Leaf Wetness Duration Models Using Advanced Machine Learning Algorithms: Application to Farms in Gyeonggi Province, South Korea


Abstract
:1. Introduction
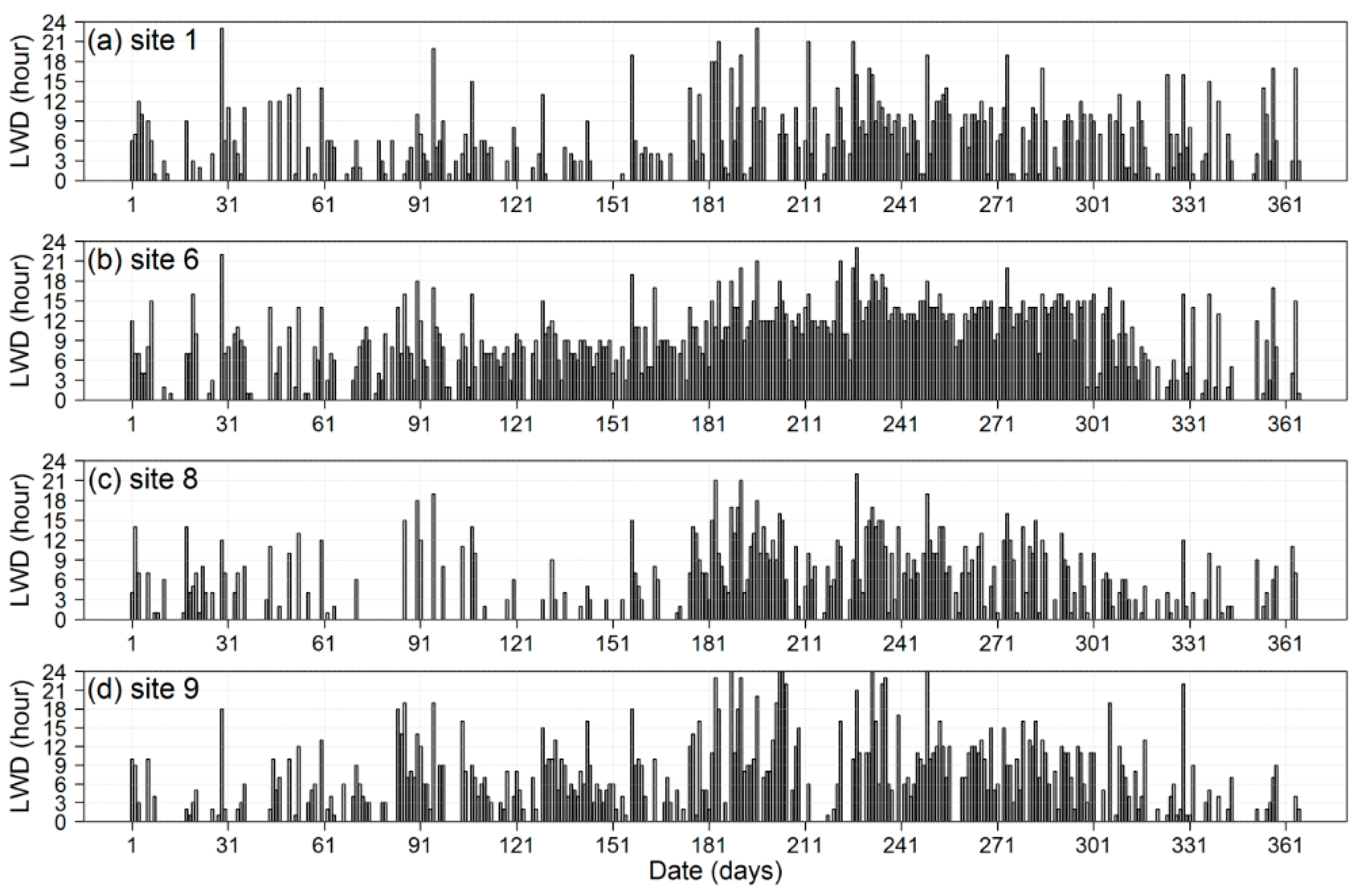
2. Data
3. Methods
3.1. Existing LWD Prediction Models
3.1.1. Classification and Regression Tree/Stepwise Linear Discriminant (CART)
3.1.2. Number of Hours of Relative Humidity (NHRH)
3.1.3. Penman-Monteith (PM)
3.2. ML Algorithms
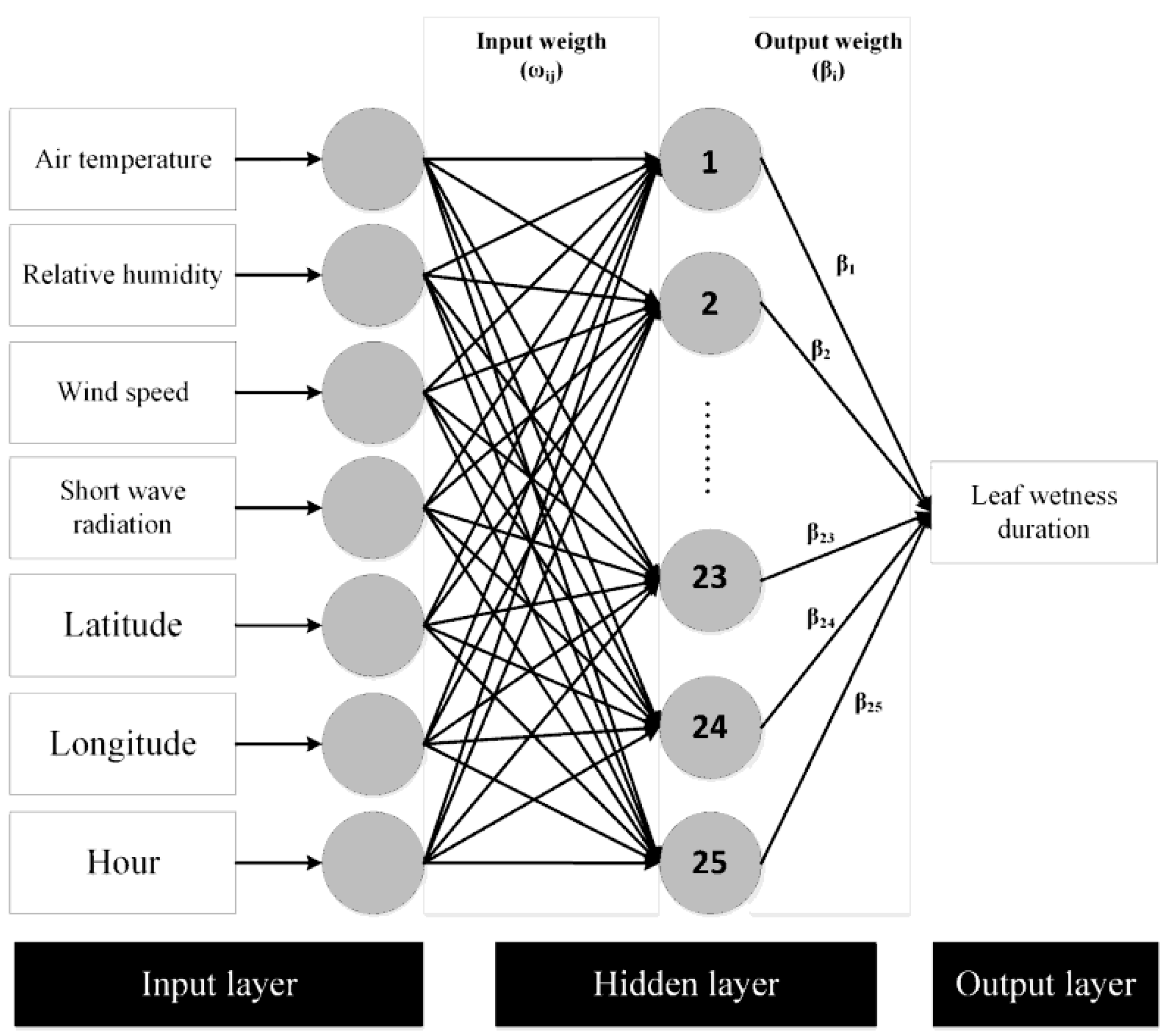
3.2.1. Regularized Extreme Learning Machine
3.2.2. Random Forest
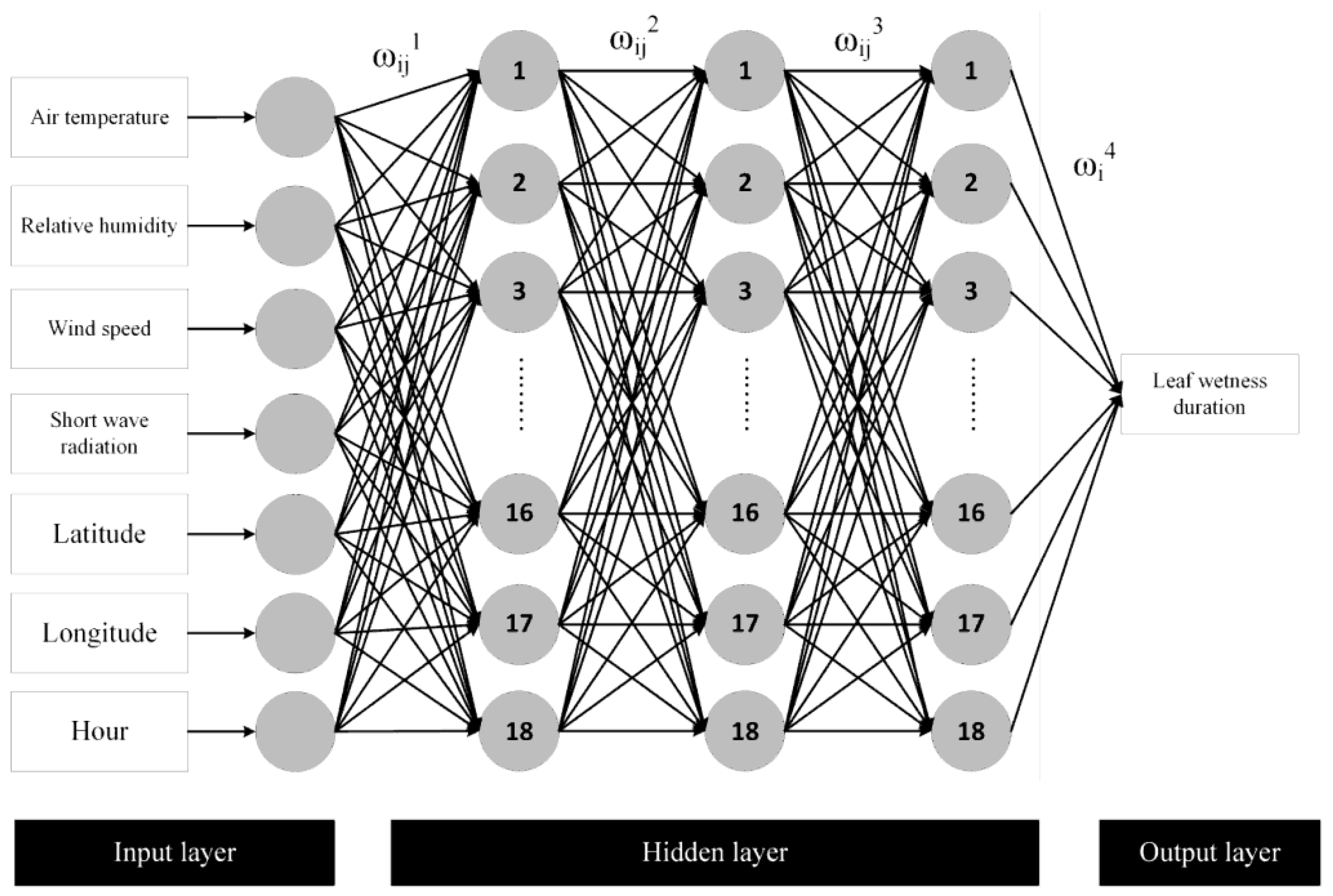
3.2.3. Deep Neural Network
3.3. Evaluation Measures
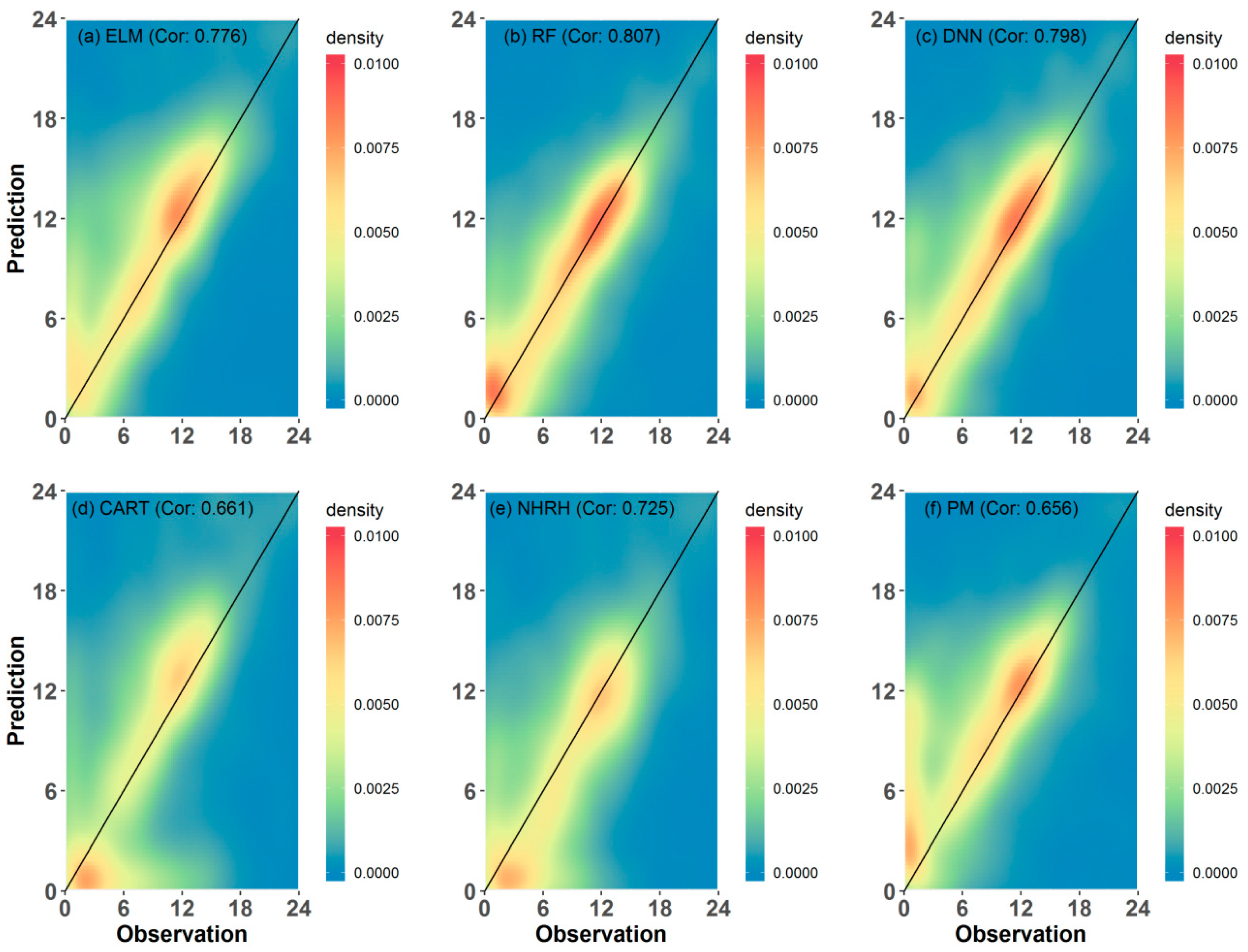
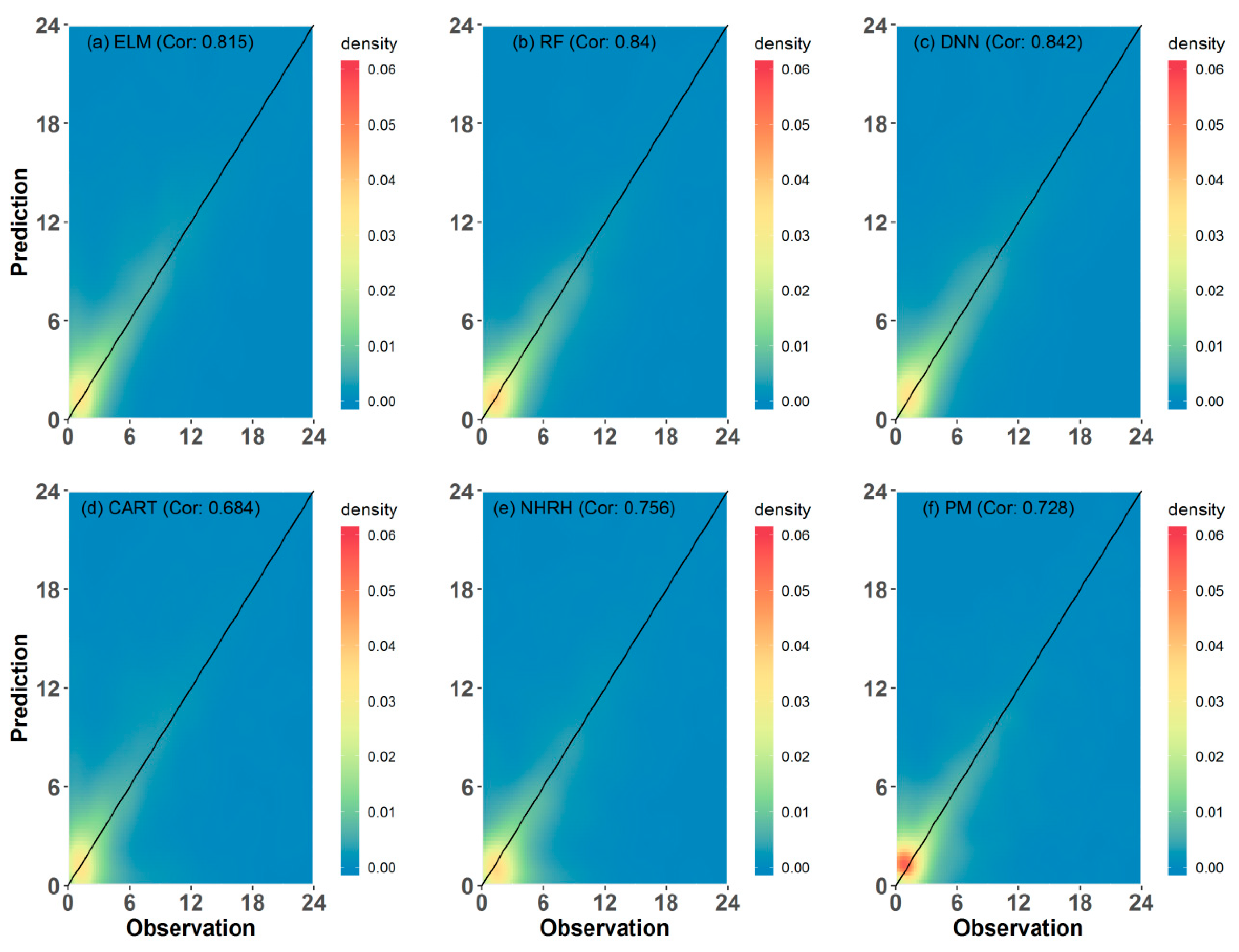
4. Results
5. Discussion
6. Conclusions
- (1)
- The ML-based models outperform the existing models in LWD prediction for farms in Gyeonggi province, South Korea. The ML-based models provide better performances than the existing models based on all employed evaluation measures. Additionally, the worst model among the ML-based models has a comparable performance in LWD prediction to the existing models. Its performance is better than or equivalent to those of the existing models based on all employed evaluation measures.
- (2)
- Among the employed models, the RF model is the best for LWD based on the results of evaluation measures for all data. Additionally, it leads to the best performance for seven among nine sites. Although the DNN demonstrates the best performance for two sites, performance of the RF model would be nearly comparable to that of the DNN. Thus, for ML algorithms used in LWD prediction models, the RF algorithm is a good candidate.
- (3)
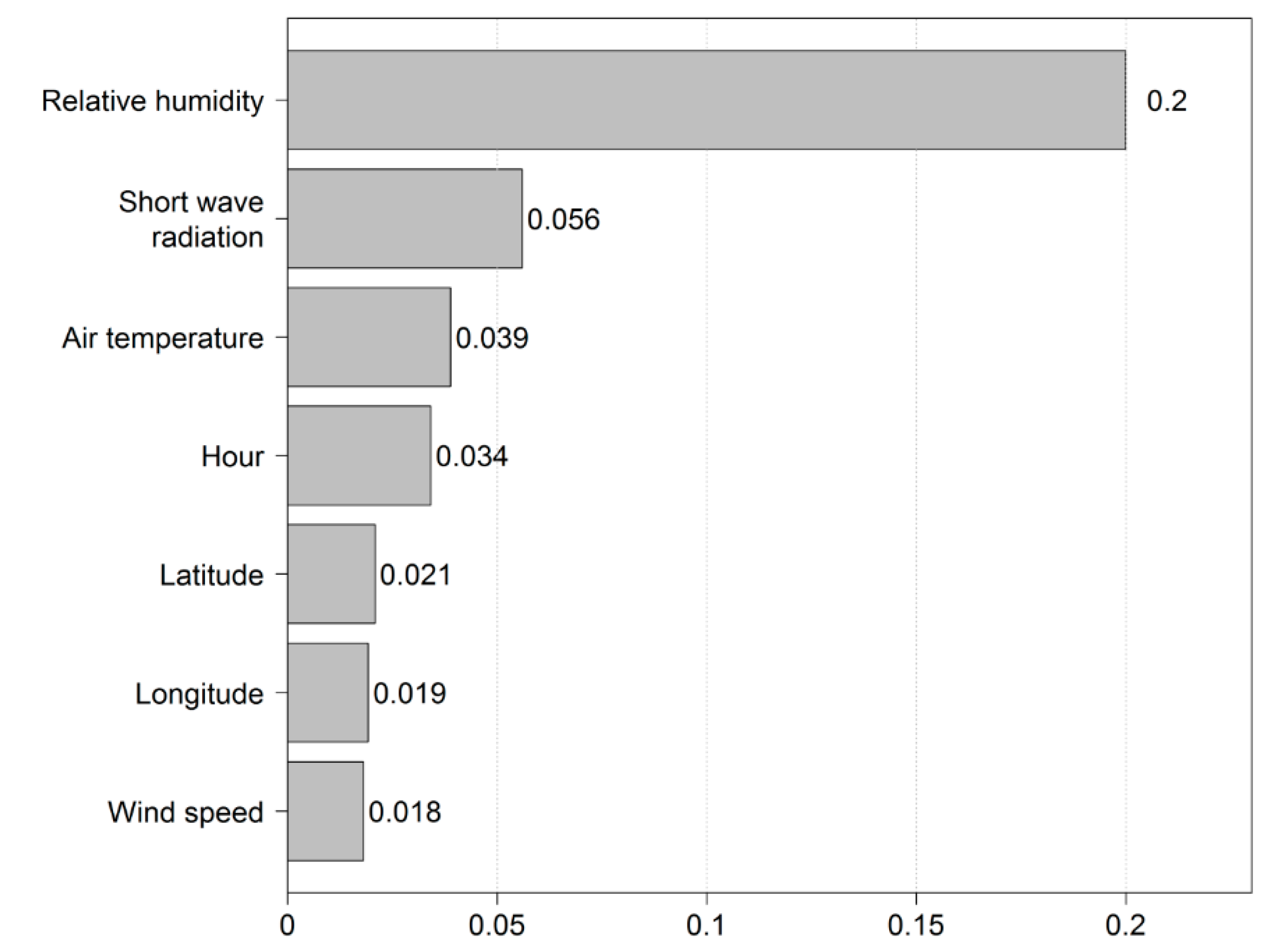
- The strengths of associations between input variables and LW are, in descending order, RH, short wave radiation, Tair, hour, latitude, longitude, and WS based on the results of variable importance from the RF model. The first three variables in this ordered list are meteorological variables; the meteorological information is the most important in explaining LW phenomena. The hour variable representing the diurnal cycle is more important than geographical information and WS data.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gleason, M.L.; Ricker, M.D.; MacNab, A.A.; East, D.A.; Pitblado, R.E.; Latin, R.X. Disease-Warning Systems for Processing Tomatoes in Eastern North America: Are We There Yet? Plant Dis. 1995, 79, 113–121. [Google Scholar] [CrossRef]
- Gillespie, T.J.; Sentelhas, P.C. Agrometeorology and plant disease management: A happy marriage. Sci. Agric. 2008, 65, 71–75. [Google Scholar] [CrossRef]
- Huber, L.; Gillespie, T.J. Modeling Leaf Wetness in Relation to Plant Disease Epidemiology. Annu. Rev. Phytopathol. 1992, 30, 553–577. [Google Scholar] [CrossRef]
- Schmitz, H.F.; Grant, R.H. Precipitation and dew in a soybean canopy: Spatial variations in leaf wetness and implications for Phakopsora pachyrhizi infection. Agric. For. Meteorol. 2009, 149, 1621–1627. [Google Scholar] [CrossRef]
- Magarey, R.D.; Russo, J.M.; Seem, R.C.; Gadoury, D.M. Surface wetness duration under controlled environmental conditions. Agric. For. Meteorol. 2005, 128, 111–122. [Google Scholar] [CrossRef]
- Rowlandson, T.; Gleason, M.; Sentelhas, P.; Gillespie, T.; Thomas, C.; Hornbuckle, B. Reconsidering Leaf Wetness Duration Determination for Plant Disease Management. Plant Dis. 2015, 99, 310–319. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gleason, M.L.; Duttweiler, K.B.; Batzer, J.C.; Taylor, S.E.; Sentelhas, P.C.; Monteiro, J.E.B.A.; Gillespie, T.J. Obtaining weather data for input to crop disease-warning systems: Leaf wetness duration as a case study. Sci. Agric. 2008, 65, 76–87. [Google Scholar] [CrossRef]
- Miranda, R.A.C.; Davies, T.D.; Cornell, S.E. A laboratory assessment of wetness sensors for leaf, fruit and trunk surfaces. Agric. For. Meteorol. 2000, 102, 263–274. [Google Scholar] [CrossRef]
- Sentelhas, P.C.; Gillespie, T.J.; Gleason, M.L.; Monteiro, J.E.B.A.; Helland, S.T. Operational exposure of leaf wetness sensors. Agric. For. Meteorol. 2004, 126, 59–72. [Google Scholar] [CrossRef]
- Sentelhas, P.C.; Gillespie, T.J.; Santos, E.A. Leaf wetness duration measurement: Comparison of cylindrical and flat plate sensors under different field conditions. Int. J. Biometeorol. 2007, 51, 265–273. [Google Scholar] [CrossRef]
- Rao, P.S.; Gillespie, T.J.; Schaafsma, A.W. Estimating wetness duration on maize ears from meteorological observations. Can. J. Soil Sci. 1998, 78, 149–154. [Google Scholar] [CrossRef]
- Kim, K.S.; Taylor, S.E.; Gleason, M.L.; Koehler, K.J. Model to Enhance Site-Specific Estimation of Leaf Wetness Duration. Plant Dis. 2002, 86, 179–185. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Papastamati, K.; McCartney, H.A.; Bosch, F.V.D. Modelling leaf wetness duration during the rosette stage of oilseed rape. Agric. For. Meteorol. 2004, 123, 69–78. [Google Scholar] [CrossRef] [Green Version]
- Leca, A.; Parisi, L.; Lacointe, A.; Saudreau, M. Comparison of Penman–Monteith and non-linear energy balance approaches for estimating leaf wetness duration and apple scab infection. Agric. For. Meteorol. 2011, 151, 1158–1162. [Google Scholar] [CrossRef]
- Sentelhas, P.C.; Gillespie, T.J.; Gleason, M.L.; Monteiro, J.E.B.M.; Pezzopane, J.R.M.; Pedro, M.J. Evaluation of a Penman–Monteith approach to provide “reference” and crop canopy leaf wetness duration estimates. Agric. For. Meteorol. 2006, 141, 105–117. [Google Scholar] [CrossRef]
- Gillespie, T.J.; Srivastava, B.; Pitblado, R.E. Using Operational Weather Data to Schedule Fungicide Sprays on Tomatoes in Southern Ontario, Canada. J. Appl. Meteorol. Climatol. 1993, 32, 567–573. [Google Scholar] [CrossRef] [Green Version]
- Gleason, M.L.; Taylor, S.E.; Loughin, T.M.; Koehler, K.J. Development and validation of an empirical model to estimate the duration of dew periods. Plant Dis. 1994, 78, 1011–1016. [Google Scholar] [CrossRef]
- Sentelhas, P.C.; Dalla Marta, A.; Orlandini, S.; Santos, E.A.; Gillespie, T.J.; Gleason, M.L. Suitability of relative humidity as an estimator of leaf wetness duration. Agric. For. Meteorol. 2008, 148, 392–400. [Google Scholar] [CrossRef]
- Montone, V.O.; Fraisse, C.W.; Peres, N.A.; Sentelhas, P.C.; Gleason, M.; Ellis, M.; Schnabel, G. Evaluation of leaf wetness duration models for operational use in strawberry disease-warning systems in four US states. Int. J. Biometeorol. 2016, 60, 1761–1774. [Google Scholar] [CrossRef]
- Alvares, C.A.; de Mattos, E.M.; Sentelhas, P.C.; Miranda, A.C.; Stape, J.L. Modeling temporal and spatial variability of leaf wetness duration in Brazil. Theor. Appl. Climatol. 2014, 120, 455–467. [Google Scholar] [CrossRef]
- Mashonjowa, E.; Ronsse, F.; Mubvuma, M.; Milford, J.R.; Pieters, J.G. Estimation of leaf wetness duration for greenhouse roses using a dynamic greenhouse climate model in Zimbabwe. Comput. Electron. Agric. 2013, 95, 70–81. [Google Scholar] [CrossRef]
- Kim, K.S.; Taylor, S.E.; Gleason, M.L.; Villalobos, R.; Arauz, L.F. Estimation of leaf wetness duration using empirical models in northwestern Costa Rica. Agric. For. Meteorol. 2005, 129, 53–67. [Google Scholar] [CrossRef]
- Stella, A.; Caliendo, G.; Melgani, F.; Goller, R.; Barazzuol, M.; La Porta, N. Leaf Wetness Evaluation Using Artificial Neural Network for Improving Apple Scab Fight. Environments 2017, 4, 42. [Google Scholar] [CrossRef]
- Wang, H.; Sanchez-Molina, J.; Li, M.; Rodríguez Díaz, F. Improving the Performance of Vegetable Leaf Wetness Duration Models in Greenhouses Using Decision Tree Learning. Water 2019, 11, 158. [Google Scholar] [CrossRef]
- Park, J.S.; Seo, Y.A.; Kim, K.R.; Ha, J.C. Evaluating the prediction models of leaf wetness duration for citrus orchards in Jeju, South Korea. Korean J. Argric. For. Meteorol. 2018, 20, 262–276. [Google Scholar] [CrossRef]
- Marta, A.D.; De Vincenzi, M.; Dietrich, S.; Orlandini, S. Neural network for the estimation of leaf wetness duration: Application to a Plasmopara viticola infection forecasting. Phys. Chem. Earth 2005, 30, 91–96. [Google Scholar] [CrossRef]
- Francl, L.J.; Panigrahi, S. Artificial neural network models of wheat leaf wetness. Agric. For. Meteorol. 1997, 88, 57–65. [Google Scholar] [CrossRef]
- Chtioui, Y.; Panigrahi, S.; Francl, L. A generalized regression neural network and its application for leaf wetness prediction to forecast plant disease. Chemom. Intell. Lab. Syst. 1999, 48, 47–58. [Google Scholar] [CrossRef]
- Kim, K.S.; Taylor, S.E.; Gleason, M.L. Development and validation of a leaf wetness duration model using a fuzzy logic system. Agric. For. Meteorol. 2004, 127, 53–64. [Google Scholar] [CrossRef]
- Fan, J.; Yue, W.; Wu, L.; Zhang, F.; Cai, H.; Wang, X.; Lu, X.; Xiang, Y. Evaluation of SVM, ELM and four tree-based ensemble models for predicting daily reference evapotranspiration using limited meteorological data in different climates of China. Agric. For. Meteorol. 2018, 263, 225–241. [Google Scholar] [CrossRef]
- Tao, Y.; Gao, X.; Hsu, K.; Sorooshian, S.; Ihler, A. A Deep Neural Network Modeling Framework to Reduce Bias in Satellite Precipitation Products. J. Hydrometeorol. 2016, 17, 931–945. [Google Scholar] [CrossRef]
- Lu, X.; Ju, Y.; Wu, L.; Fan, J.; Zhang, F.; Li, Z. Daily pan evaporation modeling from local and cross-station data using three tree-basedmachine learning models. J. Hydrol. 2018, 566, 668–684. [Google Scholar] [CrossRef]
- Monteith, J.L.; Unsworth, M.H. Principles of Environmental Physics. In Principles of Environmental Physics, 4th ed.; Monteith, J.L., Unsworth, M.H., Eds.; Academic Press: Boston, MA, USA, 2013. [Google Scholar]
- Walter, I.A.; Allen, R.G.; Elliott, R.; Jensen, M.E.; Itenfisu, D.; Mecham, B.; Howel, T.A.; Snyder, R.; Brown, P.; Echings, S.; et al. ASCE’s Standardized Reference Evapotranspiration Equation. In Watershed Management and Operations Management 2000; ASCE: Reston, VA, USA, 2000; pp. 1–11. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Peña, M.; Dool, H.V.D. Consolidation of Multimodel Forecasts by Ridge Regression: Application to Pacific Sea Surface Temperature. J. Clim. 2008, 21, 6521–6538. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Zhou, H.; Ding, X.; Zhang, R. Extreme Learning Machine for Regression and Multiclass Classification. IEEE Trans. Syst. Man Cybern. B Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef]
- Yang, T.; Asanjan, A.A.; Welles, E.; Gao, X.; Sorooshian, S.; Liu, X. Developing reservoir monthly inflow forecasts using Artificial Intelligence and Climate Phenomenon Information. Water Resour. Res. 2017, 53, 2786–2812. [Google Scholar] [CrossRef]
- Pang, B.; Yue, J.; Zhao, G.; Xu, Z. Statistical Downscaling of Temperature with the Random Forest Model. Adv. Met. 2017, 2017, 7265178. [Google Scholar] [CrossRef]
- Choi, C.; Kim, J.; Kim, J.; Kim, D.; Bae, Y.; Kim, H.S. Development of Heavy Rain Damage Prediction Model Using Machine Learning Based on Big Data. Adv. Met. 2018, 2018, 5024930. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Wright, M.N.; Ziegler, A. Ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. J. Stat. Softw. 2017, 77, 1–17. [Google Scholar] [CrossRef]
- Lee, K.J.; Kang, J.Y.; Lee, D.Y.; Jang, S.W.; Lee, S.; Lee, B.W.; Kim, K.S. Use of an Empirical Model to Estimate Leaf Wetness Duration for Operation of a Disease Warning System Under a Shade in a Ginseng Field. Plant Dis. 2016, 100, 25–31. [Google Scholar] [CrossRef] [PubMed]
- Bassimba, D.D.M.; Intrigliolo, D.S.; Dalla Marta, A.; Orlandini, S.; Vicent, A. Leaf wetness duration in irrigated citrus orchards in the Mediterranean climate conditions. Agric. For. Meteorol. 2017, 234–235, 182–195. [Google Scholar] [CrossRef]
- Beruski, G.C.; Gleason, M.L.; Sentelhas, P.C.; Pereira, A.B. Leaf wetness duration estimation and its influence on a soybean rust warning system. Australas. Plant Pathol. 2019, 48, 395–408. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Site | Latitude (Degree) | Longitude (Degree) | Elevation (m) | Field Type |
|---|---|---|---|---|
| 1 | 37.221 | 127.039 | 45 | Rice field |
| 2 | 37.039 | 126.864 | 24 | Rice field |
| 3 | 37.012 | 127.306 | 34 | Rice field |
| 4 | 37.217 | 126.702 | 6 | Grape orchard |
| 5 | 37.178 | 127.302 | 150 | Rice field |
| 6 | 37.350 | 127.625 | 57 | Apple orchard |
| 7 | 37.844 | 127.502 | 68 | Rice field |
| 8 | 37.600 | 127.251 | 65 | Pear orchard |
| 9 | 38.036 | 127.201 | 101 | Apple orchard |
| Variables | Site1 | Site2 | Site3 | Site4 | Site5 | Site6 | Site7 | Site8 | Site9 |
|---|---|---|---|---|---|---|---|---|---|
| Air temperature | 12.0 (11.2) | 11.2 (11.0) | 11.5 (11.5) | 11.5 (11.2) | 10.7 (11.3) | 10.8 (12.0) | 10.6 (11.8) | 10.9 (11.3) | 10.3 (12.0) |
| Relative humidity | 66.7 (20.2) | 75.1 (20.3) | 73.4 (19.6) | 73.2 (20.6) | 72.0 (21.7) | 72.7 (23.3) | 73.0 (21.6) | 69.3 (23.3) | 71.5 (23.8) |
| Short wave radiation | 0.52 (0.82) | 0.55 (0.84) | 0.46 (0.75) | 0.54 (0.83) | 0.54 (0.83) | 0.51 (0.79) | 0.49 (0.80) | 0.46 (0.73) | 0.46 (0.77) |
| Wind speed | 1.368 (1.384) | 1.816 (1.779) | 0.954 (1.373) | 1.302 (1.496) | 0.963 (1.164) | 0.640 (0.919) | 0.733 (1.069) | 0.892 (0.966) | 0.823 (1.010) |
| LW | 0.259 (0.438) | 0.383 (0.486) | 0.379 (0.485) | 0.340 (0.474) | 0.365 (0.481) | 0.404 (0.491) | 0.373 (0.484) | 0.220 (0.414) | 0.296 (0.456) |
| LWD | 5.68 (6.40) | 8.62 (5.78) | 8.33 (5.92) | 7.47 (6.03) | 8.12 (5.94) | 8.74 (5.97) | 7.99 (6.38) | 4.90 (6.03) | 6.33 (6.15) |
| ELM | RF | DNN | CART | NHRH | PM | |
|---|---|---|---|---|---|---|
| Cor. | 0.776 | 0.807 | 0.798 | 0.661 | 0.725 | 0.656 |
| RMSE | 4.484 | 3.681 | 4.020 | 5.429 | 4.606 | 5.180 |
| mBias | 1.724 | 0.388 | 1.116 | 0.323 | −0.028 | 1.831 |
| MAE | 2.851 | 2.314 | 2.502 | 3.479 | 2.999 | 3.526 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, J.; Shin, J.-Y.; Kim, K.R.; Ha, J.-C. Leaf Wetness Duration Models Using Advanced Machine Learning Algorithms: Application to Farms in Gyeonggi Province, South Korea. Water 2019, 11, 1878. https://doi.org/10.3390/w11091878
Park J, Shin J-Y, Kim KR, Ha J-C. Leaf Wetness Duration Models Using Advanced Machine Learning Algorithms: Application to Farms in Gyeonggi Province, South Korea. Water. 2019; 11(9):1878. https://doi.org/10.3390/w11091878
Chicago/Turabian StylePark, Junsang, Ju-Young Shin, Kyu Rang Kim, and Jong-Chul Ha. 2019. "Leaf Wetness Duration Models Using Advanced Machine Learning Algorithms: Application to Farms in Gyeonggi Province, South Korea" Water 11, no. 9: 1878. https://doi.org/10.3390/w11091878
APA StylePark, J., Shin, J. -Y., Kim, K. R., & Ha, J. -C. (2019). Leaf Wetness Duration Models Using Advanced Machine Learning Algorithms: Application to Farms in Gyeonggi Province, South Korea. Water, 11(9), 1878. https://doi.org/10.3390/w11091878