This section presents the methodology employed in this research, structured in three different subsections. The first one deals with the treatment of the input data and the fitting of the marginal distributions that are part of the copula. The second one exposes the theoretical aspects about copulas and their formulation for their subsequent practical application. Also, it exposes the treatment of the river junction by means of the use of conditional copulas. Finally, the third subsection presents the procedure to carry out a Monte Carlo simulation with the aim of obtaining multiple synthetic hydrographs for different return periods, downstream of the junction of both rivers.
2.1. Statistical Analysis of Flow Peaks and Volumes
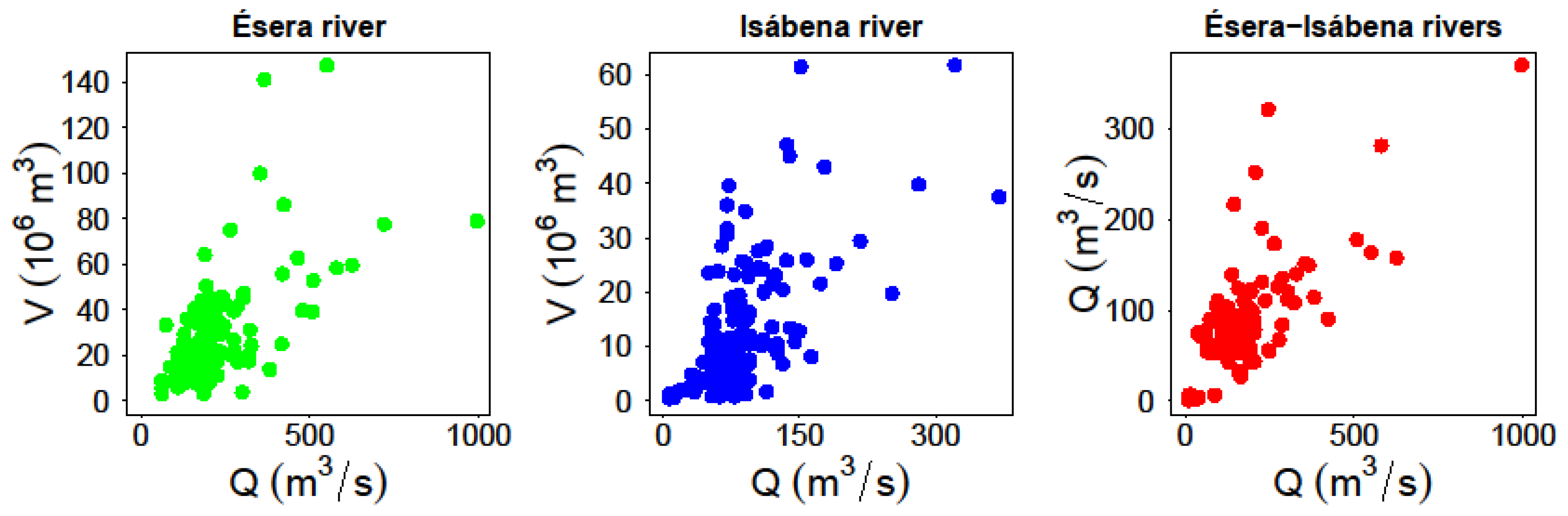
This research develops a POT (peaks over threshold) analysis applied to
Q and
V variables, where
Q is the flow peak expressed in m
3/s and
V the volume expressed in 10
6 m
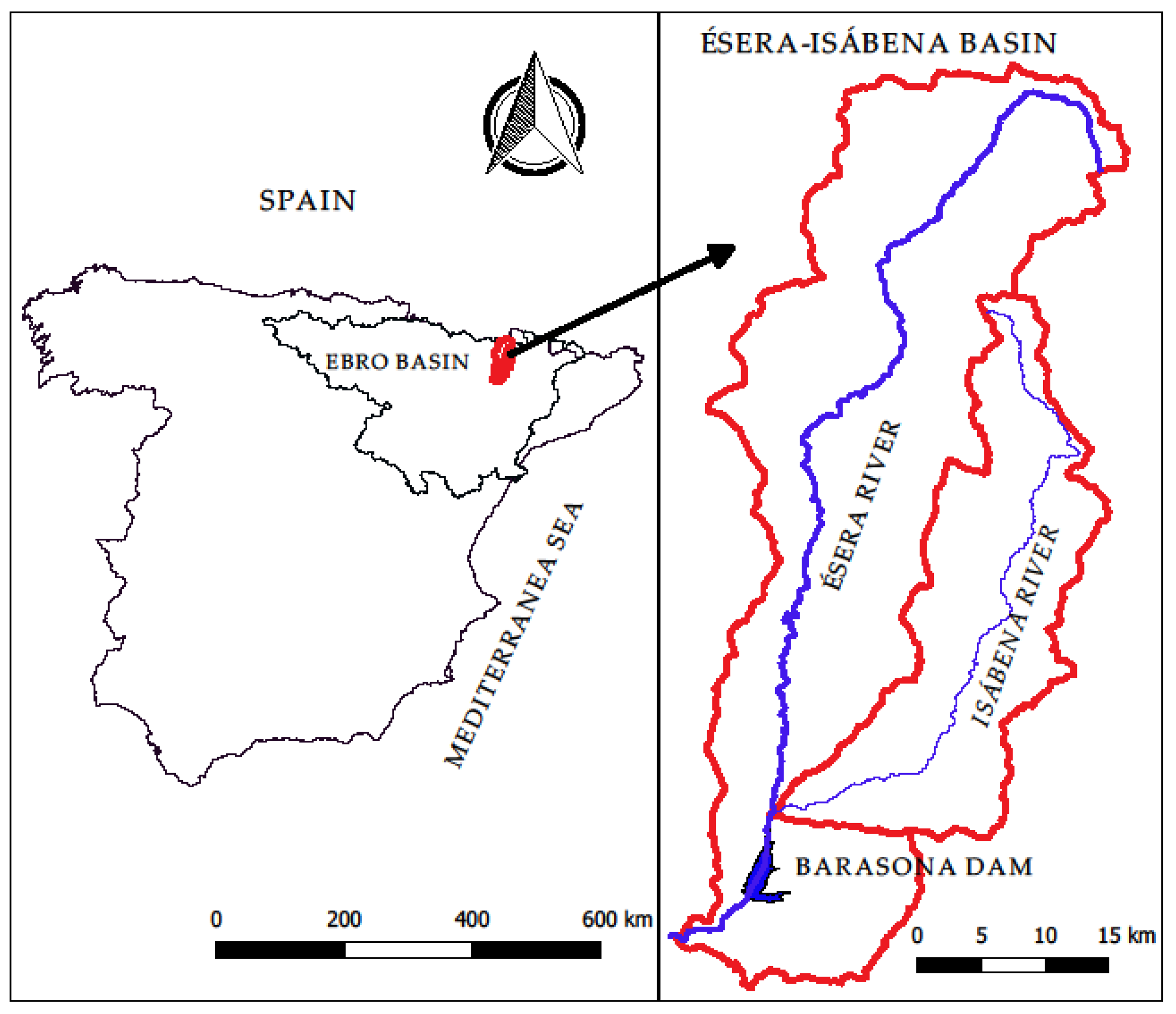
3 corresponding to the maximum hydrographs historically registered in the gauge stations of the two rivers Ésera and Isábena, belonging to the Ebro system, Spain.
Section 3 describes the hydrological characteristics of these rivers in detail, as well as the available data sample and the developed analysis.
The starting hydrological information consists of ordinary and extraordinary flood hydrographs. In each gauge station, and for each historical event, both the flow peak
(Q) and volume (
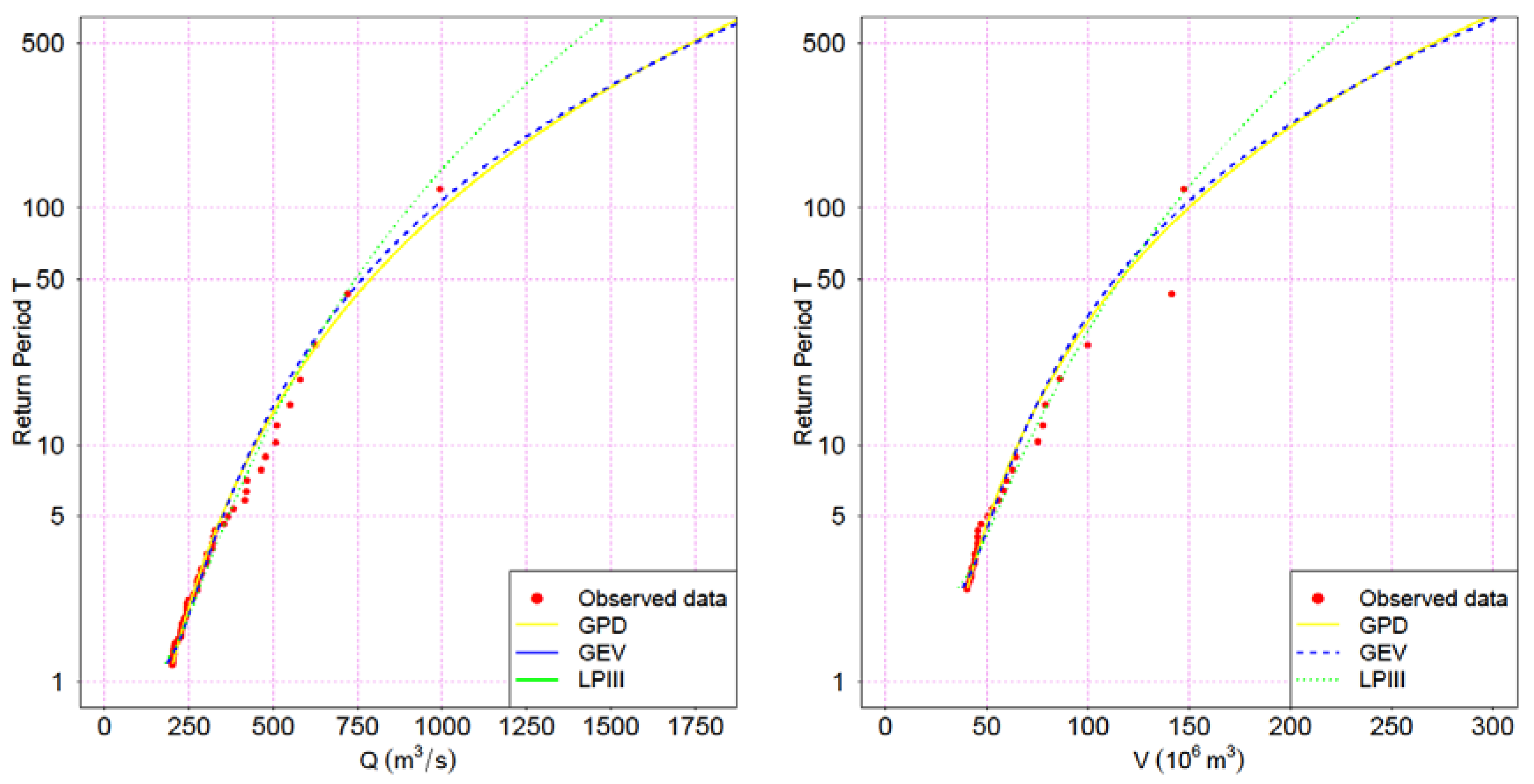
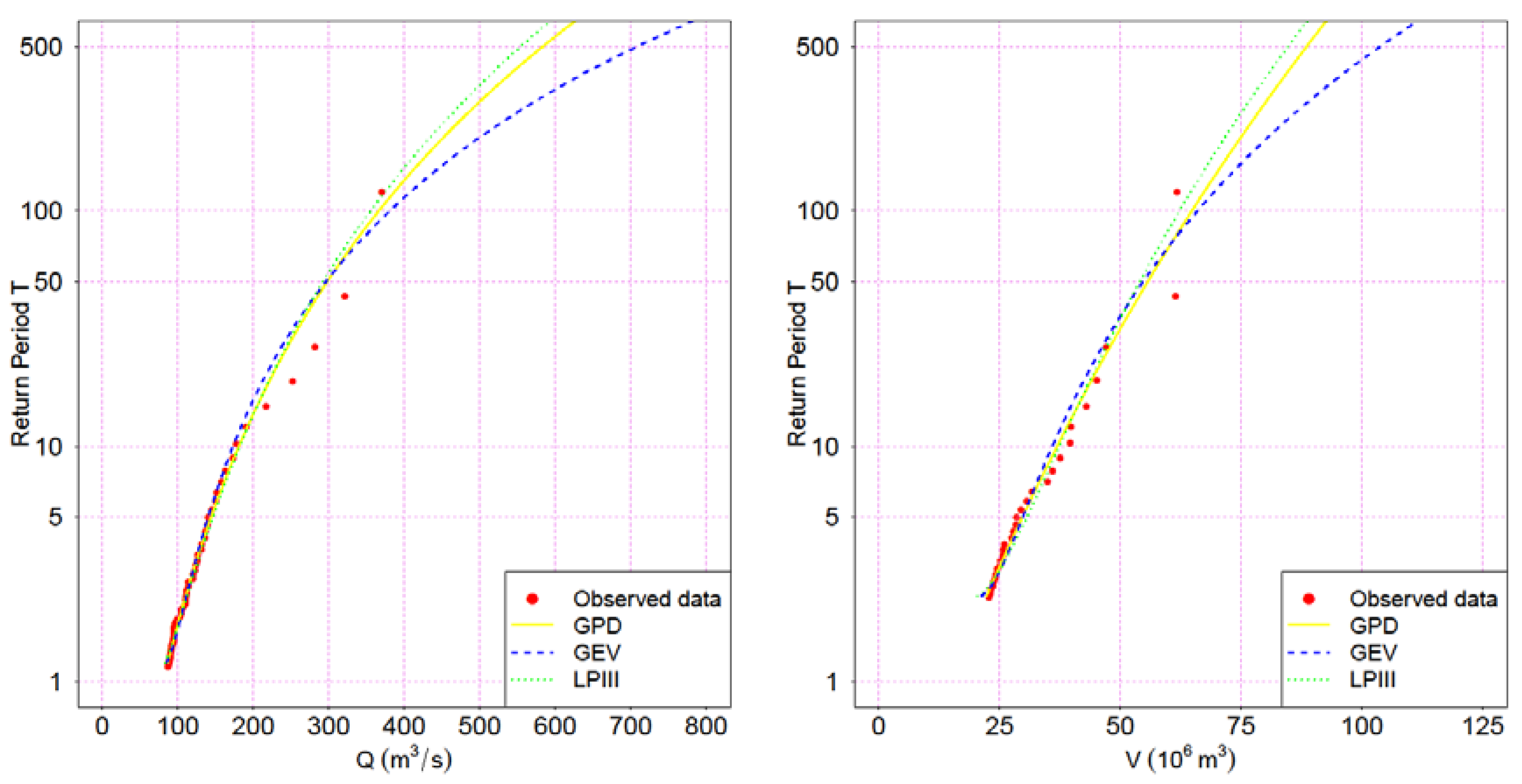
V) are identified. For each of the samples a univariate statistical POT analysis was done. Although General Pareto Distribution (GPD) is the theoretically consistent choice in this case [
22,
23], other common distributions in flood frequency studies were tested for comparison purposes, i.e., General Extreme Value (GEV), and Log Pearson III (LPIII).
Several parameter estimation procedures and goodness-of-fit tests might be perfectly adequate for the purposes of the applied research case study presented herein. For the benefit of a homogeneous treatment for the chosen distribution functions, and not being the central issue in the methodological framework developed, probability weighted moments
(PWM) method has been generally adopted as parameter estimation procedure [
24,
25]. It is a well-known, extensively used method, particularly interesting for high quantile estimators [
23,
24,
25]. Concerning goodness-of-fit tests, the Anderson-Darling test was applied.
The application of the goodness-of-fit test allows to choose, for each case, the distribution function that provides the best representation of the observed data. This determines the marginal distribution functions of the flow peak and volume variables of the hydrograph, a previous step needed before applying it to statistical copulas.
2.2. Copula Modeling
Copulas allow to tackle the problem of bivariate statistical modeling of stochastic hydrological variables, separating the analysis of the univariate marginal distributions, on the one hand, from the aspects that define the statistical dependence structure among these variables, on the other one. The independent analysis of these two matters enables the subsequent building of a common distribution function [
7].
A copula can be defined as a distribution function,
C, of
m-variables with uniformly distributed marginal functions
,
,
for
, through the following expression (Equation (1)):
where
H is the multivariate distribution function.
The practical use of copulas in the statistical hydrological analysis consists of four steps:
2.2.1. Analysis of the Observed Statistical Dependence among Variables
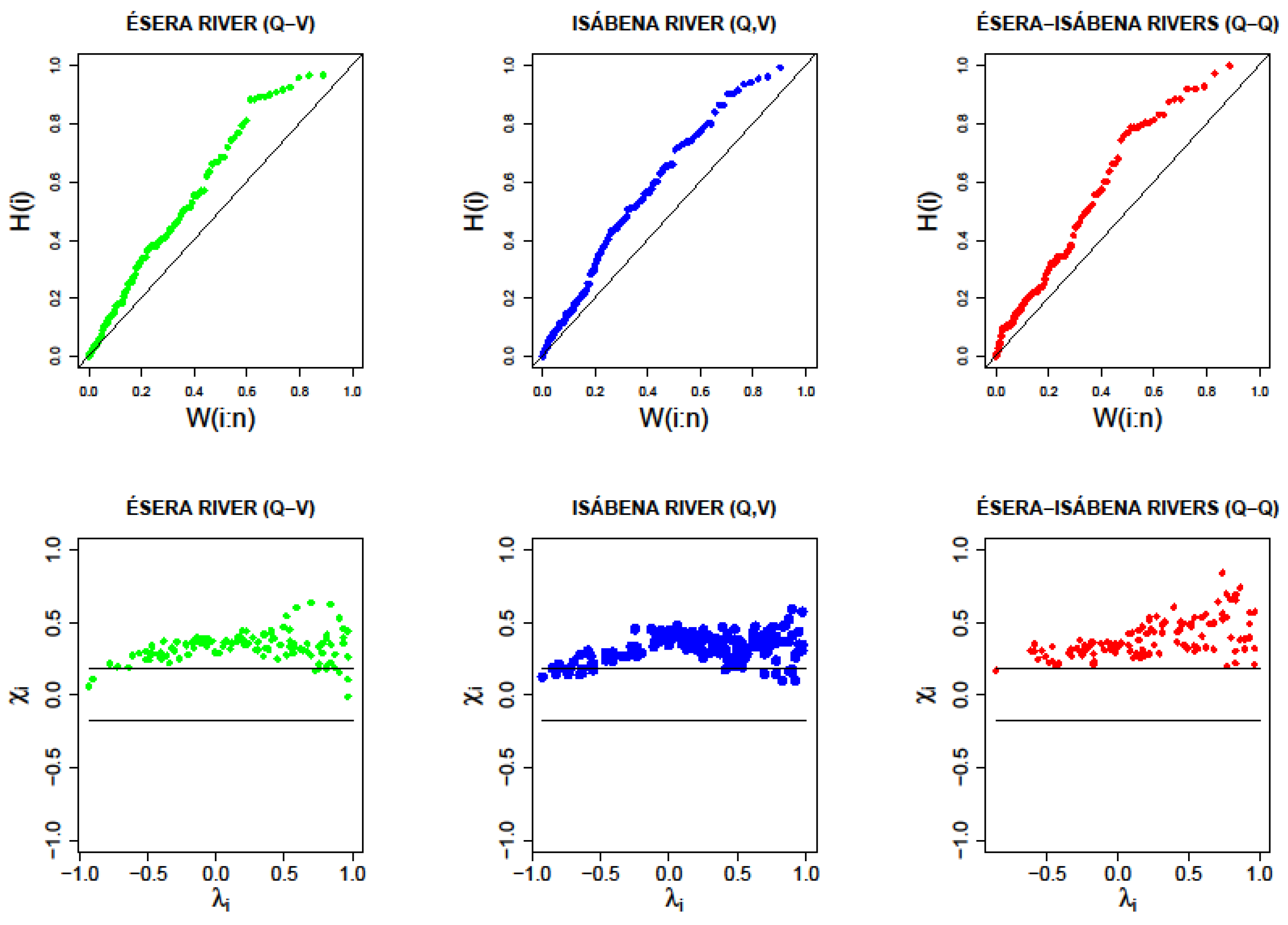
The first section focuses on estimating the degree of statistical dependence among variables, a paramount aspect for the proper selection of the copula to be later employed.
With this aim, the graphic methods, ranks or pair scatterplots, K-plots and Chi-plots, among others, can be particularly useful to identify the existing empirical statistical dependence. In parallel, analytical methods make it possible to quantify this dependence, necessary for the implementation of copulas (γ-Pearson, ρ-Sperman and τ-Kendall are the most usual ones). In [
26] a comprehensive review of these methods can be found.
These former statistical analyses allow to direct the proper choice of the best-suited copula. In [
11] 10 different types of copulas from three families are described and applied to the case of the hydrographs in the river Danube. These are: Archimedean copulas (Ali-Mikhail-Haq, Clayton, Frank, Joe, Gumbel), extreme value copulas (Hüsler–Reiss (H–R), Galambos, Tawn), and other copulas (normal, Plackett, FGM).
2.2.2. Copula Selection
For the case of extreme value hydrological variables (i.e., high return periods), as it is the object of the study in the present paper, the best-suited copulas are the so-called extreme value copulas, since they capture the dependence among highly fluctuant variables in a more generic way than other types of copulas. An interesting study assessing limitations, properties and key aspects for a proper copula selection can be found in [
27]. It should be pointed out that the Gumbel copula happens to be the only copula that is at the same time Archimedean and extreme-value [
5,
6,
28].
Table 1 shows the characteristic function that defines each of these copulas.
2.2.3. Copula Fitting
The goal of this section is to determine the different methods that lead to the estimation of the copula parameter providing the best-fit to the original observed sample. Essentially, there exist two groups of methods:
Methods based in ranges, where the determination of the parameter is independent from the copula marginals. Among these ones, the maximum pseudo-likelihood method (MPL), Kendall’s inversion and Sperman’s inversion are worth noticing.
Methods where the choice of the parameter depends on marginals: inference function for margins (IFM) method proposed by [
29].
There is no consensus in the bibliography about the suitability of the above-mentioned methods, and opinions in both senses can be found [
30]. In this research, methods belonging to the first group were employed and the three mentioned methods were compared.
2.2.4. Goodness-of-Fit of the Model
With regard to the last point, the goodness-of-fit of the copula, there is also a wide variety of tests in the available literature, both graphic and analytical ones. As for the analytical tests, three groups can be named, whether they are based on empirical copulas, Kendal’s transformation and Rosenblatt transformation [
26].
The results indicate that overall, the Cramér-von Mises statistics (
Sn based on the empirical copula) shows the best behavior for all copula models, making it possible to differentiate among extreme value copulas [
31]. It is important to calculate the p value associated to the goodness-of-fit test to formally assess whether the selected model is suitable.
The
p value is obtained through a parametric bootstrap-based procedure that was validated in [
31,
32].
The
Sn statistics can be written as Equation (2).
where
Sn is the Cramer-Von Mises statistics,
A is the Pickands dependence function,
An is a non-parametric estimator of
A and
is a parametric estimator of
A.
Given the specific interest in high return period hydrographs, the dependence coefficients at the distribution tail have also been used as indicators of goodness-of-fit, and are given by
:
where
w, is a threshold value, such that
and
F(x) and
G(y) are the marginal distributions of the copula.
The
value is associated to the degree of statistical dependence observed among variables in the upper tail of the distribution and is described in [
33,
34,
35,
36,
37], who propose different expressions for the empirical calculation of that statistic. Following the recommendation of [
36], the present research employs the estimator proposed by [
38], which is expressed as follows:
where
n is the size of the sample,
u = Fx(xi) and
v = Gy(yi).
The capacity of the different copulas to reproduce the statistical dependence observed in the distribution tail can be assessed through the comparison between empirical and theoretical values of the statistic.
The theoretical values of
for a given copula
C(u,v) can be obtained as [
33]:
where
C is the copula
Applying this expression for each of the three used copulas, the following theoretical expressions of
are obtained,
Table 2.
2.3. Hydrographs Generation
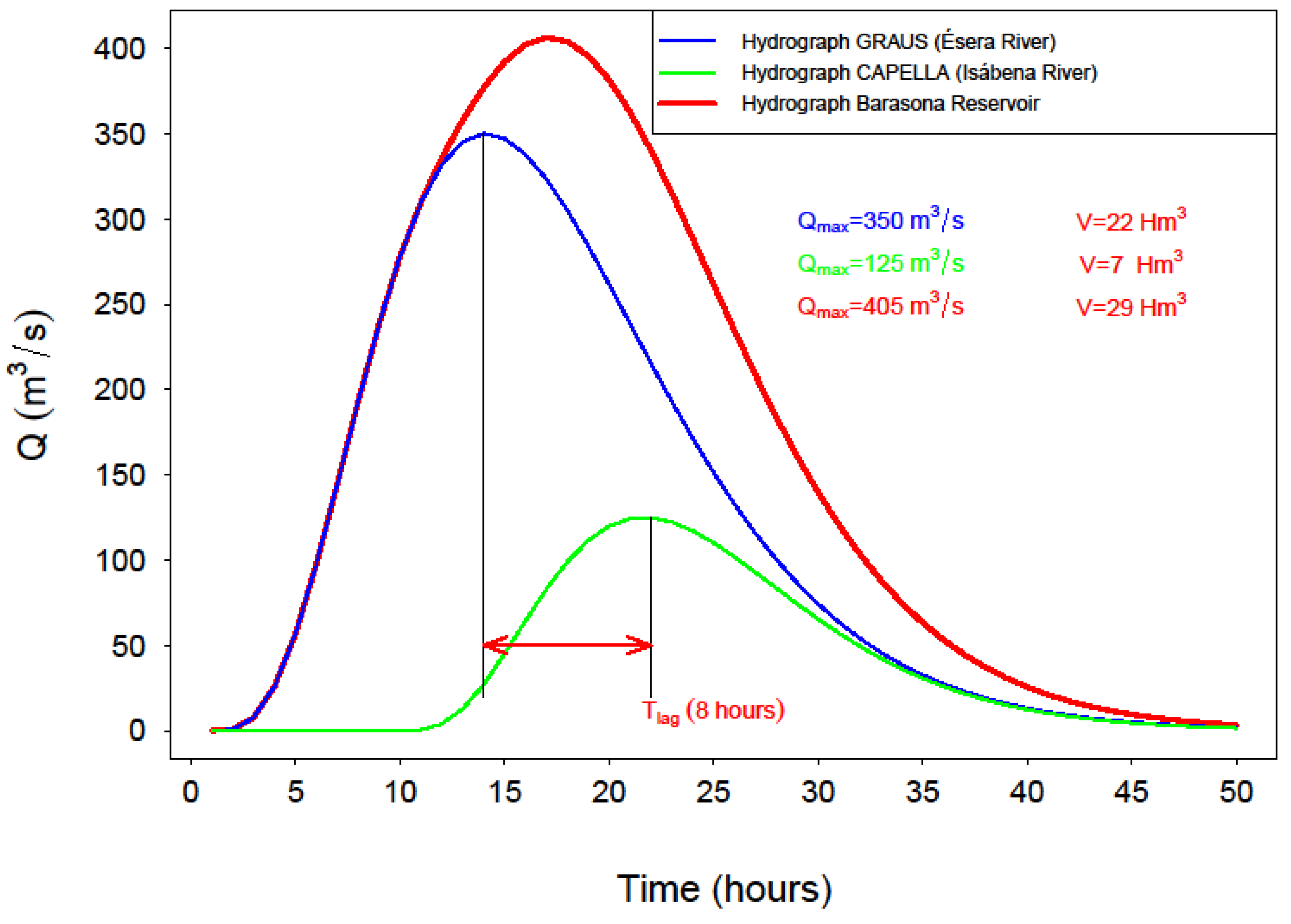
The problem analyzed in the present research is focused on the generation of flood hydrographs downstream of the junction of two rivers.
While it is true that the hydrograph volume can be approximated as the arithmetic addition of the partial flood volumes, it is not the case when it comes to flow, due to the existing time lag between both partial events.
This problem has been studied by several authors. For instance, Prohaska et al. [
15,
16,
17] analyzed the multiple-coincidence of flood waves on the main river and its tributaries. Klein et al. [
10] analyzed the probability of hydrological loads using copulas. Schulte et al. [
39] analyzed multivariate flood peak coincidence using copulas.
Chen et al. [
18] analyzed the coincidence of flood magnitudes and flood occurrence dates based on 4-dimensional Gumbel copula for the upper Yangtze River in China and the Colorado River in the United States. Zhang et al. [
40] analyzed the coincidence probability of flood for the middle and the lower Weihe river and its tributaries based on the Latin hypercube sampling method. But in the two papers mentioned above, only the peak flow of the flood event was discussed.
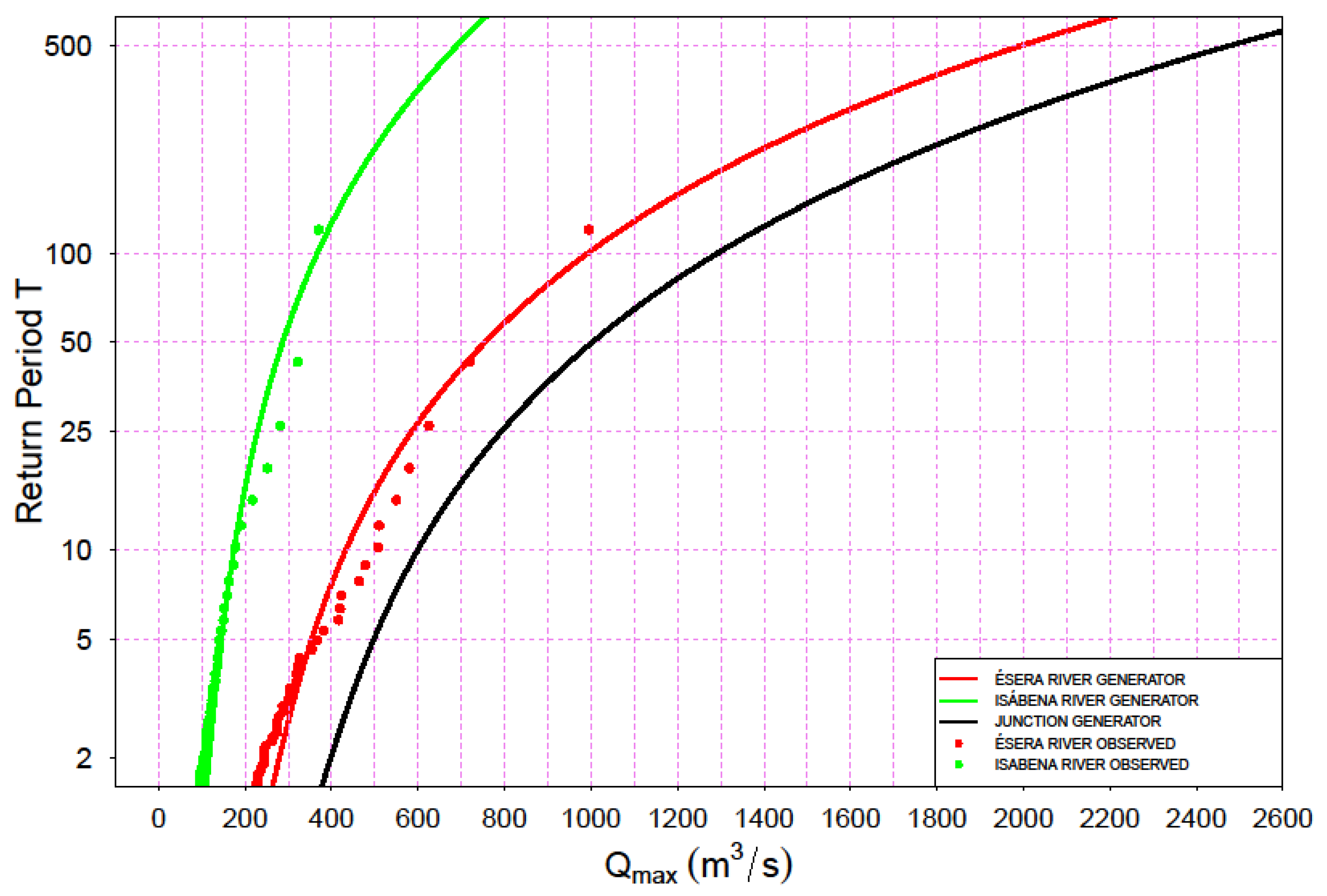
The present research analyzes the case of flood hydrographs generation downstream of the junction of two rivers, according to the following hypotheses: existence of gauges or flow measurements in each river, and the presence of a reservoir controlled by a large dam located downstream the junction of both rivers.
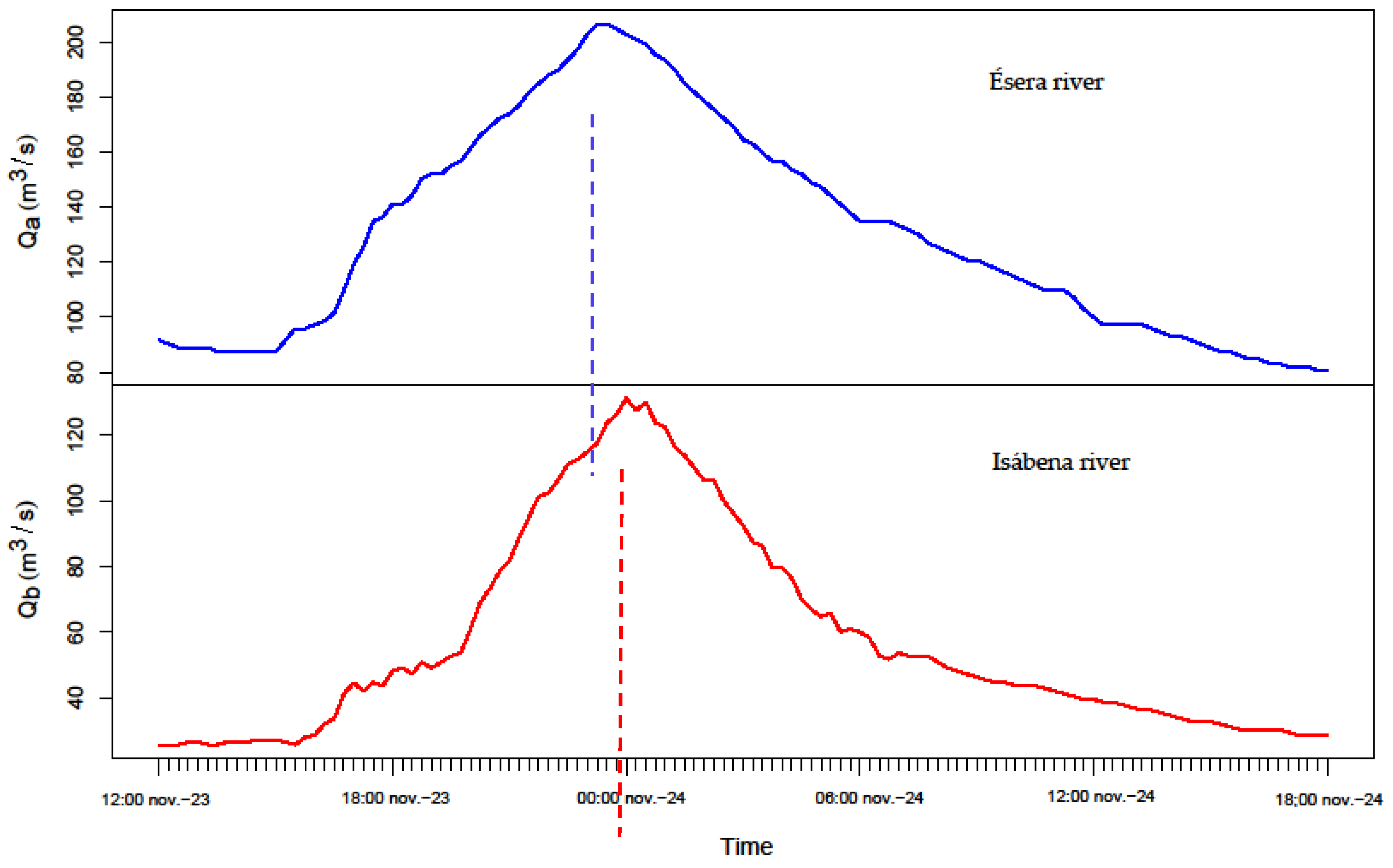
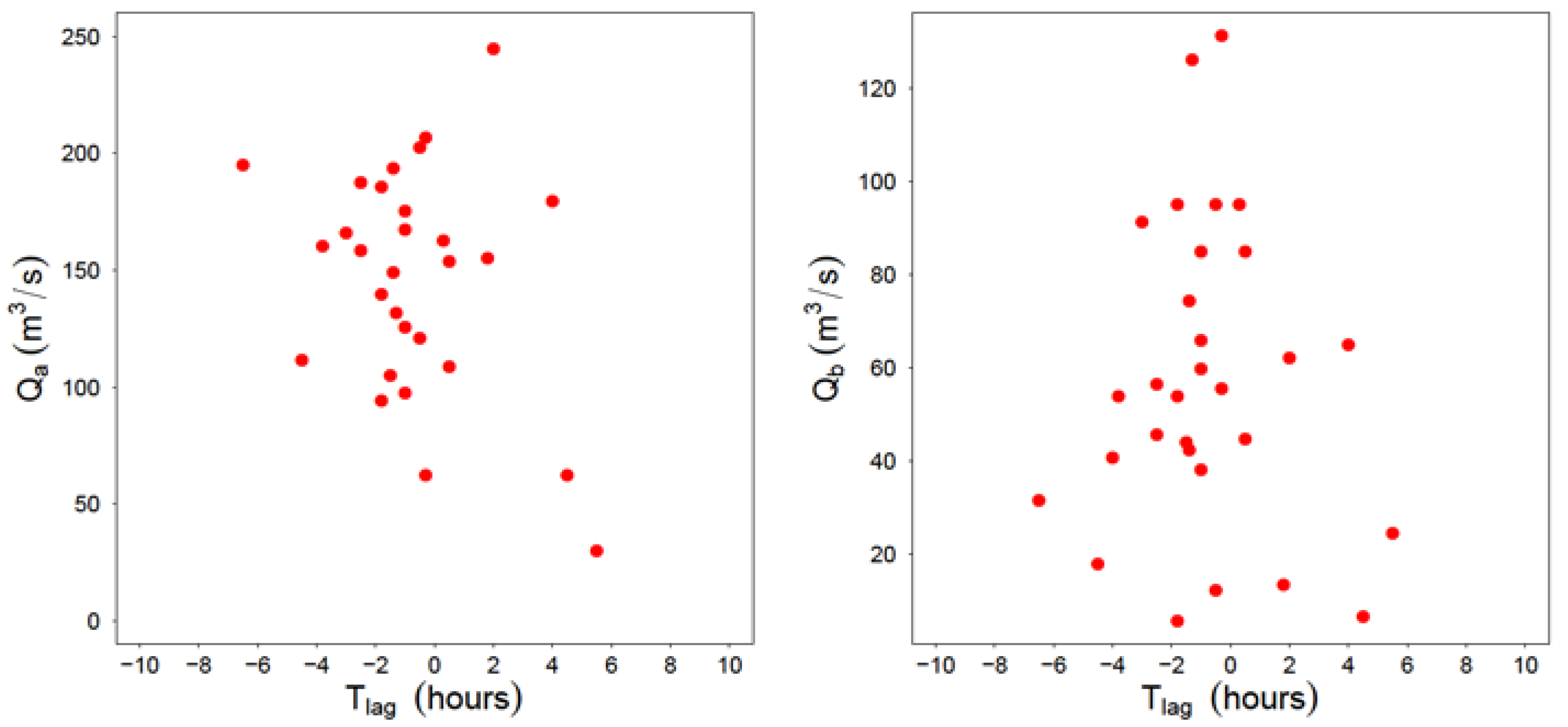
Under this assumption, when calling each river “a” and “b”, 5 main variables are involved in the analysis of the hydrographs: Qa, Va, Qb, Vb and ta−b, where ta−b, is the time lag between the flow peaks of rivers a and b.
An important additional hypothesis is added: the statistical Independence of time lag ta−b with regard to the rest of variables. This hypothesis will be discussed later in the paper within the context of the analyzed case study. Under these hypotheses, it is feasible to propose the following general methodological scheme for the generation of synthetic hydrographs at the entrance of the reservoir, downstream of the junction of both rivers:
- -
Generation of a copula that relates peak flows: Qa, Qb.
- -
Generation of a conditional copula for each of the rivers, where the main involved variables are: Qa, Va.
- -
Determination of Va from the already obtained values Qa.
- -
Generation of a conditional copula Qb, Vb; where Vb is determined from the already obtained values of Qb values.
- -
ta−b values are derived from a chosen theoretical distribution function representing adequately the empirical values observed in the sample (
Section 3.1, Table 6).
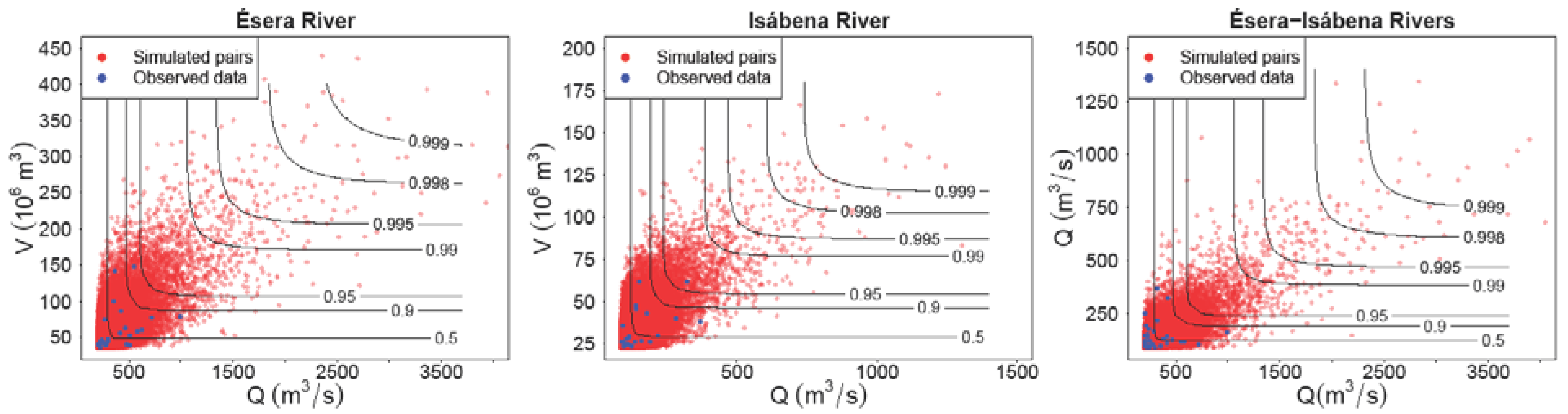
The goal is to generate
n pairs (
q,
v) from the original sample of observations at the gauge station (
Q,
V). Firstly, the marginal distributions
FQ and
FV of
Q and
V and the copula function
C2 are obtained. By virtue of Sklar theorem, it is necessary to generate (
x,
y) pairs and to transform (
x,
y) into
(q,
v) through the following expressions, Equations (6) and (7):
To generate the variables (
x, y) the concept of conditional distribution, Equation (8), of
Y given the event
X = x, such that:
The resulting algorithm is as follows:
It starts with the generation of pairs (x, t) which are uniformly distributed within the range [0; 1] and are also independent.
The variable
y is determined through the following expression, Equation (9):
Finally, the variables (q, v) are calculated through the expressions Equations (6) and (7).
The details of the algorithm of generation can be consulted at [
41,
42].
For the complete definition of synthetic hydrographs, besides the essential variables-flow peak and total volume-, it becomes necessary to introduce a theoretical time pattern for the hydrograph. Literature provides different alternatives, among which triangular shapes and gamma functions stand out by their simplicity. For the application presented herein, the gamma shaped hydrograph is adopted. This hypothesis is a classic approximation in hydrology, proposed by mid-twentieth century investigators [
43,
44], and provides an ideal representation of the most usual cases found in the observed hydrographs, since it contemplates a rising branch until reaching the peak, followed by a more gradual decrease and more extended period in time.
Basically, the gamma shape results from the convolution of an instantaneous unit hydrograph of a cascade of
n equal linear reservoirs [
44].
Although there exists a variety of methods to estimate the parameters of this hydrograph, a practical procedure to determine it is as follows. Time to the peak is firstly calculated by using the simplest triangular formulation of the hydrograph, and then both parameters of the gamma function are estimated. This method is proposed by [
21]. Equation (10) shows the theoretical resulting expression.
where
,
β and
γ must satisfy
and
.
Equation (10) is used as the basis of an iterative numerical process to reach a solution, after the estimation of
. More details of this iterative process can be found in [
45].
Other hydrograph shapes which could be employed within the framework of the present research are those suggested by [
1] or [
4].















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}