



Comparison of Machine Learning-Based Prediction of Qualitative and Quantitative Digital Soil-Mapping Approaches for Eastern Districts of Tamil Nadu, India

 , , , , ,
, , , , ,
Abstract
:1. Introduction
2. Materials and Methods
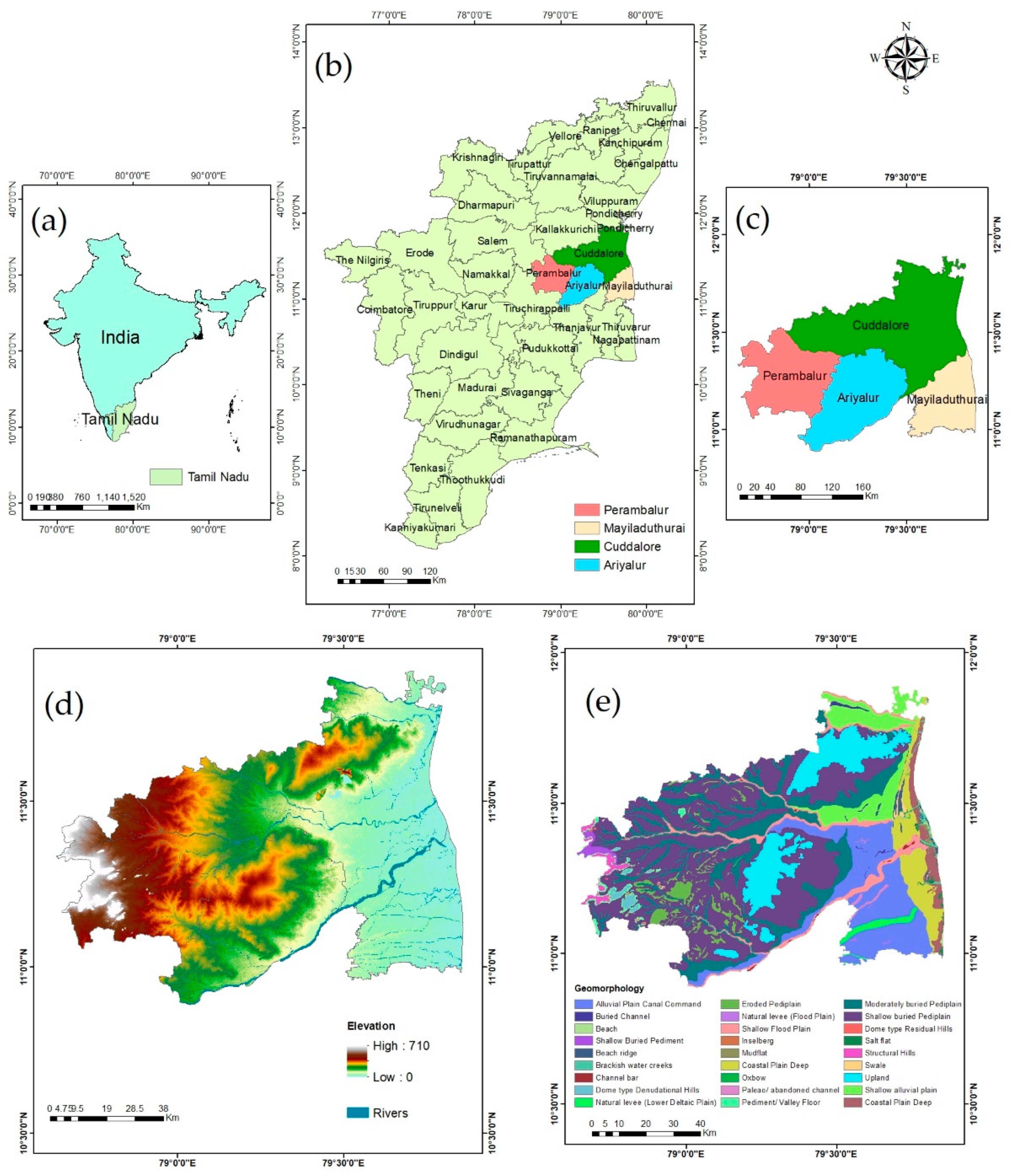
2.1. Study Area
2.2. Soil Data
2.3. Environmental Covariates
2.4. Model Development
2.4.1. Multiple Linear Regression (MLR)
2.4.2. Multinomial Logistic Regression (MnLR)
2.4.3. k-Nearest Neighbour (k-NN)
2.4.4. Decision Trees (Regression Trees)
2.4.5. Decision Trees (C5.0)
2.4.6. Naïve Bayes (NB) Classifier
2.4.7. Support Vector Regression/Machine (SVR/M)
2.4.8. Cubist Regression
2.4.9. Random Forest (RF)
2.5. Model Validation
2.5.1. Quantitative Soil Attributes
2.5.2. Qualitative Soil Attributes
2.5.3. Variable Importance Measure
3. Results
3.1. Descriptive Statistics
3.2. Model Comparison and Evaluation
3.2.1. Quantitative Soil Attributes
3.2.2. Qualitative Soil Attributes
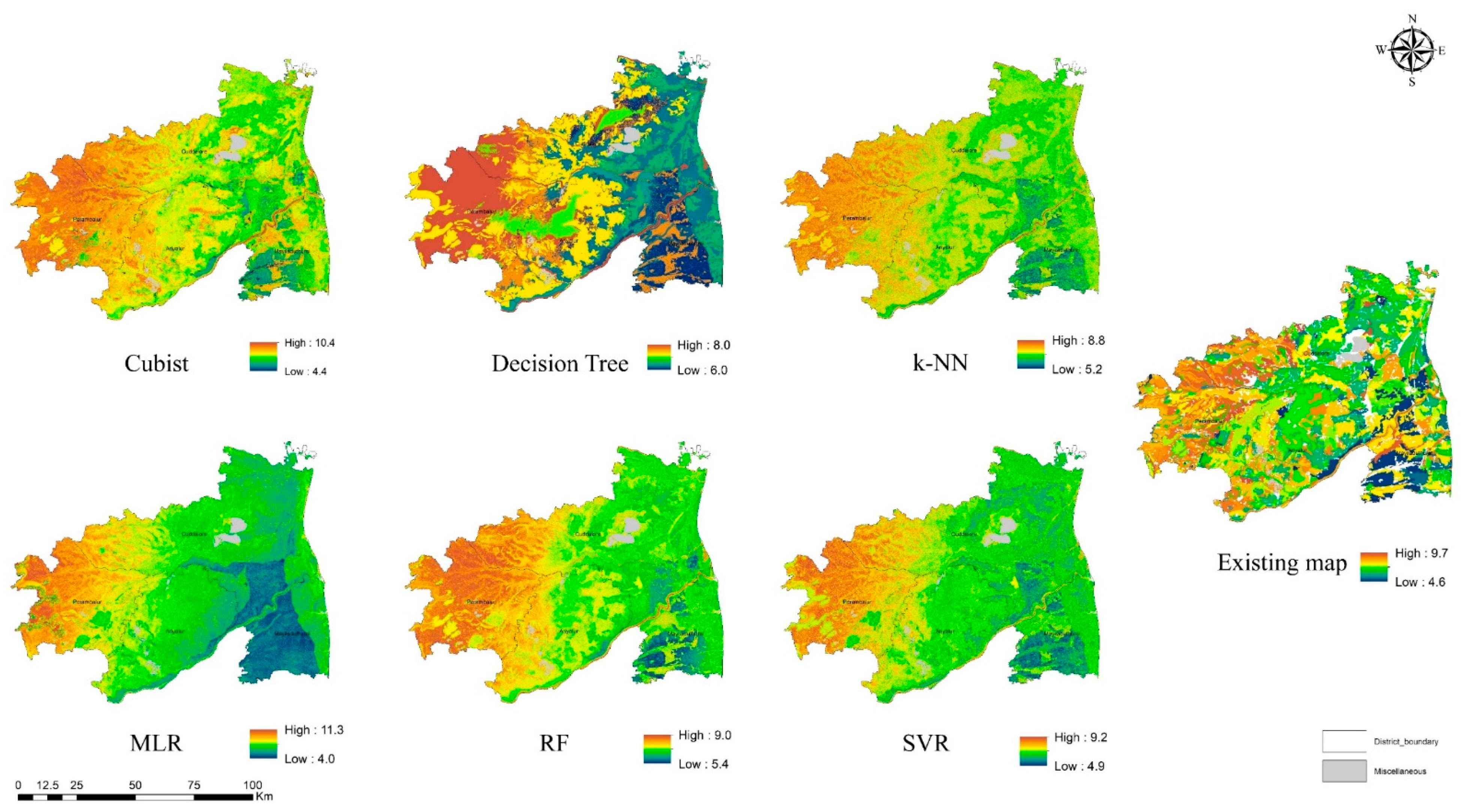
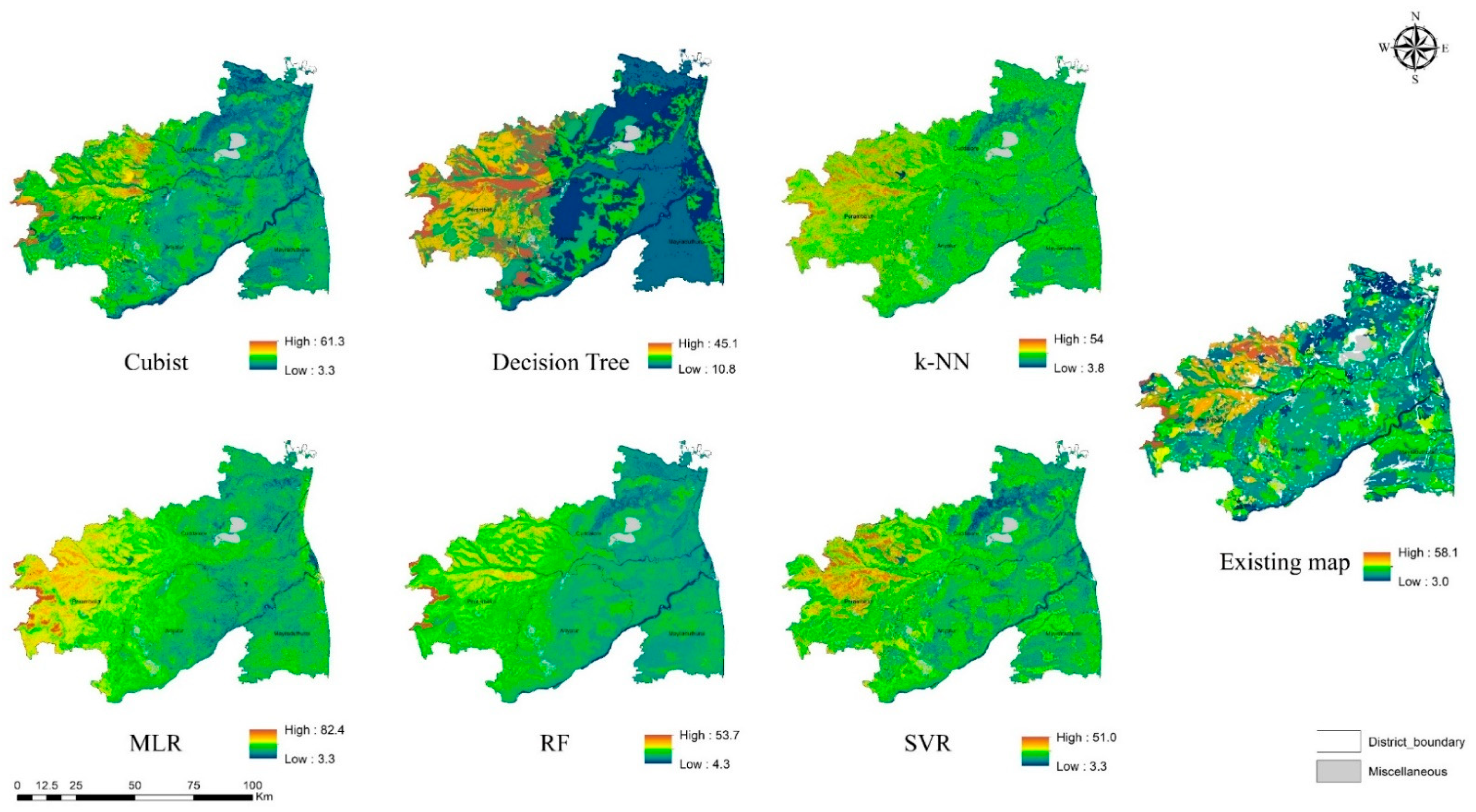
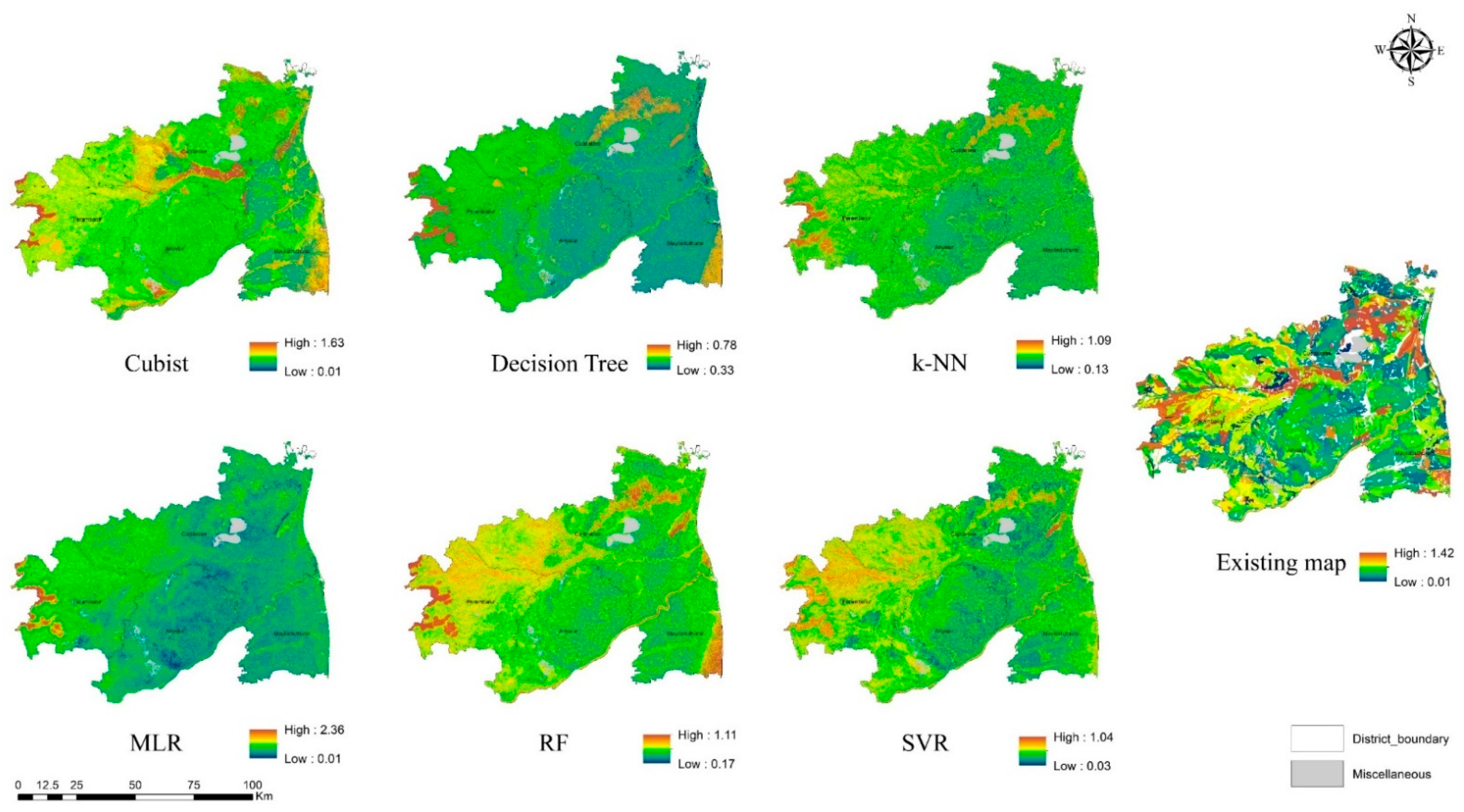
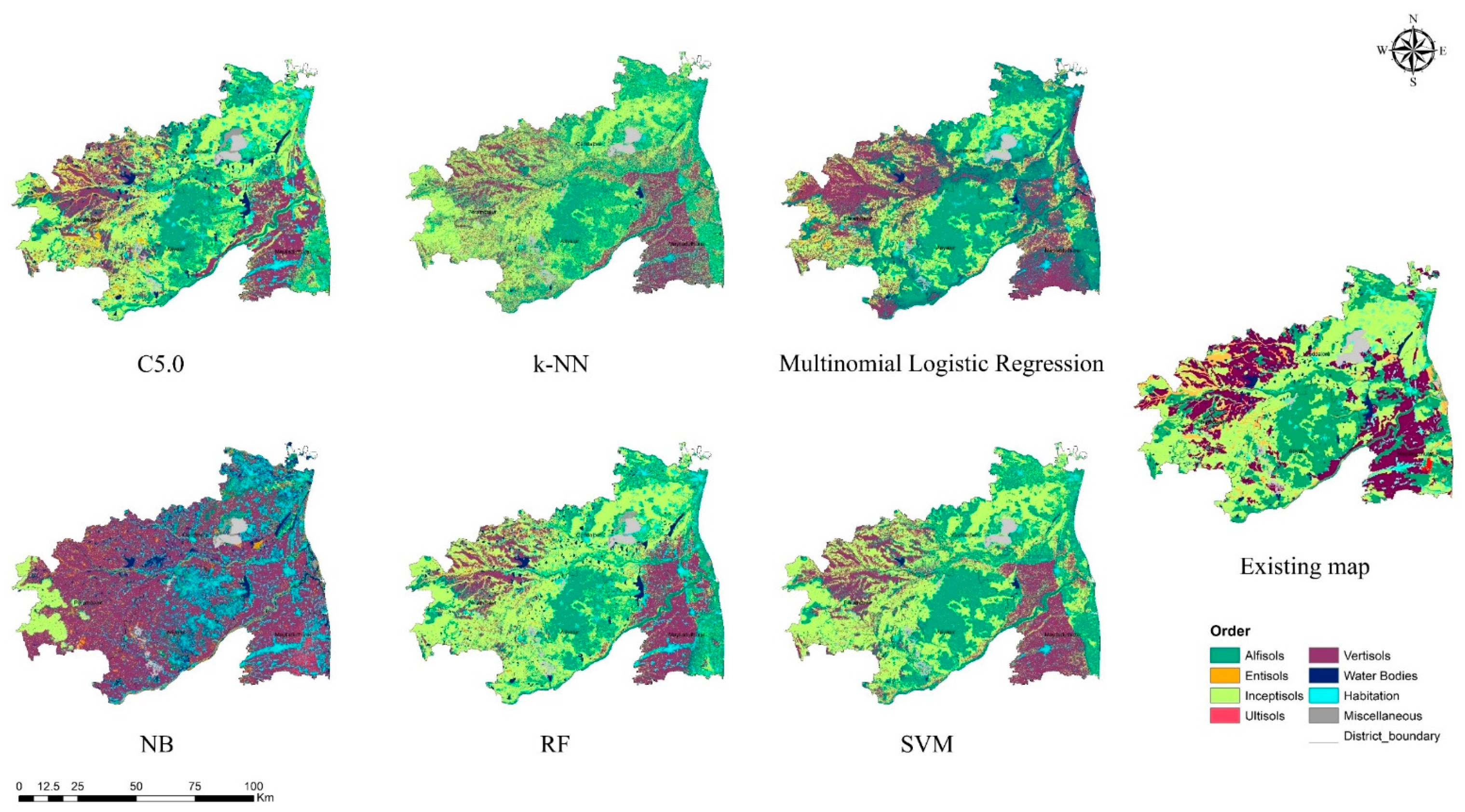
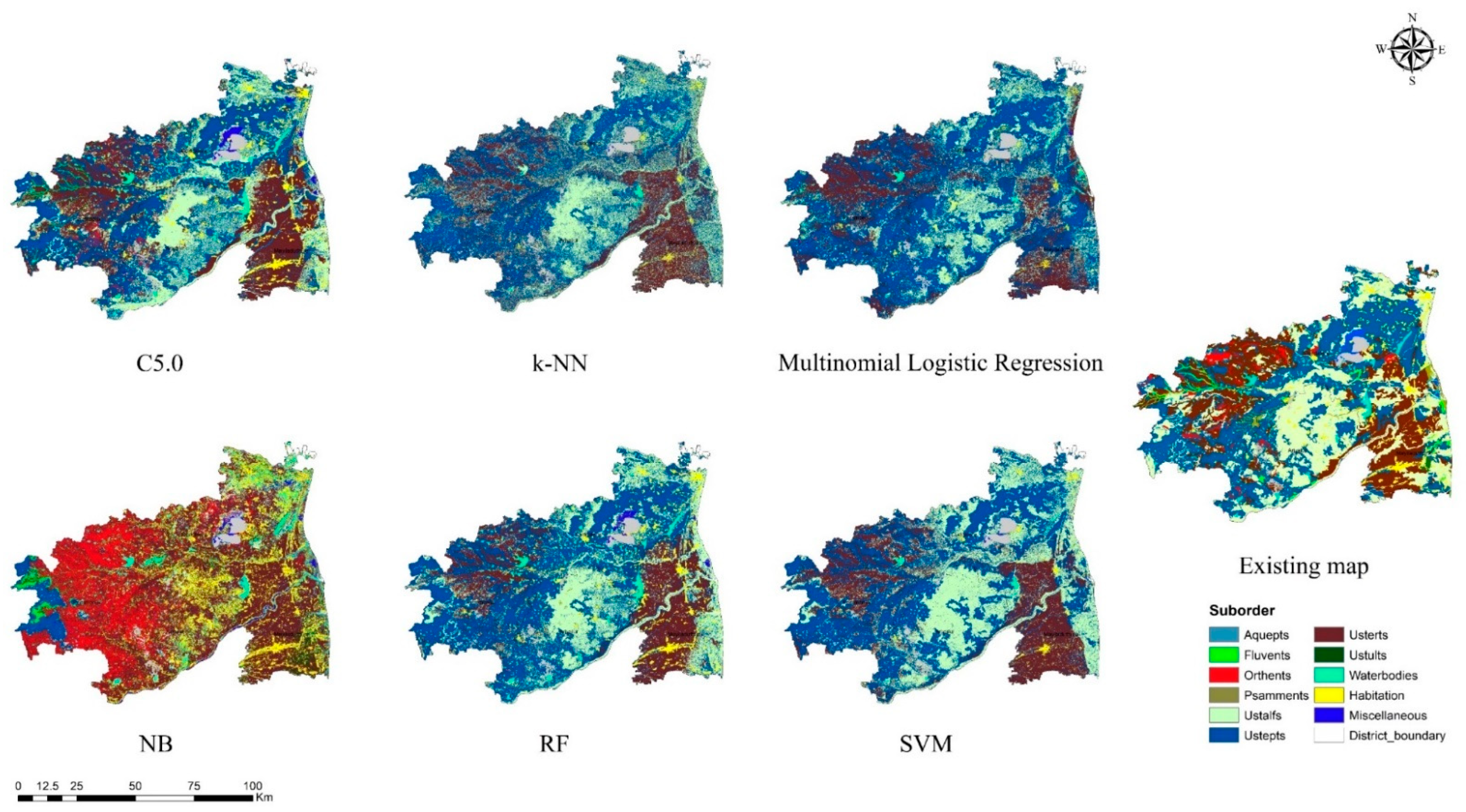
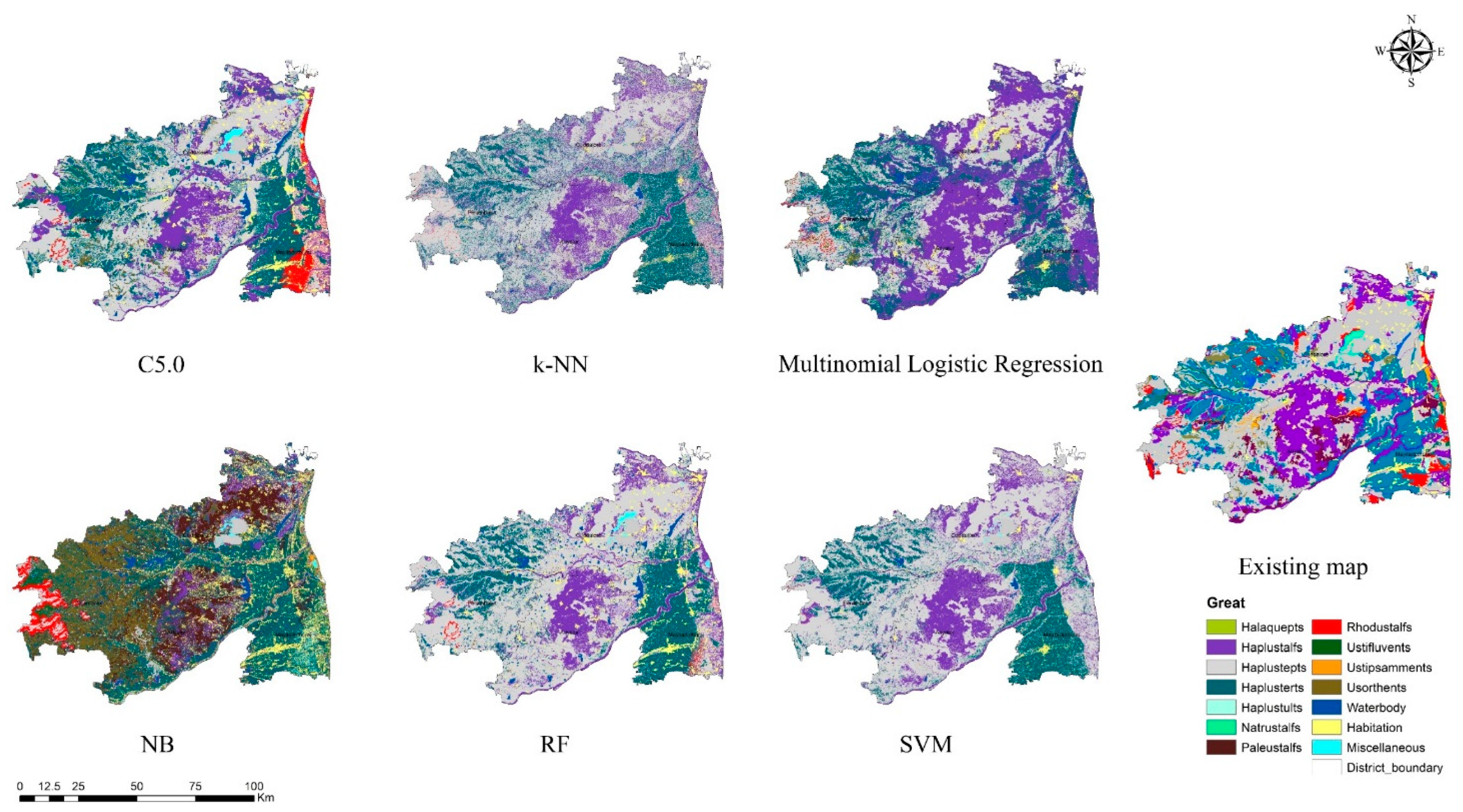
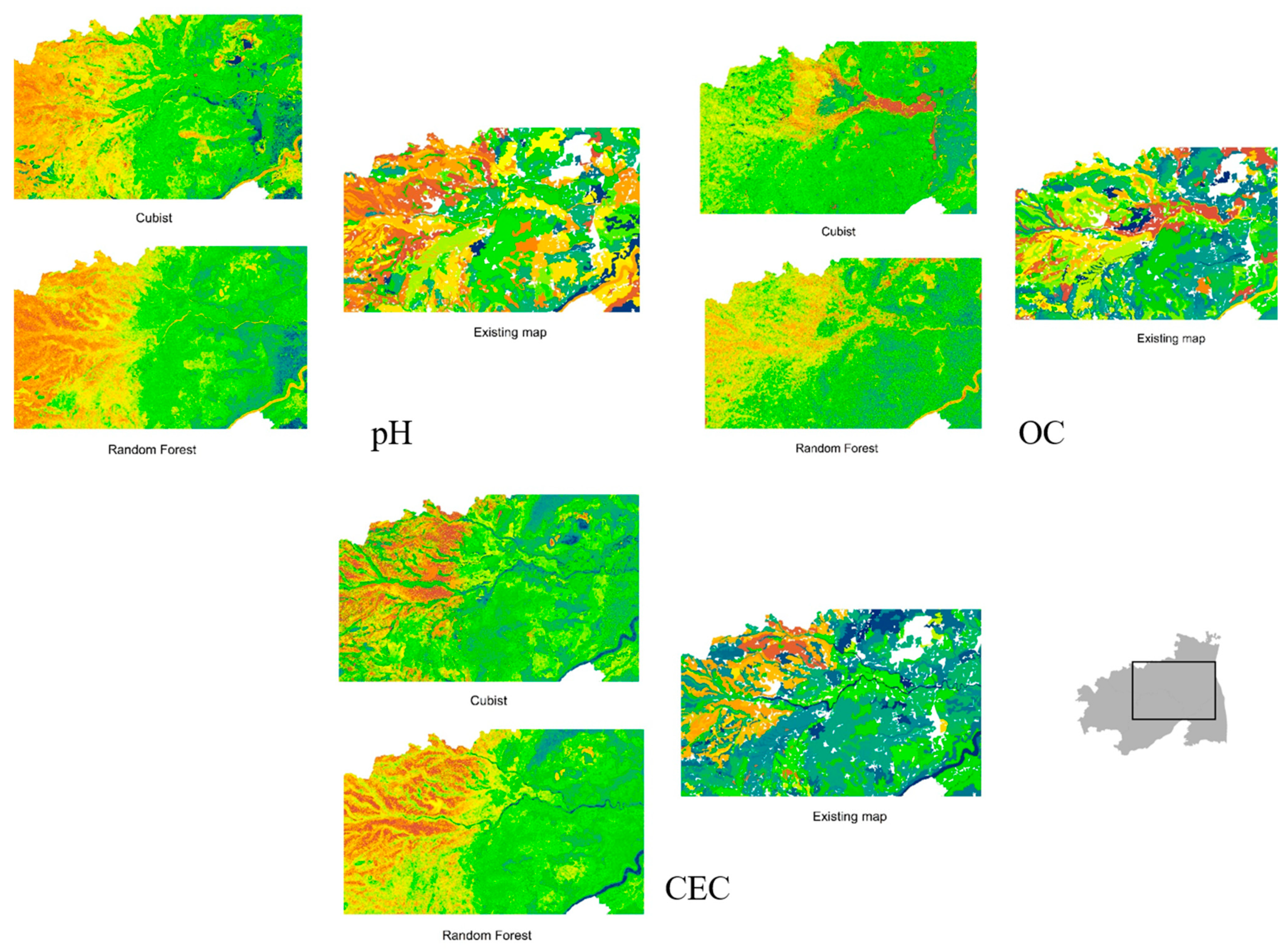
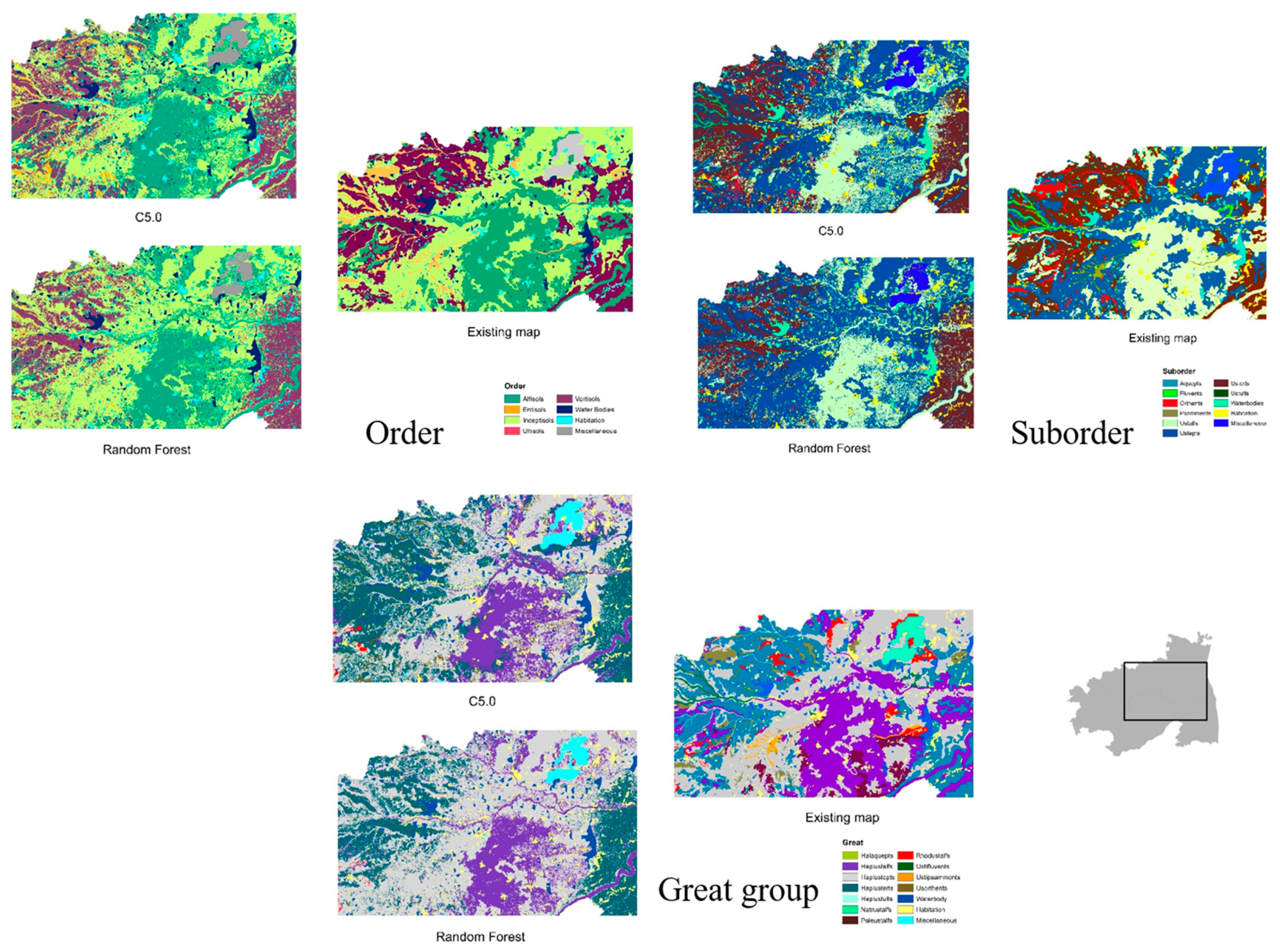
3.3. Visual Assessment
3.4. Permutation Feature Importance
4. Discussion
4.1. Model Efficiency and Performance
4.1.1. Quantitative Soil Attributes
4.1.2. Qualitative Soil Attributes
4.2. Potential Applications at the Farm Level and Policy Decisions
5. Conclusions
- From the suite of machine learning algorithms compared for mapping three continuous soil attributes and three soil taxonomical units, it can be inferred from the visual interpretation that all the algorithms provided a reasonable spatial prediction of the soil attributes, except for the NB classifier.
- Among the ML models, the tree-based ensemble (RF) and rule-based models (Cubist and C5.0) efficiently predicted the soil properties spatially. The efficiency of the models can be further increased by adopting appropriate sampling and tuning methods.
- The probability-based machine learning algorithms (NB and multinomial logistic regression) produced biased and crude results, which might have been due to the inclusion of continuous covariate predictors for the model calibration. Hence, the transformation of covariate predictors and the implementation of suitable variable selection techniques can improve the accuracy of the predictions.
- The results of k-NN, SVM, and SVR with default parameterisation were used to deduce the potential of the models, which was further increased by the appropriate tuning of parameters. The time required for the computation of SVM/SVR parameterisation is tedious for a larger dataset; hence, it is recommended for limited observations at a smaller scale.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dash, P.K.; Panigrahi, N.; Mishra, A. Identifying opportunities to improve digital soil mapping in India: A systematic review. Geoderma Reg. 2021, 28, e00478. [Google Scholar] [CrossRef]
- Zhu, A.-X.; Hudson, B.; Burt, J.; Lubich, K.; Simonson, D. Soil mapping using GIS, expert knowledge, and fuzzy logic. Soil Sci. Soc. Am. J. 2001, 65, 1463–1472. [Google Scholar] [CrossRef] [Green Version]
- Bui, E.N.; Searle, R.D.; Wilson, P.R.; Philip, S.R.; Thomas, M.; Brough, D.; Harms, B.; Hill, J.V.; Holmes, K.; Smolinski, H.J. Soil surveyor knowledge in digital soil mapping and assessment in Australia. Geoderma Reg. 2020, 22, e00299. [Google Scholar] [CrossRef]
- Dharumarajan, S.; Hegde, R.; Singh, S.K. Spatial prediction of major soil properties using Random Forest techniques—A case study in semi-arid tropics of South India. Geoderma Reg. 2017, 10, 154–162. [Google Scholar] [CrossRef]
- Zhang, G.-l.; Feng, L.; Song, X.-d. Recent progress and future prospect of digital soil mapping: A review. J. Integr. Agric. 2017, 16, 2871–2885. [Google Scholar] [CrossRef]
- Lagacherie, P.; McBratney, A. Spatial soil information systems and spatial soil inference systems: Perspectives for digital soil mapping. Dev. Soil Sci. 2006, 31, 3–22. [Google Scholar]
- Minasny, B.; McBratney, A.B. Digital soil mapping: A brief history and some lessons. Geoderma 2016, 264, 301–311. [Google Scholar] [CrossRef]
- Zeraatpisheh, M.; Jafari, A.; Bodaghabadi, M.B.; Ayoubi, S.; Taghizadeh-Mehrjardi, R.; Toomanian, N.; Kerry, R.; Xu, M. Conventional and digital soil mapping in Iran: Past, present, and future. Catena 2020, 188, 104424. [Google Scholar] [CrossRef]
- Song, Y.-Q.; Yang, L.-A.; Li, B.; Hu, Y.-M.; Wang, A.-L.; Zhou, W.; Cui, X.-S.; Liu, Y.-L. Spatial prediction of soil organic matter using a hybrid geostatistical model of an extreme learning machine and ordinary kriging. Sustainability 2017, 9, 754. [Google Scholar] [CrossRef] [Green Version]
- Wiesmeier, M.; Barthold, F.; Blank, B.; Kögel-Knabner, I. Digital mapping of soil organic matter stocks using Random Forest modeling in a semi-arid steppe ecosystem. Plant Soil 2011, 340, 7–24. [Google Scholar] [CrossRef]
- Dharumarajan, S.; Hegde, R. Digital mapping of soil texture classes using Random Forest classification algorithm. Soil Use Manag. 2020, 38, 135–149. [Google Scholar] [CrossRef]
- Vaysse, K.; Lagacherie, P. Using quantile regression forest to estimate uncertainty of digital soil mapping products. Geoderma 2017, 291, 55–64. [Google Scholar] [CrossRef]
- Dharumarajan, S.; Vasundhara, R.; Suputhra, A.; Lalitha, M.; Hegde, R. Prediction of soil depth in Karnataka using digital soil mapping approach. J. Indian Soc. Remote Sens. 2020, 48, 1593–1600. [Google Scholar] [CrossRef]
- Rossel, R.A.V.; Behrens, T. Using data mining to model and interpret soil diffuse reflectance spectra. Geoderma 2010, 158, 46–54. [Google Scholar] [CrossRef]
- Maynard, J.J.; Levi, M.R. Hyper-temporal remote sensing for digital soil mapping: Characterizing soil-vegetation response to climatic variability. Geoderma 2017, 285, 94–109. [Google Scholar] [CrossRef] [Green Version]
- Taalab, K.; Corstanje, R.; Zawadzka, J.; Mayr, T.; Whelan, M.J.; Hannam, J.A.; Creamer, R. On the application of Bayesian Networks in Digital Soil Mapping. Geoderma 2015, 259–260, 134–148. [Google Scholar] [CrossRef]
- Freire, S.; de Lisboa, N.; Fonseca, I.; Brasil, R.; Rocha, J.; Tenedório, J.A. Using artificial neural networks for digital soil mapping—A comparison of MLP and SOM approaches. In Proceedings of the AGILE, Nashville, TN, USA, 5–9 August 2013. [Google Scholar]
- Mulder, V.L.; Lacoste, M.; Richer-de-Forges, A.C.; Martin, M.P.; Arrouays, D. National versus global modelling the 3D distribution of soil organic carbon in mainland France. Geoderma 2016, 263, 16–34. [Google Scholar] [CrossRef]
- Malone, B.P.; Minasny, B.; McBratney, A.B. Categorical soil attribute modeling and mapping. In Using R for Digital Soil Mapping; Springer: Berlin/Heidelberg, Germany, 2017; pp. 151–167. [Google Scholar]
- Zhang, Y.; Ji, W.; Saurette, D.D.; Easher, T.H.; Li, H.; Shi, Z.; Adamchuk, V.I.; Biswas, A. Three-dimensional digital soil mapping of multiple soil properties at a field-scale using regression kriging. Geoderma 2020, 366, 114253. [Google Scholar] [CrossRef]
- Padarian, J.; Minasny, B.; McBratney, A.B. Using deep learning for digital soil mapping. Soil 2019, 5, 79–89. [Google Scholar] [CrossRef] [Green Version]
- Wadoux, A.M.-C.; Padarian, J.; Minasny, B. Multi-source data integration for soil mapping using deep learning. Soil 2019, 5, 107–119. [Google Scholar] [CrossRef] [Green Version]
- Kalambukattu, J.G.; Kumar, S.; Arya Raj, R. Digital soil mapping in a Himalayan watershed using remote sensing and terrain parameters employing artificial neural network model. Environ. Earth Sci. 2018, 77, 203. [Google Scholar] [CrossRef]
- Chang, C.-W.; Laird, D.A.; Mausbach, M.J.; Hurburgh, C.R. Near-infrared reflectance spectroscopy–principal components regression analyses of soil properties. Soil Sci. Soc. Am. J. 2001, 65, 480–490. [Google Scholar] [CrossRef] [Green Version]
- Yang, R.-M.; Zhang, G.-L.; Liu, F.; Lu, Y.-Y.; Yang, F.; Yang, F.; Yang, M.; Zhao, Y.-G.; Li, D.-C. Comparison of boosted regression tree and random forest models for mapping topsoil organic carbon concentration in an alpine ecosystem. Ecol. Indic. 2016, 60, 870–878. [Google Scholar] [CrossRef]
- Wang, B.; Waters, C.; Orgill, S.; Gray, J.; Cowie, A.; Clark, A.; Li Liu, D. High resolution mapping of soil organic carbon stocks using remote sensing variables in the semi-arid rangelands of eastern Australia. Sci. Total Environ. 2018, 630, 367–378. [Google Scholar] [CrossRef] [PubMed]
- Brungard, C.; Nauman, T.; Duniway, M.; Veblen, K.; Nehring, K.; White, D.; Salley, S.; Anchang, J. Regional ensemble modeling reduces uncertainty for digital soil mapping. Geoderma 2021, 397, 114998. [Google Scholar] [CrossRef]
- Pahlavan-Rad, M.R.; Khormali, F.; Toomanian, N.; Brungard, C.W.; Kiani, F.; Komaki, C.B.; Bogaert, P. Legacy soil maps as a covariate in digital soil mapping: A case study from Northern Iran. Geoderma 2016, 279, 141–148. [Google Scholar] [CrossRef]
- Kaya, F.; Başayiğit, L. Spatial Prediction and Digital Mapping of Soil Texture Classes in a Floodplain Using Multinomial Logistic Regression. In Proceedings of the International Conference on Intelligent and Fuzzy Systems, Istanbul, Turkey, 24–26 August 2021; pp. 463–473. [Google Scholar]
- Mansuy, N.; Thiffault, E.; Paré, D.; Bernier, P.; Guindon, L.; Villemaire, P.; Poirier, V.; Beaudoin, A. Digital mapping of soil properties in Canadian managed forests at 250m of resolution using the k-nearest neighbor method. Geoderma 2014, 235–236, 59–73. [Google Scholar] [CrossRef]
- Khaledian, Y.; Miller, B.A. Selecting appropriate machine learning methods for digital soil mapping. Appl. Math. Model. 2020, 81, 401–418. [Google Scholar] [CrossRef]
- Casalicchio, G.; Molnar, C.; Bischl, B. Visualizing the feature importance for black box models. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Dublin, Ireland, 10–14 September 2018; pp. 655–670. [Google Scholar]
- NRIS. Manual of National Wastelands Monitoring Using Multitemporal Satellite Data; National Remote Sensing Agency, Department of Space, Government of India: New Delhi, India, 2007; p. 98.
- NRSC. Land Use/Land Cover Database on 1:50,000 Scale, Natural Resources Census Project, LUCMD, LRUMG, RSAA; National Remote Sensing Centre, ISRO: Hyderabad, India, 2016.
- NRSC. Lithology, Physiography and Soils of Tamil Nadu at 1:50,000 Scale, Natural Resources Census Project; National Remote Sensing Centre, ISRO in Collaboration with Institute of Remote Sensing and Tamil Nadu Agricultural University: Hyderabad, India, 2012.
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Ripley, B.; Venables, W.; Ripley, M.B. Package ‘nnet’. R Package Version 2016, 7, 700. [Google Scholar]
- Kuhn, M. Building predictive models in R using the caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef] [Green Version]
- Therneau, T.; Atkinson, B.; Ripley, B.; Ripley, M.B. Package ‘rpart’. R Package Version 4.1.19. Available online: cran.ma.ic.ac.uk/web/packages/rpart/rpart.pdf (accessed on 23 June 2021).
- Kuhn, M.; Quinlan, R. C50: C5.0 Decision Trees and Rule-Based Models. CRAN UTC. Available online: https://cran.r-project.org/web/packages/C50/C50.pdf (accessed on 23 June 2021).
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics, Probability Theory Group. (Formerly: E1071), TU Wien [R Package Version 1.7-12]. Available online: https://cran.r-project.org/web/packages/e1071/e1071.pdf (accessed on 23 June 2021).
- Kuhn, M.; Weston, S.; Keefer, C.; Kuhn, M.M. Package ‘Cubist’. Rule- and Instance-Based Regression Modeling. R Package Version 0.4.1. Available online: https://cran.r-project.org/web/packages/Cubist/Cubist.pdf (accessed on 23 June 2021).
- Liaw, A.; Wiener, M. Classification and Regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112. [Google Scholar]
- Jafari, A.; Finke, P.; Vande Wauw, J.; Ayoubi, S.; Khademi, H. Spatial prediction of USDA-great soil groups in the arid Zarand region, Iran: Comparing logistic regression approaches to predict diagnostic horizons and soil types. Eur. J. Soil Sci. 2012, 63, 284–298. [Google Scholar] [CrossRef]
- Kempen, B.; Brus, D.J.; Heuvelink, G.B.; Stoorvogel, J.J. Updating the 1: 50,000 Dutch soil map using legacy soil data: A multinomial logistic regression approach. Geoderma 2009, 151, 311–326. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, L.; Ma, T.; Shen, F.; Cai, Y.; Zhou, C. A self-training semi-supervised machine learning method for predictive mapping of soil classes with limited sample data. Geoderma 2021, 384, 114809. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef] [Green Version]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26. [Google Scholar]
- Therneau, T.M.; Atkinson, E.J. An Introduction to Recursive Partitioning Using the RPART Routines; Mayo Foundation: Scottsdale, AZ, USA, 2019; p. 60. [Google Scholar]
- Quinlan, J.R. C4. 5: Programming for machine learning. Morgan Kauffmann 1993, 38, 49. [Google Scholar]
- Leung, K.M. Naive bayesian classifier. Polytech. Univ. Dep. Comput. Sci./Financ. Risk Eng. 2007, 2007, 123–156. [Google Scholar]
- Lamichhane, S.; Kumar, L.; Wilson, B. Digital soil mapping algorithms and covariates for soil organic carbon mapping and their implications: A review. Geoderma 2019, 352, 395–413. [Google Scholar] [CrossRef]
- Zhang, M.; Shi, W. Systematic comparison of five machine-learning methods in classification and interpolation of soil particle size fractions using different transformed data. Hydrol. Earth Syst. Sci. Discuss. 2019, 24, 1–39. [Google Scholar]
- Quinlan, J.R. Learning with continuous classes. In Proceedings of the 5th Australian Joint Conference on Artificial Intelligence, Hobart, Tasmania, 16–18 November 1992; pp. 343–348. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Grimm, R.; Behrens, T.; Märker, M.; Elsenbeer, H. Soil organic carbon concentrations and stocks on Barro Colorado Island—Digital soil mapping using Random Forests analysis. Geoderma 2008, 146, 102–113. [Google Scholar] [CrossRef]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Pontius, R.G.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Fisher, A.; Rudin, C.; Dominici, F. All Models are Wrong, but Many are Useful: Learning a Variable’s Importance by Studying an Entire Class of Prediction Models Simultaneously. J. Mach. Learn. Res. 2019, 20, 177. [Google Scholar] [PubMed]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable. 2020. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 23 June 2021).
- Taghizadeh-Mehrjardi, R.; Hamzehpour, N.; Hassanzadeh, M.; Heung, B.; Goydaragh, M.G.; Schmidt, K.; Scholten, T. Enhancing the accuracy of machine learning models using the super learner technique in digital soil mapping. Geoderma 2021, 399, 115108. [Google Scholar] [CrossRef]
- Holmes, K.W.; Kyriakidis, P.C.; Chadwick, O.A.; Soares, J.V.; Roberts, D.A. Multi-scale variability in tropical soil nutrients following land-cover change. Biogeochemistry 2005, 74, 173–203. [Google Scholar] [CrossRef]
- Were, K.; Bui, D.T.; Dick, Ø.B.; Singh, B.R. A comparative assessment of support vector regression, artificial neural networks, and random forests for predicting and mapping soil organic carbon stocks across an Afromontane landscape. Ecol. Indic. 2015, 52, 394–403. [Google Scholar] [CrossRef]
- McBratney, A.B.; Santos, M.M.; Minasny, B. On digital soil mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Mishra, U.; Lal, R.; Slater, B.; Calhoun, F.; Liu, D.; Van Meirvenne, M. Predicting soil organic carbon stock using profile depth distribution functions and ordinary kriging. Soil Sci. Soc. Am. J. 2009, 73, 614–621. [Google Scholar] [CrossRef] [Green Version]
- Minasny, B.; McBratney, A.B.; Malone, B.P.; Wheeler, I. Digital mapping of soil carbon. Adv. Agron. 2013, 118, 1–47. [Google Scholar]
- Bockheim, J.; Gennadiyev, A.; Hartemink, A.; Brevik, E. Soil-forming factors and Soil Taxonomy. Geoderma 2014, 226–227, 231–237. [Google Scholar] [CrossRef]
- Purushothaman, N.K.; Reddy, N.N.; Das, B.S. National-scale maps for soil aggregate size distribution parameters using pedotransfer functions and digital soil mapping data products. Geoderma 2022, 424, 116006. [Google Scholar] [CrossRef]
- Forkuor, G.; Hounkpatin, O.K.; Welp, G.; Thiel, M. High resolution mapping of soil properties using remote sensing variables in south-western Burkina Faso: A comparison of machine learning and multiple linear regression models. PLoS ONE 2017, 12, e0170478. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Malone, B.P.; McBratney, A.; Minasny, B.; Laslett, G. Mapping continuous depth functions of soil carbon storage and available water capacity. Geoderma 2009, 154, 138–152. [Google Scholar] [CrossRef]
- Stoorvogel, J.; Kempen, B.; Heuvelink, G.; De Bruin, S. Implementation and evaluation of existing knowledge for digital soil mapping in Senegal. Geoderma 2009, 149, 161–170. [Google Scholar] [CrossRef]
- Mosleh, Z.; Salehi, M.H.; Jafari, A.; Borujeni, I.E.; Mehnatkesh, A. The effectiveness of digital soil mapping to predict soil properties over low-relief areas. Environ. Monit. Assess. 2016, 188, 195. [Google Scholar] [CrossRef]
- de Carvalho Junior, W.; Lagacherie, P.; da Silva Chagas, C.; Calderano Filho, B.; Bhering, S.B. A regional-scale assessment of digital mapping of soil attributes in a tropical hillslope environment. Geoderma 2014, 232–234, 479–486. [Google Scholar] [CrossRef]
- Yang, L.; He, X.; Shen, F.; Zhou, C.; Zhu, A.-X.; Gao, B.; Chen, Z.; Li, M. Improving prediction of soil organic carbon content in croplands using phenological parameters extracted from NDVI time series data. Soil Tillage Res. 2020, 196, 104465. [Google Scholar] [CrossRef]
- Kingsley, J.; Isong, I.A.; Kebonye, N.M.; Ayito, E.O.; Agyeman, P.C.; Afu, S.M. Using Machine Learning Algorithms to Estimate Soil Organic Carbon Variability with Environmental Variables and Soil Nutrient Indicators in an Alluvial Soil. Land 2020, 9, 487. [Google Scholar] [CrossRef]
- Kasraei, B.; Heung, B.; Saurette, D.D.; Schmidt, M.G.; Bulmer, C.E.; Bethel, W. Quantile regression as a generic approach for estimating uncertainty of digital soil maps produced from machine-learning. Environ. Model. Softw. 2021, 144, 105139. [Google Scholar] [CrossRef]
- Dharumarajan, S.; Hegde, R.; Janani, N.; Singh, S. The need for digital soil mapping in India. Geoderma Reg. 2019, 16, e00204. [Google Scholar] [CrossRef]
- Dharumarajan, S.; Lalitha, M.; Niranjana, K.; Hegde, R. Evaluation of digital soil mapping approach for predicting soil fertility parameters—a case study from Karnataka Plateau, India. Arab. J. Geosci. 2022, 15, 386. [Google Scholar] [CrossRef]
- Mello, F.A.; Demattê, J.A.; Rizzo, R.; de Mello, D.C.; Poppiel, R.R.; Silvero, N.E.; Safanelli, J.L.; Bellinaso, H.; Bonfatti, B.R.; Gomez, A.M. Complex hydrological knowledge to support digital soil mapping. Geoderma 2022, 409, 115638. [Google Scholar] [CrossRef]
- Zeraatpisheh, M.; Garosi, Y.; Owliaie, H.R.; Ayoubi, S.; Taghizadeh-Mehrjardi, R.; Scholten, T.; Xu, M. Improving the spatial prediction of soil organic carbon using environmental covariates selection: A comparison of a group of environmental covariates. Catena 2022, 208, 105723. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Minasny, B.; Sarmadian, F.; Malone, B. Digital mapping of soil salinity in Ardakan region, central Iran. Geoderma 2014, 213, 15–28. [Google Scholar] [CrossRef]
- Keskin, H.; Grunwald, S.; Harris, W.G. Digital mapping of soil carbon fractions with machine learning. Geoderma 2019, 339, 40–58. [Google Scholar] [CrossRef]
- Cianfrani, C.; Buri, A.; Verrecchia, E.; Guisan, A. Generalizing soil properties in geographic space: Approaches used and ways forward. PLoS ONE 2018, 13, e0208823. [Google Scholar] [CrossRef]
- Heung, B.; Ho, H.C.; Zhang, J.; Knudby, A.; Bulmer, C.E.; Schmidt, M.G. An overview and comparison of machine-learning techniques for classification purposes in digital soil mapping. Geoderma 2016, 265, 62–77. [Google Scholar] [CrossRef]
- Sarmento, E.C.; Giasson, E.; Weber, E.; Flores, C.A.; Hasenack, H. Prediction of soil orders with high spatial resolution: Response of different classifiers to sampling density. Pesqui. Agropecuária Bras. 2012, 47, 1395–1403. [Google Scholar] [CrossRef]
- Coelho, F.F.; Giasson, E.; Campos, A.R.; Tiecher, T.; Costa, J.J.F.; Coblinski, J.A. Digital soil class mapping in Brazil: A systematic review. Sci. Agric. 2020, 78, e20190227. [Google Scholar] [CrossRef]
- Heung, B.; Hodúl, M.; Schmidt, M.G. Comparing the use of training data derived from legacy soil pits and soil survey polygons for mapping soil classes. Geoderma 2017, 290, 51–68. [Google Scholar] [CrossRef]
- Meier, M.; Souza, E.d.; Francelino, M.R.; Fernandes Filho, E.I.; Schaefer, C.E.G.R. Digital soil mapping using machine learning algorithms in a tropical mountainous area. Rev. Bras. De Ciência Do Solo 2018, 42, e0170421. [Google Scholar] [CrossRef] [Green Version]
- Brungard, C.W.; Boettinger, J.L.; Duniway, M.C.; Wills, S.A.; Edwards, T.C., Jr. Machine learning for predicting soil classes in three semi-arid landscapes. Geoderma 2015, 239–240, 68–83. [Google Scholar] [CrossRef] [Green Version]
- Taghizadeh-Mehrjardi, R.; Nabiollahi, K.; Minasny, B.; Triantafilis, J. Comparing data mining classifiers to predict spatial distribution of USDA-family soil groups in Baneh region, Iran. Geoderma 2015, 253, 67–77. [Google Scholar] [CrossRef]
- Zeraatpisheh, M.; Ayoubi, S.; Jafari, A.; Finke, P. Comparing the efficiency of digital and conventional soil mapping to predict soil types in a semi-arid region in Iran. Geomorphology 2017, 285, 186–204. [Google Scholar] [CrossRef]
- Jeune, W.; Francelino, M.R.; Souza, E.d.; Fernandes Filho, E.I.; Rocha, G.C. Multinomial logistic regression and random forest classifiers in digital mapping of soil classes in western Haiti. Rev. Bras. De Ciência Do Solo 2018, 42, e0170133. [Google Scholar] [CrossRef]
- Taghizadeh-Mehrjardi, R.; Minasny, B.; Toomanian, N.; Zeraatpisheh, M.; Amirian-Chakan, A.; Triantafilis, J. Digital mapping of soil classes using ensemble of models in Isfahan region, Iran. Soil Syst. 2019, 3, 37. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. An application of hierarchical kappa-type statistics in the assessment of majority agreement among multiple observers. Biometrics 1977, 33, 363–374. [Google Scholar] [CrossRef]
- Marsman, B.; de Gruijter, J.J. Quality of Soil Maps: A Comparison of Soil Survey Methods in a Sandy Area; ISRIC, Soil Survey Insitute: Wageningen, The Netherlands, 1986. [Google Scholar]
- Collard, F.; Kempen, B.; Heuvelink, G.B.; Saby, N.P.; de Forges, A.C.R.; Lehmann, S.; Nehlig, P.; Arrouays, D. Refining a reconnaissance soil map by calibrating regression models with data from the same map (Normandy, France). Geoderma Reg. 2014, 1, 21–30. [Google Scholar] [CrossRef]
- Wadoux, A.M.-C.; Minasny, B.; McBratney, A.B. Machine learning for digital soil mapping: Applications, challenges and suggested solutions. Earth-Sci. Rev. 2020, 210, 103359. [Google Scholar] [CrossRef]
- Das, B.; Sarathjith, M.; Santra, P.; Sahoo, R.; Srivastava, R.; Routray, A.; Ray, S. Hyperspectral remote sensing: Opportunities, status and challenges for rapid soil assessment in India. Curr. Sci. 2015, 108, 860–868. [Google Scholar]
- Vista, S.; Gaihre, Y. Fertilizer Management for Horticultural Crops Using Digital Soil Maps. In Proceedings of the Tenth National Horticulture Workshop, Lalitpur, Nepal, 28 February–1 March 2021; p. 311. [Google Scholar]
- Premasudha, B.; Leena, H. ICT enabled proposed solutions for soil fertility management in Indian agriculture. In Proceedings of the International Conference on Data Engineering and Communication Technology, Pune, India, 15–16 December 2017; pp. 749–757. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Covariate | Parameter | Scale | Type |
|---|---|---|---|
| Climate | Mean Annual Temperature | °C/30 s | N |
| Mean Annual Rainfall | mm/30 s | N | |
| Organisms | Land Use and Land Cover Map | 1:50,000 scale | C |
| Landsat 8: Band 1 | 30 m | N | |
| Landsat 8: Band 2 | 30 m | N | |
| Landsat 8: Band 3 | 30 m | N | |
| Landsat 8: Band 4 | 30 m | N | |
| Landsat 8: Band 5 | 30 m | N | |
| Normalised Difference Vegetation Index | 30 m | N | |
| Relief | Elevation (SRTM DEM) | 30 m | N |
| Slope Gradient | 30 m | N | |
| Profile Curvature | 30 m | N | |
| Tangential Curvature | 30 m | N | |
| Convergence Index | 30 m | N | |
| Catchment Area | 30 m | N | |
| Modified Catchment Area | 30 m | N | |
| Catchment Slope | 30 m | N | |
| Multiresolution Index of Valley Bottom Flatness | 30 m | N | |
| Multiresolution Index of Ridge Top Flatness | 30 m | N | |
| Topographic Position Index | 30 m | N | |
| Mid-Slope Position | 30 m | N | |
| Terrain Surface Texture | 30 m | N | |
| Valley Depth | 30 m | N | |
| Slope Height | 30 m | N | |
| Normalised Height | 30 m | N | |
| Standardised Height | 30 m | N | |
| Topographic Wetness Index | 30 m | N | |
| Slope Length | 30 m | N | |
| Fuzzy Landform Element Classification | 30 m | C | |
| Stream Power Index | 30 m | N | |
| Geomorphons | 30 m | C | |
| Physiography | 1:50,000 scale | C | |
| Parent Material | Carbonate Difference Ratio (Band 4 − Band 3)/(Band 4 + Band 3) | 30 m | N |
| Clay Difference Ratio (Band 6 − Band 7)/(Band 6 + Band 7) | 30 m | N | |
| Ferrous Minerals Difference Ratio (Band 6 − Band 5)/(Band 6 + Band 5) | 30 m | N | |
| Iron Difference Ratio (Band 4 − Band 7)/(Band 4 + Band 7) | 30 m | N | |
| Rock Outcrop Difference Ratio (Band 6 − Band 3)/(Band 6 + Band 3) | 30 m | N | |
| Geomorphology | 1:50,000 scale | C |
| Machine Learning Algorithms | R Package | Hyperparameters |
|---|---|---|
| Multiple Linear Regression | lm [36] | None |
| Multinomial Logistic Regression | nnet [37] | Default |
| k-Nearest Neighbor | caret [38] | k |
| Decision Tree (Regression Trees) | rpart [39] | minspilt; cp |
| Decision Tree (C5.0) | C50 [40] | trails, rules, control (CF, minCases, earlyStopping) |
| Naïve Bayes | e1071 [41] | Default |
| Support Vector Machine/Regression | e1071 [41] | Default |
| Cubist | cubist [42] | committees; control (rules and extrapolation) |
| Random Forest | randomForest [43] | mtry, ntree |
| Soil Properties | Unit | Minimum | Maximum | Mean | Median | SD | CV |
|---|---|---|---|---|---|---|---|
| pH | - | 4.6 | 9.8 | 7.2 | 7.2 | 0.95 | 13.12 |
| Organic Carbon | % | 0.10 | 1.42 | 0.49 | 0.44 | 0.26 | 53.06 |
| Cation Exchange Capacity | meq/L | 3.03 | 58.1 | 19.51 | 17.29 | 11.24 | 57.61 |
| Quantitative Soil Attribute | Machine Learning Algorithms | Validation | |||
|---|---|---|---|---|---|
| R2 | CCC | RMSE | Bias | ||
| pH | Cubist | 0.31 | 0.53 | 0.81 | −0.02 |
| Decision Tree | 0.27 | 0.44 | 0.81 | −0.01 | |
| k-Nearest Neighbour | 0.19 | 0.37 | 0.86 | 0.01 | |
| Multiple Linear Regression | 0.20 | 0.34 | 0.85 | −0.01 | |
| Random Forest | 0.38 | 0.50 | 0.75 | −0.01 | |
| Support Vector Regression | 0.25 | 0.45 | 0.83 | −0.03 | |
| Organic Carbon | Cubist | 0.12 | 0.29 | 0.25 | −0.02 |
| Decision Tree | 0.06 | 0.16 | 0.26 | −0.01 | |
| k-Nearest Neighbour | 0.04 | 0.13 | 0.26 | −0.01 | |
| Multiple Linear Regression | 0.04 | 0.09 | 0.26 | −0.01 | |
| Random Forest | 0.13 | 0.19 | 0.25 | 0.00 | |
| Support Vector Regression | 0.06 | 0.16 | 0.26 | −0.04 | |
| Cation Exchange Capacity (CEC) | Cubist | 0.29 | 0.52 | 9.93 | −0.39 |
| Decision Tree | 0.22 | 0.38 | 10.01 | 0.12 | |
| k-Nearest Neighbour | 0.15 | 0.31 | 10.44 | 0.45 | |
| Multiple Linear Regression | 0.14 | 0.29 | 10.49 | 0.43 | |
| Random Forest | 0.40 | 0.52 | 8.84 | 0.34 | |
| Support Vector Regression | 0.17 | 0.34 | 10.39 | −0.94 | |
| Qualitative Soil Attributes | Machine Learning Algorithms | Validation | ||||
|---|---|---|---|---|---|---|
| OA (%) | Kappa | Q (%) | A (%) | TD (%) | ||
| Order | Decision Trees (C5.0) | 65 | 0.51 | 5.40 | 30.13 | 35.53 |
| k-Nearest Neighbour | 51 | 0.29 | 9.27 | 40.40 | 49.67 | |
| Multinomial Logistic Regression | 46 | 0.26 | 18.93 | 35.67 | 54.60 | |
| Naïve Bayes | 31 | 0.15 | 53.00 | 16.47 | 69.47 | |
| Random Forest | 67 | 0.52 | 7.87 | 26.00 | 33.87 | |
| Support Vector Machine | 55 | 0.35 | 11.47 | 33.67 | 45.13 | |
| Suborder | Decision Trees (C5.0) | 64 | 0.50 | 5.00 | 31.20 | 36.20 |
| k-Nearest Neighbour | 50 | 0.28 | 10.00 | 40.13 | 50.13 | |
| Multinomial Logistic Regression | 46 | 0.21 | 17.47 | 37.07 | 54.53 | |
| Naïve Bayes | 26 | 0.13 | 52.93 | 21.40 | 74.33 | |
| Random Forest | 65 | 0.50 | 9.47 | 25.67 | 35.13 | |
| Support Vector Machine | 55 | 0.35 | 11.40 | 34.00 | 45.40 | |
| Great group | Decision Trees (C5.0) | 65 | 0.53 | 6.33 | 29.00 | 35.33 |
| k-Nearest Neighbour | 50 | 0.30 | 13.67 | 36.40 | 50.07 | |
| Multinomial Logistic Regression | 46 | 0.28 | 19.00 | 35.00 | 54.00 | |
| Naïve Bayes | 27 | 0.17 | 48.00 | 25.53 | 73.53 | |
| Random Forest | 65 | 0.50 | 15.00 | 20.33 | 35.33 | |
| Support Vector Machine | 54 | 0.32 | 17.80 | 29.13 | 46.93 | |
| Soil Attributes | Covariates | Machine Learning Algorithms | |||||
|---|---|---|---|---|---|---|---|
| Cubist | Decision Trees | k-NN | MLR | RF | SVR | ||
| pH | Climate (%) | 2.8 | 3.0 | 2.4 | 3.6 | 3.2 | 2.1 |
| Organisms (%) | 21.6 | 0.0 | 0 | 8.3 | 6.3 | 11.8 | |
| Terrain (%) | 52.5 | 93.1 | 97.6 | 10.1 | 84.0 | 76.9 | |
| Parent material (%) | 23.1 | 3.8 | 0 | 77.9 | 6.5 | 9.2 | |
| OC | Climate (%) | 4.0 | 4.6 | 4.8 | 5.6 | 3.2 | 3.0 |
| Organisms (%) | 24.5 | 38.7 | 22.1 | 33.2 | 29.1 | 32.1 | |
| Terrain (%) | 52.3 | 52.1 | 61.1 | 5.3 | 58.9 | 43.1 | |
| Parent material (%) | 19.2 | 4.5 | 12.0 | 55.9 | 8.8 | 21.9 | |
| CEC | Climate (%) | 3.6 | 1.3 | 2.1 | 2.1 | 2.5 | 2.2 |
| Organisms (%) | 30.4 | 9.7 | 20.9 | 31.2 | 11.2 | 22.7 | |
| Terrain (%) | 47.2 | 81.3 | 62.8 | 9.7 | 80.0 | 64.7 | |
| Parent material (%) | 18.7 | 7.7 | 14.2 | 57.0 | 6.2 | 10.3 | |
| C5.0 | k-NN | MnLR | NB | RF | SVM | ||
| Order | Climate (%) | 4.7 | 2.4 | 4.5 | 3.3 | 3.0 | 3.0 |
| Organisms (%) | 6.1 | 22.8 | 62.2 | 0.0 | 10.5 | 21.6 | |
| Terrain (%) | 82.4 | 62.3 | 33.2 | 91.2 | 79.2 | 61.8 | |
| Parent material (%) | 6.7 | 12.6 | 0.0 | 5.5 | 7.2 | 13.7 | |
| Suborder | Climate (%) | 3.2 | 3.4 | 3.1 | 4.0 | 4.6 | 3.2 |
| Organisms (%) | 2.1 | 17.1 | 62.5 | 62.6 | 7.3 | 22.2 | |
| Terrain (%) | 90.6 | 62.3 | 34.2 | 0.0 | 84.9 | 61.8 | |
| Parent material (%) | 4.1 | 17.2 | 0.1 | 33.3 | 3.2 | 12.8 | |
| Great group | Climate (%) | 2.3 | 3.1 | 4.6 | 3.00 | 2.1 | 3.0 |
| Organisms (%) | 5.6 | 20.1 | 54.0 | 14.68 | 11.1 | 24.9 | |
| Terrain (%) | 87.9 | 62.5 | 41.3 | 82.31 | 81.9 | 61.1 | |
| Parent material (%) | 4.2 | 14.2 | 0.0 | 0.00 | 4.9 | 11.0 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumaraperumal, R.; Pazhanivelan, S.; Geethalakshmi, V.; Nivas Raj, M.; Muthumanickam, D.; Kaliaperumal, R.; Shankar, V.; Nair, A.M.; Yadav, M.K.; Tarun Kshatriya, T.V. Comparison of Machine Learning-Based Prediction of Qualitative and Quantitative Digital Soil-Mapping Approaches for Eastern Districts of Tamil Nadu, India. Land 2022, 11, 2279. https://doi.org/10.3390/land11122279
Kumaraperumal R, Pazhanivelan S, Geethalakshmi V, Nivas Raj M, Muthumanickam D, Kaliaperumal R, Shankar V, Nair AM, Yadav MK, Tarun Kshatriya TV. Comparison of Machine Learning-Based Prediction of Qualitative and Quantitative Digital Soil-Mapping Approaches for Eastern Districts of Tamil Nadu, India. Land. 2022; 11(12):2279. https://doi.org/10.3390/land11122279
Chicago/Turabian StyleKumaraperumal, Ramalingam, Sellaperumal Pazhanivelan, Vellingiri Geethalakshmi, Moorthi Nivas Raj, Dhanaraju Muthumanickam, Ragunath Kaliaperumal, Vishnu Shankar, Athira Manikandan Nair, Manoj Kumar Yadav, and Thamizh Vendan Tarun Kshatriya. 2022. "Comparison of Machine Learning-Based Prediction of Qualitative and Quantitative Digital Soil-Mapping Approaches for Eastern Districts of Tamil Nadu, India" Land 11, no. 12: 2279. https://doi.org/10.3390/land11122279
APA StyleKumaraperumal, R., Pazhanivelan, S., Geethalakshmi, V., Nivas Raj, M., Muthumanickam, D., Kaliaperumal, R., Shankar, V., Nair, A. M., Yadav, M. K., & Tarun Kshatriya, T. V. (2022). Comparison of Machine Learning-Based Prediction of Qualitative and Quantitative Digital Soil-Mapping Approaches for Eastern Districts of Tamil Nadu, India. Land, 11(12), 2279. https://doi.org/10.3390/land11122279