A Secure, Scalable and Elastic Autonomic Computing Systems Paradigm: Supporting Dynamic Adaptation of Self-* Services from an Autonomic Cloud


Abstract
:
1. Introduction
- A computing system implements a manageability interface to shares its data with external autonomic managers.
- An autonomic manager registers with the autonomic cloud offering software management services.
- The computing system registers its managed resources with the autonomic cloud to buy the management services.
- -
- If the serverApp becomes corrupted due to system-file(s) delete/overwrite/corrupt, the serverAppProtectionManager automatically copies the corrupted/deleted file(s) from the backup and keeps the server working. In an ordinary system (with no protection), the server stays down until files are manually uploaded/reinstalled.
- -
- The databaseConnectivityManager keeps the database-server active so that the connection with the trading-server is live.
- -
- The logbaseManager controls the memory space used by the trade log of clients.
- A secure, scalable and elastic autonomic computing system (SSE-ACS) paradigm is presented to improve the autonomic computing design concept.
- An efficient service adaptation scheme is designed to offer self-management capabilities as S*SAAS from an autonomic cloud.
- Experimental evaluations are logged for statically-configured local AMs, dynamically-configured AMs from a server machine, and the runtime registering of AMs from the autonomic cloud. The system optimizes the CPU share using elastic AMs, which resulted in the improved execution time of the business logic.
- For software applications requiring the continuous support of self-management services, the proposed system achieves a significant improvement in security, scalability, elasticity, autonomic efficiency, and issue resolving time, compared to the state-of-the-art approaches.
2. Related Work
3. Materials and Methods
- A layer for initial registration, authentication and validation is added on the resource side.
- A connection controller is defined inside the autonomic manager.
- An algorithm is provided for initial registration, continuous authentication and validation.
- An algorithm is provided for the elastic self-management process.
3.1. Modified Design for Secure, Scalable and Elastic ACSs
3.2. Layered Approach for Dynamic Adaptation of Self-* Services: Offering Self-* Capabilities as a Service
4. Results and Discussion
4.1. Experimental Setup
- Stock trade forecasting service: Australian stock market information [42] is retrieved for leading companies and the forecasting service is executed using this data to predict stock trends.
- Server-farm management and server-load balancing service: Five VMs are created to handle the client’s requests. The ServerFarm&Load manager activates/deactivates VMs with the increase/decrease of the processing load.
- Installed application protection service: Server program files are manually deleted while the server is active. This service recovers the deleted files from the backup to keep the system running.
- Database connectivity control service: The Database (DB)-service is manually reduced to cause an interruption. This service restarts the DB-service immediately to keep the DB live.
- Log-base memory management service: Continuous client requests cause the log memory to fill. This service deletes old files to clear the required space.
- ○
- The load balancer checks the load for VM1. If it exceeds the set limit, it shifts the extra load to VM2 and boots VM3 to idle state.
- ○
- If the load in VM2 is too high, it shifts the extra load to VM3 and boots VM4, and so on.
- ○
- On the decrease of the processing load, the load balancer turn off idle VMs, keeping at least two VMs always active.
4.2. Experimental Results
4.2.1. Autonomic Managers Delivering Self-* Services
4.2.2. The Security Impact of the SSE-ACS Paradigm
- Vulnerability-i:
- The serverFarm&loadBalancingManager accesses information related to the forecastManager, which is an access privilege concern.
- Vulnerability-ii:
- The forecastManager accesses the serverFarm and turns a server ON/OFF in the serverFarm. It transfers the server’s load without having privileges.
- Vulnerability-iii:
- An intruder autonomic manager uses the sensors/effectors of the forecastManager to manipulate stock trade data.
- Implementation-1:
- A single AM controls the server and performs the tasks of serverFarm&loadBalancingManager and forecastManager. AM and MR run on the same machine.
- Implementation-2:
- The AM of case1 runs on another machine and controls the server.
- Implementation-3:
- The serverFarm&loadBalancingManager and forecastingManager are implemented as separate managers. The AMs and MRs run on the same machine.
- Implementation-4:
- The AMs of case 3 and MR (server) run on separate machines.
4.2.3. Scalability and Elasticity Impact of SSE-ACS Paradigm
4.2.4. S*SAAS Performance Measures
- -
- The management of a huge amount of highly sensitive data generated by medical sensor networks covering scalability, availability and security issues [34].
- -
- A cloud-based distributed toolbox to optimally manage the energy dispatch from renewable resources utilizing the GPU and WRNN predictors [35].
- -
- Cloud-based energy serving a multi-agent system using web service techniques with backend information agents involved [36].
- -
- A neural-network-driven forecasting setup to manage the power production and dispatch in a smart grid [37]
- -
- A user wants to run their own application over the cloud to process their own data utilizing encrypted computation [47]
4.3. Socio-Economic Benefits of the Proposed Research
4.4. Complexity Analysis
5. Conclusions
Authors Contribution
Acknowledgments
Conflicts of Interest
Nomenclature
| ACS | Autonomic Computing System |
| AM | Autonomic Manager |
| CC | Connection Controller |
| CIA | Confidentiality, Integrity, Availability |
| CPU | Central Processing Unit |
| CVSS | Common Vulnerability Scoring System |
| MR | Managed Resource |
| PC | Personal Computer |
| PKI | Public Key Infrastructure |
| RAV | Registration, Authentication and Validation |
| RSA | Rivest, Shamir & Adleman (public key encryption technology) |
| RSI | Relative Strength Index |
| SSE-ACS | Secure, Scalable and Elastic Autonomic Computing System |
| SMP | Self-Management Process |
| SO | Stochastic Oscillator |
| William’s % R | William’s % Relative Strength |
| MFI | Money Flow Index |
| MACD | Moving Average Convergence Divergence |
| L14 | Lowest of the previous 14 trading sessions |
| H14 | Highest of the previous 14 trading session |
References
- Ahuja, K.; Dangey, H. Autonomic Computing: An emerging perspective and issues. In Proceedings of the IEEE International Conference on Issues and Challenges in Intelligent Computing Techniques, Ghaziabad, India, 7–8 February 2014; pp. 471–475. [Google Scholar] [CrossRef]
- White, S.R.; Hanson, J.E.; Whalley, I.; Chess, D.M.; Kephart, J.O. An architectural approach to autonomic computing. In Proceedings of the IEEE International Conference on Autonomic Computing, New York, NY, USA, 17–18 May 2004; pp. 2–9. [Google Scholar] [CrossRef]
- Hariri, S.; Khargharia, B.; Chen, H.; Yang, J.; Zhang, Y.; Parashar, M.; Liu, H. The autonomic computing paradigm. Clust. Comput. 2006, 9, 5–17. [Google Scholar] [CrossRef]
- Okon, S.C.; Asagba, P.O. Self-Organization and Self-Healing: Rationale and Strategies for Designing and Developing a Dependable Software System. IJIRCCE 2014, 2, 3687–3698. [Google Scholar]
- Raibulet, C. Hints on Quality Evaluation of Self-Systems. In Proceedings of the IEEE Eighth International Conference on Self-Adaptive and Self-Organizing Systems (SASO), London, UK, 8–12 September 2014; pp. 185–186. [Google Scholar] [CrossRef]
- Wolf, T.D.; Holvoet, T. A Taxonomy for Self-* Properties in Decentralised Autonomic Computing. In Autonomic Computing: Concepts, Infrastructure and Applications; Parashar, M., Hariri, S., Eds.; CRC Press/Taylor & Francis: Boca Raton, FL, USA, 2006; Chapter 1; pp. 3–24. [Google Scholar]
- Mittal, P.; Singhal, A.; Bansal, A. A Study on Architecture of Autonomic Computing-Self Managed Systems. IJCA 2014, 92, 6–9. [Google Scholar] [CrossRef]
- Kumar, K.P.; Naik, N.S. Self-Healing model for software application. In Proceedings of the IEEE International Conference on Recent Advances and Innovations in Engineering (ICRAIE, 2014), Jaipur, India, 9–11 May 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Jacob, B.; Lanyon-Hogg, R.; Nadgir, D.K.; Yassin, A.F. A practical guide to the IBM autonomic computing toolkit. In IBM Redbooks; IBM Corp. International Technical Support Organization: North Castle, NY, USA, 2004. [Google Scholar]
- Manoel, E.; Nielson, M.J.; Salahshour, A.; KVL, S.S.; Sudarshanan, S. Problem determination using self-managing autonomic technology. In IBM Redbooks; IBM International Technical Support Organization: North Castle, NY, USA, 2005. [Google Scholar]
- IBM, Coorporation. An Architectural Blueprint for Autonomic Computing; IBM White Paper; IBM: Hawthorne, NY, USA, 2006; Volume 31, pp. 1–6. [Google Scholar]
- Miller, B. The Autonomic Computing Edge: Keeping in Touch with Touchpoints. Article Series on Autonomic Architecture. 2005. Available online: http://www.ibm.com/developerworks/autonomic/library/ac-edge5 (accessed on 2 January 2016).
- Shuaib, H.; Anthony, R.J.; Pelc, M. A framework for certifying autonomic computing systems. In Proceedings of the IARIA 7th International Conference on Autonomic and Autonomous Systems, Venice, Italy, 22–27 May 2011; ICAS: Venice, Italy; Mestre, Italy, 2011; pp. 122–127. [Google Scholar]
- First.org. Common Vulnerability Score System v3.0. first.org. 2015. Available online: https://www.first.org/cvss/user-guide (accessed on 5 March 2017).
- Wang, J.A.; Wang, H.; Guo, M.; Xia, M. Security metrics for software systems. In Proceedings of the ACM 47th Annual Southeast Regional Conference, Clemson, South Carolina, 19–21 March 2009. [Google Scholar] [CrossRef]
- Nzekwa, R.A.; Rouvoy, R.; Seinturier, L. Modelling feedback control loops for self- adaptive systems. In Proceedings of the Third International DisCoTec Workshop on Context-Aware Adaptation Mechanisms for Pervasive and Ubiquitous Services, Amsterdam, The Netherlands, 10 June 2010; pp. 1–6. [Google Scholar]
- Bezerra, D.S.; Martins, R.; Martins, J.S.B. A Policy-Based Autonomic Model Suitable for Quality of Service Management. J. Netw. 2009, 4, 495–504. [Google Scholar] [CrossRef]
- Horn, P. Autonomic Computing: IBM’s Perspective on the State of Information Technology; IBM Corp.: North Castle, NY, USA, 2001. [Google Scholar]
- Kephart, J.O.; Chess, D.M. The vision of autonomic computing. Computer 2003, 36, 41–50. [Google Scholar] [CrossRef]
- McCann, J.; Huebscher, M. Evaluation issues in autonomic computing. In Proceedings of the Grid and Cooperative Computing Workshops, Wuhan, China, 21–24 October 2004; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2004; Volume 3252, pp. 597–608. [Google Scholar] [CrossRef]
- Abuseta, Y.; Swesi, K. Design patterns for self-adaptive systems engineering. IJSEA 2015, 6, 11–28. [Google Scholar] [CrossRef]
- Gandrille, E.; Hamon, C.; Lalanda, P. Linking Reference and Runtime Architectures in Autonomic Systems. In Proceedings of the IST-115 Symposium on Architecture Definition and Evaluation, Toulouse, France, 13–14 May 2013; pp. 1–8. [Google Scholar]
- Ramirez, A.J.; Cheng, B.H. Design patterns for developing dynamically adaptive systems. In Proceedings of the 2010 ICSE Workshop on Software Engineering for Adaptive and Self-Managing Systems, Cape Town, South Africa, 3–4 May 2010; pp. 49–58. [Google Scholar] [CrossRef]
- Chen, S.L.; Chen, Y.Y.; Hsu, C. A new approach to integrate internet-of-things and software-as-a-service model for logistic systems: A case study. Sensors 2014, 14, 6144–6164. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.W.; Han, J.; Park, J.H.; Jeong, Y.S. DIaaS: Resource Management System for the Intra-Cloud with On-Premise Desktops. Symmetry 2017, 9, 1–17. [Google Scholar] [CrossRef]
- Atighetchi, M.; Ishakian, V.; Loyall, J.; Pal, P.; Sinclair, A.; Grant, R. Metrinome: Continuous Monitoring and Security Validation of Distributed Systems. CSIAC 2014, 2, 20–26. [Google Scholar]
- El-Kabbany, G.F.; Rasslan, M. Security Issues in Distributed Computing System Models. In Security Solutions for Hyperconnectivity and the Internet of Things, by Mohamed Eltayeb, Maurice Dawson Marwan Omar; IGI Global: Hershey, PA, USA, 2016; Chapter 9; pp. 211–259. [Google Scholar] [CrossRef]
- Mishra, K.S.; Tripathi, A.K. Some Issues, Challenges and Problems of Distributed Software System. IJCSIT 2014, 5, 4922–4925. [Google Scholar]
- Kumar, M.; Agrawal, N. Analysis of Different Security Issues and Attacks in Distributed System A-Review. IJARCSSE 2013, 3, 232–237. [Google Scholar]
- Berket, K.; Essiari, A.; Muratas, A. PKI-based security for peer-to-peer information sharing. In Proceedings of the IEEE Fourth International Conference on Peer-to-Peer Computing, Zurich, Switzerland, 27 August 2004; pp. 45–52. [Google Scholar] [CrossRef]
- Bing, Y.; Yanni, H.; Hanning, Y.; Zhou, X.; Xu, Z. A cost-effective scheme supporting adaptive service migration in cloud data center. Front. Comput. Sci. 2015, 9, 875–886. [Google Scholar]
- Masood, R.; Shibli, M.A.; Ghazi, Y.; Kanwal, A.; Ali, A. Cloud authorization: Exploring techniques and approach towards effective access control framework. Front. Comput. Sci. 2015, 9, 297–321. [Google Scholar] [CrossRef]
- Shi, W.; He, D. A security enhanced mutual authentication scheme based on nonce and smart cards. JCIE 2014, 37, 1090–1095. [Google Scholar] [CrossRef]
- Lounis, A.; Hadjidj, A.; Bouabdallah, A.; Challal, Y. Secure and scalable cloud-based architecture for e-health wireless sensor networks. In Proceedings of the IEEE 21 international conference on Computer communications and networks (ICCCN), Munich, Germany, 30 July–2 August 2012; pp. 1–7. [Google Scholar]
- Bonanno, F.; Capizzi, G.; Sciuto, G.L.; Napoli, C.; Pappalardo, G.; Tramontana, E. A novel cloud-distributed toolbox for optimal energy dispatch management from renewables in igss by using wrnn predictors and gpu parallel solutions. In Proceedings of the IEEE International Symposium on Power Electronics, Electrical Drives, Automation and Motion (SPEEDAM), Ischia, Italy, 18–20 June 2014; pp. 1077–1084. [Google Scholar]
- Yang, S.Y. A novel cloud information agent system with Web service techniques: Example of an energy-saving multi-agent system. Expert Syst. Appl. 2013, 40, 1758–1785. [Google Scholar] [CrossRef]
- Napoli, C.; Pappalardo, G.; Tina, G.M.; Tramontana, E. Cooperative strategy for optimal management of smart grids by wavelet rnns and cloud computing. IEEE Trans. Neural Netw. Learn. Syst. 2016, 27, 1672–1685. [Google Scholar] [CrossRef] [PubMed]
- TechTarget. X.509 Certificate of Public Key Infrastructure (PKI). Available online: http://searchsecurity.techtarget.com/definition/X509-certificate (accessed on 4 January 2016).
- Tseng, Y.M.; Yu, C.H. Towards Scalable Key Management for Secure Multicast Communication. Inf. Technol. Control 2012, 41, 173–182. [Google Scholar] [CrossRef]
- vmware.com. Available online: https://docs.vmware.com/en/VMware-vSphere/6.5/vsphere-esxi-vcenter-server-65-installation-setup-guide.pdf (accessed on 4 January 2016).
- Python. psutil 5.4.2, Pyhton. Available online: https://pypi.python.org/pypi/psutil (accessed on 1 September 2017).
- MarketIndex.com. Available online: https://www.marketindex.com.au/ (accessed on 1 February 2016).
- Lo, A.W.; Mamaysky, H.; Wang, J. Foundations of technical analysis: Computational algorithms, statistical inference and empirical implementation. J. Financ. 2000, 55, 1705–1765. [Google Scholar] [CrossRef]
- StockCharts.com. Available online: http://stockcharts.com/school/doku.php?id=chart_school:technical_indicators:introduction_to_technical_indicators_and_oscillators (accessed on 6 January 2016).
- Yahoo Finance(marketindex), Yahoo Finance API. Available online: https://www.marketindex.com.au/yahoo-finance-api (accessed on 5 February 2016).
- Yahoo.com, Yahoo Query Language. Available online: https://developer.yahoo.com/yql/ (accessed on 1 February 2016).
- Fletcher, C.W.; Dijk, M.V.; Devadas, S. A secure processor architecture for encrypted computation on untrusted programs. In Proceedings of the Seventh ACM Workshop on Scalable Trusted Computing, Raleigh, NC, USA, 15 October 2012; pp. 3–8. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author-Year | Autonomic Perspective | Control Loop | No of Layers | Building Blocks | Generic | Technique Used | Policy Format | Policy Storage |
|---|---|---|---|---|---|---|---|---|
| Mittal et al. 2014 [7] | IBM | Explicit | 4 | Autonomic Manager + Resources | Yes | Not Defined | Available | Knowledge Base |
| Ahuja & Dangey 2014 [1] | IBM | Explicit | 4 | Autonomic Manager + Resources | Yes | Policy Based | Not Available | Knowledge Base |
| Kumar & Naik 2014 [8] | IBM | Explicit | 4 | Autonomic Manager + Resources | Not Defined | Rule-Based | Algorithm | Implicit |
| Shuaib et al. 2011 [13] | IMD | Explicit | 3 | Layers | Yes | Rule-Based | Rules | MIB |
| Nzekwa et al. 2010 [16] | Data stream model & SOA | Implicit | 1 | Agents | No | Data-Oriented Model | Implicit | Implicit |
| Bazerra et al. 2009 [17] | PB Model | Explicit | 3 | Modules | Not Defined | Policy-Based | XML-Based | Autonomic Database |
| Okon & Asagba 2014 [4] | IBM | Explicit | 1 | Modules | Yes | Policy/Rule | Not Defined | Not Defined |
| Input: A registration/connection/interaction request. Output: A secure connection for communication between the AM and MR. Start 1. Receive AM request at the MR touchpoint 2. Identify request type a) If (registration based request) Get registration credentials //Registrar is activated If (credential correct) Enter AM_Id in the AuthenticationTable Store SensorId-MonitorId and ExecutorId-EffectorId relationships in AuthorizationTable Allot login credentials Forward request with login credentials to (b) Else Display Error ‘Invalid Registration Credentials’ End b) If (Login-credential-based request) Get login credentials //Authenticator in action If (Authentic credentials) Generate token for further communication Forward as token-based request to (c) Else Display Error ‘Invalid Login Credentials’ End c) If (Token-based request) Get token //Validator is triggered If (valid token) Grant access to the touchpoint End Else Display Error ‘Invalid Token’ End End |
| Input: The value of context attributes from sensors. Output: System state is readjusted accordingly. Start 1 - Sensor gets context attribute value on event or periodically - Sensor sends context attribute’s reading to monitor 2 - Monitor reads thresholds for context attributes from threshold table If (Threshold violation) Log the violation in system state log Notify the violation to Analyser Else Log the state change in system state log End 3 - Analyser reads violations from system state log - Analyser determines the cause of violation by consulting symptoms repository. If (cause of violation determined) Send adaptation request to Planner Else Display/Log ‘violation occurred’ on screen/logFile End 4 - Planner interprets adaptation request If (policies exist for adaptation request) Prepare change plan from policies Send List of actions to Executor Else Display/Log adaptation request with a message ‘contact system expert’ End 5 - Repeat until all change plans executed by Executer - Send a change plan with parameter values to concerned Effectors - Effectors set attributes values in CAs - Effector send acknowledgement to Executor End 6 - Executor updates the system state log End |
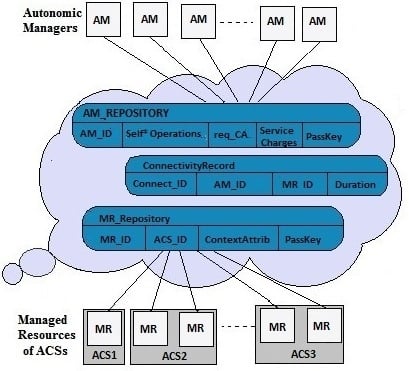
| (1) AM registers itself with the AM_Repository in the Autonomic_Cloud by sending a registration request. |
| (2) ACS asks for available self-management services from the Autonomic_Cloud and selects a required service. |
| (3) ACS registers itself and its MR(s) with the MR_Repository in the Autonomic_Cloud by a sending registration request. |
| (4) Autonomic_Cloud links the AM with the MR of the ACS by storing a record in the ConnectvityRecord table. |
| (5) ACS uses the self-* service provided by the AM with a pay-per-use policy. |
| (6) Autonomic_Cloud keeps track of the services provided by AM and used by the ACS to facilitate its pay-per-use policy. |
| Given period's close-ups and close-downs |
| Most recent closing price |
| Lowest and highest of previous 14 trading sessions (L14, H14) |
| High, low and closing stock prices |
| Volume traded |
| Relative Strength Index (RSI) |
| Stochastic Oscillator (SO) |
| William’s % R |
| Money Flow Index (MFI) |
| Moving Average Convergence Divergence (MACD) |
| Condition | Symptom | Action |
|---|---|---|
| RSI < 30 | Indicates stock oversold, showing buy signal | Buy shares |
| SO-%D < 20 | Indicates oversold, price will increase in near future | |
| MFI < 20 | Shares oversold | |
| %R < −80 | Buy signal | |
| MACD above the signal line | Indicates buy signal | |
| RSI > 70 | Indicates stock overbought, showing sell signal | Sell shares |
| SO-%D > 80 | Indicates overbought, price will decrease in near future | |
| %R > −20 | Sell signal | |
| MFI > 80 | Shares overbought | |
| MACD below the signal line | Indicates sell signal |
| Security Parameters | Attack Cases | Vulnerability Involved | ACS with Single AM (AM and MR Running on Same Machine) | ACS with Single AM (AM and MR Running on Different Machines) | ACS with Multiple AM (AM and MR Running on Same Machine) | ACS with Multiple AM (AM and MR Running on Different Machines) | SSE-ACS Paradigm Based on the ACS System |
|---|---|---|---|---|---|---|---|
| Access Control (Authorization, Authentication) | Wrongly pretending to be someone else | Vulnerability-i | X | ⦸ | X | ⦸ | ☑ |
| Confidentiality | Unauthorized Access | Vulnerability-i Vulnerability-ii | XX | XX | ⦸⦸ | ⦸⦸ | ☑☑ |
| Eavesdropping | Vulnerability-iii | X | ⦸ | X | ⦸ | ☑ | |
| Snooping | Vulnerability-iii | X | ⦸ | X | ⦸ | ☑ | |
| Integrity | Denial of Receipt | Vulnerability-i Vulnerability-ii | XX | XX | ⦸⦸ | ⦸⦸ | ✓ |
| Repudiation | Vulnerability-i Vulnerability-ii | XX | XX | ⦸⦸ | -,⦸ ⦸⦸ | ✓ | |
| Spoofing | Vulnerability-iii | X | ⦸ | X | ⦸ | ☑ | |
| Modification | Vulnerability-iii | X | ⦸ | X | ⦸ | ☑☑ | |
| Unauthorized Access | Vulnerability-i Vulnerability-ii | XX | XX | ⦸⦸ | ⦸⦸ | ☑☑☑ | |
| CPU overload | Vulnerability-iii | XX | XX | ⦸⦸ | ⦸ ⦸⦸ | ☑ | |
| Communication Errors | Vulnerability-iii | X | ⦸ | ⦸⦸ | ⦸ | ☑ | |
| Availability | Denial of Receipt | Vulnerability-iii | XX | - | X | - | ✓ ☑☑☑ |
| Delay | Vulnerability-iii | X | ⦸ | X | ⦸ | ||
| Repudiation | Vulnerability-i Vulnerability-ii | XX | XX | - ⦸ | -,⦸ ⦸⦸ |
| Parameter | Without Security (IBM-ACS) | With Security (SSE-ACS) | Comments |
|---|---|---|---|
| Attack Vector | Local | Local | The attacked point is a resource touchpoint and the vulnerability is exploited by autonomic managers. In the case of an existing model, the unauthorized AM succeeds. In SSE-ACS, the attack fails. |
| Attack Complexity | Low | High | With no authentication, specialized access condition does not exist. The attacker obtains repeatable success against the vulnerable component. With an authentication layer, the attack is unsuccessful. |
| Privileges Required | Low | High | In the existing model, an attacker presents itself as a privileged component and exploits the system. Authentication layer and privilege maintenance in SSE-ACS makes the attack unsuccessful. |
| User Interaction | None | None | The vulnerability is exploited by an AM. User interaction is not required for the attack. |
| Scope | Changed | Changed | The vulnerability exploitation is initiated by an unauthorized autonomic manager. The under-attack component is a touchpoint and the affected component is the resource. In the existing model, the attack succeeds, whereas the SSE-ACS prevents the attack. |
| Confidentiality Impact | High | Low | In the existing model, access to restricted information is obtained from the attacked resource. The disclosed information may present a serious impact. In SSE-ACS, authentication restricts the attack and hence the confidentiality impact is low. |
| Integrity Impact | High | None | In the existing model, the absence of authentication causes the loss of confidentiality, as all resources under the touchpoint are disclosed to the attacker. In SSE-ACS, the authentication layer controls unauthorized access and hence the integrity impact is cleared. |
| Availability Impact | High | Low | In the existing model, the attacker AM denies access to resources under the impacted touchpoint. The RAV controls access of a resource and hence the availability impact is low in SSE-ACS |
| Attack vector without authentication: CVSS:3.0/AV:L/AC:L/PR:L/UI:N/S:C /C:H/I:H/A:H CVSS Score:8.8 | Attack vector with authentication: CVSS:3.0/AV:L/AC:H/PR:H/UI:N/S:C/C:L/I:N/A:L CVSS Score:3.9 | ||
| Process Name | No. of Times Process Was Activated in One Hour | Process Action Time (AVG) | AVG CPU %Age Usage | AVG Memory Usage (KBs) |
|---|---|---|---|---|
| serverFarm & loadBalancingManager | 8 | 5 s | 4.42 | 916 |
| Forecast Manager | 5 | 2 s | 1.31 | 773 |
| serverApp Protection Manager | 2 | 90 s | 8.55 | 596 |
| Database Connectivity Manager | 2 | 110 s | 14.65 | 926 |
| Logbase Manager | 12 | 20 s | 4.54 | 1609 |
| Total | 33.47 | 4820 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaleel, A.; Arshad, S.; Shoaib, M. A Secure, Scalable and Elastic Autonomic Computing Systems Paradigm: Supporting Dynamic Adaptation of Self-* Services from an Autonomic Cloud. Symmetry 2018, 10, 141. https://doi.org/10.3390/sym10050141
Jaleel A, Arshad S, Shoaib M. A Secure, Scalable and Elastic Autonomic Computing Systems Paradigm: Supporting Dynamic Adaptation of Self-* Services from an Autonomic Cloud. Symmetry. 2018; 10(5):141. https://doi.org/10.3390/sym10050141
Chicago/Turabian StyleJaleel, Abdul, Shazia Arshad, and Muhammad Shoaib. 2018. "A Secure, Scalable and Elastic Autonomic Computing Systems Paradigm: Supporting Dynamic Adaptation of Self-* Services from an Autonomic Cloud" Symmetry 10, no. 5: 141. https://doi.org/10.3390/sym10050141
APA StyleJaleel, A., Arshad, S., & Shoaib, M. (2018). A Secure, Scalable and Elastic Autonomic Computing Systems Paradigm: Supporting Dynamic Adaptation of Self-* Services from an Autonomic Cloud. Symmetry, 10(5), 141. https://doi.org/10.3390/sym10050141