1. Introduction
There is currently little research on detecting the detailed information (size, shape, orientation, etc.) of small symmetric magnetic anomalies underground. Butler et al. (2012) had established a magnetic model about unexploded ordnance, but he did not describe how to detect them quickly and safely. It needs more engineering applications. Like Butler, most scholars are committed to establishing detailed magnetic field models and have achieved certain results. But this requires a lot of theoretical reasoning and formula derivation, and the model is ideal and different from the actual one. In fact, when we need to detect targets such as underground unexploded ordnance, iron pipe mines, or other ferromagnetic objects, we need to know the details of their shape, model, and orientation. In this way, we can be more efficient and safer in the subsequent processing, regardless of the object or the personnel. It is necessary and urgent to find a magnetic detection method for obtaining a detailed information on small magnetic anomalies underground. Most of these are symmetrical ferromagnetic objects. Detecting symmetrical underground targets is also the beginning of our research. Studying symmetric ferromagnetic objects and symmetry in geomagnetic signals is conducive to the exploration of detailed information on underground small targets.
In the past two decades, the magnetic gradient tensor which is symmetric has received extensive attention from scholars in various countries, providing a new way to detect and explain the shape, size, attitude, and other information of magnetic objects [
1,
2,
3,
4,
5,
6,
7]. Currently there is extensive research on magnetic gradient tensor data, including interpretations and applications, magnetic object localization [
2,
3,
8], and other local magnetic anomaly identification methods [
6,
7,
8,
9]. All of them require complicated theoretical derivation, formula calculation, algorithm design, and a large amount of magnetic data, and they cannot leave the range of calculation or inversion of magnetic data based on complex theoretical formulas and models. They are limited by the accuracy of measurement data, and sometimes geomagnetic objects cannot be clearly distinguished. They mostly focus on remote sense or aeromagnetic data integration and objects localization. There is currently no way to detect the orientation or other details of small underground ferromagnetic objects which are at shallow depth.
Thinking above, a method using support vector machine (SVM) to detect underground symmetric magnetic objects has been proposed. In 1995, support vector machine [
10,
11] was used as an algorithm for pattern recognition, which was first suggested by Cortes and Vapnik. SVM refers to a machine learning model with learning algorithms that process information used for classification as well as regression analysis [
10,
11]. SVMs can mark as remaining with one of two classes based on the training examples given. A new model built by an SVM’s training algorithm can arrange new instances to one class or another, turning it into a nonprobabilistic binary linear classifier. SVM requires a large number of training sample training the networks [
12]. Firstly, we need to build a database based on the training sample; the more complete the database, the more and better the classification effect. It approaches infinitely close to detecting any unknown object as long as the training sample is sufficient.
Ehret [
13] proposed a fresh rock categorization approach for ground-penetrating radar (GPR) data using SVM, which described the hierarchical boundaries among diverse rocks. Mode recognition technology used for magnetic data can simplify the recognition of anomalies [
14]. In addition, pictures can show a symmetric magnetic object’s form. Various methods by many authors [
15,
16,
17,
18,
19,
20] in recent years verified that two-dimensional approaches designed specifically for geophysics also can deal with physical information. To classify and recognize objects based on magnetic anomaly data, many approaches to pattern recognition technology were improved [
21], proposing textural features for image classification according to gray tone spatial dependence matrices that describe spatial relationships between pixel values. One primary classification feature is the texture in geophysical images [
13]. It was thought that these features are also very suitable for magnetic anomalies in pictures.
In the last few years, people began to use discrete wavelet transform (DWT) in digital media and engineering analysis image processing, data compression, edge detection, and geographical exploration [
22,
23,
24,
25,
26,
27,
28]. The wide adoption of this technique is partly due to its outstanding property of representing signals localized in both space–time and frequency domains. Magnetic anomalies are not only the product of complex geological processes, but also a collection of deep information and shallow information, regional geological information and local exploration information. Magnetic anomaly data is a mixture of different types of magnetic sources with extremely different frequencies. This kind of mixture must be accompanied by high frequency noise interference. Compared with noise which includes high frequency noise of the instrument and other big ferromagnetic objects’ signals, the geomagnetic anomaly signal approximates a static signal with a low frequency. Therefore, using time-frequency analysis to reduce noise is a very suitable way and DWT is a mature time-frequency analysis method.
LBP refers to the operator that expresses partial structural characters of an image that has significant merits such as grayscale and rotation invariance. Ojala et al. first suggested it in 1994 as a way to structure character extraction [
22,
23]. In addition, these extracted characters are partial structural characters of pictures. Because LBP features are simple to calculate and have good results, they have been widely used in many fields. LBP adapts to complex signals of different scales and matches well with geomagnetic anomaly signals. Combining extracted LBP texture features with SVM is an important application of pattern recognition [
22,
23].
Considering all that, we propose a method to identify the orientation or recognize the attitude of small underground shallow ferromagnetic objects. Firstly, we get nine component signals from the original data, and progress those using DWT to reduce noise. Then, we extract the LBP feature of the nine component signals and construct them into feature vectors. Eventually, we train and classify based on the SVM. Experiments show that this method can effectively identify the orientation of small underground shallow ferromagnetic objects.
2. Geomagnetic Gradient Tensor Matrix
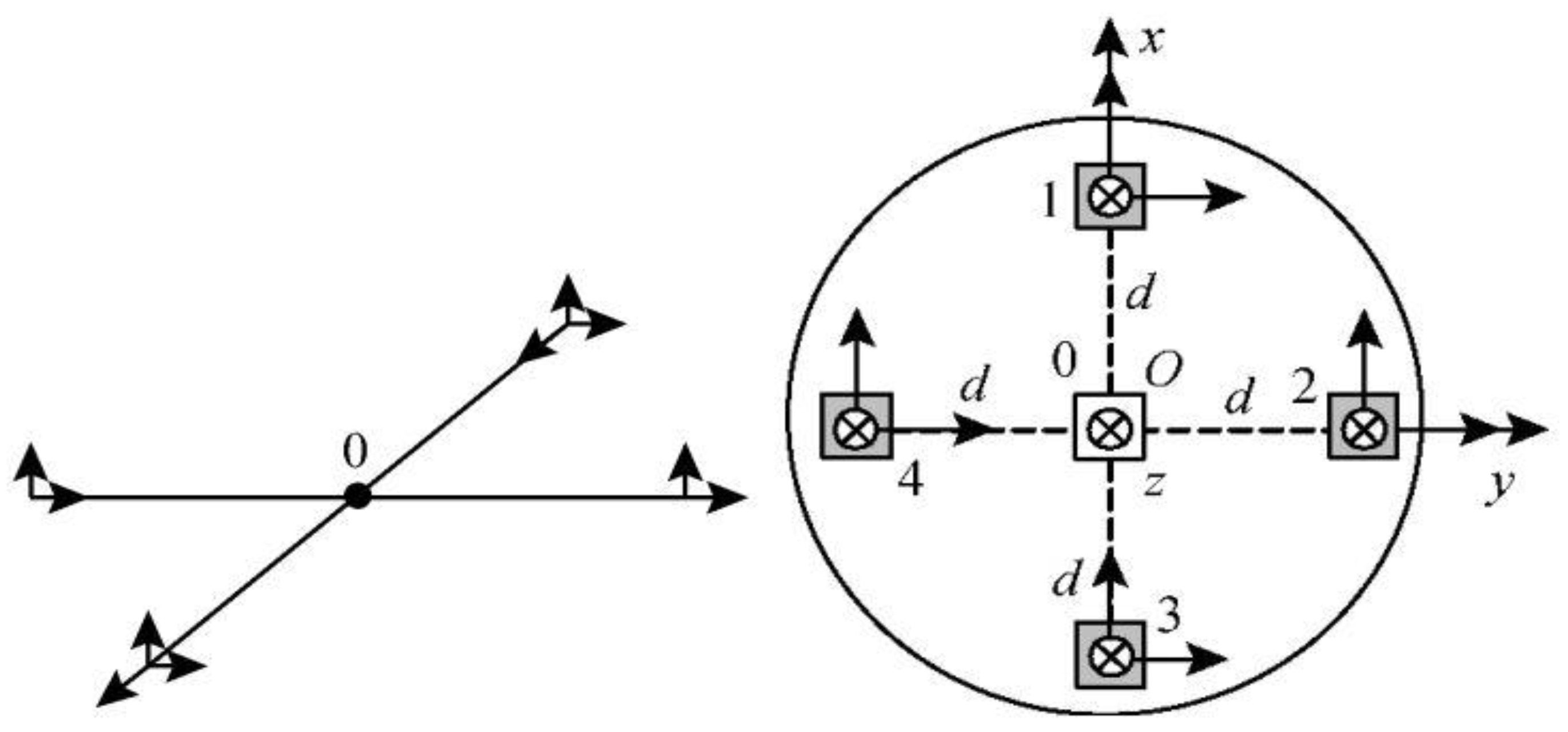
Here we briefly introduce the theory of magnetic anomaly especially the magnetic gradient tensor, and derive the analytical formula of the magnetic gradient tensor and other quantities based on the four-flux gate sensor cross array detector, shown in
Figure 1.
Equation (1) represents the relationship between magnetic scalar potential
, magnetic field vector, and magnetic gradient tensor. It is clear that the gradient tensor is symmetric and traceless,
, so there are only five independent components in the gradient tensor matrix [
3,
4,
5]. Equation (2) is used to derive total magnetic intensity (TMI) from the magnetic field vector [
2,
3,
4,
5]:
Figure 1 shows the four-flux gate sensor cross array detector we used, which is symmetrically placed. There is a fluxgate sensor in each of the four positions 1, 2, 3, and 4. We used the average value of four sensors (1, 2, 3, and 4) as the value of position O. From the three components (
) of the magnetic field vector measured by the flux gate directly, TMI can be solved according to Equation (2). TMI is calculated from the
of position O. The magnetic gradient tensor algorithm is based on the flux gate position difference calculation. Taking the array of
Figure 1 as an example, the formula of the magnetic gradient tensor matrix G is as follows [
1,
2,
3,
4,
5]:
where
represents the magnetic field vector of the
flux gate sensor in direction
and
is the baseline distance.
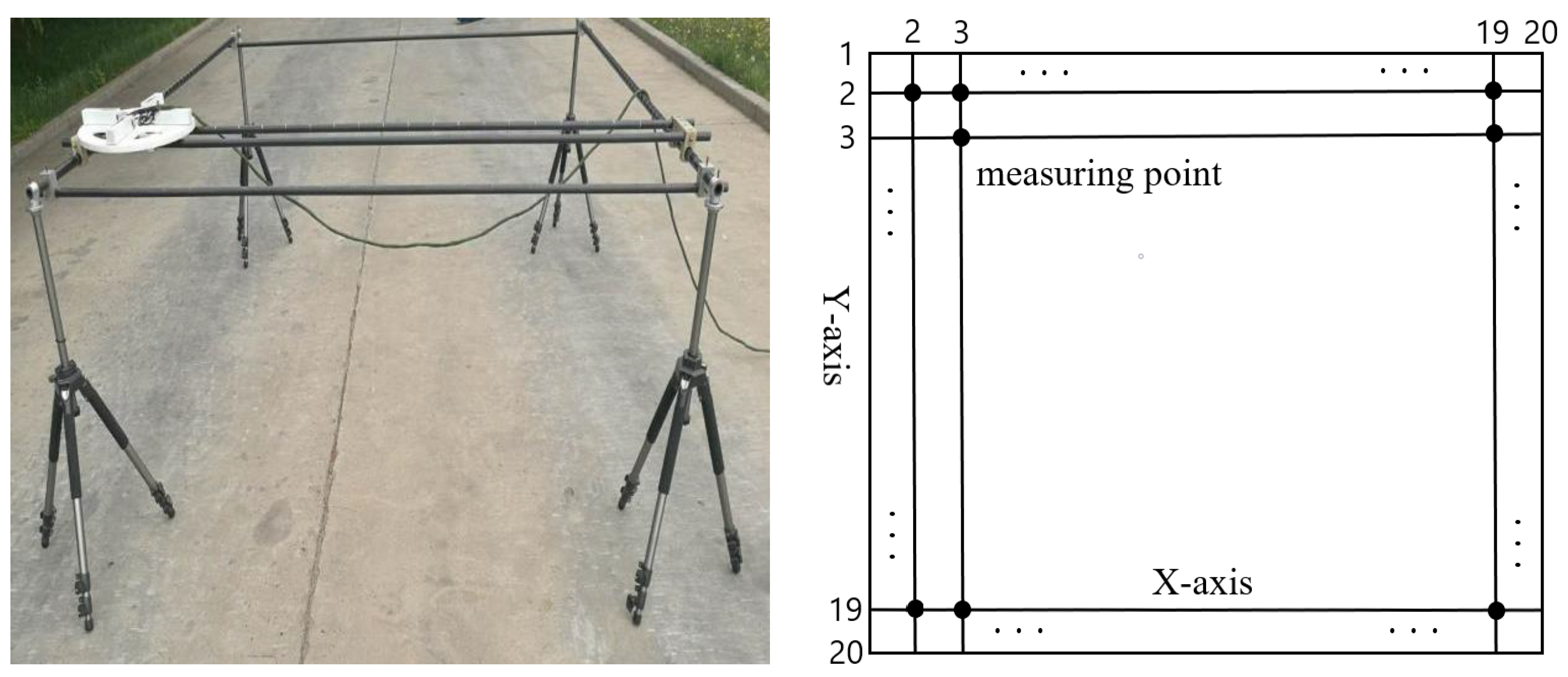
Figure 2 shows the design of the laboratory table, which is symmetric. It is a square plane with a length of 2 m and a measuring point set every 0.1 m. There are 20 scales on each side, with a total of 20 × 20 measuring points. The design of the laboratory table is like a 20 × 20 grid. The measured data are like a 20 × 20 square matrix. We can detect the data of each point by moving the flux gate sensors (the white device in
Figure 2) on the bench. It will take half an hour to detect an original signal.
Because every point detected by the flux gate sensors contains the information of the three components (
) of the magnetic field vector, which are detected by the flux gate sensors directly, the magnetic gradient tensor matrix for each point can be calculated by Equation (3). In addition, TMI for each can be calculated according to Equation (2). Eventually, nine 20 × 20 square matrices based on nine conponent signals including total magnetic intensity (TMI), the three components (
) of the magnetic field vector, and five tensor matrix independent elements (
) [
1,
2,
3,
4,
5] can be separated from the original signals.
3. Discrete Wavelet Transform
We briefly introduce the theoretical basis of DWT. Some information is from Wikipedia.
Discrete wavelet transform (DWT) is a new analysis method that can localize the analysis of time (space) frequency. It can automatically adapt to the needs of time-frequency analysis, so it can focus on any detail of the signal and solve the difficult problem of Fourier transform, becoming a major breakthrough in scientific methods since the Fourier transform [
25]. For magnetic anomaly signals detected by the flux gates, it must contain the noise of the magnetic background field and the mixture of other large ferromagnetic objects in the background. Therefore, before we extract the features of the two-dimensional signal, we must first reduce its noise, otherwise a large amount of information will be submerged in the noise. The frequency of the geomagnetic signal is low, while the frequency of the noise is high, and the two are closely mixed so it is not easy to separate them. The DWT method, which is more suitable for analyzing this variety of local frequency band, is used here. DWT noise reduction can support significant signal spikes as well as abrupt signals [
26,
27,
28]. So wavelet transform is used to eliminate static in transient signals and suppress disturbance from high-frequency noise, and discrete wavelets are used to eliminate static in two-dimensional signals [
25,
26,
27,
28,
29].
There are finest time frequency position characteristics in discrete wavelet transform, and their linear representation is: , which retains the wavelet coefficients mainly controlled by the signal, and finds and removes the wavelet coefficients controlled by noise (as in threshold processing). The remaining wavelet coefficients are inversely transformed to obtain the denoised signal.
The dispersed wavelet transform [
30] from signal
is calculated by passing it through a series of filters. Primarily these specimens pass through one low-pass filter within pulse response
, leading to the curl of both:
The high-pass filter is used to disintegrate concurrent signals. The production provides particular quantities (high-pass) and similar quantities (low-pass). It is worth noting that the high-pass and low-pass filters are interrelated in what is called a quadrature mirror filter. Duplicating this decomposable process can add immense frequency resolution and the similar quantities disintegrate into two kinds of filters, which are then downsampled. It can be referred to as a binary tree or a filter bank, that has panel joints showing subspace with diverse time frequency localization.
The signal disintegrates into two kinds of frequencies in every process. As a result of decomposable procedures, this input signal should be
and
times to express the quantity of levels. At the same time, these procedures are at half time resolution because every filter output has 50% of the signal character, but every output has 50% of input frequency band, therefore we can use the subsampling operator to duplicate the frequency resolution [
31].
Thus the implementation of the filter bank’s wavelets can be expressed as calculating the wavelet modulus of discrete units of subclass wavelets for the known superclass wavelet
. In terms of the discrete wavelet transform, the superclass wavelet is transformed as well as proportioned through the energy of both:
where
refers to the proportion parameter and
refers to the shift parameter, and they are integers [
25,
26,
27,
28,
29].
Evoking the wavelet modulus
of signal
refers to the prediction of
to a wavelet, making
a signal of distance
. In terms of a subclass wavelet in the upper discrete group:
Arrange
at a certain proportion;
refers to a sigma function of
alone [
32]. According to the upper equality,
can be seen as the convolution of
including the superclass wavelet’s addition with spreading, reflection, and standardization, and
catches samples at panel joints
. However, it is apparent that this detail of coefficients supports level
of the discrete wavelet transform. Thus for a suitable selection of
and
, this particular modulus of this filter group is in accordance with the wavelet modulus of a discrete group of subclass wavelets for the existing superclass wavelet
[
25,
26,
27,
28,
29].
There are mature DWT noise reduction algorithms in Matlab. We have carried out experiments in Matlab to prove the DWT noise reduction of geomagnetic signals.
4. Local Binary Pattern Feature
For symmetric signals, the local binary pattern feature can better represent the signal information. LBP refers to a kind of optical descriptor applied for categorizing in computer vision, i.e., an operator applied to express the partial structure characters of an image that has the characteristics of multiresolution, constant grayscale, and constant rotation. It is mainly used for texture extraction in feature extraction [
33,
34,
35,
36,
37].
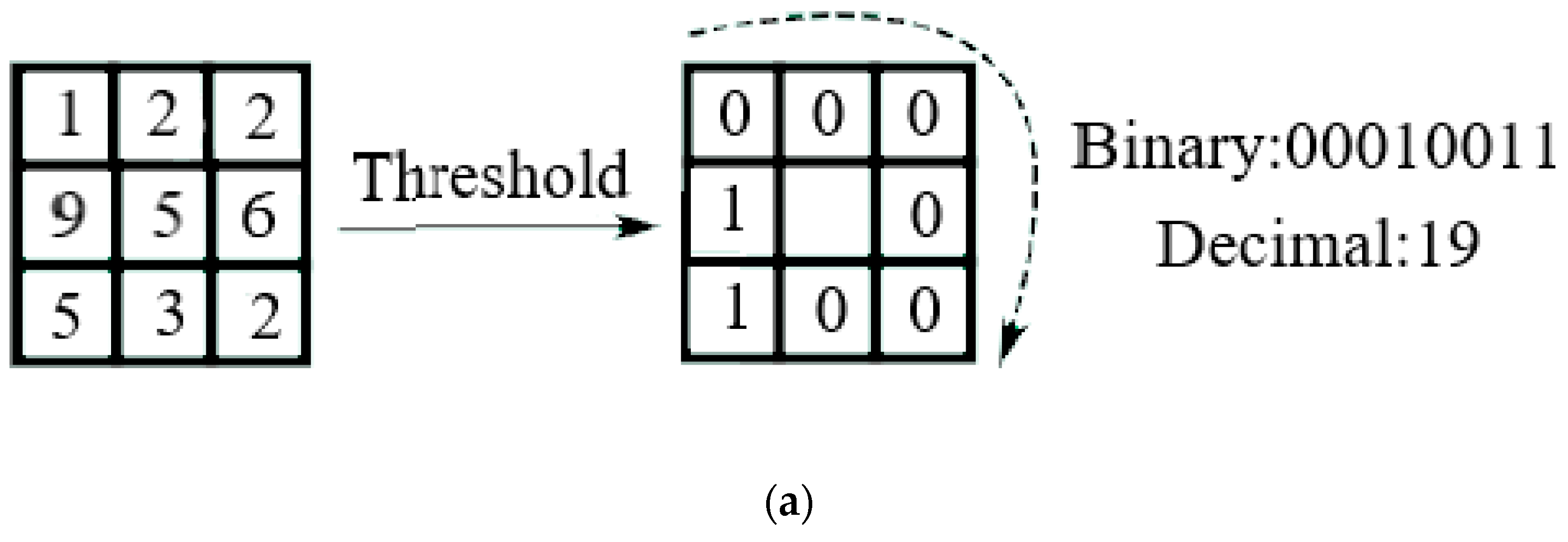
The initial LBP operator is interpreted within the vicinity of the 3 × 3 picture element, with the neighborhood key picture element as doorway, and the gray values of the close eight-picture elements are contrasted with the picture element values of the neighborhood center, and when the circumjacent pixels are bigger than that central picture element volume, the location of the picture element is designated as 1, otherwise 0.
Thus, eight points in the 3 × 3 vicinity are contrasted to generate eight-bit binary encodings, and the eight-bit binary encodings are sequentially arranged to form one binary number [
37,
38,
39], as shown in
Figure 3. This binary number is the LBP volume of the key picture element, and the LBP volume has
possibilities. Therefore, there are 256 LBP values. The LBP volume of the key picture element reflects the texture information of the area around the pixel. The above process can be represented by an image, as in
Figure 3 [
33,
34,
35,
36,
37,
38,
39,
40,
41].
The LBP character vector is made as follows:
Start
Step 1: The examined window will be separated into cells, for example, 16 × 16 picture elements in every cell.
Step 2: Regarding every picture element in one cell, contrast the picture element with each of its eight neighbors (such as positions on upper left, middle left, left lower, upper right, and so on). Align the picture elements along a circle, for example, clockwise or anticlockwise. See
Figure 3 for details.
Step 3: If the neighbor’s volume is smaller than the key picture element’s volume, it is designated as 0; otherwise 1. This provides an eight-digit binary encoding (always conveniently transform to decimal system).
where
is the key picture element within strength
and
is the strength of the interpreted picture element.
refers to the blip facility, explained as follows:
Step 4: Count the column diagram, through the cel, of the vibrational frequency of every “figure” coming out, for example, every mixture of picture elements that are smaller or bigger than the key. The column diagram can be 256-dimension character vectors.
Step 5: Alternatively regularize the column diagram.
Step 6: Conjoin the (regularized) column diagrams of all cells. This provides a character vector for the complete window.
End
Next we will perform feature analysis to verify the classification effect of LBP features.
5. Simulation and Analysis
To prove the feasibility of the LBP feature in the classification, we simulated the process of feature extraction. We establish six magnetic anomaly models of one magnetic source with six different orientations in MATLAB. The format of the simulation data is the same as that measured by the device shown in
Figure 1 and
Figure 2, which are 20 × 20 matrices, as in
Figure 4. The six orientations are our target to classify using SVM.
The magnetic source of six models is the same cylinder with a length of 1 m and a diameter of 0.2 m, with relative magnetic permeability setting to 4000 in MATLAB, and the theory and equations come from reference [
42]. It is in a depth of 2 m. We set all the six to vertical magnetization, and only the orientations are different and the rest of the conditions are the same, and the orientation conditions are shown in
Table 1. Since we have analyzed the noise in
Figure 5, we are not adding noise again in the simulation.
Taking type 1 as an example,
Figure 4 shows the nine component signals. We can see from the figure that the magnetic anomaly signal of the symmetrical ferromagnetic object has good symmetry, which has great advantages for the signal processed later. Typical and obvious image features like those symmetrical textures in the image also facilitate pattern recognition. We can use this diagram to have an intuitive understanding of the signals to be processed.
The angle of inclination is the angle between the central axis of the cylinder and the x-y plane, and the downward direction is positive. The declination is the angle between the central axis of the cylinder and the x-axis, and the counterclockwise direction is positive.
The purpose of our simulation is to analyze the classification ability and effect of the LBP feature of the orientations and verify the feasibility of the above method. Feature selection is one of the key steps in SVM. The pros and cons of selected features directly affect the classification results. We define two kinds of feature classification ability: interclass discrimination, which is the degree of feature dispersion between classes, the larger the better; and intraclass aggregation, which is the degree of feature aggregation within classes, the greater the better [
43,
44].
Then, we extracted the LBP features of the nine component signals of the six orientations and analyzed their classification effects.
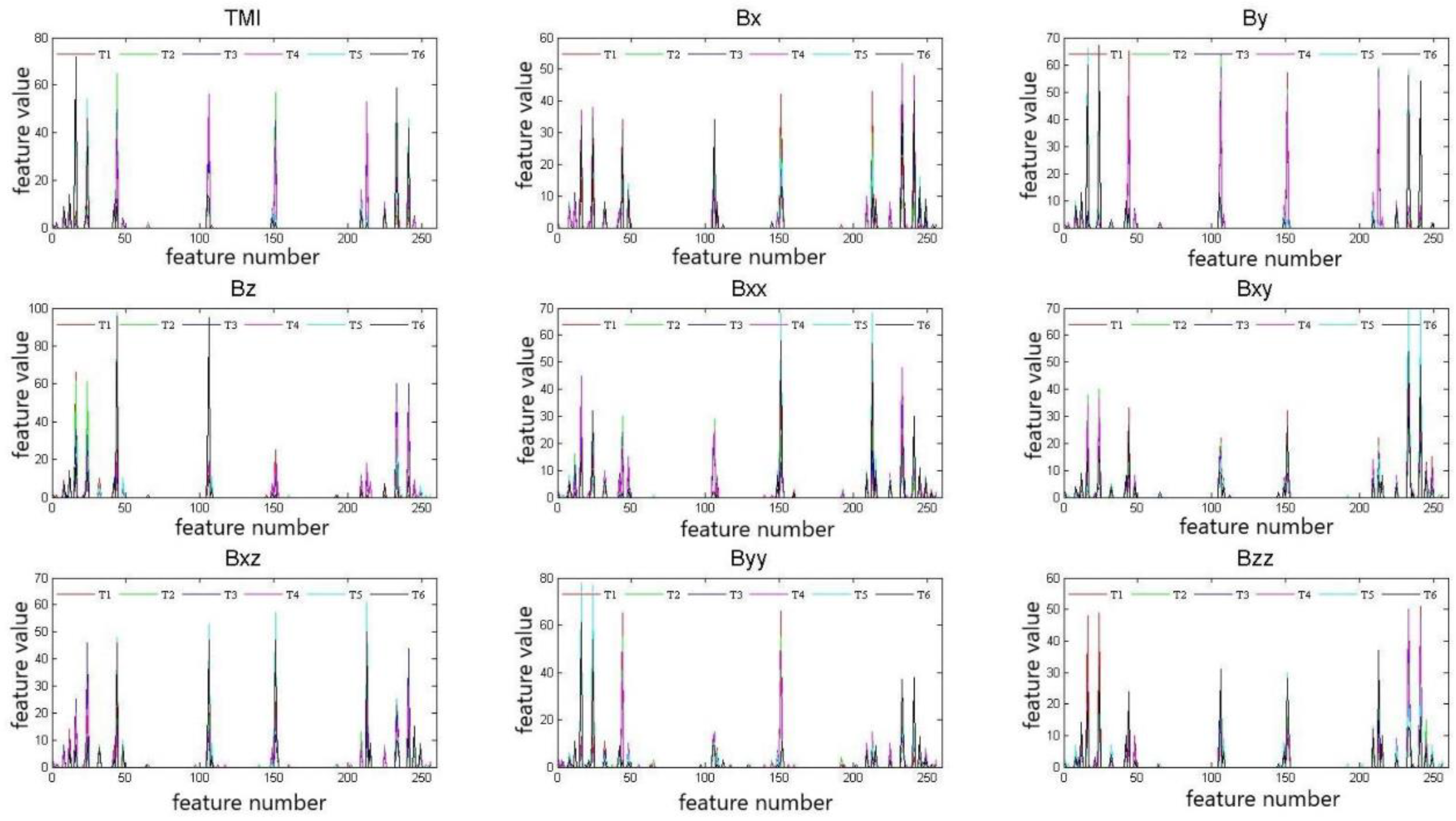
Each component signal’s LBP is a one-dimensional vector, and the length depends on the number of LBP features, and we can extract 256 values from each component as features. Here, we have a 9 × 256 matrix of features relative to each orientation. It can be seen in
Figure 5 and
Figure 6 that the LBP features of the nine component signals have good interclass discrimination and intraclass aggregation [
43,
44,
45].
We can judge whether a feature has the ability to classify different orientations by observing the aggregation and dispersion of the data. In
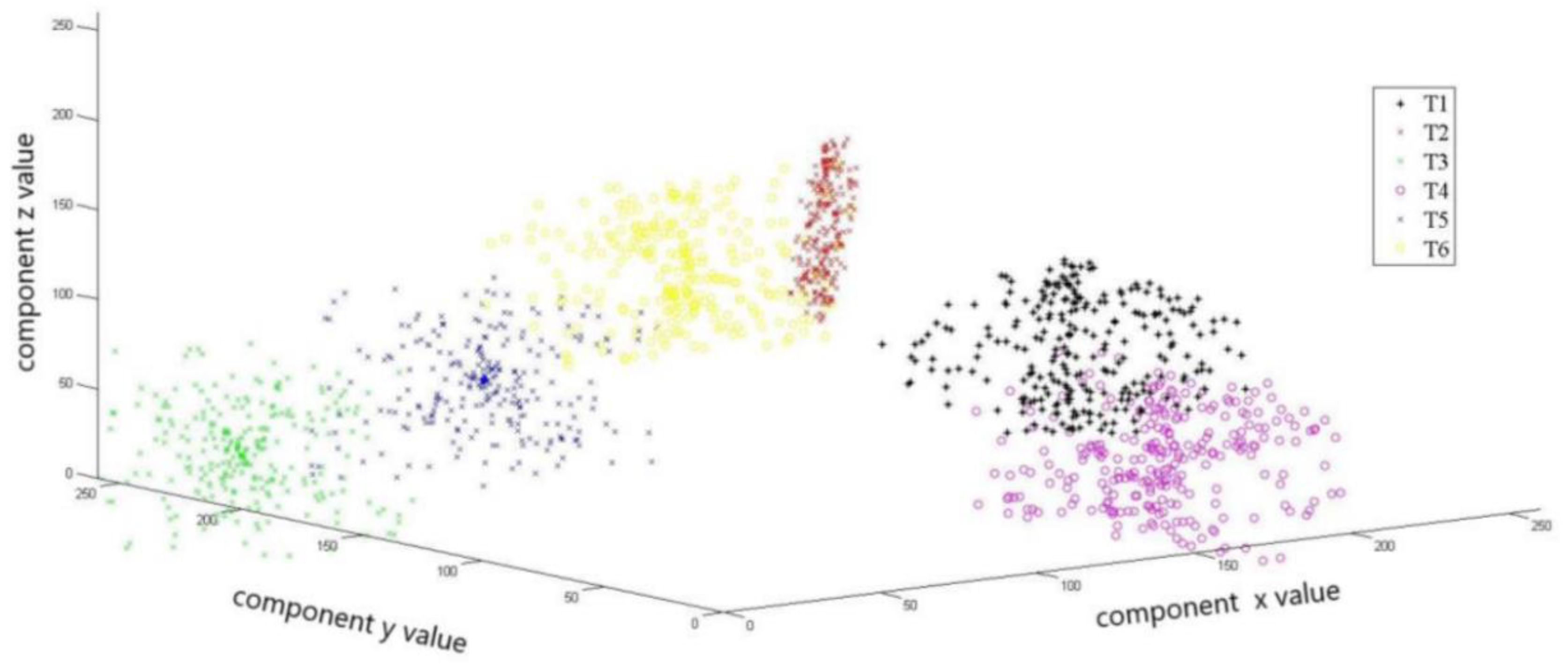
Figure 5, each line in a different color is a type of orientation. This image is an analysis of the LBP from the perspective of each component signal, which illustrates the distinguishing of the six orientations’ LBP feature of the different components. T1 is Type 1, T2 is Type 2, and so on. The numerical value of the vertical axis in the figure represents the LBP features, and the horizontal axis represents the number of 256 features. The more different the feature values, the better the classification performance. It can be seen that although there is some confusion, six types can be distinguished. The combination of the nine components aims to eliminate confusion as much as possible and improve the accuracy of classification.
In
Figure 6, points of each color represent a type of LBP feature data that is made up of three components signals (the
axes each represent a component signal) of each orientation. The three kinds of components are randomly selected, and a three-dimensional scattergram is established. The purpose is to visually observe the classification effect of these nine attributes to distinguish the six orientations. It can be seen that the LBP feature data of the six orientations are obviously different, although there is still a small intersection, but it does not greatly affect the classification. In sum, the LBP data show an ability to identify different orientations. We can obviously see the dispersion and aggregation between classes, which means the LBP data of the same orientation get together. In contrast, the LBP data of different orientations are separated into parts. So we can conclude that the LBP features of the different orientations can be used to identify the symmetrical magnetic objects.
Where, for example, the LBP values of
are 2, 3, and 4, respectively, so the corresponding point coordinates are (2, 3, 4). We can get all points like this. Similarly, the three component signals’ LBP features, which have the sum 3 (components) × 6 (orientations) × 256 (features), are in the three-dimensional system of coordinates in
Figure 7.
6. Experimental Verification
In order to prove the feasibility of the method, an experiment was conducted using the experimental table and four-flux gate sensor cross array detector shown in
Figure 1 and
Figure 2. The target is a solid steel cylinder 1 m long and 20 cm in diameter at a horizontal depth of 1 m.
First, the same six orientations as the simulation were set (see
Table 1 for details). At our experimental location, the magnetic inclination angle was 55°, the magnetic declination was −9°, and the classification labels were set to 1, 2, 3, 4, 5, and 6. In this paper, in order to not be redundant, only six orientations were designed for experiment. We only prove the feasibility of this method in theory. In practical engineering applications, the more the training samples of orientations constructed, the more the orientations which can be recognized. It can theoretically recognize any unknown object as long as the training sample is sufficient. Until any unknown orientation or size is detected. This is the basic theory of pattern recognition. In the support vector machine, the classification result is represented by an integer, with the number 1 representing type 1 orientation, and so on. After the nine component signals were separated according to the method mentioned above, they were subjected to wavelet denoise processing.
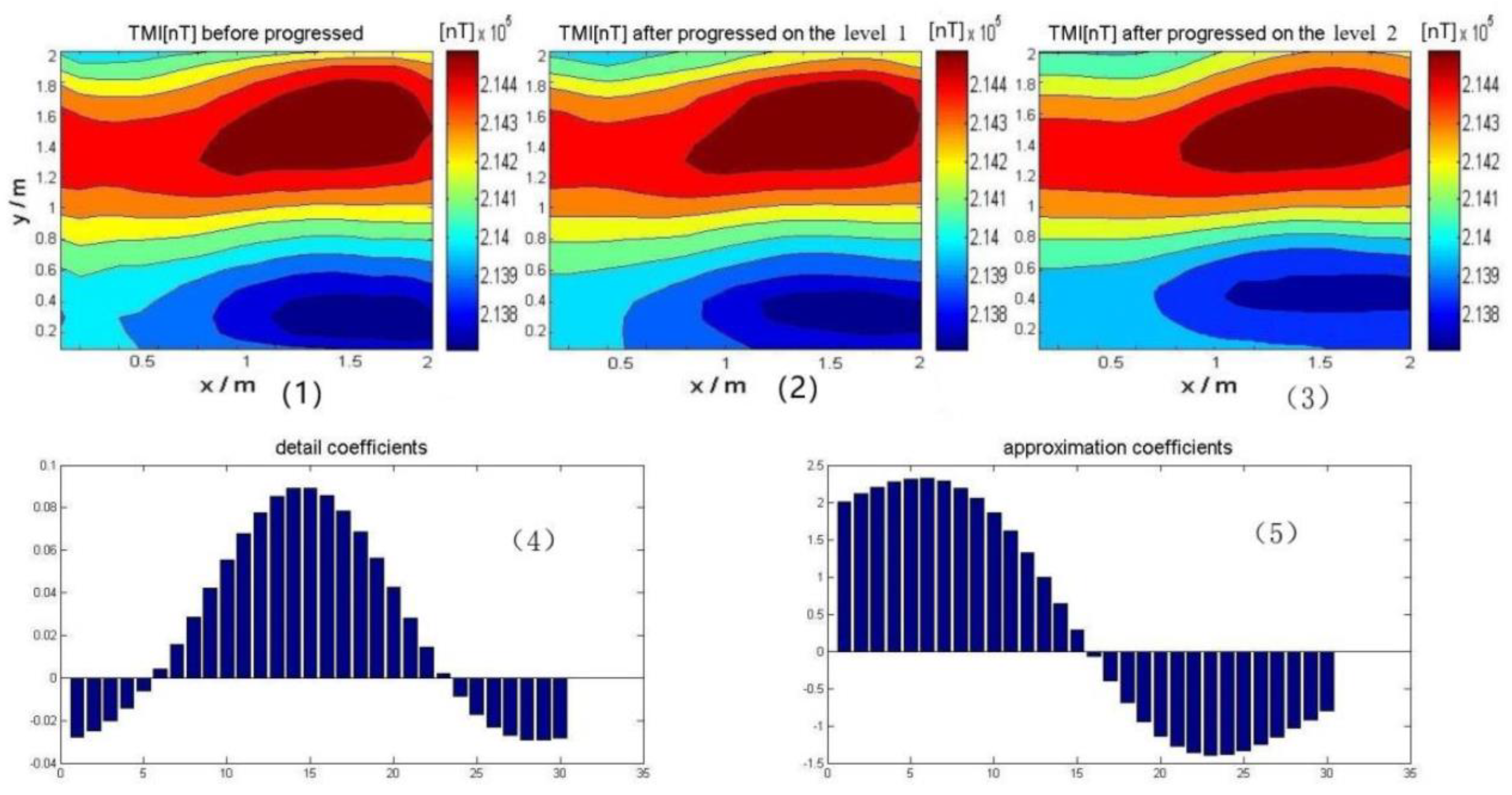
To prove the effect of this DWT noise reduction,
Figure 7 shows the TMI image, which is calculated from the original signal detected by our detector at the orientation of Type1 in experiment, before and after noise reduction. Just only use TMI data as an example for analysis.
Figure 7 shows TMI from our target placed parallel to the
x-axis of the experiment table. We detected the three components (
) of the magnetic field vector through flux gate sensors, and calculated TMI by Equation (2). According to the figure, we know that this initial magnetic anomaly signal contains a lot of noise and interference. Discrete wavelet transform can effectively reduce the noise and make the signal clearer and more obvious. Of course, the different decomposition levels have different effects. We compared the signal-to-noise ratio (SNR) under two conditions, which is shown in Equation (10). We can conclude that when the level is 1, the SNR is equal to 44.3 (dB) and when the level is 2, the SNR is equal to 57.2 (dB). We can get the same opinion on the image. When the level is 2, the denoising effect is smoother and better, so we chose level 2.
where the
is the signal before DWT, and
is the signal after DWT. The bigger the SNR, the better the noise reduction effect.
As an example,
Figure 8 shows images of the nine components of magnetic anomaly after wavelet processing of just one type of orientation. The other five orientations are similar to those in
Figure 8.
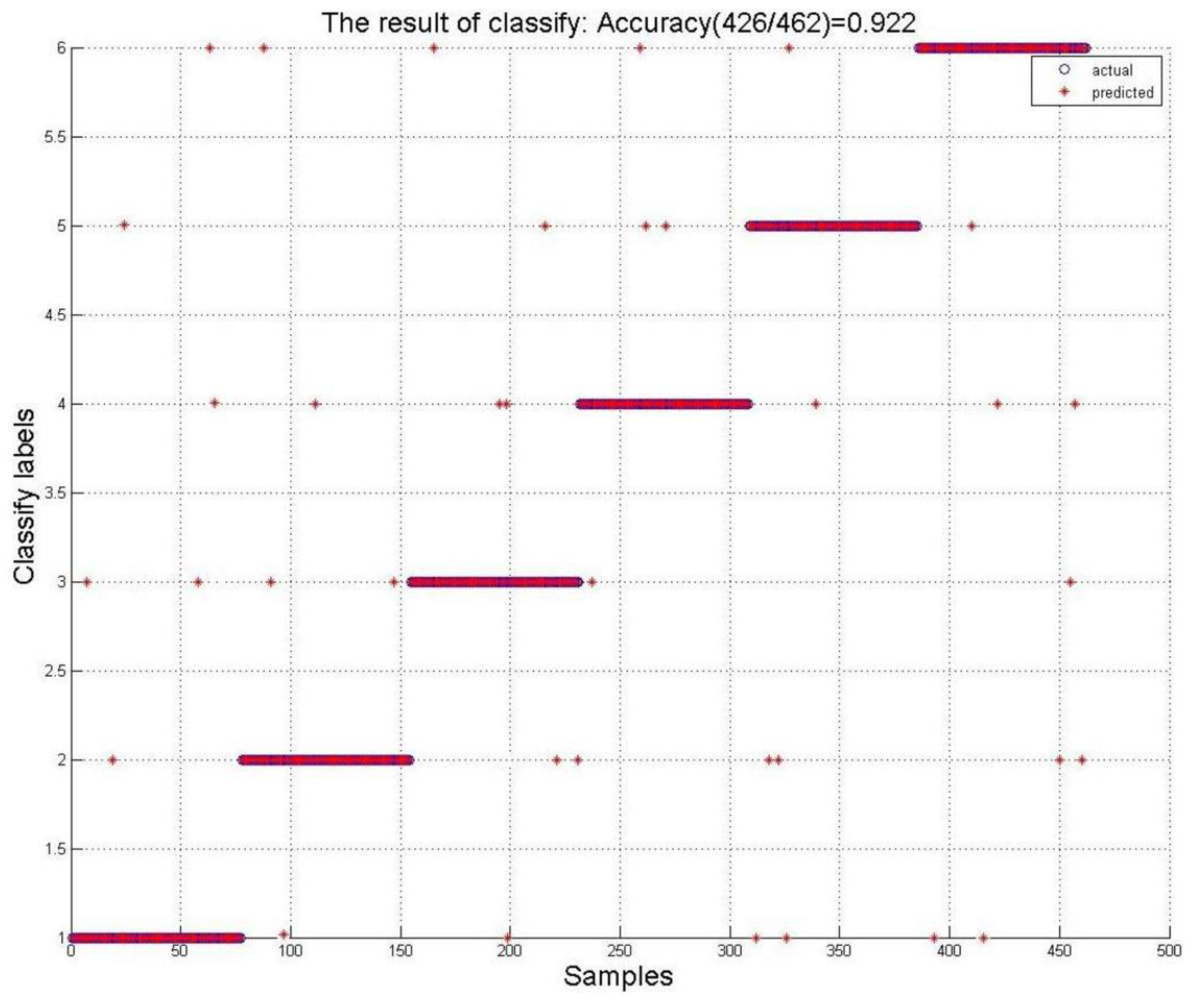
Then, the experimental signal’s LBP features were then extracted and constructed as a feature vectors. We use experimental data to train the support vector machine and use other experimental data to test the classifier. We have a 9 × 256 matrix of features relative to each orientation. Because we set 6 orientations, we have a 9 × 1536 features vector. Every column (9 × 1) is a sample which corresponding to a label. We have 1536 samples. The construction of the support vector machine requires a training sample to train the classification network, and verification of the classification requires a test sample. So we divided feature vectors into training samples and test samples according to a classic ratio of 7:3. We have 1074 training samples to train the SVM and use 462 test samples to predict the six orientations. Each sample (including training samples and test samples) corresponds to a label (1, 2, 3, 4, 5, 6). The training sample is to enable the SVM to establish a network of relationships between samples and labels, for example, if input the samples of type 1, the SVM will only output the label 1; while input the samples of type 2, the SVM will output the label 2. After that, we input the test sample into the SVM and we get a set of labels from trained SVM. The test samples itself also have a set of labels. The comparison of the two sets of labels from the test samples is shown in
Figure 9. It shows the classification effect of the SVM. In practical applications, the data of the unknown object we detect are equivalent to the test samples. In
Figure 9, the result of classify based on the test samples is displayed. The actual labels are their own labels, and the predicted labels are the output of the SVM trained by the training samples. The comparison of actual labels and predicted labels can prove the accuracy.
The SVM was constructed using the training samples described above, and the test samples were classified using the SVM. The SVM predicts the test sample and compares the predicted result with the actual result to obtain the correct rate of classification, as shown in
Figure 9.
According to the classification results, the experiment proves that this method has a high accuracy rate in the object orientation recognition of underground magnetic anomalies.
7. Conclusions
(1) We introduce machine learning into the field of symmetric magnetic object recognition. Using the support vector machine to identify the underground objects’ orientation, a good recognition effect is achieved, and the formula derivation and analytical calculation of a large amount of magnetic measurement data are avoided.
(2) The nine component signals of the magnetic anomaly are extracted to identify symmetric magnetic objects, and the magnetic anomaly data are further processed by discrete wavelet transform, which compensates for the lack of accuracy of certain magnetic data, improving data quality. Also, we extract LBP features and prove that it can be used in 2D magnetic anomaly signals.
(3) This paper only introduces a way of thinking to identify the orientation of symmetric magnetic objects. This paper only establishes a classification identification of an object and six orientations to prove the feasibility of this method in theory. For engineering applications it is not enough. This paper only provides an idea. In engineering applications, we can collect more training samples to identify more targets. We can detect small shallow targets by building a database (including hundreds of kinds and thousands of orientations) or enough training samples rather than magnetic model and magnetic field inversion or calculation. This is also the idea of pattern recognition.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}