Effect of Multicollinearity on the Bivariate Frequency Analysis of Annual Maximum Rainfall Events


Abstract
:1. Introduction
2. Theoretical Background
2.1. Multicollinearity
2.1.1. Multicollinearity Problem in Regression Analysis
2.1.2. Possible Multicollinearity Issue in Frequency Analysis
2.2. Copula
3. Annual Maximum Rainfall Events in Seoul, Korea
4. Evaluation of Multicollinearity Problem with Observed Data
4.1. Results of Bivariate Frequency Analysis
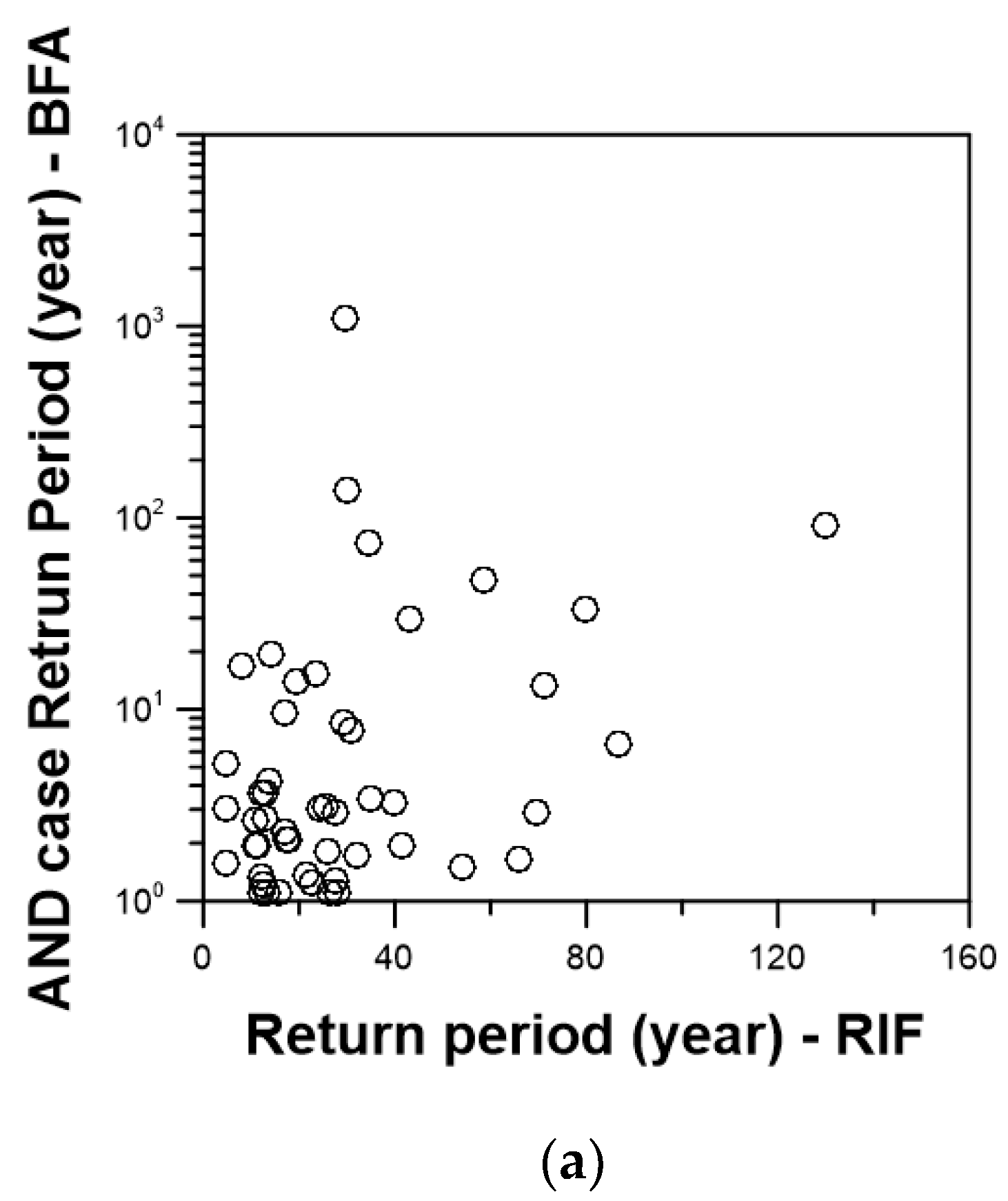
4.2. Effect of Multicollinearity on the Estimated Return Periods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- De Haan, L.; De Ronde, J. Sea and wind: Multivariate extremes at work. Extremes 1998, 1, 7. [Google Scholar] [CrossRef]
- Yue, S. Applicability of the Nagao–Kadoya bivariate exponential distribution for modeling two correlated exponentially distributed variates. Stoch. Environ. Res. Risk Assess. 2001, 15, 244–260. [Google Scholar] [CrossRef]
- Yue, S.; Wang, C. A comparison of two bivariate extreme value distributions. Stoch. Environ. Res. Risk Assess. 2004, 18, 61–66. [Google Scholar] [CrossRef]
- Yue, S. Joint probability distribution of annual maximum storm peaks and amounts as represented by daily rainfalls. Hydrol. Sci. J. 2000, 45, 315–326. [Google Scholar] [CrossRef]
- Herr, H.D.; Krzysztofowicz, R. Generic probability distribution of rainfall in space: The bivariate model. J. Hydrol. 2005, 306, 234–263. [Google Scholar] [CrossRef]
- Nadarajah, S. A bivariate pareto model for drought. Stoch. Environ. Res. Risk Assess. 2009, 23, 811–822. [Google Scholar] [CrossRef]
- Mirabbasi, R.; Fakheri-Fard, A.; Dinpashoh, Y. Bivariate drought frequency analysis using the copula method. Theor. Appl. Climatol. 2012, 108, 191–206. [Google Scholar] [CrossRef]
- Yoo, J.; Kwon, H.-H.; Kim, T.-W.; Ahn, J.-H. Drought frequency analysis using cluster analysis and bivariate probability distribution. J. Hydrol. 2012, 420, 102–111. [Google Scholar] [CrossRef]
- Zhang, L.; Singh, V. Bivariate flood frequency analysis using the copula method. J. Hydrol. Eng. 2006, 11, 150–164. [Google Scholar] [CrossRef]
- Grimaldi, S.; Serinaldi, F. Asymmetric copula in multivariate flood frequency analysis. Adv. Water Resour. 2006, 29, 1155–1167. [Google Scholar] [CrossRef]
- Chebana, F.; Ouarda, T.B. Depth-based multivariate descriptive statistics with hydrological applications. J. Geophys. Res. Atmos. 2011, 116, D10120. [Google Scholar] [CrossRef]
- De Michele, C.; Salvadori, G.; Canossi, M.; Petaccia, A.; Rosso, R. Bivariate statistical approach to check adequacy of dam spillway. J. Hydrol. Eng. 2005, 10, 50–57. [Google Scholar] [CrossRef]
- Park, C.-S.; Yoo, C.-S.; Jun, C.-H. Bivariate Rainfall Frequency Analysis and Rainfall-runoff Analysis for Independent Rainfall Events. J. Korea Water Resour. Assoc. 2012, 45, 713–727. [Google Scholar] [CrossRef]
- Yoon, P.; Kim, T.-W.; Yoo, C. Rainfall frequency analysis using a mixed GEV distribution: A case study for annual maximum rainfalls in South Korea. Stoch. Environ. Res. Risk Assess. 2013, 27, 1143–1153. [Google Scholar] [CrossRef]
- De Michele, C.; Salvadori, G. A generalized Pareto intensity-duration model of storm rainfall exploiting 2-copulas. J. Geophys. Res. 2003, 108. [Google Scholar] [CrossRef]
- Bacchi, B.; Becciu, G.; Kottegoda, N.T. Bivariate exponential model applied to intensities and durations of extreme rainfall. J. Hydrol. 1994, 155, 225–236. [Google Scholar] [CrossRef]
- Yue, S. A bivariate gamma distribution for use in multivariate flood frequency analysis. Hydrol. Process. 2001, 15, 1033–1045. [Google Scholar] [CrossRef]
- Zhang, L.; Singh, V.P. Bivariate rainfall frequency distributions using Archimedean copulas. J. Hydrol. 2007, 332, 93–109. [Google Scholar] [CrossRef]
- Sklar, M. Fonctions de repartition an dimensions et leurs marges. Publ. Inst. Stat. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- Fu, G.; Butler, D. Copula-based frequency analysis of overflow and flooding in urban drainage systems. J. Hydrol. 2014, 510, 49–58. [Google Scholar] [CrossRef]
- Lee, D.R.; Jeong, S.M. A SpatialTemporal Characteristics of Rainfall in the Han River Basin. J. Korean Assoc. Hydrol. Sci. 1992, 25, 75–85. [Google Scholar]
- Yoo, C.; Park, C. Comparison of Annual Maximum Rainfall Series and Annual Maximum Independent Rainfall Event Series. J. Korea Water Resour. Assoc. 2012, 45, 431–444. [Google Scholar] [CrossRef]
- Rodriguez-Iturbe, I.; De Power, B.F.; Valdes, J. Rectangular pulses point process models for rainfall: Analysis of empirical data. J. Geophys. Res. Atmos. 1987, 92, 9645–9656. [Google Scholar] [CrossRef]
- Onof, C.; Wheater, H.S. Modelling of British rainfall using a random parameter Bartlett-Lewis rectangular pulse model. J. Hydrol. 1993, 149, 67–95. [Google Scholar] [CrossRef]
- Smithers, J.; Pegram, G.; Schulze, R. Design rainfall estimation in South Africa using Bartlett–Lewis rectangular pulse rainfall models. J. Hydrol. 2002, 258, 83–99. [Google Scholar] [CrossRef]
- Yoo, C.; Kim, D.; Kim, T.-W.; Hwang, K.-N. Quantification of drought using a rectangular pulses Poisson process model. J. Hydrol. 2008, 355, 34–48. [Google Scholar] [CrossRef]
- Burton, A.; Fowler, H.; Blenkinsop, S.; Kilsby, C. Downscaling transient climate change using a Neyman–Scott Rectangular Pulses stochastic rainfall model. J. Hydrol. 2010, 381, 18–32. [Google Scholar] [CrossRef]
- Gräler, B.; van den Berg, M.; Vandenberghe, S.; Petroselli, A.; Grimaldi, S.; De Baets, B.; Verhoest, N. Multivariate return periods in hydrology: A critical and practical review focusing on synthetic design hydrograph estimation. Hydrol. Earth Syst. Sci. 2013, 17, 1281–1296. [Google Scholar] [CrossRef]
- Jain, A.; Vinnarasi, R.; Dhanya, C. Intensity-Duration-Frequency Relationship using Event Based Approach. J. Agroecol. Nat. Resour. Manag. 2015, 2, 178–180. [Google Scholar]
- Chong, I.G.; Jun, C.-H. Performance of some variable selection methods when multicollinearity is present. Chemom. Intell. Lab. Syst. 2005, 78, 103–112. [Google Scholar] [CrossRef]
- Silvey, S. Multicollinearity and imprecise estimation. J. R. Stat. Soc. Ser. B Methodol. 1969, 31, 539–552. [Google Scholar] [CrossRef]
- Farrar, D.E.; Glauber, R.R. Multicollinearity in regression analysis: The problem revisited. Rev. Econ. Stat. 1967, 49, 92–107. [Google Scholar] [CrossRef]
- Cortina, J.M. Interaction, nonlinearity, and multicollinearity: Implications for multiple regression. J. Manag. 1993, 19, 915–922. [Google Scholar] [CrossRef]
- Wheeler, D.; Tiefelsdorf, M. Multicollinearity and correlation among local regression coefficients in geographically weighted regression. J. Geogr. Syst. 2005, 7, 161–187. [Google Scholar] [CrossRef]
- Harvey, A. Some comments on multicollinearity in regression. Appl. Stat. 1977, 26, 188–191. [Google Scholar] [CrossRef]
- Morrow-Howell, N. The M word: Multicollinearity in multiple regression. Soc. Work Res. 1994, 18, 247–251. [Google Scholar] [CrossRef]
- Viswesvaran, C. Multiple Regression in Behavioral Research: Explanation and Prediction. Pers. Psychol. 1998, 51, 223. [Google Scholar]
- Allison, P.D. Multiple Regression: A Primer; Pine Forge Press: Newbury Park, CA, USA, 1999. [Google Scholar]
- Kutner, M.; Nachtsheim, C.; Neter, J.J. Applied Linear Regression Models; McGraw-Hill: New York, NY, USA, 2004. [Google Scholar]
- Robinson, C.; Schumacker, R.E. Interaction effects: Centering, variance inflation factor, and interpretation issues. Mult. Linear Regres. Viewp. 2009, 35, 6–11. [Google Scholar]
- Demuth, S.; Steffensmeier, D. Ethnicity effects on sentence outcomes in large urban courts: Comparisons among White, Black, and Hispanic defendants. Soc. Sci. Q. 2004, 85, 994–1011. [Google Scholar] [CrossRef]
- O’brien, R.M. A caution regarding rules of thumb for variance inflation factors. Qual. Quant. 2007, 41, 673–690. [Google Scholar] [CrossRef]
- Gilliam, J.; Chatterjee, S.; Grable, J. Measuring the perception of financial risk tolerance: A tale of two measures. J. Financ. Counsel. Plan. 2010, 21, 1–14. [Google Scholar]
- Lee, W.H.; Park, S.D.; Choi, S.Y. A derivation of the typical probable rainfall intensity formula in Korea. J. Korean Soc. Civ. Eng. 1993, 13, 115–120. [Google Scholar]
- Nelsen, R.B. An Introduction to Copulas; Springer Science & Business Media: Berlin, Germany, 2007. [Google Scholar]
- Genest, C.; Favre, A.-C. Everything you always wanted to know about copula modeling but were afraid to ask. J. Hydrol. Eng. 2007, 12, 347–368. [Google Scholar] [CrossRef]
- Salvadori, G.; De Michele, C.; Kottegoda, N.T.; Rosso, R. Extremes in Nature: An Approach Using Copulas; Springer Science & Business Media: Berlin, Germany, 2007. [Google Scholar]
- Clayton, D.G. A model for association in bivariate life tables and its application in epidemiological studies of familial tendency in chronic disease incidence. Biometrika 1978, 65, 141–151. [Google Scholar] [CrossRef]
- Frank, M.J. On the simultaneous associativity of F (x, y) and x+y− F (x, y). Aequ. Math. 1979, 19, 194–226. [Google Scholar] [CrossRef]
- Hutchinson, T.P.; Lai, C.D. Continuous Bivariate Distributions Emphasising Applications; Rumsby Scientific Publishing: Adelaide, Australia, 1990. [Google Scholar]
- Schmidt, R.; Stadtmüller, U. Non-parametric estimation of tail dependence. Scand. J. Stat. 2006, 33, 307–335. [Google Scholar] [CrossRef]
- Brooks, C.; Burke, S.P. Information criteria for GARCH model selection. Eur. J. Financ. 2003, 9, 557–580. [Google Scholar] [CrossRef]
- Juneja, V.K.; Melendres, M.V.; Huang, L.; Gumudavelli, V.; Subbiah, J.; Thippareddi, H. Modeling the effect of temperature on growth of Salmonella in chicken. Food Microbiol. 2007, 24, 328–335. [Google Scholar] [CrossRef]
- Gringorten, I.I. A plotting rule for extreme probability paper. J. Geophys. Res. 1963, 68, 813–814. [Google Scholar] [CrossRef]
- Yevjevich, V. Probability and Statistics in Hydrology; Water Resources Publications, LLC: Highlands Ranch, CO, USA, 1972. [Google Scholar]
- Salvadori, G.; De Michele, C. On the use of copulas in hydrology: Theory and practice. J. Hydrol. Eng. 2007, 12, 369–380. [Google Scholar] [CrossRef]
- Yoo, C.; Park, M.; Kim, H.J.; Jun, C. Comparison of annual maximum rainfall events of modern rain gauge data (1961–2010) and Chukwooki data (1777–1910) in Seoul, Korea. J. Water Clim. Chang. 2018, 9, 58–73. [Google Scholar] [CrossRef]
- Park, M.; Yoo, C.; Kim, H.; Jun, C. Bivariate frequency analysis of annual maximum rainfall event series in Seoul, Korea. J. Hydrol. Eng. 2013, 19, 1080–1088. [Google Scholar] [CrossRef]
- Bernard, M.M. Formulas for rainfall intensities of long duration. Trans. Am. Soc. Civ. Eng. 1932, 96, 592–606. [Google Scholar]
- Brutsaert, W. Hydrology: An Introduction; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Gupta, S.K. Modern Hydrology and Sustainable Water Development; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Naghettini, M. Fundamentals of Statistical Hydrology; Springer: Berlin, Germany, 2017. [Google Scholar]
- Genest, C.; Rémillard, B.; Beaudoin, D. Goodness-of-fit tests for copulas: A review and a power study. Insur. Math. Econ. 2009, 44, 199–213. [Google Scholar] [CrossRef]
- Salvadori, G.; Durante, F.; De Michele, C. On the return period and design in a multivariate framework. Hydrol. Earth Syst. Sci. 2011, 15, 3293–3305. [Google Scholar] [CrossRef]
- Pappada, R.; Durante, F.; Salvadori, G. Quantification of the environmental structural risk with spoiling ties: Is randomization worthwhile? Stoch. Environ. Res. Risk Assess. 2017, 31, 2483–2497. [Google Scholar] [CrossRef]
- De Michele, C.; Salvadori, G.; Vezzoli, R.; Pecora, S. Multivariate assessment of droughts: Frequency analysis and Dynamic Return Period. Water Resour. Res. 2013, 49, 6985–6994. [Google Scholar] [CrossRef]
- Salvadori, G.; Tomasicchio, G.R.; D’Alessandro, F. Practical guidelines for multivariate analysis and design in coastal and off-shore engineering. Coast. Eng. 2014, 88, 1–14. [Google Scholar] [CrossRef]
- Brunner, M.I.; Seibert, J.; Favre, A.C. Bivariate return periods and their importance for flood peak and volume estimation. Wiley Interdiscip. Rev. Water 2016, 3, 819–833. [Google Scholar] [CrossRef]
- Kroll, C.N.; Song, P. Impact of multicollinearity on small sample hydrologic regression models. Water Resour. Res. 2013, 49, 3756–3769. [Google Scholar] [CrossRef]









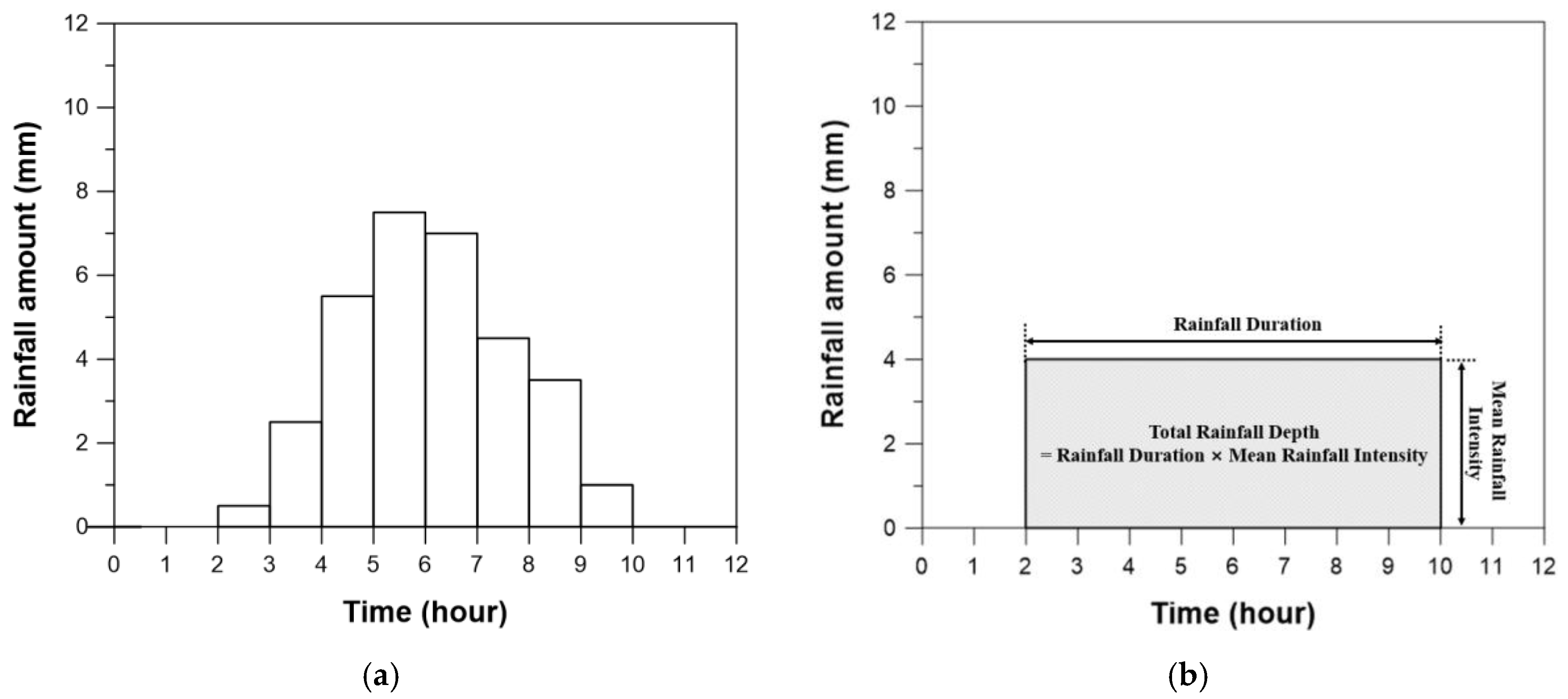{kind=link}
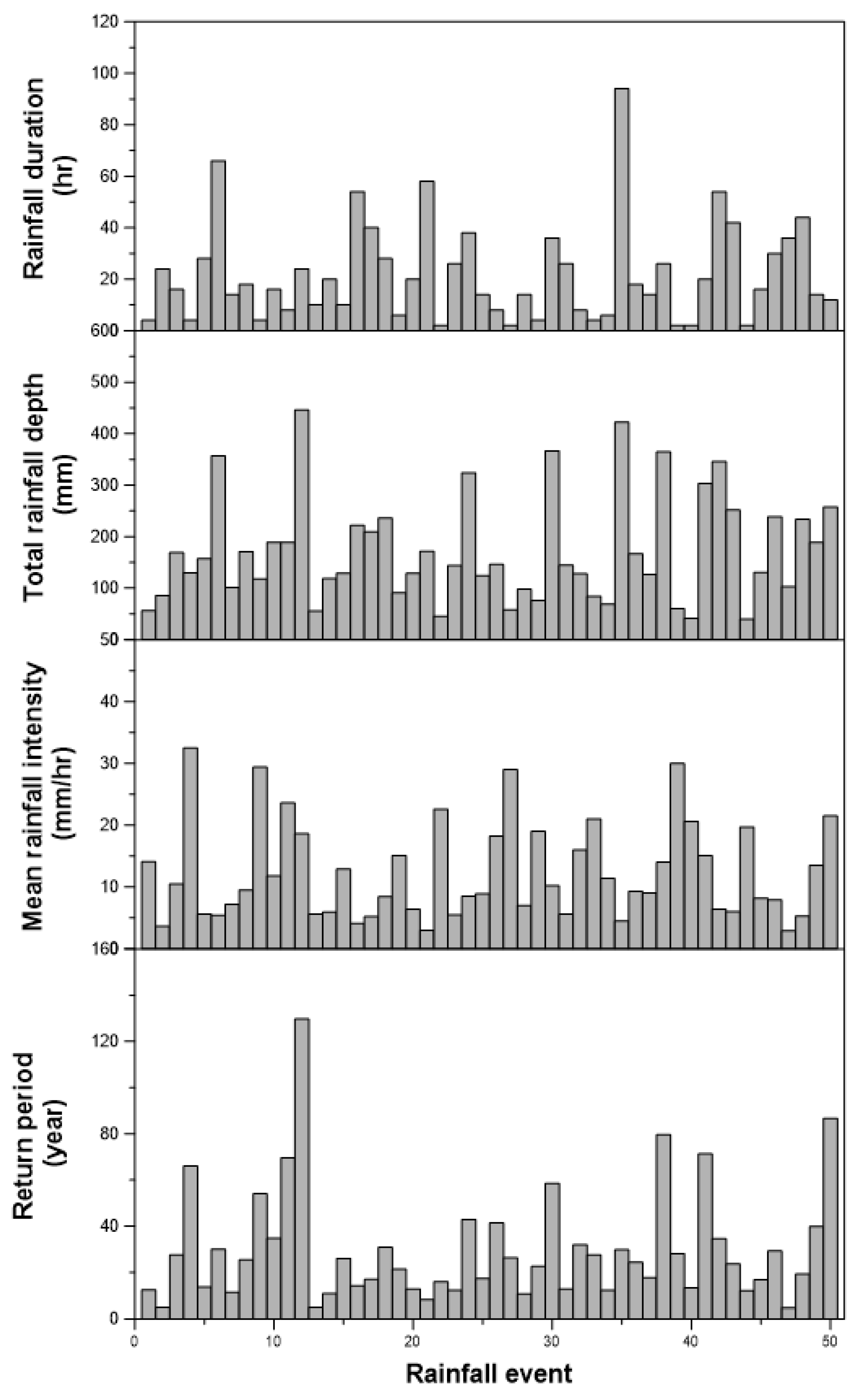{kind=link}
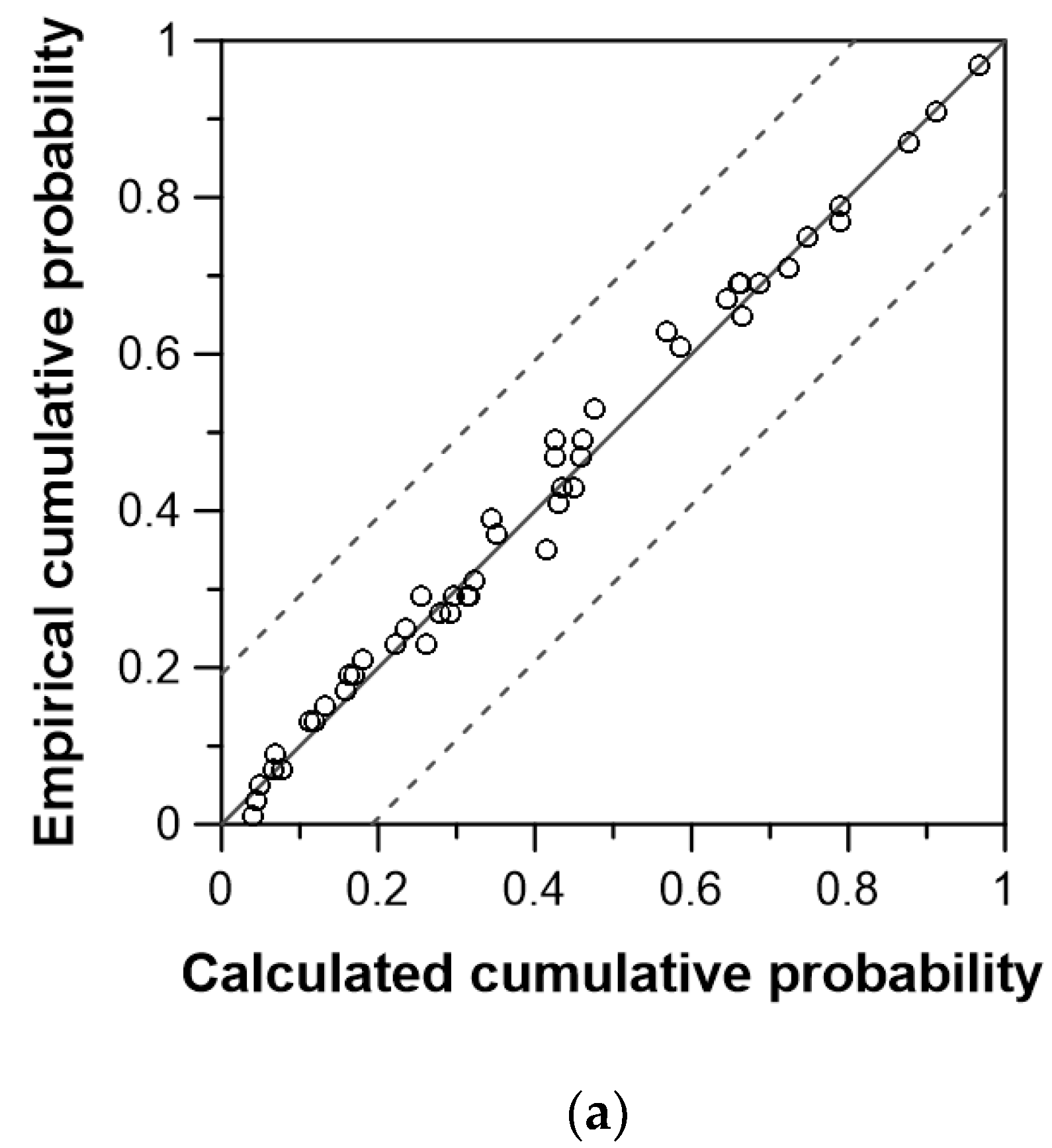{kind=link}
{kind=link}
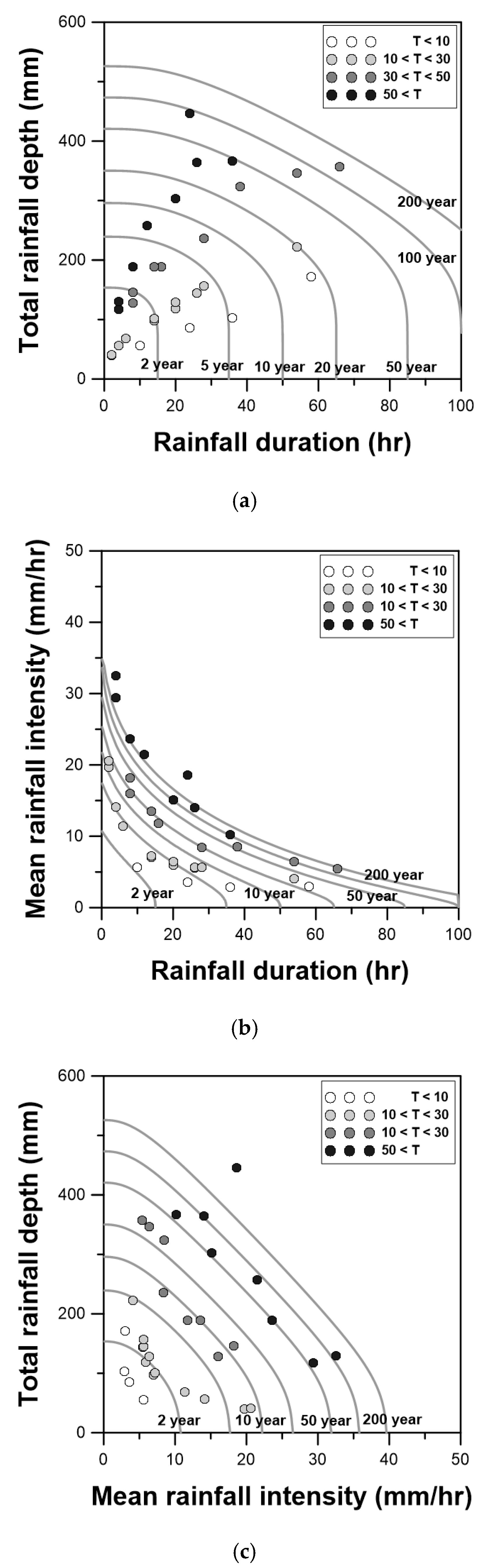{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean | Standard Deviation | Range | |
|---|---|---|---|
| Rainfall duration (hour) | 21.7 | 19.0 | 2.0–94.0 |
| Total rainfall depth (mm) | 172.1 | 102.9 | 39.4–446.0 |
| Mean rainfall intensity (mm/hour) | 12.3 | 7.7 | 2.9–32.5 |
| Copula Model | Total Rainfall Depth and Rainfall Duration | Mean Rainfall Intensity and Rainfall Duration | Total Rainfall Depth and Mean Rainfall Intensity |
|---|---|---|---|
| Clayton | 2.65 | NA | NA |
| Frank | 7.17 | −1.19 | −1.02 |
| Gumbel-Hougaard | 2.32 | NA | NA |
| Gaussian | 0.78 | −0.82 | −0.28 |
| Case | Clayton | Frank | Gumbel-Hougaard | Gaussian |
|---|---|---|---|---|
| Total rainfall depth and rainfall duration | 0.4461 | 0.6009 | 0.5120 | 0.9306 |
| Mean rainfall intensity and rainfall duration | NA | 0.3841 | NA | 0.6199 |
| Total rainfall depth and mean rainfall intensity | NA | 0.3012 | NA | 0.3412 |
| Case | Clayton | Frank | Gumbel-Hougaard | Gaussian | |
|---|---|---|---|---|---|
| MSE | Total rainfall depth and rainfall duration | 0.000352 | 0.000916 | 0.0216 | 0.000881 |
| Mean rainfall intensity and rainfall duration | NA | 0.00449 | NA | 0.00161 | |
| Total rainfall depth and mean rainfall intensity | NA | 0.00132 | NA | 0.00168 | |
| AIC | Total rainfall depth and rainfall duration | −156.206 | −149.911 | −81.323 | −150.757 |
| Mean rainfall intensity and rainfall duration | NA | −115.382 | NA | −137.620 | |
| Total rainfall depth and mean rainfall intensity | NA | −141.971 | NA | −136.681 |
| Case | Mean | Range |
|---|---|---|
| Total rainfall depth and rainfall duration | 34.1 | 1.1–1105.0 |
| Mean rainfall intensity and rainfall duration | 118.2 | 2.1–1289.4 |
| Total rainfall depth and mean rainfall intensity | 31.1 | 1.3–629.6 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoo, C.; Cho, E. Effect of Multicollinearity on the Bivariate Frequency Analysis of Annual Maximum Rainfall Events. Water 2019, 11, 905. https://doi.org/10.3390/w11050905
Yoo C, Cho E. Effect of Multicollinearity on the Bivariate Frequency Analysis of Annual Maximum Rainfall Events. Water. 2019; 11(5):905. https://doi.org/10.3390/w11050905
Chicago/Turabian StyleYoo, Chulsang, and Eunsaem Cho. 2019. "Effect of Multicollinearity on the Bivariate Frequency Analysis of Annual Maximum Rainfall Events" Water 11, no. 5: 905. https://doi.org/10.3390/w11050905
APA StyleYoo, C., & Cho, E. (2019). Effect of Multicollinearity on the Bivariate Frequency Analysis of Annual Maximum Rainfall Events. Water, 11(5), 905. https://doi.org/10.3390/w11050905