1. Introduction
Water distribution systems (WDSs) are essential infrastructures of every city and town, the purpose of which is to satisfy the water requirements of the population, of agriculture and for industry with the required quality and quantity. The hydraulic steady-state solutions of WDSs (the flows and heads) is the foundation of many, if not all, WDS academic research and industry application. Therefore, the speed and accuracy of the hydraulic simulation model that is used to find the steady-state of WDSs underpin the quality of the research outputs and industry applications. The quest for a solution method for finding the steady-state solution of a looped WDS can date back to 1936. Since then, the research community diverged into three main branches: (1) loop-based methods, (2) null-space method, and (3) range space methods.
The loop-based methods use the loop energy equations and continuity equations to model the demand-driven steady-state of WDSs. The first loop-based methods and the first WDS solution method is the Hardy–Cross method [
1]. The Hardy–Cross method is an iterative manual method that uses successive approximation to solve the above nonlinear system of equations in which a set of initial flows that satisfies the mass conservation equations is successively corrected until the stopping test has been met. The loop identification and the requirement that the initial guess of flows must satisfy continuity are the factors that affect the performance of the Hardy–Cross method. The performance of the loop-based methods is dependent on the sum of the length of all identified loop. The Shortest Cycle Basis [
2] is the best set of loops that minimizes the time that is required to execute any loop-based method. This is because the use of the shortest cycle basis can achieve the minimum number of non-zeros in the key matrix. Ref. [
3] explored the use of minimum loops in the Newton–Raphson loop flows method and showed the time used to identify the shortest cycle basis is 100 to 10,000 times the time used to solve the network. Ref. [
4] proposed two algorithms to select a set of network loops to achieve a highly sparse matrix. Although a smaller number of non-zeros in the Schur complement was reported in Creaco and Franchini [
3], the substantial improvement in terms of the efficiency reported by Alvarruiz et al. [
4] suggests the latter algorithm is the better practical choice. The overhead to identify the shortest cycle basis is clearly the bottleneck in the loop-based method even though the loop identification algorithm is only required to execute once for a given network topology.
The null-space methods, methods that operate in the subspace defined by a null space that is orthogonal to the column of the unknown-head node-arc incidences matrix, partitions the network into a spanning tree acyclic graph and the complementary chord tree edges. The addition of any chord tree pipe to the spanning tree graph creates a loop. The null-space method, in the context of WDS solution methods, is a special case of the loop-based methods. This is because the cycle basis created by any spanning tree graph and chord edges is a subset of the set of all cycle bases of the loop-based method, whereas the cycle basis of the loop-based method (particularly the shortest cycle basis) cannot be expressed as a combination of a spanning tree graph and the complementary chord tree edges. By sacrificing the generality, the null-space method requires fewer computation resources to find a combination of spanning tree graph and chord tree edges. Rahal [
5] proposed a co-tree flows formulation in which it is necessary to (1) identify the associated circulating graph; (2) determine the demands that are to be carried by the spanning tree branches; (3) find the associated chain of branches closing a circuit for each co-tree chord; and (4) compute pseudo link head losses. Later, Elhay et al. [
6] exploits the relationship between the co-tree flows and spanning tree flow by applying the Schilders’ factorization [
7] to permute the A1 matrix into a lower triangular square block at the top, representing a spanning tree, and a rectangular block below, representing the corresponding co-tree.
The range space methods include a collection of methods that operate in the subspace defined by the rows of the unknown-head node-arc incidences matrix. The global gradient algorithm [
8] is the most widely used WDS solution method, which solves for the flows and the heads in WDSs simultaneously by exploiting the block structure of the Jacobian matrix to reduce the size of the key matrix in the linearization of the Newton method. The graph matrix partitioning algorithm (GMPA) [
9] exploits the linear relationship between the flows in the internal trees and the flows in the superlinks to speed up the solution process of the GGA.
In addition to the different solution methods developed for the simulation of the WDS steady-state, network partitioning using graph theory has been another active research avenue. Network partitioning identifies sections of a WDS network that are hydraulically independent. The first graph structure that is exploited is the forest component of a WDS. A tree in a graph is any two vertices are connected by exactly one edge. Most WDSs have trees, the collections of which are called forests. Simpson et al. [
10] proposed a forest-core partitioning algorithm to partition a WDS graph into its linear forest component and nonlinear core component. The flows in the forest pipes can be computed a priori and the heads in the forest nodes can be computed a posteriori by a linear process. Qiu et al. [
11] proposed a bridge-block partitioning algorithm to partition a WDS graph into several linear independent blocks and bridges. The steady-state solution of one block of a WDS can be computed independently from other WDS blocks.
EPANET2 [
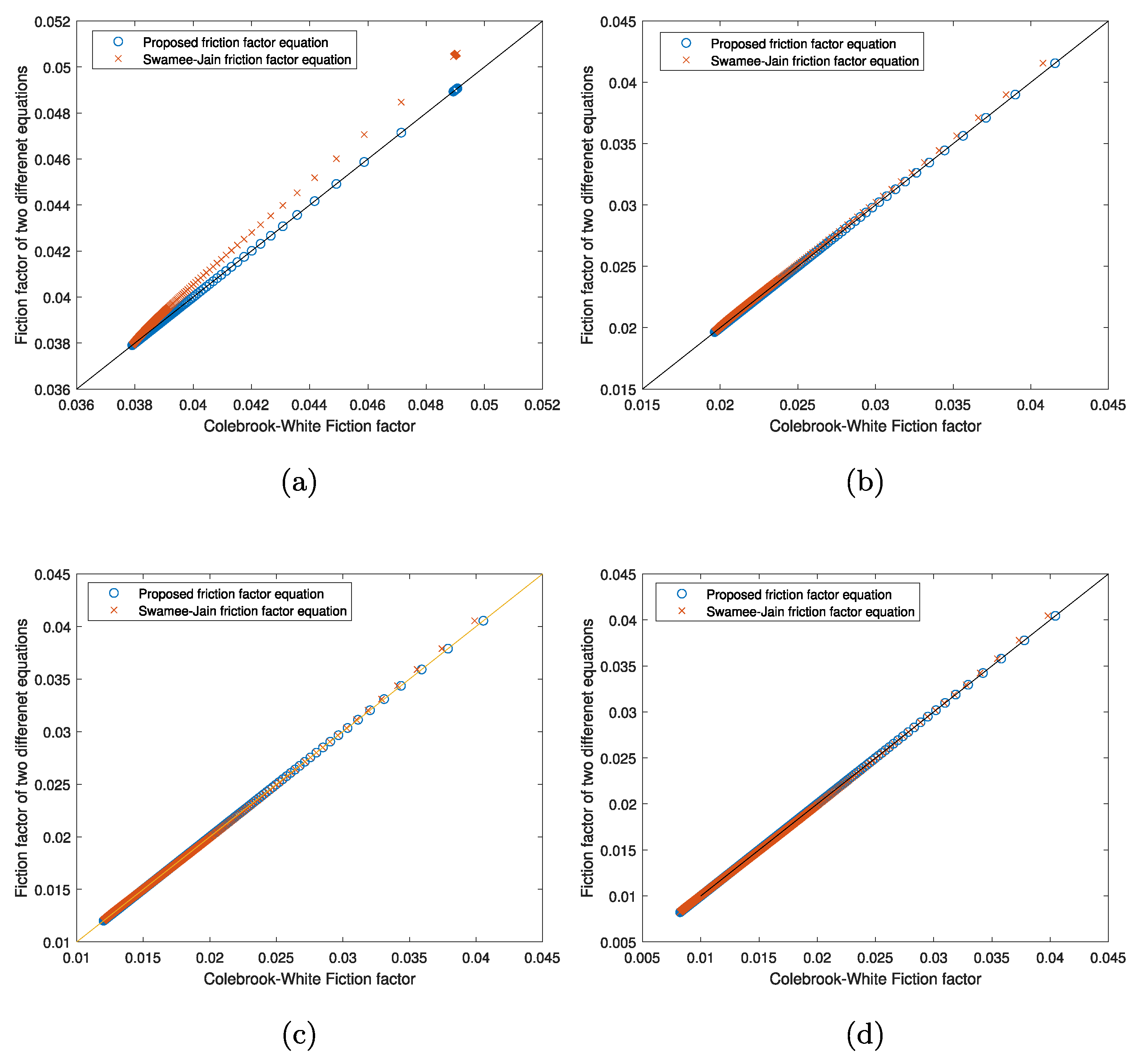
12] is one of the most widely used WDS simulation packages, in which the GGA is used to provide steady-state demand-driven solution of WDSs. The code for EPANET 2 is in the public domain, allowing many studies to be conducted. These include the least-cost design and operation of WDSs, sensor placement, chlorine decay models calibration, contamination event detection, network vulnerability analysis, cyber-attack detection, network decontamination, and many others. Any inaccuracies that existed in the WDS solution method used will be inherited and sometimes exacerbated. One of the accuracy-related problems is the use of the Swamee–Jain equation [
13], an approximation of the implicit Colebrook–White equation [
14], a general equation that can be used when the Reynolds number is greater than or equal to 4000, to calculate the friction factor. It is reported in Swamee and Jain [
13] that the errors involved in friction factor are within 1% for
and when
. All WDS solution methods that are currently available (1) ignored the above 1% error and (2) extended the applicability of the Swamee–Jain equation to calculate the friction factor when
and all values of
. This is mainly due to the solutions of the inexplicit Colebrook–White equation are required many times for multiple iterations, which is time-consuming.
In this paper, an iterative solution method that finds the steady-state demand-driven WDS solution using the Colebrook–White equation for the turbulent flow regime is proposed. This is achieved by (1) expressing the Colebrook–White equation, an implicit function, as an explicit, exact, and differentiable function to describe the friction factor in the turbulent flow regime, (2) using the Hagen-Poiseuille equation to describe the friction factor in the laminar flow regime, and (3) using cubic interpolation to fit a curve between the turbulent and the laminar flow regimes to describe the transitional flow regime. It is important to note that unlike the Swamee–Jain equation, the explicit expression of the Colebrook–White equation agree at all points, the use of which eliminates the inaccuracy that is associated with the Swamee–Jain equation. It is shown in this paper that the different steady-state solutions of WDSs are observed which can be a critical problem for some research areas (such as the least-cost design and operation, contamination event detection, network vulnerability analysis, sensor placement, district meter area, etc.).
This paper is organized as follows. A description of the general WDS demand-driven steady-state problem is given in the next section. This is followed by
Section 3 the derivation of the proposed head formulation.
Section 4 gives an algorithmic description of the proposed head formulation, followed by the validation of the proposed friction factor equation against the Colebrook–White equation. Six case study networks are then described in
Section 6, the results of which are discussed in the next section. The last section offers some conclusions.
2. General WDS Demand-Driven Steady-State Problem
2.1. Definitions and Notation
Consider a water distribution system that contains pipes, junctions, and fixed-head nodes.
The -th node of the network has two properties: its nodal demand and its elevation head . Let denote the vector of unknown heads, denote the vector of nodal demands, denote the vector of fixed-head elevations.
The p-th pipe of the network can be characterized by its diameter , length , flows , and Hazen–William coefficient for Hazen–William head loss model or roughness height for Darcy–Weisbach head loss model. Let denote the vector of unknown flows, denote the vector of Hazen–William coefficients, denote the vector of roughness heights, denote the vector of pipe lengths, denote the vector of pipe diameters,
The matrix is the full-rank, unknown-head, node-arc incidence matrix. The matrix is the fixed-head node-arc incidence matrix. The head loss exponent n is assumed to be dependent only on the head loss model: for the Darcy–Weisbach head loss model and for the Hazen-Williams head loss model. The head loss within the pipe p is modeled by . Denote by , a diagonal square matrix with elements for . Denote by , a diagonal square matrix where the p-th element on its diagonal .
2.2. System of Equations
The steady-state flows and heads in a WDS system are modeled by the demand-driven model (DDM) continuity Equation (
1) and the energy conservation Equation (
2):
which can be expressed as
where its Jacobian matrix used in the solution process is
and it is sometimes referred to as a nonlinear saddle point problem [
15].
This nonlinear system is often solved by the Newton method, in which
and
are repeatedly computed from
and
by
until the relative differences
and
are sufficiently small.
3. Derivation of the Head Formulation
Consider the continuity equations in Equation (
1) and a vector of unknown heads,
h, for the
nodes in a network.
Assume the flows in pipe
p can be expressed as a function of the head loss in pipe
p:
Let
denote the
j-th column of the
matrix, the continuity equation can be rewritten as:
is the mass balance equation expressed for every node in a WDS.
The partial derivative of
with respect to
can be expressed as:
in which the partial derivative of
with respect to
can be expressed as:
As a result, Equation (
7) can be written as:
where the first matrix of the matrix multiplication above can be written as
, which is
, and the partial derivative of
(Equation (
6)) with respect to
can be expressed as:
Substitute Equation (
10) into Equation (
9), we get:
where the third matrix in the matrix multiplication above can be expressed as
, which is
. Denote by
, a diagonal square matrix where the
p-th element on its diagonal
. The Jacobian matrix in Equation (
11) can be expressed as:
Omitting term
for the demand-driven analysis, this new WDS solution method can be solved by the Newton method in which
are repeatedly computed from
using:
Moving
to the right-hand-side of Equation (
13), we get:
Equation (
6) is now derived for Hazen-Williams and Darcy–Weisbach head loss models in the next subsections.
3.1. Hazen-Williams Equation
The Hazen-Williams Equation head loss equation is
and can be rewritten as:
and the partial derivative of
(Equation (
16)) with respect to
can be expressed as:
3.2. Darcy–Weisbach Equation
The Darcy–Weisbach head loss equation is:
Equation (
18) can be rearranged into
The friction factor for turbulent flow regime (
) can be calculated by using the Colebrook–White equation:
in which the Reynolds number is
Substitute Equations (
19) and (
21) into the RHS of Equation (
20), we get:
Denote by
, the hydraulic gradient in pipe
p. The friction factor in pipe
p can be expressed as:
The friction factor for laminar flow regime (
) can be calculated by using the Hagen-Poiseuille equation:
Substitute Equation (
24) into Equation (
18), we get:
The friction factor for transitional flow regime (
) can be calculated by using a cubic interpolation between the laminar flow regime and the turbulent flow regime using:
in which
,
,
,
,
,
is the friction factor for pipe
p when the Reynolds number is 4000, and
is the derivative of friction factor when the Reynolds number is 4000.
Let
, we can express:
Let
, the flows in pipe
p as a function of the head loss in pipe
p (Equation (
6)) for the Darcy–Weisbach head loss model can be expressed as
where its derivative can be expressed as:
in which
and
. It is important to note that special care must be taken to calculate the
value for laminar flows as the pipe head loss will be cancelled when calculating the pipe flow:
as a result, the derivative of the pipe flow with respect to the pipe head loss in the laminar flow regime can be expressed:
which is a constant value. Therefore, a pipe with zero head loss will not cause any numerical problems as a result of the zero head loss.
Finally,
and
need to be identified for pipe
p for all pipes.
can be easily identified as
for any pipes and
. Therefore,
The determination of
involves the solution of
using the implicit Colebrook–White equation for pipe
p when
and substitute the value of
in Equation (
2). This is only time when the direct solution of the implicit Colebrook–White Equation is required.
4. Head Formulation Algorithm
The steps of the proposed head formulation are described in Algorithm 1. The proposed head formulation, a single-phase formulation, within the iterative phase (between lines 4 and 18 in Algorithm 1 is similar in terms of the computational intensive when compared to the global gradient algorithm, a two-phase formulation.
Meanwhile, the overhead of the proposed head formulation, particularly the computation of the that requires the solution of the Colebrook–White equation for the Darcy–Weisbach head loss model, can increase the computation burden of the algorithm. However, as the manufacturing limitation, there is only a limit number of pipes that is available for the construction of WDSs. Therefore, the number of combinations of the pipe roughness heights and pipe diameters is limited, so does the number of distinct values of . This is also true for the least-cost design problem of a WDS. value is only required to be computed and stored for each of the commercially available pipes a priori. This stored value can then be retrieved during the optimization phase.
Moreover, Equation (
16) is just an inverse function of Equation (
15). As a result, the
required in the proposed head formulation is the inverse of the
required in the GGA. Therefore, the Schur Complement in the GGA,
, is the same as the Jacobian matrix shown in Equation (
12) as
. Thus, if the proposed head formulation and the GGA starts with the same initial starting points when applied to a WDS with Hazen-Williams head loss model, they will also have the same iterative solutions and the same final solution.
| Algorithm 1: Head formulation |
![Water 13 01163 i001]() |
7. Results and Discussion
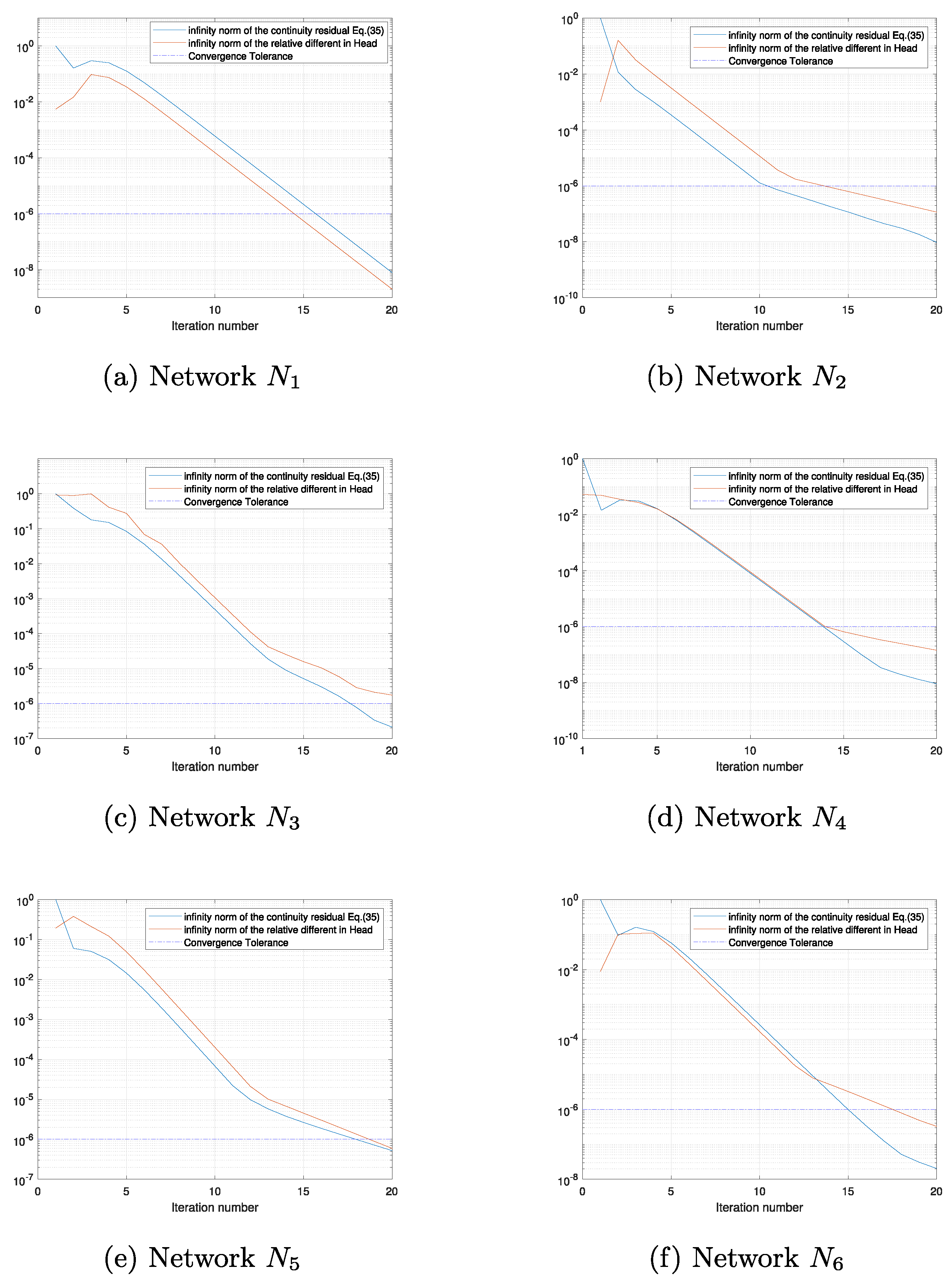
Figure 2 shows the convergence of the proposed iterative head formulation. Networks
and
are both relatively small network, both of which have a small number of loops (11 loops for network
and 14 loops for network
). The stopping test and the continuity residual have been met for both smaller size networks. However, convergence problem has been observed for the medium size networks (networks
and
) and large size networks (networks
and
). It is worth noting that the relatively head differences use in the stopping test has a better convergence property that the continuity residual. This is particularly pronounced in network
as shown in
Figure 2b. The stopping test has been met at seven iteration, whereas the continuity residual is
. This significant difference is also observed in
Figure 2c–f for networks
–
.
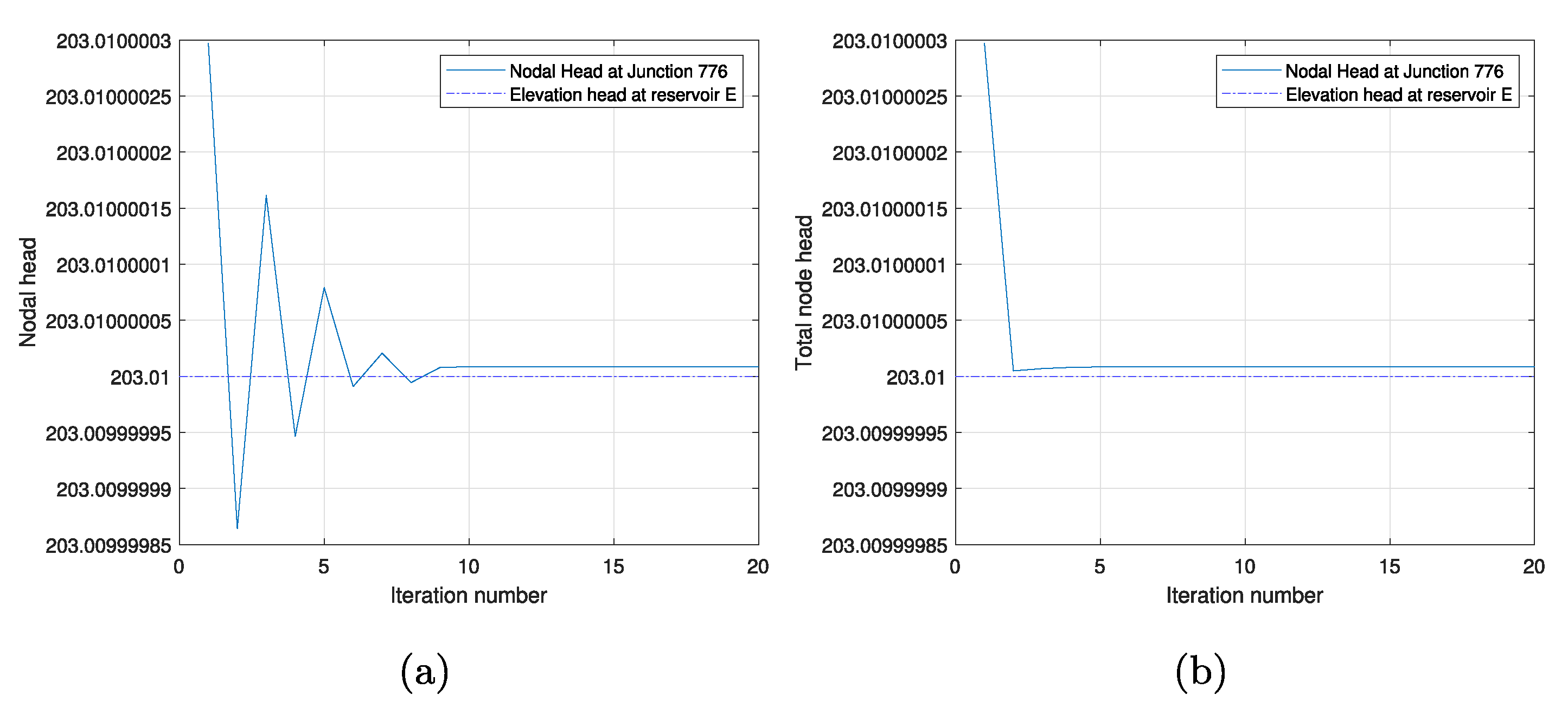
Using junction 776 and reservoir E in network
as an example, the head iterates of junction 776 is observed to be oscillating around the elevation head of reservoir E as shown in
Figure 3a. The relative head difference of the nodal head at junction 775 is
at 6th iteration. However, this small perturbation in the nodal head caused the flow direction reversed. This flow direction reversal happened three more times while the value of the nodal heads converges to the true value. This is because the pipe (Pipe 1865) that connects junction 776 and reservoir E is 1 m in length and 0.999 m in diameter with 0.15 mm roughness height, which means the resistance factor of pipe 1865 is a very small value. This can also be seen from
Figure 3a as the head loss between reservoir E and junction 776 is
.
Once a damping factor of 0.67 has been applied, the head convergence of this particular node is more well-behaved as a faster convergence is achieved and no head oscillation has been observed as can be seen from
Figure 3b. Please note that in
Figure 3b and in
Figure 4 the damped Newton’s method was used. Within this scheme, the derivative within the Newton method is multiplied by a damping factor between zero and one for accelerating convergence. On the one hand, the application of the damping factor caused a slower head convergence of the node that is well-behaved before its application. This can be seen from
Figure 4a,b as a slower rate of convergence is observed when compared to that from
Figure 2a,b. On the other hand, the application of the damping factor guaranteed convergence for networks
–
as shown in
Figure 4c–f when compared to before the application of the damping factor as shown in
Figure 2c–f.
The convergence properties, including the relative head differences, continuity residuals, energy residuals, and Colebrook–White equation residuals, at the final iteration of the proposed head formulation after applying the damping factor is shown in
Table 2.
Table 3 presents the detailed timing results of pre-processing, iterative phase and post-processing operations of the GGA and proposed head formulation applied to the six case study networks. The total wall-clock time required to apply the proposed head formulation is higher than that required by the GGA for all six case study networks. This is because the proposed head formulation requires more time to perform the iterative phase while the GGA and the proposed head formulation require a similar time to execute the pre-processing and post-processing operations. In addition, a similar amount of per-iteration runtime is required by the GGA and the proposed head formulation, which means the longer wall-clock time required by the proposed head formulation is the result of higher number of iterations required due the damping factor applied.
Table 4 shows the detailed statistics of the absolute head differences between the GGA and the proposed head formulation applied to each of the six case study networks. This head differences in the results of optimization problems can cause constraints violation of the optimal solution identified. Take the Balerma network
, one of the well explored network, as an example. This problem is first introduced by [
17]. Two least-cost designs presented by [
23,
24], both of which using the GGA formulation to find the steady-state solution in which the Swamee–Jain equation is used to model the pipe friction factors, have found to have nodal pressure violations when using the proposed head formulation as shown in
Table 5, in which the Colebrook–White equation is used to model the pipe friction factors. The above two least-cost designs of network
are both infeasible as the Swamee–Jain equation approximates the Colebrook–White equation. This is because (1) the errors involved in Swamee–Jain friction factor are within 1% for
and
as reported in [
13], whereas GGA has extended the applicability of the Swamee–Jain equation to all values of
and
and (2) the errors involved in Swamee–Jain friction factor have been ignored in all optimization problems.
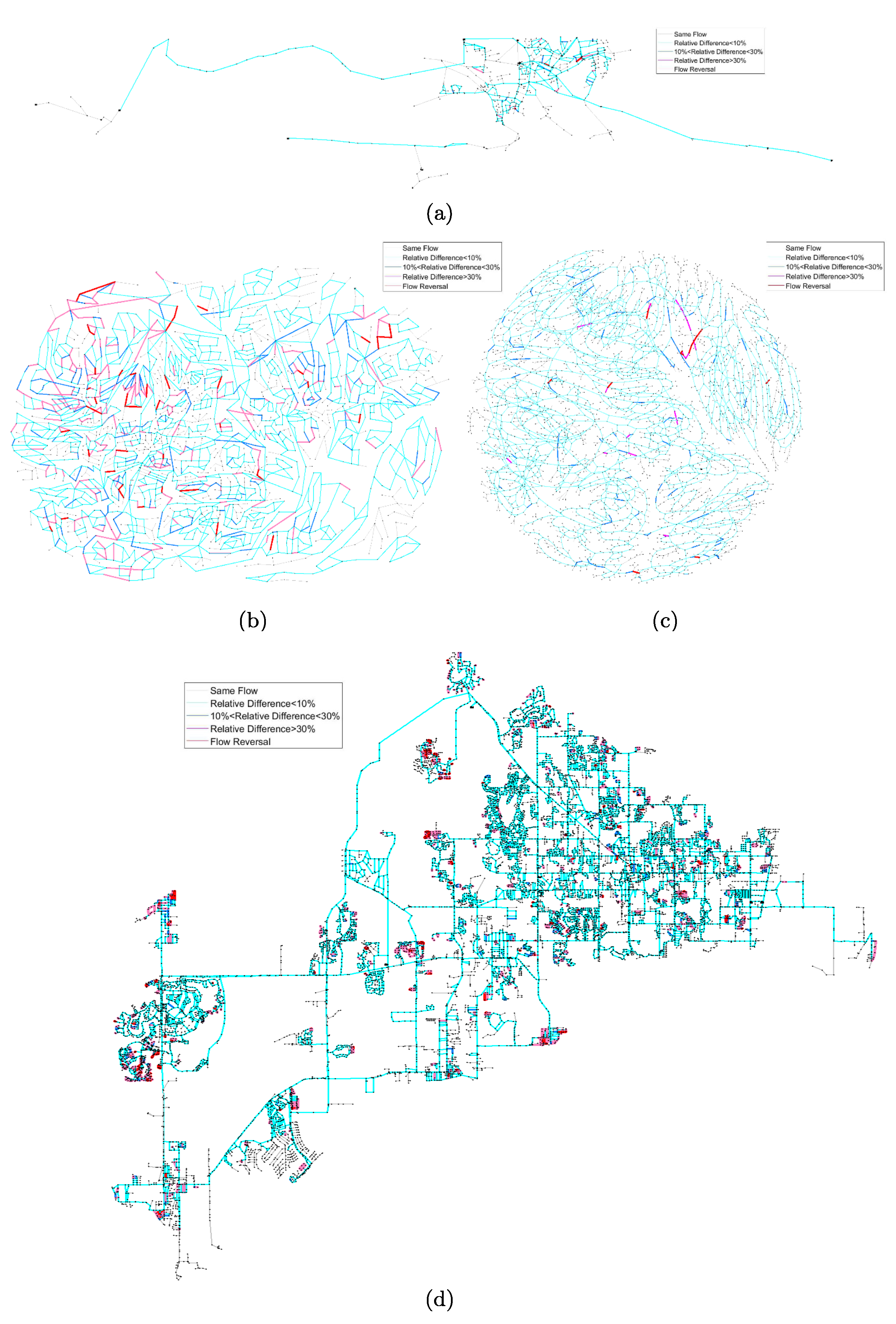
In addition to the differences in the head solutions, the use of friction factor produced by the Colebrook–White equation in the proposed head formulation also produces different flow results when compared to that produced by the GGA as shown in
Table 6 and the spatial distribution of the pipes with different flows is shown in
Figure 5. The flows of the pipes in the looped component found by using the proposed head formulation for each of the six case study networks are different from that found by using the GGA, whereas the flows of the pipes in the forest component found by using the head formulation for each of the six case study networks are the same as that found by using the GGA. In addition, the number of pipes with flow direction reversal is ranging from six pipes in network
to 730 pipes in network
.
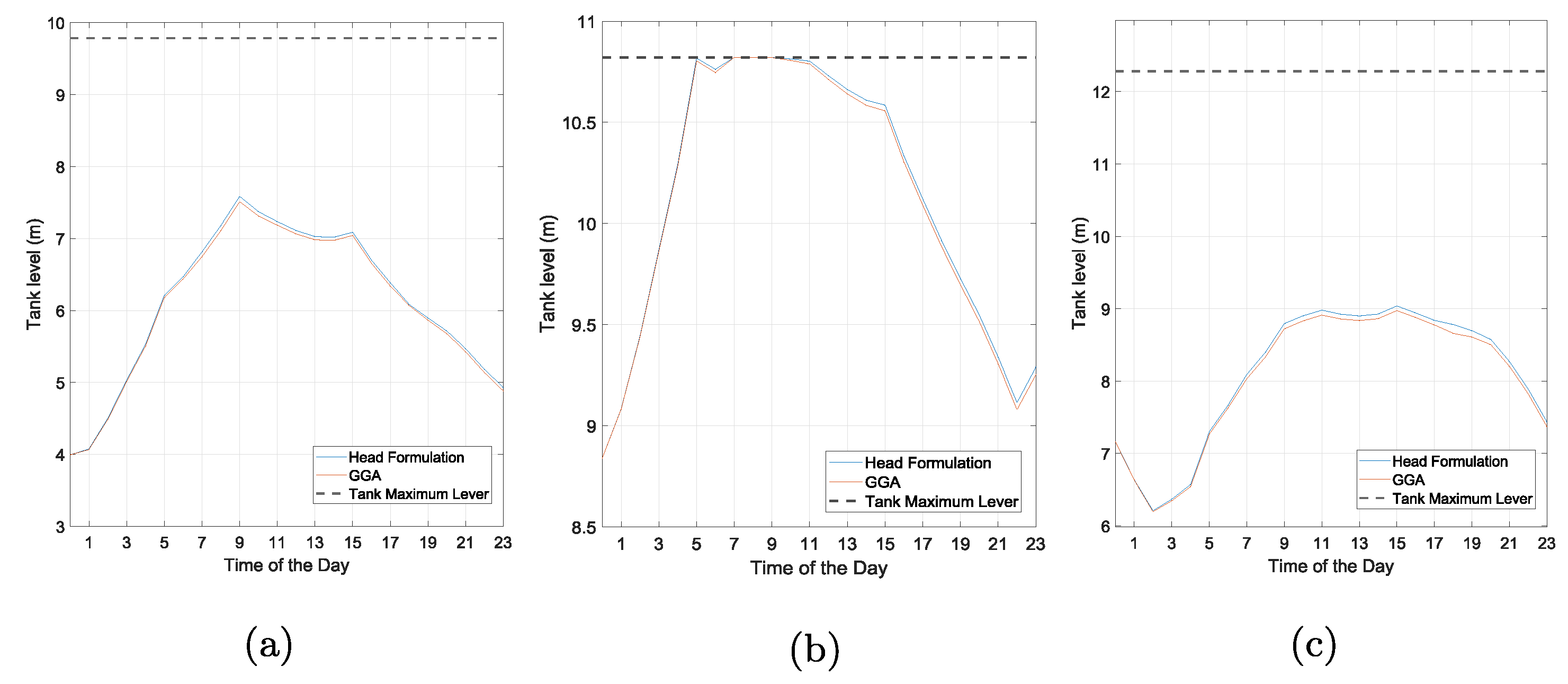
In addition to the single-period steady-state WDS simulation where the boundary conditions (pumps and tanks) are fixed, errors caused by the difference between the Colebrook–White equation and the Swamee–Jain equation can accumulate as the boundary condition in the extended-period simulation. The error accumulation is manifested as the different tank level at each time step, the time when an operation activated by the trigger level, and the pump operating points. Net3 in EPANET is used as an example to demonstrate the error accumulation described above. It is important to note that the Net3, which is a simple WDS with 92 nodes, two reservoirs, three tanks, two pumps, and 117 pipes, in EPANET has been converted from the Hazen-William head loss model to the Darcy–Weisbach head loss model. The model difference between the GGA and the head formulation is relatively small between 00:00 to 05:00, which is also observed in network
. As can be seen from
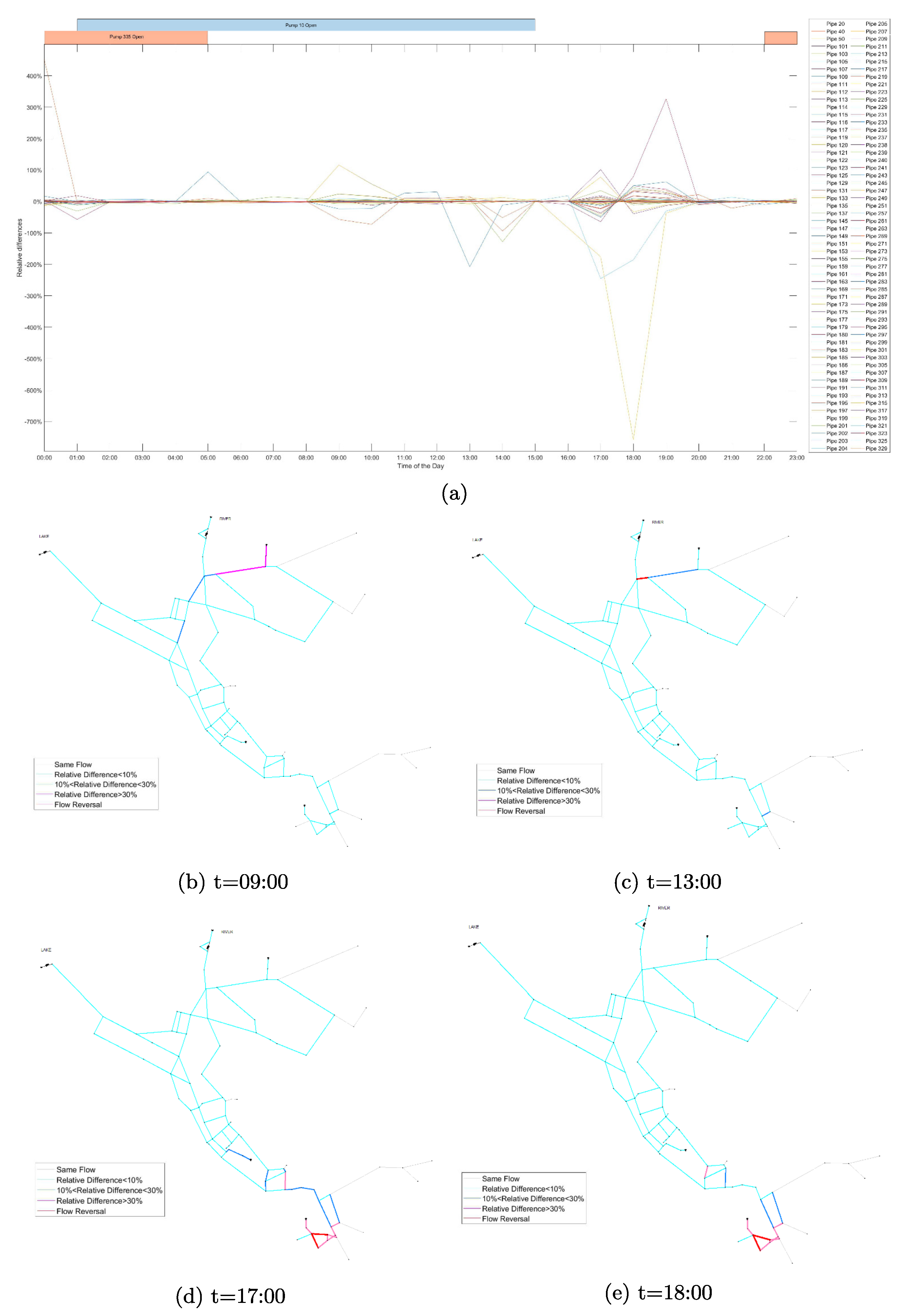
Figure 6, however, the tank levels start to diverge as the tank level rises. This is because the insignificant model errors for small network can accumulate over a period of time in the form of boundary conditions. It is also worth noting that when the tank operation mode changes, from filling to discharging or from discharging to filling, the tank level differences between the two model start to narrowing, because the cancelling of errors, but never reaching zero. The maximum tank level difference is 0.074 m for tank 1, 0.12 m for tank 2 and 0.37 m for tank 3. Due to the error build-up in the boundary conditions, the differences between GGA and the head formulation flow results are relatively small with no flow direction reversal before the mid-day as can be seen from
Figure 7a. After 12:00, however, significant differences between GGA and the head formulation flow results are observed with the reversal of flow direction as can be seen from
Figure 7c–e. Finally, flow result differences start to decrease as the tank level differences narrow. The GGA and the head formulation start with the same tank levels and end up with different tank levels over the 24 h simulation period. This boundary condition differences will keep accumulating over a longer simulation period.
9. Conclusions
This paper presents an efficient iterative head formulation for the steady-state demand-driven solution of water distribution systems for both Darcy–Weisbach and Hazen-Williams head loss model. When the Hazen-Williams head loss model is used, the proposed solution method produces the same final and iterative flow and head solutions if the same initial guess is used as the global gradient algorithm. When the Darcy–Weisbach head loss model is used, an exact and explicit expression of the inexplicit Colebrook–White friction factor equation is proposed in this study. A cubic interpolation between this explicit expression of the inexplicit Colebrook-White equation for the turbulent flow regime and the Hagen-Poiseuille equation for the laminar flow regime is generated to describe the friction factor in the transitional flow regime.
The main features of the proposed head formulation of the steady-state demand-driven WDS simulation include:
- (1)
friction factor for the turbulent flow regime can be calculated using an explicit and exact expression of the Colebrook–White equation without the need for an iterative method;
- (2)
the use of the proposed head formulation can significantly improve the accuracy of the steady-state demand-driven solution of WDSs when compared to the GGA. This is because the proposed head formulation uses an explicit and exact expression of the Colebrook–White equation to calculate friction factor for the turbulent flow regime as opposed to the Swamee–Jain equation, an approximation of the Colebrook–White equation, used in previous WDS solution methods.
The efficacy of the proposed head formulation has been demonstrated by applying it to six case study networks, the results of which have been validated using the continuity residuals, energy residuals, and Colebrook–White residuals. It should also be observed that the proposed method could be selected for analytical (e.g., Di Nucci [
26]) and for numerical applications (e.g., Pasculli [
27]), and in particular for improving the Wall Function.Differences between the proposed head formulation and the GGA have been observed in both the flows and heads. On the one hand, the flow differences, particularly the flow direction reversal, can be a critical problem for some research areas such as water quality simulation, contamination source identification, water hammer analysis, WDS network calibration, sensor placement, and network clustering. On the other hand, the heads differences can cause pressure violations in the WDS least-cost design when the GGA is used to perform the steady-state demand-driven analysis. It is important to note that damping factor has been applied to the Newton method to achieve a more stable convergence. The choice of initial guess, another important factor in the Newton method convergence, and inclusion of valves, pumps, and other network elements will be interesting avenues for future research.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}