1. Introduction
Data assimilation (DA) is a complex process that involves combining information from different sources in order to produce accurate estimates of the true state of a physical system such as the atmosphere. Sources of information include computational models of the system, a background probability distribution, and observations collected at discrete time instances. With model state denoted by the prior probability density encapsulates the knowledge about the system state before incorporating any other source of information such as the observations. Let be a measurement (observation) vector. The observation likelihood function quantifies the mismatch between the model predictions (of observed quantities) and the collected measurements. A standard application of Bayes’ theorem provides the posterior probability distribution that provides an improved description of the unknown true state of the system of interest.
In the ideal case where the underlying probability distributions are Gaussian, the model dynamics is linear, and the observations are linearly related to the model state, the posterior can be obtained analytically for example by applying Kalman filter (KF) Equations [
1,
2]. For large dimensional problems the computational cost of the standard Kalman filter is prohibitive, and in practice the probability distributions are approximated using small ensembles. The ensemble-based approximation has led to the ensemble Kalman filter (EnKF) family of methods [
3,
4,
5,
6]. Several modifications of EnKF, for example [
7,
8,
9,
10,
11,
12], have been introduced in the literature to solve practical DA problems of different complexities.
One of the drawbacks of the EnKF family is the reliance on an ensemble update formula that comes from the linear Gaussian theory. Several approaches have been proposed in the literature to alleviate the limitations of the Gaussian assumptions. The maximum likelihood ensemble filter (MLEF) [
13,
14,
15] computes the maximum a posteriori estimate of the state in the ensemble space. The iterative EnKF [
10,
16] (IEnKF) extends MLEF to handle nonlinearity in models as well as in observations. IEnKF, however, assumes that the underlying probability distributions are Gaussian and the analysis state is best estimated by the posterior mode.
These families of filters can generally be tuned (e.g., using inflation and localization) for optimal performance on the problem at hand. However, if the posterior is a multimodal distribution, these filters are expected to diverge, or at best capture a single probability mode, especially in the case of long-term forecasts. Only a small number of filtering methodologies designed to work in the presence of highly non-Gaussian errors are available, and their efficiency with realistic models is yet to be established. These promising methods can be classified into two classes, particle filtering, and MCMC sampling. In this work, we focus on using MCMC to sample the posterior distribution.
The Hybrid/Hamiltonian Monte Carlo (HMC) sampling filter was proposed in [
17] as a fully non-Gaussian filtering algorithm, and has been extended to the four-dimensional (smoothing) setting in [
17,
18,
19,
20]. The HMC sampling filter is a sequential DA filtering scheme that works by directly sampling the posterior probability distribution via an HMC approach [
21,
22]. The HMC filter is designed to handle cases where the underlying probability distributions are non-Gaussian. Nevertheless, the first HMC formulation presented in [
17] assumes that the prior distribution can always be approximated by a Gaussian distribution. This assumption was introduced for simplicity of implementation; however, it can be too restrictive in many cases, and may lead to inaccurate conclusions. This strong assumption needs to be relaxed in order to accurately sample from the true posterior, while preserving computational efficiency.
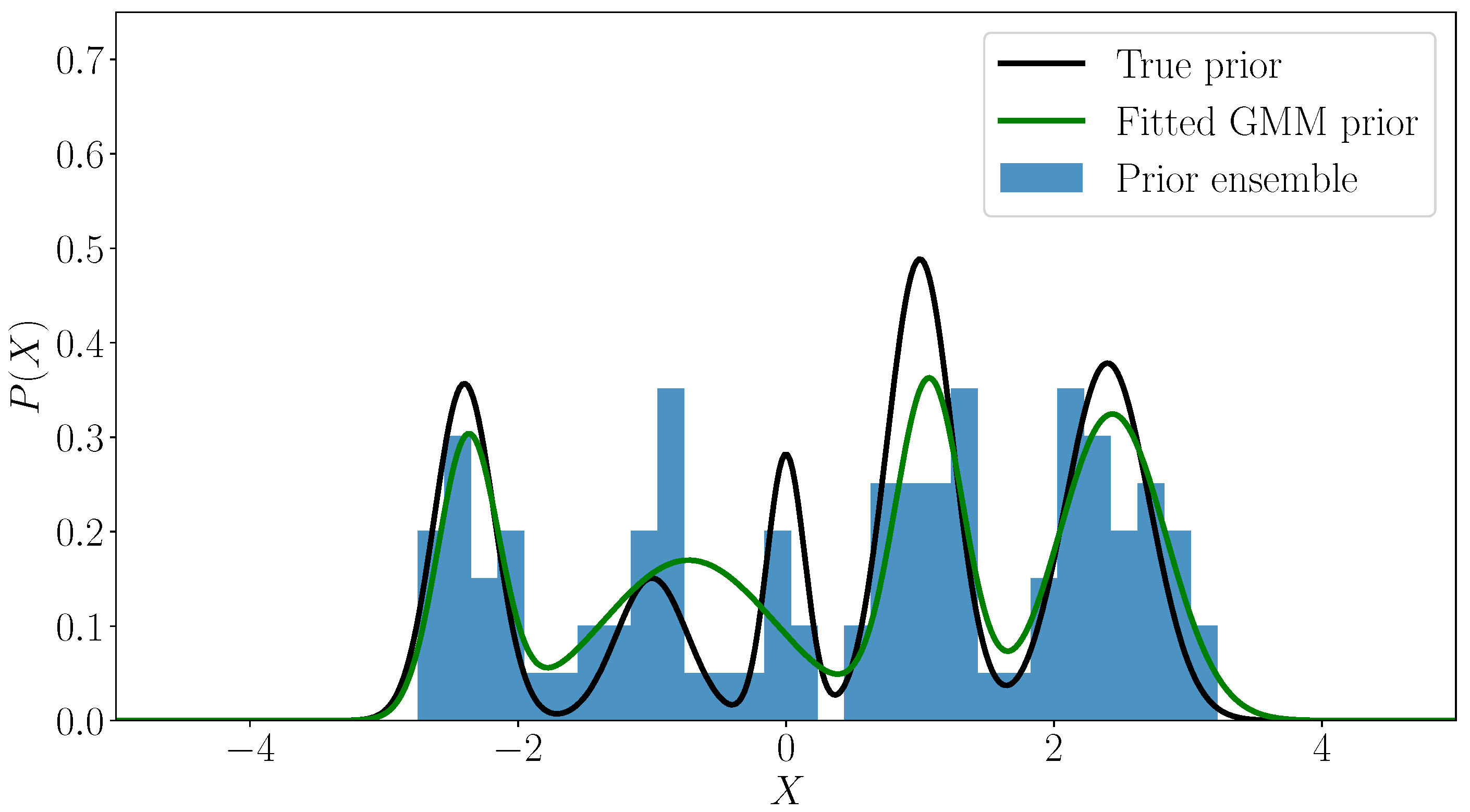
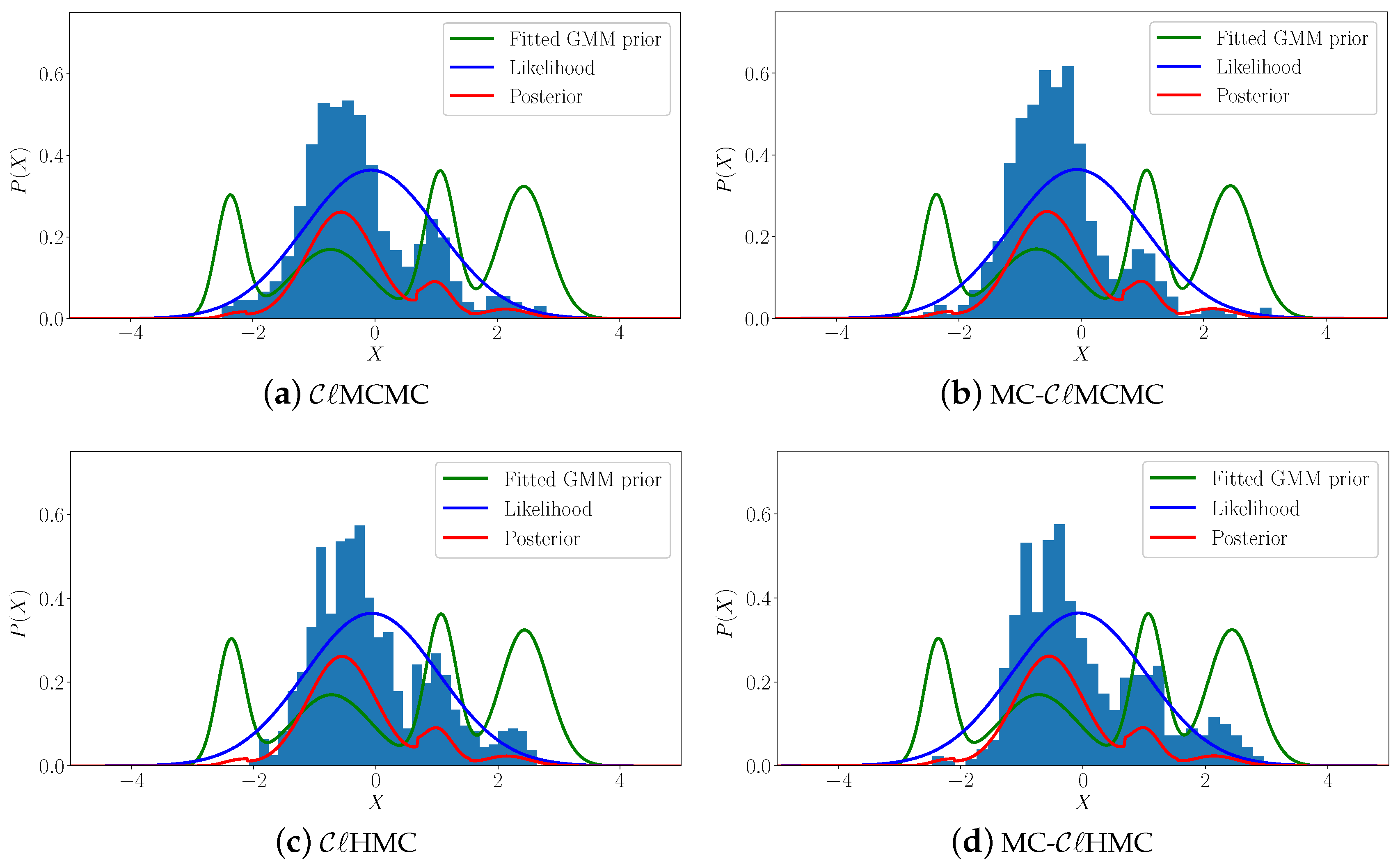
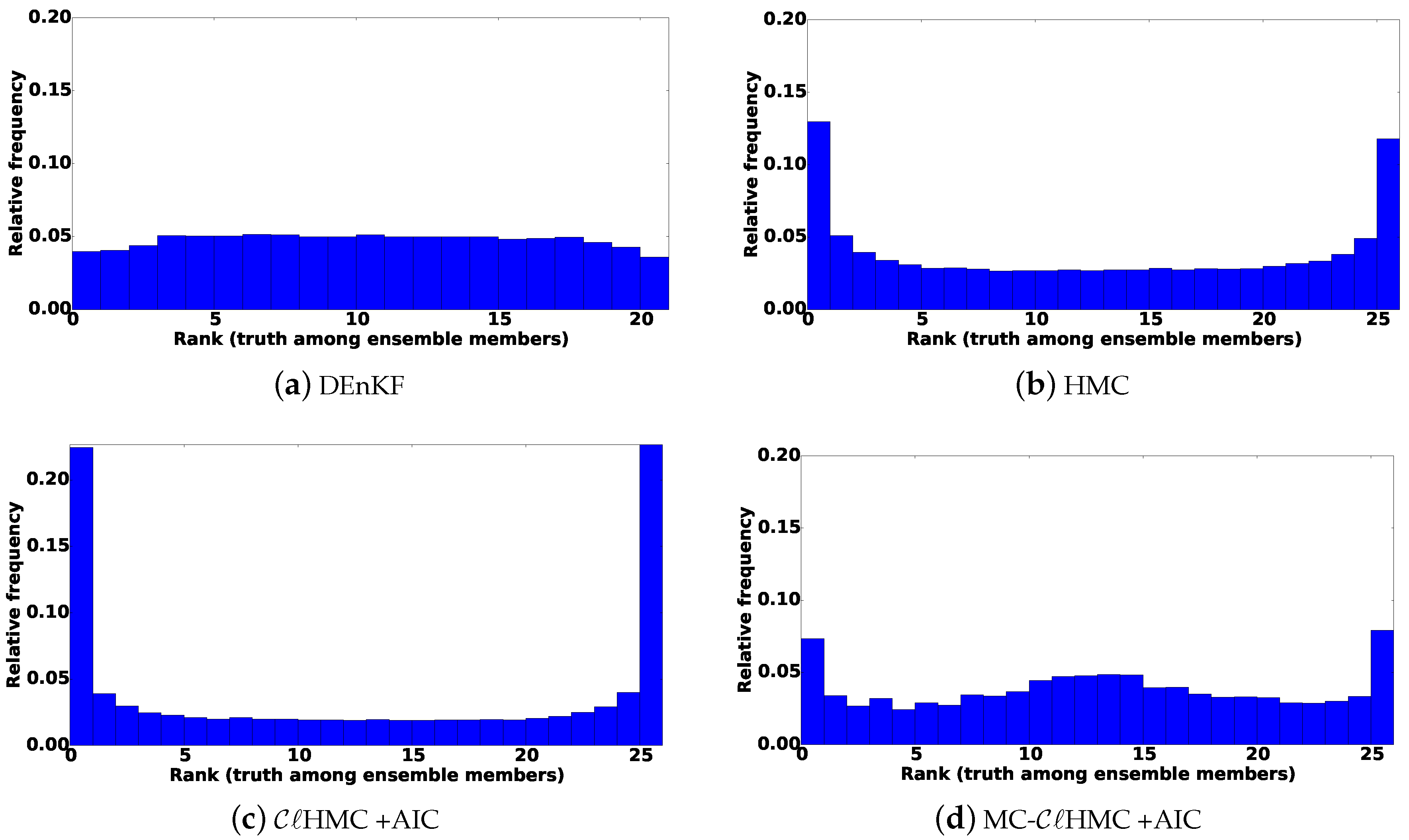
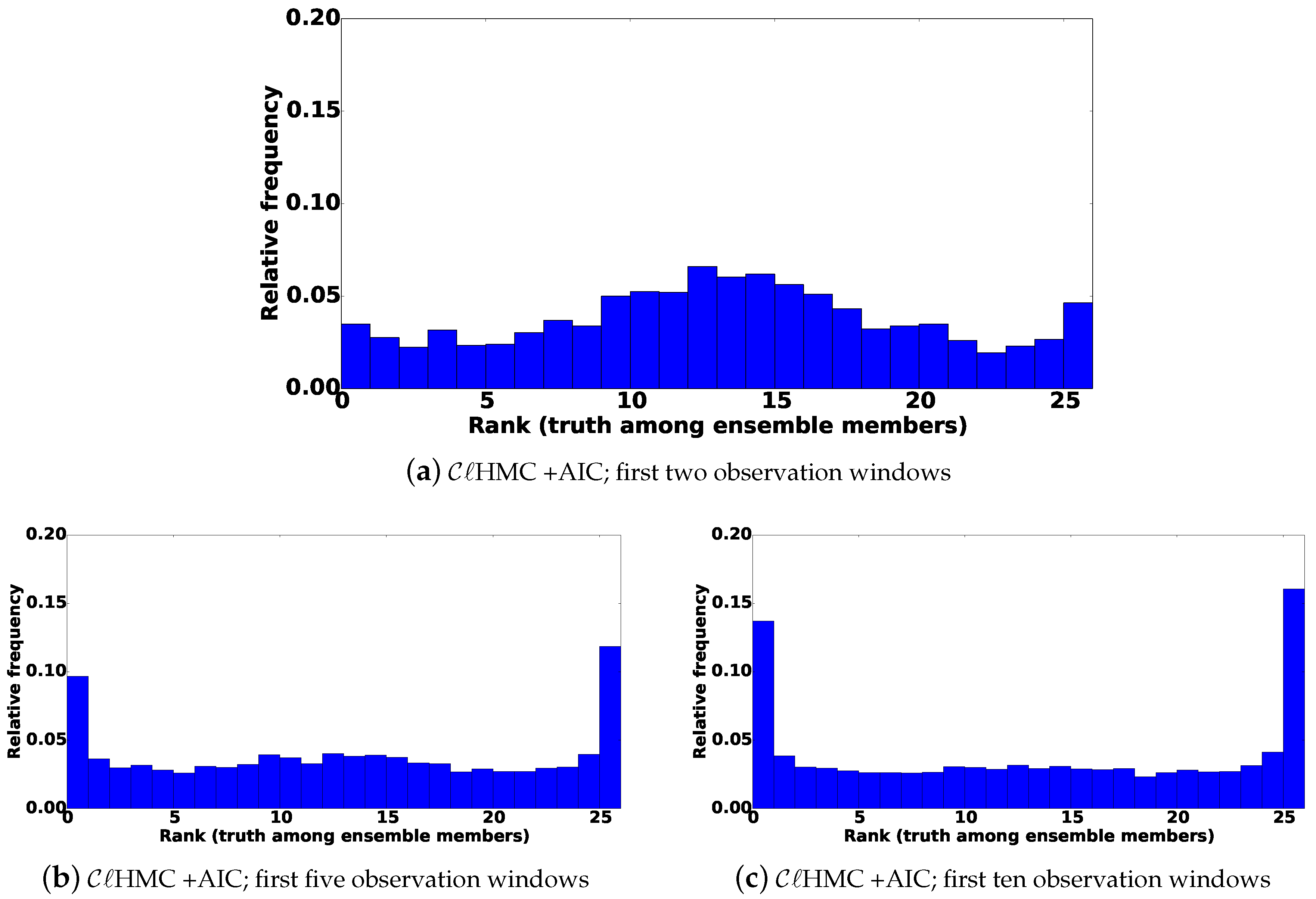
In this work, we propose relaxing the Gaussian prior assumption, using a Gaussian Mixture Model (GMM) to approximate the prior distribution. Specifically, in the forecast phase of the filter, the prior is represented by a GMM that is fitted to the forecast ensemble via a clustering step. The posterior is formulated accordingly. In the analysis step the resulting mixture posterior is sampled following an MCMC approach. The resulting algorithm is named the “cluster MCMC () sampling filter”, and the version in which HMC is used to sample the posterior is named cluster HMC () sampling filter. In order to improve the sampling from the mixture posterior, more efficient versions namely “multi-chain (MC-)“, and “multi-chain (MC-)“, filters are also discussed.
The proposed MCMC filtering algorithms are not suggested as replacements for EnKF in the linear-Gaussian settings. MCMC algorithms are generally expensive, compared to EnKF, and should be considered only when the linear-Gaussian assumption is highly violated, which can cause the conventional EnKF to fail. The numerical experiments presented herein, are carried out in both linear and nonlinear settings. Experiments with linear settings aim to compare the performance of the proposed algorithms, in the presence of benchmark results produced by EnKF. This has the benefit of demonstrating the advantage of replacing the Gaussian prior with a GMM, for MCMC sampling, even in the simplified linear settings. Numerical results with nonlinear settings, where EnKF fails, suggest that the proposed relaxation of the Gaussian-prior assumption is beneficial, especially for the sequential application of MCMC sampling filters in the presence of nonlinearities.
Using a GMM to approximate the prior density, given the forecast ensemble, was presented in [
11,
23] as a means to solve the nonlinear filtering problem. In [
23], a continuous approximation of the prior density was built as a sum of Gaussian kernels, where the number of kernels is equal to the ensemble size. Assuming a Gaussian likelihood function, the posterior was formulated as a GMM with updated mixture parameters. The updated means and covariance matrices of the GMM posterior were obtained by applying the convolution rule of Gaussians to the prior mixture components and the likelihood, and the analysis ensemble was generated by direct sampling from the GMM posterior. On the other hand, the approach presented in [
11] works by fitting a GMM to the prior ensemble with the number of mixture components detected using Akaike information criterion. The EnKF equations are applied to each of the components in the mixture distribution to generate an analysis ensemble from the GMM posterior.
Unlike the existing approaches [
11,
23], the methodology proposed herein is fully non-Gaussian, and does not limit the posterior density to a Gaussian mixture distribution or Gaussian likelihood functions. Moreover, the posterior distribution is directly sampled, and is not approximated by a Gaussian mixture distribution.
The remaining part of the paper is organized as follows.
Section 2 reviews the original formulation of the HMC sampling filter.
Section 3 explains how GMM can be used to approximate the prior distribution, and presents the new cluster sampling filters. Numerical results and discussions are presented in
Section 4. Conclusions are drawn in
Section 5.
3. Cluster Sampling Filters
Section 3.1 provides a brief overviews on mixture distributions, and review how a GMM can be used to represent the prior distribution given an ensemble of forecasts.
Section 3.2 describes the posterior distribution, and presents the new cluster sampling filters.
3.1. Mixture Models
The probability distribution
is said to be a mixture of
probability distributions
, if
takes the form:
The weights are commonly referred to as the mixing weights, and are the densities of the mixing components.
3.1.1. Gaussian Mixture Models (GMM)
A GMM is a special case of (
13) where the mixture components are Gaussian densities, that is
with
being the parameters of the
ith Gaussian component.
Fitting a GMM to a given data set is one of the most popular approaches for density estimation [
32,
33,
34]. Given a data set
sampled from an unknown probability distribution
, one can estimate the density function
by a GMM; the parameters of the GMM, i.e., the mixing weights
, the means
, and the covariances
of the mixture components, can be inferred from the data.
The most popular approach to obtain the maximum likelihood estimate of the GMM parameters is the expectation-maximization (EM) algorithm [
34]. EM is an iterative procedure that alternates between two steps, expectation (E) and maximization (M). At iteration
the E-step computes the expectation of the complete log-likelihood based on the posterior probability of
belonging to the
ith component, with the parameters
from the previous iteration. In particular, the following quantity
is evaluated:
Here is the parameter set of all the mixture components, and is the probability that the eth ensemble member lies under the ith mixture component.
In the M-step, the new parameters
are obtained by maximizing the conditional probability
Q in (
14) with respect to the parameters
. The updated parameters
are given by the analytical formulas:
To initialize the parameters for the EM iterations, the mixing weights are simply chosen to be equal
, the means
can be randomly selected from the given ensemble, and the covariance matrices of the components can be all set to covariance matrix of the full ensemble. Regardless of the initialization, the convergence of the EM algorithm is ensured by the fact that it monotonically increases the observed data log-likelihood at each iteration [
34], that is:
EM algorithm achieves the improvement of the data log-likelihood indirectly by improving the quantity over consecutive iterations, i.e., .
3.1.2. Model Selection
Before EM iterations start, the number of mixture components
must be detected. To decide on the number of components in the prior mixture, model selection is employed. This process refers to the statistical decision of choosing a model, out of a set of candidate models, to give the best trade-off between model fit and complexity. Here, the best number of components
can be selected with common model selection methodologies such as Akaike Information Criterion (AIC) and Bayesian Information Criterion (BIC):
where
is the set of optimal parameters for the candidate GMM model with
components.
The best number of components
minimizes the AIC or BIC criterion [
35,
36]. The main difference between the two criteria, as explained by the second terms in Equation (
16), is that BIC imposes greater penalty on the number of parameters (
) of the candidate GMM model. For small or moderate numbers of samples BIC often chooses models that are too simple because of its heavy penalty on complexity.
3.2. Cluster Sampling Filters
The prior distribution is approximated by a GMM fitted to the forecast ensemble, e.g., using an EM clustering step. The prior PDF reads:
where the weights
quantify the probability that an ensemble member
belongs to the
ith component, and
are the mean and the covariance matrix associated with the
ith component of the mixture model at time instance
.
Assuming Gaussian observation errors, the posterior can be formulated using Equations (
6), (
9), and (
17) as follows:
In general the posterior PDF (
18) will not correspond to a Gaussian mixture due to the nonlinearity of the observation operator. This makes analytical solutions not possible. Here we seek to sample directly from the posterior PDF (
18) following a MCMC approach. A proposal distribution and acceptance/rejection criterion, are the backbones of any MCMC sampler.
The simplest proposal is a Gaussian centered around the current state of the Markov chain. Specifically, at the
rth iteration of the chain, the proposal is
, where
is the current state of the chain, and
is the ensemble-based covariance matrix
where
is the forecast ensemble mean. The Metropolis-Hastings acceptance/rejection, in this case, can be evaluated using the acceptance probability
, where
is the proposed state, e.g., sampled from
. We refer to this approach of filtering as the cluster MCMC (
) sampling filter.
Gradient-based MCMC sampling methods, such as the HMC sampler, use the gradient of the negative log-posterior to direct the sampler towards high-probability regions, and thus yielding low rejection rates. Specifically, the HMC sampler require setting the potential energy term in the Hamiltonian (
1) to the negative-log of the posterior distribution (
18). The potential energy term
Equation (
20) is expected to suffer from numerical difficulties due to evaluating the logarithm of a sum of very small values. To address the accumulation of roundoff errors, and without loss of generality, we assume from now on that the terms in Equation (
20) under the sum are sorted in decreasing order, i.e.,
,
. The potential energy function (
20) is rewritten as:
The gradient of the potential energy (
21) is:
The cluster HMC sampling filter (
) results by replacing the potential energy function (
10b) and its derivative (
11) in the HMC sampling filter, with Equations (
21) and (
22) respectively. The steps of the
sampling filter are explained in Algorithm 1.
Note that in the case where the mixture contains a single component (one Gaussian distribution), the potential energy function (
21) and its gradient (
22) reduce to the following, respectively:
This shows that the sampling filter proposed herein, reduces to the original HMC filter when the EM algorithm detects a single component during the prior density approximation phase.
The Sampling Algorithm
As in the HMC sampling filter, information about the analysis probability density at the previous time
is captured by the analysis ensemble of states
. The forecast step consists of two stages. First, the model (
12) is used to integrate each analysis ensemble member forward to time
where observations are available. Next, a clustering scheme (e.g., EM) is used to generate the parameters of the GMM. The analysis step constructs a Markov chain starting from an initial state
, and proceeds by sampling the posterior PDF (
18) at stationarity. Here the superscript over
refers to the iteration number in the Markov chain.
It is worth mentioning that the Hamiltonian system used as a mechanism to generate proposals for the Markov Chain, along with its associated pseudo time-step settings, are independent from the physical model being simulated.
As discussed in [
17], Algorithm 1 can be used either as a non-Gaussian filter, or as a replenishment tool for parallel implementations of the traditional filters such as EnKF.
| Algorithm 1 Cluster HMC sampling filter () |
- 1:
Forecast step: given an analysis ensemble at time ; - i-
generate the forecast ensemble using the model :
- ii-
Use AIC/BIC criteria to detect the number of mixture components in the GMM, then use EM to estimate the GMM parameters .
- 2:
Analysis step: given the observation at time point follow the steps i to v: - i-
Initialize the Markov Chain () to be to the best estimate available, e.g., to the mean of the joint forecast ensemble, or the mixture component mean with maximum likelihood. - ii-
Choose a positive definite mass matrix . A recommended choice is to set to be a diagonal matrix whose diagonal is equal to the diagonal of the posterior precision matrix. The precisions calculated from the prior ensemble can be used as a proxy. - iii-
Set the potential energy function to ( 21), and its derivative to ( 22). - iv-
Initialize the chain with a state and generate ensemble members from the posterior distribution ( 18) as follows: - (1)
Draw a random vector . - (2)
Use a symplectic numerical integrator (e.g., Verlet, 2-Stage, or 3-Stage [ 17, 29]) to advance the current state by a pseudo-time increment T to obtain a proposal state :
- (a)
Evaluate the energy loss : - (b)
Calculate the acceptance probability: - (c)
Discard both . - (d)
(Acceptance/Rejection) Draw a uniform random variable : - i-
If accept the proposal as the next sample: ; - ii-
If reject the proposal and continue with the current state: .
- (e)
Repeat steps 1 to 6 until distinct samples are drawn.
- v-
Use the generated samples as an analysis ensemble. The analysis ensemble can be used to infer the posterior moments, e.g., posterior mean and posterior covariance matrix.
- 3:
Increase time and repeat steps 1 and 2.
|
3.3. Computational Considerations
To initialize the Markov chain one seeks a state that is likely with respect to the analysis distribution. Therefore one can start with the background ensemble mean, or with the mean of the component that has the highest weight. Alternatively, one can apply a traditional EnKF step and use the mean analysis to initialize the chain.
The joint ensemble mean and covariance matrix can be evaluated using the forecast ensemble, or using the GMM parameters. Given the GMM parameters
, the joint background mean and covariance matrix are, respectively:
Both the potential energy (
21) and its gradient (
22) require evaluating the determinants of the covariance matrices associated with the mixture components. This is a computationally expensive process that is best avoided for large-scale problems. A simple remedy is to force the covariance matrices
to be diagonal while constructing the GMM.
When the Algorithm 1 is applied sequentially, at some steps a single mixture component could be detected in the prior ensemble. In this case, forcing a diagonal covariance structure does not help, and we fall back to the standard HMC sampler, where the full ensemble covariance matrix is utilized.
3.4. A Multi-Chain Version of the Filter (MC-)
Given the special geometry of the posterior mixture distribution, one can construct separate Markov chains for different components of the posterior. These chains can run in parallel to independently sample different regions of the analysis distribution. By running a Markov chain starting at each component of the mixture distribution we ensure that the proposed algorithm navigates all modes of the posterior, and covers all regions of high probability. The parameters of the jumping distribution for each of the chains can be tuned locally based on the statistics of the ensemble points belonging to the corresponding component in the mixture.
A multi-chain version of the filter (MC-) is developed by choosing the proposal of the ith chain to be .
Running an HMC sampling chain under each of the posterior mixture components formulates the multi-chain (MC-) sampling filter. In this case, the diagonal of the mass matrix can be set globally for all components, for example using the diagonal of the precision matrix of the forecast ensemble, or can be chosen locally based on the second-order moments estimated from the prior ensemble under the corresponding component in the prior mixture. This local choice of the mass matrix does not change the marginal density of the target variable.
The local ensemble size (sample size per chain) can be specified based on the prior weight of the corresponding component multiplied by the likelihood of the mean of that component. Every chain is initialized to the mean of the corresponding component in the prior mixture.
The computational cost of the original HMC sampling filter depends greatly on the parameters of the Markov chain. A comprehensive discussion of the cost of the HMC sampling filter is given in
Section 4.1 [
17]. The
sampling filter replaces the Gaussian prior with a GMM, which introduces an additional cost for utilizing the EM algorithm. This added cost, however, is negligible compared to cost of the sampling step. Moreover, MC-
allows running the chains in parallel, which reduces the computational cost by a factor of up to the number of posterior probability modes
. This approach is potentially very efficient, not only because it reduces the total running time of the sampler, but also because it favors an increased acceptance rate.
5. Conclusions and Future Work
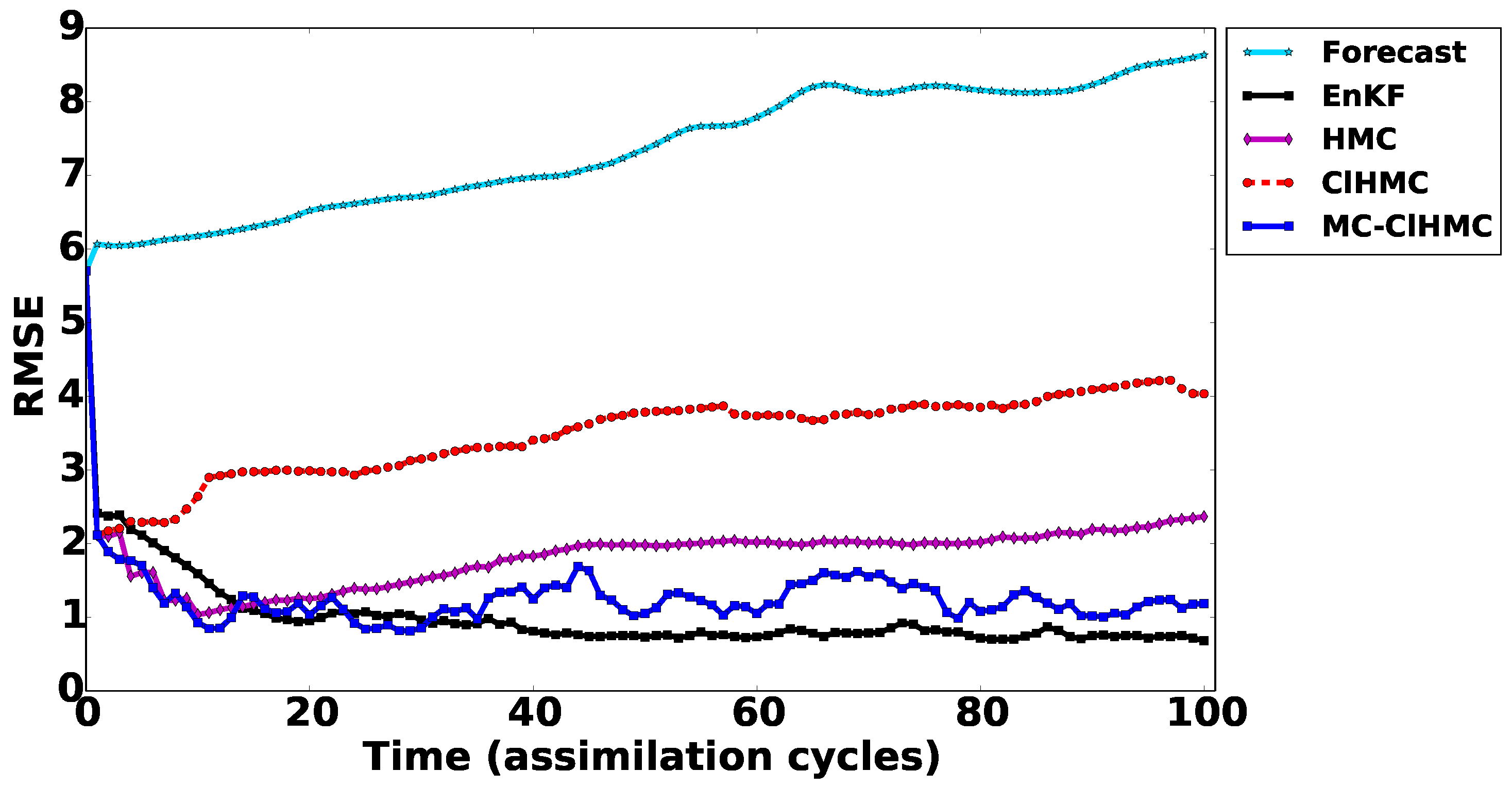
This work presents a set of fully non-Gaussian sampling filters for sequential data assimilation. The filters use a GMM to approximate the prior distribution, given the forecast ensemble. The posterior mixture distribution is directly sampled following a MCMC approach. Several proposals are suggested for the MCMC sampling step. The filter uses a Gaussian proposal, and follows a HMC approach for sampling the posterior, using a single Markov chain. These two versions may suffer from high-rejection rates, and may fail to sample all posterior probability modes, especially in highly non-linear settings. More efficient multi-chain versions of and , namely MC- and MC- respectively, are developed in order to alleviate such difficulties.
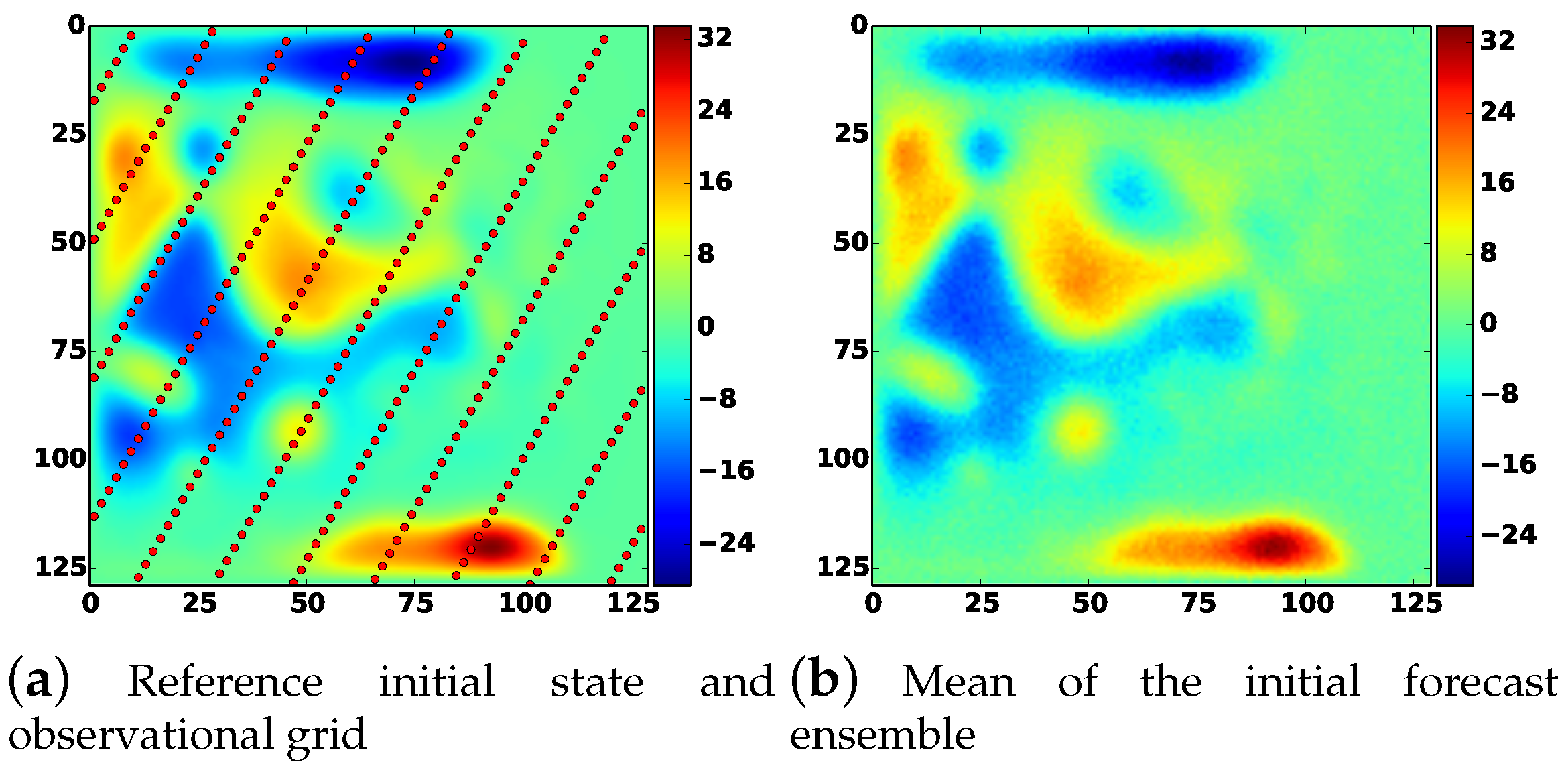
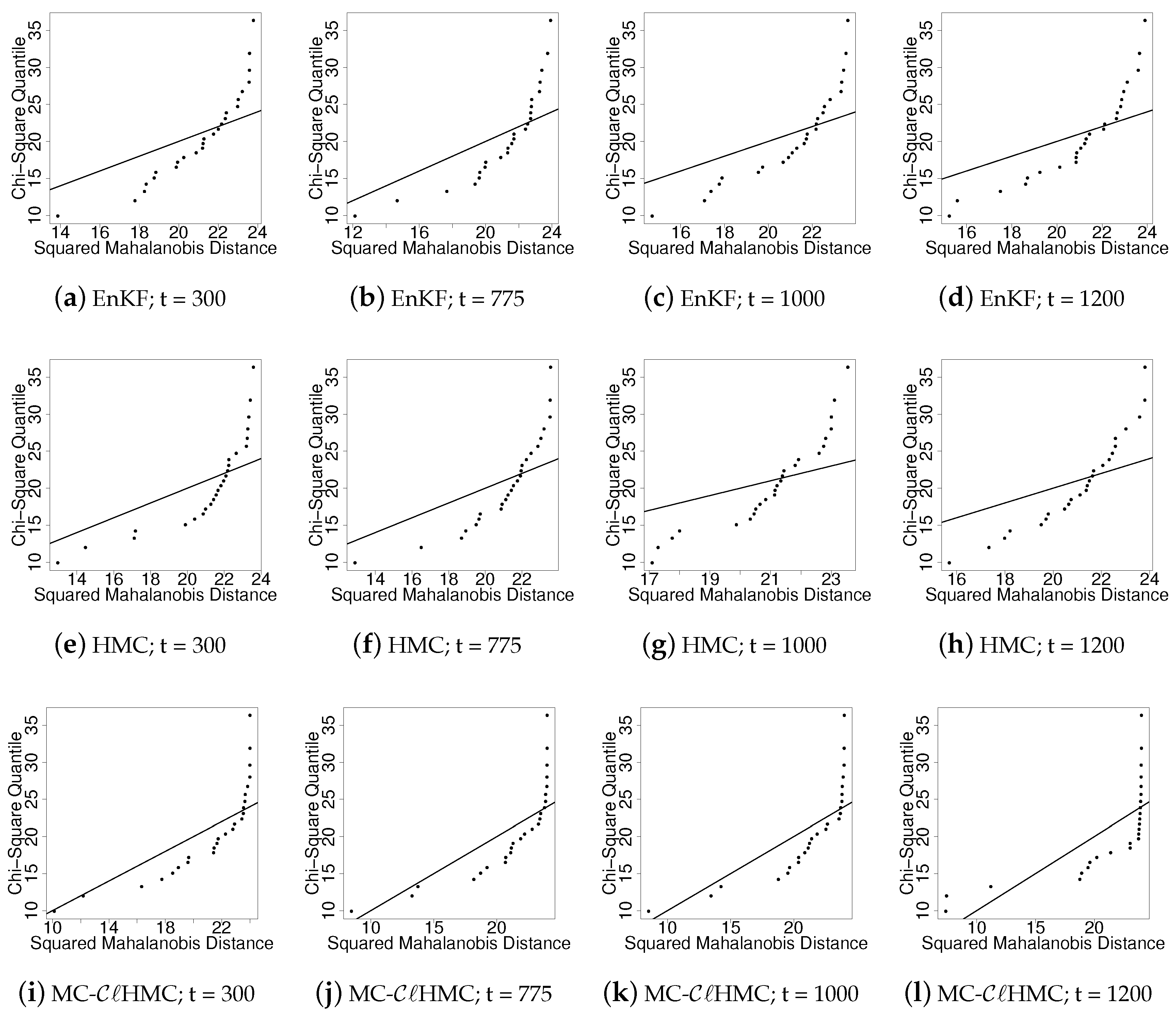
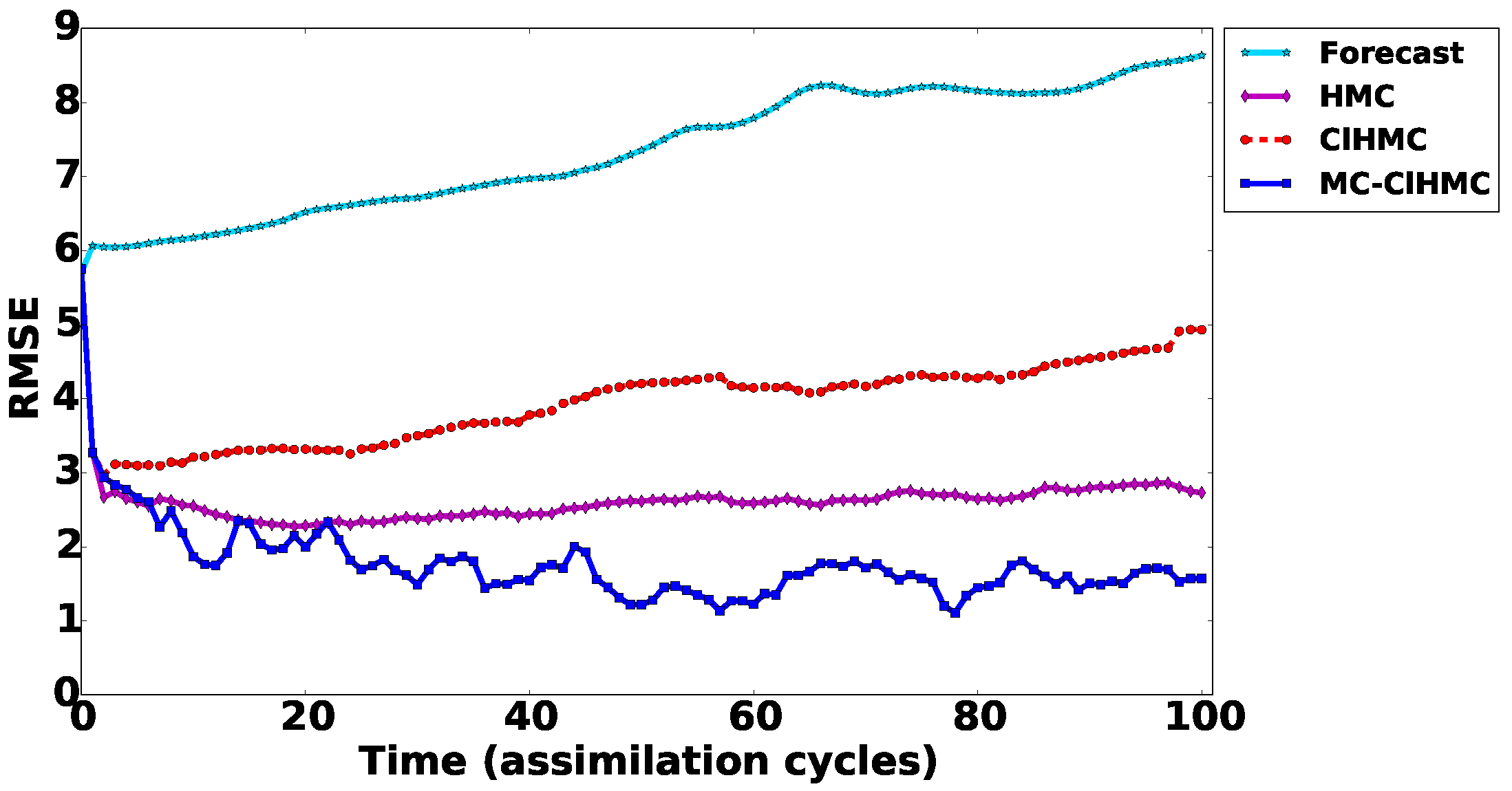
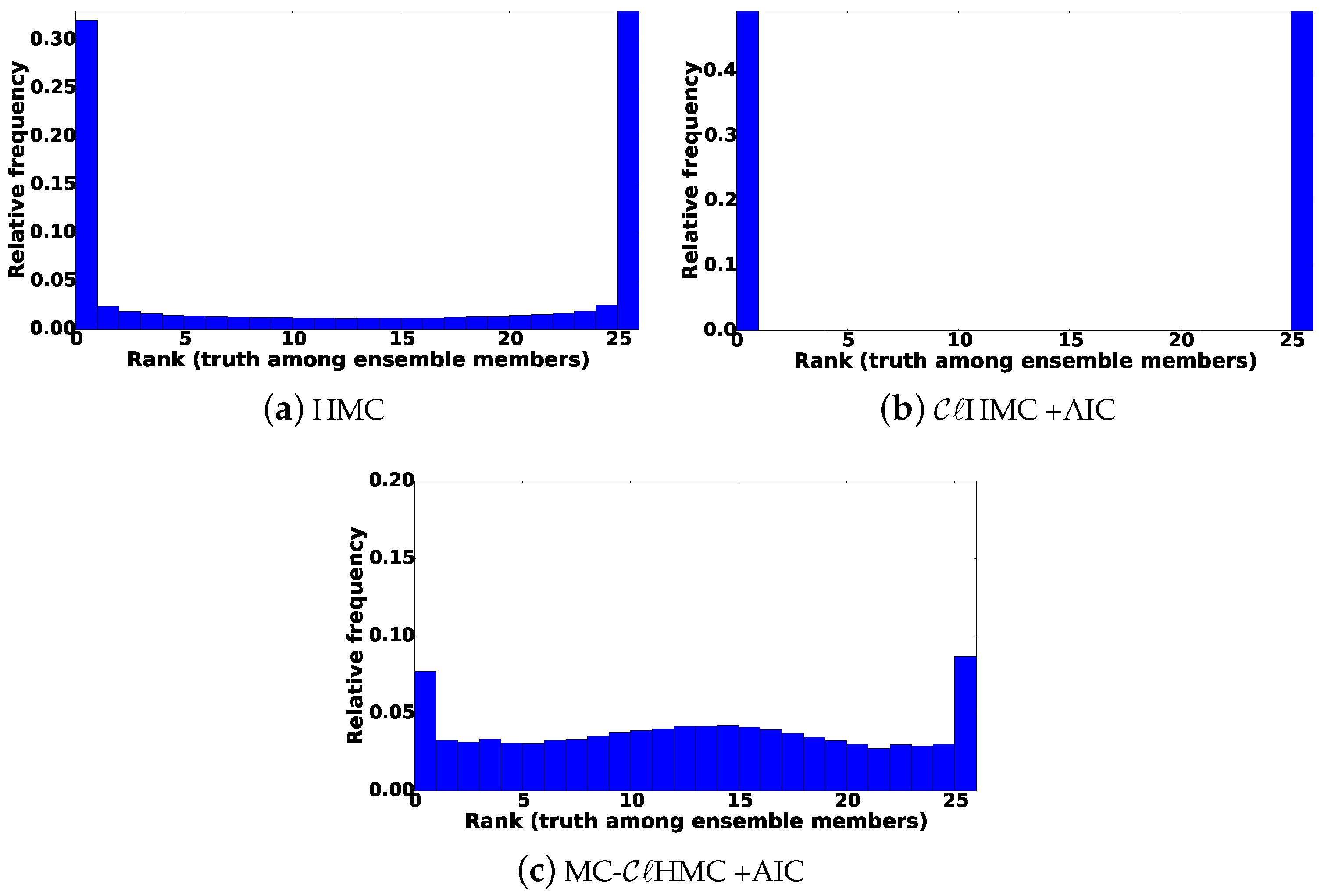
Numerical experiments are carried out using a simple one-dimensional example, and a nonlinear 1.5-layer reduced-gravity quasi geostrophic model in the presence of observation operators of different levels of nonlinearity. The results show that the new methodologies are much more efficient that the original HMC sampling filter especially in the presence of a highly nonlinear observation operator.
The multi-chain cluster sampling filters, MC- and MC-, deserve further investigation. For example the local sample sizes here are selected based on the prior weight multiplied by the likelihood of the corresponding component mean. An optimal selection of the local ensemble size is required to guarantee efficient sampling from the target distribution.
Instead of using MC-
filter, one can use
with geometrically tempered Hamiltonian sampler as recently proposed in [
44], such as to guarantee navigation between separate modes of the posterior. Alternatively, the posterior distribution can be split into
target distributions with different potential energy functions and associated gradients. This is equivalent to running independent HMC sampling filters in different regions of the state space under the target posterior.
The authors have started to investigate the ideas discussed here, in addition to testing the proposed methodologies with automatically tuned HMC samplers.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}