Flood Hydrograph Prediction Using Machine Learning Methods





Abstract
:1. Introduction
2. Material and Methods
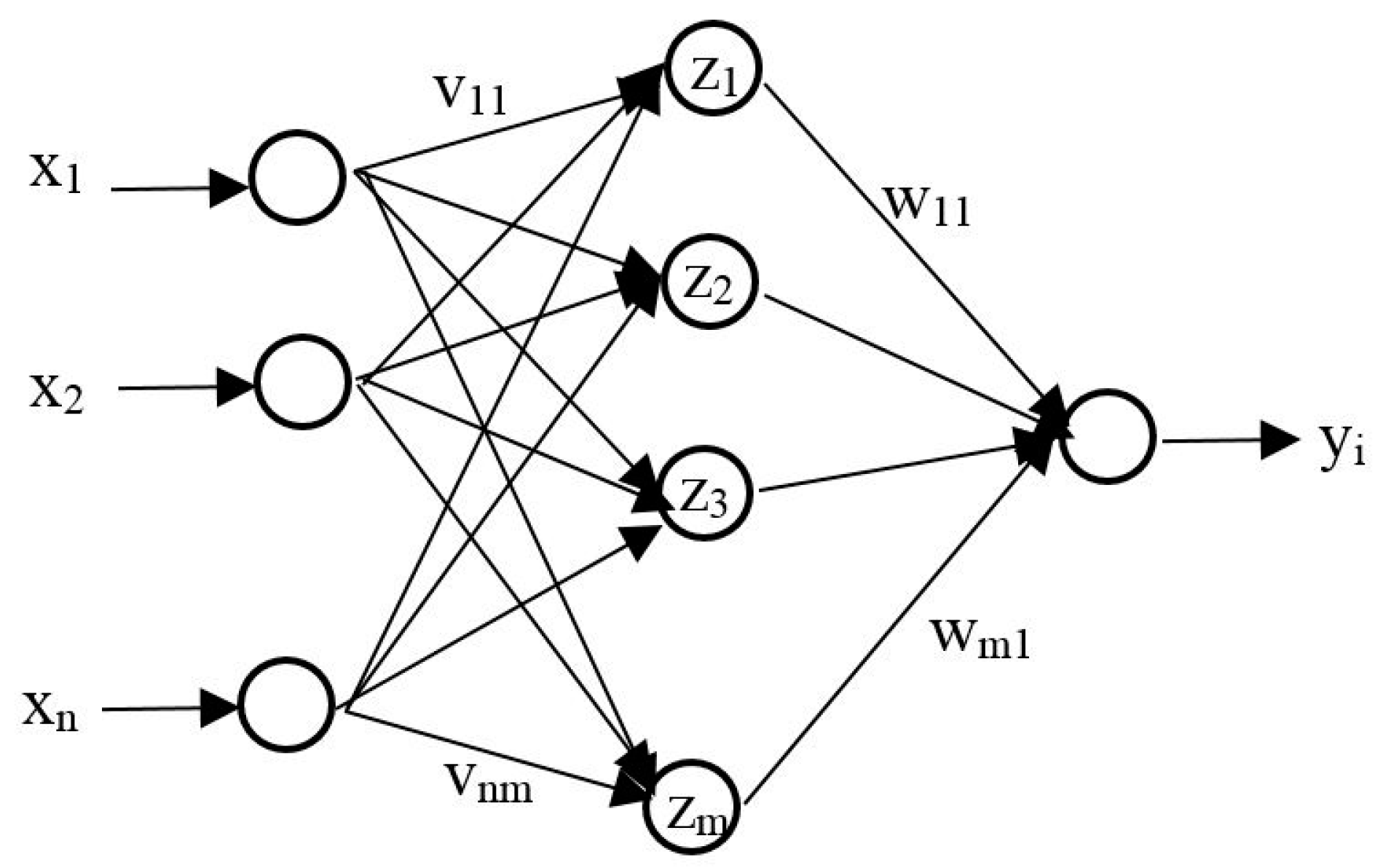
2.1. Artificial Neural Network (ANN)
2.2. Genetic Algorithm (GA)
2.3. Particle Swarm Optimization (PSO)
2.4. Ant Colony Optimization (ACO)
2.5. Data and Catchment
3. Results and Discussion
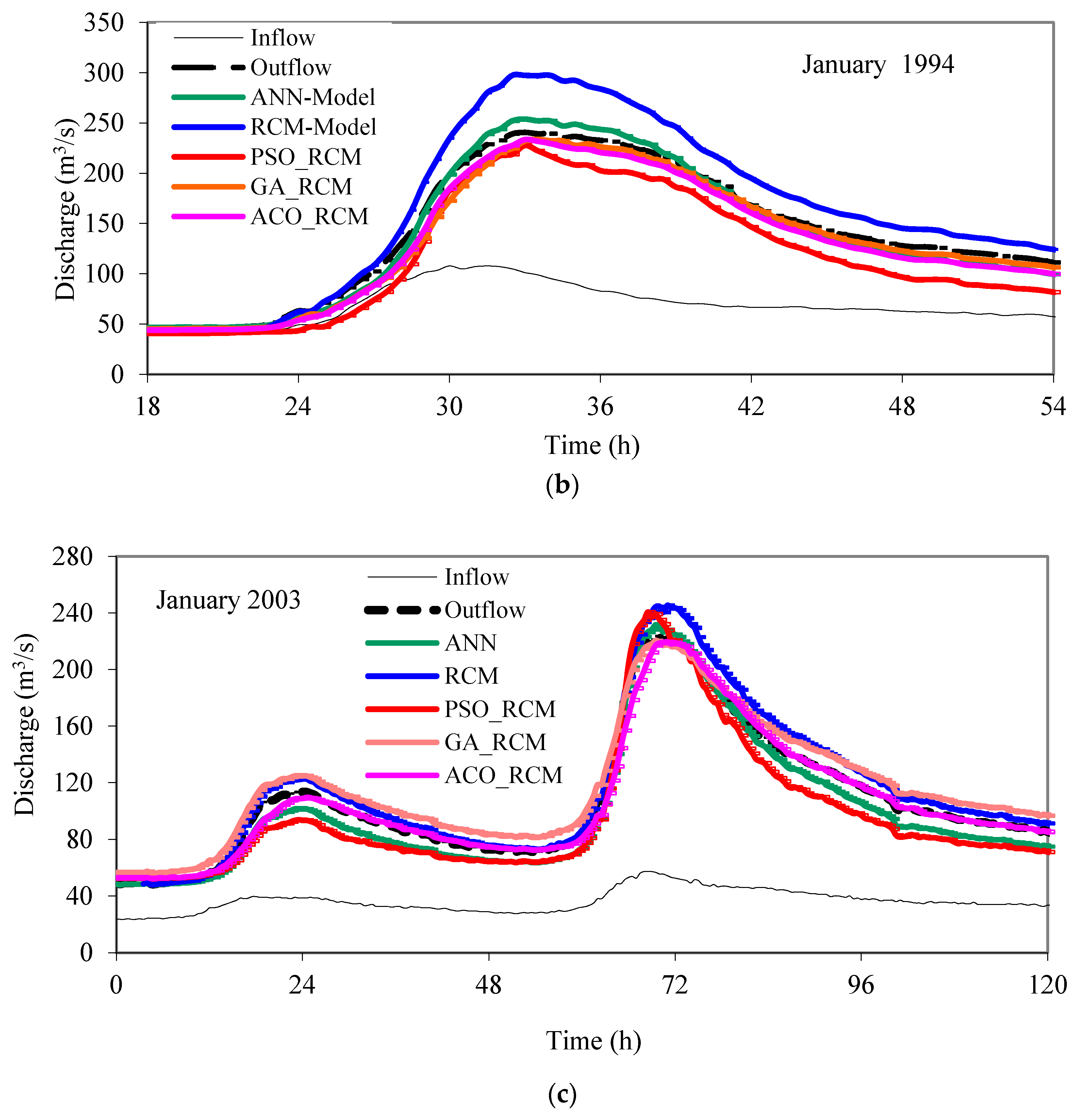
3.1. Real Hydrograph Predictions
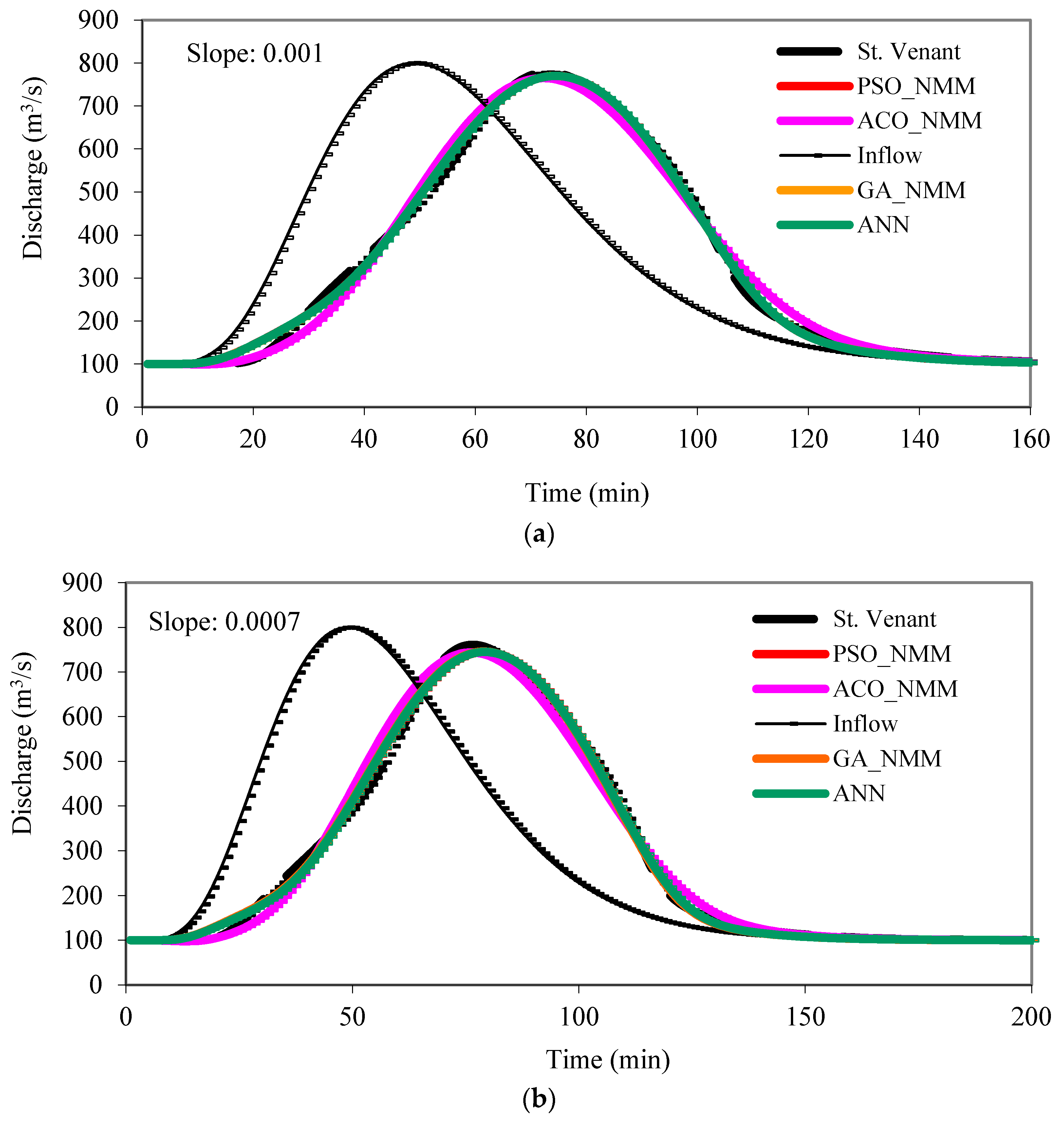
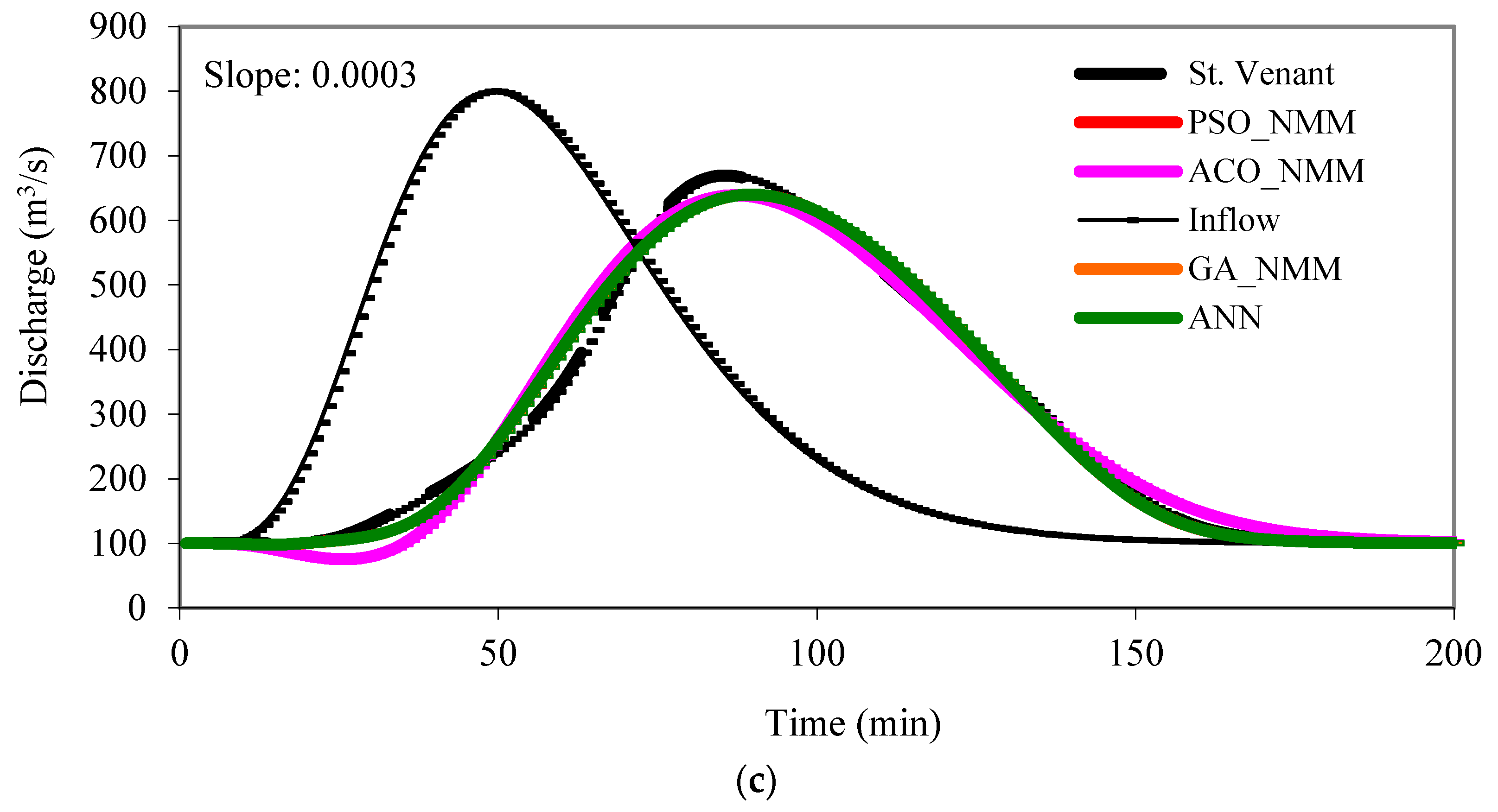
3.2. Hydrograph Predictions in an Artificial Channel Reach
4. Concluding Remarks
- Machine learning methods can make good predictions of flood hydrographs, using substantially less data, such as easily measurable flow stage. Hence, they can be conveniently adopted for predictions in poorly gauged stations, which is the common case in developing countries. The machine learning methods can be employed in conjunction with the physically based models employing the data acquired by newly developed technologies (the remote sensing, satellite).
- It is proved by using field data that machine learning algorithms, such as GA, ACO, and PSO are optimization methods without being considered black box models. Since there is a mathematical relation, they both have interpolation and extrapolation capabilities. One more advantage of these models is that one can propose a new equation, such as RCM, provided that it physically makes sense, and by one of these methods, one can find optimal values of the coefficients and exponents of the equation. These methods are robust and efficient and have low computational cost and fast convergence.
- It is shown that RCM model, whose parameters were optimized by the machine learning algorithm, (GA-RCM, PSO_RCM and ACO_RCM), was able to successfully predict event-based individual storm hydrographs having a different magnitude of lateral inflows at the investigated river reach of the Upper Tiber River basin in central Italy. It closely captured the trends, time to peak, and peak rates of the storms with on average, less than 1% and 5% errors, respectively.
- Likewise, the machine learning-based nonlinear Muskingum models (NMM) can successfully be employed for predicting flood hydrographs. They are able to capture the peak discharge values as well as the timing of the peaks and the flood volumes, and the rising and recession limbs of the hydrographs. Their performance is as good as the St. Venant model.
- The use of machine learning for discharge prediction is essential for hydrological practices, considering that often, for many river gauging sites, the maintenance is missing, and streamflow measurements are more and more limited to few strategic gauged river sections. The option to monitor only water levels at gage sites makes these approaches very appealing for their capability to relate, by RCM, local stages and remote discharge.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Henderson, F.M. Open Channel Flow; MacMillan: New York, NY, USA, 1966. [Google Scholar]
- Chaudhry, M.H. Open-Channel Flow; Prentice Hall: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Barbetta, S.; Franchini, M.; Melone, F.; Moramarco, T. Enhancement and comprehensive evaluation of the Rating Curve Model for different river sites. J. Hydrol. 2012, 464–465, 376–387. [Google Scholar] [CrossRef]
- Kundzewicz, Z.W.; Napiorkowski, J.J. Nonlinear models of dynamic hydrology. Hydrol. Sci. J. 1986, 312, 163–185. [Google Scholar] [CrossRef]
- Barbetta, S.; Moramarco, T.; Perumal, M. A Muskingum-based methodology for river discharge estimation and rating curve development under significant lateral inflow conditions. J. Hydrol. 2017, 554, 216–232. [Google Scholar] [CrossRef]
- ASCE Task Committee. Artificial neural networks in hydrology. I: Preliminary concepts. J. Hydrol. Eng. 2000, 5, 115–123. [Google Scholar]
- Tayfur, G. Modern optimization methods in water resources planning, engineering and management. Water Resour. Manag. 2017, 31, 3205–3233. [Google Scholar] [CrossRef]
- Tayfur, G.; Moramarco, T.; Singh, V.P. Predicting and forecasting flow discharge at sites receiving significant lateral inflow. Hydrol. Process. 2007, 21, 1848–1859. [Google Scholar] [CrossRef] [Green Version]
- Tayfur, G.; Moramarco, T. Predicting hourly-based flow discharge hydrographs from level data using genetic algorithms. J. Hydrol. 2008, 352, 77–93. [Google Scholar] [CrossRef] [Green Version]
- Tayfur, G.; Barbetta, S.; Moramarco, T. Genetic algorithm-based discharge estimation at sites receiving lateral inflows. J. Hydrol. Eng. 2009, 14, 463–474. [Google Scholar] [CrossRef]
- Tayfur, G. Soft Computing in Water Resources Engineering: Artificial Neural Networks, Fuzzy Logic, and Genetic Algorithm; WIT Press: Southampton, UK, 2012. [Google Scholar]
- Perumal, M.; Tayfur, G.; Rao, C.M.; Gurarslan, G. Evaluation of a physically based quasi-linear and a conceptually based nonlinear Muskingum methods. J. Hydrol. 2017, 546, 437–449. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Sen, Z. Genetic Algorithm and Optimization Methods; Su Vakfı Yayınları: Istanbul, Turkey, 2004. (In Turkish) [Google Scholar]
- Goldberg, D.E. Computer-Aided Gas Pipeline Operation Using Genetic Algorithms and Rule Learning. Ph.D. Thesis, University of Michigan, Ann Arbor, MI, USA, 1983. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the IEEE International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar] [CrossRef]
- Kumar, D.N.; Reddy, M.J. Multipurpose reservoir operation using particle swarm optimization. J. Water Resour. Plan. Manag. 2007, 133, 192–201. [Google Scholar] [CrossRef]
- Shourian, M.; Mousavi, S.J.; Tahershamsi, A. Basin-wide water resources planning by integrating PSO algorithm and MODSIM. Water Resour. Manag. 2008, 22, 1347–1366. [Google Scholar] [CrossRef]
- Ostadrahimi, L.; Marino, M.A.; Afshar, A. Multi-reservoir operation rules: Multi-swarm PSO-based optimization approach. Water Resour. Manag. 2012, 26, 407–427. [Google Scholar] [CrossRef]
- Moghaddam, A.; Behmanesh, J.; Farsijani, A. Parameters estimation for the new four-parameter nonlinear Muskingum model using the particle swarm optimization. Water Resour. Manag. 2016, 30, 2143–2160. [Google Scholar] [CrossRef]
- Afshar, A.; Shojaei, N.; Sagharjooghifarahani, M. Multiobjective calibration of reservoir water quality modeling using multiobjective particle swarm optimization (MOPSO). Water Resour. Manag. 2013, 27, 1931–1947. [Google Scholar] [CrossRef]
- Dorigo, M. Optimization, Learning and Natural Algorithms. Ph.D. Thesis, Dipartimento di Elettronica, Politecnico di Milano, Milano, Italy, 1992. (In Italian). [Google Scholar]
- Dorigo, M.; Maniezzo, V.; Colorni, A. Ant system: Optimization by a colony of cooperating agents. IEEE Trans. Syst. Man Cybern. Part B Cybern. 1996, 26, 29–41. [Google Scholar] [CrossRef] [PubMed]
- Moramarco, M.; Barbetta, S.; Melone, F.; Singh, V.P. Relating local stage and remote discharge with significant lateral inflow. J. Hydrol. Eng. 2005, 10, 58–69. [Google Scholar] [CrossRef]
- Chow, V.T.; Maidment, D.R.; Mays, L.W. Applied Hydrology; McGraw-Hill: New York, NY, USA, 1988. [Google Scholar]
- Chang, F.J.; Chiang, Y.M.; Ho, Y.H. Multi-step-ahead flood forecasts by neuro-fuzzy networks with effective rainfall-runoff patterns. J. Flood Risk Manag. 2015, 8, 224–236. [Google Scholar] [CrossRef]
- Chang, F.J.; Chen, P.A.; Lu, Y.R.; Huang, E.; Chang, K.Y. Real-time multi-step-ahead water level forecasting by recurrent neural networks for urban flood control. J. Hydrol. 2014, 517, 836–846. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Santa Lucia Station | Ponte Felcino Station | TL (h) | Duration (h) | |||
|---|---|---|---|---|---|---|
| December 1990 | 8 | 418 | 9 | 404 | 2 | 98 |
| January 1994 | 35 | 108 | 50 | 241 | 3 | 122 |
| May 1995 * | 4 | 71 | 8 | 138 | 4 | 217 |
| January 1997 * | 18 | 120 | 36 | 225 | 3 | 77 |
| June 1997 * | 5 | 345 | 10 | 449 | 5 | 114 |
| January 2003 | 24 | 58 | 50 | 218 | 3 | 150 |
| February 2004 * | 22 | 91 | 55 | 276 | 3 | 98 |
| Algorithm | α | β |
|---|---|---|
| GA | 1.22 | −5.86 |
| PSO | 1.20 | −5.90 |
| ACO | 1.23 | −5.84 |
| December 1990 | January 1994 | January 2003 | ||
|---|---|---|---|---|
| EQp (%) | ||||
| ANN | −5 | 4 | 5 | |
| GA_RCM | 10 | −3 | −1 | |
| PSO_RCM | 2 | −4 | 10 | |
| ACO_RCM | 2 | −3 | −2 | |
| RCM | 10 | 10 | 12 | |
| ETp (%) | ||||
| ANN | 0 | 0 | 0 | |
| GA_RCM | 0 | 2 | 0 | |
| PSO_RCM | 0 | 2 | −2 | |
| ACO_RCM | 0 | 2 | 0 | |
| RCM | −10 | −2 | 4 | |
| MAE (m3/s) | Mean | |||
| ANN | 8.5 | 5.6 | 8.7 | 7.6 |
| GA_RCM | 12.7 | 4.4 | 4.7 | 7.3 |
| PSO_RCM | 6.2 | 12.0 | 15.4 | 11.2 |
| ACO_RCM | 4.6 | 3.5 | 9.1 | 5.7 |
| RCM | 10.4 | 13.2 | 14.9 | 12.8 |
| RMSE (m3/s) | Mean | |||
| ANN | 10.3 | 7.0 | 9.2 | 8.8 |
| GA_RCM | 15.7 | 7.1 | 6.1 | 9.6 |
| PSO_RCM | 8.5 | 14.7 | 17.6 | 13.6 |
| ACO_RCM | 6.4 | 6.3 | 9.8 | 7.5 |
| RCM | 16.2 | 17.7 | 15.9 | 16.6 |
| Algorithm | K | x | m |
|---|---|---|---|
| GA | 0.0057 | 0.45 | 2.20 |
| PSO | 0.0056 | 0.45 | 2.21 |
| ACO | 0.0059 | 0.45 | 2.21 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tayfur, G.; Singh, V.P.; Moramarco, T.; Barbetta, S. Flood Hydrograph Prediction Using Machine Learning Methods. Water 2018, 10, 968. https://doi.org/10.3390/w10080968
Tayfur G, Singh VP, Moramarco T, Barbetta S. Flood Hydrograph Prediction Using Machine Learning Methods. Water. 2018; 10(8):968. https://doi.org/10.3390/w10080968
Chicago/Turabian StyleTayfur, Gokmen, Vijay P. Singh, Tommaso Moramarco, and Silvia Barbetta. 2018. "Flood Hydrograph Prediction Using Machine Learning Methods" Water 10, no. 8: 968. https://doi.org/10.3390/w10080968
APA StyleTayfur, G., Singh, V. P., Moramarco, T., & Barbetta, S. (2018). Flood Hydrograph Prediction Using Machine Learning Methods. Water, 10(8), 968. https://doi.org/10.3390/w10080968