Structure Learning
In this section, we will illustrate FPHC for network structure learning. Firstly, the neighbors of each node are obtained by FPNS, and then we perform a greedy hill-climbing search in the restricted space. The algorithm begins with an empty graph. In each iteration, operators (add-edge, delete-edge, reverse-edge) will be tried on the graph to find the highest scoring operator. When the total score is stable, the algorithm returns the highest scoring DAG. Here, in our work, FPHC uses the BDeu score to evaluate the structure. However, FPHC performs the search in a restricted space. That means, only the edges that are included in the neighbor set will be considered. It is important to note that FPNS does not make a distinction between parents and children. Mainly because it is difficult to distinguish whether neighbor node X is a parent or a child of target node T without knowing the other nodes of the network. The structure with the highest score will be returned until the algorithm reaches convergence.
Previous studies [
21,
38] have shown that constraining the search space can improve the efficiency over the original greedy search-and-score method. FPHC is presented based on this idea, but an efficient neighbor selection algorithm (FPNS) is applied. In FPNS, only pairwise relationships need to be calculated for MI, as powerful metrics. Estimation of pairwise mutual information needs a smaller sample size than testing conditional independence in MMPC, which is an exponential to the size of conditioning set. The smaller sample sizes for accurately estimating MI, compared with MMPC, makes FPHC more suitable and efficient for most practical problems. In addition, the FPNS algorithm is deterministic rather than heuristic and will lead to reliable and stable outputs. Hence, FPHC is more efficient and robust.
2.7. Time Complexity of FPNS Algorithms
According to the analysis, we know that the same procedures are applied to each node. For target node T, we will check the position to find the position k that maximizes statistic Q in the flooding phase. Hence, the time complexity is . Suppose includes all the other nodes in the worst case, the times for calculating the DPI Level of each node in will be . The time complexity in pruning phase will be . Hence, in the worst-case scenario, time complexity is . However, the FPNS algorithm runs faster than the estimated worst time, even if on a very small sample size.
5. Conclusions
In this paper, we propose a novel hybrid method FPHC based on the Bayesian network for GRN reconstruction. FPHC follows the idea of the hybrid method, but uses a new neighbor selection method based on the flooding-and-pruning strategy in a workable and effective way, and then applies search-and-score approach on the reduced search space to learn the network structure. Especially, FPHC provides a new way to reduce the search space, which is more sample efficient. With this, it improves the Bayesian network learning on limited data, which is common in a biological sense and gives an opportunity to improve GRN reconstruction with less sample size. In particular, FPNS runs faster than MMPC on all the networks and datasets. In our experiments, FPHC outperforms the existing methods on small data sets and is comparable to the state-of-the-art methods with enough data. Furthermore, experiments were carried out on various biological networks. The results show that FPHC is more suitable in terms of GRN reconstruction.
As a hybrid method, FPHC uses the similar idea as described in Sparse Candidate and MMHC. However, different with common constraint-based algorithms, FPHC applies a new way to select the candidate neighbor set by using the flooding-and-pruning strategy. FPHC adopts a deterministic approach to identify the neighbors of each node and complete it in one iteration. This makes FPHS run faster than the other method. FPHC is a workable and effective algorithm on different datasets and alleviates the problems of the sparse candidate and MMPC. Experiments on various networks and datasets show that it outperforms the previously presented MMPC algorithm in the phase of neighbor selection and shows significant improvement on small datasets. In addition, the algorithm uses an adjustable parameter to satisfy different requirements. Especially as we give reasonable and detailed guidance on selecting the specified parameter.
Finally, the FPHC algorithm is workable and effective for learning a network structure due to the accurately reduced search space, especially for small datasets and biological scene. In the future, we would like to study the FPHC algorithm in terms of local learning and consider integrating multiple genomic data.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}