Hybrid Machine Learning Models for Soil Saturated Conductivity Prediction




Abstract
:1. Introduction
2. Methodology
2.1. Base Models
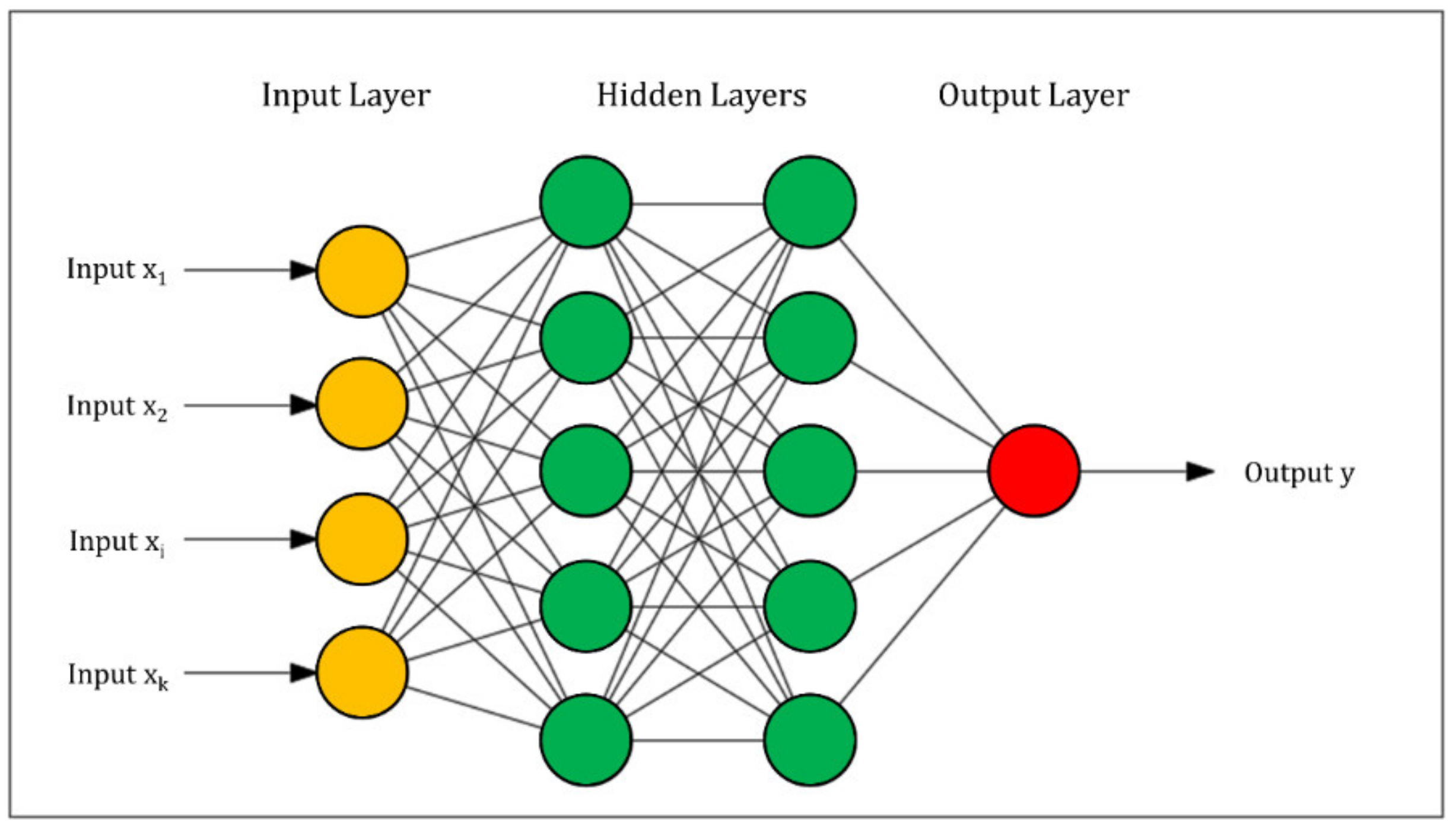
2.1.1. Multilayer Perceptron
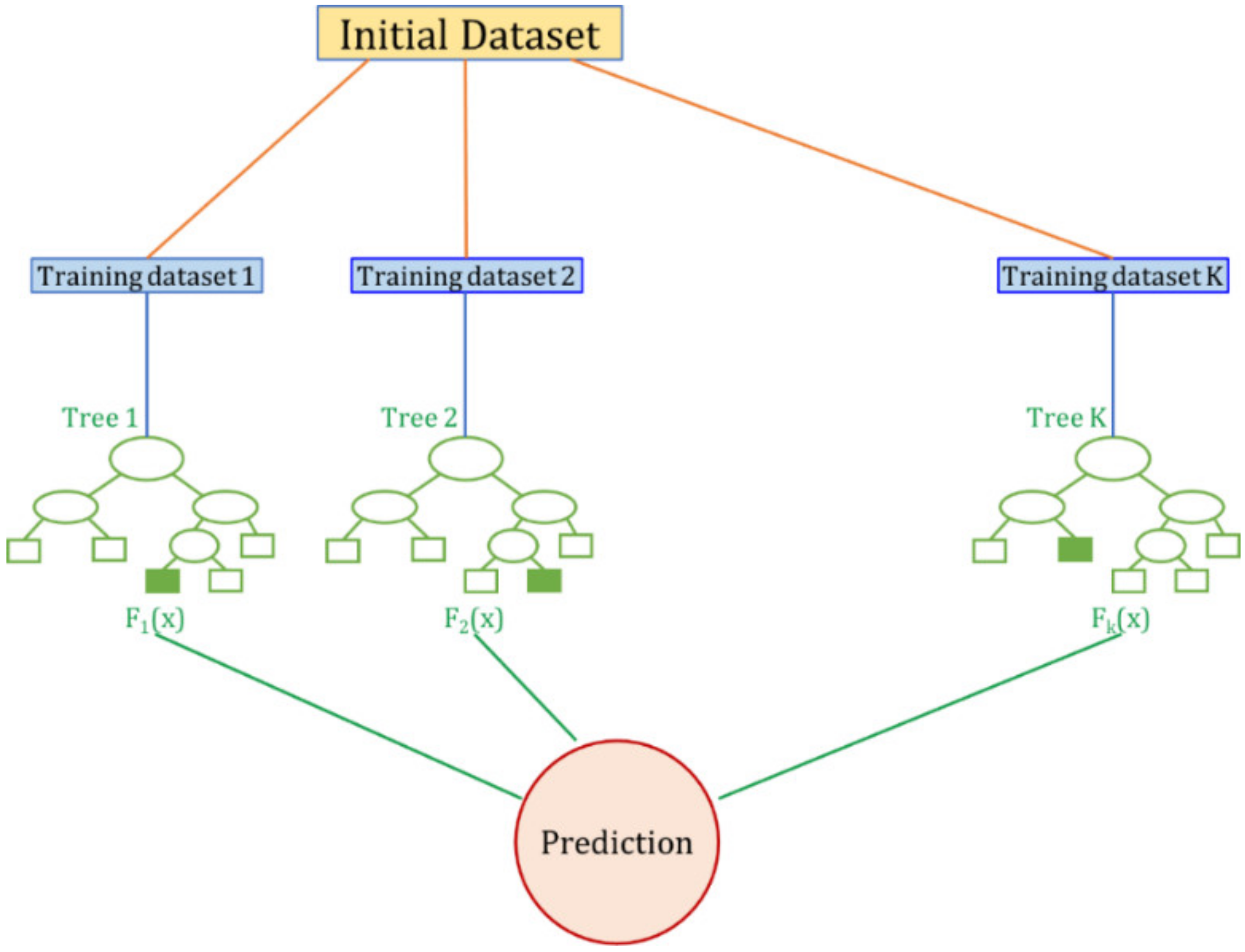
2.1.2. Random Forest
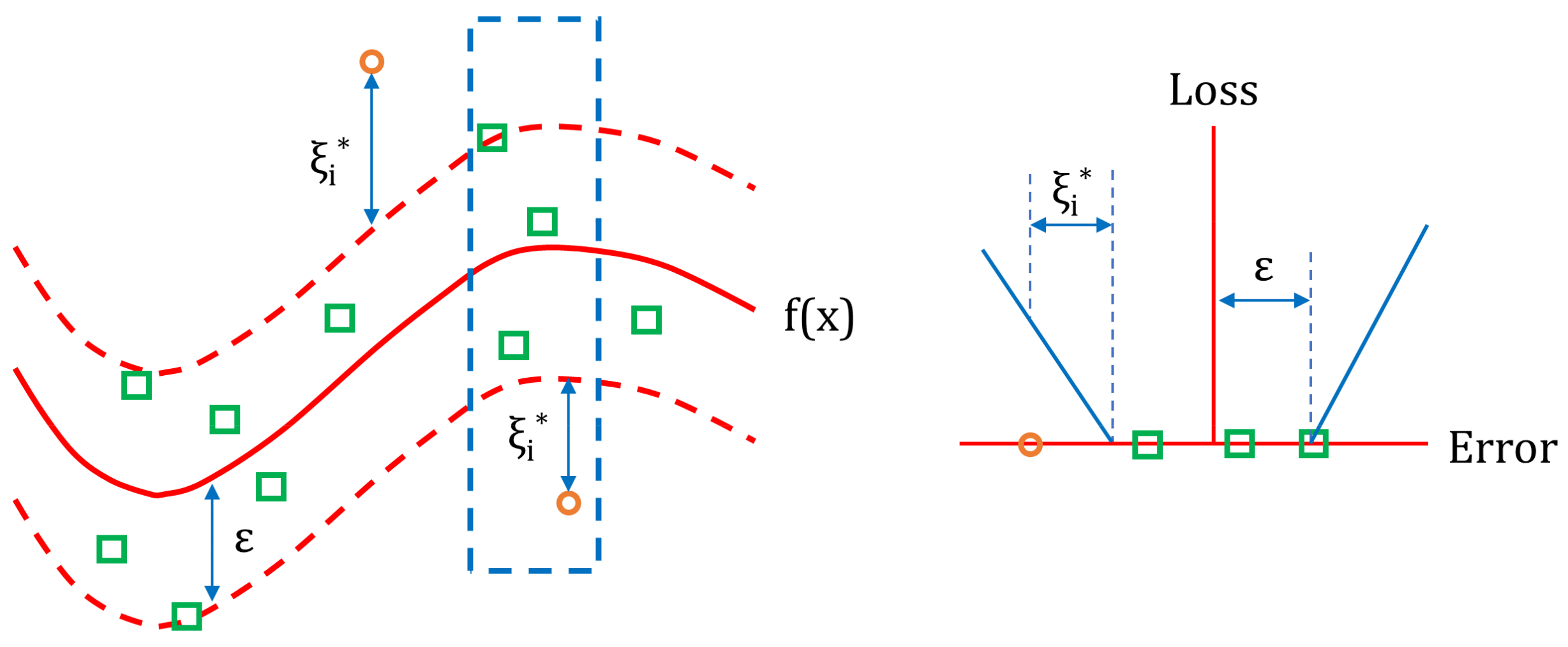
2.1.3. Support Vector Regression
2.2. Hybrid Models and Evaluation Metrics
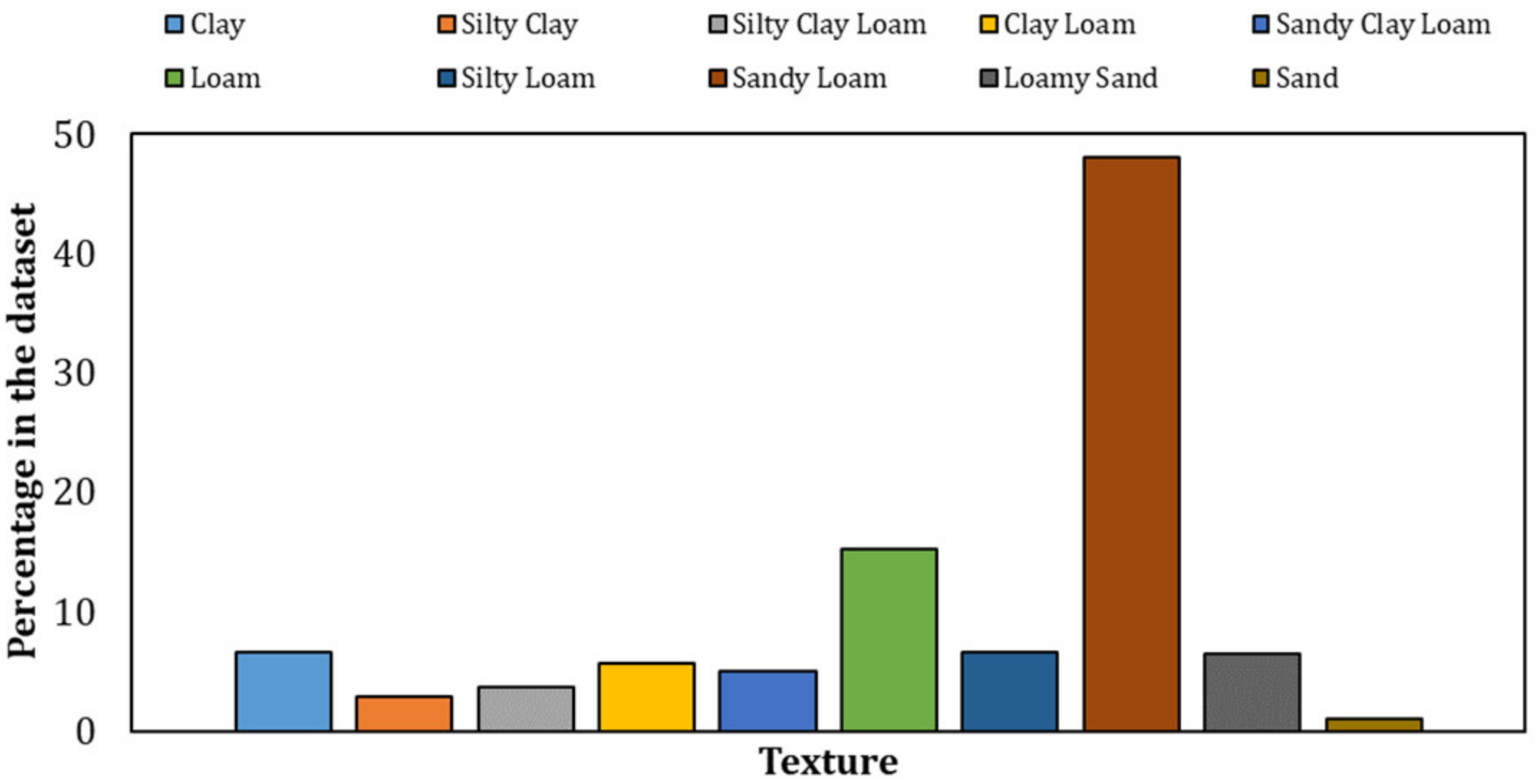
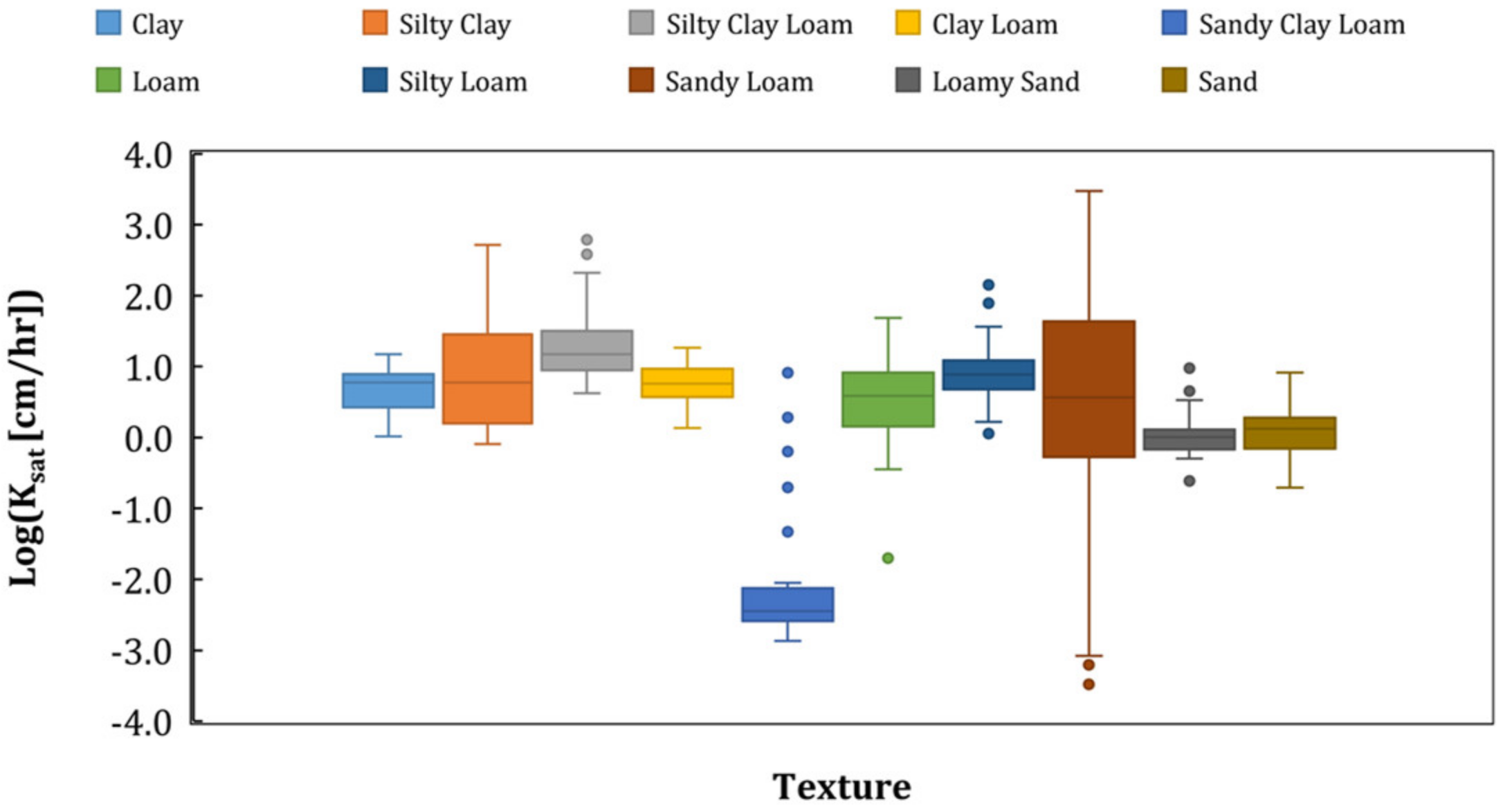
2.3. Training Dataset
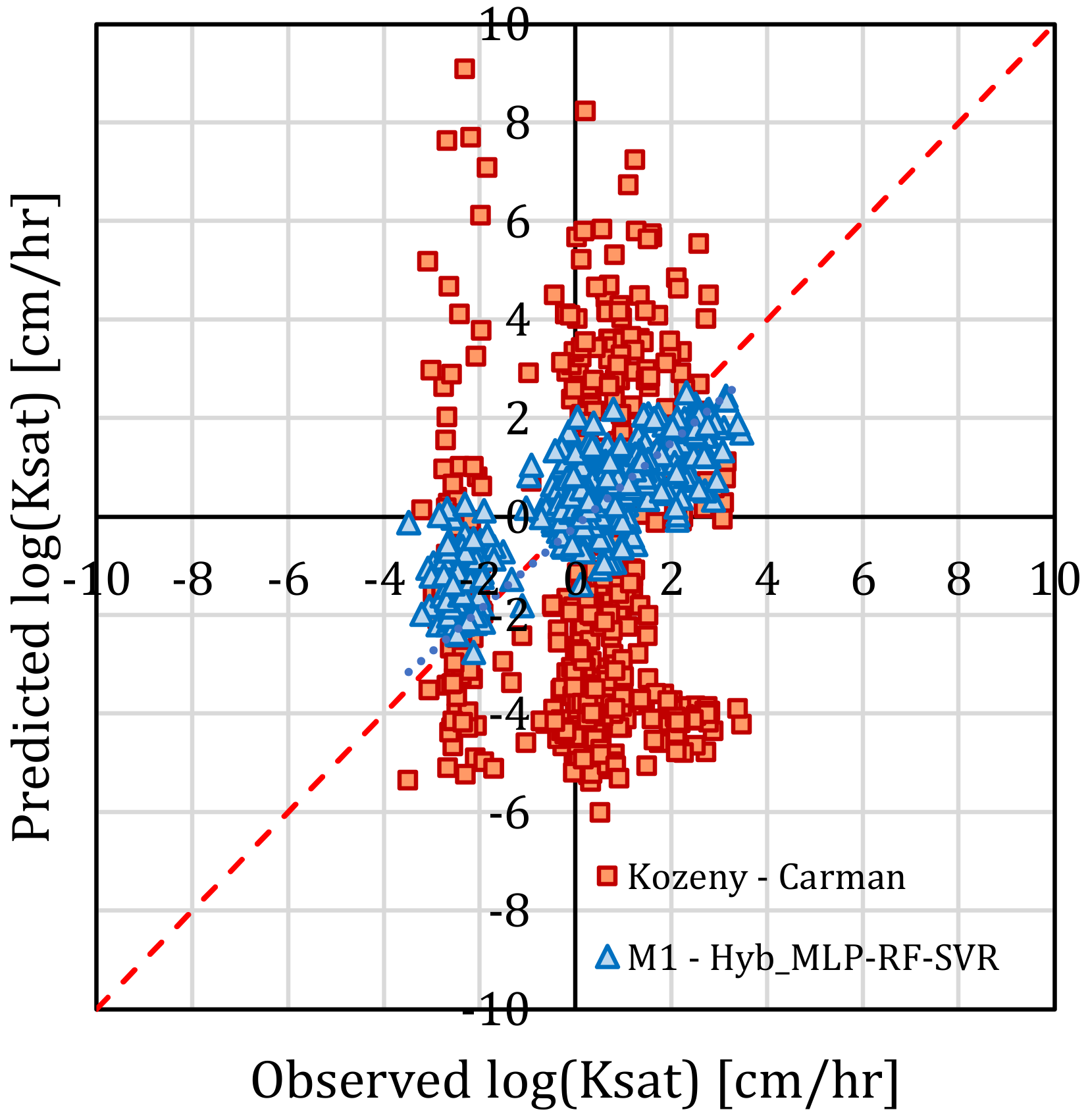
3. Results
- -
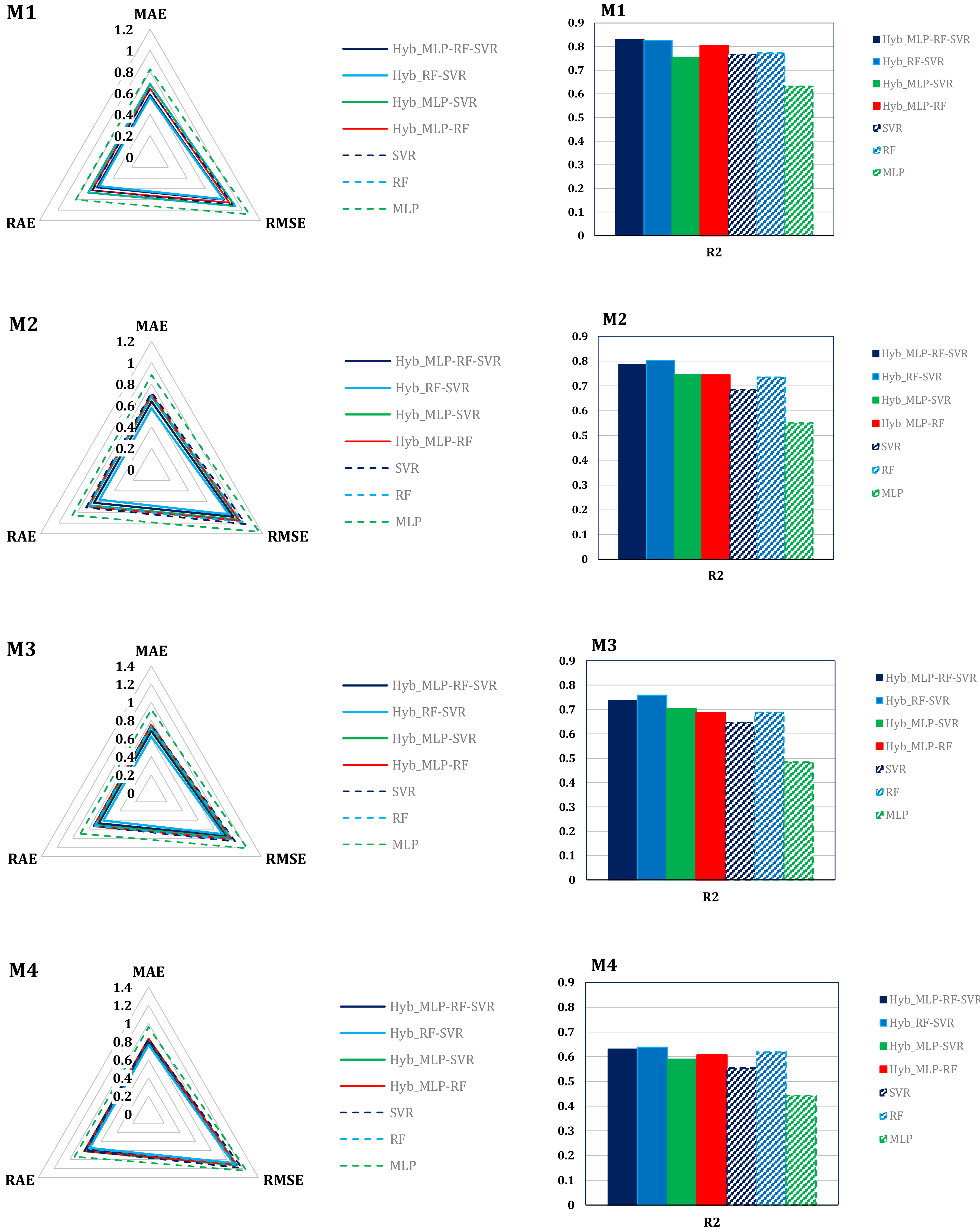
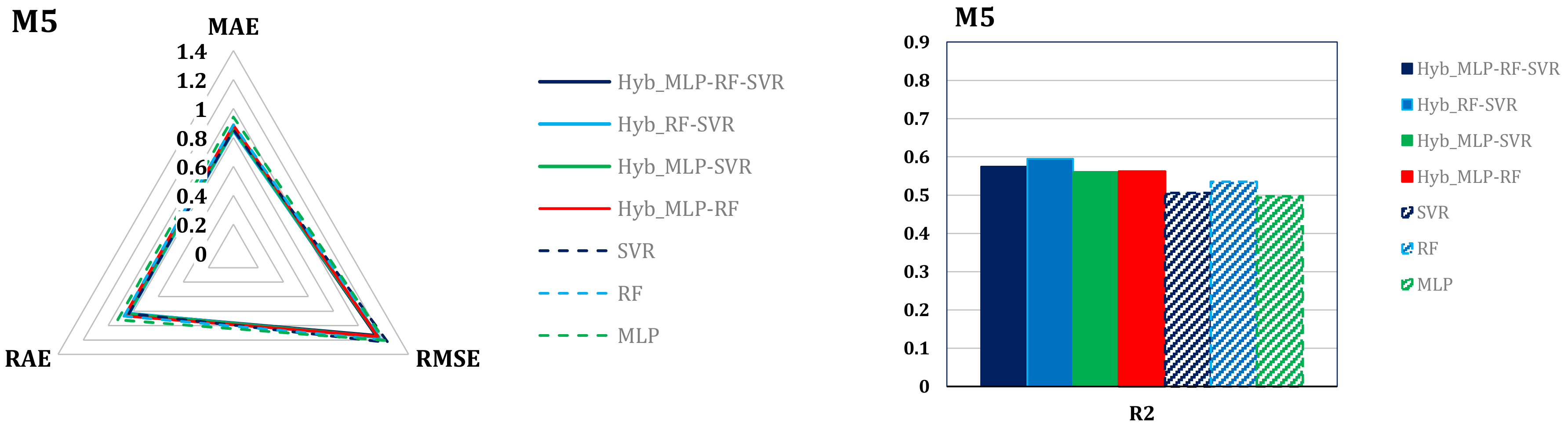
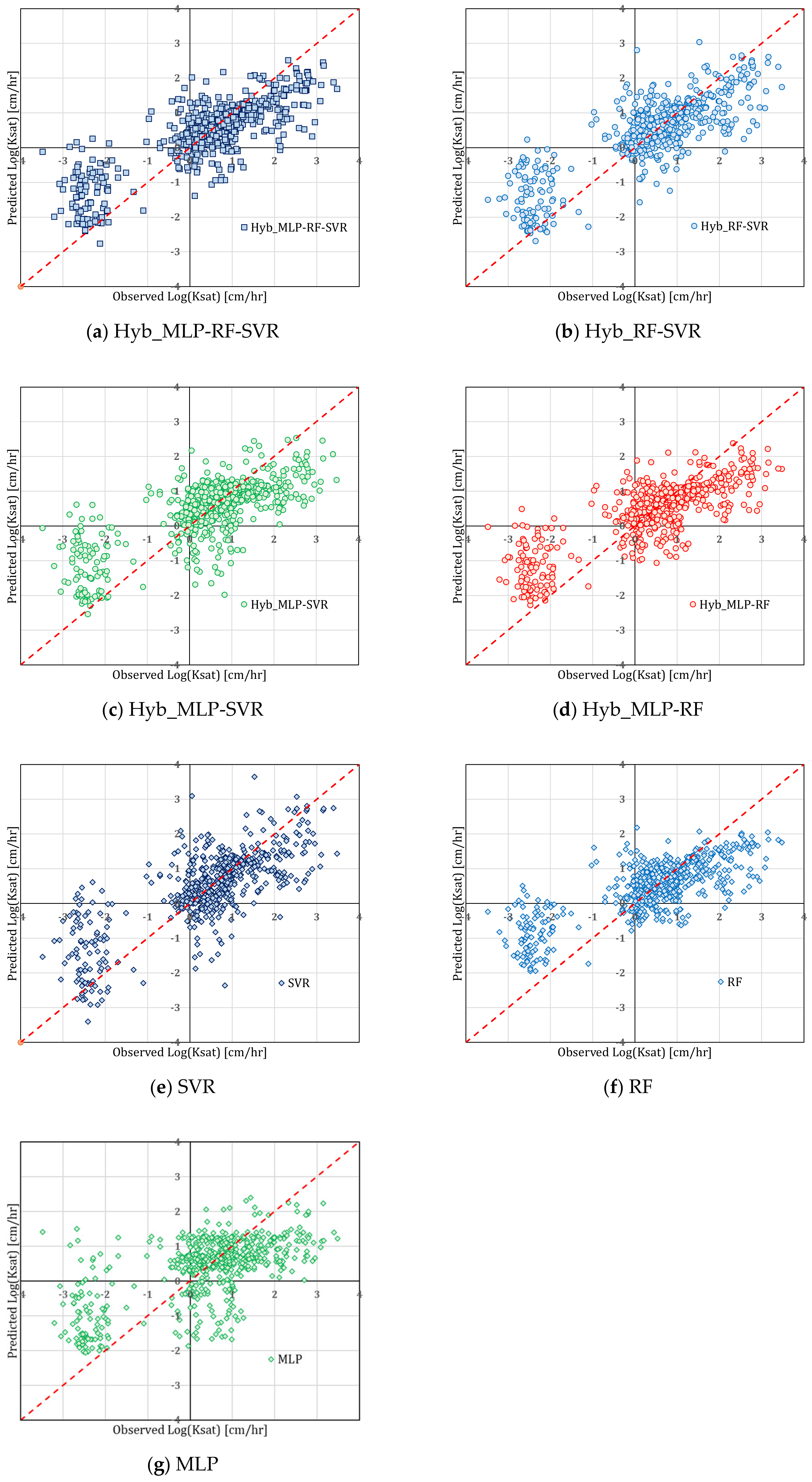
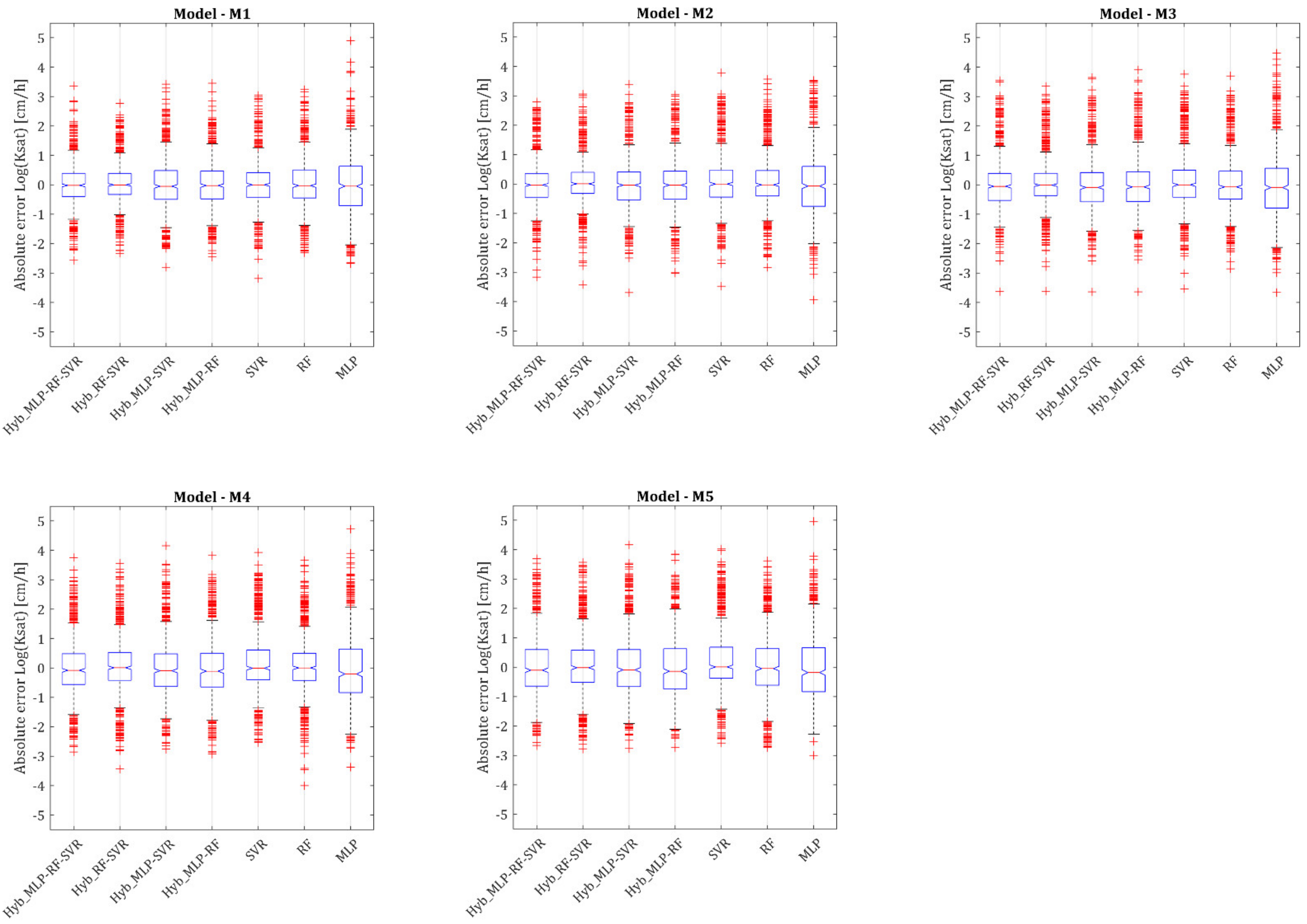
- All variants of the M1 and M2 models have a negligible bias. A more appreciable, albeit slight bias is observed in the SVR and MLP based variants of the M4 and M5 models.
- -
- The Hyb_MLP-RF-SVR and Hyb_RF-SVR variants are characterized by the lowest variance of the absolute error within all the considered models, in particular within the M1 and M2 models.
- -
- Model M1 shows the lowest number of outliers.
- -
- The distribution of the error in all variants of the M3, M4, and especially M5 models, is clearly asymmetrical.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adamowski, J.; Chan, H.F. A wavelet neural network conjunction model for groundwater level forecasting. J. Hydrol. 2011, 407, 28–40. [Google Scholar] [CrossRef]
- Alamanis, N.; Papageorgiou, G.; Chantzopoulou, P.; Chouliaras, I. Investigation on the influence of permeability coefficient k of the soil mass on construction settlements. Cases of infrastructure settlements in Greece. Wseas Trans. Environ. Dev. 2019, 15, 95–105. [Google Scholar]
- Alyamani, M.S.; Şen, Z. Determination of hydraulic conductivity from complete grain-size distribution curves. Groundwater 1993, 31, 551–555. [Google Scholar] [CrossRef]
- Angelaki, A.; Singh Nain, S.; Singh, V.; Sihag, P. Estimation of models for cumulative infiltration of soil using machine learning methods. ISH J. Hydraul. Eng. 2021, 27, 162–169. [Google Scholar] [CrossRef]
- Araya, S.N.; Ghezzehei, T.A. Using machine learning for prediction of saturated hydraulic conductivity and its sensitivity to soil structural perturbations. Water Resour. Res. 2019, 55, 5715–5737. [Google Scholar] [CrossRef]
- Azamathulla, H.M.; Wu, F.C. Support vector machine approach for longitudinal dispersion coefficients in natural streams. Appl. Soft Comput. 2011, 11, 2902–2905. [Google Scholar] [CrossRef]
- Boadu, F.K. Hydraulic conductivity of soils from grain-size distribution: New models. J. Geotech. Geoenviron. Eng. 2000, 126, 739–746. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Routledge: Abingdon, UK, 2017. [Google Scholar]
- Bui, D.T.; Khosravi, K.; Tiefenbacher, J.; Nguyen, H.; Kazakis, N. Improving prediction of water quality indices using novel hybrid machine-learning algorithms. Sci. Total Environ. 2020, 721, 137612. [Google Scholar] [CrossRef]
- Carman, P.C. Permeability of saturated sands, soils and clays. J. Agric. Sci. 1939, 29, 263–273. [Google Scholar] [CrossRef]
- Carman, P.C. Flow of Gas through Porous Media; Butterworths Scientific Publications: London, UK, 1956. [Google Scholar]
- Chapuis, R.P. Predicting the saturated hydraulic conductivity of soils: A review. Bull. Eng. Geol. Environ. 2012, 71, 401–434. [Google Scholar] [CrossRef]
- Chapuis, R.P.; Aubertin, M. On the use of the Kozeny Carman equation to predict the hydraulic conductivity of soils. Can. Geotech. J. 2003, 40, 616–628. [Google Scholar] [CrossRef]
- Crawford, J.W. The relationship between structure and the hydraulic conductivity of soil. Eur. J. Soil Sci. 1994, 45, 493–502. [Google Scholar] [CrossRef]
- Di Nunno, F.; Granata, F. Groundwater level prediction in Apulia region (Southern Italy) using NARX neural network. Environ. Res. 2020, 190, 110062. [Google Scholar] [CrossRef] [PubMed]
- Freeze, R.A.; Cherry, J.A. Groundwater; Prentice Hall Inc.: Hoboken, NJ, USA, 1979. [Google Scholar]
- Fushiki, T. Estimation of prediction error by using K-fold cross-validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar] [CrossRef]
- Granata, F. Evapotranspiration evaluation models based on machine learning algorithms—A comparative study. Agric. Water Manag. 2019, 217, 303–315. [Google Scholar] [CrossRef]
- Granata, F.; Di Nunno, F. Artificial Intelligence models for prediction of the tide level in Venice. Stoch. Environ. Res. Risk Assess. 2021, 35, 2537–2548. [Google Scholar] [CrossRef]
- Granata, F.; Di Nunno, F. Forecasting evapotranspiration in different climates using ensembles of recurrent neural networks. Agric. Water Manag. 2021, 255, 107040. [Google Scholar] [CrossRef]
- Han, H.; Giménez, D.; Lilly, A. Textural averages of saturated soil hydraulic conductivity predicted from water retention data. Geoderma 2008, 146, 121–128. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall Inc.: Hoboken, NJ, USA, 1994. [Google Scholar]
- Hu, W.; She, D.; Shao, M.; Chun, K.P.; Si, B. Effects of initial soil water content and saturated hydraulic conductivity variability on small watershed runoff simulation using LISEM. Hydrol. Sci. J. 2015, 60, 1137–1154. [Google Scholar] [CrossRef]
- Hong, B.; Li, X.A.; Wang, L.; Li, L.; Xue, Q.; Meng, J. Using the effective void ratio and specific surface area in the Kozeny–Carman equation to predict the hydraulic conductivity of loess. Water 2020, 12, 24. [Google Scholar] [CrossRef] [Green Version]
- Jabro, J.D. Estimation of saturated hydraulic conductivity of soils from particle size distribution and bulk density data. Trans. ASAE 1992, 35, 557–560. [Google Scholar] [CrossRef]
- Jorda, H.; Bechtold, M.; Jarvis, N.; Koestel, J. Using boosted regression trees to explore key factors controlling saturated and near-saturated hydraulic conductivity. Eur. J. Soil Sci. 2015, 66, 744–756. [Google Scholar] [CrossRef]
- Kişi, Ö. Streamflow forecasting using different artificial neural network algorithms. J. Hydrol. Eng. 2007, 12, 532–539. [Google Scholar] [CrossRef]
- Kittler, J.; Hatef, M.; Duin, R.P.W.; Matas, J. On Combining Classifiers. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 226–239. [Google Scholar] [CrossRef] [Green Version]
- Knoll, L.; Breuer, L.; Bach, M. Large scale prediction of groundwater nitrate concentrations from spatial data using machine learning. Sci. Total Environ. 2019, 668, 1317–1327. [Google Scholar] [CrossRef]
- Kotlar, A.M.; Iversen, B.V.; de Jong van Lier, Q. Evaluation of parametric and nonparametric machine-learning techniques for prediction of saturated and near-saturated hydraulic conductivity. Vadose Zone J. 2019, 18, 1–13. [Google Scholar] [CrossRef]
- Kozeny, J. Ueber kapillare Leitung des Wassers im Boden. Sitzungsberichte Wiener Akademie 1927, 136, 271–306. [Google Scholar]
- Kumar, M.; Sihag, P. Assessment of infiltration rate of soil using empirical and machine learning-based models. Irrig. Drain. 2019, 68, 588–601. [Google Scholar] [CrossRef]
- Modoni, G.; Darini, G.; Spacagna, R.L.; Saroli, M.; Russo, G.; Croce, P. Spatial analysis of subsidence induced by groundwater withdrawal. Eng. Geol. 2013, 167, 59–71. [Google Scholar] [CrossRef]
- Montzka, C.; Herbst, M.; Weihermüller, L.; Verhoef, A.; Vereecken, H. A global data set of soil hydraulic properties and sub-grid variability of soil water retention and hydraulic conductivity curves. Earth Syst. Sci. Data 2017, 9, 529–543. [Google Scholar] [CrossRef] [Green Version]
- Najafzadeh, M.; Etemad-Shahidi, A.; Lim, S.Y. Scour prediction in long contractions using ANFIS and SVM. Ocean Eng. 2016, 111, 128–135. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Oliveto, G. Riprap incipient motion for overtopping flows with machine learning models. J. Hydroinform. 2020, 22, 749–767. [Google Scholar] [CrossRef]
- Odong, J. Evaluation of empirical formulae for determination of hydraulic conductivity based on grain-size analysis. J. Am. Sci. 2007, 3, 54–60. [Google Scholar]
- Olsen, H.W. Hydraulic flow through saturated clays. In Clays Clay Miner; Ingerson, E., Ed.; Elsevier: Amsterdam, The Netherlands, 1962; pp. 131–161. [Google Scholar]
- Pham, B.T.; Prakash, I. A novel hybrid model of bagging-based naïve bayes trees for landslide susceptibility assessment. Bull. Eng. Geol. Environ. 2019, 78, 1911–1925. [Google Scholar] [CrossRef]
- Rahmati, M.; Weihermüller, L.; Vanderborght, J.; Pachepsky, Y.A.; Mao, L.; Sadeghi, S.H.; Moosavi, N.; Kheirfam, H.; Montzka, C.; Van Looy, K.; et al. Development and analysis of the Soil Water Infiltration Global database. Earth Syst. Sci. Data 2018, 10, 1237–1263. [Google Scholar] [CrossRef] [Green Version]
- Ren, X.; Zhao, Y.; Deng, Q.; Kang, J.; Li, D.; Wang, D. A relation of hydraulic conductivity—Void ratio for soils based on Kozeny-Carman equation. Eng. Geol. 2016, 213, 89–97. [Google Scholar] [CrossRef]
- Saberi-Movahed, F.; Najafzadeh, M.; Mehrpooya, A. Receiving more accurate predictions for longitudinal dispersion coefficients in water pipelines: Training group method of data handling using extreme learning machine conceptions. Water Resour. Manag. 2020, 34, 529–561. [Google Scholar] [CrossRef]
- Sammen, S.S.; Ghorbani, M.A.; Malik, A.; Tikhamarine, Y.; AmirRahmani, M.; Al-Ansari, N.; Chau, K.W. Enhanced artificial neural network with Harris hawks optimization for predicting scour depth downstream of ski-jump spillway. Appl. Sci. 2020, 10, 5160. [Google Scholar] [CrossRef]
- Sihag, P.; Karimi, S.M.; Angelaki, A. Random forest, M5P and regression analysis to estimate the field unsaturated hydraulic conductivity. Appl. Water Sci. 2019, 9, 129. [Google Scholar] [CrossRef] [Green Version]
- Sihag, P.; Dursun, O.F.; Sammen, S.S.; Malik, A.; Chauhan, A. Prediction of aeration efficiency of parshall and modified venturi flumes: Application of soft computing versus regression models. Water Supply 2021, 21, 4068–4085. [Google Scholar] [CrossRef]
- Singh, U.K.; Jamei, M.; Karbasi, M.; Malik, A.; Pandey, M. Application of a modern multi-level ensemble approach for the estimation of critical shear stress in cohesive sediment mixture. J. Hydrol. 2022, 607, 127549. [Google Scholar] [CrossRef]
- Taylor, D.W. Fundamentals of Soil Mechanics; Wiley: New York, NY, USA, 1948; p. 12. [Google Scholar]
- Todd, D.K.; Mays, L.W. Groundwater Hydrology; Wiley: New York, NY, USA, 2004; p. 659. [Google Scholar]
- Wang, W.C.; Chau, K.W.; Cheng, C.T.; Qiu, L. A comparison of performance of several artificial intelligence methods for forecasting monthly discharge time series. J. Hydrol. 2009, 374, 294–306. [Google Scholar] [CrossRef] [Green Version]
- Woolhiser, D.A.; Smith, R.E.; Giraldez, J.V. Effects of spatial variability of saturated hydraulic conductivity on Hortonian overland flow. Water Resour. Res. 1996, 32, 671–678. [Google Scholar] [CrossRef]
- Wu, J.; Cui, Z.; Chen, Y.; Kong, D.; Wang, Y.G. A new hybrid model to predict the electrical load in five states of Australia. Energy 2019, 166, 598–609. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Clay | Silt | Sand | dg | Sg | OC | Db | WC_s | Log(Ksat) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| [%] | [%] | [%] | [mm] | [%] | [g/cm3] | [cm3/cm3] | Log [cm/hr] | |||
| Clay | Minimum value | 40.40 | 9.0 | 4.60 | 0.002 | 6.147 | 0.650 | 0.461 | 0.217 | 0.014 |
| 1st Quartile | 48.500 | 35.0 | 9.525 | 0.005 | 9.339 | 3.413 | 0.754 | 0.326 | 0.423 | |
| Median | 51.000 | 37.3 | 11.7 | 0.007 | 10.383 | 4.350 | 0.977 | 0.397 | 0.777 | |
| 3rd Quartile | 55.800 | 38.8 | 15.375 | 0.009 | 11.914 | 6.230 | 1.101 | 0.481 | 0.892 | |
| Maximum value | 80.000 | 39.8 | 36.0 | 0.024 | 21.520 | 11.572 | 1.468 | 0.590 | 1.174 | |
| Mean | 53.557 | 33.661 | 12.777 | 0.008 | 10.846 | 5.212 | 0.963 | 0.402 | 0.668 | |
| Standard Deviation | 9.071 | 8.818 | 6.660 | 0.004 | 3.114 | 2.661 | 0.242 | 0.102 | 0.322 | |
| Skewness | 1.359 | −1.812 | 1.656 | 2.028 | 1.603 | 1.044 | 0.127 | 0.178 | −0.887 | |
| Silty Clay | Minimum value | 44.900 | 40.5 | 1.0 | 0.005 | 5.490 | 2.230 | 0.687 | 0.232 | −0.095 |
| 1st Quartile | 45.200 | 43.5 | 8.525 | 0.008 | 8.545 | 2.230 | 0.861 | 0.286 | 0.197 | |
| Median | 45.400 | 43.5 | 10.0 | 0.009 | 9.206 | 4.630 | 0.973 | 0.348 | 0.777 | |
| 3rd Quartile | 45.550 | 46.2 | 11.1 | 0.009 | 9.716 | 4.910 | 1.283 | 0.408 | 1.457 | |
| Maximum value | 55.800 | 46.4 | 13.5 | 0.010 | 10.849 | 8.680 | 1.580 | 0.471 | 2.718 | |
| Mean | 46.922 | 43.883 | 9.194 | 0.008 | 8.905 | 4.240 | 1.064 | 0.348 | 0.956 | |
| Standard Deviation | 3.833 | 2.130 | 3.357 | 0.002 | 1.424 | 2.053 | 0.268 | 0.074 | 0.859 | |
| Skewness | 1.976 | −0.329 | −1.180 | −1.618 | −1.016 | 0.927 | 0.348 | −0.073 | 0.638 | |
| Silty Clay Loam | Minimum value | 27.404 | 42.969 | 3.872 | 0.008 | 6.339 | 0.690 | 0.758 | 0.015 | 0.626 |
| 1st Quartile | 29.319 | 47.2 | 13.39 | 0.012 | 9.032 | 1.600 | 1.062 | 0.161 | 0.946 | |
| Median | 35.400 | 49.0 | 15.09 | 0.015 | 10.017 | 2.371 | 1.202 | 0.393 | 1.172 | |
| 3rd Quartile | 38.100 | 55.723 | 17.145 | 0.018 | 10.730 | 4.110 | 1.310 | 0.485 | 1.502 | |
| Maximum value | 39.651 | 63.734 | 19.70 | 0.020 | 12.421 | 6.780 | 1.476 | 0.549 | 2.787 | |
| Mean | 34.068 | 51.633 | 14.300 | 0.015 | 9.786 | 2.786 | 1.184 | 0.319 | 1.349 | |
| Standard Deviation | 4.398 | 6.164 | 4.446 | 0.003 | 1.800 | 1.590 | 0.190 | 0.187 | 0.592 | |
| Skewness | −0.387 | 0.326 | −1.147 | 0.065 | −0.623 | 0.763 | −0.353 | −0.421 | 1.199 | |
| Clay Loam | Minimum value | 27.003 | 21.926 | 20.70 | 0.016 | 11.302 | 0.577 | 0.617 | 0.030 | 0.134 |
| 1st Quartile | 29.000 | 39.575 | 23.0 | 0.019 | 13.122 | 2.165 | 0.982 | 0.356 | 0.572 | |
| Median | 30.600 | 40.5 | 25.95 | 0.024 | 13.728 | 3.045 | 1.173 | 0.433 | 0.759 | |
| 3rd Quartile | 34.830 | 44.029 | 30.800 | 0.031 | 14.638 | 3.570 | 1.406 | 0.538 | 0.969 | |
| Maximum value | 38.300 | 50.647 | 43.403 | 0.050 | 21.252 | 5.200 | 1.531 | 0.648 | 1.265 | |
| Mean | 31.971 | 40.888 | 27.141 | 0.026 | 14.110 | 2.938 | 1.190 | 0.433 | 0.726 | |
| Standard Deviation | 3.347 | 5.747 | 6.139 | 0.008 | 1.980 | 1.198 | 0.232 | 0.135 | 0.344 | |
| Skewness | 0.308 | −1.097 | 1.309 | 1.442 | 1.477 | −0.094 | −0.452 | −0.832 | −0.318 | |
| Sandy Clay Loam | Minimum value | 20.000 | 10.555 | 45.379 | 0.055 | 15.840 | 0.293 | 1.031 | 0.336 | −2.870 |
| 1st Quartile | 20.969 | 18.671 | 51.945 | 0.076 | 16.435 | 0.741 | 1.341 | 0.449 | −2.588 | |
| Median | 22.758 | 21.910 | 53.375 | 0.092 | 17.368 | 1.389 | 1.399 | 0.467 | −2.448 | |
| 3rd Quartile | 27.076 | 25.784 | 56.926 | 0.103 | 19.436 | 6.506 | 1.449 | 0.496 | −2.125 | |
| Maximum value | 32.275 | 27.318 | 68.335 | 0.161 | 22.447 | 9.614 | 1.570 | 0.577 | 0.915 | |
| Mean | 24.057 | 21.917 | 54.026 | 0.089 | 18.027 | 3.333 | 1.380 | 0.469 | −2.046 | |
| Standard Deviation | 3.968 | 4.153 | 4.422 | 0.023 | 1.970 | 3.358 | 0.113 | 0.050 | 0.969 | |
| Skewness | 0.915 | −0.631 | 0.875 | 0.767 | 0.934 | 0.813 | −1.091 | −0.247 | 1.917 |
| Clay | Silt | Sand | dg | Sg | OC | Db | WC_s | Log(Ksat) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| [%] | [%] | [%] | [mm] | [%] | [g/cm3] | [cm3/cm3] | Log [cm/hr] | |||
| Loam | Minimum value | 8.870 | 28.993 | 26.81 | 0.030 | 9.990 | 0.098 | 0.875 | 0.006 | −1.699 |
| 1st Quartile | 15.603 | 35.765 | 35.440 | 0.050 | 11.906 | 1.015 | 1.304 | 0.282 | 0.156 | |
| Median | 18.631 | 41.008 | 41.985 | 0.065 | 12.505 | 1.658 | 1.370 | 0.461 | 0.585 | |
| 3rd Quartile | 22.502 | 45.496 | 45.563 | 0.086 | 14.077 | 2.521 | 1.448 | 0.509 | 0.916 | |
| Maximum value | 25.535 | 49.488 | 51.959 | 0.123 | 17.176 | 5.968 | 1.653 | 0.679 | 1.687 | |
| Mean | 18.637 | 40.497 | 40.866 | 0.067 | 13.087 | 1.902 | 1.361 | 0.389 | 0.521 | |
| Standard Deviation | 4.137 | 5.913 | 6.601 | 0.021 | 1.651 | 1.181 | 0.164 | 0.189 | 0.482 | |
| Skewness | −0.042 | −0.353 | −0.264 | 0.286 | 0.646 | 1.013 | −0.979 | −0.963 | −1.055 | |
| Silty Loam | Minimum value | 2.029 | 50.011 | 2.30 | 0.017 | 3.862 | 1.020 | 0.342 | 0.012 | 0.057 |
| 1st Quartile | 18.176 | 52.020 | 21.915 | 0.026 | 9.334 | 1.923 | 1.289 | 0.250 | 0.681 | |
| Median | 21.504 | 53.940 | 24.840 | 0.032 | 10.379 | 2.190 | 1.414 | 0.372 | 0.891 | |
| 3rd Quartile | 22.732 | 57.445 | 27.650 | 0.040 | 10.985 | 2.497 | 1.487 | 0.479 | 1.086 | |
| Maximum value | 26.786 | 81.600 | 34.320 | 0.074 | 11.610 | 87.900 | 1.658 | 0.871 | 2.153 | |
| Mean | 19.762 | 56.092 | 24.146 | 0.035 | 9.846 | 8.286 | 1.334 | 0.352 | 0.930 | |
| Standard Deviation | 5.828 | 6.572 | 6.001 | 0.013 | 1.752 | 22.353 | 0.314 | 0.223 | 0.432 | |
| Skewness | −1.926 | 2.102 | −1.183 | 1.278 | −1.822 | 3.450 | −2.314 | 0.511 | 0.631 | |
| Sandy Loam | Minimum value | 3.094 | 6.984 | 52.20 | 0.095 | 6.874 | 0.195 | 0.472 | 0.032 | −3.481 |
| 1st Quartile | 10.30 | 18.006 | 59.76 | 0.146 | 10.555 | 0.752 | 1.213 | 0.378 | −0.275 | |
| Median | 11.667 | 21.900 | 66.90 | 0.207 | 11.206 | 1.293 | 1.360 | 0.476 | 0.564 | |
| 3rd Quartile | 15.271 | 25.856 | 69.60 | 0.240 | 13.397 | 3.490 | 1.503 | 0.528 | 1.637 | |
| Maximum value | 19.954 | 38.397 | 79.537 | 0.349 | 16.195 | 9.897 | 1.852 | 0.740 | 3.478 | |
| Mean | 12.526 | 22.225 | 65.249 | 0.200 | 11.852 | 2.383 | 1.314 | 0.460 | 0.375 | |
| Standard Deviation | 3.367 | 5.696 | 6.915 | 0.064 | 1.968 | 2.252 | 0.263 | 0.101 | 1.712 | |
| Skewness | 0.298 | 0.055 | −0.074 | 0.344 | 0.264 | 1.503 | −0.937 | −0.670 | −0.550 | |
| Loamy Sand | Minimum value | 0.684 | 9.279 | 74.870 | 0.359 | 4.277 | 0.480 | 1.010 | 0.211 | −0.614 |
| 1st Quartile | 1.023 | 14.600 | 80.346 | 0.399 | 4.357 | 2.439 | 1.408 | 0.344 | −0.166 | |
| Median | 1.023 | 15.407 | 83.570 | 0.542 | 4.357 | 5.000 | 1.724 | 0.388 | 0.007 | |
| 3rd Quartile | 5.559 | 15.407 | 83.570 | 0.542 | 7.097 | 5.000 | 1.914 | 0.419 | 0.111 | |
| Maximum value | 9.378 | 22.283 | 86.329 | 0.555 | 8.960 | 9.970 | 1.958 | 0.525 | 0.976 | |
| Mean | 3.120 | 14.855 | 82.025 | 0.485 | 5.571 | 4.428 | 1.637 | 0.388 | 0.040 | |
| Standard Deviation | 2.760 | 2.396 | 2.735 | 0.078 | 1.598 | 2.406 | 0.272 | 0.065 | 0.319 | |
| Skewness | 0.866 | −0.067 | −0.971 | −0.677 | 0.806 | 0.431 | −0.513 | −0.119 | 1.092 | |
| Sand | Minimum value | 0.159 | 0.00 | 96.064 | 0.871 | 2.015 | 0.090 | 0.843 | 0.400 | −0.706 |
| 1st Quartile | 0.193 | 0.591 | 96.653 | 0.881 | 2.054 | 8.003 | 0.843 | 0.481 | −0.155 | |
| Median | 0.653 | 2.170 | 97.086 | 0.892 | 2.208 | 8.500 | 1.042 | 0.607 | 0.123 | |
| 3rd Quartile | 1.743 | 3.181 | 97.617 | 0.901 | 2.577 | 8.500 | 1.375 | 0.682 | 0.281 | |
| Maximum value | 2.344 | 3.731 | 97.656 | 0.909 | 2.855 | 8.766 | 1.610 | 0.682 | 0.915 | |
| Mean | 0.992 | 1.942 | 97.032 | 0.891 | 2.332 | 7.032 | 1.133 | 0.574 | 0.090 | |
| Standard Deviation | 0.973 | 1.609 | 0.665 | 0.015 | 0.354 | 3.415 | 0.339 | 0.126 | 0.545 | |
| Skewness | 0.582 | −0.150 | −0.434 | −0.151 | 0.791 | −2.406 | 0.463 | −0.425 | 0.084 |
| Model | Input Variables | Algorithm | R2 | MAE Log10 [cm/h] | RMSE Log10 [cm/h] | RAE |
|---|---|---|---|---|---|---|
| M1 | Clay, Silt, Sand, dg, Sg, OC, Db, WCs | Hyb_MLP-RF-SVR | 0.829 | 0.582 | 0.802 | 57.19% |
| Hyb_RF-SVR | 0.826 | 0.562 | 0.796 | 55.16% | ||
| Hyb_MLP-SVR | 0.755 | 0.683 | 0.921 | 67.02% | ||
| Hyb_MLP-RF | 0.803 | 0.642 | 0.861 | 63.05% | ||
| SVR | 0.766 | 0.637 | 0.898 | 62.51% | ||
| RF | 0.773 | 0.677 | 0.929 | 66.46% | ||
| MLP | 0.632 | 0.821 | 1.079 | 80.63% | ||
| M2 | dg, Sg, OC, Db, WCs | Hyb_MLP-RF-SVR | 0.786 | 0.634 | 0.884 | 62.29% |
| Hyb_RF-SVR | 0.802 | 0.572 | 0.838 | 56.19% | ||
| Hyb_MLP-SVR | 0.747 | 0.684 | 0.937 | 67.15% | ||
| Hyb_MLP-RF | 0.744 | 0.699 | 0.955 | 68.76% | ||
| SVR | 0.685 | 0.721 | 1.019 | 70.82% | ||
| RF | 0.735 | 0.689 | 0.979 | 67.72% | ||
| MLP | 0.551 | 0.882 | 1.164 | 85.58% | ||
| M3 | dg, Sg, Db, WCs | Hyb_MLP-RF-SVR | 0.737 | 0.681 | 0.956 | 66.96% |
| Hyb_RF-SVR | 0.759 | 0.622 | 0.910 | 61.04% | ||
| Hyb_MLP-SVR | 0.703 | 0.724 | 0.999 | 71.07% | ||
| Hyb_MLP-RF | 0.687 | 0.749 | 1.026 | 73.65% | ||
| SVR | 0.647 | 0.748 | 1.069 | 73.51% | ||
| RF | 0.688 | 0.737 | 1.035 | 72.40% | ||
| MLP | 0.484 | 0.918 | 1.221 | 90.19% | ||
| M4 | dg, Sg, OC, Db | Hyb_MLP-RF-SVR | 0.631 | 0.793 | 1.084 | 77.89% |
| Hyb_RF-SVR | 0.638 | 0.762 | 1.075 | 74.79% | ||
| Hyb_MLP-SVR | 0.59 | 0.829 | 1.126 | 81.49% | ||
| Hyb_MLP-RF | 0.606 | 0.831 | 1.111 | 81.61% | ||
| SVR | 0.554 | 0.827 | 1.188 | 81.26% | ||
| RF | 0.619 | 0.775 | 1.101 | 76.14% | ||
| MLP | 0.443 | 0.957 | 1.252 | 93.95% | ||
| M5 | dg, Sg, Db | Hyb_MLP-RF-SVR | 0.574 | 0.856 | 1.142 | 84.07% |
| Hyb_RF-SVR | 0.595 | 0.848 | 1.164 | 83.37% | ||
| Hyb_MLP-SVR | 0.561 | 0.861 | 1.155 | 84.46% | ||
| Hyb_MLP-RF | 0.562 | 0.884 | 1.152 | 86.79% | ||
| SVR | 0.506 | 0.851 | 1.235 | 83.47% | ||
| RF | 0.535 | 0.889 | 1.197 | 87.26% | ||
| MLP | 0.497 | 0.941 | 1.208 | 92.32% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Granata, F.; Di Nunno, F.; Modoni, G. Hybrid Machine Learning Models for Soil Saturated Conductivity Prediction. Water 2022, 14, 1729. https://doi.org/10.3390/w14111729
Granata F, Di Nunno F, Modoni G. Hybrid Machine Learning Models for Soil Saturated Conductivity Prediction. Water. 2022; 14(11):1729. https://doi.org/10.3390/w14111729
Chicago/Turabian StyleGranata, Francesco, Fabio Di Nunno, and Giuseppe Modoni. 2022. "Hybrid Machine Learning Models for Soil Saturated Conductivity Prediction" Water 14, no. 11: 1729. https://doi.org/10.3390/w14111729
APA StyleGranata, F., Di Nunno, F., & Modoni, G. (2022). Hybrid Machine Learning Models for Soil Saturated Conductivity Prediction. Water, 14(11), 1729. https://doi.org/10.3390/w14111729