1. Introduction
The Yangtze River is the largest river, and the most important navigation channel, in China. In recent decades, systematic river training works have been carried out on this waterway. Various channel training structures, such as spur dikes and revetments, have been built, which play important roles in protecting key shorelines, controlling unfavorable riverbed evolution, and increasing the navigability of the channel. However, as time has passed, water and sand scour have caused the channel training structures to sustain various levels of damage, impairing their ability to regulate the channel.
At present, research on channel training structures is mostly focused on the damage mechanism, such as local scour in the vicinity of the structures [
1,
2,
3] and turbulent flow around the structures [
4,
5,
6], and how changes in structure design parameters affect the water flow and sediment transport characteristics [
7,
8]. Little research about evaluating the damage level of the channel training structures has been carried out so far. It is very important to evaluate the damage level of these structures in order to maintain them over time. There are many factors that could affect the running condition of the training structures. These factors are difficult to describe quantitatively. Some researchers use a number to describe the stability of hydraulic engineering structures; for example,
Ns in Equation (1). This equation was proposed by Hudson (1959) [
9] to calculate the mass of stones in a rubble mound breakwater.
Ns describes the stability of the structures, and is a function of the slope angle
and the stability coefficient
as shown in Equation (2).
is related to the damage ratio (
D) of the rubble mound breakwater.
where
,
is the mass density of the unit,
is the mass density of the water.
H is the wave height.
Since some factors, such as the size of the structures and the duration of a wave attack, are not considered in the Hudson’s formula, researchers have further developed this formula and given various definitions for the damage parameter (damage level), such as
,
, and
S shown in
Table 1 [
10,
11,
12,
13,
14].
With regard to the channel training structures in the Yangtze River, Han proposed Equation (3) to calculate the volume damage ratio of a spur dike and Equation (4) to calculate the area damage ratio of a flexible mattress for beach protection [
15,
16]. The damage levels are evaluated based on the damage ratios. Besides this, the strength reduction method can also be used to evaluate the damage level. Niu [
17] used this method to obtain the stability number of the slope.
is the damage volume of the spur dike,
is the total volume of the spur dike,
is the length of the spur dike,
is the maximum velocity,
is the incipient velocity,
is the angle of the spur dike.
is the damage area of beach protection flexible mattress,
is the total area of beach protection flexible mattress,
is the maximum of beach width,
is the maximum of beach length,
B is the width of the river,
d is average water depth,
v is the water velocity.
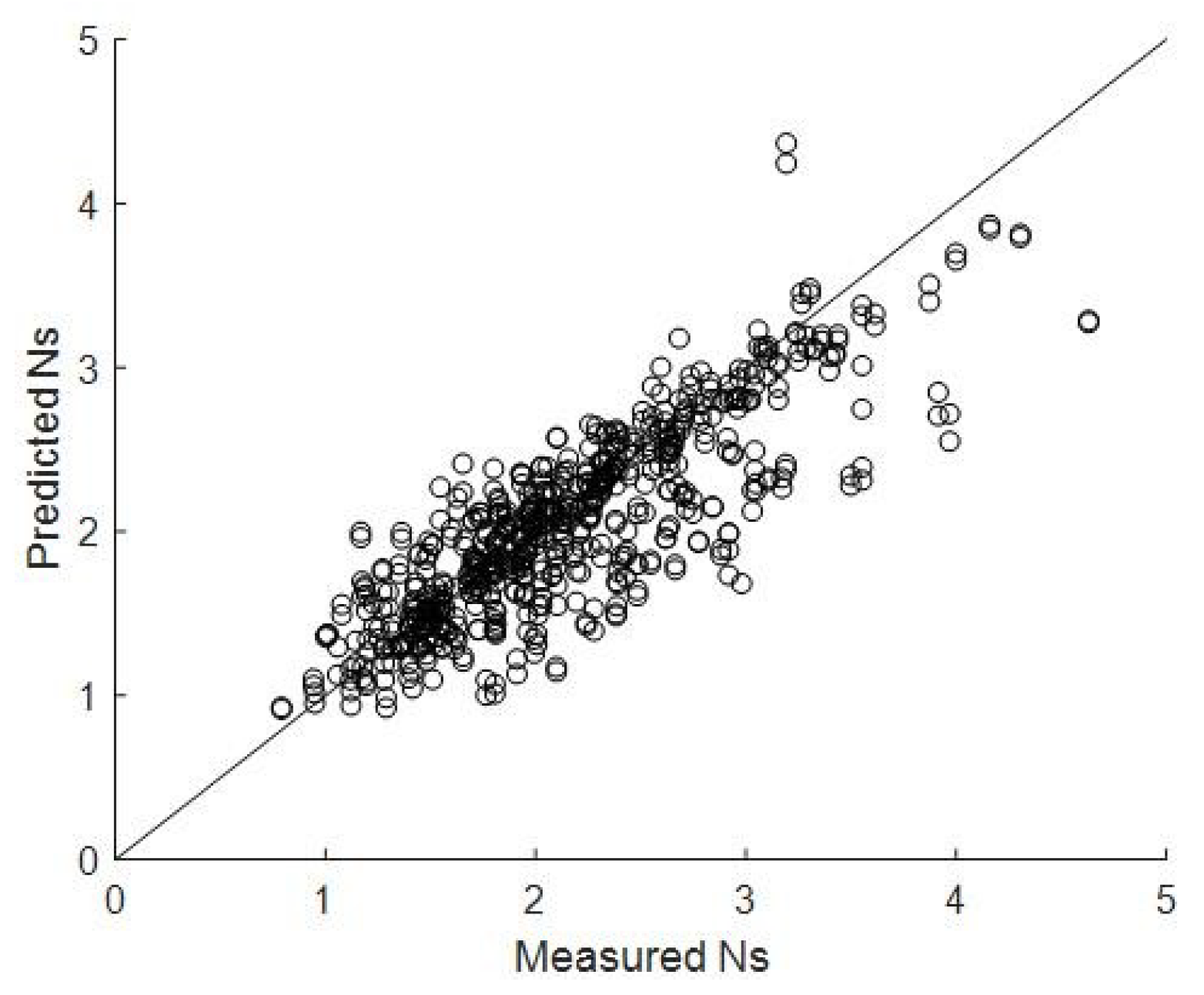
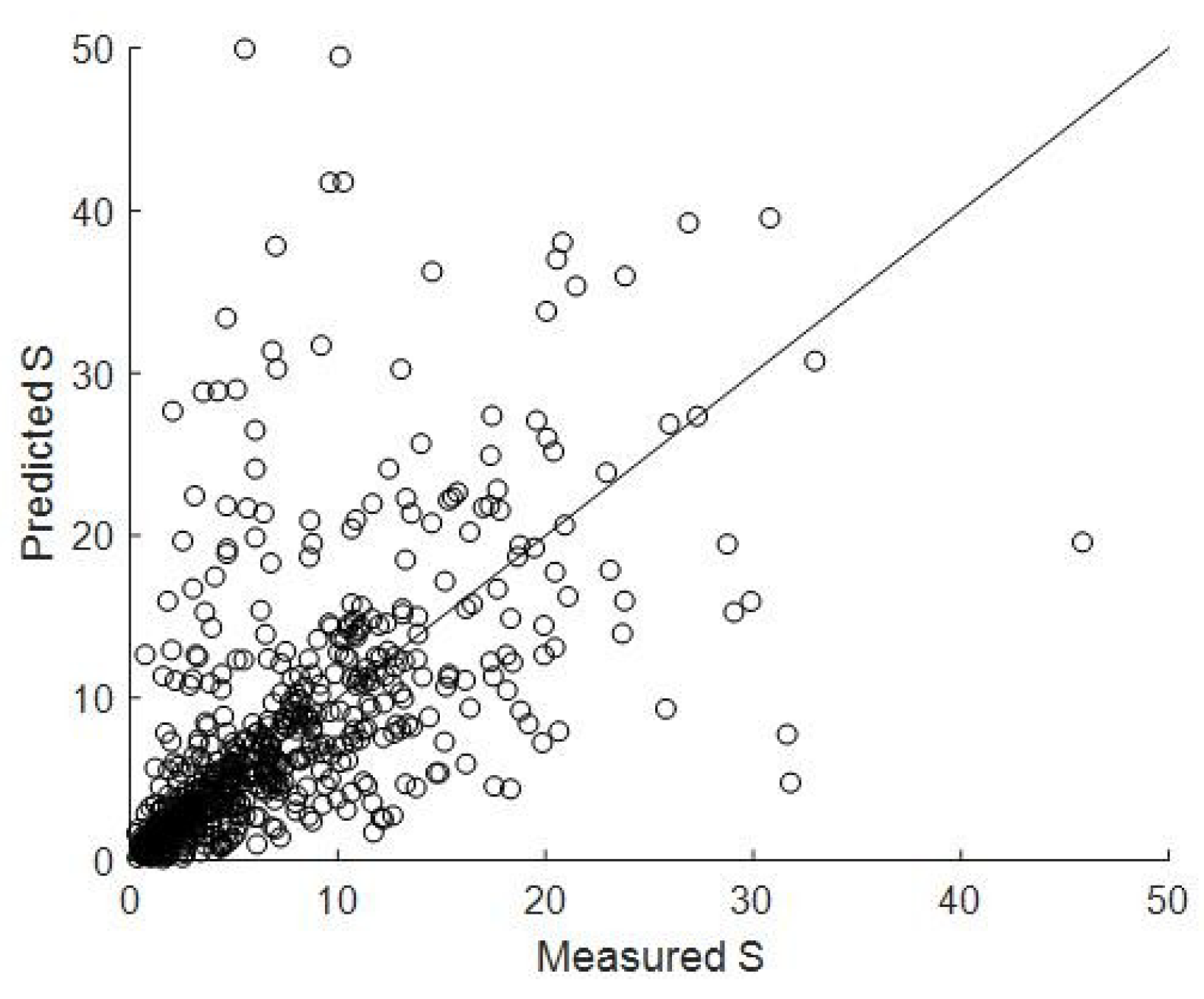
As can be seen in
Figure 1 and
Figure 2, the stability numbers and the damage levels that are calculated by the empirical formulae do not agree well with those observed in the experiments, so a neural network was proposed to analyze the stability number and the damage level of the structures. Mase [
18] proposed a back-propagation neural network model to analyze the stability of the rubble-mound breakwater based on the data from Van der Meer’s 1988 experiment. The stability numbers and damage levels predicted by the trained model are more accurate than those given by the formulae. Dong et al. [
19] established five different neural network models to predict the stability numbers and damage levels, and compared the structure and accuracy of the five neural network models. Besides the neural network, a fuzzy logic approach [
20,
21] and a support vector machine [
22,
23] can also be effective tools to predict the stability number and the damage level.
Little research has been done on the methods for evaluating the damage level of river training structures on the Yangtze River. It is hard to evaluate the damage level of river training structures quantitatively, since there are so many interrelated factors that affect the operating condition of the river training structures. Currently, the most common method to evaluate the damage level of the river training structures on the Yangtze River channel is to classify the damage level empirically according to measured data and the damage condition as observed on site. Damage to the river training structures can be classified into four levels, as shown in
Table 2.
Previous studies have shown that supervised machine learning approaches could be effective tools to predict the damage level of hydraulic structures. During the early stages of study and application of a new river training structure, the empirical classification results of the damage level will not be reliable enough, but would form the training labels of the supervised machine learning algorithm. Then, the use of a data-mining algorithm would be required. The primary purpose of this paper is to present a data-driven model without involving the hydrodynamic factors to evaluate the damage level of the river training structures. In the following sections, a machine learning approach is proposed to evaluate the damage level of a spur dike with tooth-shaped structures, which is a new type of river training structure that has been built near the estuary of the Yangtze River. Two machine learning models were built based on the experimental data in Fei (2017) [
24]. First, we used the support vector machine (SVM) algorithm to build a supervised training model to predict the damage level of the validation samples. Then, we combined a Kohonen neural network with the support vector machine to build an unsupervised evaluation model (KNN-SVM), which could be seen as a novel approach to predict the water damage level of spur dikes.
2. Materials and Methods
2.1. The 12.5 m Deep-Water Channel Training Project on the Yangtze River below Nanjing
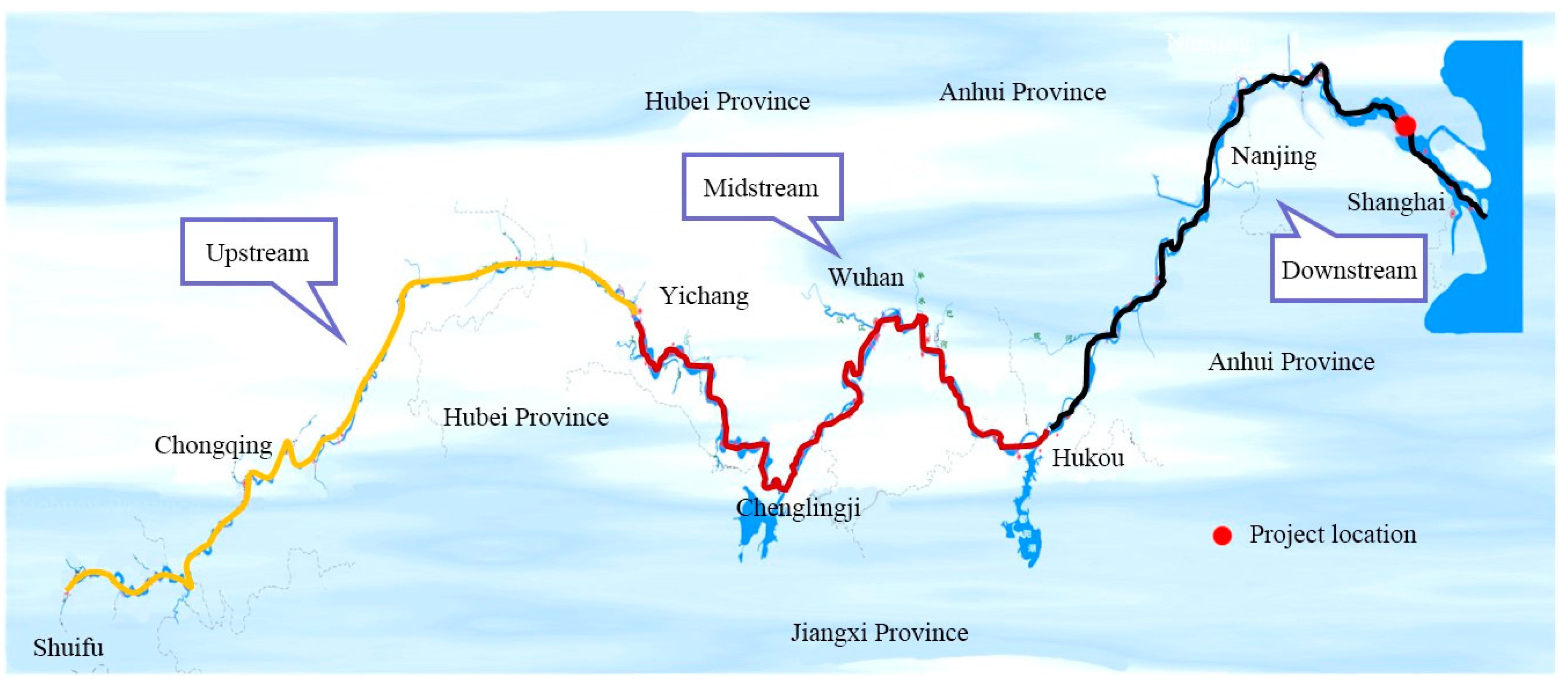
The Yangtze River is a major navigation channel in China, and is known as the “Golden Channel”. The length of the main stem of the Yangtze River is 6300 km. The stream above Yichang is the upper reach of the Yangtze River, which is 4505 km long. The stream between Yichang and Hukou is the middle reach, which is 955 km long. The stream below Hukou is the lower reach, which is 938 km long, as shown in
Figure 3. Since 2012, Phase 1 of the 12.5 m Deep-Water Channel Training Project has been carried out downstream of Nanjing to regulate the 56-km-long channel between Taicang and Nantong in order to increase the depth of the channel to 12.5 m.
The regulated channel is near the estuary; therefore, it is influenced by both the river flow and the tidal flow. During the flood season, the tide could reach the Jiangyin–Jiulong reach; during the drought season, the tide could reach the Yizheng–Zhenjiang reach. When an extraordinary flood occurs (82,300 m3/s), the tide can only affect the estuary reach. Sediment transport is complicated in a tidal estuary. The medium size of the bed load is 0.15~0.25 mm, and the medium size of the suspended load is 0.005~0.02 mm. The sediment concentration is influenced by sediment from upstream that is provided by the river and sediment from downstream that is provided by the tide. Since the Three Gorges Reservoir started operating, the sediment concentration in this section has decreased to 0.1~0.3 kg/m3.
The project aims at protecting the beach, stabilizing the channel, guiding the flow, and increasing the channel’s depth. A 34.95-km-long submerged dike, 11 spur dikes, and four revetments have been built in the Tongzhousha–Baimaosha reach.
2.2. The New Type of River Training Structure on the Yangtze River
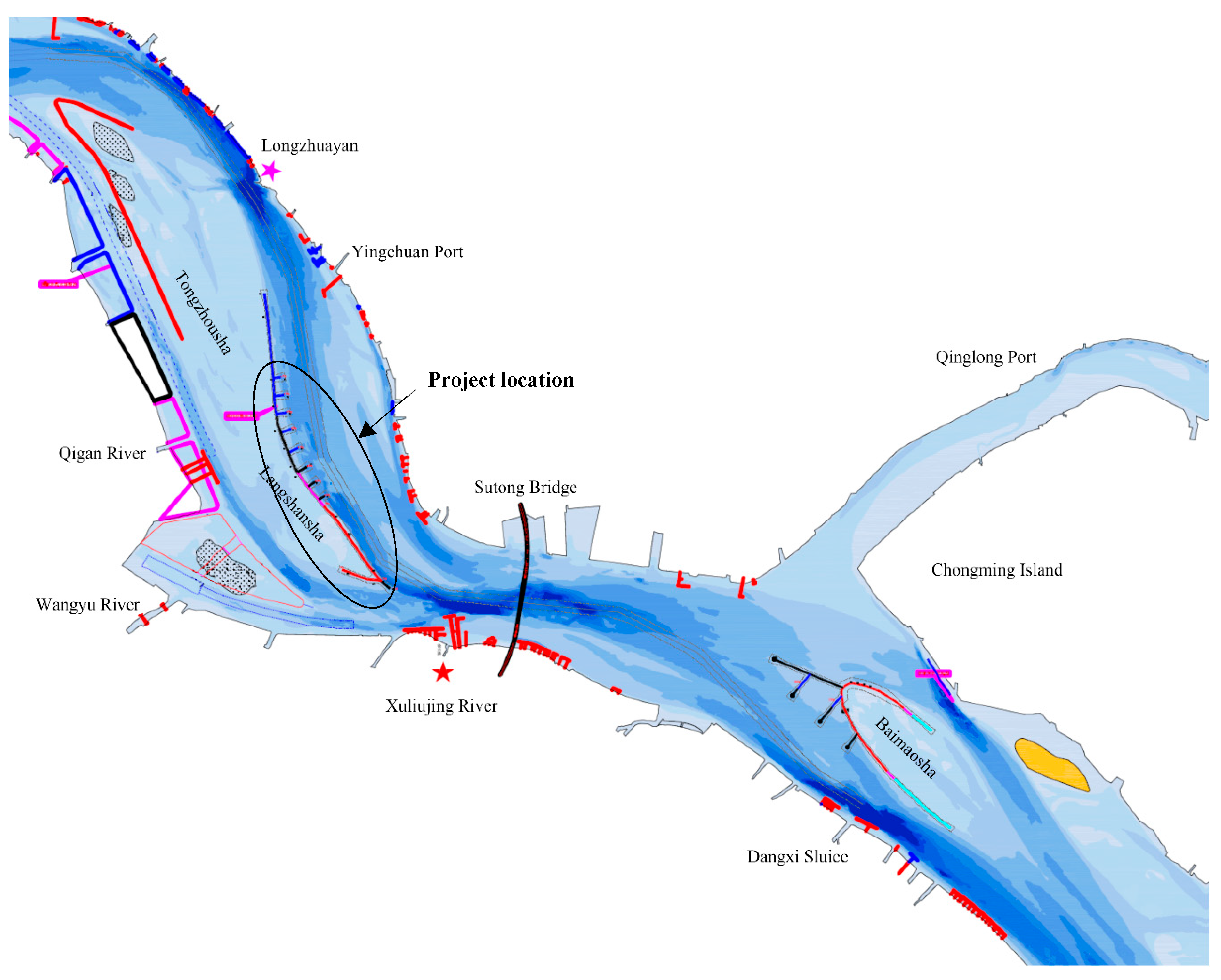
A spur dike with tooth-shaped structures is a new type of river training structure that was first used near the estuary of the Yangtze River in the Tongshazhou reach (shown in
Figure 4). Spur dikes with tooth-shape structures were built perpendicular to the revetments. They were expected to control unfavorable riverbed evolution under the wave action and the river current and provide a habitat for the aquatic organisms. Their research and application are still at an early stage. The characteristics of the flow field have recently been researched using a numerical simulation [
25,
26]. Tong et al. [
27] carried out a series of experiments to study the stability of spur dikes with tooth-shaped structures.
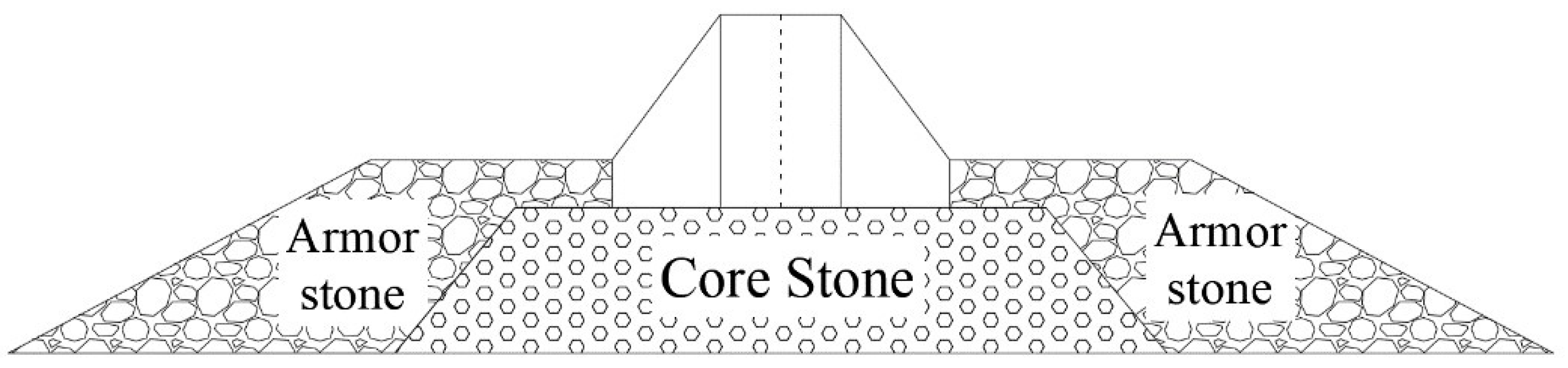
Figure 5 shows the profile of a spur dike with tooth-shaped structures. The spur dike consists of two parts: the upper part is made of precast concrete, and the lower part of the dike is core stone covered by armor stones. The size of each part is marked in
Figure 5. It is a submerged dike. Each spur dike block is 6.2 m long, 7 m wide, and 4 m high. A three-dimensional (3D) view of the spur dike array can be seen in
Figure 6. The weight of each block is 155.16 t, and the volume of each block is 64.65 m
3. The weight of the core stone ranges from 1 kg to 100 kg, and the thickness of the core stone layer is 3 m. The weight of the armor stone ranges from 200 kg to 300 kg, and the armor stone layer is 4 m high.
2.3. Data Sets
All data used to train the model in this paper were from flume experiments that were conducted by Fei [
24]. And the data sets were obtained from the doctoral thesis of Fei (2017). In this paper, we might not have the right to share all the experiment data, but the data was public and available. This section provides a brief introduction of the experiment in order to clarify the source and meaning of the data.
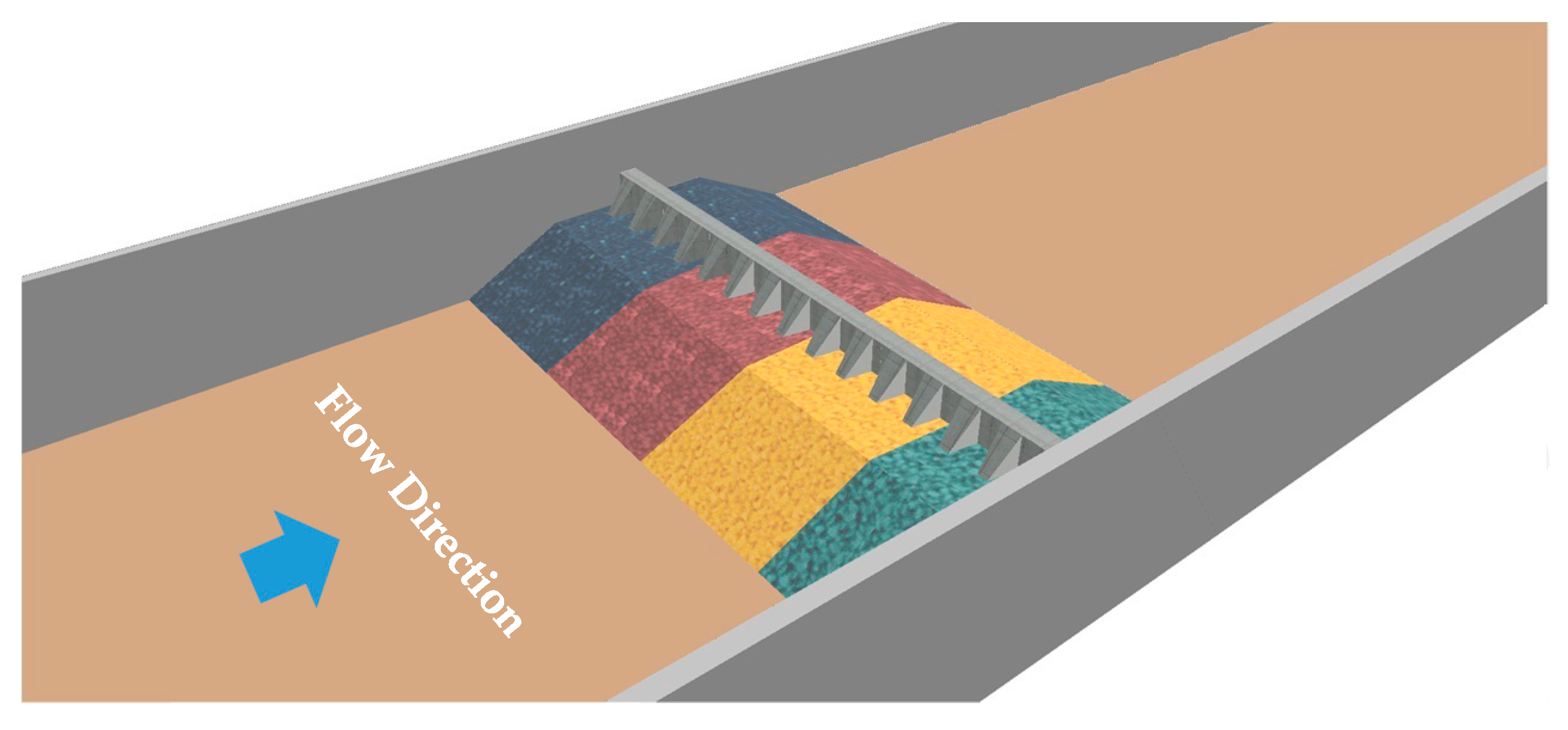
The experiment was set up in a flume that was 40 m long and 2 m wide. A 15-meter-long movable bed section in the middle part of the flume was the main experimental area. A 15-cm-deep layer of uniform sediment (
D50 = 0.075 mm) covered the movable bed reach. Eight dike blocks (shown in
Figure 7) stood in a line in the flume, and the central axis of the spur dike was perpendicular to the flow direction. The block models were made of concrete. The core stones were placed under the spur dike. The armor stones were divided equally into four parts in the transverse direction and dyed with four different colors in order to trace them (
Figure 8). Both the horizontal scale and the vertical scale of the model were 1:25.
The experimental conditions were based on the actual hydrological condition of the 12.5 m Deep-Water Channel Regulation Project on the Yangtze River. The water depth ranged from 26 cm to 36.5 cm (corresponding to 6.5~9.2 m on site) based on the Froude similarity, and, similarly, the velocity upstream of the spur dike ranged from 15 cm/s to 33 cm/s (corresponding to 0.75~1.65 m/s on site). Each experiment lasted for 3 h.
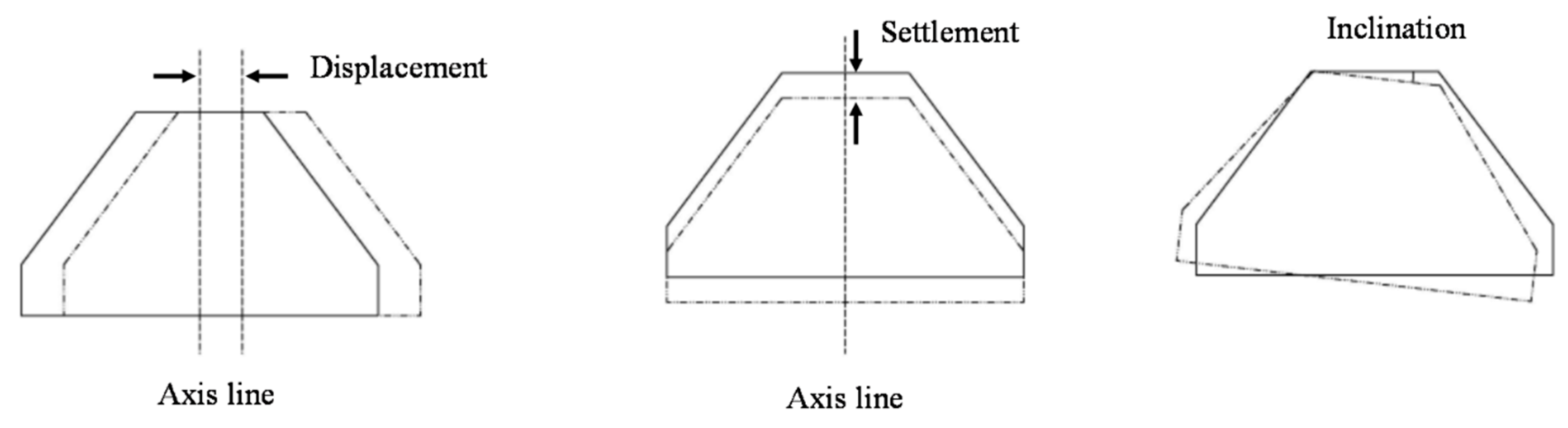
The flow drag and local scour in the vicinity of the structure were the main reasons for the damage to the spur dike [
24]. Displacement, settlement, and inclination were the three major damage patterns.
Figure 9 shows the schematic diagram of these damage patterns. After a 3-h flow attack experiment, the values of the displacement, settlement, and inclination were measured. Twenty-one (21) measurement points were placed on the axis line of the spur dikes at an equal distance. Each set of data included the values of displacement, settlement, and inclination at a measurement point. Sixteen (16) groups of data were measured, and 336 sets of experimental data were collected in total, which are used in this paper to train the machine learning model.
2.4. The Kohonen Neural Network
Self-organized Feature Maps (SOM) was proposed by Kohonen [
28], and is known as a Kohonen neural network (KNN). KNN is an unsupervised learning model for cluster analysis.
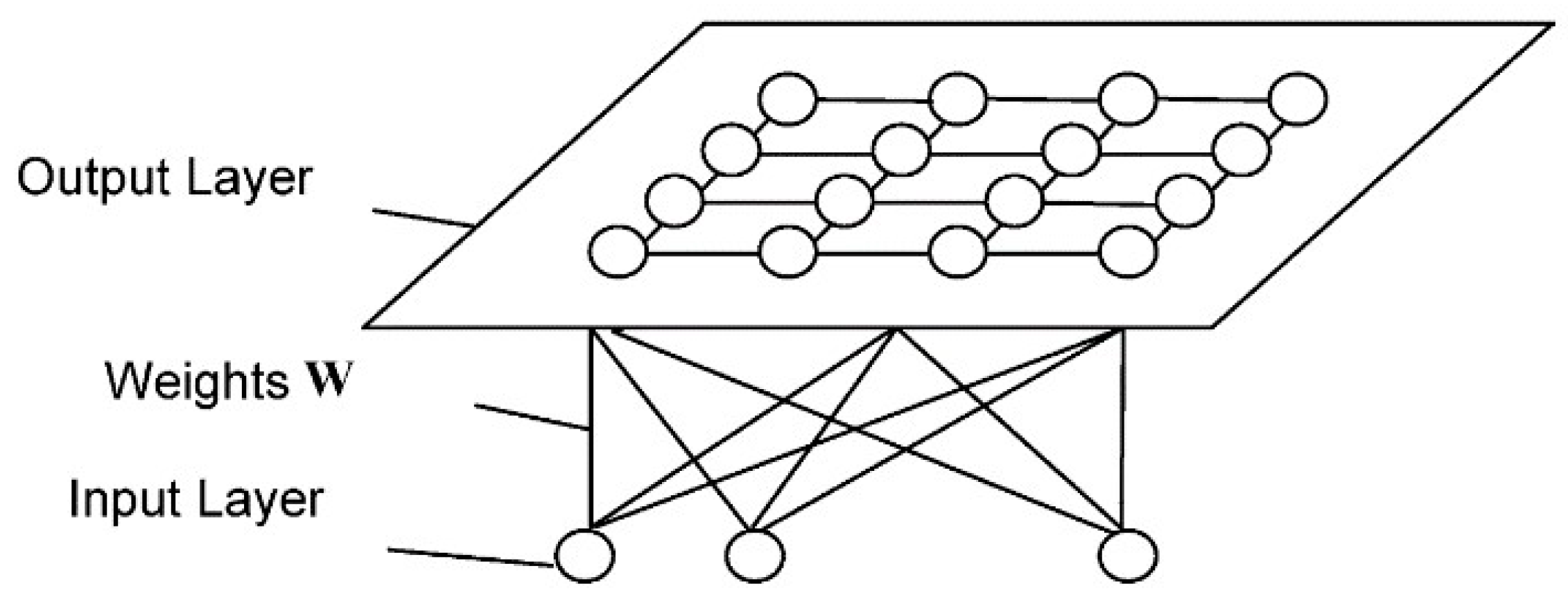
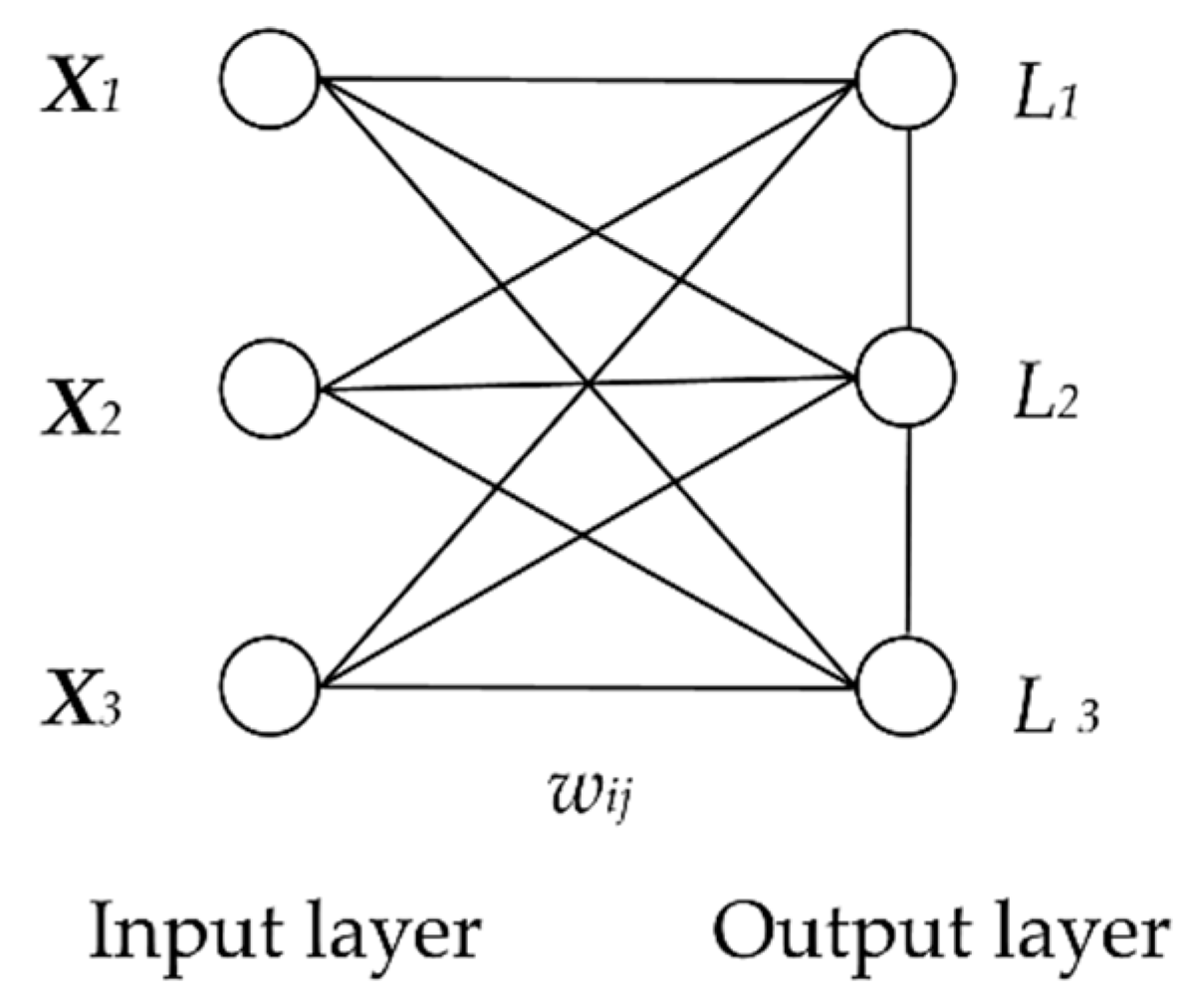
Figure 10 shows the usual structure of KNN [
29]. It has two layers, the input layer and the output layer. The number of neurons in the input layer is determined by the input vector dimension. The neurons of the output layer are placed on a two-dimensional matrix. There are weights between the neurons in the input layer and the neurons in the output layer. There are also weights on the output layers between the output neurons. For this paper, a one-dimensional KNN was used, whose structure is shown in
Figure 11. There were three neurons (X
1, X
2 and X
3) in the input layer, standing for the input data of displacement, settlement, and inclination. Damage to the spur dike in the flume experiment was classified into three levels (L1, L
2 and L
3), so three neurons were set in the output layer.
Assuming that there are N neurons in the input layer and M neurons in the output layer, here is a brief introduction of the training process of the network. More detailed information about KNN can be found in Kohonen [
30] and Waller et al. [
31]:
Step 1: Initialize the weights Wij randomly (i = 1, 2, 3, …, n; j = 1, 2, 3, …, m). Wij are the weights between the input layer and the output layer.
Step 2: Calculate the Euclidean distance between the randomly selected input
Xi and weight vectors
Wij.
Step 3: The neuron that has the minimum Euclidean distance to the input vector
X is defined as the winner and marked as
c. The winner has a neighborhood of
Nc(t) whose radius is
r. The neighborhood radius size (
r) changes linearly in the training process as shown in Equation (6).
where
T is the total number of training loops,
s is the current training loop,
is the maximum neighborhood radius size,
is referred to as the initial neighborhood size, and
is the minimum neighborhood radius size.
Step 4: The weight of the winner neuron and the weights of other neurons within the neighborhood of
Nc(t) are adjusted using Equation (8). Meanwhile, the other weights retain the original value.
where
is the learning rate, which changes linearly in the training process just like the neighborhood size,
are the positions of the neurons
c and
t, respectively, and “norm” stands for the Euclidean distance between two neurons as shown in Equation (9).
where
and
are the
x coordinate value and the
y coordinate value of neuron
t, and
and
are the
x coordinate value and the
y coordinate value of neuron
c.Step 5: Adjust the learning rate and neighborhood radius. If s = T, then the algorithm ends, if not, go back to step 2, and new data are used to repeat the training steps.
2.5. Support Vector Machine
Support vector machine (SVM) is a frequently used data-driven model for prediction and classification. It was developed by Vapnik [
32]. SVM is formulated based on the structure risk minimization principle. It has a great advantage in solving nonlinear problems with a small sample. SVM has been widely used in hydrological prediction [
33,
34] and anomaly detection [
23,
35].
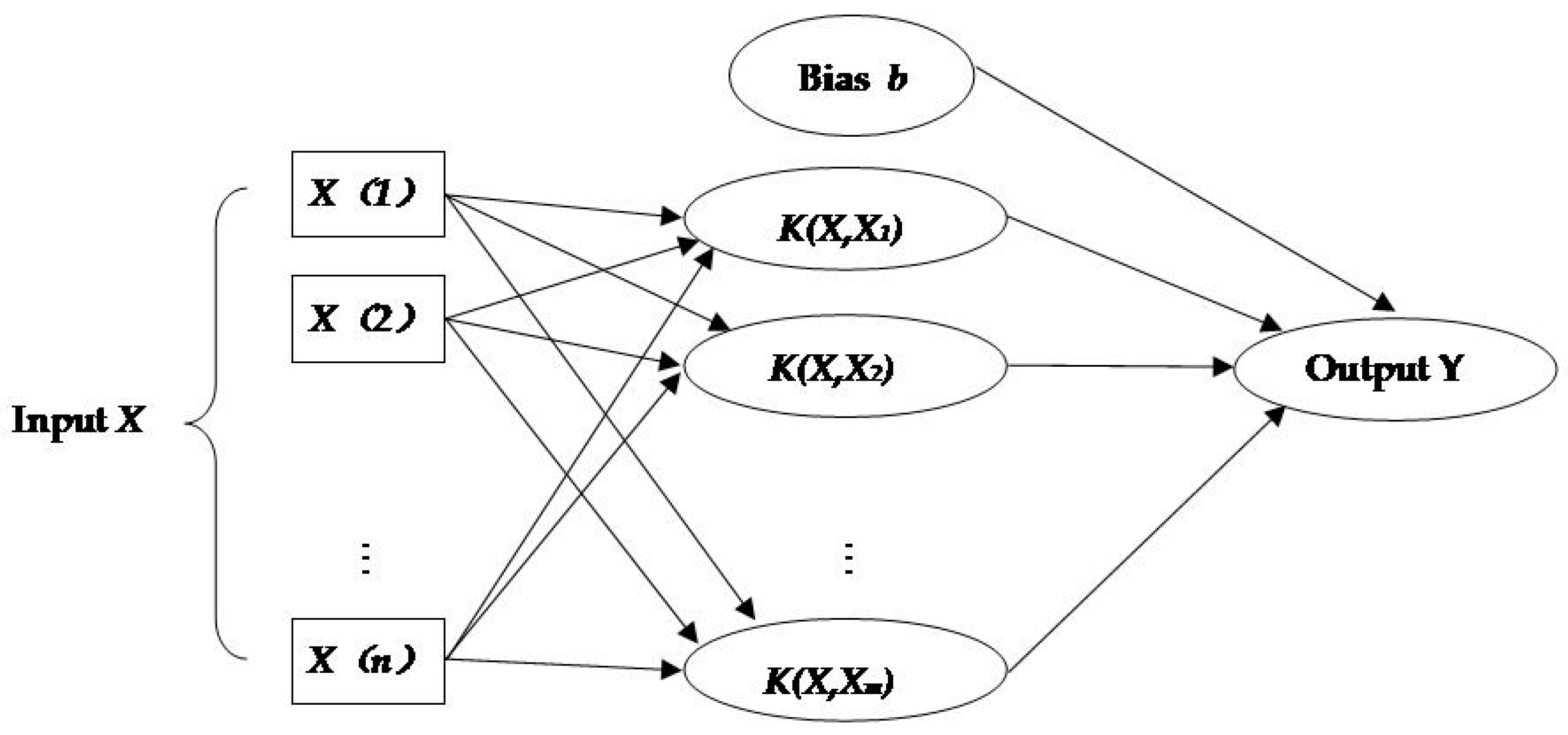
Figure 12 shows the structure of support vector machine.
The C-SVC model was selected in this study, which is a widely used two-class SVM model. The training process of C-SVC is as follows:
Consider a training set:
where
is the input vector, and
is the training label of the input vector.
A nonlinear (linear) function
is used to map the input vector
from a
d-dimensional input space to a
dh-dimensional feature space. The optimal hyperplane in the feature space is then defined as:
where
w is the weight vector and
b is the bias. The optimal hyper-plane must obey the following rule:
The classifier can be written as:
The support vector machine aims at constructing a hyperplane with the maximal distance between the two classes. It has been proved that finding the maximum distance is equivalent to finding the minimum of
:
A slack variable
and a positive regularization constant
C are introduced into Equation (15). The greater the value of
C is, the less error can be tolerated. The problem of finding the optimal hyperplane can be generalized as follows:
The penalty magnitude of the classifier function is determined by the positive regularization constant
C. If the value of
C is too small, the accuracy of the prediction of the model will be too low. On the other hand, if the value of
C is too large, the training model may be over-fit to the training data [
36].
The function
in the classifier function is given by the kernel function
, and the most frequently used kernel functions are shown in
Table 3, where
determines the spread of the kernel functions.
3. Results and Discussion
Not every instance of damage to a spur dike can be detected [
37], and slight damage may not affect the spur dike’s regular operation. The damage to the spur dike was classified into three levels. The classification criteria were set empirically according to the damage condition of the spur dike in the flume experiment and the field observation as shown in
Table 4. The 336 experiment data sets were categorized into these three damage levels.
A supervised training model (SVM) and an unsupervised KNN-SVM model were built to predict the damage levels. For the SVM model, 100 sets of data were selected randomly as training data, and the remaining 30 sets of data were used as a validation sample, as shown in
Table 5. All of the 336 sets of experimental data were used to train the unsupervised Kohonen model.
3.1. The Supervised Training Model
Choosing appropriate values for the positive regularization constant
C and the spread
g in the kernel function is the key to building an SVM model with high accuracy. In this paper, the values of
C and
g were selected using k-fold cross validation [
38] (3-fold cross validation was used in this paper). The optimal parameters that generate the highest regression accuracy for different kernel functions are shown in
Table 6. As we can see in the table, the models with a radial basis function (RBF) and a sigmoid function have higher regression accuracy for this research. If the value of
C is too large, the training model may be over-fit to the training data [
36]. So, the RBF kernel function and the corresponding optimal parameters were chosen to train the SVM model. In this paper, “libsvm”, which was an open source software developed by Chang and Lin [
39], was selected to build the SVM model. The open source code for the SVM model can be downloaded on the web site of
https://www.csie.ntu.edu.tw/~cjlin/libsvm/.
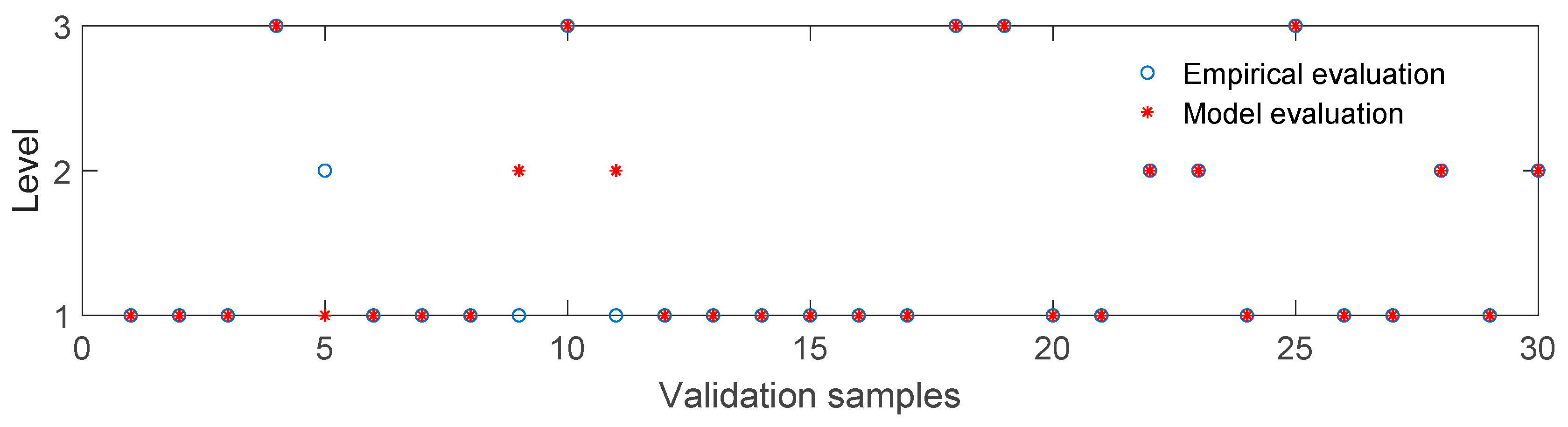
After the training process, the model was used to predict the damage levels of the validation sample.
Figure 13 shows the comparison between the damage levels of the validation sample predicted by the model and evaluated according to the empirical criteria. Twenty-seven (27) samples were predicted correctly by the model, so the accuracy was 90%. This suggests that the support vector machine model can be an effective tool to predict the damage level of a spur dike. The damage levels of one data set predicted by the model were higher than the ones evaluated by the empirical criteria, and another two data sets were in the opposite situation. When the model is used for extrapolating the damage level of real spur dikes on the Yangtze River, the number of training data sets should be enough. No less than 50 sets of training data should be provided by the empirical criteria before the model training process.
3.2. The Unsupervised Model
In most cases, measurement data are available but the classification criteria of the damage levels are unknown, so no training data are available to build the SVM prediction model. To solve this kind of problem, an unsupervised model was proposed by combining KNN and SVM. KNN is a data-mining algorithm that can classify data with a common feature through observing, analyzing, and comparing the data. In the KNN training process, the weights Wij are randomly initialized, so the winner neuron (damage level) might be different for the same data set in different simulation processes. Then, the SVM model was introduced to mitigate the problem of the unsteady output of the KNN model. To obtain a steady result, the predicted results of KNN were selected as the training data of the SVM model in combination with the corresponding measured data (inclination, displacement, settlement); then, a steady damage level evaluation result was given by SVM.
During the training process of the KNN model, the learning rate
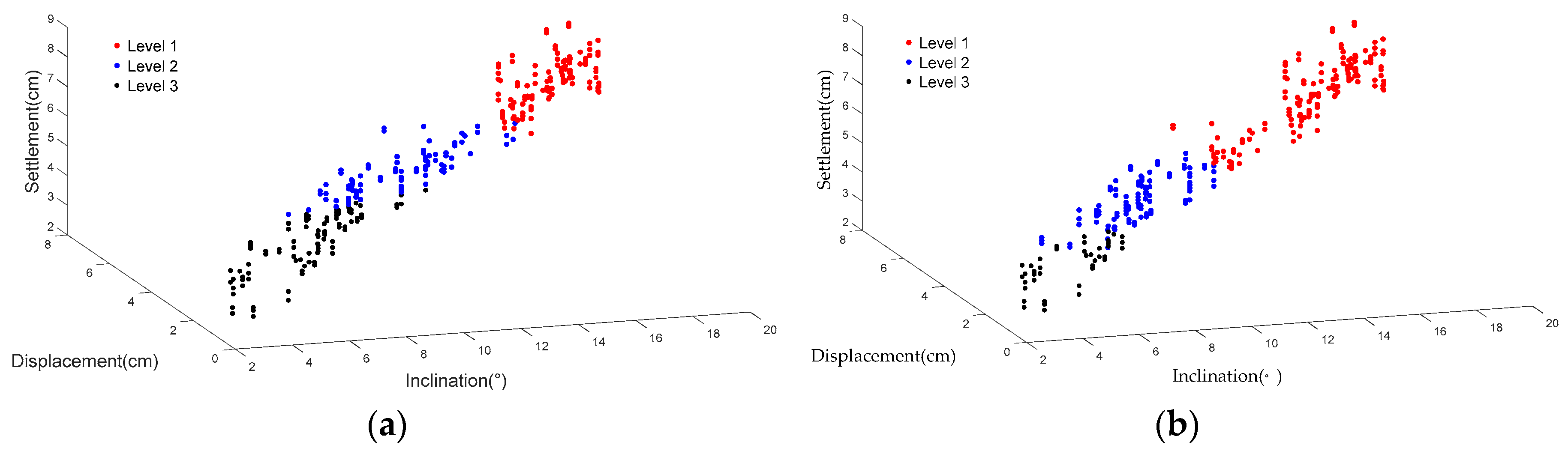
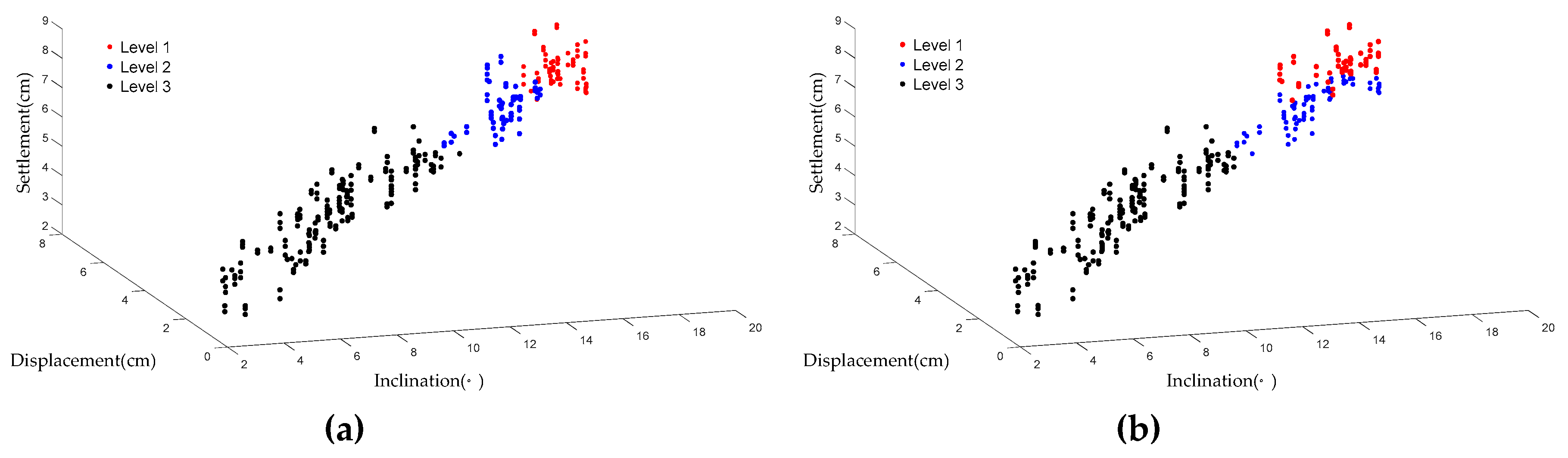
was reduced from 0.1 to 0.01, and the neighborhood radius was reduced from 1.5 to 0.4. Two thousand (2000) loops were run to adjust the learning rate and the neighborhood radius until the network converged. The number of training loops for initial covering of the input space was determined by the neighborhood radius and the learning rate. In this case, about after 200 training loops, a satisfactory result can be given when compared with the empirical damage level classification. If more training loops are set, then a more precise result will be given. After several training processes, the measurement data were classified by the KNN model. The results show that the damage level classification of the KNN model demonstrated two main classification patterns, as shown in
Figure 14 and
Figure 15.
In the KNN training process, the weights
Wij were randomly initialized, so the winner neuron might be different for the same data set in different simulation processes, as can be seen in
Figure 14a,b and
Figure 15a,b. In the classification pattern (I), about half of the data sets were evaluated as Level 1, while in pattern (II), about half of the data sets were evaluated as Level 3. That indicates that the classification criteria in pattern (I) were much stricter than in pattern (II). For spur dikes, relatively strict classification criteria are helpful for maintaining the river training structures; therefore, the classification pattern (I) and its classification criteria were preferred for this research.
With regard to the classification pattern (I), the results of different training processes with the same model parameters were not exactly the same, as shown in
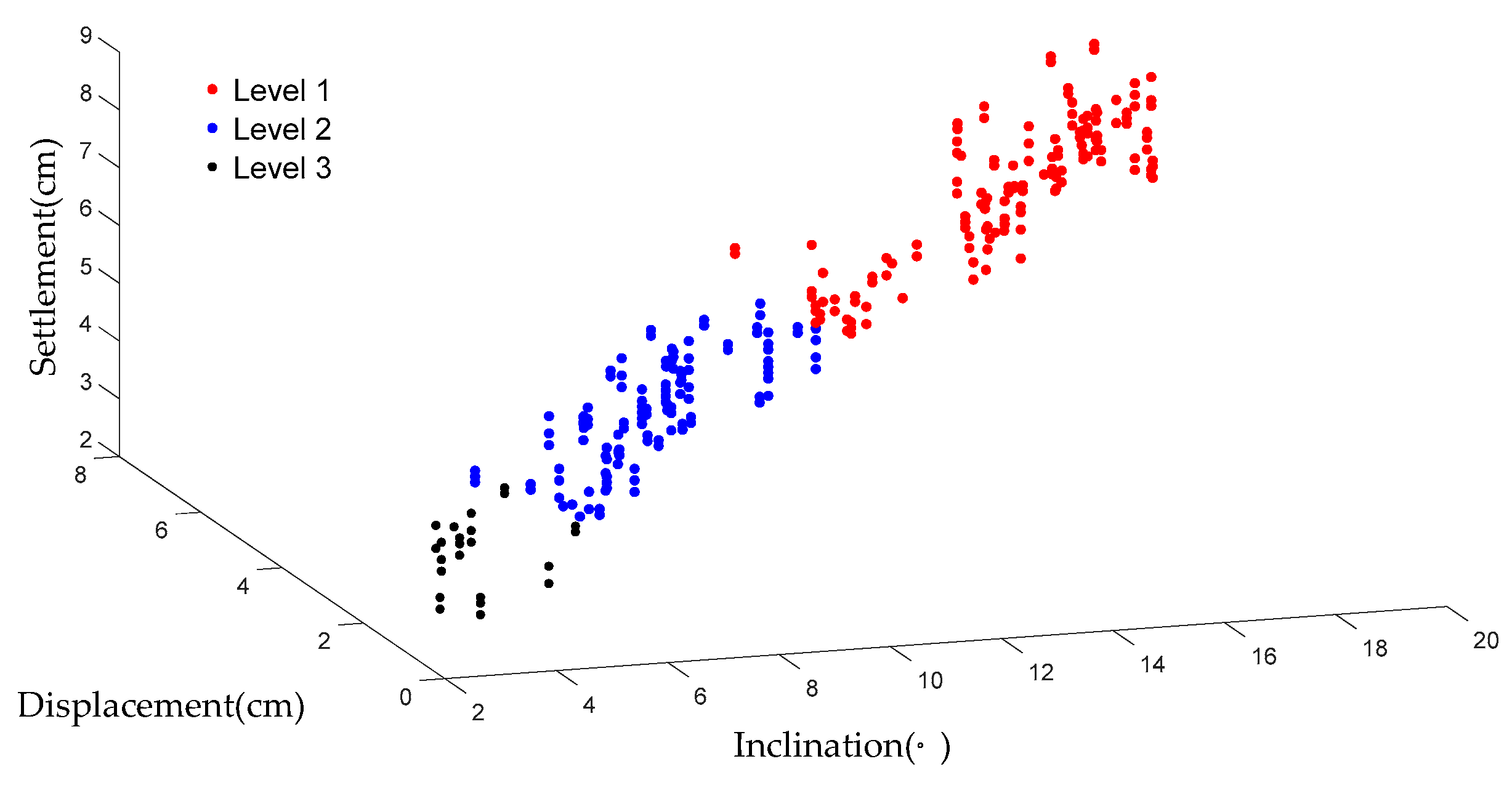
Figure 14a,b, especially for the data sets near the critical values of damage between different damage levels. A stable output of damage level prediction is necessary in practical engineering, so the predicted damage levels of the KNN model together with the corresponding experiment data were input to the SVM model to conduct supervised training. To train the SVM model, 50 sets of the classification pattern (I) results together with the corresponding experiment data were used as the training data of the SVM model. After the learning process, the damage levels were classified by the SVM model and are shown in
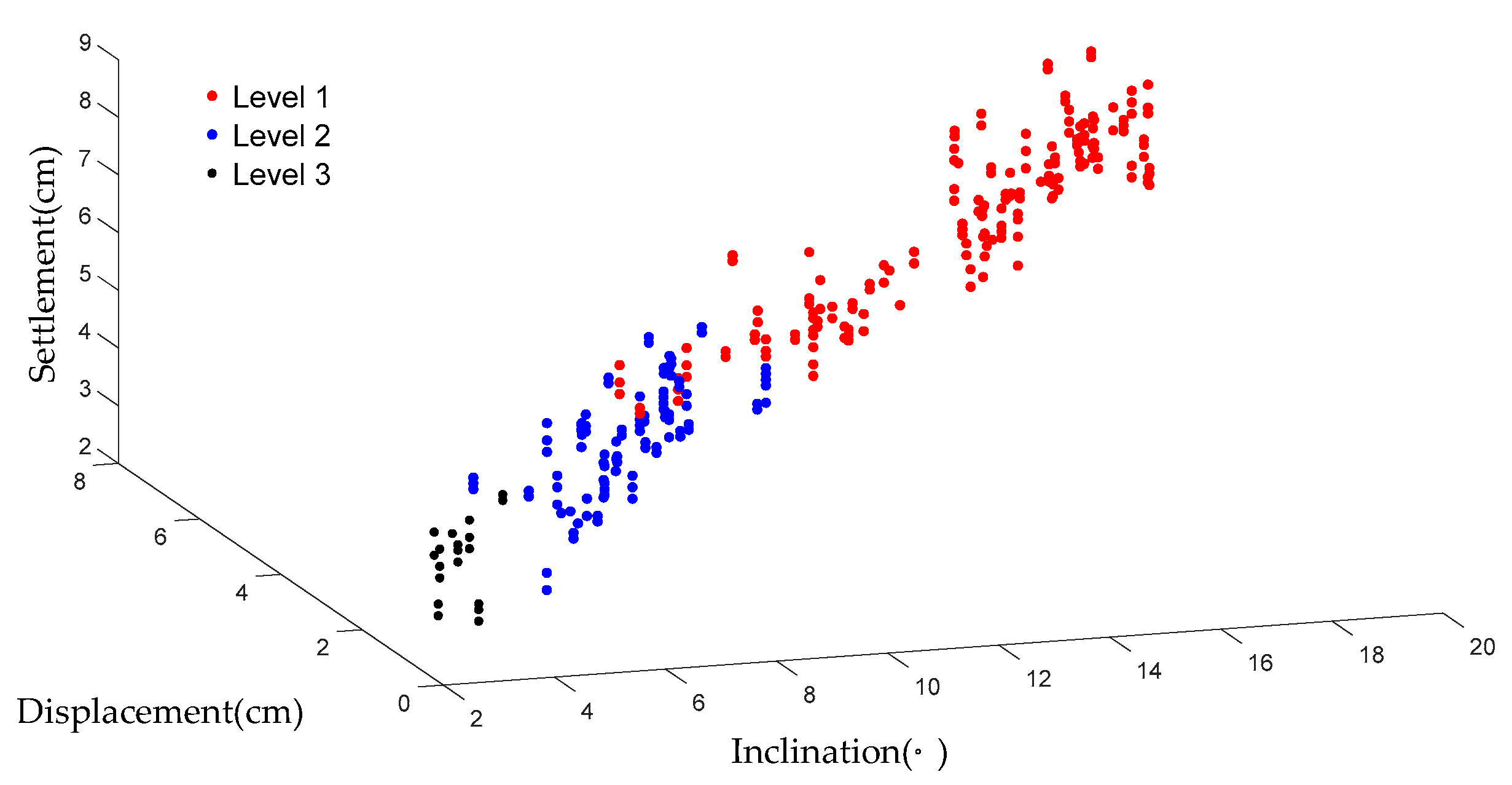
Figure 16. The damage levels classified according to the empirical criteria are shown in
Figure 17. It can be seen from the comparison between
Figure 16 and
Figure 17 that most of the damage levels classified by the model and the empirical approach were the same. The data sets whose damage levels were evaluated differently by the model and the empirical approach lay in the critical range between different damage levels. This indicates that the classification criteria of the model were slightly different from the empirical classification criteria.
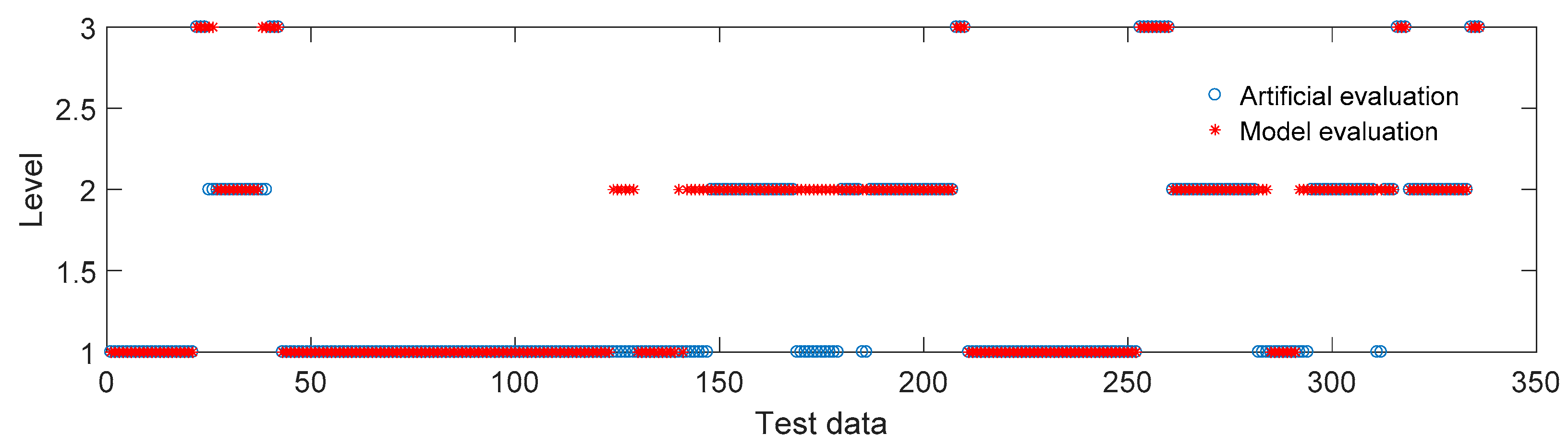
The comparison between the damage levels classified by the unsupervised model and the empirical approach is shown in
Figure 18. The damage levels evaluated by the model and the empirical approach of 298 data sets, which was 88.7% of the 336 data sets in total, were the same. As for the remaining 38 data sets, most of the damage levels evaluated by the empirical approach were higher than the damage levels evaluated by the model as shown in
Figure 18. This indicates that the empirical classification criteria (
Table 4) were slightly stricter than the classification criteria of the unsupervised model. The potential risk of using the KNN-SVM model for extrapolating the damage level of other structures is the uncertain winner neuron for the same training data in different training processes, and this would lead to different classification results. Then, an empirical evaluation result needs to be provided as a reference.
4. Conclusions
A supervised support vector machine model was built based on the empirical damage level evaluation results. The high accuracy achieved in predicting the damage levels of the validation data sets indicated that the trained SVM model can be an effective tool for evaluating the practical damage level of spur dikes with tooth-shaped structures.
An advanced unsupervised evaluation method, namely the KNN-SVM model, was proposed. The data-mining algorithm Kohonen neural network was selected to initially classify the damage levels. Then, the SVM model was adopted to learn from the results predicted by KNN, and stable evaluation results were achieved. The prediction of the model agreed well with the empirical evaluation results. The KNN-SVM model can be an effective method to evaluate the damage level of spur dikes and other similar structures. Meanwhile, the result predicted by the unsupervised data-mining model could be a reference for the stability study of spur dikes with tooth-shaped structures.
In this paper, the model inputs only included the displacement, settlement, and inclination of the spur dike. In a further study, more parameters of the spur dike will be considered to develop a more practical KNN-SVM model to evaluate the damage level of a spur dike.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}