1. Introduction
With the continuous advancement of global industry and the economic activities of human society depending heavily on resource consumption [
1], the problem of climate warming caused by excessive greenhouse gas emissions is becoming increasingly serious [
2,
3]. From 2000 to 2019, global carbon emissions increased from 232 billion tons to 344 billion tons. To tackle climate change, promoting the transformation of the economic development mode to green and low-carbon and implementing carbon emission reduction measures are essential [
4,
5]. Controlling carbon emissions and achieving net zero emissions are common goals of global climate governance. Only some European countries, such as France and Germany, have achieved overall carbon reduction [
6]. Most responsibility for carbon emissions lies with industrialized countries [
7]. Some developed countries have imposed strict restrictions on the use of fossil fuels to cope with the increase in carbon emissions [
8]. Climate change is a global issue that brings a serious challenge to developing countries [
9]. China has committed to reach a carbon peak by 2030 and become carbon neutral by 2060. The proposal of carbon peaking and carbon neutrality goals has also become an opportunity and challenge for society’s comprehensive green transformation [
10]. To achieve the “double carbon” target, the Chinese government promulgates many related files. The implementation of carbon emission reduction policies will accelerate the comprehensive green and low-carbon transformation of the economy. The 14th Five Year Plan for China’s national economic and social development and the outline of long-term goals for 2035 put forward the objectives and tasks related to the ecological environment, such as achieving remarkable results in the green transformation of production and lifestyle, more reasonable allocation of energy resources, significantly improving utilization efficiency, and reducing energy intensity and carbon dioxide emissions by 13.5% and 18%, respectively. The government will improve the dual control system of total energy consumption and energy intensity, focus on controlling fossil energy consumption, and further promote low-carbon transformation in industry, construction, transportation, and other key fields [
11].
China is facing huge pressure to reduce carbon emissions, with primary energy consumption accounting for 26.1% of global primary energy consumption in 2020 [
12]. Since being identified as a low-carbon pilot city in 2012, Beijing has achieved positive results in low-carbon development. Industrial structure and energy structure have been optimized, and the problem of economy, energy, and population have been alleviated, which has gradually promoted the goal of carbon emission reduction [
13,
14]. In 2020, coal consumption in Beijing accounted for 1.5% of the total energy consumption. Therefore, the space for reducing carbon emissions through the removal of coal is relatively small [
15]. During the 14th Five Year Plan period, Beijing will carry out special actions on pollutants and carbon emission reduction. These actions will be effectively combined with economic growth, green energy development, and industrial structure optimization to ensure a steady decline in carbon emission reduction. Beijing will continue to support the growth of green energy and environmental protection sectors, prioritize the low-carbon transformation of key industries, conduct concurrent research on the path to carbon neutrality, encourage regional collaborative emission reduction, and speed up the achievement of carbon neutrality goals.
In recent years, carbon emission reduction has received extensive attention. Many scholars have researched the path of carbon emission reduction in different industries and regions and put forward some targeted emission reduction measures. Khalil et al. [
16] evaluated carbon reduction levels through the Global Cleantech Innovation Program (GCIP) project and compared the differences between zero-emission technologies and traditional practices, thereby providing support for Pakistan’s carbon reduction efforts. Chhabra et al. [
17] examined the impact of trade openness and institutional quality on CO
2 emissions in BRICS countries and discovered that trade openness aggravates CO
2 emissions. Konstantinavicete and Bobinaite [
18] evaluated the carbon dioxide emission coefficients of the energy industry in EU countries and compared the estimated carbon dioxide emissions with the calculations provided by the IPCC. Honma et al. [
19] examined the carbon efficiency of the metal industry in Japan and analyzed the relationship between carbon emission, output, and carbon efficiency. Gordic et al. [
20] found that European grid-connected households can reduce their carbon footprint using electricity generated from local renewable energy, and voluntary carbon offset can become a practical solution for achieving a carbon-neutral household. Wu et al. [
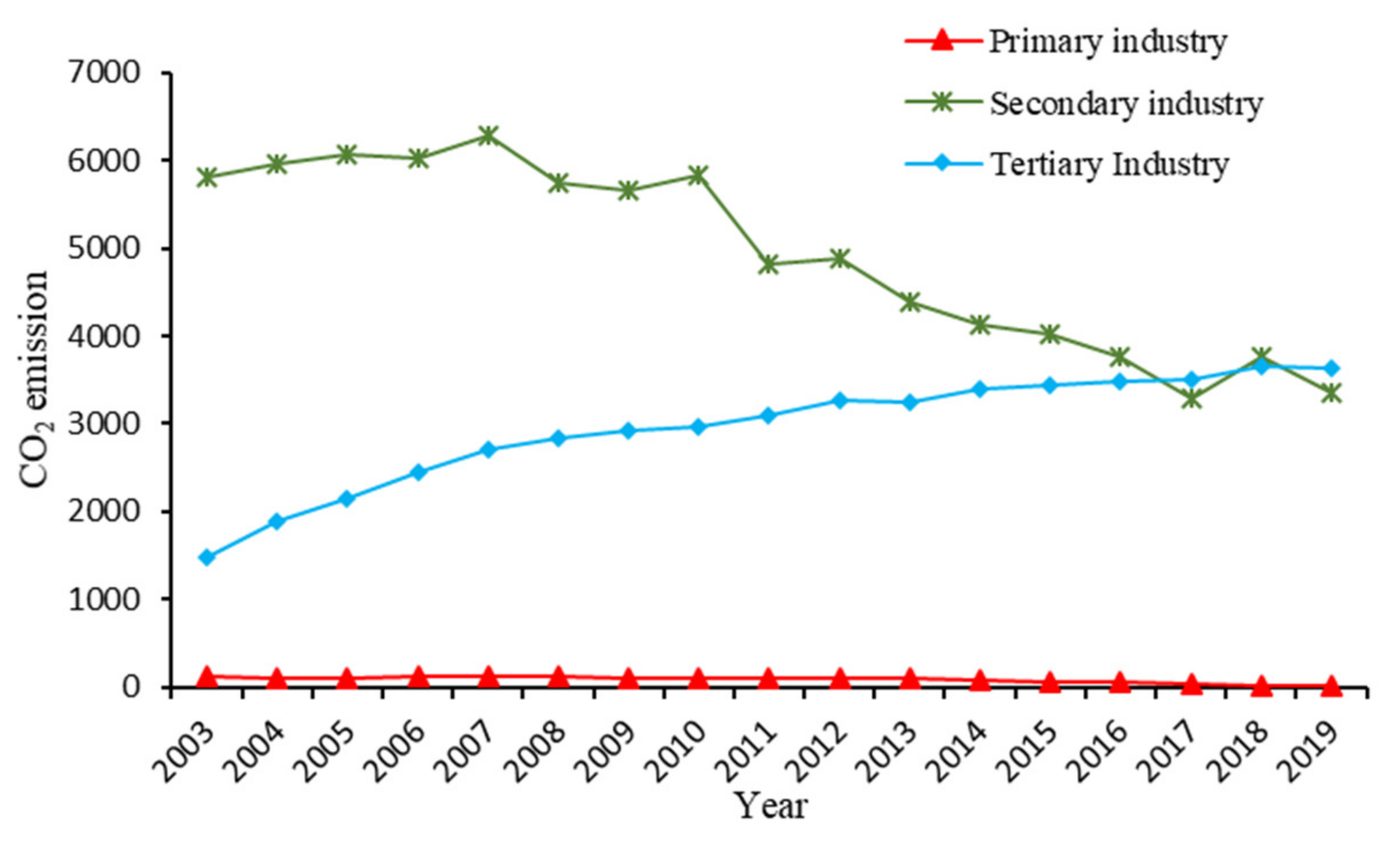
21] considered that improving the percentage of tertiary industry and decreasing the percentage of primary industry and secondary industries are beneficial for improving total factor carbon emission efficiency and energy efficiency utilization.
Furthermore, reasonable prediction of carbon emission levels is an essential reference basis for optimizing carbon emission reduction measures. Some scholars used the nonlinear multivariate grey model [
22], random forest model [
23], machine learning algorithms [
24], and deep neural networks [
25] to predict and analyze the carbon emission levels of different regions and departments. Additional research has investigated the decomposition of influencing factors of carbon emission [
26,
27]. However, few studies predicted carbon dioxide emission by combining the GM (1,1) model with the backpropagation (BP) neural network model and analyzing the influencing factors of carbon emission using the threshold model in Beijing.
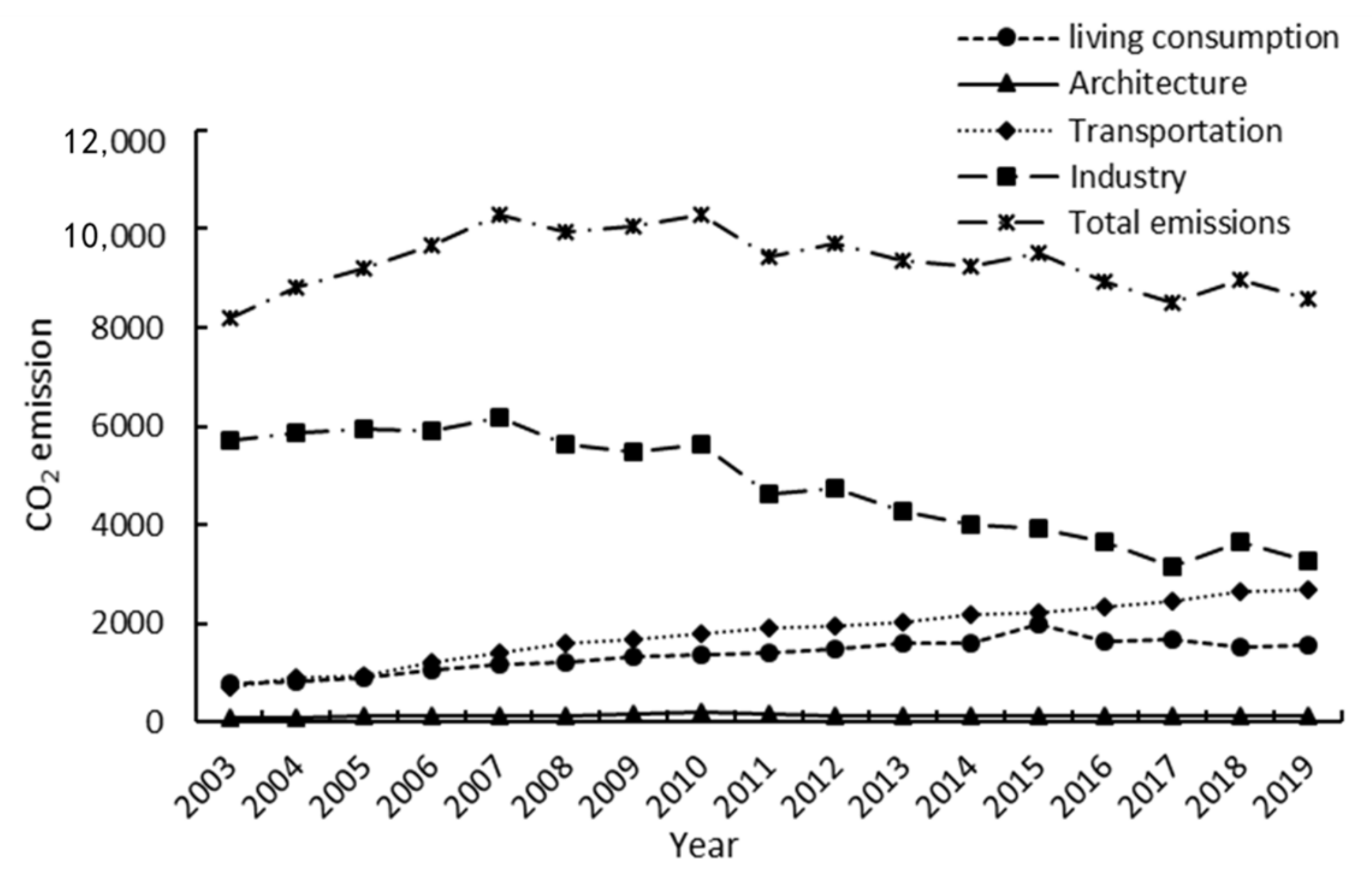
This paper calculates carbon emissions of the sub-sector in Beijing, analyzes carbon emission characteristics, makes a time series dynamic prediction of carbon emission levels before 2030 using the grey GM (1,1) model and BP neural network model, and examines the factors of carbon emission using the threshold model. Based on the results, several suggestions for carbon emission reduction are put forward. A single prediction method may have a consistent trend in the predicted results, leading to the possibility of inaccurate results. To avoid the shortcomings of single method prediction, this study considers the advantages and disadvantages of the GM (1,1) model and BP neural network model and combines these two methods to predict carbon emissions, which can ensure the prediction results are more reliable. For the advanced analysis of the impact of the economic development level on carbon emissions, we introduced the level of technological development as a threshold value. We not only observed the changes in carbon emissions under the influence of a single factor but also effectively analyzed the impact of control variables included in the extended STRPAT model on carbon emissions. This paper studies carbon emission reduction from the perspectives of carbon emission prediction and influencing factors, thereby providing effective support for carbon emission reduction work.
2. Model and Methodology
2.1. GM (1,1) Grey Prediction Model
The grey model is simple and capable of better handling sudden parameter changes without many data points for prediction updates [
28]. The GM (1,1) model, the basic model of the grey prediction model, is a prediction method with a small amount of data and is suitable for uncertain systems [
29]. Compared with other prediction models, the advantage of the GM (1,1) model is that it only requires a small sample size, at least four data values, to summarize the rules of the original data and to predict the values. Additionally, the GM (1,1) model can make accurate predictions for monotonic processes [
30]. It is widely used in predicting energy consumption [
31], greenhouse gas emissions [
32], Novel Coronavirus [
33], air pollution [
34], and other fields. This paper applies the GM (1,1) model to predict carbon dioxide emissions in Beijing. The sample size is fully suitable for the data requirements of this model. The prediction results based on the GM (1,1) model are more accurate than those based on the complex network prediction model, which requires larger samples.
The modeling process is as follows:
Set the original data as:
The formula satisfies the condition of , K = 1, 2, …N.
Conduct an accumulation calculation to obtain:
Suppose
satisfies the first-order ordinary differential equation:
is a constant.
The discrete value of equally spaced sampling is:
At this time, the condition t is satisfied, , and the and values are estimated by the least square method.
Because the calculation of
involves the two time values of
, the mean value of the two nodes before and after is taken for the calculation. Therefore, based on the original sequence
and the accumulated sequence
, the average sequence is calculated as follows:
The data matrix is constructed as follows:
Therefore, the matrix form is as follows:
By calculating the values of and , and bringing the calculated values into Formula (7), we successively calculate the fitting value when K = 1, 2, …N − 1 and the predicted value when K is greater than or equal to n.
Regardless of whether the data before the construction of the model can carry out high-precision GM (1,1), prediction requires testing. Generally,
is subject to the level ratio test. It is considered that
can be used for GM (1,1) modeling and prediction if the following conditions are met
The prediction results of the model should also be tested accordingly, and the posterior error test should be adopted.
is the mean of
. The variance of
is as follows:
is the residual and
is the residual’s mean value. The variance of the residual between the actual value and the fitted value of
is as follows:
The ratio of calculated posterior error is as follows:
The small error probability values are as follows:
The prediction accuracy is comprehensively evaluated according to the actual calculation data and the accuracy standard. The accuracy of the forecast is higher when is smaller, and is larger.
2.2. BP Neural Network Model
Artificial neural networks appeared in the middle of the 19th century and were widely used after 1940. Backpropagation (BP) neural networks, one of the most popular artificial neural network models, are neural networks that simulate the structure and thinking modes of the human brain. They are utilized extensively in a variety of domains, including nano samples volume determination [
35], nonlinear fitting [
36], management system construction [
37], data mining [
38], and other fields. The BP algorithm is an error back propagation network learning algorithm proposed by Rumelhart and McClelland [
39]. The BP neural network is a perception that uses the BP algorithm to adjust weights. It contains two procedures known as forward signal transmission and reverse error propagation. The structure of the general BP neural network prediction model is shown in
Figure 1. m, n, and i represent the number of layers, respectively, and X and Z represent the input and output of data.
2.3. Carbon Emissions Drivers Model Construction
The IPAT model of environmental pressure regulation was first suggested by Ehrlich and Holdren [
40], and the precise formula is as follows:
I is the interpreted variable, indicating the environmental impact. P is population impact, A is the degree of affluence, and T is the technical influence factor.
Richard and Eugene [
41] proposed the environmental impact assessment model (STIRPAT) and incorporated the elasticity coefficient to examine the effects of each driving element on the environment in order to solve the shortcomings of the model that is too simple. The precise formula is written as follows:
where
a is the model coefficient;
b,
c, and
d depict the indices of variables
P,
A, and
T;
ε is the model error term.
The model is improved and expanded to be applied to the analysis of driving factors of carbon emissions, and relevant indicators of natural factors and traffic structure are added. The formula is as follows:
where
H and
L represent specific indicators of natural factors and traffic structure, respectively; f and g represent their indices.
The STIRPAT model is a nonlinear model with multiple driving factors and generally analyzes the logarithm of the formula data. Therefore, the driving factors selected according to the model can be effectively applied to the threshold regression model. The approach of merging the extended environmental impact assessment model with the threshold model is used to examine the influence relationship of each driving element on carbon emissions in order to effectively identify the variables that cause carbon dioxide emissions.
The threshold effect refers to a variable indicator reaching a specific value and causing a shift in the relationship between other variable indices. Hansen’s panel threshold model [
42] endogenously divides the intervals according to the data’s characteristics and finds the threshold values, which can effectively avoid the bias caused by artificially divided sample intervals or quadratic term models. Its advantage is that it can assess the existence of a threshold feature, determine the precise threshold value, and perform a significant test on the threshold effect.
We use the technology level at various stages as the threshold variable to examine the nonlinear relationship between the level of economic development of the core explanatory variable and the carbon emissions of the explained variable. The multiple threshold model is constructed by logarithmic processing of data, as shown in the formula:
t is the year,
s is the number of threshold values,
I(.) is the indicative function,
γ is the threshold, and
ε is the random disturbances. x
1 is the core explanatory variable; x
i is the control variable. The value of
i is 1 to
N.
N is the number of control variables.
3. Data Description
To calculate carbon dioxide emissions in Beijing, this paper adopts the carbon dioxide data provided by Guan [
43] and Shan [
44] (
https://www.ceads.net/data/province/ (accessed on 20 March 2023)) and combines the IPCC national greenhouse gas guidelines method. We mainly focus on the carbon dioxide emission from the primary energy of raw coal, coke, crude oil, fuel oil, gasoline, kerosene, diesel, natural gas, and liquefied petroleum gas. The data come from the Beijing Statistical Yearbook from 2004 to 2020. The following is the calculation formula for total carbon dioxide emissions from primary energy combustion:
where
EC stands for carbon emissions,
ECi represents the carbon emission of the
ith energy source, and
Ei represents the
ith energy consumption.
CGi represents the low calorific value of the ith energy source,
CCi stands for carbon content per unit calorific value, and
COFi indicates the carbon oxidation factor.
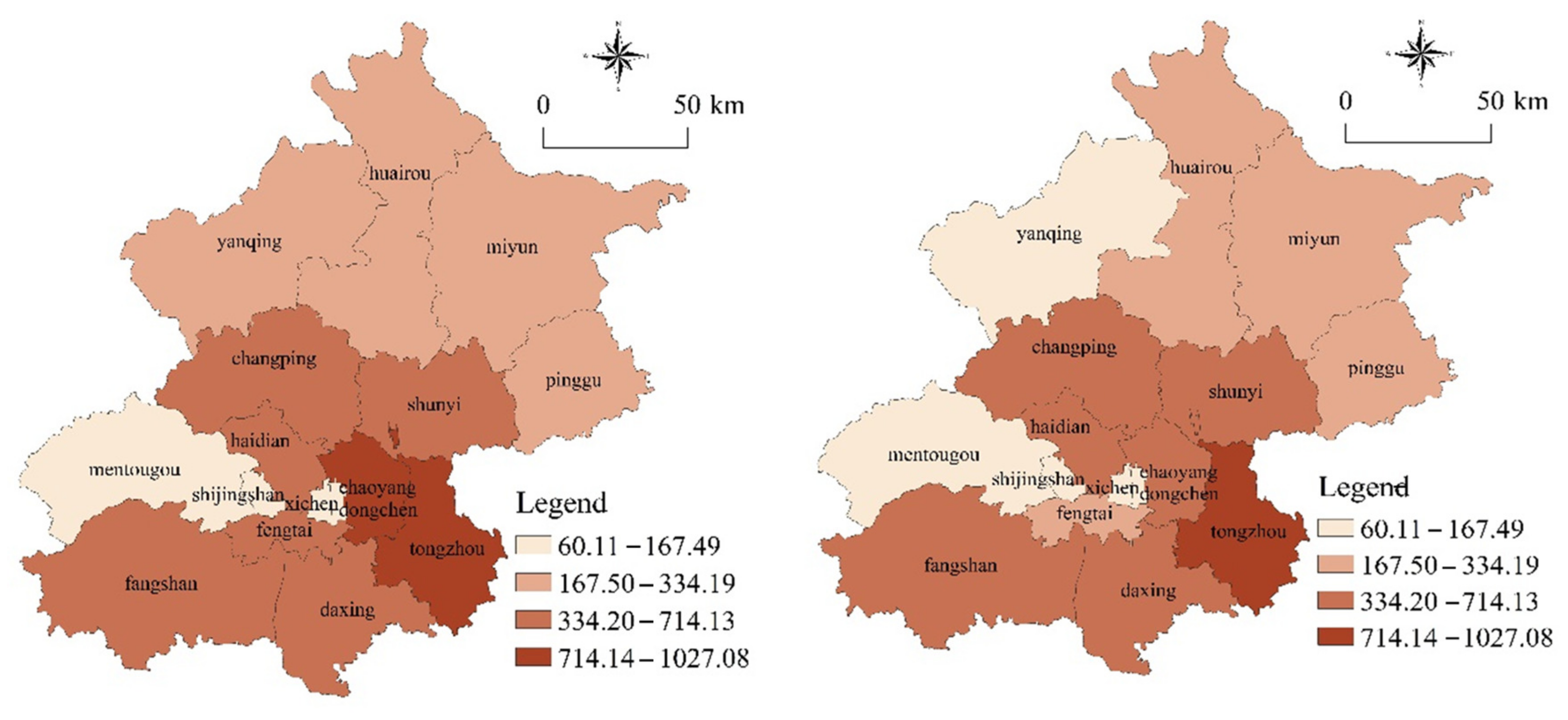
The carbon dioxide emissions of 16 districts in Beijing were calculated. Considering the availability of data, we selected carbon dioxide emissions during the period of 2003 and 2017 to further observe the temporal variation characteristics of carbon dioxide emissions in various districts, as shown in
Figure 2.
Figure 2 demonstrates that the carbon dioxide emissions in Chaoyang District, Yanqing County, and Fengtai District in 2017 were much lower than those in 2003, indicating the significant progress made in energy saving and emission reduction.
5. Discussion
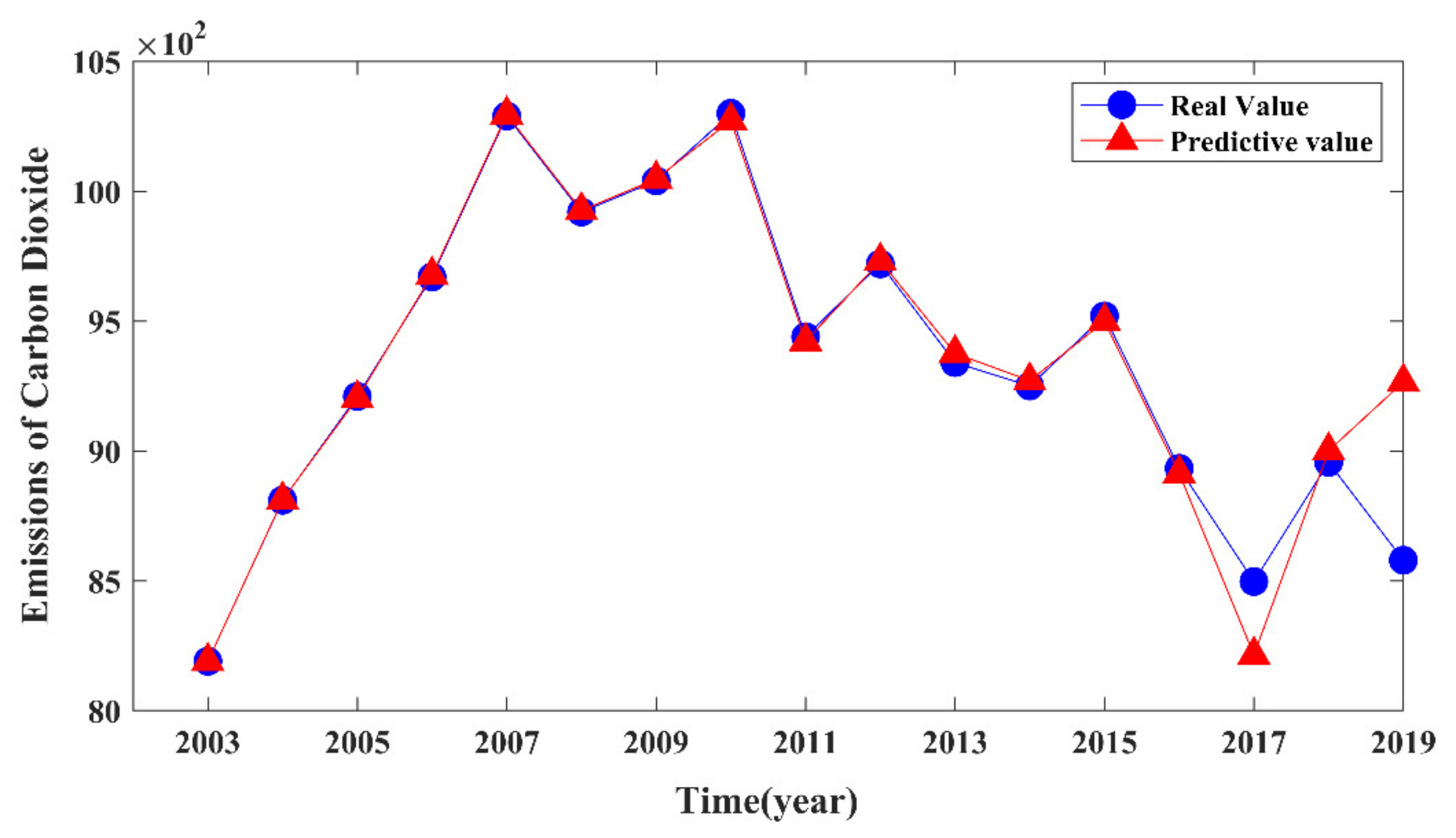
According to the predicted analysis results, it can be verified that the GM (1,1) model can be used to predict with scanty amounts of imperfect data and be appropriated for data prediction with clear trends. It can be used for short-term forecasting activities. This finding is consistent with previous studies [
47]. The BP neural network model can effectively analyze nonlinear data samples by constructing a parallel interconnected network composed of multiple nonlinear simple units. This backpropagation algorithm aims to enhance the connectivity between layers to obtain optimal results [
48]. Therefore, it is necessary to combine the BP neural network advantages in nonlinear quantitative analysis of data with the characteristics of the GM (1,1) model of research on carbon emission prediction trends. Based on the two prediction results, the carbon emission prediction trend can be described.
From the regression results in
Table 5, it can be seen that Beijing’s carbon dioxide emissions can be reduced in proportion to a decrease in energy intensity. This finding is in line with the studies of Chen et al. [
49]. In Beijing, carbon emissions can be reduced by improving the technical level and rationally planning the traffic structure. Similarly, Awan et al. [
50] and Sun et al. [
51] demonstrated that technological innovation is beneficial for reducing carbon dioxide emissions from a variety of sectors. High-quality economic development can also accelerate the reduction of carbon dioxide emissions, and scientifically expanding the area of urban green space can effectively increase carbon absorption in Beijing. The previous studies indicated that economic development promotes carbon dioxide emissions in selected Sub-Saharan African (SSA) countries [
52]. Although their research differs from the regions in this paper, the research results on the impact of economic growth on carbon emissions are similar. Then, the implementation mode of Beijing’s carbon emission reduction path is further explored from the aspect of threshold regression analysis of driving factors. Based on the above discussion, it can be concluded that the relevant research findings are not only applicable to the studied region but also provide a reference for the carbon reduction work of other regions and countries.
The limitations and improvements of this paper are mainly in the following aspects. First, we used the GM (1,1) model to predict carbon emissions. This model predicts current data, easily ignoring new information and failing to consider the impact of more factors. It also has certain requirements for data, which must be positive and have the same time interval. As for further work, we can improve the methods based on actual data to obtain more accurate forecast results. Second, we used data in Beijing for threshold regression analysis. In order to obtain reliable regression results, although we conducted repeated sampling of time series data, there may also be a problem of insufficient sample size. In future research, we can analyze the national data and form panel data for regression to make the research results more reliable. Third, due to the limitations in data availability, the studied factors affecting carbon emissions are limited. Thus, we should further develop and use different indicators in future research to fully analyze the influencing factors of carbon emissions reduction.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}