Development of Water Level Prediction Models Using Machine Learning in Wetlands: A Case Study of Upo Wetland in South Korea



Abstract
:1. Introduction
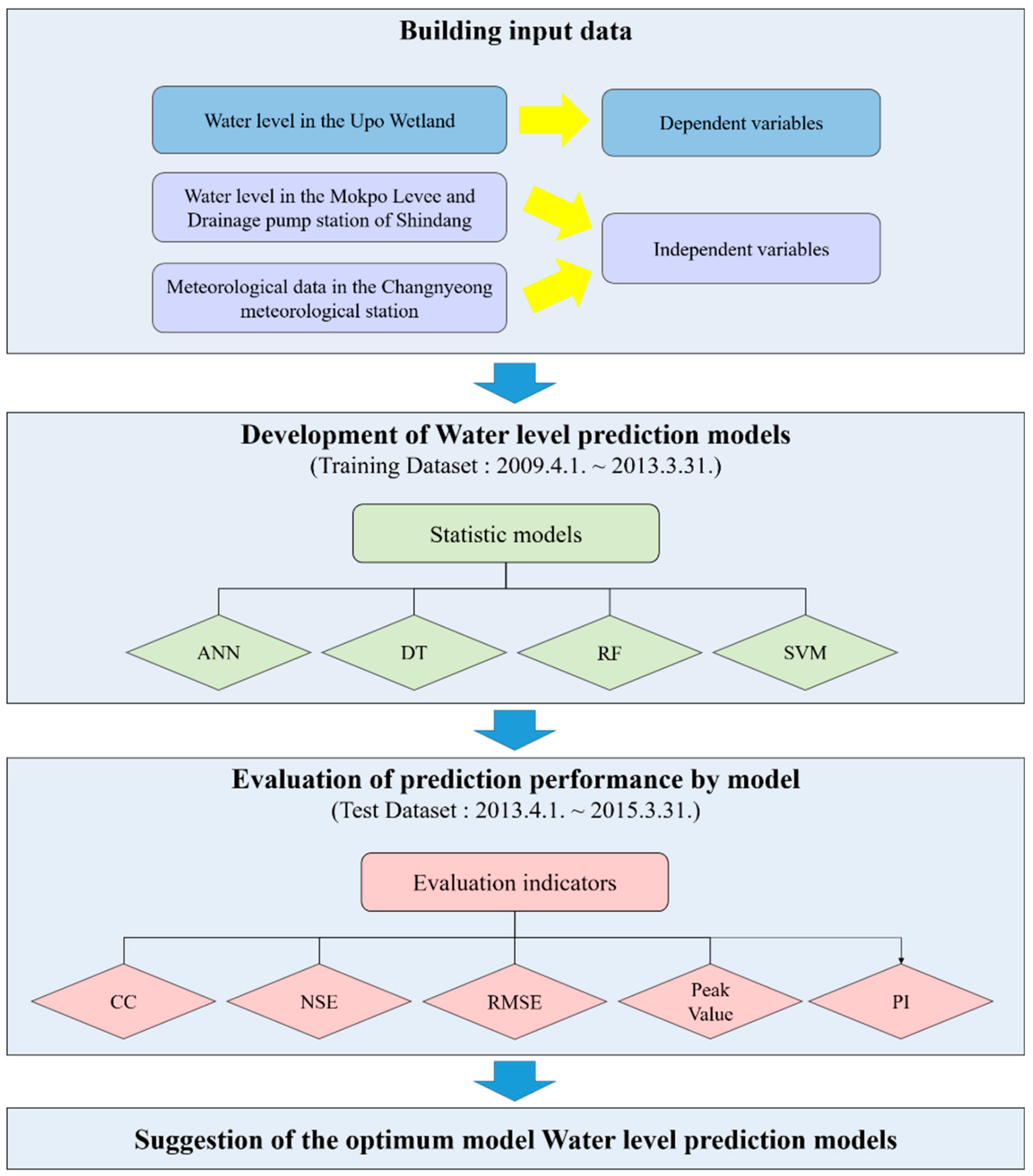
2. Materials and Methods
2.1. Study Area
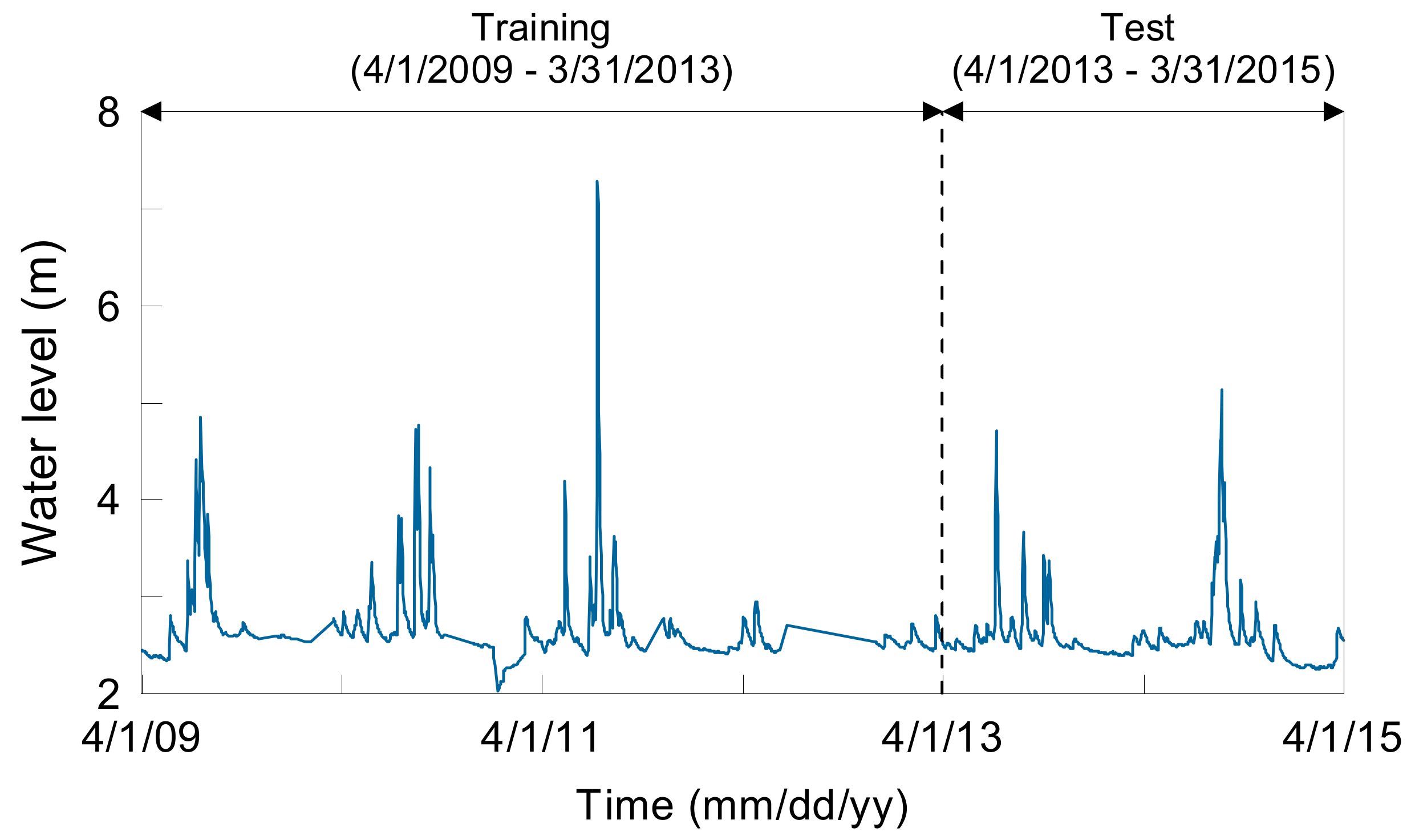
2.2. Data Used
2.2.1. Dependent Variables
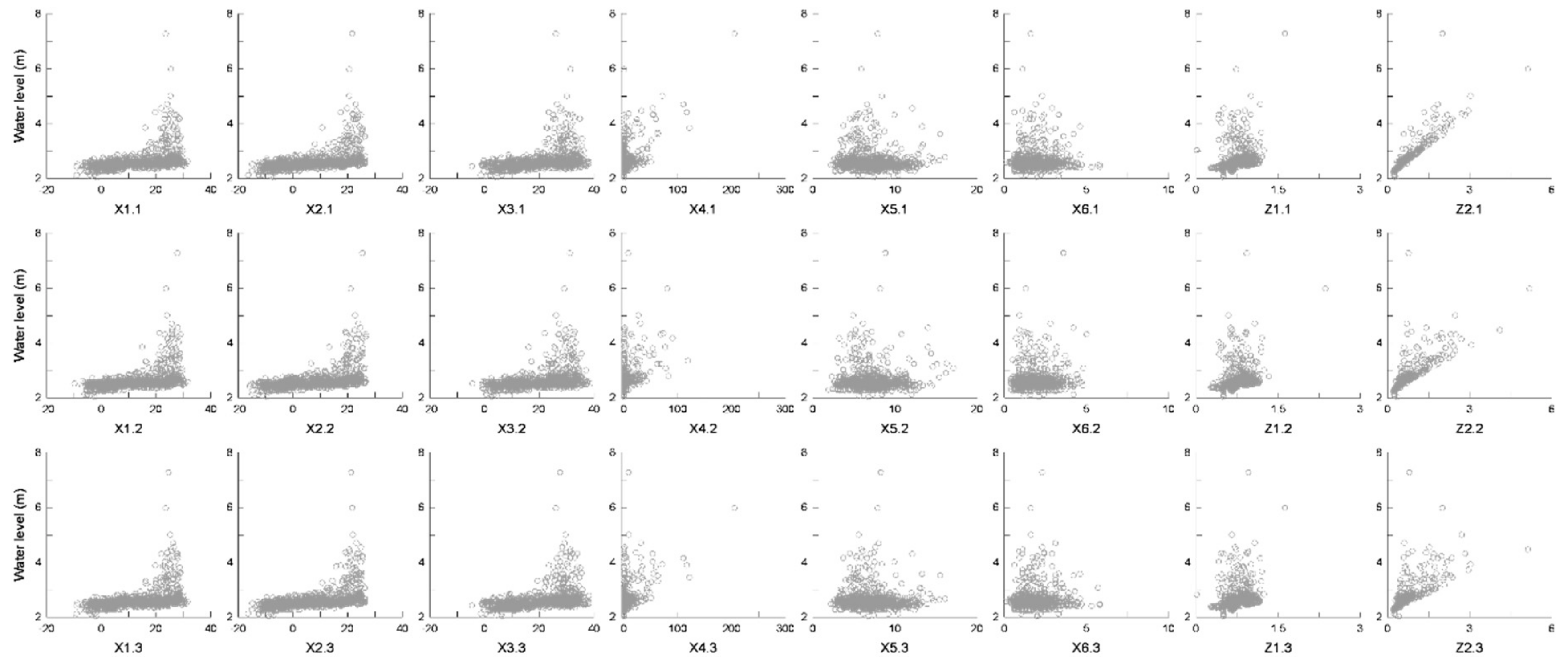
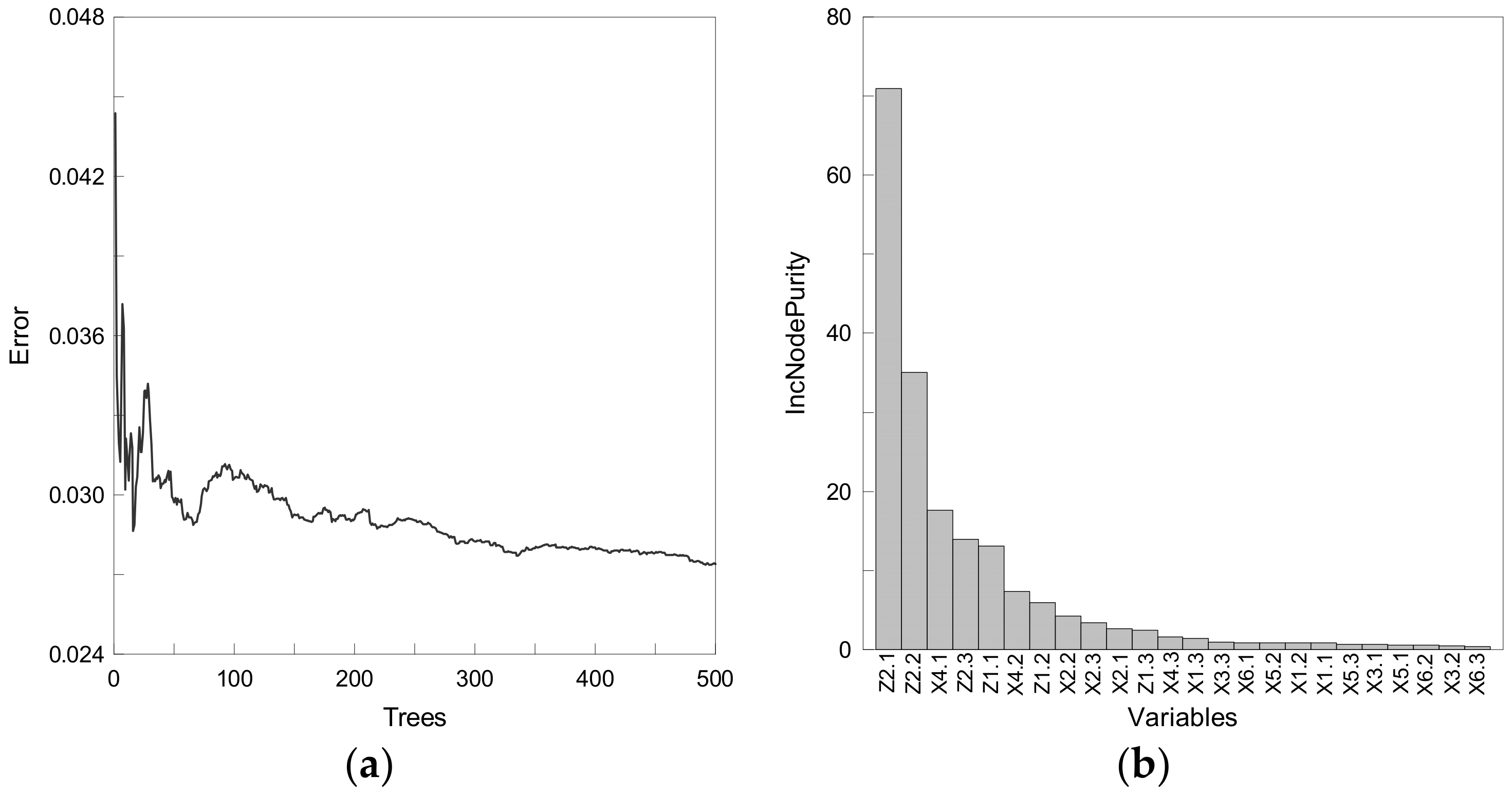
2.2.2. Independent Variables
2.3. Machine Learning Techniques
2.3.1. Overview
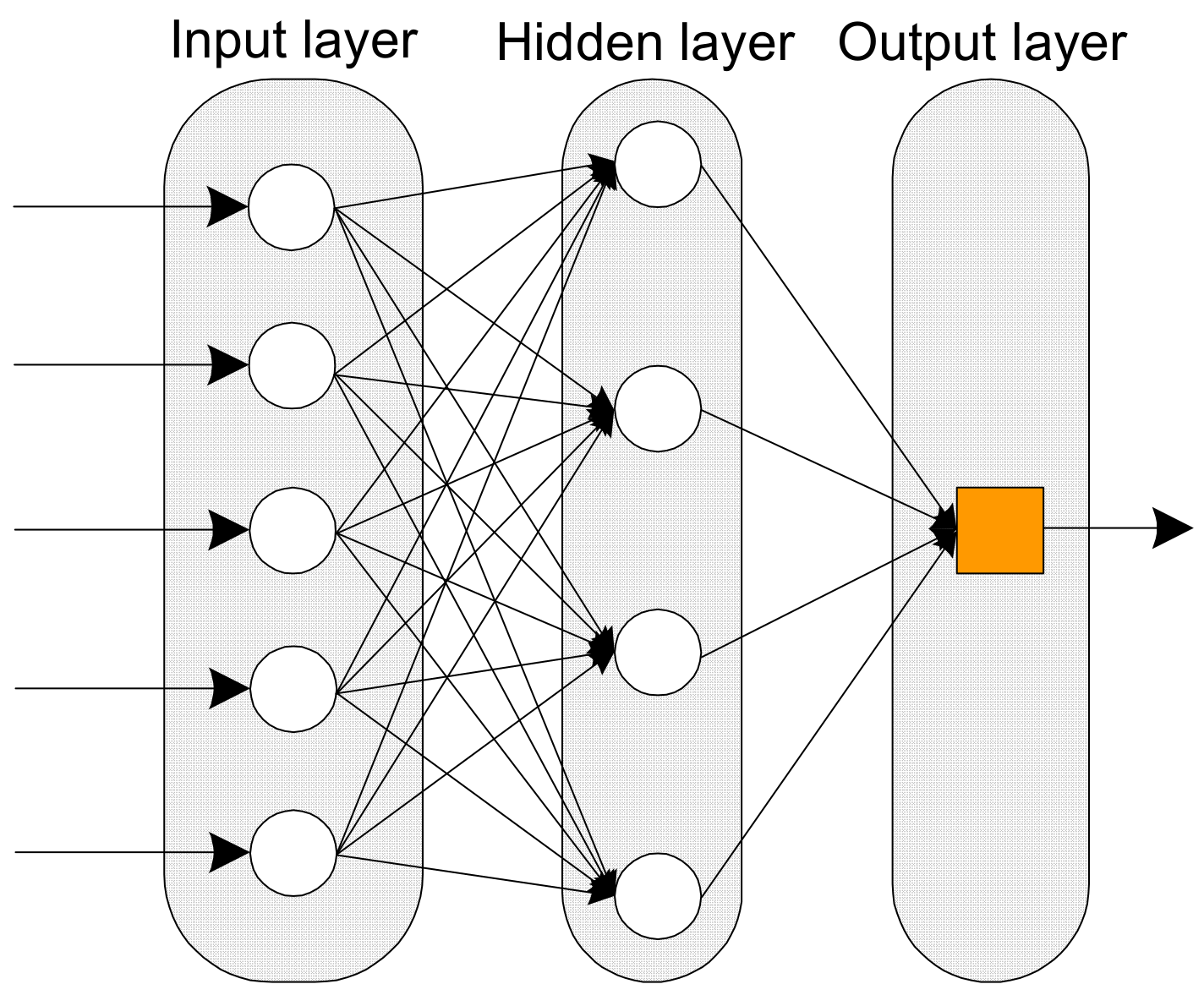
2.3.2. Artificial Neural Network
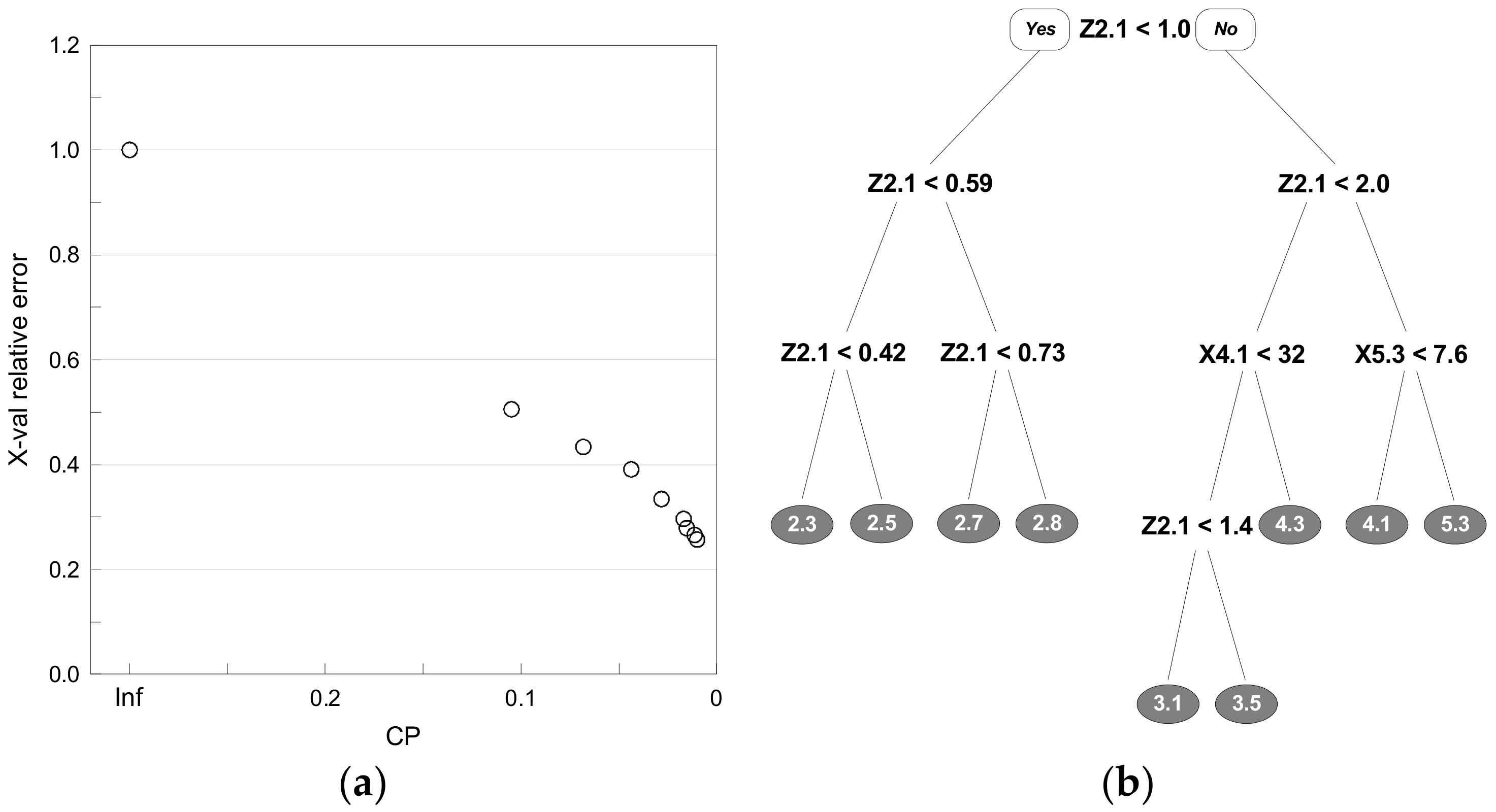
2.3.3. Decision Tree
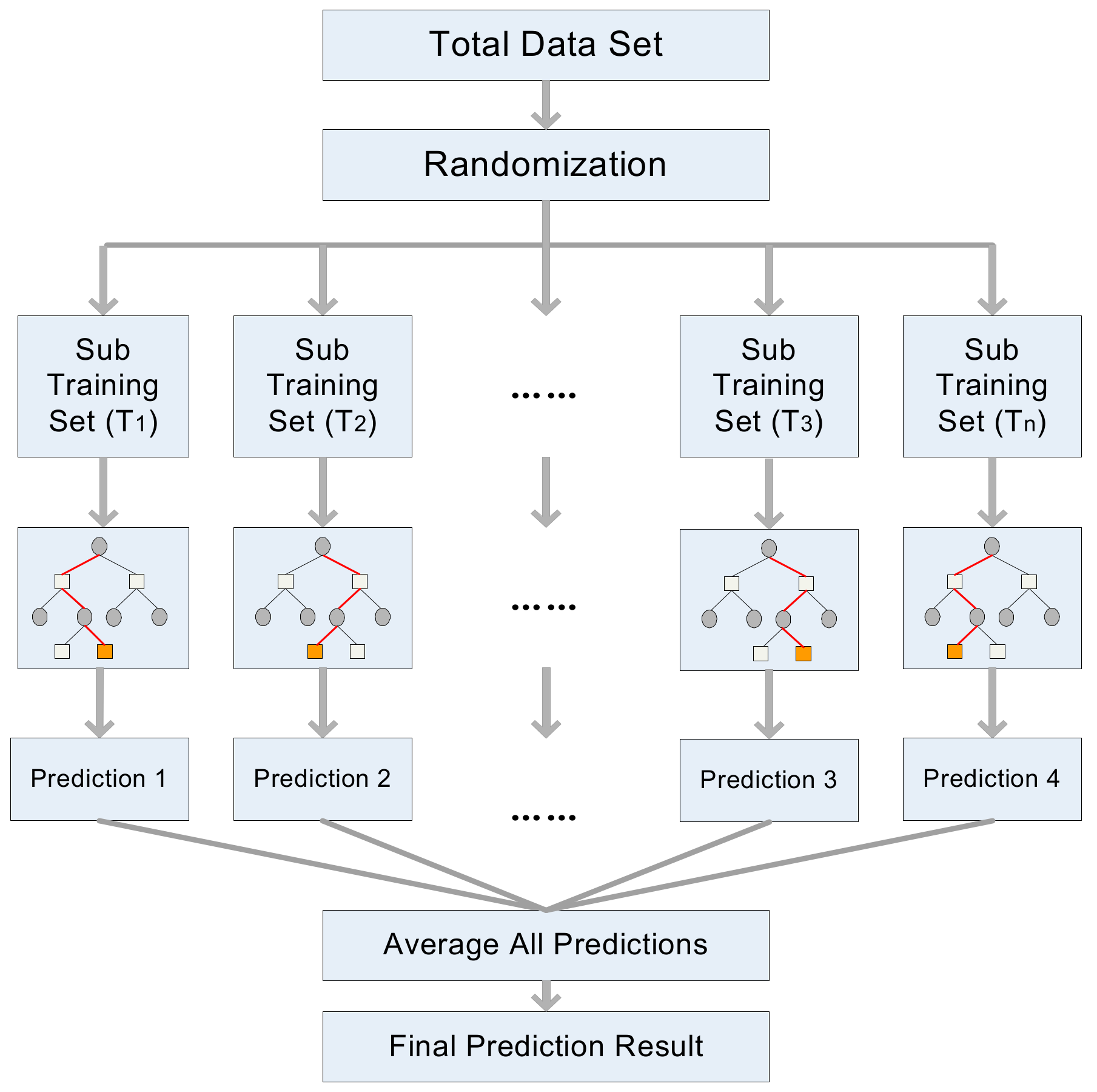
2.3.4. Random Forest
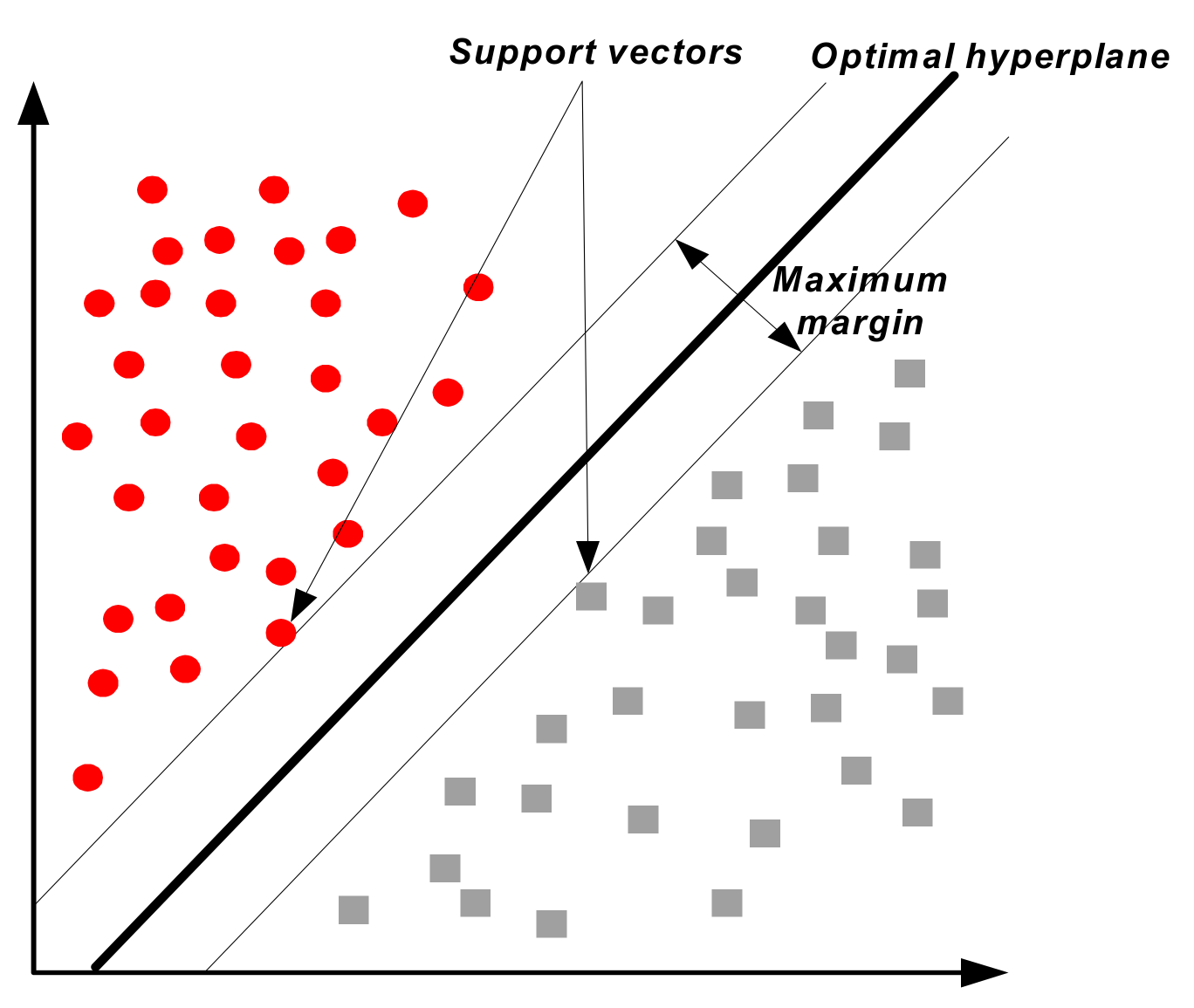
2.3.5. Support Vector Machine
2.4. Metrics for Evaluation
3. Results
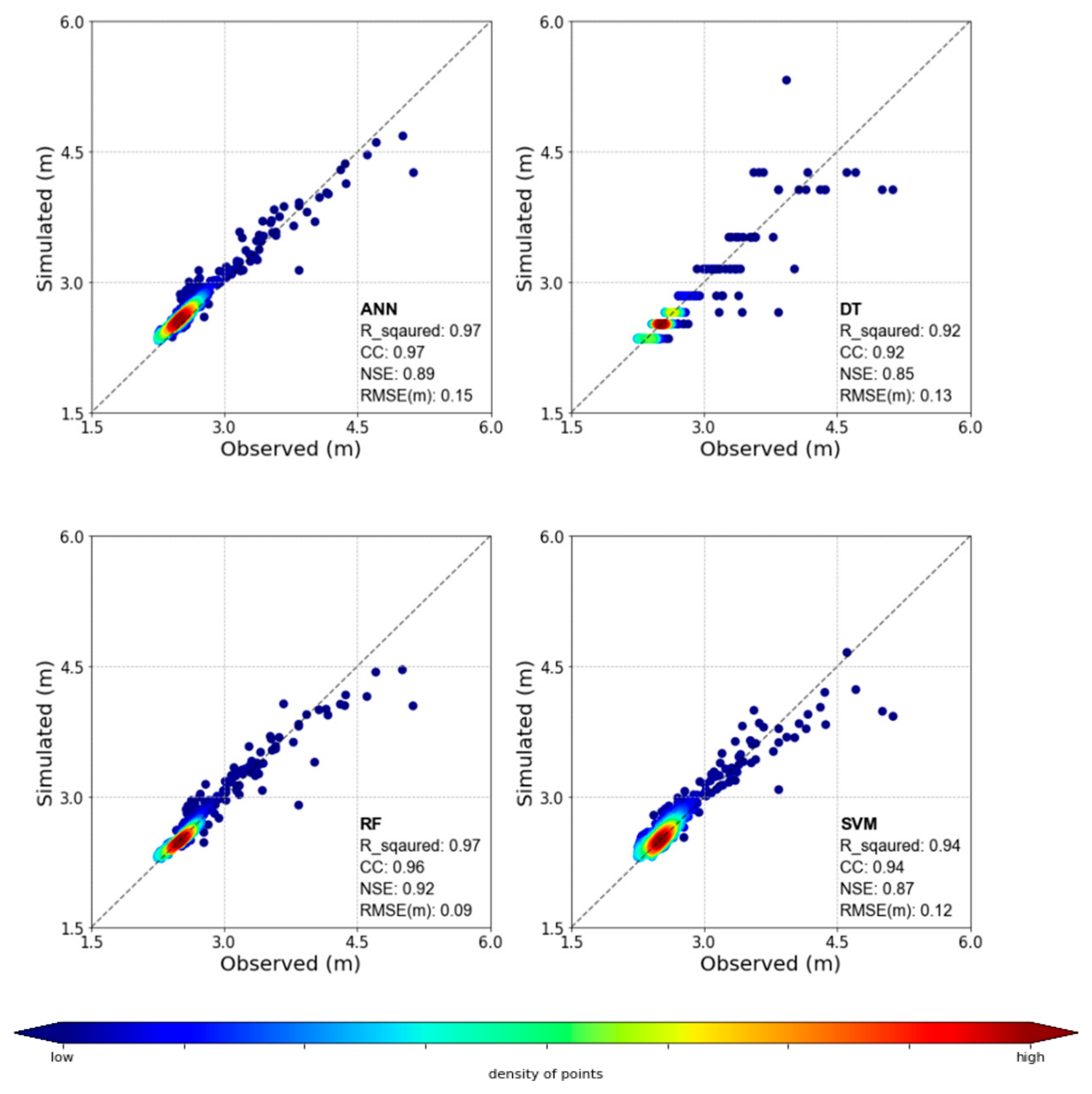
3.1. ANN
3.2. Decision Tree
3.3. Random Forest
3.4. Support Vector Machine
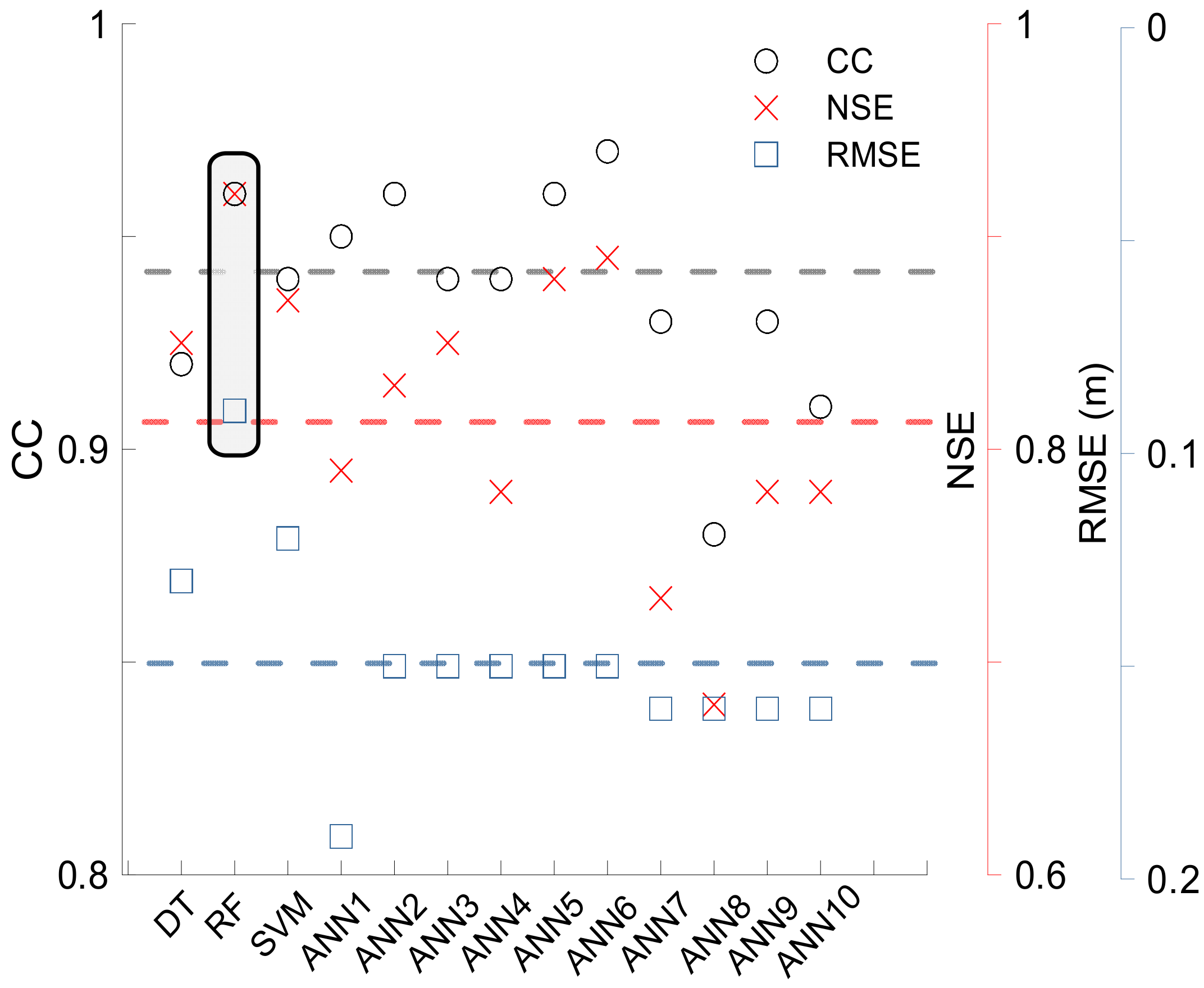
3.5. Evaluation Results
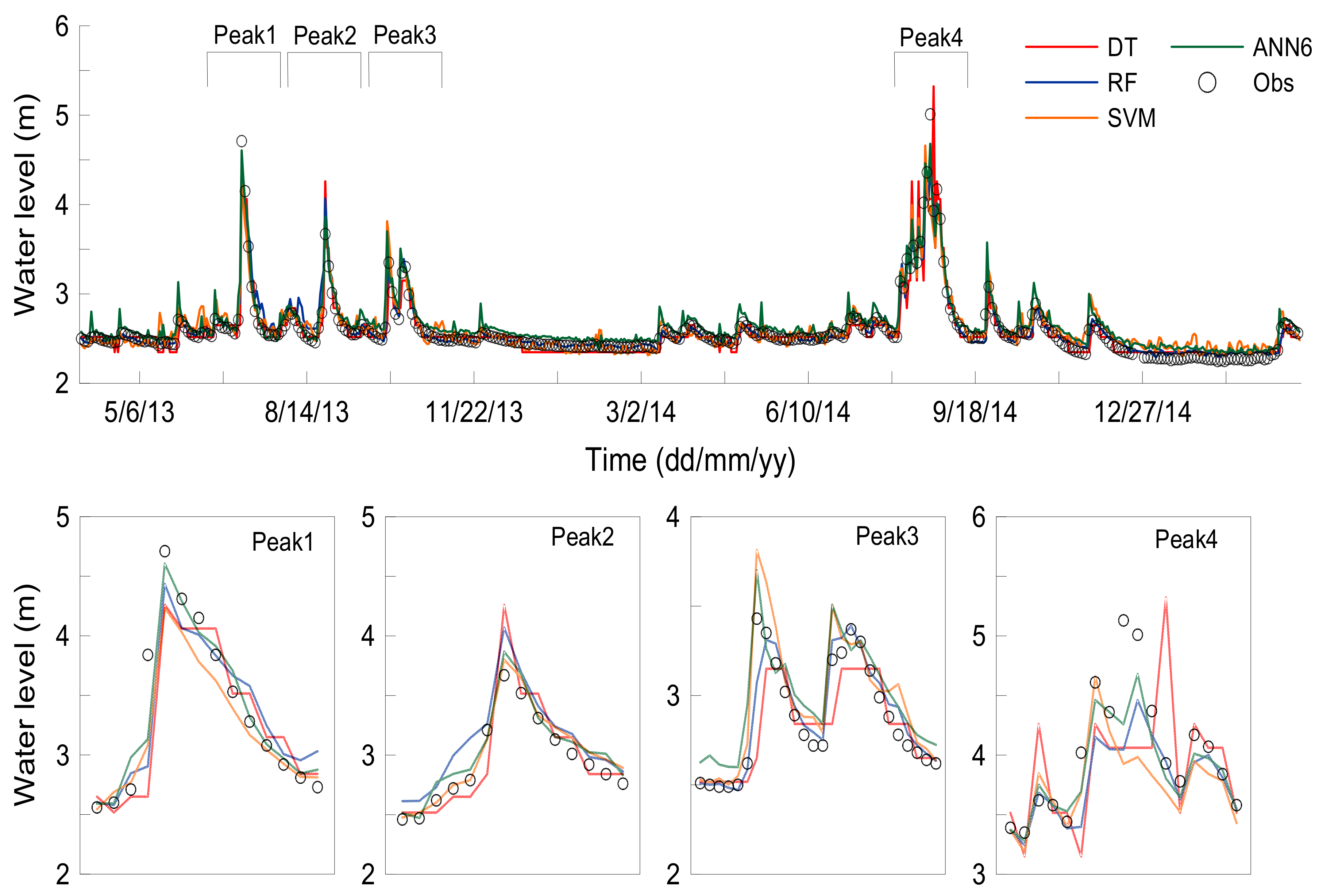
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Mitsch, W.J.; Gosselink, J.G. Wetlands, 4th ed.; Van Nostrand Reinhold: New York, NY, USA, 2007. [Google Scholar]
- Kwak, J.W.; Kim, G.H.; Kim, J.W.; Singh, V.P.; Kim, H.S. Assessment of hydrological regimes for vegetation on riparian wetlands in Han River Basin, Korea. Terr. Atmos. Ocean. Sci. 2017, 28, 1055–1067. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.W.; Lee, B.E.; Kim, J.G.; Oh, S.H.; Jung, J.W.; Lee, M.J.; Kim, H.S. Functional Assessment of Gangcheon Replacement Wetland Using Modified HGM. J. Wetl. Res. 2017, 19, 318–326. [Google Scholar]
- Environment Canada. Where Land Meets Water: Understanding Wetlands of the Great Lakes; Canadian Wildlife Service: Downsview, ON, Canada, 2002.
- Keddy, P.A. Wetland Ecology: Principles and Conservation; Cambridge University: Cambridge, UK, 2000. [Google Scholar]
- Bittmann, E. Grundlagen und Methoden des biologischen Wasserbaus. In Der Biologische Wasserbau an den Bundesstrassen; Bundesanstalt f. Gewaesserkunde: Koblenz, Germany, 1965; pp. 1–56. [Google Scholar]
- Kim, J.W. Prediction and Evaluation of Hydro-Ecology, Functions, and Sustainability of a Wetland under Climate Change. Ph.D. Thesis, Inha University, Incheon, Korea, 2019. [Google Scholar]
- Environment Agency. A Guide to Monitoring Water Levels and Flows at Wetland Sites; Environment Agency: Bristol, UK, 1996.
- Ministry of Environment. The 3rd Wetland Conservation Master Plan; Ministry of Environment: Sejong, Korea, 2018.
- Kumar, A.P.S.; Sudheer, K.P.; Jain, S.K.; Agarwal, P.K. Rainfall runoff modeling using artificial neural networks: Comparison of network types. Hydrol. Process. 2005, 19, 1277–1291. [Google Scholar] [CrossRef]
- Yu, P.S.; Chen, S.T.; Chang, I.F. Support vector regression for real-time flood stage forecasting. J. Hydrol. 2006, 328, 704–716. [Google Scholar] [CrossRef]
- Chau, K.W. Particle swarm optimization training algorithm for ANNs in stage prediction of shing mun river. J. Hydrol. 2006, 329, 363–367. [Google Scholar] [CrossRef] [Green Version]
- Wilson, G.; Khondker, M.H. Data selection for a flood forecasting neural network. In Proceedings of the 4th International Conference on Hydroinformatics, Cedar Rapids, IA, USA, 23–27 August 2000. [Google Scholar]
- Bazartseren, B.; Hildebrandt, G.; Holz, K.P. Short-term water level prediction using neural networks and neuro-fuzzy approach. Neurocomputing 2003, 55, 439–450. [Google Scholar] [CrossRef]
- Tiwari, M.K.; Chatterjee, C. Development of an accurate and reliable hourly flood forecasting model using wavelet-bootstrap-ANN (WBANN) hybrid approach. J. Hydrol. 2010, 394, 458–470. [Google Scholar] [CrossRef]
- Jun, H.D.; Lee, J.H. A Methodology for Flood Forecasting and Warning Based on the Characteristic of Observed Water Levels Between Upstream and Downstream. J. Korean Soc. Hazard Mitig. 2013, 13, 367–374. [Google Scholar] [CrossRef] [Green Version]
- Byeon, S.J.; Lee, S.H.; Choi, G.W.; Jung, J.G. Use of Gauged Water Level and Precipitation Data to Predict Short Term Water Level Changes. Korean Rev. Crisis Emerg. Manag. 2014, 10, 247–264. [Google Scholar]
- Castillo, J.M.M.; Cspedes, J.M.S.; Cuchango, H.E.E. Water Level Prediction Using Artificial Neural Network Model. Int. J. Appl. Eng. Res. 2018, 13, 14378–14381. [Google Scholar]
- Shamseldin, A.Y.; O’Connor, K.M. A real-time combination method for the outputs of different rainfall-runoff models. Hydrol. Sci. J. 1999, 44, 895–912. [Google Scholar] [CrossRef]
- Georgakakos, K.P.; Seo, D.J.; Gupta, H.; Schaake, J.; Butts, M.B. Towards the characterization of stream-flow simulation uncertainty through multi-model ensembles. J. Hydrol. 2004, 298, 222–241. [Google Scholar] [CrossRef]
- Young, C.C.; Liu, W.C. Prediction and modelling of rainfall–runoff during typhoon events using a physically-based and artificial neural network hybrid model. Hydrol. Sci. J. 2015, 60, 2102–2116. [Google Scholar] [CrossRef]
- Jothiprakash, V.; Magar, R.B. Multi-time-step ahead daily and hourly intermittent reservoir inflow prediction by artificial intelligent techniques using lumped and distributed data. J. Hydrol. 2012, 450, 293–307. [Google Scholar] [CrossRef]
- Booker, D.J.; Woods, R.A. Comparing and combining physically-based and empirically-based approaches for estimating the hydrology of ungauged catchments. J. Hydrol. 2014, 508, 227–239. [Google Scholar] [CrossRef] [Green Version]
- Yang, T.; Gao, X.; Sorooshian, S.; Li, X. Simulating California reservoir operation using the classification and regression-tree algorithm combined with a shuffled crossvalidation scheme. Water Resour. Res. 2016, 52, 1626–1651. [Google Scholar] [CrossRef] [Green Version]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Kim, J.; Han, H.; Johnson, L.E.; Lim, S.; Cifelli, R. Hybrid machine learning framework for hydrological assessment. J. Hydrol. 2019, 577, 123913. [Google Scholar] [CrossRef]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965; University of California Press: Berkeley, CA, USA, 1967; Volume 1, pp. 281–297. [Google Scholar]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 59–69. [Google Scholar] [CrossRef]
- Adamowski, J.; Chan, H.F. A wavelet neural network conjunction model for groundwater level forecasting. J. Hydrol. 2011, 407, 28–40. [Google Scholar] [CrossRef]
- Partal, T.; Cigizoglu, H.K. Estimation and forecasting of daily suspended sediment data using wavelet-neural networks. J. Hydrol. 2008, 358, 317–331. [Google Scholar] [CrossRef]
- Rajaee, T.; Nourani, V.; Mohammad, Z.K.; Kisi, O. River suspended sediment load prediction: Application of ANN and wavelet conjunction model. J. Hydrol. Eng. 2011, 16, 613–627. [Google Scholar] [CrossRef]
- Adnan, R.; Ruslan, F.A.; Samad, A.M.; Zain, Z.M. Flood Water Level Modelling and Prediction Using Artificial Neural Network: Case Study of Sungai Batu Pahat in Johor. In Proceedings of the 2012 IEEE Control and System Graduate Research Colloquium, Shah Alam, Malaysia, 16–17 July 2012; pp. 22–25. [Google Scholar]
- Kisi, O.; Shiri, J.; Nikoofar, B. Forecasting daily lake levels using artificial intelligence approaches. Comput. Geosci. 2012, 41, 169–180. [Google Scholar] [CrossRef]
- Hipni, A.; El-Shafie, A.; Najah, A.; Karim, O.A.; Hussain, A.; Mukhlisin, M. Daily forecasting of dam water levels: Comparing a support vector machine (SVM) model with adaptive neuro fuzzy inference system (ANFIS). Water Resour. Manag. 2013, 27, 3803–3823. [Google Scholar] [CrossRef]
- Young, C.C.; Liu, W.C.; Hsieh, W.L. Predicting the Water Level Fluctuation in an Alpine Lake Using Physically Based, Artificial Neural Network, and Time Series Forecasting Models. Math. Probl. Eng. 2015. [Google Scholar] [CrossRef] [Green Version]
- Rezaeianzadeh, M.; Kalin, L.; Anderson, C. Wetland Water-Level Prediction Using ANN in Conjunction with Base-Flow Recession Analysis. J. Hydrol. Eng. 2015, 22, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Rezaeianzadeh, M.; Kalin, L.; Hantush, M. An Integrated Approach for Modeling Wetland Water Level: Application to a Headwater Wetland in Coastal Alabama, USA. Water 2018, 10, 879. [Google Scholar] [CrossRef] [Green Version]
- Nakdong River Basin Environmental Office. Conservation Plan of Upo Wetland Reservation Area; Nakdong River Basin Environmental Office: Changwon, Korea, 2016.
- Ministry of Construction & Transportation. A Study on Improving the Ecological-Flood Function in Upo Wetland; Ministry of Construction & Transportation: Sejong, Korea, 2007.
- Cover, T.; Thomas, J. Elements of Information Theory; John Wiley & Sons: New York, NY, USA, 1991. [Google Scholar]
- Ross, B.C. Mutual information between discrete and continuous data sets. PLoS ONE 2014, 9, e87357. [Google Scholar] [CrossRef]
- Kinney, J.B.; Atwal, G.S. Equitability, mutual information, and the maximal information coefficient. PNAS 2014, 111, 3354–3359. [Google Scholar] [CrossRef] [Green Version]
- Yaseen, Z.M.; El-Shafie, A.; Jaafar, O.; Afan, H.A.; Sayl, K.N. Artificial inteligence based models for stream-flow forecasting: 2000–2015. J. Hydrol. 2015, 530, 829–844. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Choi, C.; Kim, J.; Kim, J.; Kim, H.S. Development of Combined Heavy Rain Damage Prediction Models with Machine Learning. Water 2019, 11, 2516. [Google Scholar] [CrossRef] [Green Version]
- Choi, C.; Kim, J.; Kim, J.; Kim, D.; Bae, Y.; Kim, H.S. Development of heavy rain damage prediction model using machine learning based on big data. Adv. Meteorol. 2018. [Google Scholar] [CrossRef] [Green Version]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.J.; Vapnik, V. Support vector regression machines. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 1997; pp. 155–161. [Google Scholar]
- Kim, S.J.; Ryoo, E.C.; Jung, M.K.; Kim, J.K.; Ahn, H.C. Application of support vector regression for improving the performance of the emotion prediction model. J. Intell. Inf. Syst. 2012, 18, 185–202. [Google Scholar]
- Gunn, S.R. Support vector machines for classification and regression. ISIS Tech. Rep. 1998, 14, 5–16. [Google Scholar]
- Basak, D.; Pal, S.; Patranabis, D.C. Support vector regression. Neural Inf. Process.-Lett. Rev. 2007, 11, 203–224. [Google Scholar]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Hwang, S.H.; Ham, D.H.; Kim, J.H. A new measure for assessing the efficiency of hydrological data-driven forecasting models. Hydrol. Sci. J. 2012, 57, 1257–1274. [Google Scholar] [CrossRef] [Green Version]
- Lantz, B. Machine Learning with R; Packt Publishing Ltd.: Birmingham, UK, 2015. [Google Scholar]
- Baba, N. A new approach for finding the global minimum of error function of neural networks. Neural Netw. 1989, 2, 367–373. [Google Scholar] [CrossRef]
- Lewis, N.D.C. Deep Learning Made Easy with R: A Gentle Introduction for Data Science; CreateSpace Independent Publishing Platform: Seattle, WA, USA, 2016. [Google Scholar]
- Falas, T.; Stafylopatis, A.G. The impact of the error function selection in neural network-based classifiers. Int. Jt. Conf. Neural Netw. 1999, 3, 1799–1804. [Google Scholar]
- Cory, L. Mastering Machine Learning with R; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Water Level | Training Period | Test Period |
|---|---|---|
| <3 m | 90.91% | 92.54% |
| 3–4 m | 7.04% | 5.94% |
| >4 m | 2.05% | 1.52% |
| Variable | Description | Variable | Description | Variable | Description |
|---|---|---|---|---|---|
| X1.1 | Average temperature (1 day ago) | X1.2 | Average temperature (2 days ago) | X1.3 | Average temperature (3 days ago) |
| X2.1 | Minimum temperature (1 day ago) | X2.2 | Minimum temperature (2 days ago) | X2.3 | Minimum temperature (3 days ago) |
| X3.1 | Maximum temperature (1 day ago) | X3.2 | Maximum temperature (2 days ago) | X3.3 | Maximum temperature (3 days ago) |
| X4.1 | Precipitation (1 day ago) | X4.2 | Precipitation (2 days ago) | X4.3 | Precipitation (3 days ago) |
| X5.1 | Maximum instantaneous wind speed (1 day ago) | X5.2 | Maximum instantaneous wind speed (2 days ago) | X5.3 | Maximum instantaneous wind speed (3 days ago) |
| X6.1 | Average wind speed (1 day ago) | X6.2 | Average wind speed (2 days ago) | X6.3 | Average wind speed (3 days ago) |
| Z1.1 | Water level of Shindang (1 day ago) | Z1.2 | Water level of Shindang (2 days ago) | Z1.3 | Water level of Shindang (3 days ago) |
| Z2.1 | Water level of Mokpo (1 day ago) | Z2.2 | Water level of Mokpo (2 days ago) | Z2.3 | Water level of Mokpo (3 days ago) |
| Node | Average | Standard Deviation | Node | Average | Standard Deviation |
|---|---|---|---|---|---|
| 1 | 0.19 | 0.08 | 6 | 0.15 | 0.03 |
| 2 | 0.15 | 0.05 | 7 | 0.16 | 0.03 |
| 3 | 0.15 | 0.03 | 8 | 0.16 | 0.02 |
| 4 | 0.15 | 0.03 | 9 | 0.16 | 0.02 |
| 5 | 0.15 | 0.02 | 10 | 0.16 | 0.03 |
| Model | PI | Model | PI |
|---|---|---|---|
| DT | −0.62 | ANN5 | −0.25 |
| RF | 0.19 | ANN6 | −0.18 |
| SVM | −0.40 | ANN7 | −1.85 |
| ANN1 | −1.21 | ANN8 | −2.45 |
| ANN2 | −0.84 | ANN9 | −1.33 |
| ANN3 | −0.63 | ANN10 | −1.37 |
| ANN4 | −1.32 |
| No | Date | ANN | DT | RF | SVM | ||||
|---|---|---|---|---|---|---|---|---|---|
| Peak (%) | Time (day) | Peak (%) | Time (day) | Peak (%) | Time (day) | Peak (%) | Time (day) | ||
| 1 | 6 July 2013 | −2.2 | 0 | −9.6 | 0 | −5.8 | 0 | −10.1 | 0 |
| 2 | 15 August 2013 | 5.4 | 0 | 16.1 | 0 | 10.9 | 0 | 3.6 | 0 |
| 3 | 11 October 2013 | −3.4 | −2 | −6.5 | 0 | 0.6 | 0 | −2.5 | −2 |
| 4 | 22 August 2014 | −6.6 | 1 | −18.9 | 3 | −10.9 | 1 | −20.5 | −2 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, C.; Kim, J.; Han, H.; Han, D.; Kim, H.S. Development of Water Level Prediction Models Using Machine Learning in Wetlands: A Case Study of Upo Wetland in South Korea. Water 2020, 12, 93. https://doi.org/10.3390/w12010093
Choi C, Kim J, Han H, Han D, Kim HS. Development of Water Level Prediction Models Using Machine Learning in Wetlands: A Case Study of Upo Wetland in South Korea. Water. 2020; 12(1):93. https://doi.org/10.3390/w12010093
Chicago/Turabian StyleChoi, Changhyun, Jungwook Kim, Heechan Han, Daegun Han, and Hung Soo Kim. 2020. "Development of Water Level Prediction Models Using Machine Learning in Wetlands: A Case Study of Upo Wetland in South Korea" Water 12, no. 1: 93. https://doi.org/10.3390/w12010093
APA StyleChoi, C., Kim, J., Han, H., Han, D., & Kim, H. S. (2020). Development of Water Level Prediction Models Using Machine Learning in Wetlands: A Case Study of Upo Wetland in South Korea. Water, 12(1), 93. https://doi.org/10.3390/w12010093