3.2. Feature Selection
The analysis initially focused on identifying potential multicollinearity among the meteorological variables within all three cities. Variables exhibiting a high degree of correlation, as defined by a threshold value exceeding ±0.8, were earmarked for exclusion. The derived correlation matrix, which outlines these correlations, is depicted in
Figure 5a. Subsequently, the feature selection was refined using random forest importance scores, with a preference for continuous meteorological variables. This step is summarized in
Figure 5b. Of the 17 assessed features, 6 were excluded to address multicollinearity concerns.
For the seven identified dust sources, a similar approach assessed the correlations among identical meteorological variables across different sources. The correlations among these features were visualized in heat maps: temperature correlations are shown in
Figure 6a, humidity in
Figure 6b, precipitation in
Figure 6c, and pressure in
Figure 6d. Wind speed and direction were excluded from the exclusion criteria applied to other variables due to their direct effect on dust events.
Subsequently, the random forest method was utilized to refine the feature selection, removing one feature from each pair with a high correlation. From the 28 features initially analyzed, 18 were excluded to eliminate multicollinearity, with a particular focus on temperature (DS2, DS3, DS4, DS5, DS6, and DS7), humidity (DS1, DS2, DS3, DS4, DS5, and DS6), and pressure (DS1, DS2, DS3, DS4, DS6, and DS7) features. The importance of each feature to dust storm frequency and the excluded features are highlighted in red in
Figure 6e.
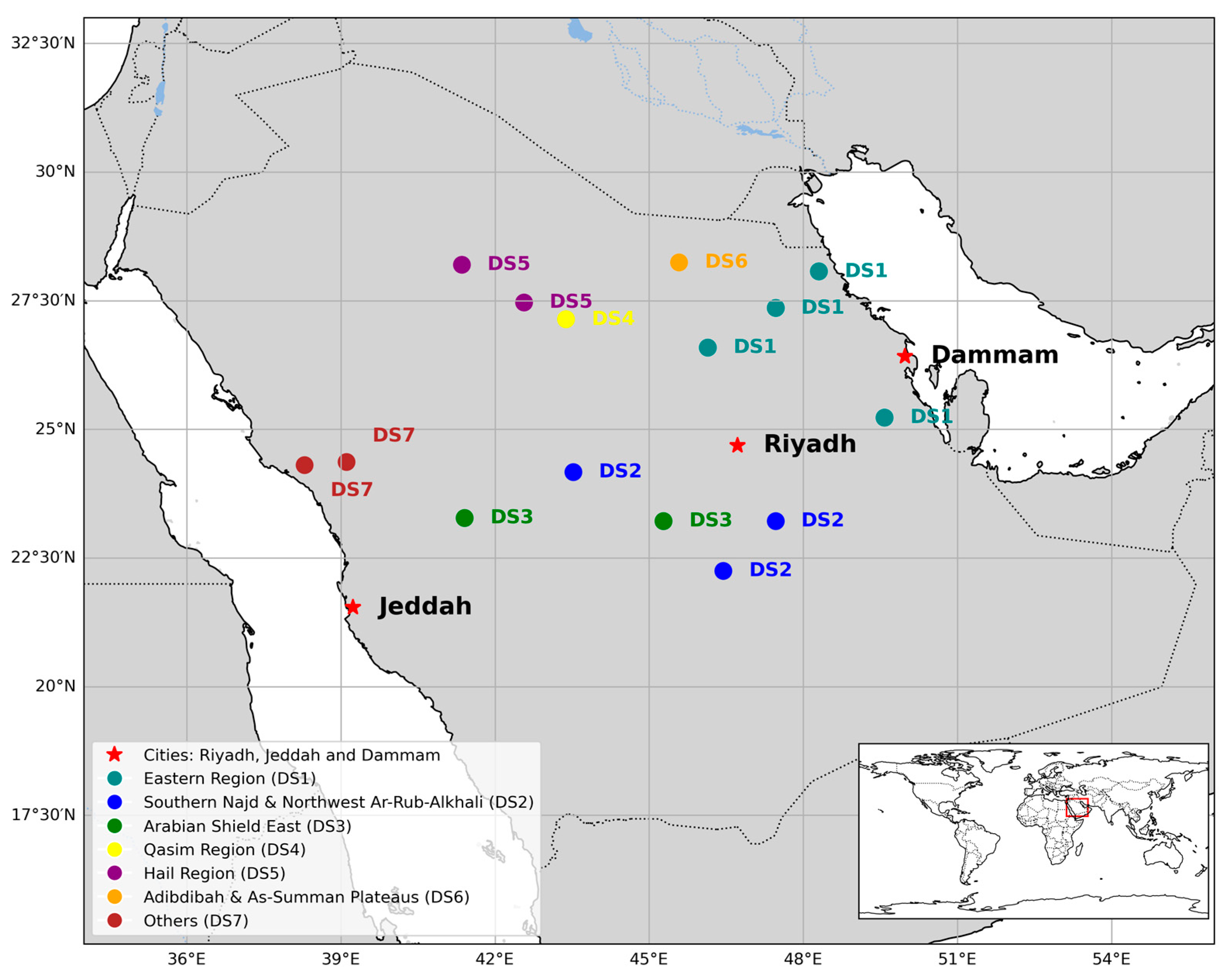
In our study on Riyadh, Jeddah, and Dammam, we included three land cover features representing distinct classes, while excluding land cover data for all dust source areas due to the assumed minimal variability. Instead, we focused on the meteorological and vegetative factors more related to dust emissions in these areas. Additionally, we incorporated features such as seasonal variations, wind directions, windy days, and the previous month’s dust storm frequency directly into our model, thereby bypassing the initial feature selection. Their impact was evaluated using the SHAP values in
Section 3.4. Ultimately, the features selected for the final model are detailed in
Table A1 (
Appendix A).
3.3. Comparison of the Results of Different Predicting Models
The comparative performance of the models employed to predict monthly dust storm frequency across three major cities in Saudi Arabia, Riyadh, Jeddah, and Dammam, is presented in
Table 6. The models evaluated include MLR, SVR, GBRT, LSTM, TCN, and a persistence method used as a baseline for comparison; the accuracy matrices used are MAE, RMSE, and R
2.
In Riyadh, which has more regular dust storm occurrences, the LSTM and TCN outperform traditional regression approaches, with R
2 values of 0.50 and 0.51, respectively, indicating that they capture the complex temporal patterns of dust storms in the region. The negative R
2 value for the persistence method suggests that this approach is insufficient for such dynamic weather events. For Jeddah, the task is more challenging, as indicated by the close performance metrics across the models. This complexity can be attributed to the coastal city’s variable climate, the influence of remote dust sources in Africa across the Red Sea [
6], and the less frequent nature of dust storms. The LSTM model exhibits the lowest MAE and RMSE values, indicating its effectiveness in capturing long-term temporal dependencies within the aggregated data. Dammam also shows that the LSTM model demonstrates the highest R
2 value of 0.64, suggesting a strong model fit. The models performed better in predicting dust storms for Riyadh due to the city’s more consistent and defined seasonal patterns, driven by its desert climate. The coastal climate and variable interactions in Jeddah and Dammam could introduce additional complexity in dust storm forecasting, thus affecting model accuracy.
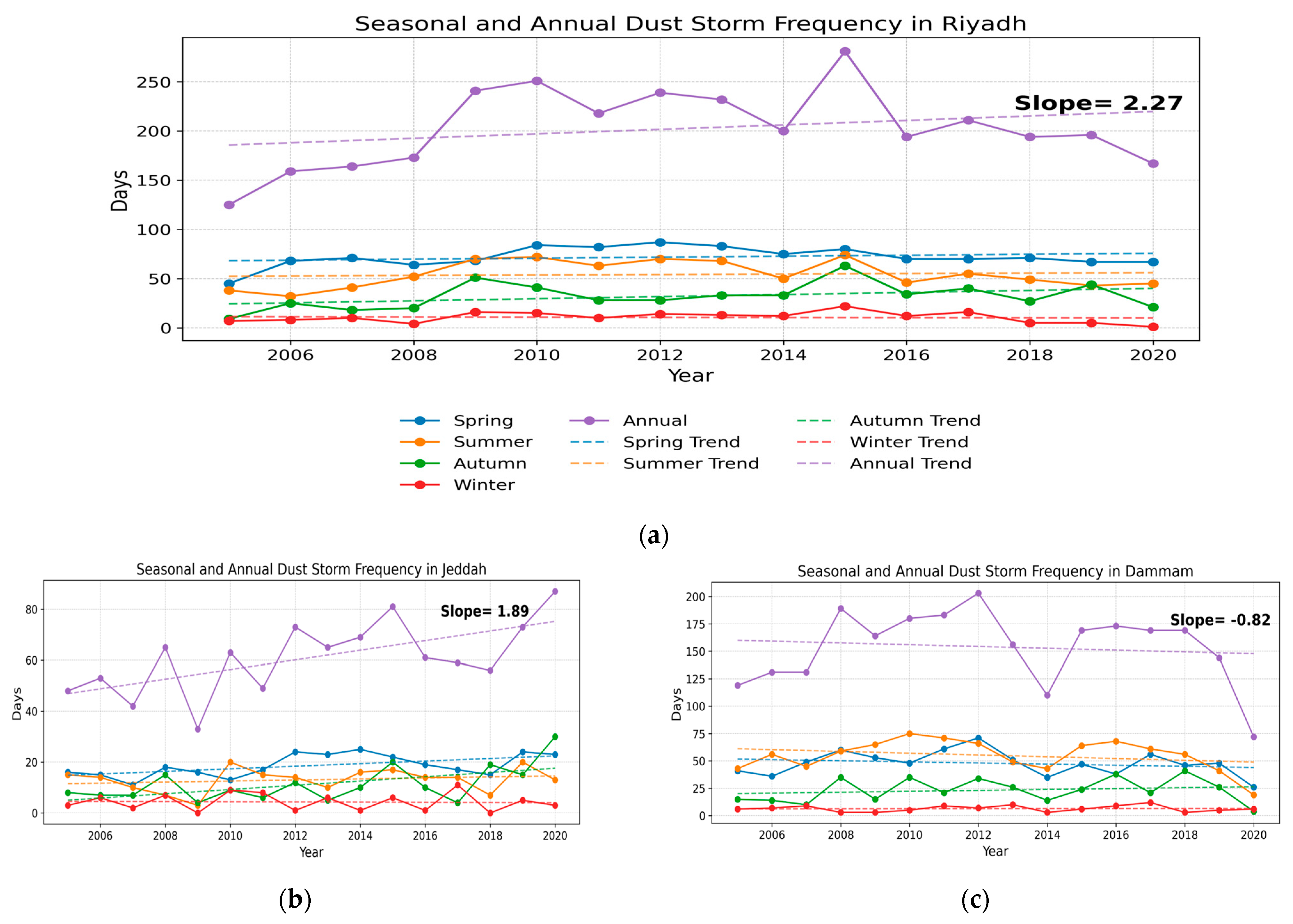
Plotting the actual dust storm frequencies against the predictions made by each model over the test period from June 2016 to November 2020 shows the variability in their predictive capabilities across different time frames.
Figure 7,
Figure 8 and
Figure 9 present the time series of actual dust storm frequencies alongside the corresponding predictions generated by each model over the test period from June 2016 to November 2020. The figures show the seasonal variations and annual trends, with peak frequencies observed during certain months, indicative of the cyclical nature of dust storm occurrences.
The LSTM model’s performance revealed a pattern of underestimating high-activity periods. In Riyadh (
Figure 7), notable underpredictions occurred in early 2017 and December 2018, with a significant shortfall in December 2018, when the actual frequency spiked. In Jeddah (
Figure 8), the LSTM fell short during unexpected events. Dammam (
Figure 9) shows a similar trend despite occasional accurate predictions. The LSTM model requires refinement to improve its accuracy during peak activity periods.
The TCN model shows varied accuracy for predicting dust storm frequencies in Riyadh, Jeddah, and Dammam. In Riyadh, it closely captured higher-frequency events but tended to slightly overestimate them during other times, such as late 2019 and 2020. In Jeddah, the TCN model consistently underestimated the dust storm frequency, particularly in high-activity months (e.g., January and August 2020), indicating that it might not fully detect sudden spikes in dust storm activity. Dammam experienced similar underestimation issues with the TCN model, especially during peak periods. However, an exception occurred in 2020, which was a year marked by unusually lower activity, where the model tended to overestimate the frequency, highlighting a reversal in the trend of underestimation seen in other periods and cities.
The SVR model tended to overestimate Riyadh dust storm occurrences, particularly in periods of lower dust storm activity, as observed in late 2018 and early 2019. This suggests a bias in the model toward higher frequency predictions during periods of low activity. Conversely, in Jeddah, the SVR model consistently underestimated actual dust storm frequencies, notably during high-activity periods, such as August 2020, when it predicted significantly fewer storms than what occurred. This pattern of underestimation extends to Dammam, where the model similarly undervalued dust storm frequencies across various periods.
By contrast, the GBRT model demonstrated significant adaptability and responsiveness to changes. In Riyadh, the GBRT aligned with the actual dust storm frequency, accurately capturing the spike in December 2018 and the high-activity trends of early 2019; thus, these findings are consistent with the efficacy of the gradient-boosting techniques highlighted in previous studies [
21,
22,
34]. In Jeddah, GBRT showcased an improved predictive capability, closely matching the actual frequencies in instances such as February and March 2020. However, it struggled with sudden increases in activity, similar to the SVR model, as seen in August 2020. Dammam’s results align with those of other cities, with its predictions closely matching actual occurrences, thereby demonstrating its capability to capture trends and peaks. This performance across the cities underscores GBRT’s potential in environmental forecasting, especially in capturing sudden events.
The MLR model’s performance varied, with a general tendency toward overprediction in some instances and underprediction in others. This variability underscores the challenges linear models face in capturing the complex, non-linear dynamics of dust storms. The predictions have a consistent pattern of overestimation across the entire period for Riyadh and Jeddah. Conversely, Dammam shows better results, but they still include underprediction and overprediction, reflecting MLR’s struggle with the complex factors driving dust storms. For that, the non-linear models (e.g., GBRT, TCN) provide a better fit.
Among the models analyzed, the GBRT and TCN models stand out for their precision in capturing high-frequency dust storm events. The TCN model exhibited a slight edge in accurately mirroring the actual data, particularly in forecasting the magnitude of the activity peaks. The LSTM model, while providing a smoother predictive curve, and the SVR model, with its conservative estimations, offered valuable insights into the trade-offs between capturing long-term trends and responding to immediate changes in dust storm activity.
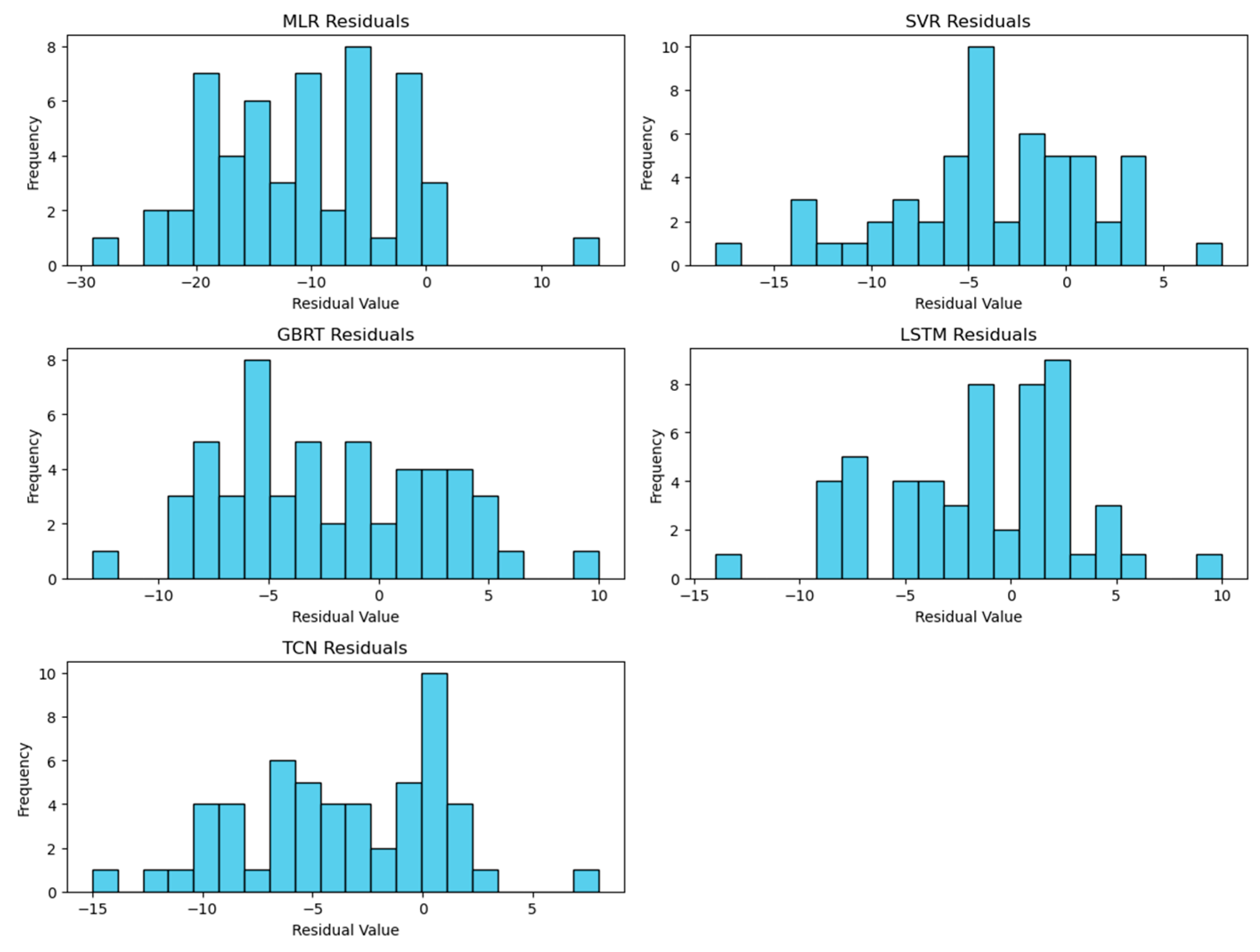
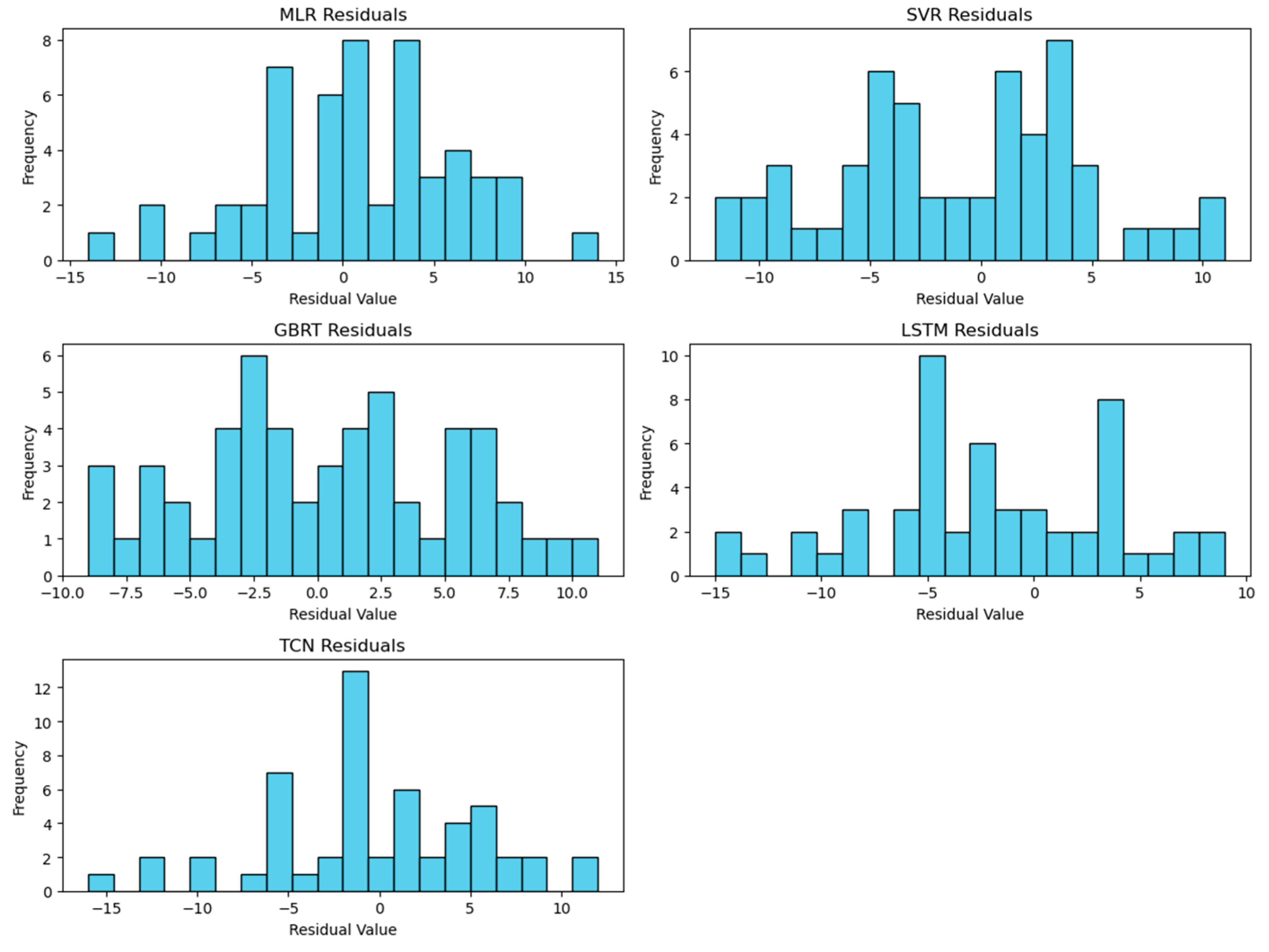
The residuals for the LSTM and TCN models for Riyadh are presented in
Figure 10, illustrating their predictive accuracy and error distributions. A complete set of residual visualizations across all evaluated models for all cities is in
Appendix A,
Figure A1,
Figure A2 and
Figure A3.
The residuals (i.e., the differences between the observed and prediction values) in
Figure 10 highlight a generally low distribution, affirming their efficacy in accurately predicting dust storm occurrences for most of the evaluated period. However, the LSTM model shows a slightly broader range of positive residuals, which suggests instances in which it underpredicted actual events more so than the TCN model.
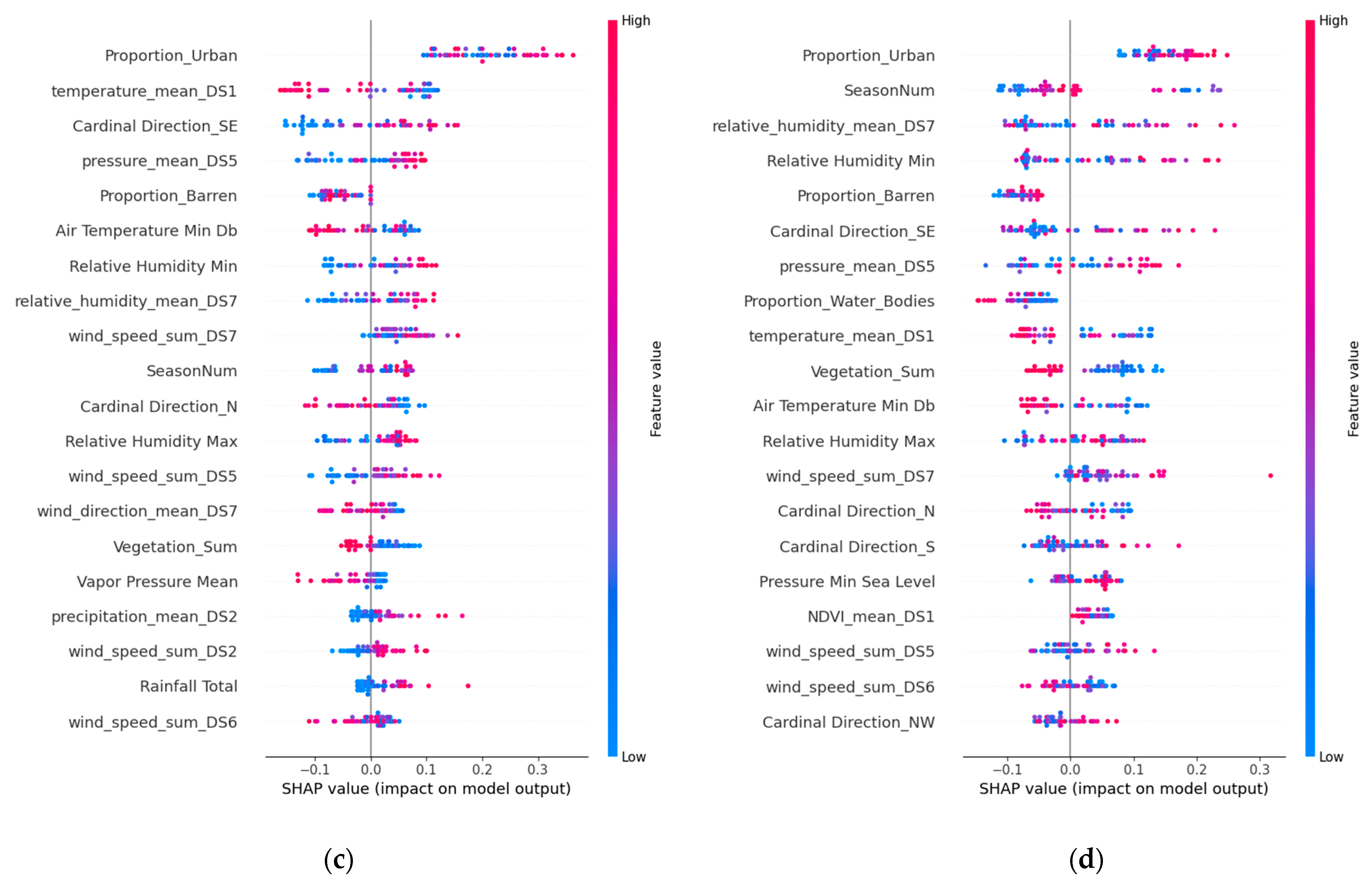
3.4. Assessing Feature Contributions Using SHAP Values
SHAP values help quantify the importance of various predictors in various models, such as SVR, GBRT, LSTM, and TCN (but excluding MLR due to its low performance). We aimed to understand how environmental features and specific dust sources affect model predictions. Among 62 predictors for forecasting dust storms, the top 20 were identified as significant. In
Figure 11,
Figure 12 and
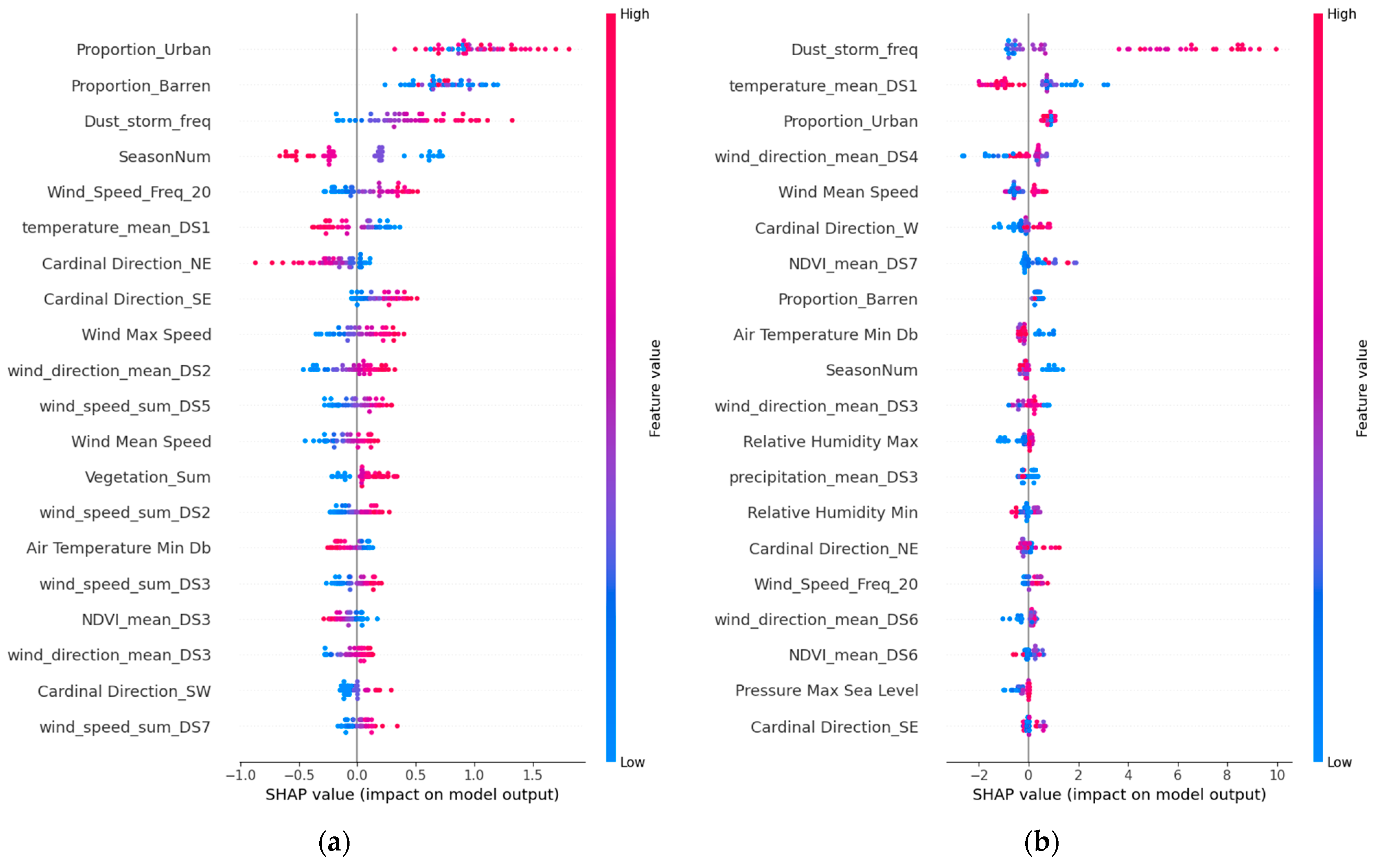
Figure 13, which analyze these predictors for Riyadh, Jeddah, and Dammam, the red dots indicate higher feature values, while the blue dots have lower values. Their position on the SHAP value axis reveals whether these features positively or negatively affected the predictions. This analysis shows the intricate relationships among the meteorological, urban, and vegetation factors in dust storm dynamics across the three cities.
Seasonal variations, denoted as “SeasonNum”, highlight the temporal variability in dust storm occurrences, suggesting that seasonal shifts in wind patterns are critical in initiating and transporting dust storms.
In Riyadh (
Figure 10), the meteorological conditions and specific wind patterns from dust sources notably affect dust storm frequency. Features like “Air Temperature Min” (e.g., SHAP value: 0.33 in GBRT), specific wind directions, such as “NE” and “SE”, and wind directions from specific dust sources, such as “wind_direction_mean_DS4” (SHAP value: 0.66) and “wind_direction_mean_DS3” (SHAP value: 0.30) in GBRT, are pivotal. The wind speed, particularly the “Wind Mean Speed” and “Wind_Speed_Freq_20,” with SHAP values of 0.47 and 0.23, respectively, in GBRT, plays a significant role in prediction. The “wind_speed_sum_DS” feature, which is the sum of windy days with more than 20 km/h for areas like DS2, DS3, and DS6, especially in the TCN model, underlines the influence of wind speeds from these sources on dust storm occurrences.
Jeddah’s analysis (
Figure 11) points to the significant roles of wind characteristics, including speed (“Wind Mean Speed”, with a SHAP value of 0.201 in GBRT) and wind direction from dust sources (“wind_direction_mean_DS5” at 0.314 and “wind_direction_mean_DS7” at 0.291 in GBRT), as crucial in influencing dust patterns. The SVR, LSTM and TCN models also reflect the importance of these factors, although they have varying degrees of impact, indicating a complex interplay among the factors.
Meteorological and wind-related factors similarly influenced Dammam’s pattern (
Figure 12). The key features include “Air Temperature Min” with a SHAP value of 0.33 in the GBRT model. Wind direction in dust sources, particularly “wind_direction_mean_DS2” (0.66 SHAP value) and “wind_direction_mean_DS3” (0.30 SHAP value), in the GBRT model. Wind speed factors like “Wind Mean Speed” (0.47 SHAP value) and “Wind_Speed_Freq_20” (0.23 SHAP value) also play a critical role in the prediction output.
The analyses of Riyadh, Jeddah, and Dammam also emphasize the impact of the relative humidity, precipitation, and urban and barren lands on dust activity. Urban areas, particularly in Riyadh and Jeddah, alongside barren lands, significantly affect dust storm dynamics. These findings highlight the complex influences of environmental, urban, and vegetative factors on dust storm patterns, underscoring the importance of integrating these elements into predictive models for effective forecasting and mitigation strategies. The greatest impact on urban areas was observed in the SVR model for Riyadh (SHAP value: 1.02) and barren areas in the GBRT model (SHAP value: 0.75), highlighting the critical roles of urbanization and land surface conditions in influencing dust storm occurrences. A previous study [
5] identified urbanization as a key driver of changing dust storm patterns in Saudi Arabia, supporting our findings regarding the need to consider urban expansion and natural land conditions in dust storm frequency analysis. Further support for the influence of barren areas on dust storm activity in the study by [
17] corroborates our findings by showing how drying wetlands and expanding barren lands amplify dust occurrence.
The vegetation dynamics offer contrasting insights. The “Vegetation_Sum” feature, which includes croplands, herbaceous areas, and shrublands, shows a positive correlation with dust storm frequency in our models for Riyadh, with the highest SHAP value observed in the GBRT model (SHAP value: 0.80). This suggests that areas with heavier vegetation, potentially reflecting intensive agricultural activities on cropland, may contribute to dust storm occurrences, likely due to soil disturbance and reduced soil moisture, which turn these areas into dust sources, as reported previously [
53]. Conversely, the “NDVI_mean” feature demonstrates a negative correlation with dust storm frequency, indicating that increased vegetation health and density, as captured by higher NDVI values, can mitigate dust storm activity. The greatest negative impact of the NDVI on dust storm frequency was observed in the GBRT model for Jeddah (SHAP value: −0.64), suggesting that healthier vegetation cover plays a crucial role in stabilizing soils and reducing dust emissions. Therefore, the health and density of vegetation within identified dust source areas, such as “NDVI_mean_DS7” and “NDVI_mean_DS3”, inversely affect dust storm frequency. Similarly, for Dammam, GBRT underscores NDVI_mean_DS3 with a SHAP value of 0.49 and NDVI_mean_DS1 with a SHAP value of 0.23, suggesting NDVI’s substantial role, as mentioned in [
54,
55].
This analysis explains the complex interplay between meteorological, environmental conditions, urbanization, and dust sources that influence dust storm frequency. It underscores the need for integrated dust storm management strategies that consider urban planning, vegetation cover enhancement, and targeted mitigation efforts based on seasonal and meteorological factors.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















