Variational Bayesian Neural Network for Ensemble Flood Forecasting

 , ,
, ,
Abstract
:1. Introduction
- (1)
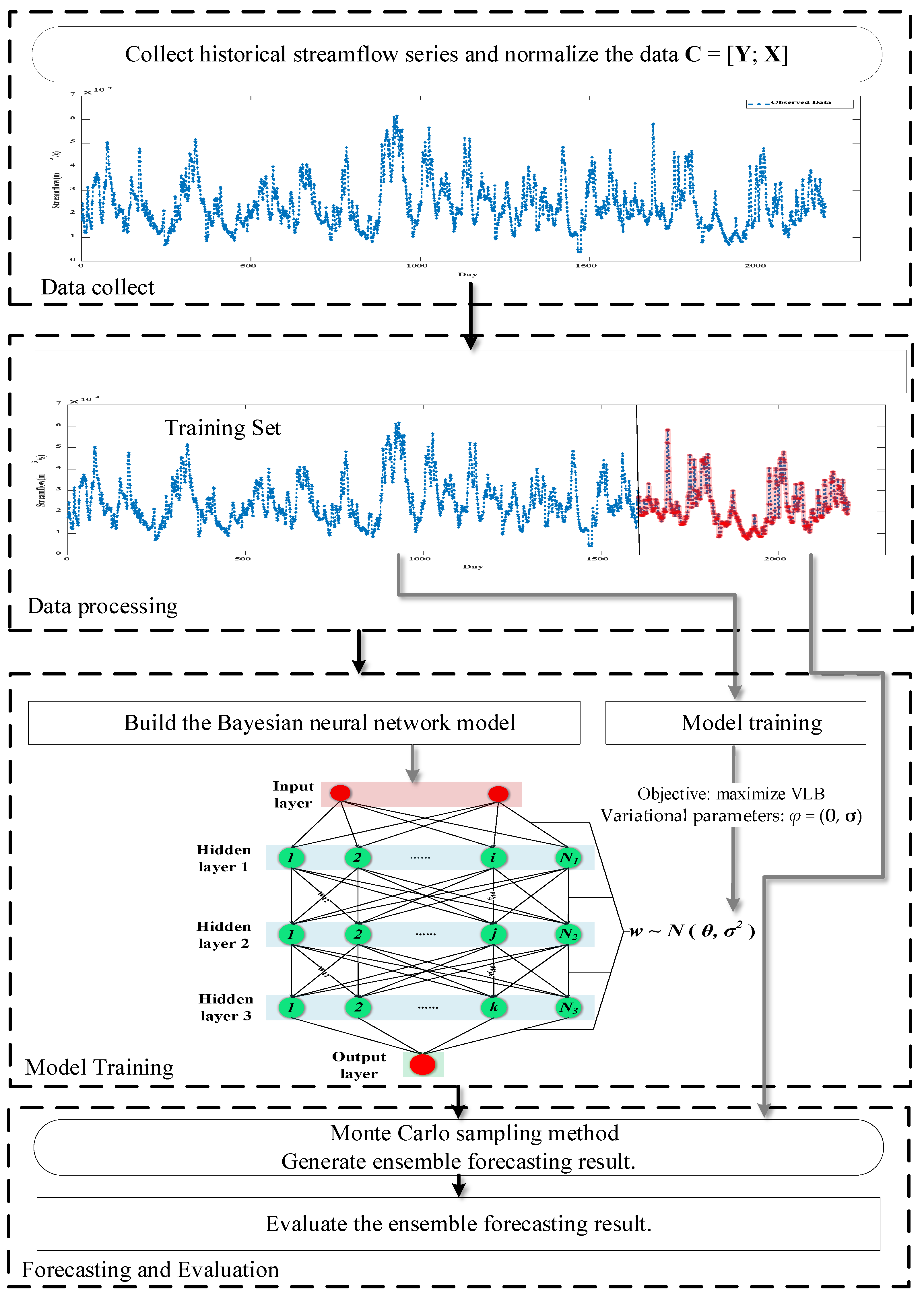
- The variational inference technique is used for the BNN model, and the variational lower bound of the VBNN is derived as the objective of the variational parameters. Monte Carlo method is applied in forecasting process, which converts model parameters’ uncertainty into model output uncertainty.
- (2)
- The VBNN is applied to a flood forecasting case study on the upstream of the Yangtze River. The performance of the VBNN is tested through several verification metrics. Experimental results show that the VBNN obtains better performance than other comparison models in terms of both accuracy and reliability.
- (3)
- Flood forecasting uncertainty estimation of the proposed ensemble forecasting model is shown. The experimental result shows that the VBNN can not only give accurate forecast results but also quantify the uncertainty of flood forecasting, which provides more useful information for water resources managers.
2. Methodology
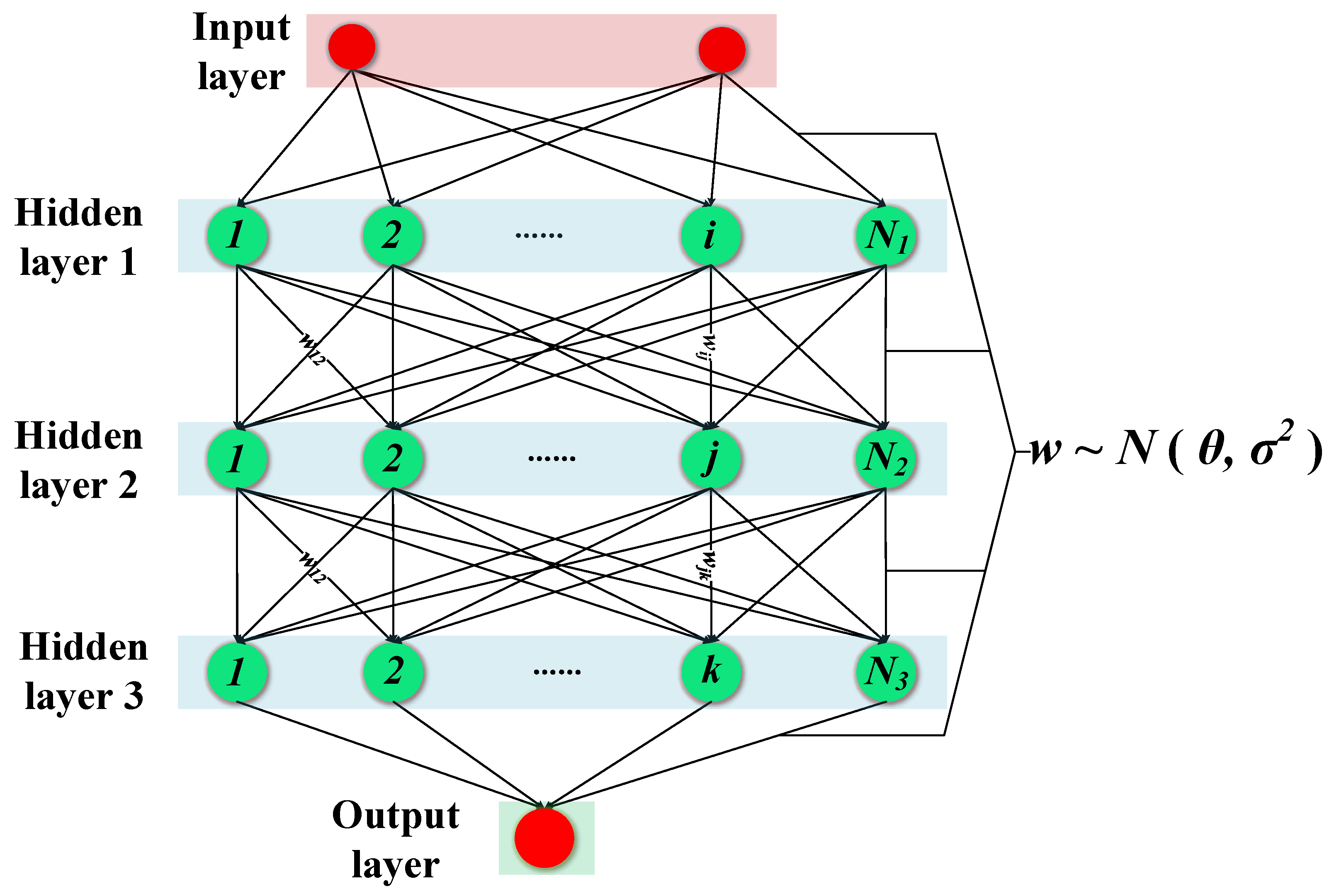
2.1. Bayesian Neural Network (BNN)
2.2. Variational Inference for BNN (VBNN)
2.3. Ensemble Forecasting
2.4. Flowchart of VBNN
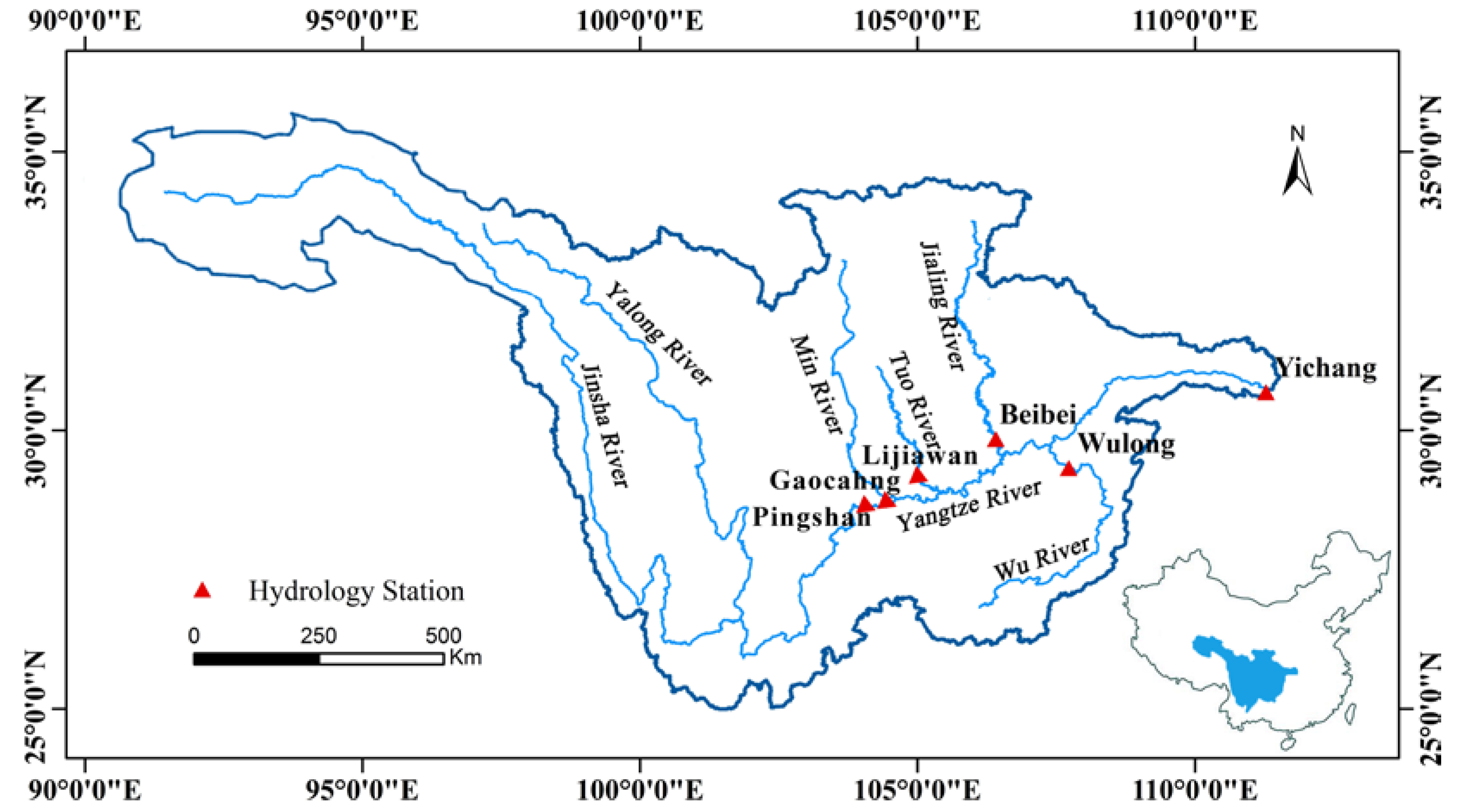
3. Study Area and Data
4. Results and Verification
4.1. Model Development
- (1)
- VBNN: In this paper, the VBNN consisted of 1 input layer, 3 hidden layers (the neural network node of each hidden layer was set as 40), and 1 output layer. A stochastic optimization method, Adam [29], was used to train the VBNN. In this study, the learning rate of Adam was set as 0.001 and the epoch was 10,000.
- (2)
- NN: In order to compare with the VBNN model, an NN was also developed for this flood forecasting case. The network structure of NN was the same as that of the VBNN. The optimization method, learning rate, and epoch were also the same as those of the VBNN.
- (3)
- GPR: An NN was devolved mainly to compare the forecast accuracy of VBNN. The GPR was devolved for forecast reliability comparison. GPR is a popular machine learning method that can give probabilistic predictions.
- (4)
- HMM: HMM is also a powerful probabilistic forecasting model. In HMM, the expectation-maximization algorithm was firstly executed, and then Gaussian mixture regression method was used to give the conditional probability density function of the forecasted flood.
4.2. Verification Metrics
4.3. Results
4.3.1. Forecasting Skill Verification
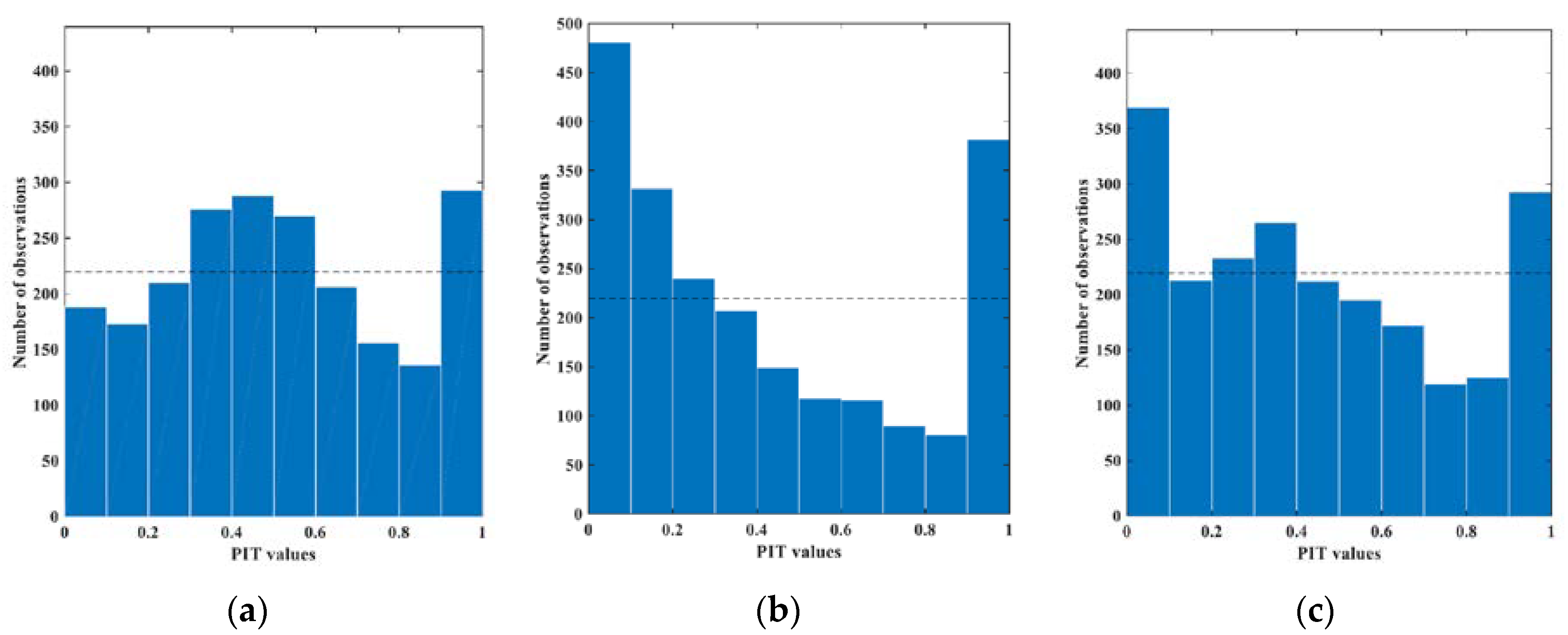
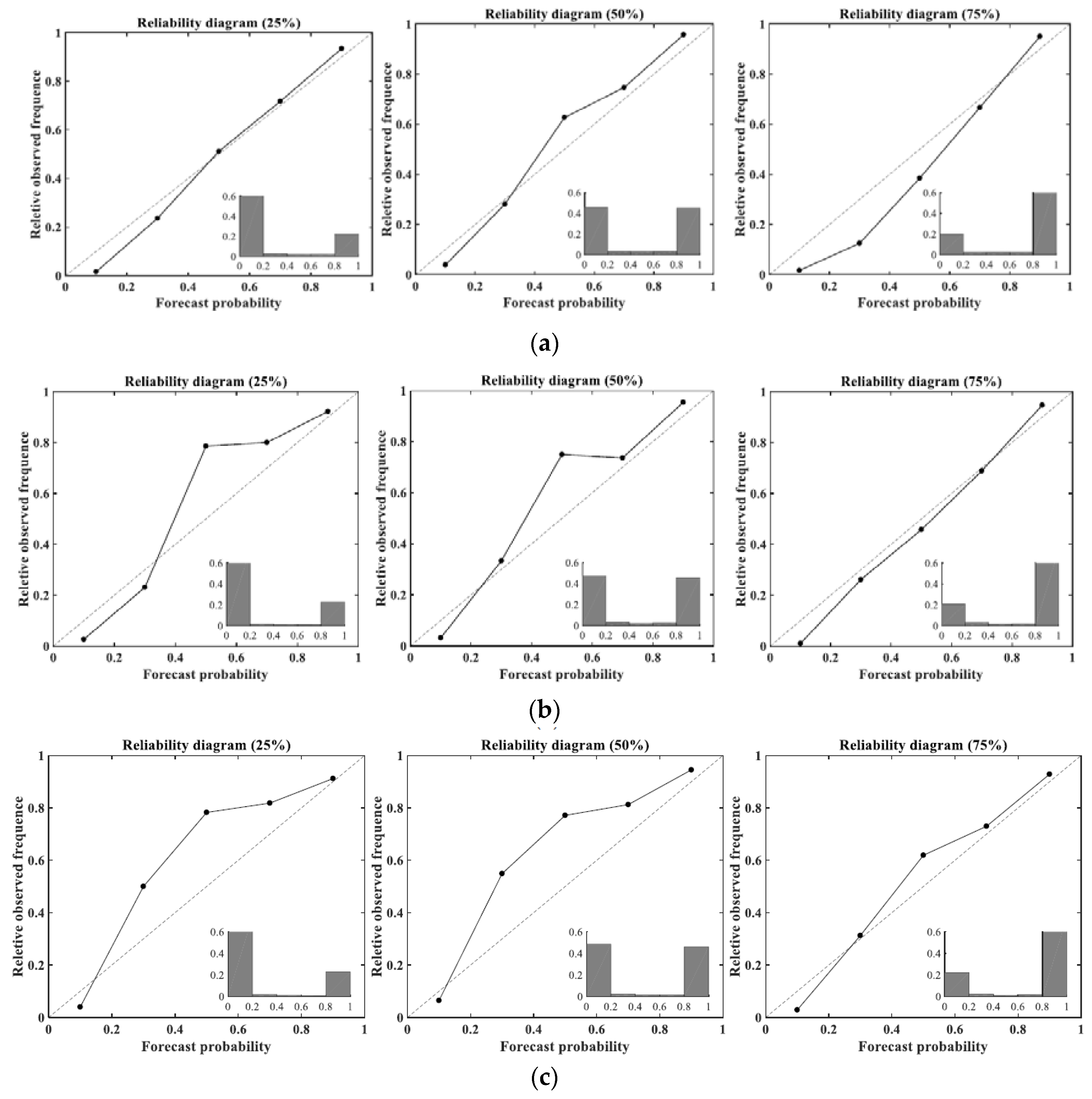
4.3.2. Reliability of Forecasting
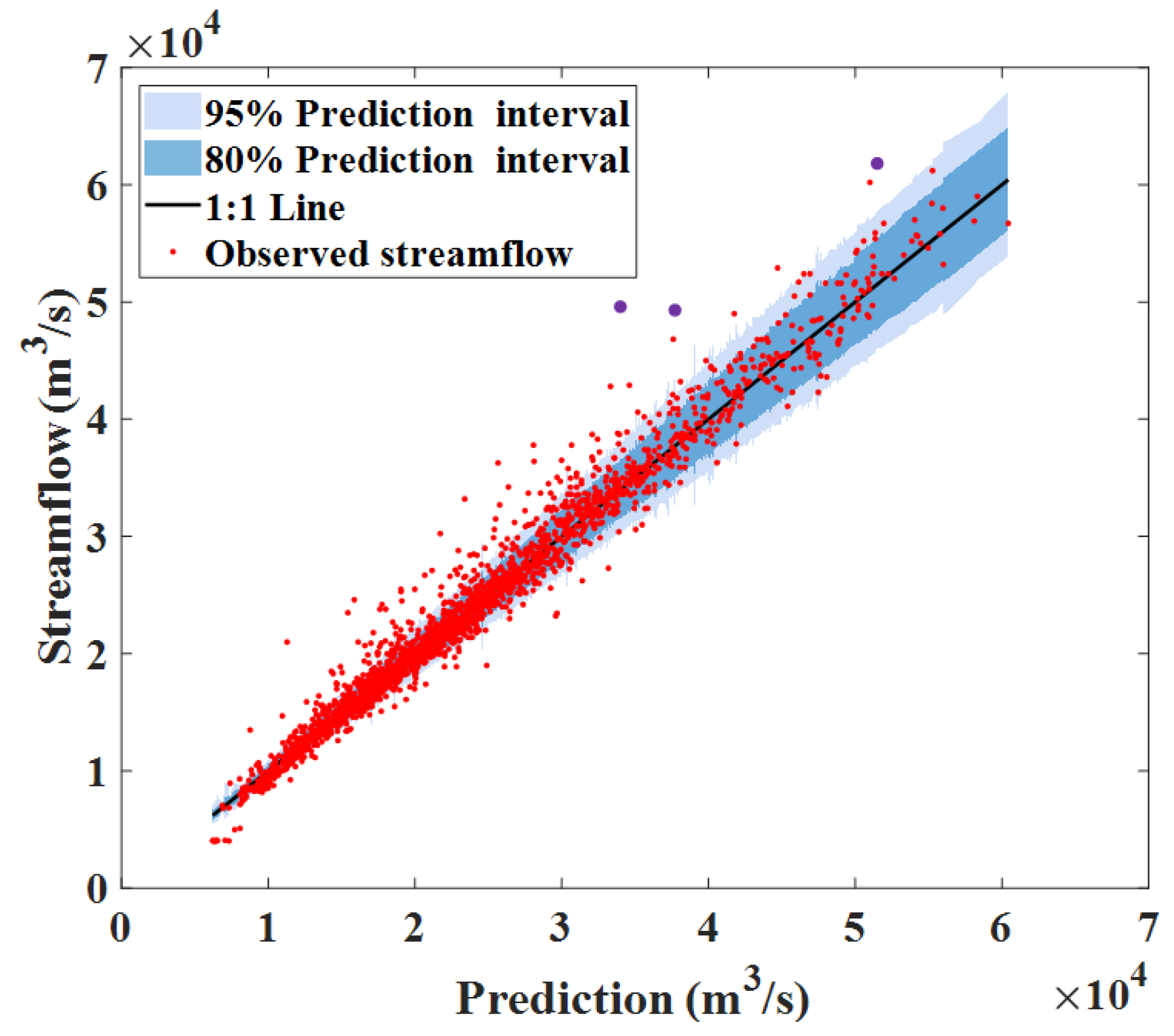
4.3.3. Uncertainty Estimation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cutter, S.L.; Ismail-Zadeh, A.; Alcántara-Ayala, I.; Altan, O.; Baker, D.N.; Briceño, S.; Gupta, H.; Holloway, A.; Johnston, D.; McBean, G.A.; et al. Global risks: Pool knowledge to stem losses from disasters. Nature 2015, 522, 277–279. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Qin, H.; Mo, L.; Wang, Y.; Chen, D.; Pang, S.; Yin, X. Hierarchical flood operation rules optimization using multi-objective cultured evolutionary algorithm based on decomposition. Water Resour. Manag. 2018. [Google Scholar] [CrossRef]
- Liu, Y.; Qin, H.; Zhang, Z.; Yao, L.; Wang, Y.; Li, J.; Liu, G.; Zhou, J. Deriving reservoir operation rule based on bayesian deep learning method considering multiple uncertainties. J. Hydrol. 2019, 579, 124207. [Google Scholar] [CrossRef]
- Haltiner, J.P.; Salas, J.D. Short-term forecasting of snowmelt runoff using ARMAX models. J. Am. Water Resour. Assoc. 1988, 24, 1083–1089. [Google Scholar] [CrossRef]
- Salas, J.D.; Iii, G.Q.T.; Bartolini, P. Approaches to multivariate modeling of water resources time series 1. J. Am. Water Resour. Assoc. 1985, 21, 683–708. [Google Scholar] [CrossRef]
- Dibike, Y.B.; Velickov, S.; Solomatine, D.; Abbott, M.B. Model induction with support vector machines: Introduction and applications. J. Comput. Civ. Eng. 2001, 15, 208–216. [Google Scholar] [CrossRef]
- Wu, C.L.; Chau, K.W.; Li, Y.S. Predicting monthly streamflow using data-driven models coupled with data-preprocessing techniques. Water Resour. Res. 2009, 45, 2263–2289. [Google Scholar] [CrossRef] [Green Version]
- Mutlu, E.; Chaubey, I.; Hexmoor, H.; Bajwa, S.G. Comparison of artificial neural network models for hydrologic predictions at multiple gauging stations in an agricultural watershed. Hydrol. Process. 2008, 22, 5097–5106. [Google Scholar] [CrossRef]
- Castellano-Méndez, M.A.; González-Manteiga, W.; Febrero-Bande, M.; Prada-Sánchez, M.J.; Lozano-Calderón, R. Modelling of the monthly and daily behaviour of the runoff of the Xallas river using Box-Jenkins and neural networks methods. J. Hydrol. 2004, 296, 38–58. [Google Scholar] [CrossRef]
- Chiang, Y.; Chang, L.; Chang, F. Comparison of static-feedforward and dynamic-feedback neural networks for rainfall-runoff modeling. J. Hydrol. 2004, 290, 297–311. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Cloke, H.L.; Pappenberger, F. Ensemble flood forecasting: A review. J. Hydrol. 2009, 375, 613–626. [Google Scholar] [CrossRef]
- Shrestha, D.L.; Robertson, D.E.; Bennett, J.C.; Wang, Q.J. Improving precipitation forecasts by generating ensembles through postprocessing. Mon. Water Weather Rev. 2015, 143, 3642–3663. [Google Scholar] [CrossRef]
- De Gooijer, J.G.; Hyndman, R.J. 25 years of time series forecasting. Int. J. Forecast. 2006, 22, 443–473. [Google Scholar] [CrossRef] [Green Version]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Lower upper bound estimation method for construction of neural network-based prediction intervals. IEEE Trans. Neural Netw. 2011, 22, 337–346. [Google Scholar] [CrossRef]
- Ye, L.; Zhou, J.; Gupta, H.V.; Zhang, H.; Zeng, X.; Chen, L. Efficient estimation of flood forecast prediction intervals via single- and multi-objective versions of the lube method. Hydrol. Process. 2016, 30, 2703–2716. [Google Scholar] [CrossRef]
- Wang, Q.J.; Robertson, D.E.; Chiew, F.H.S. A Bayesian joint probability modeling approach for seasonal forecasting of streamflows at multiple sites. Water Resour. Res. 2009, 45, 641–648. [Google Scholar] [CrossRef]
- Wang, Q.J.; Robertson, D.E. Multisite probabilistic forecasting of seasonal flows for streams with zero value occurrences. Water Resour. Res. 2011, 47, 155–170. [Google Scholar] [CrossRef]
- Zhao, T.; Schepen, A.; Wang, Q.J. Ensemble forecasting of sub-seasonal to seasonal streamflow by a Bayesian joint probability modelling approach. J. Hydrol. 2016, 541, 839–849. [Google Scholar] [CrossRef]
- Sun, A.Y.; Wang, D.; Xu, X. Monthly streamflow forecasting using Gaussian Process Regression. J. Hydrol. 2014, 511, 72–81. [Google Scholar] [CrossRef]
- Ye, L.; Zhou, J.; Zeng, X.; Guo, J.; Zhang, X. Multi-objective optimization for construction of prediction interval of hydrological models based on ensemble simulations. J. Hydrol. 2014, 519, 925–933. [Google Scholar] [CrossRef]
- Liu, Y.; Qin, H.; Zhang, Z.; Pei, S.; Jiang, Z.; Feng, Z.; Zhou, J. Probabilistic spatiotemporal wind speed forecasting based on a variational Bayesian deep learning model. Appl. Energy 2020. [Google Scholar] [CrossRef]
- Mackay, D.J.C. A practical bayesian framework for backpropagation networks. Neural Comput. 1992, 4, 448–472. [Google Scholar] [CrossRef]
- Neal, R.M. Bayesian Learning for Neural Networks. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 1995. [Google Scholar]
- Taormina, R.; Chau, K. ANN-based interval forecasting of streamflow discharges using the LUBE method and MOFIPS. Eng. Appl. Artif. Intell. 2015, 45, 429–440. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning (Information Science and Statistics); Springer: New York, NY, USA, 2006. [Google Scholar]
- Tishby; Levin; Solla. Consistent inference of probabilities in layered networks: Predictions and generalizations. In Proceedings of the International 1989 Joint Conference on Neural Networks, Washington, DC, USA, 6 August 2002; pp. 403–409. [Google Scholar]
- Liu, Y.; Ye, L.; Qin, H.; Hong, X.; Ye, J.; Yin, X. Monthly streamflow forecasting based on hidden Markov model and Gaussian Mixture Regression. J. Hydrol. 2018, 561, 146–159. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3nd International Conference on Learning Representations 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Hersbach, H. Decomposition of the continuous ranked probability score for ensemble prediction systems. Weather Forecast. 2000, 15, 559–570. [Google Scholar] [CrossRef]
- Laio, F.; Tamea, S. Verification tools for probabilistic forecasts of continuous hydrological variables. Hydrol. Earth Syst. Sci. 2007, 11, 1267–1277. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Training Set (m3/s) | Test Set (m3/s) | ||||||
|---|---|---|---|---|---|---|---|---|
| Min | Max | Mean | std | Min | Max | Mean | std | |
| Yichang | 4120 | 69,500 | 25,223 | 10,012 | 4020 | 61,700 | 23,943 | 10,317 |
| Pingshan | 1380 | 28,600 | 8360 | 3925 | 1980 | 23,500 | 8809 | 4241 |
| Gaochang | 911 | 31,400 | 5319 | 2589 | 926 | 22,300 | 4731 | 2341 |
| Lijiawan | 24 | 14,500 | 882 | 1006 | 16 | 6720 | 647 | 832 |
| Beibei | 464 | 43,600 | 4443 | 4358 | 100 | 28,700 | 3283 | 3704 |
| Wulong | 288 | 19,900 | 2608 | 2322 | 368 | 20,400 | 2723 | 2547 |
| Year | RMSE (m3/s) | NSE | CRPS (m3/s) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| VBNN | NN | GPR | HMM | VBNN | NN | GPR | HMM | VBNN | GPR | HMM | |
| 1991 | 1809 | 1998 | 1807 | 1821 | 0.9588 | 0.9497 | 0.9589 | 0.9582 | 882 | 907 | 971 |
| 1992 | 1076 | 1442 | 1099 | 1102 | 0.9815 | 0.9668 | 0.9807 | 0.9806 | 583 | 615 | 684 |
| 1993 | 1493 | 1501 | 1794 | 1580 | 0.9834 | 0.9832 | 0.976 | 0.9814 | 810 | 1047 | 909 |
| 1994 | 1309 | 1409 | 1404 | 1310 | 0.9352 | 0.9249 | 0.9255 | 0.9351 | 519 | 666 | 572 |
| 1995 | 1464 | 1634 | 1416 | 1412 | 0.9358 | 0.9201 | 0.94 | 0.9404 | 771 | 754 | 760 |
| 1996 | 1715 | 1628 | 1640 | 1549 | 0.9588 | 0.9629 | 0.9623 | 0.9664 | 784 | 767 | 754 |
| 1997 | 1487 | 1571 | 1635 | 1524 | 0.9737 | 0.9707 | 0.9682 | 0.9724 | 666 | 852 | 780 |
| 1998 | 2887 | 2615 | 2759 | 2625 | 0.9669 | 0.9729 | 0.9698 | 0.9727 | 1339 | 1380 | 1305 |
| 1999 | 1788 | 1747 | 1735 | 1668 | 0.97 | 0.9714 | 0.9718 | 0.9739 | 886 | 868 | 877 |
| 2000 | 1889 | 1899 | 1859 | 1788 | 0.9547 | 0.9542 | 0.9561 | 0.9594 | 886 | 880 | 855 |
| 2001 | 1118 | 1587 | 1219 | 1262 | 0.978 | 0.9557 | 0.9739 | 0.972 | 628 | 684 | 708 |
| 2002 | 1262 | 1396 | 1251 | 1173 | 0.9824 | 0.9785 | 0.9827 | 0.9848 | 586 | 613 | 578 |
| 2003 | 2343 | 2463 | 2717 | 2476 | 0.9437 | 0.9378 | 0.8731 | 0.8831 | 1259 | 1836 | 1807 |
| 2004 | 1900 | 2010 | 1927 | 1973 | 0.9333 | 0.9308 | 0.9364 | 0.9382 | 952 | 954 | 988 |
| 2005 | 1690 | 1845 | 1754 | 1747 | 0.9692 | 0.9657 | 0.969 | 0.9712 | 807 | 783 | 835 |
| 2006 | 1050 | 1137 | 1630 | 1446 | 0.9481 | 0.9392 | 0.8248 | 0.9015 | 585 | 1312 | 1001 |
| mean | 1643 | 1743 | 1728 | 1654 | 0.9608 | 0.9553 | 0.9481 | 0.9557 | 815 | 913 | 889 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhan, X.; Qin, H.; Liu, Y.; Yao, L.; Xie, W.; Liu, G.; Zhou, J. Variational Bayesian Neural Network for Ensemble Flood Forecasting. Water 2020, 12, 2740. https://doi.org/10.3390/w12102740
Zhan X, Qin H, Liu Y, Yao L, Xie W, Liu G, Zhou J. Variational Bayesian Neural Network for Ensemble Flood Forecasting. Water. 2020; 12(10):2740. https://doi.org/10.3390/w12102740
Chicago/Turabian StyleZhan, Xiaoyan, Hui Qin, Yongqi Liu, Liqiang Yao, Wei Xie, Guanjun Liu, and Jianzhong Zhou. 2020. "Variational Bayesian Neural Network for Ensemble Flood Forecasting" Water 12, no. 10: 2740. https://doi.org/10.3390/w12102740
APA StyleZhan, X., Qin, H., Liu, Y., Yao, L., Xie, W., Liu, G., & Zhou, J. (2020). Variational Bayesian Neural Network for Ensemble Flood Forecasting. Water, 12(10), 2740. https://doi.org/10.3390/w12102740