Contextual Modulation in Mammalian Neocortex is Asymmetric


Abstract
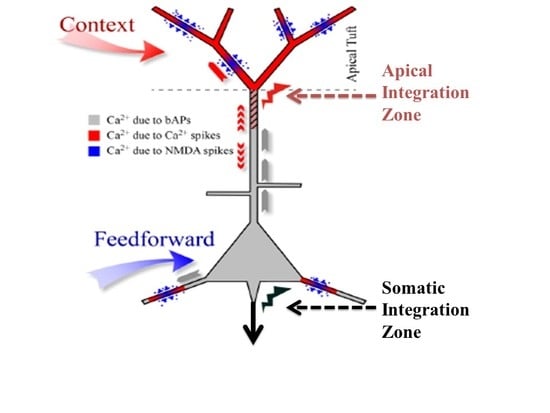
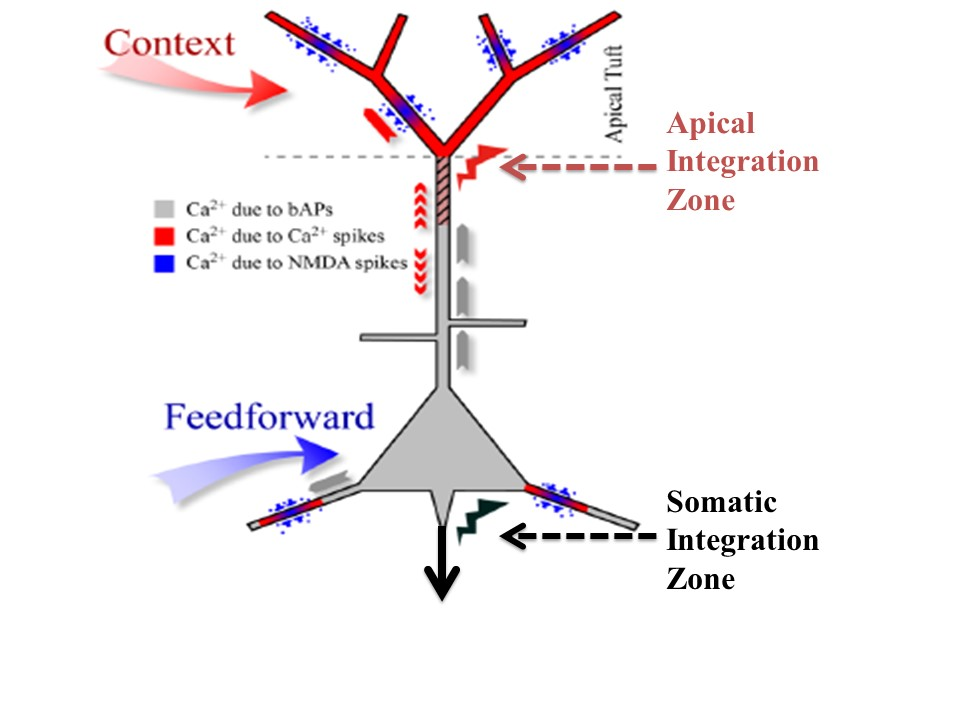
:
1. Introduction
2. Methods
2.1. Notation and Definitions
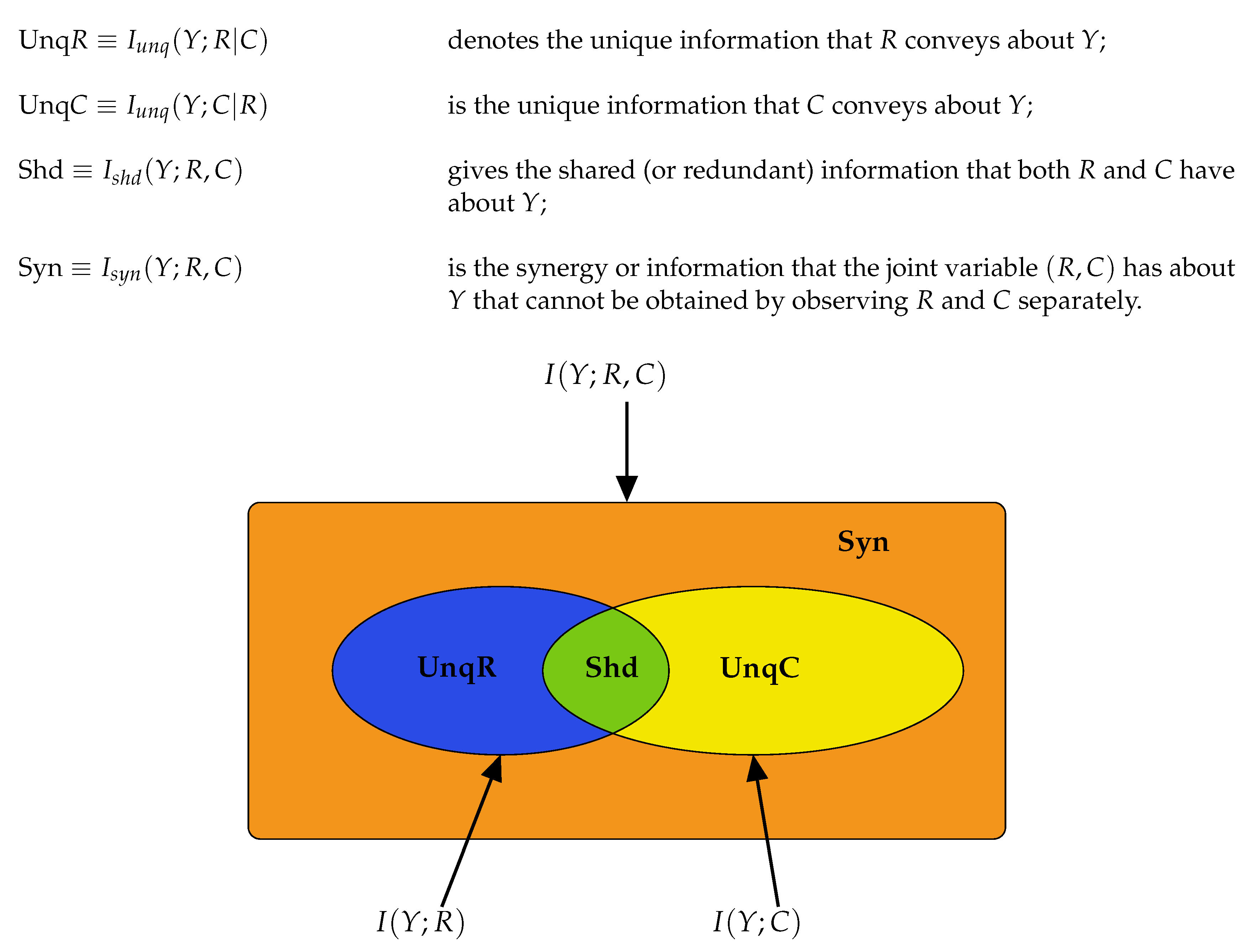
2.2. Partial Information Decompositions
2.3. Transfer Functions
2.4. Different Signal-Strength Scenarios
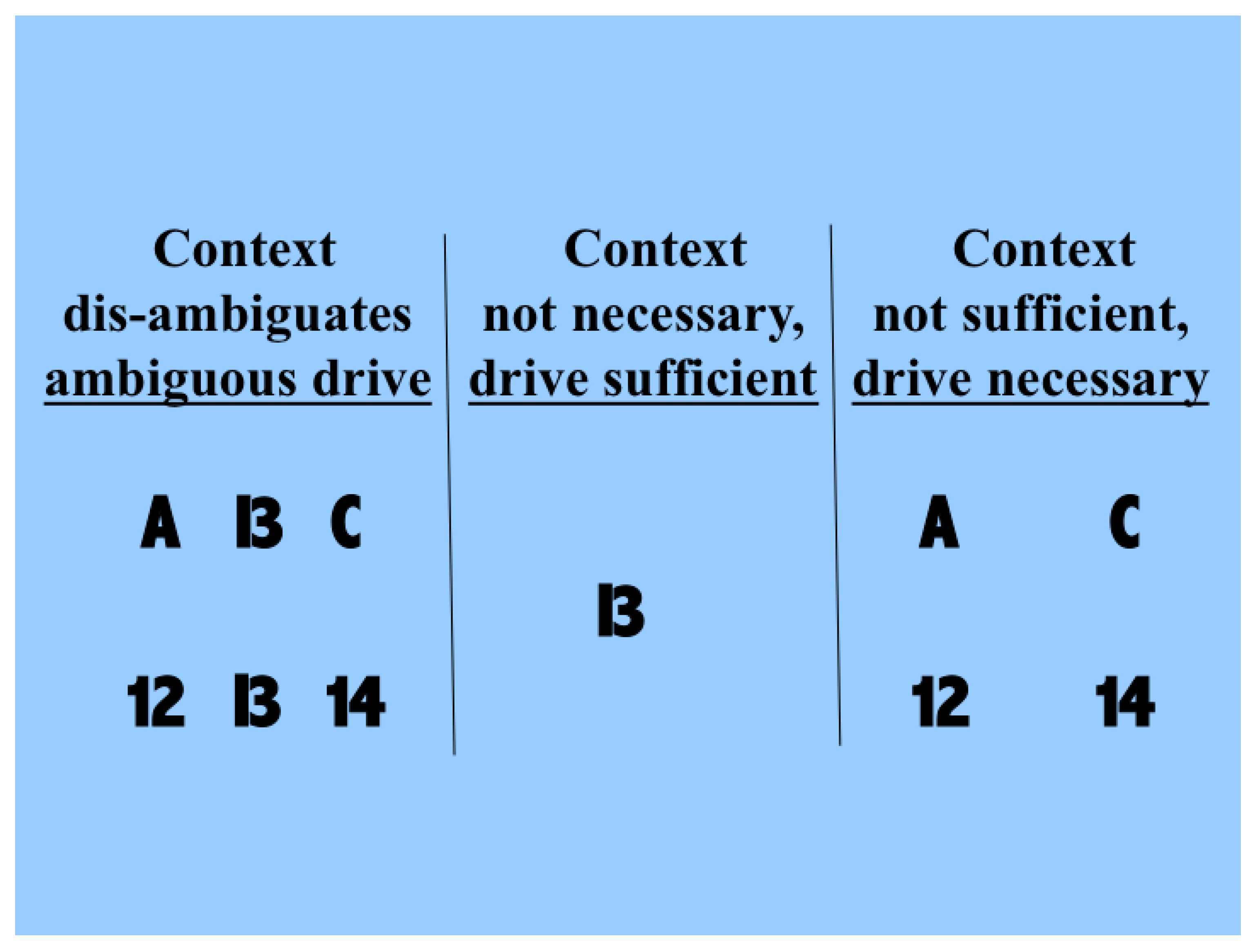
- CM1:
- The drive, R, is sufficient for the output to transmit information about the input, so context, C, is not necessary.
- CM2:
- The drive, R, is necessary for the output to transmit information about the input, so context, C, is not sufficient.
- CM3:
- The output can transmit unique information about the drive, R, but little or no unique information or misinformation about the context, C.
- CM4:
- The context can strengthen the transmission of information about R when R is weak.
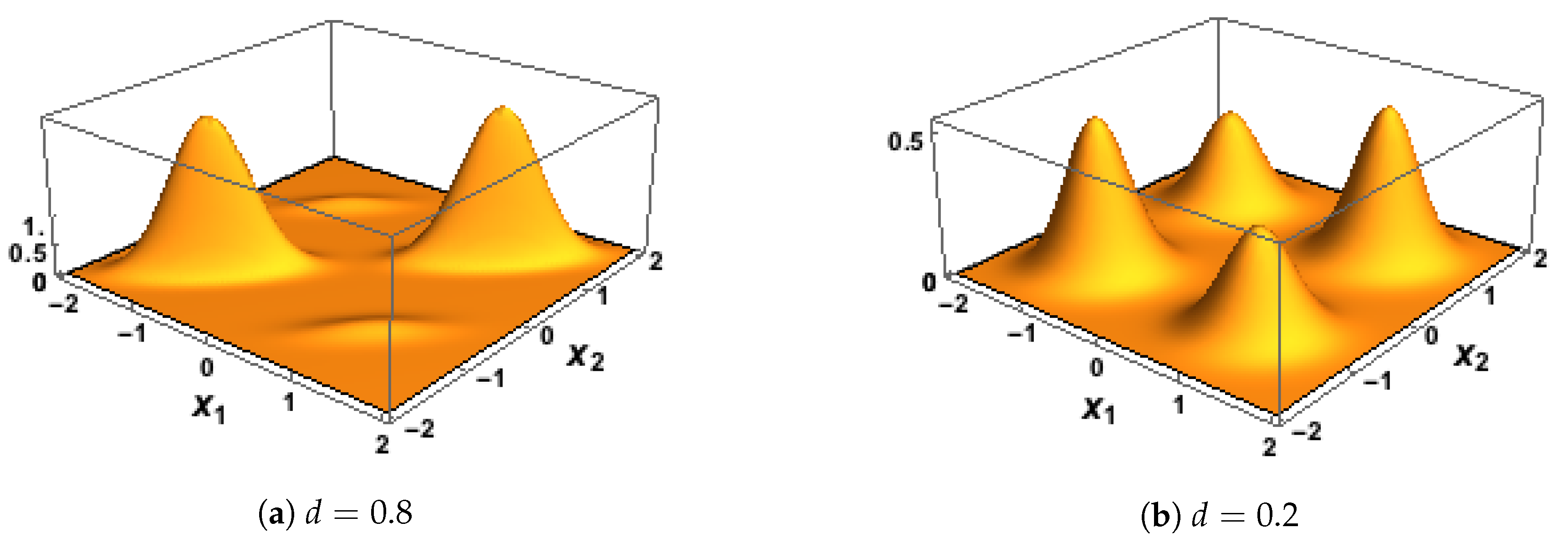
2.5. Bivariate Gaussian Mixture Model (BGM)
2.6. Single Bivariate Gaussian Model (SBG)
2.7. First Simulation, with Inputs Generated Using the BGM Model
2.8. The Second Simulation, with Inputs Generated Using the SBG Model
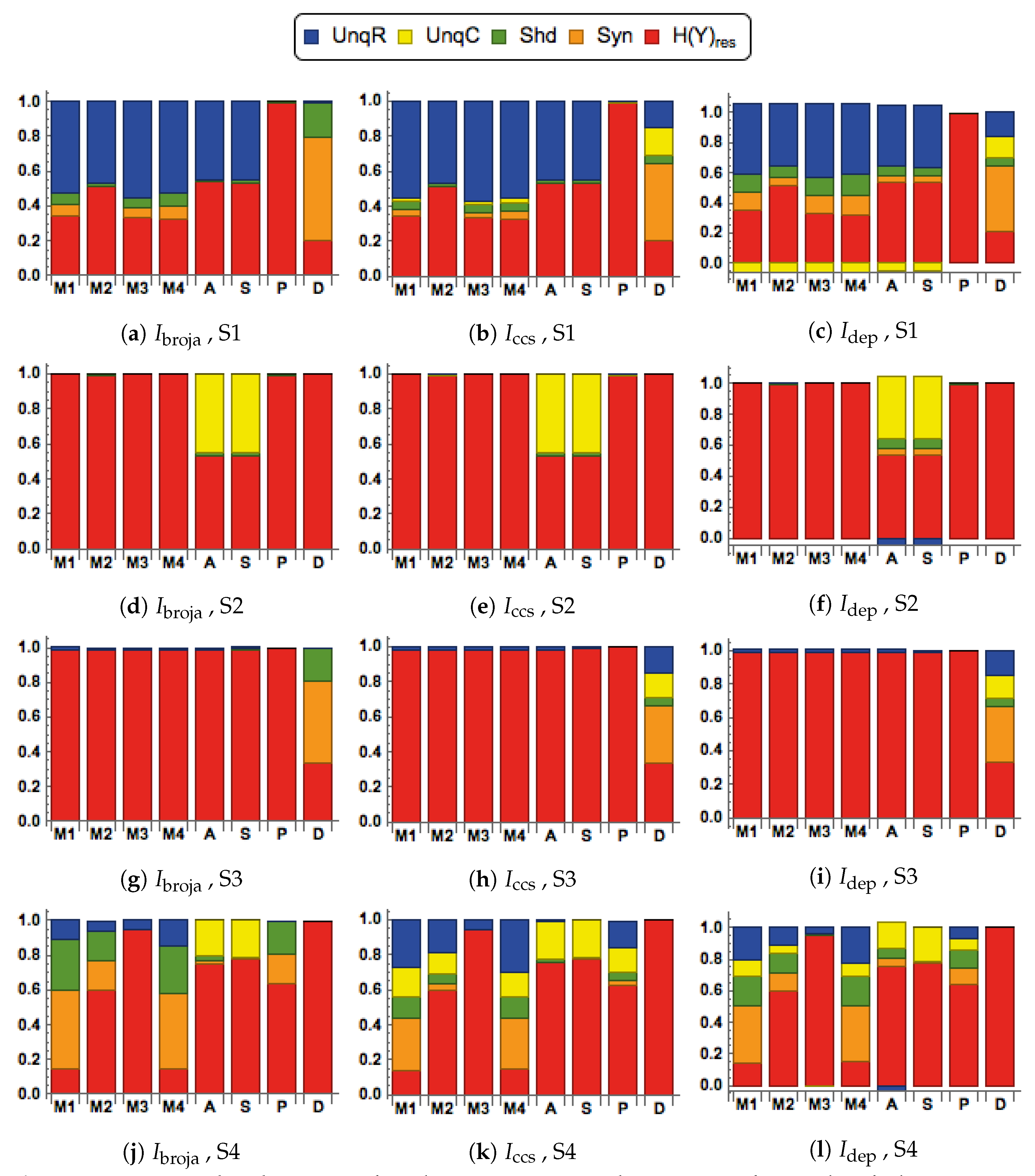
3. The Results
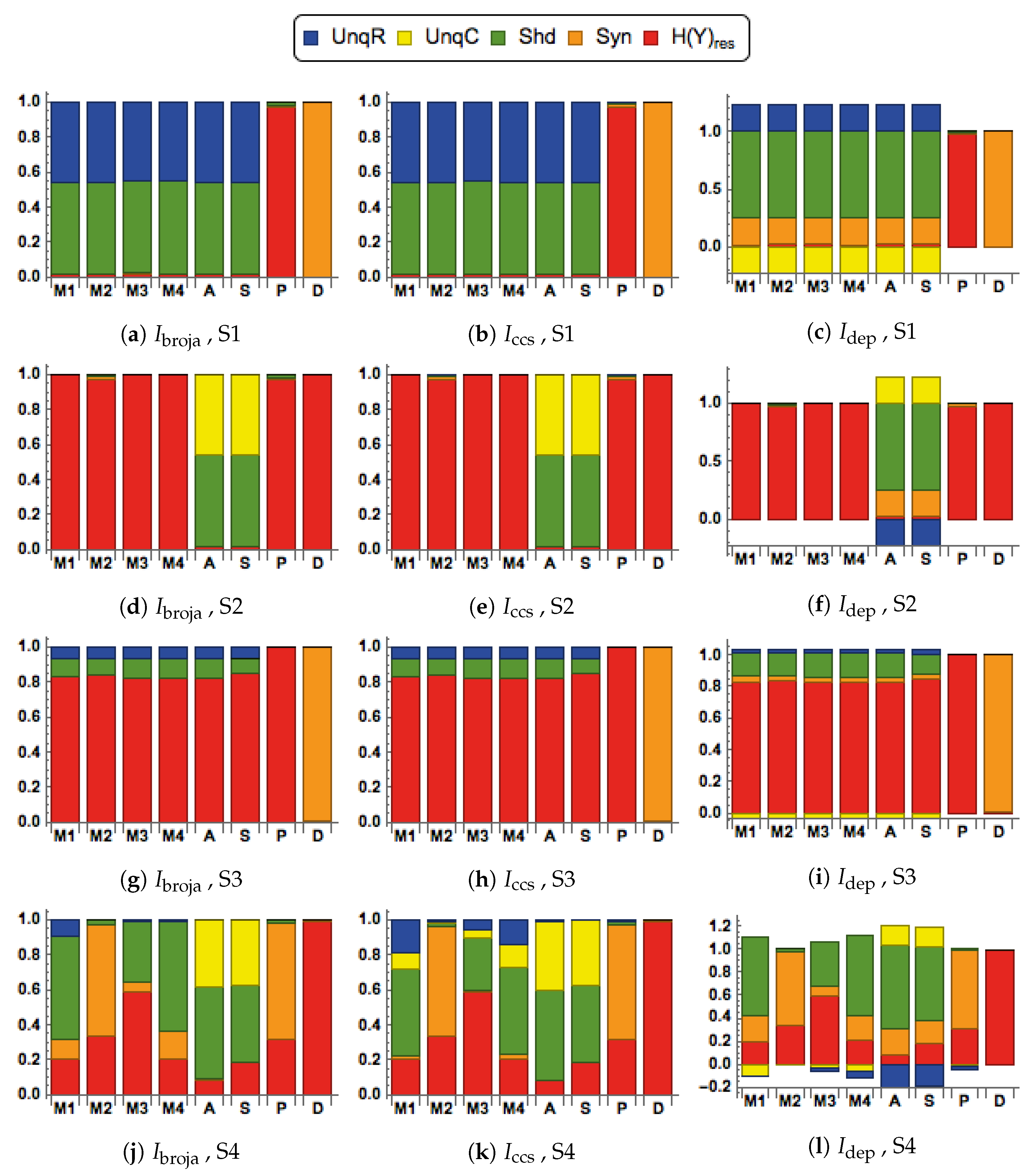
3.1. First Simulation, with Inputs Generated Using the BGM Model
3.1.1. Distinctive Information Transmission Properties of Contextual Modulation
3.1.2. Comparison of Five Different Forms of Information Decomposition
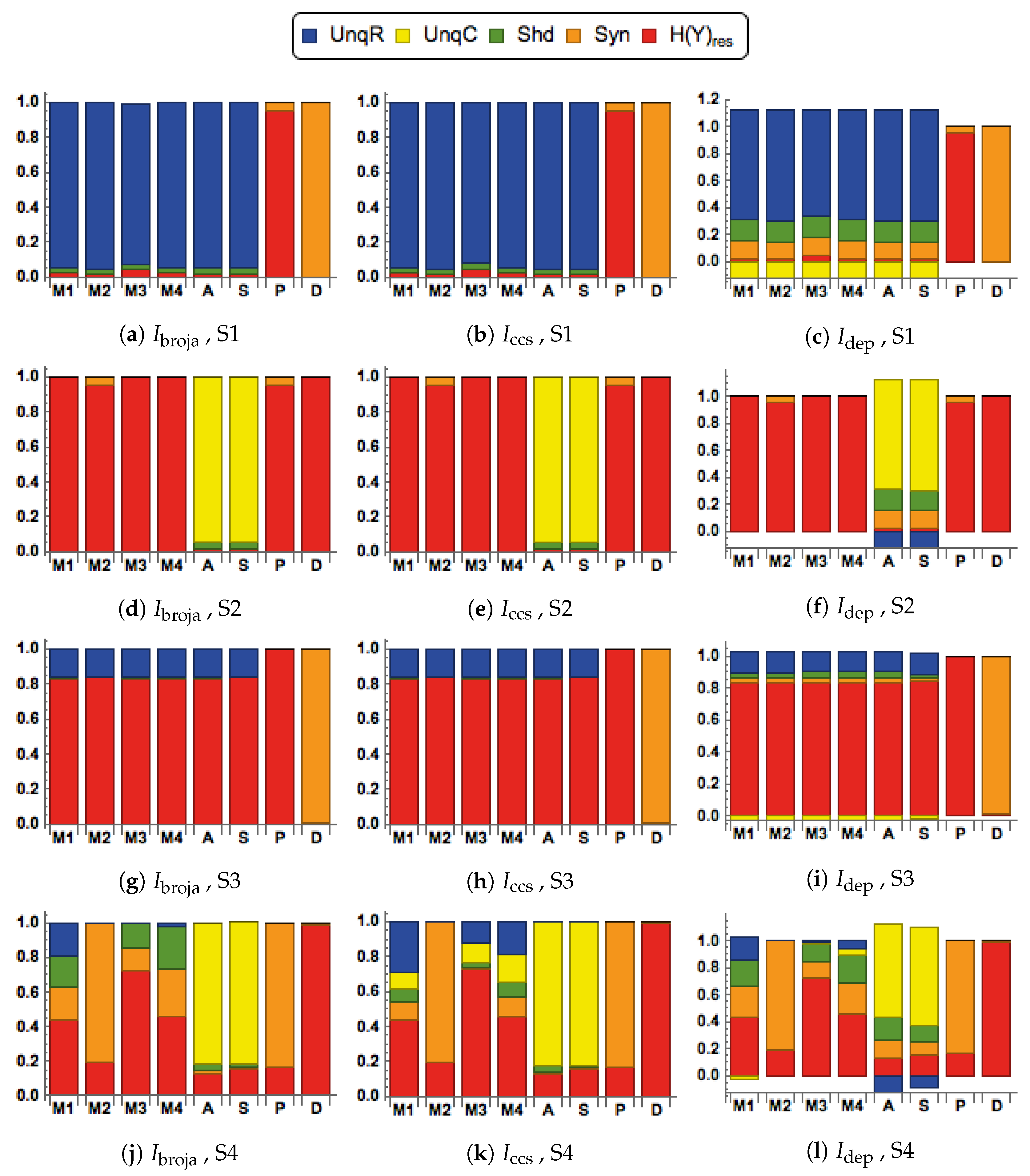
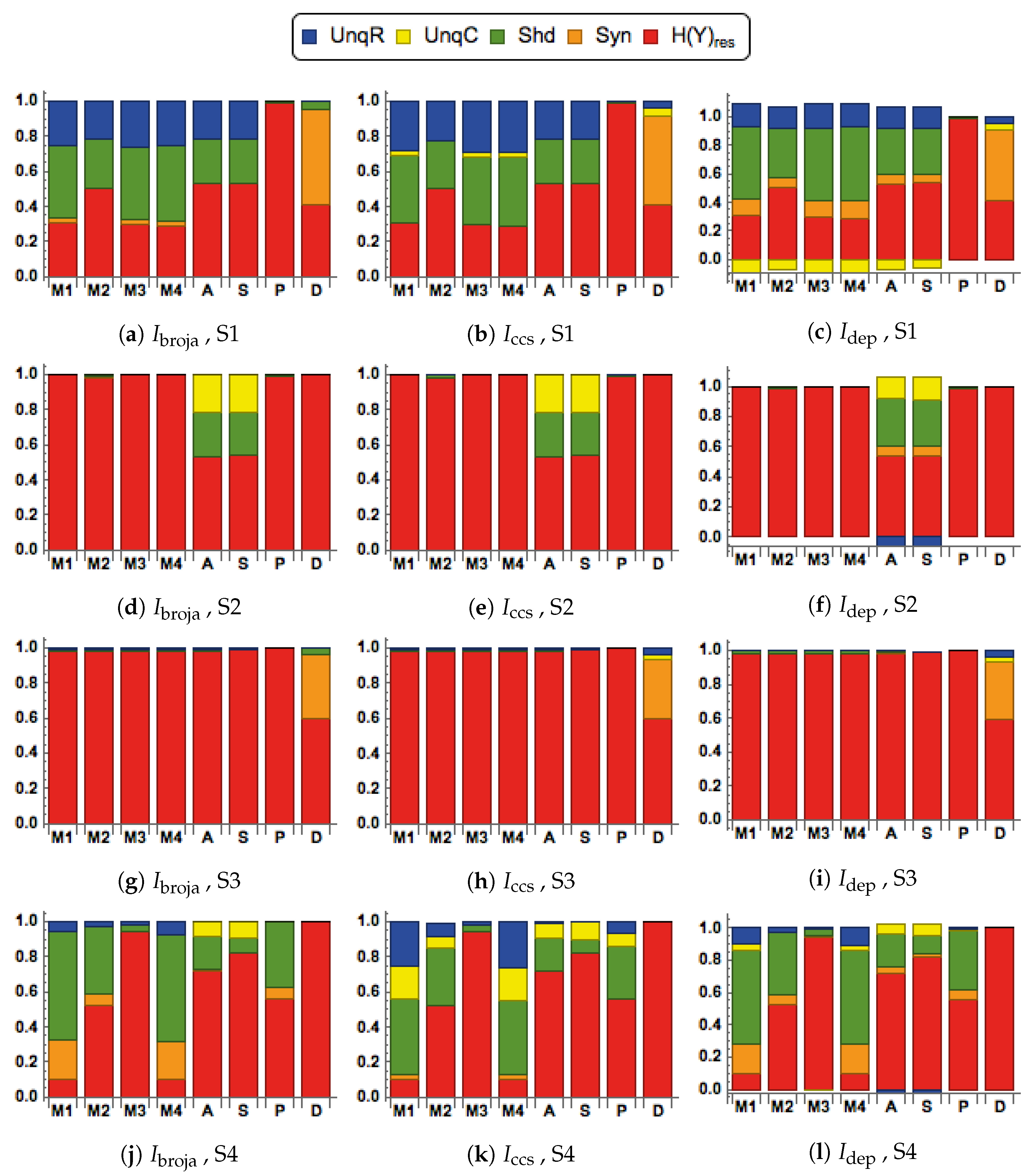
3.2. Second Simulation, with Inputs Generated Using the SBG Model
3.2.1. Distinctive Information Transmission Properties of Contextual Modulation
3.2.2. Comparison of Five Different Forms of Information Decomposition
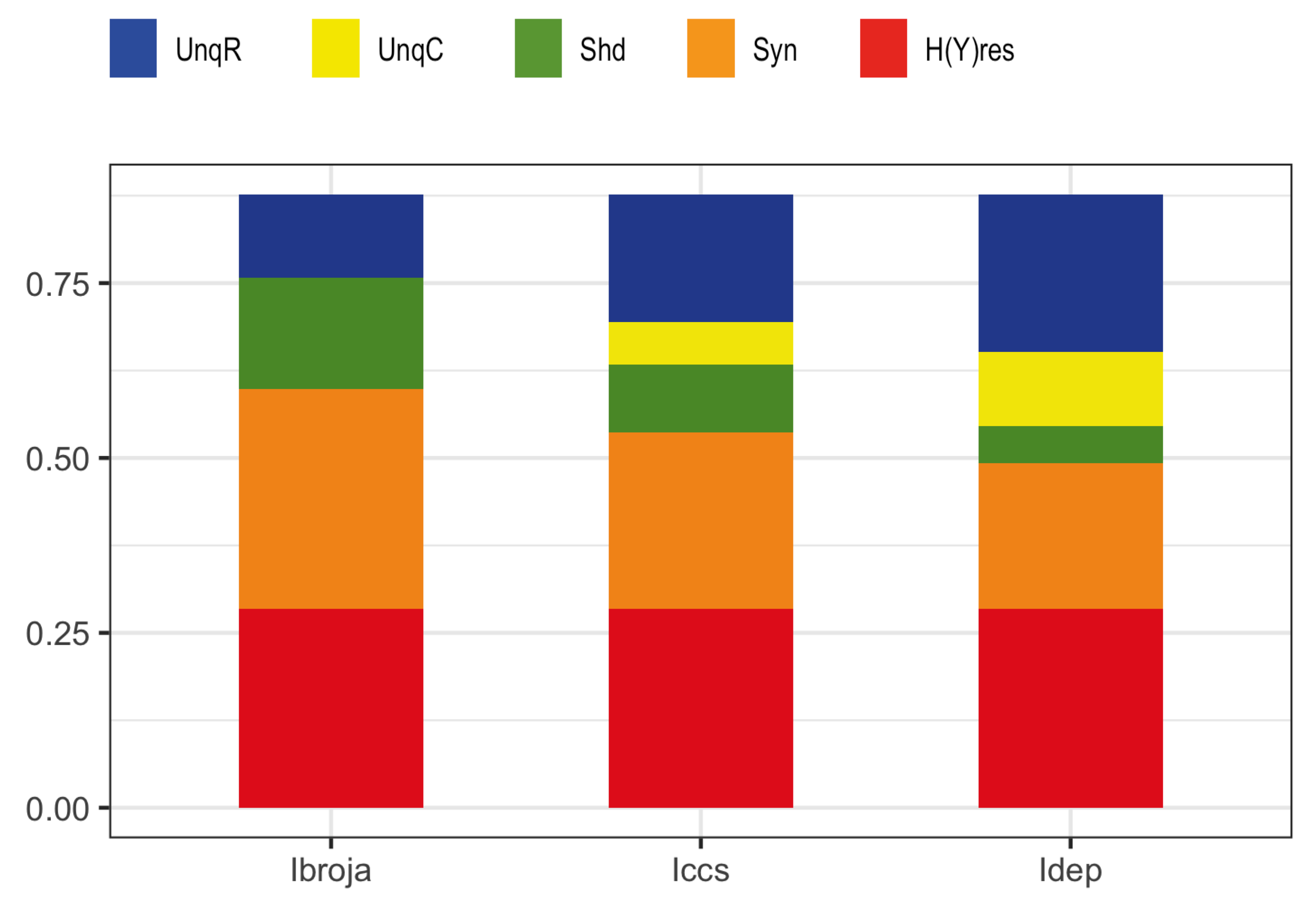
3.3. Partial Information Decomposition of Binarized Action Potential Data from a Detailed Multi-Compartment Model of A Neuron
4. Conclusions and Discussion
4.1. Contextual Modulation Contrasts with the Arithmetic Operators
4.2. There are Various Forms of Contextual Modulation
4.3. Is Coordinate Transformation an Example of Contextual Modulation?
4.4. Is the Contrast Between ‘Modulation’ and ‘Drive’ Adequately Defined?
4.5. What Forms of Modulation Occur in Neocortex?
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Nomenclature
| Mathematical Symbols | |
| Y | A discrete random variable representing the binary output |
| y | A realization of the random variable Y |
| R | A continuous random variable representing the receptive field input |
| r | A realization of the random variable R |
| C | A continuous random variable representing the contextual field input |
| c | A realization of the random variable C |
A univariate and bivariate probability mass functions, e.g., | |
Bivariate probability density functions, as in | |
Mean vector and covariance matrix, as in | |
The mixing proportions in the bivariate Gaussian mixture model, as in | |
Continuous random variables following various Gaussian probability models | |
The realized values of random variables | |
The signal strengths used to compute r and c | |
The general form of transfer function, given receptive field input r and contextual field input c, as in (1). | |
| Classical Information Terms | |
The Shannon entropy of the random variable Y | |
The residual entropy of the output random variable Y, which is equal to , the entropy in Y that is not shared with R or C. | |
The Shannon entropy where the random variable is evident in the text | |
The Shannon entropy of a bivariate random vector, e.g., | |
The Shannon entropy of the trivariate random vector | |
The mutual information shared between two random variables, e.g., | |
The local mutual information shared between realizations of two random variables, e.g., | |
The mutual information shared between the random variable Y and the random vector | |
The conditional mutual information shared between the random variables Y and R but not shared with C | |
The mutual information shared between the random variables Y and C but not shared with R | |
The interaction information – a measure involving synergy and shared information which involves all three random variables . |
| Partial Information Decomposition | |
| PID | Partial Information Decomposition, with components UnqR, UnqC, Shd and Syn, defined in Section 2.2 |
The PID developed by Bertschinger et al. [49] | |
The PID developed by Williams and Beer [30] | |
The PID developed by Harder et al. [48] | |
The PID developed by Ince [51] | |
The PID developed by James et al. [52] |
| Other Acronyms | |
| M1–M4 | Four modulatory transfer functions, with with transfer function , as defined in Section 2.3 |
| A, S, P, D | Four arithmetic transfer function, with e.g., A with transfer function , as defined in Section 2.3 |
| S1–S4 | Four signal-strength scenarios, as defined in Section 2.4 |
| CM1–CM4 | Four key properties of contextual modulation, as defined in Section 2.4 |
| BGM | Bivariate Gaussian Mixture Model, as defined in Section 2.5 |
| SBG | Single bivariate Gaussian Model, as defined in Section 2.6 |
| AP | Action potential |
References
- Silver, R.A. Neuronal arithmetic. Nat. Rev. Neurosci. 2010, 11, 474–489. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ferguson, K.A.; Cardin, J.A. Mechanisms underlying gain modulation in the cortex. Nat. Neurosci. Rev. 2020, 21, 80–92. [Google Scholar] [CrossRef] [PubMed]
- Salinas, E. Gain Modulation. In Encyclopedia of Neuroscience; Squire, L.R., Ed.; Academic Press: Oxford, UK, 2009; Volume 4, pp. 485–490. [Google Scholar]
- Carandini, M.; Heeger, D.J. Normalization as a canonical neural computation. Nat. Rev. Neurosci. 2012, 13, 51–62. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eldar, E.; Cohen, J.D.; Niv, Y. The effects of neural gain on attention and learning. Nat. Neurosci. 2013, 16, 1146–1153. [Google Scholar] [CrossRef] [PubMed]
- Phillips, W.A.; Clark, A.; Silverstein, S.M. On the functions, mechanisms, and malfunctions of intracortical contextual modulation. Neurosci. Biobehav. Rev. 2015, 52, 1–20. [Google Scholar] [CrossRef]
- Rolls, E.T. Cerebral Cortex: Principles of Operation; Oxford University Press: Oxford, UK, 2016. [Google Scholar]
- Larkum, M.E.; Zhu, J.J.; Sakmann, B. A new cellular mechanism for coupling inputs arriving at different cortical layers. Nature 1999, 98, 338–341. [Google Scholar] [CrossRef]
- Larkum, M. A cellular mechanism for cortical associations: An organizing principle for the cerebral cortex. Trends Neurosci. 2013, 36, 141–151. [Google Scholar] [CrossRef]
- Major, G.; Larkum, M.E.; Schiller, J. Active properties of neocortical pyramidal neuron dendrites. Annu. Rev. Neurosci. 2013, 36, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Jadi, J.P.; Behabadi, B.F.; Poleg-Polsky, A.; Schiller, J.; Mel, B.W. An augmented two-layer model captures nonlinear analog spatial integration effects in pyramidal neuron dendrites. Proc. IEEE 2014, 102, 782–798. [Google Scholar] [CrossRef] [Green Version]
- Lamme, V.A.F. Beyond the classical receptive field: Contextual modulation of V1 responses. In The Visual Neurosciences; Werner, J.S., Chalupa, L.M., Eds.; MIT Press: Cambridge, MA, USA, 2004; pp. 720–732. [Google Scholar]
- Phillips, W.A. Cognitive functions of intracellular mechanisms for contextual amplification. Brain Cogn. 2017, 112, 39–53. [Google Scholar] [CrossRef]
- Gilbert, C.; Li, W. Top-down influences on visual processing. Nat. Rev. Neurosci. 2013, 14, 350–363. [Google Scholar] [CrossRef]
- Li, Z. Border ownership from intracortical interactions in visual area V2. Neuron 2005, 47, 143–153. [Google Scholar]
- Mehrani, P.; Tsotsos, J.K. Early recurrence enables figure border ownership. arXiv 2019, arXiv:1901.03201. [Google Scholar]
- Schwartz, O.; Hsu, A.; Dayan, P. Space and time in visual context. Nat. Rev. Neurosci. 2007, 8, 522–535. [Google Scholar] [CrossRef] [PubMed]
- Sharpee, T.O.; Victor, J.D. Contextual modulation of V1 receptive fields depends on their spatial symmetry. J. Comput. Neurosci. 2008, 26, 203–218. [Google Scholar] [CrossRef] [PubMed]
- Zhou, H.; Schafer, R.J.; Desimone, R. Pulvinar-cortex interactions in vision and attention. Neuron 2016, 89, 209–220. [Google Scholar] [CrossRef] [Green Version]
- Reynolds, J.H.; Heeger, D.J. The normalization model of attention. Neuron 2009, 61, 168–185. [Google Scholar] [CrossRef] [Green Version]
- Rothenstein, A.L.; Tsotsos, J.K. Attentional modulation and selection—An integrated approach. PLoS ONE 2014, 9. [Google Scholar] [CrossRef]
- Shipp, S.; Adams, D.L.; Moutoussis, K.; Zeki, S. Feature binding in the feedback layers of area V2. Cereb. Cortex 2009, 19, 2230–2239. [Google Scholar] [CrossRef] [Green Version]
- Siegel, M.; Körding, K.P.; König, P. Integrating top-down and bottom-up sensory processing by somato-dendritic interactions. J. Comput. Neurosci. 2000, 8, 161–173. [Google Scholar] [CrossRef]
- Spratling, M.W.; Johnson, M.H. A feedback model of visual attention. J. Cogn. Neurosci. 2004, 16, 219–237. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Phillips, W.A.; Kay, J.; Smyth, D. The discovery of structure by multi-stream networks of local processors with contextual guidance. Netw. Comput. Neural Syst. 1995, 6, 225–246. [Google Scholar] [CrossRef]
- Kay, J.; Floreano, D.; Phillips, W.A. Contextually guided unsupervised learning using local multivariate binary processors. Neural Netw. 1998, 11, 117–140. [Google Scholar] [CrossRef] [Green Version]
- Kay, J.W.; Phillips, W.A. Coherent infomax as a computational goal for neural systems. Bull. Math. Biol. 2011, 73, 344–372. [Google Scholar] [CrossRef] [PubMed]
- Lizier, J.T.; Bertschinger, N.; Jost, J.; Wibral, M. Information Decomposition of Target Effects from Multi-Source Interactions: Perspectives on Previous, Current and Future Work. Entropy 2018, 20, 307. [Google Scholar] [CrossRef] [Green Version]
- Kay, J.W.; Ince, R.A.A.; Dering, B.; Phillips, W.A. Partial and Entropic Information Decompositions of a Neuronal Modulatory Interaction. Entropy 2017, 19, 560. [Google Scholar] [CrossRef] [Green Version]
- Williams, P.L.; Beer, R.D. Nonnegative decomposition of multivariate information. arXiv 2010, arXiv:1004.2515. [Google Scholar]
- Wibral, M.; Lizier, J.T.; Priesemann, V. Bits from brains for biologically inspired computing. Comput. Intell. 2015, 2, 5. [Google Scholar] [CrossRef] [Green Version]
- Wibral, M.; Priesemann, V.; Kay, J.W.; Lizier, J.T.; Phillips, W.A. Partial information decomposition as a unified approach to the specification of neural goal functions. Brain Cogn. 2017, 112, 25–38. [Google Scholar] [CrossRef] [Green Version]
- Salinas, E. Fast remapping of sensory stimuli onto motor actions on the basis of contextual modulation. J. Neurosci. 2004, 24, 1113–1118. [Google Scholar] [CrossRef]
- Phillips, W.A.; Larkum, M.E.; Harley, C.W.; Silverstein, S.M. The effects of arousal on apical amplification and conscious state. Neurosci. Conscious. 2016, 2016, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Helmholtz, H. Handbuch der Physiologischen Optik; Southall, J.P.C., Ed.; English trans.; Dover: New York, NY, USA, 1962; Volume 3. [Google Scholar]
- Sherman, S.M.; Guillery, R.W. On the actions that one nerve cell can have on another: Distinguishing ‘drivers’ from ‘modulators’. Proc. Natl. Acad. Sci. USA 1998, 95, 7121–7126. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Phillips, W.A. Mindful neurons. Q. J. Exp. Psychol. 2019, 72, 661–672. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Santoro, A.; Marris, L.; Akerman, C.J.; Hinton, G. Backpropagation and the brain. Nat. Rev. Neurosci. 2020. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley-Interscience: New York, NY, USA, 1991. [Google Scholar]
- McGill, W.J. Multivariate Information Transmission. Psychometrika 1954, 19, 97–116. [Google Scholar] [CrossRef]
- Schneidman, E.; Bialek, W.; Berry, M.J. Synergy, Redundancy, and Population Codes. J. Neurosci. 2003, 23, 11539–11553. [Google Scholar] [CrossRef]
- Gat, I.; Tishby, N. Synergy and redundancy among brain cells of behaving monkeys. In Proceedings of the 1998 Conference on Advances in Neural Information Processing Systems 2, Denver, CO, USA, 30 November–5 December 1998; MIT Press: Cambridge, MA, USA, 1999; pp. 111–117. [Google Scholar]
- Wibral, M.; Finn, C.; Wollstadt, P.; Lizier, J.T.; Priesemann, V. Quantifying Information Modification in Developing Neural Networks via Partial Information Decomposition. Entropy 2017, 19, 494. [Google Scholar] [CrossRef] [Green Version]
- Ince, R.A.A.; Giordano, B.L.; Kayser, C.; Rousselet, G.A.; Gross, J.; Schyns, P.G. A Statistical Framework for Neuroimaging Data Analysis Based on Mutual Information Estimated via a Gaussian Copula. Hum. Brain Mapp. 2017, 38, 1541–1573. [Google Scholar] [CrossRef]
- Park, H.; Ince, R.A.A.; Schyns, P.G.; Thut, G.; Gross, J. Representational interactions during audiovisual speech entrainment: Redundancy in left posterior superior temporal gyrus and synergy in left motor cortex. PLoS Biol. 2018, 16, e2006558. [Google Scholar] [CrossRef]
- James, R.G.; Ellison, C.J.; Crutchfield, J.P. A Python package for discrete information theory. J. Open Source Softw. 2018, 25, 738. [Google Scholar] [CrossRef]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. E 2013, 87. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying Unique Information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef] [Green Version]
- Griffith, V.; Koch, C. Quantifying synergistic mutual information. In Guided Self-Organization: Inception. Emergence, Complexity and Computation; Springer: Berlin/Heidelberg, Germany, 2014; Volume 9, pp. 159–190. [Google Scholar]
- Ince, R.A.A. Measuring multivariate redundant information with pointwise common change in surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef] [Green Version]
- James, R.G.; Emenheiser, J.; Crutchfield, J.P. Unique Information via Dependency Constraints. J. Phys. Math. Theor. 2018, 52, 014002. [Google Scholar] [CrossRef] [Green Version]
- Finn, C.; Lizier, J.T. Pointwise Partial Information Decomposition Using the Specificity and Ambiguity Lattices. Entropy 2018, 20, 297. [Google Scholar] [CrossRef] [Green Version]
- Makkeh, A.; Gutknecht, A.J.; Wibral, M. A differentiable measure of pointwise shared information. arXiv 2020, arXiv:2002.03356. [Google Scholar]
- Lizier, J.T. Measuring the Dynamics of Information Processing on a Local Scale. In Directed Information Measures in Neuroscience; Wibral, M., Vicente, R., Lizier, J.T., Eds.; Springer: Heidelberg, Germany, 2014; pp. 161–193. [Google Scholar]
- Shai, A.S.; Anastassiou, C.A.; Larkum, M.E.; Koch, C. Physiology of Layer 5 Pyramidal Neurons in Mouse Primary Visual Cortex: Coincidence Detection through Bursting. PLoS Comput. Biol. 2015, 1, e1004090. [Google Scholar] [CrossRef] [Green Version]
- Available online: https://senselab.med.yale.edu/ModelDB/ShowModel.cshtml?model=180373&file=/ShaiEtAl2015/data/spikes_.dat#tabs-2 (accessed on 2 May 2020).
- Salinas, E.; Their, P. Gain modulation: A major computational principle of the central nervous system. Neuron 2000, 27, 15–21. [Google Scholar] [CrossRef] [Green Version]
- Salinas, E.; Sejnowski, T.J. Gain modulation in the central nervous system: Where behavior, neurophysiology, and computation meet. Neuroscientist 2001, 7, 430–440. [Google Scholar] [CrossRef]
- Timme, N.M.; Ito, S.; Myroshnychenko, M.; Nigam, S.; Shimono, M.; Yeh, F.C.; Hottowy, P.; Litke, A.M.; Beggs, J.M. High-Degree Neurons Feed Cortical Computations. PLoS Comput. Biol. 2016, 12, 1–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S1 | Scenario 1: Strong R, with C near 0 | () |
| S2 | Scenario 2: R near zero, with strong C | () |
| S3 | Scenario 3: Weak R, with C near 0 | () |
| S4 | Scenario 4: Weak R, with moderate C | () |
| H(Y) | ||||||
|---|---|---|---|---|---|---|
| 0.88 | 0.28 | 0.16 | 0.43 | 0.31 | 0.59 | 0.16 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kay, J.W.; Phillips, W.A. Contextual Modulation in Mammalian Neocortex is Asymmetric. Symmetry 2020, 12, 815. https://doi.org/10.3390/sym12050815
Kay JW, Phillips WA. Contextual Modulation in Mammalian Neocortex is Asymmetric. Symmetry. 2020; 12(5):815. https://doi.org/10.3390/sym12050815
Chicago/Turabian StyleKay, Jim W., and William A. Phillips. 2020. "Contextual Modulation in Mammalian Neocortex is Asymmetric" Symmetry 12, no. 5: 815. https://doi.org/10.3390/sym12050815
APA StyleKay, J. W., & Phillips, W. A. (2020). Contextual Modulation in Mammalian Neocortex is Asymmetric. Symmetry, 12(5), 815. https://doi.org/10.3390/sym12050815