A Performance Comparison of Machine Learning Algorithms for Arced Labyrinth Spillways



Abstract
:1. Introduction
1.1. Problem Statement
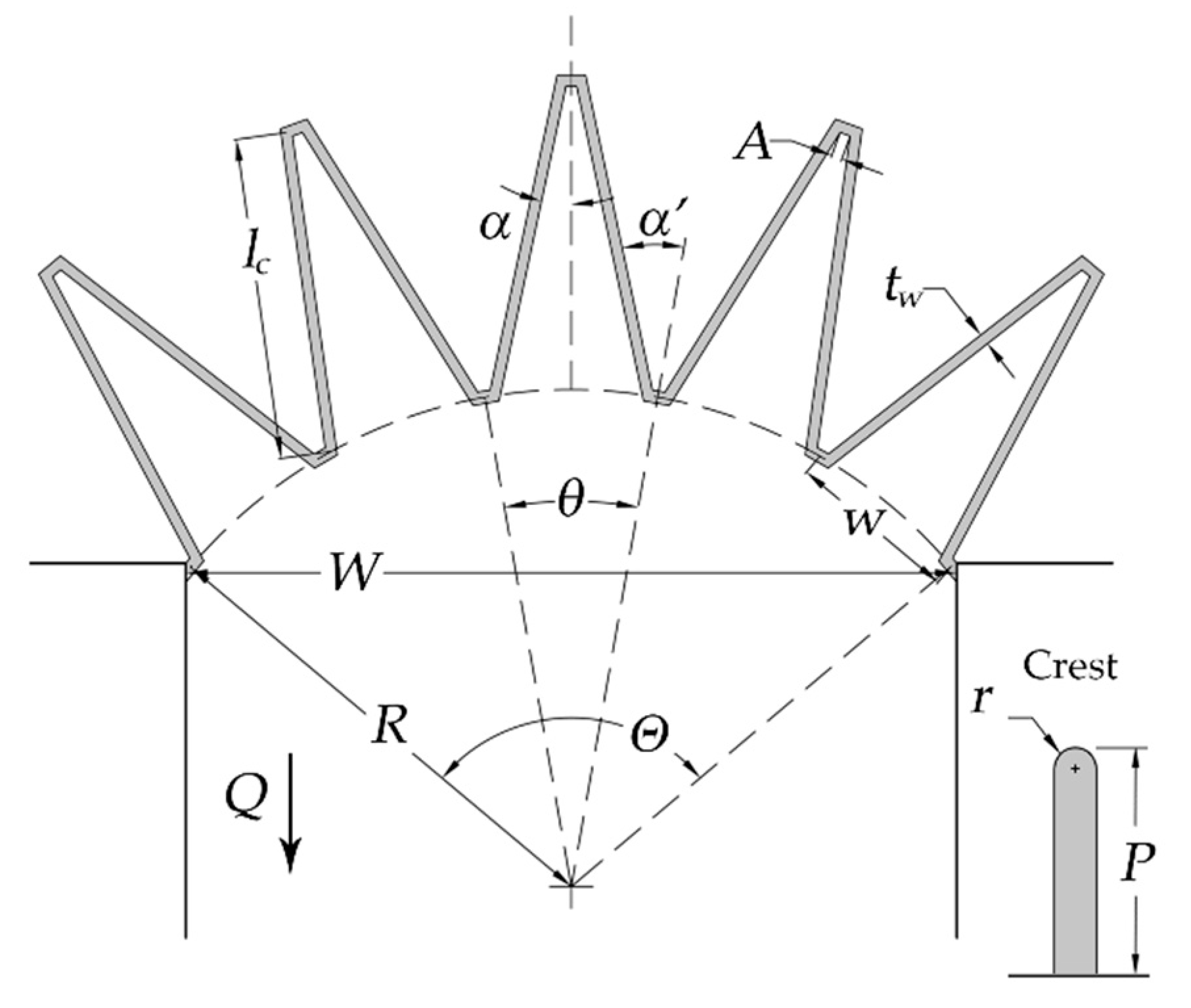
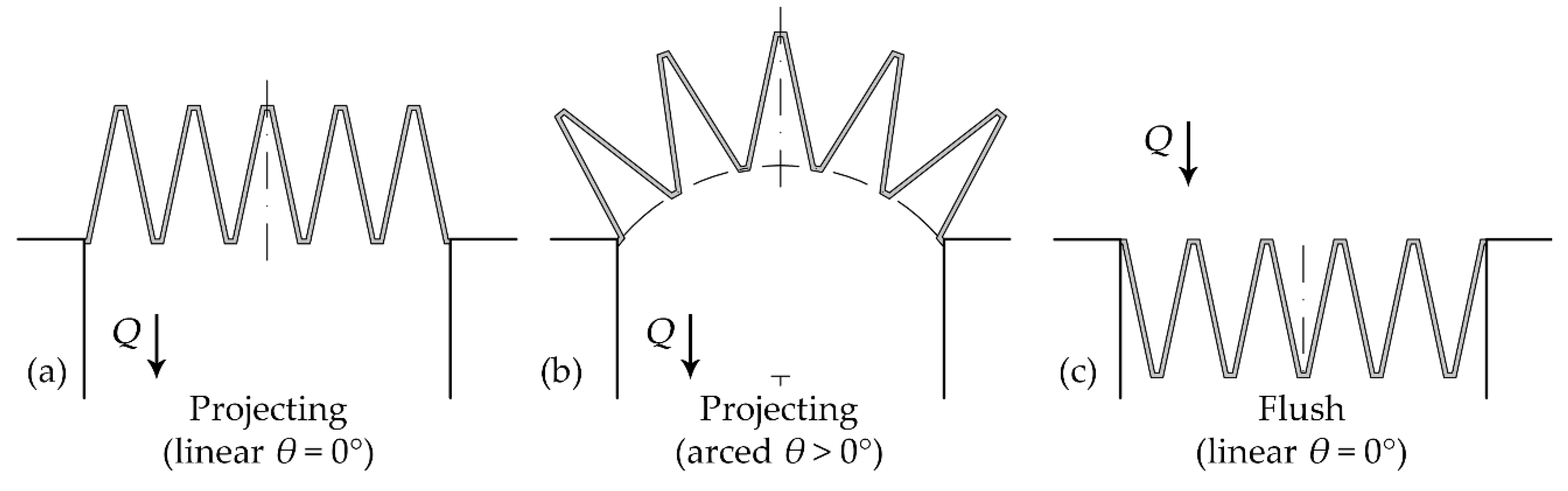
1.2. Labyrinth Weirs
1.3. Machine Learning
- They are robust against the presence of uninformative or highly correlated inputs, which are automatically neglected during model training.
- They can handle numerical and categorical predictors with little pre-processing.
- They are less prone to overfitting than other ML algorithms.
- They account for input interaction.
- Obtaining a unique function for estimating the discharge coefficient in terms of the geometric features and the headwater ratio (H/P);
- Comparing the results obtained with both ML algorithms in terms of the following:
- ○
- Accuracy;
- ○
- Robustness;
- ○
- Interpolation;
- ○
- Possibilities to draw conclusions on the system performance from model interpretation;
- ○
- Applicability.
2. Experimental Approach
2.1. Physical Modeling
2.2. Estimation of Cd
2.3. Model Fitting
2.3.1. Random Forests
2.3.2. Neural Networks
- For the numerical variables (H/P, α and θ), the absolute values were taken.
- For Lin/NonLin, the difference between Olden importance was considered.
- For ArcP/Proj/Flu, the standard deviation was used.
- The results were scaled to sum to 100.
3. Results
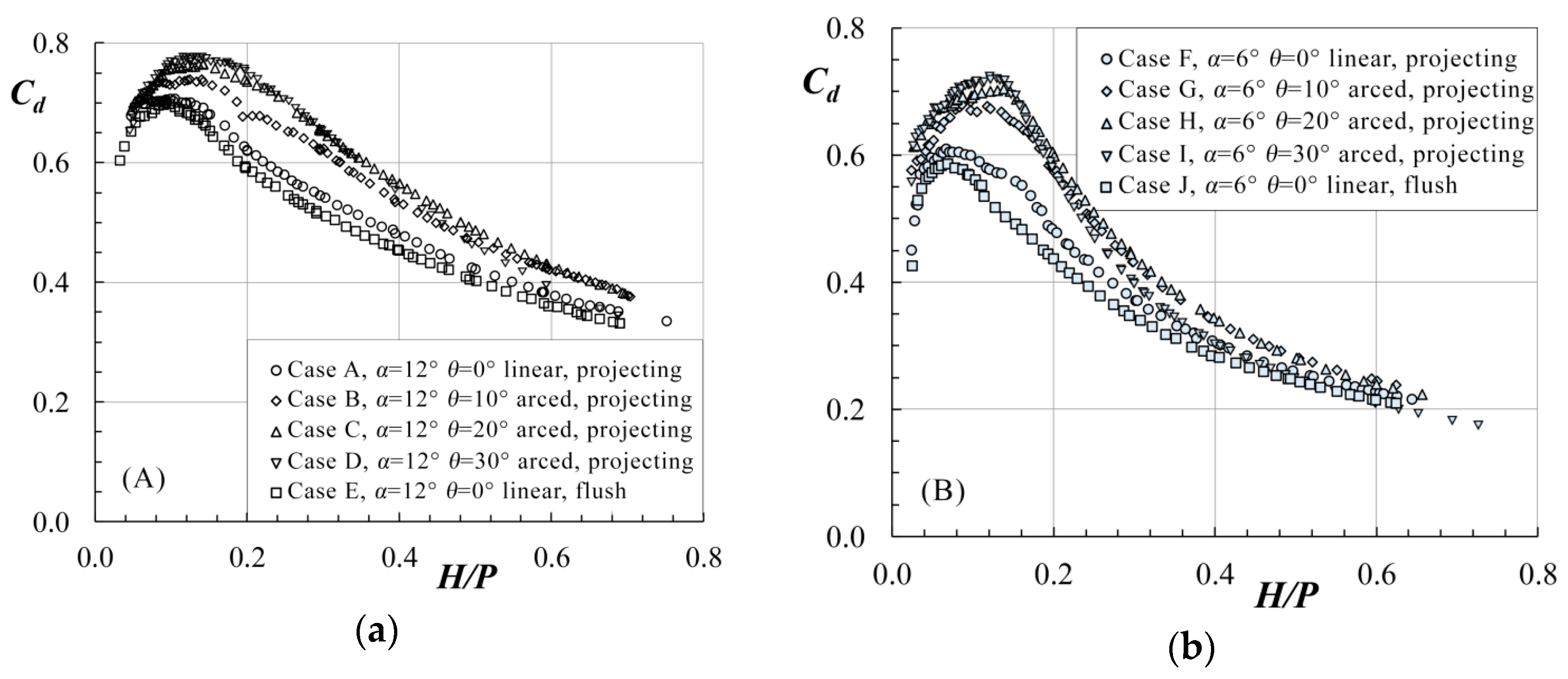
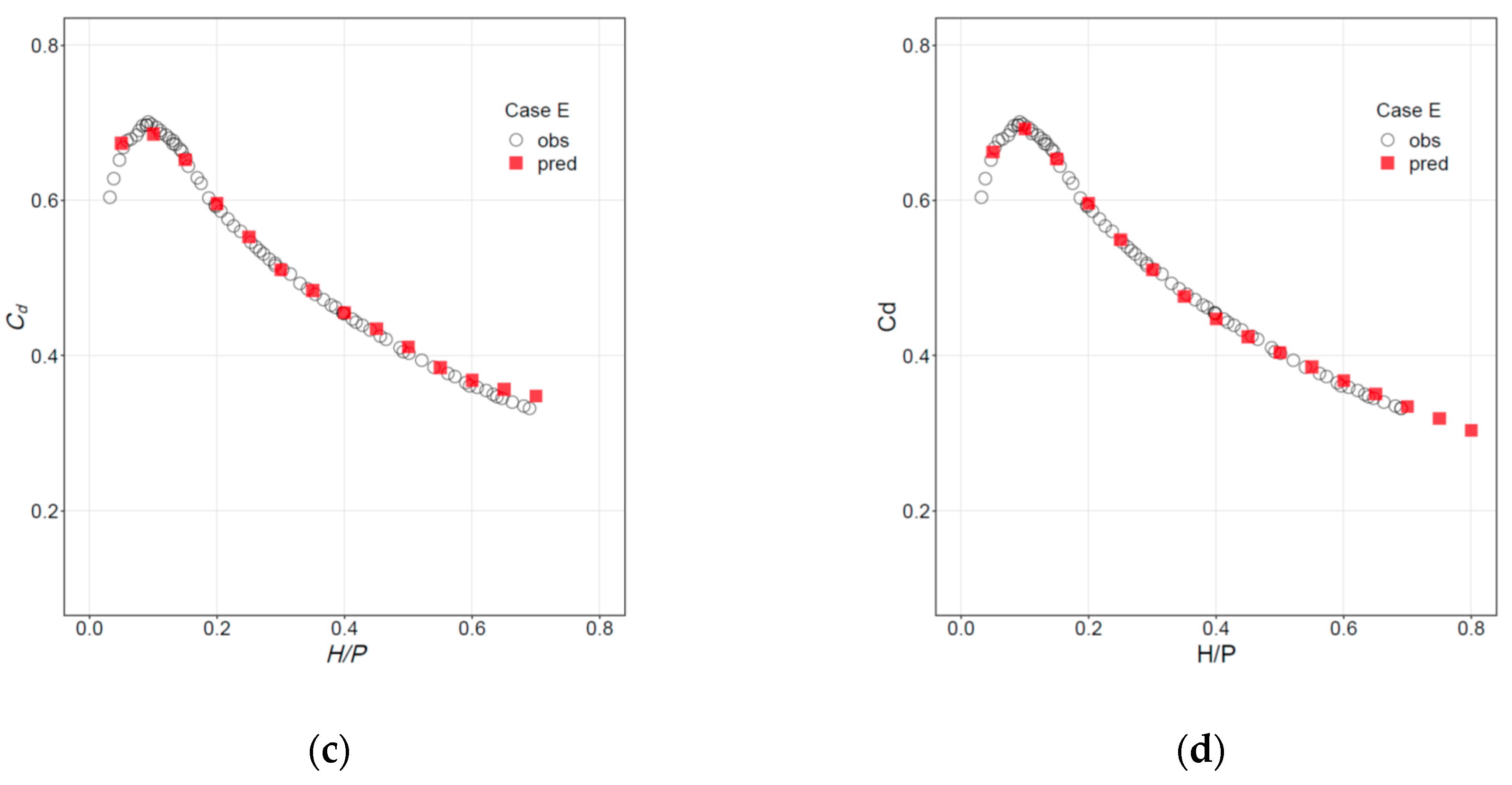
3.1. Unique Expression
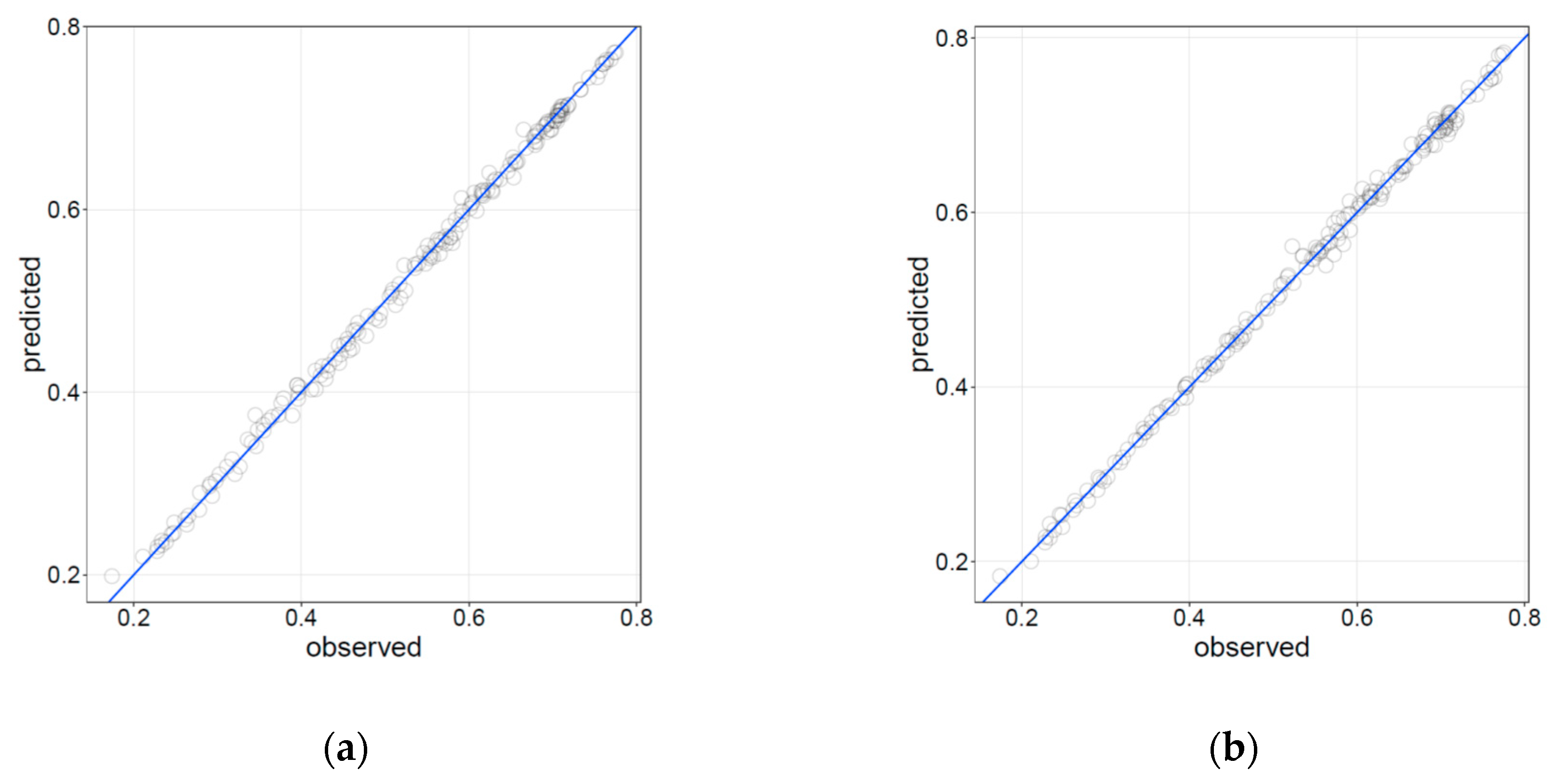
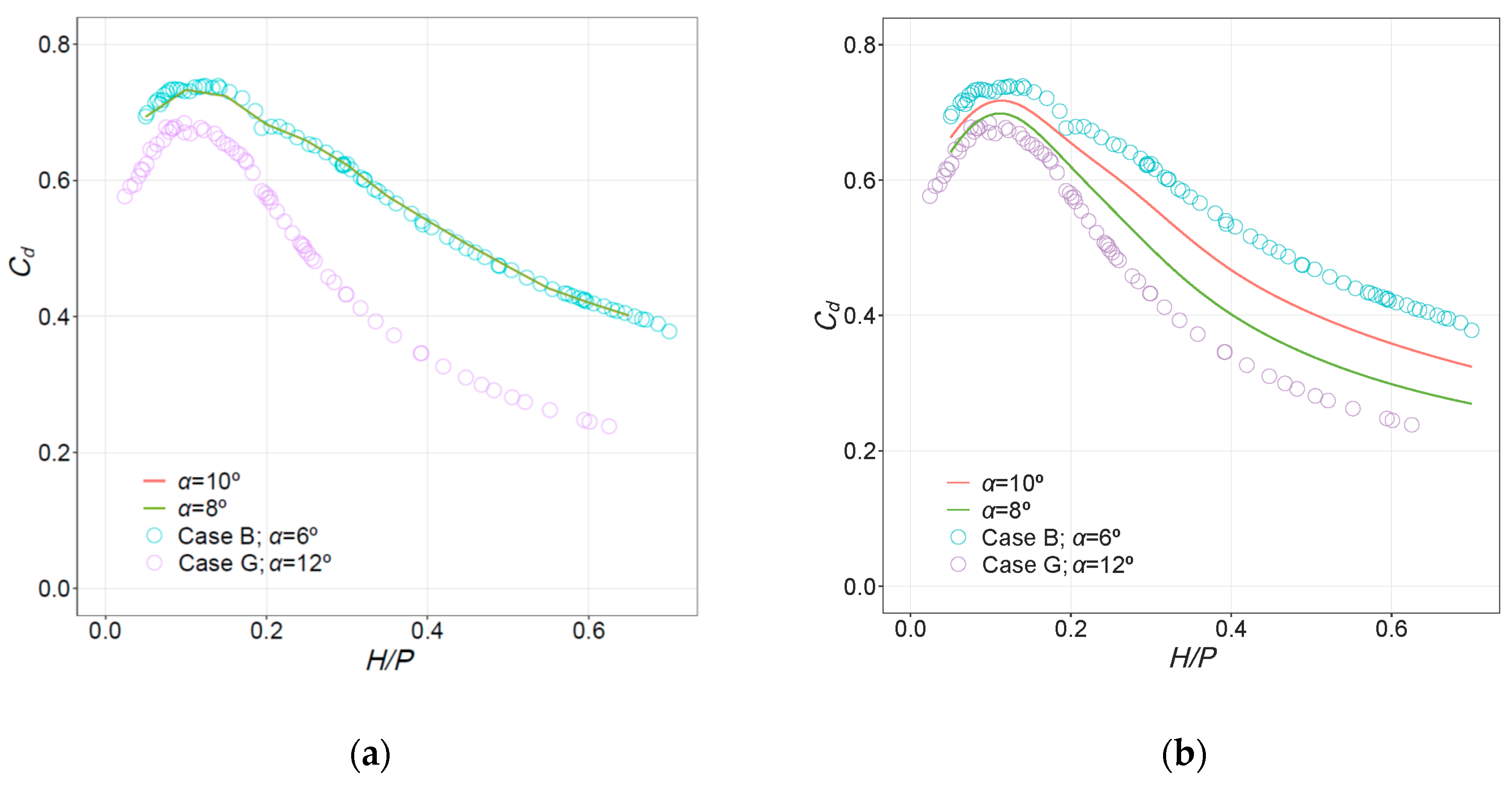
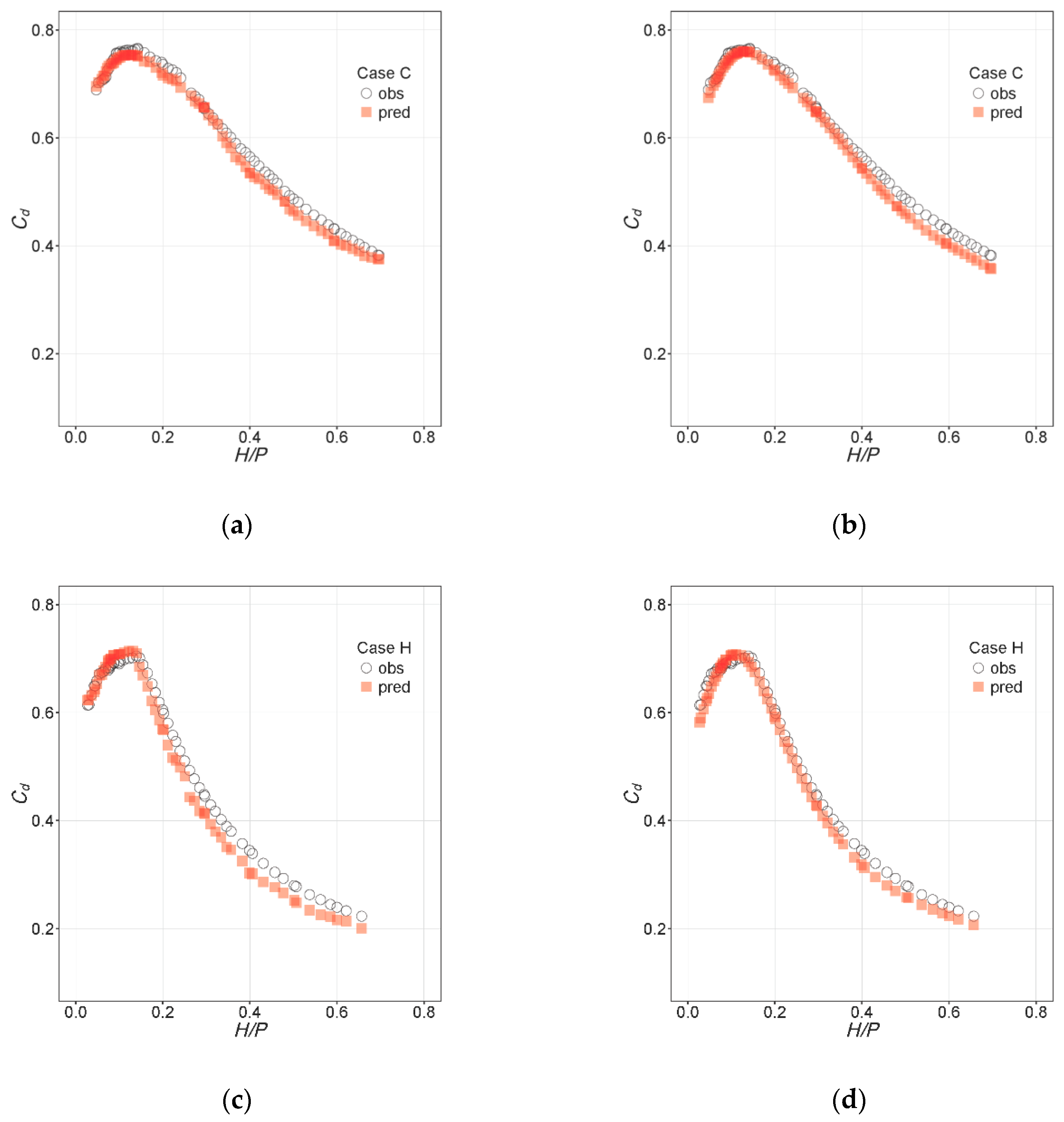
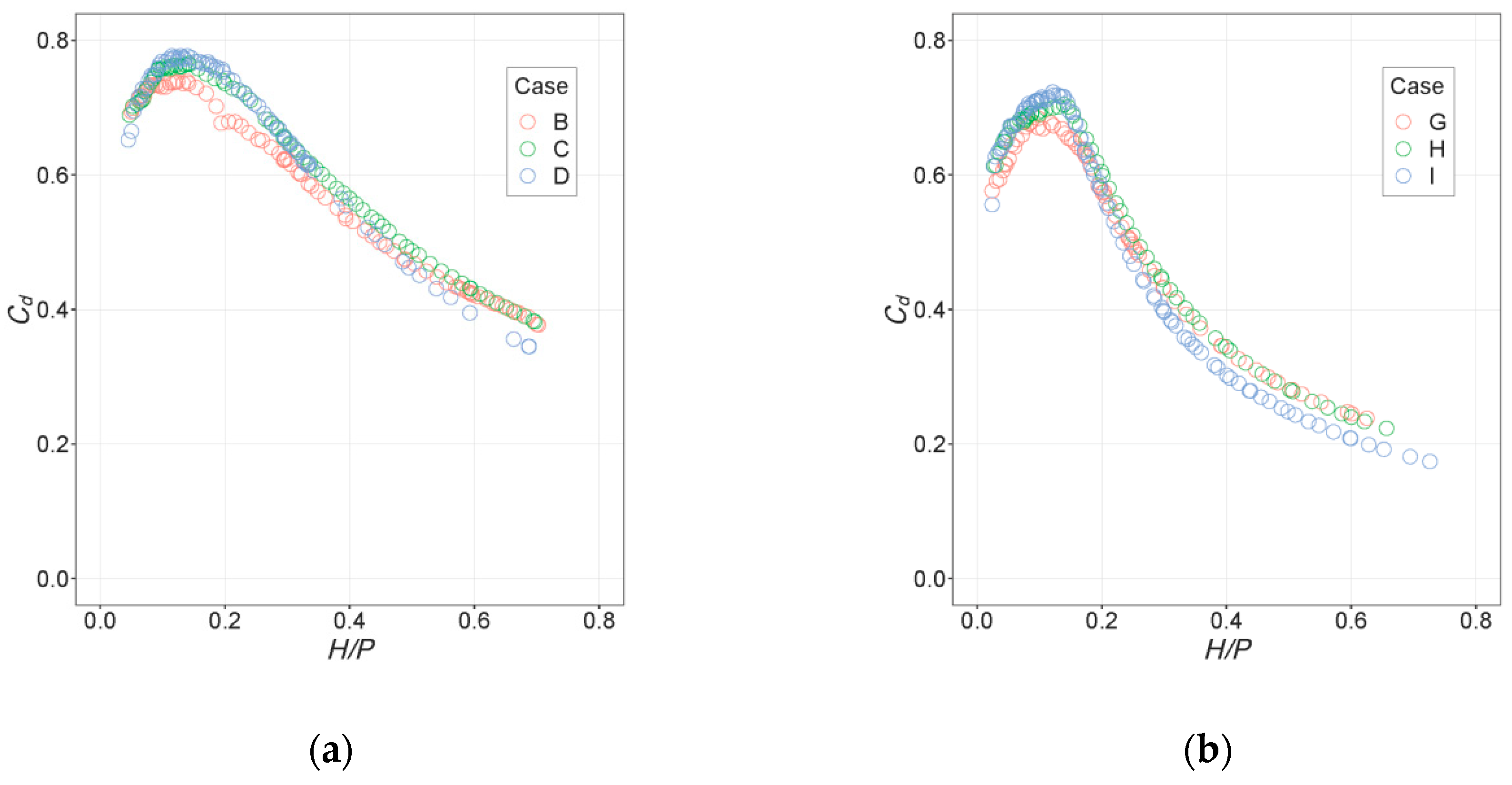
3.2. Interpolation
3.3. Model Interpretation
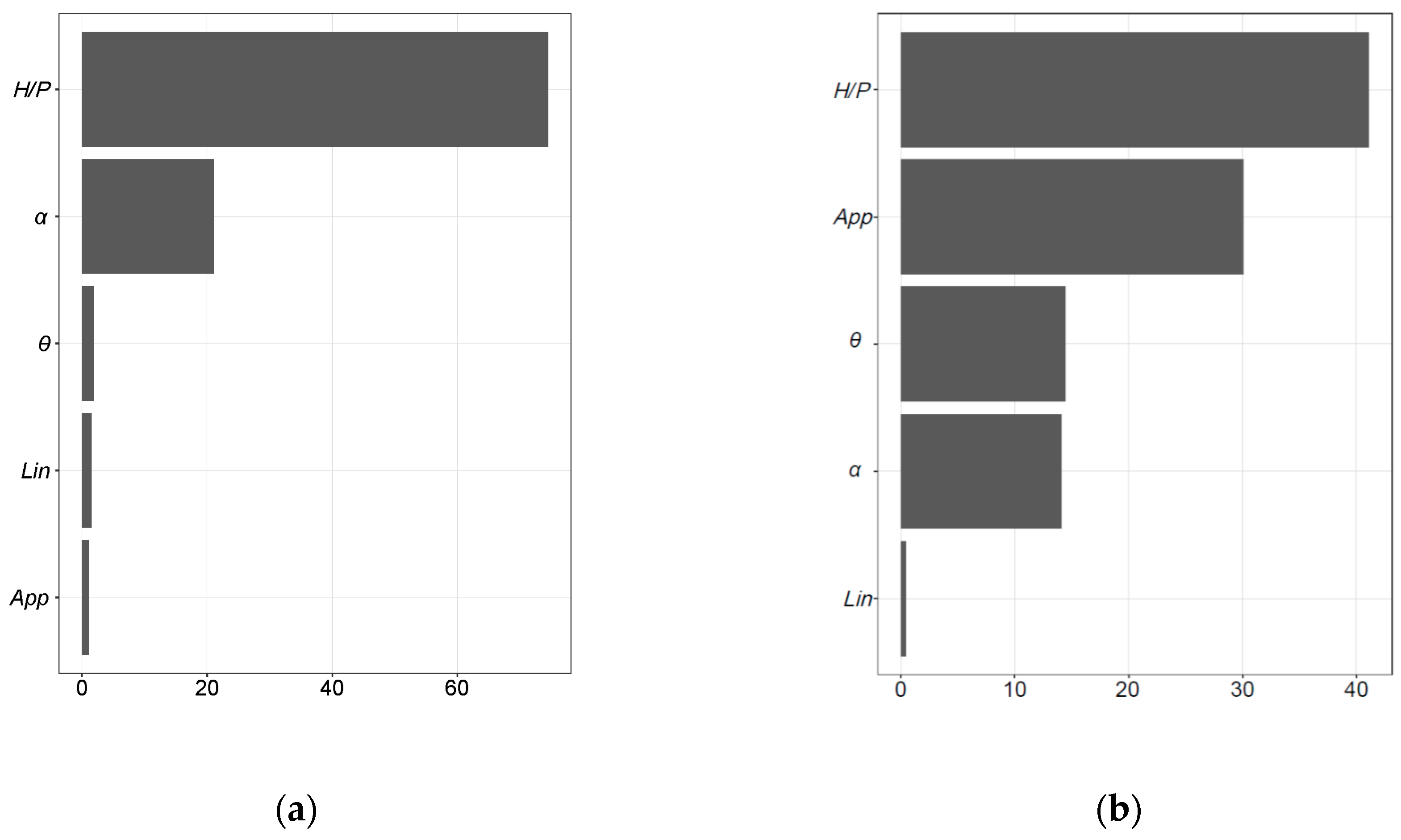
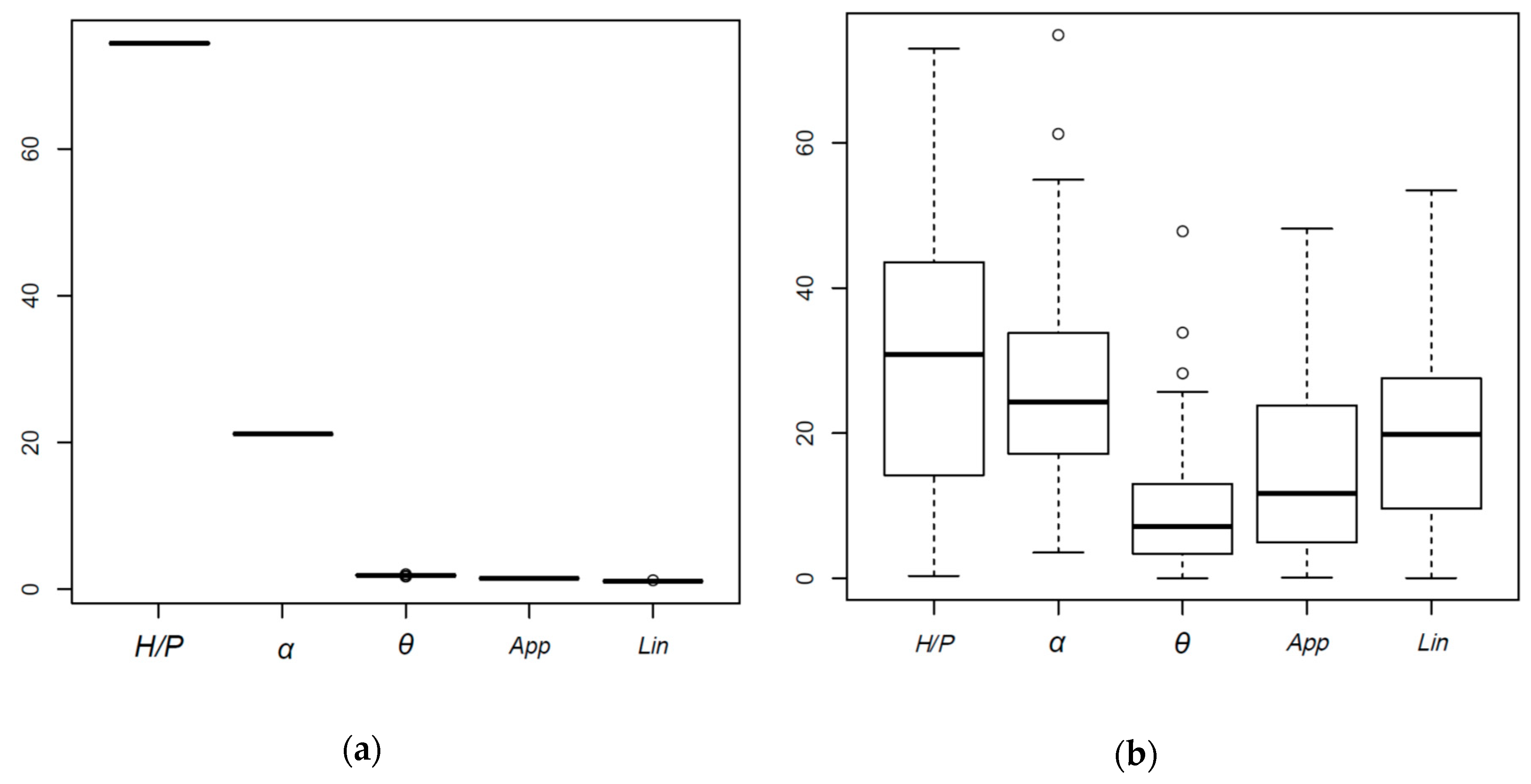
3.3.1. Variable Importance
3.3.2. Partial Dependence Plots
3.4. Non-Tested Geometries
4. Discussion
4.1. Unique Expression
4.2. Interpolation
4.3. Model Interpretation
- The nature of each model and the respective procedures for calculating the importance of the variable set are different.
- Some variables were strongly correlated. For example, all cases with Lin = 1 also have θ = 0.
- The random component of each algorithm influences the results.
4.4. External Validation
5. Summary and Conclusions
- Both algorithms may obtain a unique mapping that relates discharge to hydraulic head and the geometry of the tested configurations. This is an alternative to other commonly used methods such as curve-fitting experimental data (e.g., polynomials), as it avoids the iterative process of selecting terms and the need to handle complex expressions.
- Although the analysis of these models is more complex, some tools are available to obtain an estimate of the effect of each input variable in the system response, which can be useful for the design of laboratory test campaigns. This is particularly applicable for arced labyrinth spillways where there are many parameters and limited published information.
- The NN models offered reasonable predictions of the discharge curves for intermediate configurations between those tested in the laboratory. Although their precision cannot be quantified because experimental results are not available for intermediate configurations, the results suggest that they can be used to reduce the number of configurations to be tested experimentally in certain settings. These results also follow similar observed trends for linear labyrinth weirs located in a channel [8].
- For those same intermediate cases, the RF model estimation was incorrect; variation along numeric variables for which little training data are available (e.g., α in the case study) occurs in steps. A more diverse dataset would be required to obtain a good interpolation with an RF model in this instance.
- The results of the NN models can vary significantly due to the random component of the initialization of the weights at the beginning of the training. Thus, an appropriate training is critical to obtain valid results.
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Purvis, K. Where Are the World’s Most Water-Stressed Cities? The Guardian. 2016. Available online: https://www.theguardian.com/cities/2016/jul/29/where-world-most-water-stressed-cities-drought (accessed on 15 March 2019).
- Conner, R. The United Nations World Water Development Report 2015: Water for a Sustainable World; United Nations Educational, Scientific and Cultural Organization: Paris, France, 2015. [Google Scholar]
- Crookston, B.M.; Paxson, G.S.; Campbell, D.B. Effective spillways: Harmonizing labyrinth weir hydraulic efficiency and project requirements. In Labyrinth and Piano Key Weirs II—PKW 2013; Erpicum, S., Laugier, F., Pfister, M., Pirotton, M., Cicéro, G.-M., Schleiss, A., Eds.; CRC Press: London, UK, 2013. [Google Scholar]
- Gentilini, B. Stramazzi con cresta a planta obliqua e a zig-zag. In Memorie e Studi dell Instituto di Idraulica e Construzioni Idrauliche del Regil Politecnico di Milano, No. 48; Politecnico di Milano: Milano, Italy, 1941. (In Italian) [Google Scholar]
- Taylor, G. The Performance of Labyrinth Weirs. Ph.D. Thesis, University of Nottingham, Nottingham, UK, 1968. [Google Scholar]
- Magalhães, A.; Lorena, M. Hydraulic Design of Labyrinth Weirs; Report No. 736; National Laboratory of Civil Engineering: Lisbon, Portugal, 1989. [Google Scholar]
- Tullis, P.; Amanian, N.; Waldron, D. Design of labyrinth weir spillways. J. Hydraul. Eng. 1995, 121, 247–255. [Google Scholar] [CrossRef]
- Crookston, B.M. Labyrinth Weirs. Ph.D. Thesis, Utah State University, Logan, UT, USA, 2010. [Google Scholar]
- Labyrinth and Piano Key Weirs; Erpicum, S.; Laugier, F.; Boillat, J.-L.; Pirotton, M.; Reverchon, B.; Schleiss, A.J. (Eds.) CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Labyrinth and Piano Key Weirs II—PKW 2013; Erpicum, S.; Laugier, F.; Pfister, M.; Pirotton, M.; Cicero, G.-M.; Schleiss, A. (Eds.) CRC Press: London, UK, 2013. [Google Scholar]
- San Mauro, J.; Salazar, F.; Toledo, M.A.; Caballero, F.J.; Ponce-Farfan, C.; Ramos, T. Physical and numerical modeling of labyrinth weirs with polyhedral bottom. Ing. Agua 2016, 20, 127–138. [Google Scholar] [CrossRef]
- Erpicum, S.; Tullis, B.P.; Lodomez, M.; Archambeau, P.; Dwals, B.; Pirotton, M. Scale effects in physical piano key weir models. J. Hydraul. Res. 2016, 54, 692–698. [Google Scholar] [CrossRef]
- Pfister, M.; Battisacco, E.; De Cesare, G.; Schleiss, A.J. Scale effects related to the rate curve of cylindrically crested Piano Key weirs. In Labyrinth and Piano Key Weirs II—PKW 2013; CRC Press/Balkema: Leiden, The Netherlands, 2013. [Google Scholar]
- Lopes, R.; Matos, J.; Melo, J. Discharge capacity and residual energy of labyrinth weirs. In International Junior Researcher and Engineer Workshop on Hydraulic Structures (IJREWHS ‘06); Montemor-o-Novo, Hydraulic Model Report No. CH61/06; Div. of Civil Engineering, The University of Queensland: Brisbane, Australia, 2006; pp. 47–55. [Google Scholar]
- Lopes, R.; Matos, J.; Melo, J. Characteristic depths and energy dissipation downstream of a labyrinth weir. In International Junior Researcher and Engineer Workshop on Hydraulic Structures (IJREWHS ‘08); PLUS-Pisa University Press: Pisa, Italy, 2018. [Google Scholar]
- Pfister, M.; Capobianco, D.; Tullis, B.; Schleiss, A. Debris-blocking sensitivity of piano key weirs under reservoir-type approach flow. J. Hydraul. Eng. 2013, 139, 1134–1141. [Google Scholar] [CrossRef]
- Crookston, B.M.; Mortensen, D.; Stanard, T.; Tullis, B.P.; Vasquez, V. Debris and maintenance of labyrinth spillways. In Proceedings of the 35th Annual USSD Conference, Louisville, KY, USA, 13–17 April 2015; [CD-ROM]. USSD: Westminster, CO, USA, 2015. [Google Scholar]
- Darvas, L. Discussion of performance and design of labyrinth weirs, by Hay and Taylor. J. Hydraul. Eng. 1971, 97, 1246–1251. [Google Scholar]
- Yildiz, D.; Uzecek, E. Modeling the performance of labyrinth spillways. Hydropower 1996, 3, 71–76. [Google Scholar]
- Page, D.; García, V.; Ninot, C. Aliviaderos en laberinto. presa de María Cristina. Ing. Civil 2007, 146, 5–20. (In Spanish) [Google Scholar]
- Crookston, B.M.; Tullis, B.P. Arced labyrinth weirs. J. Hydraul. Eng. 2012, 138, 555–562. [Google Scholar] [CrossRef]
- Crookston, B.M.; Tullis, B.P. Discharge efficiency of reservoir-application-specific labyrinth weirs. J. Irrig. Drain. Eng. 2012, 138, 564–568. [Google Scholar] [CrossRef]
- Christensen, N.A. Flow Characteristics of Arced Labyrinth Weirs. Master’s Thesis, Utah State University, Logan, UT, USA, 2012. [Google Scholar]
- Thompson, E.; Cox, N.; Ebner, L.; Tullis, B. The hydraulic design of an arced labyrinth weir at Isabella Dam. In Hydraulic Structures and Water System Management, Proceedings of the 6th IAHR International Symposium on Hydraulic Structures, Portland, OR, USA, 27–30 June 2016; Crookston, B., Tullis, B., Eds.; Utah State University: Logan, UT, USA, 2016; pp. 230–239. ISBN 978-1-884575-75-4. [Google Scholar] [CrossRef]
- Cremona, C.; Santos, J. Structural health monitoring as a big-data problem. Struct. Eng. Int. 2018, 28, 243–254. [Google Scholar] [CrossRef]
- Dawson, C.W.; Wilby, R.L. Hydrological modelling using artificial neural networks. Prog. Phys. Geogr. 2001, 25, 80–108. [Google Scholar] [CrossRef]
- ASCE Task Committee on Application of Artificial Neural Networks in Hydrology. Artificial neural networks in hydrology. I: Preliminary concepts. J. Hydrol. Eng. 2000, 5, 115–123. [Google Scholar] [CrossRef]
- ASCE Task Committee on Application of Artificial Neural Networks in Hydrology. Artificial neural networks in hydrology. II: Hydrologic applications. J. Hydrol. Eng. 2000, 5, 124–137. [Google Scholar] [CrossRef]
- de Granrut, M.; Simon, A.; Dias, D. Artificial neural networks for the interpretation of piezometric levels at the rock-concrete interface of arch dams. Eng. Struct. 2019, 178, 616–634. [Google Scholar] [CrossRef]
- Mata, J.; Leitão, N.S.; De Castro, A.T.; Da Costa, J.S. Construction of decision rules for early detection of a developing concrete arch dam failure scenario. A discriminant approach. Comput. Struct. 2014, 142, 45–53. [Google Scholar] [CrossRef]
- Salazar, F.; Toledo, M.A.; Oñate, E.; Morán, R. An empirical comparison of machine learning techniques for dam behaviour modelling. Struct. Saf. 2015, 56, 9–17. [Google Scholar] [CrossRef] [Green Version]
- Salazar, F.; Toledo, M.Á.; Oñate, E.; Suárez, B. Interpretation of dam deformation and leakage with boosted regression trees. Eng. Struct. 2016, 119, 230–251. [Google Scholar] [CrossRef]
- Salazar, F.; Toledo, M.Á.; González, J.M.; Oñate, E. Early detection of anomalies in dam performance: A methodology based on boosted regression trees. Struct. Control Health Monit. 2017, 24. [Google Scholar] [CrossRef]
- Herrera, M.; Torgo, L.; Izquierdo, J.; Pérez-García, R. Predictive models for forecasting hourly urban water demand. J. Hydrol. 2010, 387, 141–150. [Google Scholar] [CrossRef]
- Valero, D.; Bung, D.B. Artificial Neural Networks and pattern recognition for air-water flow velocity estimation using a single-tip optical fibre probe. J. Hydro-Environ. Res. 2018, 19, 150–159. [Google Scholar] [CrossRef]
- Bashiri Atrabi, H.; Dewals, B.; Pirotton, M.; Archambeau, P.; Erpicum, S. Towards a new design equation for piano key weirs discharge capacity. In Proceedings of the 6th International Symposium on Hydraulic Structures, Portland, OR, USA, 27–30 June 2016. [Google Scholar]
- Emiroglu, M.E.; Kisi, O. Prediction of discharge coefficient for trapezoidal labyrinth side weir using a neuro-fuzzy approach. Water Resour. Manag. 2013, 27, 1473–1488. [Google Scholar] [CrossRef]
- Azamathulla, H.M.; Haghiabi, A.H.; Parsaie, A. Prediction of side weir discharge coefficient by support vector machine technique. Water Sci. Technol. Water Supply 2016, 16, 1002–1016. [Google Scholar] [CrossRef]
- Salazar, F.; Morán, R.; Rossi, R.; Oñate, E. Analysis of the discharge capacity of ra-dial-gated spillways using CFD and ANN—Oliana Dam case study. J. Hydraul. Res. 2013, 51, 244–252. [Google Scholar] [CrossRef]
- Mata, J. Interpretation of concrete dam behaviour with artificial neural network and multiple linear regression models. Eng. Struct. 2011, 33, 903–910. [Google Scholar] [CrossRef]
- Salazar, F.; Morán, R.; Toledo, M.Á.; Oñate, E. Data-based models for the prediction of dam behaviour: A review and some methodological considerations. Arch. Comput. Methods Eng. 2017, 24, 1–21. [Google Scholar] [CrossRef]
- Díaz-Uriarte, R.; De Andres, S.A. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7. [Google Scholar] [CrossRef] [PubMed]
- Tullis, B.; Young, N.; Crookston, B. Size-scale effects of labyrinth weir hydraulics. In Proceedings of the 7th IAHR International Symposium on Hydraulic Structures, Aachen, Germany, 15–18 May 2018. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria; Available online: https://www.R-project.org/ (accessed on 15 March 2019).
- Breiman, L. Statistical modeling: The two cultures (with comments and a rejoinder by the author). Stat. Sci. 2001, 16, 199–231. [Google Scholar] [CrossRef]
- Ishwaran, H.; Kogalur, U.B. Random survival forests for R. R News 2008, 7, 25–31. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002; ISBN 0-387-95457-0. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: New York, NY, USA, 1995. [Google Scholar]
- Kuhn, M. Caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar]
- Olden, J.D.; Jackson, D.A. Illuminating the “black box”: A randomization approach for understanding variable contributions in artificial neural networks. Ecol. Model. 2002, 154, 135–150. [Google Scholar] [CrossRef]
- Beck, M. NeuralNetTools: Visualization and analysis tools for neural networks. J. Stat. Softw. 2018, 85, 1–20. [Google Scholar] [CrossRef] [PubMed]
- Greenwell, B.M. pdp: An R package for constructing partial dependence plots. R J. 2017, 9, 421–436. [Google Scholar] [CrossRef]
- Machiels, O.; Pirotton, M.; Pierre, A.; Dewals, B.; Erpicum, S. Experimental parametric study and design of Piano Key Weirs. J. Hydraul. Res. 2014, 52, 326–335. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | α (°) | θ (°) | Number of Cycles | Reservoir Orientation |
|---|---|---|---|---|
| A | 12 | 0 | 5 | Linear, projecting |
| B | 12 | 10 | 5 | Arced, projecting |
| C | 12 | 20 | 5 | Arced, projecting |
| D | 12 | 30 | 5 | Arced, projecting |
| E | 12 | 0 | 5 | Linear, flush |
| F | 6 | 0 | 5 | Linear, projecting |
| G | 6 | 10 | 5 | Arced, projecting |
| H | 6 | 20 | 5 | Arced, projecting |
| I | 6 | 30 | 5 | Arced, projecting |
| J | 6 | 0 | 5 | Linear, flush |
| Variable | Code | Values | Units |
|---|---|---|---|
| Head over crest | H/P | 0–0.75 | - |
| Cycle sidewall angle | α | 6°, 12° | (°) |
| Cycle arc angle | θ | 0°, 10°, 20°, 30° | (°) |
| Linearity | Lin | Linear, non-linear | - |
| Approach configuration | App | Flush, projecting, arc projecting | - |
| Case | Original Variable | New Variables | ||
|---|---|---|---|---|
| Configuration | Arc Projecting | Flushed | Projecting | |
| E | Flushed | 0 | 1 | 0 |
| F | Projecting | 0 | 0 | 1 |
| G | Arc Projecting | 1 | 0 | 0 |
| Algorithm | Dataset | ME 1 | RMSE 2 | MAE 3 | MAPE 4 |
|---|---|---|---|---|---|
| Random forest | Training | 0.001 | 0.008 | 0.006 | 1.258 |
| Validation | 0.000 | 0.008 | 0.006 | 1.382 | |
| Neural networks | Training | 0.000 | 0.008 | 0.006 | 1.147 |
| Validation | 0.000 | 0.008 | 0.006 | 1.255 |
| Algorithm | Case | RMSE | MAPE |
|---|---|---|---|
| Random forest | C | 0.016 | 2.500 |
| H | 0.027 | 5.625 | |
| Neural networks | C | 0.018 | 2.947 |
| H | 0.018 | 3.883 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Salazar, F.; Crookston, B.M. A Performance Comparison of Machine Learning Algorithms for Arced Labyrinth Spillways. Water 2019, 11, 544. https://doi.org/10.3390/w11030544
Salazar F, Crookston BM. A Performance Comparison of Machine Learning Algorithms for Arced Labyrinth Spillways. Water. 2019; 11(3):544. https://doi.org/10.3390/w11030544
Chicago/Turabian StyleSalazar, Fernando, and Brian M. Crookston. 2019. "A Performance Comparison of Machine Learning Algorithms for Arced Labyrinth Spillways" Water 11, no. 3: 544. https://doi.org/10.3390/w11030544
APA StyleSalazar, F., & Crookston, B. M. (2019). A Performance Comparison of Machine Learning Algorithms for Arced Labyrinth Spillways. Water, 11(3), 544. https://doi.org/10.3390/w11030544