
Towards an Extension of the Model Conditional Processor: Predictive Uncertainty Quantification of Monthly Streamflow via Gaussian Mixture Models and Clusters

 , and
, and 
Abstract
:1. Introduction
2. Materials and Methods
- Uncertainty of weather forecasts has been substantially reduced because past observations are employed as the hydrological model’s input.
- Predictions and observations correlating, and this system performance will continue in the future. Similarly, modelled variables are stationary during the calibration and application period. Non-stationarity can be accounted for using deterministic model non-stationarity [71,72]. Such extension is not considered in the present contribution, but a discussion is provided in Section 4.
- A single deterministic model with a single parameter set is considered. Section 4 will discuss the possible extension of the GMCP post-processor to multi-model applications.
- The calibration dataset is long enough to ensure sufficient information to upgrade the deterministic and post-processor models. The predictive capacity of the models is limited by proper calibration, which implies that sufficiently long records of observed data, guiding to a variety of hydrologic conditions, are available for model training.
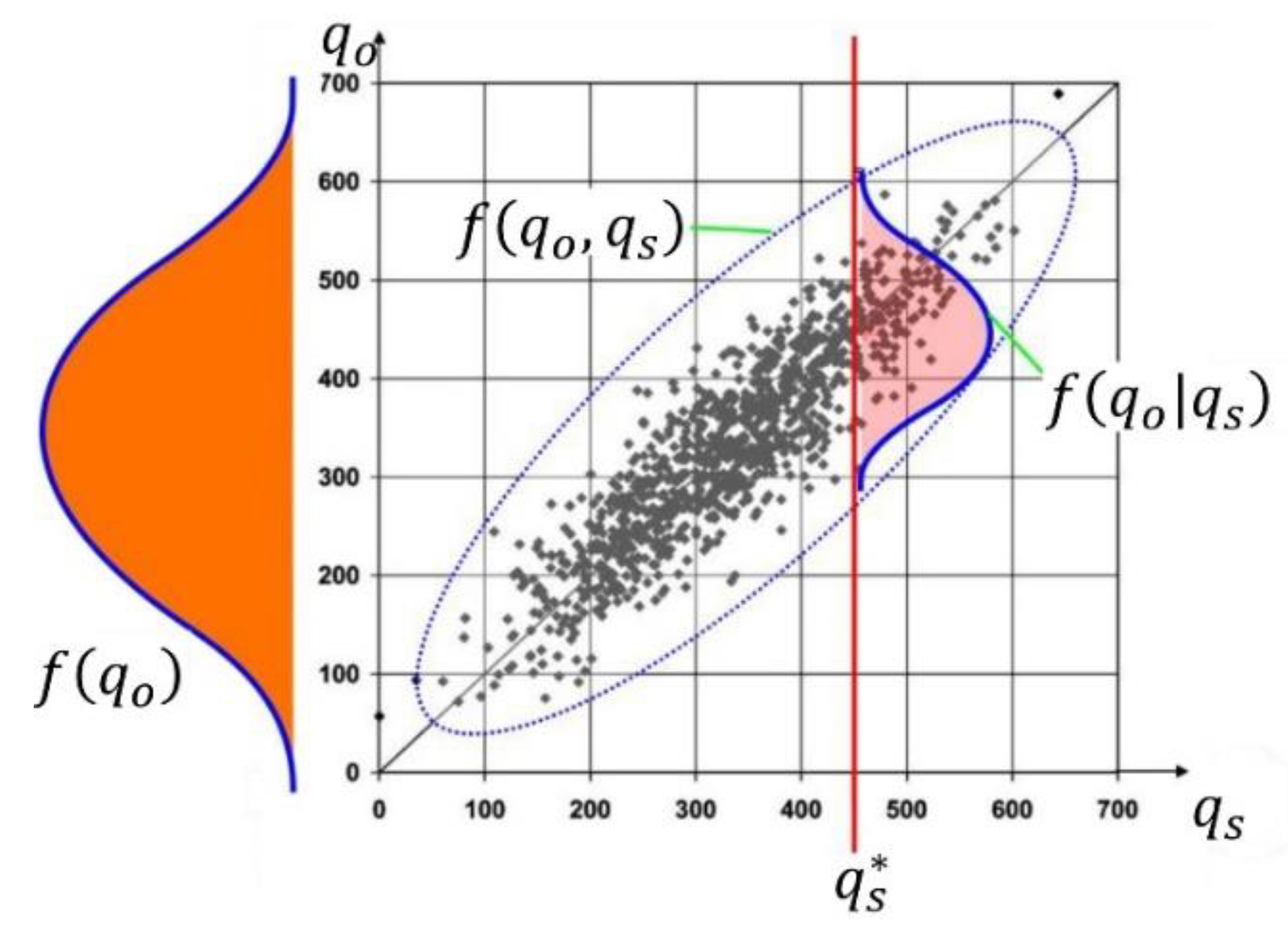
2.1. Predictive Uncertainty
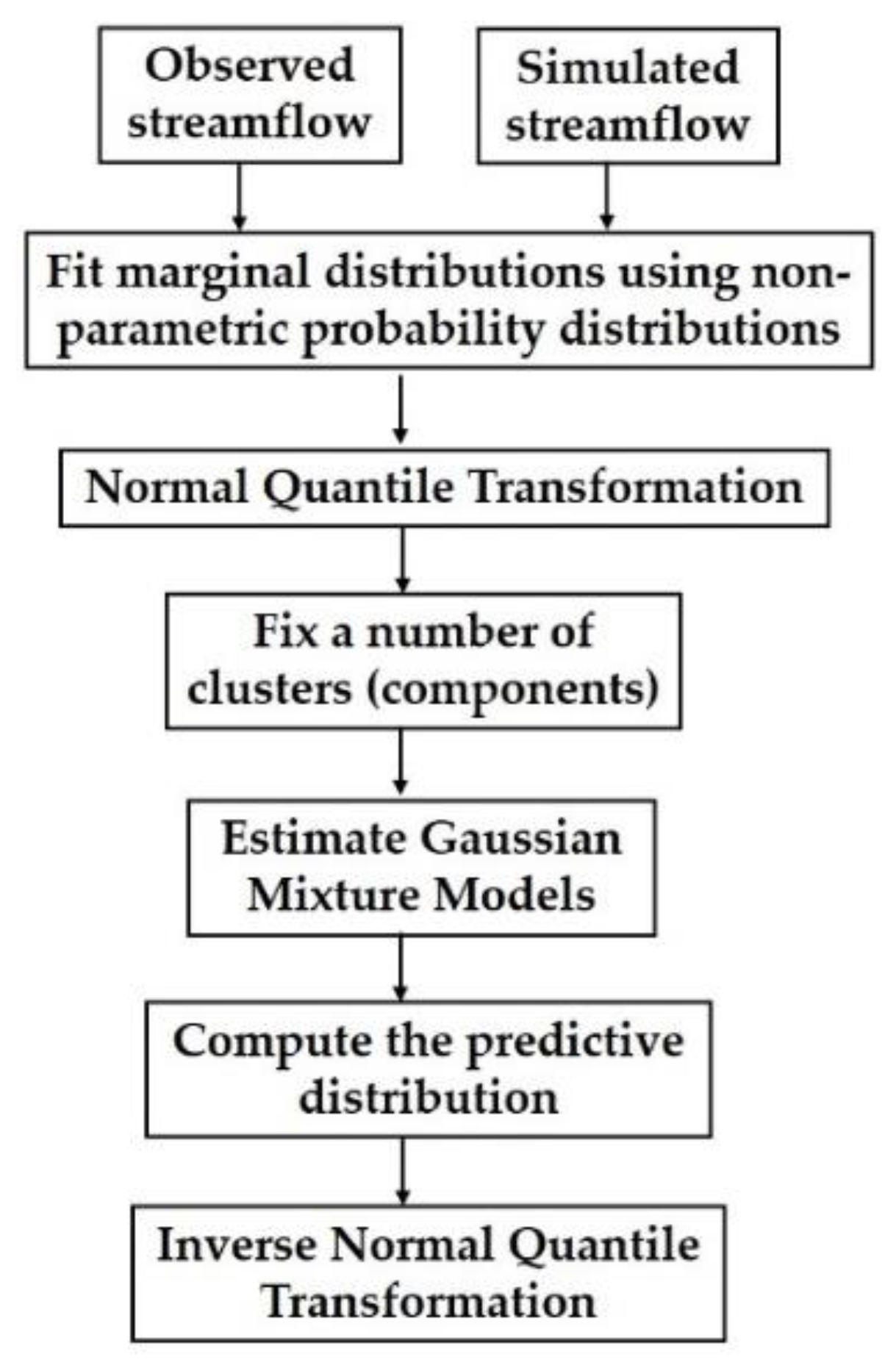
2.2. Marginal Distribution and Normal Quantile Transformation
2.3. Hydrological Post-Processing Methods
2.3.1. Model Conditional Processor (MCP)
2.3.2. MCP Using Truncated Normal Distribution (MCPt)
2.3.3. Gaussian Mixture Clustering Post-Processor (GMCP)
2.4. Case Studies
2.5. Hydrological Model
2.6. Verification Indices
2.7. Comparison Frame
3. Results
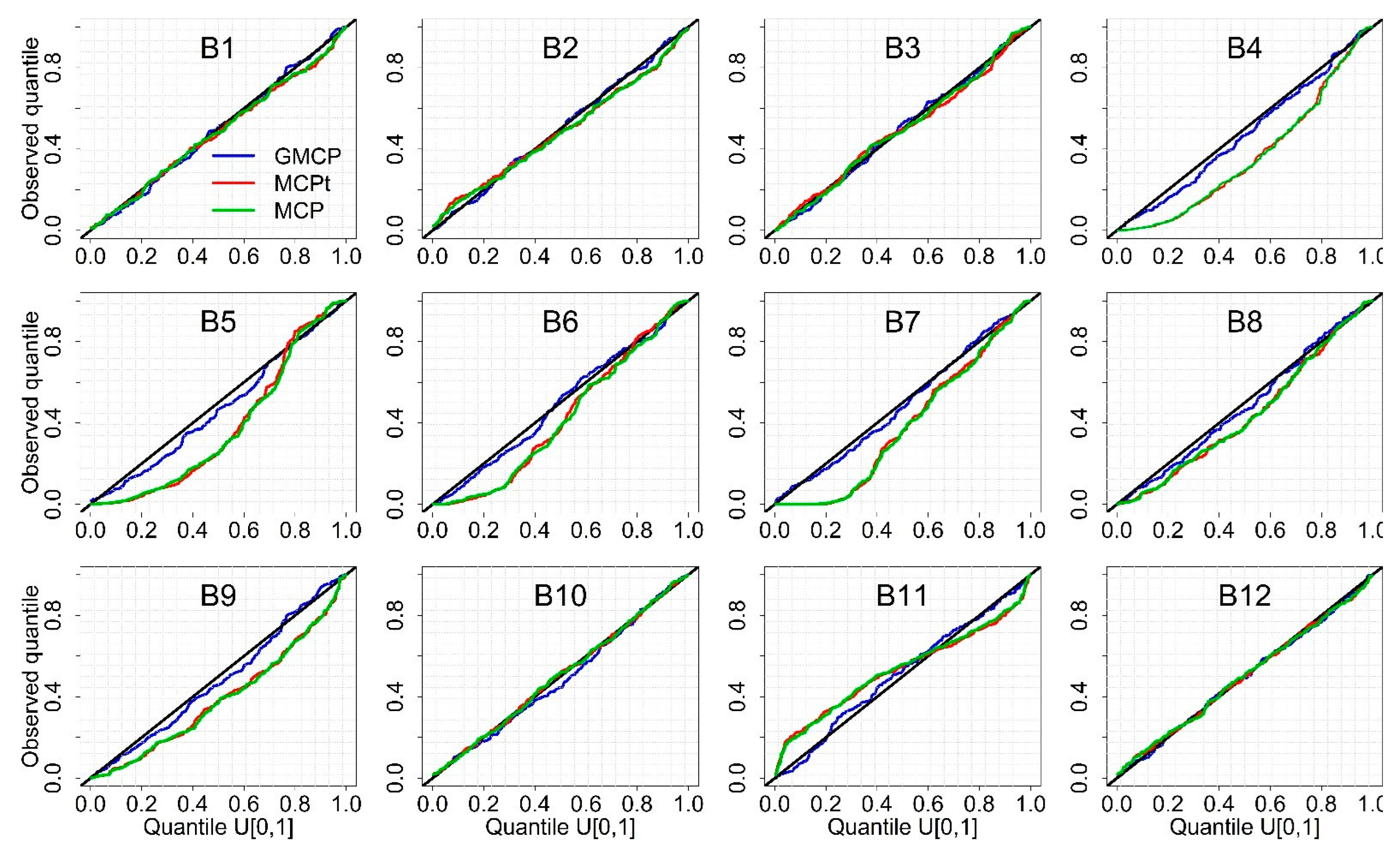
3.1. Comparison of Post-Processors: Individual Verification Indices
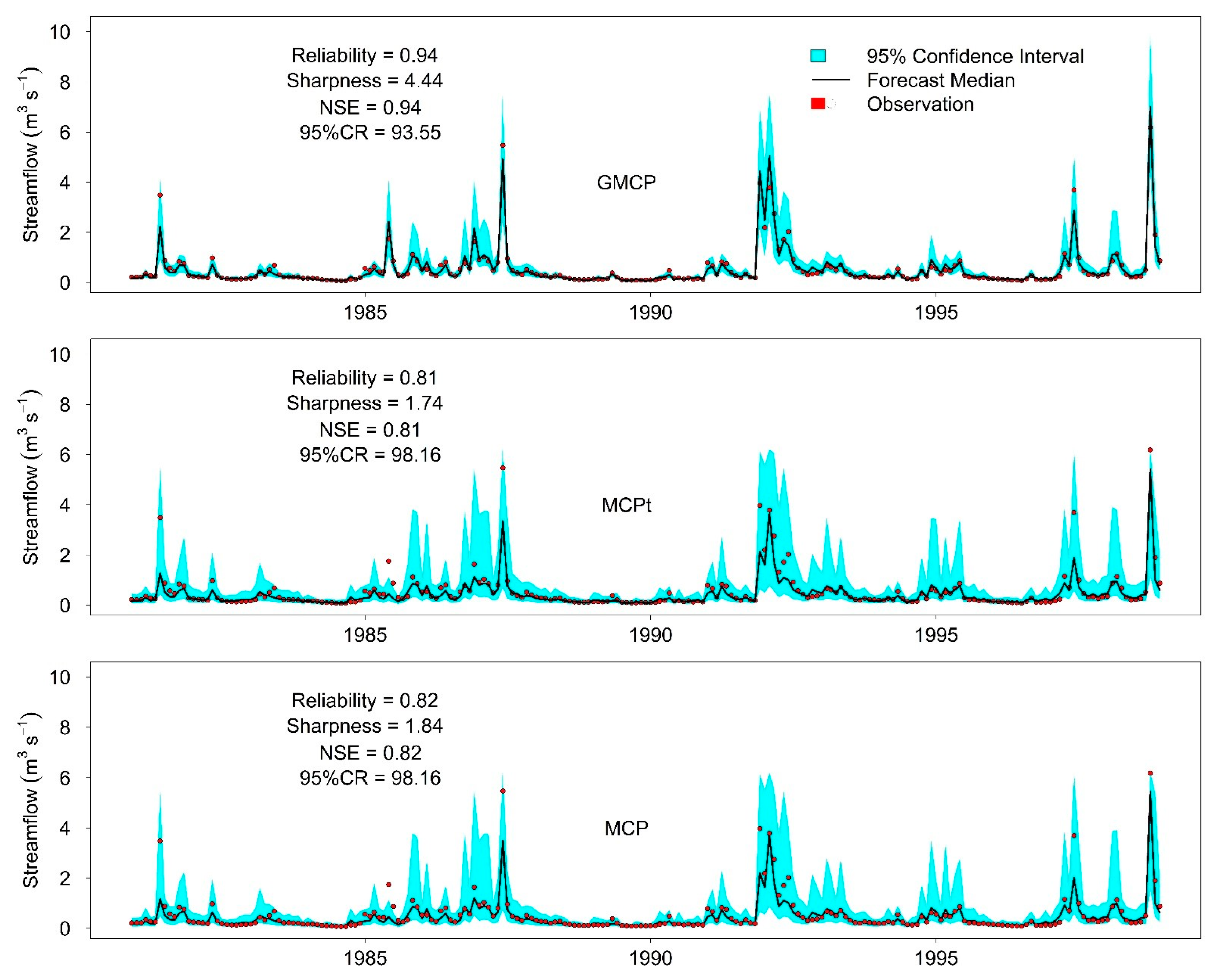
3.2. Uncertainty Bands in San Marcos Catchment (B11)
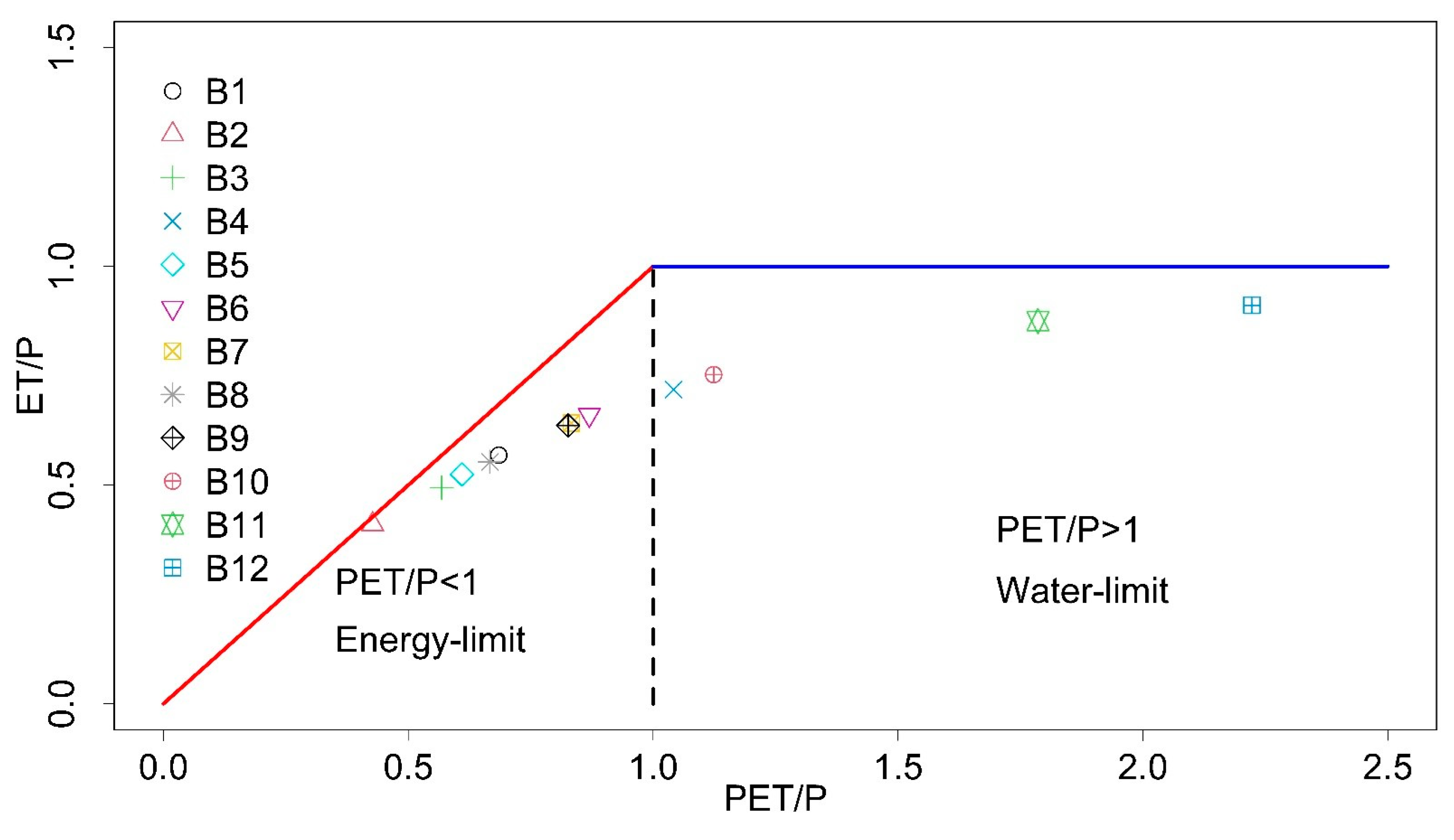
3.3. Influence of the Aridity Index
4. Discussion
5. Conclusions and Summary
- In general, all three post-processors showed promising results. However, the GMCP post-processor has shown significant potential in generating more reliable, sharp, and accurate monthly streamflow predictions than the MCP and MCPt methods, especially in dry catchments.
- The MCP and MCPt methods provided similar performances for monthly streamflow predictions regarding the NSE index, reliability, sharpness, and containing ratio (95%CR).
- The MCP and MCPt showed a better performance in wet catchments than in dry catchments.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Stakhiv, E.; Stewart, B. Needs for Climate Information in Support of Decision-Making in the Water Sector. Procedia Environ. Sci. 2010, 1, 102–119. [Google Scholar] [CrossRef] [Green Version]
- Hamilton, S.H.; Fu, B.; Guillaume, J.H.; Badham, J.; Elsawah, S.; Gober, P.; Hunt, R.J.; Iwanaga, T.; Jakeman, A.J.; Ames, D.P.; et al. A framework for characterising and evaluating the effectiveness of environmental modelling. Environ. Model. Softw. 2019, 118, 83–98. [Google Scholar] [CrossRef] [Green Version]
- Chang, F.J.; Guo, S. Advances in Hydrologic Forecasts and Water Resources Management. Water 2020, 12, 1819. [Google Scholar] [CrossRef]
- Kavetski, D.; Kuczera, G.; Franks, S.W. Bayesian analysis of input uncertainty in hydrological modeling: 1. Theory. Water Resour. Res. 2006, 42, W03408. [Google Scholar] [CrossRef]
- Gan, Y.; Liang, X.-Z.; Duan, Q.; Ye, A.; Di, Z.; Hong, Y.; Li, J. A systematic assessment and reduction of parametric uncertainties for a distributed hydrological model. J. Hydrol. 2018, 564, 697–711. [Google Scholar] [CrossRef]
- Renard, B.; Kavetski, D.; Kuczera, G.; Thyer, M.; Franks, S.W. Understanding predictive uncertainty in hydrologic modeling: The challenge of identifying input and structural errors. Water Resour. Res. 2010, 46, W05521. [Google Scholar] [CrossRef]
- Bulygina, N.; Gupta, H. Estimating the uncertain mathematical structure of a water balance model via Bayesian data assimilation. Water Resour. Res. 2009, 45, W00B13. [Google Scholar] [CrossRef]
- Clark, M.P.; Slater, A.G.; Rupp, D.E.; Woods, R.A.; Vrugt, J.A.; Gupta, H.V.; Wagener, T.; Hay, L.E. Framework for Understanding Structural Errors (FUSE): A modular framework to diagnose differences between hydrological models. Water Resour. Res. 2008, 44, W00B02. [Google Scholar] [CrossRef]
- Reichle, R.H.; Mclaughlin, D.B.; Entekhabi, D. Hydrologic Data Assimilation with the Ensemble Kalman Filter. American Meteorol. Soc. 2002, 130, 103–114. [Google Scholar] [CrossRef] [Green Version]
- Clark, M.P.; Kavetski, D. Ancient numerical daemons of conceptual hydrological modeling: 1. Fidelity and efficiency of time stepping schemes. Water Resour. Res. 2010, 46, W10510. [Google Scholar] [CrossRef]
- Reichert, P. Conceptual and Practical Aspects of Quantifying Uncertainty in Environmental Modelling and Decision Support. 2012. Available online: https://www.semanticscholar.org/paper/Conceptual-and-Practical-Aspects-of-Quantifying-in-Reichert/4dbd0397c9cb925cff1eea445e8d18428ef4a95a (accessed on 16 July 2019).
- McInerney, D.; Thyer, M.; Kavetski, D.; Bennett, B.; Lerat, J.; Gibbs, M.; Kuczera, G. A simplified approach to produce probabilistic hydrological model predictions. Environ. Model. Softw. 2018, 109, 306–314. [Google Scholar] [CrossRef]
- Krzysztofowicz, R. Bayesian theory of probabilistic forecasting via deterministic hydrologic model. Water Resour. Res. 1999, 35, 2739–2750. [Google Scholar] [CrossRef] [Green Version]
- Todini, E. A model conditional processor to assess predictive uncertainty in flood forecasting. Int. J. River Basin Manag. 2008, 6, 123–137. [Google Scholar] [CrossRef]
- Loucks, D.P.; van Beek, E. Water Resource Systems Planning and Management; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar]
- Todini, E. Paradigmatic changes required in water resources management to benefit from probabilistic forecasts. Water Secur. 2018, 3, 9–17. [Google Scholar] [CrossRef]
- Refsgaard, J.C.; van der Sluijs, J.P.; Højberg, A.L.; Vanrolleghem, P.A. Uncertainty in the environmental modelling process—A framework and guidance. Environ. Model. Softw. 2007, 22, 1543–1556. [Google Scholar] [CrossRef] [Green Version]
- Prieto, C.; le Vine, N.; Kavetski, D.; García, E.; Medina, R. Flow Prediction in Ungauged Catchments Using Probabilistic Random Forests Regionalization and New Statistical Adequacy Tests. Water Resour. Res. 2019, 55, 4364–4392. [Google Scholar] [CrossRef]
- Ye, A.; Duan, Q.; Yuan, X.; Wood, E.F.; Schaake, J. Hydrologic post-processing of MOPEX streamflow simulations. J. Hydrol. 2014, 508, 147–156. [Google Scholar] [CrossRef]
- Hopson, T.M.; Wood, A.; Weerts, A.H. Motivation and overview of hydrological ensemble post-processing. In Handbook of Hydrometeorological Ensemble Forecasting; Springer: Berlin/Heidelberg, Germany, 2019; pp. 783–793. [Google Scholar]
- Montanari, A.; Koutsoyiannis, D. A blueprint for process-based modeling of uncertain hydrological systems. Water Resour. Res. 2012, 48, W09555. [Google Scholar] [CrossRef]
- Farmer, W.H.; Vogel, R.M. On the deterministic and stochastic use of hydrologic models. Water Resour. Res. 2016, 52, 5619–5633. [Google Scholar] [CrossRef] [Green Version]
- Montanari, A.; Brath, A. A stochastic approach for assessing the uncertainty of rainfall-runoff simulations. Water Resour. Res. 2004, 40, W01106. [Google Scholar] [CrossRef]
- Montanari, A.; Grossi, G. Estimating the uncertainty of hydrological forecasts: A statistical approach. Water Resour. Res. 2008, 44, W00B08. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.J.; Robertson, D.E.; Chiew, F.H.S. A Bayesian joint probability modeling approach for seasonal forecasting of streamflows at multiple sites. Water Resour. Res. 2009, 45, W05407. [Google Scholar] [CrossRef]
- Zhao, L.; Duan, Q.; Schaake, J.; Ye, A.; Xia, J. A hydrologic post-processor for ensemble streamflow predictions. Adv. Geosci. 2011, 29, 51–59. [Google Scholar] [CrossRef] [Green Version]
- McInerney, D.; Thyer, M.; Kavetski, D.; Lerat, J.; Kuczera, G. Improving probabilistic prediction of daily streamflow by identifying Pareto optimal approaches for modeling heteroscedastic residual errors. Water Resour. Res. 2017, 53, 2199–2239. [Google Scholar] [CrossRef]
- Schoups, G.; Vrugt, J.A. A formal likelihood function for parameter and predictive inference of hydrologic models with correlated, heteroscedastic, and non-Gaussian errors. Water Resour. Res. 2010, 46, W10531. [Google Scholar] [CrossRef] [Green Version]
- Smith, T.; Marshall, L.; Sharma, A. Modeling residual hydrologic errors with Bayesian inference. J. Hydrol. 2015, 528, 29–37. Available online: https://www.sciencedirect.com/science/article/pii/S0022169415004011 (accessed on 3 May 2017). [CrossRef]
- Sorooshian, S.; Dracup, J.A. Stochastic parameter estimation procedures for hydrologie rainfall-runoff models: Correlated and heteroscedastic error cases. Water Resour. Res. 1980, 16, 430–442. [Google Scholar] [CrossRef]
- Van Der Waerden, B. Order tests for two-sample problem and their power I. Indag. Math. 1952, 55, 453–458. [Google Scholar] [CrossRef]
- Box, G.E.P.; Cox, D.R. An Analysis of Transformations. J. R. Stat. Soc. 1964, 26, 211–252. Available online: https://www.semanticscholar.org/paper/An-Analysis-of-Transformations-Box-Cox/6e820cf11712b9041bb625634612a535476f0960 (accessed on 24 May 2019). [CrossRef]
- Wang, Q.J.; Shrestha, D.L.; Robertson, D.E.; Pokhrel, P. A log-sinh transformation for data normalization and variance stabilization. Water Resour. Res. 2012, 48, W05514. [Google Scholar] [CrossRef]
- Krzysztofowicz, R.; Kelly, K.S. Hydrologic uncertainty processor for probabilistic river stage forecasting. Water Resour. Res. 2000, 36, 3265–3277. [Google Scholar] [CrossRef]
- Coccia, G.; Todini, E. Recent developments in predictive uncertainty assessment based on the model conditional processor approach. Hydrol. Earth Syst. Sci. 2011, 15, 3253–3274. [Google Scholar] [CrossRef] [Green Version]
- Weerts, A.H.; Winsemius, H.C.; Verkade, J.S. Estimation of predictive hydrological uncertainty using quantile regression: Examples from the National Flood Forecasting System (England and Wales). Hydrol. Earth Syst. Sci. 2011, 15, 255–265. [Google Scholar] [CrossRef] [Green Version]
- Tyralis, H.; Papacharalampous, G. Quantile-Based Hydrological Modelling. Water 2021, 13, 3420. [Google Scholar] [CrossRef]
- Raftery, A.E.; Gneiting, T.; Balabdaoui, F.; Polakowski, M. Using Bayesian Model Averaging to Calibrate Forecast Ensembles. Mon. Weather Rev. 2005, 133, 1155–1174. [Google Scholar] [CrossRef] [Green Version]
- Darbandsari, P.; Coulibaly, P. Inter-Comparison of Different Bayesian Model Averaging Modifications in Streamflow Simulation. Water 2019, 11, 1707. [Google Scholar] [CrossRef] [Green Version]
- Evin, G.; Thyer, M.; Kavetski, D.; McInerney, D.; Kuczera, G. Comparison of joint versus postprocessor approaches for hydrological uncertainty estimation accounting for error autocorrelation and heteroscedasticity. Water Resour. Res. 2014, 50, 2350–2375. [Google Scholar] [CrossRef]
- Woldemeskel, F.; McInerney, D.; Lerat, J.; Thyer, M.; Kavetski, D.; Shin, D.; Tuteja, N.; Kuczera, G. Evaluating post-processing approaches for monthly and seasonal streamflow forecasts. Hydrol. Earth Syst. Sci. 2018, 22, 6257–6278. [Google Scholar] [CrossRef] [Green Version]
- Brown, J.D.; Seo, D.-J. Evaluation of a nonparametric post-processor for bias correction and uncertainty estimation of hydrologic predictions. Hydrol. Process. 2013, 27, 83–105. [Google Scholar] [CrossRef]
- Solomatine, D.P.; Shrestha, D.L. A novel method to estimate model uncertainty using machine learning techniques. Water Resour. Res. 2009, 45, W00B11. [Google Scholar] [CrossRef]
- López, P.L.; Verkade, J.S.; Weerts, A.H.; Solomatine, D.P. Alternative configurations of quantile regression for estimating predictive uncertainty in water level forecasts for the upper Severn River: A comparison. Hydrol. Earth Syst. Sci. 2014, 18, 3411–3428. [Google Scholar] [CrossRef] [Green Version]
- Sikorska, A.E.; Montanari, A.; Koutsoyiannis, D. Estimating the Uncertainty of Hydrological Predictions through Data-Driven Resampling Techniques. J. Hydrol. Eng. 2015, 20, A4014009. [Google Scholar] [CrossRef]
- Ehlers, L.B.; Wani, O.; Koch, J.; Sonnenborg, T.O.; Refsgaard, J.C. Using a simple post-processor to predict residual uncertainty for multiple hydrological model outputs. Adv. Water Resour. 2019, 129, 16–30. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G.; Burnetas, A.; Langousis, A. Hydrological post-processing using stacked generalization of quantile regression algorithms: Large-scale application over CONUS. J. Hydrol. 2019, 577, 123957. [Google Scholar] [CrossRef]
- Papacharalampous, G.; Tyralis, H.; Langousis, A.; Jayawardena, A.W.; Sivakumar, B.; Mamassis, N.; Montanari, A.; Koutsoyiannis, D. Probabilistic Hydrological Post-Processing at Scale: Why and How to Apply Machine-Learning Quantile Regression Algorithms. Water 2019, 11, 2126. [Google Scholar] [CrossRef] [Green Version]
- Schefzik, R.; Thorarinsdottir, T.L.; Gneiting, T. Uncertainty Quantification in Complex Simulation Models Using Ensemble Copula Coupling. Stat. Sci. 2013, 28, 616–640. [Google Scholar] [CrossRef]
- Madadgar, S.; Moradkhani, H. Improved Bayesian multimodeling: Integration of copulas and Bayesian model averaging. Water Resour. Res. 2014, 50, 9586–9603. [Google Scholar] [CrossRef] [Green Version]
- Klein, B.; Meissner, D.; Kobialka, H.-U.; Reggiani, P. Predictive Uncertainty Estimation of Hydrological Multi-Model Ensembles Using Pair-Copula Construction. Water 2016, 8, 125. [Google Scholar] [CrossRef]
- Li, W.; Duan, Q.; Miao, C.; Ye, A.; Gong, W.; Di, Z. A review on statistical postprocessing methods for hydrometeorological ensemble forecasting. Wiley Interdiscip. Rev. Water 2017, 4, e1246. [Google Scholar] [CrossRef]
- Moges, E.; Demissie, Y.; Larsen, L.; Yassin, F. Review: Sources of Hydrological Model Uncertainties and Advances in Their Analysis. Water 2020, 13, 28. [Google Scholar] [CrossRef]
- Matott, L.S.; Babendreier, J.E.; Purucker, S.T. Evaluating uncertainty in integrated environmental models: A review of concepts and tools. Water Resour. Res. 2009, 45, 6421. [Google Scholar] [CrossRef] [Green Version]
- Reggiani, P.; Coccia, G.; Mukhopadhyay, B. Predictive Uncertainty Estimation on a Precipitation and Temperature Reanalysis Ensemble for Shigar Basin, Central Karakoram. Water 2016, 8, 263. [Google Scholar] [CrossRef] [Green Version]
- Barbetta, S.; Coccia, G.; Moramarco, T.; Todini, E. Case Study: A Real-Time Flood Forecasting System with Predictive Uncertainty Estimation for the Godavari River, India. Water 2016, 8, 463. [Google Scholar] [CrossRef] [Green Version]
- Biondi, D.; Todini, E. Comparing Hydrological Postprocessors Including Ensemble Predictions into Full Predictive Probability Distribution of Streamflow. Water Resour. Res. 2018, 54, 9860–9882. [Google Scholar] [CrossRef] [Green Version]
- Massari, C.; Maggioni, V.; Barbetta, S.; Brocca, L.; Ciabatta, L.; Camici, S.; Moramarco, T.; Coccia, G.; Todini, E. Complementing near-real time satellite rainfall products with satellite soil moisture-derived rainfall through a Bayesian Inversion approach. J. Hydrol. 2019, 573, 341–351. [Google Scholar] [CrossRef]
- Parviz, L.; Rasouli, K. Development of Precipitation Forecast Model Based on Artificial Intelligence and Subseasonal Clustering. J. Hydrol. Eng. 2019, 24, 04019053. [Google Scholar] [CrossRef]
- Yu, Y.; Shao, Q.; Lin, Z. Regionalization study of maximum daily temperature based on grid data by an objective hybrid clustering approach. J. Hydrol. 2018, 564, 149–163. [Google Scholar] [CrossRef]
- Basu, B.; Srinivas, V.V. Regional flood frequency analysis using kernel-based fuzzy clustering approach. Water Resour. Res. 2014, 50, 3295–3316. [Google Scholar] [CrossRef]
- Zhang, H.; Huang, G.H.; Wang, D.; Zhang, X. Multi-period calibration of a semi-distributed hydrological model based on hydroclimatic clustering. Adv. Water Resour. 2011, 34, 1292–1303. [Google Scholar] [CrossRef]
- Schaefli, B.; Talamba, D.B.; Musy, A. Quantifying hydrological modeling errors through a mixture of normal distributions. J. Hydrol. 2007, 332, 303–315. [Google Scholar] [CrossRef]
- Smith, T.; Sharma, A.; Marshall, L.; Mehrotra, R.; Sisson, S. Development of a formal likelihood function for improved Bayesian inference of ephemeral catchments. Water Resour. Res. 2010, 46, W12551. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Wang, Q.J.; Bennett, J.C.; Robertson, D.E. Error reduction and representation in stages (ERRIS) in hydrological modelling for ensemble streamflow forecasting. Hydrol. Earth Syst. Sci. 2016, 20, 3561–3579. [Google Scholar] [CrossRef] [Green Version]
- Feng, K.; Zhou, J.; Liu, Y.; Lu, C.; He, Z. Hydrological Uncertainty Processor (HUP) with Estimation of the Marginal Distribution by a Gaussian Mixture Model. Water Resour. Manag. 2019, 33, 2975–2990. [Google Scholar] [CrossRef]
- Yang, X.; Zhou, J.; Fang, W.; Wang, Y. An Ensemble Flow Forecast Method Based on Autoregressive Model and Hydrological Uncertainty Processer. Water 2020, 12, 3138. [Google Scholar] [CrossRef]
- Kim, K.H.; Yun, S.T.; Park, S.S.; Joo, Y.; Kim, T.S. Model-based clustering of hydrochemical data to demarcate natural versus human impacts on bedrock groundwater quality in rural areas, South Korea. J. Hydrol. 2014, 519, 626–636. [Google Scholar] [CrossRef]
- Duan, Q.; Schaake, J.; Andréassian, V.; Franks, S.; Goteti, G.; Gupta, H.; Gusev, Y.; Habets, F.; Hall, A.; Hay, L.; et al. Model Parameter Estimation Experiment (MOPEX): An overview of science strategy and major results from the second and third workshops. J. Hydrol. 2006, 320, 3–17. [Google Scholar] [CrossRef] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing. Vienna, Austria. 2013. Available online: Ftp://ftp.uvigo.es/CRAN/web/packages/dplR/vignettes/intro-dplR.pdf (accessed on 16 April 2019).
- Pathiraja, S.; Marshall, L.; Sharma, A.; Moradkhani, H. Detecting non-stationary hydrologic model parameters in a paired catchment system using data assimilation. Adv. Water Resour. 2016, 94, 103–119. [Google Scholar] [CrossRef]
- Deb, P.; Kiem, A.S. Evaluation of rainfall–runoff model performance under non-stationary hydroclimatic conditions. Hydrol. Sci. J. 2020, 65, 1667–1684. [Google Scholar] [CrossRef]
- Simonoff, J.S. Smoothing Methods in Statistics; Springer: New York, NY, USA, 1996. [Google Scholar]
- Duong, T. Ks: Kernel density estimation and kernel discriminant analysis for multivariate data in R. J. Stat. Softw. 2007, 21, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Wolfe, J.H. Pattern clustering by multivariate mixture analysis. Multivariate Behav. Res. 1970, 5, 329–350. [Google Scholar] [CrossRef]
- Boehmke, B.; Greenwell, B.M. Hands-On Machine Learning with R, 1st ed.; Chapman and Hall: London, UK; CRC: Boca Raton, FL, USA, 2019. [Google Scholar]
- Banfield, J.D.; Raftery, A.E. Model-Based Gaussian and Non-Gaussian Clustering. Biometrics 1993, 49, 821. [Google Scholar] [CrossRef]
- Fraley, C.; Raftery, A.E. Model-based clustering, discriminant analysis, and density estimation. J. Am. Stat. Assoc. 2002, 97, 611–631. [Google Scholar] [CrossRef]
- James, L.F.; Priebe, C.E.; Marchette, D.J. Consistent estimation of mixture complexity. Ann. Stat. 2001, 29, 1281–1296. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Peel, D. Finite Mixture Models; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2000. [Google Scholar]
- Melnykov, V.; Maitra, R. Finite mixture models and model-based clustering. Stat. Surv. 2010, 4, 80–116. [Google Scholar] [CrossRef]
- McLachlan, G.J.; Krishnan, T. The EM Algorithm and Extensions; Wiley-Interscience: Hoboken, NJ, USA, 2008. [Google Scholar]
- Zhang, W.; Di, Y. Model-based clustering with measurement or estimation errors. Genes 2020, 11, 185. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Franz, K.J.; Hogue, T.S. Evaluating uncertainty estimates in hydrologic models: Borrowing measures from the forecast verification community. Hydrol. Earth Syst. Sci. 2011, 15, 3367–3382. [Google Scholar] [CrossRef] [Green Version]
- Perrin, C.; Michel, C.; Andréassian, V. Improvement of a parsimonious model for streamflow simulation. J. Hydrol. 2003, 279, 275–289. [Google Scholar] [CrossRef]
- Laio, F.; Tamea, S. Verification tools for probabilistic forecasts of continuous hydrological variables. Hydrol. Earth Syst. Sci. 2007, 11, 1267–1277. [Google Scholar] [CrossRef] [Green Version]
- Thyer, M.; Renard, B.; Kavetski, D.; Kuczera, G.; Franks, S.W.; Srikanthan, S. Critical evaluation of parameter consistency and predictive uncertainty in hydrological modeling: A case study using Bayesian total error analysis. Water Resour. Res. 2009, 45, W00B14. [Google Scholar] [CrossRef] [Green Version]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Kavetski, D.; Clark, M.P. Ancient numerical daemons of conceptual hydrological modeling: 2. Impact of time stepping schemes on model analysis and prediction. Water Resour. Res. 2010, 46, 2009WR008896. [Google Scholar] [CrossRef] [Green Version]
- Gupta, H.V.; Perrin, C.; Blöschl, G.; Montanari, A.; Kumar, R.; Clark, M.; Andréassian, V. Large-sample hydrology: A need to balance depth with breadth. Hydrol. Earth Syst. Sci. 2014, 18, 463–477. [Google Scholar] [CrossRef] [Green Version]
- Martinez, G.F.; Gupta, H.V. Toward improved identification of hydrological models: A diagnostic evaluation of the ‘abcd’ monthly water balance model for the conterminous United States. Water Resour. Res. 2010, 46, W08507. [Google Scholar] [CrossRef]
- Gneiting, T.; Balabdaoui, F.; Raftery, A.E. Probabilistic forecasts, calibration and sharpness. J. R. Stat. Soc. Ser. B Stat. Methodol. 2007, 69, 243–268. [Google Scholar] [CrossRef] [Green Version]
- Tolson, B.A.; Shoemaker, C.A. Efficient prediction uncertainty approximation in the calibration of environmental simulation models. Water Resour. Res. 2008, 44, 4411. [Google Scholar] [CrossRef]
- Bourgin, F.; Ramos, M.H.; Thirel, G.; Andréassian, V. Investigating the interactions between data assimilation and post-processing in hydrological ensemble forecasting. J. Hydrol. 2014, 519, 2775–2784. [Google Scholar] [CrossRef]
- Papacharalampous, G.; Tyralis, H.; Koutsoyiannis, D.; Montanari, A. Quantification of predictive uncertainty in hydrological modelling by harnessing the wisdom of the crowd: A large-sample experiment at monthly timescale. Adv. Water Resour. 2020, 136, 103470. [Google Scholar] [CrossRef] [Green Version]
- Hunter, J.; Thyer, M.; McInerney, D.; Kavetski, D. Achieving high-quality probabilistic predictions from hydrological models calibrated with a wide range of objective functions. J. Hydrol. 2021, 603, 126578. [Google Scholar] [CrossRef]
- Breaban, M.; Luchian, H. A unifying criterion for unsupervised clustering and feature selection. Pattern Recognit. 2011, 44, 854–865. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Station Name | Elev. | Area (km2) | P | PET | Q | Run-Off Index (Q/P) | Aridity Index (PET/P) |
|---|---|---|---|---|---|---|---|---|
| B1 | Amite River Near Denham Springs, LA | 0 | 3315 | 1560 | 1068.5 | 612 | 0.39 | 0.67 |
| B2 | French Broad River at Asheville, NC | 594 | 2448 | 1378 | 588.9 | 795 | 0.58 | 0.43 |
| B3 | Tygart Valley River at Philippi, WV | 390 | 2372 | 1164 | 661.4 | 736 | 0.63 | 0.57 |
| B4 | Spring River Near Waco, MO | 254 | 3015 | 1075 | 1119.8 | 300 | 0.28 | 1.04 |
| B5 | S Branch Potomac River Nr Springfield, WV | 171 | 3810 | 1043 | 636 | 339 | 0.33 | 0.61 |
| B6 | Monocacy R At Jug Bridge Nr Frederick, MD | 71 | 2116 | 1042 | 906.1 | 421 | 0.4 | 0.87 |
| B7 | Rappahannock River Nr Fredericksburg, VA | 17 | 4134 | 1028 | 856.7 | 375 | 0.36 | 0.83 |
| B8 | Bluestone River Nr Pipestem, WV | 465 | 1020 | 1017 | 678 | 419 | 0.41 | 0.67 |
| B9 | East Fork White River at Columbus, IN | 184 | 4421 | 1014 | 838 | 377 | 0.37 | 0.83 |
| B10 | English River at Kalona, IA | 193 | 1484 | 881 | 989.9 | 261 | 0.3 | 1.12 |
| B11 | San Marcos River at Luling, TX | 98 | 2170 | 819 | 1462.5 | 170 | 0.21 | 1.79 |
| B12 | Guadalupe River Nr Spring Branch, TX | 289 | 3406 | 761 | 1691.1 | 116 | 0.15 | 2.22 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Romero-Cuellar, J.; Gastulo-Tapia, C.J.; Hernández-López, M.R.; Prieto Sierra, C.; Francés, F. Towards an Extension of the Model Conditional Processor: Predictive Uncertainty Quantification of Monthly Streamflow via Gaussian Mixture Models and Clusters. Water 2022, 14, 1261. https://doi.org/10.3390/w14081261
Romero-Cuellar J, Gastulo-Tapia CJ, Hernández-López MR, Prieto Sierra C, Francés F. Towards an Extension of the Model Conditional Processor: Predictive Uncertainty Quantification of Monthly Streamflow via Gaussian Mixture Models and Clusters. Water. 2022; 14(8):1261. https://doi.org/10.3390/w14081261
Chicago/Turabian StyleRomero-Cuellar, Jonathan, Cristhian J. Gastulo-Tapia, Mario R. Hernández-López, Cristina Prieto Sierra, and Félix Francés. 2022. "Towards an Extension of the Model Conditional Processor: Predictive Uncertainty Quantification of Monthly Streamflow via Gaussian Mixture Models and Clusters" Water 14, no. 8: 1261. https://doi.org/10.3390/w14081261
APA StyleRomero-Cuellar, J., Gastulo-Tapia, C. J., Hernández-López, M. R., Prieto Sierra, C., & Francés, F. (2022). Towards an Extension of the Model Conditional Processor: Predictive Uncertainty Quantification of Monthly Streamflow via Gaussian Mixture Models and Clusters. Water, 14(8), 1261. https://doi.org/10.3390/w14081261