PM2.5 Prediction Based on Random Forest, XGBoost, and Deep Learning Using Multisource Remote Sensing Data

 ,
,  , and
, and
Abstract
:1. Introduction
2. Experiments
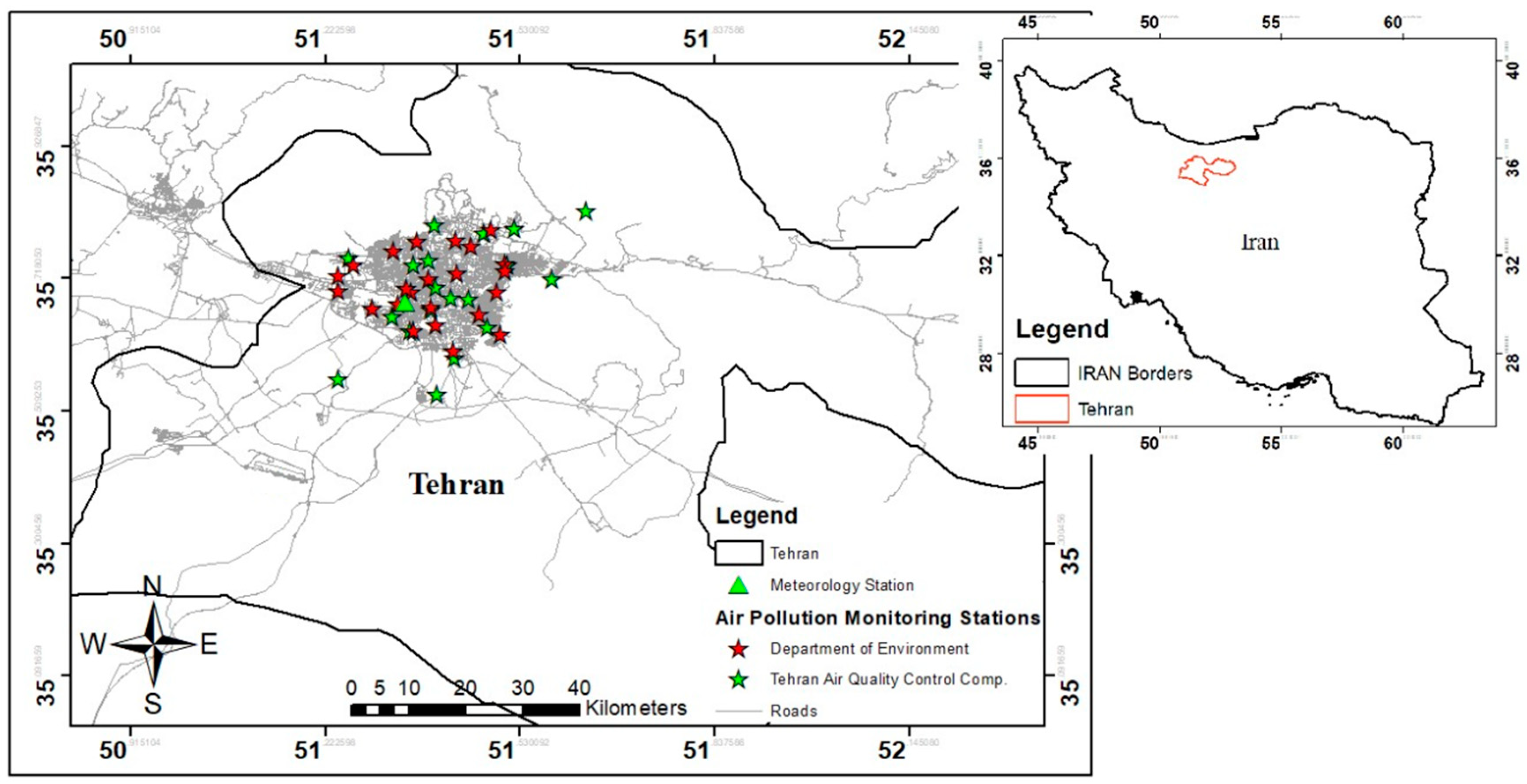
2.1. Study Area
2.2. Data
2.2.1. PM2.5 Air pollution Data
2.2.2. Aerosol Optical Depth (AOD) Data
2.2.3. Meteorological Data
2.3. Methodology
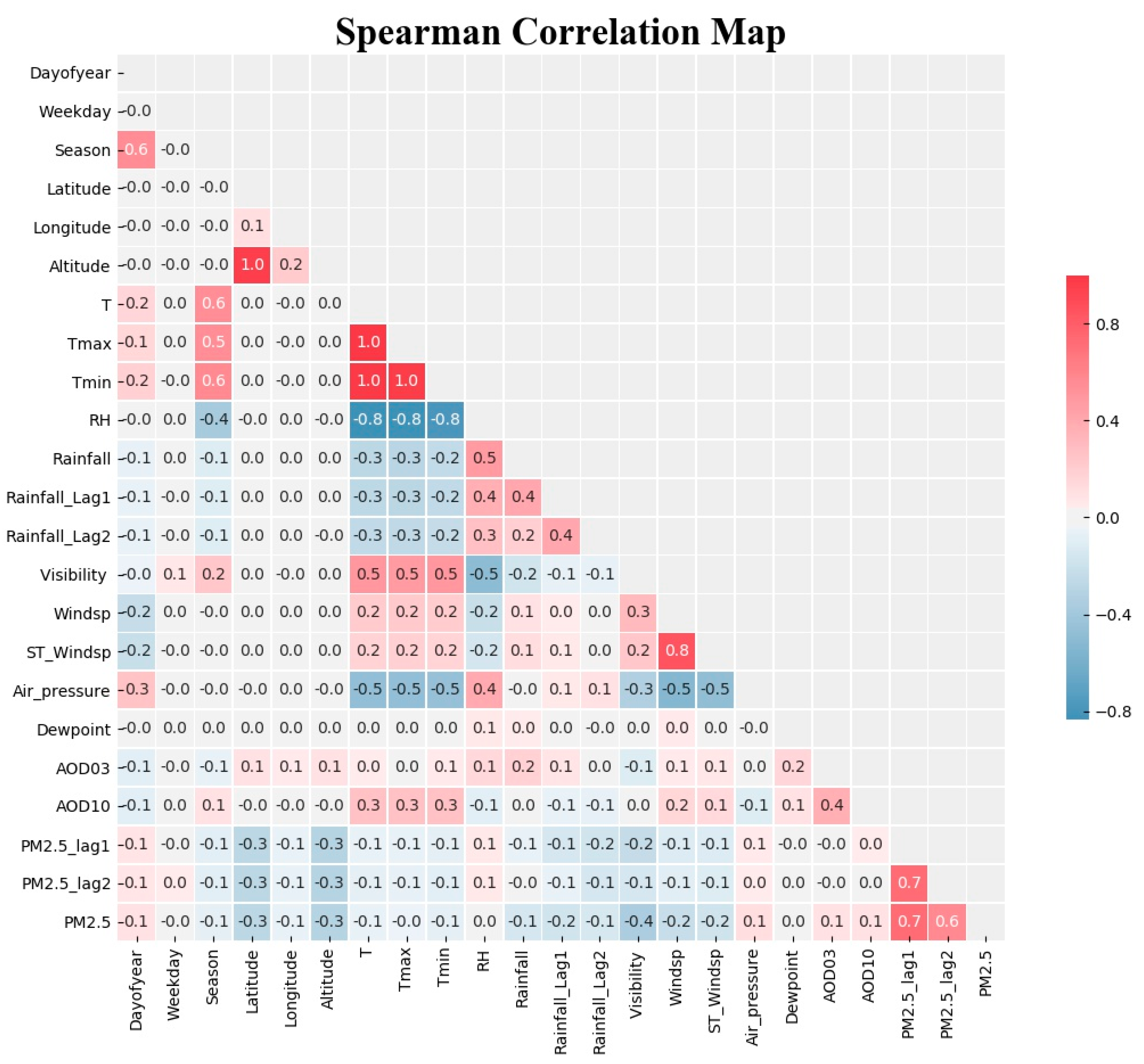
2.3.1. Data Preprocessing and Matching
2.3.2. Normalization
2.3.3. Random Forest Modeling
2.3.4. Extreme Gradient Boosting
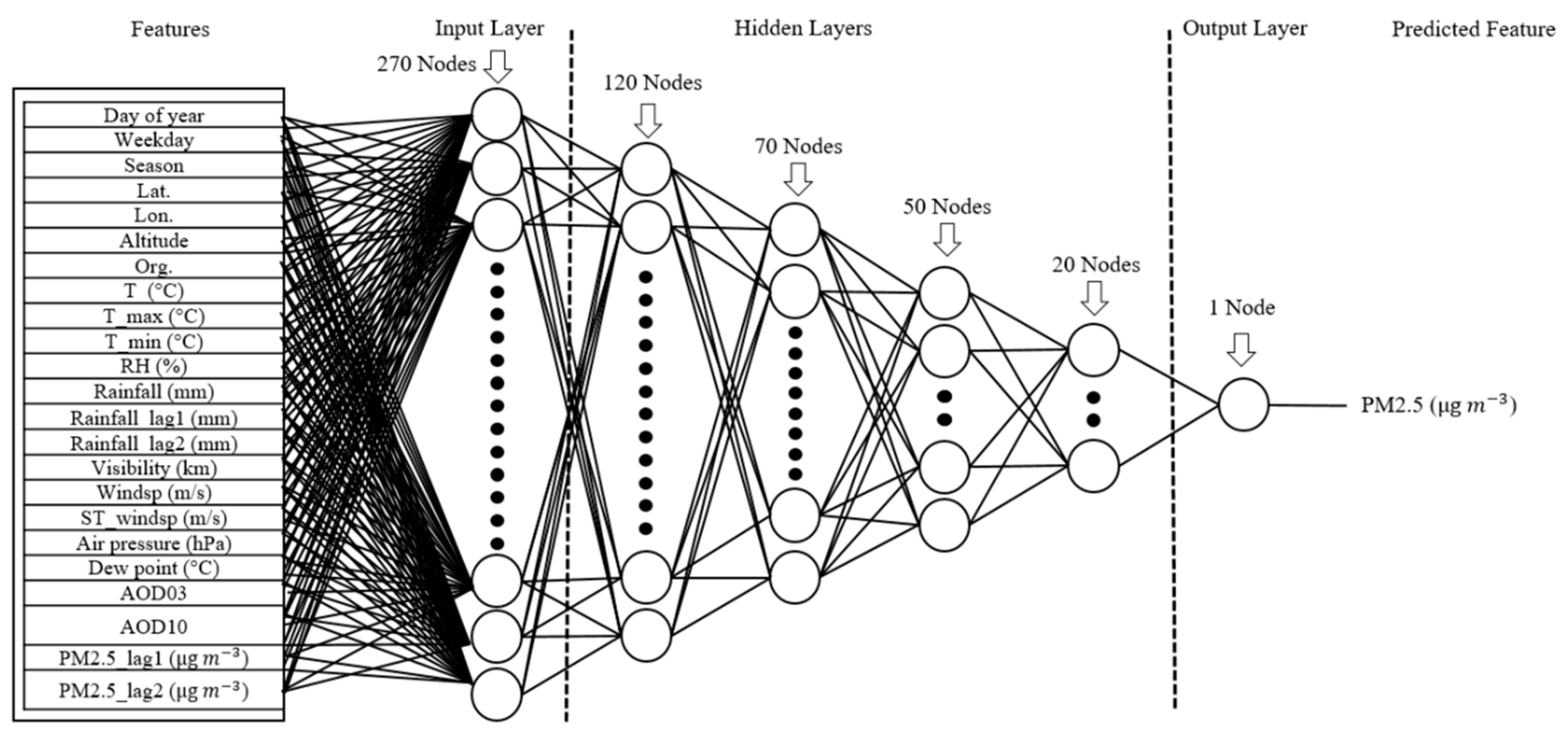
2.3.5. Deep Learning
2.3.6. Feature Importance Assessment
3. Results
3.1. Model Performance Validation
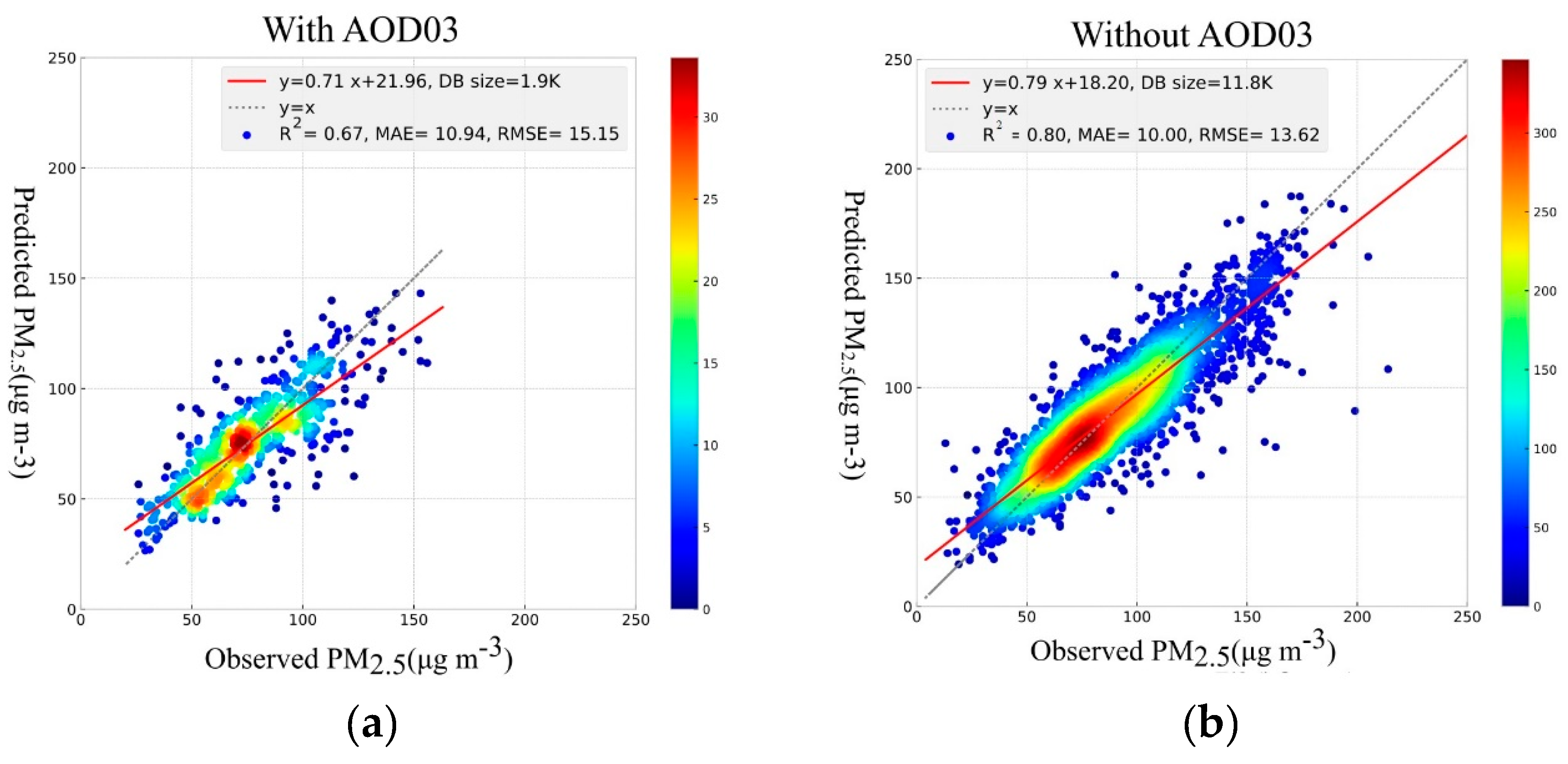
3.1.1. Random Forest
3.1.2. XGBoost
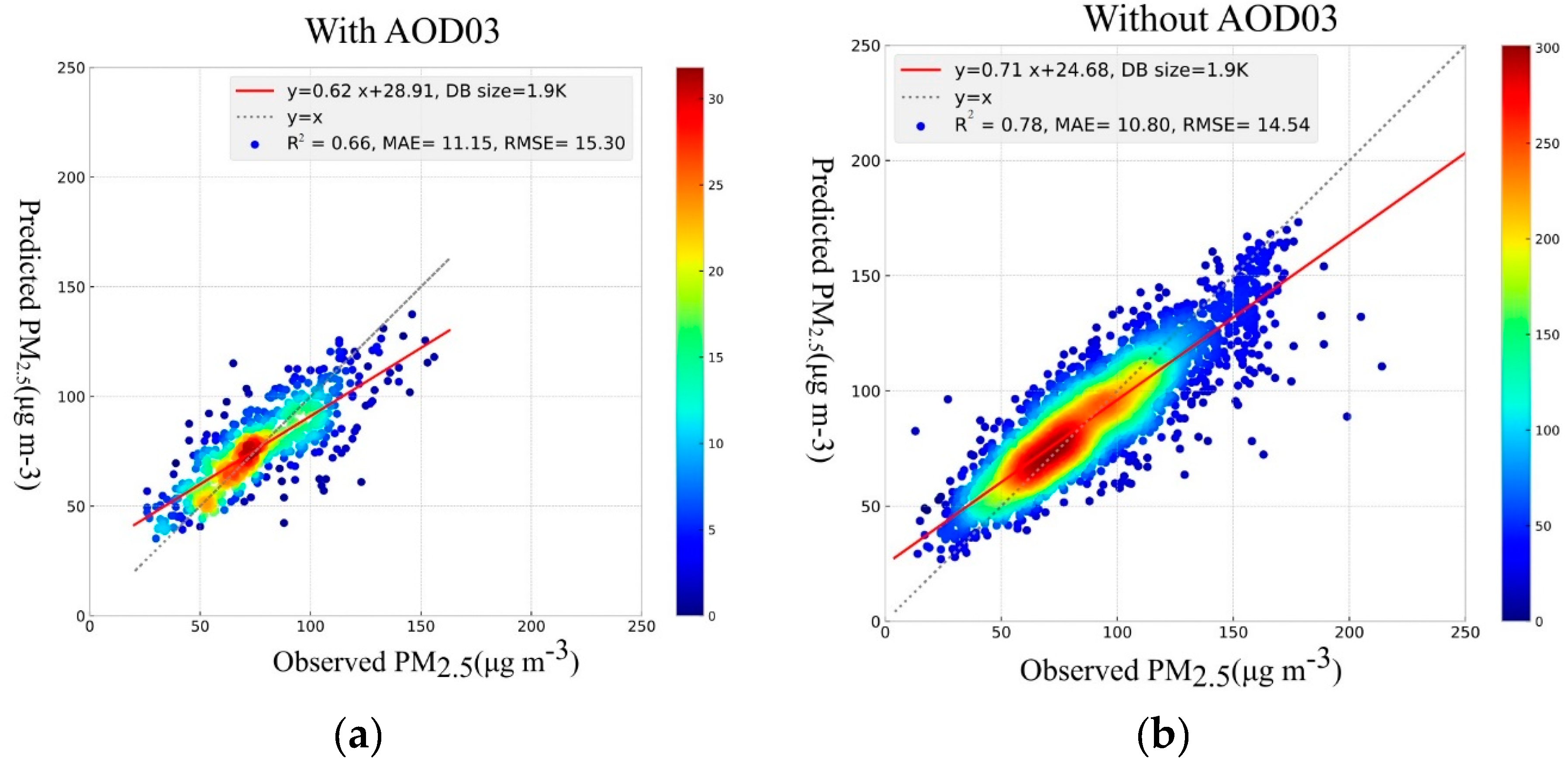
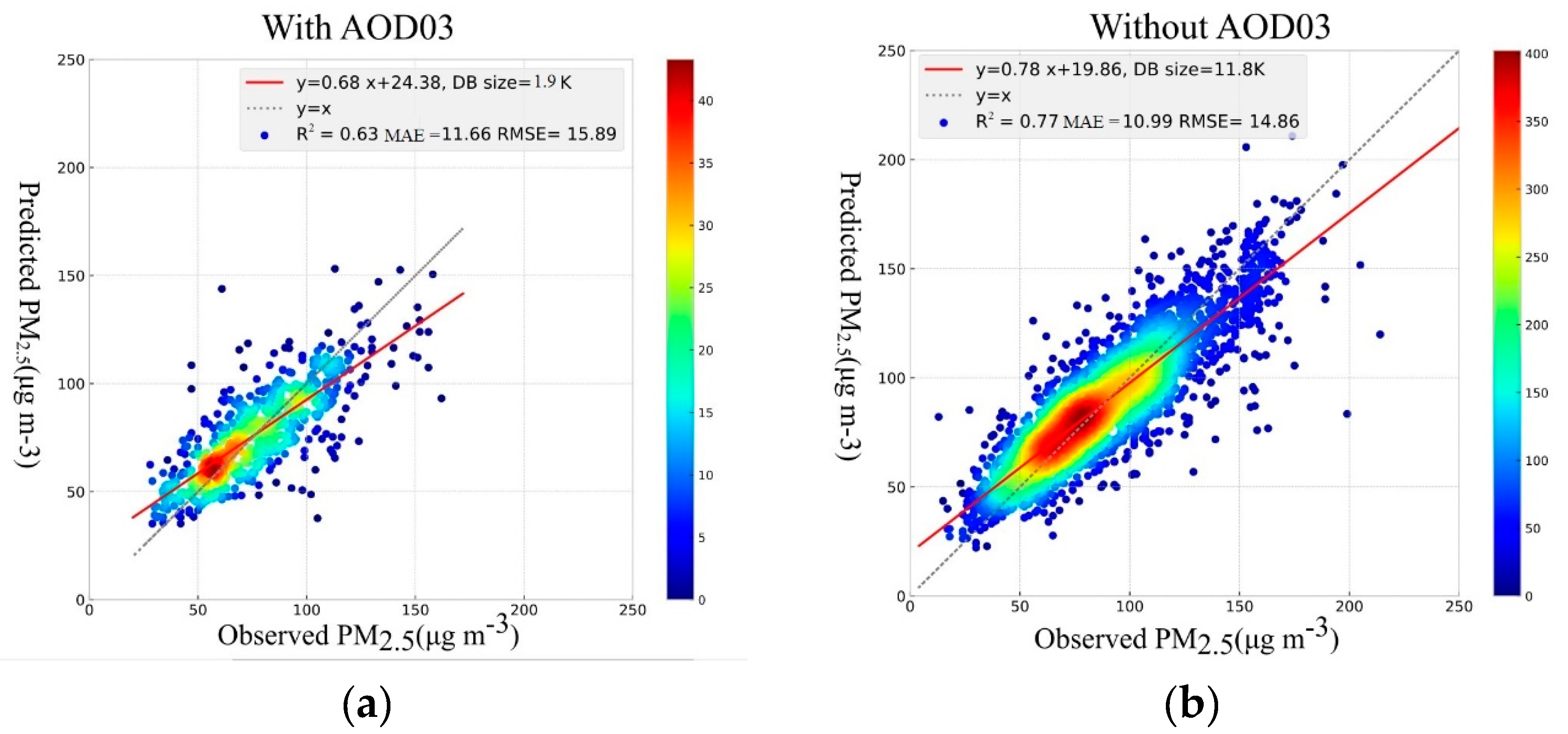
3.1.3. Deep Learning
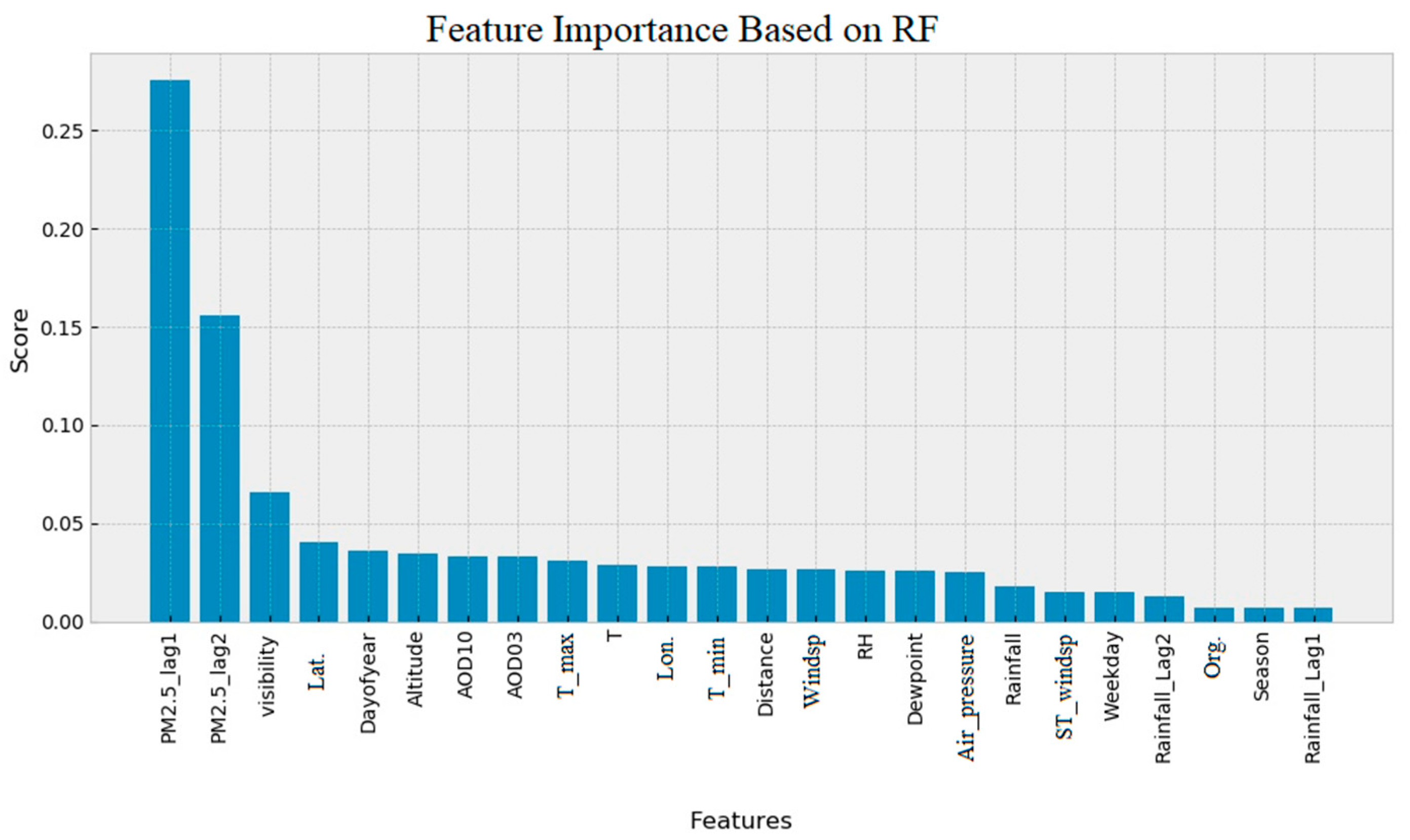
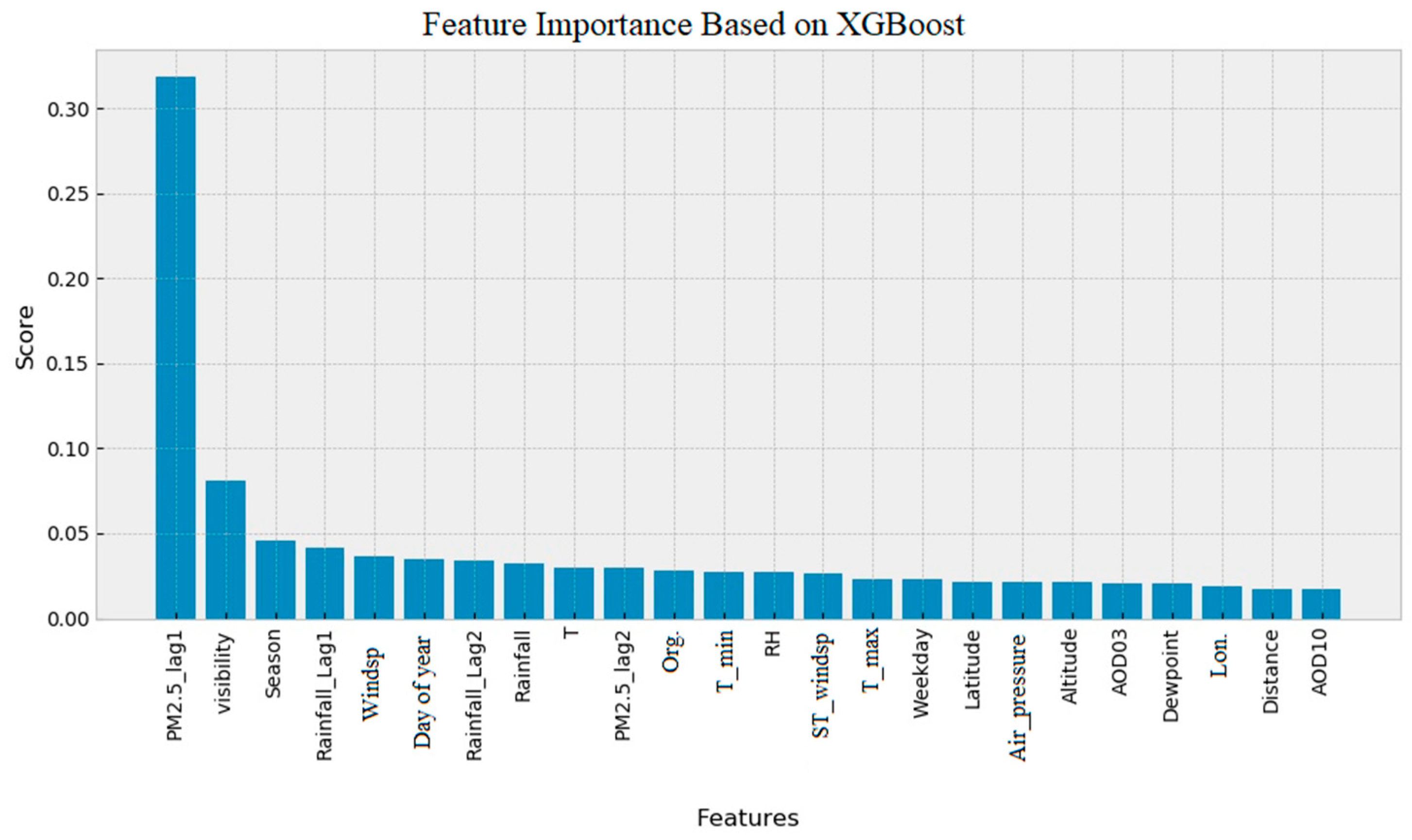
3.2. Feature Importance Assessment
3.2.1. RF and XGBoost Feature Importance Ranking
3.2.2. Feature Permutation Using Deep Neural Network
3.2.3. MAE Based Feature Elimination Using XGBoost
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Riojas-Rodríguez, H.; Romieu, I.; Hernández-Ávila, M. Air pollution. In Occupational and Environmental Health; Oxford University Press: Oxford, UK, 2017; pp. 345–364. ISBN 9780190662677. [Google Scholar]
- Brunekreef, B.; Holgate, S.T. Air pollution and health. Lancet 2002, 360, 1233–1242. [Google Scholar] [CrossRef]
- Guarnieri, M.; Balmes, J.R. Outdoor air pollution and asthma. Lancet 2014, 383, 1581–1592. [Google Scholar] [CrossRef] [Green Version]
- Akimoto, H. Global Air Quality and Pollution. Science 2003, 302, 1716–1719. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Z. Energy and Air Pollution. In Comprehensive Energy Systems; Elsevier: Amsterdam, Netherlands, 2018; Volume 1–5, pp. 909–949. ISBN 9780128095973. [Google Scholar]
- Nowak, D.J.; Crane, D.E.; Stevens, J.C. Air pollution removal by urban trees and shrubs in the United States. Urban For. Urban Green. 2006, 4, 115–123. [Google Scholar] [CrossRef]
- Shen, H.; Li, T.; Yuan, Q.; Zhang, L. Estimating Regional Ground-Level PM2.5 Directly From Satellite Top-Of-Atmosphere Reflectance Using Deep Belief Networks. J. Geophys. Res. Atmos. 2018, 123, 13875–13886. [Google Scholar] [CrossRef]
- Al Hanai, A.H.; Antkiewicz, D.S.; Hemming, J.D.C.; Shafer, M.M.; Lai, A.M.; Arhami, M.; Hosseini, V.; Schauer, J.J. Seasonal variations in the oxidative stress and inflammatory potential of PM2.5 in Tehran using an alveolar macrophage model; The role of chemical composition and sources. Environ. Int. 2019, 417–427. [Google Scholar] [CrossRef]
- Laden, F.; Schwartz, J.; Speizer, F.E.; Dockery, D.W. Reduction in fine particulate air pollution and mortality: Extended follow-up of the Harvard Six Cities Study. Am. J. Respir. Crit. Care Med. 2006, 173, 667–672. [Google Scholar] [CrossRef] [PubMed]
- Evans, J.; van Donkelaar, A.; Martin, R.V.; Burnett, R.; Rainham, D.G.; Birkett, N.J.; Krewski, D. Estimates of global mortality attributable to particulate air pollution using satellite imagery. Environ. Res. 2013, 120, 33–42. [Google Scholar] [CrossRef]
- Rojas-Rueda, D.; de Nazelle, A.; Teixidó, O.; Nieuwenhuijsen, M.J. Health impact assessment of increasing public transport and cycling use in Barcelona: A morbidity and burden of disease approach. Prev. Med. (Baltim). 2013, 57, 573–579. [Google Scholar] [CrossRef]
- Taghvaee, S.; Sowlat, M.H.; Hassanvand, M.S.; Yunesian, M.; Naddafi, K.; Sioutas, C. Source-specific lung cancer risk assessment of ambient PM2.5 -bound polycyclic aromatic hydrocarbons (PAHs) in central Tehran. Environ. Int. 2018, 120, 321–332. [Google Scholar] [CrossRef]
- Shamsoddini, A.; Aboodi, M.R.; Karami, J. Tehran air pollutants prediction based on Random Forest feature selection method. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. ISPRS Arch. 2017, 42, 483–488. [Google Scholar] [CrossRef]
- Arhami, M.; Shahne, M.Z.; Hosseini, V.; Roufigar Haghighat, N.; Lai, A.M.; Schauer, J.J. Seasonal trends in the composition and sources of PM2.5 and carbonaceous aerosol in Tehran, Iran. Environ. Pollut. 2018, 239, 69–81. [Google Scholar] [CrossRef] [PubMed]
- Arhami, M.; Hosseini, V.; Zare Shahne, M.; Bigdeli, M.; Lai, A.; Schauer, J.J. Seasonal trends, chemical speciation and source apportionment of fine PM in Tehran. Atmos. Environ. 2017, 153, 70–82. [Google Scholar] [CrossRef]
- Qi, Y.; Li, Q.; Karimian, H.; Liu, D. A hybrid model for spatiotemporal forecasting of PM2.5 based on graph convolutional neural network and long short-term memory. Sci. Total Environ. 2019, 664, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Shahbazi, H.; Karimi, S.; Hosseini, V.; Yazgi, D.; Torbatian, S. A novel regression imputation framework for Tehran air pollution monitoring network using outputs from WRF and CAMx models. Atmos. Environ. 2018, 187, 24–33. [Google Scholar] [CrossRef]
- Dehghan, A.; Khanjani, N.; Bahrampour, A.; Goudarzi, G.; Yunesian, M. The relation between air pollution and respiratory deaths in Tehran, Iran- using generalized additive models. BMC Pulm. Med. 2018, 18. [Google Scholar] [CrossRef] [PubMed]
- UN-DESA World Urbanization Prospects: The 2018 Revision. Dep. Econ. Soc. Aff. 2018, 2.
- Ansari, M.; Ehrampoush, M.H. Meteorological correlates and AirQ + health risk assessment of ambient fine particulate matter in Tehran, Iran. Environ. Res. 2019, 141–150. [Google Scholar] [CrossRef]
- Faridi, S.; Shamsipour, M.; Krzyzanowski, M.; Künzli, N.; Amini, H.; Azimi, F.; Malkawi, M.; Momeniha, F.; Gholampour, A.; Hassanvand, M.S.; et al. Long-term trends and health impact of PM2.5 and O3 in Tehran, Iran, 2006–2015. Environ. Int. 2018, 114, 37–49. [Google Scholar] [CrossRef]
- Hadei, M.; Hopke, P.K.; Nazari, S.S.H.; Yarahmadi, M.; Shahsavani, A.; Alipour, M.R. Estimation of mortality and hospital admissions attributed to criteria air pollutants in Tehran metropolis, Iran (2013–2016). Aerosol Air Qual. Res. 2017, 17, 2474–2481. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, L.; Tao, J.; Zhang, Y.; Su, L. Satellite-based estimation of regional particulate matter (PM) in Beijing using vertical-and-RH correcting method. Remote Sens. Environ. 2010, 114, 50–63. [Google Scholar] [CrossRef]
- Gupta, P.; Christopher, S.A.; Wang, J.; Gehrig, R.; Lee, Y.; Kumar, N. Satellite remote sensing of particulate matter and air quality assessment over global cities. Atmos. Environ. 2006, 40, 5880–5892. [Google Scholar] [CrossRef]
- Engel-Cox, J.A.; Holloman, C.H.; Coutant, B.W.; Hoff, R.M. Qualitative and quantitative evaluation of MODIS satellite sensor data for regional and urban scale air quality. Atmos. Environ. 2004, 38, 2495–2509. [Google Scholar] [CrossRef]
- van Donkelaar, A.; Martin, R.V.; Brauer, M.; Kahn, R.; Levy, R.; Verduzco, C.; Villeneuve, P.J. Global estimates of ambient fine particulate matter concentrations from satellite-based aerosol optical depth: Development and application. Environ. Health Perspect. 2010, 118, 847–855. [Google Scholar] [CrossRef] [PubMed]
- Ma, Z.; Hu, X.; Huang, L.; Bi, J.; Liu, Y. Estimating ground-level PM2.5 in china using satellite remote sensing. Environ. Sci. Technol. 2014, 48, 7436–7444. [Google Scholar] [CrossRef] [PubMed]
- Geng, G.; Zhang, Q.; Martin, R.V.; van Donkelaar, A.; Huo, H.; Che, H.; Lin, J.; He, K. Estimating long-term PM2.5 concentrations in China using satellite-based aerosol optical depth and a chemical transport model. Remote Sens. Environ. 2015, 166, 262–270. [Google Scholar] [CrossRef]
- Shang, Z.; Deng, T.; He, J.; Duan, X. A novel model for hourly PM2.5 concentration prediction based on CART and EELM. Sci. Total Environ. 2019, 651, 3043–3052. [Google Scholar] [CrossRef]
- Wen, C.; Liu, S.; Yao, X.; Peng, L.; Li, X.; Hu, Y.; Chi, T. A novel spatiotemporal convolutional long short-term neural network for air pollution prediction. Sci. Total Environ. 2019, 654, 1091–1099. [Google Scholar] [CrossRef]
- Liu, W.; Guo, G.; Chen, F.; Chen, Y. Meteorological pattern analysis assisted daily PM2.5 grades prediction using SVM optimized by PSO algorithm. Atmos. Pollut. Res. 2019. [Google Scholar] [CrossRef]
- Delavar, M.; Gholami, A.; Shiran, G.; Rashidi, Y.; Nakhaeizadeh, G.; Fedra, K.; Hatefi Afshar, S. A Novel Method for Improving Air Pollution Prediction Based on Machine Learning Approaches: A Case Study Applied to the Capital City of Tehran. ISPRS Int. J. Geo-Inf. 2019, 8, 99. [Google Scholar] [CrossRef]
- Qin, D.; Yu, J.; Zou, G.; Yong, R.; Zhao, Q.; Zhang, B. A Novel Combined Prediction Scheme Based on CNN and LSTM for Urban PM2.5 Concentration. IEEE Access 2019, 7, 20050–20059. [Google Scholar] [CrossRef]
- Wang, Q.; Zeng, Q.; Tao, J.; Sun, L.; Zhang, L.; Gu, T.; Wang, Z.; Chen, L. Estimating PM2.5 concentrations based on MODIS AOD and NAQPMS data over beijing–tianjin–hebei. Sensors 2019, 19. [Google Scholar]
- Li, T.; Shen, H.; Yuan, Q.; Zhang, X.; Zhang, L. Estimating Ground-Level PM2.5 by Fusing Satellite and Station Observations: A Geo-Intelligent Deep Learning Approach. Geophys. Res. Lett. 2017, 44, 11985–11993. [Google Scholar] [CrossRef]
- Ni, X.; Cao, C.; Zhou, Y.; Cui, X.; Singh, R.P. Spatio-temporal pattern estimation of PM2.5 in Beijing-Tianjin-Hebei Region based on MODIS AOD and meteorological data using the back propagation neural network. Atmosphere 2018, 9, 105. [Google Scholar]
- Tong, W.; Li, L.; Zhou, X.; Hamilton, A.; Zhang, K. Deep learning PM2.5 concentrations with bidirectional LSTM RNN. Air Qual. Atmos. Health 2019, 12, 411–423. [Google Scholar] [CrossRef]
- Huang, C.J.; Kuo, P.H. A deep cnn-lstm model for particulate matter (PM2.5) forecasting in smart cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Chang, F.J.; Chang, L.C.; Kao, I.F.; Wang, Y.S. Explore a deep learning multi-output neural network for regional multi-step-ahead air quality forecasts. J. Clean. Prod. 2019, 209, 134–145. [Google Scholar] [CrossRef]
- Hadei, M.; Yarahmadi, M.; Jafari, A.J.; Farhadi, M.; Nazari, S.S.H.; Emam, B.; Namvar, Z.; Shahsavani, A. Effects of meteorological variables and holidays on the concentrations of PM10, PM2.5, O3, NO2, SO2, and CO in Tehran (2014–2018). J. Air Pollut. Health 2019. [Google Scholar] [CrossRef]
- Nabavi, S.O.; Haimberger, L.; Abbasi, E. Assessing PM2.5 concentrations in Tehran, Iran, from space using MAIAC, deep blue, and dark target AOD and machine learning algorithms. Atmos. Pollut. Res. 2019, 10, 889–903. [Google Scholar] [CrossRef]
- Tehran’s Municipality ICT Website. Available online: airnow.tehran.ir (accessed on 12 May 2019).
- Air Pollution Monitoring System platform of the Department of Environment. Available online: aqms.doe.ir (accessed on 12 May 2019).
- Guleria, R.P.; Kuniyal, J.C.; Rawat, P.S.; Thakur, H.K.; Sharma, M.; Sharma, N.L.; Dhyani, P.P.; Singh, M. Validation of MODIS retrieval aerosol optical depth and an investigation of aerosol transport over Mohal in north western Indian Himalaya. Int. J. Remote Sens. 2012, 33, 5379–5401. [Google Scholar] [CrossRef]
- Portal, NASA Atmosphere Archive & Distribution System (LAADS) Archive. Available online: https://ladsweb.modaps.eosdis.nasa.gov (accessed on 12 May 2019).
- Iran Meteorological Organization. Available online: http://www.irimo.ir/far (accessed on 12 May 2019).
- Junninen, H.; Niska, H.; Tuppurainen, K.; Ruuskanen, J.; Kolehmainen, M. Methods for imputation of missing values in air quality data sets. Atmos. Environ. 2004, 38, 2895–2907. [Google Scholar] [CrossRef]
- Mousavi, S.S.; Schukat, M.; Howley, E. Deep Reinforcement Learning: An Overview. In Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2018; Volume 16, pp. 426–440. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the International Conference on Document Analysis and Recognition, ICDAR, Montreal, QC, Canada, 14–15 August 1995; pp. 278–282. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining—KDD ’16, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Schmidhuber, J. Deep Learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Kalash, M.; Rochan, M.; Mohammed, N.; Bruce, N.D.B.; Wang, Y.; Iqbal, F. Malware Classification with Deep Convolutional Neural Networks. In Proceedings of the 2018 9th IFIP International Conference on New Technologies, Mobility and Security, NTMS 2018—Proceedings, Paris, France, 26–28 February 2018; pp. 1–5. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; Volume 2016, pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 25 (NIPS 2012), neural information processing systems: University of Toronto. Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Li, T.; Shen, H.; Yuan, Q.; Zhang, L. Deep learning for ground-level PM2.5 prediction from satellite remote sensing data. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; Volume 2018, pp. 7581–7584. [Google Scholar]
- Xie, J. Deep neural network for PM2.5 pollution forecasting based on manifold learning. In Proceedings of the 2017 International Conference on Sensing, Diagnostics, Prognostics, and Control, SDPC 2017, Shanghai, China, 16–18 August 2017; Volume 2017, pp. 236–240. [Google Scholar]
- Bengio, Y.; Boulanger-Lewandowski, N.; Pascanu, R. Advances in optimizing recurrent networks. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing—Proceedings, Vancouver, BC, Canada, 26–30 May 2013; 2013; pp. 8624–8628. [Google Scholar] [Green Version]
- Strobl, C.; Boulesteix, A.-L.; Zeileis, A.; Hothorn, T. Bias in random forest variable importance measures: Illustrations, sources and a solution. BMC Bioinform. 2007, 8, 25. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Type | Parameter | Abbreviation | Unit | Period | Source |
|---|---|---|---|---|---|
| Climatic | Temperature | T | °C | 2015.1–2018.12 | IRAN Meteorological Organization |
| Temperature max | T_max | °C | |||
| Temperature min | T_min | °C | |||
| Relative humidity | RH | % | |||
| Daily rainfall | Rainfall | mm | |||
| Visibility | Visibility | km | |||
| Wind speed | Windsp | m/s | |||
| Sustained wind speed | ST_windsp | m/s | |||
| Air pressure | Air_pressure | hPa | |||
| Dew point | Dew point | °C | |||
| Ground measured | PM2.5 | PM2.5 | µg m−3 | 2015.1–2018.12 | airnow.tehran.ir aqms.doe.ir |
| Satellite products | MODIS AODs from Aqua satellite | AOD03 AOD10 | unitless | 2015.1–2018.12 | NASA Atmosphere Archive & Distribution System (LAADS) Archive |
| unitless |
| Parameter | Range | Optimum Value |
|---|---|---|
| n_estimators | 70 to 150 | 130 |
| max_features | [Auto, SQRT, Log2] | SQRT |
| min_samples_split | [2,4,8] | 2 |
| bootstrap | [True, False] | False |
| Parameter | Range | Optimum Value |
|---|---|---|
| n_estimators | 70 to 1000 | 200 |
| max_depth | 1 to 10 | 8 |
| gamma | 0.1 to 1 | 0.7 |
| min_child_weight | 3 to 10 | 8 |
| Layer | Layer Type | Neurons Count | Regularization Type | Regularization Value | Activation Function |
|---|---|---|---|---|---|
| 1 | Input | 270 | None | 0 | relu |
| 2 | Hidden | 120 | L2 | 0.002 | relu |
| 3 | Hidden | 70 | L2 | 0.002 | relu |
| 4 | Hidden | 50 | L2 | 0.002 | relu |
| 5 | Hidden | 20 | L2, L1 | 0.001, 0.001 | relu |
| 6 | Output | 1 | None | 0 | relu |
| Method | Include | Record Size | R2 | MAE (µg m−3) | RMSE (µg m−3) | Time-Cost (s) |
|---|---|---|---|---|---|---|
| Random Forest | AODs 1 | 1900 | 0.66 | 11.15 | 15.30 | 02 |
| Random Forest | AOD10 | 11800 | 0.78 | 10.80 | 14.54 | 17 |
| Random Forest | No AODs | 11800 | 0.78 | 10.78 | 14.47 | 17 |
| XGBoost | AODs | 1900 | 0.67 | 10.94 | 15.15 | 03 |
| XGBoost | AOD10 | 11800 | 0.80 | 10.00 | 13.62 | 19 |
| XGBoost | No AODs | 11800 | 0.80 | 10.00 | 13.66 | 19 |
| Deep Learning | AODs | 1900 | 0.63 | 11.66 | 15.89 | 30 |
| Deep Learning | AOD10 | 11800 | 0.77 | 10.88 | 14.65 | 87 |
| Deep Learning | No AODs | 11800 | 0.76 | 11.12 | 15.11 | 76 |
| Permuted Feature | R2 | MAE (µg m−3) | RMSE (µg m−3) | Ranking | R2 Based on Ranking |
|---|---|---|---|---|---|
| PM2.5_lag1 | 0.21 | 20.63 | 27.32 | 1 | 0.528 |
| Windsp | 0.53 | 15.09 | 21.06 | 2 | 0.564 |
| Visibility | 0.54 | 15.09 | 20.92 | 3 | 0.613 |
| ST_windsp | 0.57 | 14.48 | 20.26 | 4 | 0.620 |
| RH | 0.58 | 14.64 | 20.08 | 5 | 0.704 |
| T_min | 0.61 | 14.62 | 19.27 | 6 | 0.718 |
| Altitude | 0.62 | 14.28 | 19.03 | 7 | 0.737 |
| T | 0.64 | 13.58 | 18.58 | 8 | 0.741 |
| PM2.5_lag2 | 0.66 | 13.48 | 18.02 | 9 | 0.740 |
| Day of year | 0.68 | 13.07 | 17.50 | 10 | 0.749 |
| Air_pressure | 0.68 | 12.98 | 17.37 | 11 | 0.752 |
| T_max | 0.69 | 12.91 | 17.28 | 12 | 0.758 |
| Season | 0.69 | 12.80 | 17.21 | 13 | 0.763 |
| Weekday | 0.69 | 12.98 | 17.20 | 14 | 0.774 |
| Dew point | 0.71 | 12.26 | 16.49 | 15 | 0.776 |
| AOD10 | 0.72 | 12.15 | 16.32 | 16 | 0.776 |
| Rainfall_Lag2 | 0.72 | 11.93 | 16.25 | 17 | 0.771 |
| Distance | 0.73 | 11.97 | 16.08 | 18 | 0.773 |
| Lat. | 0.73 | 11.99 | 16.07 | 19 | 0.765 |
| Rainfall_Lag1 | 0.74 | 11.70 | 15.82 | 20 | 0.768 |
| Lon. | 0.75 | 11.70 | 15.56 | 21 | 0.760 |
| Rainfall | 0.75 | 11.33 | 15.41 | 22 | 0.771 |
| Org.1 | 0.75 | 11.41 | 15.40 | 23 | 0.760 |
| Well Trained Model | 0.77 | 10.88 | 14.65 | - | - |
| Features | Ranking | R2 Based on Median of Rankings Using XGBoost | ||||
|---|---|---|---|---|---|---|
| Permuted Features DNN | RF Built in | XGBoost Built in | XGB Feature Removal | Median of Rankings | ||
| PM2.5_lag1 | 1 | 1 | 1 | 1 | 1 | 0.509 |
| Visibility | 3 | 3 | 2 | 4 | 3 | 0.597 |
| Windsp | 2 | 13 | 5 | 3 | 4 | 0.699 |
| Day of year | 10 | 5 | 6 | 2 | 5.5 | 0.761 |
| Altitude | 7 | 6 | 19 | 9 | 8 | 0.776 |
| PM2.5_lag2 | 9 | 2 | 10 | 8 | 8.5 | 0.776 |
| T | 8 | 9 | 9 | 21 | 9 | 0.783 |
| Lat. | 19 | 4 | 17 | 5 | 11 | 0.784 |
| T_min | 6 | 11 | 12 | 17 | 11.5 | 0.785 |
| T_max | 12 | 8 | 15 | 13 | 12.5 | 0.792 |
| RH | 5 | 14 | 13 | 23 | 13.5 | 0.794 |
| Air_pressure | 11 | 16 | 18 | 6 | 13.5 | 0.799 |
| Season | 13 | 22 | 3 | 14 | 13.5 | 0.797 |
| AOD10 | 16 | 7 | 23 | 12 | 14 | 0.800 |
| Rainfall | 22 | 17 | 8 | 11 | 14 | 0.798 |
| Dew point | 15 | 15 | 20 | 7 | 15 | 0.800 |
| Rainfall_Lag1 | 20 | 23 | 4 | 10 | 15 | 0.799 |
| Weekday | 14 | 19 | 16 | 15 | 15.5 | 0.800 |
| ST_windsp | 4 | 18 | 14 | 20 | 16 | 0.804 |
| Rainfall_Lag2 | 17 | 20 | 7 | 18 | 17.5 | 0.803 |
| Distance | 18 | 12 | 22 | 19 | 18.5 | 0.803 |
| Org. | 23 | 21 | 11 | 16 | 18.5 | 0.805 |
| Lon. | 21 | 10 | 21 | 22 | 21 | 0.805 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zamani Joharestani, M.; Cao, C.; Ni, X.; Bashir, B.; Talebiesfandarani, S. PM2.5 Prediction Based on Random Forest, XGBoost, and Deep Learning Using Multisource Remote Sensing Data. Atmosphere 2019, 10, 373. https://doi.org/10.3390/atmos10070373
Zamani Joharestani M, Cao C, Ni X, Bashir B, Talebiesfandarani S. PM2.5 Prediction Based on Random Forest, XGBoost, and Deep Learning Using Multisource Remote Sensing Data. Atmosphere. 2019; 10(7):373. https://doi.org/10.3390/atmos10070373
Chicago/Turabian StyleZamani Joharestani, Mehdi, Chunxiang Cao, Xiliang Ni, Barjeece Bashir, and Somayeh Talebiesfandarani. 2019. "PM2.5 Prediction Based on Random Forest, XGBoost, and Deep Learning Using Multisource Remote Sensing Data" Atmosphere 10, no. 7: 373. https://doi.org/10.3390/atmos10070373
APA StyleZamani Joharestani, M., Cao, C., Ni, X., Bashir, B., & Talebiesfandarani, S. (2019). PM2.5 Prediction Based on Random Forest, XGBoost, and Deep Learning Using Multisource Remote Sensing Data. Atmosphere, 10(7), 373. https://doi.org/10.3390/atmos10070373