AIM: Annealing in Memory for Vision Applications

Abstract
:1. Introduction
2. Overview of the Ising Model
3. Annealing in Memory Architecture
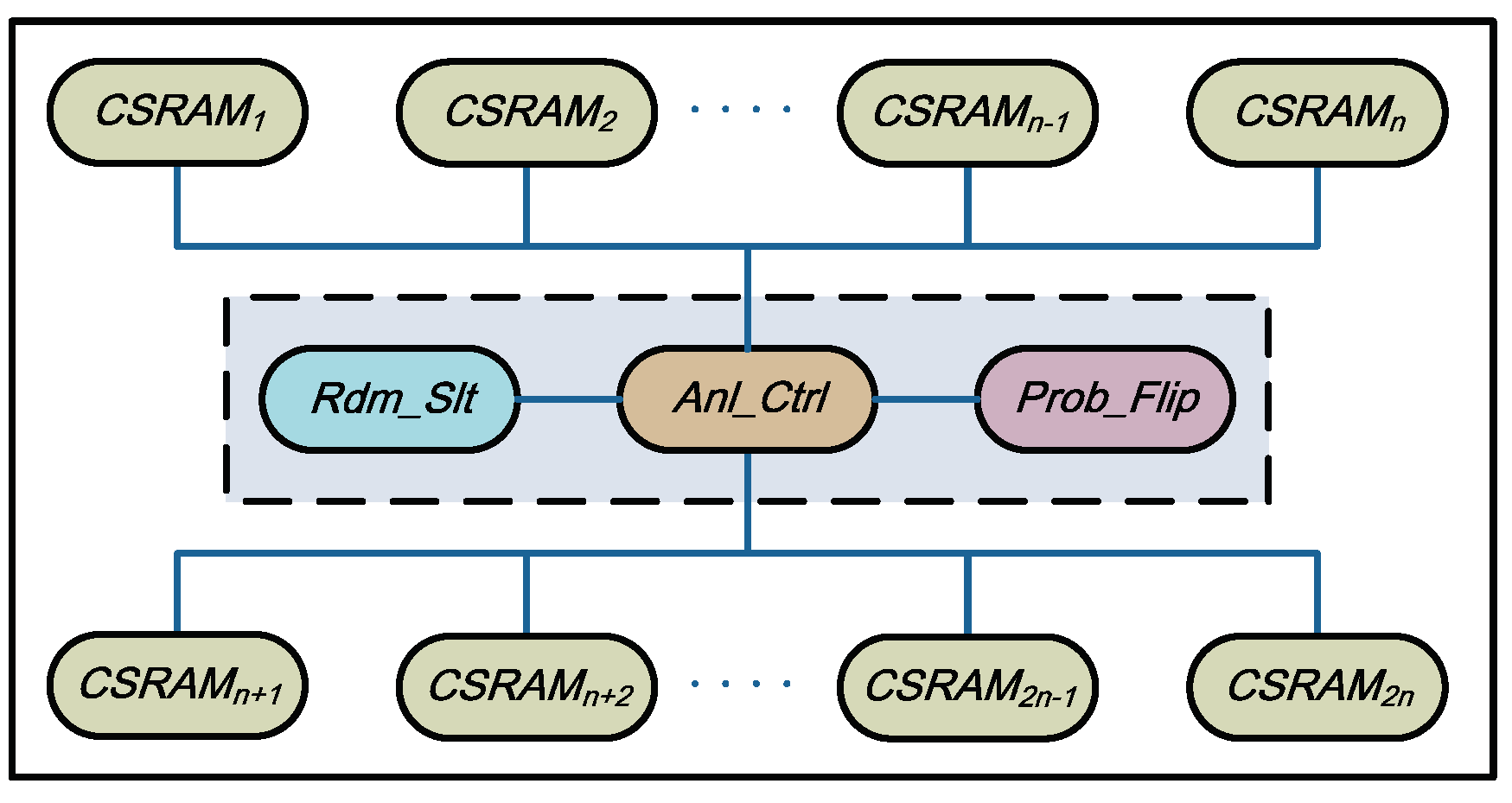
3.1. Top-Level Architecture
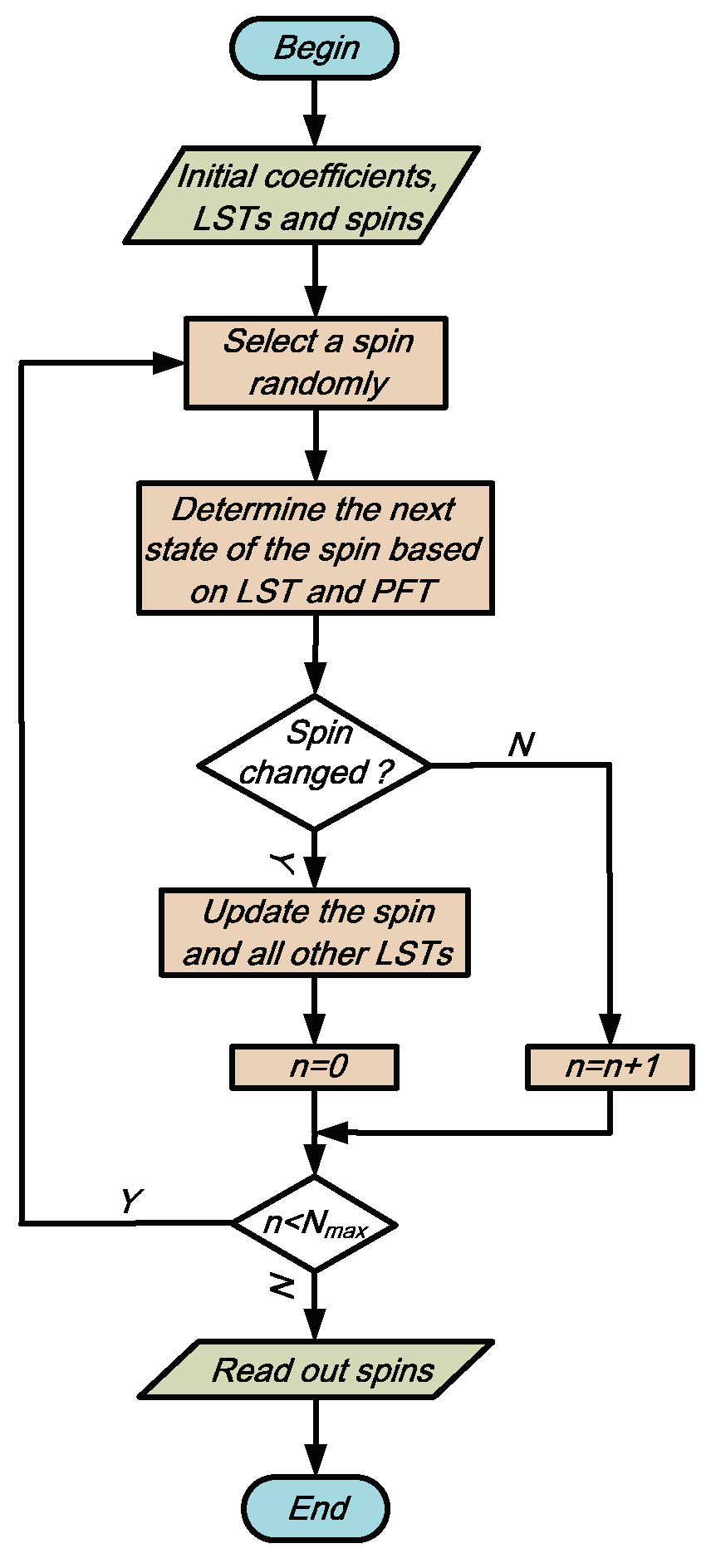
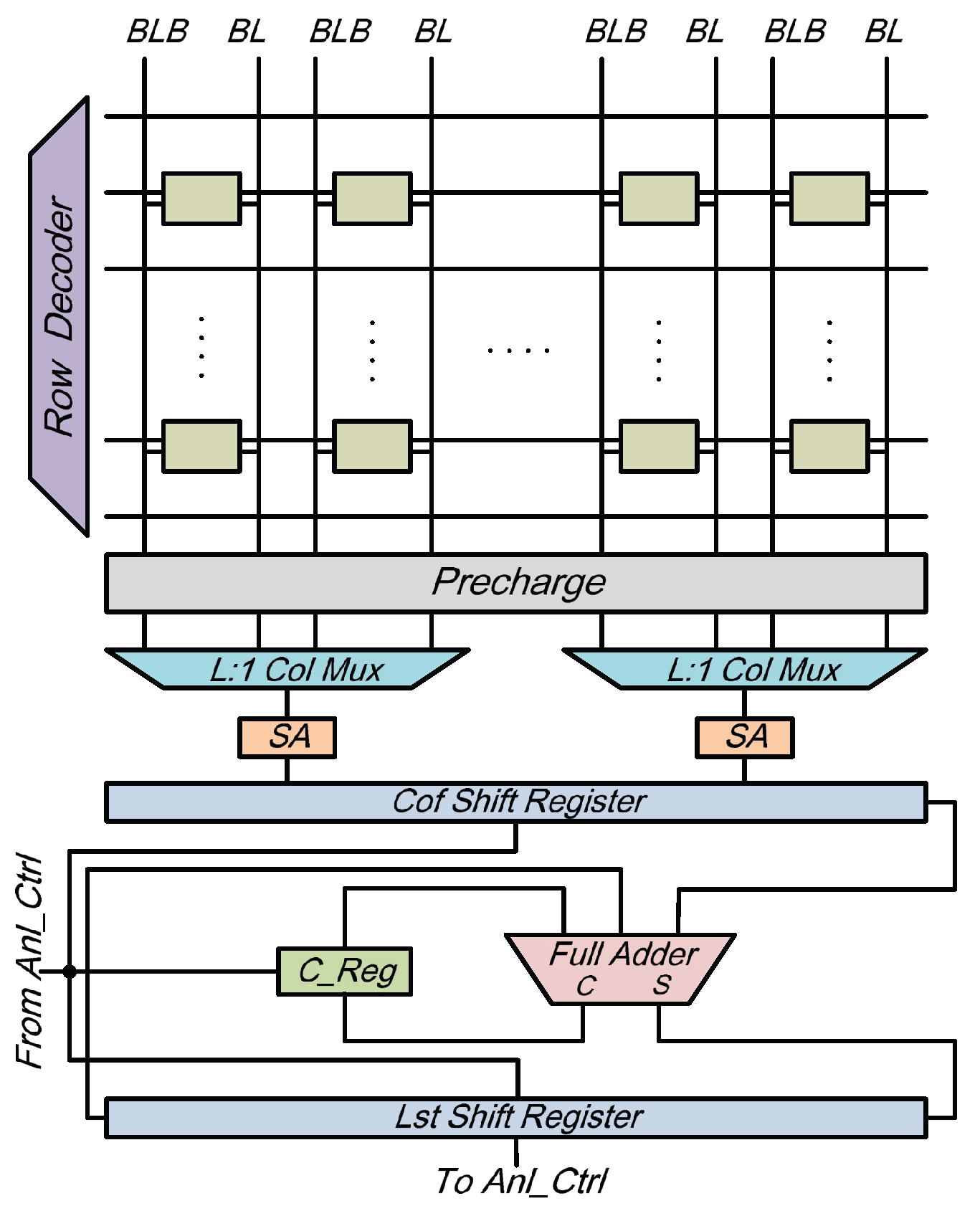
3.2. Local Search in Memory
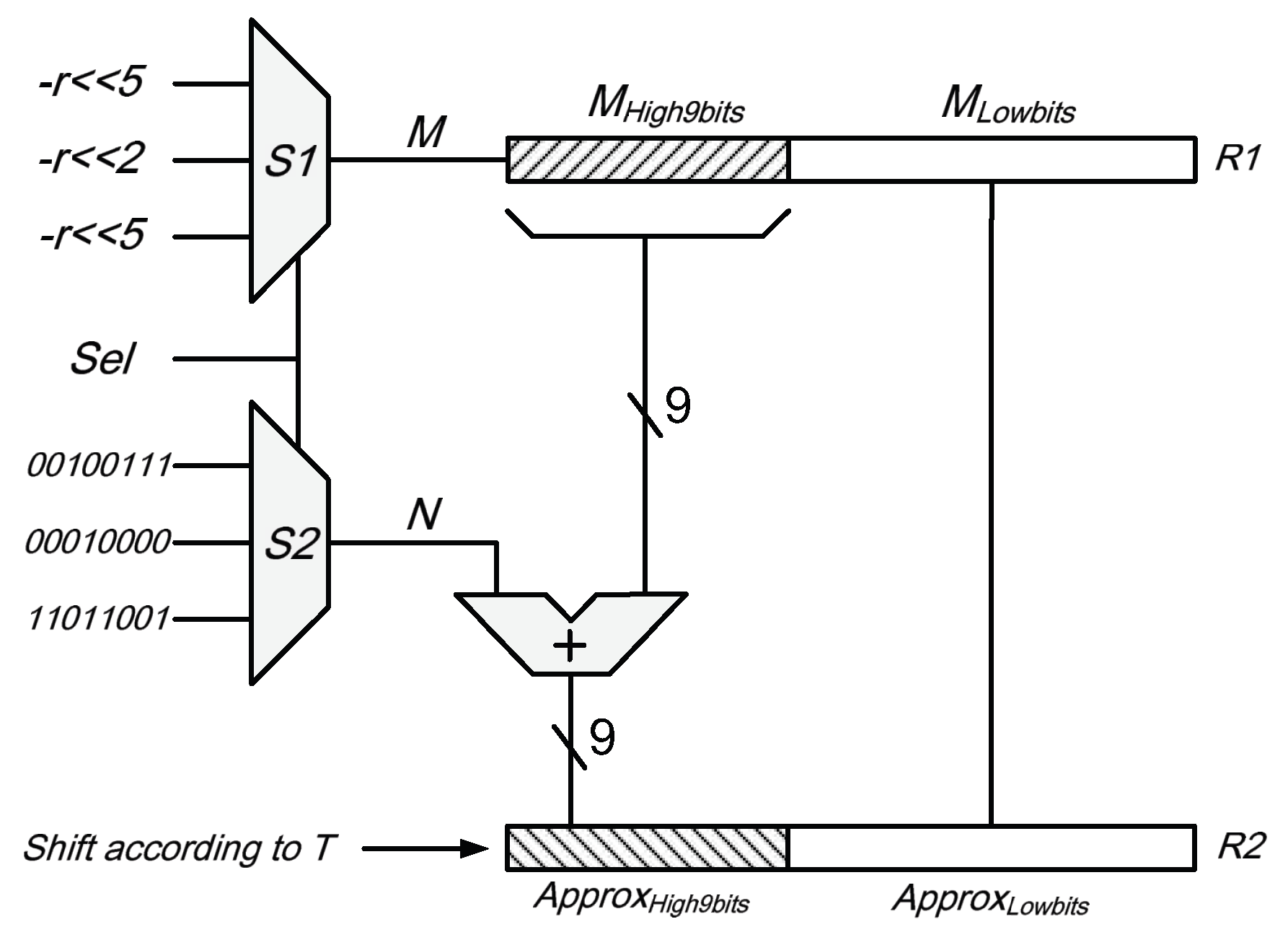
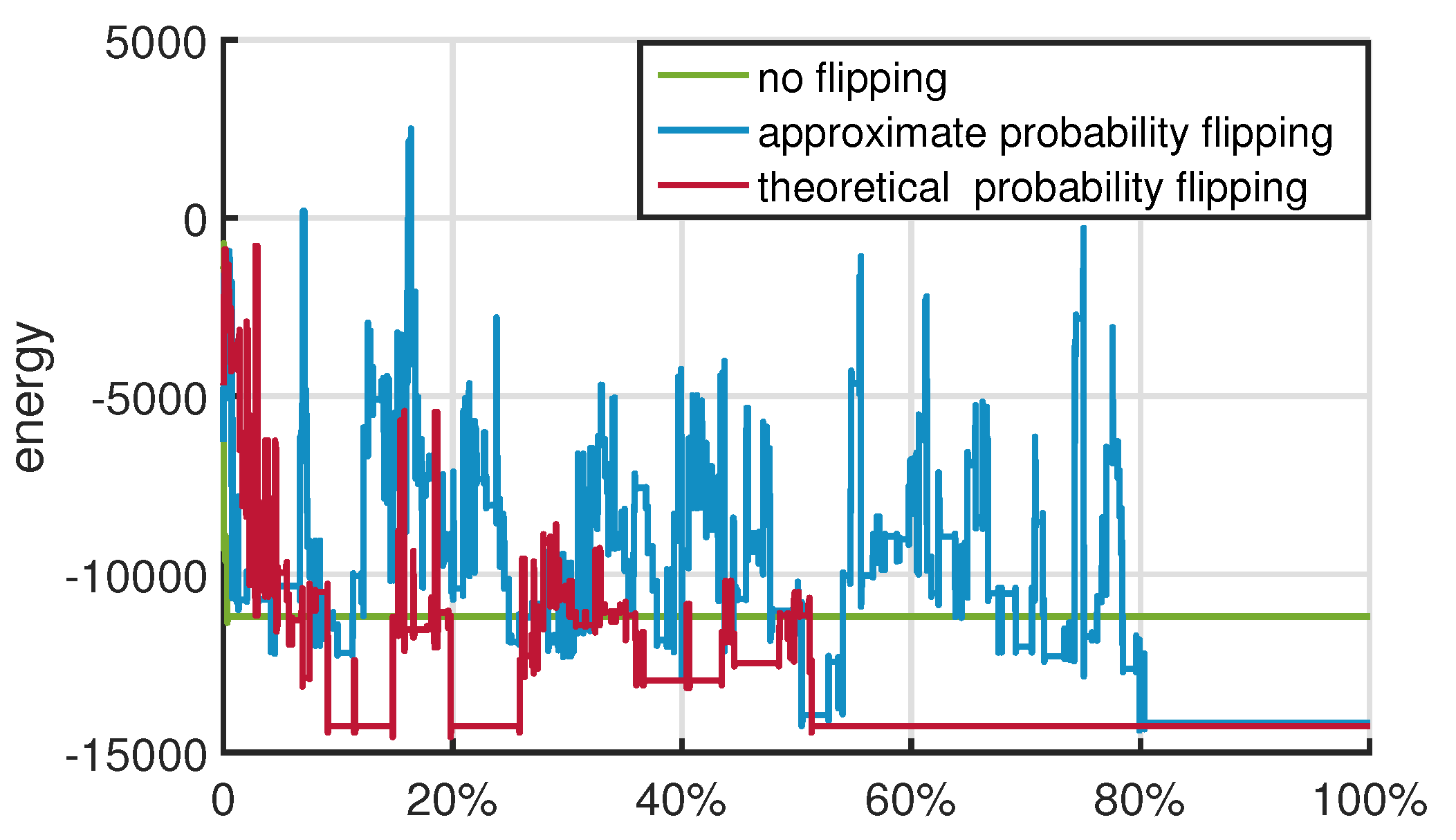
3.3. Approximate Probability Flipping Method
3.4. Hardware Performance
4. Application
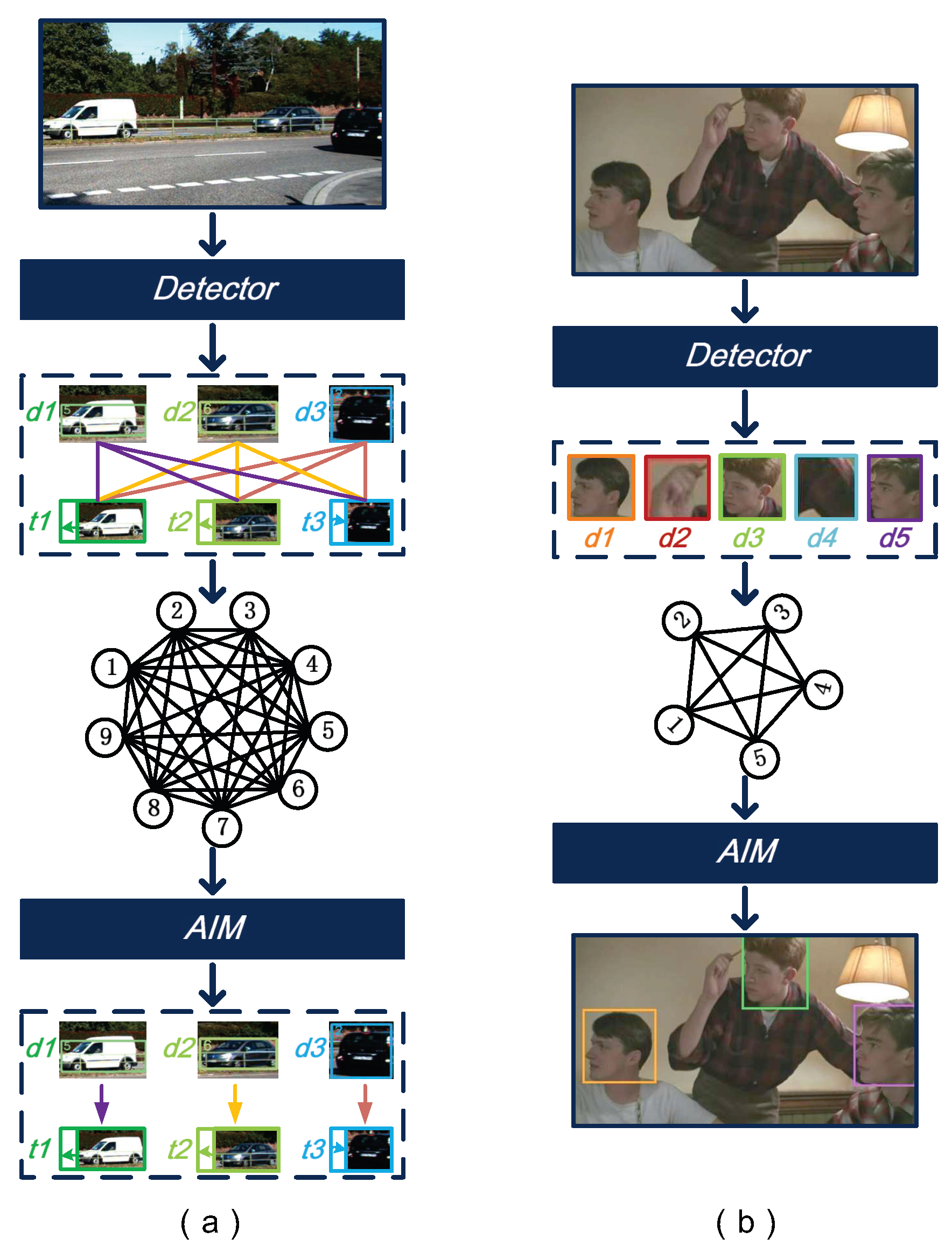
4.1. Mapping MOT to AIM
4.2. Mapping MPHD to AIM
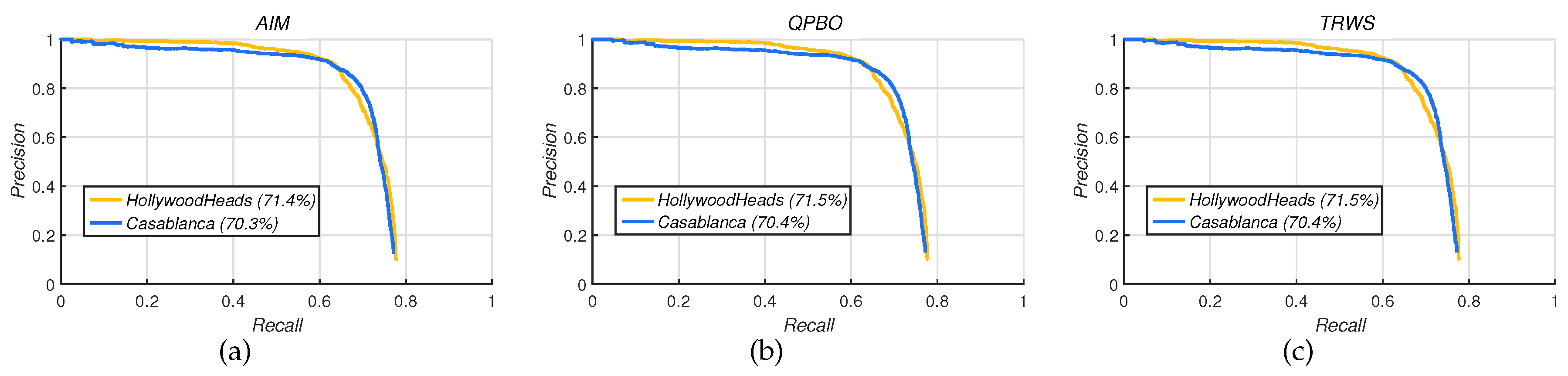
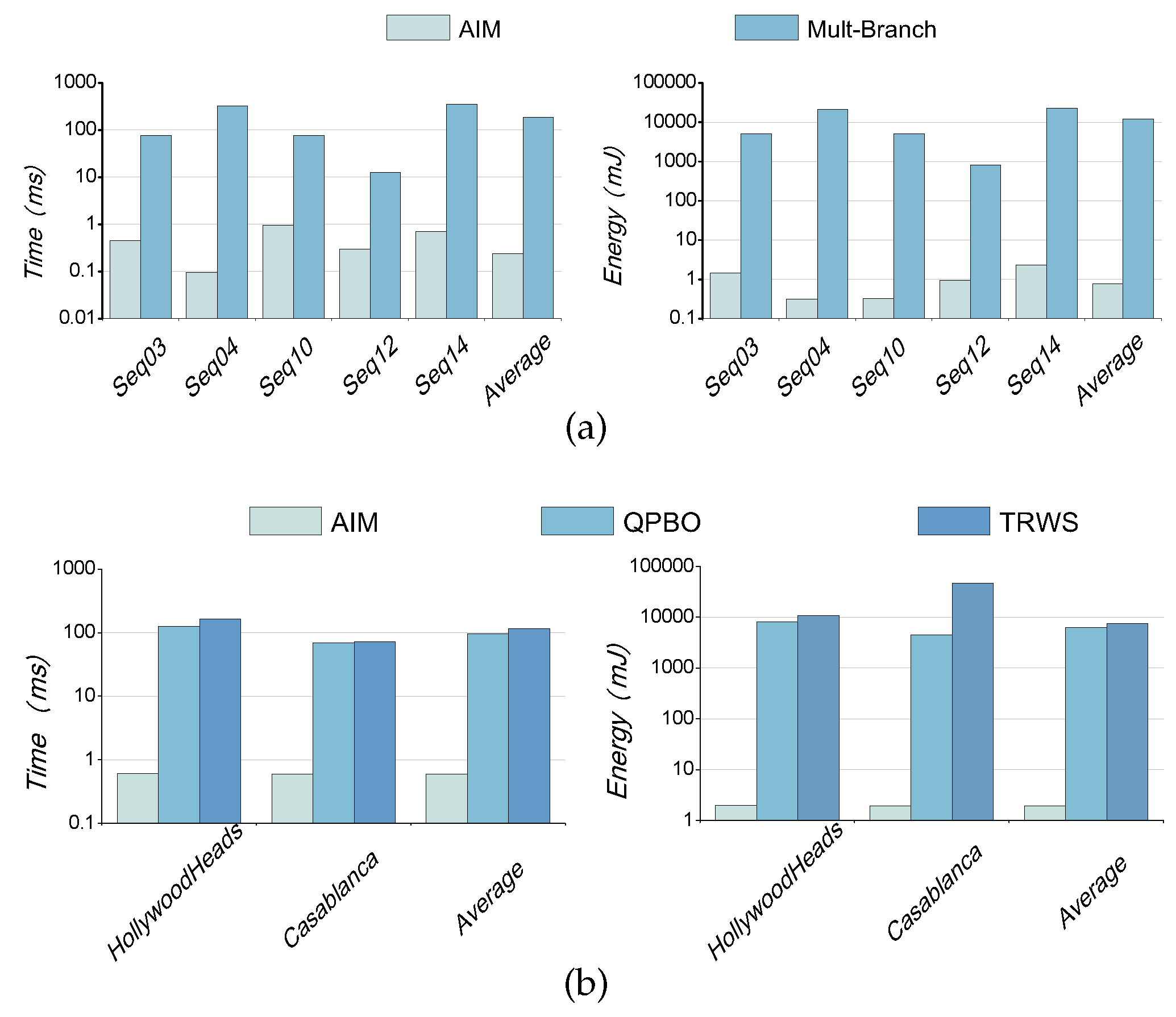
4.3. Evaluation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Moore, G.E. Progress in digital integrated electronics. In Proceedings of the Electron Devices Meeting, Washington, DC, USA, 1–3 December 1975; Volume 21, pp. 11–13. [Google Scholar]
- Chen, Y.; Luo, T.; Liu, S.; Zhang, S.; He, L.; Wang, J.; Li, L.; Chen, T.; Xu, Z.; Sun, N.; et al. Dadiannao: A machine-learning supercomputer. In Proceedings of the 47th Annual IEEE/ACM International Symposium on Microarchitecture, Cambridge, UK, 13–17 December 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 609–622. [Google Scholar]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid-State Circuits 2016, 52, 127–138. [Google Scholar] [CrossRef] [Green Version]
- Gao, M.; Pu, J.; Yang, X.; Horowitz, M.; Kozyrakis, C. Tetris: Scalable and efficient neural network acceleration with 3d memory. In Proceedings of the Twenty-Second International Conference on Architectural Support for Programming Languages and Operating Systems, Xi’an, China, 8–12 April 2017; pp. 751–764. [Google Scholar]
- Merolla, P.A.; Arthur, J.V.; Alvarez-Icaza, R.; Cassidy, A.S.; Sawada, J.; Akopyan, F.; Jackson, B.L.; Imam, N.; Guo, C.; Nakamura, Y.; et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 2014, 345, 668–673. [Google Scholar] [CrossRef] [PubMed]
- Akopyan, F.; Sawada, J.; Cassidy, A.; Alvarez-Icaza, R.; Arthur, J.; Merolla, P.; Imam, N.; Nakamura, Y.; Datta, P.; Nam, G.J.; et al. Truenorth: Design and tool flow of a 65 mw 1 million neuron programmable neurosynaptic chip. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2015, 34, 1537–1557. [Google Scholar] [CrossRef]
- Lin, C.K.; Wild, A.; Chinya, G.N.; Davies, M.; Wang, H. Programming Spiking Neural Networks on Intel Loihi. Computer 2018, 51, 52–61. [Google Scholar] [CrossRef]
- Johnson, M.W.; Amin, M.H.; Gildert, S.; Lanting, T.; Hamze, F.; Dickson, N.; Harris, R.; Berkley, A.J.; Johansson, J.; Bunyk, P.; et al. Quantum annealing with manufactured spins. Nature 2011, 473, 194–198. [Google Scholar] [CrossRef]
- Arute, F.; Arya, K.; Babbush, R.; Bacon, D.; Bardin, J.C.; Barends, R.; Biswas, R.; Boixo, S.; Brandao, F.G.; Buell, D.A.; et al. Quantum supremacy using a programmable superconducting processor. Nature 2019, 574, 505–510. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yamaoka, M.; Yoshimura, C.; Hayashi, M.; Okuyama, T.; Aoki, H.; Mizuno, H. 24.3 20k-spin Ising chip for combinational optimization problem with CMOS annealing. In Proceedings of the 2015 IEEE International Solid-State Circuits Conference-(ISSCC) Digest of Technical Papers, San Francisco, CA, USA, 11–15 February 2015; pp. 1–3. [Google Scholar]
- Zhang, J.; Chen, S.; Wang, Y. Advancing CMOS-Type Ising Arithmetic Unit into the Domain of Real-World Applications. IEEE Trans. Comput. 2017, 67, 604–616. [Google Scholar] [CrossRef]
- Matsubara, S.; Tamura, H.; Takatsu, M.; Yoo, D.; Vatankhahghadim, B.; Yamasaki, H.; Miyazawa, T.; Tsukamoto, S.; Watanabe, Y.; Takemoto, K.; et al. Ising-model optimizer with parallel-trial bit-sieve engine. In Proceedings of the Conference on Complex, Intelligent, and Software Intensive Systems, Turin, Italy, 10–13 July 2017; Springer: Berlin, Germany, 2017; pp. 432–438. [Google Scholar]
- Zhang, J.; Chen, S.; Wang, Z.; Wang, L.; Lv, L.; Wang, Y. Pre-Calculating Ising Memory: Low Cost Method to Enhance Traditional Memory with Ising Ability. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Firenze Fiera Spa, Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Takemoto, T.; Hayashi, M.; Yoshimura, C.; Yamaoka, M. 2.6 A 2× 30k-Spin Multichip Scalable Annealing Processor Based on a Processing-In-Memory Approach for Solving Large-Scale Combinatorial Optimization Problems. In Proceedings of the 2019 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 17–21 February 2019; pp. 52–54. [Google Scholar]
- Skubiszewski, M. An exact hardware implementation of the Boltzmann machine. In Proceedings of the Fourth IEEE Symposium on Parallel and Distributed Processing, Arlington, TX, USA, 1–4 December 1992; pp. 107–110. [Google Scholar]
- Brush, S.G. History of the Lenz-Ising model. Rev. Mod. Phys. 1967, 39, 883. [Google Scholar] [CrossRef]
- Papadimitriou, C.H.; Steiglitz, K. Combinatorial Optimization; Prentice Hall: Englewood Cliffs, NJ, USA, 1982; Volume 24. [Google Scholar]
- Karp, R.M. Reducibility among combinatorial problems. In Complexity of Computer Computations; Springer: Berlin, Germany, 1972; pp. 85–103. [Google Scholar]
- Osep, A.; Mehner, W.; Mathias, M.; Leibe, B. Combined image-and world-space tracking in traffic scenes. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1988–1995. [Google Scholar]
- Vu, T.H.; Osokin, A.; Laptev, I. Context-aware CNNs for person head detection. In Proceedings of the IEEE International Conference on Computer Vision, Araucano Park, Las Condes, Chile, 11–13 December 2015. [Google Scholar]
- De Gloria, A.; Faraboschi, P. Application specific parallel architectures. In Proceedings of the International Conference on Massively Parallel Computing Systems, Ischia, Italy, 2–6 May 1994. [Google Scholar]
- Liu, C.W.; Ou, S.H.; Chang, K.C.; Lin, T.C.; Chen, S.K. A Low-Error, Cost-Efficient Design Procedure for Evaluating Logarithms to Be Used in a Logarithmic Arithmetic Processor. IEEE Trans. Comput. 2016, 65, 1158–1164. [Google Scholar] [CrossRef]
- Geiger, A. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics. Eurasip J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef] [Green Version]
- Ren, X. Finding people in archive films through tracking. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Values |
|---|---|
| Clock frequency | 1 GHz |
| Chip area | 85 mm |
| Chip power | 3.26 W |
| Number of SRAM array | 4096 |
| Area of SRAM array | 19.86 m |
| Area of CSRAM | 20.74 m |
| Pedestrians | MOTA | MOTP | ID | Frag | MT | PT | ML |
|---|---|---|---|---|---|---|---|
| Multi-branch | 46.76% | 75.98% | 1 | 12 | 60.00% | 30.00% | 10.00% |
| AIM | 47.12% | 76.03% | 1 | 12 | 60.00% | 30.00% | 10.00% |
| Cars | MOTA | MOTP | ID | Frag | MT | PT | ML |
| Multi-branch | 69.79% | 83.86% | 4 | 19 | 60.34% | 29.31% | 10.34% |
| AIM | 70.00% | 83.84% | 4 | 21 | 60.34% | 29.31% | 10.34% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Hu, X.; Zhang, J.; Lv, Z.; Guo, Y. AIM: Annealing in Memory for Vision Applications. Symmetry 2020, 12, 480. https://doi.org/10.3390/sym12030480
Wang Z, Hu X, Zhang J, Lv Z, Guo Y. AIM: Annealing in Memory for Vision Applications. Symmetry. 2020; 12(3):480. https://doi.org/10.3390/sym12030480
Chicago/Turabian StyleWang, Zhi, Xiao Hu, Jian Zhang, Zhao Lv, and Yang Guo. 2020. "AIM: Annealing in Memory for Vision Applications" Symmetry 12, no. 3: 480. https://doi.org/10.3390/sym12030480
APA StyleWang, Z., Hu, X., Zhang, J., Lv, Z., & Guo, Y. (2020). AIM: Annealing in Memory for Vision Applications. Symmetry, 12(3), 480. https://doi.org/10.3390/sym12030480