Development of a Deep Learning-Based Prediction Model for Water Consumption at the Household Level




Abstract
:1. Introduction
2. Materials and Methods
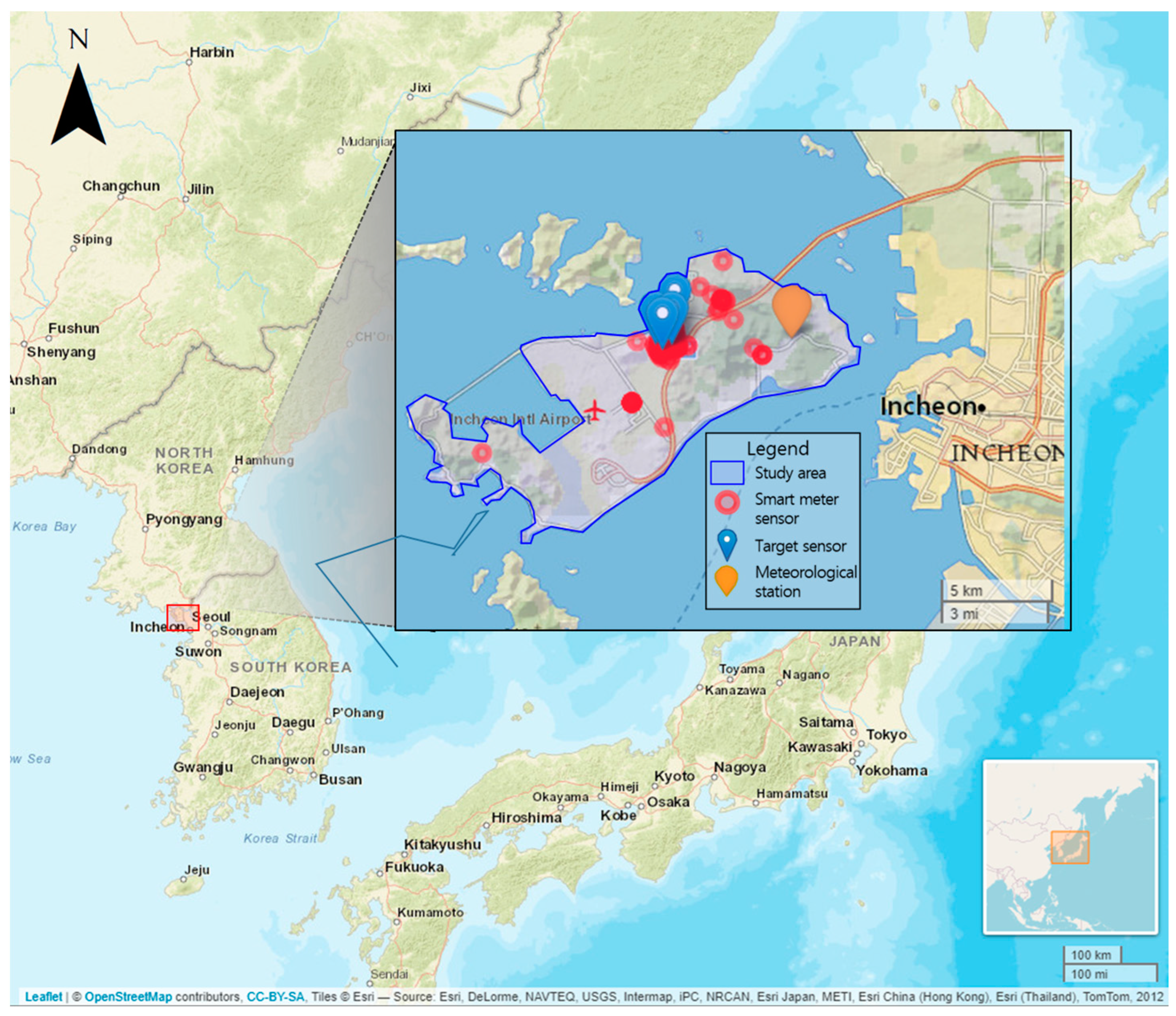
2.1. Study Area
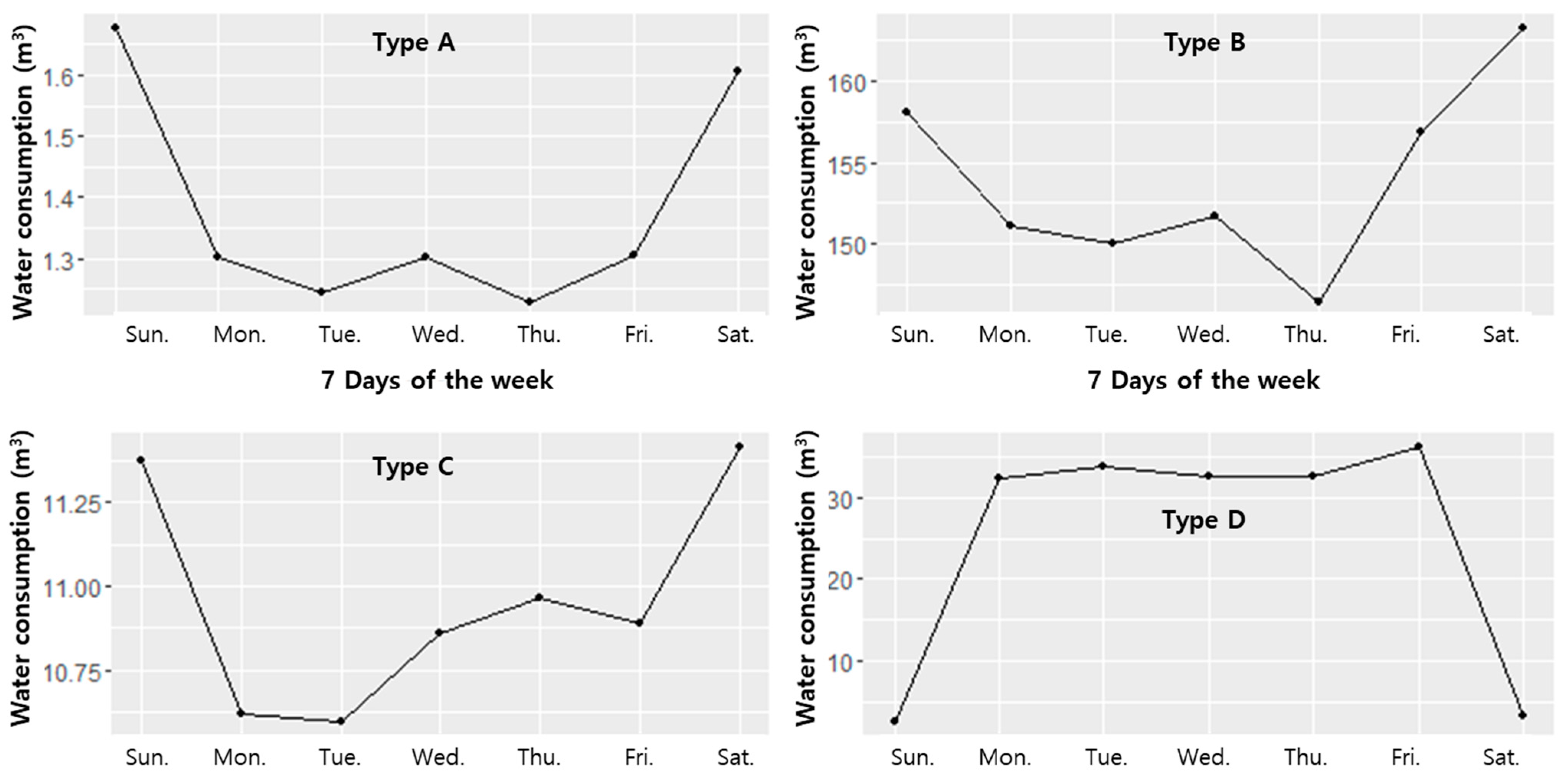
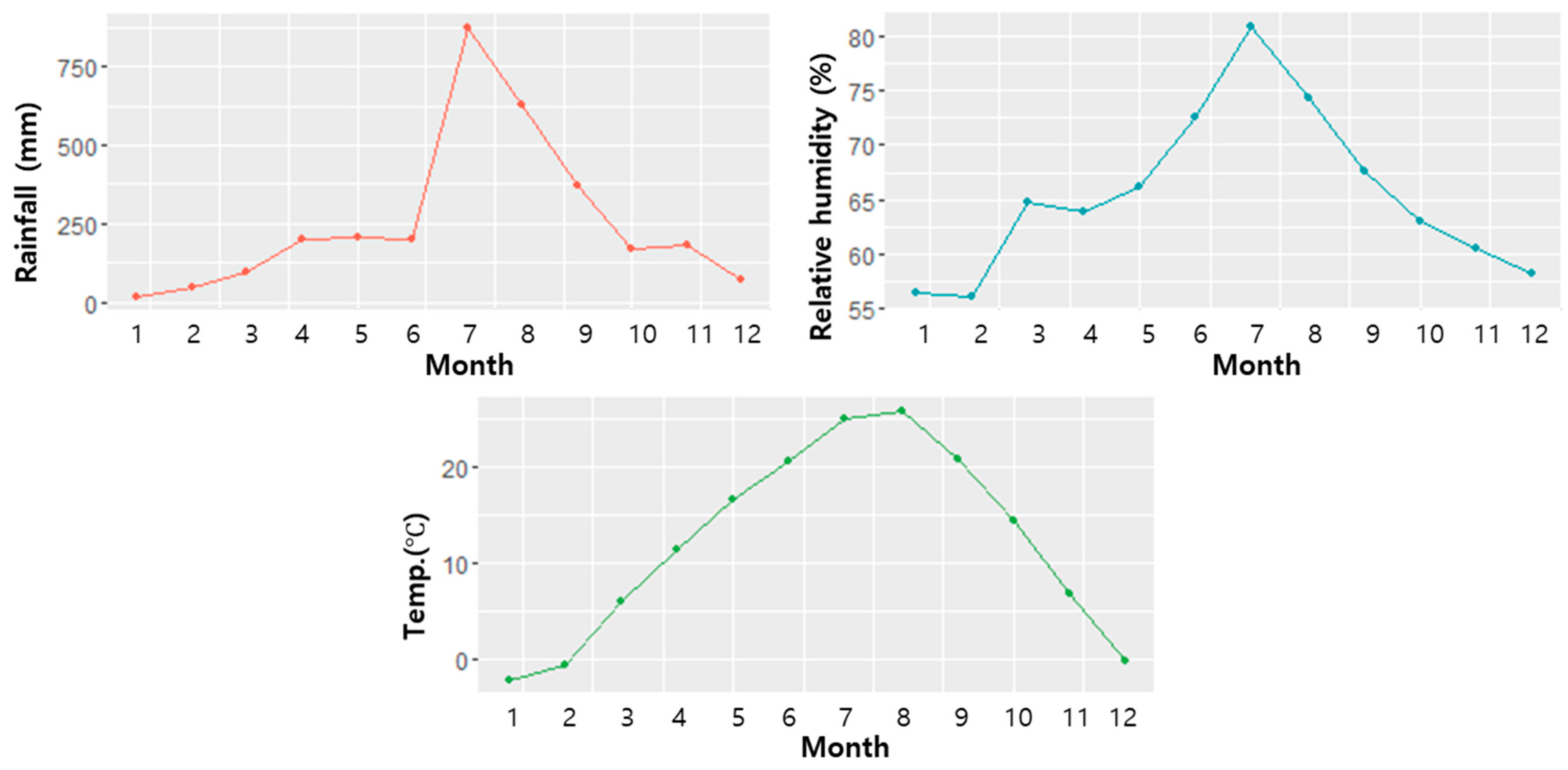
2.2. Data Description
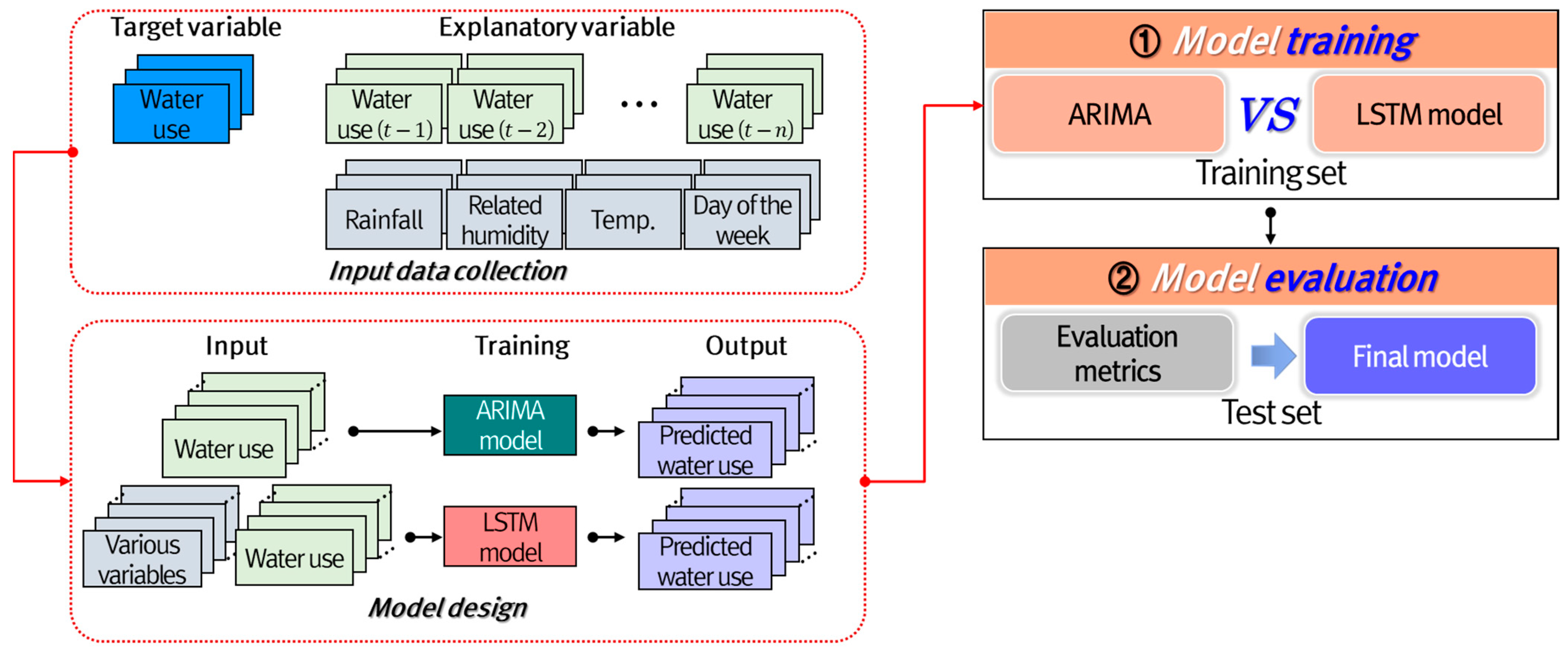
2.3. Methodology for Water Consumption Prediction
2.3.1. ARIMA Model
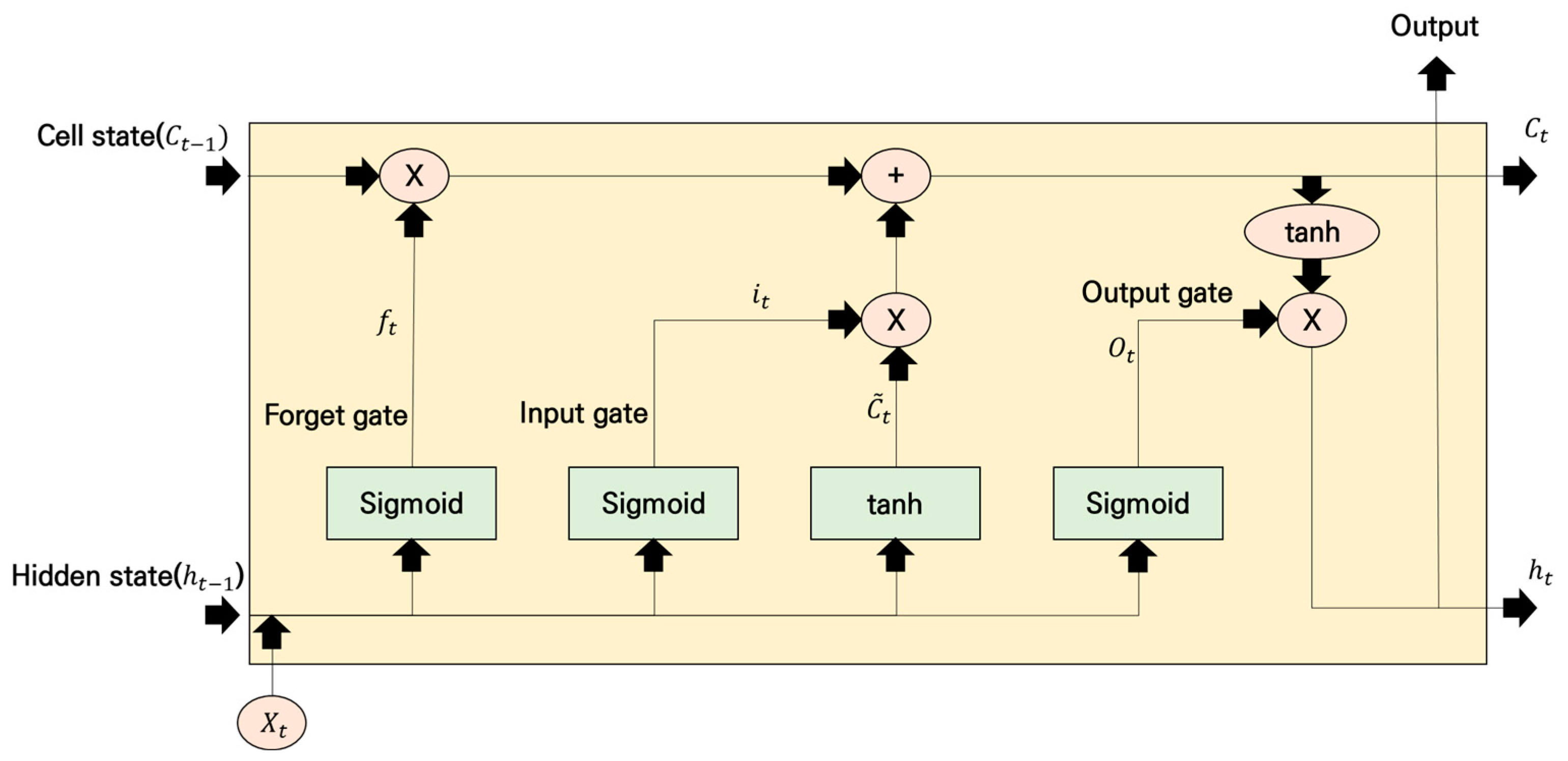
2.3.2. LSTM Model
2.4. Evaluation Metrics
3. Results
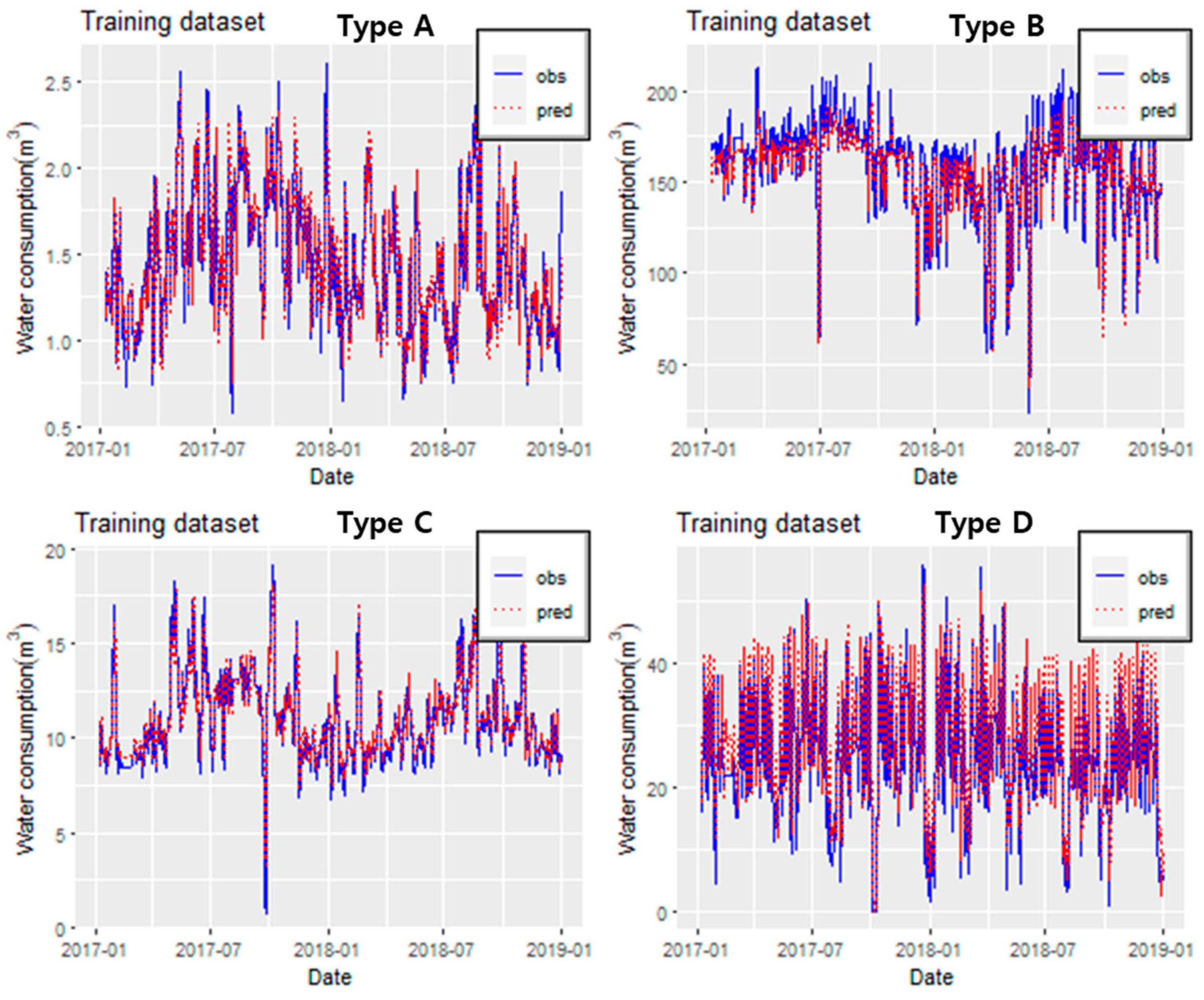
3.1. Application of the ARIMA Model
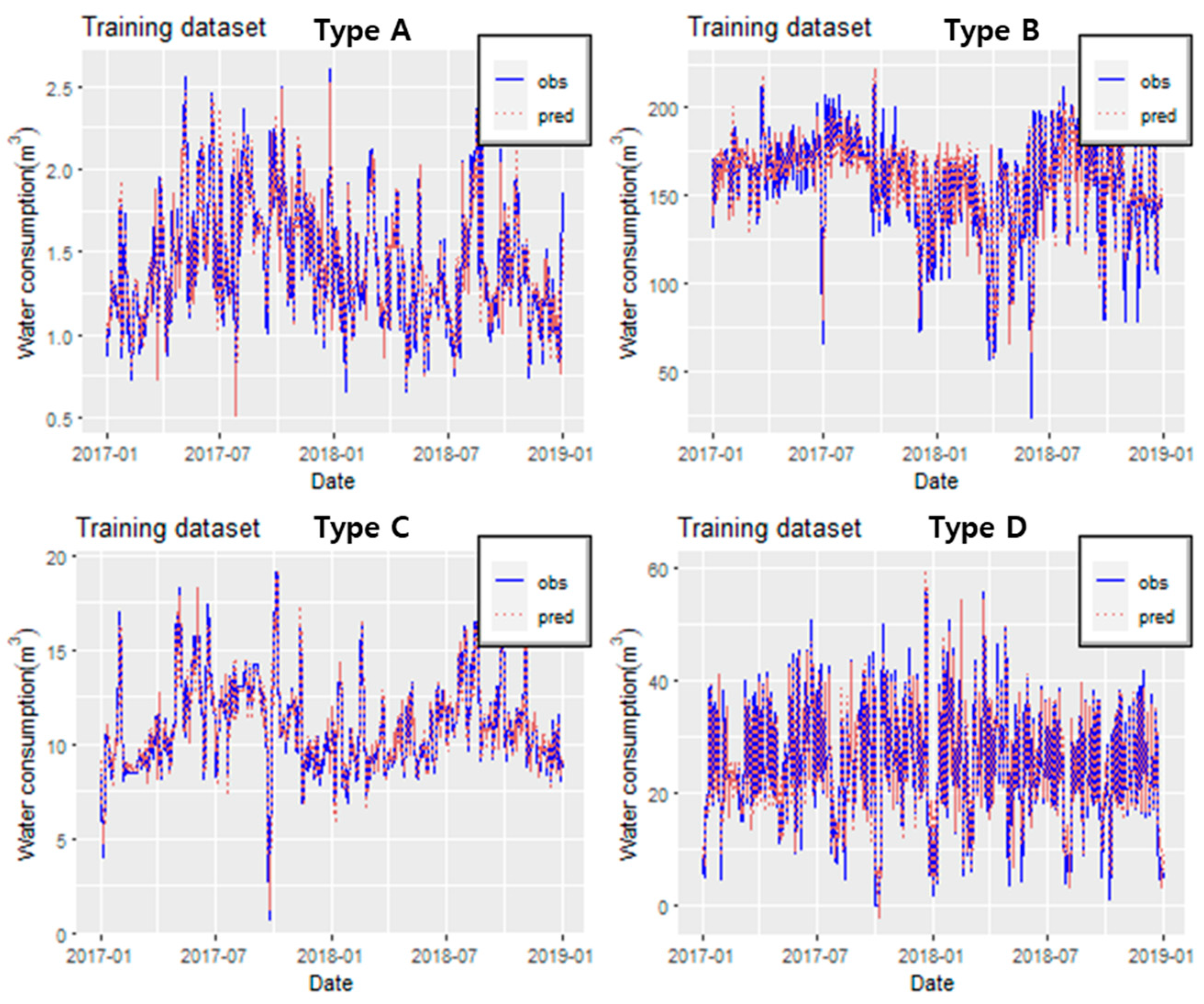
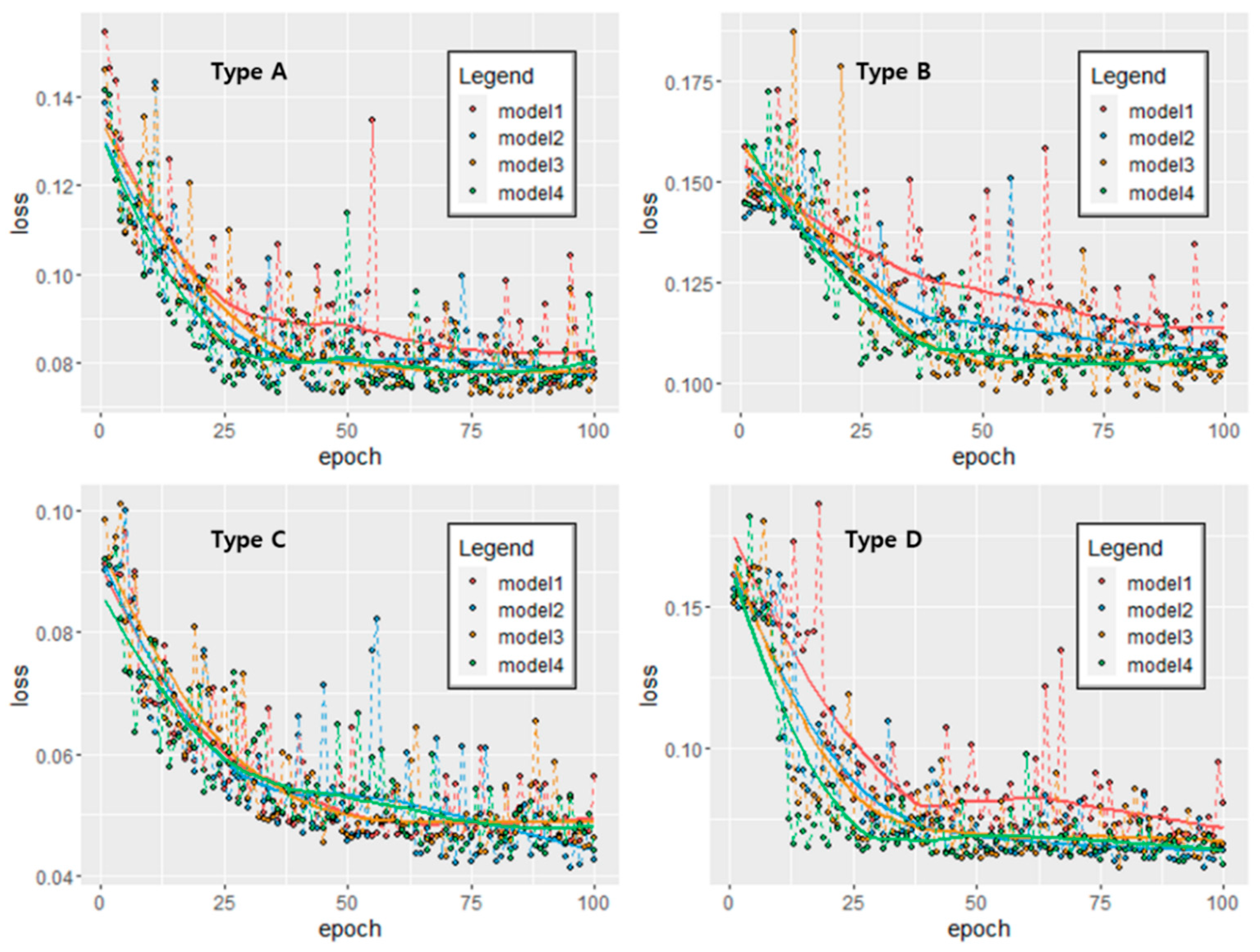
3.2. Application of the LSTM Model
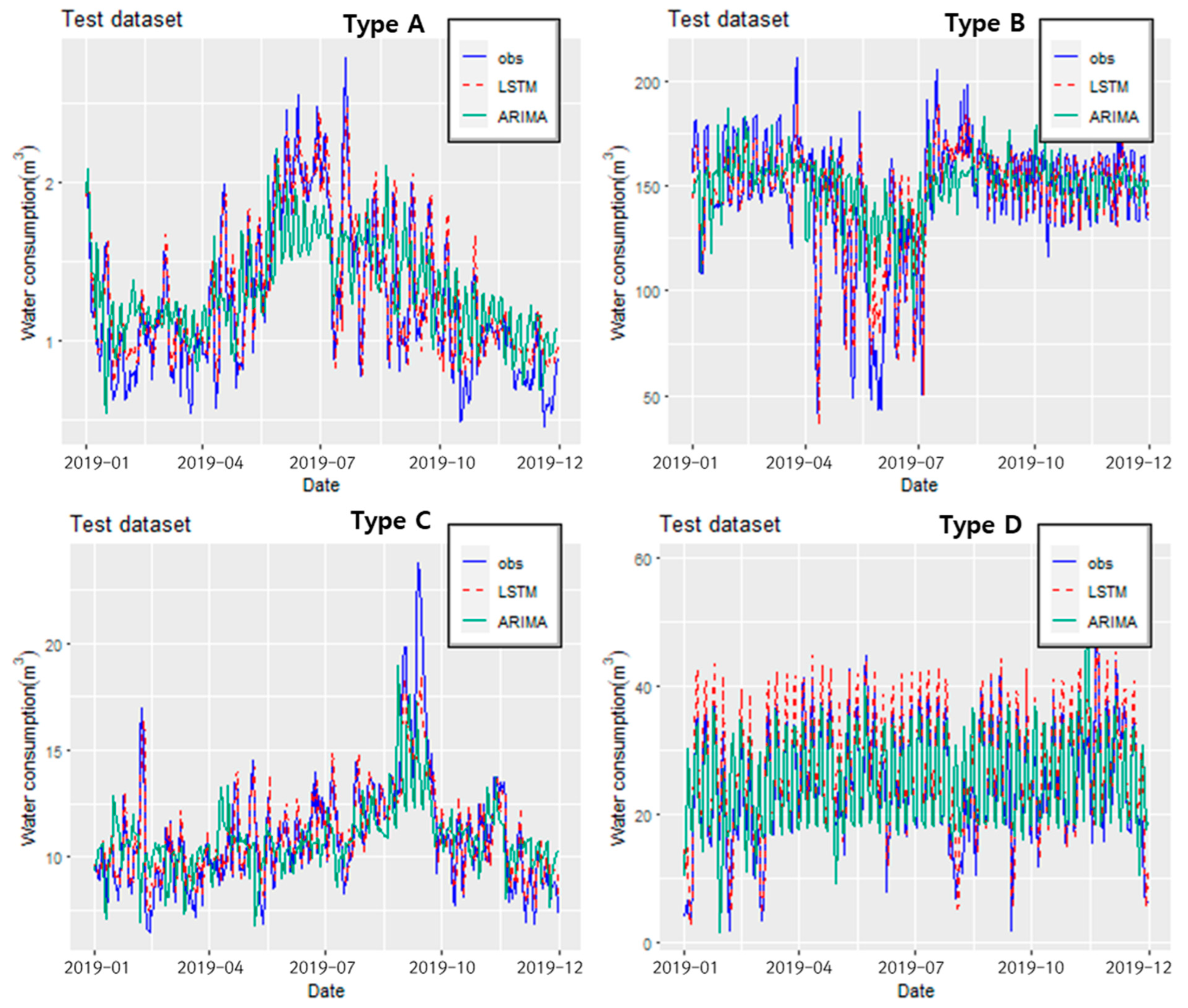
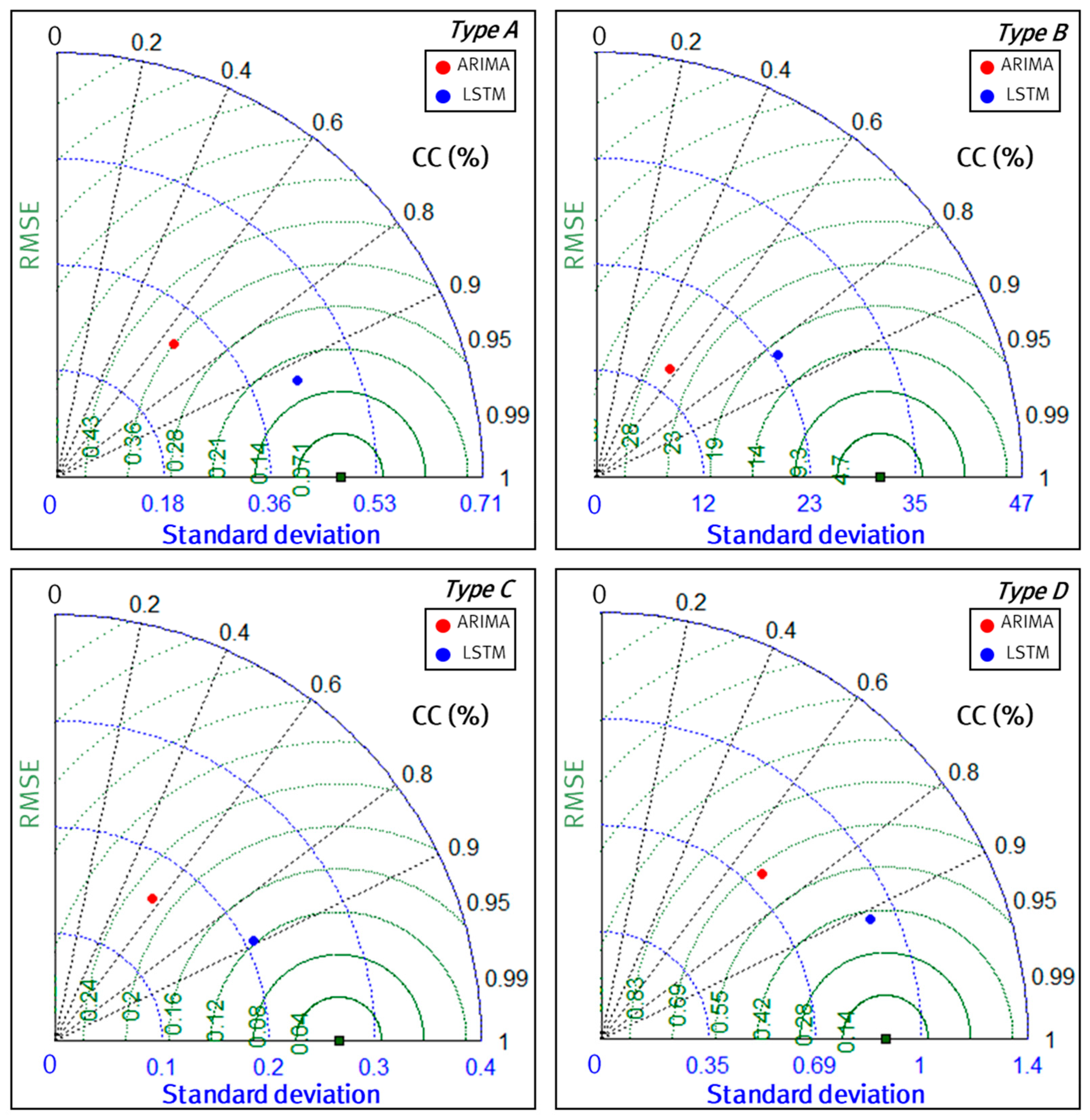
3.3. Performance Evaluation of Each Model
4. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Korea Environmental Industry & Technology Institute (KEITI). Water and Sewerage R&D Technology Trend Report; KEITI: Seoul, Korea, 2020. [Google Scholar]
- Ministry of Environmental (MOE). Water Supply Statistics; Ministry of Environmental: Sejong, Korea, 2019.
- Adamowski, J.; Chan, H.F.; Prasher, S.O.; Ozga-Zielinski, B.; Sliusarieva, A. Comparison of multiple linear and nonlinear regression, autoregressive integrated moving average, artificial neural network, and wavelet artificial neural network methods for urban water demand forecasting in Montreal, Canada. Water Resour. Res. 2012, 48. [Google Scholar] [CrossRef]
- Tripathi, A.; Kaur, S.; Sankaranarayanan, S.; Narayanan, L.K.; Tom, R.J. Water demand prediction for housing apartments using time series analysis. Int. J. Intell. Inf. Technol. 2019, 15, 57–75. [Google Scholar] [CrossRef]
- Razali, S.N.A.M.; Rusiman, M.S.; Zawawi, N.I.; Arbin, N. Forecasting of Water Consumptions Expenditure Using Holt-Winter’s and ARIMA. J. Phys. Conf. Ser. 2018, 995, 012041. [Google Scholar] [CrossRef] [Green Version]
- Du, H.; Zhao, Z.; Xue, H. ARIMA-M: A new model for daily water consumption prediction based on the autoregressive inte-grated moving average model and the markov chain error correction. Water 2020, 12, 760. [Google Scholar] [CrossRef] [Green Version]
- Alvisi, S.; Franchini, M.; Marinelli, A. A short-term, pattern-based model for water-demand forecasting. J. Hydroinform. 2007, 9, 39–50. [Google Scholar] [CrossRef] [Green Version]
- Atsalakis, G.; Minoudaki, C.; Markatos, N.; Stamou, A.; Beltrao, J.; Panagopoulos, T. Daily irrigation water demand prediction using adaptive neuro-fuzzy inferences systems (anfis). In Proceedings of the 3rd IASME/WSEAS International Conference on Energy, Environment, Ecosystems and Sustainable Development, Agios Nikolaos, Greece, 24–26 July 2007; pp. 369–374. [Google Scholar]
- Oliveira, P.J.; Steffen, J.L.; Cheung, P. Parameter Estimation of Seasonal Arima Models for Water Demand Forecasting Using the Harmony Search Algorithm. Procedia Eng. 2017, 186, 177–185. [Google Scholar] [CrossRef]
- Zubaidi, S.L.; Al-Bugharbee, H.; Muhsen, Y.R.; Hashim, K.; Alkhaddar, R.M.; Hmeesh, W.H. The Prediction of Municipal Water Demand in Iraq: A Case Study of Baghdad Governorate. In Proceedings of the 12th International Conference on Developments in eSystems Engineering, Kazan, Russia, 7–10 October 2019; pp. 274–277. [Google Scholar] [CrossRef]
- Li, H.; Wang, X.; Guo, H. Uncertain time series forecasting method for the water demand prediction in Beijing. Water Supply 2021, 22, 3254. [Google Scholar] [CrossRef]
- Xiang, Z.; Yan, J.; Demir, I. A rainfall-runoff model with LSTM-based sequence-to-sequence learning. Water Resour. Res. 2020, 56, e2019WR025326. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall–runoff modelling using Long Short-Term Memory (LSTM) networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Lee, M.; Han, H.; Kim, D.; Bae, Y.; Kim, H.S. Case Study: Development of the CNN Model Considering Teleconnection for Spatial Downscaling of Precipitation in a Climate Change Scenario. Sustainability 2022, 14, 4719. [Google Scholar] [CrossRef]
- Velasco, L.C.P.; Granados, A.R.B.; Ortega, J.M.A.; Pagtalunan, K.V.D. Performance analysis of artificial neural networks training algorithms and transfer functions for medium-term water consumption forecasting. Int. J. Adv. Sci. Appl. 2018, 9, 109–116. [Google Scholar] [CrossRef] [Green Version]
- Gagliardi, F.; Alvisi, S.; Franchini, M.; Guidorzi, M. A comparison between pattern-based and neural network short-term water demand forecasting models. Water Sci. Technol. Water Supply 2017, 17, 1426–1435. [Google Scholar] [CrossRef]
- Boudhaouia, A.; Wira, P. A Real-Time Data Analysis Platform for Short-Term Water Consumption Forecasting with Machine Learning. Forecasting 2021, 3, 682–694. [Google Scholar] [CrossRef]
- Salloom, T.; Kaynak, O.; He, W. A novel deep neural network architecture for real-time water demand forecasting. J. Hydrol. 2021, 599, 126353. [Google Scholar] [CrossRef]
- Bougadis, J.; Adamowski, K.; Diduch, R. Short-term municipal water demand forecasting. Hydrol. Processes Inter-Natl. J. 2005, 19, 137–148. [Google Scholar] [CrossRef]
- Herrera, M.; Torgo, L.; Izquierdo, J.; Pérez-García, R. Predictive models for forecasting hourly urban water demand. J. Hydrol. 2010, 387, 141–150. [Google Scholar] [CrossRef]
- Awad, M.; Zaid-Alkelani, M. Prediction of Water Demand Using Artificial Neural Networks Models and Statistical Model. Int. J. Intell. Syst. Appl. 2019, 11, 40–55. [Google Scholar] [CrossRef]
- Mu, L.; Zheng, F.; Tao, R.; Zhang, Q.; Kapelan, Z. Hourly and Daily Urban Water Demand Predictions Using a Long Short-Term Memory Based Model. J. Water Resour. Plan. Manag. 2020, 146, 05020017. [Google Scholar] [CrossRef]
- Firat, M.; Yurdusev, M.A.; Turan, M.E. Evaluation of Artificial Neural Network Techniques for Municipal Water Consumption Modeling. Water Resour. Manag. 2009, 23, 617–632. [Google Scholar] [CrossRef]
- Adamowski, J.; Karapataki, C. Comparison of multivariate regression and artificial neural networks for peak urban wa-ter-demand forecasting: Evaluation of different ANN learning algorithms. J. Hydrol. Eng. 2010, 15, 729–743. [Google Scholar] [CrossRef] [Green Version]
- Al-Zahrani, M.A.; Abo-Monasar, A. Urban Residential Water Demand Prediction Based on Artificial Neural Networks and Time Series Models. Water Resour. Manag. 2015, 29, 3651–3662. [Google Scholar] [CrossRef]
- Zubaidi, S.L.; Ortega-Martorell, S.; Kot, P.; Alkhaddar, R.M.; Abdellatif, M.; Gharghan, S.K.; Hashim, K. A method for pre-dicting long-term municipal water demands under climate change. Water Resour. Manag. 2020, 34, 1265–1279. [Google Scholar] [CrossRef]
- Bakker, M.; van Duist, H.; van Schagen, K.; Vreeburg, J.; Rietveld, L. Improving the Performance of Water Demand Forecasting Models by Using Weather Input. Procedia Eng. 2014, 70, 93–102. [Google Scholar] [CrossRef] [Green Version]
- Polebitski, A.S.; Palmer, R.N. Seasonal Residential Water Demand Forecasting for Census Tracts. J. Water Resour. Plan. Manag. 2010, 136, 27–36. [Google Scholar] [CrossRef]
- Piasecki, A.; Jurasz, J.; Kaźmierczak, B. Forecasting Daily Water Consumption: A Case Study in Torun, Poland. Period. Polytech. Civ. Eng. 2018, 62, 8241–8318. [Google Scholar] [CrossRef] [Green Version]
- Bennett, C.; Stewart, R.; Beal, C. ANN-based residential water end-use demand forecasting model. Expert Syst. Appl. 2013, 40, 1014–1023. [Google Scholar] [CrossRef] [Green Version]
- Candelieri, A.; Soldi, D.; Archetti, F. Short-term forecasting of hourly water consumption by using automatic metering readers data. Procedia Eng. 2015, 119, 844–853. [Google Scholar] [CrossRef]
- Vijai, P.; Sivakumar, P.B. Performance comparison of techniques for water demand forecasting. Procedia Comput. Sci. 2018, 143, 258–266. [Google Scholar] [CrossRef]
- Faiz, M.; Daniel, A.K. Wireless Sensor Network Based Distribution and Prediction of Water Consumption in Residential Houses Using ANN. In Proceedings of the International Conference on Internet of Things and Connected Technologies, Wuhan, China, 22–25 April 2022; pp. 107–116. [Google Scholar] [CrossRef]
- Water Services Regulation Authority. Business Retail Price Review 2016: Final Determinations; Water Services Regulation Authority: Birmingham, UK, 2016.
- Xenochristou, M.; Kapelan, Z.; Hutton, C. Using Smart Demand-Metering Data and Customer Characteristics to Investigate Influence of Weather on Water Consumption in the UK. J. Water Resour. Plan. Manag. 2020, 146, 04019073. [Google Scholar] [CrossRef]
- Xenochristou, M.; Hutton, C.; Hofman, J.; Kapelan, Z. Water Demand Forecasting Accuracy and Influencing Factors at Different Spatial Scales Using a Gradient Boosting Machine. Water Resour. Res. 2020, 56, e2019WR026304. [Google Scholar] [CrossRef]
- Korea Agency for Infrastructure Technology Advancement (KAIA). Water Grid Intelligence Research; KAIA: Anyang, Korea, 2017. [Google Scholar]
- Choi, J.; Kim, J. Analysis of water consumption dart from smart water meter using machine learning and deep learning algorithms. J. Inst. Electron. Inf. Eng. 2018, 55, 31–39. [Google Scholar]
- Bhansali, R.J. Linear Prediction by Autoregressive Model Fitting in the Time Domain. Ann. Stat. 1978, 6, 224–231. [Google Scholar] [CrossRef]
- Broersen, P.M. Autoregressive model orders for Durbin’s MA and ARMA estimators. IEEE Trans. Signal Process. 2000, 48, 2454–2457. [Google Scholar] [CrossRef]
- Cai, Z.; Tiwari, R.C. Application of a local linear autoregressive model to BOD time series. Env. Off. J. Int. Env. Soc. 2000, 11, 341–350. [Google Scholar] [CrossRef]
- Durbin, J. Efficient estimation of parameters in moving-average models. Biometrika 1959, 46, 306–316. [Google Scholar] [CrossRef]
- Galbraith, J.W.; Ullah, A.; Zinde-Walsh, V. Estimation of the Vector Moving Average Model by Vector Autoregression. Econ. Rev. 2002, 21, 205–219. [Google Scholar] [CrossRef]
- Akrami, S.A.; El-Shafie, A.; Naseri, M.; Santos, C.A.G. Rainfall data analyzing using moving average (MA) model and wavelet multi-resolution intelligent model for noise evaluation to improve the forecasting accuracy. Neural Comput. Appl. 2014, 25, 1853–1861. [Google Scholar] [CrossRef]
- Chen, J.-F.; Wang, W.-M.; Huang, C.-M. Analysis of an adaptive time-series autoregressive moving-average (ARMA) model for short-term load forecasting. Electr. Power Syst. Res. 1995, 34, 187–196. [Google Scholar] [CrossRef]
- Benjamin, M.A.; Rigby, R.A.; Stasinopoulos, D.M. Generalized autoregressive moving average models. J. Am. Stat. Assoc. 2003, 98, 214–223. [Google Scholar] [CrossRef]
- Pappas, S.S.; Ekonomou, L.; Karamousantas, D.C.; Chatzarakis, G.E.; Katsikas, S.K.; Liatsis, P. Electricity demand loads modeling using AutoRegressive Moving Average (ARMA) models. Energy 2008, 33, 1353–1360. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control, 5th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2015; pp. 23–88. ISBN 9781118674925. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Sagheer, A.; Kotb, M. Time series forecasting of petroleum production using deep LSTM recurrent networks. Neurocomputing 2018, 323, 203–213. [Google Scholar] [CrossRef]
- Liu, P.; Wang, J.; Sangaiah, A.K.; Xie, Y.; Yin, X. Analysis and Prediction of Water Quality Using LSTM Deep Neural Networks in IoT Environment. Sustainability 2019, 11, 2058. [Google Scholar] [CrossRef] [Green Version]
- Anagnostis, A.; Papageorgiou, E.; Bochtis, D. Application of Artificial Neural Networks for Natural Gas Consumption Forecasting. Sustainability 2020, 12, 6409. [Google Scholar] [CrossRef]
- Taylor, K.E. Summarizing multiple aspects of model performance in a single diagram. J. Geophys. Res. Atmos. 2001, 106, 7183–7192. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Type A | Type B | Type C | Type D |
|---|---|---|---|---|
| Use type | Residential | Residential | Commercial | Public |
| Detail information | Detached house (1 household) | Apartment (366 households) | Restaurant | Elementary school |
| water consumption range (m3) | 0.5–2.8 | 23.8–214.8 | 0.78–23.7 | 0–55.9 |
| Mean (m3) | 1.38 | 153.9 | 10.96 | 24.79 |
| Standard deviation (m3) | 0.42 | 30.13 | 2.48 | 9.95 |
| Type | Parameter p | Parameter d | Parameter q |
|---|---|---|---|
| A | 7 | 0 | 7 |
| B | 8 | 0 | 8 |
| C | 8 | 0 | 8 |
| D | 7 | 0 | 7 |
| Type | Correlation | RMSE |
|---|---|---|
| A | 93.91% | 0.13 |
| B | 87.31% | 14.02 |
| C | 95.18% | 0.73 |
| D | 96.02% | 2.87 |
| Variable | Abbreviation | Description |
|---|---|---|
| Target variable | Water consumption corresponding to day | |
| Explanatory variable | Water consumption before day | |
| Water consumption before day | ||
| Water consumption before day | ||
| Water consumption before day | ||
| Water consumption before day | ||
| Water consumption before day | ||
| Water consumption before day | ||
| T | Daily air temperature | |
| Daily rainfall | ||
| Daily relative humidity | ||
| Weekday and weekend |
| Model | Units | Batch Size | Epoch |
|---|---|---|---|
| Model 1 | 6 | 12 | 100 |
| Model 2 | 12 | 12 | 100 |
| Model 3 | 24 | 12 | 100 |
| Model 4 | 36 | 12 | 100 |
| Type | Correlation | RMSE |
|---|---|---|
| A | 90.29% | 0.17 |
| B | 80.96% | 17.07 |
| C | 92.00% | 0.93 |
| D | 93.71% | 4.24 |
| ARIMA | LSTM | |||
|---|---|---|---|---|
| Type | Correlation | RMSE | Correlation | RMSE |
| A | 65.81% | 0.36 | 92.70% | 0.19 |
| B | 55.42% | 26.37 | 82.96% | 17.58 |
| C | 56.42% | 2.21 | 89.15% | 1.24 |
| D | 69.79% | 6.71 | 91.29% | 4.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Lee, H.; Lee, M.; Han, H.; Kim, D.; Kim, H.S. Development of a Deep Learning-Based Prediction Model for Water Consumption at the Household Level. Water 2022, 14, 1512. https://doi.org/10.3390/w14091512
Kim J, Lee H, Lee M, Han H, Kim D, Kim HS. Development of a Deep Learning-Based Prediction Model for Water Consumption at the Household Level. Water. 2022; 14(9):1512. https://doi.org/10.3390/w14091512
Chicago/Turabian StyleKim, Jongsung, Haneul Lee, Myungjin Lee, Heechan Han, Donghyun Kim, and Hung Soo Kim. 2022. "Development of a Deep Learning-Based Prediction Model for Water Consumption at the Household Level" Water 14, no. 9: 1512. https://doi.org/10.3390/w14091512
APA StyleKim, J., Lee, H., Lee, M., Han, H., Kim, D., & Kim, H. S. (2022). Development of a Deep Learning-Based Prediction Model for Water Consumption at the Household Level. Water, 14(9), 1512. https://doi.org/10.3390/w14091512