
A Lagrangian Backward Air Parcel Trajectories Clustering Framework


Abstract
:1. Introduction
2. Related Work
3. Methodology
3.1. Lagrangian Trajectory Model
- the atmospheric conditions (such as humidity or pressure) are the same anywhere inside the air parcel;
- the air inside an air parcel is isolated from the exterior; thus, there is no heat exchange between the interior and exterior of an air parcel;
- the air parcel does not have a specific dimension but must be large enough to contain a significant number of molecules.
3.2. HYSPLIT (Hybrid Single-Particle Lagrangian Integrated Transport Model)
3.3. Air Parcel Trajectory Clustering
3.4. The DenLAC Algorithm
3.4.1. The Probability Density Function
3.4.2. Kernel Density Estimation
3.4.3. Density Levels
3.4.4. DenLAC Fundamentals and Pipeline
- estimation of the probability density function of the input dataset through employing a non-parametric density estimation method—Kernel Density Estimation;
- outlier identification and displacement, applying the Inter Quartile Range method on the probability density function, computed at the previous step;
- assignation of each input dataset object to a density bin, after re-estimating the probability density function on the filtered dataset; the objects are allocated to their corresponding density bins according to their density probability value, using a histogram;
- extraction of the connected components comprising each density bin, using the nearest neighbors approach;
- merging the previously computed connected components to yield the final clusters; the connected components are combined hierarchically, based on the minimum distance between them.
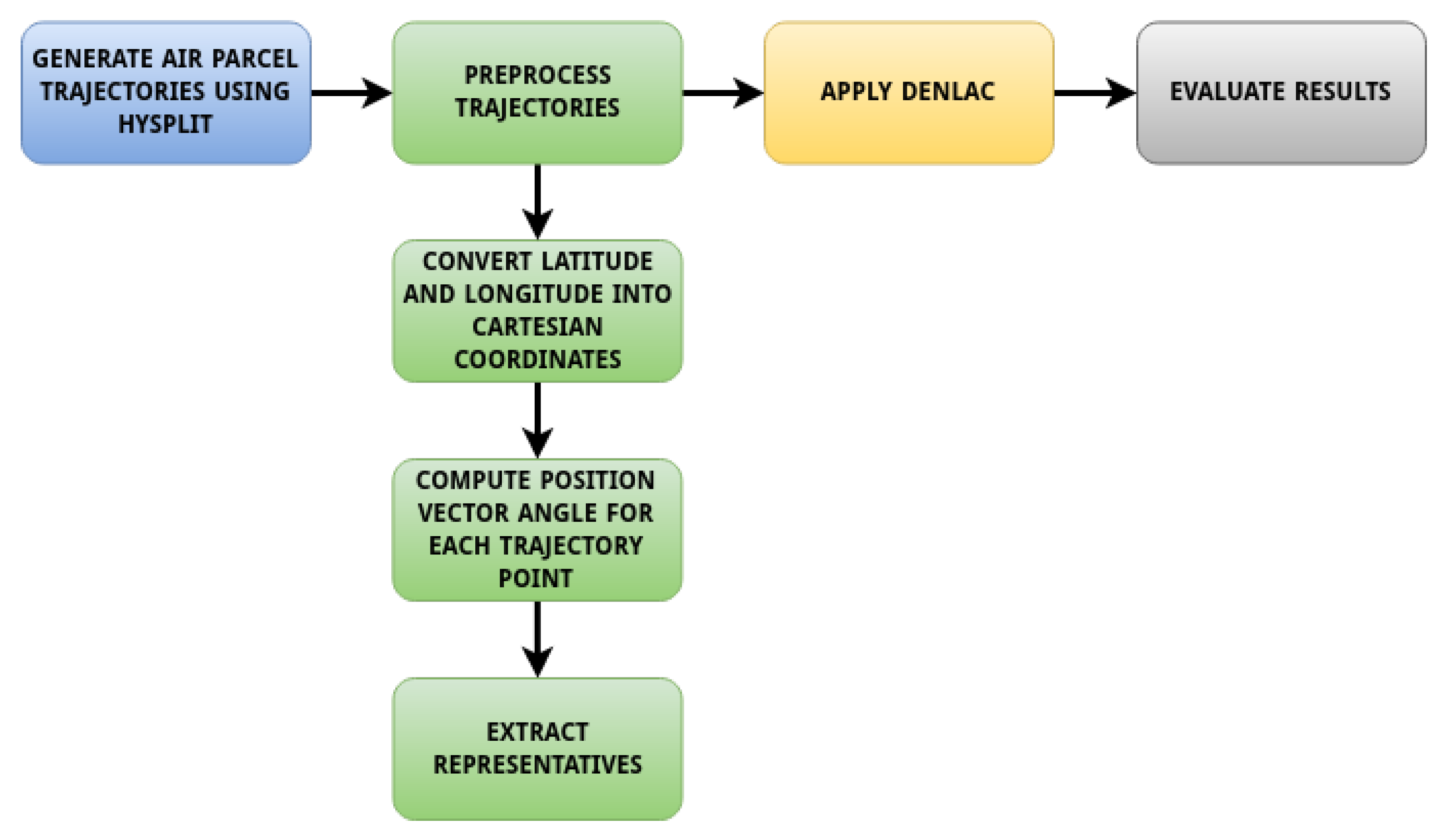
4. Method Pipeline
- employing the HYSPLIT trajectory model to generate some backward trajectories initiated in the region of interest;
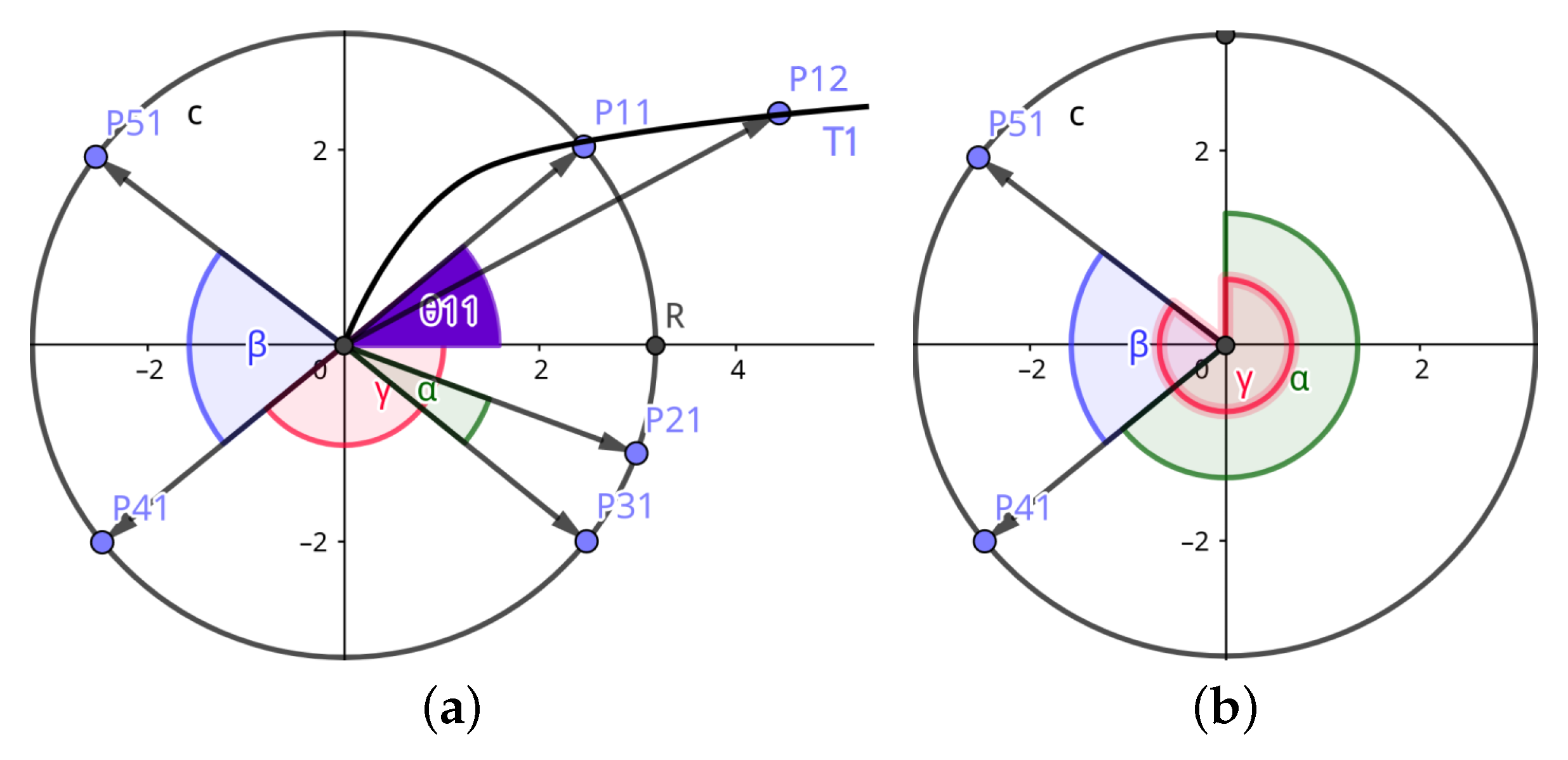
- preprocessing the previously computed trajectories to improve the accuracy and efficiency of the clustering operation; this phase contains the essence of our method: representing each trajectory as the set of the angles between its points’ position vectors and the axis;
- applying the DenLAC clustering algorithms on the preprocessed trajectories data;
- evaluating our results using several internal measures. To ensure correctness we assign the initial trajectories to the computed clusters and use the Fréchet distance to determine the dissimilarity between two trajectories.
4.1. Expressing Trajectories as One-Dimensional Arrays
5. Experimental Results
5.1. Experimental Setup
5.2. Dataset
5.3. Evaluation Measures
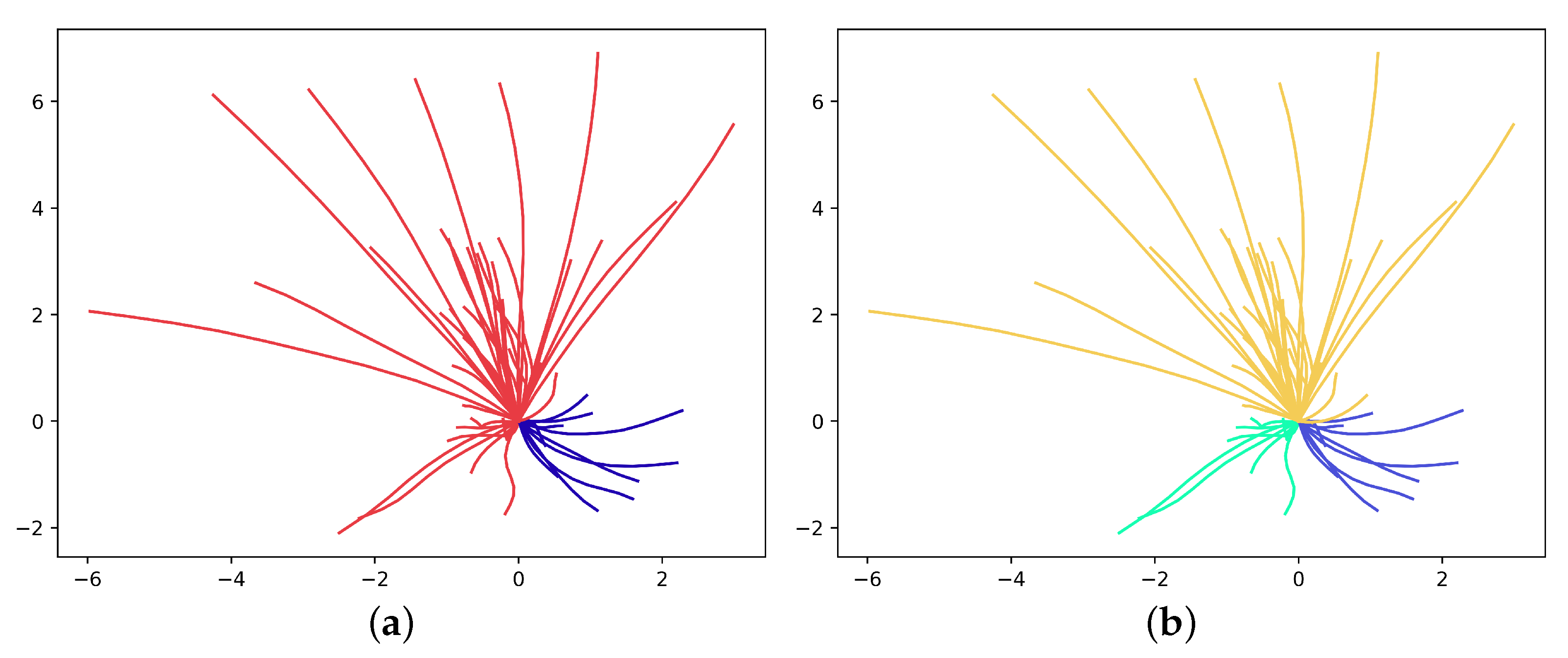
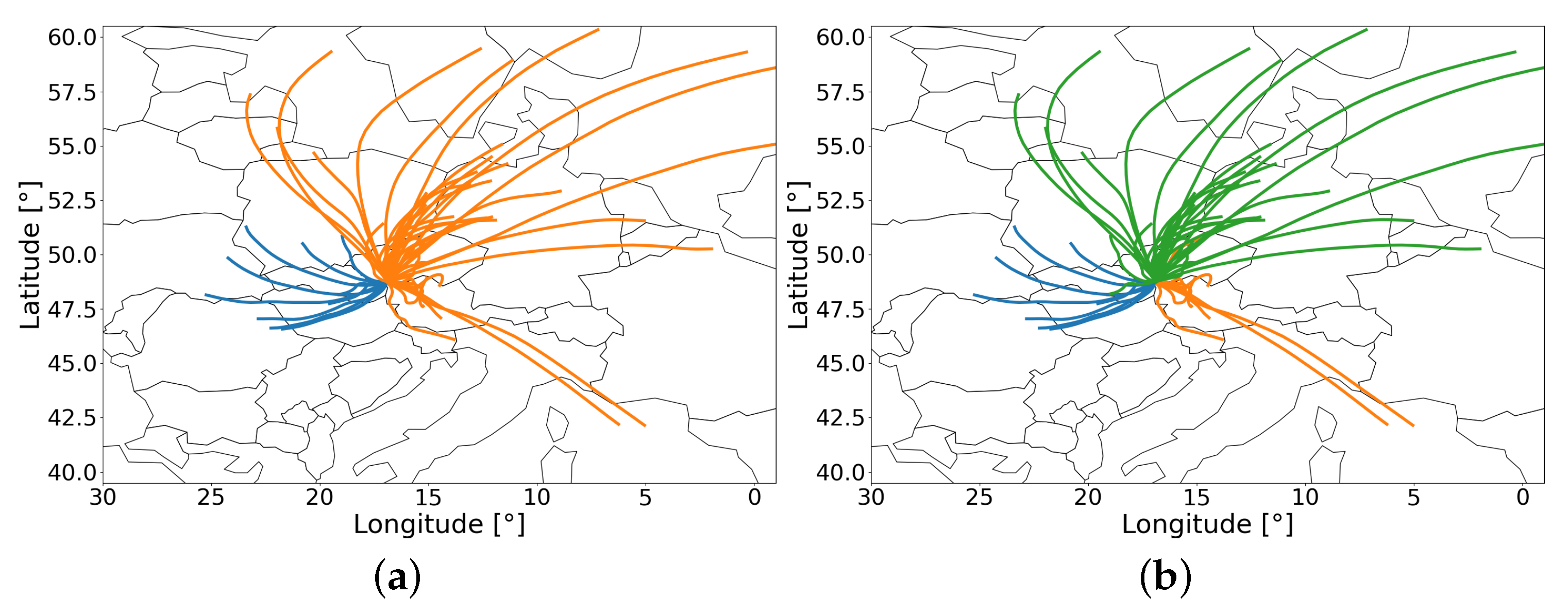
5.4. Results
- the unbalanced clustering: one or two trajectories each belong to their cluster, while the rest of the trajectories are assigned to a single, large cluster;
- the random clustering: trajectories are assigned randomly to two or three clusters.
6. Conclusions
- providing a complete system, from trajectory generation and preprocessing to the visualization of the final;
- improving the performance of the clustering process by representing trajectories as one-dimensional arrays; for this purpose, we define a custom, easy to compute (thus significantly efficient) dissimilarity measure;
- improving the accuracy of the clustering process by employing a flexible clustering algorithm called DenLAC, that can handle various types of clusters: elongated, spherical, of different sizes and densities, with noise and outliers.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hao, C.; Song, L.; Zhao, W. HYSPLIT-based demarcation of regions affected by water vapors from the South China Sea and the Bay of Bengal. Eur. J. Remote Sens. 2021, 54, 348–355. [Google Scholar] [CrossRef]
- Juhlke, T.R.; Meier, C.; van Geldern, R.; Vanselow, K.A.; Wernicke, J.; Baidulloeva, J.; Barth, J.A.; Weise, S.M. Assessing moisture sources of precipitation in the Western Pamir Mountains (Tajikistan, Central Asia) using deuterium excess. Tellus B Chem. Phys. Meteorol. 2019, 71, 1601987. [Google Scholar] [CrossRef] [Green Version]
- Karaca, F.; Camci, F. Distant source contributions to PM10 profile evaluated by SOM based cluster analysis of air mass trajectory sets. Atmos. Environ. 2010, 44, 892–899. [Google Scholar] [CrossRef]
- Borge, R.; Lumbreras, J.; Vardoulakis, S.; Kassomenos, P.; Rodríguez, E. Analysis of long-range transport influences on urban PM10 using two-stage atmospheric trajectory clusters. Atmos. Environ. 2007, 41, 4434–4450. [Google Scholar] [CrossRef]
- Rădulescu, I.M.; Boicea, A.; Truică, C.O.; Apostol, E.S.; Mocanu, M.; Rădulescu, F. DenLAC: Density Levels Aggregation Clustering—A Flexible Clustering Method. In International Conference on Computational Science; Springer: Berlin/Heidelberg, Germany, 2021; pp. 316–329. [Google Scholar]
- Davies, D.L.; Bouldin, D.W. A cluster separation measure. IEEE Trans. Pattern Anal. Mach. Intell. 1979, PAMI-1, 224–227. [Google Scholar] [CrossRef]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun.-Stat.-Theory Methods 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Rapolaki, R.; Blamey, R.; Hermes, J.; Reason, C. Moisture sources associated with heavy rainfall over the Limpopo River Basin, southern Africa. Clim. Dyn. 2020, 55, 1473–1487. [Google Scholar] [CrossRef]
- Stein, A.; Draxler, R.R.; Rolph, G.D.; Stunder, B.J.; Cohen, M.; Ngan, F. NOAA’s HYSPLIT atmospheric transport and dispersion modeling system. Bull. Am. Meteorol. Soc. 2015, 96, 2059–2077. [Google Scholar] [CrossRef]
- Shi, Y.; Jiang, Z.; Liu, Z.; Li, L. A Lagrangian analysis of water vapor sources and pathways for precipitation in East China in different stages of the East Asian summer monsoon. J. Clim. 2020, 33, 977–992. [Google Scholar] [CrossRef]
- Gustafsson, M.; Rayner, D.; Chen, D. Extreme rainfall events in southern Sweden: Where does the moisture come from? Tellus A Dyn. Meteorol. Oceanogr. 2010, 62, 605–616. [Google Scholar] [CrossRef]
- Bowman, K.P.; Lin, J.C.; Stohl, A.; Draxler, R.; Konopka, P.; Andrews, A.; Brunner, D. Input data requirements for Lagrangian trajectory models. Bull. Am. Meteorol. Soc. 2013, 94, 1051–1058. [Google Scholar] [CrossRef]
- Sprenger, M.; Wernli, H. The LAGRANTO Lagrangian analysis tool–version 2.0. Geosci. Model Dev. 2015, 8, 2569–2586. [Google Scholar] [CrossRef] [Green Version]
- Yuan, G.; Sun, P.; Zhao, J.; Li, D.; Wang, C. A review of moving object trajectory clustering algorithms. Artif. Intell. Rev. 2017, 47, 123–144. [Google Scholar] [CrossRef]
- Bian, J.; Tian, D.; Tang, Y.; Tao, D. A survey on trajectory clustering analysis. arXiv 2018, arXiv:1802.06971. [Google Scholar]
- Alt, H.; Godau, M. Measuring the resemblance of polygonal curves. In Proceedings of the Eighth Annual Symposium on Computational Geometry, Berlin, Germany, 10–12 June 1992; pp. 102–109. [Google Scholar]
- Chen, Y.C. A tutorial on kernel density estimation and recent advances. Biostat. Epidemiol. 2017, 1, 161–187. [Google Scholar] [CrossRef]
- Chaudhuri, K.; Dasgupta, S. Rates of Convergence for the Cluster Tree. Advances in Neural Information Processing Systems. 2010; pp. 343–351. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.188.2410&rep=rep1&type=pdf (accessed on 10 December 2021).
- Hartigan, J.A. Consistency of single linkage for high-density clusters. J. Am. Stat. Assoc. 1981, 76, 388–394. [Google Scholar] [CrossRef]
- Cui, L.; Song, X.; Zhong, G. Comparative Analysis of Three Methods for HYSPLIT Atmospheric Trajectories Clustering. Atmosphere 2021, 12, 698. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Xiong, H.; Gao, X.; Wu, J. Understanding of internal clustering validation measures. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13 December 2010; pp. 911–916. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Explanation |
|---|---|
| CH | Calinski–Harabasz Index |
| DBI | Davies–Bouldin Index |
| DenLAC | Density Levels Aggregation Clustering |
| GDAS | Global Data Assimilation System |
| GFS | Global Forecast System |
| HYSPLIT model | Hybrid Single-Particle Lagrangian Integrated Trajectory model |
| KDE | Kernel Density Estimation |
| NCEP | National Center for Environmental Prediction |
| NOAA | National Oceanic and Atmospheric Administration |
| DB | CH | S | |
|---|---|---|---|
| 2 clusters | 0.561 | 21.68 | 0.590 |
| unbalanced (2 clusters) | 2.604 | 0.369 | 0.166 |
| random (2 clusters) | 10.08 | 2.455 | 0.051 |
| 3 clusters | 5.591 | 8.327 | 0.798 |
| unbalanced (3 clusters) | 3.835 | 0.330 | 0.180 |
| random (3 clusters) | 18.79 | 1.153 | −0.087 |
| DB | CH | S | |
|---|---|---|---|
| 2 clusters | 0.470 | 28.211 | 0.208 |
| unbalanced (2 clusters) | 0.277 | 3.459 | 0.216 |
| random (2 clusters) | 3.063 | 8.186 | 0.008 |
| 3 clusters | 0.550 | 22.560 | 0.251 |
| unbalanced (3 clusters) | 0.375 | 3.352 | 0.181 |
| random (3 clusters) | 4.209 | 6.617 | −0.076 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rădulescu, I.-M.; Boicea, A.; Rădulescu, F.; Popeangă, D.-C. A Lagrangian Backward Air Parcel Trajectories Clustering Framework. Water 2021, 13, 3638. https://doi.org/10.3390/w13243638
Rădulescu I-M, Boicea A, Rădulescu F, Popeangă D-C. A Lagrangian Backward Air Parcel Trajectories Clustering Framework. Water. 2021; 13(24):3638. https://doi.org/10.3390/w13243638
Chicago/Turabian StyleRădulescu, Iulia-Maria, Alexandru Boicea, Florin Rădulescu, and Daniel-Călin Popeangă. 2021. "A Lagrangian Backward Air Parcel Trajectories Clustering Framework" Water 13, no. 24: 3638. https://doi.org/10.3390/w13243638
APA StyleRădulescu, I. -M., Boicea, A., Rădulescu, F., & Popeangă, D. -C. (2021). A Lagrangian Backward Air Parcel Trajectories Clustering Framework. Water, 13(24), 3638. https://doi.org/10.3390/w13243638