Water Quality Prediction Model of a Water Diversion Project Based on the Improved Artificial Bee Colony–Backpropagation Neural Network

Abstract
:1. Introduction
2. Research Methods
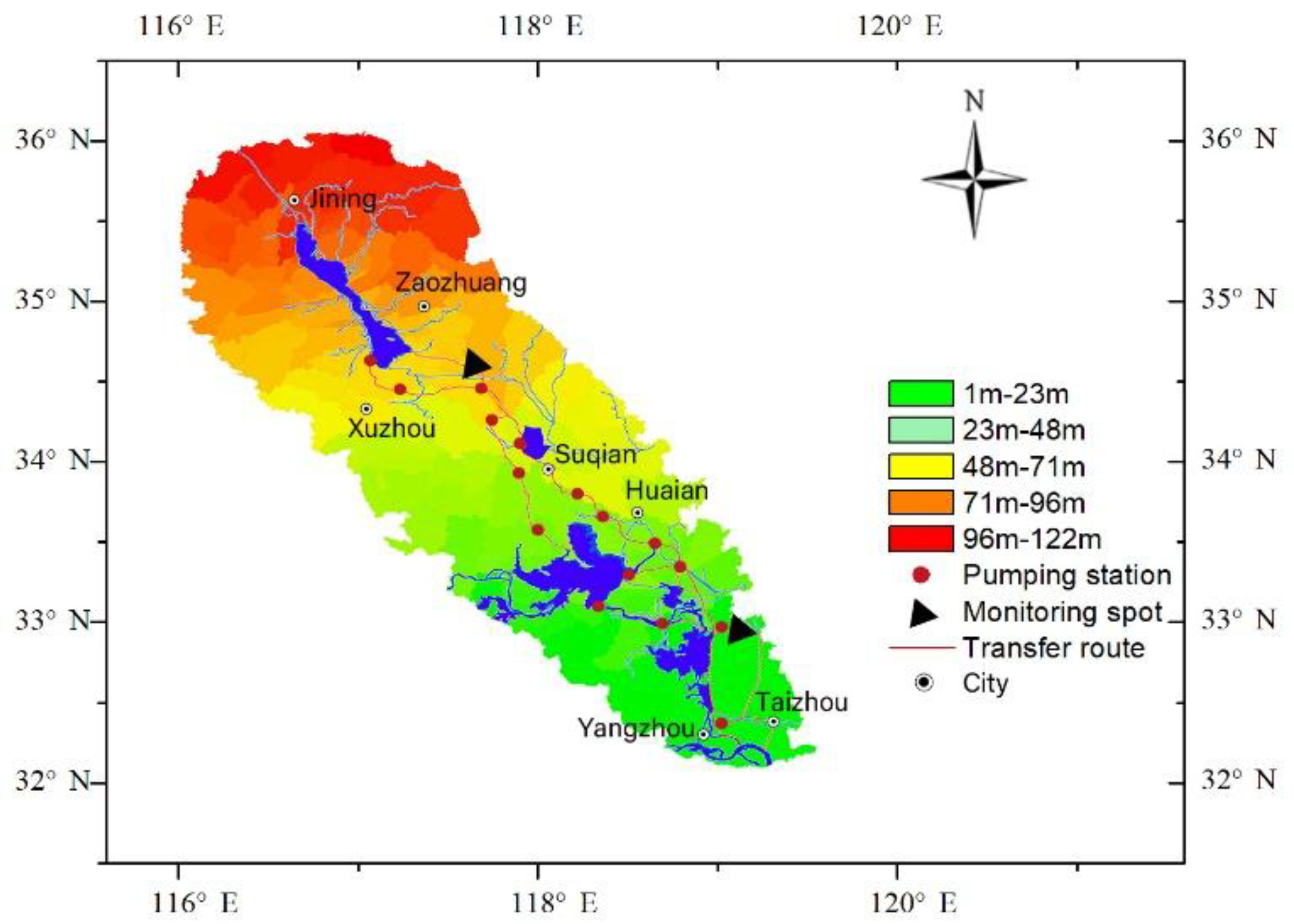
2.1. Research Area
2.2. Research Data
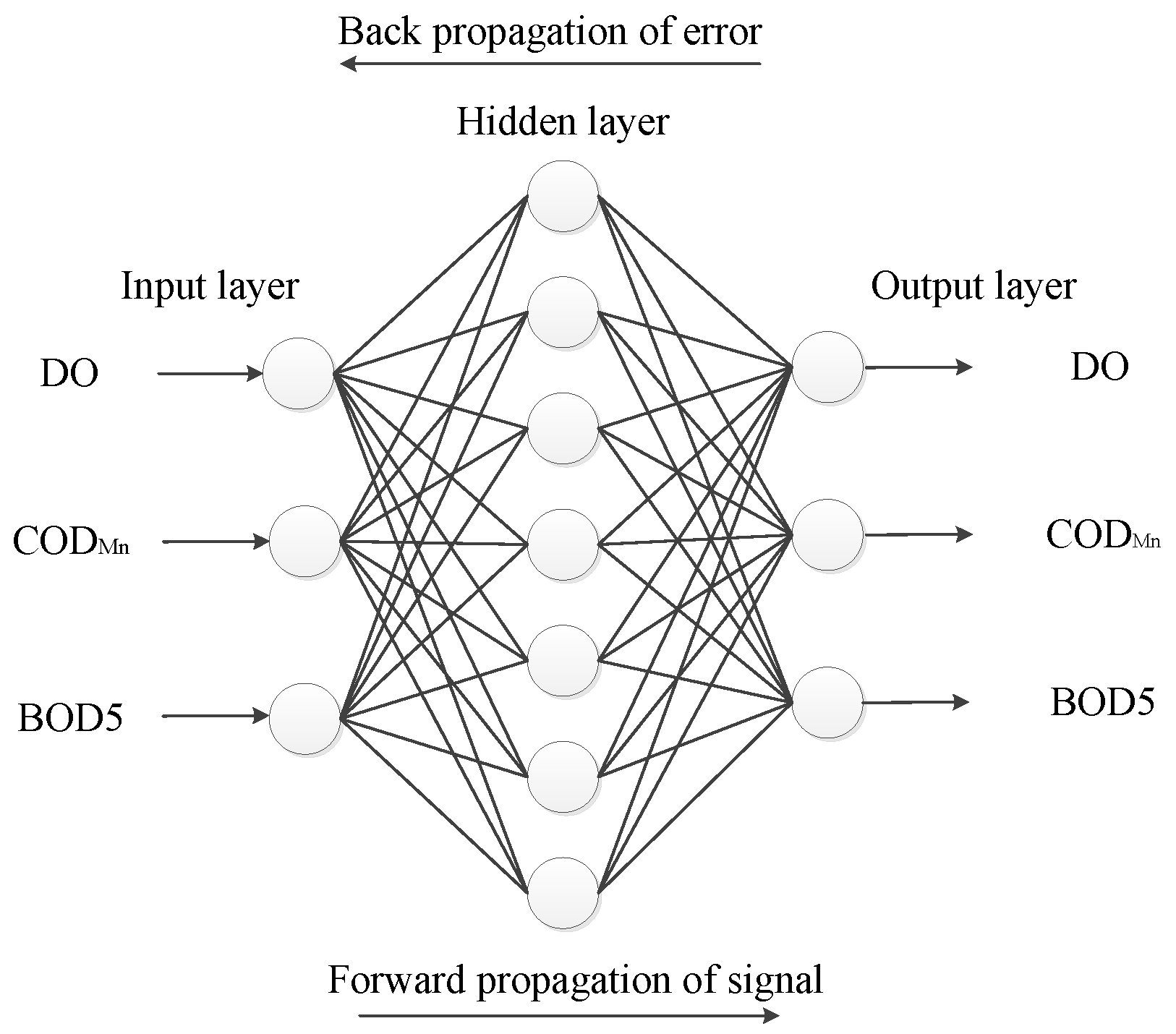
2.3. Principle of Backpropagation Neural Network
2.4. Principle of the Artificial Bee Colony Algorithm
2.5. ABC-BP Neural Network Model
3. Research Design and Process
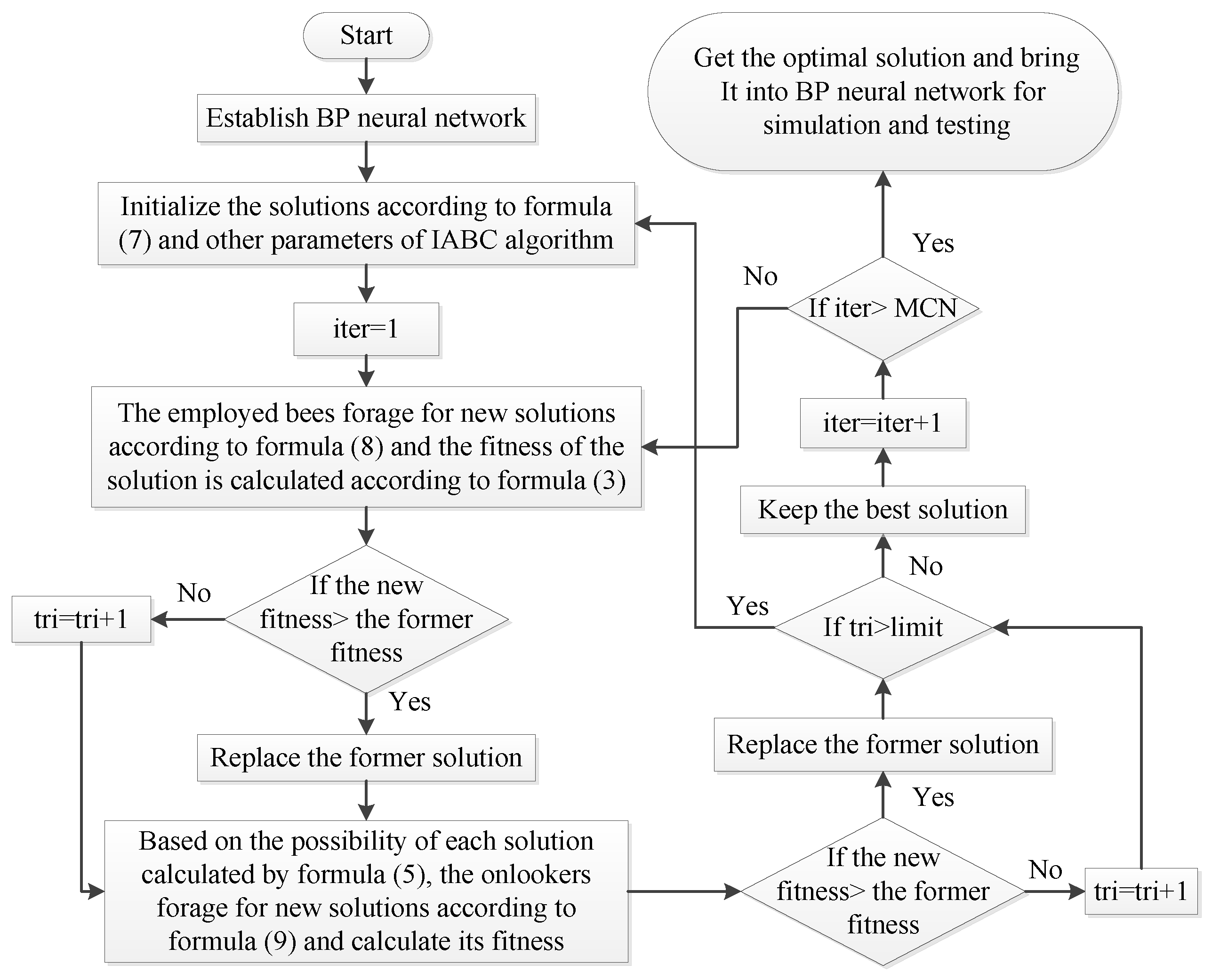
3.1. An Improved Artificial Bee Colony Algorithm
3.1.1. Defects of the ABC Algorithm
3.1.2. Improvement of ABC Algorithm
3.2. Experiment Setting
3.2.1. Objective Function
3.2.2. Parameters Initialization of the IABC-BP Algorithm
3.3. Result Verification
3.3.1. Relative Error
3.3.2. Coefficient of Determination
3.3.3. Nash–Sutcliffe Efficiency Coefficient
4. Results and Analyses
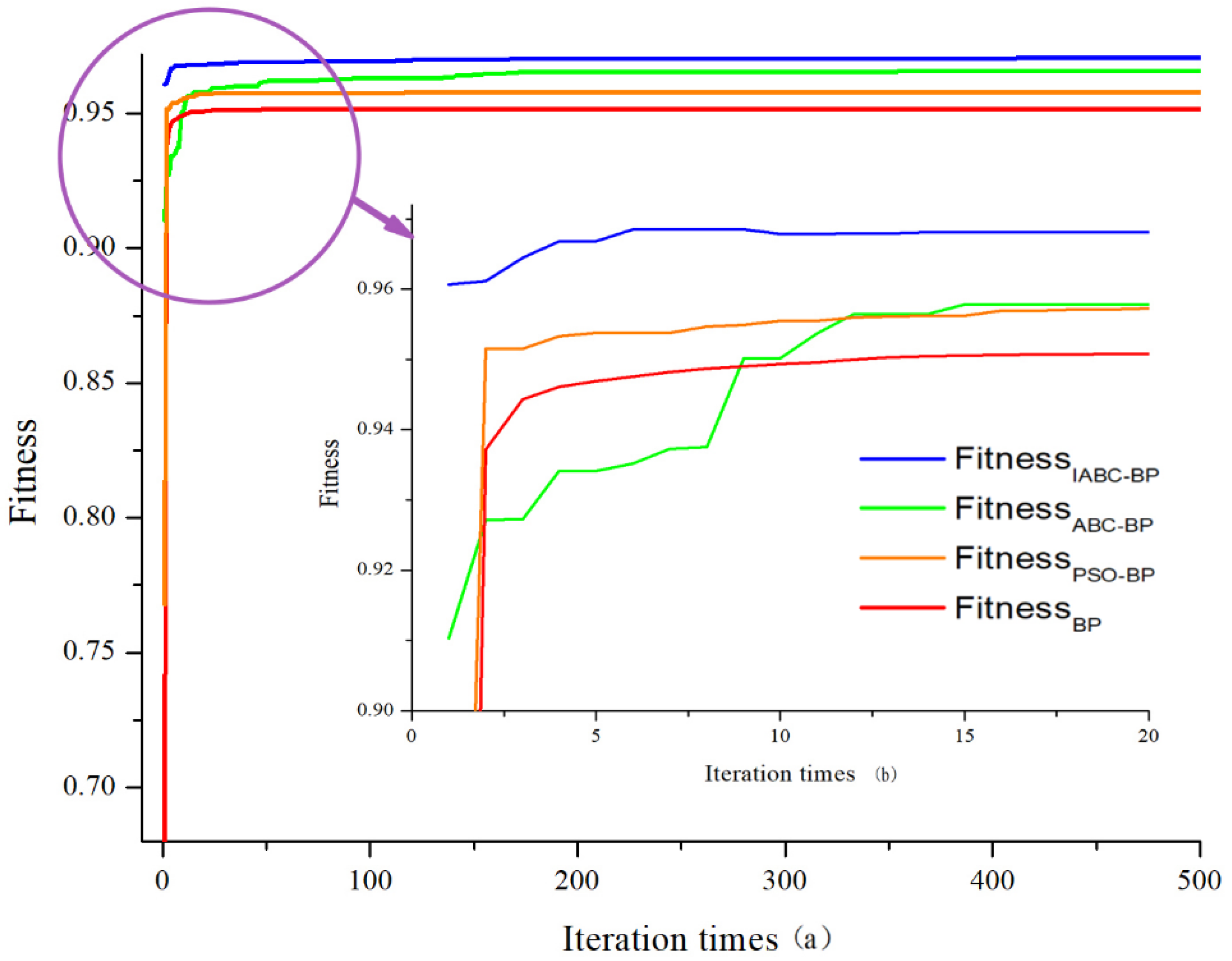
4.1. Convergence Performance Analysis
4.1.1. Convergence Accuracy
4.1.2. Convergence Speed
4.2. Results Analysis
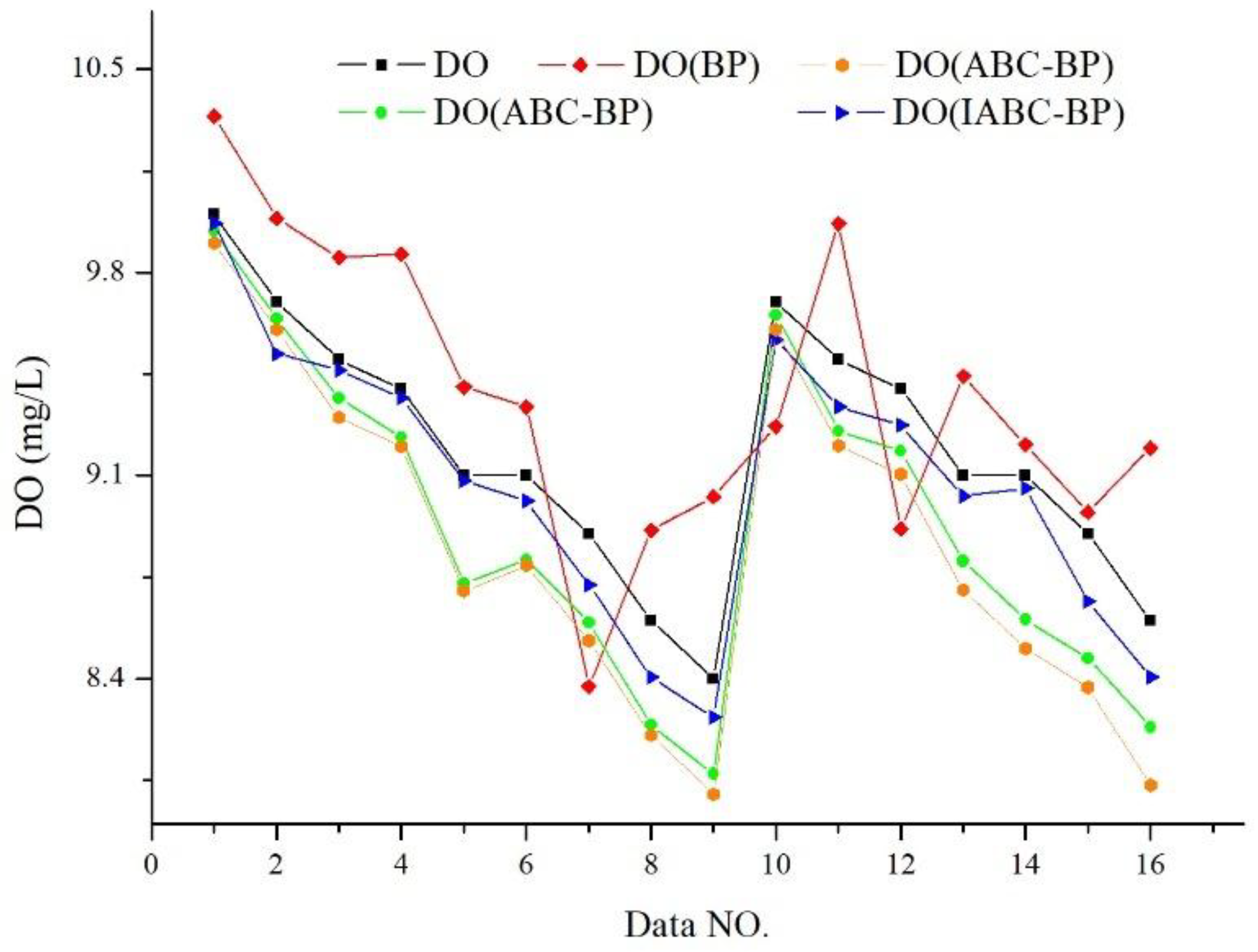
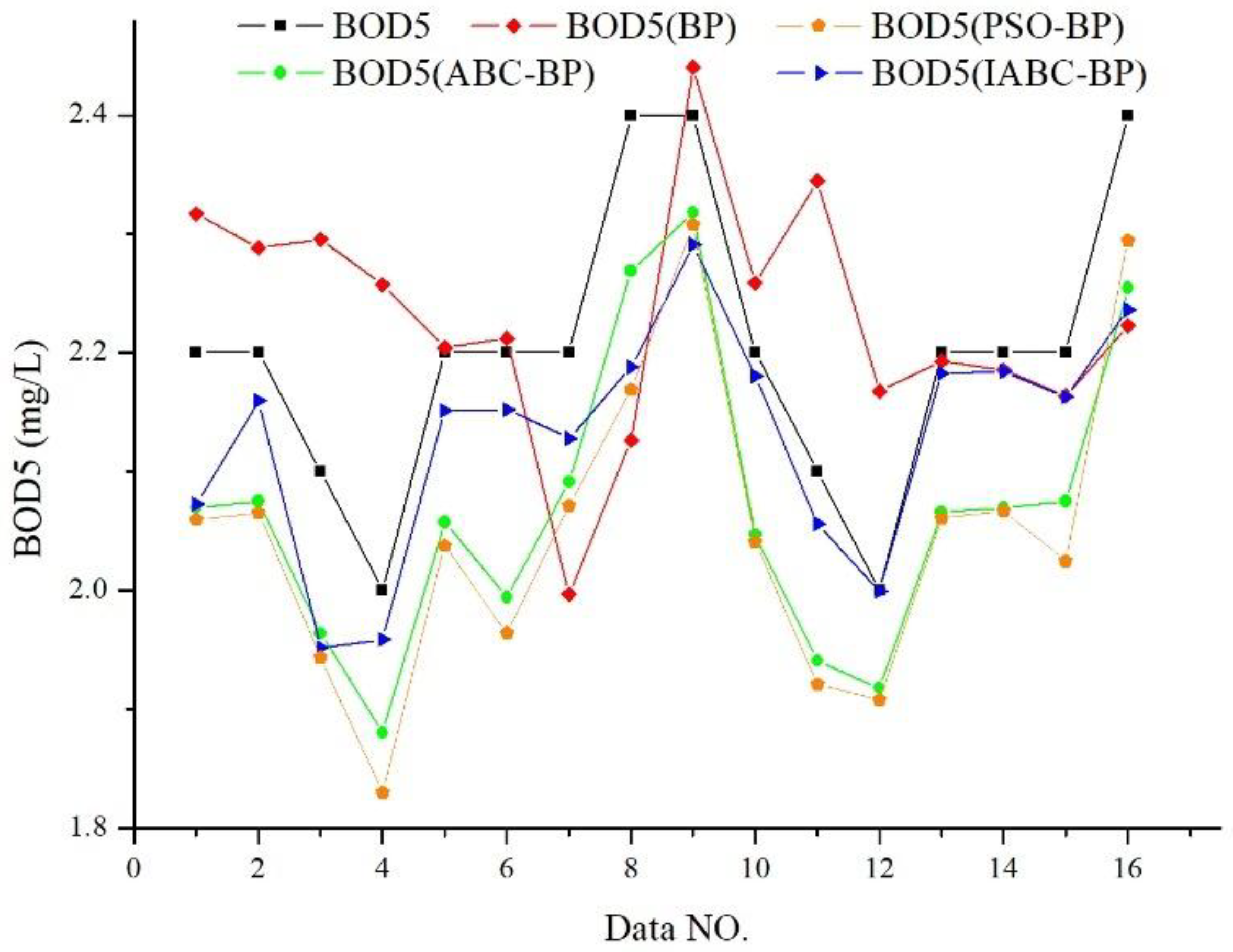
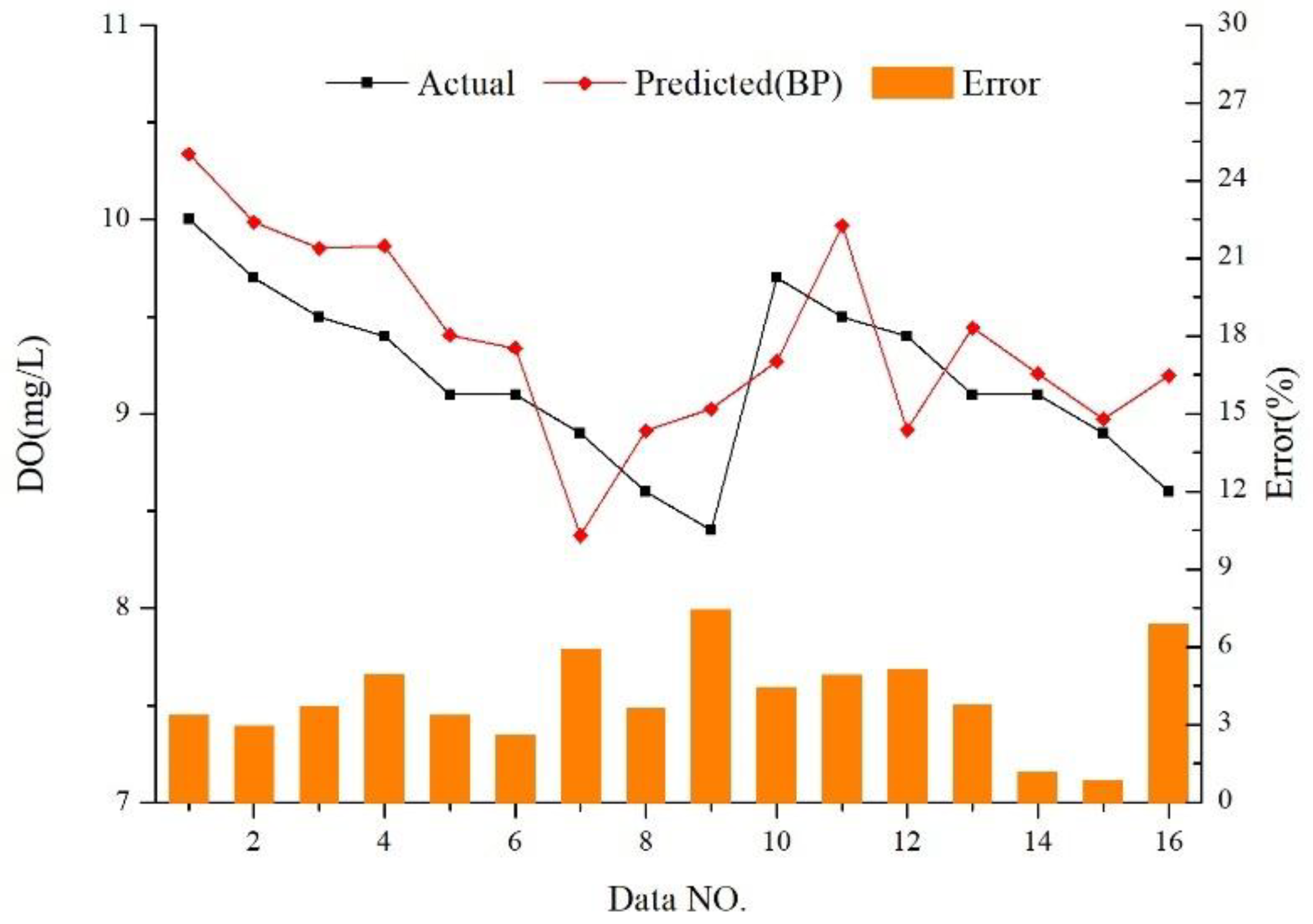
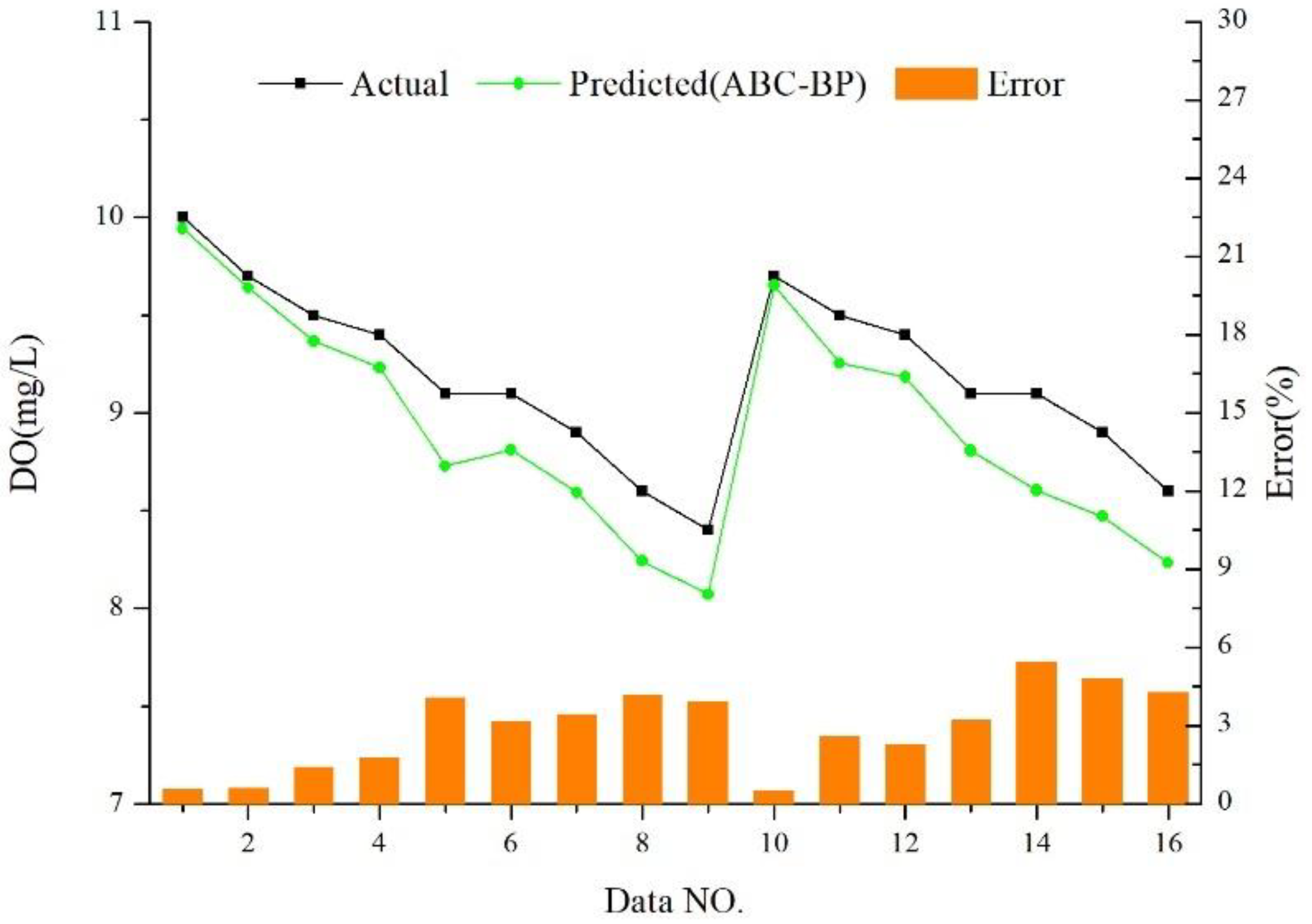
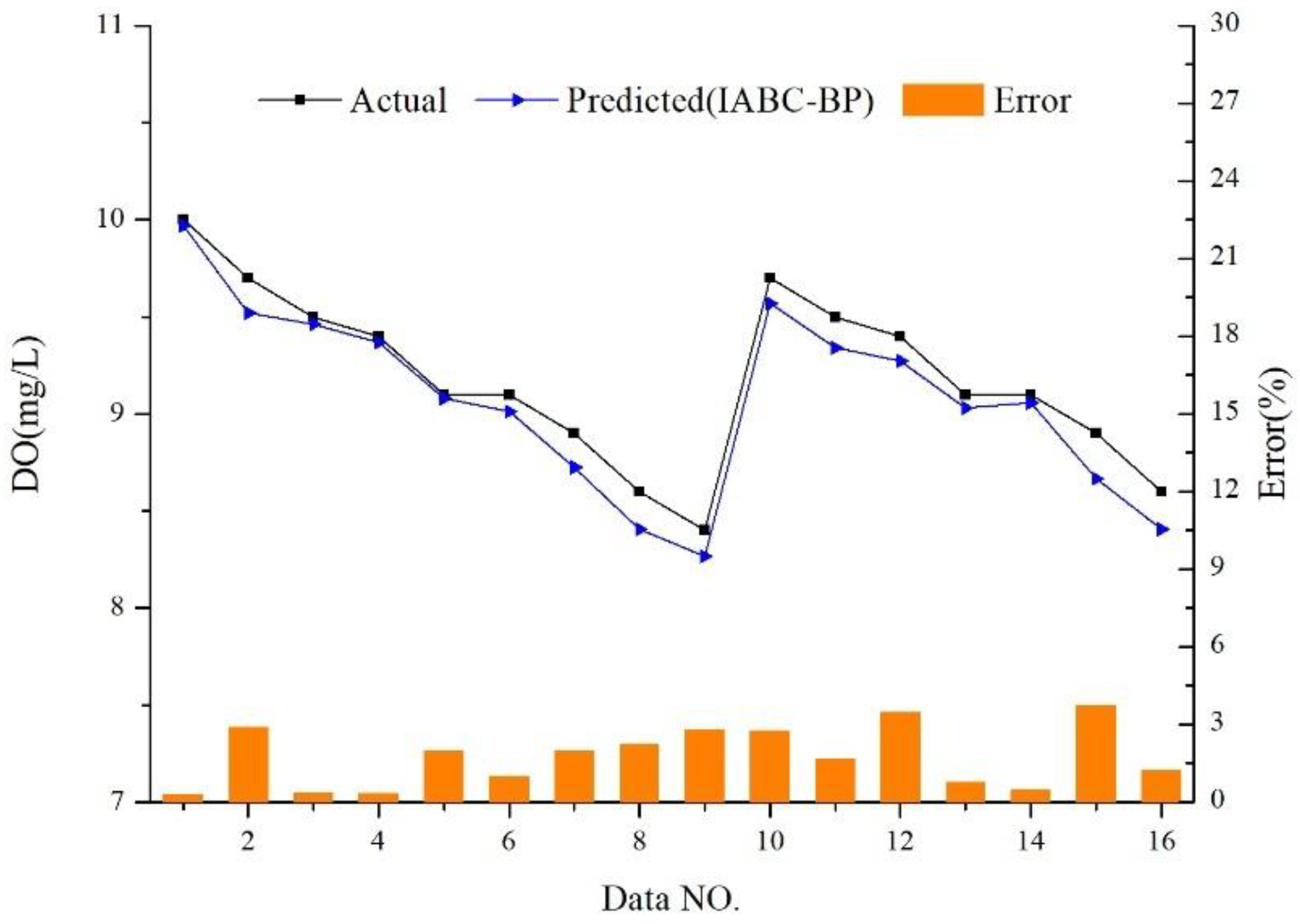
4.2.1. Relative Error (RE)
4.2.2. Coefficient of Determination
4.2.3. Nash–Sutcliffe Efficiency Coefficient (NSE)
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, Y.S.; Liu, W.J.; Wu, Y.Y.; Wang, D. A review of progress in research on water quality models in America. Water Resour. Hydropower Eng. 2006, 2, 15. (In Chinese) [Google Scholar]
- Xiang, N. Exploration for Water Quality Assessment and Prediction based on Neural Networks and Artificial Bee Colony Algorithm. Ph.D. Thesis, South China University of Technology, Guangzhou, China.
- Qiu, L.; Huang, X.; Li, H.L. Comprehensive water quality prediction based on fuzzy weight Markov model. Yangtze River 2007, 38, 75–77. (In Chinese) [Google Scholar]
- Lettenmaier, D.P. Detection of trends in water quality data from records with dependent observations. Water Resour. Res. 1976, 12, 1037–1046. [Google Scholar] [CrossRef]
- Liang, J. Application of Support Vector Machine in Water Quality Evaluation and Prediction. Ph.D. Thesis, Zhejiang University of Technology, Hangzhou, China, 2009. [Google Scholar]
- Ju, Z.C.; Wang, X.; Gong, Y.X. Prediction of water quality in Yellow River based on BP neural network model. J. Qinghai Univ. 2017, 35, 88–92. [Google Scholar]
- Yang, Y.M. Researches on Extreme Learning Theory for System Identification and Applications. Ph.D. Thesis, Hunan University, Changsha, China, 2013. [Google Scholar]
- Maier, H.R.; Dandy, G.C. The use of artificial neural networks for the prediction of water quality parameters. Water Resour. Res. 1996, 32, 1013–1022. [Google Scholar] [CrossRef]
- Cao, J.H.; Lin, H.W.; Zhang, S.C. Prediction of water quality index in Danjiangkou reservoir based on BP neural network. Electron. Des. Eng. 2010, 18, 17–19. (In Chinese) [Google Scholar]
- Chang, Q.C. BP neural network improved algorithm to predict the application of water quality. Gansu Environ. Study Monit. 2002, 3, 186–188. (In Chinese) [Google Scholar]
- Chen, D.Y.; Zhang, X.Z. Application of variable structure neural network in prediction of future water quality parameters. Sci. Technol. Eng. 2008, 1577–1579. (In Chinese) [Google Scholar]
- Singh, K.P.; Basant, A.; Malik, A.; Jain, G. Artificial neural network modeling of the river water quality—A case study. Ecol. Model. 2009, 220, 888–895. [Google Scholar] [CrossRef]
- Zheng, G.Y.; Luo, F.; Chen, W.B. Quality prediction of waste water treatment based on Immune Particle Swarm Neural Networks. Microprocessors 2010, 31, 75–77. (In Chinese) [Google Scholar]
- Gao, F.; Feng, M.Q.; Teng, S.F. On the way for forecasting the water quality by BP neural network based on the PSO. J. Saf. Environ. 2015, 15, 338–341. [Google Scholar]
- Zhang, X.D.; Gao, M.T. Water quality prediction method based on IGA-BP. Chin. J. Environ. Eng. 2016, 10, 1566–1571. [Google Scholar]
- Wang, Z.; Shao, D.; Yang, H.; Yang, S. Prediction of water quality in South to North Water Transfer Project of China based on GA-optimized general regression neural network. Water Sci. Technol. Water Supply 2015, 15, 150–157. [Google Scholar] [CrossRef]
- Huo, J.; Liu, L.; Zhang, Y. An improved multi-cores parallel artificial Bee colony optimization algorithm for parameters calibration of hydrological model. Future Gener. Comput. Syst. 2018, 81, 492–504. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. On the performance of artificial bee colony (ABC) algorithm. Appl. Soft Comput. 2008, 8, 687–697. [Google Scholar] [CrossRef]
- Karaboga, D.; Akay, B. A comparative study of artificial bee colony algorithm. Appl. Math. Comput. 2009, 214, 108–132. [Google Scholar] [CrossRef]
- Su, C.H.; Xiang, N.; Chen, G.Y.; Wang, F. Water quality evaluation model based on artificial bee colony algorithm and BP neural network. Chin. J. Environ. Eng. 2012, 6, 699–704. [Google Scholar]
- Zhang, Z.S.; Hu, Y.G.; Zhao, H.W.; Feng, Y.Z.; Feng, P.Q. A Study on the Improved Genetic Algorithm and Its Implementation. Microelectronics 2002, 32, 273–275. [Google Scholar]
- Bao, L.; Zeng, J.C. A bi-group differential artificial bee colony algorithm. Control Theory Appl. 2011, 28, 266–272. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifi-cation | pH (Non-Dimensional) | DO ≥ (mg/L) | CODMn ≤ (mg/L) | NH3-N ≤ (mg/L) | Petroleum ≤ (mg/L) | Volatile Phenol ≤ (mg/L) | BOD5 ≤ (mg/L) |
|---|---|---|---|---|---|---|---|
| I | 6~9 | 7.5 | 2 | 0.15 | 0.05 | 0.002 | 3 |
| II | 6~9 | 6 | 4 | 0.5 | 0.05 | 0.002 | 3 |
| III | 6~9 | 5 | 6 | 1.0 | 0.05 | 0.005 | 4 |
| IV | 6~9 | 3 | 10 | 1.5 | 0.5 | 0.01 | 6 |
| V | 6~9 | 2 | 15 | 2.0 | 1.0 | 0.1 | 10 |
| Parameters | Max | Min | Mean | Std. Dev. | Skewness | Kurtosis |
|---|---|---|---|---|---|---|
| Water temperature (°C) | 19.00 | 6.80 | 14.29 | 4.3245 | 0.0048 | −1.8145 |
| Potential of Hydrogen | 8.21 | 7.76 | 7.99 | 0.1135 | 0.0267 | −0.9186 |
| Dissolved oxygen (mg/L) | 12.40 | 6.30 | 9.19 | 1.5658 | −0.2266 | −0.8880 |
| Permanganate index (mg/L) | 6.00 | 3.00 | 4.81 | 0.6107 | −0.2669 | 0.6001 |
| Biochemical Oxygen Demand of five days (mg/L) | 3.70 | 0.23 | 2.91 | 0.4986 | −0.1729 | −1.2901 |
| Ammonia nitrogen (mg/L) | 0.93 | 1.90 | 0.49 | 0.1206 | 0.0223 | 2.6669 |
| Content of petroleum (mg/L) | <DL | <DL | - | - | - | - |
| Content of volatile phenol (mg/L) | <DL | <DL | - | - | - | - |
| Iteration Times | FitnessBP | FitnessPSO-BP- | FitnessABC-BP | FitnessIABC-BP |
|---|---|---|---|---|
| 1 | 0.6770 | 0.7678 | 0.9103 | 0.9606 |
| 2 | 0.9372 | 0.9515 | 0.9271 | 0.9611 |
| 3 | 0.9443 | 0.9515 | 0.9272 | 0.9644 |
| 4 | 0.9461 | 0.9533 | 0.9341 | 0.9667 |
| 5 | 0.9469 | 0.9537 | 0.9341 | 0.9667 |
| 10 | 0.9493 | 0.9554 | 0.9501 | 0.9678 |
| 20 | 0.9507 | 0.9572 | 0.9578 | 0.9681 |
| 50 | 0.9514 | 0.9574 | 0.9616 | 0.9690 |
| 100 | 0.9515 | 0.9576 | 0.9632 | 0.9693 |
| 200 | 0.9515 | 0.9577 | 0.9648 | 0.9702 |
| 300 | 0.9515 | 0.9577 | 0.9652 | 0.9704 |
| 400 | 0.9515 | 0.9577 | 0.9656 | 0.9705 |
| 500 | 0.9515 | 0.9577 | 0.9657 | 0.9705 |
| Name of Model | BP | PSO-BP | ABC-BP | IABC-BP |
|---|---|---|---|---|
| 0.658 | 0.918 | 0.942 | 0.981 |
| Name of Model | BP | PSO-BP | ABC-BP | IABC-BP |
|---|---|---|---|---|
| 0.134 | 0.296 | 0.541 | 0.805 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Fang, G.; Huang, X.; Zhang, Y. Water Quality Prediction Model of a Water Diversion Project Based on the Improved Artificial Bee Colony–Backpropagation Neural Network. Water 2018, 10, 806. https://doi.org/10.3390/w10060806
Chen S, Fang G, Huang X, Zhang Y. Water Quality Prediction Model of a Water Diversion Project Based on the Improved Artificial Bee Colony–Backpropagation Neural Network. Water. 2018; 10(6):806. https://doi.org/10.3390/w10060806
Chicago/Turabian StyleChen, Siyu, Guohua Fang, Xianfeng Huang, and Yuhong Zhang. 2018. "Water Quality Prediction Model of a Water Diversion Project Based on the Improved Artificial Bee Colony–Backpropagation Neural Network" Water 10, no. 6: 806. https://doi.org/10.3390/w10060806
APA StyleChen, S., Fang, G., Huang, X., & Zhang, Y. (2018). Water Quality Prediction Model of a Water Diversion Project Based on the Improved Artificial Bee Colony–Backpropagation Neural Network. Water, 10(6), 806. https://doi.org/10.3390/w10060806