
Spatial Spillover Effects of Agricultural Transport Costs in Peru




Abstract
:
1. Introduction
2. Theoretical Setting
2.1. Agricultural Transport Costs Model
2.2. Empirical Specification
3. Exploratory Spatial Flow Data Analysis
3.1. Agricultural Transport Costs in Peru
3.2. ESFDA of Agricultural Transport Costs
3.2.1. Moran’s I Test of Global Spatial Autocorrelation of Flows
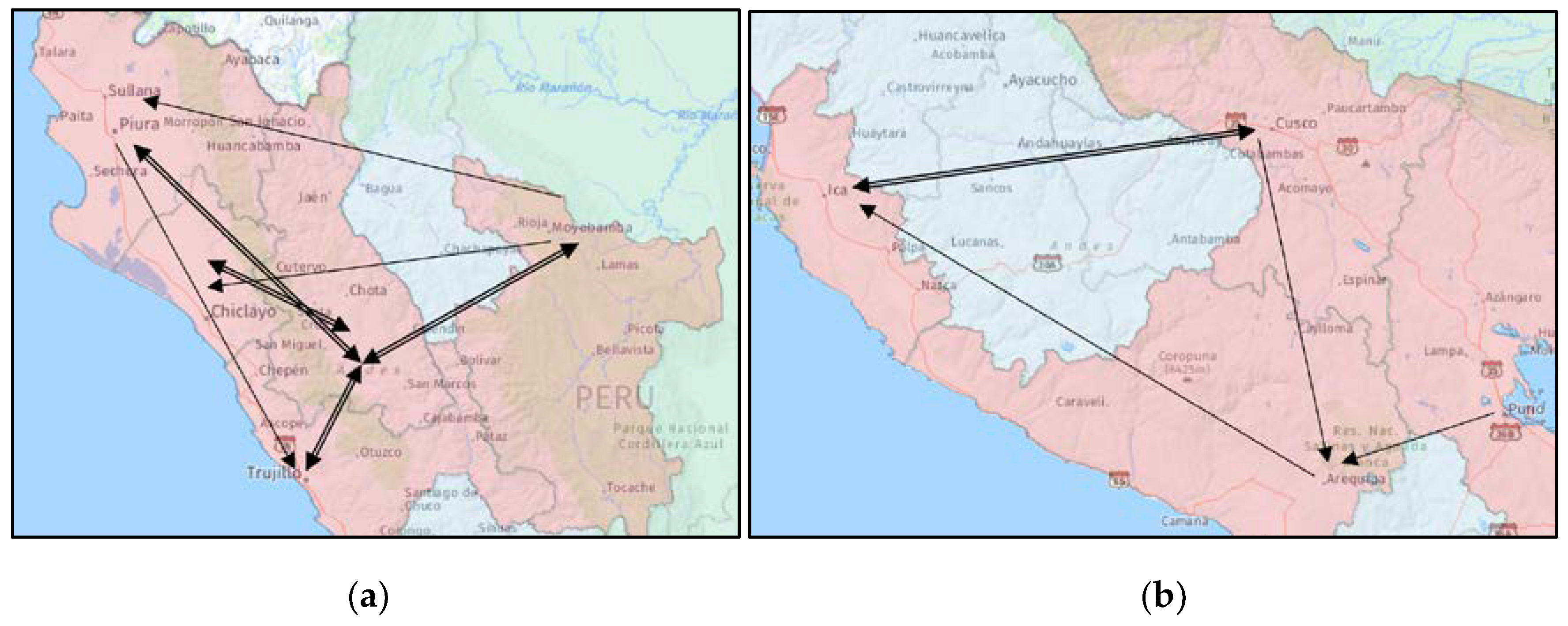
3.2.2. Moran Scatterplots of Spatial Flows
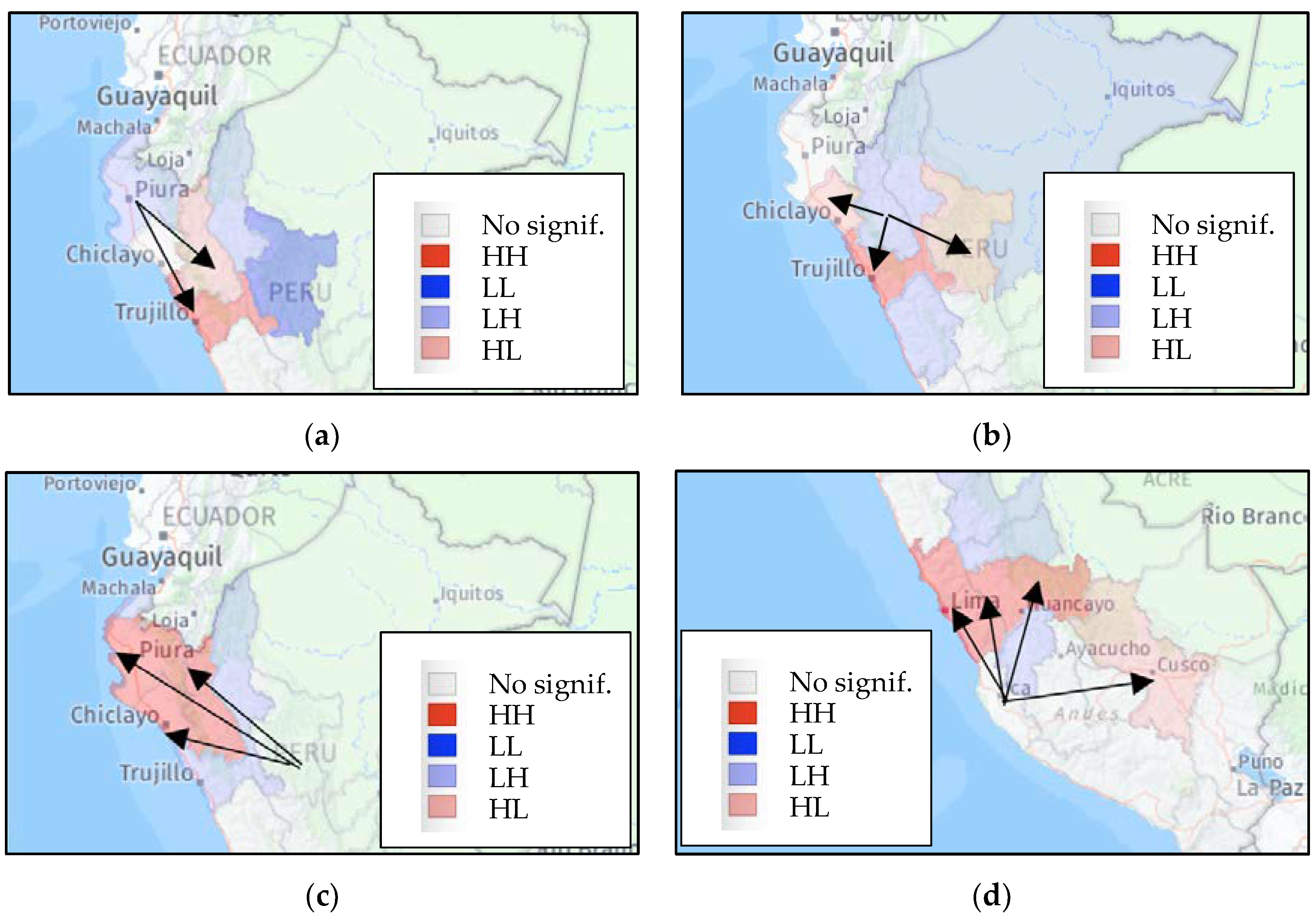
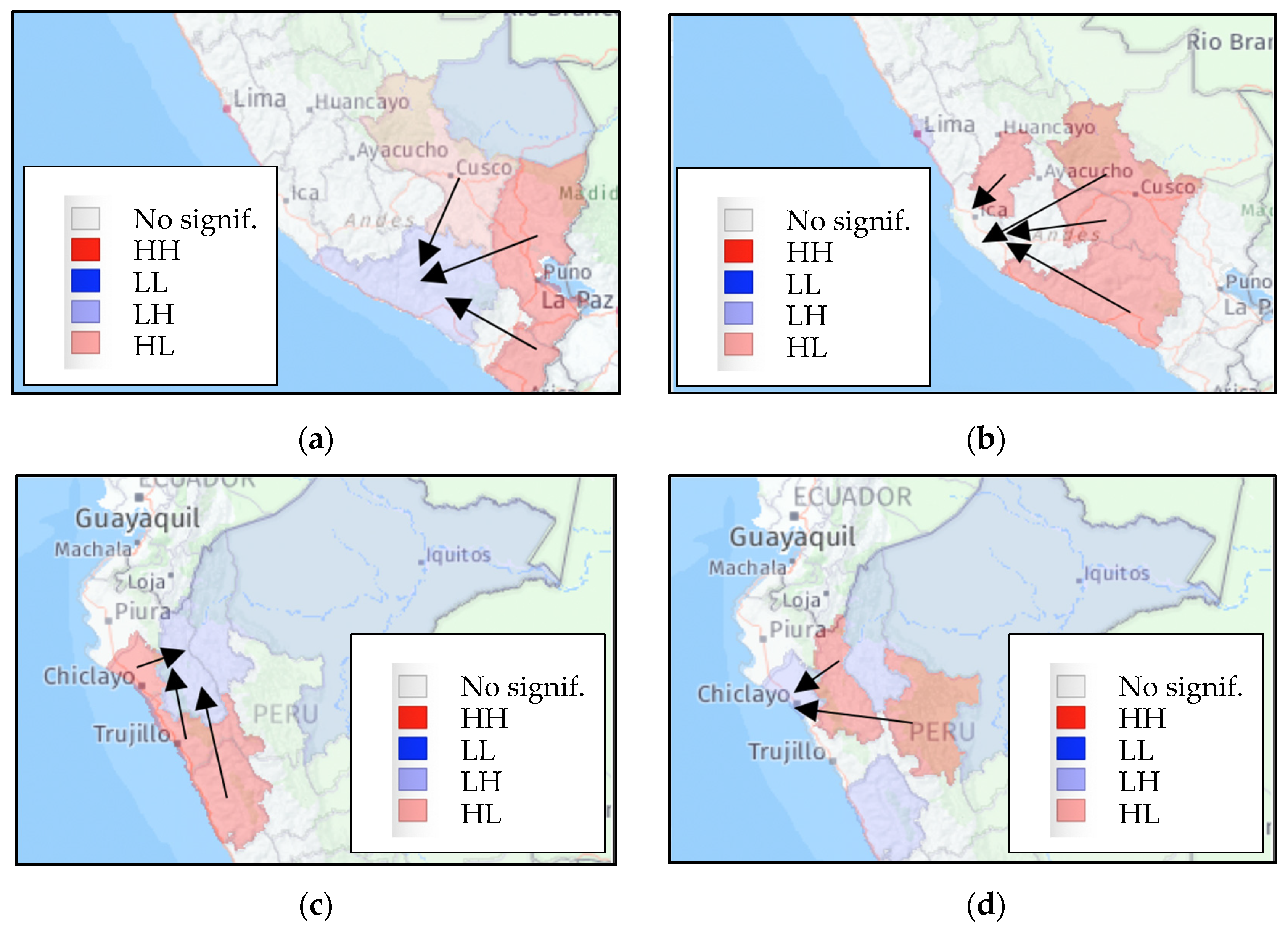
3.2.3. LISA Tests of Local Spatial Autocorrelation of Flows
4. Econometric Modelling
4.1. Non-Spatial Origin-Destination Model
- Gross value added in each region, which measures regional economic dynamics. Since agricultural trade flows are directly proportional to the economic activity in regional economies, we would expect a positive relationship between these flows and the gross value added.
- Consumer price index variation for agricultural products in each region, which approximates the price-demand relationship of agricultural goods. Prices increment should reduce the demand for goods, and lead to reductions of agricultural trade flows, thus effects associated with change to consumer price index should be negative with respect to trade flows.
- Paved neighbourhood road length in each region measures road transport network efficiency. A better-quality infrastructure should lead to more trade, therefore, we would expect a positive relationship between trade flows and paved neighbourhood road length.
4.2. Spatial Origin-Destination Model
4.2.1. Specification
4.2.2. Estimation of the SAR Origin-Destination Model
5. Discussion on the Effect Estimates
5.1. Non-Spatial Origin-Destination Model
5.2. Spatial Origin-Destination Model
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krugman, P. Increasing returns and economic geography. J. Political Econ. 1991, 99, 483–499. [Google Scholar] [CrossRef]
- McCann, P. Transport costs and new economic geography. J. Econ. Geogr. 2005, 5, 305–318. [Google Scholar] [CrossRef]
- Fingleton, B.; McCann, P. Sinking the iceberg? On the treatment of transport costs in new economic geography. In New Directions in Economic Geography; Fingleton, B., Ed.; Edward Elgar: Cheltenham, UK, 2007; Chapter 6; pp. 168–203. [Google Scholar] [CrossRef]
- Garretsen, H.; Martin, R. Rethinking (New) Economic Geography models: Taking geography and history more seriously. Spat. Econ. Anal. 2010, 5, 127–160. [Google Scholar] [CrossRef]
- Samuelson, P.A. The transfer problem and transport costs, II: Analysis of effects of trade impediments. Econ. J. 1954, 64, 264–289. [Google Scholar] [CrossRef]
- Fujita, M.; Krugman, P.R.; Venables, A.J. The Spatial Economy: Cities, Regions, and International Trade; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar] [CrossRef]
- Von Thünen, J.H. Der Isolierte Staat in Beziehung auf Nationalalo Konomie und Landwirtschaft; 1826 Reprinted by Fischer, G. Stuttgart; Pergamon Press: Oxford, UK, 1966. [Google Scholar]
- Picard, P.M.; Zeng, D.-Z. Agricultural sector and industrial agglomeration. J. Dev. Econ. 2005, 77, 75–106. [Google Scholar] [CrossRef]
- Tanaka, K. Transport Costs, Distance, and Time: Evidence from the Japanese Census of Logistics; IDE Discussion Papers; Institute of Developing Economies, Japan External Trade Organization: Chiba, Japan, 2010; Volume 241. [Google Scholar]
- Evans, C.L.; Harrigan, J. Distance, time, and specialization: Lean retailing in general equilibrium. Am. Econ. Rev. 2005, 95, 292–313. [Google Scholar] [CrossRef]
- Djankov, S.; Freund, C.; Pham, C.S. Trading on Time. Rev. Econ. Stat. 2010, 92, 166–173. [Google Scholar] [CrossRef]
- IFPRI. Constructing a Typology of Rural Communities of the Peruvian Highlands Using Stochastic Profit Frontier Estimation; International Food Policy Research Institute: Washington, DC, USA, 2009. [Google Scholar]
- Richards, P. It’s not just where you farm; it’s whether your neighbor does too. How agglomeration economies are shaping new agricultural landscapes. J. Econ. Geogr. 2018, 18, 87–110. [Google Scholar] [CrossRef]
- Rangel-Preciado, J.; Parejo-Moruno, F.M.; Cruz-Hidalgo, E.; Castellano-Álvarez, F.J. Rural Districts and Business Agglomerations in Low-Density Business Environments. The Case of Extremadura (Spain). Land 2021, 10, 280. [Google Scholar] [CrossRef]
- Läpple, D.; Renwick, A.; Cullinan, J.; Thorne, F. What drives innovation in the agricultural sector? A spatial analysis of knowledge spillovers. Land Use Policy 2016, 56, 238–250. [Google Scholar] [CrossRef]
- Ranjan, P.; Tobias, J.L. Bayesian inference for the gravity model. J. Appl. Econom. 2007, 22, 817–838. [Google Scholar] [CrossRef]
- Herrera-Catalán, P.; Chasco, C. Agglomeration on the periphery? Exploratory spatial analysis of agricultural transport flows in Peru. In Agglomeration Economies and Rural Development; Parejo-Moruno, F., Rangel-Preciado, J., Eds.; Dykinson Publishing: Madrid, Spain, in press.
- Anselin, L. GeoDa Workbook. 2021. Available online: https://geodacenter.github.io/documentation.html (accessed on 14 November 2021).
- World Bank. Peru—Towards a System Integrated City: A New Vision for Growth; World Bank Group: Washington, DC, USA, 2016. [Google Scholar]
- Karp, L.S.; Perloff, J.M. A Synthesis of Agricultural Trade Economics. In Handbook of Agricultural Economics; Gardner, B.L., Rausser, G.C., Eds.; Elsevier: Amsterdam, The Netherlands, 2002; Chapter 37; pp. 3035–3213. [Google Scholar] [CrossRef]
- Martin, W. Economic growth, convergence, and agricultural economics. Agric. Econ. 2019, 50, 7–27. [Google Scholar] [CrossRef] [Green Version]
- McCalla, A.F. Impact of macroeconomic policies upon agricultural trade and international agricultural development. Am. J. Agric. Econ. 1982, 64, 861–868. [Google Scholar] [CrossRef]
- Diaz-Bonilla, E.; Robinson, S. Macroeconomics, macrosectoral policies, and agriculture in developing countries. In Handbook of Agricultural Economics; Pingali, P., Evenson, R., Eds.; Academic Press: Burlington, ON, Canada, 2010; Chapter 61; pp. 3035–3213. [Google Scholar] [CrossRef]
- Combes, P.-P.; Lafourcade, M. Transport costs: Measures, determinants, and regional policy implications for France. J. Econ. Geogr. 2005, 5, 319–349. [Google Scholar] [CrossRef]
- Sotelo, S. Domestic Trade Frictions and Agriculture. J. Political Econ. 2020, 128, 2690–2738. [Google Scholar] [CrossRef] [Green Version]
- LeSage, J.P.; Pace, R.K. Spatial econometrics modeling of Origin-Destination Flows. J. Reg. Sci. 2008, 48, 941–967. [Google Scholar] [CrossRef]
- LeSage, J.P.; Pace, R.K. Introduction to Spatial Econometrics; CRC Press, Taylor & Francis Group: Boca Raton, FL, USA, 2009. [Google Scholar] [CrossRef] [Green Version]
- Anselin, L. Spatial Econometrics: Methods and Models; Kluwer Academic Publishers: Amsterdam, The Netherlands, 1988. [Google Scholar] [CrossRef] [Green Version]
- LeSage, J.P.; Thomas-Agnan, C. Interpreting spatial econometric origin-destination flow models. J. Reg. Sci. 2015, 55, 188–208. [Google Scholar] [CrossRef]
- LeSage, J.P.; Fischer, M.M.; Scherngell, T. Knowledge spillovers across Europe, evidence from a poisson spatial interaction model with spatial effects. Pap. Reg. Sci. 2007, 86, 393–421. [Google Scholar] [CrossRef] [Green Version]
- Sellner, R.; Fischer, M.M.; Koch, M. A spatial autoregressive Poisson gravity model. Geogr. Anal. 2013, 45, 180–200. [Google Scholar] [CrossRef] [Green Version]
- Martínez-García, M.P.; Morales, J. Resource effect in the Core–Periphery model. Spat. Econ. Anal. 2019, 14, 339–360. [Google Scholar] [CrossRef]
- Beghin, J.C.; Schweizer, H. Agricultural Trade Costs. Appl. Econ. Perspect. Policy 2021, 43, 500–530. [Google Scholar] [CrossRef]
- Cai, J.; Li, X.; Liu, L.; Chen, Y.; Wang, X.; Lu, S. Coupling and coordinated development of new urbanization and agroecological environment in China. Sci. Total Environ. 2021, 776, 145837. [Google Scholar] [CrossRef] [PubMed]
- Forslid, R.; Okubo, T. Agglomeration of low-productive entrepreneurs to large regions: A simple model. Spat. Econ. Anal. 2021, 16, 471–486. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, M.; Hendry, L.C.; Bu, M.; Wang, S. Supplier Development Practices for Sustainability: A Multi-Stakeholder Perspective. Bus. Strateg. Environ. 2018, 27, 100–116. [Google Scholar] [CrossRef] [Green Version]
- Mishra, P.K.; Dey, K. Governance of agricultural value chains: Coordination, control and safeguarding. J. Rural Stud. 2018, 64, 135–147. [Google Scholar] [CrossRef]
- Flynn, A. Investigating the implementation of SME-friendly policy in public procurement. Policy Stud. UK 2018, 39, 422–443. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| D1 | D2 | Dn | O1 | O2 | … | On | |||
| O1 | τ 11 | τ12 | … | τ1n | D1 | τ11 | τ21 | … | τn1 |
| O2 | τ 21 | τ22 | … | τ2n | D2 | τ12 | τ22 | … | τn2 |
| … | … | … | … | … | … | … | … | … | |
| On | τn1 | τn2 | … | τnn | Dn | τ1n | τ2n | … | τnn |
| (a) | (b) | ||||||||
| Clusters in Origin Regions | Clusters in Destination Regions | ||||||
|---|---|---|---|---|---|---|---|
| Destination | Origin | Moran I | LISA | Origin | Destination | Moran I | LISA |
| Arequipa | 0.272 *** | Cajamarca | 0.184 *** | ||||
| Cusco | 0.311 *** | La Libertad | 0.518 *** | ||||
| Puno | 0.331 *** | Lambayeque | 0.664 *** | ||||
| Tacna | 0.430 ** | San Martín | 0.175 *** | ||||
| Cajamarca | 0.224 *** | Ica | 0.164 ** | ||||
| Ancash | 0.060 ** | Cusco | 0.163 *** | ||||
| La Libertad | 0.258 *** | Junín | 0.192 ** | ||||
| Lambayeque | 0.039 ** | Lima | 0.086 ** | ||||
| MLC a | 0.331 ** | ||||||
| Ica | 0.103 *** | Piura | 0.122 ** | ||||
| Apurímac | 0.152 ** | Cajamarca | 0.013 ** | ||||
| Arequipa | 0.605 ** | La Libertad | 0.243 *** | ||||
| Cusco | 0.008 ** | ||||||
| Huancavelica | 0.233 ** | ||||||
| Lambayeque | 0.127 ** | San Martín | 0.129 ** | ||||
| Cajamarca | 0.351 *** | Cajamarca | 0.354 ** | ||||
| San Martín | 0.168 ** | Lambayeque | 0.182 ** | ||||
| Piura | 0.447 ** | ||||||
| Variable | Description | Units | Mean | Std | Min | Max |
|---|---|---|---|---|---|---|
| Dependent variable | ||||||
| Agricultural trade flows | Agricultural transport costs between each pair of regions. Authors calculations (see Section 3.2). | Dollar per ton/h | 351,504.6 | 542,531.8 | 732.7 | 3,336,130.4 |
| Independent variables | ||||||
| Regional economic dynamics | Gross value added in each region. National Institute of Statistics and Informatics (INEI) | (Index 2007 = 100) | 137.3 | 20.6 | 89.0 | 189.8 |
| Price-demand relationships | Consumer price index variation for agricultural goods in each region. INEI. | Consumer Price Index | 2.8 | 1.3 | 0.4 | 5.7 |
| Road transport network efficiency | Paved neighbourhood roads length in each region. Ministry of Transport and Communications (MTC). | km | 77.6 | 94.1 | 66.2 | 403.3 |
| Spatial variable | Distance between each pair of regions. Authors calculations based on data from INEI. | km | 720.1 | 413.7 | 56.1 | 1948.9 |
| Variable | Least-Squares Model | Spatial Autoregressive | |
|---|---|---|---|
| Coefficient | Coefficient | ||
| Constant | −13.5381 * | −8.6443 | |
| βd | consumer price index for agricultural goods | −0.6002 ** | −0.2285 |
| βd | paved neighbourhood roads | 0.6885 *** | 0.3143 *** |
| βd | regional gross value added | 3.5698 *** | 1.4912 |
| βo | consumer price index for agricultural goods | −0.3295 | 0.0579 |
| βo | paved neighbourhood roads | 0.1188 | 0.0653 |
| βo | regional gross value added | 0.0008 | 0.1286 |
| log(distance) | −0.0085 *** | −0.0007 | |
| log(distance2) | 0.30 × 10−5 *** | 0.13 × 10−6 | |
| ρd | −0.1817 * | ||
| ρo | 0.6435 *** | ||
| ρw | 0.4874 *** | ||
| Variables | Least-Squares Model | Spatial Autoregressive | ||||
|---|---|---|---|---|---|---|
| Mean | Median | Std. Dev. | Mean | Median | Std. Dev. | |
| Origin-consumer price index for agricultural goods | 0.0637 | 0.0614 | 0.3079 | −0.1532 | −0.1316 | 1.0399 |
| Origin-paved neighbourhood roads | 0.0595 | 0.0596 | 0.0956 | 0.5969 | 0.4749 | 0.7727 |
| Origin-regional gross value added | 0.1681 | 0.1422 | 1.0593 | 2.5751 | 2.0815 | 5.1307 |
| Destination-consumer price index for agricultural goods | −0.2081 | −0.2102 | 0.3007 | -0.5848 | −0.5369 | 1.1752 |
| Destination-paved neighbourhood roads | 0.2967 | 0.2960 | 0.1036 | 1.0031 | 0.8885 | 0.8138 |
| Destination-regional gross value added | 1.4238 | 1.4327 | 1.0543 | 4.6975 | 4.1212 | 5.5379 |
| Intraregional-consumer price index for agricultural goods | −0.0060 | −0.0060 | 0.0180 | −0.0207 | −0.0186 | 0.0564 |
| Intraregional-paved neighbourhood roads | 0.0148 | 0.0149 | 0.0059 | 0.0453 | 0.0409 | 0.0352 |
| Intraregional-regional gross value added | 0.0663 | 0.0661 | 0.0628 | 0.2052 | 0.1807 | 0.2516 |
| Network-consumer price index for agricultural goods | -- | -- | -- | −5.7770 | −4.0858 | 19.0636 |
| Network-paved neighbourhood roads | -- | -- | -- | 12.3269 | 9.3101 | 17.7252 |
| Network-regional gross value added | -- | -- | -- | 56.3468 | 38.4989 | 109.0265 |
| Total-consumer price index for agricultural goods | −0.1504 | −0.1511 | 0.4493 | −6.5357 | −4.7502 | 21.1928 |
| Total-paved neighbourhood roads | 0.3711 | 0.3721 | 0.1471 | 13.9721 | 10.7266 | 19.3182 |
| Total-regional gross value added | 1.6582 | 1.6515 | 1.5710 | 63.8246 | 44.3224 | 119.5158 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Herrera-Catalán, P.; Chasco, C.; Torero, M. Spatial Spillover Effects of Agricultural Transport Costs in Peru. Land 2022, 11, 58. https://doi.org/10.3390/land11010058
Herrera-Catalán P, Chasco C, Torero M. Spatial Spillover Effects of Agricultural Transport Costs in Peru. Land. 2022; 11(1):58. https://doi.org/10.3390/land11010058
Chicago/Turabian StyleHerrera-Catalán, Pedro, Coro Chasco, and Máximo Torero. 2022. "Spatial Spillover Effects of Agricultural Transport Costs in Peru" Land 11, no. 1: 58. https://doi.org/10.3390/land11010058
APA StyleHerrera-Catalán, P., Chasco, C., & Torero, M. (2022). Spatial Spillover Effects of Agricultural Transport Costs in Peru. Land, 11(1), 58. https://doi.org/10.3390/land11010058