1. Introduction
Image recognition has received a great deal of interest in recent years. With images variability in illumination, viewpoint, shape, etc., object localization has been a challenging problem in this domain.
Bounding boxes on objects provide a valuable estimation of the regions of interest in an image. With human-annotated bounding boxes, supervised methods are used to train a large number of images to get promising results. However, image annotations are time-consuming and labor-intensive. Particularly, these manual annotations prevent several important applications (such as object detection [
1,
2], object tracking [
3] and human pose estimation [
4], etc.) from going large-scale. For instance, if an excellent object detector asks for 1000 bounding boxes for training, learning detectors for 10 k classes would require 10 million bounding boxes. Unsupervised methods use statistics tools to discover objects automatically, which does not require full annotations [
5]. Such results are not promising. The state-of-the-art convolutional neural network (CNN) [
6] is an effective method to extract discriminative appearance and transfer knowledge to find the object position, but it requires a large volume of sample training and hardware calculation ability.
To overcome these limitations, our work evaluates weakly-supervised approaches, which have been applied to image classification and localization tasks [
7,
8,
9,
10,
11,
12,
13,
14,
15]. The main advantage of weakly-supervised learning is that it requires less detailed annotations compared to the fully-supervised method. By allowing extra requirements for annotations instead of applying a set of labels given at the image level, weakly-supervised object localization (WSOL) can be effective for various applications [
9,
10]. Most approaches of WSOL are discriminative methods, which train noisy and clean images in the same way. Hence, ignoring labels could be noisy at the image level. In addition, these methods attempt to localize each class of objects independently from other classes, which leads to a number of limitations for object localization. On the one hand, ignoring objects and sharing some homogeneity can increase ambiguity for each class. On the other hand, although the appearance of objects can vary in different classes, the backgrounds are still all relevant. Iteratively calculating background information will increase the calculation cost.
To solve the above-mentioned problems, we developed a hierarchical Bayesian model, which consists of an object, parts and features. In order to represent visual objects, a collection of spatially constrained parts were defined as latent variables. This modification captures the dependencies regarding feature location and the appearance so that the objects can reuse the same parts in different proportions. Moreover, some parts transfer the same features in different spatial configurations to share among classes. Those object parts that have a few similar characters are detected, and they are considered as noisy images. For a better illustration of this work, we present the co-localization framework in
Figure 1.
According to the above discussion, we make three contributions to this work:
- (1)
We propose a novel framework based on the Bayesian hierarchical topic model for weakly supervised object localization. Without extra requirements of object annotations, latent parts and appearances are given information together at the class level to increase the recognition of an object. In addition, the appearance and correspondence position are modeled jointly to help visualize the object parts.
- (2)
We show how the joint Bayesian model utilizes the benefits of shared parts to help object co-localization throughout the dataset. Through sharing a common set of features, the same semantic objects can be found simultaneously in each class. Through parts sharing, a few training images can make robust predictions of the objects. Meanwhile, with a small amount of training data and feature sharing, our model can save a great deal of computational resources.
- (3)
We define a constraint to distinguish between noisy images and clean images. Noisy images can be found by measuring the rate of transferring information of shared parts in each category. Furthermore, to illustrate the effectiveness of our model, we present the experiments performed on two challenging datasets, which represent the difficulties of intra-class variation and inter-class diversity. The results demonstrate that our method is robust in object discovery and localization.
The remaining sections are organized as follows. Related work is presented in
Section 2.
Section 3 presents the proposed model and parameters learning algorithm.
Section 4 experimentally verifies the proposed method. Finally,
Section 5 discusses and concludes the work.
2. Related Work
Weakly Supervised Object Localization. WSOL is a task of simultaneously locating objects in the images and learning their appearances, only using the weak labels indicating the presence/absence of the objects of interest. Due to the limitations of fully-annotated objects, WSOL has been attracting increasing attention. Many studies address this problem as multiple instance learning (MIL) [
3,
4,
7,
10,
13], which alternates between selecting positive instances and learning object detectors. It, therefore, leads to a local minimum problem. Although many efforts have been made to overcome this problem by seeking better initialization models and optimization strategies [
15], the localization performance is still limited.
Co-localization is a special WSOL to explore three types of cues existing in object localization tasks: the first cue is object saliency, which describes a region containing an object looking different from the other regions of an image. Alexe et al. [
12] initialized object positions using the objectness method, which generates thousands of subwindows as candidate regions for saliency discovering. Most of the discriminative methods [
2,
5,
7,
10,
11,
12,
13,
14,
15] for saliency regions are following this method. For instance, Pandey et al. [
2] introduced deformable part-based models (DPM) by exploiting latent SVMs to enhance the supervision of bounding boxes. The second cue is similarities in intra-class, which describes a region containing an object that looks similar to other regions. These regions represent different images but contain similar objects in the same category [
11]. The third cue is the difference in inter-class, which describes regions of interest that looks different to any other regions without the object of interest. To the best of our knowledge, Deselaers et al. [
8] is the first one who employed a conditional random field (CRF) algorithm and generic prior knowledge to combine these three cues for WSOL. Tang et al. [
11] presented a joint image-box formulation for discovering the similar objects in intra-class and turned the co-localization problem into a convex quadratic program. All these methods are discriminative and tend to return a bounding box to reflect the position of an object.
Recent work modifies CNN architectures for image classification as well as learn to localize objects by convolutional layers [
8,
9,
10]. Other methods, like transfer learning [
16,
17] and self-taught learning [
18], also provide effective cues for WSOL.
In contrast to these localization studies based on discriminative models, our method does not require a series of candidate bounding boxes. Instead, we take advantage of the generative models which are flexible to utilize object similarities and to cope with class variations and diversity.
Topic models for object localization. Topic models were originally developed for text analysis and have been successfully transferred to image classification and localization tasks [
19,
20]. Based on bag of words (BoW) model, topic models are used to cluster a set of discriminative features for classes of interest. However, features in topic models have no spatial information, thus, it cannot explicitly model the intra- and inter-class structure of feature distributions.
Recently, improved topic models with detailed structural information [
21,
22,
23,
24] have been proposed for object localization. Both unsupervised and supervised learning methods can be formulated to topic models. As unsupervised LDA and PLSA models have limited ability for image applications, supervised extension of these two models are more popular to incorporate class label variables. The classLDA (cLDA) [
25] and supervised LDA (sLDA) [
26] are classic models of this family. Via the weakly supervised class label information, Wang et al. [
21] proposed a latent category learning method based on the extent to which PLSA could select the most discriminative category to localize objects in a clutter background. Sudderth et al. [
23] developed a rich hierarchical topic model to capture features of the spatial structures with fixed classes. In addition, prior information is another unique advantage of topic models for specified vision tasks. Shi et al. [
22] integrated geometry prior to topic models and proposed a novel Bayesian joint model for weakly supervised object localization. Niu et al. [
24] proposed a novel knowledge-based topic model, named LDA with a mixture of Dirichlet trees to incorporate the must-links into topic modeling for object discovery. Object co-localization was explored in weakly supervised setups with multiple object categories in topic models [
22,
23,
24]. Unlike the existing discriminative methods that treat different classes as unrelated entities, ref. [
22] shared background similarities in the class. To those bounding boxes that were drawn around objects lack some strong supervision, ref. [
23] learned both a hierarchical structure for visual appearance and its correspondence geometry information. We take advantage of [
22,
23,
24] sharing some common features within and between-class to cope with class variations and diversity. In addition, ref. [
10,
11] focused on the co-localization problem with optimization and CNN respectively, and [
11] also to pay attention to noisy images.
3. Methods
We introduced a novel topic model to localize a common set of features shared among classes. Object, parts, and features were modeled jointly in a hierarchical structure. Although objects are different in viewpoint, scale and size, etc., they are supposed to have some common features in each class. Conjugate priors were chosen for parameters learning. Gibbs sampling was adapted to update the features posterior distribution. Each part encoded a distribution over the features after learning. In addition, a constraint was defined to distinguish between noisy and clean images to co-localize object accurately.
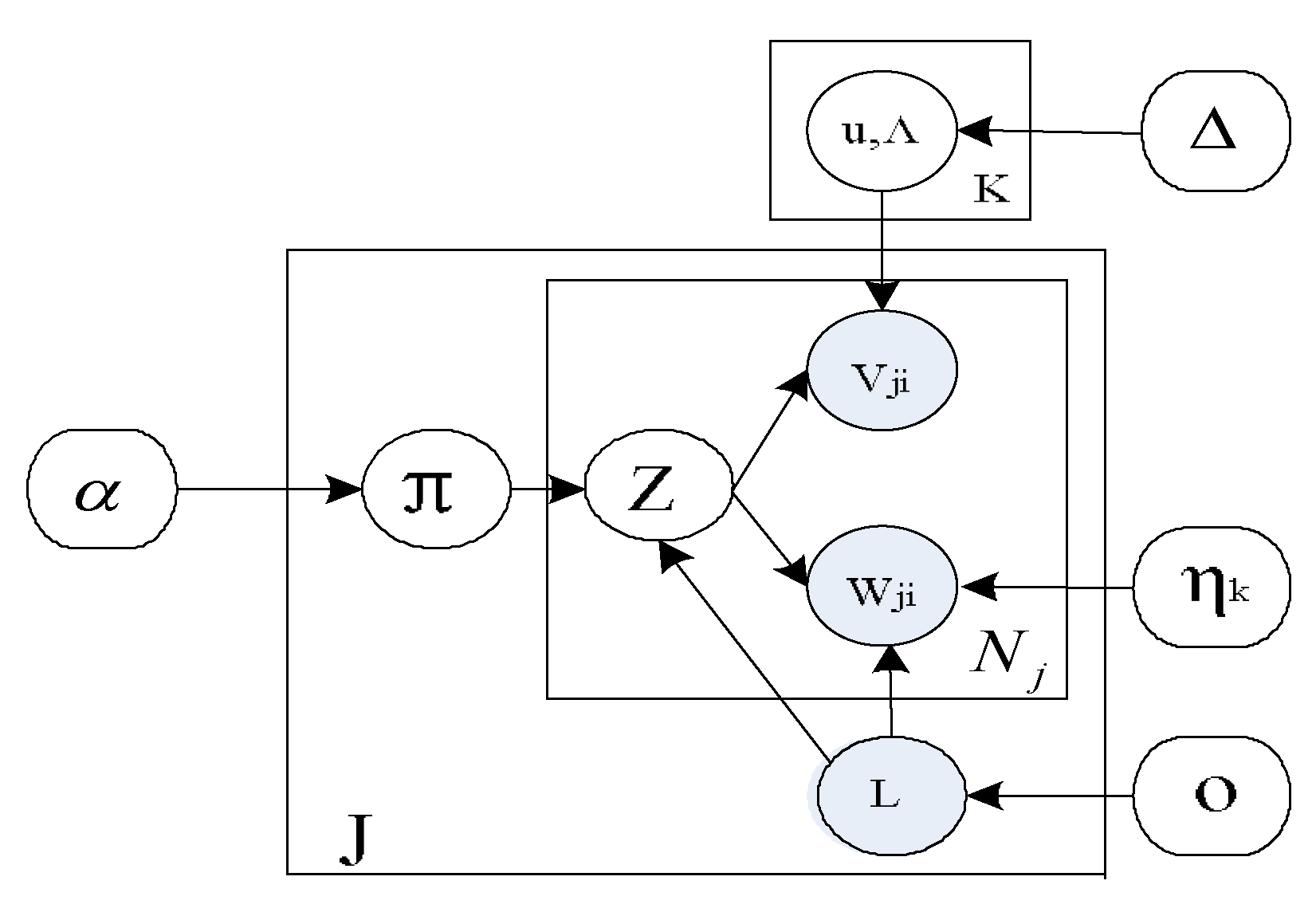
3.1. Symbol Description
Given an image with features, K-means algorithm is used to partition image features into K clusters. We define these clusters as a codebook W of visual words. Thus, the image j is represented as the appearance and correspondence Gaussian position , respectively.
3.2. The Joint Topic Model for Objects
Our topic model is a type of statistical model, specifying a joint probability distribution over observations. Given a set of
J training images known with category information, the process of our generative Bayesian model is shown in
Table 1.
Where Multi, Dir and
N indicate Multinomial, Dirichlet and Normal distributions with specified parameters. These priors are chosen because they are conjugates to model parameters and hence, can enable efficient inference. For this joint model, shared parts are formalized as groups of features that are spatially clustered. Each object is a mixture of multinomial topic distributions and reuses shared parts in different proportions. We correlate class label
L with appearance variable
w, as shown in
Figure 2, where parts are formalized as groups of features that are spatially clustered and have predictable appearances. This correlation makes conditional distributions of topics dependent on classes. Furthermore, as a larger set of topics are available per class, the model has greater ability to model inter-class structure.
To capture the intra structure of object, we define K distinct parts, which generate features with different typical appearance
and location
. The particular part
associated with each feature is independently sampled from a category-specific multinomial distribution
. When learning model from training data, we assign a conjugate Dirichlet prior
to these parts association probabilities, where
is a hyperparameter. It reflects prior knowledge of presence of each object class. Each part
is then defined by a multinomial distribution
on the discrete set of
appearance descriptor, and a Gaussian distribution
, described as
,
. The joint distribution of all variables in the model is therefore:
3.3. Parameters Learning
To learn the parameters defining the parts of the model, we employ a Gibbs sampling algorithm. From the joint model’s Markov properties, the posterior distribution over part assignments is as follows:
Let
represents the number of features in classes of object
l assigned to part
k, and
the appearance descriptor assigned to part
k by
.
indicates the number of times of visual word. Using standard expression with Dirichlet priors to predict likelihood function, the first two terms of posterior are written as:
These probabilities are achieved through the pseudo-counts contributed by Dirichlet priors. To the third item of Equation (2), it represents object
l assigned to words
w is endowed with its own topic simplex.
where
denotes the parameters of mixture components (
) and
the mixing probabilities (
). Both of the parameters are defined as Dirichlet distributions:
As to the last item of the position likelihood, it depends on the visual words that are a set of features assigned to the same part by .
To the above equation, the mean
and covariance
are given by regularized moment-matching of the features attributed to the part. Therefore, the Gaussian likelihood can make an accurate approximation for position.
where
indicates the total number of features of any appearance assigned to part
K.
d represents features dimension and
is an inverse-Wishart hyperparameter. All of these priors are conjugate to the posterior of position distributions. Combine above equations, each of
K candidate assignments
can be evaluated or a new part of that feature can be sampled.
3.4. Supervision via Class Label Constraint on both of Appearances and Topics
In our weakly supervised topic model, l is used to encode the object supervision from class labels. As the topic simplex is smaller than the word simplex, it is limited to simultaneously model rich intra-class structure and to locate the objects separately. However, our goal is to discover and co-localize images that each contain a common object by exchanging and sharing information within and between-class, which puts more emphasis on class similarity. Therefore, we correlate class label l to topics and visual words together to form strong supervision on object position. Finally, the model can harness the benefits of both topics of supervision, as each topic is learned under the class supervision and topic discovery, as several topics are discovered per class.
3.5. Probabilistic Parts Sharing
To specify the WSOL task, we factor the images into combinations of K shared parts. All the position densities of shared parts depicted in Gaussian mixture models are pre-computed to a dedicated table for fast lookup. Therefore, each shared part corresponds to one object class, which can be learned with both a distribution over the size of appearance, and the spatial location of these appearance within an image. Objects are discovered and localized by means of transferring different proportions of shared parts.
3.6. Object Localization
Object transfers shared parts to compose its own parts in each class. In some special cases, it exploits parts from other classes, depending on which better explains the object. After the learning process, each latent part will be given both a distribution over the sized appearance vocabulary of each feature, as well as over the spatial location of these appearances within each image. In this way, objects are represented as a collection of spatially constrained parts. Then, a bounding box for topic K in image j can be obtained directly from the parts distribution of Gaussian. We do it through aligning a window to the max of four directions depicted by standard deviation ellipses. Final localization is the most standing-out region at the end.
To the noisy images, we use the information entropy to sort parts in the class, and then extend to the whole dataset to formalize global shared parts matrix. Those objects that share few similar characters with the entropy of sharing parts are considered as noisy images. A constraint is defined to distinguish between noisy and clean images as follows:
where
represents image composed of different proportions of shared parts.
indicates the total number of appearance assigned to parts
K in each image.
is the formula of information entropy. If
, image
j is considered as a noisy image.
3.7. Complexity
To the complexity of our model, supposing an image j is composed of K topics with features during training process, a Gibbs sampling algorithm update each feature assignment requiring operations. These assignments also account for posterior distributions of topic parameters, which is logically to be inferred.
4. Experiments
We perform experiments on two datasets, the PASCAL VOC 2007 dataset [
27] and Object Discovery dataset [
28]. Following [
29] in weakly supervised localization, we use CorLoc to evaluate performance. CorLoc is defined as the percentage of images correctly localized according to the PASCAL-criterion:
, where
is the predicted box and
is the groundtruth box. All CorLoc results are given in percentages.
4.1. Experimental Settings
For each category with 21 training images, maximally stable extremal regions (MSER) is considered to represent interest regions as it favors larger, and more homogeneous image regions. As SIFT descriptor is invariant to lighting, pose and scale changes, it is used to characterize the appearance of interest regions. K-means clustering is used to identify a finite dictionary of W appearance patterns, where each feature is mapped to a disjoint set of visual words. We set the size of the dictionary with W = 300. In addition, hyperparameters used in our model are set as follows: The clustering rate ; the inverse-Wishart prior = 6; the class information O = 1/number of classes is endowed with a uniform distribution; the multinomial appearance distributions are assigned symmetric Dirichlet priors and ; the number of shared parts are setting as K = 6 per each class. Lastly, our model updates the parts with Gibbs iterations 200 times.
4.2. PASCAL VOC 2007 6 × 2
PASCAL VOC 2007 6 × 2 is a subset of PASCAL VOC 2007. This subset consists of 6 classes images (airplane, bicycle, boat, bus, horse and motorbike) from the left and right point of view. Each class contains between 21 and 50 images for a total of 478 images, so that 21 images are used for training in each class. We test our method on this subset and compare with previous methods.
Table 2 shows CorLoc results for three terms combinations on PASCAL VOC 2007 6 × 2. We perform our method with heuristic pattern on each operation. Firstly, with no left or right information on each category, 6 classes are adopted to verify experimental performance of the original method, referring to the third row of
Table 2. As the average of CorLoc results is not satisfactory, we turn to include the constraint to cope with noisy images. In this particular case, the results are improved nearly 15%. Lastly, we do the full experiment on the whole dataset with 12 classes labels included. The results have been significantly improved with 17% comparing with the second experiment. The reason is that our model has greater ability to model inter-class structure and allows a much larger set of topic distributions possible per class.
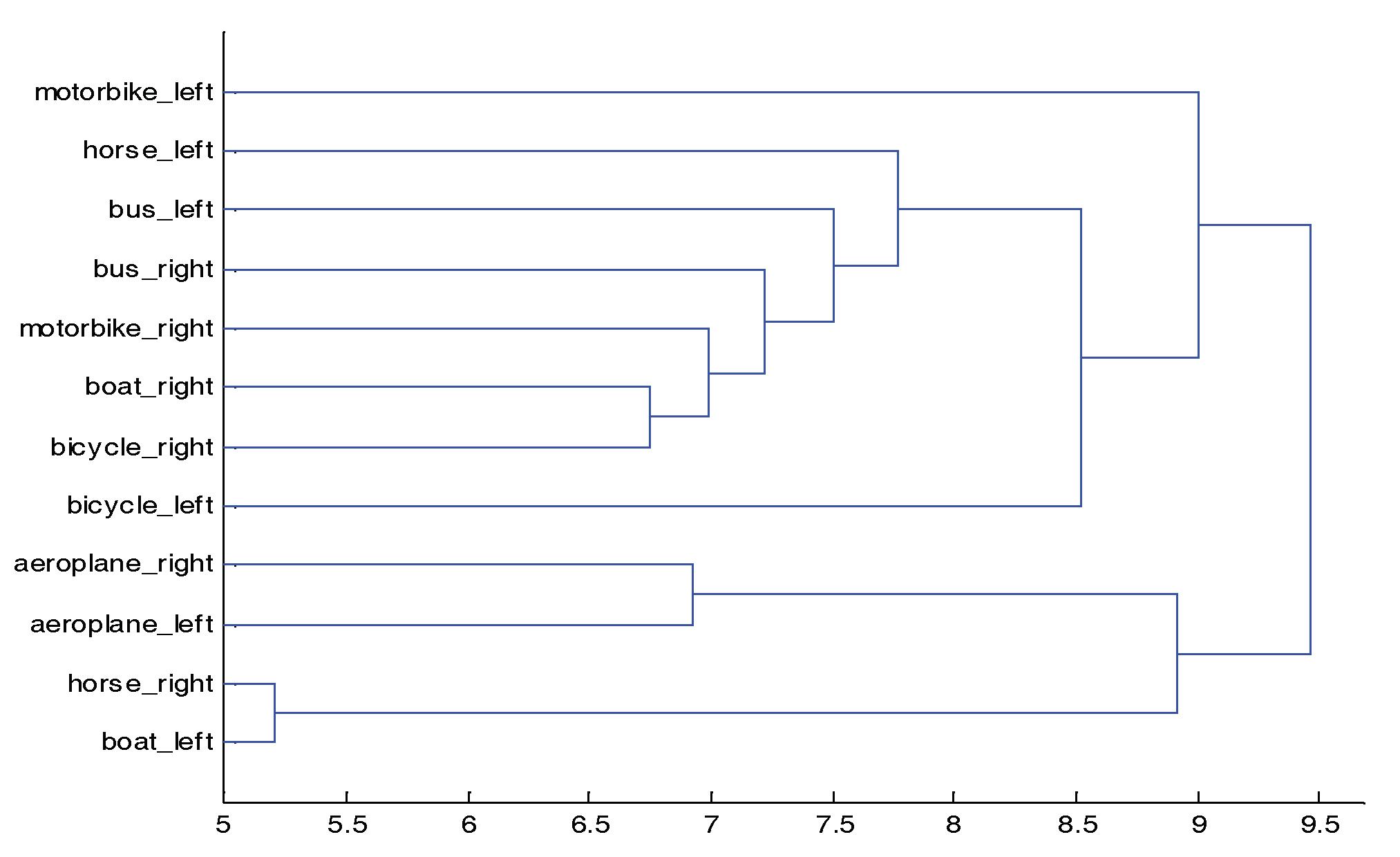
In addition to the CorLoc results, we calculate the distance of each class to analyze its similarity. The similarity in intra-class enables model shares some parts for co-localization effectively but the similarity in inter-class cause interference when the appearances of objects look the same in different classes.
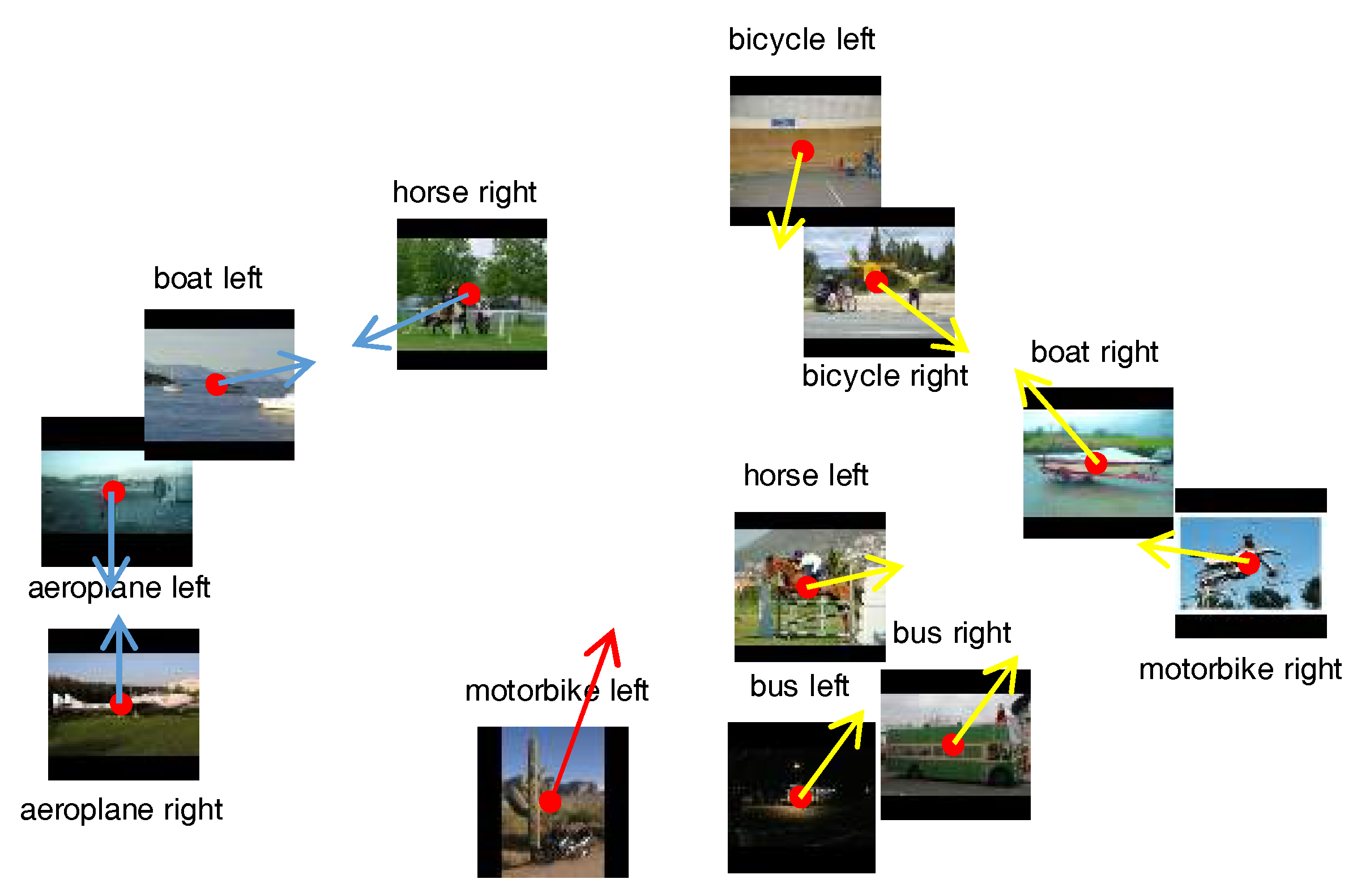
Figure 3 shows the distribution of different object parts produced by multidimensional scaling. Except for boats, motorbikes and horses, the remaining classes seem to closely match the labels of category similarity. The reason for the deviation may be due to the fact that some learned parts are too similar to distinguish among classes.
Figure 3 also indicates that sharing the common features can allow us to introduce prior correlations between parameters of nearby classes in the dataset.
Table 3 shows our results outperforming the previous methods that do not use noisy images in PASCAL VOC 2007 6 × 2.
In
Figure 4, 12 images are chosen per class to visualize the object co-localization. Our model simultaneously introduces the appearance and position of the image features. The appearances which have the maximum posterior are selected and the correspondence position use ellipses to represent the saliency parts. From
Figure 4, we can see the model demonstrates objects localization eliminating clutters in the background and transferring attention to objects themselves. In the bicycle_left class, the bicycle in the first image is not found. It is the same to the fourth image in (b) airplane_right and (f) boat_right in their class. The reason for this phenomenon is that few common features are detected to formalize an effective part of sharing. These unfound objects appear throughout the dataset and thus considered as noisy images. However, whether or not an image will be considered as noisy image depends on the number of matching parts that we have defined in Equation (11). Furthermore, this visualization also demonstrates that our model depends on the most expressive component of the parts to achieve object discrimination.
4.3. Object Discovery Dataset
The object discovery dataset [
28] is composed of three categories: airplane, car and horse. Through the query of the class name, the images were downloaded automatically by using the Bing search engine. Thus, there were some noisy images in the dataset without accurate query. This dataset was originally introduced for co-segmentation. For a better comparison with the previous methods of co-segmentation and co-localization results, we drew a tight bounding box around the ground truth segmentations. The experimental data settings were the same as the ones used in PASCAL VOC 2007 6 × 2 and 100 image subset was used to be consistent with [
11,
28].
Table 4 gives the Corloc results on three categories. The Corloc results are comparing with previous methods on the same dataset. Obviously, there were improvements in the airplane, but there were some decreased data in the car. This is because there were more noisy images that were found in the airplane category. Our results also demonstrated the defined constraint is an effective method to find noisy images.
In
Figure 5, we visualize some examples of co-localization results on the three categories. From these bounding boxes of objects, it can be seen that the objects are discovered and localized simultaneously, while ignoring a wide range of viewpoints, locations and background clutter. Object shared parts can be used to explain the reasons for this visualization.
4.4. Time Complexity
Our experiments are conducted on a 2.5 GHz Intel Dual-core i5 processor. All images are cropped to the size of implemented with MATLAB tools. Approximately 1.5 s is taken per image to extract SIFT features. With 21 images per class for training, our hierarchical model takes about 27 h and 8 h of PASCAL VOC 2007 6 × 2 and object discovery dataset, respectively. It requires about 6 min per image. However, during the testing process, it takes about 30 ms to localize the position of each object with Gaussian mixture algorithm.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}