
Stream Temperature Predictions for River Basin Management in the Pacific Northwest and Mid-Atlantic Regions Using Machine Learning

 ,
,  , , , , and
, , , , and
Abstract
:1. Introduction
2. Data and Methods
2.1. Data Sources and Software
2.2. Sites/Station Selection
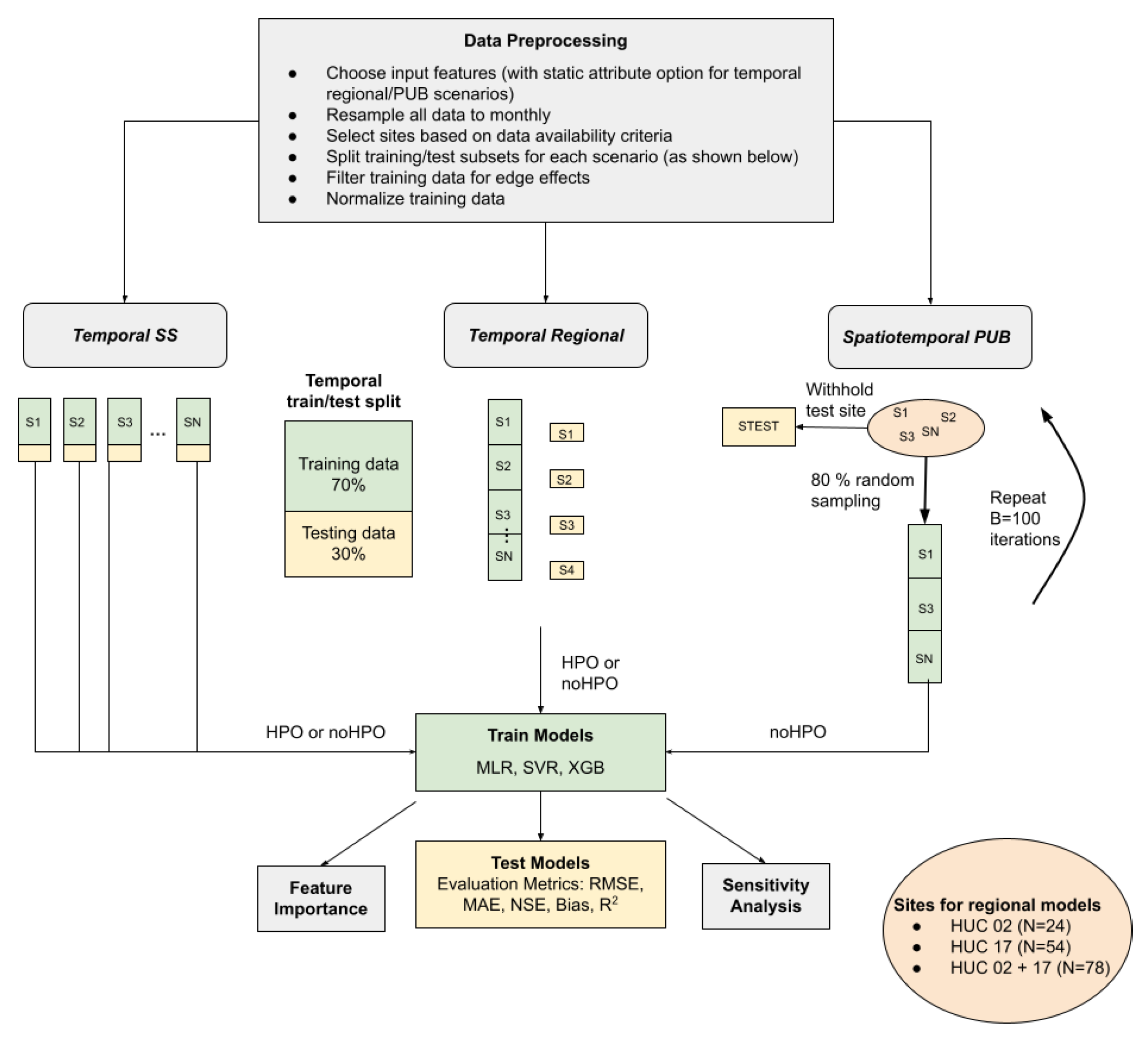
2.3. Model Setup
2.3.1. Model Description
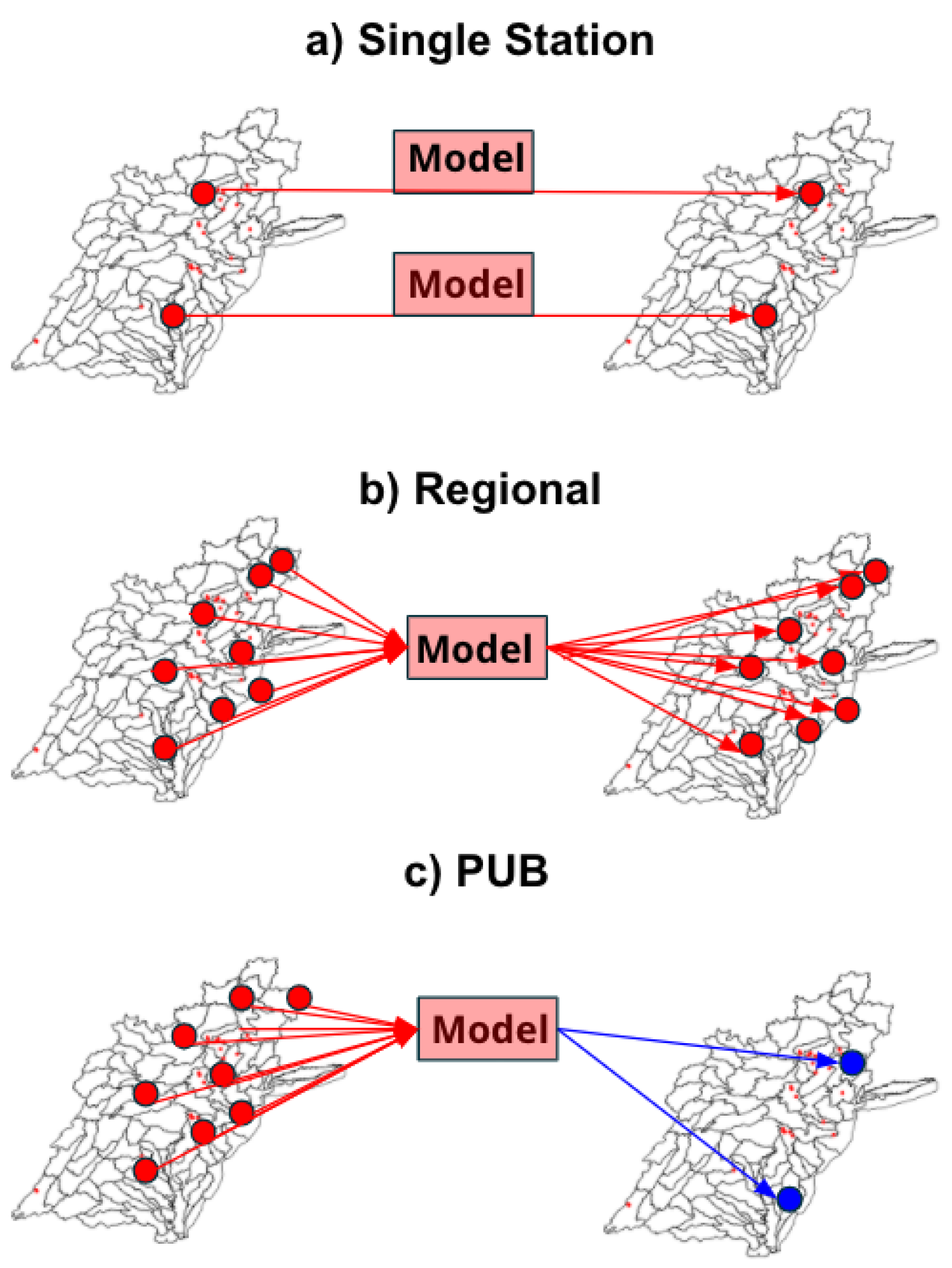
2.3.2. Modeling Scenarios
2.3.3. Input Feature Selection and Preprocessing
2.3.4. Model Training
| Algorithm 1: The ensemble algorithm used to train the models for the spatiotemporal PUB scenario. |
|
2.3.5. Model Configurations
2.4. Model Evaluation
2.4.1. Evaluation Metrics
2.4.2. Feature Importance
3. Results
3.1. Temporal Single Station (SS) Scenario
3.1.1. Model Performance
3.1.2. Feature Importance
3.1.3. Model Sensitivity
3.2. Temporal Regional Scenarios
3.2.1. Model Performance
3.2.2. Feature Importance
3.2.3. Model Sensitivity
3.3. PUB Scenario
3.3.1. Model Performance
3.3.2. Feature Importance
3.3.3. Model Sensitivity
4. Discussion
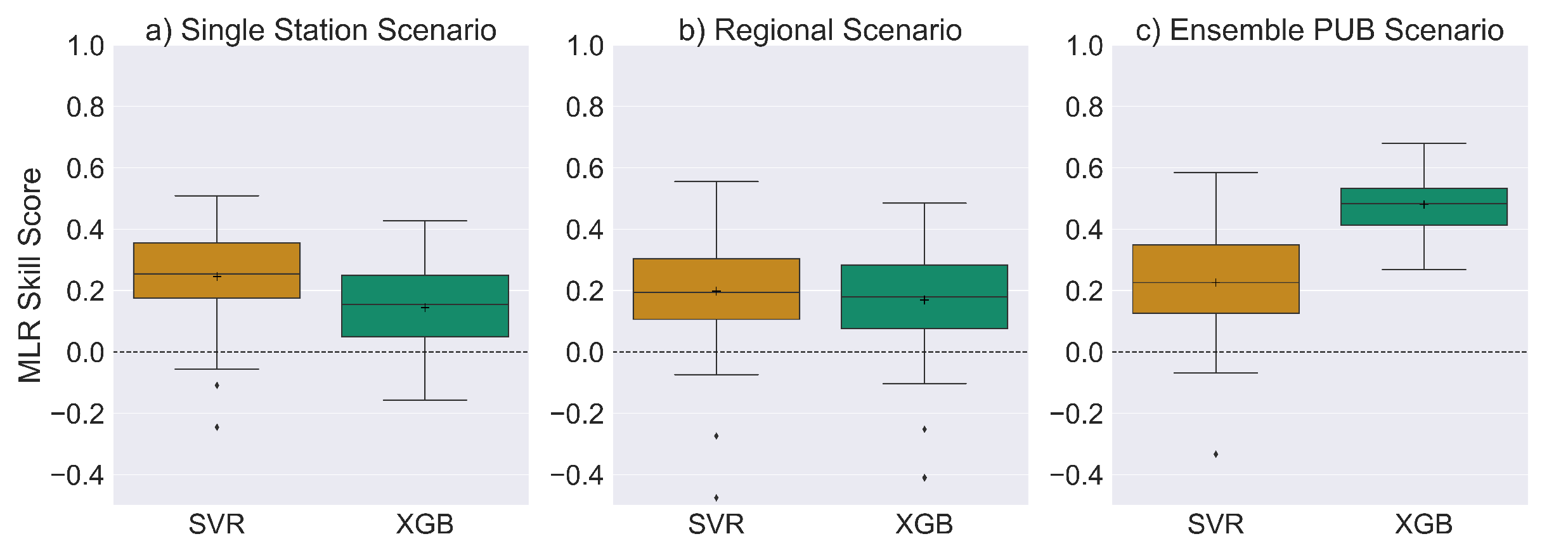
4.1. Comparison of Machine Learning and Statistical Model Performance
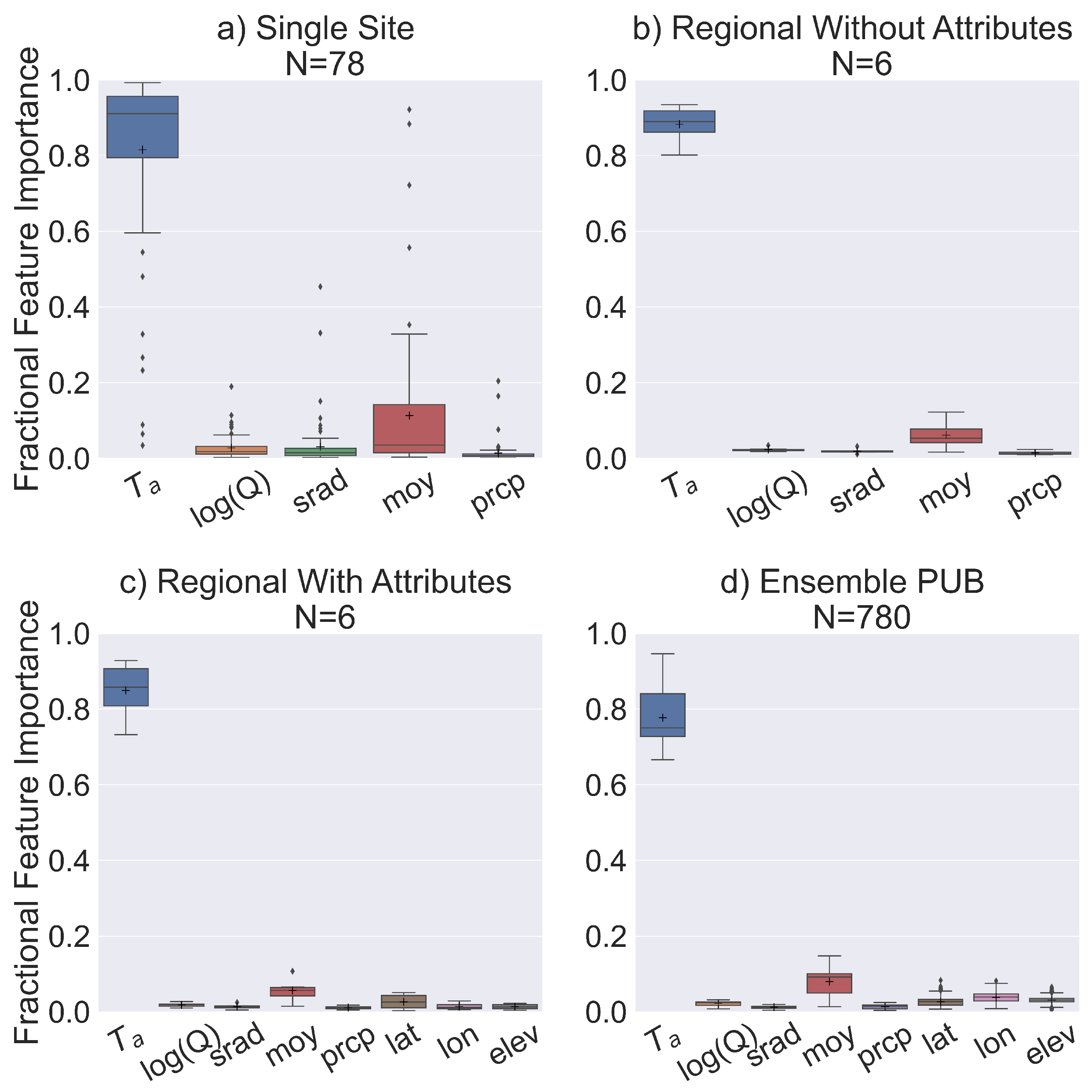
4.2. Factors Influencing Monthly Stream Temperature
4.3. Local and Regional Predictions
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Van Vliet, M.; Ludwig, F.; Zwolsman, J.; Weedon, G.; Kabat, P. Global river temperatures and sensitivity to atmospheric warming and changes in river flow. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Abbott, B.W.; Bishop, K.; Zarnetske, J.P.; Hannah, D.M.; Frei, R.J.; Minaudo, C.; Chapin, F.S.; Krause, S.; Conner, L.; Ellison, D.; et al. A water cycle for the Anthropocene. Hydrol. Process. 2019, 33, 3046–3052. [Google Scholar] [CrossRef]
- Förster, H.; Lilliestam, J. Modeling thermoelectric power generation in view of climate change. Reg. Environ. Chang. 2010, 10, 327–338. [Google Scholar]
- Van Vliet, M.T.; Wiberg, D.; Leduc, S.; Riahi, K. Power-generation system vulnerability and adaptation to changes in climate and water resources. Nat. Clim. Chang. 2016, 6, 375–380. [Google Scholar]
- Lawrence, D.J.; Stewart-Koster, B.; Olden, J.D.; Ruesch, A.S.; Torgersen, C.E.; Lawler, J.J.; Butcher, D.P.; Crown, J.K. The interactive effects of climate change, riparian management, and a nonnative predator on stream-rearing salmon. Ecol. Appl. 2014, 24, 895–912. [Google Scholar] [PubMed]
- van Vliet, M.T.; Franssen, W.H.; Yearsley, J.R.; Ludwig, F.; Haddeland, I.; Lettenmaier, D.P.; Kabat, P. Global river discharge and water temperature under climate change. Glob. Environ. Chang. 2013, 23, 450–464. [Google Scholar]
- Heck, M.P.; Schultz, L.D.; Hockman-Wert, D.; Dinger, E.C.; Dunham, J.B. Monitoring Stream Temperatures—Guide for Non-Specialists; Technical Report; US Geological Survey: Washington, DC, USA, 2018.
- Benyahya, L.; Caissie, D.; St-Hilaire, A.; Ouarda, T.B.; Bobée, B. A review of statistical water temperature models. Can. Water Resour. J. 2007, 32, 179–192. [Google Scholar]
- Caissie, D. The thermal regime of rivers: A review. Freshw. Biol. 2006, 51, 1389–1406. [Google Scholar]
- Gitau, M.W.; Chen, J.; Ma, Z. Water quality indices as tools for decision making and management. Water Resour. Manag. 2016, 30, 2591–2610. [Google Scholar]
- Liu, L.; Hejazi, M.; Li, H.; Forman, B.; Zhang, X. Vulnerability of US thermoelectric power generation to climate change when incorporating state-level environmental regulations—Nature Energy. Nat. Energy 2017, 2, 1–5. [Google Scholar] [CrossRef]
- Huang, B.; Langpap, C.; Adams, R.M. The value of in-stream water temperature forecasts for fisheries management. Contemp. Econ. Policy 2012, 30, 247–261. [Google Scholar]
- Mijares, V.; Gitau, M.; Johnson, D.R. A method for assessing and predicting water quality status for improved decision-making and management. Water Resour. Manag. 2019, 33, 509–522. [Google Scholar]
- Mantua, N.; Tohver, I.; Hamlet, A. Climate change impacts on streamflow extremes and summertime stream temperature and their possible consequences for freshwater salmon habitat in Washington State. Clim. Chang. 2010, 102, 187–223. [Google Scholar]
- Wilby, R.; Orr, H.; Watts, G.; Battarbee, R.; Berry, P.; Chadd, R.; Dugdale, S.; Dunbar, M.; Elliott, J.; Extence, C.; et al. Evidence needed to manage freshwater ecosystems in a changing climate: Turning adaptation principles into practice. Sci. Total Environ. 2010, 408, 4150–4164. [Google Scholar] [PubMed]
- Lovett, G.M.; Burns, D.A.; Driscoll, C.T.; Jenkins, J.C.; Mitchell, M.J.; Rustad, L.; Shanley, J.B.; Likens, G.E.; Haeuber, R. Who needs environmental monitoring? Front. Ecol. Environ. 2007, 5, 253–260. [Google Scholar]
- Neumann, J.L.; Arnal, L.; Emerton, R.E.; Griffith, H.; Hyslop, S.; Theofanidi, S.; Cloke, H.L. Can seasonal hydrological forecasts inform local decisions and actions? A decision-making activity. Geosci. Commun. 2018, 1, 35–57. [Google Scholar]
- Rahmani, F.; Shen, C.; Oliver, S.; Lawson, K.; Appling, A. Deep learning approaches for improving prediction of daily stream temperature in data-scarce, unmonitored, and dammed basins. Hydrol. Process. 2021, 35, e14400. [Google Scholar]
- Kędra, M.; Wiejaczka, Ł. Climatic and dam-induced impacts on river water temperature: Assessment and management implications. Sci. Total Environ. 2018, 626, 1474–1483. [Google Scholar]
- Zhang, X.; Li, H.Y.; Leung, L.R.; Liu, L.; Hejazi, M.I.; Forman, B.A.; Yigzaw, W. River Regulation Alleviates the Impacts of Climate Change on U.S. Thermoelectricity Production. J. Geophys. Res. Atmos. 2020, 125, e2019JD031618. [Google Scholar] [CrossRef]
- Kelleher, C.; Wagener, T.; Gooseff, M.; McGlynn, B.; McGuire, K.; Marshall, L. Investigating controls on the thermal sensitivity of Pennsylvania streams. Hydrol. Process. 2012, 26, 771–785. [Google Scholar]
- Borman, M.; Larson, L. A case study of river temperature response to agricultural land use and environmental thermal patterns. J. Soil Water Conserv. 2003, 58, 8–12. [Google Scholar]
- Sanders, M.J.; Markstrom, S.L.; Regan, R.S.; Atkinson, R.D. Documentation of a Daily Mean Stream Temperature Module—An Enhancement to the Precipitation-Runoff Modeling System; Technical Report; US Geological Survey: Washington, DC, USA, 2017.
- Li, H.Y.; Leung, L.R.; Tesfa, T.; Voisin, N.; Hejazi, M.; Liu, L.; Liu, Y.; Rice, J.; Wu, H.; Yang, X. Modeling stream temperature in the Anthropocene: An earth system modeling approach. J. Adv. Model. Earth Syst. 2015, 7, 1661–1679. [Google Scholar]
- Van Vliet, M.; Yearsley, J.; Franssen, W.; Ludwig, F.; Haddeland, I.; Lettenmaier, D.; Kabat, P. Coupled daily streamflow and water temperature modelling in large river basins. Hydrol. Earth Syst. Sci. 2012, 16, 4303–4321. [Google Scholar]
- Zhu, S.; Piotrowski, A.P. River/stream water temperature forecasting using artificial intelligence models: A systematic review. Acta Geophys. 2020, 68, 1433–1442. [Google Scholar] [CrossRef]
- Wehrly, K.E.; Brenden, T.O.; Wang, L. A comparison of statistical approaches for predicting stream temperatures across heterogeneous landscapes 1. JAWRA J. Am. Water Resour. Assoc. 2009, 45, 986–997. [Google Scholar]
- Chang, H.; Psaris, M. Local landscape predictors of maximum stream temperature and thermal sensitivity in the Columbia River Basin, USA. Sci. Total Environ. 2013, 461, 587–600. [Google Scholar]
- Daigle, A.; St-Hilaire, A.; Peters, D.; Baird, D. Multivariate modelling of water temperature in the Okanagan watershed. Can. Water Resour. J. 2010, 35, 237–258. [Google Scholar]
- Sohrabi, M.M.; Benjankar, R.; Tonina, D.; Wenger, S.J.; Isaak, D.J. Estimation of daily stream water temperatures with a Bayesian regression approach. Hydrol. Process. 2017, 31, 1719–1733. [Google Scholar]
- Toffolon, M.; Piccolroaz, S. A hybrid model for river water temperature as a function of air temperature and discharge. Environ. Res. Lett. 2015, 10, 114011. [Google Scholar]
- Gallice, A.; Schaefli, B.; Lehning, M.; Parlange, M.B.; Huwald, H. Stream temperature prediction in ungauged basins: Review of recent approaches and description of a new physics-derived statistical model. Hydrol. Earth Syst. Sci. 2015, 19, 3727–3753. [Google Scholar] [CrossRef] [Green Version]
- Hill, R.A.; Hawkins, C.P.; Carlisle, D.M. Predicting thermal reference conditions for USA streams and rivers. Freshw. Sci. 2013, 32, 39–55. [Google Scholar]
- Isaak, D.J.; Luce, C.H.; Rieman, B.E.; Nagel, D.E.; Peterson, E.E.; Horan, D.L.; Parkes, S.; Chandler, G.L. Effects of climate change and wildfire on stream temperatures and salmonid thermal habitat in a mountain river network. Ecol. Appl. 2010, 20, 1350–1371. [Google Scholar] [PubMed] [Green Version]
- Arismendi, I.; Safeeq, M.; Dunham, J.B.; Johnson, S.L. Can air temperature be used to project influences of climate change on stream temperature? Environ. Res. Lett. 2014, 9, 084015. [Google Scholar]
- Hrachowitz, M.; Soulsby, C.; Imholt, C.; Malcolm, I.; Tetzlaff, D. Thermal regimes in a large upland salmon river: A simple model to identify the influence of landscape controls and climate change on maximum temperatures. Hydrol. Process. 2010, 24, 3374–3391. [Google Scholar]
- Isaak, D.J.; Wenger, S.J.; Peterson, E.E.; Ver Hoef, J.M.; Nagel, D.E.; Luce, C.H.; Hostetler, S.W.; Dunham, J.B.; Roper, B.B.; Wollrab, S.P.; et al. The NorWeST summer stream temperature model and scenarios for the western US: A crowd-sourced database and new geospatial tools foster a user community and predict broad climate warming of rivers and streams. Water Resour. Res. 2017, 53, 9181–9205. [Google Scholar]
- Piotrowski, A.P.; Napiorkowski, J.J. Simple modifications of the nonlinear regression stream temperature model for daily data. J. Hydrol. 2019, 572, 308–328. [Google Scholar]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall-runoff modelling using Long Short-Term Memory (LSTM) networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef] [Green Version]
- Rahmani, F.; Lawson, K.; Ouyang, W.; Appling, A.; Oliver, S.; Shen, C. Exploring the exceptional performance of a deep learning stream temperature model and the value of streamflow data. Environ. Res. Lett. 2021, 16, 024025. [Google Scholar]
- Zhi, W.; Feng, D.; Tsai, W.P.; Sterle, G.; Harpold, A.; Shen, C.; Li, L. From hydrometeorology to river water quality: Can a deep learning model predict dissolved oxygen at the continental scale? Environ. Sci. Technol. 2021, 55, 2357–2368. [Google Scholar]
- Feigl, M.; Lebiedzinski, K.; Herrnegger, M.; Schulz, K. Machine-learning methods for stream water temperature prediction. Hydrol. Earth Syst. Sci. 2021, 25, 2951–2977. [Google Scholar]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. Adv. Neural Inf. Process. Syst. 1997, 9, 155–161. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar]
- Rajesh, M.; Rehana, S. Prediction of river water temperature using machine learning algorithms: A tropical river system of India. J. Hydroinform. 2021, 23, 605–626. [Google Scholar]
- Lu, H.; Ma, X. Hybrid decision tree-based machine learning models for short-term water quality prediction. Chemosphere 2020, 249, 126169. [Google Scholar] [PubMed]
- Turschwell, M.P.; Peterson, E.E.; Balcombe, S.R.; Sheldon, F. To aggregate or not? Capturing the spatio-temporal complexity of the thermal regime. Ecol. Indic. 2016, 67, 39–48. [Google Scholar]
- Rehana, S. River water temperature modelling under climate change using support vector regression. In Hydrology in a Changing World; Springer: Cham, Switzerland, 2019; pp. 171–183. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar]
- Jia, X.; Lin, B.; Zwart, J.; Sadler, J.; Appling, A.; Oliver, S.; Read, J. Graph-based Reinforcement Learning for Active Learning in Real Time: An Application in Modeling River Networks. In Proceedings of the 2021 SIAM International Conference on Data Mining (SDM) SIAM, Virtual Event, 29 April–1 May 2021; pp. 621–629. [Google Scholar]
- Kratzert, F.; Klotz, D.; Herrnegger, M.; Sampson, A.K.; Hochreiter, S.; Nearing, G.S. Toward improved predictions in ungauged basins: Exploiting the power of machine learning. Water Resour. Res. 2019, 55, 11344–11354. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- USGS National Water Information System. Available online: https://waterdata.usgs.gov/nwis (accessed on 16 July 2022).
- Thornton, P.E.; Shrestha, R.; Thornton, M.; Kao, S.C.; Wei, Y.; Wilson, B.E. Gridded daily weather data for North America with comprehensive uncertainty quantification. Sci. Data 2021, 8, 1–17. [Google Scholar]
- Varadharajan, C.; Hendrix, V.C.; Christianson, D.S.; Burrus, M.; Wong, C.; Hubbard, S.S.; Agarwal, D.A. BASIN-3D: A brokering framework to integrate diverse environmental data. Comput. Geosci. 2022, 159, 105024. [Google Scholar]
- Daymet Pixel Extraction Tool. Available online: https://daymet.ornl.gov/single-pixel/api (accessed on 16 July 2022).
- Weierbach, H.; Lima, A.; Willard, J.; Hendrix, V.; Christianson, D.; Lubich, M.; Varadharajan, C. Dataset for “Stream Temperature Predictions for River Basin Management in the Pacific Northwest and Mid-Atlantic Regions Using Machine Learning”. ESS-DIVE Repos. 2022. [Google Scholar] [CrossRef]
- Falcone, J.A. GAGES-II: Geospatial Attributes of Gages for Evaluating Streamflow; Technical Report; US Geological Survey: Washington, DC, USA, 2011.
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In Proceedings of the International Conference on Machine Learning. PMLR, Atlanta, GA, USA, 16–21 June 2013; pp. 115–123. [Google Scholar]
- Pandas Development Team, T. Pandas-dev/Pandas: Pandas. 2020. [Google Scholar] [CrossRef]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 56–61. [Google Scholar] [CrossRef] [Green Version]
- USGS Site Information Figure. Available online: https://help.waterdata.usgs.gov/tutorials/site-information/what-is-my-watershed-address-and-how-will-it-help-me-find-usgs-data (accessed on 7 March 2022).
- Nielsen, D. Tree Boosting with Xgboost—Why Does Xgboost Win “Every” Machine Learning Competition? Master’s Thesis, Norwegian University of Science and Technology, Trondheim, Norway, 2016. [Google Scholar]
- Hestness, J.; Narang, S.; Ardalani, N.; Diamos, G.; Jun, H.; Kianinejad, H.; Patwary, M.; Ali, M.; Yang, Y.; Zhou, Y. Deep learning scaling is predictable, empirically. arXiv 2017, arXiv:1712.00409. [Google Scholar]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Olive, D.J. Multiple linear regression. In Linear Regression; Springer: Cham, Switzerland, 2017; pp. 17–83. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for hyper-parameter optimization. Adv. Neural Inf. Process. Syst. 2011, 24, 2546–2554. [Google Scholar]
- Bergstra, J.; Yamins, D.; Cox, D.D. Hyperopt: A python library for optimizing the hyperparameters of machine learning algorithms. In Proceedings of the 12th Python in Science Conference, Austin, TX, USA, 24–29 June 2013; Volume 13, p. 20. [Google Scholar]
- Jackson, E.K.; Roberts, W.; Nelsen, B.; Williams, G.P.; Nelson, E.J.; Ames, D.P. Introductory overview: Error metrics for hydrologic modelling—A review of common practices and an open source library to facilitate use and adoption. Environ. Model. Softw. 2019, 119, 32–48. [Google Scholar] [CrossRef]
- Hsieh, W.W. Machine Learning Methods in the Environmental Sciences: Neural Networks and Kernels; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Zounemat-Kermani, M.; Batelaan, O.; Fadaee, M.; Hinkelmann, R. Ensemble machine learning paradigms in hydrology: A review. J. Hydrol. 2021, 598, 126266. [Google Scholar]
- Dion, P.; Martel, J.L.; Arsenault, R. Hydrological ensemble forecasting using a multi-model framework. J. Hydrol. 2021, 600, 126537. [Google Scholar]
- Jiang, S.; Ren, L.; Yang, X.; Ma, M.; Liu, Y. Multi-model ensemble hydrologic prediction and uncertainties analysis. Proc. Int. Assoc. Hydrol. Sci. 2014, 364, 249–254. [Google Scholar]
- Fleming, S.W.; Bourdin, D.R.; Campbell, D.; Stull, R.B.; Gardner, T. Development and operational testing of a super-ensemble artificial intelligence flood-forecast model for a Pacific Northwest river. JAWRA J. Am. Water Resour. Assoc. 2015, 51, 502–512. [Google Scholar]
- Fleming, S.W.; Garen, D.C.; Goodbody, A.G.; McCarthy, C.S.; Landers, L.C. Assessing the new Natural Resources Conservation Service water supply forecast model for the American West: A challenging test of explainable, automated, ensemble artificial intelligence. J. Hydrol. 2021, 602, 126782. [Google Scholar]
- Kratzert, F.; Klotz, D.; Shalev, G.; Klambauer, G.; Hochreiter, S.; Nearing, G. Towards Learning Universal, Regional, and Local Hydrological Behaviors via Machine-Learning Applied to Large-Sample Datasets. arXiv 2019, arXiv:1907.08456. [Google Scholar]
- DeWeber, J.T.; Wagner, T. A regional neural network ensemble for predicting mean daily river water temperature. J. Hydrol. 2014, 517, 187–200. [Google Scholar]
- Zhu, S.; Nyarko, E.K.; Hadzima-Nyarko, M. Modelling daily water temperature from air temperature for the Missouri River. PeerJ 2018, 6, e4894. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
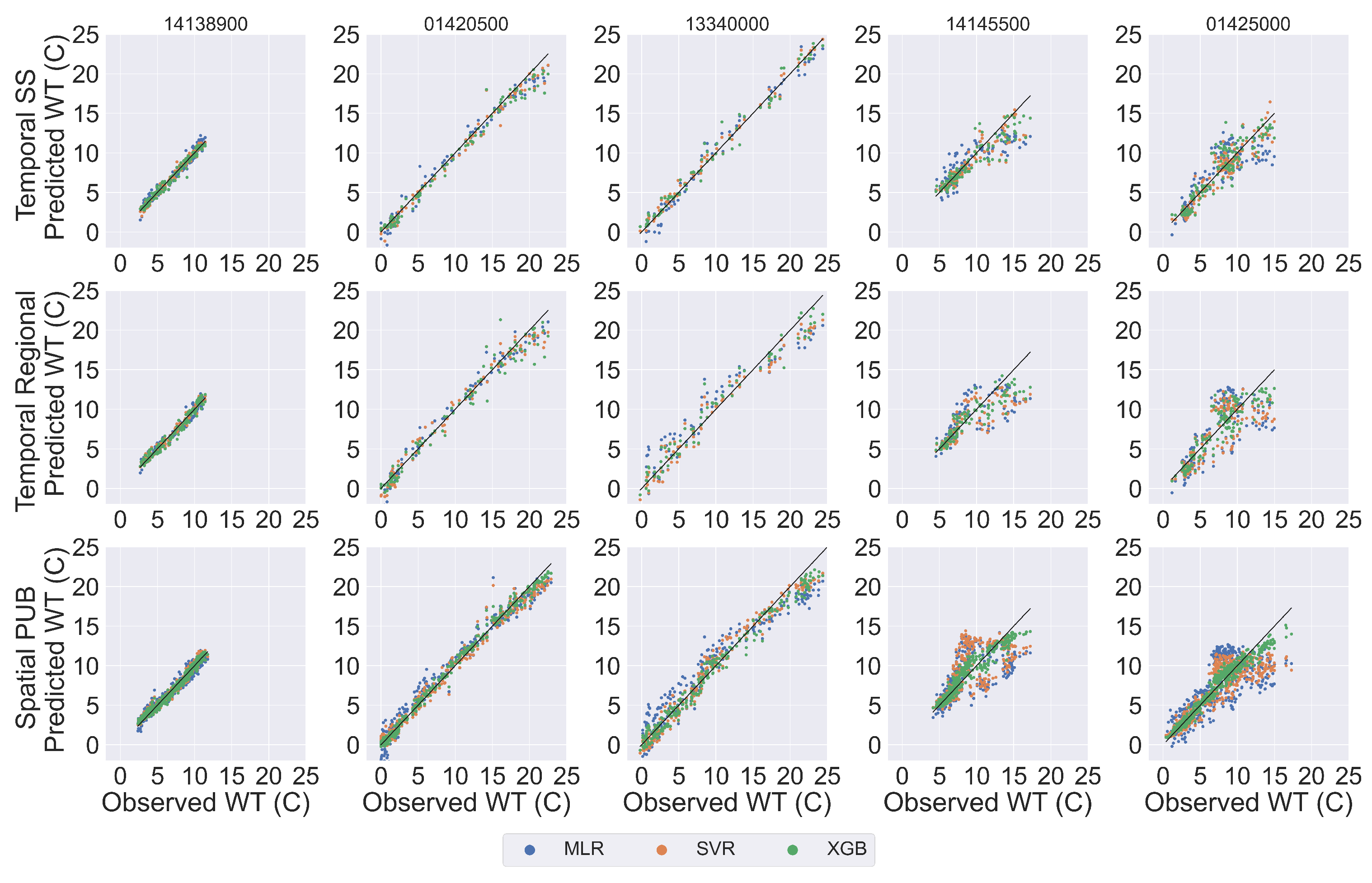{kind=link}
{kind=link}
| Configuration Name | Training Subset 1 | Training Attributes | HPO |
|---|---|---|---|
| Temporal Single Station Scenario | |||
| SS_HPO | HUC 02 + 17 | NA | HyperoptTPE |
| SS_noHPO | HUC 02 + 17 | NA | None |
| Temporal Regional Scenario | |||
| 02_17_MR_noAtt_noHPO | HUC 02 + 17 | lat/lon/elev | None |
| 02_17_MR_noAtt_HPO | HUC 02 + 17 | None | HyperoptTPE |
| 02_17_MR_Att_HPO | HUC 02 + 17 | None | HyperoptTPE |
| 02_17_MR_Att_noHPO | HUC 02 + 17 | lat/lon/elev | None |
| 02_17_MR_Att_Drain_noHPO | HUC 02 + 17 GAGES | lat/lon/elev/drain | None |
| 02_17_MR_Att_Drain_HPO | HUC 02 + 17 GAGES | lat/lon/elev/drain | HyperoptTPE |
| 02_17_SR_noAtt_noHPO | HUC 02 + 17 | lat/lon/elev | None |
| 02_17_SR_noAtt_HPO | HUC 02 + 17 | None | HyperoptTPE |
| 02_17_SR_Att_HPO | HUC 02 + 17 | None | HyperoptTPE |
| 02_17_SR_Att_noHPO | HUC 02 + 17 | lat/lon/elev | None |
| 02_17_SR_Att_Drain_noHPO | HUC 02 + 17 GAGES | lat/lon/elev/drain | None |
| PUB Scenario | |||
| PUB_02_17_SR | HUC 02 + HUC 17 | lat/lon/elev | None |
| Configuration Name | MLR | SVR | XGB | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Q1 | /Q2 | Q3 | Ext 1 | Q1 | /Q2 | Q3 | Ext 1 | Q1 | /Q2 | Q3 | Ext 1 | |
| Temporal Predictions—SS | ||||||||||||
| SS_02_17_HPO | 0.72 | 1.07/1.03 | 1.23 | 1.28 | 0.53 | 0.81/0.69 | 0.93 | 0.72 | 0.62 | 0.89/0.84 | 1.04 | 0.72 |
| SS_02_17_noHPO | 0.72 | 1.07/1.03 | 1.23 | 1.28 | 0.59 | 0.89/0.80 | 1.06 | 1.09 | 0.68 | 0.94/0.92 | 1.06 | 1.09 |
| Temporal Predictions—Regional | ||||||||||||
| 02_17_MR_noAtt_noHPO | 0.93 | 1.35/1.32 | 1.67 | 1.58 | 0.79 | 1.15/1.11 | 1.35 | 1.10 | 0.76 | 1.10/1.13 | 1.37 | 1.10 |
| 02_17_MR_noAtt_HPO | 0.93 | 1.35/1.32 | 1.67 | 1.58 | 0.80 | 1.18/1.18 | 1.42 | 1.21 | 0.90 | 1.23/1.20 | 1.44 | 1.21 |
| 02_17_MR_Att_HPO | 0.93 | 1.35/1.32 | 1.67 | 1.58 | 0.78 | 1.12/0.96 | 1.25 | 1.10 | 0.89 | 1.24/1.25 | 1.44 | 1.10 |
| 02_17_MR_Att_noHPO | 0.93 | 1.35/1.32 | 1.67 | 1.58 | 0.73 | 1.08/0.94 | 1.27 | 1.06 | 0.77 | 1.05/1.03 | 1.30 | 1.06 |
| 02_17_MR_Att_Drain_noHPO 2 | 0.91 | 1.31/1.25 | 1.62 | 1.57 | 0.70 | 0.99/0.86 | 1.19 | 1.02 | 0.73 | 1.02/1.02 | 1.22 | 1.02 |
| 02_17_MR_Att_Drain_HPO 2 | 0.91 | 1.31/1.25 | 1.62 | 1.57 | 0.81 | 1.16/1.08 | 1.26 | 1.34 | 0.91 | 1.23/1.22 | 1.41 | 1.34 |
| 02_17_SR_noAtt_noHPO | 0.97 | 1.30/1.24 | 1.44 | 1.56 | 0.75 | 1.11/0.99 | 1.30 | 1.19 | 0.80 | 1.09/1.08 | 1.28 | 1.19 |
| 02_17_SR_noAtt_HPO | 0.97 | 1.30/1.24 | 1.44 | 1.56 | 0.75 | 1.14/1.01 | 1.32 | 1.14 | 0.94 | 1.21/1.17 | 1.42 | 1.14 |
| 02_17_SR_Att_HPO | 0.97 | 1.30/1.24 | 1.44 | 1.56 | 0.74 | 1.09/0.93 | 1.25 | 1.05 | 0.90 | 1.17/1.08 | 1.39 | 1.05 |
| 02_17_SR_Att_noHPO | 0.97 | 1.30/1.24 | 1.44 | 1.56 | 0.69 | 1.03/0.92 | 1.21 | 1.14 | 0.77 | 1.03/1.02 | 1.25 | 1.14 |
| 02_17_SR_Att_Drain_noHPO | 0.96 | 1.26/1.21 | 1.41 | 1.55 | 0.65 | 0.95/0.89 | 1.14 | 1.05 | 0.76 | 1.01/0.98 | 1.21 | 1.05 |
| Spatial Predictions—PUB | ||||||||||||
| PUB_02_17_SR | 0.92 | 1.30/1.20 | 1.47 | 1.56 | 0.70 | 0.99/0.89 | 1.15 | 1.08 | 0.50 | 0.64/0.61 | 0.72 | 1.08 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Weierbach, H.; Lima, A.R.; Willard, J.D.; Hendrix, V.C.; Christianson, D.S.; Lubich, M.; Varadharajan, C. Stream Temperature Predictions for River Basin Management in the Pacific Northwest and Mid-Atlantic Regions Using Machine Learning. Water 2022, 14, 1032. https://doi.org/10.3390/w14071032
Weierbach H, Lima AR, Willard JD, Hendrix VC, Christianson DS, Lubich M, Varadharajan C. Stream Temperature Predictions for River Basin Management in the Pacific Northwest and Mid-Atlantic Regions Using Machine Learning. Water. 2022; 14(7):1032. https://doi.org/10.3390/w14071032
Chicago/Turabian StyleWeierbach, Helen, Aranildo R. Lima, Jared D. Willard, Valerie C. Hendrix, Danielle S. Christianson, Michaelle Lubich, and Charuleka Varadharajan. 2022. "Stream Temperature Predictions for River Basin Management in the Pacific Northwest and Mid-Atlantic Regions Using Machine Learning" Water 14, no. 7: 1032. https://doi.org/10.3390/w14071032
APA StyleWeierbach, H., Lima, A. R., Willard, J. D., Hendrix, V. C., Christianson, D. S., Lubich, M., & Varadharajan, C. (2022). Stream Temperature Predictions for River Basin Management in the Pacific Northwest and Mid-Atlantic Regions Using Machine Learning. Water, 14(7), 1032. https://doi.org/10.3390/w14071032