An Ensemble Decomposition-Based Artificial Intelligence Approach for Daily Streamflow Prediction

Abstract
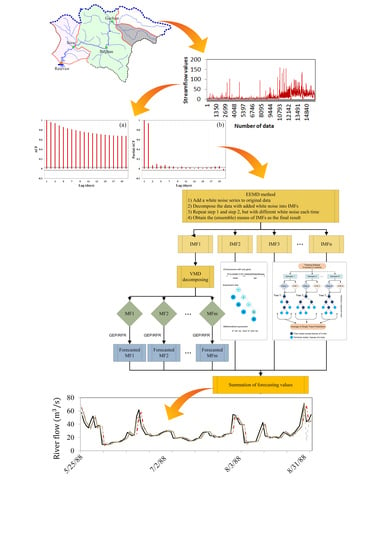
:
1. Introduction
2. Methodology and Data Description
2.1. Gene Expression Programming
2.2. Random Forest Regression
- (1)
- Use the original training dataset X (N samples) to draw k samples randomly by the bootstrap resampling technique to construct k regression trees. In this process, the probability related to the samples that would not be drawn can be computed by . If N achieved to infinity, p ≈ 0.37 which expresses that roughly 37% of the samples of original training dataset X are not drawn and these data are known as out-of-bag (OOB) data. Likewise, the training dataset, these OOB data can be applied for testing samples.
- (2)
- Moreover, unpruned regression trees corresponding to k bootstrap samples are created. During the growing process of trees, in each node, a attribute is randomly considered from all A attributes (input parameters) as internal nodes (a < A). Then, based on the principle of minimum Gini index (a measure of how each variable contributes to the homogeneity of the nodes and leaves), an optimum attribute is determined from an attribute as a split variable to build the branches hierarchy.
- (3)
- The final random forest regression model is constituted by generated k regression trees. To evaluate the model estimation performance, two indices namely coefficients of determination () and mean square error of OOB (MSEOOB) are employed.where n is the total OOB samples, yi and ŷi are the observed and predicted output values, respectively, and is the OOB variance of predicted output.
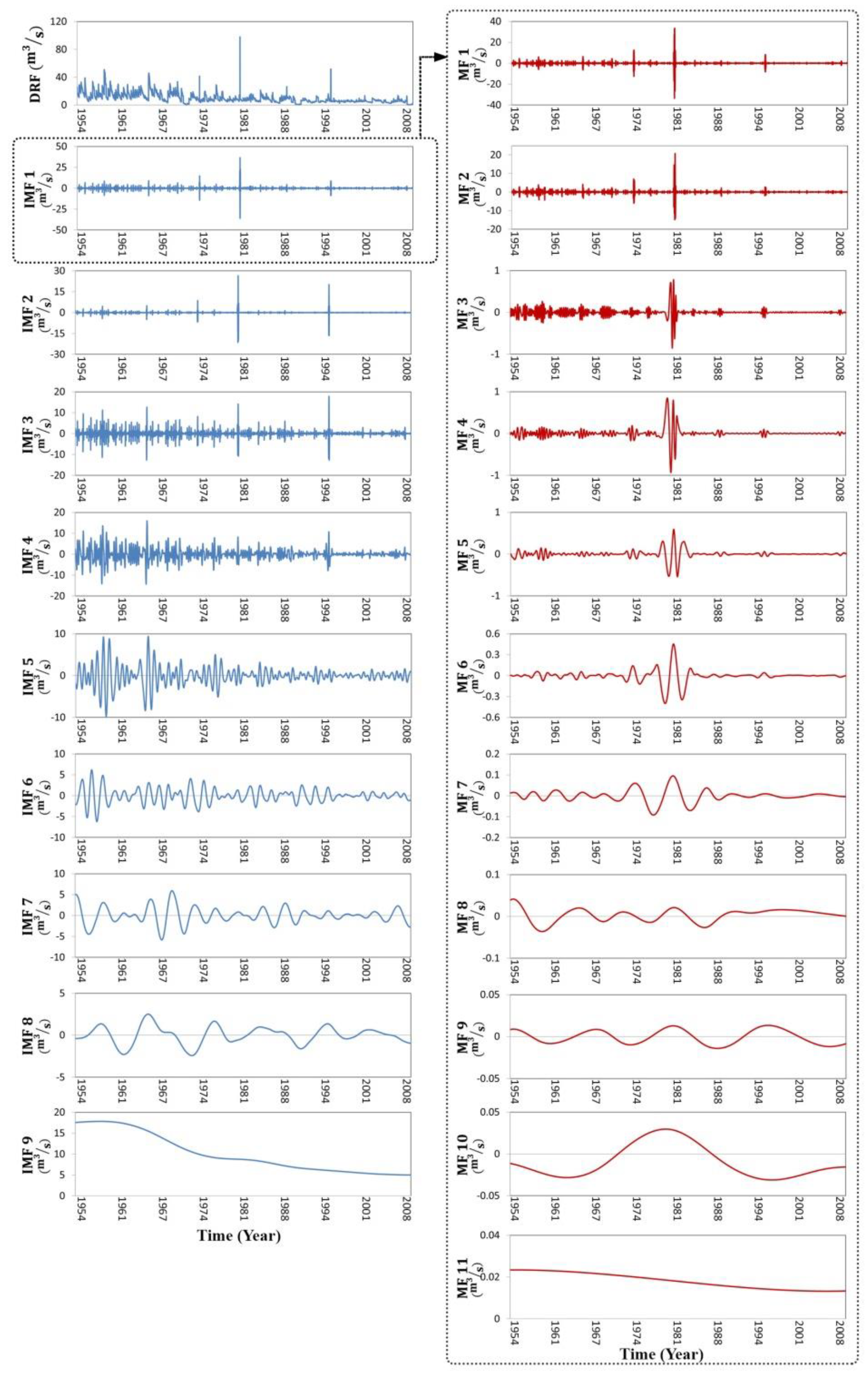
2.3. Ensemble Empirical Mode Decomposition
2.4. Variational Mode Decomposition
2.5. Model Assessment Criteria
- Ratio of RMSE to standard deviation (RSD): RSD, proposed by Singh et al. [60] is a model evaluation metric to assess the differences between a model’s prediction and the observed data in hydrological simulation. This metric is calculated based on RMSE and standard deviation (STDEV) of the observed data points. The lower the value of the RSD the higher the performance of the model.
- Uncertainty at 95% (U95): U95 is defined as a 95% uncertainty confidence.
- Reliability of model (%): This statistic shows the satisfactory state of the model’s forecast by the probability [19].
- Resilience of model (%): This indicator defines how quickly the model forecast is likely to recover once an unqualified forecast has occurred [61].where and denote the measured and estimated values, respectively; is the average of observed values, and N is the number of datasets. RAEi is the value for the ith data, Ki is the number of times that the threshold value (δ) of the qualified forecast is greater than or equal to the RAE value. δ is set to 20% according to the Chinese standard (GB/T 22482-2008). Ri is the number of times that model forecast is likely to transfer from unqualified into qualified forecast in the ith data.
2.6. Uncertainty Analysis
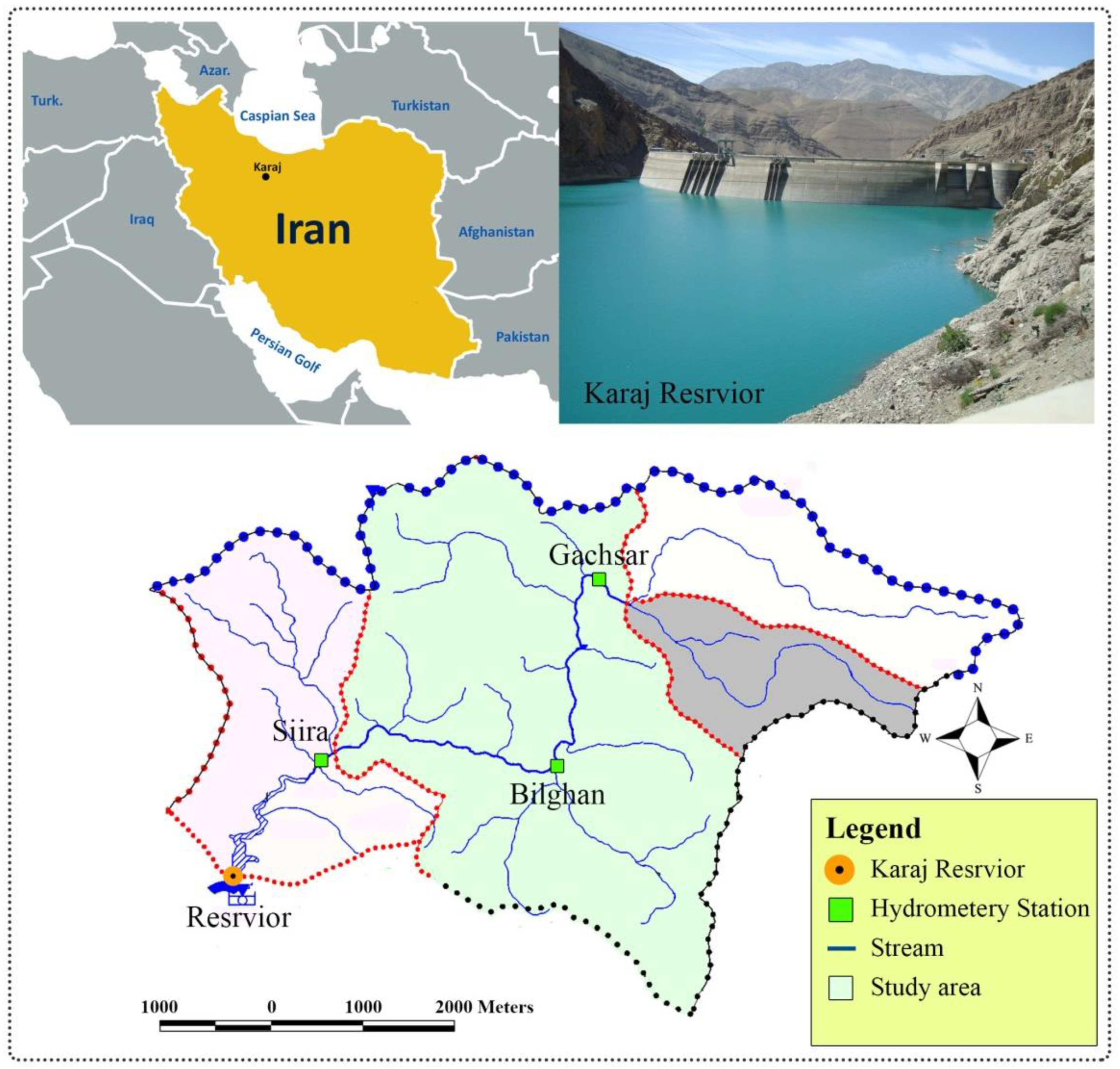
2.7. Case Study and Data Analysis
3. Results and Discussion
3.1. Input Variables Selection and Model Development
3.2. Application
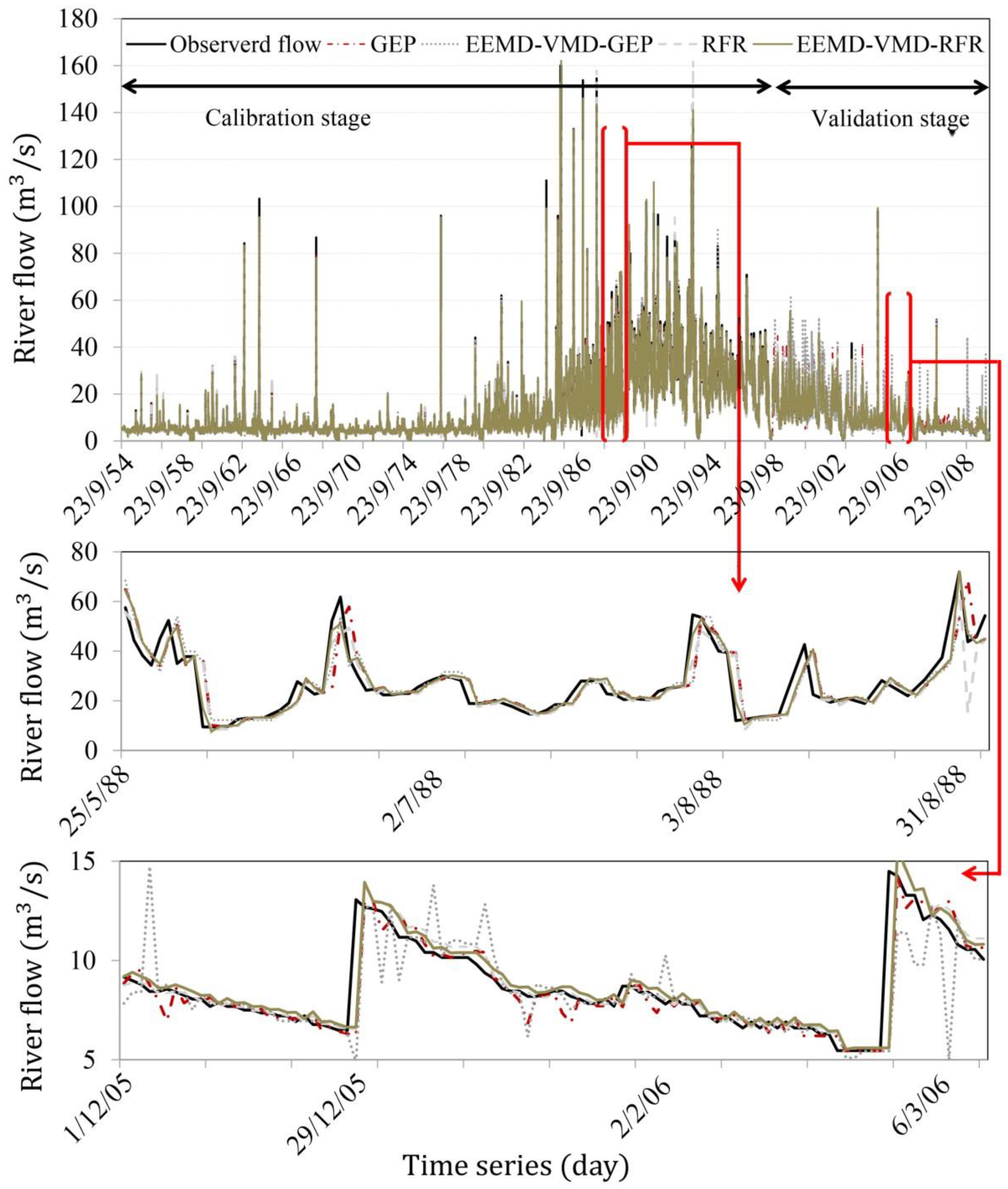
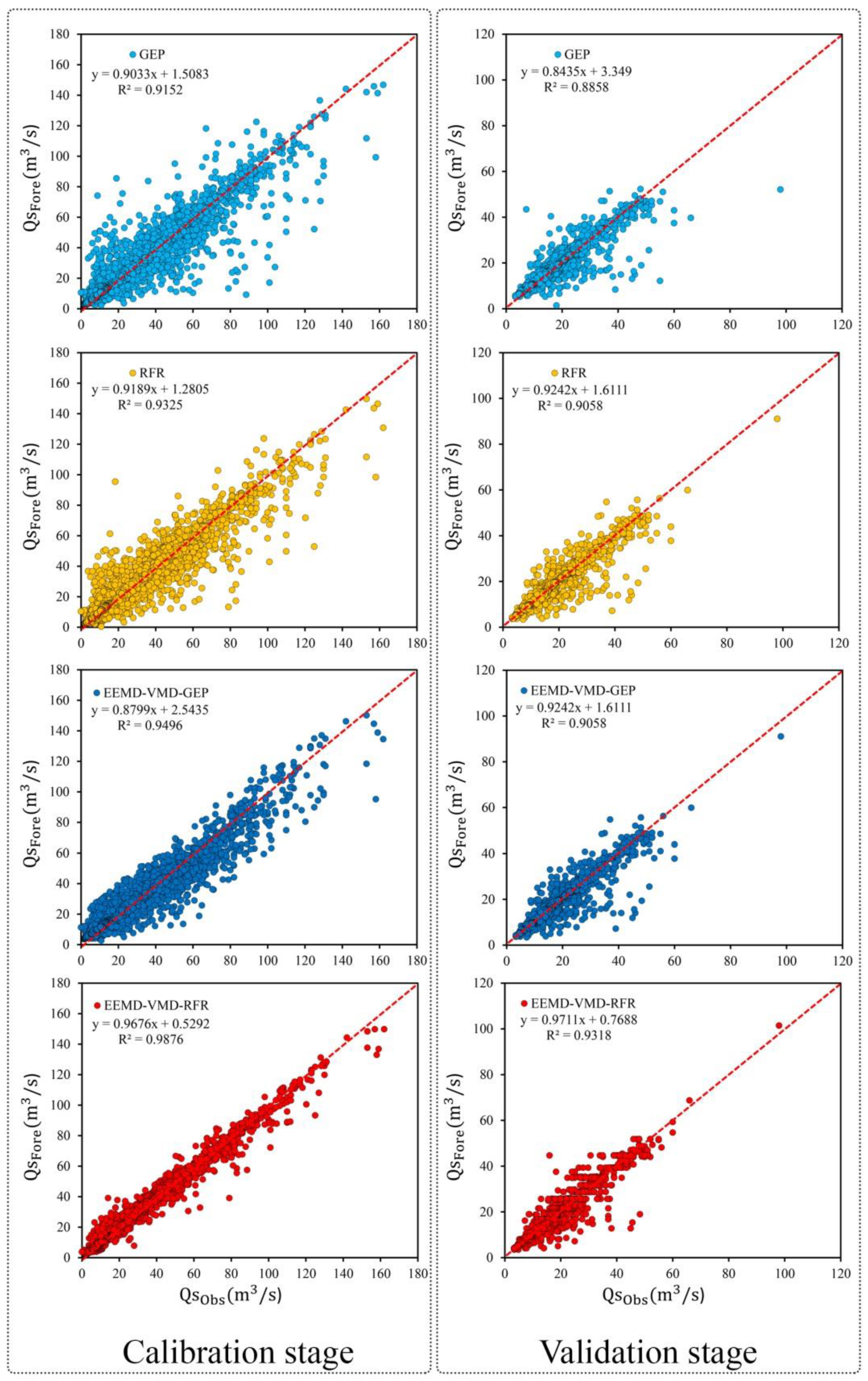
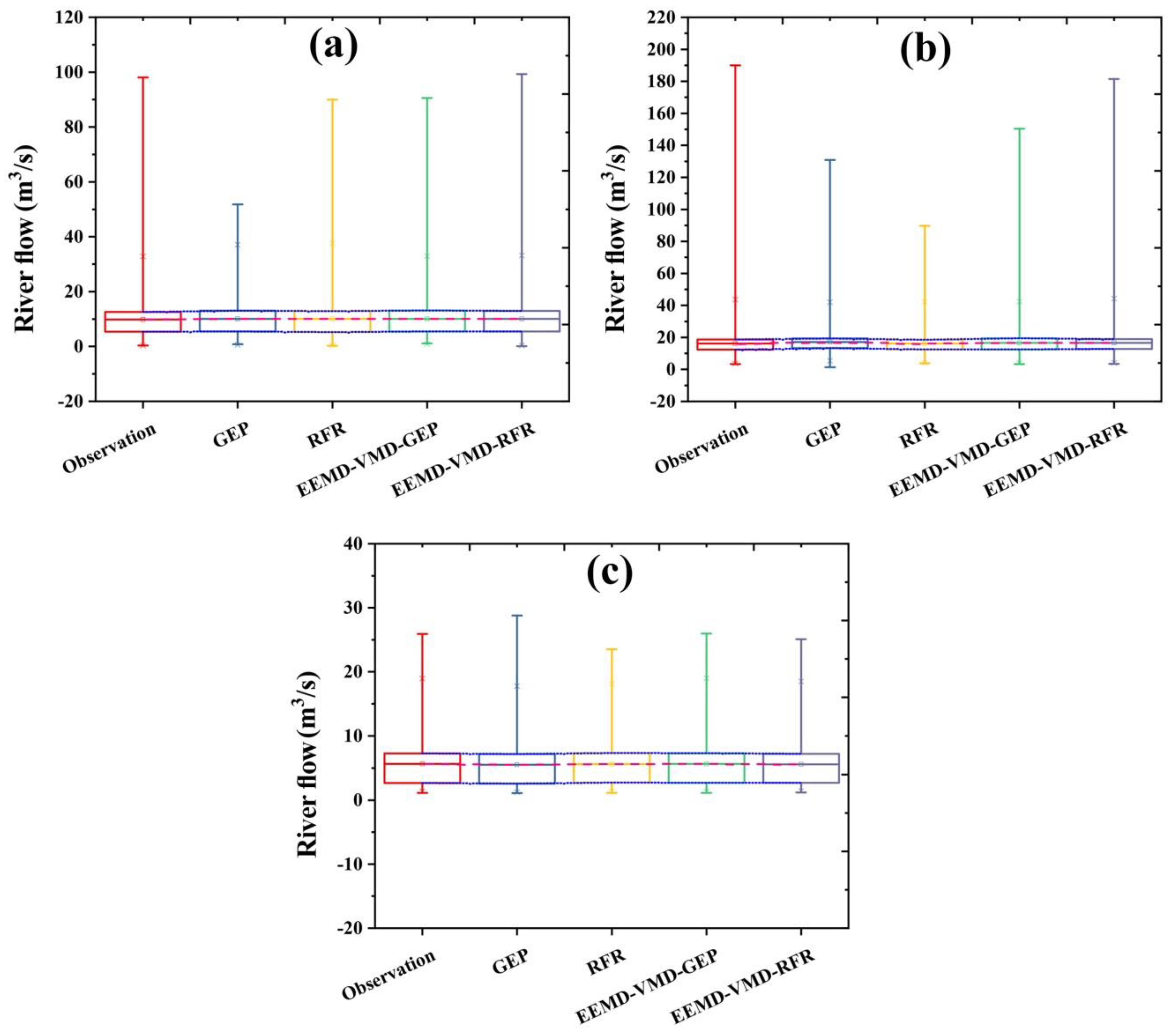
3.2.1. The Siira Gauging Station
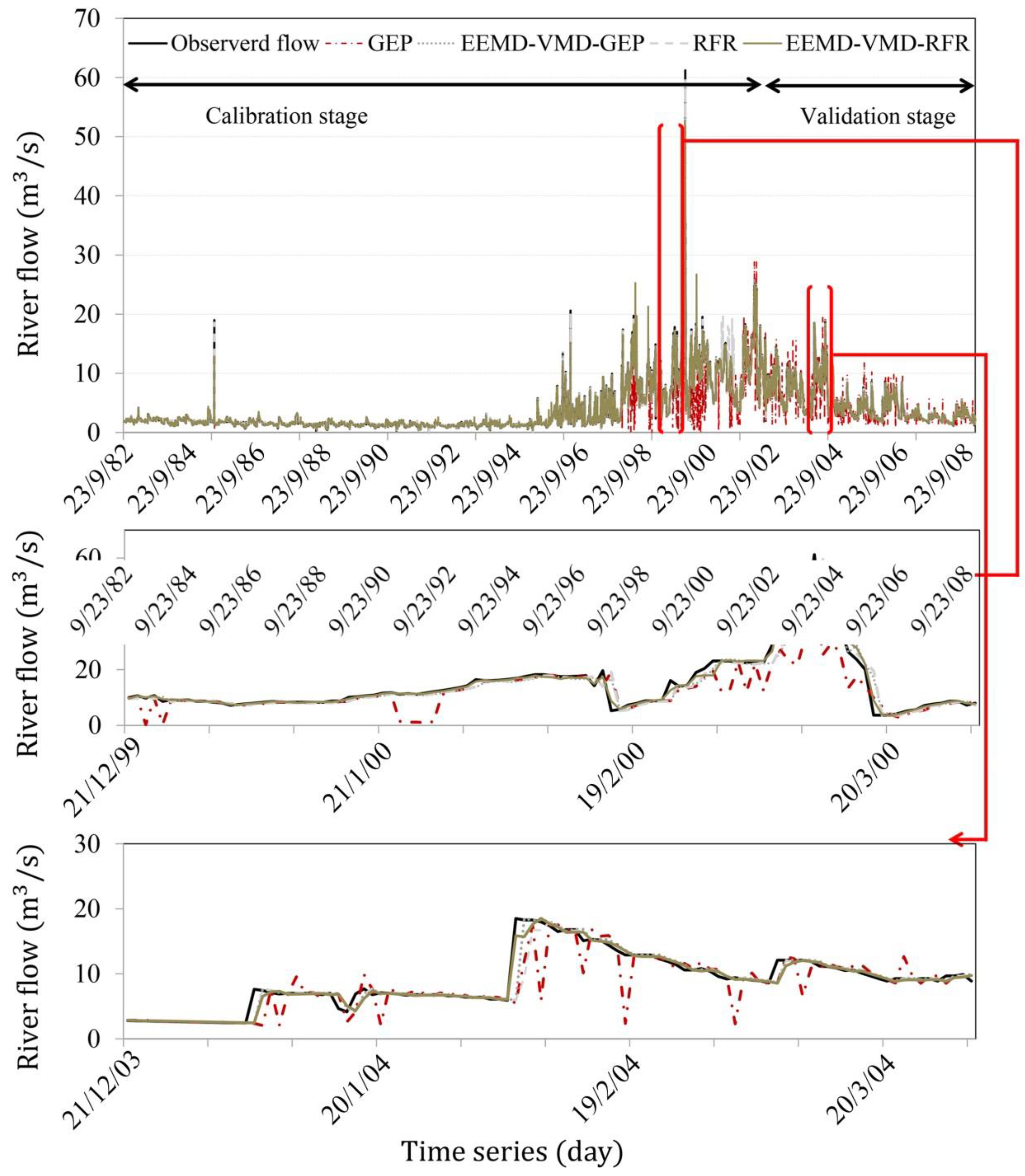
3.2.2. The Bilghan Gauging Station
3.2.3. The Gachsar Gauging Station
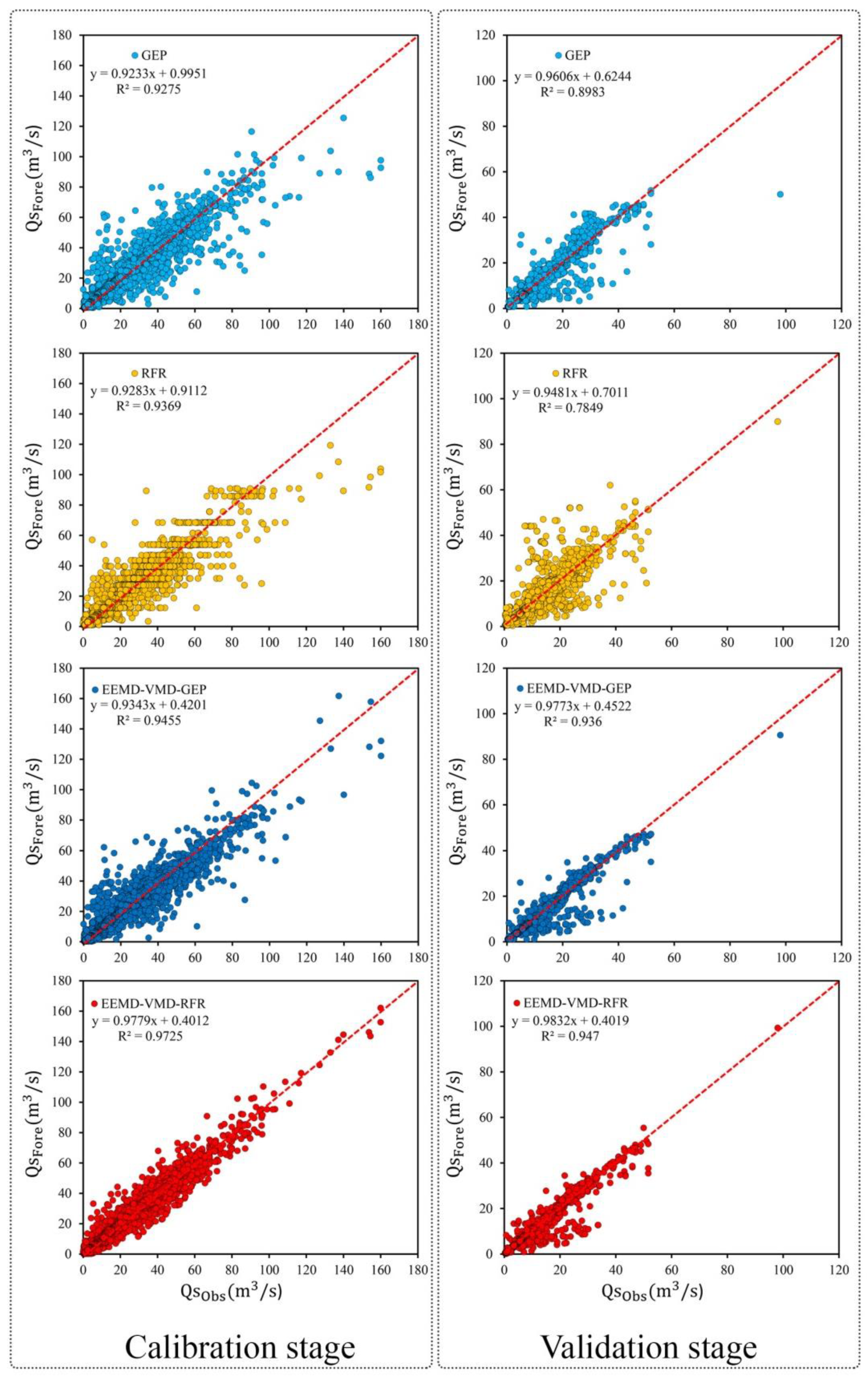
3.2.4. Further Comparison Among Proposed Models
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Yuan, X.; Chen, C.; Lei, X.; Yuan, Y.; Adnan, R.M. Monthly runoff forecasting based on LSTM–ALO model. Stoch. Environ. Res. Risk Assess. 2018, 32, 2199–2212. [Google Scholar] [CrossRef]
- Yu, Y.; Zhang, H.; Singh, V. Forward prediction of runoff data in data-scarce basins with an improved ensemble empirical mode decomposition (EEMD) model. Water 2018, 10, 388. [Google Scholar] [CrossRef]
- Adamowski, J.; Sun, K. Development of a coupled wavelet transform and neural network method for flow forecasting of non-perennial rivers in semi-arid watersheds. J. Hydrol. 2010, 390, 85–91. [Google Scholar] [CrossRef]
- Chitsaz, N.; Azarnivand, A.; Araghinejad, S. Pre-processing of data-driven river flow forecasting models by singular value decomposition (SVD) technique. Hydrol. Sci. J. 2016, 61, 2164–2178. [Google Scholar] [CrossRef]
- Humphrey, G.B.; Gibbs, M.S.; Dandy, G.C.; Maier, H.R. A hybrid approach to monthly streamflow forecasting: Integrating hydrological model outputs into a Bayesian artificial neural network. J. Hydrol. 2016, 540, 623–640. [Google Scholar] [CrossRef]
- Abdollahi, S.; Raeisi, J.; Khalilianpour, M.; Ahmadi, F.; Kisi, O. Daily mean streamflow prediction in perennial and non-perennial rivers using four data driven techniques. Water Resour. Manag. 2017, 31, 4855–4874. [Google Scholar] [CrossRef]
- Mehr, A.D. An improved gene expression programming model for streamflow forecasting in intermittent streams. J. Hydrol. 2018, 563, 669–678. [Google Scholar] [CrossRef]
- Rezaie-Balf, M.; Kisi, O. New formulation for forecasting streamflow: Evolutionary polynomial regression vs. extreme learning machine. Hydrol. Res. 2018, 49, 939–953. [Google Scholar] [CrossRef]
- Rezaie-Balf, M.; Noori, R.; Berndtsson, R.; Ghaemi, A.; Ghiasi, B. Evolutionary polynomial regression approach to predict longitudinal dispersion coefficient in rivers. J. Water Supply Res. Technol. AQUA 2018, 67, 447–457. [Google Scholar]
- Chang, T.K.; Talei, A.; Alaghmand, S.; Ooi, M.P.L. Choice of rainfall inputs for event-based rainfall-runoff modeling in a catchment with multiple rainfall stations using data-driven techniques. J. Hydrol. 2017, 545, 100–108. [Google Scholar] [CrossRef]
- Zare, M.; Koch, M. Groundwater level fluctuations simulation and prediction by ANFIS-and hybrid Wavelet-ANFIS/Fuzzy C-Means (FCM) clustering models: Application to the Miandarband plain. J. Hydro. Environ. Res. 2018, 18, 63–76. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Rezaie Balf, M.; Rashedi, E. Prediction of maximum scour depth around piers with debris accumulation using EPR, MT, and GEP models. J. Hydroinform. 2016, 18, 867–884. [Google Scholar] [CrossRef]
- Shahrara, N.; Çelik, T.; Gandomi, A.H. Gene expression programming approach to cost estimation formulation for utility projects. J. Civ. Eng. Manag. 2017, 23, 85–95. [Google Scholar] [CrossRef]
- Wang, L.; Kisi, O.; Zounemat-Kermani, M.; Zhu, Z.; Gong, W.; Niu, Z.; Liu, H.; Liu, Z. Prediction of solar radiation in China using different adaptive neuro-fuzzy methods and M5 model tree. Int. J. Climatol. 2017, 37, 1141–1155. [Google Scholar] [CrossRef]
- Sattar, A.A.; Elhakeem, M.; Rezaie-Balf, M.; Gharabaghi, B.; Bonakdari, H. Artificial intelligence models for prediction of the aeration efficiency of the stepped weir. Flow Meas. Instrum. 2019, 65, 78–89. [Google Scholar] [CrossRef]
- Li, X.; Sha, J.; Wang, Z.-L. A comparative study of multiple linear regression, artificial neural network and support vector machine for the prediction of dissolved oxygen. Hydrol. Res. 2017, 48, 1214–1225. [Google Scholar] [CrossRef]
- Kisi, O.; Parmar, K.S.; Soni, K.; Demir, V. Modeling of air pollutants using least square support vector regression, multivariate adaptive regression spline, and M5 model tree models. Air Qual. Atmos. Health 2017, 10, 873–883. [Google Scholar] [CrossRef]
- Zhang, D.; Lin, J.; Peng, Q.; Wang, D.; Yang, T.; Sorooshian, S.; Liu, X.; Zhuang, J. Modeling and simulating of reservoir operation using the artificial neural network, support vector regression, deep learning algorithm. J. Hydrol. 2018, 565, 720–736. [Google Scholar] [CrossRef]
- Chen, L.; Sun, N.; Zhou, C.; Zhou, J.; Zhou, Y.; Zhang, J.; Zhou, Q. Flood Forecasting Based on an Improved Extreme Learning Machine Model Combined with the Backtracking Search Optimization Algorithm. Water 2018, 10, 1362. [Google Scholar] [CrossRef]
- Chen, X.Y.; Chau, K.W.; Busari, A.O. A comparative study of population-based optimization algorithms for downstream river flow forecasting by a hybrid neural network model. Eng. Appl. Artif. Intell. 2015, 46, 258–268. [Google Scholar] [CrossRef]
- Ahani, A.; Shourian, M.; Rad, P.R. Performance assessment of the linear, nonlinear and nonparametric data driven models in river flow forecasting. Water Resour. Manag. 2018, 32, 383–399. [Google Scholar] [CrossRef]
- Baydaroğlu, Ö.; Koçak, K.; Duran, K. River flow prediction using hybrid models of support vector regression with the wavelet transform, singular spectrum analysis and chaotic approach. Meteorol. Atmos. Phys. 2018, 130, 349–359. [Google Scholar] [CrossRef]
- Bou-Fakhreddine, B.; Mougharbel, I.; Faye, A.; Chakra, S.A.; Pollet, Y. Daily river flow prediction based on Two-Phase Constructive Fuzzy Systems Modeling: A case of hydrological–meteorological measurements asymmetry. J. Hydrol. 2018, 558, 255–265. [Google Scholar] [CrossRef]
- Yin, Z.; Feng, Q.; Wen, X.; Deo, R.C.; Yang, L.; Si, J.; He, Z. Design and evaluation of SVR, MARS and M5Tree models for 1, 2 and 3-day lead time forecasting of river flow data in a semiarid mountainous catchment. Stoch. Environ. Res. Risk A 2018, 32, 2457–2476. [Google Scholar] [CrossRef]
- Wu, C.L.; Chau, K.W. Rainfall–runoff modeling using artificial neural network coupled with singular spectrum analysis. J. Hydrol. 2011, 399, 394–409. [Google Scholar] [CrossRef]
- Kim, S.; Seo, Y.; Rezaie-Balf, M.; Kisi, O.; Ghorbani, M.A.; Singh, V.P. Evaluation of daily solar radiation flux using soft computing approaches based on different meteorological information: Peninsula vs. continent. Theor. Appl. Climatol. 2018. [Google Scholar] [CrossRef]
- Benedetto, F.; Giunta, G.; Mastroeni, L. A maximum entropy method to assess the predictability of financial and commodity prices. Digit. Signal Process. 2015, 46, 19–31. [Google Scholar] [CrossRef]
- Zakhrouf, M.; Bouchelkia, H.; Stamboul, M.; Kim, S.; Heddam, S. Time series forecasting of river flow using an integrated approach of wavelet multi-resolution analysis and evolutionary data-driven models. A case study: Sebaou River (Algeria). Phys. Geogr. 2018, 39, 506–522. [Google Scholar] [CrossRef]
- Hu, T.; Wu, F.; Zhang, X. Rainfall–runoff modeling using principal component analysis and neural network. Hydrol. Res. 2007, 38, 235–248. [Google Scholar] [CrossRef]
- Ravikumar, P.; Somashekar, R.K. Principal component analysis and hydrochemical facies characterization to evaluate groundwater quality in Varahi river basin, Karnataka state, India. Appl. Water Sci. 2017, 7, 745–755. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, N.E. Ensemble empirical mode decomposition: A noise-assisted data analysis method. Adv. Adapt. Data Anal. 2009, 1, 1–41. [Google Scholar] [CrossRef]
- Baykasoğlu, A.; Güllü, H.; Çanakçı, H.; Özbakır, L. Prediction of compressive and tensile strength of limestone via genetic programming. Expert Syst. Appl. 2008, 35, 111–123. [Google Scholar] [CrossRef]
- Yuan, X.; Tan, Q.; Lei, X.; Yuan, Y.; Wu, X. Wind power prediction using hybrid autoregressive fractionally integrated moving average and least square support vector machine. Energy 2017, 129, 122–137. [Google Scholar] [CrossRef]
- Huang, N.E.; Wu, Z. A review on Hilbert-Huang transform: Method and its applications to geophysical studies. Rev. Geophys. 2008, 46. [Google Scholar] [CrossRef]
- Abdoos, A.A. A new intelligent method based on combination of VMD and ELM for short term wind power forecasting. Neurocomputing 2016, 203, 111–120. [Google Scholar] [CrossRef]
- Liu, H.; Mi, X.; Li, Y. Smart multi-step deep learning model for wind speed forecasting based on variational mode decomposition, singular spectrum analysis, LSTM network and ELM. Energy Convers. Manag. 2018, 159, 54–64. [Google Scholar] [CrossRef]
- Naik, J.; Dash, S.; Dash, P.K.; Bisoi, R. Short term wind power forecasting using hybrid variational mode decomposition and multi-kernel regularized pseudo inverse neural network. Renew. Energy 2018, 118, 180–212. [Google Scholar] [CrossRef]
- Wang, Y.; Markert, R.; Xiang, J.; Zheng, W. Research on variational mode decomposition and its application in detecting rub-impact fault of the rotor system. Mech. Syst. Signal Process. 2015, 60, 243–251. [Google Scholar] [CrossRef]
- Seo, Y.; Kim, S.; Singh, V.P. Comparison of different heuristic and decomposition techniques for river stage modeling. Environ. Monit. Assess. 2018, 190, 392. [Google Scholar] [CrossRef]
- Seo, Y.; Kim, S.; Singh, V. Machine learning models coupled with variational mode decomposition: A new approach for modeling daily rainfall-runoff. Atmosphere 2018, 9, 251. [Google Scholar] [CrossRef]
- Rezaie-Balf, M.; Kisi, O.; Chua, L.H. Application of ensemble empirical mode decomposition based on machine learning methodologies in forecasting monthly pan evaporation. Hydrol. Res. 2018. [Google Scholar] [CrossRef]
- Napolitano, G.; Serinaldi, F.; See, L. Impact of EMD decomposition and random initialization of weights in ANN hindcasting of daily stream flow series: An empirical examination. J. Hydrol. 2011, 406, 199–214. [Google Scholar] [CrossRef]
- Wang, W.C.; Xu, D.M.; Chau, K.W.; Chen, S. Improved annual rainfall-runoff forecasting using PSO–SVM model based on EEMD. J. Hydroinform. 2013, 15, 1377–1390. [Google Scholar] [CrossRef]
- Li, G.; Ma, X.; Yang, H. A hybrid model for monthly precipitation time series forecasting based on variational mode decomposition with extreme learning machine. Information 2018, 9, 177. [Google Scholar] [CrossRef]
- Ferreira, C. Gene expression programming and the evolution of computer programs. In Recent Developments in Biologically Inspired Computing; Igi Global: Hershey, PA, USA, 2005; pp. 82–103. [Google Scholar]
- Ferreira, C. Gene Expression Programming: Mathematical Modeling by an Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2006; Volume 21. [Google Scholar]
- Gandomi, A.H.; Babanajad, S.K.; Alavi, A.H.; Farnam, Y. Novel approach to strength modeling of concrete under triaxial compression. J. Mater. Civ. Eng. 2012, 24, 1132–1143. [Google Scholar] [CrossRef]
- Gandomi, A.H.; Alavi, A.H.; Kazemi, S.; Gandomi, M. Formulation of shear strength of slender RC beams using gene expression programming, part I: Without shear reinforcement. Autom. Constr. 2014, 42, 112–121. [Google Scholar] [CrossRef]
- Dey, P.; Das, A.K. A utilization of GEP (gene expression programming) metamodel and PSO (particle swarm optimization) tool to predict and optimize the forced convection around a cylinder. Energy 2016, 95, 447–458. [Google Scholar] [CrossRef]
- Kaboli, S.H.A.; Fallahpour, A.; Selvaraj, J.; Rahim, N.A. Long-term electrical energy consumption formulating and forecasting via optimized gene expression programming. Energy 2017, 126, 144–164. [Google Scholar] [CrossRef]
- Samadianfard, S.; Asadi, E.; Jarhan, S.; Kazemi, H.; Kheshtgar, S.; Kisi, O.; Sajjadi, S.; Manaf, A.A. Wavelet neural networks and gene expression programming models to predict short-term soil temperature at different depths. Soil Tillage Res. 2018, 175, 37–50. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Svetnik, V.; Liaw, A.; Tong, C.; Culberson, J.C.; Sheridan, R.P.; Feuston, B.P. Random forest: A classification and regression tool for compound classification and QSAR modeling. J. Chem. Inf. Comput. Sci. 2003, 43, 1947–1958. [Google Scholar] [CrossRef]
- Cootes, T.F.; Ionita, M.C.; Lindner, C.; Sauer, P. Robust and accurate shape model fitting using random forest regression voting. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 278–291. [Google Scholar]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Chi, C.T.; Liu, H.H. The empirical mode decomposition and the hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Huang, N.E.; Wu, M.L.C.; Long, S.R.; Shen, S.S.; Qu, W.; Gloersen, P.; Fan, K.L. A confidence limit for the empirical mode decomposition and Hilbert spectral analysis. Proc. Math. Phys. Eng. Sci. 2003, 459, 2317–2345. [Google Scholar] [CrossRef]
- Lei, Y.; He, Z.; Zi, Y. Application of the EEMD method to rotor fault diagnosis of rotating machinery. Mech. Syst. Signal Process. 2009, 23, 1327–1338. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, G.; Li, M.; Yin, H. Variational mode decomposition denoising combined the detrended fluctuation analysis. Signal Process. 2016, 125, 349–364. [Google Scholar] [CrossRef]
- Singh, J.; Knapp, H.V.; Arnold, J.G.; Demissie, M. Hydrological modeling of the iroquois river watershed using HSPF and SWAT 1. J. Am. Water Resour. Assoc. 2005, 41, 343–360. [Google Scholar] [CrossRef]
- Zhou, Y.; Chang, F.J.; Guo, S.; Ba, H.; He, S. A robust recurrent anfis for modeling multi-step-ahead flood forecast of three gorges reservoir in the Yangtze River. Hydrol. Earth Syst. Sci. Discuss. 2017. [Google Scholar] [CrossRef]
- Samadi, S.; Tufford, D.; Carbone, G. Assessing prediction uncertainty of a semi-distributed hydrology model for a shallow aquifer dominated environmental system. J. Am. Water Resour. Assoc. 2017, 53, 1368–1389. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Rezaie-Balf, M.; Tafarojnoruz, A. Prediction of riprap stone size under overtopping flow using data-driven models. Int. J. River Basin Manag. 2018, 16, 505–512. [Google Scholar] [CrossRef]
- Newcombe, R.G. Two-sided confidence intervals for the single proportion: Comparison of seven methods. Stat. Med. 1998, 17, 857–872. [Google Scholar] [CrossRef]
- Tabari, H.; Aghajanloo, M.B. Temporal pattern of aridity index in Iran with considering precipitation and evapotranspiration trends. Int. J. Climatol. 2013, 33, 396–409. [Google Scholar] [CrossRef]
- Fallah-Mehdipour, E.; Bozorg Haddad, O.; Mariño, M.A. Extraction of optimal operation rules in an aquifer-dam system: Genetic programming approach. J. Irrig. Drain. Eng. 2013, 139, 872–879. [Google Scholar] [CrossRef]
- Heidarnejad, M.; Golmaee, S.H.; Mosaedi, A.; Ahmadi, M.Z. Estimation of sediment volume in Karaj Dam Reservoir (Iran) by hydrometry method and a comparison with hydrography method. Lake Reserv. Manag. 2006, 22, 233–239. [Google Scholar] [CrossRef]
- Yozgatligil, C.; Yazici, C. Comparison of homogeneity tests for temperature using a simulation study. Int. J. Climatol. 2016, 36, 62–81. [Google Scholar] [CrossRef]
- Nkiaka, E.; Nawaz, N.R.; Lovett, J.C. Analysis of rainfall variability in the Logone catchment, Lake Chad basin. Int. J. Climatol. 2017, 37, 3553–3564. [Google Scholar] [CrossRef]
- Kazemzadeh, M.; Malekian, A. Homogeneity analysis of streamflow records in arid and semi-arid regions of northwestern Iran. J. Arid Land 2018, 10, 493–506. [Google Scholar] [CrossRef]
- Wijngaard, J.B.; Tank, A.K.; Können, G.P. Homogeneity of 20th century European daily temperature and precipitation series. Int. J. Climatol. 2003, 23, 679–692. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Q.; Zhang, G.; Nie, Z.; Gui, Z.; Que, H. A novel hybrid data-driven model for daily land surface temperature forecasting using long short-term memory neural network based on ensemble empirical mode decomposition. Int. J. Environ. Res. Public Health 2018, 15, 1032. [Google Scholar] [CrossRef] [PubMed]
- Niu, M.; Hu, Y.; Sun, S.; Liu, Y. A novel hybrid decomposition-ensemble model based on VMD and HGWO for container throughput forecasting. Appl. Math. Model. 2018, 57, 163–178. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
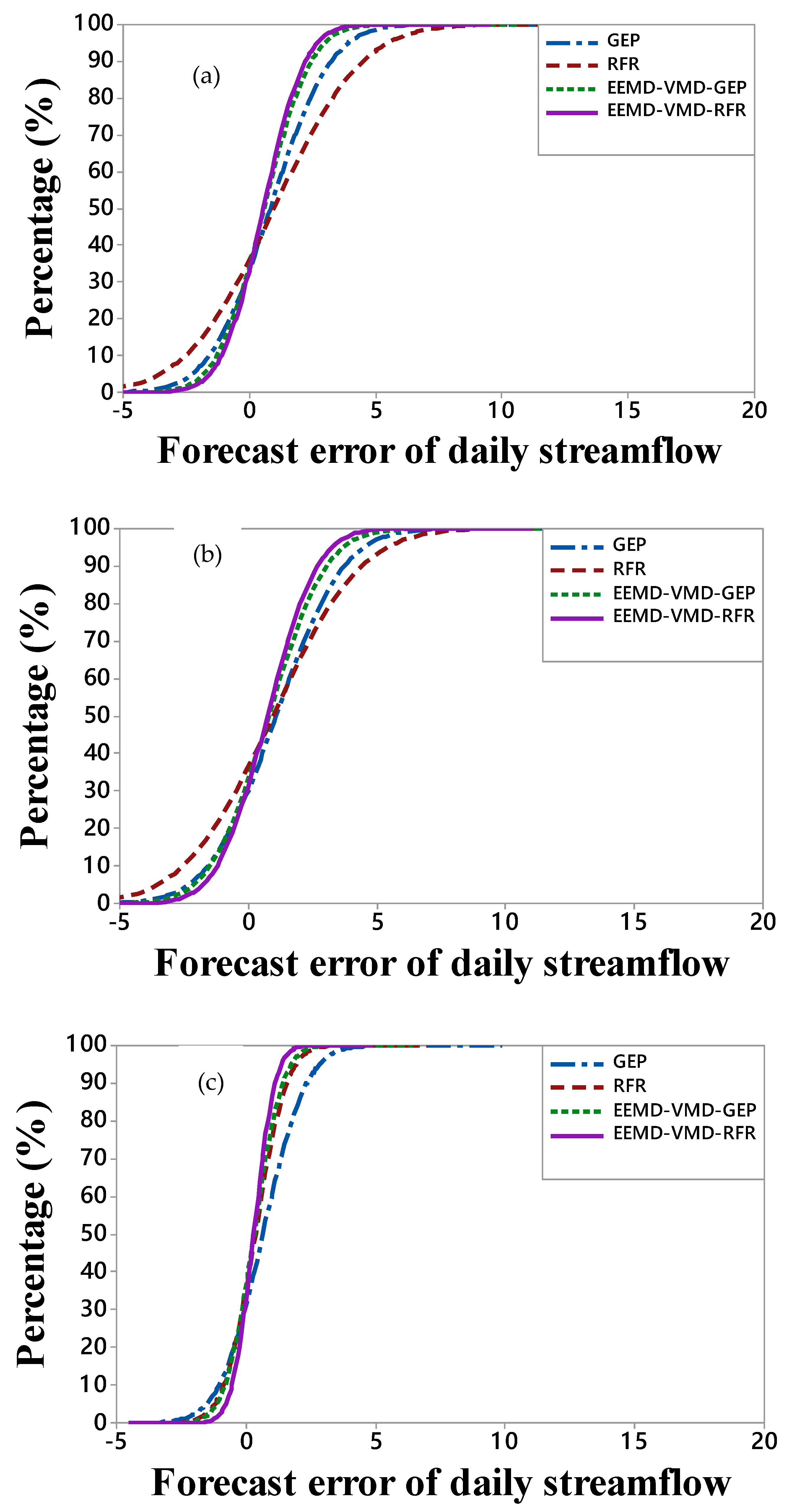{kind=link}
| Station | Crd | El (m) | Xmin (m3/s) | Xmax (m3/s) | Xmean (m3/s) | Sx | Cv | Csx |
|---|---|---|---|---|---|---|---|---|
| Siira | 36°01′ N 51°09′ E | 1898 | 0 | 160 | 11.8 | 12.54 | 157.35 | 2.64 |
| Bilghan | 36°00′ N 51°17′ E | 2138 | 0 | 194 | 15.81 | 14.04 | 197.17 | 3.21 |
| Gachsar | 36°06′ N 51°19′ E | 2258 | 0 | 61 | 3.93 | 3.99 | 15.96 | 2.34 |
| Station | Parameter Value | Input Variable | ||||||
|---|---|---|---|---|---|---|---|---|
| Qs(t−1) | Qs(t−2) | Qs(t−3) | Qs(t−4) | Qs(t−5) | Qs(t−6) | Qs(t−7) | ||
| Siira | R | 0.97** | 0.95** | 0.94** | 0.92** | 0.89** | 0.86** | 0.82** |
| P-value | 0.00 | 0.00 | 0.00 | 0.00 | 0.002 | 0.005 | 0.008 | |
| Bilghan | R | 0.97** | 0.95** | 0.93** | 0.91** | 0.88** | 0.84** | - |
| P-value | 0.00 | 0.00 | 0.00 | 0.001 | 0.002 | 0.004 | - | |
| Gachsar | R | 0.95** | 0.92** | 0.88** | 0.82** | - | - | - |
| P-value | 0.00 | 0.00 | 0.002 | 0.006 | - | - | - | |
| Station | Pettitt Test | Van Neumann Test | ||||
|---|---|---|---|---|---|---|
| P-value | Statistics | Class | P-value | Statistics | Class | |
| Siira | 0.462 | 252 | A | 0.006 | 2.38 | A |
| Bilghan | 0.69 | 240 | A | 0.026 | 1.74 | A |
| Gachsar | 0.133 | 92 | A | 0.02 | 1.52 | A |
| Model | Design Parameters | |||||||
|---|---|---|---|---|---|---|---|---|
| GEP | Chromosomes | Gene size | HEAD SIZE | Linking Function | Mutation Rate | Crossover Rate | One and two point recombination rate | IS and RIS transposition rate |
| 40 | 3 | 8 | Addition | 0.01 | 0.8 | 0.3 | 0.1 | |
| RFR | Bag size percent | Leaf | Batch size | Surrogate | Delta Criterion | Number of depth | Seed | Out-of-Bag error |
| 200 | 8 | 100 | True | 0.1007 | 0 | 1 | False | |
| Models | Statistical Error Indices | |||
|---|---|---|---|---|
| GEP | RFR | EEMD-VMD-GEP | EEMD-VMD-RFR | |
| Total Available Data in Calibration Stage | ||||
| NSE | 0.927 | 0.93 | 0.944 | 0.972 |
| RMSE (m3/s) | 3.731 | 3.482 | 3.26 | 2.3 |
| MAE (m3/s) | 1.313 | 1.358 | 1.301 | 1.056 |
| RSD (m3/s) | 0.269 | 0.251 | 0.235 | 0.166 |
| U95 | 28.116 | 27.99 | 27.82 | 27.32 |
| Reliability (%) | 85.94 | 86.47 | 89.08 | 90.96 |
| Resilience (%) | 67.24 | 54.79 | 69.44 | 71.21 |
| Total Available Data in Validation Stage | ||||
| NSE | 0.892 | 0.75 | 0.933 | 0.944 |
| RMSE (m3/s) | 2.286 | 3.491 | 1.806 | 1.645 |
| MAE (m3/s) | 0.906 | 1.282 | 0.722 | 0.683 |
| RSD (m3/s) | 0.327 | 0.499 | 0.258 | 0.235 |
| U95 | 14.403 | 15.303 | 14.13 | 14.06 |
| Reliability (%) | 89.49 | 85.68 | 92.69 | 95.88 |
| Resilience (%) | 68.44 | 61.674 | 78.47 | 82.43 |
| Models | Mean Prediction Error | Width of Uncertainty Band | Median | 95% Predictive Error Interval |
|---|---|---|---|---|
| Siira Station | ||||
| GEP | 0.236 | ±4.456 | 7.719 | −4.22 to 4.69 |
| RFR | 0.189 | ±6.831 | 7.788 | −6.64 to 7.02 |
| EEMD-VMD-GEP | 0.208 | ±3.511 | 7.695 | −3.28 to 3.74 |
| EEMD-VMD-RFR | 0.172 | ±3.192 | 7.401 | −2.95 to 3.42 |
| Models | Statistical Error Indices | |||
|---|---|---|---|---|
| GEP | RFR | EEMD-VMD-GEP | EEMD-VMD-RFR | |
| Total Available Data in Calibration Stage | ||||
| NSE | 0.915 | 0.932 | 0.94 | 0.98 |
| RMSE (m3/s) | 4.55 | 4.063 | 3.73 | 1.768 |
| MAE (m3/s) | 1.655 | 1.508 | 2.11 | 0.747 |
| RSD (m3/s) | 0.291 | 0.261 | 0.24 | 0.11 |
| U95 | 31.84 | 31.61 | 31.46 | 30.79 |
| Reliability (%) | 88.36 | 90.27 | 93.52 | 96.49 |
| Resilience (%) | 59.66 | 64.93 | 71.67 | 79.15 |
| Total Available Data in Validation Period | ||||
| NSE | 0.85 | 0.87 | 0.90 | 0.92 |
| RMSE (m3/s) | 2.704 | 2.61 | 2.358 | 2.061 |
| MAE (m3/s) | 1.442 | 1.29 | 1.08 | 1.02 |
| RSD (m3/s) | 0.357 | 0.33 | 0.311 | 0.272 |
| U95 | 15.75 | 15.83 | 15.24 | 14.66 |
| Reliability (%) | 88.507 | 93.89 | 95.64 | 96.82 |
| Resilience (%) | 55.39 | 81.97 | 82.02 | 86.85 |
| Models | Mean Prediction Error | Width of Uncertainty Band | Median | 95% Predictive Error Interval |
|---|---|---|---|---|
| Bilghan Station | ||||
| GEP | 1.102 | ±5.058 | 16.52 | −4.25 to 5.86 |
| RFR | 0.811 | ±5.514 | 15.684 | −5.53 to 5.49 |
| EEMD-VMD-GEP | 0.483 | ±4.563 | 15.804 | −4.18 to 4.94 |
| EEMD-VMD-RFR | 0.301 | ±3.922 | 15.78 | −3.62 to 4.22 |
| Models | Statistical Error Indices | |||
|---|---|---|---|---|
| GEP | RFR | EEMD-VMD-GEP | EEMD-VMD-RFR | |
| Total available data in calibration stage | ||||
| NSE | 0.89 | 0.934 | 0.95 | 0.98 |
| RMSE (m3/s) | 1.879 | 0.964 | 0.84 | 0.53 |
| MAE (m3/s) | 0.519 | 0.256 | 0.237 | 0.137 |
| RSD (m3/s) | 0.497 | 0.255 | 0.222 | 0.141 |
| U95 | 5.274 | 7.64 | 7.59 | 7.482 |
| Reliability (%) | 91.52 | 93.98 | 94.06 | 96.16 |
| Resilience (%) | 54.49 | 78.65 | 77.18 | 85.33 |
| Total available data in validation period | ||||
| NSE | 0.865 | 0.93 | 0.95 | 0.97 |
| RMSE (m3/s) | 1.47 | 1.013 | 0.62 | 0.516 |
| MAE(m3/s) | 0.647 | 0.357 | 0.302 | 0.29 |
| RSD (m3/s) | 0.366 | 0.252 | 0.229 | 0.178 |
| U95 | 8.38 | 8.12 | 8.078 | 7.95 |
| Reliability (%) | 86.7 | 95.91 | 96.27 | 97.56 |
| Resilience (%) | 69.97 | 84.82 | 92.15 | 88.29 |
| Models | Mean Prediction Error | Width of Uncertainty Band | Median | 95% predictive Error Interval |
|---|---|---|---|---|
| Gachsar station | ||||
| GEP | 0.103 | ±2.876 | 4.11 | −2.97 to 2.77 |
| RFR | 0.084 | ±1.986 | 4.236 | −1.99 to 1.98 |
| EEMD-VMD-GEP | 0.021 | ±1.808 | 4.186 | −1.78 to 1.83 |
| EEMD-VMD-RFR | 0.006 | ±1.402 | 4.15 | −1.54 to 1.66 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rezaie-Balf, M.; Fani Nowbandegani, S.; Samadi, S.Z.; Fallah, H.; Alaghmand, S. An Ensemble Decomposition-Based Artificial Intelligence Approach for Daily Streamflow Prediction. Water 2019, 11, 709. https://doi.org/10.3390/w11040709
Rezaie-Balf M, Fani Nowbandegani S, Samadi SZ, Fallah H, Alaghmand S. An Ensemble Decomposition-Based Artificial Intelligence Approach for Daily Streamflow Prediction. Water. 2019; 11(4):709. https://doi.org/10.3390/w11040709
Chicago/Turabian StyleRezaie-Balf, Mohammad, Sajad Fani Nowbandegani, S. Zahra Samadi, Hossein Fallah, and Sina Alaghmand. 2019. "An Ensemble Decomposition-Based Artificial Intelligence Approach for Daily Streamflow Prediction" Water 11, no. 4: 709. https://doi.org/10.3390/w11040709
APA StyleRezaie-Balf, M., Fani Nowbandegani, S., Samadi, S. Z., Fallah, H., & Alaghmand, S. (2019). An Ensemble Decomposition-Based Artificial Intelligence Approach for Daily Streamflow Prediction. Water, 11(4), 709. https://doi.org/10.3390/w11040709