1. Introduction
The general condition of America’s infrastructure is alarmingly poor. According to the American Society of Civil Engineers (ASCE) 2021 Infrastructure Report Card, the average grade point for the overall infrastructure is C-. It is estimated that
$2.6 trillion is needed for the next 10 years to restore the nation’s infrastructure systems to good condition. Among these systems, wastewater received a grade of D+ and needs more than
$270 billion in improvements over the next 10 years. Sewer pipelines are the primary component of wastewater systems, and they consume approximately 80% of the capital investment for wastewater. There are nearly 800,000 miles of public sewer pipelines, and many of them are at the end of their service life [
1]. As a result, understanding the current condition of the sewer system is a critical step for infrastructure asset management strategies and improving national wastewater systems [
2].
Quality data that document the current condition of sewer pipelines is fundamental for the development of sewer asset management tools and strategies [
3]. Significant efforts have been made to evaluate the condition of sewer systems and determine the factors affecting them. Several different deterioration models have been developed to assess pipe conditions. These models can be divided into two groups: (1) function-based models, and (2) data-based models [
4,
5]. Function-based models use statistical methods such as regressions and Markov chains, while data-based models use artificial intelligence (AI) and machine learning techniques such as artificial neural networks (ANN) or random forests [
6,
7,
8,
9,
10,
11]. These models determined the main factors that have significant effects on pipe condition, such as age, depth, length, soil type, location, size, and material; however, a common concern raised by those studies was data availability and data quality [
7,
9,
12,
13].
Artificial intelligence (AI) and machine learning have recently gained popularity as methods for data analysis; yet, in most cases, the necessary data infrastructure is not present to use such tools. Before adopting AI and machine learning algorithms, a solid foundation for data is necessary [
14]. Data science requirements are shown in
Figure 1. Data collection is at the bottom of the pyramid. Then, reliable data flow and structured data storage are needed to make it accessible. Data quality management, an underrated side of data science, and data preparation is the next step in making it reliable for optimization and analytics. Although these two procedures are essential to data science, they are frequently neglected. While the amount of collected data is increasing rapidly, evaluating data quality is becoming a big issue [
15]. Any data analytics tools, charts, and algorithms will be worthless if they have been developed based on low-quality data.
The accessibility and reliability of the current sewer inspection data are questionable due to several different factors, such as operator experience, input errors, data schema problems, data standard versions, and data collection software incompatibilities. Due to the quality issues in the current data collection practices, it is estimated that between 25% and 50% of data is eliminated to make the data ready for analysis [
16,
17]. This approach may result in underestimation of the severity of the current condition of the system and false outputs. To address this problem and to resolve reliability issues in the collected databases, a comprehensive data quality evaluation framework must be developed.
The evaluation of data quality is typically taken into account in response to the issues that arose throughout the decision-making process. This reactive strategy may address the problems with the present database, but it will not go to the root of the issue and prevent further quality problems. Since data defects can happen at any time and have an impact on the quality of the data, data quality evaluation is a continual endeavor [
18].
Data quality should be considered through the intended use of the data and will be defined based on the relevance to the context of the data to be used [
19]. Data quality is a long-lasting issue in the field of civil infrastructure condition assessment [
20].
Currently, closed-circuit television inspection (CCTV) is the major source of information (more than 60%) for defining maintenance and rehabilitation projects for sewer systems [
21]. As a result, the quality of the obtained CCTV data plays a crucial part in the correctness of the final conclusions. It has been found that the likelihood to overestimate a pipe in bad condition is 20%, and the probability to underestimate a pipe in good condition is 15%. It has been noticed that to generate the data for this evaluation, only 65% of total inspections have been analyzed, and the rest of the data has been neglected due to inconsistency, incompleteness, and lack of reference keys [
17]. This data elimination practice would result in underestimating the severity of the system by neglecting the assets that could have more severe conditions in the system.
It has been acknowledged that each database’s data quality needs to be assessed to remedy this issue in sewer inspection data. The objective of data quality evaluation is to ensure that the inspection data are accurate and consistent with other datasets. This process is a significant step in developing sewer systems data inventory by integrating existing datasets [
22,
23].
The objective of this research is to provide a framework for evaluating the data quality of the collected sewer system databases for the first time. The data quality metrics were developed based on the literature and sewer inspection data requirements. Then, the data were evaluated based on the defined metrics to determine the quality problems within the database. The results were reported, and the root cause of each quality issue was identified to provide the correction suggestion and implement the resolution.
2. Literature Review
Municipalities have been recording multiple forms of data on sewer pipe conditions, including closed-circuit TV, sonar, laser, and acoustic, as a basis for capital improvement and asset management plans. However, the benefits of data-driven decisions can only be obtained if data quality is guaranteed. In previous studies on the quality issues of sewer inspection data, it was concluded that the quality problems mainly occurred due to the operators’ level of experience [
24,
25,
26]. Fisher explained that the quality of inspection data depends on the skill and motivation of the operator [
24]. Comparing sewer pipe inspections by various operators, only 16% of the 307 inspections found similar numbers of defects. The following suggestions have also been made to improve the quality of sewer pipe inspections [
26].
The inspection coding system should be simplified to avoid misclassification of the defects.
The defect image should be evaluated with the defect information to avoid misinterpretation of the defects.
The sewer inspectors should be provided with reliable feedback on their inspection evaluations.
Although these suggestions can improve the quality of the inspection records, they do not address the current issues within the sewer inspection databases.
As the usage of data analysis of the collected infrastructure data for asset management decisions is trending up, poor data quality can have a negative impact on the condition of infrastructure due to ineffective decisions and poorly performing decision models [
27]. It is challenging to assess data quality if it is not quantitatively defined. Moreover, the data context should be taken into account when enhancing data quality [
28]. The data quality evaluation consists of three steps: (a) identify, (b) measure, and c) resolve. Decision making and data quality management are facilitated by this procedure. The procedure for evaluating data quality is shown in
Figure 2 [
29,
30]. This study focused on identifying and measuring data quality problems.
The quality evaluation for every database differs. Thus, domain experts should identify the database rule, metrics, and evaluation process. These rules and metrics could be domain-independent or domain-specific based on the database requirements [
31]. Then, the quality measures identified and established in the previous step were used to evaluate a database. Finally, the cause of data quality problems can be identified and addressed to avoid future problems as well. The quality assessment process is the main focus of this work.
Data quality evaluation has become the center of attention, specifically in business and healthcare sectors where data analysis is the main decision support tool [
32,
33,
34,
35]. Developing an evaluation process and defining a set of data quality metrics is a regular practice in many academic and professional fields. Data quality is a rational approach to defining a set of dimensions to measure and improve the quality of data. Defining the data quality dimensions for a database is the first difficult step [
36], since dimensions should consider specific applications and uses of the data.
Data quality is a multi-dimensional concept that includes both subjective perceptions and objective measurements. The experience of the individuals involved with the data forms a subjective assessment of the data quality. Objective assessment can be divided into two categories: (1) task-dependent or (2) task-independent. Task-independent metrics are developed without considering database rules or restrictions, while task-dependent metrics include them. Pipino et al. [
23] provided three functional forms for objective data quality metrics that consider objective and subjective assessments:
Simple Ratio: The ratio of the positive outcome to the total outcome is a simple way to measure different dimensions. It considers that 1 or 100% is the total desired outcome, and the ratio will show positive outcomes.
Min or Max Operations: This form is used when the data quality dimension is a combination of several variables. The min or max values will be compared to the preassigned values.
Weighted average: The weighted average can be calculated for dimensions with multiple variables. Each variable is weighted according to its importance between 0 and 1 with the sum of 1. This form can provide an appropriate measurement if precisely developed.
In previous studies, several different sets of data quality metrics have been developed for data quality evaluations.
Table 1 shows the most common data quality metrics.
These metrics are used to assess different data quality dimensions. In order to measure these metrics, definitions should be provided, and the measurement techniques should be defined. These techniques can be quantitative or qualitative based on the provided definition [
35].
5. Discussion
Data quality is one of the major challenges in the asset management process since decision-makers rely more on data to implement their objectives. Data error rates exceeding 75% have been observed in the civil engineering industry, and errors of up to 30% are usual [
42]. Asset management’s primary goal is to provide a proper level of service by effectively managing the infrastructure through repair and replacement. The structural and hydraulic performance of the sewer network serves as the basis for these initiatives, with structural performance serving as the primary budgetary consideration [
17,
43].
The data quality evaluation framework was developed based on five data quality metrics. These metrics are defined quantitatively to measure the different quality dimensions of sewer inspection data. Each metric was calculated based on data availability and relevancy.
Table 9 shows the total quality evaluation of DB1.
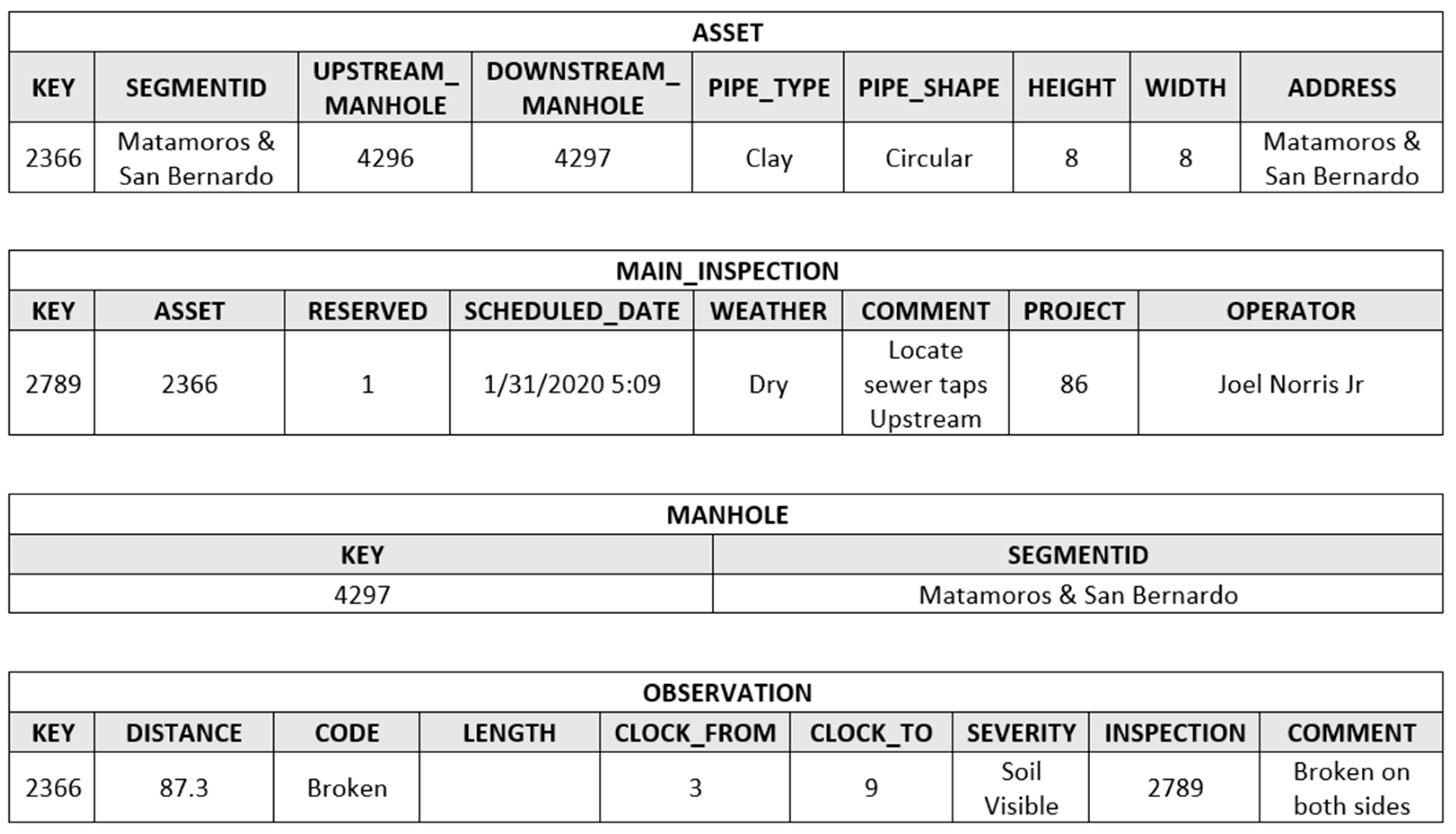
Redundancy and inconsistency are major issues in the data. Redundancy is mainly related to the schema and can be addressed through normalization. This metric can help municipalities avoid further mistakes in the decision-making problem. One significant problem regarding redundancy is determining asset location. It has been noticed that poor data management has resulted in mislocating assets. High-quality GIS data can resolve this problem. In DB1, it has been calculated that manholes have only 47.55% uniqueness and pipes have 59.72%.
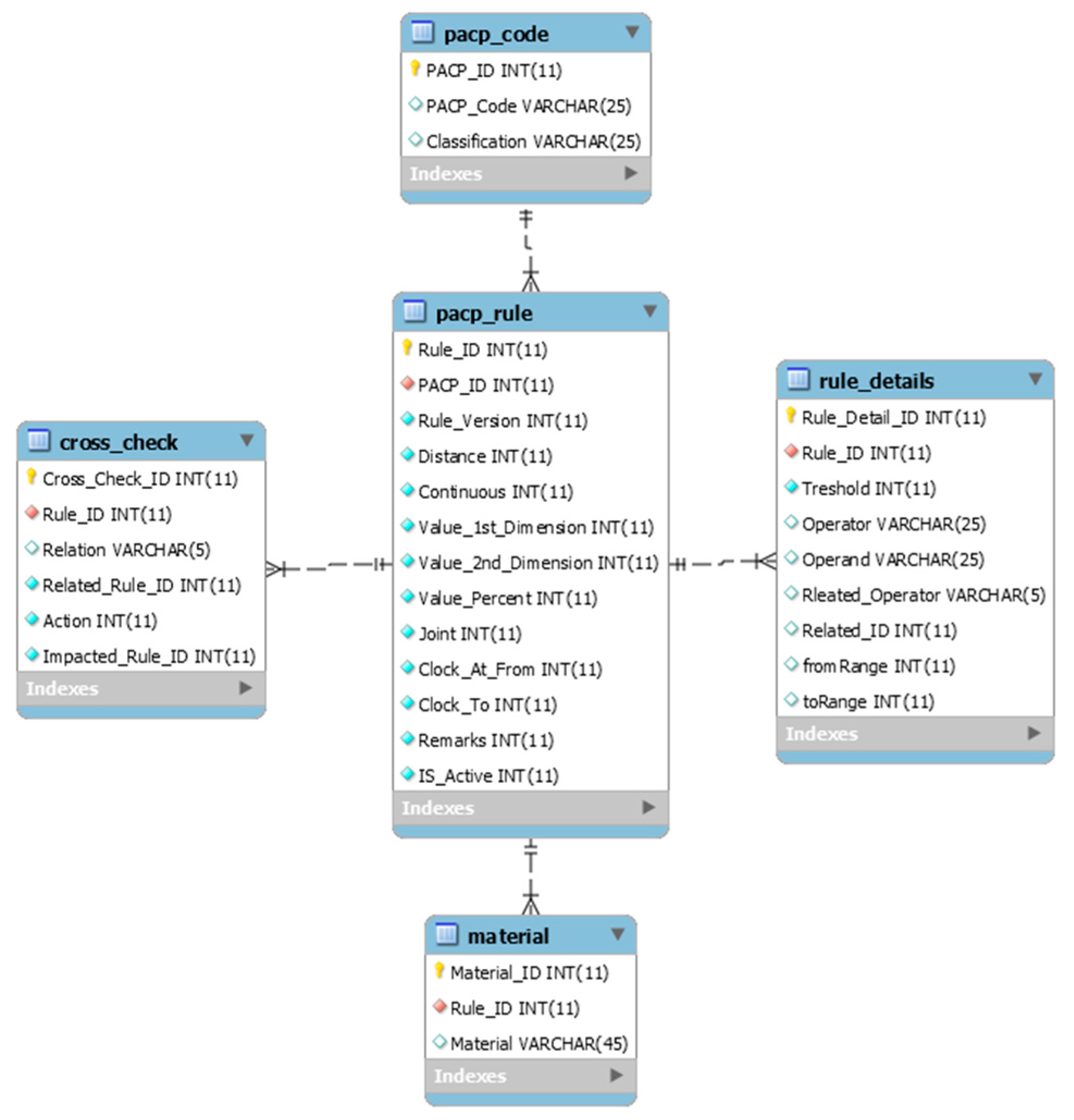
Inconsistency can cause issues when integrating databases into a common repository. The same data has been stored in different locations and formats. This can also cause problems in query and script development to retrieve data. In the ‘ASSET’ table, the SEGMENTID was developed based on inconsistent criteria. Some were related to the Downstream Manhole or Upstream Manhole, and the others were a combination of those two or even unrelated. This type of inconsistency can also cause incompatibility issues when different databases are being analyzed together. Developing proper metadata can resolve the inconsistency problems.
Validity evaluates the database to comply with the data rules and standards. While municipalities are using the PACP coding system, their final database is not always PACP compatible. The validity metric can provide the PACP compatibility of the database. This can help municipalities understand the condition of their data and provide them with a solution to access their data across different software platforms. It can also help operators understand the common mistakes at the time of collecting data.
6. Conclusions
The effectiveness of sewer asset management decisions hinges upon the quality of condition assessment data collected on the sewer infrastructure. However, the quality of the data collected by the municipalities varies among municipalities. This research showed that 11% to 35% of sewer inspection records have quality issues that need to be addressed in order to develop optimum asset management decisions. Thus, it is important to develop a data quality evaluation framework to identify and measure the current problems within the collected databases and to provide a feasible resolution to address them and prevent similar problems in the future.
In this paper, a data quality evaluation framework was developed based on five quality metrics to provide a quantitative assessment of current problems. Each metric was calculated based on the data context. It has been noticed that data consistency and uniqueness are the major problems in the collected databases. These two can be addressed by implementing robust database management practices. Database normalization can help reduce data redundancy and improve data integrity. In addition, GIS integration will resolve inconsistencies and improve the accuracy of the data. By addressing these problems, the development of infrastructure asset management plans can be facilitated.
One of the main problems in evaluating data quality is data accessibility. This problem was found in all the collected databases, specifically in DB1, where the city could only extract a few amounts of data. This is one of the major limitations in the evaluation and analysis of sewer system databases. Differences in data management practices among municipalities are another challenge. For instance, while some providers stored their data in a single data repository (DB1 and DB2), others kept their data in separate datasets based on different criteria (DB3 and DB4). This practice resulted in several small databases, which made the proposed data quality evaluation more complicated. Although most of the databases were collected in the PACP standard, some interoperability issues occurred because the data were exported from different software into nonstandard data structures, which proved to be a common problem.
This study contributed to developing a quantitative analysis of the quality problems in sewer inspection data and, for the first time, providing tools for industry stakeholders to address these problems.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}