
Enhanced Automatic Identification of Urban Community Green Space Based on Semantic Segmentation




Abstract
:1. Introduction
- We produced an open UCGS semantic segmentation dataset. UCGS in shadows is identified in the dataset for better extraction;
- We proposed a method that automatically screened urban communities from remotely sensed images. Our method improved efficiency in avoiding misclassified rural fields;
- We developed a segmentation decoder with two auxiliary decoders for HRNet to improve the overall performance of urban community green space extraction.
2. Methods
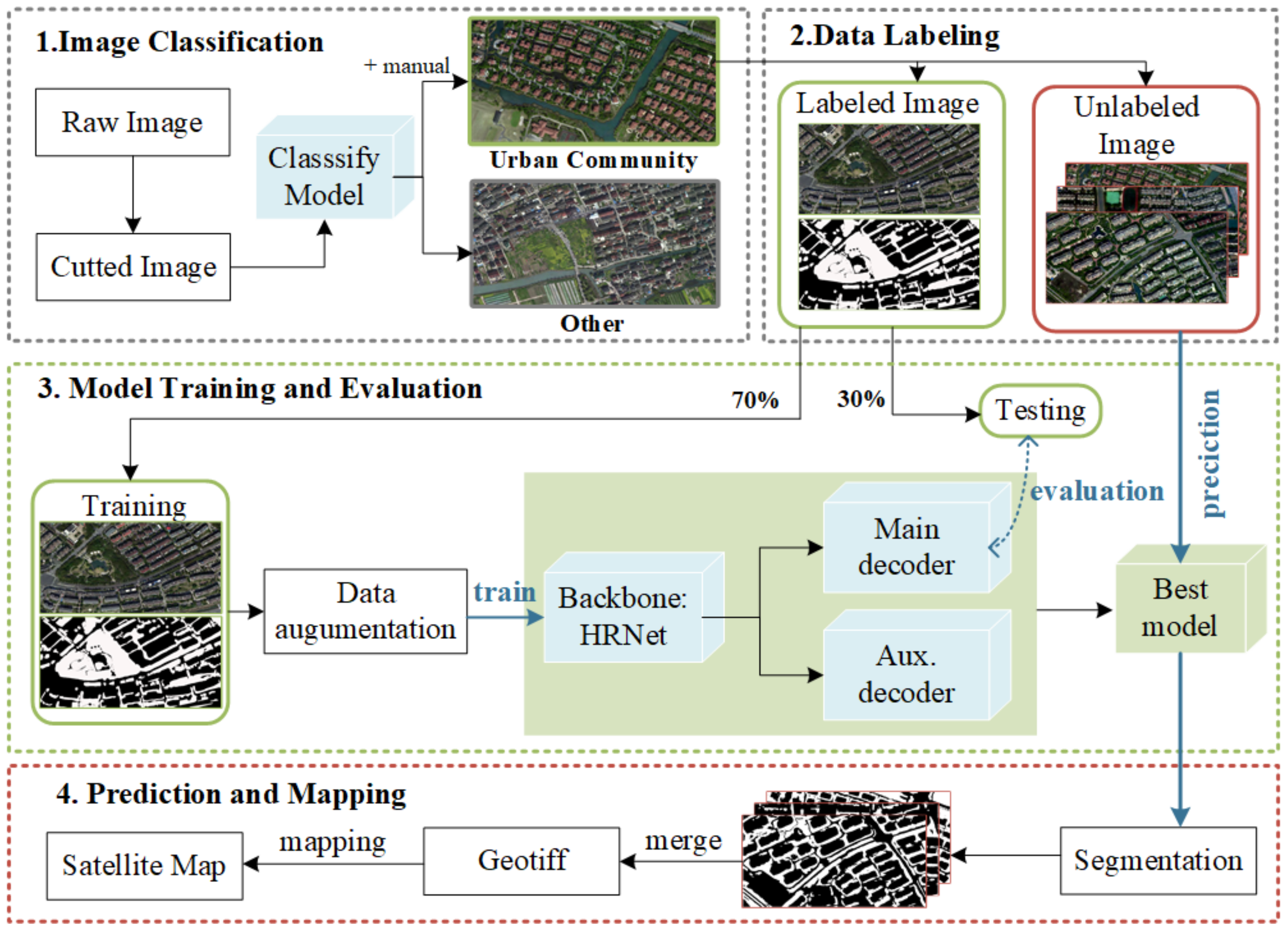
2.1. The Overall Workflow
2.2. Image Classification
2.2.1. Study Area and Data Sources
2.2.2. Classify Urban Community Images
2.3. Data Labeling
2.4. Model Training and Evaluation
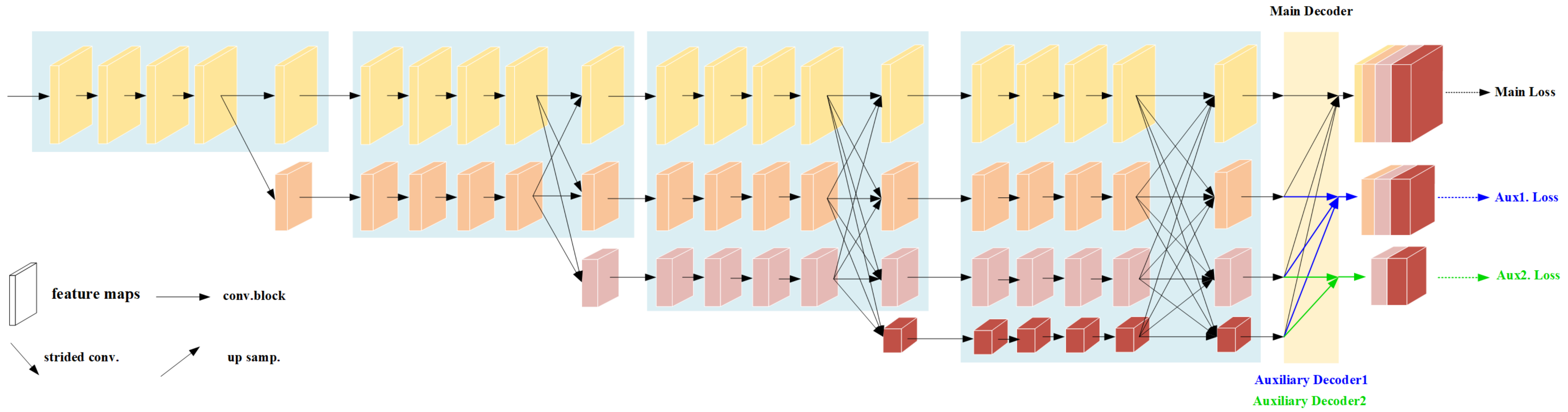
2.4.1. Network Structure
2.4.2. HRNet Backbone
2.4.3. Main Decoder and Auxiliary Decoder
2.4.4. Online Hard Example Mining
2.4.5. Loss Function
2.4.6. Parameters for Evaluation
2.5. Prediction and Mapping
3. Results
3.1. Experimental Settings
3.1.1. Implementation Details
3.1.2. Models for Comparison
3.2. Comparison of Different Classification Methods
3.3. Improvement on the Classification of Urban Community Green Space in Shades
3.4. Green Space Distribution of the Sampled Areas
4. Discussion
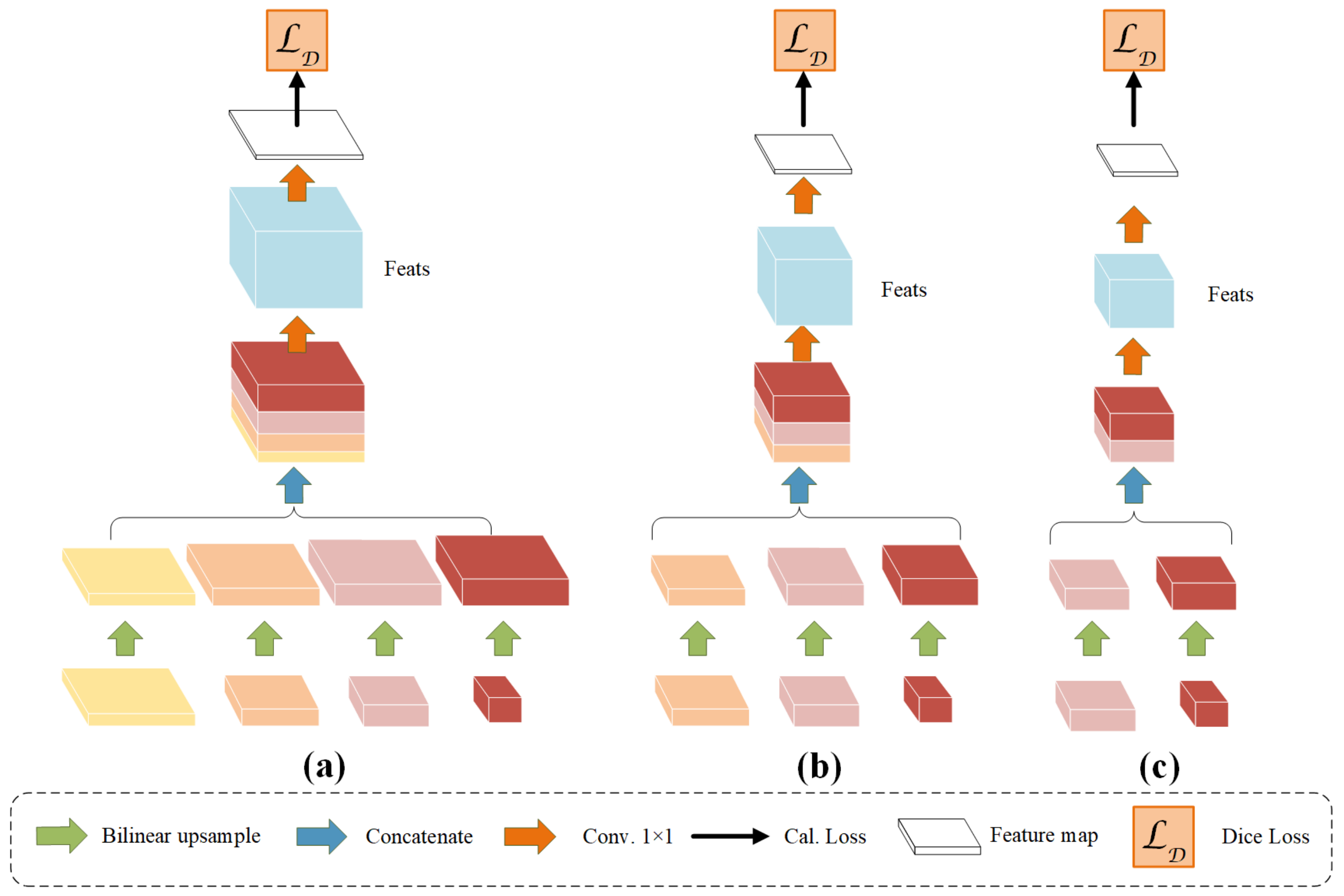
4.1. Different Input Combinations for Auxiliary Decoder
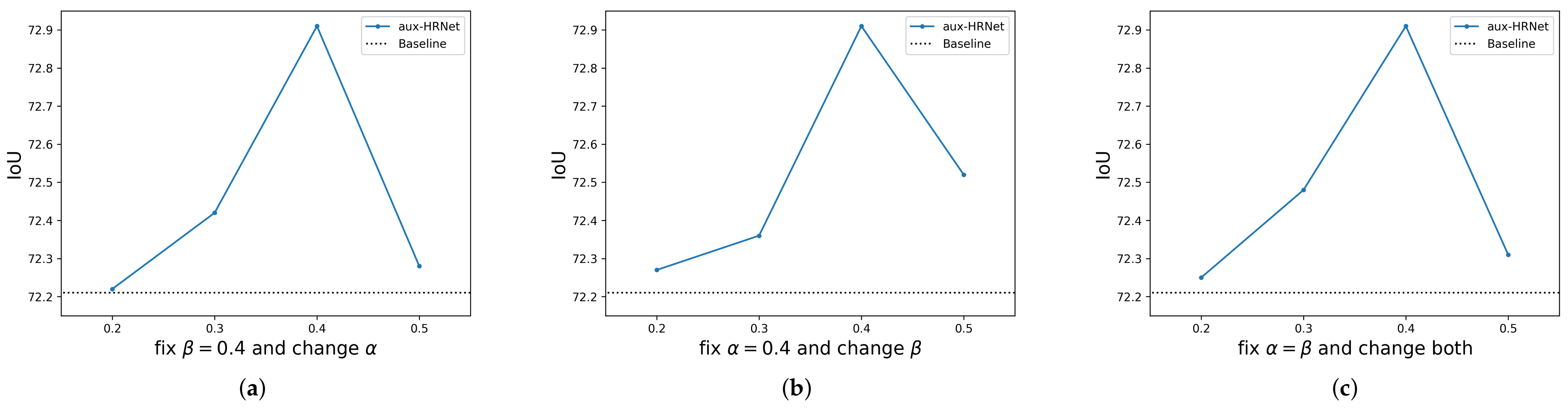
4.2. Different Weights of Auxiliary Learning
4.3. Influences of Training Tricks
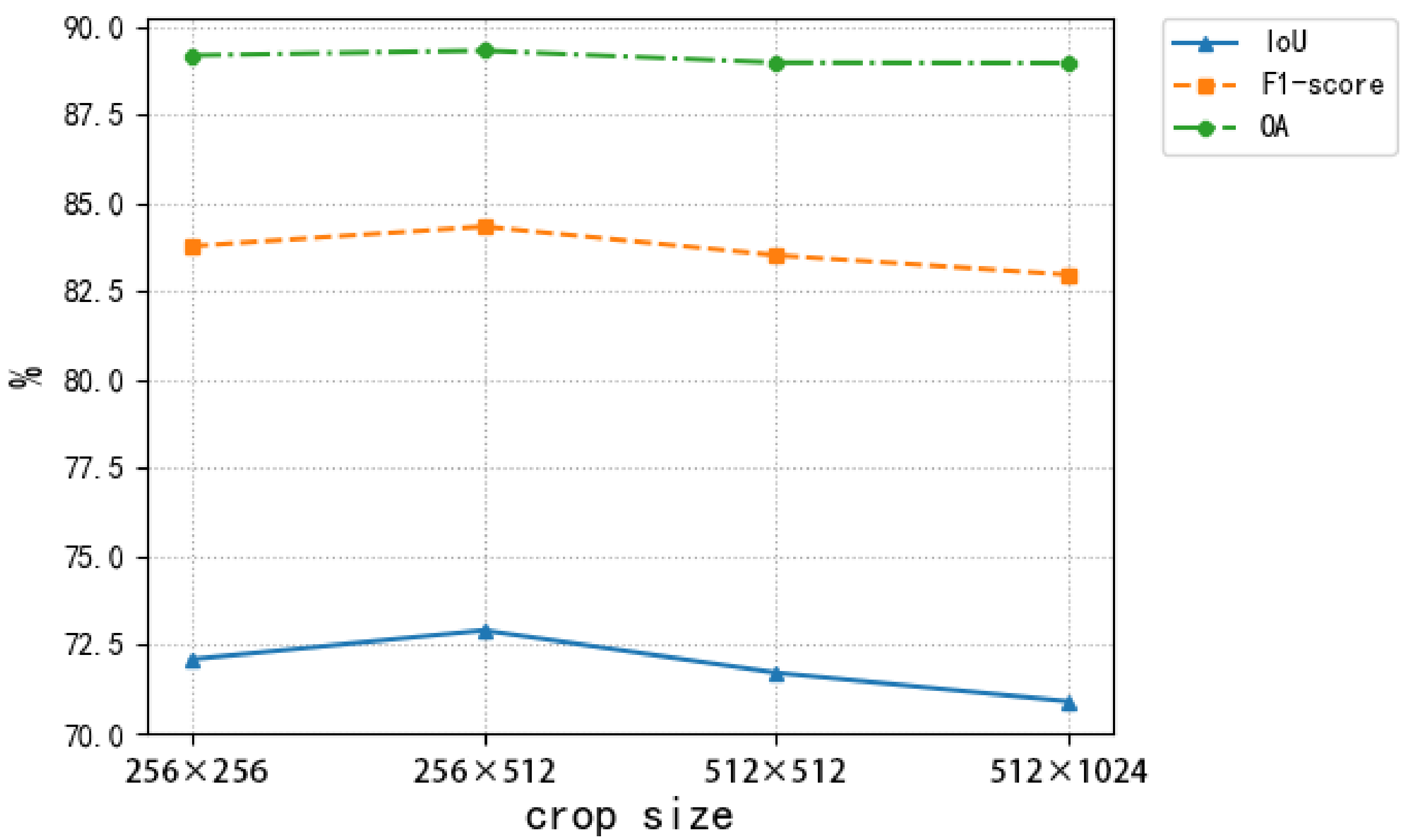
4.4. Sensitivity Analysis on Input Image Size
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kabisch, N.; Haase, D. Green spaces of European cities revisited for 1990–2006. Landsc. Urban Plan. 2013, 110, 113–122. [Google Scholar] [CrossRef]
- Xu, X.; Duan, X.; Sun, H.; Sun, Q. Green Space Changes and Planning in the Capital Region of China. Environ. Manag. 2011, 47, 456–467. [Google Scholar] [CrossRef] [PubMed]
- Kopecká, M.; Szatmári, D.; Rosina, K. Analysis of Urban Green Spaces Based on Sentinel-2A: Case Studies from Slovakia. Land 2017, 6, 25. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Li, L.; Shen, J.; Sun, Y.; Lian, Z. Five hypotheses concerned with bedroom environment and sleep quality: A questionnaire survey in Shanghai city, China. Build. Environ. 2021, 205, 108252. [Google Scholar] [CrossRef]
- Cao, T.; Lian, Z.; Zhu, J.; Xu, X.; Du, H.; Zhao, Q. Parametric study on the sleep thermal environment. Build. Simul. 2021, 15, 885–898. [Google Scholar] [CrossRef]
- Xu, X.; Lian, Z.; Shen, J.; Lan, L.; Sun, Y. Environmental factors affecting sleep quality in summer: A field study in Shanghai, China. J. Therm. Biol. 2021, 99, 102977. [Google Scholar] [CrossRef]
- Gupta, K.; Kumar, P.; Pathan, S.; Sharma, K. Urban Neighborhood Green Index—A measure of green spaces in urban areas. Landsc. Urban Plan. 2012, 105, 325–335. [Google Scholar] [CrossRef]
- Han, J.; Zhao, X.; Zhang, H.; Liu, Y. Analyzing the Spatial Heterogeneity of the Built Environment and Its Impact on the Urban Thermal Environment—Case Study of Downtown Shanghai. Sustainability 2021, 13, 11302. [Google Scholar] [CrossRef]
- Huerta, R.E.; Yépez, F.D.; Lozano-García, D.F.; Guerra Cobián, V.H.; Ferriño Fierro, A.L.; de León Gómez, H.; Cavazos González, R.A.; Vargas-Martínez, A. Mapping Urban Green Spaces at the Metropolitan Level Using Very High Resolution Satellite Imagery and Deep Learning Techniques for Semantic Segmentation. Remote Sens. 2021, 13, 2031. [Google Scholar] [CrossRef]
- Shojanoori, R.; Shafri, H. Review on the use of remote sensing for urban forest monitoring. Arboric. Urban For. 2016, 42, 400–417. [Google Scholar] [CrossRef]
- Wang, G. Concatenated Residual Attention UNet for Semantic Segmentation of Urban Green Space. Forests 2021, 12, 1441. [Google Scholar]
- Lanlan, W.; Lirong, X.; Hui, P. Quantitative evaluation of field oilseed rape image segmentation based on RGB vegetation index. J. Huazhong Agric. Univ. 2019, 38, 5. [Google Scholar]
- Tucker, C.J.; Pinzon, J.E.; Brown, M.E.; Slayback, D.A.; Pak, E.W.; Mahoney, R.; Vermote, E.F.; Saleous, N.E. An extended AVHRR 8-km NDVI dataset compatible with MODIS and SPOT vegetation NDVI data. Int. J. Remote Sens. 2005, 26, 4485–4498. [Google Scholar] [CrossRef]
- Khan, B.; Yang, S.; Hong, W.; Yan, H. Extraction of Urban Green Spaces Based on Gaofen-2 Satellite Imagery. IOP Conf. Ser. Earth Environ. Sci. 2021, 693, 012119. [Google Scholar] [CrossRef]
- Huete, A.R. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Ostu, N. A threshold selection method from gray-histogram. IEEE Trans. Syst. Man Cybern. 1979, 9, 62–66. [Google Scholar]
- Shen, C.; Li, M.; Li, F.; Chen, J.; Lu, Y. Study on urban green space extraction from QUICKBIRD imagery based on decision tree. In Proceedings of the 18th International Conference on Geoinformatics: GIScience in Change, Geoinformatics 2010, Beijing, China, 18–20 June 2010; pp. 1–4. [Google Scholar] [CrossRef]
- Kluczek, M.; Zagajewski, B.; Kycko, M. Airborne HySpex Hyperspectral Versus Multitemporal Sentinel-2 Images for Mountain Plant Communities Mapping. Remote Sens. 2022, 14, 1209. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Feng, Q.; Liu, J.; Gong, J. UAV Remote Sensing for Urban Vegetation Mapping Using Random Forest and Texture Analysis. Remote Sens. 2015, 7, 1074–1094. [Google Scholar] [CrossRef] [Green Version]
- Dempster, A.P. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. 1977, 39, 1–22. [Google Scholar]
- Blakey, T.; Melesse, A.; Hall, M.O. Supervised Classification of Benthic Reflectance in Shallow Subtropical Waters Using a Generalized Pixel-Based Classifier across a Time Series. Remote Sens. 2015, 7, 5098–5116. [Google Scholar] [CrossRef] [Green Version]
- Mengya, L.I.; Zhu, X.; Jia, X. Urban Green Space Extraction Based on Object Oriented High Resolution Remote Sensing Data. Beijing Surv. Mapp. 2019, 2, 196–200. [Google Scholar]
- Fung, T.; So, L.L.H.; Chen, Y.; Shi, P.; Wang, J. Analysis of green space in Chongqing and Nanjing, cities of China with ASTER images using object-oriented image classification and landscape metric analysis. Int. J. Remote Sens. 2008, 29, 7159–7180. [Google Scholar] [CrossRef]
- Whiteside, T.G.; Boggs, G.S.; Maier, S.W. Comparing object-based and pixel-based classifications for mapping savannas. Int. J. Appl. Earth Obs. Geoinf. 2011, 13, 884–893. [Google Scholar] [CrossRef]
- Mäyrä, J.; Keski-Saari, S.; Kivinen, S.; Tanhuanpää, T.; Hurskainen, P.; Kullberg, P.; Poikolainen, L.; Viinikka, A.; Tuominen, S.; Kumpula, T.; et al. Tree species classification from airborne hyperspectral and LiDAR data using 3D convolutional neural networks. Remote Sens. Environ. 2021, 256, 112322. [Google Scholar] [CrossRef]
- Gidaris, S.; Komodakis, N. Object Detection via a Multi-region and Semantic Segmentation-Aware CNN Model. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Washington, DC, USA, 7–13 December 2015. [Google Scholar]
- Xu, Z.; Zhou, Y.; Wang, S.; Wang, L.; Wang, Z. U-Net for urban green space classification in GF-2 remote sensing images. Image Graph 2021, 26, 14. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional networks for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision ECCV, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liu, W.; Yue, A.; Shi, W.; Ji, J.; Deng, R. An Automatic Extraction Architecture of Urban Green Space Based on DeepLabv3plus Semantic Segmentation Model. In Proceedings of the 2019 IEEE 4th International Conference on Image, Vision and Computing (ICIVC), Xiamen, China, 5–7 July 2019. [Google Scholar]
- Zhou, C.; Xianyun, F.; Xiangwei, G.; Xiaoxue, W.; Huimin, Z. Extraction of urban green space with high resolution remote sensing image segmentation. Bull. Surv. Mapp. 2020, 12, 17–20. [Google Scholar]
- Xu, Z.; Zhou, Y.; Wang, S.; Wang, L.; Wang, Z. A Novel Intelligent Classification Method for Urban Green Space Based on High-Resolution Remote Sensing Images. Remote Sens. 2020, 12, 3845. [Google Scholar] [CrossRef]
- Nijhawan, R.; Sharma, H.; Sahni, H.; Batra, A. A Deep Learning Hybrid CNN Framework Approach for Vegetation Cover Mapping Using Deep Features. In Proceedings of the International Conference on Signal-image Technology & Internet-Based Systems, SITIS 2017, Jaipur, India, 4–7 December 2017. [Google Scholar]
- Jin, B.; Ye, P.; Zhang, X.; Song, W.; Li, S. Object-Oriented Method Combined with Deep Convolutional Neural Networks for Land-Use-Type Classification of Remote Sensing Images. J. Indian Soc. Remote Sens. 2019, 47, 951–965. [Google Scholar] [CrossRef] [Green Version]
- Fan, Y.; Ding, X.; Wu, J.; Ge, J.; Li, Y. High spatial-resolution classification of urban surfaces using a deep learning method. Build. Environ. 2021, 200, 107949. [Google Scholar] [CrossRef]
- Tong, X.Y.; Xia, G.S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef] [Green Version]
- ISPRS Potsdam. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-potsdam.html (accessed on 28 April 2022).
- ISPRS Vaihingen. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-vaihingen.html (accessed on 28 April 2022).
- Wang, J.; Zheng, Z.; Ma, A.; Lu, X.; Zhong, Y. LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, Virtual, 6 December 2021. [Google Scholar]
- Yang, Z.; Fang, C.; Li, G.; Mu, X. Integrating multiple semantics data to assess the dynamic change of urban green space in Beijing, China. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102479. [Google Scholar] [CrossRef]
- Moreno-Armendáriz, M.A.; Calvo, H.; Duchanoy, C.A.; López-Juárez, A.P.; Vargas-Monroy, I.A.; Suárez-Castañón, M.S. Deep Green Diagnostics: Urban Green Space Analysis Using Deep Learning and Drone Images. Sensors 2019, 19, 5287. [Google Scholar] [CrossRef] [Green Version]
- Wang, L.; Zhang, C.; Li, R.; Duan, C.; Meng, X.; Atkinson, P.M. Scale-Aware Neural Network for Semantic Segmentation of Multi-Resolution Remote Sensing Images. Remote Sens. 2021, 13, 5015. [Google Scholar] [CrossRef]
- Gong, Y.; Li, X.; Cong, X.; Liu, H. Research on the Complexity of Forms and Structures of Urban Green Spaces Based on Fractal Models. Complexity 2020, 2020, 4213412. [Google Scholar] [CrossRef]
- Tu, Q. Shanghai Master Plan 2017–2035: “Excellent Global City”. Tous Urbains 2019, 27–28, 58–63. [Google Scholar]
- Wu, Z.; Chen, R.; Meadows, M.E.; Sengupta, D.; Xu, D. Changing urban green spaces in Shanghai: Trends, drivers and policy implications. Land Use Policy 2019, 87, 104080. [Google Scholar] [CrossRef]
- SMSB. Shanghai Urban Green Space In Main Years. Available online: http://tjj.sh.gov.cn/tjnj/nj20.htm?d1=2020tjnjen/E1116.htm (accessed on 30 April 2022).
- Sky Map. Available online: http://shanghai.tianditu.gov.cn/map/views/map.html (accessed on 30 April 2022).
- 91 Satellite Image Assistant. Available online: http://www.qianfansoft.net/ (accessed on 30 April 2022).
- National Platform for Common Geospatial Information Services. Available online: https://www.tianditu.gov.cn/ (accessed on 30 April 2022).
- Shanghai Surveying & Mapping Institute. Available online: http://www.shsmi.cn/ (accessed on 30 April 2022).
- Nan, K.K.; Zhi-Gang, L.I.; Xie, C.K.; Che, S.Q. Effect of Green Space Structure on the Thermal Environment of Residential Area in Shanghai. J. Shanghai Jiaotong Univ. Agric. Sci. 2016, 34, 61–67. [Google Scholar]
- Feng, Y.; Yang, Q.; Hong, Z.; Cui, L. Modelling coastal land use change by incorporating spatial autocorrelation into cellular automata models. Geocarto Int. 2018, 33, 470–488. [Google Scholar] [CrossRef]
- Chen, D.; Long, X.; Li, Z.; Liao, C.; Xie, C.; Che, S. Exploring the Determinants of Urban Green Space Utilization Based on Microblog Check-In Data in Shanghai, China. Forests 2021, 12, 1783. [Google Scholar] [CrossRef]
- Labelme Tool. Available online: http://labelme2.csail.mit.edu/Release3.0/ (accessed on 30 April 2022).
- Ministry of Construction. National Garden and Park Urban Standard; Number 106; Urban Construction: Seoul, Korea, 2000. [Google Scholar]
- Gao, X.; Zhang, Z.; Fei, X. Urban Green Space Landscape Pattern Evaluation Based on High Spatial Resolution Images. In Proceedings of the Geo-Informatics in Resource Management and Sustainable Ecosystem—International Symposium, GRMSE 2013, Wuhan, China, 8–10 November 2013; Proceedings, Part I, Communications in Computer and Information Science. Bian, F., Xie, Y., Cui, X., Zeng, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 398, pp. 100–106. [Google Scholar] [CrossRef]
- Weng, X.; Yan, Y.; Dong, G.; Shu, C.; Wang, B.; Wang, H.; Zhang, J. Deep Multi-Branch Aggregation Network for Real-Time Semantic Segmentation in Street Scenes. arXiv 2022, arXiv:2203.04037. [Google Scholar] [CrossRef]
- Ernst, P.; Ghosh, S.; Rose, G.; Nürnberger, A. Dual Branch Prior-SegNet: CNN for Interventional CBCT using Planning Scan and Auxiliary Segmentation Loss. arXiv 2022, arXiv:2205.10353. [Google Scholar]
- Toshniwal, S.; Tang, H.; Lu, L.; Livescu, K. Multitask Learning with Low-Level Auxiliary Tasks for Encoder-Decoder Based Speech Recognition. arXiv 2017, arXiv:1704.01631. [Google Scholar]
- Russo, P.; Tommasi, T.; Caputo, B. Towards Multi-source Adaptive Semantic Segmentation. In Proceedings of the Image Analysis and Processing—ICIAP 2019—20th International Conference, Trento, Italy, 9–13 September 2019; Proceedings, Part I, Lecture Notes in Computer Science. Ricci, E., Bulò, S.R., Snoek, C., Lanz, O., Messelodi, S., Sebe, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11751, pp. 292–301. [Google Scholar] [CrossRef]
- Zhang, X.; Zhu, X.; Zhang, X.; Zhang, N.; Li, P.; Wang, L. SegGAN: Semantic Segmentation with Generative Adversarial Network. In Proceedings of the Fourth IEEE International Conference on Multimedia Big Data, BigMM 2018, Xi’an, China, 13–16 September 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. arXiv 2019, arXiv:1902.09212. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Liu, S.; Davison, A.J.; Johns, E. Self-supervised generalisation with meta auxiliary learning. In Proceedings of the 33rd International Conference on Neural Information Processing Systems 2019, NeurIPS 2019, Vancouver, BC, Canada, 4–8 December 2019; pp. 1679–1689. [Google Scholar]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. OpenAI Blog 2018. in progress. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training Region-based Object Detectors with Online Hard Example Mining. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 July 2016. [Google Scholar]
- Huang, Q.; Sun, J.; Hui, D.; Wang, X.; Wang, G. Robust liver vessel extraction using 3D U-Net with variant dice loss function. Comput. Biol. Med. 2018, 101, S0010482518302385. [Google Scholar] [CrossRef]
- White, A.E.; Dikow, R.B.; Baugh, M.; Jenkins, A.; Frandsen, P.B. Generating segmentation masks of herbarium specimens and a data set for training segmentation models using deep learning. Appl. Plant Sci. 2020, 8, e11352. [Google Scholar] [CrossRef]
- Liu, H.; Feng, J.; Feng, Z.; Lu, J.; Zhou, J. Left Atrium Segmentation in CT Volumes with Fully Convolutional Networks. In Proceedings of the Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support—Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, Held in Conjunction with MICCAI 2017, Québec City, QC, Canada, 14 September 2017; Lecture Notes in Computer Science. Cardoso, M.J., Arbel, T., Carneiro, G., Syeda-Mahmood, T.F., Tavares, J.M.R.S., Moradi, M., Bradley, A.P., Greenspan, H., Papa, J.P., Madabhushi, A., et al., Eds.; Springer: Cham, Switerland, 2017; Volume 10553, pp. 39–46. [Google Scholar] [CrossRef]
- Dice, L.R. Measures of the Amount of Ecologic Association Between Species. Ecology 1944, 26, 297–302. [Google Scholar] [CrossRef]
- Guindon, B.; Zhang, Y. Application of the Dice Coefficient to Accuracy Assessment of Object-Based Image Classification. Can. J. Remote Sens. 2017, 43, 48–61. [Google Scholar] [CrossRef]
- QGIS. Available online: https://www.qgis.org/en/site/ (accessed on 6 June 2022).
- Fleet, C.; Kowal, K.C.; Pridal, P. Georeferencer: Crowdsourced Georeferencing for Map Library Collections. D-Lib Mag. 2012, 18, 52. [Google Scholar] [CrossRef]
- Contributors, M. MMSegmentation: OpenMMLab Semantic Segmentation Toolbox and Benchmark. 2020. Available online: https://github.com/open-mmlab/mmsegmentation (accessed on 6 June 2022).
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding Data Augmentation for Classification: When to Warp? In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA) 2016, Gold Coast, Australia, 30 November–2 December 2016; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Zheng, Q.; Yang, M.; Tian, X.; Jiang, N.; Wang, D. A Full Stage Data Augmentation Method in Deep Convolutional Neural Network for Natural Image Classification. Discret. Dyn. Nat. Soc. 2020, 2020, 11. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Dept, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of Tricks for Image Classification with Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 558–567. [Google Scholar] [CrossRef] [Green Version]
- Stefanidis, S.P.; Chatzichristaki, C.A.; Stefanidis, P.S. An ArcGIS toolbox for estimation and mapping soil erosion. J. Environ. Prot. Ecol. 2021, 22, 689–696. [Google Scholar]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Rodríguez, J.G. A Review on Deep Learning Techniques Applied to Semantic Segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Satellite | Location | Acquisition Date | Area (km2) |
|---|---|---|---|---|
| A | GF-2 | Baoshan District and Yangpu District | 2021/10/5 | 41.23 |
| B | GF-2 | Huangpu District and Pudong New Area | 2019/11/9 & 2021/11/19 | 41.23 |
| C | GF-2 | Pudong New Area | 2018/4/10 & 2021/10/23 | 41.23 |
| D | GF-2 | Minhang District | 2020/5/3 | 41.23 |
| Accuracy Evaluation Criteria | Formula |
|---|---|
| Precision | Precision |
| Recall | Recall |
| IoU | IoU |
| F1-score | F1-score |
| OA | OA |
| Method | Backbone | Precision | Recall | IoU | F1-Score | OA |
|---|---|---|---|---|---|---|
| HRNetV2 | HRNet-W48 | 82.05 | 85.76 | 72.21 | 83.87 | 88.92 |
| HRNetV2 | HRNet-W18 | 78.58 | 88.92 | 71.57 | 83.43 | 88.14 |
| FCN | Unet | 82.91 | 84.44 | 71.92 | 83.67 | 88.93 |
| Deeplabv3+ | ResNet-50 | 84.81 | 82.04 | 71.53 | 83.4 | 89.03 |
| Deeplabv3 | ResNet-50 | 84.14 | 82.13 | 71.11 | 83.12 | 88.8 |
| FCN | ResNet-50 | 81.2 | 85.33 | 71.25 | 83.21 | 88.44 |
| PSPNet | ResNet-50 | 83.47 | 81.39 | 70.1 | 82.42 | 88.34 |
| Maximum Likelihood | - | 70.56 | 75.75 | 57.26 | 72.33 | 61.69 |
| Random Forest | - | 64.89 | 82.23 | 56.26 | 71.48 | 79.1 |
| Ours | HRNet-W48 | 83.01 | 85.69 | 72.91 | 84.33 | 89.31 |
| Ours | HRNet-W18 | 84.46 | 83.3 | 72.23 | 83.88 | 89.24 |
| Area | A | B | C | D |
|---|---|---|---|---|
| Percentage of UCGS | 19.00% | 12.14% | 22.32% | 21.62% |
| Comb. | Aux. | Feature Map | IoU | F1-Score | OA | |||
|---|---|---|---|---|---|---|---|---|
| (a) | aux1 | 🗸 | 🗸 | 🗸 | 72.42 | 84.01 | 88.97 | |
| (b) | aux1 | 🗸 | 🗸 | 🗸 | 71.97 | 83.7 | 89.1 | |
| aux2 | 🗸 | 🗸 | ||||||
| (c) | aux1 | 🗸 | 🗸 | 🗸 | 72.16 | 83.83 | 88.76 | |
| (d) (Ours) | aux1 | 🗸 | 🗸 | 🗸 | 72.91 | 84.33 | 89.31 | |
| aux2 | 🗸 | 🗸 | ||||||
| Method | OHEM | Rescale | UCGS | Other | mIoU | mFscore | OA | |||
|---|---|---|---|---|---|---|---|---|---|---|
| IoU | F1-Score | IoU | F1-Score | |||||||
| 🗸 | 🗸 | 72.21 | 83.87 | 84.44 | 91.56 | 78.32 | 87.71 | 88.91 | ||
| HRNetV2 | 🗸 | 71.79 | 83.58 | 83.83 | 91.21 | 77.81 | 87.39 | 88.54 | ||
| 🗸 | 70.9 | 82.97 | 83.64 | 91.09 | 77.27 | 87.03 | 88.3 | |||
| 🗸 | 🗸 | 72.91 | 84.33 | 84.98 | 91.88 | 78.95 | 88.11 | 89.31 | ||
| Ours | 🗸 | 72.89 | 84.32 | 83.83 | 91.21 | 78.76 | 88 | 89.12 | ||
| 🗸 | 71.56 | 83.42 | 83.67 | 91.11 | 77.62 | 87.27 | 88.43 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Shao, S.; Zhu, Y.; Wang, Y.; Rao, F.; Dai, X.; Lai, D. Enhanced Automatic Identification of Urban Community Green Space Based on Semantic Segmentation. Land 2022, 11, 905. https://doi.org/10.3390/land11060905
Chen J, Shao S, Zhu Y, Wang Y, Rao F, Dai X, Lai D. Enhanced Automatic Identification of Urban Community Green Space Based on Semantic Segmentation. Land. 2022; 11(6):905. https://doi.org/10.3390/land11060905
Chicago/Turabian StyleChen, Jiangxi, Siyu Shao, Yifei Zhu, Yu Wang, Fujie Rao, Xilei Dai, and Dayi Lai. 2022. "Enhanced Automatic Identification of Urban Community Green Space Based on Semantic Segmentation" Land 11, no. 6: 905. https://doi.org/10.3390/land11060905
APA StyleChen, J., Shao, S., Zhu, Y., Wang, Y., Rao, F., Dai, X., & Lai, D. (2022). Enhanced Automatic Identification of Urban Community Green Space Based on Semantic Segmentation. Land, 11(6), 905. https://doi.org/10.3390/land11060905