1. Introduction
Accurate and reliable streamflow forecasting is an important basis for rational allocation and sustainable utilization of water resources [
1,
2]. It can not only provide key decision-making information for avoiding natural disasters such as floods and droughts but also be conducive to the safe and economic operation of reservoirs and the coordination of water utilization among different departments in order to realize the most comprehensive benefits [
3]. As is well known, the evolution of a water cycle system is affected by the synthetical effects of weather, the underlying surface, the ocean, and climate. Such a complex water cycle system will produce streamflow with many natural characteristics such as high-dimensional nonlinearity, non-stationarity, wet and dry alternation, and uneven spatial and temporal distribution. These inherent features make it difficult to predict streamflow accurately, especially in a changing environment.
Most historical studies focused on studying new streamflow forecasting models to adapt to the changing world. The forecasting models can be roughly divided into two main classes: physical models (PMs) and data-driven models (DDMs) [
4]. Models in the first group use a series of mathematical and physical equations to represent evaporation, interception, infiltration, and other key processes of a water cycle system. Hence, PMs always have high demands in many areas, requiring, e.g., a deep understanding of the physical mechanisms of hydrological processes, large amounts of input climate data, large numbers of parameters to be estimated, large computational resources, and so on. Therefore, they are rarely used in practice.
Unlike PMs, DDMs have simpler model structures and need less modeling data. Early DDMs mainly focused on regression models such as linear regression models, autoregressive models, autoregressive moving average (ARMA) models, autoregressive integrated moving average models, moving average models, and so on [
5]. Due to the nonlinearities and uncertainties of streamflow, existing regression methods often do not provide the desired forecasting accuracy. Nowadays, with the development of machine learning (ML) techniques, DDMs have attracted much more attention as an alternative forecasting tool for monthly streamflow. To date, a number of DDMs based on ML techniques have been utilized successfully for streamflow forecasting. For example, ANNs (artificial neural networks) are widely used to describe hydrological behavior and have a good nonlinear fitting performance in comparison to traditional regression models [
6]. Support vector machine (SVM) and least squares support vector machine (LSSVM) models are also employed in streamflow forecasting, and show good performances [
7,
8]. Evolutionary adaptive neuro-fuzzy inference systems (ANFIS) [
9,
10], extreme learning machine (ELM) [
4,
11,
12] and random forest (RF) [
13,
14] models have also shown potential for streamflow forecasting. Recently, deep learning techniques such as convolutional neural networks (CNNs) [
15], long short-term memory networks (LSTMs) [
16,
17] and their associated variants, gated recurrent units (GRU) [
18], stacked LSTMs (S-LSTMs), and bidirectional LSTMs (Bi-LSTMs) [
19] have been popular in hydrology forecasting. However, pure ML models still provide poor forecasting accuracy for complex nonlinear and non-stationary runoff series when the model is developed with only previous rainfall information as input [
20].
To further promote the performance of a DDM based on machine learning, two methods are often utilized. The first approach is to consider more climate factors as inputs rather than just rainfall information [
21,
22,
23,
24]. In this case, the more factors that are considered, the more complex the prediction model will be. Thus, an efficient input variable selection (IVS) method must be used. Unfortunately, there are no general methods available at present. Widely used IVS techniques can be divided into wrapper (also called model-based) and filter (also called model-free) methods [
25,
26]. The wrapper method depends on the idea of training and testing several forecasting models with different input sets and determining the optimal input set with the best model performance. Unlike the wrapper approach, filter approaches directly determine the optimal input vector according to some index relating the candidate input vector and the forecasted variable (such as distance between classes, statistical correlation, or information theory). Representative and widely used filter approaches include Pearson correlation coefficient (PCC) [
27,
28] and partial mutual information (PMI) [
26] methods. Usually, wrapper approaches achieve better performances, but they have higher computational resource requirements than filter methods. In this paper, a wrapper method is applied to determine the optimal predictors, to take advantage of the easy hybridization of machine learning techniques. In this paper, two types of IVS are adopted. One is a filter method named PCC, which is well-known for its simple operation. The other is random forest (RF), a typical ML method with the advantage over other commonly used ANNs and SVMs of needing no optimization [
29]. In most previous applications of RF in hydrological prediction, it has been used as a prediction model rather than an IVS method. Pham et al. [
30] evaluated the potential of RF to achieve streamflow forecasts. Shen et al. [
31] used RF for correcting daily discharge predictions. Ahana et al. [
32] examined the abilities of LSTM, ELM, and RF to predict monthly streamflow. This paper focuses on the utilization of the ability of RF for feature selection.
Another way to improve the performance of DDM forecasting models is by using hybrid models, which integrate signal decomposition algorithms and/or optimization algorithms. For example, Yaseen et al. [
33] applied three different bio-inspired optimization algorithms (GA, PSO, and DE) to optimize the membership function of ANFIS. Chen et al. [
4] used BSA to optimize the parameters of the standard ELM model, to improve flood forecasting accuracy. Maheswaran and Khosa [
34] proposed a wavelet–Volterra coupled (WVC) model for one-month-ahead streamflow forecasting. Kalteh [
35] investigated the relative accuracy of artificial neural network (ANN) and SVR models coupled with wavelet transforms in monthly river flow forecasting and compared them to regular ANN and SVR models, respectively. Sun et al. [
27] considered the merits of adaptive variational mode decomposition (AVMD), a backtracking search algorithm (BSA), and regularized extreme learning machine (RELM) to develop a novel hybrid wind speed forecasting model. All this research suggested that hybrid models outperform single models. Unfortunately, coupling signal decomposition algorithms may introduce large decomposition errors when performing decomposition without using future information [
6].
Additionally, most research using DDMs has focused on providing deterministic results with a single point value. However, deterministic forecasting cannot quantify the internal uncertainty level of forecasting, so it provides limited information for decision makers in relevant departments [
36]. To better support modern water resources management, it is also valuable to predict an interval covering possible future streamflow, since forecasting errors are inevitable. Interval forecasting approaches can be divided into two groups: parametric and nonparametric methods. Parametric methods assume that the predictive distribution follows a given parametric distribution. The normal distribution is a widely used distribution. Nonparametric methods relax the assumption regarding the shape of the predictive distribution. Widely used nonparametric interval forecasting methods include kernel density estimation, quartile regression (QR), and bootstrap-based techniques [
27,
37]. Nowadays, a very well-known ML method named Gaussian process regression (GPR), which is a nonparametric kernel-based probabilistic approach, has gained considerable attention in various fields such as biodiesel properties [
38] and solar irradiance [
39] forecasting. The main merit of GPR over other ML methods is that it inherits the strong learning ability of ML and the strong reasoning capacity of the Bayesian method for solving uncertainty problems. Therefore, it can provide both deterministic forecasting results and the uncertainty interval for a given significance level.
In general, the existing research based on DDMs has room for improvement in the following aspects:
- (1)
Model inputs lack climate information. Natural hydrological and other geophysical processes are interactive, and therefore model inputs only taking rainfall and/or streamflow into consideration do not fully characterize the impact of climate change on runoff.
- (2)
The widely used PCC input selection method reflects linear relationships between streamflow and its potential forecasting factors, which is not entirely consistent with the actual relationships between them.
- (3)
Numerous studies focus on 1-month-ahead streamflow forecasting and provide deterministic forecasting results, which cannot provide sufficient decision-making information for reliable and safe water resource management.
To address the above questions, in this study, a multi-scale-variables-driven streamflow forecasting (MVDSF) framework is proposed. In the MVDSF framework, many climate factors and circulation factors are first adopted as supplementary predictors to represent climate change. Then, the dimensions of the input data are reduced to save computing resources and modeling time and to reduce the risk of overfitting. After that, using the selected variables as inputs, a data-driven model is constructed, and its parameters are optimized using a grid search algorithm. Finally, the well-tuned data-driven model is applied to predict streamflow.
Here, this framework is realized by combining RF and GPR with multi-scale variables (hydrometeorology, climate predictors) as inputs. The framework is referred to as RF-GPR-MV. The motivation behind the choice of RF is that it is a powerful tool for feature selection for high-dimensional variables but has been less frequently investigated with respect to monthly streamflow forecasting. The reason behind the choice of GPR is that: (1) it has been less frequently investigated in the field of multi-step-ahead monthly streamflow forecasting, (2) it has a fast learning speed compared to other ML models (ANN, SVM, and ELM), and (3) it has both nonlinear fitting ability and uncertainty quantification ability.
The RF-GPR-MV model can provide both deterministic and probabilistic streamflow prediction results. The RF is applied to reduce the input dimensions, and the GPR is applied as the base forecasting module. Comparative experiments have been conducted to verify the proposed RF-GPR-MV model at different hydrological stations. Specifically, the commonly used PCC is separately integrated with the single GPR and two frequently used classical neural networks (BP and GRNN) to validate the effectiveness of the proposed RF-GPR-MV when using high-dimensional inputs. Additionally, to illustrate the effect of climatic factors and circulation indices on forecasting accuracy, input that only uses the previous streamflow and antecedent precipitation is also adopted. Thus, several comparison models are constructed, abbreviated as PCC-GPR-MV, PCC-GPR-QP, PCC-BP-QP, and PCC-GRNN-QP. These models are applied to forecast the 1-month-ahead to 12-month-ahead streamflow at the two main hydrological stations in the Jinsha River basin. The results reveal that the RF-GPR-MV outperforms the other comparison models, emphasizing the contributions of climate and circulation indicators for monthly streamflow forecasting with long lead times.
The main contributions of this paper are as follows:
- (1)
A high-dimensional nonlinear candidate input factor set with more than 400 items is constructed for the first time.
- (2)
A hybrid RF-GPR-MV model in a MVDSF framework is designed for multi-step-ahead monthly streamflow forecasting.
- (3)
The impact of different factors that contribute to the improvement of the hybrid model are evaluated quantitatively.
The reminder of this paper is organized as follows.
Section 2 is the Materials and Methods section.
Section 3 presents the framework and procedure of the model.
Section 4 is a case study.
Section 5 provides and discusses the results. Finally,
Section 6 concludes this paper with a summary.
2. Materials and Methods
2.1. Streamflow Prediction Based on ML
Monthly streamflow prediction can be considered as a nonlinear regression problem. For this nonlinear regression problem, the main goal is to find a hydrologic cycle system transfer model for the relationship between streamflow Q and many covariates X based on n observed pairs , and then make predictions for the streamflow. The covariates include local meteorological (precipitation, potential evapotranspiration, temperature, and humidity) and global climate information.
The streamflow forecasting can be mathematically expressed as:
where
is the predicted streamflow at time
t +
d,
L represents the lead time,
stands for the historical flow with
time steps,
represents the antecedent precipitation up to
time steps, and
represents the other relevant local meteorological and/or global climate and circulation factors up to
time steps that make higher contributions to the streamflow at time
t +
d.
The other relevant factors include local meteorological indices such as potential evapotranspiration, temperature, humidity, and/or the flow from major control stations in the upper reaches, together with climate indices such as ENSO. In addition, di, i = 1, 2, and 3 is the time lag for these relevant factors and is a hydrologic cycle system transfer function to describe the complicated nonlinear interaction between the flow and its relevant factors at the basin scale.
Two categories of models can be employed to estimate the function . One category includes PMs such as the famous Xin’anjiang hydrological model, and the other category includes DDMs based on ML techniques.
In many cases, DDMs based on ML can be used to replace PMs for multi-step advance monthly runoff prediction, for reasons such as insufficient understanding of the physical mechanisms of the water cycle, the low accuracy of long-term meteorological prediction results, and the lack of modeling data in some areas. In addition, DDMs are easy to implement and can be combined with other emerging technologies to improve their prediction performance.
In this paper, a new DDM named RF-GPR-MV is proposed by integrating RF and GPR for multi-step-ahead monthly streamflow forecasting. To further improve the physical fundamentals of the forecasting model, as well as local hydrometeorological factors, some global climate factors are also considered, in order to represent climate change in the proposed model. In this novel hybrid model, RF is applied to find the optimal input vector from the huge number of candidate input variables, and GPR, a well-known ML technique, is adopted as a basic forecasting module to characterize the hydrologic cycle system transfer function . The theories of RF and GPR are presented in the following subsections.
2.2. Random Forest
Random forest (RF) is an ensemble machine learning method for improving the performance of classification and regression trees, as well as for reducing overfitting risk. It has become popular since it was brought out and has been widely utilized in many fields such as rainfall forecasting [
40], solar radiation forecasting [
41], urban water consumption [
42], and land cover classification [
43]. It is a powerful machine learning tool for identifying features and/or fitting nonlinear relationships for high-dimensional data, especially in the case of small samples. In addition, it also can give an importance score for each input feature variable by permuting each feature.
Since all the data used in this study are time series, the rest of this section is limited to regression issues. For a given input vector
X with
m features, with a corresponding output vector Y, a training set
Sn with
n observations can be constructed:
The bootstrap sampling technique is firstly employed to obtain training samples from the original data. A bootstrap sample is generated by randomly selecting
n observations with replacements from the original training data. Each observation has the same probability 1/
n of being chosen and may appear more than once. The bootstrap samples
are used to establish
B regression trees, and the rest of the out-of-bag (OOB) data
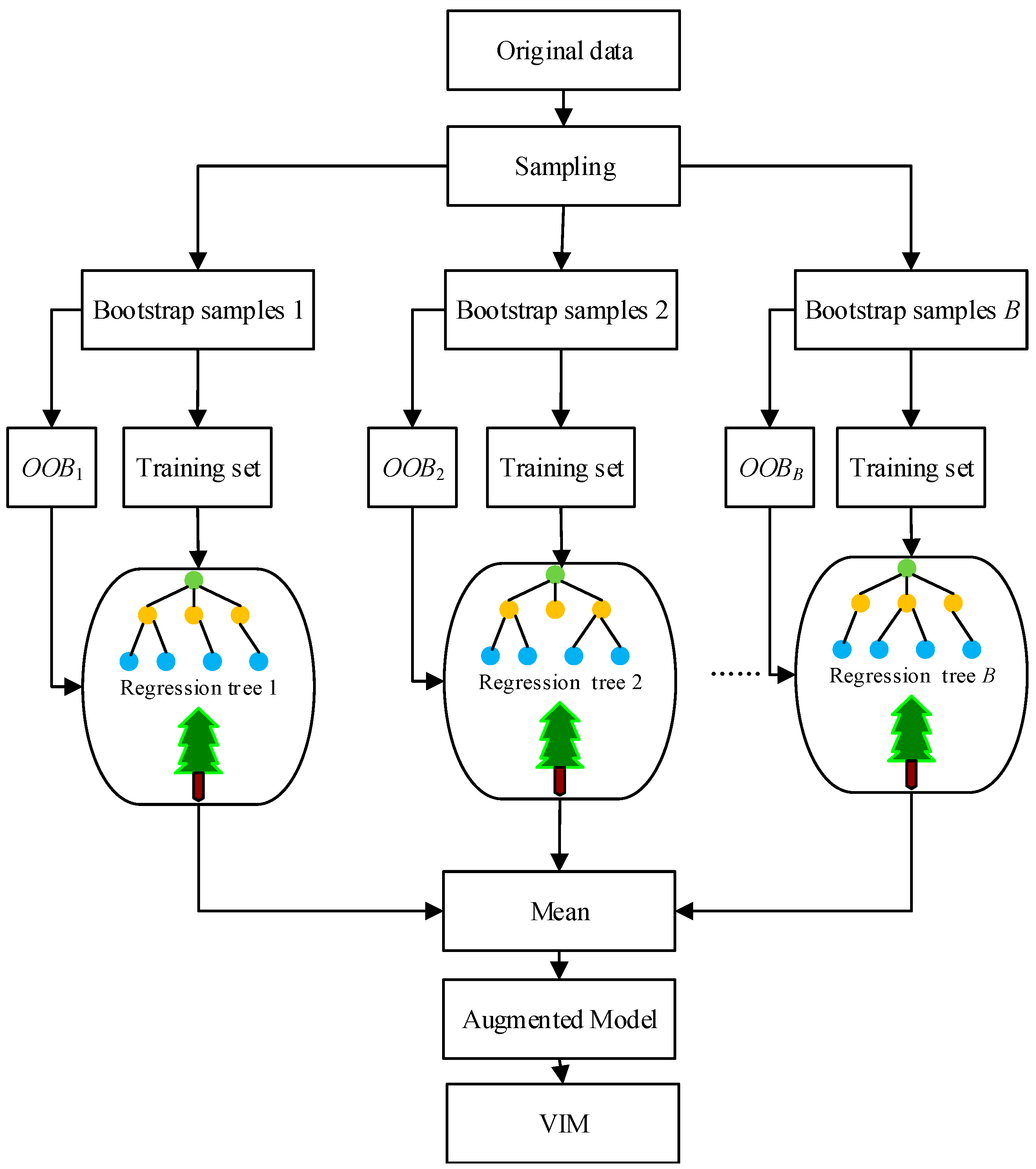
are applied to verify the performance of the built regression trees. All these trees compose a random forest, as shown in
Figure 1. The final prediction results of the RF are obtained by aggregating all the regression trees. The prediction precision of each regression tree can be represented by the mean squared error (MSE) between the predicted values and the observed values of the OOB data.
The i-th regression tree Tb (b = 1, 2, …, B) is employed to predict the output of .
There are many factors affecting the generation of streamflow, and these factors interact with each other. The correlations between variables must be considered in the process of determining the RF importance measure. The procedure of RF for estimating the correlated variable importance measure can be briefly described as follows:
Step 1. Estimate the mean vector and covariance matrix from the original data .
Step 2. Grow unpruned regression trees Tb (b = 1, 2, …, B) to fit the bootstrap samples.
Step 3. Use the regression trees Ti to forecast the corresponding OOB data, where the estimation is .
Step 4. Divide the into two parts: vector and matrix .
Step 5. Generate a new matrix and vector on the basis of vector and matrix . Their mean vectors and covariance matrices are different from the original and , and the new ones should be used in the transformation process. For the multivariate normal distribution, , ,, and can be calculated as shown below.
The
and
of
X can be written as:
The conditional mean vector and covariance matrix can be acquired via:
After that, the Nataf transform can be used to generate the normal correlation samples and .
Step 6. Construct new matrices
and
based on matrix
, vector
, and matrix
.
Step 7. Use the regression tree to predict the response of and the response of , respectively. The errors of the correlated variables can be obtained, and the average values are the impact of variable Xi.
2.3. Gaussian Process Regression
GPR, a very well-known machine learning (ML) method, is a nonparametric Bayesian approach [
44]. It was developed by combining Bayesian and statistical theory. This method not only inherits the flexible inductive reasoning ability of Bayesian methods but also has the parallel processing, self-organizing, adaptive, and self-learning abilities of ML. Hence, it has obvious advantages in solving high-dimensional complex nonlinear regression problems with few samples. These characteristics mean that GPR is widely applied in theoretical research and many practical engineering problems [
38].
Given a training set
with
n observations, where
y is the variable to be predicted (such as monthly streamflow),
X is the input vector for
y with
m-dimensional factors. In the GRP model, the input vector
X and the target output
y should obey the following equation:
where
represents the latent nonlinear function and its prior probability distribution,
is a Gaussian distribution, the random residuals
are assumed to have iid Gaussian distributions with mean 0 and variance
, and
is the
n-dimensional unit matrix.
The stochastic process state set of the input variable
X follows an
n-dimensional joint Gaussian distribution. According to the definition of a Gaussian process, the state set g of the stochastic process is a Gaussian process, and its probability function, denoted GP, can be uniquely determined by its mean function
and covariance function matrix
.
According to the properties of GP, the target output
y of the training input sample
Sn and the output of testing sample
follow the multivariate Gaussian distribution as follows:
where
is the covariance matrix of the testing input set
and the training input variables
X, and
is the covariance for
itself.
Under the given conditions of the training input data
X and output
y, the posterior distribution of the predicted value
can be inferred according to the Bayesian posterior probability mathematical formula of the new input
:
where
is the expected value of
and
is the posterior variance for
, to measure the uncertainty of the predicted results.
Based on the above statement, a GP can be determined by its mean function and the covariance function (CoF) matrix. The standard GP can be transformed into a Gaussian distribution with a mean function of 0. Hence, the key task of solving the GPR model is to determine its covariance function. The GPR requires that its covariance function is a positive definite matrix in the case of a finite input sample size. The above requirements satisfy the Mercer theorem, so the covariance function of the GPR is also called a kernel function and is used to measure the fitting degree between the measured value and the predicted value. There are a variety of choices for the CoF, among which the isotropic squared exponential covariance function (covSEiso) is the most widely used, because the covSEiso has the characteristic of being infinitely differentiable and can then ensure that the GPR is very smooth. Its mathematical expression is:
where
is the signal variance linked to the general function variance and
l is the scale of the variance. In addition,
gives the local correlation and
l characterizes the correlation between the input and output. A smaller value of
l means that the predicted results of the model change rapidly in the input space, indicating weak correlation.
Generally,
is called the hyperparameter set for the CoF of the GPR. The most commonly used method for solving hyperparameters is the maximum likelihood function (MLF). MLF is used to estimate the unknown hyperparameters from the training data by inference. In this process of inference, the conditional probability
of the training sample is calculated first, and then its likelihood function
can be obtained. The mathematical expression for
is:
Next, the derivative of
at
is calculated as:
Finally, the optimal can be obtained by minimizing the above partial derivative equation using conjugate gradient, Newton’s method, and other optimization algorithms. Once the optimal is obtained, the expected value and the posterior variance of can be calculated using Equation (9).
According to the sigma rule for Gaussian distributions, the confidence interval of the predicted value for a given confidence level 1-α can be obtained as follows:
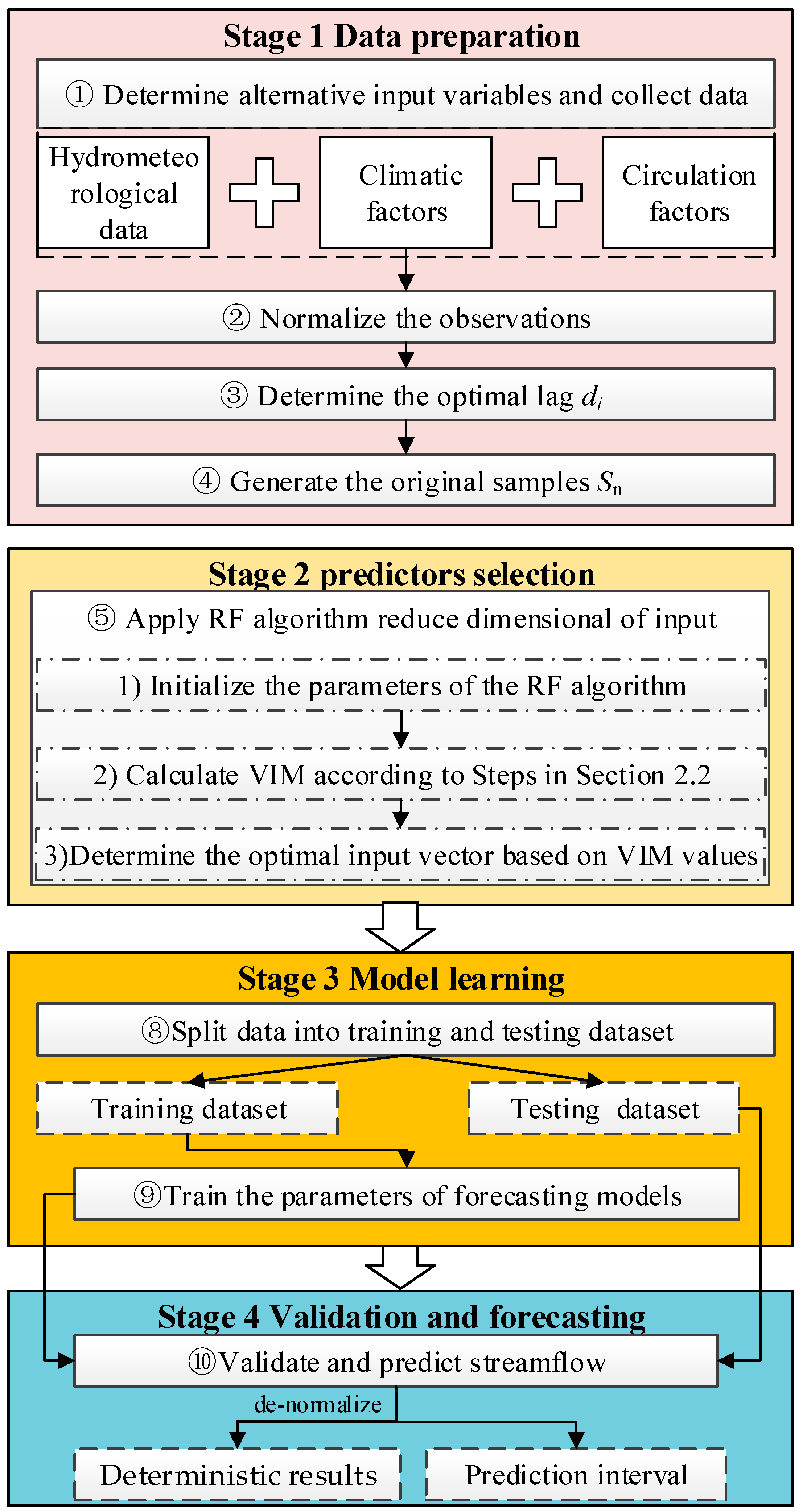
3. Framework and Procedure of the Proposed Model
Traditional DDMs for monthly streamflow forecasting lack physical mechanisms and usually provide deterministic results with a single streamflow value. They have limited capacity to forecast streamflow with nonlinear, highly irregular, non-stationary characteristics. Thus, they provide limited and less reliable information for activities related to water resource management. Therefore, in this study, an MVDSF framework is developed. It is realized by integrating RF and GPR with multi-scale variables (hydrometeorology, climate predictors) as inputs and is referred to as RF-GPR-MV. This framework contains four main stages: (1) data preparation, (2) selection of predictors, (3) model learning, and (4) validation and forecasting. In the first stage, contemporaneous data regarding hydrometeorology and climate variables associated with streamflow are collected. In the second stage, RF is applied to filter the dominant variables by discarding redundant and irrelated information, thereby reducing the dimension of the input vector. This can save time and decrease the risk of overfitting. In the third stage, GPR based on Bayesian theory is adopted to simulate the nonlinear relationships between the optimal input vector and the streamflow for a specific location. In the last stage, the optimized GPR is applied to predict the testing dataset. A diagram of the MVDSF framework is shown in
Figure 2, and the RF-GPR-MV procedure is summarized as follows:
Step 1: Make a preliminary determination of the alternative input variables and collect their historical observations.
According to the formation mechanism for streamflow, the alternative input factors can be selected and constructed from many related variables such as hydrological and meteorological variables, climate factors, and circulation indices that drive the operation of the water cycle system.
Step 2: Normalize the observations.
The potential input variables have local and teleconnected relationships with runoff, and they have different physical dimensions. Therefore, all these observations must be normalized in this step to eliminate the influence of physical dimensions.
Step 3: Determine the optimal lag di (i = 1, 2,…, m).
The response time of runoff to different variables is different. A PACF (partial autocorrelation function) is used to determine the optimal lag for each variable by forming predictors.
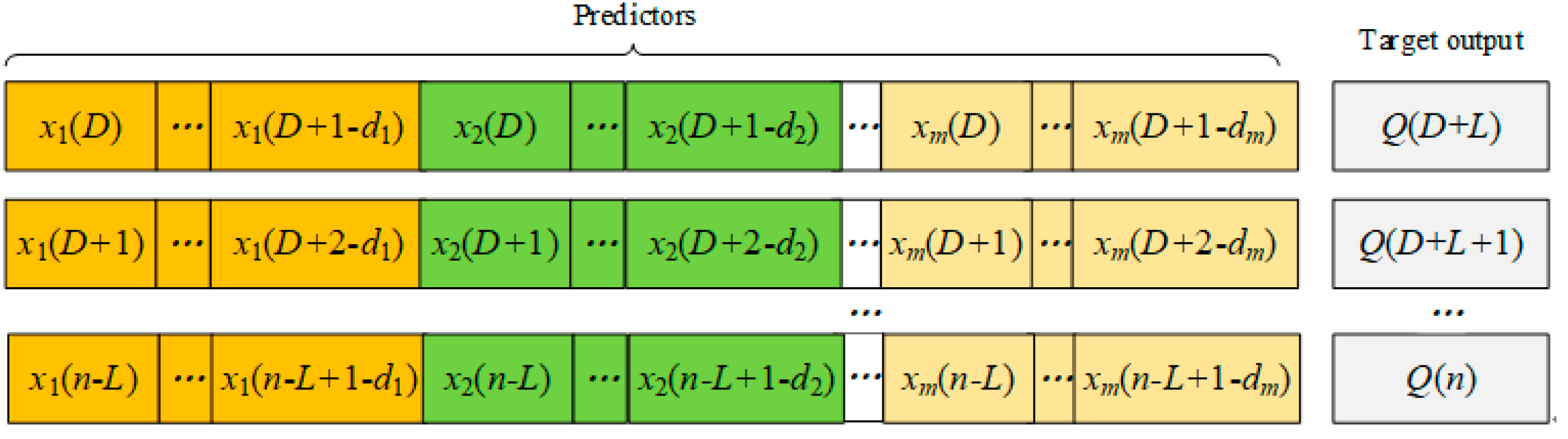
Step 4: Generate the original samples Sn.
The
Sn = {(
X1,
y1),(
X2,
y2), …, (
Xn,
yn)},
X ∈
Rm,
y ∈
R contains input predictors and the target output for different lead times, as shown in
Figure 3.
Step 5: Apply the RF algorithm to reduce the dimensions of the input.
Step 5-1: Initialize the parameters of the RF algorithm.
In this step, two key parameters of the RF will be initialized: the number of regression trees B and the maximum number of variables used to grow a regression tree mtry. Generally, mtry is recommended to be m/3, where m is the dimension of the alternative input vector.
Step 5-2: Calculate the VIM according to the steps in
Section 2.2.
Step 5-3: Determine the optimal input vector based on the VIM values.
List the VIM in descending order. Then, the variables with higher VIM values are selected.
Step 6: Split the data obtained in Step 5 into training and testing datasets.
The normalized data obtained in Step 5 are split into two sets: the training and testing datasets. In this study, the training and testing datasets account for 75% and 25%, respectively, of the monthly data.
Step 7: Train the parameters of the GPR forecasting model.
The training dataset is used to construct the GPR and learn its hyperparameters.
Step 8: Validate and predict the streamflow.
The testing dataset is applied to cross-validating and forecasting the streamflow using the optimized model produced by Step 7. The output runoff values of the forecasting model should be denormalized to the range of the target output dataset. Then the RF-GPR-MV model outputs the deterministic results and the corresponding prediction interval.
Note that the differences between the five models (RF-GPR-MV, PCC-GPR-MV, PCC-GPR-QP, PCC-BP-QP, and PCC-GRNN-QP) involved in this study are in Step 1, Step 5 and/or Step 7. For example, in PCC-BP-QP, the previous runoff and precipitation are collected in Step 1, the PCC is applied to select the input variables in Step 5, and the parameters of BP are trained in Step 7.
5. Results and Discussion
5.1. Results with Only Previous Q and P as Inputs
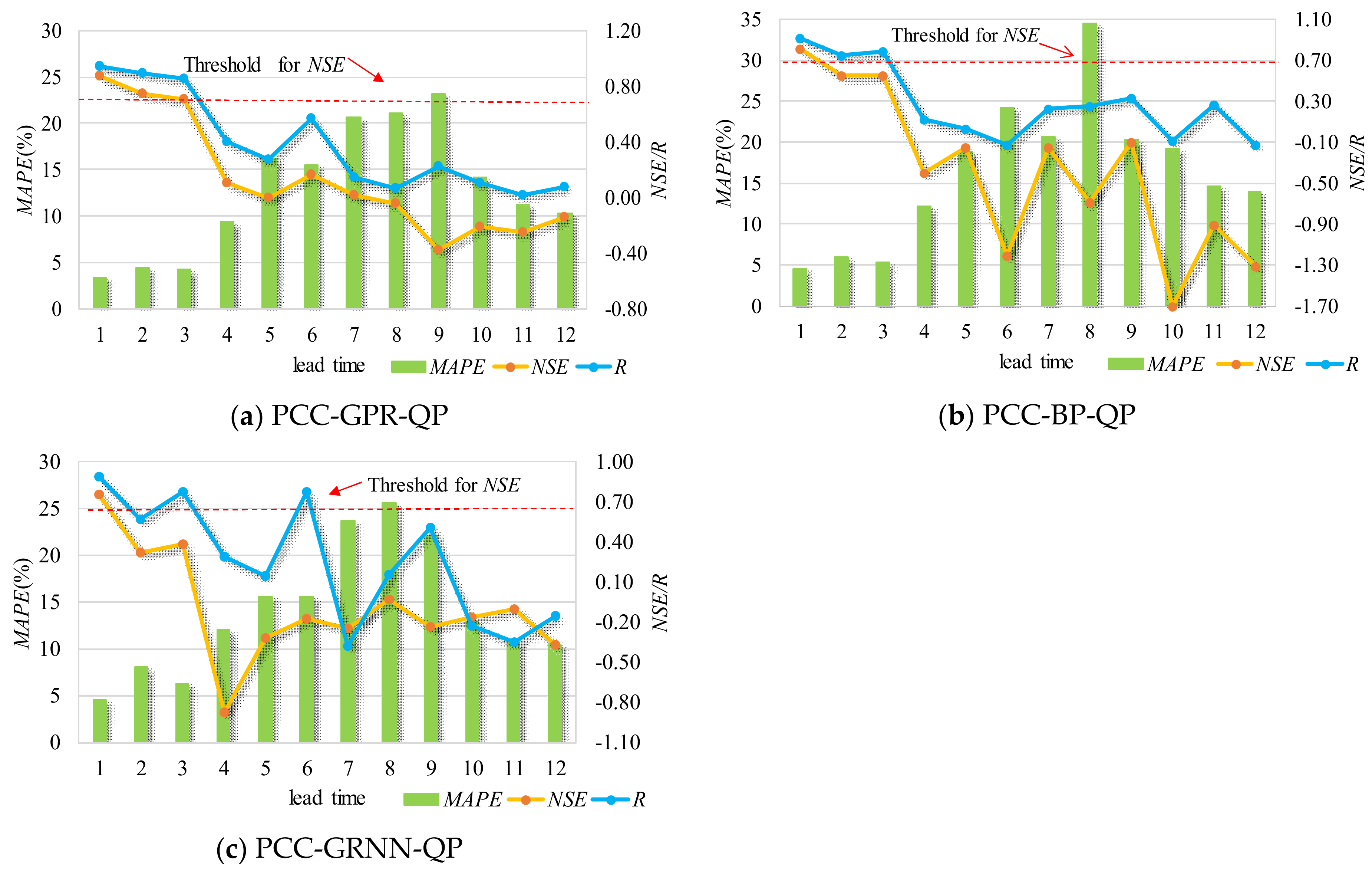
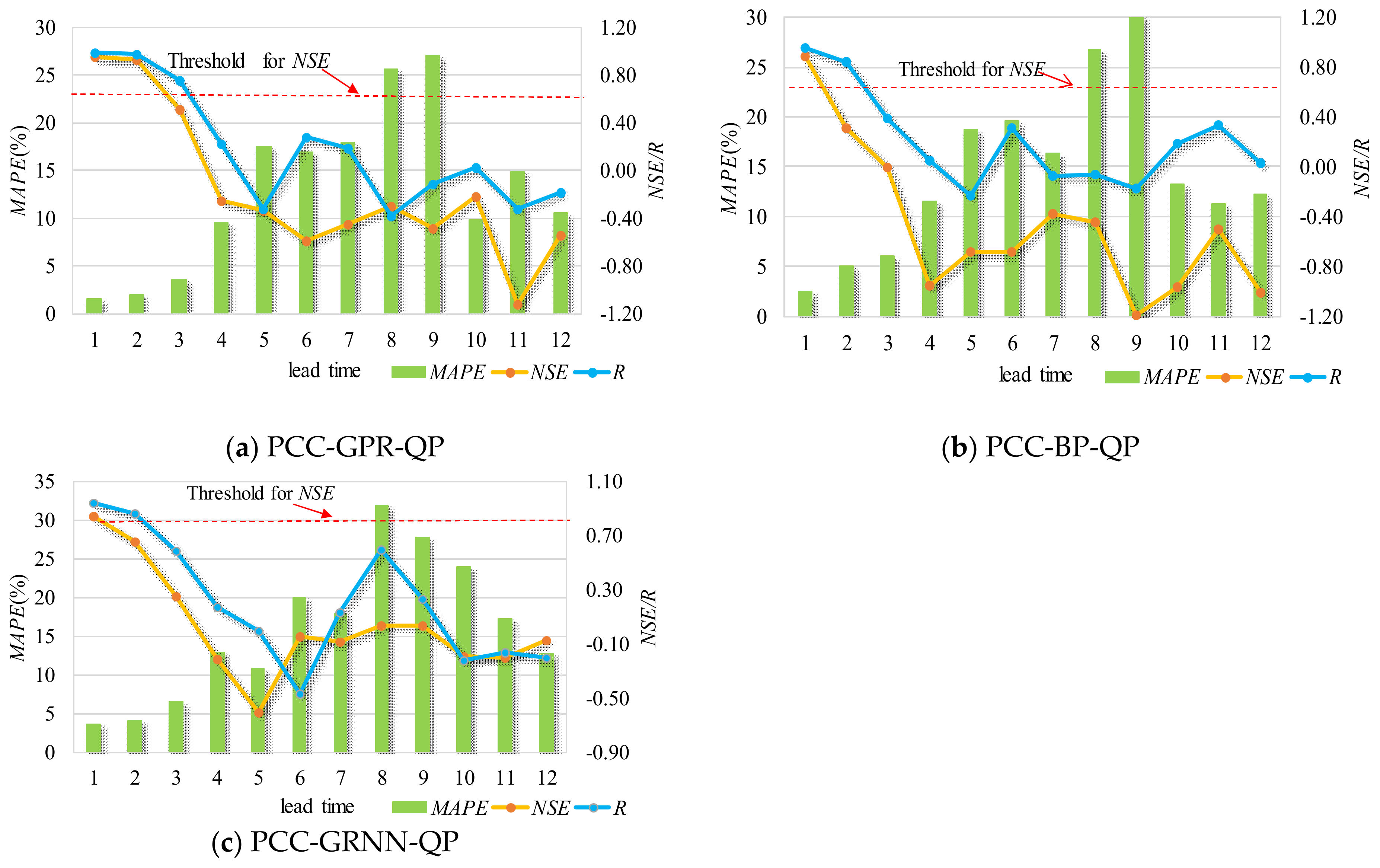
Forecasting results with different lead times using previous streamflow and precipitation for the two stations are shown in
Figure 5 and
Figure 6, where the red dashed line is the threshold of 0.7 for the NSE. For example, with regard to the forecast model for SG station, the validation period NSE values for 1- to 3-month-ahead forecasting were equal to 0.87, 0.75, and 0.71 for the PCC-GPR-QP model, compared to values of 0.81, 0.56, and 0.55 for the PCC-BP-QP model and 0.76, 0.32, and 0.38 for the PCC-GRNN-QP model. Further analysis shows that the MAPE values for the 1- to 3-month-ahead forecasting associated with PCC-GPR-QP were 5%, 6%, and 5%; less than the values for the PCC-BP-QP and PCC-GRNN-QP models.
Similarly, for PZH station, PCC-GPR-QP gave NSE values for 1- to 3-month-ahead forecasting of 0.96, 0.93, and 0.52, compared to values of 0.88, 0.31, and 0 for PCC-BP-QP and 0.84, 0.65, and 0.25 for PCC-GRNN-QP. In addition, the MAPE values for 1- to 3-month-ahead forecasting associated with the PCC-GPR-QP model were 2%, 2%, and 4%; less than for the other models under investigation.
The NSE values presented in these figures provide a clear picture of the poor accuracy of the forecasting results. Specifically, for PCC-GPR-QP, the lead time 1 and lead time 2 forecasting results for these two stations have relatively high accuracy, as their NSE values exceed the threshold of 0.7. For PCC-BP-QP, the lead time 1 forecasting results for the two stations have acceptable accuracies, with NSE values beyond the threshold of 0.7. For PCC-GRNN-QP, the lead time 1 forecasting results for stations SG and PZH have relatively good accuracies, with NSE values beyond the threshold of 0.7. Therefore, the sequence of forecasting ability for a short lead time is: GPR > BP > GRNN. Clearly, the degree of deterioration becomes dramatic as the forecast period increases, especially for GRNN and BP with long lead times.
Overall, for the same inputs and lead times, the GPR always outperforms the BP and GRNN models and has a stronger anti-disturbance ability than the other two models, and therefore it is suitable as a basic forecasting module. However, the forecasting results for PCC-GPR-QP with a lead time beyond 4 still have room for improvement.
5.2. Results with Local Hydrometeorological and Global Factors as Inputs
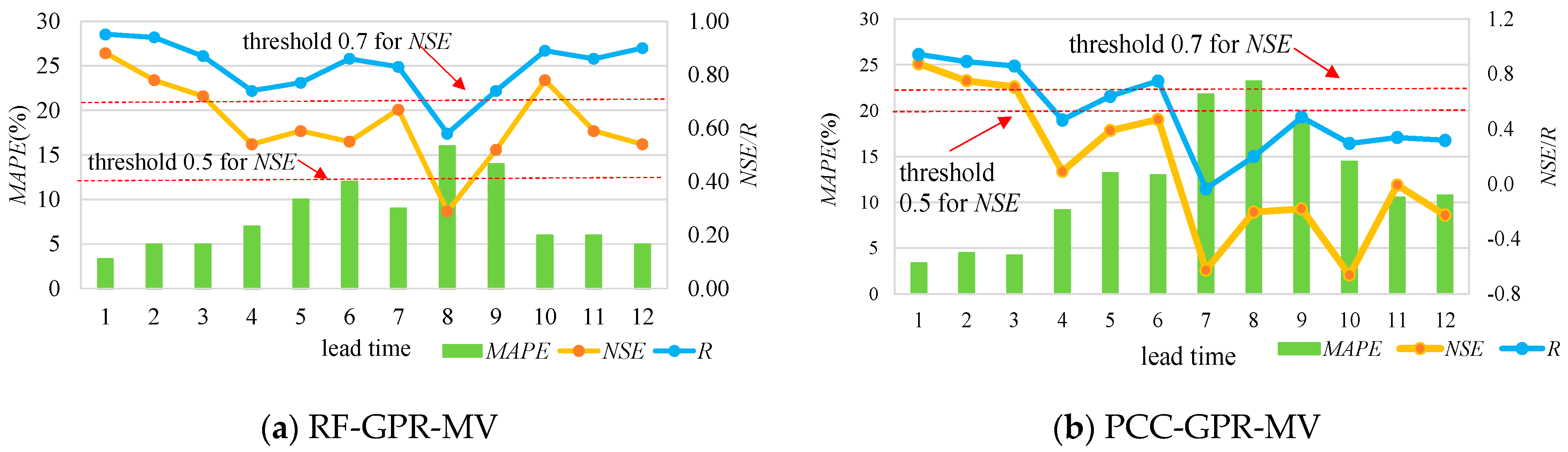
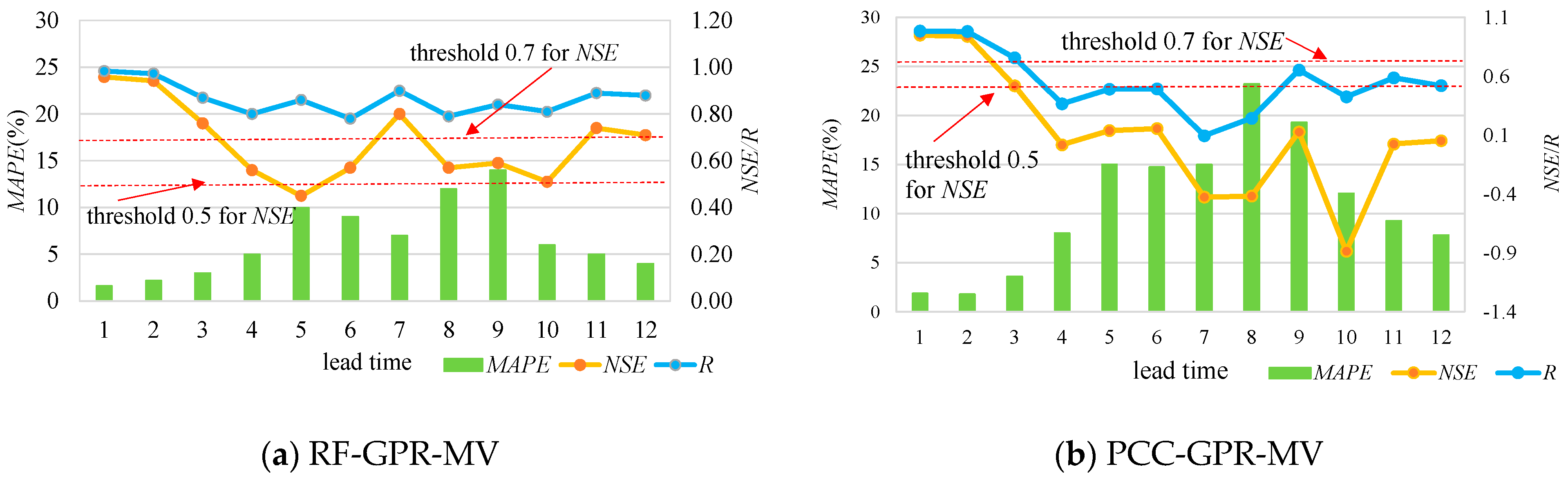
The validation results for the proposed model, RF-GPR-MV, and PCC-GPR-MV are listed in
Table 3,
Table 4,
Table 5 and
Table 6, where the NSE values beyond the threshold of 0.7 are marked in bold. Meanwhile,
Figure 7 and
Figure 8 show the forecasting results with different lead times visually, using both hydrometeorological and global climate factors as inputs for the two stations. The results show that multi-variable nonlinear RF-GPR-MV models are, in general, superior to the PCC-GPR-MV model, the PCC-GPR-QP model, the PCC-BP-QP model, and the PCC-GRNN-QP model.
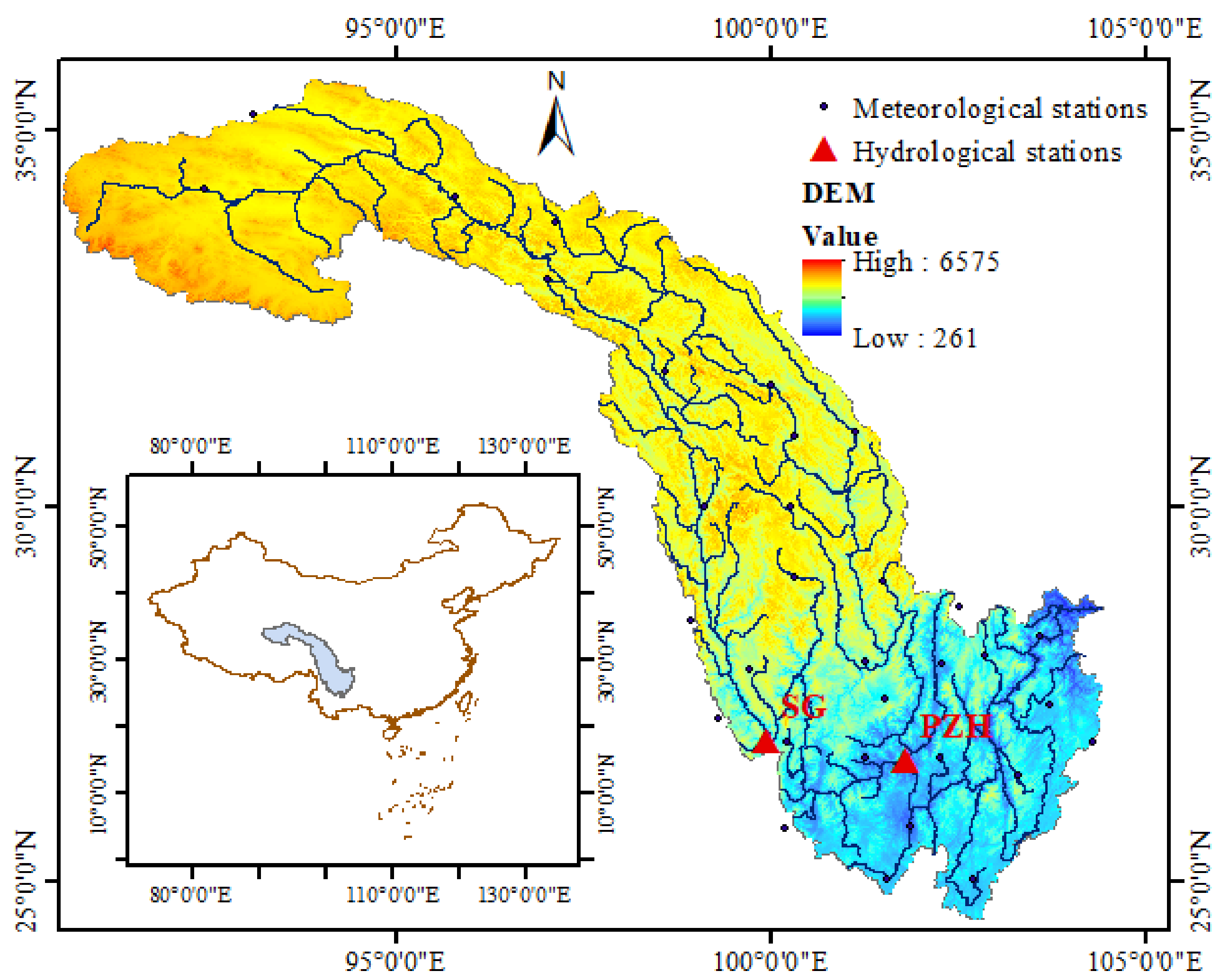
Regarding SG station, the validation period NSE values for lead times 1, 2, 3, and 10 forecasting results for the RF-GPR-MV model were 0.88, 0.78, 0.72, and 0.78, respectively, which are over the threshold of 0.7, indicating good accuracies. Those of the other lead time forecasting results, except for lead time 8 (0.29), were all beyond the threshold of 0.5, representing acceptable accuracies. The validation period NSE values for lead times 1, 2, and 3 forecasting results for PCC-GPR-MV were 0.87, 0.75, and 0.71, respectively, surpassing the threshold of 0.7, but those for the other lead times were all under the threshold of 0.5. Clearly, for the same lead time, the NSE values for RF-GPR-MV were higher than those for PCC-GPR-MV. Additionally, for the same lead time, the validation period R and the MAPE values for RF-GPR-MV have considerable accuracies or superior accuracies to those of PCC-GPR-MV.
With regard to PZH station, the validation period NSE values for the lead time 1, 2, 3, 7, 11, and 12 forecasting results for RF-GPR-MV were 0.96, 0.94, 0.76, 0.74, and 0.71, respectively, exceeding the threshold of 0.7, indicating high accuracies. Those for the other lead time forecasting results were all beyond or close to the threshold of 0.5, representing acceptable accuracies. The validation period NSE values for the lead time 1 and 2 forecasting results for PCC-GPR-MV were 0.95 and 0.94, surpassing the threshold of 0.7, but those for the others were all under the threshold of 0.5, except for that of lead time 3 (0.52), which was close to the threshold of 0.5. Additionally, in the analysis of the validation period R and MAPE values, those associated with RF-GPR-MV were considerable or superior to those of PCC-GPR-MV.
Compared with the performance of PCC-GPR-QP, that of PCC-GPR-MV showed no obvious improvement, while RF-GPR-MV showed significant enhancement. This indicates that the PCC may not be suitable for complex nonlinear relationship extraction, especially for teleconnection. Specifically, the comparison of PCC-GPR-MV and RF-GPR-MV indicates that RF-GPR-MV has lower MAPE, RMSE, and MBE, as well as higher R, NSE, and MIA values than PCC-GPR-MV for almost all lead times. In summary, RF-GPR-MV integrates the dimensionality reduction advantage of RF and the strong learning and reasoning ability of GPR to fully extract the effective information for learning and then further improve the prediction accuracy.
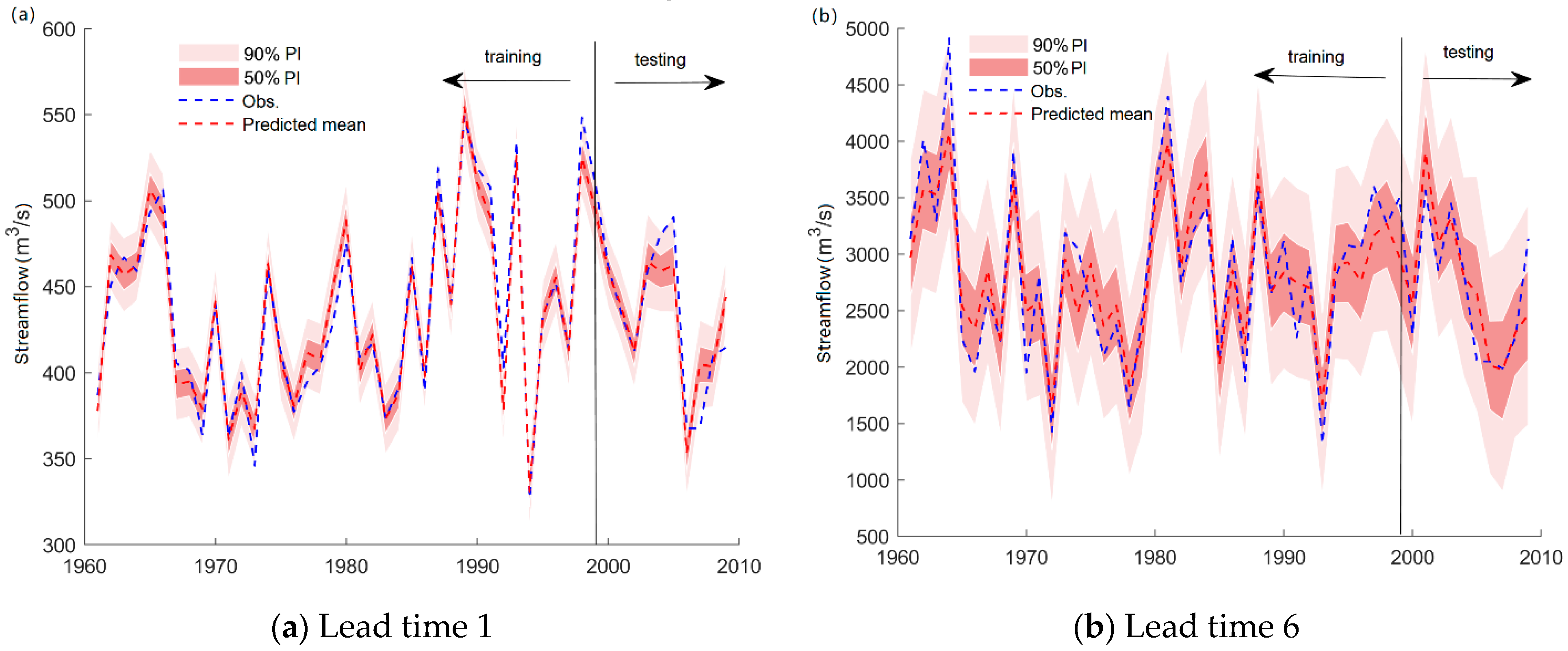
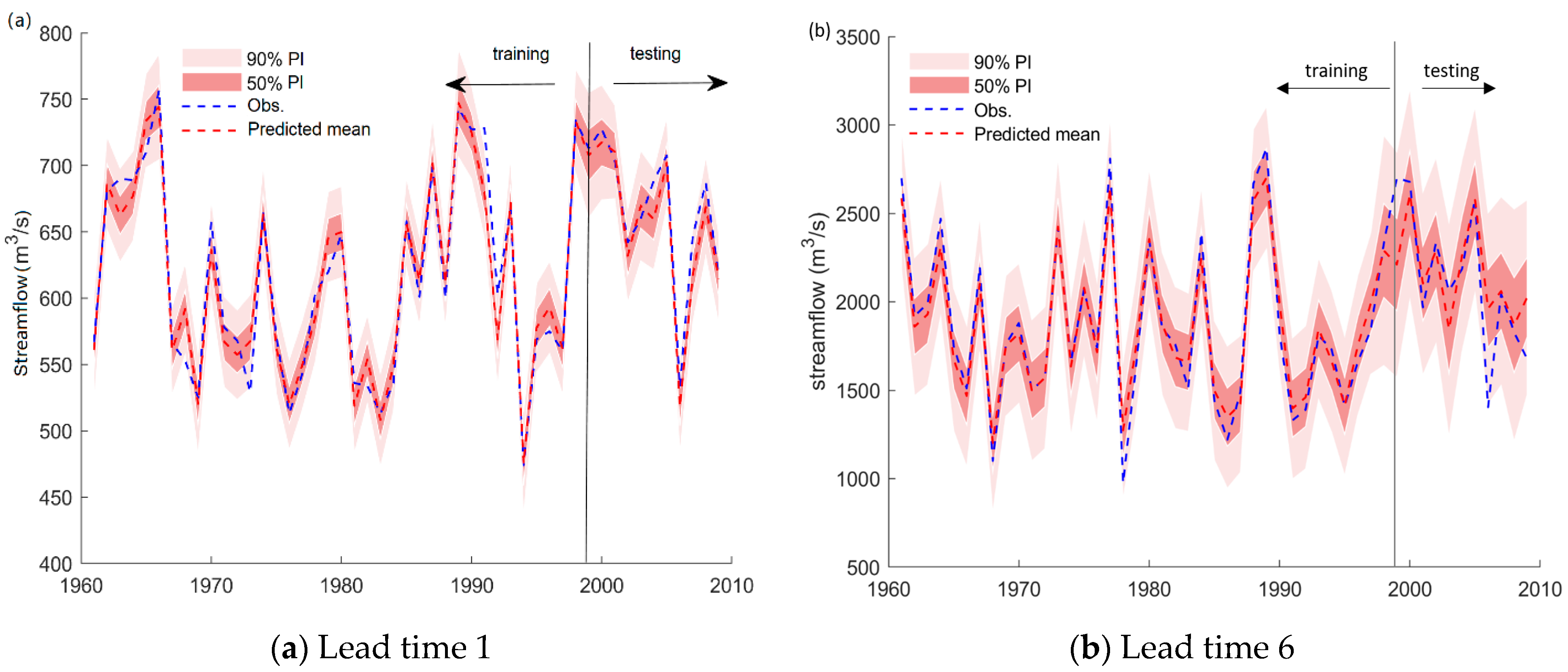
Figure 9 and
Figure 10 present the hydrograph produced by the RF-GPR-MV model in the training and testing periods. The reason for choosing the results for lead times 1 and 6 is that the observed streamflow was relatively stable when the lead time was 1, and the observed runoff fluctuated greatly when the lead time was 6, as this was close to the flood season. It shows that the prediction intervals (PIs) at the 50% confidence level generated by RF-GPR-MV can always capture the variations in streamflow during the testing phase. For both stations, the prediction interval for 6-month-ahead forecasting was significantly wider than that for 1-month-ahead forecasting, indicating a relatively high uncertainty. Although the uncertainties of forecasting with long lead times are large, they still fall within the given prediction intervals (PIs) at the 50% confidence level, except in some extremely high flow conditions.
Overall, the proposed RF-GPR-MV model using both local hydrometeorological and global climate and circulation factors not only has higher accuracy than the commonly used monthly streamflow forecasting models but can also provide both deterministic results and uncertainty bounds.
5.3. Evaluation of the Contributions of Different Factors
To quantitatively evaluate the improvement achieved by the proposed RF-GPR-MV model over the RF-GPR-QP, PCC-GPR-MV, PCC-GPR-QP, PCC-BP-QP, and PCC-GRNN-QP models, the improved percentages of the MAPE index were adopted to evaluate the impacts of the different techniques on the improvement of the hybrid model.
PMAPE is defined by:
, where MAPE
1 and MAPE
2 are the MAPE values of model 1 and model 2.
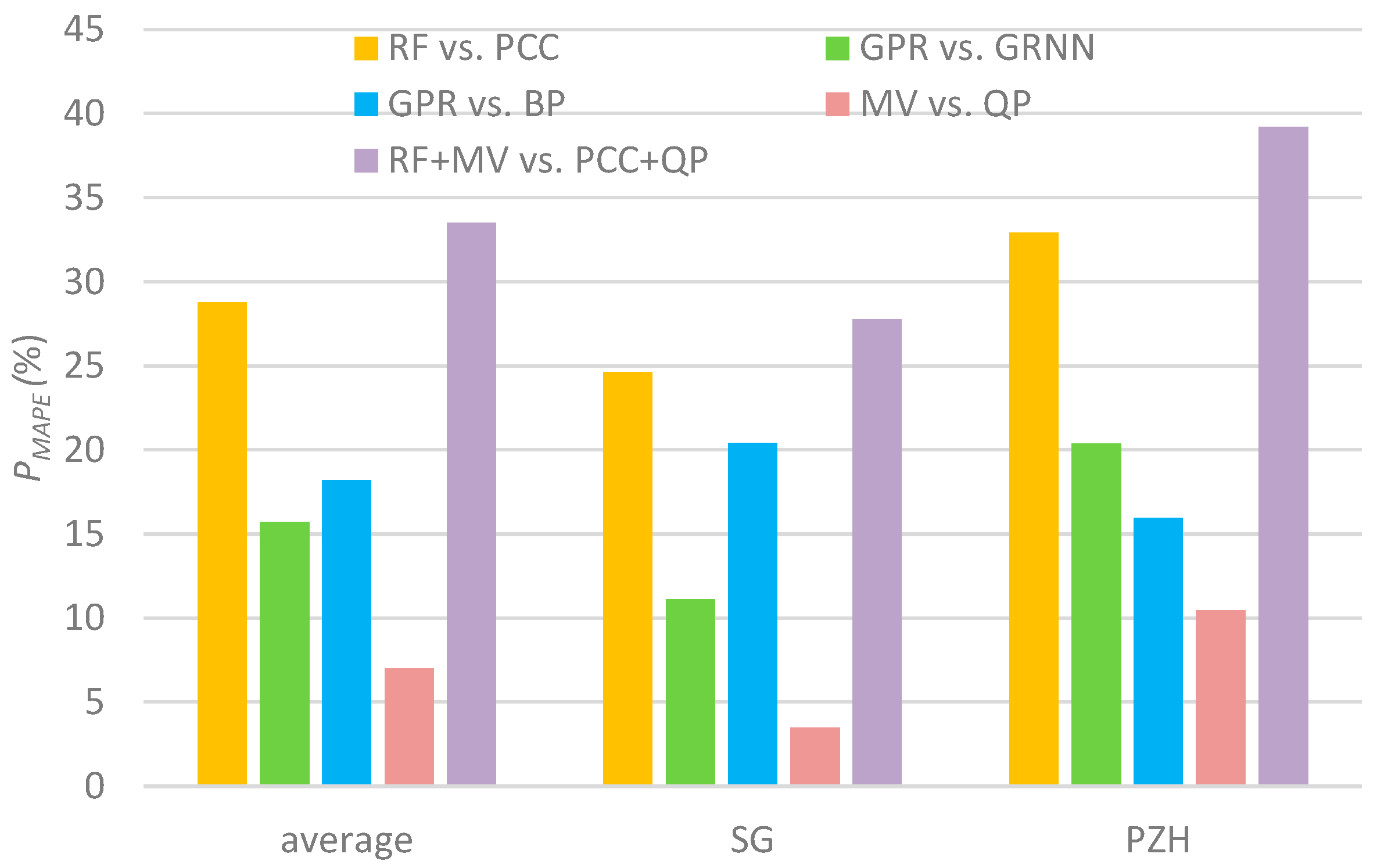
Figure 11 quantitatively displays the contributions made by the RF method, the GPR model, and/or the multiple variables (MV) as inputs to the total improvement of the RF-GPR-MV model. Clearly, all these had positive effects on the total improvement of the proposed model, though RF (average
PMAPE = 27%) contributed more than GPR (average
PMAPE = 16%), which emphasizes the critical role of the input selection approach in monthly streamflow forecasting. Additionally, compared with using only previous streamflow and rainfall, using multiple variables (MV) as inputs improved the model performance by about 5%.
Further, to quantify the contribution of large-scale factors to the model performance for different lead times, RF-GPR-MV was used, and the VIM values in descending order with the top 10 input factors provided by RF and the MAPE values for their corresponding forecasting models were compared with each other. For example,
Figure 12 and
Figure 13 present the monthly streamflow forecasting results for RF-GPR-MV with lead time 1 (January of the following year) and lead time 6 (June of the following year) using different inputs at SG station and PZH station, respectively.
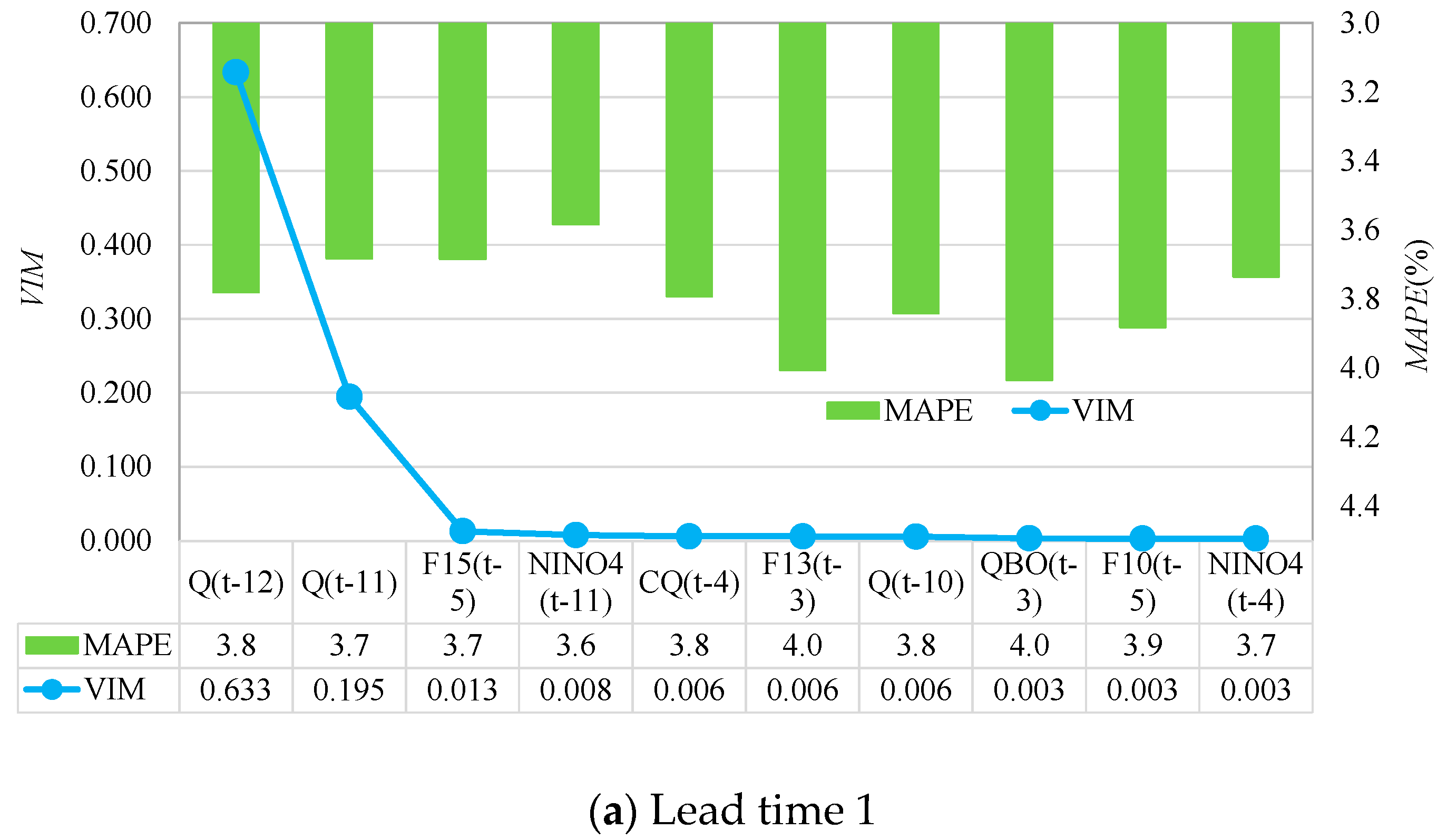
It can be seen from
Figure 12a that the forecasting results for RF-GPR-MV with lead time 1 achieved the smallest forecasting error when taking Q(t-12), Q(t-11), F15(t-5), and Niño4(t-11) as inputs. In this case, the contribution of Q(t-11) was 2.6%; when adding F15(t-5) and Niño4(t-11) as inputs, the forecasting performance was improved by 2.69% over Q(t-12) only. This shows that the contribution of the streamflow itself was greater than the contribution of large-scale climate factors for forecasting with short lead times (dry season). The results for RF-GPR-MV with lead time 6 (
Figure 12b) obtained the best performance when using all the top ten factors, including the local hydrometeorological indices P(t-2), Q(t-4), and P(t-8), the global climate factors AO(t-9), NAO(t-11), PDO(t-1), and NAO(t-2), and the circulation factors F10(t-2), F11(t-2), and SOI(t-10). Among these, the highest contribution to the monthly streamflow forecasting came from F10(t-2) (16%), followed by PDO(t-1) (15%), indicating the importance of large-scale factors in the flood season.
Figure 13a shows that the forecasting results for RF-GPR-MV with lead time 1 at PZH station achieved the lowest MAPE value when using the local hydrometeorological factors Q(t-12), Q(t-11), Q(t-9), Ap(t-9), and Q(t-10).
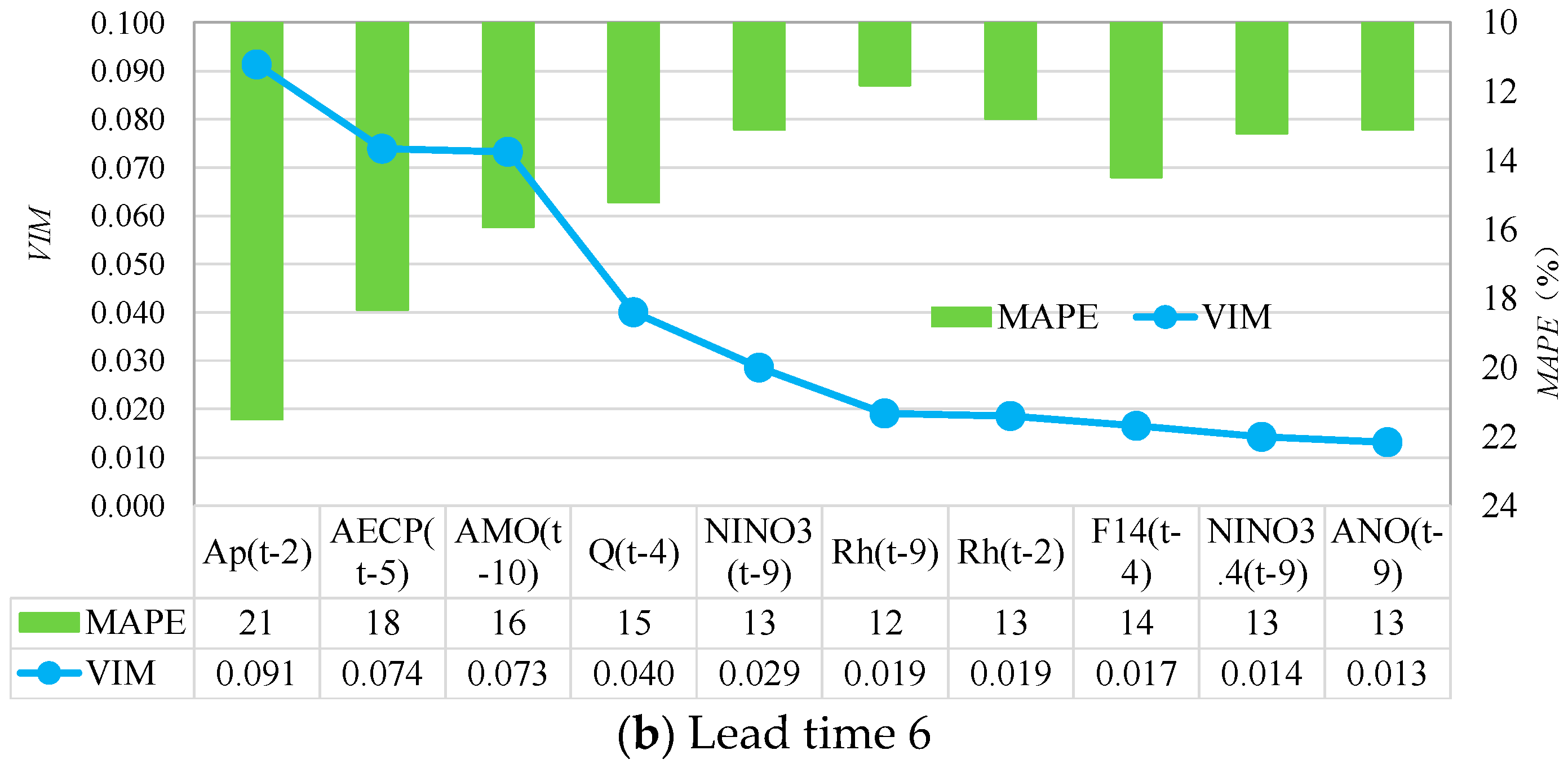
Figure 12b shows that the forecasting results with lead time 6 showed the best performance when taking Ap(t-12), AECP(t-5), AMO(t-10), Q(t-4), Niño3(t-9), and Rh(t-9) as inputs. In this case, the best input vector contained many types of variables varying from local hydrometeorological factors (Ap, Q, Rh) to large-scale climate factors (AECP, AMO, Niño3). Additionally, the forecasting performance using Q(t-4) was better by about 5% than when not using Q(t-4), while the forecasting performance with Niño3(t-9) was better by about 14% than without Niño3(t-9). This result confirms that large-scale climate factors have a great influence on local streamflow with long lead times (flood season).
These figures (
Figure 11,
Figure 12 and
Figure 13) emphasize that the addition of global climate and circulation factors can improve the forecasting performance for streamflow, especially for forecasting with long lead times. They also indicate that when the number of prediction factors continues to increase, the model’s prediction error will also increase. This phenomenon reveals that increasing the number of input factors is not always beneficial to the forecasting results. The best results are obtained with just the appropriate number of input factors.
5.4. Discussion
In this study, for SG station, the model efficiencies (in terms of the NSE) for 1-month-ahead forecasting for the PCC-GRNN-QP, PCC-BP-QP, PCC-GPR-QP, PCC-GPR-MV, and RF-GPR-MV models were found to be 0.76, 0.81, 0.87, 0.87, and 0.88, respectively. For PZH station, the NSE and MAPE values for RF-GPR-MV for 1-month-ahead forecasting were 0.96 and 2%, respectively.
In a previous study, Peng et al. [
54] employed pure BP, PSO-ANN, and MVO-ANN models for the Jinsha basin at PZH station and achieved a model efficiency (in terms of MAPE) of 10%, which is much higher than that of the RF-GPR-MV model developed in this study. In the study by Yin et al. [
55], a SWAT model using meteorological data and the ISI-MIP climate dataset was employed for the Jinsha basin for monthly streamflow forecasting, achieving a model efficiency (in terms of the NSE) of 0.82, which is lower than that of the RF-GPR-MV developed in this study. Moreover, in the study by Luo et al. [
56], autocorrelation function (ACF), partial autocorrelation function (PACF), grey correlation analysis (GCA), support vector regression (SVR), and generalized regression neural network (GRNN) models were integrated to forecast monthly streamflow in the Jinsha basin. In this study, the NSE values for GCA-SVR, GCA-GRNN, PCC/ACF-SVR, and PACF-SVR were 0.86, 0.82, 0.83, and 0.82, respectively. The NSE value for the best model (GCA-SVR) was 0.86, which is still lower than that of the RF-GPR-MV model developed in this study.
In most of the studies employing ML models [
2,
13,
28,
54], only previous streamflow and/or precipitation were taken as inputs. The results in this study revealed the positive effect of climate factors on streamflow forecasting accuracy. This conclusion is consistent with those of other studies [
22,
23,
24,
45,
56]. In previous studies based on ML models, inputs were determined by a trial-and-error method or the PACF method. Input selection is a vital task in the process of data-driven model development. The PACF method is a method of mining linear relationships. However, the correlations between streamflow and its potential forecasting factors are not always linear. The RF in this study used to determine the appropriate input combination reduced the workload and could deal with nonlinear relationships. Additionally, the RF-GPR-MV model developed in this study could provide both deterministic results and prediction intervals, which is beneficial for real water resources management.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}