
Air Pollutants over Industrial and Non-Industrial Areas: Historical Concentration Estimates

 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
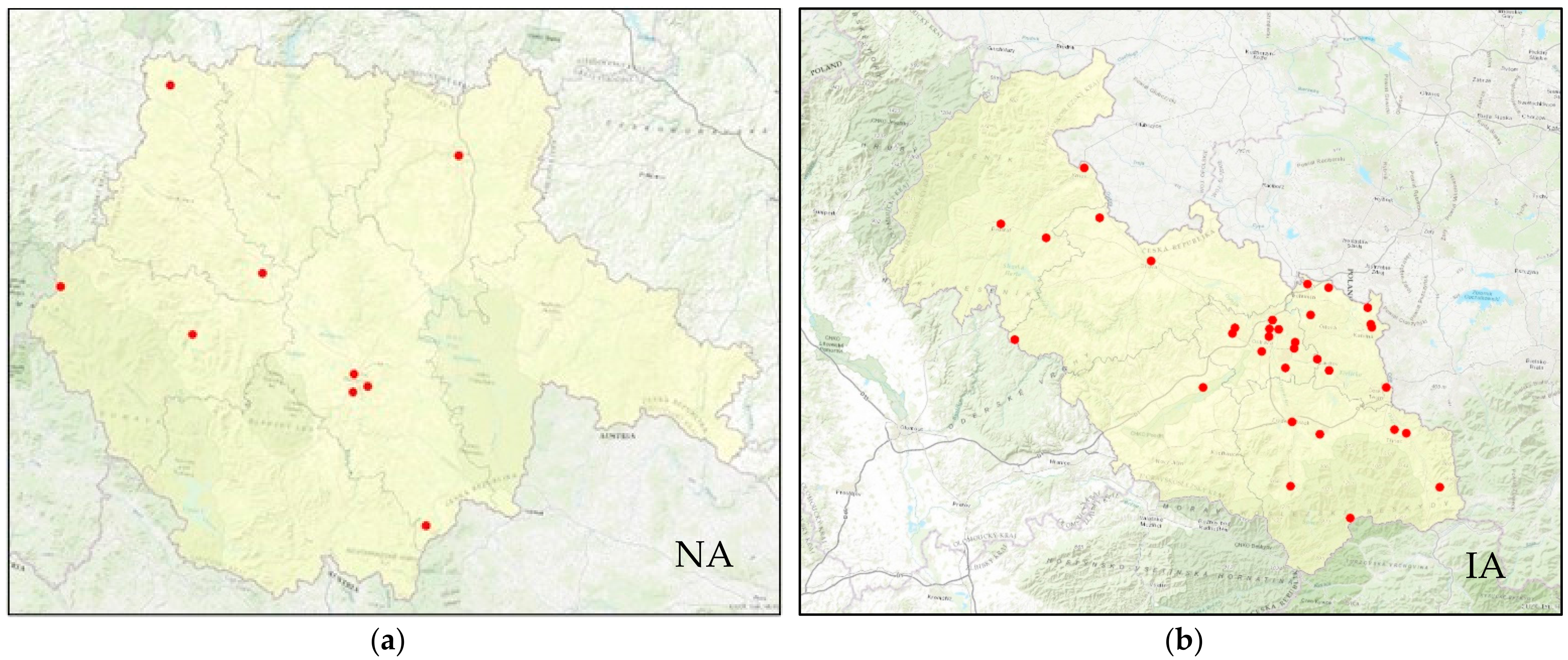
2.1. Selection of Monitored Localities
2.2. Input Data
- a.
- Air quality monitoring data—Publicly available tabular summaries of data from air quality monitoring stations from a nationally verified air quality database [9].
- b.
- Publicly available five-year average concentrations according to the Air Protection Act 201/2012 Coll., 11, paragraphs 5 and 6 for the interval 2007–2011 in shapefile format (SHP)—A regular grid of squares with 1 km step [10].
- c.
- Boundaries of the IA and NA districts in the SHP format [11].
- d.
- Areas of built-up areas of shapefile districts in shapefile format of shapefiles (SHP) [11].
- e.
- Emission balance of assessed districts for the years 1980–1997 for PM, NOx, and SO2 from data processed by the Czech Hydrometeorological Institute in Prague (CHMI).
2.3. Data Processing
- i.
- Processing of available air quality monitoring data for individual districts and assessed pollutants: tabular overviews of data from air quality monitoring stations.
- ii.
- Creation of a corresponding database of five-year average concentrations of pollutants evaluated in the SHP format (regular network of squares with a step of 1 km) and preparation of digital map data in GIS, territorial identification of the evaluated area, and built-up area.
- iii.
- Calculation of annual average concentrations from air quality monitoring data and a database of average concentrations over five years.
- iv.
- Calculation of average annual concentrations of territorial units where air quality monitoring data were not available. Correlation of data explored in Steps i, ii, and iii.
- v.
- Correction of the annual average concentrations of territorial units for residential zones.
- vi.
- Estimation of the average annual concentrations of territorial units using the emission balance database for historical periods for which air quality monitoring data were not available.
2.3.1. Processing of Air Quality Monitoring Data
2.3.2. Application of the Spatial Database and Maps of Territorial Identification
2.3.3. Calculation of Annual Average Concentrations
2.3.4. Correction of Annual Concentrations to Residential Zones
2.3.5. Estimation of Concentrations for the Years 1980–1997 Using Data from Annual Emission Balances of Assessed Districts
3. Results and Discussion
3.1. Example of the Results of the Described Methodology for Estimating Historical Air Pollutant Concentrations
3.2. Comparison of the Described Methodology for Estimating Historical Concentrations with the Standard Methodology Used
- Both procedures require GIS as a necessary tool to achieve their results.
- Unlike LUR, it is not possible to use this procedure correctly for forward-looking concentration predictions. It is suitable for estimating historical concentrations from available air quality monitoring data for the entire area of interest.
- Compared to the proposed approach, the LUR method requires a larger number of monitoring stations with a sufficiently variable number of characteristic types of monitored zones. In our case, we use a specific long-term average regular network of the air pollution characteristics database for estimation, which serves as a spatially very detailed basis for identification modelling from available air quality monitoring data.
- Unlike the LUR method, it is not necessary to define other variables, such as the distribution and intensity of emission sources and elements of pollutant efficiency, the definition of which introduces additional uncertainties into the prediction. These parameters are taken into account much more accurately by identification with the regular network of the air pollution characteristics database.
- Compared to LUR, the air quality monitoring data used in combination with the spatial database of air pollution characteristics represent in the long run a more closely linked system in terms of time and space.
- In terms of the evaluated time horizons, the complexity of processing input data and the requirement to obtain average values at the territorial level of districts, the proposed procedure is more suitable than the LUR method.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- European Environment Agency. Air Quality in Europe—2019 Report; Publications Office of the European Union: Luxembourg, 2019; Available online: https://www.eea.europa.eu/publications/air-quality-in-europe-2019 (accessed on 24 September 2021). [CrossRef]
- Eeftens, M.; Beelen, R.; de Hoogh, K.; Bellander, T.; Cesaroni, G.; Cirach, M.; Declercq, C.; Dedele, A.; Dons, E.; de Nazelle, A.; et al. Development of land use regression models for PM2.5, PM2.5 absorbance, PM10 and PM coarse in 20 European study areas; Results of the ESCAPE project. Environ. Sci. Technol. 2012, 46, 11195–11205. [Google Scholar] [CrossRef] [PubMed]
- Dostal, P.; Gazdos, F. Řízení Technologických Procesu (Management of Technological Processes); Univerzita Tomáše Bati ve Zlíně: Zlin, Czech Republic, 2006; ISBN 8073184656. [Google Scholar]
- Kim, S.-Y.; Bechle, M.; Hankey, S.; Sheppard, L.; Szpiro, A.A.; Marshall, J.D. Concentrations of criteria pollutants in the contiguous U.S., 1979–2015: Role of prediction model parsimony in integrated empirical geographic regression. PLoS ONE 2020, 15, e0228535. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- ESRI: ArcGIS Pro: Spatial Analysis in ArcGIS Pro. Available online: https://pro.arcgis.com/en/pro-app/latest/help/analysis/introduction/spatial-analysis-in-arcgis-pro.htm (accessed on 29 July 2021).
- Český Statistický Úřad. Krajská Správa ČSÚ v Ostravě: Charakteristika Moravskoslezského Kraje (Czech Statistical Office: Regional Administration of the CZSO in Ostrava: Characteristics of the Moravian-Silesian Region). Available online: https://www.czso.cz/csu/xt/charakteristika_moravskoslezskeho_kraje (accessed on 17 May 2021).
- Jirik, V.; Machaczka, O.; Miturová, H.; Tomasek, I.; Slachtova, H.; Janoutova, J.; Velicka, H.; Janout, V. Air pollution and potential health risk in ostrava region—A review. Cent. Eur. J. Public Health 2016, 24, S4–S17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Český Statistický Úřad: Krajská Správa ČSÚ v Českých Budějovicích: Charakteristika Kraje (Czech Statistical Office: Regional Administration of the CZSO in České Budějovice: Characteristics of the Region). Available online: https://www.czso.cz/csu/xc/charakteristika_kraje (accessed on 17 May 2021).
- Czech Hydrometeorological Institute: Air Pollution and Atmospheric Deposition in Data, the Czech Republic: Annual Tabular Overview. Available online: https://www.chmi.cz/files/portal/docs/uoco/isko/tab_roc/tab_roc_EN.html (accessed on 1 May 2021).
- Český Hydrometeorologický Ústav: Pětileté Průměrné Koncentrace (Czech Hydrometeorological Institute: Five-Year Average Concentrations). Available online: https://www.chmi.cz/files/portal/docs/uoco/isko/ozko/ozko_CZ.html (accessed on 1 May 2021).
- Český Úřad Zeměměřický a Katastrální: Geoportál ČÚZK: Soubor Správních Hranic a Hranic Katastrálních Území ČR (Czech Surveying and Cadastre Office: CSCO Geoportal: A Set of Administrative Borders and Borders of Cadastral Territories of the Czech Republic). Available online: https://geoportal.cuzk.cz/(S(ep0r2vsgn1lfq0s4lfefnkwb))/Default.aspx?mode=TextMeta&side=dSady_RUIAN&metadataID=CZ-CUZK-SH-V&mapid=5&head_tab=sekce-02-gp&menu=25 (accessed on 1 May 2021).
- Fernández-Somoano, A.; Llop, S.; Aguilera, I.; Tamayo-Uria, I.; Martínez, M.D.; Foraster, M.; Ballester, F.; Tardón, A. Annoyance Caused by Noise and Air Pollution during Pregnancy: Associated Factors and Correlation with Outdoor NO2 and Benzene Estimations. Int. J. Environ. Res. Public Health 2015, 12, 7044–7058. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sharma, R.; Sharma, N. Assessment of variations and correlation of ozone and its precursors, benzene, nitrogen dioxide, carbon monoxide and some Meteorological Variables at two sites of significant spatial variations in Delhi, Northern India. Pollution 2021, 7, 723–737. [Google Scholar] [CrossRef]
- Cernikovsky, L.; Krejci, B.; Blazek, Z.; Volna, V. Transboundary airpollution transport in the Czech-Polish Border Region between the cities of Ostrava and Katowice. Cent. Eur. J. Public Health 2016, 24 (Suppl.), 45–50. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jancik, P.; Pavlikova, I.; Bitta, J.; Hladky, D. Atlas Ostravského Ovzduší; Vysoká Škola Báňská—Technická Univerzita Ostrava: Ostrava, Czech Republic, 2013; ISBN 978-80-248-3006-3. [Google Scholar]
- Land Use Regression. Integrated Environmental Health Impact Assessment System. Available online: http://www.integrated-assessment.eu/eu/guidebook/land_use_regression.html (accessed on 17 May 2021).
- Vienneau, D.; de Hoogh, K.; Beelen, R.; Fischer, P.; Hoek, G.; Briggs, D. Comparison of land-use regression models between Great Britain and the Netherlands. Atmos. Environ. 2010, 44, 688–696. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IA Districts | PM10 | * PM2.5 | NO2 | SO2 | * B(a)P | * Benzene |
|---|---|---|---|---|---|---|
| BR | 7 | 4 | 9 | 13 | 3 | n/a |
| FM | 117 | 28 | 95 | 120 | 5 | 17 |
| KA | 154 | 38 | 173 | 170 | 31 | 11 |
| NJ | 36 | 8 | 31 | 38 | 8 | n/a |
| OP | 44 | 5 | 41 | 38 | 7 | 8 |
| OV | 360 | 54 | 230 | 364 | 92 | 112 |
| NA Districts | PM10 | * PM2.5 | NO2 | SO2 | * B(a)P | * Benzene |
|---|---|---|---|---|---|---|
| CB | 64 | 14 | 53 | 56 | 16 | 14 |
| CK | n/a | n/a | n/a | 2 | n/a | n/a |
| JH | n/a | n/a | 6 | 16 | n/a | n/a |
| PI | n/a | n/a | n/a | 2 | n/a | n/a |
| PR | 38 | 6 | 42 | 37 | 1 | n/a |
| ST | 12 | n/a | 8 | 22 | n/a | n/a |
| TA | 16 | n/a | 16 | 9 | n/a | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Michalik, J.; Machaczka, O.; Jirik, V.; Heryan, T.; Janout, V. Air Pollutants over Industrial and Non-Industrial Areas: Historical Concentration Estimates. Atmosphere 2022, 13, 455. https://doi.org/10.3390/atmos13030455
Michalik J, Machaczka O, Jirik V, Heryan T, Janout V. Air Pollutants over Industrial and Non-Industrial Areas: Historical Concentration Estimates. Atmosphere. 2022; 13(3):455. https://doi.org/10.3390/atmos13030455
Chicago/Turabian StyleMichalik, Jiri, Ondrej Machaczka, Vitezslav Jirik, Tomas Heryan, and Vladimir Janout. 2022. "Air Pollutants over Industrial and Non-Industrial Areas: Historical Concentration Estimates" Atmosphere 13, no. 3: 455. https://doi.org/10.3390/atmos13030455
APA StyleMichalik, J., Machaczka, O., Jirik, V., Heryan, T., & Janout, V. (2022). Air Pollutants over Industrial and Non-Industrial Areas: Historical Concentration Estimates. Atmosphere, 13(3), 455. https://doi.org/10.3390/atmos13030455