
Comparative Study for Daily Streamflow Simulation with Different Machine Learning Methods


Abstract
:1. Introduction
2. Material and Methods
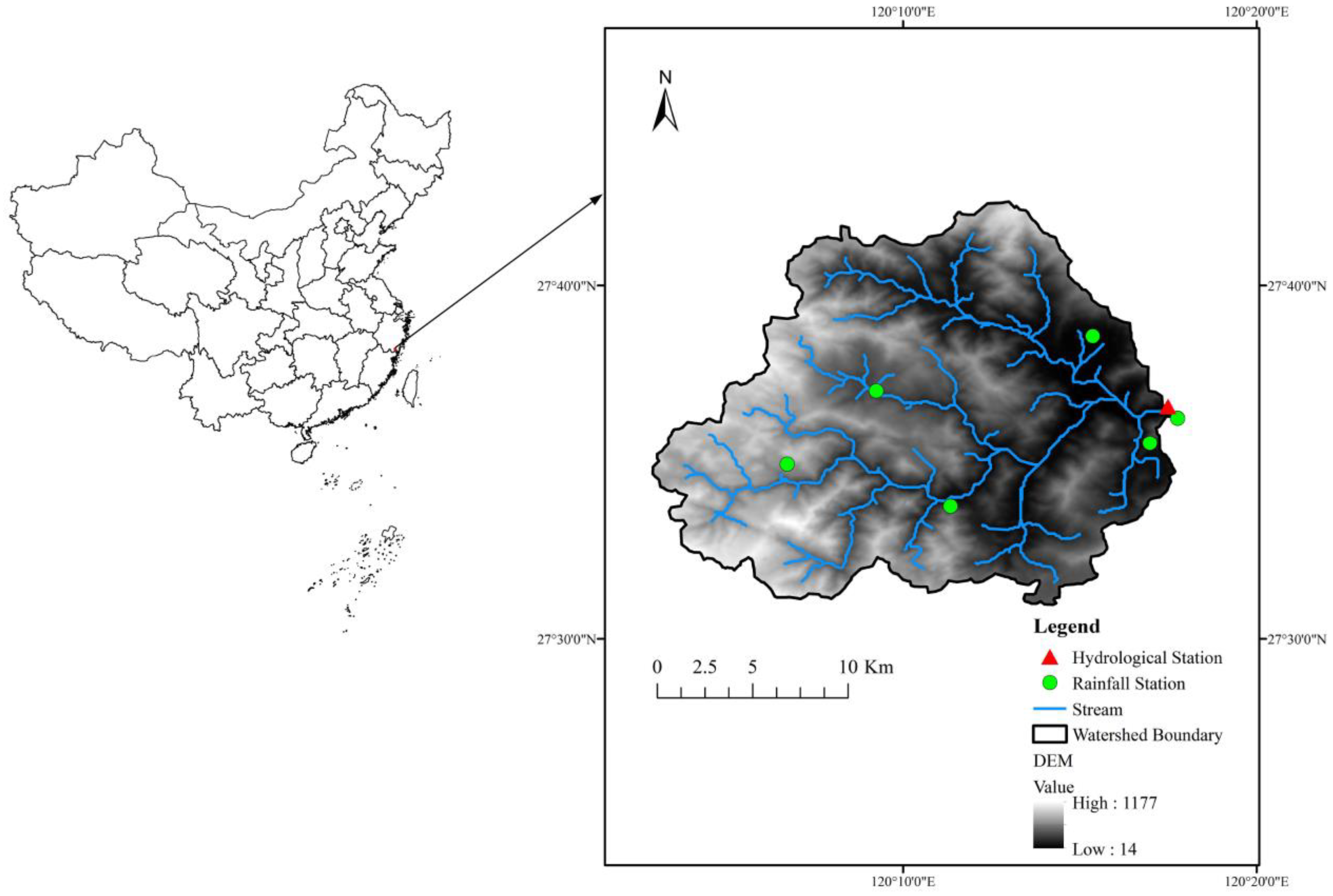
2.1. Study Area and Data Preprocessing
2.2. Support Vector Regression (SVR)
2.3. Extreme Gradient Boosting (XGBoost)
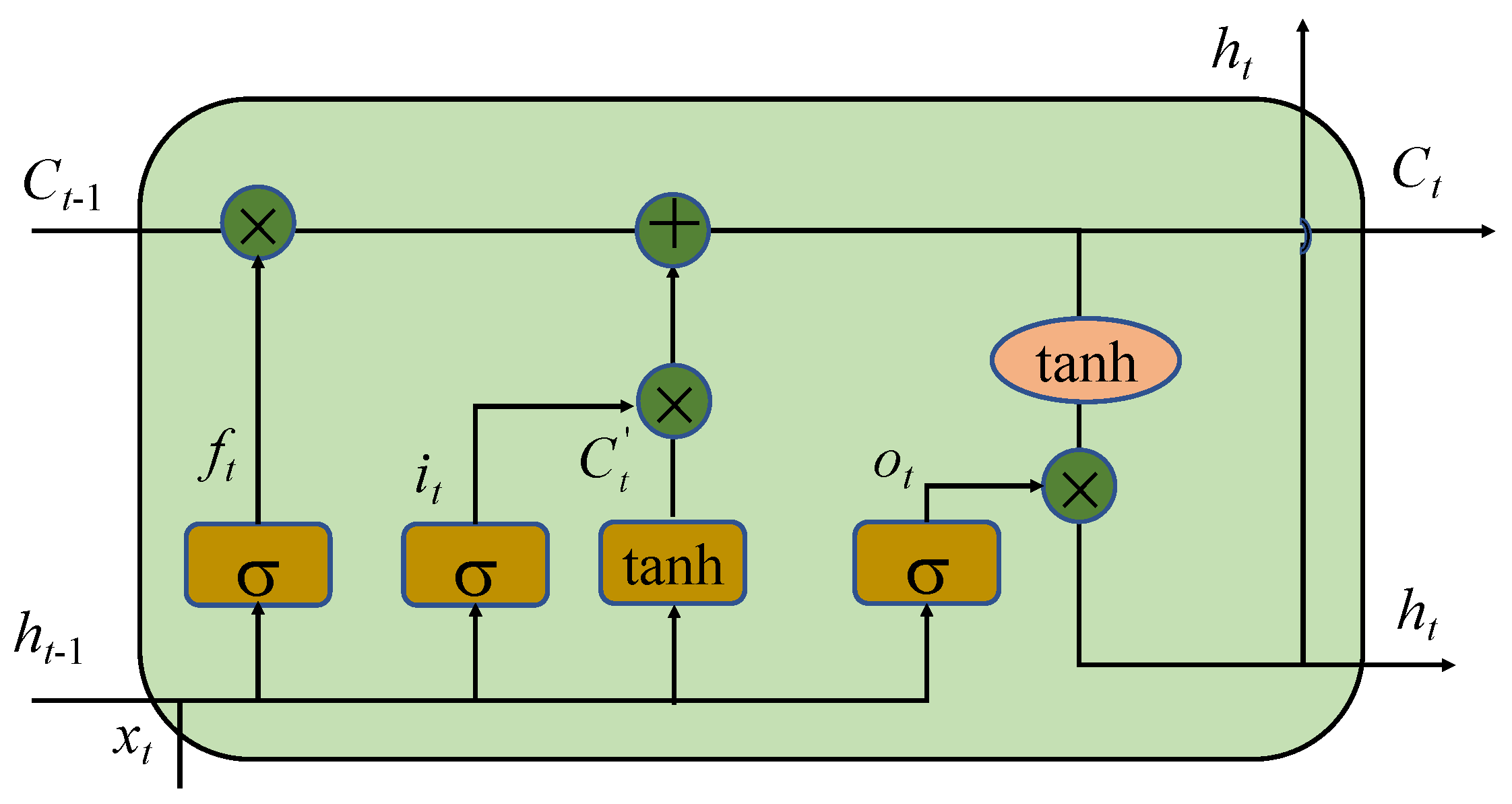
2.4. Long-Short Term Memory Neural Network (LSTM)
2.5. Bayesian Optimization
2.6. Evaluation Criteria
3. Results and Discussion
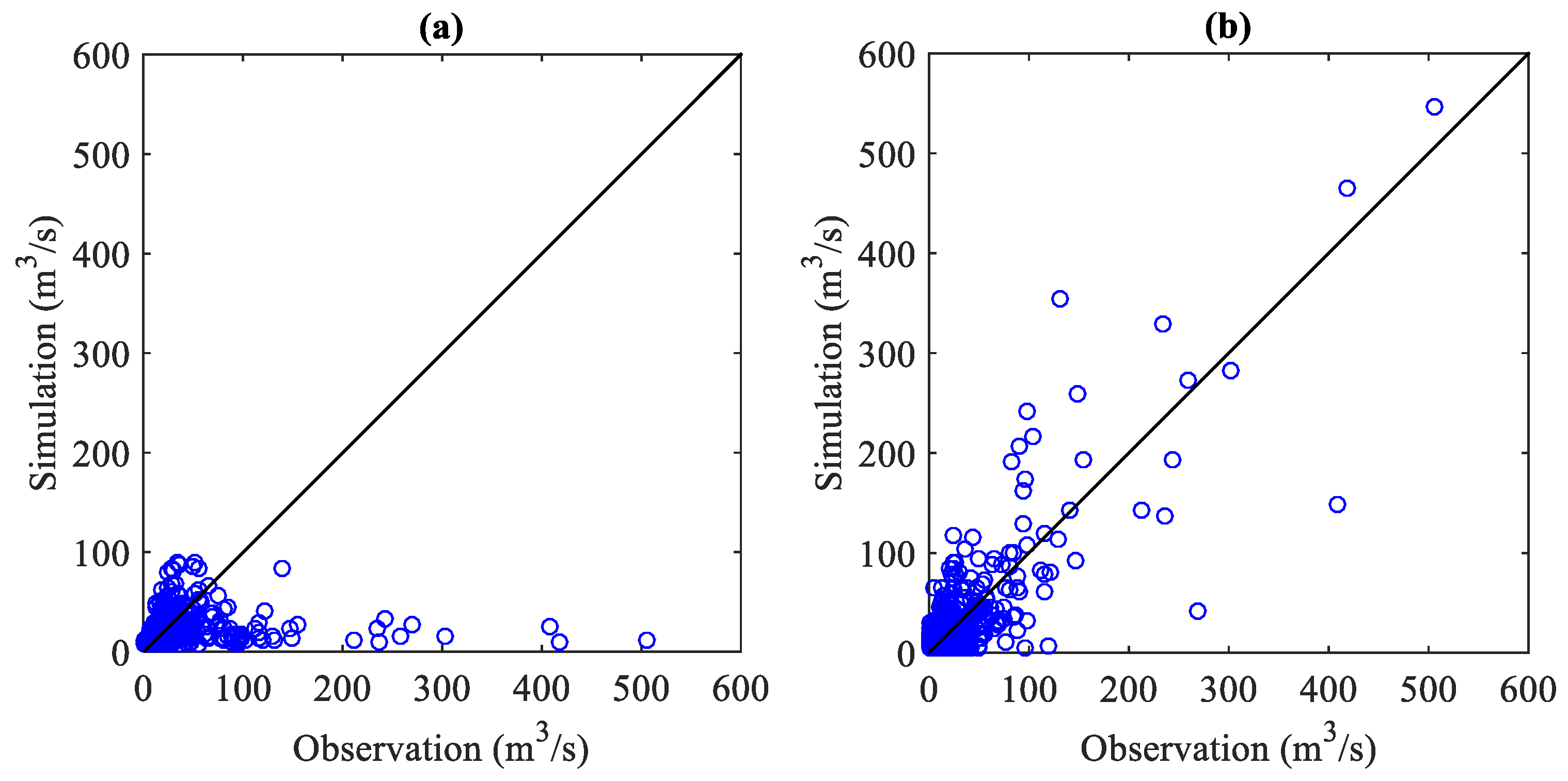
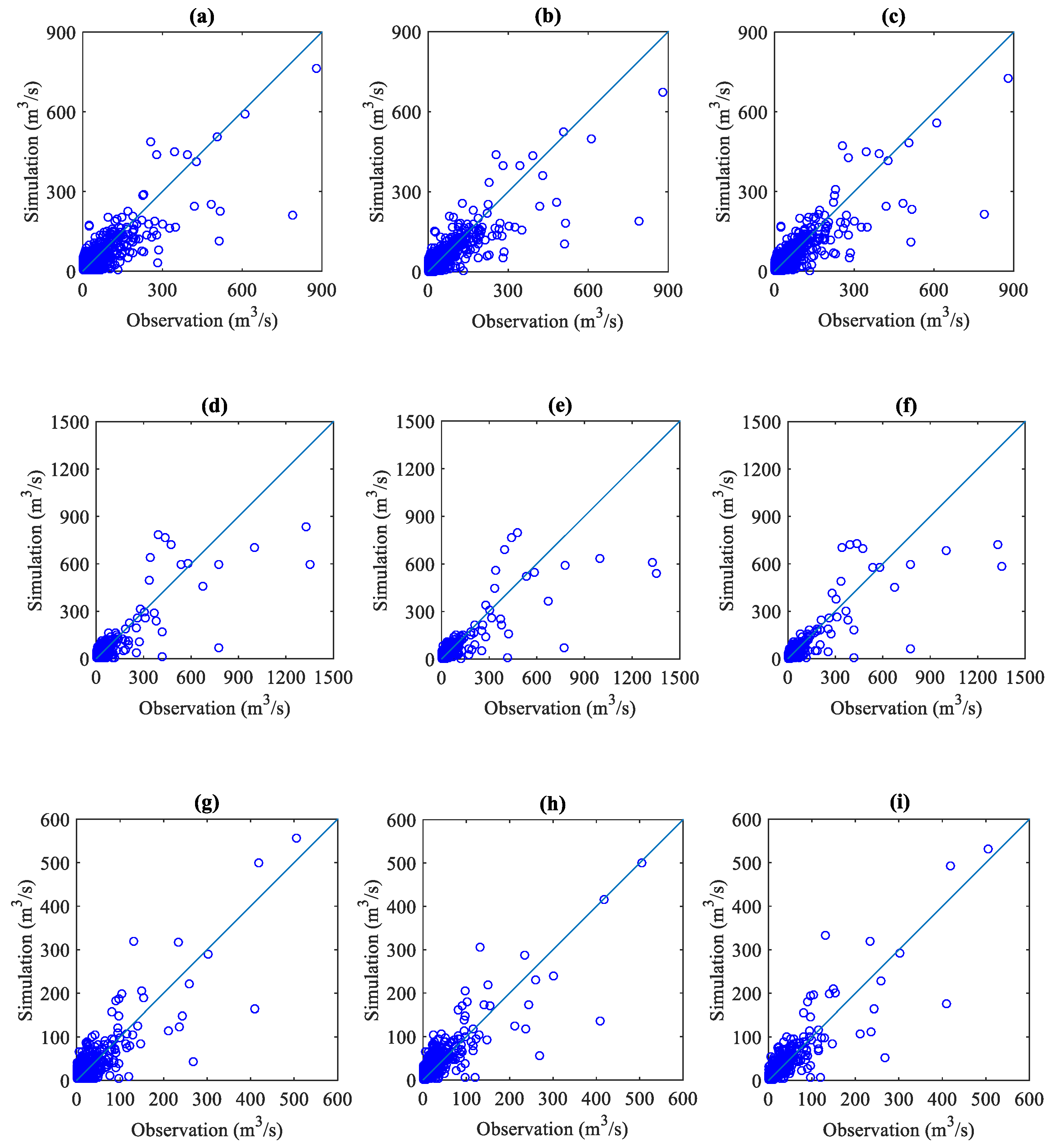
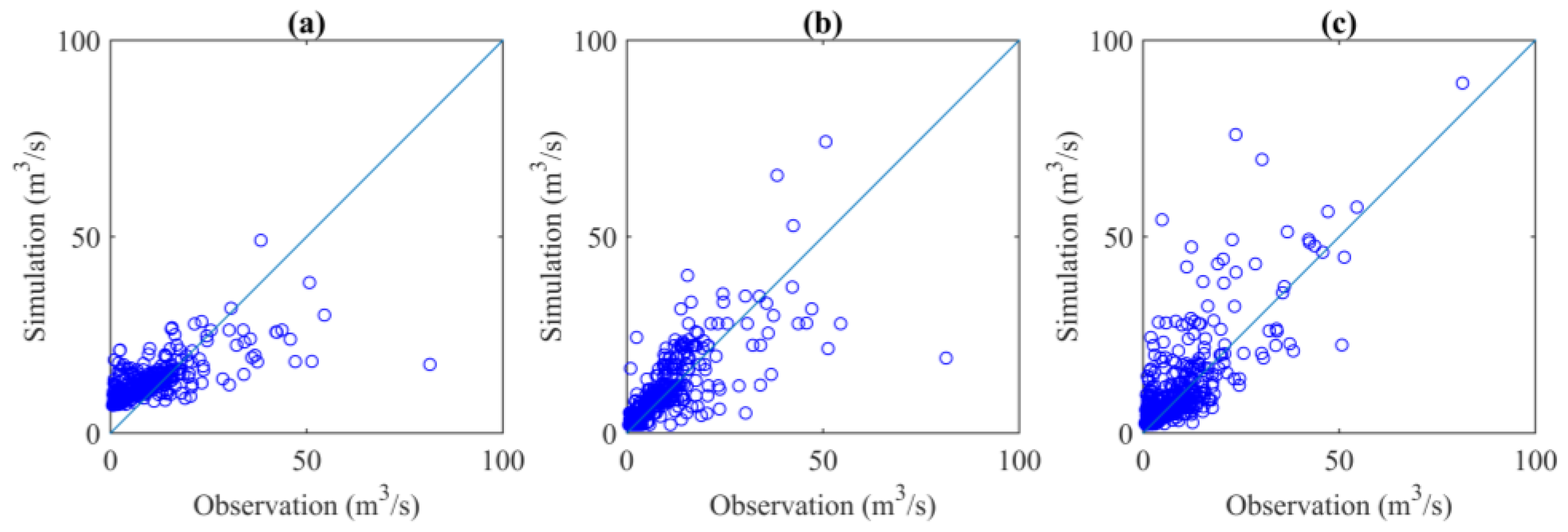
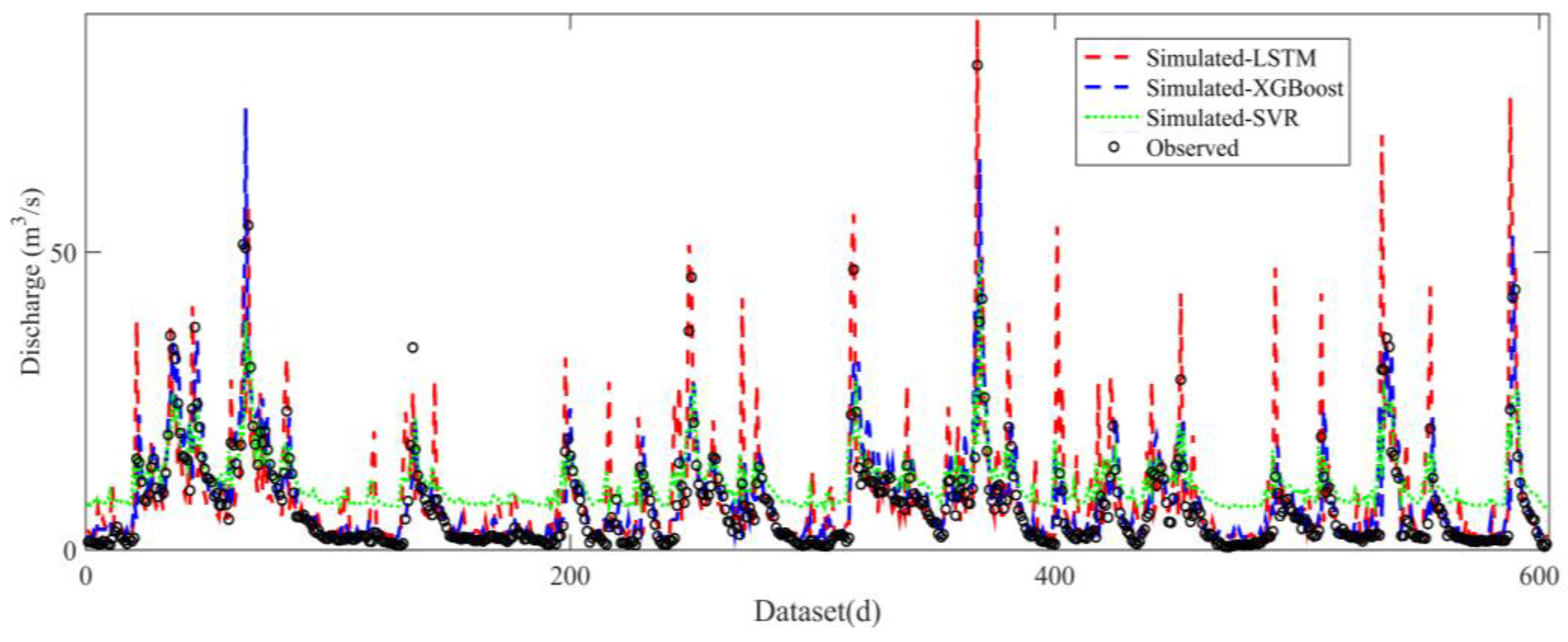
3.1. Simulation Performances with Single-Input Scenarios
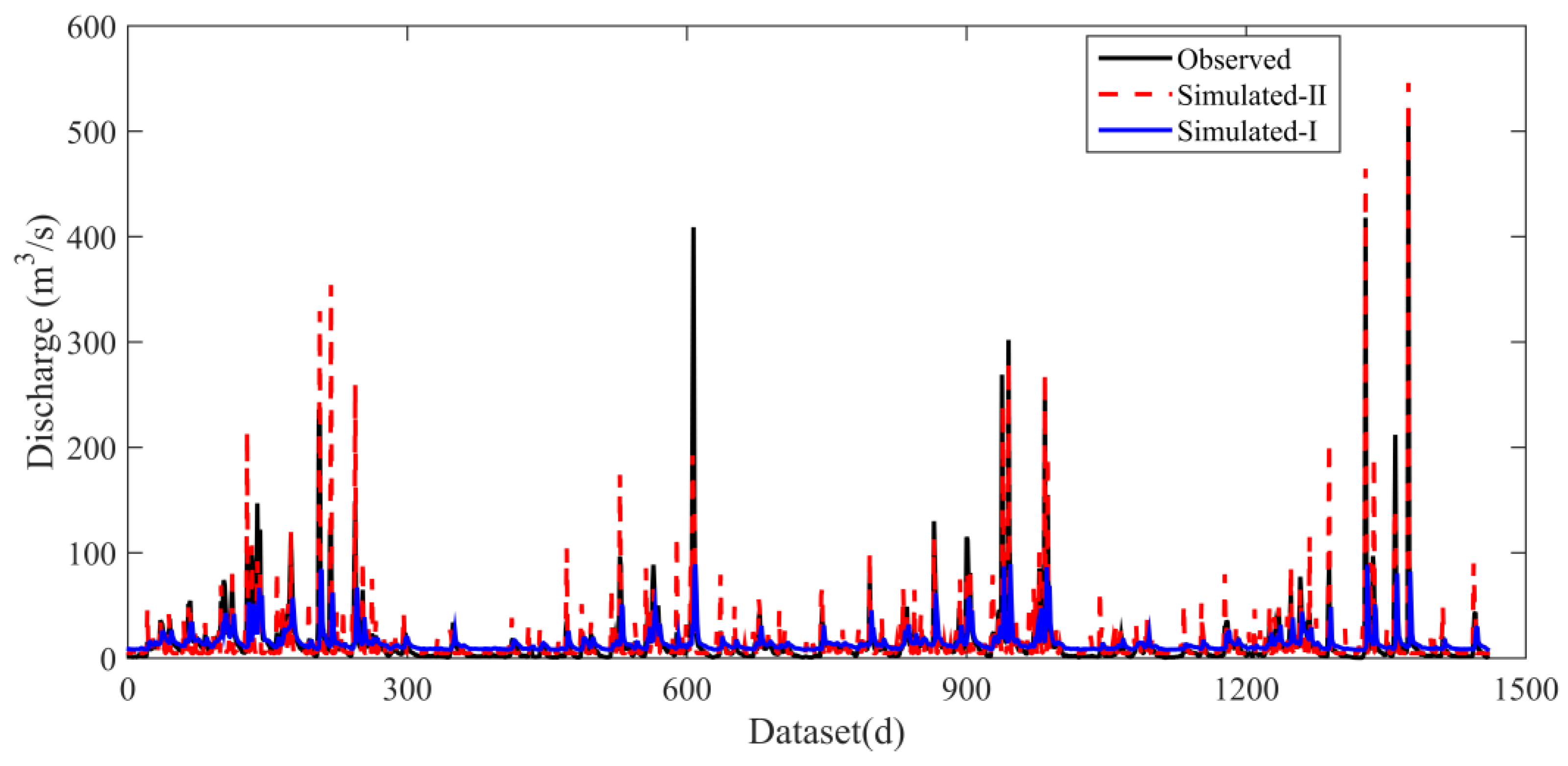
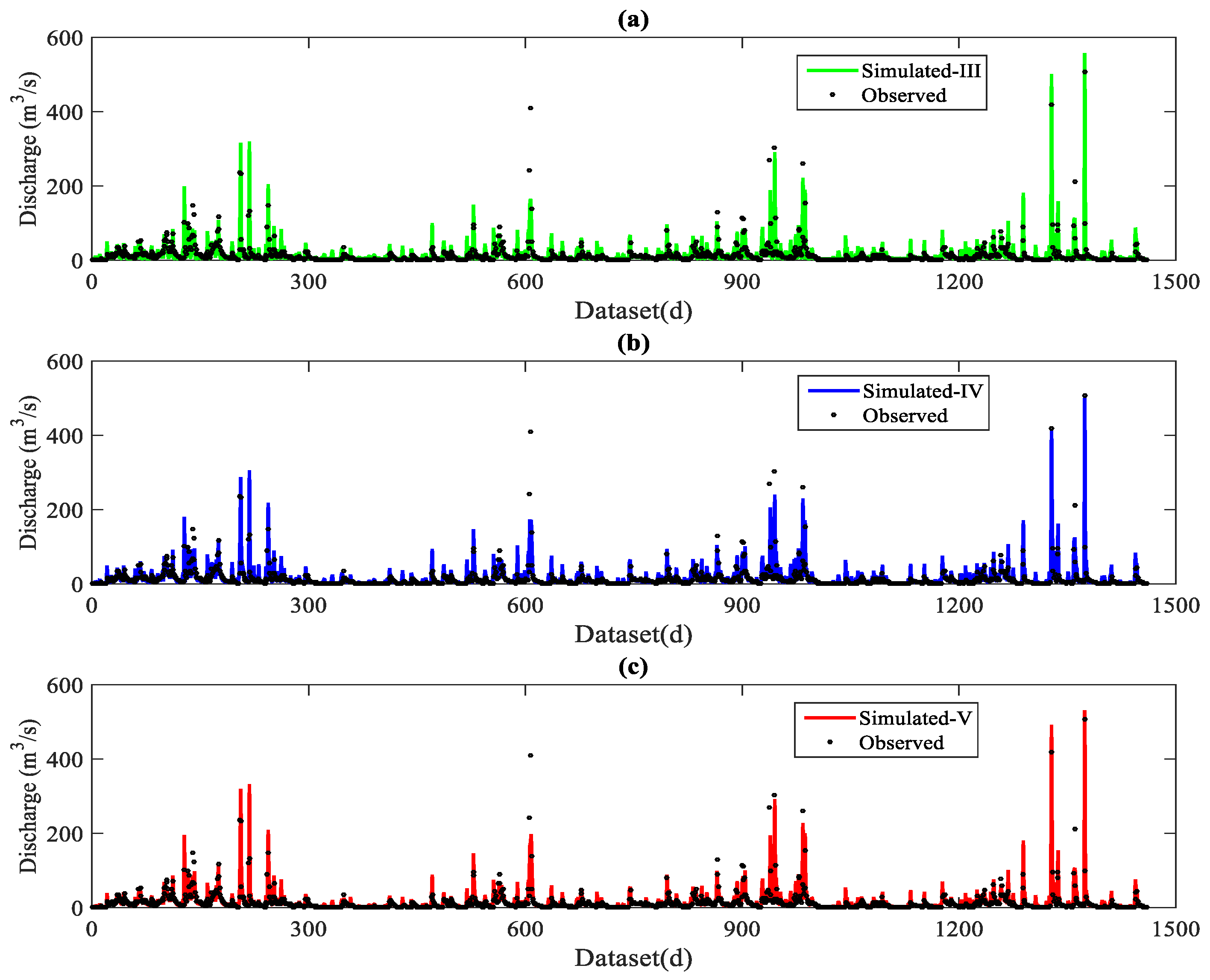
3.2. Simulation Performances with Multiple-Input Scenarios
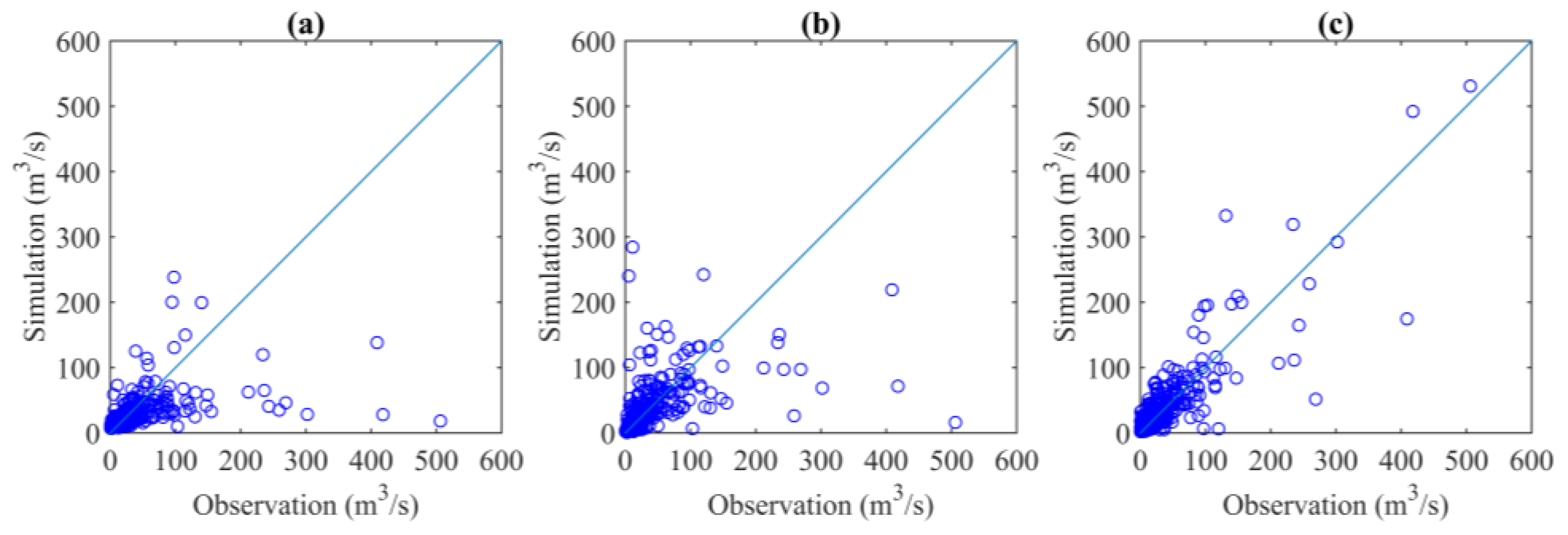
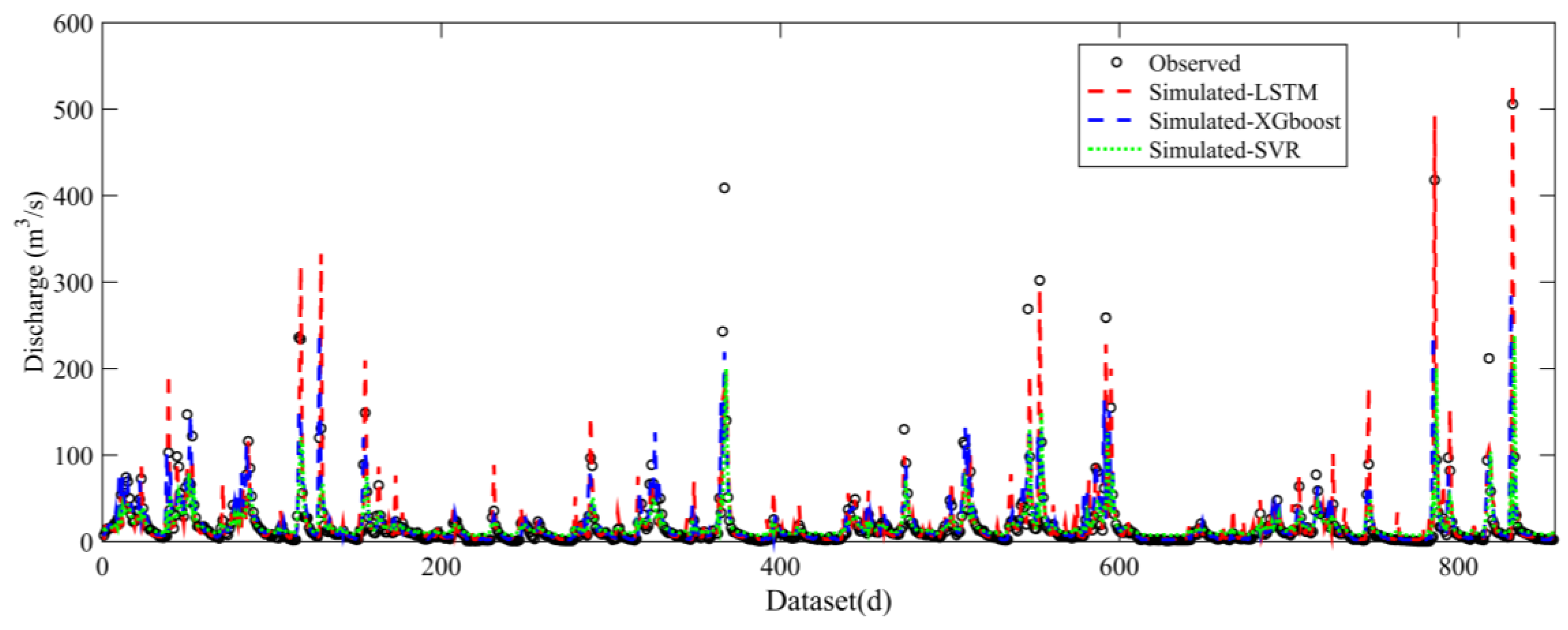
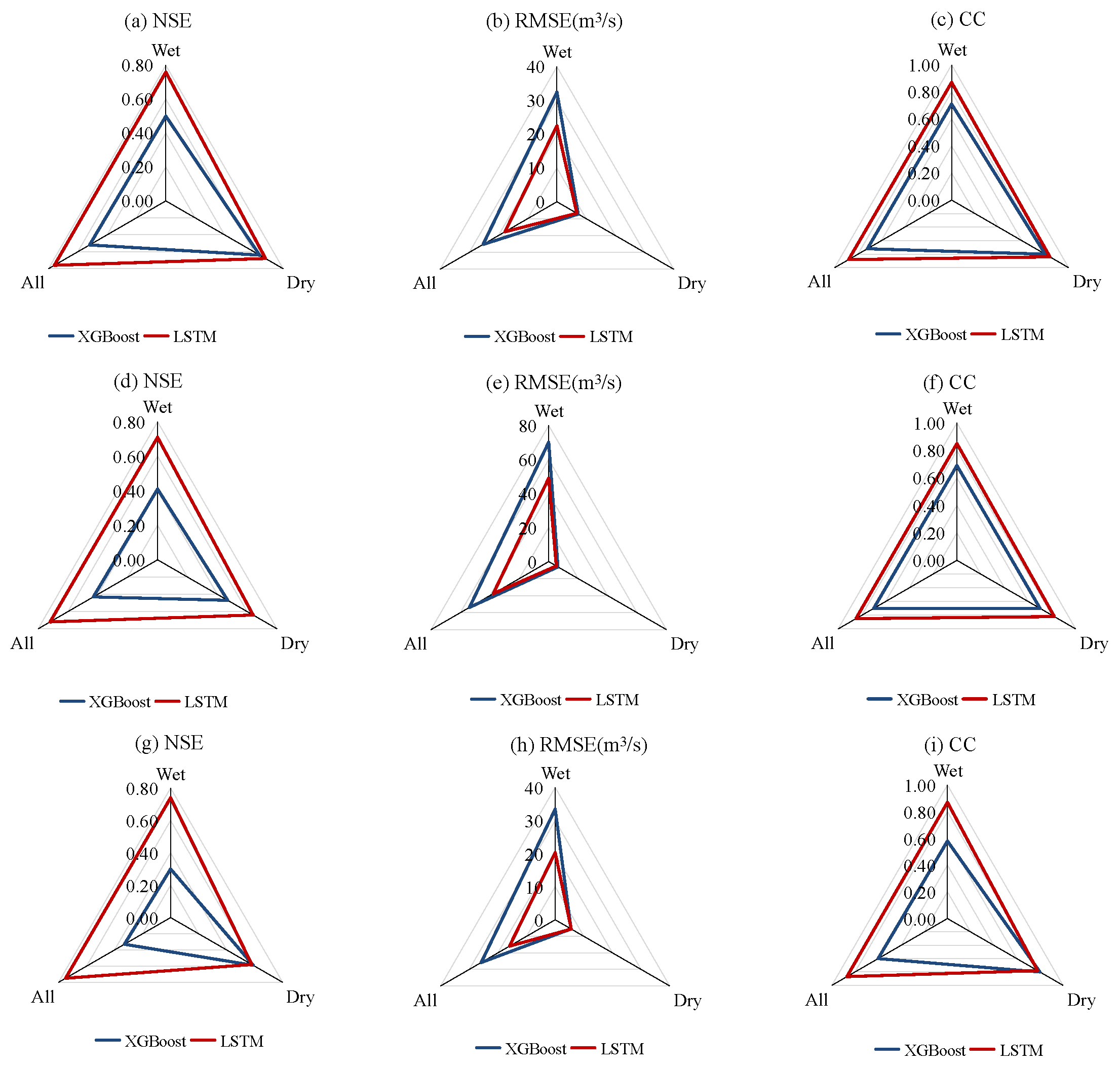
3.3. Simulation Performances during Wet and Dry Seasons
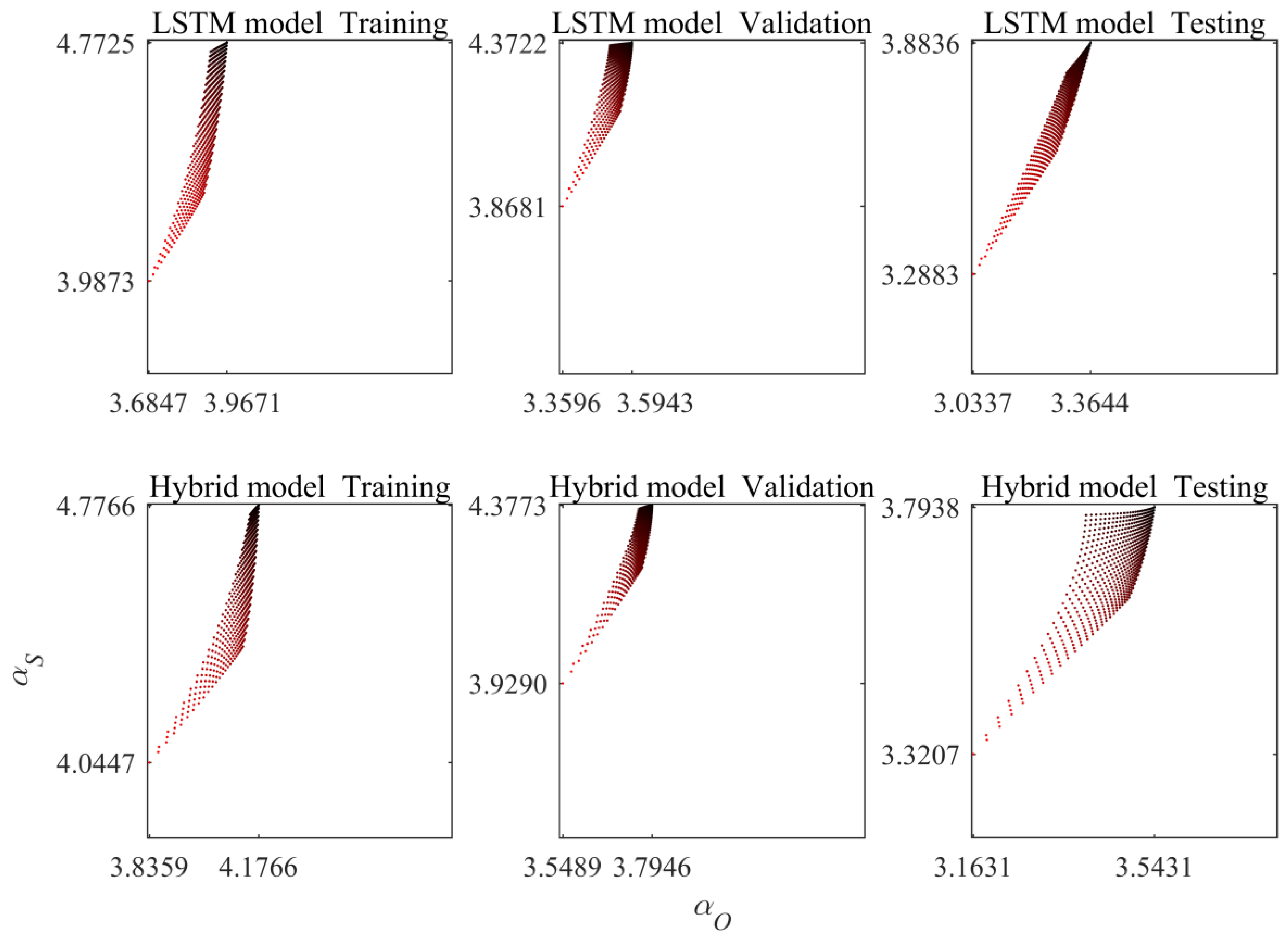
3.4. Classification of Wet and Dry Seasons for Simulation
4. Conclusions
- (1)
- The performance of LSTM models was always better than that of XGBoost, followed by that of SVR. The models with a gauged rainfall and antecedent streamflow input scenario obtained the best accuracy, indicating the roles of the spatial distribution of rainfall and antecedent water storage on streamflow fluctuations.
- (2)
- The impacts of input variables were different for SVR, XGBoost, and LSTM. The LSTM with only rainfall information as an input, and the XGBoost and SVR models with only antecedent streamflow as an input, performed much better than the LSTM model with only antecedent streamflow as an input and the XGBoost and SVR models with only rainfall information, respectively.
- (3)
- Although LSTM always yielded better performances, XGBoost showed relatively high accuracy compared with LSTM during dry seasons when trained with all datasets. Moreover, the classification of datasets according to wet and dry seasons improved the performances of LSTM especially for dry seasons. This suggests that different rainfall–runoff mechanisms dominated the runoff processes during wet and dry seasons.
- (4)
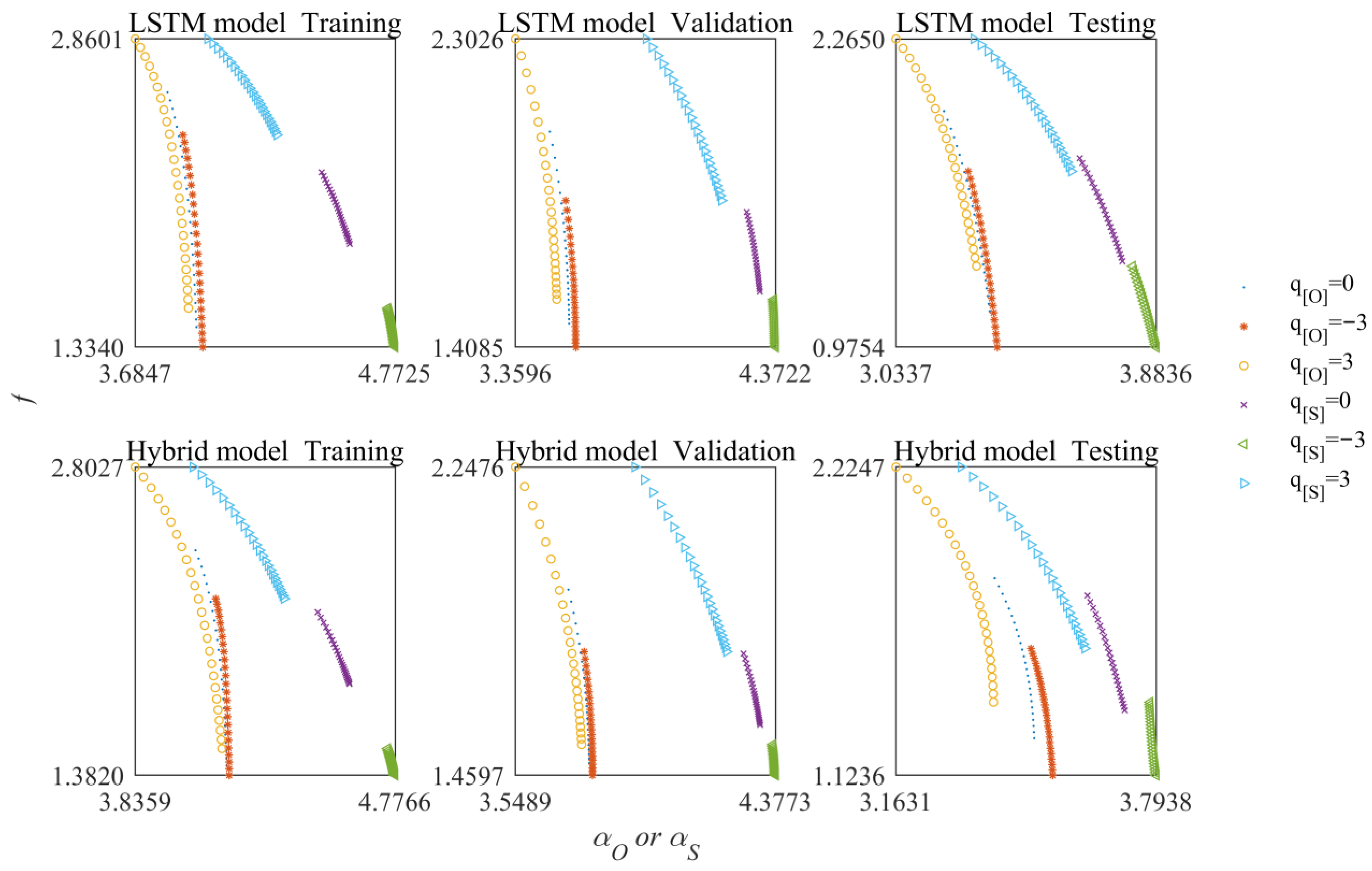
- The LSTM and a hybrid model were analyzed with the JMS method. Overall, the hybrid model outperformed the LSTM model. However, the fractal characteristics of the hybrid model were not consistent throughout the simulation period.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Valizadeh, N.; Mirzaei, M.; Allawi, M.F.; Afan, H.A.; Mohd, N.S.; Hussain, A.; El-Shafie, A. Artificial intelligence and geo-statistical models for stream-flow forecasting in ungauged stations: State of the art. Nat. Hazards 2017, 86, 1377–1392. [Google Scholar] [CrossRef]
- Yang, M.; Wang, H.; Jiang, Y.; Lu, X.; Xu, Z.; Sun, G. GECA proposed ensemble–KNN method for improved monthly runoff forecasting. Water Resour. Manag. 2020, 34, 849–863. [Google Scholar] [CrossRef]
- Yassin, M.; Asfaw, A.; Speight, V.; Shucksmith, J.D. Evaluation of Data-Driven and Process-Based Real-Time Flow Forecasting Techniques for Informing Operation of Surface Water Abstraction. J. Water Resour. Plan. Manag. 2021, 147, 04021037. [Google Scholar] [CrossRef]
- Blöschl, G.; Hall, J.; Viglione, A.; Perdigão, R.A.; Parajka, J.; Merz, B.; Lun, D.; Arheimer, B.; Aronica, G.T.; Bilibashi, A.; et al. Changing climate both increases and decreases European river floods. Nature 2019, 573, 108–111. [Google Scholar] [CrossRef]
- Lei, X.; Gao, L.; Wei, J.; Ma, M.; Xu, L.; Fan, H.; Li, X.; Gao, J.; Dang, H.; Chen, X.; et al. Contributions of climate change and human activities to runoff variations in the Poyang Lake Basin of China. Phys. Chem. Earth 2021, 123, 103019. [Google Scholar] [CrossRef]
- Yeditha, P.K.; Kasi, V.; Rathinasamy, M.; Agarwal, A. Forecasting of extreme flood events using different satellite precipitation products and wavelet-based machine learning methods. Chaos 2020, 30, 63115. [Google Scholar] [CrossRef]
- Xiang, Z.; Jun, Y.; Demir, I. A rainfall-runoff model with LSTM-based sequence-to-sequence learning. Water Resour. Res. 2020, 56, e2019WR025326. [Google Scholar] [CrossRef]
- Nearing, G.S.; Kratzert, F.; Sampson, A.K.; Pelissier, C.S.; Klotz, D.; Frame, J.M.; Prieto, C.; Gupta, H.V. What role does hydrological science play in the age of machine learning? Water Resour. Res. 2021, 57, e2020WR028091. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K.-w. Flood prediction using machine learning models: Literature review. Water 2018, 10, 1536. [Google Scholar] [CrossRef] [Green Version]
- Hamitouche, M.; Molina, J. A review of ai methods for the prediction of high-flow extremal hydrology. Water Resour. Manag. 2022, 36, 3859–3876. [Google Scholar] [CrossRef]
- Parisouj, P.; Mohebzadeh, H.; Lee, T. Employing machine learning algorithms for streamflow prediction: A case study of four river basins with different climatic zones in the United States. Water Resour. Manag. 2020, 34, 4113–4131. [Google Scholar] [CrossRef]
- Li, Y.; Wei, J.; Wang, D.; Li, B.; Huang, H.; Xu, B.; Xu, Y. A Medium and Long-Term Runoff Forecast Method Based on Massive Meteorological Data and Machine Learning Algorithms. Water 2021, 13, 1308. [Google Scholar] [CrossRef]
- Liu, J.; Ren, K.; Ming, T.; Qu, J.; Guo, W.; Li, H. Investigating the effects of local weather, streamflow lag, and global climate information on 1-month-ahead streamflow forecasting by using XGBoost and SHAP: Two case studies involving the contiguous USA. Acta Geophys. 2022, 71, 905–925. [Google Scholar] [CrossRef]
- Thapa, S.; Zhao, Z.; Li, B.; Lu, L.; Fu, D.; Shi, X.; Tang, B.; Qi, H. Snowmelt-driven streamflow prediction using machine learning techniques (LSTM, NARX, GPR, and SVR). Water 2020, 12, 1734. [Google Scholar] [CrossRef]
- Le, X.; Nguyen, D.; Jung, S.; Yeon, M.; Lee, G. Comparison of deep learning techniques for river streamflow forecasting. IEEE Access 2021, 9, 71805–71820. [Google Scholar] [CrossRef]
- Rahimzad, M.; Nia, A.M.; Zolfonoon, H.; Soltani, J.; Mehr, A.D.; Kwon, H. Performance comparison of an LSTM-based deep learning model versus conventional machine learning algorithms for streamflow forecasting. Water Resour. Manag. 2021, 35, 4167–4187. [Google Scholar] [CrossRef]
- Yeditha, P.K.; Rathinasamy, M.; Neelamsetty, S.S.; Bhattacharya, B.; Agarwal, A. Investigation of satellite rainfall-driven rainfall-runoff model using deep learning approaches in two different catchments of India. J. Hydroinform. 2022, 24, 16–37. [Google Scholar] [CrossRef]
- Feng, D.; Fang, K.; Shen, C. Enhancing streamflow forecast and extracting insights using Long-Short Term Memory Networks with data integration at continental scales. Water Resour. Res. 2020, 56, e2019WR026793. [Google Scholar] [CrossRef]
- Kim, T.; Yang, T.; Gao, S.; Zhang, L.; Ding, Z.; Wen, X.; Gourley, J.J.; Hong, Y. Can artificial intelligence and data-driven machine learning models match or even replace process-driven hydrologic models for streamflow simulation?: A case study of four watersheds with different hydro-climatic regions across the CONUS. J. Hydrol. 2021, 598, 126423. [Google Scholar] [CrossRef]
- Moosavi, V.; Fard, Z.G.; Vafakhah, M. Which one is more important in daily runoff forecasting using data driven models: Input data, model type, preprocessing or data length? J. Hydrol. 2022, 606, 127429. [Google Scholar] [CrossRef]
- Niu, W.; Feng, Z. Evaluating the performances of several artificial intelligence methods in forecasting daily streamflow time series for sustainable water resources management. Sust. Cities Soc. 2021, 64, 102562. [Google Scholar] [CrossRef]
- Rasouli, K.; Hsieh, W.W.; Cannon, A.J. Daily streamflow forecasting by machine learning methods with weather and climate inputs. J. Hydrol. 2012, 414–415, 284–293. [Google Scholar] [CrossRef]
- Chang, W.; Chen, X. Monthly rainfall-runoff modeling at watershed scale: A comparative study of data-driven and theory-driven approaches. Water 2018, 10, 1116. [Google Scholar] [CrossRef] [Green Version]
- Xiong, J.; Wang, Z.; Guo, S.; Wu, X.; Yin, J.; Wang, J.; Lai, C.; Gong, Q. High efectiveness of GRACE data in daily-scale food modeling: Case study in the Xijiang River Basin, China. Nat. Hazards 2022, 113, 507–526. [Google Scholar] [CrossRef]
- Emerton, R.E.; Stephens, E.M.; Cloke, H.L. What is the most useful approach for forecastinghydrological extremes during El Niño? Environ. Res. Commun. 2019, 1, 031002. [Google Scholar] [CrossRef]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Liu, Z.; Zhou, P.; Chen, G.; Guo, L. Evaluating a coupled discrete wavelet transform and support vector regression for daily and monthly streamflow forecasting. J. Hydrol. 2014, 519, 2822–2831. [Google Scholar] [CrossRef]
- Ikram, R.M.A.; Goliatt, L.; Kisi, O.; Trajkovic, S.; Shahid, S. Covariance matrix adaptation evolution strategy for improving machine learning approaches in streamflow prediction. Mathematics 2022, 10, 2971. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ‘16), San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Ko, C.-M.; Jeong, Y.Y.; Lee, Y.-M.; Kim, B.-S. The development of a quantitative precipitation forecast correction technique based on machine learning for hydrological applications. Atmosphere 2020, 11, 111. [Google Scholar] [CrossRef] [Green Version]
- Potdar, A.S.; Kirstetter, P.; Woods, D.; Saharia, M. Toward predicting flood event peak discharge in ungauged basins by learning universal hydrological behaviors with machine learning. J. Hydrometeorol. 2021, 22, 2971–2982. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Le, X.-H.; Ho, H.V.; Lee, G.; Jung, S. Application of Long Short-Term Memory (LSTM) Neural Network for Flood Forecasting. Water 2019, 11, 1387. [Google Scholar] [CrossRef] [Green Version]
- Brochu, E.; Cora, V.M.; de Freitas, N. A tutorial on Bayesian optimization of expensive cost functions, with application to active user modeling and hierarchical reinforcement learning. arXiv 2010, arXiv:1012.2599. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Zhang, K.; Zheng, L.; Liu, Z.; Jia, N. A deep learning based multitask model for network-wide traffic speed prediction. Neurocomputing 2020, 396, 438–450. [Google Scholar] [CrossRef]
- Alizadeh, B.; Bafti, A.G.; Kamangir, H.; Zhang, Y.; Wright, D.B.; Franz, K.J. A novel attention-based LSTM cell post-processor coupled with bayesian optimization for streamflow prediction. J. Hydrol. 2021, 601, 126526. [Google Scholar] [CrossRef]
- Nash, J.E.; Sutcliffe, J.V. River flow forecasting through conceptual models, part 1: A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Bai, Z.; Xu, X.-P.; Pan, S.; Liu, L.; Wang, Z.X. Evaluating the performance of hydrological models with joint multifractal spectra. Hydrol. Sci. J. 2022, 67, 1771–1789. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Scenarios | Input Variables |
|---|---|
| I | Qt−1 |
| II | |
| III | P1,t, P2,t, P3,t, P4,t, P5,t, P6,t |
| IV | , Qt−1 |
| V | P1,t, P2,t, P3,t, P4,t, P5,t, P6,t, Qt−1 |
| Input Scenario | Model | Training | Validation | Testing | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NSE | RMSE (m3/s) | CC | NSE | RMSE (m3/s) | CC | NSE | RMSE (m3/s) | CC | ||
| I | SVR | 0.26 | 31.55 | 0.51 | 0.22 | 63.08 | 0.47 | 0.23 | 27.79 | 0.48 |
| XGBoost | 0.32 | 30.21 | 0.56 | 0.23 | 62.69 | 0.50 | 0.27 | 26.95 | 0.53 | |
| LSTM | 0.09 | 34.83 | 0.31 | 0.04 | 69.97 | 0.21 | 0.08 | 30.34 | 0.29 | |
| II | SVR | 0.11 | 34.46 | 0.47 | 0.13 | 66.46 | 0.63 | 0.09 | 30.12 | 0.37 |
| XGBoost | 0.22 | 32.29 | 0.47 | 0.22 | 63.01 | 0.55 | 0.10 | 29.92 | 0.37 | |
| LSTM | 0.69 | 20.42 | 0.83 | 0.68 | 40.10 | 0.83 | 0.64 | 19.09 | 0.83 | |
| Input Scenario | Model | Training | Validation | Testing | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NSE | RMSE (m3/s) | CC | NSE | RMSE (m3/s) | CC | NSE | RMSE (m3/s) | CC | ||
| III | SVR | 0.12 | 34.34 | 0.48 | 0.14 | 66.25 | 0.63 | 0.10 | 30.03 | 0.37 |
| XGBoost | 0.25 | 31.60 | 0.51 | 0.31 | 59.13 | 0.61 | 0.08 | 30.40 | 0.35 | |
| LSTM | 0.70 | 20.08 | 0.84 | 0.72 | 38.09 | 0.85 | 0.67 | 18.22 | 0.84 | |
| IV | SVR | 0.35 | 29.57 | 0.60 | 0.32 | 58.70 | 0.58 | 0.31 | 26.34 | 0.56 |
| XGBoost | 0.48 | 26.36 | 0.70 | 0.40 | 55.07 | 0.70 | 0.37 | 25.02 | 0.62 | |
| LSTM | 0.72 | 19.30 | 0.85 | 0.68 | 40.32 | 0.83 | 0.70 | 17.27 | 0.85 | |
| V | SVR | 0.35 | 29.56 | 0.60 | 0.32 | 58.91 | 0.57 | 0.31 | 26.31 | 0.56 |
| XGBoost | 0.61 | 22.82 | 0.78 | 0.54 | 48.58 | 0.75 | 0.33 | 25.85 | 0.60 | |
| LSTM | 0.75 | 18.23 | 0.87 | 0.72 | 37.96 | 0.85 | 0.74 | 16.29 | 0.87 | |
| Model | Period | Training | Validation | Testing | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| NSE | RMSE (m3/s) | CC | NSE | RMSE (m3/s) | CC | NSE | RMSE (m3/s) | CC | ||
| SVR | Wet | 0.32 | 37.77 | 0.58 | 0.30 | 76.64 | 0.53 | 0.28 | 33.84 | 0.53 |
| Dry | 0.38 | 9.55 | 0.73 | 0.07 | 8.29 | 0.67 | 0.32 | 7.13 | 0.77 | |
| XGBoost | Wet | 0.60 | 29.03 | 0.78 | 0.52 | 63.22 | 0.74 | 0.30 | 33.43 | 0.57 |
| Dry | 0.56 | 8.06 | 0.76 | 0.42 | 6.54 | 0.69 | 0.58 | 5.60 | 0.79 | |
| LSTM | Wet | 0.75 | 23.19 | 0.86 | 0.71 | 49.29 | 0.84 | 0.74 | 20.47 | 0.87 |
| Dry | 0.72 | 6.44 | 0.86 | 0.45 | 6.38 | 0.83 | 0.39 | 6.76 | 0.78 | |
| k/r2 | Training | Validation | Testing |
|---|---|---|---|
| LSTM | 3.29/0.79 | 1.97/0.64 | 1.90/0.93 |
| Hybrid model | 2.48/0.76 | 1.94/0.81 | 1.06/0.65 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, R.; Bai, Z. Comparative Study for Daily Streamflow Simulation with Different Machine Learning Methods. Water 2023, 15, 1179. https://doi.org/10.3390/w15061179
Hao R, Bai Z. Comparative Study for Daily Streamflow Simulation with Different Machine Learning Methods. Water. 2023; 15(6):1179. https://doi.org/10.3390/w15061179
Chicago/Turabian StyleHao, Ruonan, and Zhixu Bai. 2023. "Comparative Study for Daily Streamflow Simulation with Different Machine Learning Methods" Water 15, no. 6: 1179. https://doi.org/10.3390/w15061179
APA StyleHao, R., & Bai, Z. (2023). Comparative Study for Daily Streamflow Simulation with Different Machine Learning Methods. Water, 15(6), 1179. https://doi.org/10.3390/w15061179