
South America Seasonal Precipitation Prediction by Gradient-Boosting Machine-Learning Approach


Abstract
:1. Introduction
2. Gradient-Boosting Learning
- GB needs an initial estimate , which is a leaf. The model can be initialized with a constant value:The first guess helps GB to build subsequent trees based on the previous trees.
- After defining , the iterative process can begin. Let m be the current iteration (tree) and M the total number of trees. For to , and compute the “pseudo-residuals”:
- Fit a tree closed under scaling to pseudo-residuals .
- Compute multiplier by solving the following one-dimensional optimization problem:
- Update the model:where is the learning rate, a free parameter.
- If convergence is reached, the output will be . If not, go to step 2.
2.1. Best Parameters for the Gradient-Boosting Approach
3. Methodology and Database
3.1. GPCP Version 2.3 Precipitation Dataset
3.2. Global Meteorological Model
3.3. Reanalysis from the NCEP/NCAR
3.4. Model Establishment
- Training and evaluation subsets were formed with data from January 1980 up to February 2017, randomly split into 75% and 25% of the set, respectively;
- The testing (prediction) subset corresponds to the period from March 2017 up to February 2020.
3.5. Performance Evaluation
4. Seasonal Precipitation Prediction: Results and Discussions
4.1. Summer Climate Forecast
4.2. Autumn Climate Forecast
4.3. Winter Climate Forecast
4.4. Spring Climate Forecast
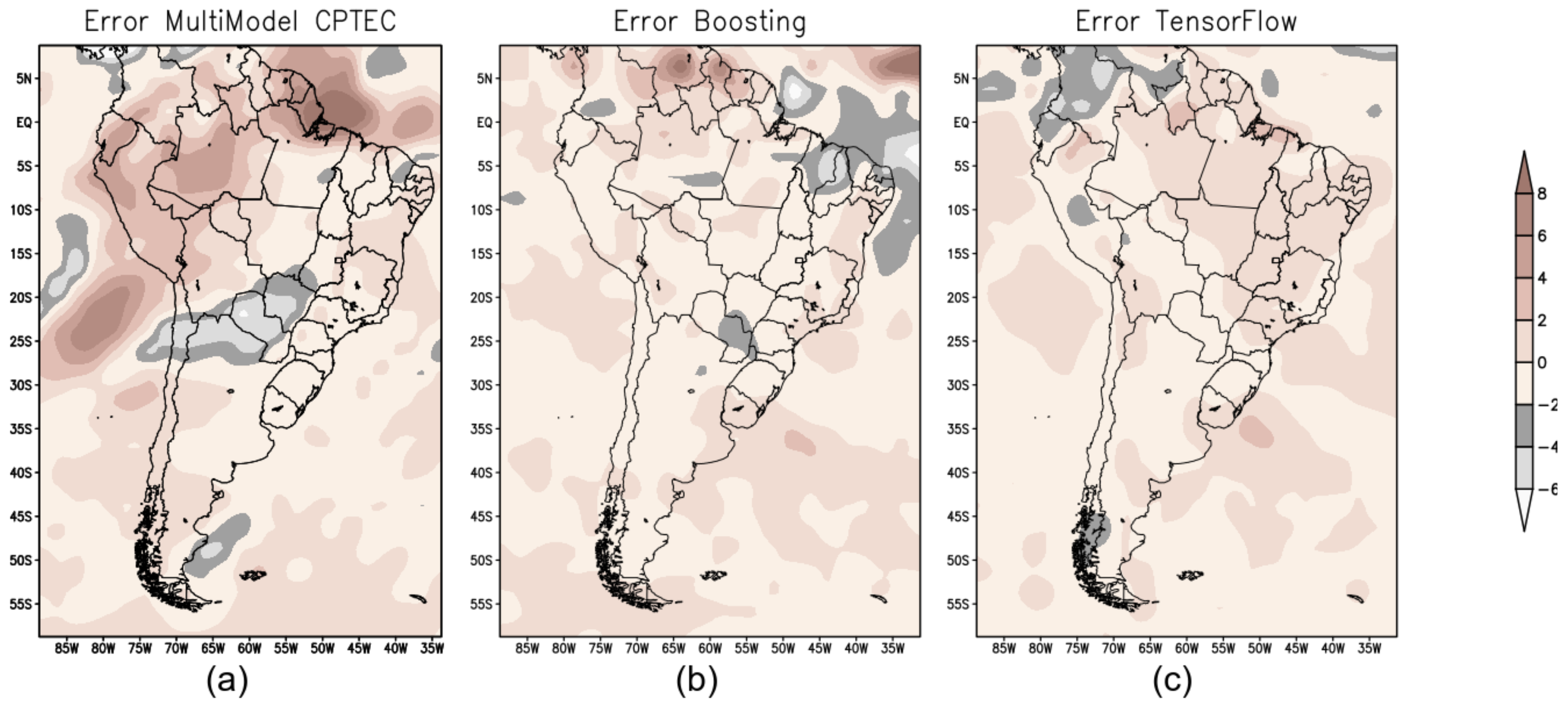
4.5. Evaluation Performance of Models and Discussions
5. Conclusions and Final Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Iseh, A.; Woma, T. Weather Forecasting Models, Methods and Applications. Int. J. Eng. Res. Technol. 2013, 2, 1945–1956. [Google Scholar]
- Lorenz, E.N. Deterministic Nonperiodic Flow. J. Atmos. Sci. 1963, 20, 130–141. [Google Scholar] [CrossRef] [Green Version]
- Figueroa, S.N.; Bonatti, J.P.; Kubota, P.Y.; Grell, G.A.; Morrison, H.; Barros, S.R.; Fernandez, J.P.; Ramirez, E.; Siqueira, L.; Luzia, G.; et al. The Brazilian global atmospheric model (BAM): Performance for tropical rainfall forecasting and sensitivity to convective scheme and horizontal resolution. Weather Forecast. 2016, 31, 1547–1572. [Google Scholar]
- Lagerquist, R.; McGovern, A.; Gagne, D.J., II. Deep Learning for Spatially Explicit Prediction of Synoptic-Scale Fronts. Weather Forecast. 2019, 34, 1137–1160. [Google Scholar] [CrossRef]
- Ham, Y.G.; Kim, J.-H.; Luo, J.J. Deep learning for multi-year ENSO forecasts. Nature 2019, 573, 568–572. [Google Scholar] [CrossRef]
- Schultz, M.G.; Betancourt, C.; Gong, B.; Kleinert, F.; Langguth, M.; Leufen, L.H.; Mozaffari, A.; Stadtler, S. Can Deep Learning Beat Numerical Weather Prediction? Philos. Trans. Royal Soc. A Math. Phys. Eng. Sci. 2021, 379, 20200097. [Google Scholar] [CrossRef]
- Agata, R.; Jaya, I.G.N.M. A comparison of extreme gradient boosting, SARIMA, exponential smoothing, and neural network models for forecasting rainfall data. J. Phys. Conf. Ser. 2019, 1397, 012073. [Google Scholar] [CrossRef]
- Cui, Z.; Qing, X.; Chai, H.; Yang, S.; Zhu, Y.; Wang, F. Real-time rainfall-runoff prediction using light gradient boosting machine coupled with singular spectrum analysis. J. Hydrol. 2021, 603, 127124. [Google Scholar] [CrossRef]
- Ukkonen, P.; Makela, A. Evaluation of Machine Learning Classifiers for Predicting Deep Convection. J. Adv. Model. Earth Syst. 2019, 11, 1784–1802. [Google Scholar] [CrossRef] [Green Version]
- Freitas, J.H.V.; França, G.B.; Menezes, W.F. Deep convection forecasting using decision tree in Rio de Janeiro metropolitan area. Anuário do Inst. de Geociências (UFRJ. Brazil) 2019, 42, 127–134. [Google Scholar]
- Anochi, J.A.; de Almeida, V.A.; de Campos Velho, H.F. Machine Learning for Climate Precipitation Prediction Modeling over South America. Remote Sens. 2021, 13, 2468. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgo, A.; Martínez-Muñoz, G. A Comparative Analysis of XGBoost. arXiv 2019, arXiv:abs/1911.01914. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Rudin, L.I.; Osher, S.; Fatemi, E. Nonlinear Total Variation Based Noise Removal Algorithms. Phys. D Nonlinear Phenoma 1992, 60, 259–268. [Google Scholar]
- Aster, R.C.; Borchers, B.; Thurber, C.H. Parameter Estimation and Inverse Problems; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Tikhonov, A.N.; Arsenin, V.Y. Solution of Ill-Posed Problems; John Wiley & Sons: Hoboken, NJ, USA, 1977. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-Generation Hyperparameter Optimization Framework. arXiv 2019, arXiv:cs.LG/1907.10902. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. In Advances in Neural Information Processing Systems 24: Proceedings of the 25th Annual Conference on Neural Information Processing Systems 2011, Granada, Spain, 12–14 December 2011; Curran Associates Inc.: New York, NY, USA, 2011; pp. 2546–2554. [Google Scholar]
- Frazier, P.I. A Tutorial on Bayesian Optimization. arXiv 2018, arXiv:abs/1807.02811. [Google Scholar]
- Adler, R.F.; Huffman, G.J.; Chang, A.; Ferraro, R.; Xie, P.P.; Janowiak, J.; Rudolf, B.; Schneider, U.; Curtis, S.; Bolvin, D.; et al. The Version-2 Global Precipitation Climatology Project (GPCP) Monthly Precipitation Analysis (1979–present). J. Hydrometeorol. 2003, 4, 1147–1167. [Google Scholar] [CrossRef]
- Kalnay, E.; Kanamitsu, M.; Kistler, R.; Collins, W.; Deaven, D.; Gandin, L.; Iredell, M.; Saha, S.; White, G.; Woollen, J.; et al. The NCEP/NCAR 40-year reanalysis project. Bull. Am. Meteorol. Soc. 1996, 77, 437–472. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. 2016. Available online: http://xxx.lanl.gov/abs/1603.04467 (accessed on 27 December 2021).
- Summer Climate Forecast. Available online: https://portal.inmet.gov.br/notasTecnicas# (accessed on 28 December 2021).
- Autumn Climate Forecast. Available online: https://portal.inmet.gov.br/notasTecnicas# (accessed on 28 December 2021).
- Ferreira, N.S. Intertropical Convergence Zone. Climanalysis Spec. Bull. 10 Years Celebr. 1996, 10, 15–16. [Google Scholar]
- Newman, P.A.; Nash, E.R. The unusual Southern Hemisphere stratosphere winter of 2002. J. Atmos. Sci. 2005, 62, 614–628. [Google Scholar]
- Prognóstico Climático de Primavera. Available online: https://portal.inmet.gov.br/notasTecnicas# (accessed on 28 December 2021).
- Barry, R.G.; Chorley, R.J. Atmosphere, Weather, and Climate; Routledge: London, UK, 1992. [Google Scholar]
- Carvalho, L.M.V.; Jones, C.; Leibman, B. The South Atlantic Convergence Zone: Intensity, Form, Persistence, and Relationships with Intraseasonal to Interannual Activity and Extreme Rainfall. J. Clim. 2004, 17, 88–108. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Zhang, N.; Tan, Y.; Hong, T.; Kirschen, D.S.; Kang, C. Combining probabilistic load forecasts. IEEE Trans. Smart Grid 2019, 10, 3664–3674. [Google Scholar] [CrossRef] [Green Version]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description |
|---|---|
| J | Maximum tree depth |
| Learning rate | |
| L2 regularization parameter | |
| L1 regularization parameter | |
| subsample | Data subsampling |
| colsample_bytree | Feature subsampling |
| Parameter | Min | Max |
|---|---|---|
| J | 6 | 36 |
| 0.9 | ||
| 0.01 | 0.9 | |
| 0.01 | 0.9 | |
| subsample | 0.5 | 1.0 |
| colsample_bytree | 0.5 | 1.0 |
| Variables | Variable Units |
|---|---|
| Surface Pressure (surface) | millibars |
| Air Temperature (surface) | degC |
| Air Temperature at 850 hPa | degC |
| Specific Humidity at 850 hPa | grams/kg |
| Meridional wind component at 850 hPa | m/s |
| Zonal wind component at 500 hPa | m/s |
| Zonal wind component at 850 hPa | m/s |
| Precipitation | mm |
| Parameter | Summer | Autumn | Winter | Spring |
|---|---|---|---|---|
| J | 34 | 9 | 35 | 34 |
| 0.12 | 0.13 | 0.1 | ||
| 0.65 | 0.16 | 0.79 | 0.81 | |
| 0.47 | 0.28 | 0.56 | 0.23 | |
| subsample | 0.74 | 0.73 | 0.91 | 0.65 |
| colsample_bytree | 0.83 | 0.78 | 0.99 | 0.92 |
| Season | Year | XGB | TF | ||||
|---|---|---|---|---|---|---|---|
| ME | COV | RMSE | ME | COV | RMSE | ||
| Summer | 2018 | −0.42 | 2.16 | 1.53 | −0.12 | 8.61 | 7.63 |
| Autumn | 2018 | 1.8 × | 1.46 | 1.20 | −0.07 | 0.85 | 0.86 |
| Winter | 2018 | 0.12 | 1.92 | 1.39 | −1.18 | 8.56 | 8.96 |
| Spring | 2018 | 0.19 | 0.93 | 0.98 | −0.96 | 3.27 | 4.20 |
| Summer | 2019 | −0.21 | −0.21 | 1.32 | 0.09 | 2.50 | 2.51 |
| Autumn | 2019 | 0.13 | 2.91 | 1.71 | −0.02 | 1.40 | 1.40 |
| Winter | 2019 | −0.21 | 2.27 | 1.52 | −0.34 | 1.20 | 1.32 |
| Spring | 2019 | −0.17 | 0.69 | 0.85 | 1.25 | 3.69 | 5.27 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Monego, V.S.; Anochi, J.A.; de Campos Velho, H.F. South America Seasonal Precipitation Prediction by Gradient-Boosting Machine-Learning Approach. Atmosphere 2022, 13, 243. https://doi.org/10.3390/atmos13020243
Monego VS, Anochi JA, de Campos Velho HF. South America Seasonal Precipitation Prediction by Gradient-Boosting Machine-Learning Approach. Atmosphere. 2022; 13(2):243. https://doi.org/10.3390/atmos13020243
Chicago/Turabian StyleMonego, Vinicius Schmidt, Juliana Aparecida Anochi, and Haroldo Fraga de Campos Velho. 2022. "South America Seasonal Precipitation Prediction by Gradient-Boosting Machine-Learning Approach" Atmosphere 13, no. 2: 243. https://doi.org/10.3390/atmos13020243
APA StyleMonego, V. S., Anochi, J. A., & de Campos Velho, H. F. (2022). South America Seasonal Precipitation Prediction by Gradient-Boosting Machine-Learning Approach. Atmosphere, 13(2), 243. https://doi.org/10.3390/atmos13020243