The recent advancement of digital imaging has stimulated a tremendous growth in the use of visual information for communication [
1,
2,
3]. Therefore, it is essential to develop reliable automatic image quality assessment (IQA) measures for the evaluation of results of image processing methods for the acquisition, storage, transmission, restoration, or enhancement. The main role of IQA measures is to provide the objective assessment and replace cumbersome tests with human subjects [
4]. The IQA measures are divided into three categories, based on the availability of reference images [
1,
5,
6]:
full-reference (FR),
reduced-reference (RR), and
no-reference (NR) approaches. In an FR-IQA measure, a distorted image is compared with its reference image, while only some statistics of the distortion-free image are available in the RR-IQA case. The peak signal-to-noise ratio (PSNR) is often used as an FR-IQA model due to its simplicity. However, it weakly correlates with human perception [
5]. Therefore, more suitable measures have been developed that employ structural information [
7], image statistical properties [
8], visual saliency maps [
9,
10], structure and contrast changes [
11], phase congruency [
12], distortion distribution [
13], or other measures [
14,
15]. The RR-IQA measures use only a part of reference data [
16].
In this work, the discussion is confined to NR approaches, which are considered challenging and highly desired due to their applicability in absence of reference images. Many measures are devoted to evaluating the perceptual quality of images distorted by Gaussian white noise, JPEG compression, contrast change, or Gaussian blur [
17,
18]. Since their practical application is limited and based on the prior knowledge of distortion types, general-purpose NR methods have been developed. Many of them assume that statistical regularities of natural images can be reflected by natural scene statistics (NSS), as the Human Visual System (HVS) is very sensitive to local regularities [
19]. Consequently, NSS characteristics of distorted images are used for the IQA in many domains, e.g., Discrete Cosine Transform (DCT) [
20], wavelet [
21,
22], or spatial [
23]. A variety of gradient-based features are often employed to model NSS [
24]. Furthermore, the use of perceptual features [
25,
26,
27] or image patches [
28] can be found in the literature.Since the supervised learning bridges image statistics with the perceptual quality, it is often applied to obtain a model used for the quality prediction. For the learning, the Support Vector Regression (SVR) [
20,
21,
23,
27], neural networks [
24], or random forests [
29] are applied. In methods that do not use supervised learning, distortion types are modeled with a set of centroids of quality levels or NSS from multiple cues [
30,
31]. Another direction is to employ a pseudo-reference image which is created and compared with a distorted image with blockiness, sharpness, and noisiness metrics [
32]. Recently, many NR-IQA approaches which use deep neural network (DNN) architectures have been introduced. They merge the feature extraction and quality prediction steps. However, they suffer from a small number of training examples available in IQA benchmark datasets or use complex architectures that are devoted to image recognition tasks. To overcome these limitations, most of them use image patches [
33,
34], train models using FR-IQA measures instead of subjective scores [
34,
35], or perform fine-tuning to adopt an architecture to the IQA [
36]. Interestingly, some DNN-based approaches use features introduced in earlier methods [
35].
The HVS is sensitive to local structures, which are often described using local binary patterns (LBP) and gradient-based statistics. However, a spatial distribution of LBP may not be able to capture more complex structures [
37]. Thus, statistics extracted from gradient maps often occur in conjunction with other approaches to improve the IQA performance [
27,
38]. Such techniques use global distributions of gradient magnitude maps [
25], relative gradient orientations or magnitude [
24,
39].
To describe an image and efficiently take into account local gradient orientations, Histogram of Oriented Gradients (HOG) descriptor can be used [
40]. However, the HOG produces high-dimensional feature vectors, which are devoted to object recognition tasks due to their discriminative capabilities. Consequently, considering its application to the IQA, it is worth noticing that an original image content of an assessed image, which is described using the HOG, may influence the quality prediction performance. The descriptor also strongly depends on the size of processed image blocks and the described neighborhood. Since the image gradient orientation captured by the HOG and its relevance for the NR-IQA is interesting and still seems largely uninvestigated, in this paper, a novel no-reference technique for the image quality assessment with a
SEt of Histogram of Ori
Ented G
Radients (HOG) descriptors [
40] (
SEER) is introduced. In the SEER, in contrary to a widely accepted application of the HOG, an image is described by a set of descriptors which are obtained taking into account different local neighborhoods. In other words, each feature vector is composed of histograms of gradient orientations calculated for image regions (cells), which are arranged together with their neighboring cells in blocks. The descriptors in the set consider different sizes of image regions and blocks. Then, each descriptor is characterized by a histogram, seen as perceptual features. In a typical image recognition system, high-dimensional descriptors are often compared with each other. However, to apply the HOG to the NR-IQA, such comparison cannot take place since a distortion-free image and its descriptors are unavailable. Furthermore, the feature vectors in the HOG are designed to discriminate objects in images. Therefore, in the SEER, to train the SVR model, statistics of descriptors are employed instead of high-dimensional vectors. To improve the IQA performance, the method processes luminance and chrominance channels of an image, as well as their high-order derivatives.
The extensive experimental evaluation of the introduced NR measure against the related state-of-the-art techniques on six popular large-scale IQA benchmark datasets, which contain various distortion types, demonstrates that the SEER provides the higher quality prediction accuracy than compared NR models and is consistent with subjective scores. The method was evaluated against hand-crafted and deep learning NR measures.
The rest of this paper is arranged as follows.
Section 1 reviews previous work on NR-IQA and
Section 2 describes the proposed measure.
Section 3 presents and discusses the experimental results obtained for the SEER and the related measures on TID2013 [
41], TID2008 [
42], CSIQ [
43], LIVE [
7], and LIVE In the Wild Image Quality Challenge (LIVE WIQC) [
44] datasets. Finally,
Section 4 concludes the paper.
1. Related Work
In this section, a brief review of previous studies closely related to the introduced work is presented.
The introduced SEER is based on gradient processing. However, there are many works which employ other features. For example, Moorthy and Bovik proposed a two-stage framework, in which distortion type is predicted and then an image is evaluated [
21]. Saad et al. trained a probabilistic model with DTC-based NSS as a single-stage framework [
20]. The generalized Gaussian distribution used for capturing NSS with locally normalized luminance coefficients is employed in Blind/Referenceless Image Spatial QUality Evaluator (BRISQUE) [
23]. A scheme which combines artifact-specific metrics and employs a generalized Laplace distribution of the difference of two adjacent pixel values in an image was introduced by Fang et al. [
45]. The measure uses three
transductive k-nearest neighbor algorithms to map the metrics into subjective scores. Normalized gradients magnitude and Laplacian of Gaussian responses were jointly used by Xue et al. [
25]. Le et al. [
46], in turn, used a histogram of local binary patterns (LBP) obtained for a gradient map. They also used LBP extracted from texture and structural maps [
38]. A more advanced gradient-based image descriptor, Speeded-Up Robust Features (SURF), is employed in the measure proposed by Oszust [
27]. In that work, the sample mean, standard deviation, entropy, skewness, kurtosis, and histogram variance for the assessed image, the image filtered with Prewitt operators, and their SURF features are used. In Optimized filteRing with binAry desCriptor for bLind imagE quality assessment technique (ORACLE) [
47], in turn, a data-driven filtering based on the appearance of Features From Accelerated Segment Test (FAST) in grayscale images is proposed. The histograms of Fast Retina Keypoint (FREAK) descriptors for keypoints detected in filtered images are used to characterize the assessed content. The sample mean, standard deviation, and histogram variance of raw local patches describing FAST keypoints in images filtered with the bilaplacian operator in the YCbCr color space are used in stATistics of pixel blocks of local fEatuRes (RATER) measure [
48]. Unlabeled data for learning Gabor features and modeling an image using the soft-assignment coding with the max pooling are employed in [
49]. In another method that uses a codebook, High Order Statistics Aggregation (HOSA) [
28], K-means clustering of normalized image patches and their description with the low and high order statistics are considered. The HOSA uses the soft assignment for an image representation and trains the SVR model for the prediction. Screen content images were assessed by Lu and Li [
50] using orientation selectivity mechanism for extraction of orientation features.
Gradient-based techniques are often employed to provide effective IQA measures [
11,
24,
25,
46]. These measures use global distributions of gradient magnitude maps [
25], relative gradient orientations or magnitude [
24,
39]. For example, in the Oriented Gradients Image Quality Assessment (OG-IQA) index, in which a correlation structure of image gradient orientations [
24] is employed to train a quality model with AdaBoosting-backpropagation neural network. In that work, histograms of gradient magnitude, relative gradient orientation, and relative gradient magnitude maps are used and characterized using the histogram variance. These gradient-based measures do not take into account local gradient distributions. Such distributions are used in the HOG to provide a feature vector composed of 1-D histograms of gradient directions of pixels within image regions (cells) [
40]. In the literature, there are FR-IQA measures which compare a reference image with the distorted image, calculating a distance between corresponding HOG vectors [
51] or produce a weight map for the FR SSIM index [
52]. In the technique proposed by Ahn et al. [
18], in turn, blurred images are assessed by comparing HOG vectors approximated by a random sample consensus set (RANSAC).
Taking into account the referred works, it can be stated that the effectiveness of the HOG in NR image quality prediction remains largely uninvestigated, and a promising application of this descriptor to the NR-IQA is introduced for the first time in this paper.
2. Proposed NR Measure
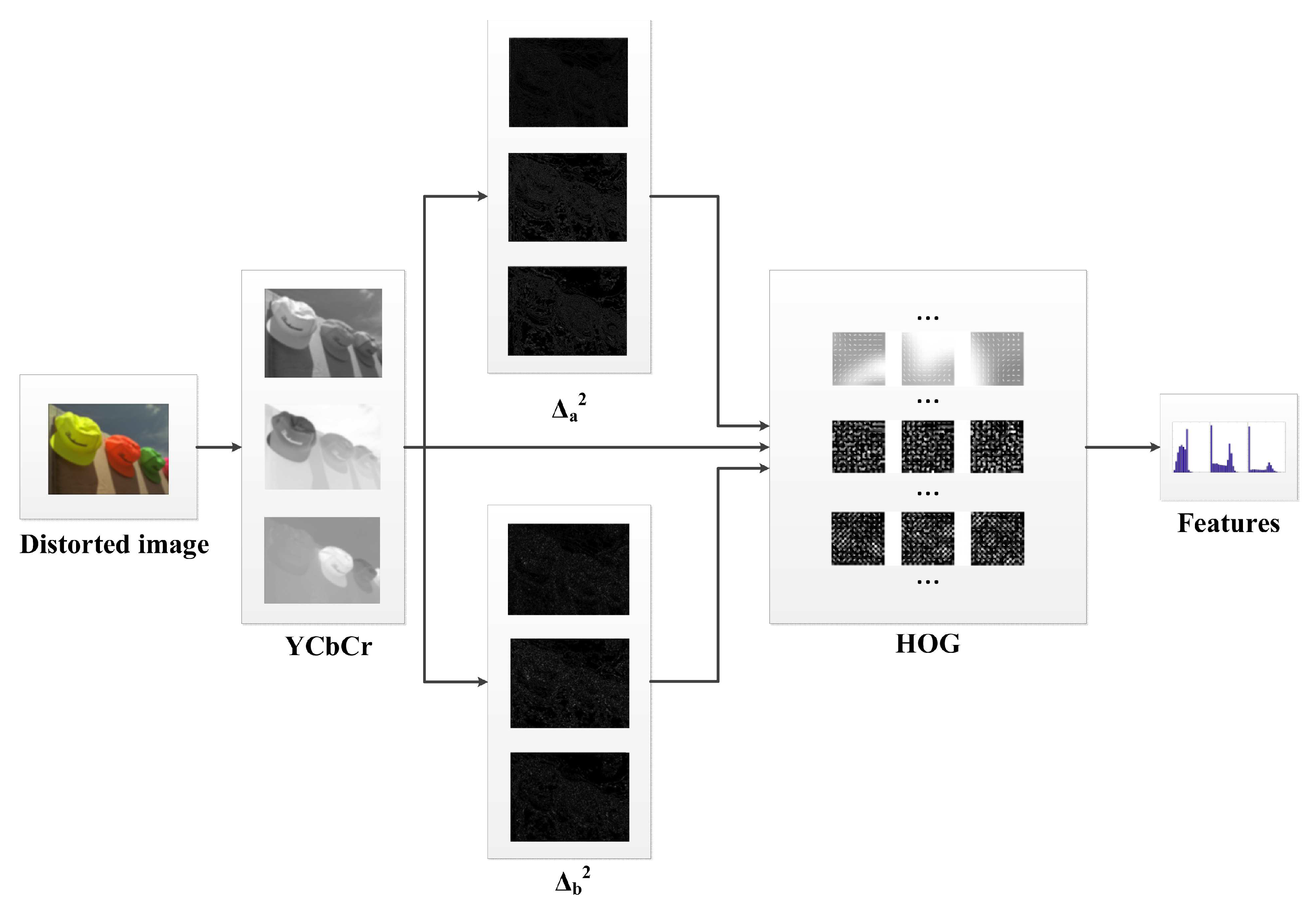
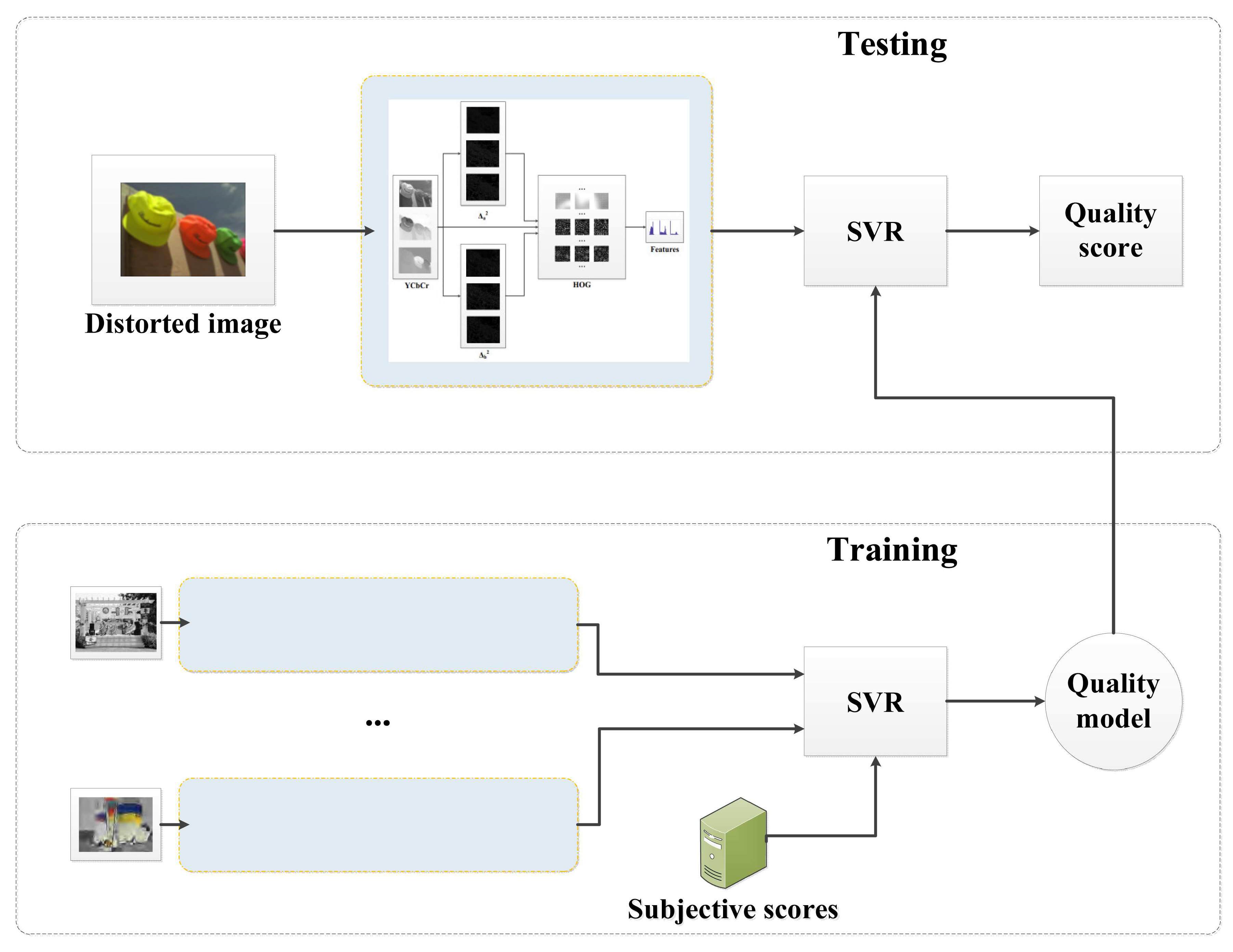
In this section, the feasibility of using the HOG for the NR-IQA is investigated. The image processing steps in the SEER are explained in details in
Figure 1, while in
Figure 2 the block diagram of the proposed method is shown. As illustrated, the measure uses the HOG and provides feature vectors for luminance and chrominance channels of a distorted image, as well as for channels filtered using two bilaplacian operators. The measure uses differently sized image regions and the way the regions are combined together in the HOG descriptors. In the SEER, the
K HOG features are obtained for each channel and their histograms are used to train a quality prediction model.
2.1. Local Gradient Orientations
The HVS is sensitive to variations in local structures [
19,
39]. Such sensitivity and the resultant subjective perception of an image are related to local semantic structural information which forms primitives in V1 [
39]. Local distributions of gradients are used in the HOG to characterize an image [
40]. Specifically, a 2D image
I is convolved with 1-D Prewitt filters in the horizontal (
) and vertical (
) directions to obtain gradients. Then, the edge magnitude is calculated as
, and its orientation is obtained as
. The orientation is then transformed to
degrees range, ensuring that the opposite directions are assigned the same angle. The
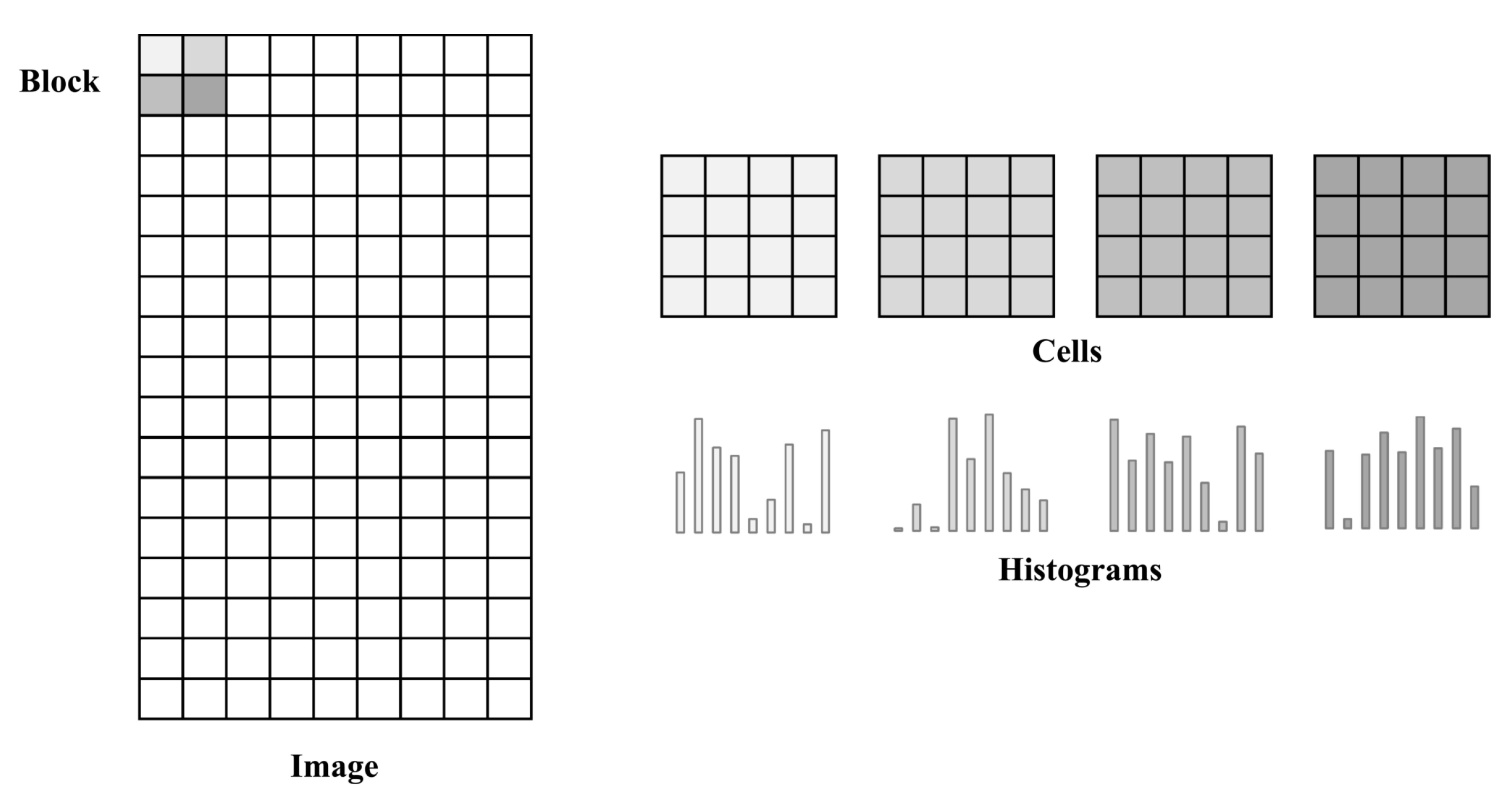
I is divided into adjacent, non-overlapping cells of size
and, for each cell, the gradient orientations are binned into
o bins with votes based on their magnitudes. To reduce aliasing, each pixel contributes to adjacent bins a fraction of its gradient magnitude. To reduce contrast changes, in turn, histograms for cells are normalized. Since gradient magnitudes carry the information about the described object in a region, to preserve the information, cells are grouped into overlapping blocks. There are
cells in each block. Then,
cell histograms are concatenated and normalized using
-norm. Finally, the obtained features for blocks are concatenated and normalized. This normalization makes the descriptor invariant against overall image contrast [
40]. The division of an image into blocks and cells is shown in
Figure 3. The number of overlapping cells between adjacent blocks is equal to
, where
. The number of dimensions in the resulting feature vector
D is calculated as:
where
M and
N denote the height and width of an image, respectively. If
is equal to
, or
to
, the length of the vector is calculated without the subtraction in the denominator. For an exemplary image
, the lengths of the feature vectors for the descriptors
and
, calculated with
, are 2,340,900 and 580,644, respectively. Such high-dimensional feature vectors are designed for robust object recognition and they cannot be used to train a quality model with the SVR. Therefore, it is shown in this paper that their histograms are sensitive to image degradation, consequently leading to the efficient application of the HOG to the NR-IQA.
2.2. Feature Extraction
In the introduced NR measure, a distorted RGB image is converted to the YCbCr color space. The YCbCr color space is specified in ITU-R BT.601 and selected as the preferred format for video broadcasting with the efficient use of the channel bandwidth [
53]. Following the finding that the image filtering can enhance the image quality prediction of NR-IQA measures [
47] and the bilapacian operator can be used to capture more information about described image regions for the IQA than it can be achieved with other filters [
48], the SEER uses the YCbCr color space and filters color channels of the assessed image with two bilaplacian kernels
and
. The bilaplacian is obtained by convolving two Laplacian kernels. The following kernels are used:
Finally, and , where “*” denotes the convolution. Consequently, a filtered channel (e.g., ) is obtained using the convolution .
To show that the HOG technique provides different feature vectors for YCbCr components,
Figure 4 presents an exemplary distorted image and the visualization of the HOG obtained for a small square image patch. For the visualization, a grid of rose plots is used. In the grid, each rose expresses the distribution of gradient orientations within a cell. The length of a petal indicates the contribution of a given orientation within the cell histogram and displays two times
o petals. As presented, the feature vectors for the descriptor
have different shapes for different YCbCr channels. The figure also contains image patches filtered with two used bilaplacian operators
and
.
As shown in
Figure 4, the differences between descriptors for channels seem to justify the need for their joint application in order to extract more information about the described image regions. Furthermore, since the size of a local structure in an image cannot be determined in advance, the method uses several HOG descriptors with cells and blocks of different sizes. The HOG descriptor produces high-dimensional features, depending on its focus on a local appearance of objects within an image. Thus, in this paper, each obtained feature vector is characterized using its histogram
. The histogram is used since it captures distributions of natural images [
24]. The values in the feature vectors for images are in the range
. Therefore, the number of bins in the histogram and its variance is calculated by dividing the range into
d intervals and using them for the determination of bin centers.
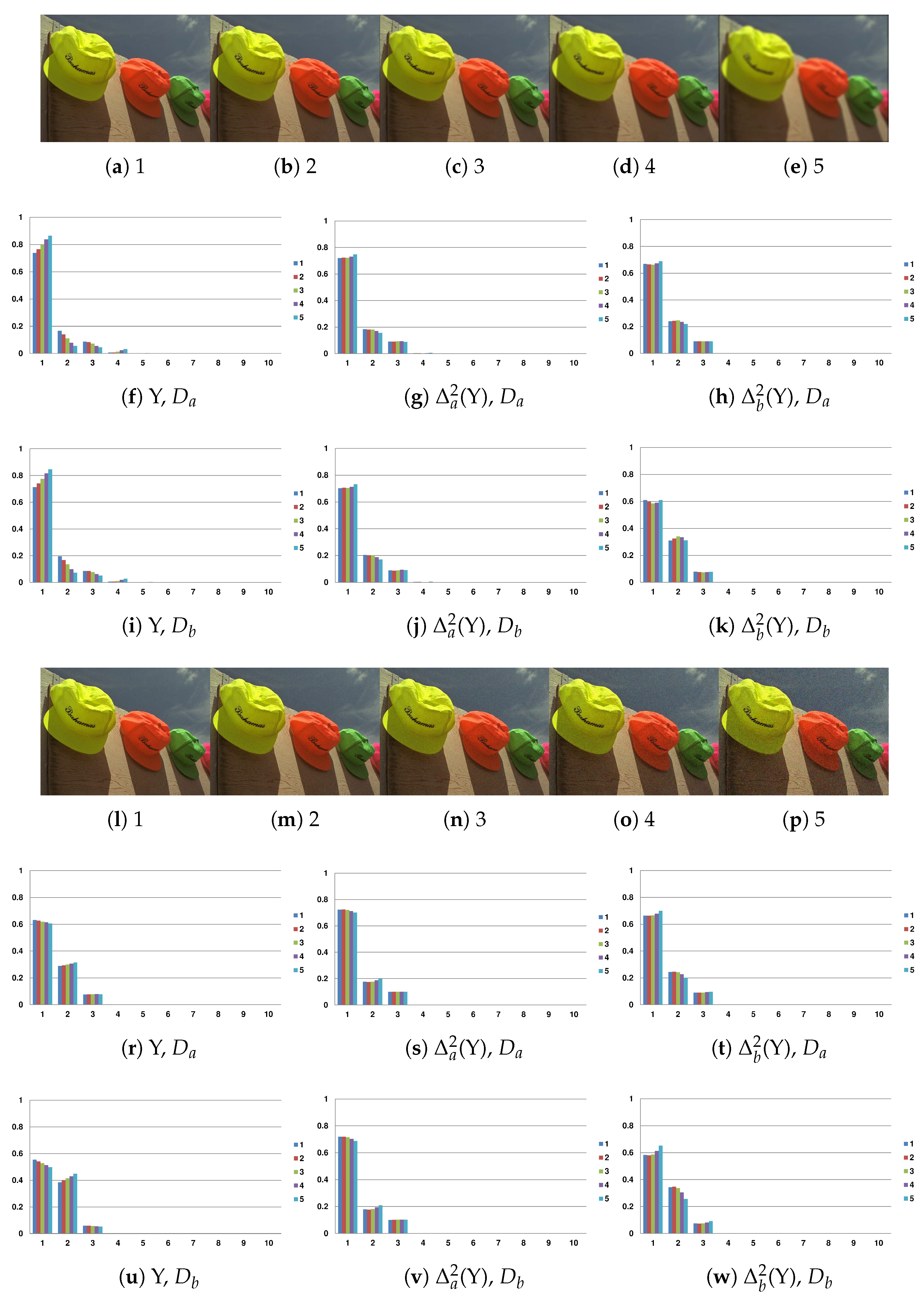
To illustrate that the used statistics can characterize the distortion severity of images, they are computed for two sequences of images distorted with Gaussian blur and Gaussian noise [
41]. Here, the descriptors
and
are used. For the computation of the histogram, 10 bins are applied. As shown in
Figure 5, the histogram responds consistently to the distortion type and its severity.
In the SEER, for YCbCr channels and channels filtered with two bilaplacian operators, feature vectors for the HOG descriptors are obtained and concatenated. This can be written as
,
,
,
,
,
,
or
, where
. There are nine HOG descriptors per
ith image, with different
C and
B. Hence, the HOG descriptors for the
I can be written as
,
,
. Finally, the perceptual feature vector is obtained as
,
,
,
,
. The parameters of HOG descriptors used in the SEER are discussed in details in
Section 3.6. Since the distortions affect images across scales [
23], the method also processes an input image which is downsampled by a factor of two to improve the quality prediction. Finally, the concatenated histograms for an input image and its downscaled version are used to train the SVR model. The SVR model which maps the vector
into subjective ratings
is obtained using LIBSVM library [
54]. Here, as in many NR techniques [
24,
46], the radial basis function (RBF) kernel is employed. Finally, given an input image, the model predicts its quality and provides the objective score
Q.
3. Experimental Results and Discussion
3.1. Datasets and Protocol
In this work, to evaluate an NR metric, six publicly available large IQA datasets were used: TID2013 [
41], TID2008 [
42], CSIQ [
43], LIVE [
7], LIVE WIQC [
44], and the Waterloo Exploration Database (WE) [
55]. The first four datasets are typically selected to evaluate recently introduced measures [
34,
56,
57], while the WE dataset, similar to the Group MAD Competition [
58,
59], is tied with a novel evaluation methodology. The LIVE WIQC dataset contains subjective scores collected in an uncontrolled manner using the Amazon Mechanical Turk. However, it contains images captured with a mobile camera and can be used for the evaluation of NR measures using real images. The TID2013 dataset is the largest and the most demanding public IQA benchmark. It consists of 3000 distorted images and covers 24 image distortion types. The other datasets contain only half (TID2008) or less than one-third of the number of the images in TID2013 (CSIQ and LIVE). The LIVE dataset contains popular distortions, such as JPEG compression, JPEG2000 compression, Gaussian blur, white noise, or simulated fast fading Rayleigh channel. It is worth noticing that some distortion types in TID2013 can be regarded as multiple, e.g., lossy compression of noisy images. Interestingly, most existing general-purpose NR measures are designed to provide an acceptable performance on the LIVE [
32]. As shown in
Section 3.3, some of them experience a drop in the performance on datasets that contain more diverse distortions. The datasets contain high-quality images, their distorted images, and related subjective scores. The subjective scores obtained in tests with human subjects are denoted as mean opinion scores (MOS) or differential MOS (DMOS). The WE dataset contains images distorted with JPEG compression, JPEG2000 compression, white Gaussian noise, and Gaussian blur. However, it does not contain subjective scores. The datasets are characterized in
Table 1.
To measure the consistency of the prediction results provided by an IQA measure with subjective ratings, the following four indices were considered [
60]: the Spearman’s Rank Correlation Coefficient (SRCC), Kendall Rank order Correlation Coefficient (KRCC), Pearson linear Correlation Coefficient (PCC), and Root Mean Square Error (RMSE). PCC and RMSE were calculated after a nonlinear mapping between the vectors of objective and subjective scores,
and
(MOS or DMOS), respectively. For the mapping, the following function was used [
60]:
where
are parameters of the fitted regression model,
Q is the objective score, and
is the fitted score.
The evaluation protocol associated with the WE dataset requires: the calculation of pristine/distorted image discriminability test (
D-test), listwise ranking consistency test (
L-test), and pairwise preference consistency test (
P-test) [
55]. The
D-test uses predictions of a model to classify distorted and pristine images. Larger values of
D denote better separability. The
L-test, in turn, adopts the average SRCC to quantify the ranking consistency among distorted images. Finally, the
P-test compares preference predictions of IQA models on pairs of images whose quality is clearly discriminable [
55], dividing the number of image pairs with correctly predicted concordance by the number of image pairs. The values obtained in tests lie in
.
3.2. Model Training
The proposed method should be trained to obtain the SVR model used for the quality prediction. Therefore, a typical protocol used for the validation of NR techniques was adopted, in which each image dataset was divided into disjoint training and testing subsets, i.e., distorted images of 80% reference images were used in training and the remaining 20% of images were used for testing [
28,
32,
46]. Then, to avoid bias and fairly compare a measure with other measures, the performance of each method was reported in terms of the median values of SRCC, KRCC, PCC, and RMSE over 100 training-testing iterations [
61].
3.3. Performance on Individual Datasets
The performance of the presented NR measure was compared with those of the related state-of-the-art techniques. The following NR measures were considered: (i) HOSA [
28]; (ii) BPRI [
32]; (iii) BRISQUE [
24]; (iv) IL-NIQE [
31]; (v) SISBLIM [
62]; (vi) OG-IQA [
24]; (vii) GWH-GLBP [
46]; and (viii) RATER [
48]. Among NR measures, which, to some extent, are similar to the SEER, the RATER, HOSA, and IL-NIQE assess color images, while the OG-IQA incorporates image gradients. The GWH-GLBP and SISBLIM are designed for the evaluation of images with multiple distortions. The RATER and BPRI are recently introduced general-purpose measures. However, due to distortion-specific steps in BPRI, its range of applicability is larger than those of distortion-specific measures, but it seems to be confined to several distortion types. As reported by Zhang et al., the IL-NIQE is superior to the BLIINDS2, DIIVINE, CORNIA, NIQE, BRISQUE, and QAC [
31]. The HOSA, in turn, is reported to outperform the GM-LOG, BRISQUE, or IL-NIQE [
28].
The experimental evaluation was conducted on five IQA datasets using the protocol shown in
Section 3.1. For the fair comparison, the parameters of all learning-based techniques were obtained aiming at their best performance [
25,
31]. The methods were run using publicly available implementations. For the SVR, the popular LIBSVM library was used [
54]. The parameters of AdaBoosting BP neural network in the OG-IQA were also determined. The methods that do not require training (BPRI, IL-NIQE, and SISBLIM) were evaluated using the defined testing subsets of images in datasets. The SEER was run with
o = 36 and
d = 30 (see
Section 3.6).
Table 2 summarizes the results on IQA datasets, where the best result for each performance index is written in bold. The table also contains average values for SRCC, KRCC, and PCC. The RMSE was not averaged due to the different range of values in the benchmarks.
As demonstrated, the introduced NR measure outperformed the state-of-the-art measures on four IQA benchmarks, i.e., the TID2013, TID2008, CSIQ, and LIVE. In the case of the LIVE WIQC dataset, the RATER and BRISQUE were slightly better than SEER, which was the third-best measure. Remarkably, the proposed measure had the highest average performance across the datasets, which confirms its usability.
To determine whether the relative performance differences between the measures are statistically significant, the Wilcoxon rank-sum test was used. The test measures the equivalence of the median values of independent samples with a 5% significance level. Here, the null hypothesis assumes that the SRCC values of compared metrics are drawn from a population with equal medians. The results are shown in
Table 3, where the symbols “−1”, “0” and “1” denote that the IQA measure in the column was statistically better with a confidence greater than 95%, indistinguishable, or worse than the SEER on a given IQA dataset, respectively. The findings are consistent with conclusions drawn from the previous experiments, i.e., the SEER was statistically better than other measures on the TID2013, TID2008, and LIVE. Taking into account the results for the CSIQ, the SEER was on pair with the RATER, as well as on pair with the RATER and BRISQUE for the LIVE WIQC.
The measures were evaluated using the methodology associated with the WE database [
55]. Here, the BRISQUE and HOSA were compared with the SEER. Since the IL-NIQE is reported to provide superior performance using this methodology [
55], it is also added to the comparison. The results reported for BRISQUE, HOSA, and IL-NIQE in [
55] are presented in
Table 4. The SEER, as other techniques, was trained on LIVE dataset. Interestingly, the IL-NIQE, which is much less correlated with subjective scores on LIVE than other measures, yielded encouraging
L and
P values. This may indicate that the relationship between distortion types, their levels, and used tests in the used methodology may require further attention, leading to its possible improvement. For example, the
P values of the measures whose performances on the databases with subjective scores were significantly different seem to be close to its upper limit. Furthermore, the assumption that image quality degrades monotonically with the distortion levels may not be true for all distortion types and content of images, which may influence the results of the
L-test [
55]. However, it can be seen that all measures provided acceptable performance in the tests on the WE database.
The comparative evaluation of the SEER with state-of-the-art NR methods that use DNN or other neural networks (NN) architectures was based on published results. Due to the large complexity of the models, and the unavailability of learning source codes for some of them, such comparison is very popular. Consequently, many papers report the performance of measures on the basis of results obtained in 10 random training–testing splits on only one or two IQA benchmarks. Furthermore, the coherent comparison of DNN-based methods is often impeded by the exclusion of some distortion types, which can make the use of the largest IQA datasets, such as the TID2013 or TID2008, superfluous.
Table 5 contains the comparison of published median values of SRCC and PCC for NN-based NR methods with those obtained for the SEER in 10 training–testing splits. Other performance indices, i.e., KRCC and RMSE, are seldom reported in the referenced works. The results for the TID2008 are not presented since the referenced works were not evaluated on this dataset. As reported, the SEER clearly outperformed other measures on the most demanding datasets, such as the TID2013 or CSIQ. The NN-based measures were better than the SEER on the LIVE dataset. The worse results of the compared models on the datasets that contain considerably more distortions can be attributed to the lack of a sufficient number of training samples or imperfections of used architectures [
36,
57]. It can be concluded that the introduced hand-crafted NR measure is highly competitive to the recently introduced techniques based on DNN or NN architectures.
3.4. Performance across Datasets
To verify whether the proposed measure is independent of a dataset, a cross-dataset validation was performed. The NR measures were trained on one IQA dataset and tested on the remaining datasets. In the experiment, the learning-based measures were compared on four datasets. The results, in terms of SRCC, reported in
Table 6, reveal that the SEER maintained acceptable generalization capability across the datasets. The best results were with bold type. In general, it achieved the best average SRCC.
3.5. Computational Complexity
The computational complexity of a given method was analyzed in terms of the average time taken to assess an image (
) from the TID2013 dataset. The experiments were performed on a 3.3 GHz Intel Core CPU with 16 GB RAM system running on Microsoft Windows 7 64 bit. For all compared methods, their Matlab implementations were used. As demonstrated in
Table 7, the SEER is of moderate complexity. It was faster than IL-NIQE and slower than RATER and HOSA, which also process color images. The execution time of the SEER strongly depends on its parameters. However, unlike other measures, the SEER can be easily run in parallel, since, for the assessed color image, the nine used HOG descriptors were executed for 18 resulting images, including YCbCr color channels, their filtered images, and downsampled images. A simultaneous run of the computation of the HOG for these images using an efficient native implementation (e.g., C++) with a GPU code of the HOG could shorten the execution time of the method up to 162 times.
3.6. Metric Configuration and Contribution of Features
In the SEER, as explained in
Section 2.2, an evaluated image is characterized using the histogram of
K HOG descriptors. Since the HOG can be used with different parameters, their choice and the resulting IQA performance of the introduced measure requires investigation. SRCC was used as the quality index, taking into account that the remaining criteria similarly indicate the performance of the method.
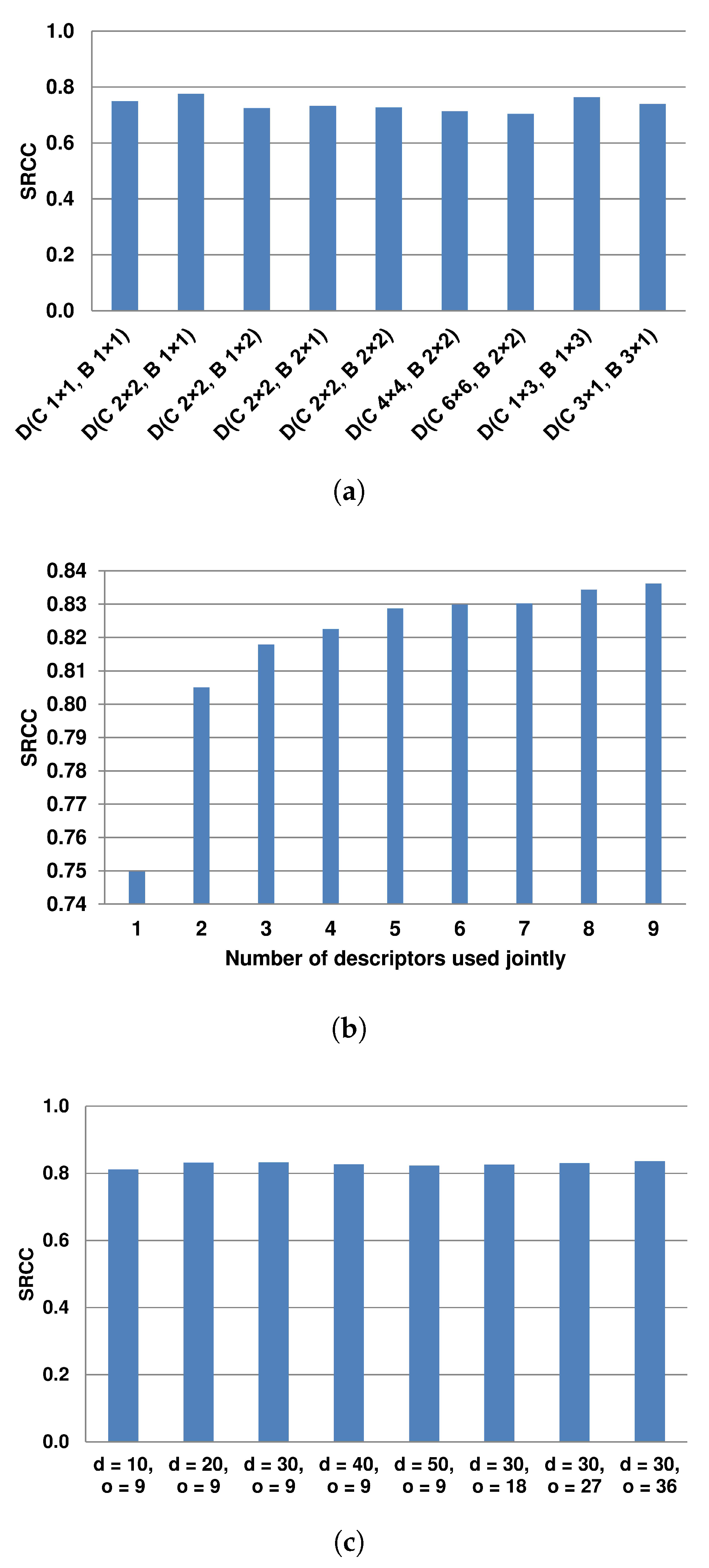
Figure 6a contains SRCC values obtained for the SEER with only one HOG descriptor, using the protocol introduced in the previous section, on the TID2013 dataset. TID2013 was used due to its size and the number of image distortions. In the experiment, the performance of the SEER with many different HOG parameters was investigated. The presented HOG descriptors were run with
and
. In the IQA, a detailed description of a pixel neighborhood is needed, confirmed by various NR approaches using LBP in which a pixel is characterized by its 8 neighbors. Therefore, HOG configurations with smaller pixel areas were taken into account to determine the IQA performance of the SEER with them. The nine HOG descriptors presented in
Figure 6a were selected to be used jointly. In the case of single application of the descriptor
, the method resembles approaches in which statistics for a gradient map, among other features, are used for the quality prediction (e.g., [
27]). To show that such joint application of the HOG descriptors is beneficial,
Figure 6b reports the performance of the method with
HOG descriptors. Since the presentation of all possible combinations of these descriptors is unfeasible, the performance is reported for the descriptors added in the order presented in
Figure 6a. Interestingly, the SEER with only two HOG descriptors delivered promising performance, outperforming the state-of-the-art measures evaluated in the previous section. It can be assumed that an application of dimensionality reduction or feature selection techniques, which would indicate the most influential descriptors or their statistics, may provide better results. However, these techniques can also deepen the dataset-dependency. Therefore, in this study, the selected
HOG descriptors were used in the SEER.
In the proposed method, the descriptors
,
,
and
contributed the most to its performance (see
Figure 6a). Apart from the size of the cell and the arrangement of cells in the block, the computation of the feature vector
in the SEER requires two additional parameters,
o and
d. Therefore, the performance of the measure was evaluated taking into account their variability. The results in terms of SRCC on the TID2013 are shown in
Figure 6c. They reveal that these two parameters almost did not affect the performance of the SEER. In other experiments with the method,
and
are used.
Since the measure uses YcbCr color space and filtered images,
Table 8 presents their contribution to its performance in terms of SRCC on the TID2013. As reported, color channels contributed similarly. However, the channels filtered using the bilaplacian operators carry the most information that can be used for the quality prediction. As reported, the channels alone could not provide satisfactory SRCC performance, which confirms their complementary relationship and justifies their joint application in the SEER.
4. Conclusions
In this work, a novel NR-IQA technique has been presented. The introduced SEER incorporates the distribution of local intensity gradients. The histogram of a set of these descriptors, obtained for YCbCr channels of a distorted image, as well as its channels filtered with bilaplacian operators, are used as perceptual features to train an SVR model for the image quality prediction. It has been shown that the use of a descriptor, which takes into account different sizes of described image regions and their mutual relationship, is beneficial to the IQA, as obtained feature vectors respond consistently to the distortion type and its severity. Furthermore, it has been demonstrated that, to deliver superior performance, the information extracted from YCbCr channels in the bilaplacian domain should be employed. The introduced technique was evaluated and compared with the state-of-the-art NR hand-crafted and NN-based measures on six IQA datasets. The experimental results demonstrate that overall the SEER outperforms the compared NR measures in terms of prediction accuracy and generalization capability.
The future work on the SEER will focus on an application of a keypoint detector that indicates image regions for the description [
27,
67]. Another promising direction of research is to train a deep learning model using features provided by the SEER, similar to the work in [
35].









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}