Convolutional Neural Network Coupled with a Transfer-Learning Approach for Time-Series Flood Predictions


Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Site
2.2. Data Acquisition
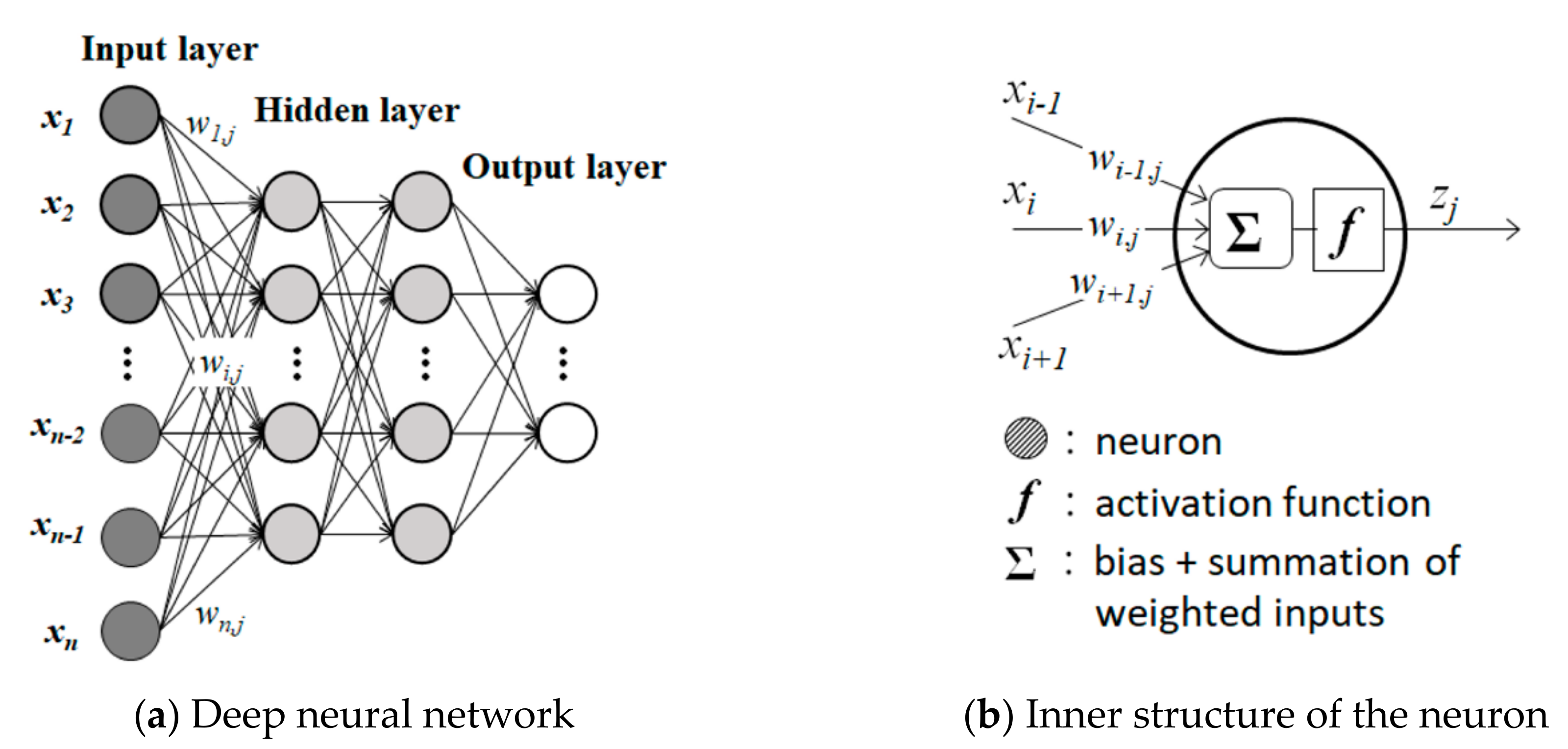
2.3. ANN and CNN Features
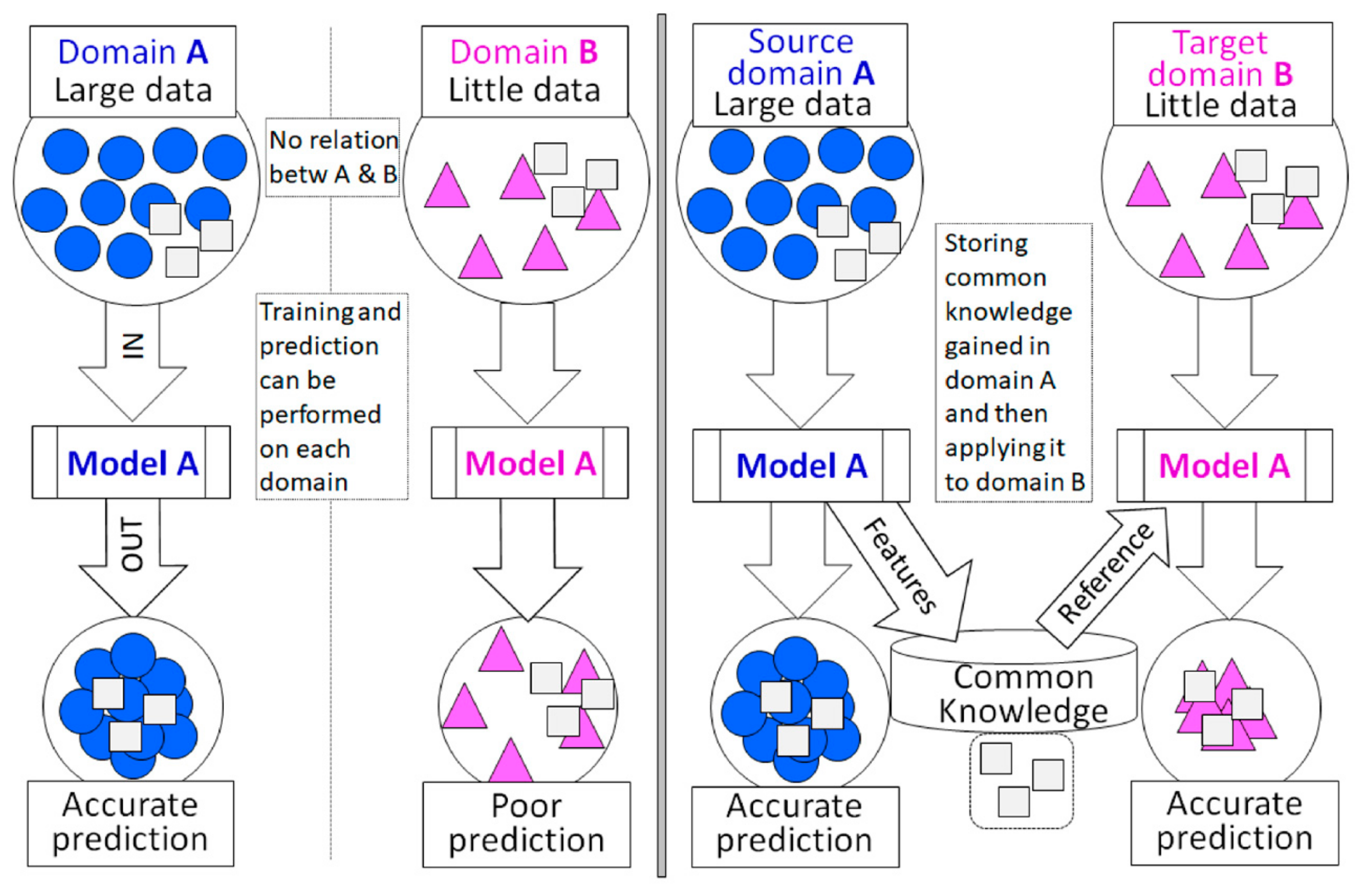
2.4. Transfer Learning
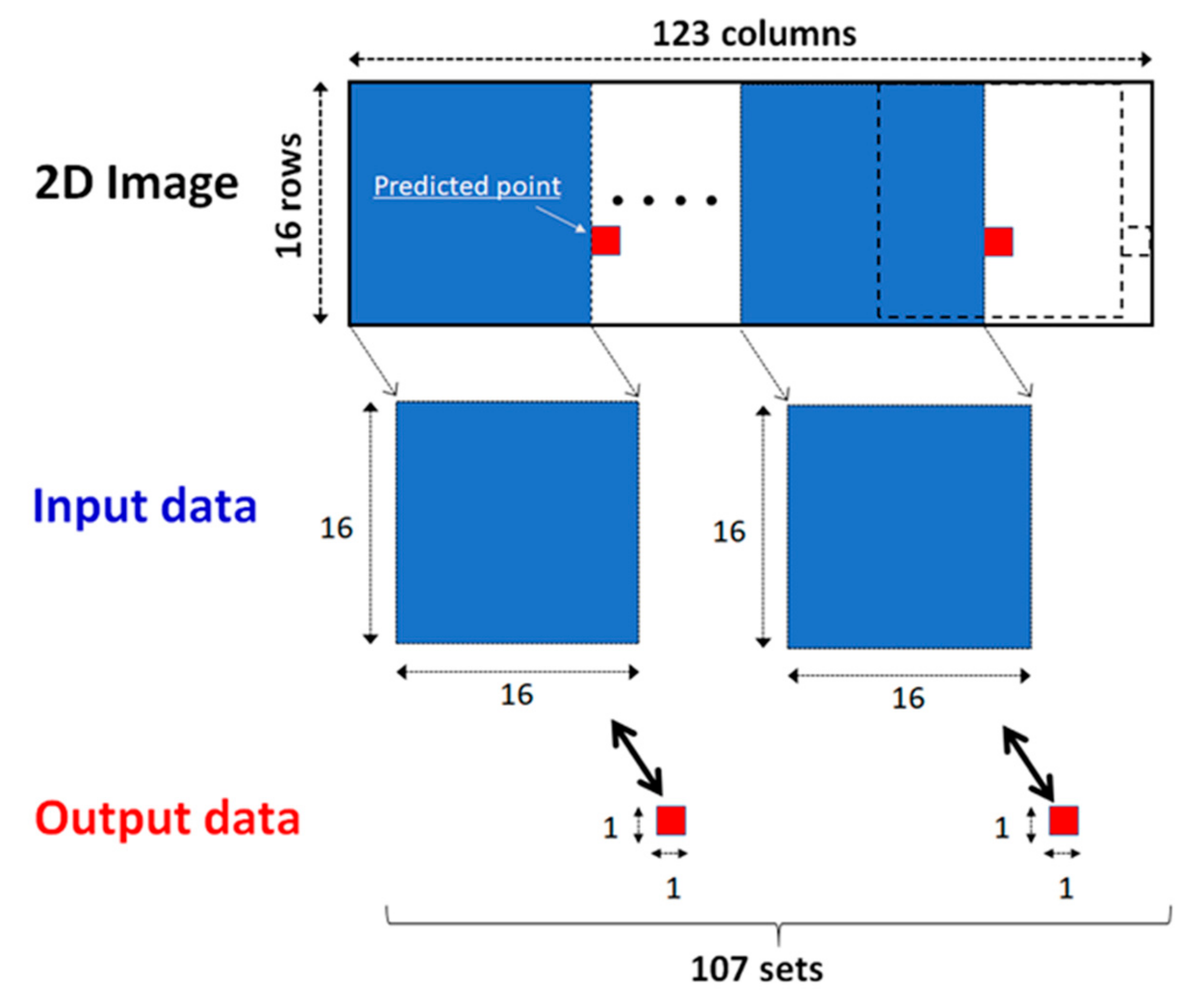
2.5. Data Conversion from Time-Series to Image
2.6. Computational Setups in CNN and CNN Transfer Learning
3. Results
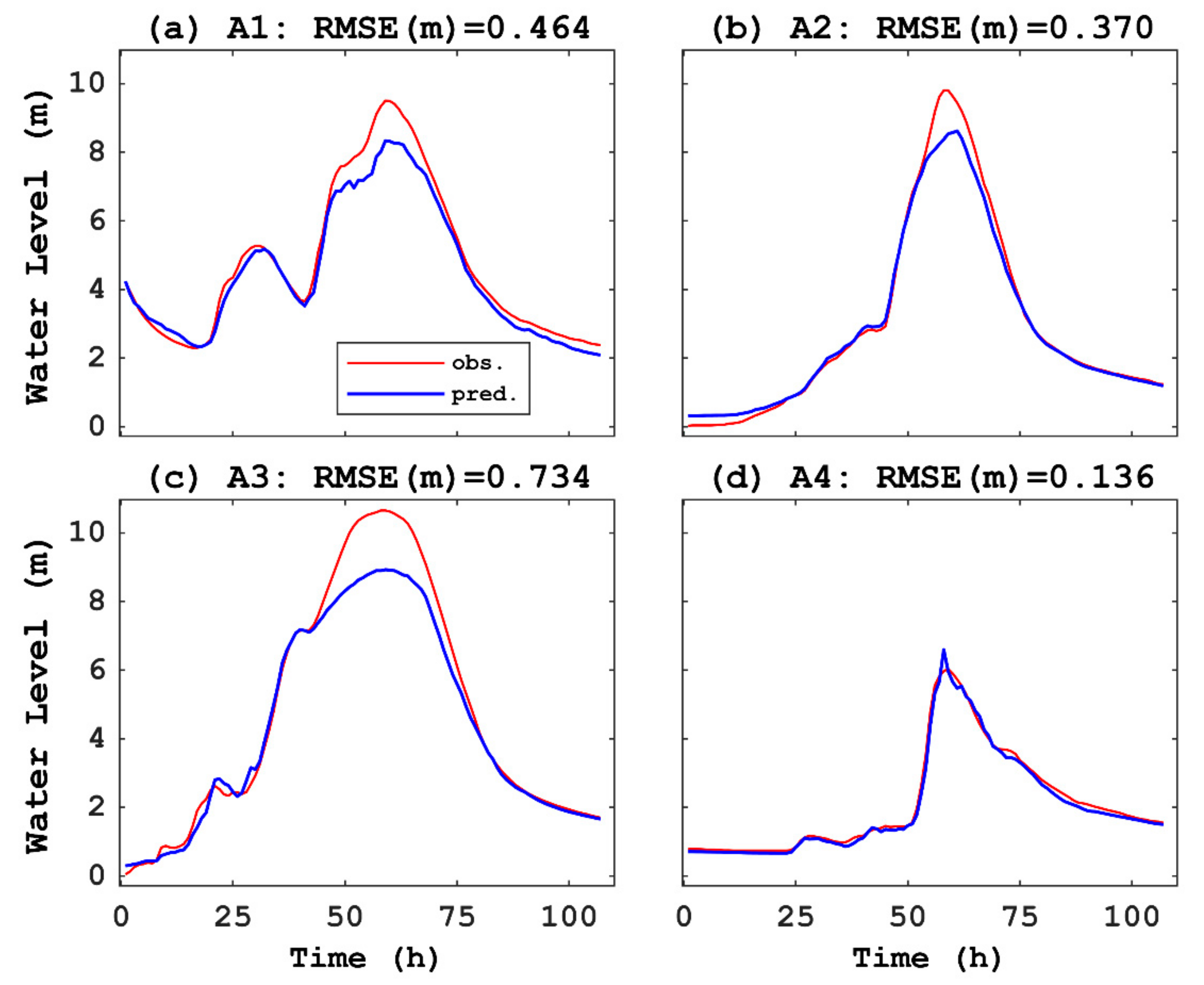
3.1. Verification of CNN Prediction With Source Datasets
3.2. Verification of CNN Transfer Learning with Target Datasets in Domain B
4. Discussion
5. Conclusions
- CNN binary classification of upward/downward trends of water levels provided highly accurate predictions for a preliminary examination.
- CNN with time-series predictions in Domain A had less than 10% errors in the total variation of water levels in each test dataset.
- CNN with transfer learning in Domain B reduced the RMSEs as the number of retrainings was increased, and the RMSEs after 20-time retrainings were slightly reduced from those of the CNN without transfer learning in Domain B with a substantially reduced computational cost.
- Lead time in the prediction should be extended from an hour to three to six hours based on the time lags for the watersheds.
- The best retraining process in deep layers should be investigated.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Case | Accuracy Rate (%) |
|---|---|
| 1 | 92.5 |
| 2 | 93.5 |
| 3 | 88.8 |
| 4 | 93.5 |
Appendix B

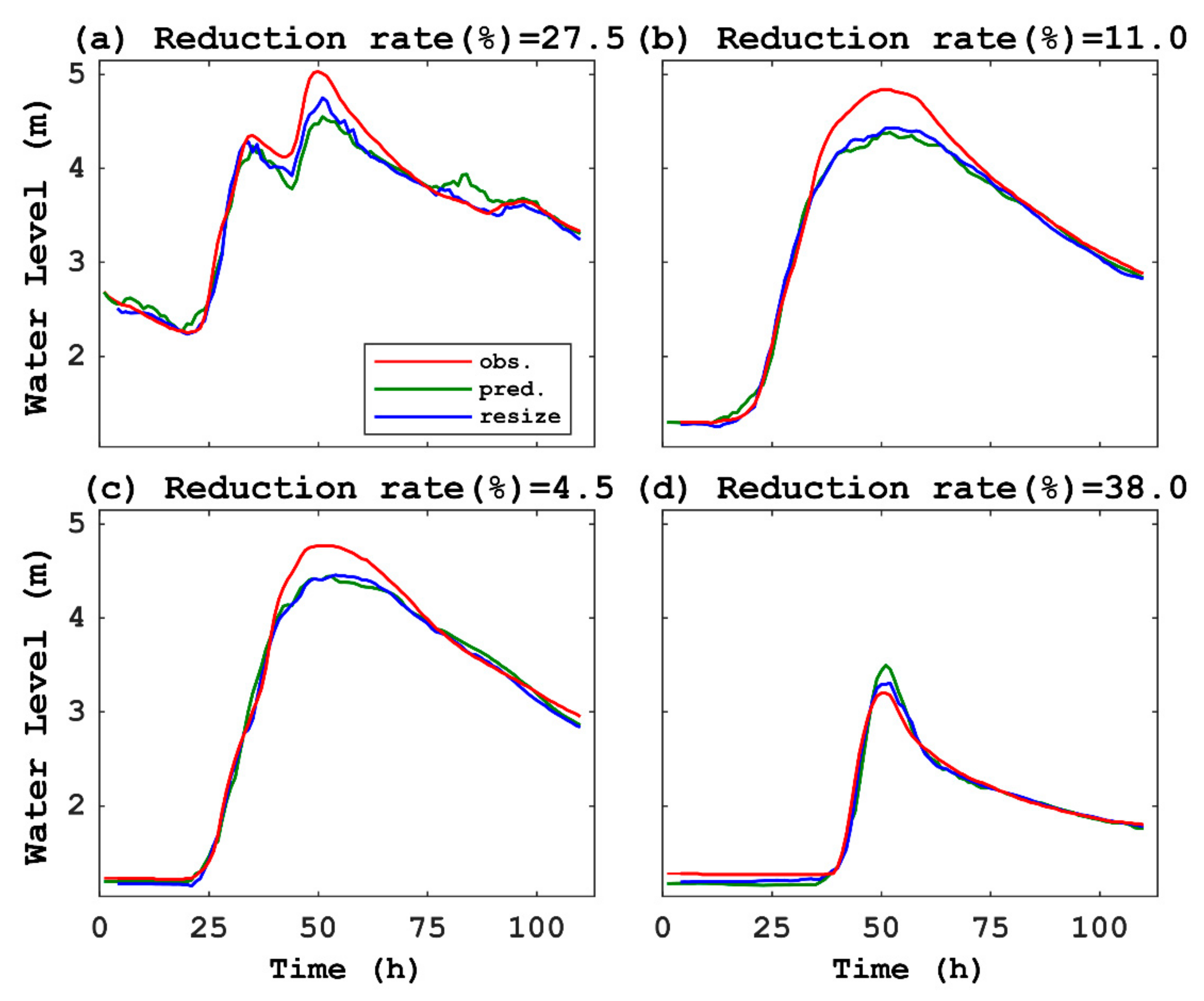
| Case | RMSE (m) of CNN with an Original Image (123 × 13 Pixels): RMSEOrg | RMSE (m) of CNN with a Resized Image (123 × 16 pixels): RMSERes | Reduced Rate of RMSE (%) 1 |
|---|---|---|---|
| B1 | 0.198 | 0.144 | 27.5 |
| B2 | 0.224 | 0.200 | 11.0 |
| B3 | 0.163 | 0.155 | 4.5 |
| B4 | 0.104 | 0.064 | 38.0 |
References
- Nevo, S.; Anisimov, V.; Elidan, G.; El-Yaniv, R.; Giencke, P.; Gigi, Y.; Hassidim, A.; Moshe, Z.; Schlesinger, M.; Shalev, G.; et al. ML for Flood Forecasting at Scale. In Proceedings of the Thirty-Second Annual Conference on the Neural Information Processing Systems (NIPS), Montréal, QC, Canada, 3–8 December 2018; Available online: https://arxiv.org/pdf/1901.09583.pdf (accessed on 31 October 2019).
- Salas, F.R.; Somos-Valenzuela, M.A.; Dugger, A.; Maidment, D.R.; Gochis, D.J.; David, C.H.; Yu, W.; Ding, D.; Clark, E.P.; Noman, N. Towards real-time continental scale streamflow simulation in continuous and discrete space. J. Am. Water Resour. Assoc. JAWRA 2018, 54, 7–27. [Google Scholar] [CrossRef]
- Realestate Blog: The Worst Disasters Caused by Heavy Rain and Typhoons in Japan: 2011 to 2018. Available online: https://resources.realestate.co.jp/living/the-top-disasters-caused-by-heavy-rain-and-typhoons-in-japan-2011-to-2018/ (accessed on 31 October 2019).
- Tokar, A.S.; Markus, M. Precipitation-runoff modeling using artificial neural networks and conceptual moldes. J. Hydrol. Eng. 2000, 5, 156–161. [Google Scholar] [CrossRef]
- Akhtar, M.K.; Corzo, G.A.; van Andel, S.J.; Jonoski, A. River flow forecasting with artificial neural networks using satellite observed precipitation pre-processed with flow length and travel time information: Case study of the Ganges river basin. Hydrol. Earth Syst. Sci. 2009, 13, 1607–1618. [Google Scholar] [CrossRef] [Green Version]
- Maier, H.R.; Jain, A.; Dandy, G.C.; Sudheer, K.P. Methods used for the development of neural networks for the prediction of water resource variables in river systems: Current status and future directions. Environ. Model. Softw. 2010, 25, 891–909. [Google Scholar] [CrossRef]
- Hitokoto, M.; Sakuraba, M.; Sei, Y. Development of the real-time river stage prediction method using deep learning. J. Jpn. Soc. Civ. Eng. JSCE Ser. B1 Hydraul. Eng. 2016, 72, I_187–I_192. [Google Scholar] [CrossRef] [Green Version]
- Hochreiter, P.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. In Proceedings of the 9th International Conference on Artificial Neural Networks (ICANN) 99, Edinburgh, UK, 7–10 September 1999; Volume 9, pp. 850–855. [Google Scholar] [CrossRef]
- Yamada, K.; Kobayashi, Y.; Nakatsugawa, M.; Kishigami, J. A case study of flood water level prediction in the Tokoro River in 2016 using recurrent neural networks. J. Jpn. Soc. Civ. Eng. JSCE Ser. B1 Hydraul. Engr. 2018, 74, I_1369–I_1374. (In Japanese) [Google Scholar] [CrossRef]
- Hu, C.; Wu, Q.; Li, H.; Jian, S.; Li, N.; Lou, Z. Deep learning with a long short-term memory networks approach for rainfall-runoff simulation. Water 2018, 10, 1543. [Google Scholar] [CrossRef] [Green Version]
- Le, X.; Ho, H.V.; Lee, G.; Jung, S. Application of long short-term memory (LSTM) neural network for flood forecasting. Water 2019, 11, 1387. [Google Scholar] [CrossRef] [Green Version]
- Pratt, L.Y. Discriminability-Based Transfer between Neural Networks. In Proceedings of the Conference of the Advances in NIPS 5, Denver, CO, USA, 30 November–3 December 1992; pp. 204–211. [Google Scholar]
- Laptev, N.; Yu, J.; Rajagopal, R. Reconstruction and regression loss for time-series transfer learning. In Proceedings of the Special Interest Group on Knowledge Discovery and Data Mining (SIGKDD) and the 4th Workshop on the Mining and LEarning from Time Series (MiLeTS), London, UK, 20 August 2018. [Google Scholar]
- Potikyan, N. Transfer Learning for Time Series Prediction. Available online: https://towardsdatascience.com/transfer-learning-for-time-series-prediction-4697f061f000 (accessed on 31 October 2019).
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Kensert, A.; Harrison, P.J.; Spjuth, O. Transfer learning with deep convolutional neural networks for classifying cellular morphological changes. SLAS Discov. 2019, 24, 466–475. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kolar, Z.; Chen, H.; Luo, X. Transfer learning and deep convolutional neural networks for safety guardrail detection in 2D images. Autom. Constr. 2018, 89, 58–70. [Google Scholar] [CrossRef]
- Visual Geometry Group, Department of Engineering Science, University of Oxford. Available online: http://www.robots.ox.ac.uk/~vgg/research/very_deep/ (accessed on 31 October 2019).
- Nakayama, H. Image feature extraction and transfer learning using deep convolutional neural networks. Inst. Electron. Inf. Commun. Eng. IEICE Tech. Rep. 2015, 115, 55–59. Available online: https://www.ieice.org/ken/paper/20150717EbBB/eng/ (accessed on 31 October 2019).
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Miyazaki, K.; Matsuo, Y. Stock prediction analysis using deep learning technique. In Proceedings of the 31st Annual Conference of the Japanese Society for Artificial Intelligence, Nagoya, Japan, 23–26 May 2017. (In Japanese). [Google Scholar]
- Suzuki, T.; Kim, S.; Tachikawa, Y.; Ichikawa, Y.; Yorozu, K. Application of convolutional neural network to occurrence prediction of heavy rainfall. J. Jpn. Soc. Civ. Eng. JSCE Ser. B1 Hydraul. Engr. 2018, 74, I_295–I_300. (In Japanese) [Google Scholar] [CrossRef]
- Ministry of Land, Infrastructure, Transport, and Tourism in Japan (MLIT Japan). Hydrology and Water Quality Database. Available online: http://www1.river.go.jp/ (accessed on 31 October 2019).
- Japan Meteorological Agency (JMA). Past Meteorological Data. Available online: http://www.data.jma.go.jp/gmd/risk/obsdl/index.php (accessed on 31 October 2019).
- Lanczos, C. An iteration method for the solution of the eigenvalue problem of linear differential and integral operators. J. Res. National Bur. Stand. 1950, 45, 255–282. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning: With Applications in R, 1st ed.; Springer: New York, NY, USA, 2013; p. 176. ISBN 978-1461471370. [Google Scholar]
- Brownlee, J. Blog: What Is the Difference between Test and Validation Datasets? Available online: https://machinelearningmastery.com/difference-test-validation-datasets/ (accessed on 31 October 2019).
- Python. Available online: http://www.python.org (accessed on 31 October 2019).
- Keras: The Python Deep Learning Library. Available online: https://keras.io/ (accessed on 31 October 2019).
- Rumelhart, D.E.; EHinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Lachenbruch, P.A.; Mickey, M.R. Estimation of error rates in discriminant analysis. Technometrics 1968, 10, 1–11. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K. Flood prediction using machine learning models: Literature review. Water 2018, 10, 1536. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.H.; Xie, S.; Chen, X.; Guttery, D.S.; Tang, C.; Sun, J.; Zhang, Y. Alcoholism identification based on an AlexNet transfer learning model. Front. Psychiatry 2019, 10, 205. [Google Scholar] [CrossRef] [PubMed] [Green Version]










| Event Name | Start Time 1 | End Time 1 | Maximum Water Level (m) During Each Event 2,3 | Remarks |
|---|---|---|---|---|
| 8/5/1992 | 8/5/1992 21:00 | 8/10/1992 23:00 | 4.56 | |
| 7/29/1993 | 7/29/1993 20:00 | 8/3/1993 22:00 | 9.50 | 3rd position |
| 8/7/1993 | 8/7/1993 2:00 | 8/12/1993 4:00 | 8.04 | |
| 8/13/1993 | 8/31/1993 19:00 | 9/5/1993 21:00 | 6.99 | |
| 6/10/1994 | 6/10/1994 20:00 | 6/15/1994 22:00 | 4.80 | |
| 6/1/1995 | 6/1/1995 6:00 | 6/6/1995 8:00 | 4.66 | |
| 6/22/1995 | 6/22/1995 15:00 | 6/27/1995 17:00 | 6.90 | |
| 7/15/1996 | 7/15/1996 19:00 | 7/20/1996 21:00 | 6.84 | |
| 8/11/1996 | 8/11/1996 23:00 | 8/17/1996 1:00 | 5.18 | |
| 8/4/1997 | 8/4/1997 0:00 | 8/9/1997 2:00 | 5.05 | |
| 7/24/1999 | 7/24/1999 0:00 | 7/29/1999 2:00 | 6.72 | |
| 8/14/1999 | 8/14/1999 15:00 | 8/19/1999 17:00 | 6.03 | |
| 9/11/1999 | 9/11/1999 20:00 | 9/16/1999 22:00 | 8.26 | |
| 9/21/1999 | 9/21/1999 19:00 | 9/26/1999 21:00 | 5.42 | |
| 5/31/2000 | 5/31/2000 14:00 | 6/5/2000 16:00 | 6.47 | |
| 6/18/2001 | 6/18/2001 20:00 | 6/23/2001 22:00 | 5.30 | |
| 8/5/2003 | 8/5/2003 10:00 | 8/10/2003 12:00 | 6.79 | |
| 8/27/2004 | 8/27/2004 10:00 | 9/1/2004 12:00 | 9.80 | 2nd position |
| 10/17/2004 | 10/17/2004 9:00 | 10/22/2004 11:00 | 7.70 | |
| 9/3/2005 | 9/3/2005 8:00 | 9/8/2005 10:00 | 10.65 | highest peak |
| 6/21/2006 | 6/21/2006 23:00 | 6/27/2006 1:00 | 4.99 | |
| 7/19/2006 | 7/19/2006 11:00 | 7/24/2006 13:00 | 5.28 | |
| 8/15/2006 | 8/15/2006 18:00 | 8/20/2006 20:00 | 5.20 | |
| 7/8/2007 | 7/8/2007 21:00 | 7/13/2007 23:00 | 5.58 | |
| 7/11/2007 | 7/11/2007 15:00 | 7/16/2007 17:00 | 7.11 | |
| 9/28/2008 | 9/28/2008 16:00 | 10/3/2008 18:00 | 5.18 | |
| 6/17/2010 | 6/17/2010 18:00 | 6/22/2010 20:00 | 6.30 | |
| 6/30/2010 | 6/30/2010 7:00 | 7/5/2010 9:00 | 9.16 | |
| 6/13/2011 | 6/13/2011 23:00 | 6/19/2011 1:00 | 4.84 | |
| 6/18/2011 | 6/18/2011 0:00 | 6/23/2011 2:00 | 4.77 | |
| 6/19/2012 | 6/19/2012 7:00 | 6/24/2012 9:00 | 5.13 | |
| 6/25/2012 | 6/25/2012 7:00 | 6/30/2012 9:00 | 4.60 | |
| 7/10/2012 | 7/10/2012 18:00 | 7/15/2012 20:00 | 5.86 | |
| 6/25/2014 | 6/25/2014 10:00 | 6/30/2014 12:00 | 5.31 | |
| 7/28/2014 | 7/28/2014 17:00 | 8/2/2014 19:00 | 6.61 | |
| 8/6/2014 | 8/6/2014 8:00 | 8/11/2014 10:00 | 6.08 | |
| 7/19/2015 | 7/19/2015 18:00 | 7/24/2015 20;00 | 5.05 | |
| 8/22/2015 | 8/22/2015 18:00 | 8/27/2015 20:00 | 4.62 | |
| 6/25/2016 | 6/25/2016 19:00 | 6/30/2016 21:00 | 6.09 | |
| 7/6/2016 | 7/6/2016 3:00 | 7/11/2016 5:00 | 5.52 | |
| 7/11/2016 | 7/11/2016 11:00 | 7/16/2016 13:00 | 6.21 | |
| 9/17/2016 | 9/17/2016 5:00 | 9/22/2016 7:00 | 7.91 | |
| 8/4/2017 | 8/4/2017 5:00 | 8/9/2017 7:00 | 5.13 |
| Event Name | Start Time 1 | End Time 1 | Maximum Water Level (m) During Each Event 2,3 | Remarks |
|---|---|---|---|---|
| 4/9/2000 | 4/9/2000 8:00 | 4/14/2000 10:00 | 3.81 | |
| 9/9/2001 | 9/9/2001 18:00 | 9/14/2001 20:00 | 4.84 | 2nd position |
| 9/30/2002 | 9/30/2002 2:00 | 10/5/2002 4:00 | 3.38 | |
| 8/7/2003 | 8/7/2003 21:00 | 8/12/2003 23:00 | 4.28 | |
| 4/18/2006 | 4/18/2006 22:00 | 4/24/2006 0:00 | 3.30 | |
| 8/17/2006 | 8/17/2006 1:00 | 8/22/2006 3:00 | 4.04 | |
| 10/6/2006 | 10/6/2006 2:00 | 10/11/2006 4:00 | 4.77 | 3rd position |
| 10/7/2009 | 10/7/2009 5:00 | 10/12/2009 7:00 | 3.33 | |
| 9/20/2011 | 9/20/2011 0:00 | 9/25/2011 2:00 | 3.20 | |
| 4/5/2013 | 4/5/2013 7:00 | 4/10/2013 9:00 | 3.71 | |
| 9/14/2013 | 9/14/2013 13:00 | 9/19/2013 15:00 | 4.33 | |
| 10/6/2015 | 10/6/2015 9:00 | 10/11/2015 11:00 | 4.15 | |
| 8/15/2016 | 8/15/2016 16:00 | 8/20/2016 18:00 | 4.17 | |
| 8/19/2016 | 8/19/2016 4:00 | 8/24/2016 6:00 | 5.03 | highest peak |
| 8/28/2016 | 8/28/2016 21:00 | 9/2/2016 23:00 | 3.46 | |
| 9/7/2016 | 9/7/2016 12:00 | 9/12/2016 14:00 | 4.15 | |
| 8/7/2019 | 8/7/2019 0:00 | 8/12/2019 2:00 | 3.22 | provisional value |
| Domain A | Domain B | |
|---|---|---|
| Number of events | 43 | 17 |
| Maximum water level (at prediction location) | 10.65 m | 5.03 m |
| Number of water level stations | 5 | 4 |
| Number of rainfall stations | 11 | 9 |
| Watershed area | 861 km2 | 1319 km2 |
| Prediction location | Hiwatashi (31.8599° N, 131.1135° E) | Hongou (43.9096° N, 144.1385° E) |
| Main river name | Oyodo River | Abashiri River |
| Source Case | Training Datasets | Validation Datasets | Test Dataset |
|---|---|---|---|
| A1 | 8/5/1992, 8/31/1993, 6/10/1994, 6/1/1995, 6/22/1995, 7/15/1996, 8/11/1996, 8/4/1997, 7/24/1999, 9/11/1999, 9/21/1999, 5/31/2000, 5/31/2000, 6/18/2001, 8/5/2003, 10/17/2004, 6/21/2006, 7/19/2006, 8/15/2006, 7/8/2007, 7/11/2007, 9/28/2008, 6/17/2010, 6/30/2010, 6/13/2011, 6/19/2012, 6/25/2012, 7/10/2012, 6/25/2014, 7/28/2014, 8/6/2014, 7/19/2015, 8/22/2015, 6/25/2016, 7/6/2016, 7/11/2016, 9/17/2016, 8/4/2017 | 8/7/1993, 8/14/1999, 8/27/2004, 9/3/2005 | 7/29/1993 |
| A2 | 7/29/1993, 8/7/1993, 8/14/1999, 9/3/2005 | 8/27/2004 | |
| A3 | 7/29/1993, 8/7/1993, 8/14/1999, 8/27/2004 | 9/3/2005 | |
| A4 | 7/29/1993, 8/7/1993, 8/27/2004, 9/3/2005 | 8/14/1999 |
| Source Case | Training Datasets | Verification Datasets | Test Dataset |
|---|---|---|---|
| B1 | 9/30/2002, 8/7/2003, 4/18/2006, 8/17/2006, 10/7/2009, 4/5/2013, 9/14/2013, 10/6/2015, 8/15/2016, 8/28/2016, 9/7/2016, 8/7/2019 | 4/9/2000, 9/9/2001, 10/6/2006, 9/20/2011 | 8/19/2016 |
| B2 | 4/9/2000, 10/6/2006, 9/20/2011, 8/19/2016 | 9/9/2001 | |
| B3 | 4/9/2000, 9/9/2001, 9/20/2011, 8/19/2016 | 10/6/2006 | |
| B4 | 4/9/2000, 9/9/2001, 10/6/2006, 8/19/2016 | 9/20/2011 |
| Parameters | Values/Function | Remarks | |
|---|---|---|---|
| Convolutional layer | Filter size | 3 × 3 | |
| Filter number | 5 | ||
| Pooling layer | Filter size | 2 × 2 | |
| Fully connected layer 1 | Neuron number | 16 | |
| Fully connected layer 2 | Neuron number | 1 | |
| Learning process | Batch size | 100 | |
| Epoch number | 100 | ||
| Learning rate | 0.001 | ||
| Optimizer | Adam | ||
| Activation function 1 to 3 | ReLU | See Figure 5a | |
| Activation function 4 | Sigmoid/softmax | See Figure 5a | |
| Loss function | Mean square error = | ci = model prediction, oi = observed data, N1 = the number of data | |
| Error evaluation | Root mean square error (RMSE) = | Same as above | |
| Case | RMSE (m) | Relative Error (%) 1 |
|---|---|---|
| A1 | 0.464 | 6.45 |
| A2 | 0.370 | 3.79 |
| A3 | 0.734 | 6.93 |
| A4 | 0.136 | 2.58 |
| Case | RMSE (m) | Relative Error (%) 1 | Reference: RMSE (m) of CNN Without Transfer Learning and With Resized Image |
|---|---|---|---|
| B1 | 0.118 | 4.24 | 0.144 |
| B2 | 0.153 | 4.30 | 0.200 |
| B3 | 0.125 | 3.52 | 0.155 |
| B4 | 0.064 | 3.34 | 0.064 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kimura, N.; Yoshinaga, I.; Sekijima, K.; Azechi, I.; Baba, D. Convolutional Neural Network Coupled with a Transfer-Learning Approach for Time-Series Flood Predictions. Water 2020, 12, 96. https://doi.org/10.3390/w12010096
Kimura N, Yoshinaga I, Sekijima K, Azechi I, Baba D. Convolutional Neural Network Coupled with a Transfer-Learning Approach for Time-Series Flood Predictions. Water. 2020; 12(1):96. https://doi.org/10.3390/w12010096
Chicago/Turabian StyleKimura, Nobuaki, Ikuo Yoshinaga, Kenji Sekijima, Issaku Azechi, and Daichi Baba. 2020. "Convolutional Neural Network Coupled with a Transfer-Learning Approach for Time-Series Flood Predictions" Water 12, no. 1: 96. https://doi.org/10.3390/w12010096
APA StyleKimura, N., Yoshinaga, I., Sekijima, K., Azechi, I., & Baba, D. (2020). Convolutional Neural Network Coupled with a Transfer-Learning Approach for Time-Series Flood Predictions. Water, 12(1), 96. https://doi.org/10.3390/w12010096