1. Introduction
Bayesian statistics is gaining popularity in hydrological modeling (e.g., [
1,
2,
3,
4,
5,
6]). It is an appealing choice for ranking candidate conceptual models [
7,
8,
9,
10], modeling propositions [
2,
11,
12,
13,
14,
15] and scenarios [
16,
17]. Due to its sound logical foundation [
18], Bayesian scientific reasoning is an appealing paradigm that brings the model up against data to let the data speak based on the principle of parsimony. The theory can naturally entertain multiple working hypotheses [
19] such that scientific and modeling propositions with good empirical evidence will stand out. This
evidence, which is also interchangeably written as
model evidence [
20], or
Bayesian model evidence (BME) [
21] is of fundamental importance in Bayesian multi-model analysis. It states the overall probability of the model to reproduce the observation data given all the parameter values that the model can assume, and thus permits the comparisons of candidate models.
Bayesian inference provides a quantitative measure of the degree of belief of a model
being true given data
. This is started by exploring the posterior probability distribution
of the parameters of interest
with the Bayesian model evidence (BME) being
such that
is the likelihood of model
and its parameter set
in reproducing the observation data
, and
is the prior densities of parameters
under model
. The likelihood
states how likely the model would reproduce the observation data for a given realization of the model parameters. By marginalizing out the model parameters, the BME
states how likely the model would reproduce the observation data given all the parameter values that the model can assume. Thus given the same observation data
, the BME is used for evaluating and ranking candidate models by their ability to reproduce the observation data. Note that the BME is also referred to in literature as
marginal likelihood [
22,
23,
24] ,
integrated likelihood [
25,
26,
27],
normalizing constant [
28],
marginal evidence [
15] , among other names. This research is of important relevance to hydrology since hydrologic systems are complex natural systems, and thus we often deal with multiple conceptual models. Multi-model analysis techniques such as Bayesian model averaging and Bayesian model selection are becoming very popular in hydrology. Estimating BME is an essential step in model diagnostics and assessment with respect to model complexity [
29], and thus is shared among these multi-model techniques. The reader is referred to a recent review article [
30] that discusses BME in relation to multi-model analysis in hydrology.
The BME can be exactly evaluated using an analytical solution, approximated using a semi-analytical solution, or numerically estimated using Monte Carlo simulation. Although exact and fast, analytical solutions are only available for simple models with prior, likelihood, and posterior being Gaussian distributions [
22,
23,
24]. Yet for practical applications in hydrology, semi-analytical solutions are most commonly used [
7,
9,
10,
12,
13,
14,
21,
26,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41]. Semi-analytical solutions include Laplace approximations [
42] and approximate information criteria such as Bayesian information criterion (BIC) [
43] and Kashyap information criterion (KIC) [
44].
Semi-analytical solutions have two main limitations. First, these methods have different simplifying assumptions and are subject to truncation error [
24]. This can lead to inaccurate estimation of the BME, resulting in contradicting results with respect to model ranking [
21,
26,
36,
38]. A second limitation of these methods is that they do not explicitly account for the impact of the prior distribution. Evaluating the BME is an important tool for model complexity analysis [
29,
45,
46,
47,
48,
49]. The main purpose for using BME as a model ranking criterion is not only to rank the candidate models based on their goodness-of-fit as this can be done by much simpler metrics, such as root mean squared error or Nash–Sutcliffe model efficiency, but also to penalize the model with higher complexity. Semi-analytical solutions such as BIC indirectly penalize model complexity through assigning penalties for each parameter regardless of its prior distribution. Other methods such as KIC and Laplace approximations would consider the Fisher information matrix to account for a prior. Accordingly, the prior distribution is not considered in strict Bayesian definition, which is that BME is the weighted average of all the likelihood values that model can assume with weights coming from the prior (Equation (2)). In other words, as the low-likelihood region in the parameter space gets wider, the BME should become lower. For example, if we used an infinite uniform prior distribution the BME will approach zero. The Fisher information matrix does not strictly account for the prior distribution according to this definition. Thus, semi-analytical solutions do not consider the prior distribution in a strict Bayesian sense. Yet it is favorable sometimes to penalize model complexity by specifying the penalty of each individual parameter through considering its prior distribution. In other words, the BME is expected to be low for peaked likelihood, wide non-informative prior and high-dimensional prior. Alternatively, the BME is high when the likelihood and the prior distributions are concentrated over the same parameter region. Accordingly, the main advantage of the Monte Carlo simulation methods is the explicit accounting for the prior. Theoretical and numerical comparison of semi-analytical technique and Monte Carlo simulation technique for evaluating the BME is beyond the scope of this work, and the reader is referred to other recent studies [
21,
24,
26].
To improve on the above limitations of semi-analytical solutions, numerical estimation of the BME with Monte Carlo based methods has become a fundamental computational problem in Bayesian statistics. Investigating the use of Monte Carlo methods to estimate BME has recently gained research interest in hydrology [
21,
24,
26,
45,
48,
50,
51,
52]. These studies leverage on the significant effort in different branches of science to develop robust BME numerical estimators with the aim of reducing the estimation bias and increasing the computational efficiency. We briefly review few of these estimators here. As indicated by Equation (2), numerical estimation of BME using Monte Carlo simulation is not a trivial task as it requires evaluating a multi-dimensional integral with a dimension equal to the number of model parameters. This can be done directly through integrating the likelihoods over the parameter space or indirectly through calculating the sample acceptance ratio. For example, Marshall et al. [
35] used the Chib and Jeliazkov method [
53] to estimate BME for comparing hydrological models. This method uses the acceptance of the Metropolis–Hasting sampler to estimate the BME. Friel and Wyse [
20] reviewed BME estimation methods and pointed out that the Chib and Jeliazkov estimator [
53] is generally accurate and exhibits very small dispersion for independent repeated runs. Although the method is flexible, Marshall et al. [
35] study noted that it can be difficult to implement with efficient Markov chain Monte Carlo (MCMC) methods for complex or high-dimensional models. This is mainly because the method of Chib and Jeliazkov [
53] requires the use of an MCMC algorithm with a single-chain proposal distribution to obtain the Metropolis–Hasting ratio. Other indirect BME estimation techniques that are based on a single-chain proposal distribution are annealed importance sampling [
54], reversible-jump MCMC [
55], and sequential Monte Carlo sampling [
56,
57]. Generally, single-chain MCMC algorithms are not as robust and convenient as multi-chain MCMC algorithms [
58,
59,
60,
61]. Multi-chain MCMC algorithms can avoid premature convergence and can better handle sampling difficulties such as high nonlinearity, multimodality, non-separablity, heavy tailed densities, and high-dimensionality [
59,
60,
61,
62]. In addition, designing the proposal distribution of single-chain MCMC algorithms is a model-specific and a time-consuming task that requires a lot of experience. Thus, it is desirable to pursue the direct likelihood-based BME estimation methods, which can be implemented with both single- and multi-chain MCMC schemes.
Direct likelihood-based methods for BME estimation employ ideas from importance sampling, nested sampling, and path sampling approaches. As the BME is the weighted average of the likelihoods where the weight comes from the prior, the most obvious solution is to sample the full prior distribution using brute-force Monte Carlo (MC) simulation. By the law of large numbers, this multidimensional integral (Equation (2)) can be estimated such that the BME is the weighted average of the likelihoods and weights come from the prior probability density function. This is known as the arithmetic mean estimator (AM) [
63], which is an importance sampling approach ([
64], p.134), such that the prior is the importance distribution. Although AM is straightforward to implement [
27,
65], it can be impractically computationally expensive to compute [
21,
24], and results in BME underestimation. This is especially true for problems with peaked likelihood and high dimensionality [
22,
24] as the high-likelihood regions are not adequately sampled. Alternatively, by using the posterior as our importance distribution, Newton and Raftery [
66] show that the harmonic mean (HM) of the posterior sample likelihoods will converge to the BME. An HM estimator is generally used [
14,
67] as it comes at no extra computational cost since the posterior distribution needs to be sampled anyway. However, an HM estimator is insensitive to the changes in the prior [
20]. Accordingly, HM is susceptible to BME overestimation, especially for peaked likelihood [
21,
22,
24]. To overcome the limitations posed by the prior sampling of AM estimator and the posterior sampling of HM estimator, Newton and Raftery [
66] propose the stabilized harmonic mean method that uses an empirical parameter to develop a mixture of the prior and the posterior samples. Yet calibration of the empirical parameter is not straightforward [
24] and the method still overestimates the BME [
22] . HM can also be prone to numerical instability that can result in an enormous underestimation of the BME [
20]. Moreover, few recent studies have shown that HM is a theoretically biased estimator [
23,
68]. However, recent advances in importance sampling methods have resulted in robust BME estimators [
48].
To avoid the above limitations is to convert the multidimensional integral in Equation (2) to a one-dimensional integral, which can be easily integrated using any quadrature rule. This can be carried out through the semi-empirical method of nested sampling [
69] and the path sampling method of thermodynamic integration [
22,
28,
70]. The nested sampling method that is popular in astronomy was introduced to the hydrology community by Elsheikh et al. [
50], and the thermodynamic integration method that is popular in phylogeny was introduced to the hydrology community by Schoups and Vrugt [
45] and Liu et al. [
24]. Nested sampling avoids sampling the full prior by converting the multidimensional integration of Equation (2) into a one-dimensional integral by relating the likelihood to the prior mass (i.e., integration of prior within a region). This is done through a nested procedure that requires local sampling instead of directly sampling from the prior to the posterior parameter space. Nested sampling is a semi-empirical procedure as the prior mass is empirically determined and involves heuristic terms. Although the method produces unbiased estimates [
20,
21,
24] and is computationally efficient [
24] , it exhibits high dispersion for repeated runs [
20,
24] and the estimation bias and dispersion grow with increasing the parameter dimension [
24,
71]. This deteriorated performance can be attributed to at least two reasons. First, the common implementation of nested sampling in hydrology uses the Metropolis–Hasting algorithm for local sampling [
21,
24,
50], which is not robust for generating samples from complex sampling space. Nevertheless, the method is computationally general, and more robust MCMC sampling methods can be accommodated [
51,
52]. Second, as the construction of the prior mass is highly uncertain [
69], the study of Lie et al. [
24] highlighted that the nested sampling procedure does not guarantee that samples are systematically generated from the prior space to the posterior space. Yet unlike nested sampling, the path sampling method of thermodynamic integration (TI) samples the full prior.
Path sampling is a theoretically unbiased and a mathematically rigorous approach that systematically and directly samples intermediate parameter density functions spanning from the prior to the posterior parameter distributions. Given the distance between any two density functions and their corresponding expected densities, the path sampling method of TI converts the multidimensional integral in Equation (2) to a simple one-dimensional integral that can be easily integrated using any quadrature rule. Lie et al. [
24] evaluated TI against semi-analytical solutions, AM, HM, and nested sampling and showed that TI outperformed the other methods in terms of solution accuracy and consistency for repeated independent runs. In addition, the groundwater model weights obtained using TI improved the predictive performance of Bayesian model averaging. However, the main drawback is that TI accuracy comes at a high computational cost [
20,
24]. To improve the computational efficiency of BME, while using a theoretically unbiased method, this study introduces the numerical estimation method of steppingstone sampling [
23], which to our knowledge has not been attempted in hydrologic modeling. Steppingstone sampling (SS) utilizes a sampling path similar to TI to bridge from the prior to posterior distributions. The main idea of SS is that given any two adjacent parameter density functions, the one which is slightly more dispersed can act as an excellent importance distribution. This makes SS more computationally efficient as it requires fewer intermediate distributions than TI to bridging from the prior to the posterior while maintaining the same accuracy of BME estimation.
With application to groundwater transport modeling, in this study, we show that accurate estimation of the BME is important for accurate penalization of more complex models and accordingly, model selection. The manuscript has four objectives. First, by comparing SS with TI, the study shows SS improves on TI in terms of computational efficiency and tuning effort. SS requires fewer intervals to discretize the path from the prior to the posterior. In addition, TI is sensitive to the location of the discretization intervals, while SS is relatively invariant. However, these results are based on a Gaussian model where the prior, posterior, and intermediate distributions can be sampled directly without using MCMC, and thus without introducing any MCMC sampling error. Second, we further show that theoretically unbiased estimators such as TI and SS could have a large bias in practice arising from numerical implementation as MCMC sampling error can introduce bias. MCMC sampling error refers to an inaccurate approximation of the target stationary distribution. Third, we additionally introduce a variant of SS—namely, multiple one-steppingstone sampling (MOSS)—that is less susceptible to sampling error, and thus can potentially overcome shortcomings of TI and SS with respect to sampling error. Fourth, we evaluate these three numerical estimators of TI, SS, and MOSS along with the two limiting cases of AM and HM using a model selection problem of four groundwater transport models with different degrees of model complexity and model fidelity. Model complexity refers to the number of model parameters, and model fidelity refers to the degree of model realism with respect to the model structure, input data, and boundary conditions. By this example, we show that accurate BME estimation results in accurate penalization of more complex models. In addition, inaccurate BME estimation affects model weights and may accordingly change the model ranking. In summary, the objective of this research is to introduce the SS estimator, and show how BME estimation bias affects the penalization of model complexity differently for different estimators. Thus, the scope of this work is the accurate estimation of BME given different Monte Carlo estimators. Studying the impact of prior distribution [
72], likelihood function [
73,
74] , model fidelity [
12,
14,
15,
47] , prior model probability [
13], input data [
75], and observation data [
2,
12] on the magnitude of BME is beyond the scope of this work. The readers are refered to a recent review article that discusses multi-model analysis in hydrology using Bayesian techiques [
76].
The manuscript is organized as follows. In the
Section 2, we introduce the five estimators and establish their theoretical connection with reference to importance sampling and path sampling techniques.
Section 3 evaluates the accuracy, numerical efficiency, and tuning of the five estimators using a high dimensional problem, which has an analytical solution and is not subject to MCMC sampling error. In
Section 4, we use multiple groundwater transport models to evaluate the impact of BME estimation bias on model complexity evaluation and model selection in the presence of MCMC sampling error. We summarize our main findings and provide recommendations in
Section 5.
3. Gaussian Model Example
We first compare the previously introduced five estimators using a Gaussian model because the true BME is available analytically and we can make direct draws from the power posteriors avoiding errors specific to MCMC sampling. We use a Gaussian model parameterized by
with
dimensions. Following [
22], we define the likelihood as a product of:
where
is a hyperparameter. The prior is the product of independent normal distributions of each parameter
sampled from a standard normal distribution. Samples for all power posterior distributions can be directly drawn from a normal distribution:
with mean 0 and variance
such that the prior(i.e.,
) is the product of
independent standard normal distributions of each
; the posterior (i.e.,
) is the product of
independent distributions of each
with mean 0 and variance
; and the true analytical solution (AS) of the BME is
for a model with
dimensions.
Using Equation (14) with
, we parameterize a path of
,
from
to
with
steps, and with the sample size
for each step
. Since we can use the same
discretization for TI, SS, and MOSS. Generally, we can always make the most of our samples by evaluating the BME using these three estimators without any extra computational effort. The only exception is that SS estimators (Equations (23) and (25)) do not need to sample the
power posterior distribution (i.e., the posterior distribution
). Thus in this estimator comparison exercise, the SS estimators are slightly disadvantaged as they need only
samples, while AM, HM, and TI estimator needs
samples. Note that for AM and HM the tuning parameter
is irrelevant and
merely indicates sample size
from the prior and posterior, respectively. We report the mean BME and its relative error based on 10 independent estimations. The relative error is defined as
where
and
are the reference solution and estimated solution, respectively. For this Gaussian model, the reference solution
is a true analytical solution (Equation (28)). We compare different estimators based on accuracy, where better accuracy is defined as less bias from the reference solution given an equal number of sample draws.
We start by observing the effect of dimensionality (D = 1, 50, and 100) on different estimators.
Table 1 shows that all the estimators work well for the simple one-dimensional case resulting in a relative error less than ±0.01%. When increasing the problem dimensionality, the performance of different estimators diverged. AM tends to underestimate the BME as the number of dimensions increases with relative error decreasing from −3.18% for the 50-dimensional problem to −30.8% for the 100-dimensional problem. HM avoided underestimating through enriching the BME estimation with samples from high-likelihood regions. However, this resulted in overestimation, which makes the model appear better-fitting than it actually is. One might argue that this HM comes at no extra computational cost as we need to sample the posterior anyway, and such overestimation is irrelevant as we are not generally interested in the absolute value of the BME, but in the relative model weight of candidate models (Equation (3)). This is true as long as the estimated BME covariates the true BME. However, the results indicate that the magnitude of overestimation increases with increasing the model complexity. Overestimation becomes much larger as the number of dimension increases with relative error increasing from 20.72% for the 50-dimensional problem to 189.34% for the 100-dimensional problem. This is mainly because HM is less sensitive to the prior, and thus inaccurately accounts for the model complexity. That can be explained by looking at the reference BME solution (
Table 1), which decreased from 2.98 × 10
−8 for the 50-dimensional to 8.88 × 10
−16 for the 100-dimensional problem due to the presence of large parameter space with low-likelihood. Increasing the contribution of low-likelihood regions is equivalent to decreasing the informativeness of prior (either due to increasing the number of dimensions or using wider parameter space for each dimension). HM tends to ignore low-likelihood regions in the parameter space, which means that it will impose less plenty than it should on complex model with superfluous parameters. This can impact model ranking as shown in the groundwater transport model selection problem in the next section. On the other hand, the performance of TI, SS, and MOSS for the 50- and 100-dimensional problems is relatively stable with relative error of less than 1%. However, this comparison is based on a fine discretization of the sampling path with
, which is not computationally efficient.
The number of steps
and their distribution according to the parameter
are important for TI, SS, and MOSS. One might wonder if
is large enough for this example, and to what extent using coarser discretization would impact these estimators. For the 100-dimensional example and setting
, we make the
steps coarser using
and
, respectively.
Table 2 indicates that very coarse discretization
is sufficient for SS and MOSS estimator yielding a relative error of less than 1%, while TI relative error for
is −8.21% and deteriorats to −29.06% for
. It is worth noting the AM and HM estimates deteriorated as well due to using fewer numbers of prior and posterior samples, respectively.
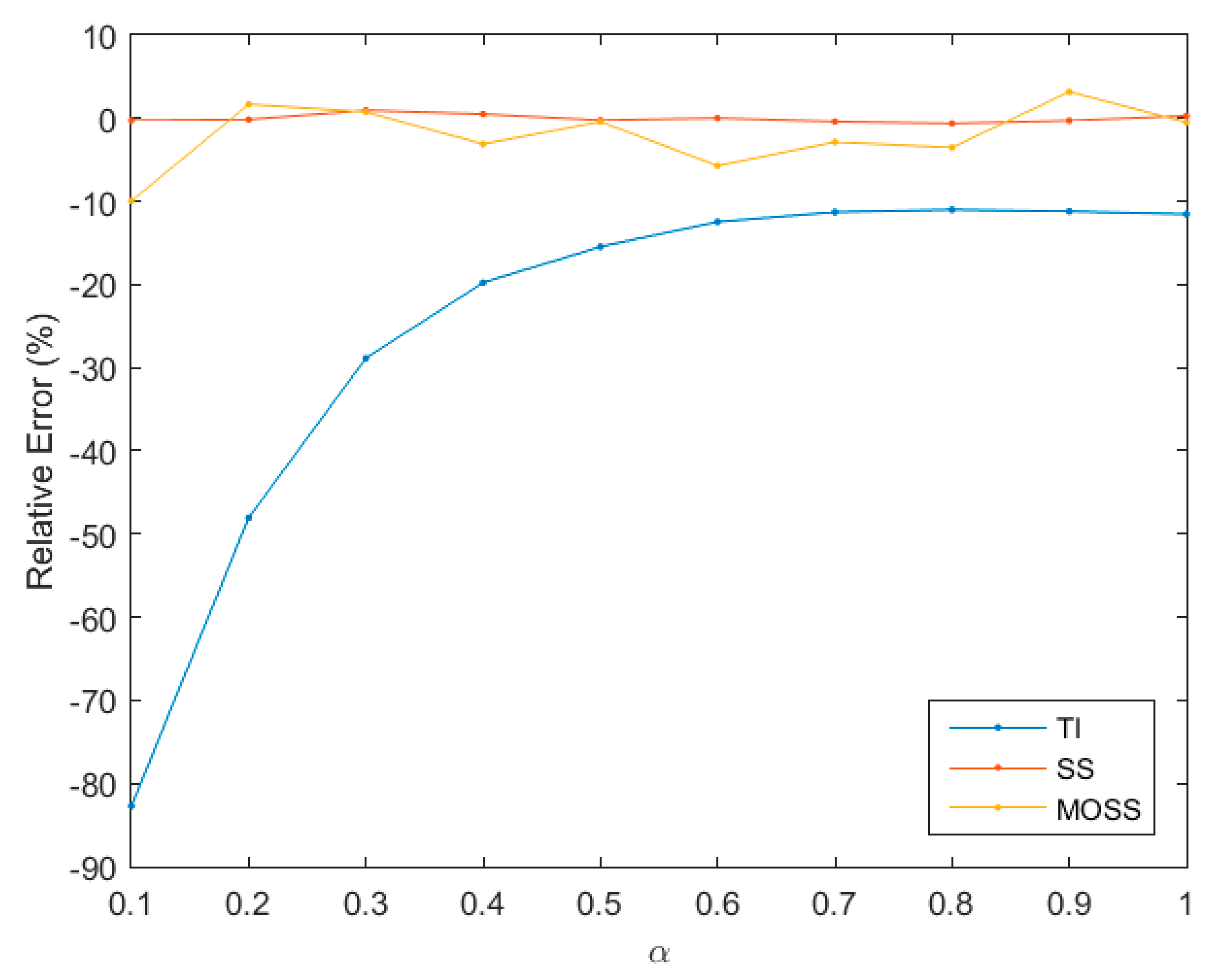
Additionally, a good estimator should have fewer parameters to tune. Using the same 100-dimensional example, we examine to what extent TI, SS, and MOSS are sensitive to locations of path steps, by fixing
and choosing different values of
as shown in
Figure 1. The results indicate that SS and MOSS have the favorable feature of being relatively invariant to
values with relative error less than −10%. TI considerably depends on locations of the path steps with relative error ranging from about −10% to −80% for different
values.
This comparison indicates that SS has relatively better performance followed by MOSS and TI for this Gaussian example. However, for this example, parameter samples can be directly sampled from a series of power posterior distributions without MCMC. Yet for almost all practical applications MCMC is needed to approximate the power posterior distributions introducing an MCMC sampling error. In the next section, we examine to what extent this MCMC sampling error can affect the performance of these three estimators. In addition, we examine to what extent the HM under-penalization of model complexity will affect the model ranking.







{kind=link}
{kind=link}
{kind=link}