Retrieving the National Main Commodity Maps in Indonesia Based on High-Resolution Remotely Sensed Data Using Cloud Computing Platform

 ,
,  ,
,  ,
,  and
and 
Abstract
:
1. Introduction
2. Materials and Methods
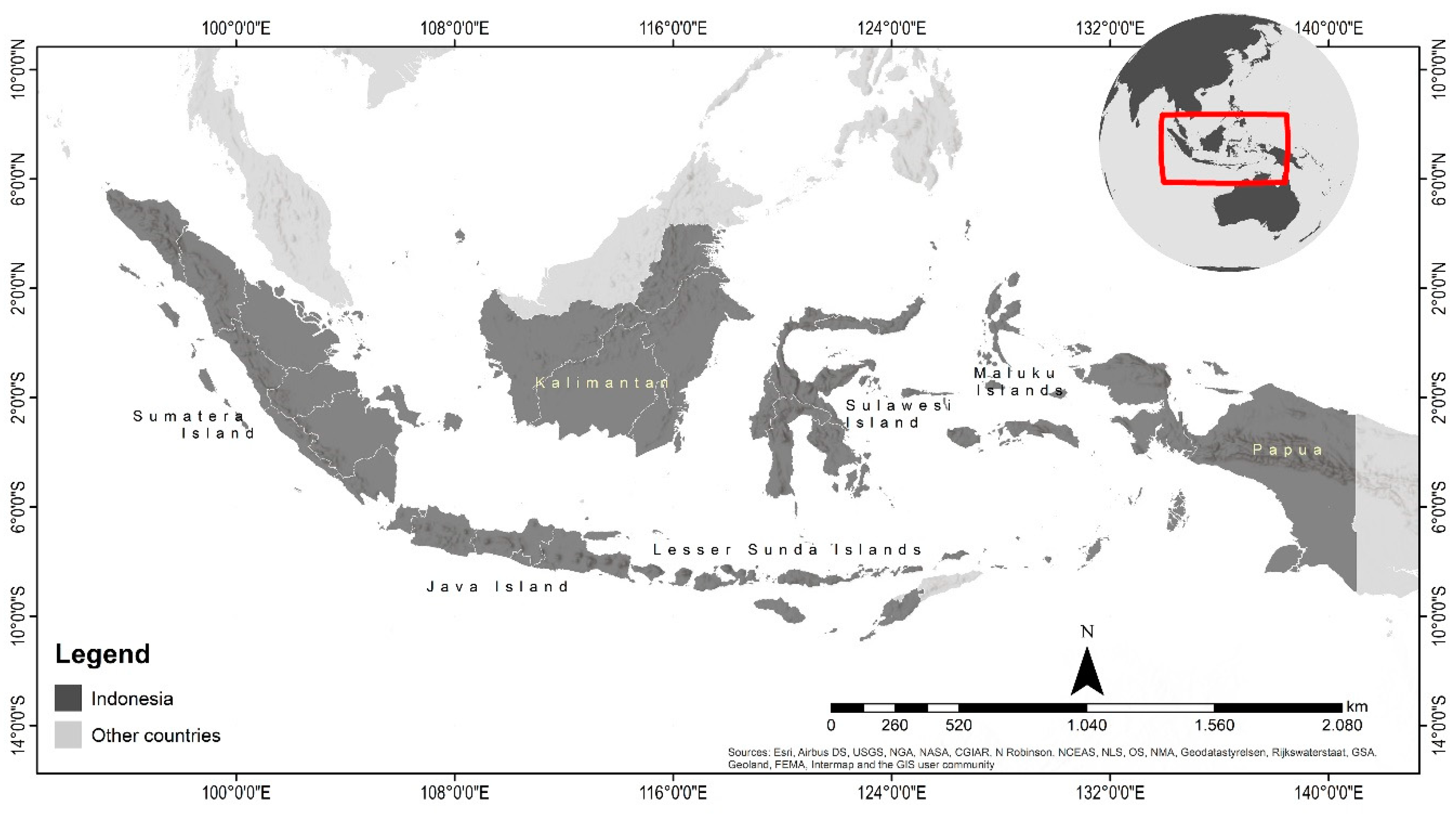
2.1. Study Area
2.2. Training Data
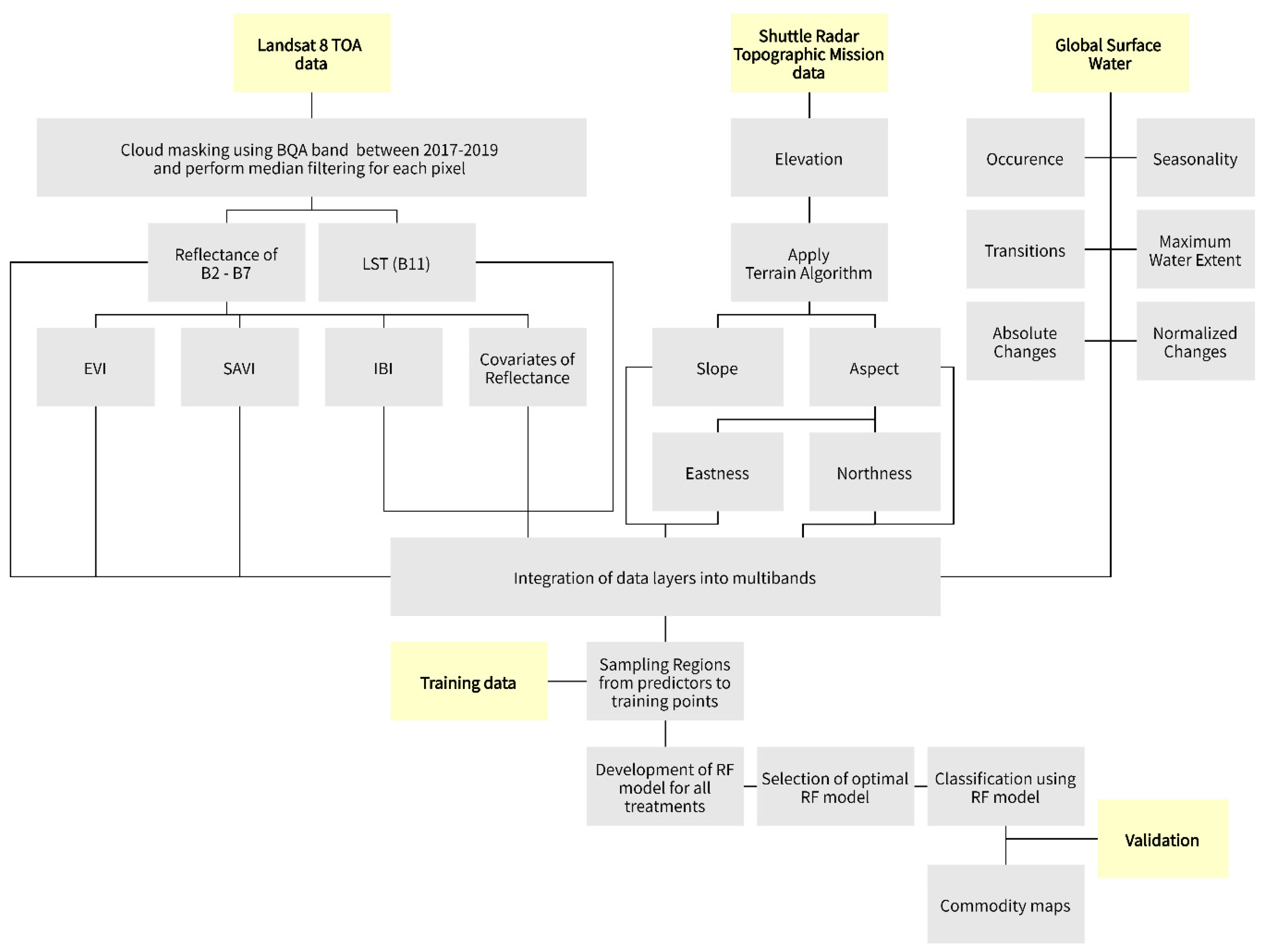
2.3. Features Derives
2.4. Commodity Cover Prediction
2.5. Model Evaluation
3. Results
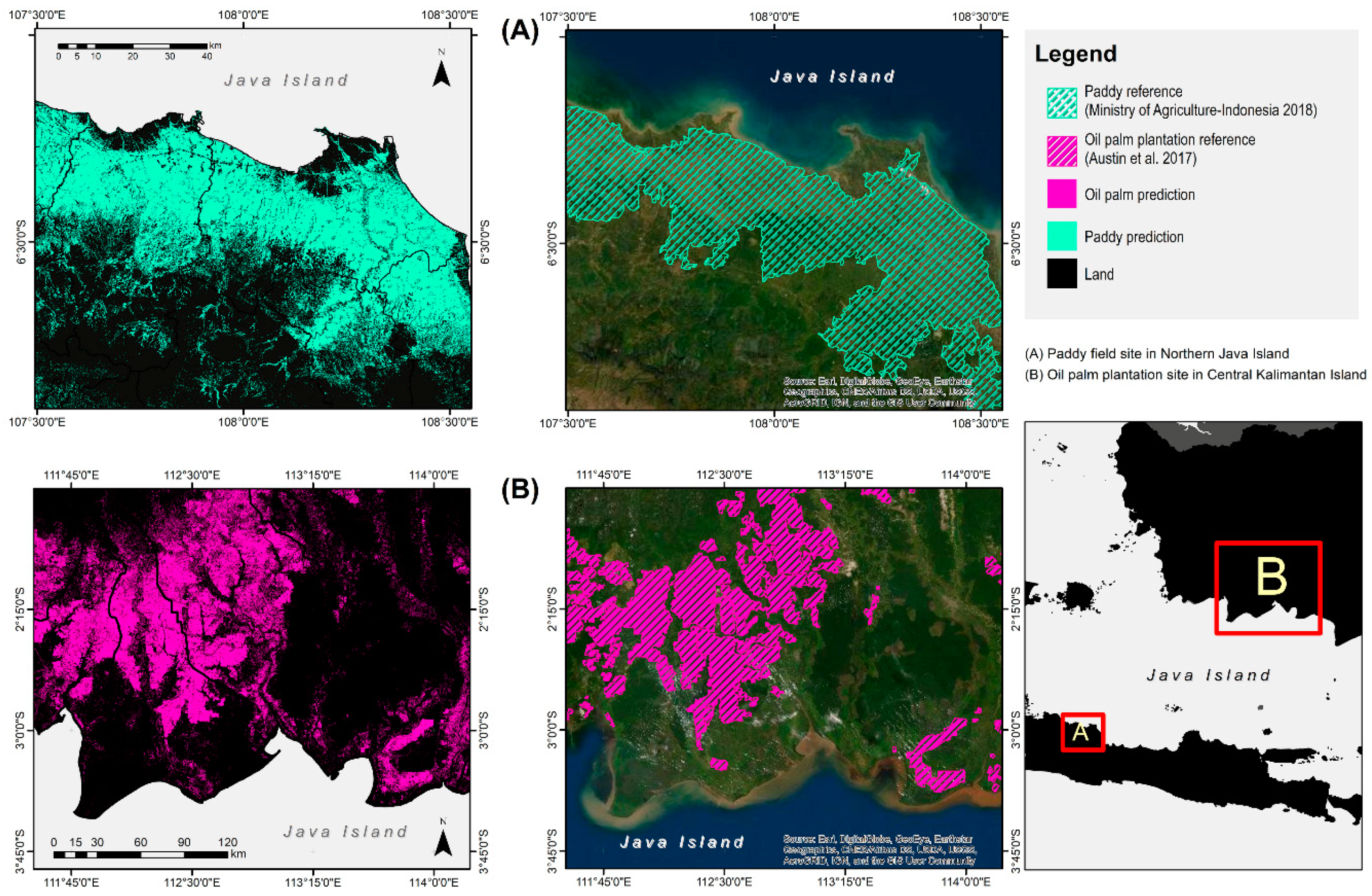
3.1. Accuracy Assessment
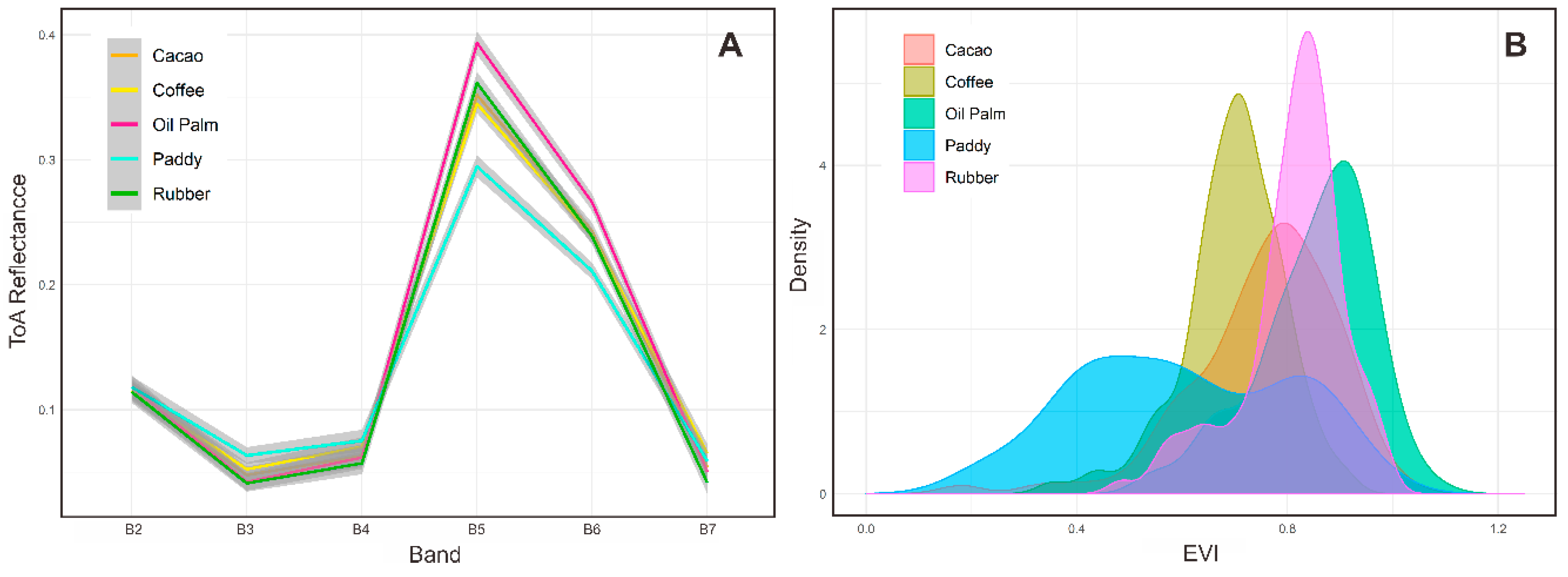
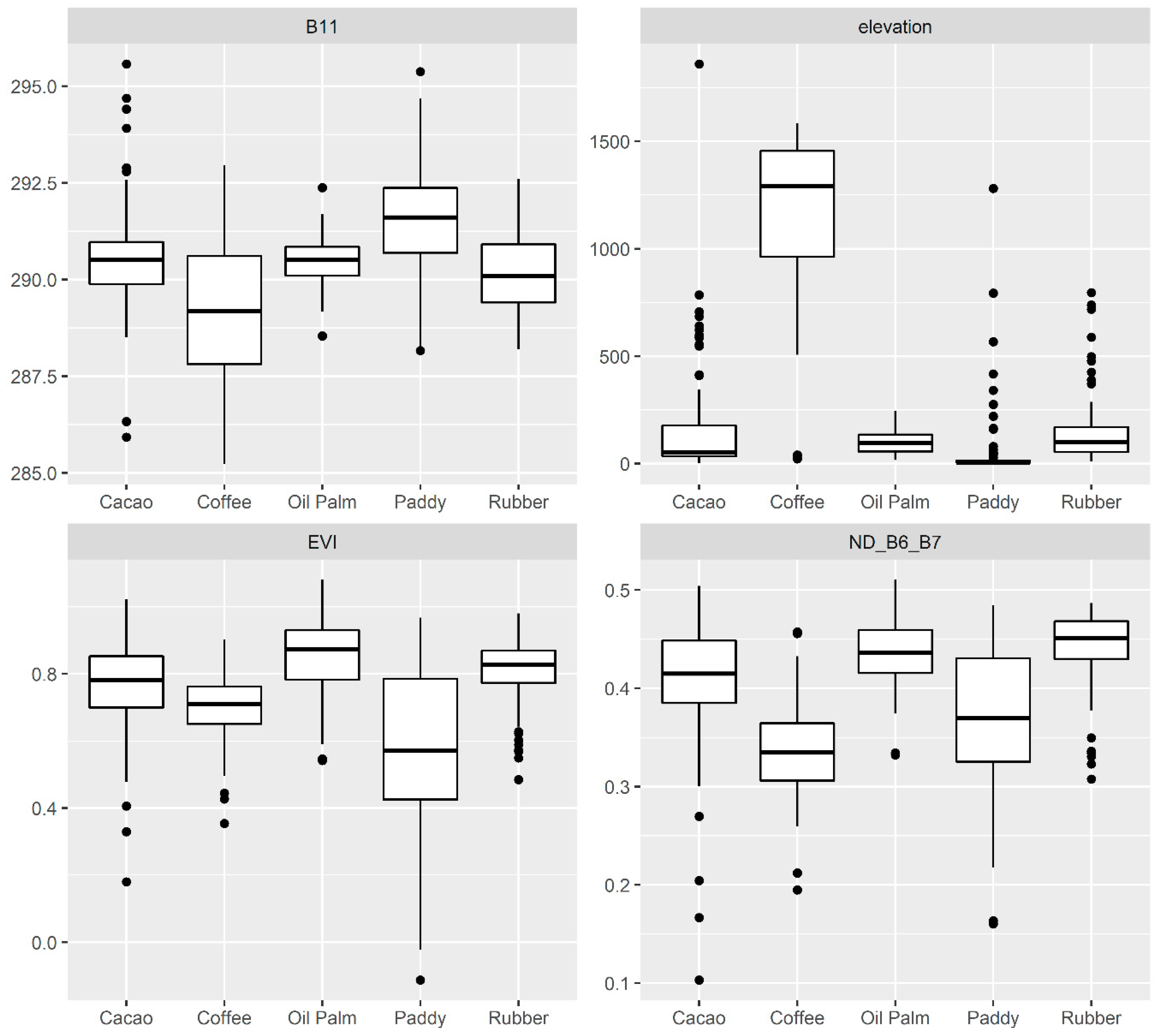
3.2. Spectral Characteristics
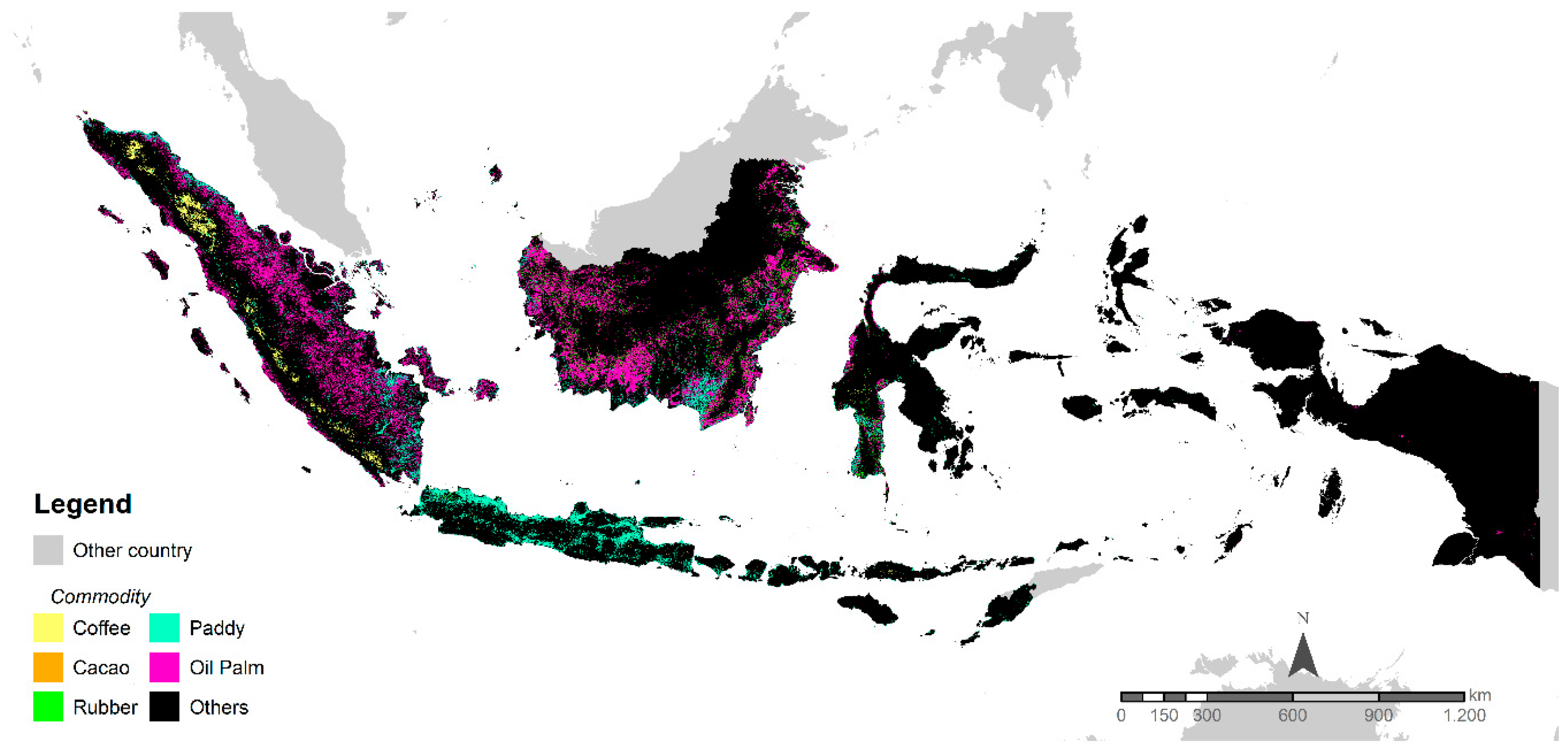
3.3. Spatial Distributions of Commodity Maps
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Alexander, P.; Rounsevell, M.D.A.; Dislich, C.; Dodson, J.R.; Engström, K.; Moran, D. Drivers for global agricultural land use change: The nexus of diet, population, yield and bioenergy. Glob. Environ. Chang. 2015, 35, 138–147. [Google Scholar] [CrossRef] [Green Version]
- Oliphant, A.J.; Thenkabail, P.S.; Teluguntla, P.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K. Mapping cropland extent of Southeast and Northeast Asia using multi-year time-series Landsat 30-m data using a Random Forest classifier on the Google Earth Engine Cloud. Int. J. Appl. Earth Obs. Geoinf. 2019, 81, 110–124. [Google Scholar] [CrossRef]
- Dirjenbun Statistik Perkebunan Indonesia 2016–2018. Stat. Perkeb. Indones. 2017. [CrossRef]
- Panuju, D.R.; Mizuno, K.; Trisasongko, B.H. The dynamics of rice production in Indonesia 1961–2009. J. Saudi Soc. Agric. Sci. 2013, 12, 27–37. [Google Scholar] [CrossRef] [Green Version]
- Purnomo, H.; Okarda, B.; Dermawan, A.; Ilham, Q.P.; Pacheco, P.; Nurfatriani, F.; Suhendang, E. Reconciling oil palm economic development and environmental conservation in Indonesia: A value chain dynamic approach. For. Policy Econ. 2020, 111, 102089. [Google Scholar] [CrossRef]
- Austin, K.G.; Mosnier, A.; Pirker, J.; McCallum, I.; Fritz, S.; Kasibhatla, P.S. Shifting patterns of oil palm driven deforestation in Indonesia and implications for zero-deforestation commitments. Land Use Policy 2017, 69, 41–48. [Google Scholar] [CrossRef] [Green Version]
- Tarigan, S.D.; Sunarti, S.W. Expansion of Oil Palm Plantations and Forest Cover Changes in Bungo and Merangin Districts, Jambi Province, Indonesia. Procedia Environ. Sci. 2015, 24, 199–205. [Google Scholar] [CrossRef] [Green Version]
- BPS. Statistik Indonesia 2019; BPS: Jakarta, Indonesia, 2019; ISBN 9788578110796. [Google Scholar]
- Neilson, J.; Wright, J.; Aklimawati, L. Geographical indications and value capture in the Indonesia coffee sector. J. Rural Stud. 2018, 59, 35–48. [Google Scholar] [CrossRef]
- Nugroho, A. The Impact of Food Safety Standard on Indonesia’s Coffee Exports. Procedia Environ. Sci. 2014, 20, 425–433. [Google Scholar] [CrossRef] [Green Version]
- Hoffmann, M.P.; Cock, J.; Samson, M.; Janetski, N.; Janetski, K.; Rötter, R.P.; Fisher, M.; Oberthür, T. Fertilizer management in smallholder cocoa farms of Indonesia under variable climate and market prices. Agric. Syst. 2020, 178, 102759. [Google Scholar] [CrossRef]
- Thenkabail, P.S.; Hanjra, M.A.; Dheeravath, V.; Gumma, M. A holistic view of global croplands and their water use for ensuring global food security in the 21st century through advanced remote sensing and non-remote sensing approaches. Remote Sens. 2010, 2, 211–261. [Google Scholar] [CrossRef] [Green Version]
- Teluguntla, P.; Thenkabail, P.; Oliphant, A.; Xiong, J.; Gumma, M.K.; Congalton, R.G.; Yadav, K.; Huete, A. A 30-m landsat-derived cropland extent product of Australia and China using Random Forest machine learning algorithm on Google Earth Engine cloud computing platform. ISPRS J. Photogramm. Remote Sens. 2018, 144, 325–340. [Google Scholar] [CrossRef]
- Phalke, A.R.; Özdoğan, M.; Thenkabail, P.S.; Erickson, T.; Gorelick, N.; Yadav, K.; Congalton, R.G. Mapping croplands of Europe, Middle East, Russia, and Central Asia using Landsat, Random Forest, and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2020, 167, 104–122. [Google Scholar] [CrossRef]
- Xie, Y.; Lark, T.J.; Brown, J.F.; Gibbs, H.K. Mapping irrigated cropland extent across the conterminous United States at 30 m resolution using a semi-automatic training approach on Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2019, 155, 136–149. [Google Scholar] [CrossRef]
- Ordway, E.M.; Asner, G.P.; Lambin, E.F. Deforestation risk due to commodity crop expansion in sub-Saharan Africa. Environ. Res. Lett. 2017, 12, 044015. [Google Scholar] [CrossRef]
- Numbisi, F.N.; Van Coillie, F.M.B.; De Wulf, R. Delineation of cocoa agroforests using multiseason sentinel-1 SAR images: A low grey level range reduces uncertainties in GLCM texture-based mapping. ISPRS Int. J. Geo Inf. 2019, 8, 179. [Google Scholar] [CrossRef] [Green Version]
- Park, S.; Im, J.; Park, S.; Yoo, C.; Han, H.; Rhee, J. Classification and mapping of paddy rice by combining Landsat and SAR time series data. Remote Sens. 2018, 10, 447. [Google Scholar] [CrossRef] [Green Version]
- Setiawan, Y.; Liyantono; Fatikhunnada, A.; Permatasari, P.A.; Aulia, M.R. Dynamics pattern analysis of paddy fields in Indonesia for developing a near real-time monitoring system using modis satellite images. In Proceedings of the Procedia Environmental Sciences; Elsevier B.V.: Amsterdam, The Netherlands, 2016; Volume 33, pp. 108–116. [Google Scholar]
- Dong, J.; Xiao, X.; Menarguez, M.A.; Zhang, G.; Qin, Y.; Thau, D.; Biradar, C.; Moore, B. Mapping paddy rice planting area in northeastern Asia with Landsat 8 images, phenology-based algorithm and Google Earth Engine. Remote Sens. Environ. 2016, 185, 142–154. [Google Scholar] [CrossRef] [Green Version]
- Kou, W.; Xiao, X.; Dong, J.; Gan, S.; Zhai, D.; Zhang, G.; Qin, Y.; Li, L. Mapping deciduous rubber plantation areas and stand ages with PALSAR and landsat images. Remote Sens. 2015, 7, 1048–1073. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Fox, J.M. Mapping rubber tree growth in mainland Southeast Asia using time-series MODIS 250 m NDVI and statistical data. Appl. Geogr. 2012, 32, 420–432. [Google Scholar] [CrossRef]
- Razak, J.A.A.; Shariff, A.R.M.; Ahmad, N.B.; Ibrahim Sameen, M. Mapping rubber trees based on phenological analysis of Landsat time series data-sets. Geocarto Int. 2018, 33, 627–650. [Google Scholar] [CrossRef]
- Mukashema, A.; Veldkamp, A.; Vrieling, A. Automated high resolution mapping of coffee in Rwanda using an expert Bayesian network. Int. J. Appl. Earth Obs. Geoinf. 2014, 33, 331–340. [Google Scholar] [CrossRef]
- Cordero-Sancho, S.; Sader, S.A. Spectral analysis and classification accuracy of coffee crops using Landsat and a topographic-environmental model. Int. J. Remote Sens. 2007, 28, 1577–1593. [Google Scholar] [CrossRef]
- Gomez, C.; Mangeas, M.; Petit, M.; Corbane, C.; Hamon, P.; Hamon, S.; De Kochko, A.; Le Pierres, D.; Poncet, V.; Despinoy, M. Use of high-resolution satellite imagery in an integrated model to predict the distribution of shade coffee tree hybrid zones. Remote Sens. Environ. 2010, 114, 2731–2744. [Google Scholar] [CrossRef]
- Kelley, L.C.; Pitcher, L.; Bacon, C. Using google earth engine to map complex shade-grown coffee landscapes in northern Nicaragua. Remote Sens. 2018, 10, 952. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Dong, J.; Tenku, S.N.; Xiao, X. Mapping oil palm plantations in cameroon using PALSAR 50-m orthorectified mosaic images. Remote Sens. 2015, 7, 1206–1224. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.S.H.; Wich, S.; Widayati, A.; Koh, L.P. Detecting industrial oil palm plantations on Landsat images with Google Earth Engine. Remote Sens. Appl. Soc. Environ. 2016, 4, 219–224. [Google Scholar] [CrossRef] [Green Version]
- Srestasathiern, P.; Rakwatin, P. Oil palm tree detection with high resolution multi-spectral satellite imagery. Remote Sens. 2014, 6, 9749–9774. [Google Scholar] [CrossRef] [Green Version]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Yamamoto, Y.; Shigetomi, Y.; Ishimura, Y.; Hattori, M. Forest change and agricultural productivity: Evidence from Indonesia. World Dev. 2019, 114, 196–207. [Google Scholar] [CrossRef]
- US Census Bureau, D.I.S. International Programs, International Data Base. Available online: https://www.census.gov/popclock/world/id (accessed on 17 August 2020).
- USGS. Using the USGS Landsat Level-1 Data Product; United States Geological Survey: Reston, VA, USA, 2019; Volume 5, pp. 27–41.
- Asner, G.P. Cloud cover in Landsat observations of the Brazilian Amazon. Int. J. Remote Sens. 2001, 22, 3855–3862. [Google Scholar] [CrossRef]
- Huete, A.; Didan, K.; Miura, T.; Rodriguez, E.P.; Gao, X.; Ferreira, L.G. Overview of the radiometric and biophysical performance of the MODIS vegetation indices. Remote Sens. Environ. 2002, 83, 195–213. [Google Scholar] [CrossRef]
- Huete, A.R. A soil-adjusted vegetation index (SAVI). Remote Sens. Environ. 1988, 25, 295–309. [Google Scholar] [CrossRef]
- Xu, H. A new index for delineating built-up land features in satellite imagery. Int. J. Remote Sens. 2008, 29, 4269–4276. [Google Scholar] [CrossRef]
- Farr, T.G.; Rosen, P.A.; Caro, E.; Crippen, R.; Duren, R.; Hensley, S.; Kobrick, M.; Paller, M.; Rodriguez, E.; Roth, L.; et al. The shuttle radar topography mission. Rev. Geophys. 2007, 45, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Pekel, J.F.; Cottam, A.; Gorelick, N.; Belward, A.S. High-resolution mapping of global surface water and its long-term changes. Nature 2016, 540, 418–422. [Google Scholar] [CrossRef]
- Shetty, S. Analysis of Machine Learning Classifiers for LULC Classification on Google Earth Engine. Master’s Thesis, University of Twente, Enchede, The Netherlands, March 2019. [Google Scholar]
- Belgiu, M.; Drăgu, L. Random Forest in Remote Sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Ham, J.S.; Chen, Y.; Crawford, M.M.; Ghosh, J. Investigation of the Random Forest framework for classification of hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 492–501. [Google Scholar] [CrossRef] [Green Version]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random Forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Pal, M. Random Forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 25, 217–222. [Google Scholar] [CrossRef]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Pontius, R.G.; Millones, M.; Pontius, R.; Gilmore, J.; Millones, M.; Pontius, R.G.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Cassidy, A.P.; Deviney, F.A. Calculating feature importance in data streams with concept drift using Online Random Forest. In Proceedings of the 2014 IEEE International Conference on Big Data (IEEE Big Data), Washington, DC, USA, 27–30 October 2014; pp. 23–28. [Google Scholar] [CrossRef]
- Lim, J.; Kim, K.M.; Jin, R. Tree species classification using hyperion and sentinel-2 data with machine learning in South Korea and China. ISPRS Int. J. Geo-Information 2019, 8, 150. [Google Scholar] [CrossRef] [Green Version]
- Calle, M.L.; Urrea, V. Letter to the editor: Stability of Random Forest importance measures. Brief. Bioinform. 2011, 12, 86–89. [Google Scholar] [CrossRef] [Green Version]
- Congalton, R.G. Accuracy assessment: A critical component of land cover mapping. In Gap Analysis: A Landscape Approach to Biodiversity Planning; Scott, J.M., Tear, T.H., Davis, F., Eds.; American Society for Photogrammetry and Remote Sensing: Bethesda, MD, USA, 1996; pp. 119–131. [Google Scholar]
- Pontius, R.G., Jr. Quantification error versus location error in comparison of categorical maps. Photogramm. Eng. Remote Sens. 2000, 66, 1011–1016. [Google Scholar]
- Nuarsa, I.W.; Nishio, F.; Hongo, C.; Mahardika, I.G. Using variance analysis of multitemporal MODIS images for rice field mapping in Bali Province, Indonesia. Int. J. Remote Sens. 2012, 33, 5402–5417. [Google Scholar] [CrossRef]
- Jelsma, I.; Woittiez, L.S.; Ollivier, J.; Dharmawan, A.H. Do wealthy farmers implement better agricultural practices? An assessment of implementation of Good Agricultural Practices among different types of independent oil palm smallholders in Riau, Indonesia. Agric. Syst. 2019, 170, 63–76. [Google Scholar] [CrossRef]
- Muhammad, M.; Liyantono; Setiawan, Y.; Fatikhunnada, A. Analysis of the Dynamics Pattern of Paddy Field Utilization Using MODIS Image in East Java. Procedia Environ. Sci. 2016, 33, 44–53. [Google Scholar] [CrossRef] [Green Version]
- Fatikhunnada, A.; Liyantono; Solahudin, M.; Buono, A.; Kato, T.; Seminar, K.B. Assessment of pre-treatment and classification methods for Java paddy field cropping pattern detection on MODIS images. Remote Sens. Appl. Soc. Environ. 2020, 17, 100281. [Google Scholar] [CrossRef]
- Permatasari, P.A.; Fatikhunnada, A.; Liyantono; Setiawan, Y.; Syartinilia; Nurdiana, A. Analysis of Agricultural Land Use Changes in Jombang Regency, East Java, Indonesia Using BFAST Method. Procedia Environ. Sci. 2016, 33, 27–35. [Google Scholar] [CrossRef] [Green Version]
- Cheng, Y.; Yu, L.; Xu, Y.; Lu, H.; Cracknell, A.P.; Kanniah, K.; Gong, P. Mapping oil palm plantation expansion in Malaysia over the past decade (2007–2016) using ALOS-1/2 PALSAR-1/2 data. Int. J. Remote Sens. 2019, 40, 7389–7408. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Use | Number of Bands | Source | Resolution |
|---|---|---|---|---|
| Landsat 8 TOA Reflectance | Spectral reflectance of B2-B7 and B11 (LST) | 7 | USGS/NASA | Spatial: 30 m Date range: 2016–2018 |
| Covariates of spectral reflectance | 15 | |||
| Enhanced Vegetation Index (EVI) | 1 | [36] | ||
| Soil-Adjusted Vegetation Index (SAVI) | 1 | [37] | ||
| Index-Based Built-Up Area Index (IBI) | 1 | [38] | ||
| Shuttle Radar Topography Mission | Elevation | 1 | [39] | Spatial: 30 m |
| Slope | 1 | |||
| Aspect | 1 | |||
| Northness | 1 | |||
| Eastness | 1 | |||
| JRC Global Surface Water | Occurrence | 1 | [40] | Spatial: 30 m |
| Seasonality | 1 | |||
| Transitions | 1 | |||
| Maximum Water Extent | 1 | |||
| Absolute Changes | 1 | |||
| Normalized Changes | 1 |
| Number of Trees | Overall Accuracy (%) | Kappa Coefficient |
|---|---|---|
| 25 | 94.5 | 0.88 |
| 50 | 88.8 | 0.67 |
| 100 | 95.2 | 0.90 |
| 500 | 92.1 | 0.78 |
| Number of Trees | N = 25 | N = 50 | N = 100 | N = 500 | ||||
|---|---|---|---|---|---|---|---|---|
| Class | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) | PA (%) | UA (%) |
| Coffee | 84.9 | 97.8 | 80.1 | 83.3 | 86.3 | 97.9 | 83.7 | 93.0 |
| Cacao | 52.2 | 90.0 | 39.6 | 88.4 | 50.7 | 94.6 | 48.5 | 91.0 |
| Rubber | 64.3 | 81.1 | 53.8 | 62.7 | 67.9 | 86.7 | 65.1 | 79.8 |
| Paddy | 87.9 | 94.6 | 71.2 | 65.8 | 90.4 | 93.5 | 83.5 | 88.6 |
| Oil Palm | 91.6 | 84.1 | 78.9 | 58.4 | 93.2 | 85.8 | 88.2 | 76.1 |
| Others | 99.2 | 97.1 | 92.9 | 95.2 | 99.5 | 97.5 | 98.7 | 96.6 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Condro, A.A.; Setiawan, Y.; Prasetyo, L.B.; Pramulya, R.; Siahaan, L. Retrieving the National Main Commodity Maps in Indonesia Based on High-Resolution Remotely Sensed Data Using Cloud Computing Platform. Land 2020, 9, 377. https://doi.org/10.3390/land9100377
Condro AA, Setiawan Y, Prasetyo LB, Pramulya R, Siahaan L. Retrieving the National Main Commodity Maps in Indonesia Based on High-Resolution Remotely Sensed Data Using Cloud Computing Platform. Land. 2020; 9(10):377. https://doi.org/10.3390/land9100377
Chicago/Turabian StyleCondro, Aryo Adhi, Yudi Setiawan, Lilik Budi Prasetyo, Rahmat Pramulya, and Lasriama Siahaan. 2020. "Retrieving the National Main Commodity Maps in Indonesia Based on High-Resolution Remotely Sensed Data Using Cloud Computing Platform" Land 9, no. 10: 377. https://doi.org/10.3390/land9100377
APA StyleCondro, A. A., Setiawan, Y., Prasetyo, L. B., Pramulya, R., & Siahaan, L. (2020). Retrieving the National Main Commodity Maps in Indonesia Based on High-Resolution Remotely Sensed Data Using Cloud Computing Platform. Land, 9(10), 377. https://doi.org/10.3390/land9100377