1. Introduction
During recent decades, increased awareness about the negative impact of eutrophication on the quality of water bodies and advances in environmental technology have given rise to more stringent wastewater treatment requirements and regulations [
1,
2]. Currently, proper monitoring of wastewater plants is one of the main challenges for water utilities worldwide, with significant environmental and cost-saving implications. Measurement and monitoring of effluent qualities are one of most important aspects. Because of the extreme working conditions, the highly complex processes of microbial growth and large measurement delays, the measurement of effluent quality parameters, such as BOD
5 (biochemical oxygen demand for 5 days), COD (chemical oxygen demand), and TN (total nitrogen) is usually difficult [
2,
3]. To describe the physical, chemical, and biological reactions in wastewater, many differential equations are required, which discourages process model construction. Because prior knowledge is not required, data-driven soft-sensor technology has become the most commonly-used method to measure the quality-related variables of biological treatment processes in the wastewater treatment. Essentially, data-driven soft-sensor technology aims to construct a certain mathematical model to describe the relationship between input and output variables, to predict hard-to-measure variables without necessarily resorting to an accurate mechanism model [
4].
Generally, the physical, chemical, and biological phenomena associated with treatment units always lead to many difficult-to-measure quality-related variables, such as biochemical oxygen demand (BOD), COD, and TN, thus complicating the reliable management of WWTPs [
5]. Even though some hardware sensors have been developed, the unacceptable costs and unreliability of the corresponding hardware sensors always make them inadequate for large amounts of WWTPs, particularly in rural areas or in developing countries. With the recent development of machine learning, data-driven soft sensor technology has been widely used in wastewater treatment processes [
6] and has become an important component of advanced process control technology [
7]. Specifically, neural network-based data-driven soft-sensors have become one of the most active research fields due to their strong nonlinear mapping ability, network topology, and robustness [
8], as well as their independence from mathematical models [
9]. However, traditional feedforward neural networks are difficult to apply for wastewater treatment processes due to failure to deal with strong dynamical issues. Wastewater processes always exhibit strong nonlinear dynamics (such as extreme weather conditions) and have coupling effects among the variables (such as recycling of the sludge in the secondary clarifier). These factors add more necessity to the wide applications of adaptive neural networks for soft-sensor modeling in WWTPs. Internal feedback connections between processing units were augmented into a neural network (NN) to formulate a recursive neural network (RNN) and to enhance the dynamic prediction ability. As one of the most typical RNN, the dynamic characteristics of Elman network has been proved by Guan et al. [
10] and Liang [
11].
Recently, many methods have been proposed to train RNNs [
12], such as the real-time recurrent learning (RTRL) [
13] algorithm, back propagation through time (BPTT) [
14], momentum gradient descent algorithm, and Levenberg-Marquardt (LM) algorithm [
15]. All of these methods have been widely used and exhibit superior capabilities. Unfortunately, they may be plagued by converging into poor local optima and a low learning rate [
16,
17]. The Kalman filter (KF) [
18] provides an inherently recursive solution to the optimal filtering estimation problem and to reducing forecast uncertainty. Moreover, the KF can be implemented in sequential mode and does not require an inversion of the approximate Hessian matrix. Unfortunately, the KF is usually only tractable for linear systems. To apply the Kalman framework to nonlinear systems, the extended Kalman filter (EKF) [
18] and unscented Kalman filter (UKF) [
19] are two common usages of nonlinear Kalman filters. The EKF, an effective second-order algorithm, can be applied to estimate the weights of RNN. The use of the EKF for training neural networks has been developed by Singhal and Wu [
20] and Puskorious and Feldkamp [
21]. Actually, the first-order truncated Taylor series expansion employed by EKF can induce large estimation errors and lead to divergence of the filter itself. These can be addressed using UKF. The UKF consistently outperforms the EKF in terms of prediction and estimation error [
22,
23]. Rudolph van der Merwe et al. proposed the algorithm of numerically effective square root form of UKF (SR-UKF) [
24], which can effectively preserve the symmetry and positive definiteness of the updated covariance. To date, the use of the group of UKF algorithms has been further expanded within the general field of probabilistic inference [
25] and machine learning [
26]. However, few researches devoted to process monitoring of effluent qualities in wastewater treatment. This paper adopts the SR-UKF to train the standard Elman network. Considering the uncertainty of statistical characteristics of the system noises in the actual system will affect the prediction performance [
27], this paper introduces an adaptive Sage-Husa noise estimation method to solve this problem. In addition, it is important that there is no restriction on weight values in the traditional training methods for Elman network, which could lead to inefficient standard Elman network model building. Therefore, this paper applies a parameter constraint algorithm to avoid large weight values.
In this study, an Elman network based on SR-UKF was proposed to monitor the effluent qualities, which can improve the prediction performance and ensure wide applicability of the Elman network. The contributions of this paper were mainly from three aspects. (i) First, this paper combined the Elman network with the Joseph form of UKF to build a soft-sensor model, thus being further able to enhance the accuracy and reliability of a soft-sensor. (ii) Second, this study proposed an adaptive method to estimate the system noise in real-time. This can ensure that the soft-sensor model is capable of achieving accurate prediction in case of suffering unknown disturbances. (iii) Finally, to ensure model weights are not updated aggressively and to guarantee that a robust model can be derived, a constraint algorithm was used to constrain the model parameter values to a reasonable range. In the proposed algorithm, the purpose of limiting weights to a specified range is mainly to ensure that the model can achieve smooth mapping, which is able to restrict the model complexity and avoid overfitting. Moreover, a weight constraining algorithm can guarantee the involvement of prior knowledge by setting up a proper weight range and then can meet the parameter setting requirements according to the specific applications. Instead of using weights randomly, limiting weight to a specified range ensures that the algorithm is manageable and that the reliability of a soft sensor can be further achieved.
Additionally, it is important to note the contributions of the proposed soft-sensors for process monitoring and management of WWTPs. The physical, chemical, and biological reactions of wastewater treatment processes often add significant nonlinearity and dynamics for modeling and result in the degradation of standard prediction models. Thus, to properly monitor quality-related but hard-to-measure effluent variables, this study uses of the proposed algorithm to update the weights of the Elman network and to improve the prediction performance. This will, in turn, provide a new way to prevent the degradation of predictive performance. Moreover, to decrease the monitoring costs, the proposed soft-sensor is further extended to a multioutput model, which can simultaneously monitor multiple effluent qualities simultaneously.
The rest of this article is organized as follows. In
Section 2, basic materials and preliminary methods are given.
Section 3 addresses the proposed models and validated case study materials.
Section 4 provides detailed results and discussions for the case study. Finally, conclusions are made.
3. Proposed Prediction Model and Validation Materials
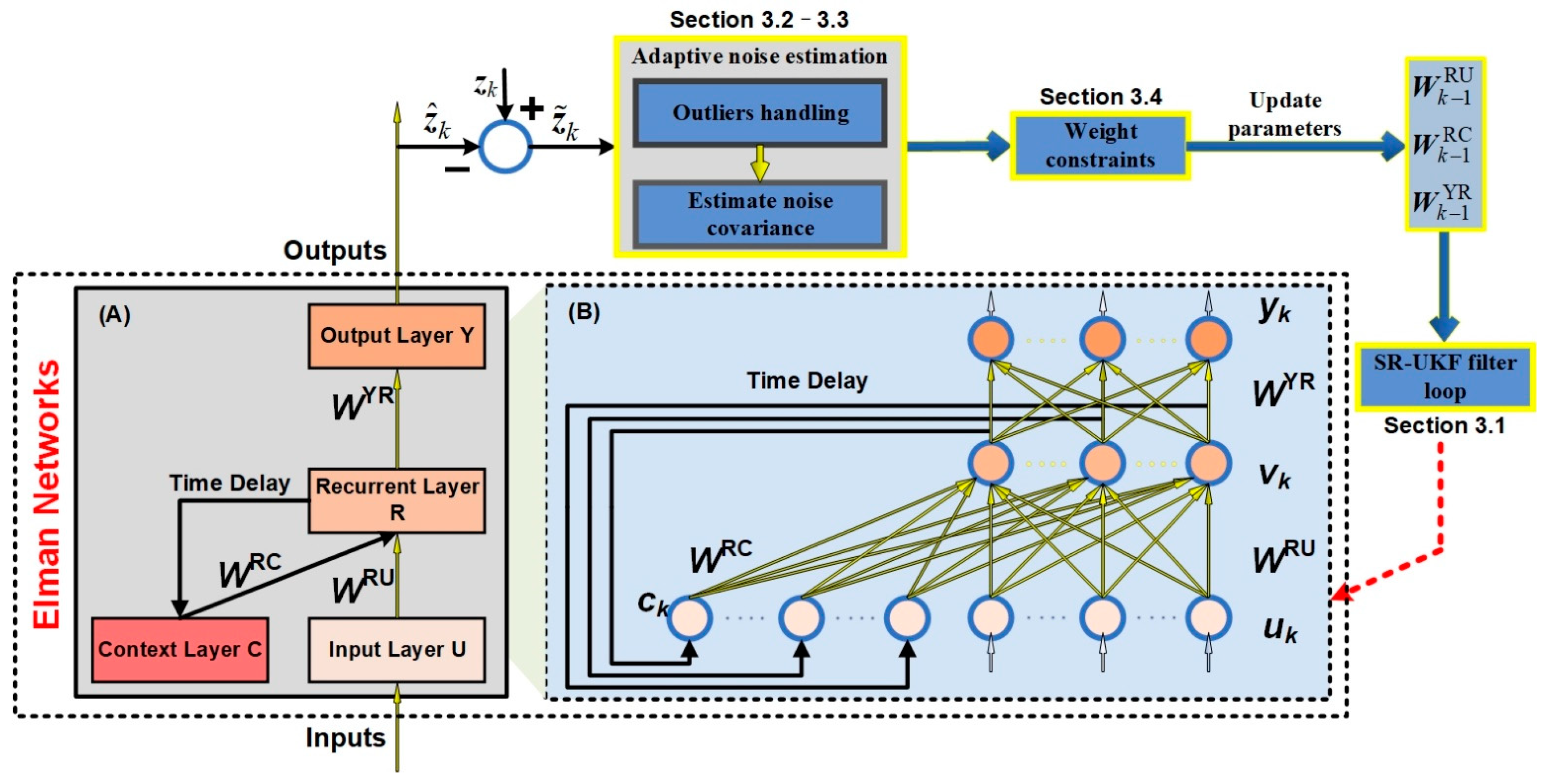
In this section, the proposed SR-UKF algorithm in parameter estimation for the Elman neural network will be described. First, an overall view of the proposed SR-UKF algorithm is given in
Section 3.1; The other subsections provide more details about the adaptive noise estimation, weight constraint and handling outliers, which are the important components of the proposed SR-UKF algorithm (
Figure 1).
This figure shows an overall view of the proposed SR-UKF algorithm. The module “Outliers handling” controls the amplification of observation error covariance and will combine the module “Estimate noise covariance” to achieve the adaptive estimation the unknown noise. The module “Weight constraints” adds parameter constraints on weight (state) values. Actually, the module “Adaptive noise estimation” and the module “Weight constraints” are independent modules. Both of the “Adaptive noise estimation” and “Weight constraints” modules could be removed, which represent the constant noise and unconstrained weights, respectively. Module A is the simplified topology of the Elman network in module B. Module B gives a more detailed expansion of module A to increase the visibility of the proposed algorithm.
3.1. Elman Network Based on SR-UKF (Elman-SR-UKF)
The training process of traditional neural networks is to adjust the parameters (or weights). Generally, the neural network method based on the Kalman filter regards the learning process of the network as the dynamic parameter estimation of the nonlinear system. That is, the weight vector in Elman is taken as the state of the system, and the weights of the network are constantly updated with the time sequence by minimizing the mean square error between the target output and the estimated output, which can improve the training accuracy. The state space model of the neural network can be rewritten as:
where
is the state vector composed of weight matrices and biases,
represents a given input,
is the model output, and
is the neural network function. Moreover,
and
are the zero-mean Gaussian process noise vector and measurement noise vector with covariance
and
, respectively. The nonlinear filtering algorithm can be used to estimate the network parameters.
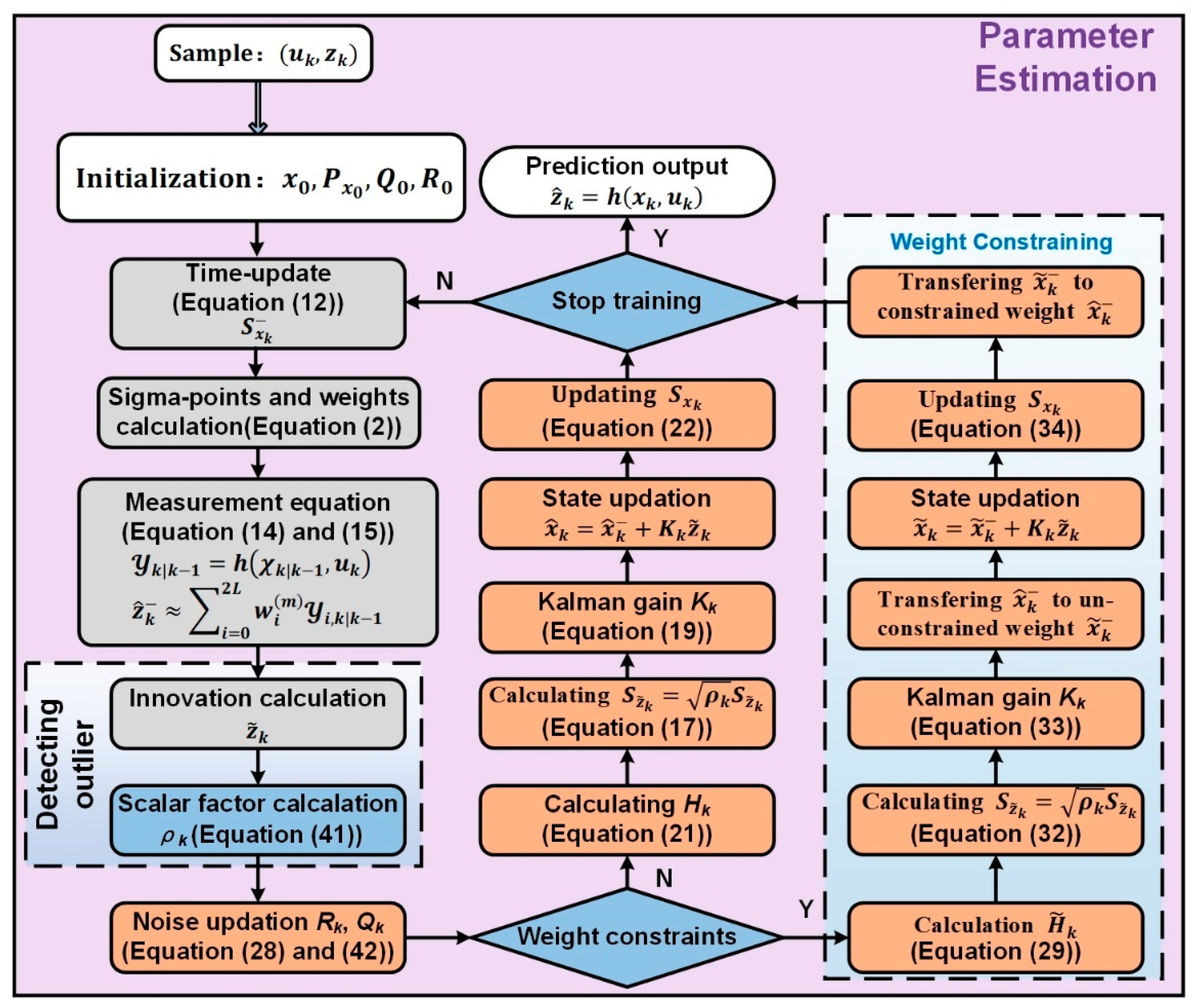
Referring to [
30,
31], the Elman network training algorithm based on SR-UKF for the state space model of Equation (9) can be concluded as Algorithm 1. Different from the reference [
24], Equation (22) in Algorithm 1 adopts the Joseph stable form [
32], which is numerically more stable because it can guarantee the symmetry and positive definite of
as long as
is a symmetric positive definite matrix. The algorithm proposed in this study is concluded as
Figure 2, and more details can be seen in
Section 3.2,
Section 3.3 and
Section 3.4.
3.2. Update the Model with Adaptive Noise Variance
In fact, the accurate knowledge of the noise covariance required by the Kalman filter framework is often unknown and time-varying. Mismatching between the assumptive noise distribution and the actual noise distribution may degrade the prediction performance. To solve this problem, adaptive noise methods are often adopted to improve the accuracy and robustness of the state estimation. In this study, adaptive Sage-Husa noise estimation is proposed. In the proposed model, both measurement noise and process noise need to be properly estimated.
| Algorithm 1 Elman-SR-UKF algorithm |
| 1: | Initialization: | |
| 2: | | (10) |
| 3: | For | |
| 4: | Time update equations: | |
| 5: | | (11) |
| 6: | | (12) |
| 7: | Calculate sigma points: | |
| 8: | | (13) |
| 9: | Measurement update equations: | |
| 10: | | (14) |
| 11: | | (15) |
| 12: | | (16) |
| 13: | | (17) |
| 14: | | (18) |
| 15: | | (19) |
| 16: | | (20) |
| 17: | | (21) |
| 18: | | (22) |
| where and are the square-root form of and , respectively, namely , . is the process noise covariance. is a composite scaling parameter. and are the true value and innovation at time step respectively. The operator zeros all the elements of a square matrix except the main diagonal. and are standard MATLAB functions, representing QR decomposition and Cholesky factor updating, respectively. The operator “/” stands for the right division operation of MATLAB. The origin of Equation (22) can be referred to the derivation of Equation (42). |
3.2.1. Adaptive Noise Estimation
Currently, the adaptive filtering algorithm is a common adaptive noise method [
33]. Assuming that the residual variable
is stable, the residual covariance can be approximated by the residual variable within the moving window:
where
is the residual variable,
is the measured value and
is the predicted value which is given in Equation (15).
is the width of the moving window. More details on how to optimize window width can be found in [
34].
Combining Equation (16) with Equation (23), the estimation of the measurement noise covariance
can be obtained as follows:
Considering that
may not be a positive definite matrix, the following rule [
35] is recommended:
where
is the
i-th diagonal element of the matrix
, and the abovementioned formula can ensure the positive definiteness of
.
Similarly, the estimation of the process noise covariance matrix
can be written as:
3.2.2. Adaptive Sage-Husa Noise Estimation
Taking into account the uncertainty of process noise, to compensate for the error caused by the variations of noise statistics and estimate the process noise covariance, this study further adopts the Sage-Husa estimator [
36] to estimate and adjust the measurement noise covariance.
where
is defined as Equation (25),
,
is the forgetting factor and
.
Similarly, the adaptive process noise covariance can be obtained:
The definition of is shown in Equation (26).
The adaptive Sage-Husa noise combines the noise covariance at the previous moment and the estimated noise covariance, which is then recursively able to estimate the unknown time-varying covariance and to achieve better robustness and accuracy.
3.3. Handling Outliers
Sensor measurements may suffer from outliers due to abnormal conditions, which easily cause the deviation of adaptive covariance from the true distribution and result in a decrease in prediction performance. Therefore, addressing outliers is imperative for accurate prediction. The abovementioned calculation shows that both the estimation of noise and the update of the state vector are directly related to the residual error. Using residual error for outlier identification is an intuitive idea.
3.3.1. Outliers Identification
This study adopted hypothesis testing to detect abnormal conditions using statistical information of residual error [
33]. The statistic
are defined as:
The statistic
is assumed to follow the distribution of
with degree-of-freedom
, where
is the dimension of the residual error vector
. Choosing the significance level
,
can be determined by
If the alternative hypothesis
holds, the statistic
is greater than the threshold, which can be represented as:
3.3.2. Parameter Adjustment
This article introduced a scalar factor
to adjust the measurement error covariance and ensure the robustness of system [
37]:
where
can be calculated as:
At the same time, the calculation of
in Equation (25) should be modified as:
When the abnormal values are detected by Equation (31), i.e., the alternative hypothesis
holds, the scale factor
amplifies the observation error covariance, which leads to a decrease in the Kalman filter gain, and then to reduce the magnitude of the state update and improve the robustness of the filter. A specific summary of the Elman-based the SR-UKF algorithm proposed in this study is shown in
Figure 2.
3.4. Weight Constraining
To limit the range of weight values and to ensure that the Elman achieves smooth mapping, this study introduces a heuristic method [
38] to constrain the weights.
In essence, this process has a similar function as the Bayesian regularization method, which prevents model overfitting and keeps the model smoother. However, this constrained algorithm may lead to a degradation of performance.
The main principle of the weight constraining algorithm is as follows: Consider the mapping , which transforms to the constraint weight space , and the mapping has the opposite effect. The function transfers the weight from an unconstrained space to a constrained space and must meet the following properties:
- (1)
is a continuously differentiable function on ;
- (2)
exists and is a continuous function ;
- (3)
.
The weight update is performed with Equations (19)–(22) in the unconstrained weight space. Once the update is completed, the unconstrained weights are converted back to the constrained space.
To perform SR-UKF recursion in the unconstrained space, some modifications are needed. For Equation (21),
can be interpreted as the derivative of output
with respect to the weight vector
of each node in Elman-SR-UKF. The derivative of the weights in the constrained space must be converted to the derivative of the weights in the unconstrained space, and then used to update the weights in the unconstrained space. This can be achieved by the following transformation:
where
and
represent the dimensions of the output and the state vector, respectively.
and
are the
i-th component of the output
and the constraint weight vector
, respectively. The conversion formula between the unconstrained weight
and the constraint weight
can be chosen as Equations (36) and (37).
According to the abovementioned formulas, when , . Additionally, when , .
The Elman-SR-UKF algorithm with constrained weights needs to rewrite
,
and
in Algorithm 1 as follows:
From Equation (39), Equation (40) can be calculated as follows:
Combining Equations (19) and (41),
can be rewritten as:
From the abovementioned formula, Equation (40) can be finally obtained.
5. Results and Discussion
First, the predicted performance was assessed by comparing the Elman-SR-UKF (Elman network based on square-root unscented Kalman filter algorithm) with the traditional Elman networks (Elman-BPTT, Elman-GDM, Elman-LM, and Elman-RTRL-LM) based on different classical training algorithms, i.e., BPTT (back propagation through time algorithm), GDM (Momentum Gradient Descent algorithm), LM (Levenberg-Marquardt algorithm) and RTRL-LM (
https://github.com/yabata/pyrenn, accessed on 20 November 2021) (real-time recurrent learning based on Levenberg-Marquardt algorithm). Then, an Elman network based on SR-UKF with different constrained weights was implemented and compared for quality-related variable prediction in the wastewater plant. In this paper, the extreme learning machine (ELM) [
42] and multi-output Gaussian process regression (MGPR) [
43] are further introduced to act as the baselines for comparisons.
A wastewater treatment system is a physical, chemical, and biological system that makes it multivariable, nonlinear, and dynamic. Generally, it is necessary to monitor multiple variables of the wastewater treatment process simultaneously. Due to the strong coupling and high interaction among the output variables, using a set of independent single-output models to predict multiple quality-related output variables is inadequate. From the perspective of practical application, this study proposed a multioutput neural network model, Elman-SR-UKF, which can deal with multivariate problems. In this case, the DQO-S, DBO-S, and SS-S in the UCI data are selected as the prediction variables.
To verify the proposed model in this study, an 18-8-3 Elman network architecture is constructed, while the activation functions
of the hidden layer and output activation functions
are designed as
logsig functions and
purelin functions, respectively. The initial value of weights is a random number between [−0.5, 0.5]. Equations (43)–(45) are used as evaluation criteria for predictive performance. The parameter definitions of the model are shown in
Table 2. The software used in this study was MATLAB R2016a.
In
Section 3.1, this study mentioned that the parameter
should ideally be a small number. However, if
is too small, the weights of the sigma points are all negative, which may easily lead to a diversion problem in the iteration. In this study,
was set to 1 to ensure the positive weights of sigma points.
represents the identity matrix. Taking into account the randomness of the initial weights, the results in
Table 3 and
Table 4 are the average results obtained by running 500 models with random initial weights. In
Table 3,
means that there is no weight constraining. Because the effect of the RTRL algorithm is nonideal, in comparison, this study uses the RTRL-based LM algorithm in the Pyrenn toolbox. Epochs represent the number of iterations required for convergence.
Table 3 shows the results of different algorithms and the values in bold represent the best results. By comparing all criterion evaluation results of the models, it can be seen that, on average, Elman-SR-UKF achieved the best prediction performance with the smallest RMSE, MRE, and R for all three outputs. The MRE represents the ratio of the absolute difference of the measurement to the actual measurement. The smallest MRE of Elman-SR-UKF for approximately 15% in SS-S and 8% in DBO-S and DQO-S can obviously represent that Elman-SR-UKF the best monitoring method among the abovementioned methods. It is clear that the RMSSD of Elman-SR-UKF is 95.3%, 76%, 254%, 177%, 119.6%, and 59.6% was better than those of Elman-BPTT, Elman-GDM, Elman-LM, Elman-RTRL-LM, ELM, and MGPR, respectively. MR of Elman-SR-UKF exhibited similar profiles.
MGPR achieved a relatively good result in terms of RMSSD and MR. However, by comparing the RMSE, R, and MRE, MGPR had a worse performance in the outputs of DBO-S and DQO-S than Elman-RTRL-LM and Elman-LM. That is because MGPR was not able to learn non-stationary process properly and some variables in the dataset were relatively stable but still did not completely follow a stationary process. The performance of ELM in this paper was not good. This is mainly because the pre-fixed input weights in ELM limited the representation capability of the model and usually could not be used for complex tasks.
The results of RMSSD and MR reflect that Elman-SR-UKF can perform well from the standpoint of the overall predictive performance of the multioutput model, which illustrates that the proposed method can exhibit excellent performance and overcome the underprediction phenomena in traditional Elman network.
In terms of convergence, Elman-SR-UKF had the fastest convergence speed, and the convergence of the Elman-RTRL-LM algorithm was faster than that of the Elman-BPTT and Elman-GDM algorithms. The convergence rates of Elman-LM and Elman-SR-UKF were faster than those of the gradient descent algorithms, such as Elman-BPTT and Elman-GDM. The Elman-LM algorithm utilized the second-order quasi-Newton optimization method to train the network, and the Elman-SR-UKF algorithm used the covariance of the second-order statistical property of variables for iteration, which indicates that the second-order method may have a faster convergence than the first-order method. Moreover, the Elman-SR-UKF algorithm had better convergence performance, which proves the effectiveness of the proposed method.
The prediction profiles of different models for output variables are further shown in
Figure 4. To clarify the prediction profiles, only the first 80 time series data in the testing dataset were shown. By comparing the prediction results of various methods, it can be seen that the Elman-SR-UKF algorithm can better track the dynamic variations of output variable SS-S, while the fitting between the predicted and real values with respect to other algorithms about SS-S was poor. This occurs mainly because the algorithm fell into a local minimum, which, in turn, proved the effectiveness of the proposed method in this study. For the variables, DBO-S and DQO-S, the Elman-LM, Elman-RTRL-LM, and Elman-SR-UKF methods had good fitting performance. In terms of the prediction results of peaks and valleys in the prediction profiles, Elman-SR-UKF had excellent prediction performance in tracking the dynamic variations of the targets and its prediction ability was better than the traditional Elman training algorithm listed above, which shows the superiority of the Elman-SR-UKF in this study.
Elman-SR-UKF assumes the parameters of the Elman network to be state random variables, and then recursively updates the posterior density of the state to optimize an instantaneous cost function. In addition, the inherent statistical averaging of the Elman-SR-UKF algorithm can be less likely to get stuck in local minima, which makes the Elman-SR-UKF able to achieve the best performance. Additionally, it is important to note that Elman-GDM achieved better performance, which is mainly because Elman-GDM added the past gradient information to the parameter update equation and still optimized the cost function toward the gradient direction. Therefore, the gradient may change a lot over relatively small regions in the search space and jump out of the local minima.
Table 4 shows the prediction results of output variables with different weight constraints in terms of RMSE, MRE, R, RMSSD, and MR. From the perspective of the maximum weight, constraints can be successfully restrained in the range of weight values, which can prevent the overfitting of the model. Nevertheless, from the results of RMSE, MRE, R, RMSSD, and MR, it can be found that weight constraints have some effects on prediction performance. This problem can result from two aspects: First, setting up constraints based on weight values makes the model less sensitive to the error. Conversely, if there is no weight constraint, it means that the model can adapt to measurement error and exhibit oversensitive behaviors, which may, in turn, bring better performance and faster convergence. However, a sensitive model with unconstrained weights may produce unstable results, thus reducing the reliability of the soft sensor model. It is envisioned that the model without weight constraints can achieve better results for a stationary dataset. In this actual activated sludge water plant, once the outliers have been preprocessed, the stationary requirement for a dataset can be guaranteed. Second, once the constrained weight values reach the saturation region, the derivative of the constrained weight with respect to the unconstrained weight becomes zero, making it difficult to perform further training with these particular weight values. In summary, weight constraints may lead to a slight degradation in performance, but its performance is still better than that of the Elman-BPTT, Elman-GMD, Elman-LM and Elman-RTRL-LM methods. Moreover, the weight constraining algorithm can better meet the parameter requirements in applications, such as fixed-point arithmetic, and improve the reliability of a soft sensor.
Figure 5 shows the convergence profiles of different weight constraints with
. As shown in
Figure 5, the convergence speed with unconstrained weights is faster than that with constrained weights, which can be attributed to the lower sensitivity to error. Although weight constraints slightly affect the convergence speed, the algorithm still converges at a relatively fast iterative speed.
The above results show that the Elman-SR-UKF can create more accurate and robust results, thus overcoming the underprediction phenomena in data-driven process monitoring [
44]. Although the main principle of this paper is different from the reference [
44], it is very easy to extend this study to the quantify the uncertainty of effluent variables forecasting. Compared with the application of Li et al. [
45,
46], this paper provides a better prediction performance and a simple sequential way to update the parameters online. Thus, this study can be successfully envisioned to be applied to process monitoring of effluent variables in wastewater plants.
In summary, according to all prediction results of the models, the Elman-SR-UKF method can perform more accurate prediction results and has a faster convergence. Of note, for the output variable SS-S, the Elman-SR-UKF can better fit the target variations, which further demonstrates the effectiveness of the proposed algorithm. From the perspective of weight constraints, the weight constraining method can effectively restrict the range of the weight values and reduce the sensitivity to the error, which can, in turn, improve the reliability of a soft sensor but may slightly affect the convergence speed and prediction performance of the model. Moreover, the prediction performance of the method with a constrained algorithm is still better than that of the Elman-BPTT, Elman-GMD, Elman-LM and Elman-RTRL-LM methods.
Remark 1. In this case study, an activated sludge-based treatment process is used for validation, which is the most commonly used treatment process around the world and covers more than 80% of WWTPs in China. However, the physical, chemical, and biological phenomena associated with treatment units (primary classifier, anaerobic, anoxic, aerobic tanks and secondary classifier) always add significant complexity to process monitoring and plant management. Moreover, the inter- and intercorrelation for the reactors and processes make the collected data exhibit strong nonlinearity and high dynamics among the variables. This renders it necessary to use adaptive and nonlinear data driven models for prediction, such as recursive neural networks. However, general RNNs cannot take into account uncertainties inside and outside WWTPs. (a) Biomass growth, death, and nutrient consumption are all sensitive to many factors, such as pH and temperature. (b) The large variety of biological species present in WWTPs makes it impossible to accurately determine all kinetic parameters with a general model. (c) The organic loads in the influent significantly fluctuate depending on the level of human activity and external environment. For instance, in urban WWTPs, the organic loads vary during the day according to the level of human activity. Additionally, they themselves are strongly affected by weather conditions and seasonal change. Kalman filters are inherently dynamic algorithms with the ability to describe uncertainties. To take into account all aforementioned uncertainties, Elman works together with Kalman filters to make predictions for quality-related but hard-to-measure effluent variables. An Elman network together with Kalman filters is also able to capture the aforementioned nonlinear relationship.
Remark 2. In this case study, the proposed soft sensor is only used for effluent quality prediction in an activated sludge process. However, there are still many hard-to-measure variables in the entire WWTPs, for example, sludge volume index (SVI) in the secondary classifier, toxic loads in the influent and N2O during the reaction. In addition to activated sludge processes, the proposed methods can be extended and used for other processes such as oxidation ditches (ODs) and sequencing bath reactors (SBRs).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}