1. Introduction
In daily life, target recognition involves all aspects of our lives, such as intelligent video surveillance and face recognition. These applications also make target recognition technology more popular. The development of related technologies has greatly enriched the application scenarios of target recognition and tracking theories. Research on related theoretical methods has also received extensively attention. Target recognition involves image processing, calculation computer vision, pattern recognition and other subjects.
Generalized target recognition includes two stages, feature extraction, and classifier classification. Through feature extraction, image, video, and other target observation data are preprocessed to extract feature information, and then the classifier algorithm implements target classification based on the feature information [
1]. Common image features can be divided into color gray statistical feature, texture edge feature, algebraic feature, and variation coefficient feature. The feature extraction methods corresponding to the above features are color histogram, gray-level co-occurrence matrix method, principal component analysis method, wavelet transform [
2]. The classic target classification algorithms include decision tree, support vector machine [
3], neural network [
4], logistic regression, and naive Bayes classification [
5,
6,
7,
8]. On the basis of a single classifier, the ensemble classifier integrates the classification results of a series of weak classifiers through an ensemble learning method, so as to obtain a better classification effect than a single classifier, mainly including Bagging and Boosting [
9]. With the development of high-performance computing equipment and the enlargement in the amount of available data, deep learning related theories and methods have developed rapidly, and the application of deep learning in the direction of target recognition has also made it break through the limitations of traditional methods based on deep neural networks [
10,
11,
12]. Classification network models include LeNet, AlexNet, VggNet.
In practical applications, multi-source sensor data is often processed in decision analysis [
13,
14,
15,
16,
17,
18,
19] as the number of sensors increases. For the problem of uncertain information processing, there are many theoretical methods such as Dempster-Shafer evidence theory [
20,
21,
22,
23,
24,
25,
26], fuzzy set theory [
27,
28], D number [
29,
30,
31,
32] and rough set theory [
33].
Smarandache [
34] firstly generalized the concepts of fuzzy sets [
35], intuitionistic fuzzy sets (IFS) [
36] and interval-valued intuitionistic fuzzy sets (IVIFS) [
37], and proposed the neutrosophic set. It is very suitable to use the neutrosophic set to deal with uncertain and inconsistent information in the real world. However, its authenticity, uncertainty, and false membership function are defined in the real number standard or non-standard subset. Therefore, non-standard intervals are not suitable for scientific and engineering applications. Therefore, Ye [
38] introduced a simplified neutrosophic set (SNS), which limits the true value, uncertainty, and false membership function to the actual standard interval
. In addition, SNS also includes single value neutrosophic set (SVNS) [
39,
40,
41] and interval neutrosophic set (INS) [
42].
As a new kind of fuzzy set, neutrosophic set [
43,
44] have been used in many fields, such as decision-making [
45,
46,
47,
48], data analysis [
49,
50], fault diagnosis [
51], the shortest path problem [
52]. There is also a lot of progress in the related theoretical research of neutrosophic set. For example, score function of pentagonal neutrosophic set [
53,
54].
Existing multi-sensor fusion methods, such as evidence theory, have complex calculation and long calculation time [
55], and there are a few methods that use neutrosophic set in multi-sensor fusion. Therefore, this paper proposes a multi-sensor fusion based on neutrosophic set. First, the complementarity vectors between multiple sensors are calculated. Then these complementarity vectors and the probability of sensor output are used to form a group of neutrosophic sets, and generated neutrosophic sets are fused through the SNWA operator. Finally, the neutrosophic set is converted to the crisp number, and the maximum value is the recognition result. The proposed method has simple calculation and fast operation, and can effectively improve the accuracy of target recognition.
The rest of this article is organized as follows:
Section 2 introduces some necessary concepts, such as neutrosophic set and multi-category evaluation standard. The proposed multi-sensor fusion recognition method is listed step by step in
Section 3. In
Section 4, an example is used to illustrate and explain the effective of proposed method. Some results discussion are shown in
Section 5.
2. Preliminaries
2.1. Neutrosophic Set
Definition 1. The the simplified neutrosophic set (SNS) is defined as follows [38]: X is a finite set, with a element of X denoted by x. A neutrosophic set (A) in X contains three parts: a truth-membership function , an indeterminacy-membership function , and a falsity-membership function . A single-valued neutrosophic set P on X is defined as: This is called a SNS. In particular, if X includes only one element, is called a SNN (the simplified neutrosophic number) and is denoted by . The numbers denote the degree of membership, the degree of indeterminacy-membership, and the degree of non-membership.
Definition 2. The crisp number of each SNN is deneutrosophicated and calculated as follows [56]: can be regarded as the score of SNN, so SNN can be sorted according to crisp number .
2.2. Commonly Used Evaluation Indicators for Multi-Classification Problems
The index for evaluating the performance of a classifier is generally the accuracy of the classifier, which is defined as the ratio of the number of samples correctly classified by the classifier to the total number of samples for a given test data set [
57].
The commonly used evaluation indicators for classification problems are precision and recall. Usually, the category of interest is regarded as the positive category, and the other categories are regarded as the negative category. The prediction of the classifier on the test data set is correct or incorrect. There are four situations as follows:
True Positive(TP): The true category is a positive example, and the predicted category is a positive example.
False Positive (FP): The true category is negative, and the predicted category is positive.
False Negative (FN): The true category is positive, and the predicted category is negative.
True Negative (TN): The true category is negative, and the predicted category is negative.
Based on the above basic concepts, the commonly used evaluation indicators for multi-classification problems are as follows.
Precision or precision rate, also known as precision (P):
Recall rate, also known as recall rate (R):
F1 score is an index used to measure the accuracy of the classification model. It also takes into account the accuracy and recall of the classification model. The score can be regarded as a harmonic average of model accuracy and recall. Its maximum value is 1 and its minimum value is 0:
2.3. AdaBoost Algorithm
AdaBoost is essentially an iterative algorithm [
58], and its core idea is to train some weak classifier
based on the initial sample using the decision tree algorithm. Use the classifier to detect the sample set. For each training sample point, adjust its weight according to whether the result of its classification is accurate: if
makes it classified correctly, reduce the weight of the sample point; otherwise, increase the sample the weight of the point. The adjusted weight is calculated according to the accuracy of the detection result. The sample set after adjusting the weight constitutes the sample set to be trained at the next level, which is used to train the next level classifier. In this way, iterate step by step to obtain a new classifier until the classifier
is obtained, and the sample detection error rate is 0.
Combine according to the error rate of the sample detection: make the weak classifier with the larger error account for the smaller weight in the combined classifier, and the weak classifier with the smaller error account for the larger weight to obtain a combined classifier.
The algorithm is essentially a comprehensive improvement of the weak classifier trained by the basic decision tree algorithm. Through continuous training of samples and weight adjustment, multiple classifiers are obtained, and the classifiers are combined by weight to obtain a comprehensive classifier that improves the ability of data classification. The whole process is as follows:
Train weak classifiers with sample sets.
Calculate the error rate of the weak classifier, and obtain the correct and incorrect sample sets.
Adjust the sample set weight according to the classification result to obtain a redistributed sample set.
After M cycles, M weak classifiers are obtained, and the joint weight of the classifier is calculated according to the detection accuracy of each weak classifier, and finally a strong classifier is obtained.
2.4. HOG Feature
Histogram of oriented gradient (HOG), which is a feature descriptor for target detection. This technology counts the number of directional gradients that appear locally in the image. This method is similar to the histogram of edge orientation and scale-invariant feature transform, but the difference is hog calculate the density matrix based on the uniform space to improve accuracy. Navneet Dalal and Bill Triggs first proposed HOG in 2005 for pedestrian detection in static images or videos [
59].
The core idea of HOG is that the shape of the detected local object can be described by the light intensity gradient or the distribution of the edge direction. By dividing the entire image into small connected areas (called cells). Each cell generates a directional gradient histogram or the edge direction of the pixel in the cell, and the descriptor is represented by combining the histogram. To improve the accuracy, the local histogram can be compared and standardized by calculating the light intensity of a larger area (called block) in the image as a measure, and then using this value (measure) to normalize all cells in the block. This normalization process completes better illumination/shadow invariance. Compared with other descriptors, the descriptors obtained by HOG maintain the invariance of geometric and optical transformations (unless the object orientation changes).
2.5. Gabor Feature
Gabor feature [
60] is a feature that can be used to describe the texture information of an image. The frequency and direction of the Gabor filter are similar to the human visual system, and it is particularly suitable for texture representation and discrimination. The Gabor feature mainly relies on the Gabor kernel to window the signal in the frequency domain, so as to describe the local frequency information of the signal.
In terms of feature extraction, Gabor wavelet transform is compared with other methods: on the one hand, it processes less data and can meet the real-time requirements of the system; on the other hand, wavelet transform is insensitive to changes in illumination and can tolerate a certain degree of when image rotation and deformation are used for recognition based on Euclidean distance, the feature pattern and the feature to be measured do not need to correspond strictly, so the robustness of the system can be improved.
2.6. D-AHP Theory
Analytic Hierarchy Process (AHP) [
61] is a systematic and hierarchical analysis method that combines qualitative and quantitative analysis. The characteristic of this method is that on the basis of in-depth research on the nature, influencing factors and internal relations of complex decision-making problems, it uses less quantitative information to mathematicize the thinking process of decision-making, thereby providing multi-objective, multi-criteria or complex decision-making problems with no structural characteristics provide simple decision-making methods.
The D-AHP method extends the traditional AHP method in theory. In the D-AHP method [
62], the derived results about the ranking and priority weights of alternatives are impacted by the credibility of providing information. A parameter
is used to express the credibility of information, and its value is associated with the cognitive ability of experts. If the comparison information used in the decision-making process is provided by an authoritative expert,
will take a smaller value. If the comparison information comes from an expert whose judgment is with low belief,
takes a higher value.
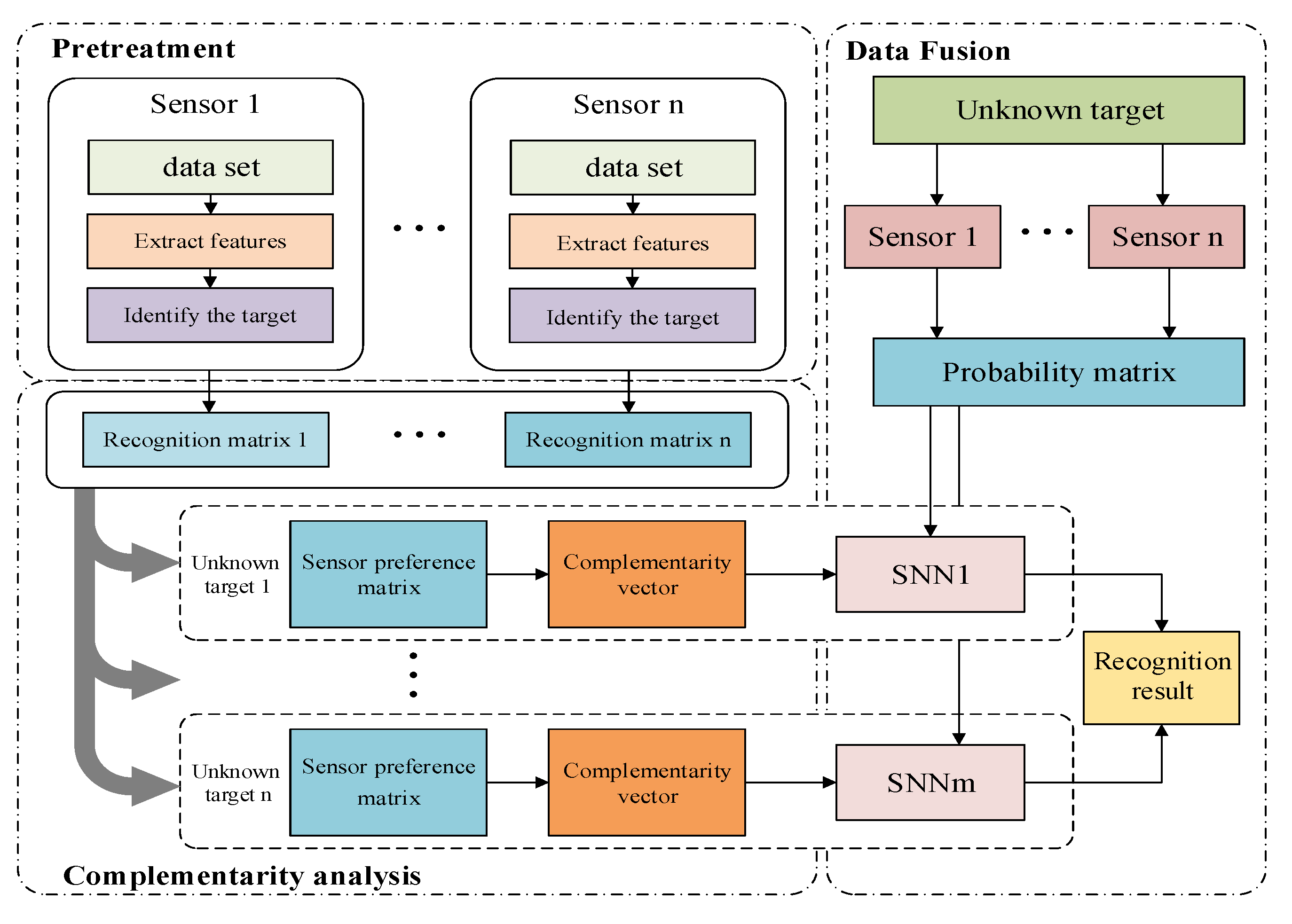
3. The Proposed Method
In general sensor recognition, the training set is inputting to train the sensor by extracting feature, and then the test set is inputting to test and get the recognition result. To improve the accuracy of multi-sensor fusion recognition, this paper proposes a fusion recognition method based on neutrosophic set. The proposed method in this paper is mainly divided into two parts: complementarity analysis and data fusion. The main steps of the method proposed in this paper are shown in
Figure 1.
The essence of complementarity is to calculate the weight of the recognition ability of the base sensor in different categories. Based on this, the data set is divided into training set, validation set, and test set. First, the base sensor preference matrix is obtained from the recognition matrix of the trained base sensor on the verification set, and then the sensor complementarity vector is calculated in each category.
Data fusion aims at different target types, based on the sensor complementarity vector, the recognition results of different sensors are generated by the neutrosophic set. Then the fusion of the neutrosophic set can be obtained in different categories, and finally the neutrosophic set is converted into crisp number, and the maximum value is taken as the recognition result.
3.1. Complementarity
The main steps of the multi-sensor complementarity analysis are proposed as follows:
According to the data test result, the sensor recognition matrix can be obtained.
The sensor preference matrix for different target types is obtained from multiple sensor recognition matrices.
The sensor complementarity vector is gotten from the sensor preference relationship matrix.
3.1.1. Sensor Recognition Matrix
Suppose there are
n types of sensors
, and
m types of target types
. For a certain data set
i, the recognition results of all its samples can be represented by the following recognition matrix
.
3.1.2. Sensor Preference Matrix
To obtain the preference relationship matrix between sensors, the preference between sensors needs to be defined. For two sensors, if the recognition performance of the sensor
on the target
is better than the recognition performance of the sensor
, then for the target
, the sensor
is better than the sensor
. The recognition results of a certain sensor on the samples in the data set i can be organized in the form of a recognition matrix, but the rows and columns become the recognized category of the sample and the true category of the sample. Furthermore, for the target of category
, according to the recognition matrix, we can get
Table 1:
Record the above matrix as
in
Table 1, where
is the number of correct recognition of the category
by the sensor,
is the number of samples that the sensor misrecognizes non-targets.
is the number of misrecognized category
samples into other categories.
is the number of samples other than the above three cases number. If the optimal performance of sensor recognition is expressed as a matrix:
Which means the category is fully recognized correctly. Then the recognition performance of this sensor to the category
is defined as
. Therefore, if there are two sensors
and
, the preference value of the recognition accuracy rate of
versus
in the category (representing the priority of the recognition ability of
over
in the category of
) is defined as:
In the same way, the recognition accuracy preference value of sensor
vs
on category
is defined as follows:
It is easy to get from the above two formulas that , which is the sum of the two preference values is 1. If , then . For the case where multiple sensors recognize at the same time, the preference relationship matrix on the category can be obtained. For each target category in the data set i, a corresponding preference relationship matrix can be obtained.
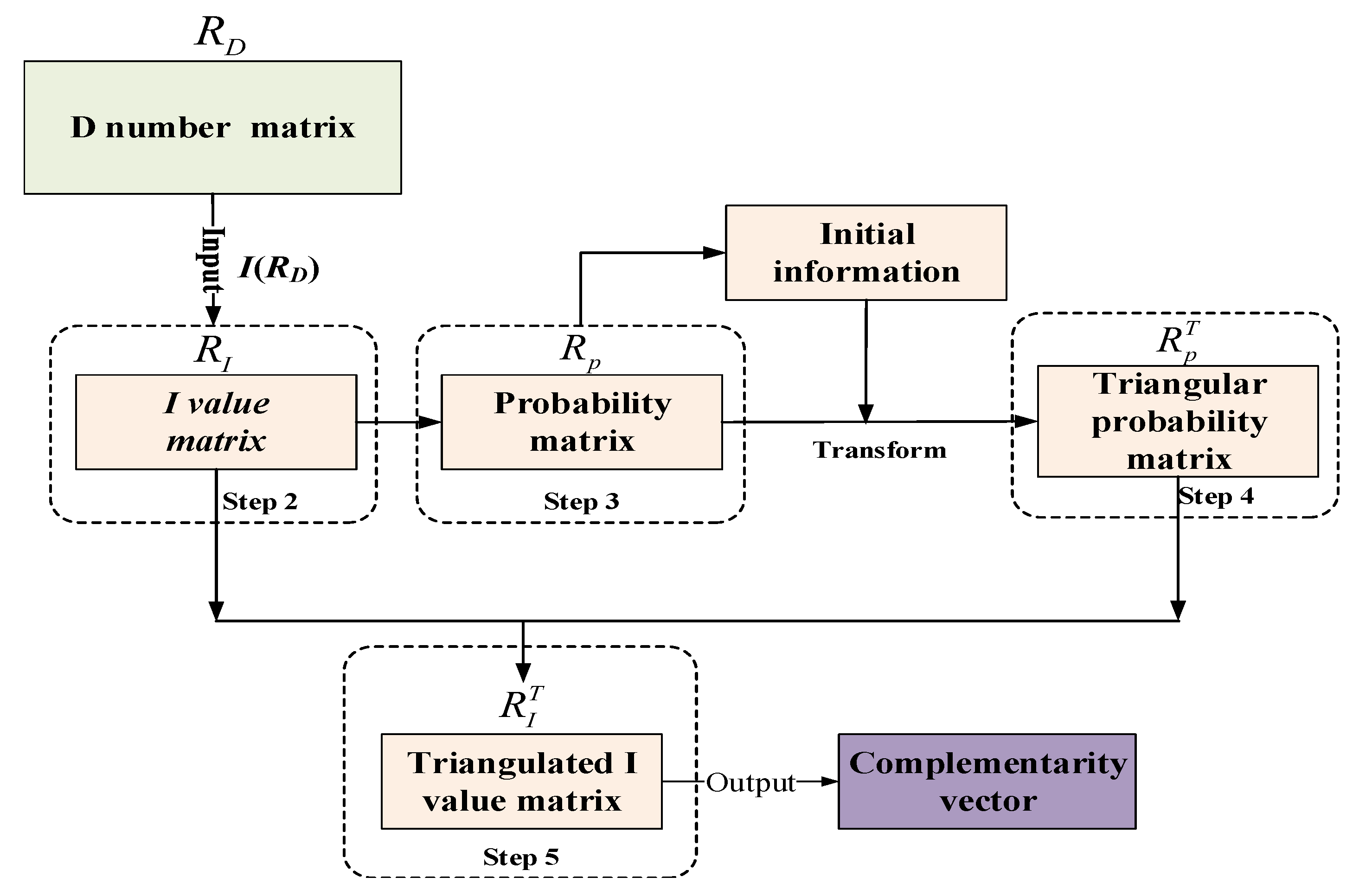
3.1.3. Sensor Complementarity Vector
Next, using the method in D-AHP theory [
62], the complementarity vector can be calculated by the preference relationship matrix.
According to the classifier preference relation matrix
of category
.
It is calculated that for each sensor complementarity vector
of category
,
is a
dimensional vector. The flowchart of the
calculation is presented as
Figure 2, the calculation steps are as follows:
Express the importance of the index relative to the evaluation target through the preference relationship, and construct the D number preference matrix .
According to the integrated representation of the D number, transform the D number preference matrix into a certain number matrix .
Construct a probability matrix based on the deterministic number matrix , and calculate the preference probability between the indicators compared in pairs.
Convert the probability matrix into a triangularized probability matrix , and sort the indicators according to their importance.
According to the index sorting result, the deterministic number matrix is expressed as a matrix , finally is obtained.
3.2. Data Fusion
For a picture with unknown target type, the probability matrix is formed via the recognition result vectors of each sensor.
where
is the probability that the sensor
considers the unknown target as the target type
.
At this time, the complementary vector is normalized to obtain the weight coefficient:
If the target type is
, the complementarity vector
and
Q can be combined to obtain a neutrosophic set
. Since there are
n sensors,
n groups neutrosophic sets can be obtained according to
Q and
as follows:
Combining
n groups of neutrosophic sets, a group of fused neutrosophic set can be obtianed, and the target recognition neutrosophic set is calculated under the imaginary target type
. Since there are
m types of target, we can finally use the SNWA operator [
63] to get
m neutrosophic sets:
Finally, convert these
m SNNs into crisp numbers, and take the maximum value as the recognition result.
5. Results
Aiming at the problem of multi-sensor target recognition, this paper proposes a new method based on the complementary characteristics of sensors in the fusion of neutrosophic set, which improves the accuracy of target type recognition. Using the identification of the sea surface vessel type as the verification scenario, the category-oriented sensor complementarity vector is constructed through feature extraction, sensor training of the target’s infrared and visible image training data. The multi-sensor neutrosophic set model is performed on the target to be recognized to realize the multi-sensor. Compared with other methods, the method proposed in this paper performs better in recognition accuracy, Compared with other fuzzy mathematics theories, the neutrosophic set theory is more helpful for us to deal with the complementary information between sensors. At the same time, the three sets of functions included in the neutrosophic set allow us to flexibly adjust the weight and other parameters, and the calculation of the neutrosophic set is simple, it takes less time to run the program. Further research will mostly concentrate on the the proposed method can be used to more complicated study to further demonstrate its efficiency.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}