1. Introduction
In probability theory, the half-logistic (HLo) distribution is a continuous probability (CPr) model for nonnegative-valued random variables (RVs). The HLo model is a random distribution reported by folding at zero the logistic (Lo) distribution centered around the origin. Due to the flexibility of the HLo model, several authors aimed to propose and study many extensions and generalizations for this model with its applications in various fields, for instance, Balakrishnan [
1], Balakrishnan and Wong [
2], Torabi and Bagheri [
3], Olapade [
4,
5,
6], Kantam et al. [
7], Jose and Manoharan [
8], Krishnarani [
9], Oliveira et al. [
10], Usman et al. [
11], Cordeiro et al. [
12], Muhammad and Liu [
13], Samuel and Kehinde [
14], Xavier and Jose [
15], Eliwa et al. [
16] and El-Morshedy et al. [
17], among others. Among all these generalizations, we take in our consideration the HLo model with two parameters (see Hashempour, [
18]). An RV
X is said to have the continuous two-parameter half-logistic (HLo-II) distribution if its cumulative distribution function (CDF) is given as
where
and
.
In several cases, lifetimes need to be recorded on a discrete scale rather than on a continuous analogue. Thus, discretizing CPr distributions has received noticeable attention in recent years. See, for example, Pillai and Jayakumar [
19], Kemp [
20], Roy [
21], Johnson et al. [
22], Jazi et al. [
23], Nekoukhou et al. [
24], Bakouch et al. [
25], Almalki and Nadarajah [
26], Chakraborty and Chakravarty [
27], Shanker and Fesshaye [
28], Inusah and Kozubowski [
29], Barbiero and Hitaj [
30], Eliwa et al. [
31,
32], Nezampour and Hamedani [
33], El-Morshedy et al. [
34,
35,
36] and Eliwa and El-Morshedy [
37], among others. Although there are a number of discrete models in the statistical literature, there is still a lot of space left to build a new discretized model that is proper under various conditions. In this article, we propose and study the discrete analogue of the HLo-II (DHLo-II) model. Some characteristics of the proposed distribution can be summarized as follows: its CDF and probability mass function (PMF) can be expressed as closed-forms; its hazard rate function (HRF) can be bathtub-, increasing- and decreasing-shaped; it can be utilized for modelling equi- and over-dispersion phenomena; and it provides the best fit for various types of data in several fields in spite of having only two parameters, especially for over-dispersion data.
The article is organized as follows. In
Section 2, we introduce the DHLo-II model based on the survival discretization approach; for more detail around this technique see Roy and Ghosh [
38] and Chakraborti et al. [
39]. Different statistical properties are discussed in
Section 3. In
Section 4, the model parameters are estimated by using the maximum likelihood method. A simulation study is presented in
Section 5. Two distinctive data sets are analyzed to show the flexibility of the DHLo-II distribution in
Section 6. Finally,
Section 7 provides some conclusions.
2. Synthesis of the DHLo-II Model
In this Section, the new discrete model can be generated by utilizing the survival discretization technique. Thus, the CDF of the DHLo-II distribution can be expressed as
where
,
and
. The corresponding PMF to Equation (
2) can be listed as
Using generalized binomial expansion, Equation (
3) can be proposed as a mixture representation of geometric (Geo) model as follows
where
and
denote the PMF of Geo distribution with parameter
. The HRF can be expressed as
where
.
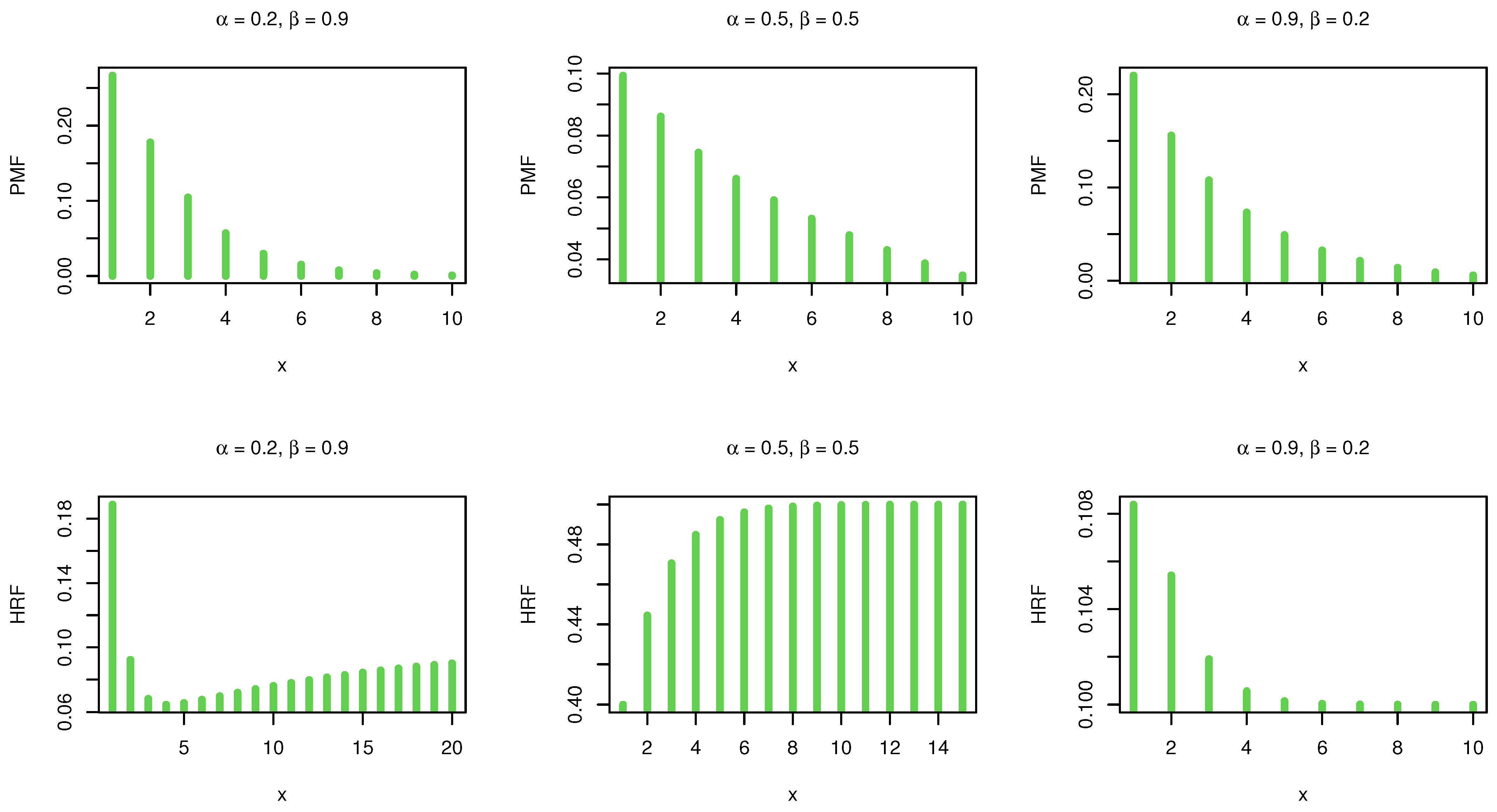
Figure 1 shows the PMF and HRF plots for various values of the DHLo-II parameters.
It is noted that the shape of the PMF is always unimodal. Further, the DHLo-II distribution can be used to model asymmetric data. Regarding the HRF, it is found that the proposed model has several shapes including bathtub, increasing and decreasing, which means this model can be utilized to analyze various types of data in different fields, especially in medicine, insurance and engineering.
3. Statistical Properties
3.1. Moments and Generating Functions
Assume
X to be a DHLo-II RV, then the probability generating the function (PrGF) can be listed as
Onreplacing
s by
in Equation (
6), the moment generating function (MGF) can be derived. Thus, the first moment of the DHLo-II distribution is
Similarly, the other moments can be derived. Based on the MGF, the mean, variance, index of dispersion (IOD), skewness and kurtosis can be listed in
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 as numerical computations (NuCo).
From
Table 1,
Table 2,
Table 3,
Table 4 and
Table 5 it is clear that: the mean, variance and IOD increase for constant values of
with
; the proposed model is appropriate only for modelling equi- and over-dispersed data, because the IOD always is greater than or equal one; and this distribution is capable of modeling positively skewed and leptokurtic data sets.
3.2. Conditional Moments
This section lists results of the conditional moments (CoMos) for the DHLo-II distribution. The CoMos can be utilized to derive the mean deviations, Bonferroni and Lorenz curves. The
CoMo of the DHLo-II model under
and
can be expressed as
and
respectively. The mean residual life function is given by
, where
is referred to as the vitality function of the distribution function
F.
3.3. Stress-Strength Analysis
Stress-strength analysis has been utilized in mechanical component design. Let
DHLo-II
and
DHLo-II
be two independent RVs, then
It is noted that the value of stress-strength depends on the model parameters only.
3.4. Residual Entropy and Cumulative Residual Entropy
Residual entropy (RE) and cumulative residual entropy (CRE) are two important measures of information theory. The RE of the RV
X is given by
whereas the CRE can be listed as
where
represents the survival function of the distribution. The previous two equations can be derived by using geometric expansion and generalized binomial expansion (simple algebra).
3.5. Order Statistics
Order statistics (OrSt) play an important role in different fields of statistical theory. Suppose
,
to be a random sample (RS) from the DHLo-II, and let
,…,
be their corresponding OrSt. Then, the CDF of the
ith OrSt
for an integer value of
x is proposed as
where
The PMF of the
ith OrSt can be formulated as
where
. The
moments of
can be proposed as
Based on Equation (
14), L-moments can be listed as
which can be utilized to discuss some descriptive statistics.
4. Maximum Likelihood Estimation (MLE)
In this section, we determine the MLE of the DHLo-II parameters according to a complete sample. Assume
to be an RS of size
n from the DHLo-II distribution. The log-likelihood function (
L) can be listed as follows
To estimate the model parameters and , the first partial derivatives and should be obtained, and then equating the resulted equations to zero “normal equations”. These two equations cannot be solved analytically. Thus, an iterative procedure such as Newton–Raphson is required to solve it numerically.
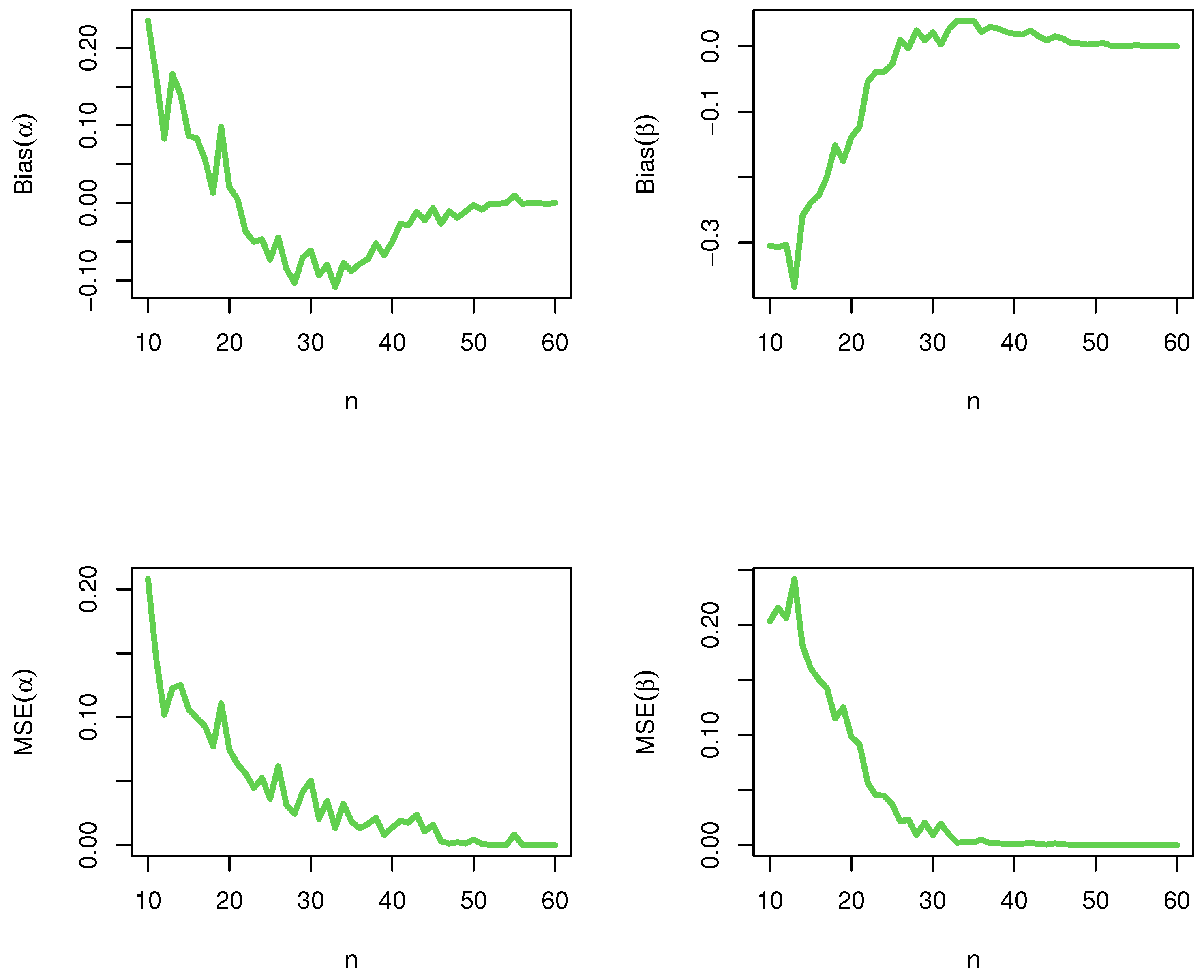
5. Simulation
In this section, we assess the performance of the maximum likelihood estimators (MLEs) with respect to sample size
n using
R software. The assessment is based on a simulation study: generate 10,000 samples of size
from DHLo-II
and DHLo-II
, respectively; compute the MLEs for the 10,000 samples, say
for
; and compute the biases and mean-squared errors (MSEs), where bias
and MSE
. The empirical results are given in
Figure 2 and
Figure 3, respectively.
From
Figure 2 and
Figure 3, it is noted that the magnitude of bias and MSE always decrease to zero as
n grows. This shows the consistency of the MLEs. We can say that the maximum likelihood approach works quite well in estimating the model parameters, and consequently, it can be used effectively for analyzing the count data.
6. Applications
In this section, we illustrate the importance and the flexibility of the DHLo-II distribution by utilizing data from different fields. We shall compare the fits of the DHLo-II distribution with some competitive models such as discrete inverse Weibull (DIW), discrete gamma Lindley (DGL), discrete Burr II (DB-II), discrete log-logistic (DLL), discrete inverse Rayleigh (DIR), discrete Burr-Hatke (DBH), discrete Lindley and discrete Pareto (DP). The fitted models are compared using some criteria, namely, the maximized log-likelihood (L), Akaike information criterion (Aic) and its corrected (Caic), Hannan–Quinn information criterion (Hqic), Bayesian information criterion (Bic), and Chi-square (Chi) test with its corresponding P-value (Pv).
6.1. Data set I: COVID-19 in Armenia
The data are listed in (
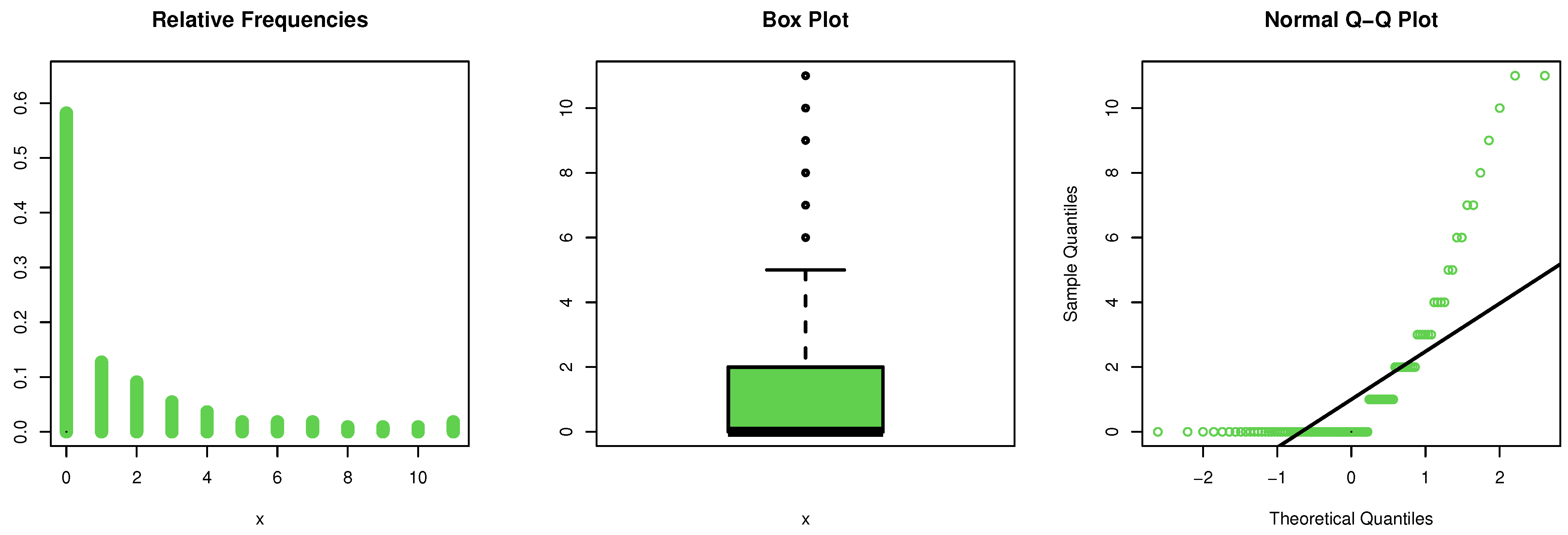
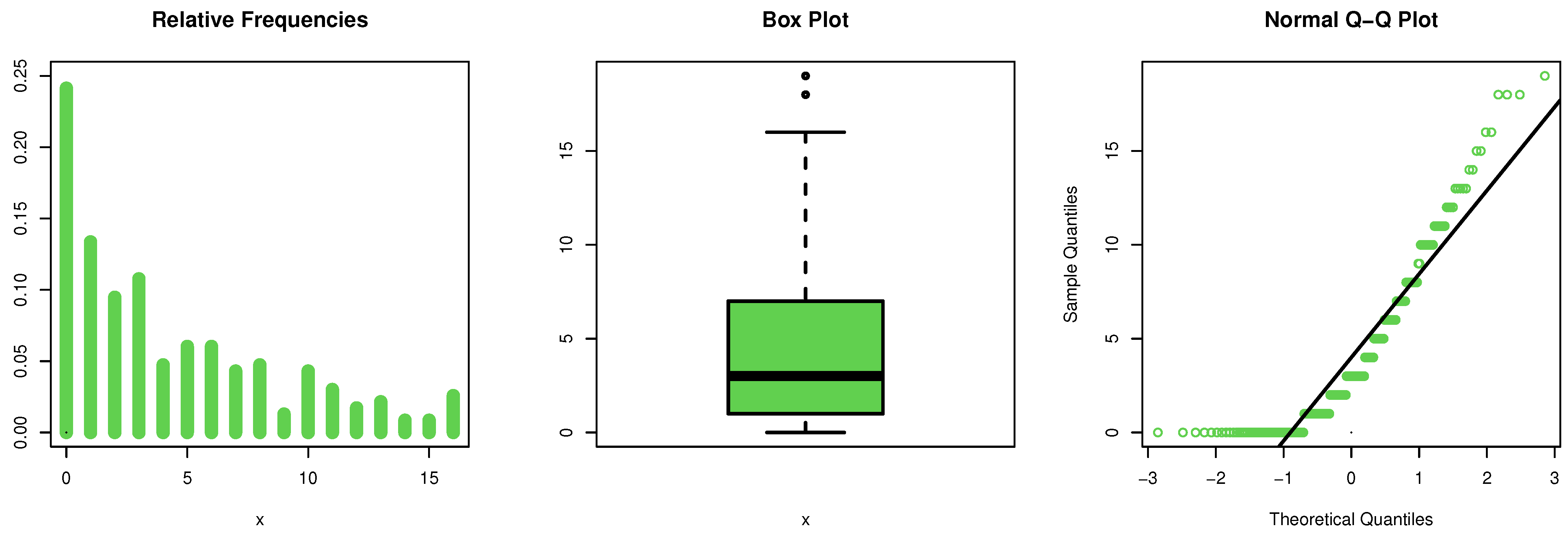
https://www.worldometers.info/coronavirus/country/armenia/, accessed on 20 July 2021) and represent the daily new deaths in Armenia for COVID-19 from 15 February to 4 October 2020. The initial mass shape for these data are explored utilizing the nonparametric kernel mass estimation (Kme) technique in
Figure 4, and it is observed that the mass is asymmetric function. The normality condition (Nc) is checked by the quantile-quantile (Qu-Qu) plot in
Figure 4. The extreme observations (ExOb) are spotted from the box plot in
Figure 4, and it is observed that some ExOb were listed.
The MLEs with their corresponding standard errors (Se), confidence intervals (CI) for the parameter(s) and goodness of fit tests for data set I are listed in
Table 6 and
Table 7.
The abbreviations “Of” and “Df” represent the observed frequency and degree of freedom, respectively. From
Table 7, it is noted that the DGL distribution works quite well in addition to the DHLo-II distribution. However, the DHLo-II model is the best among all tested distributions.
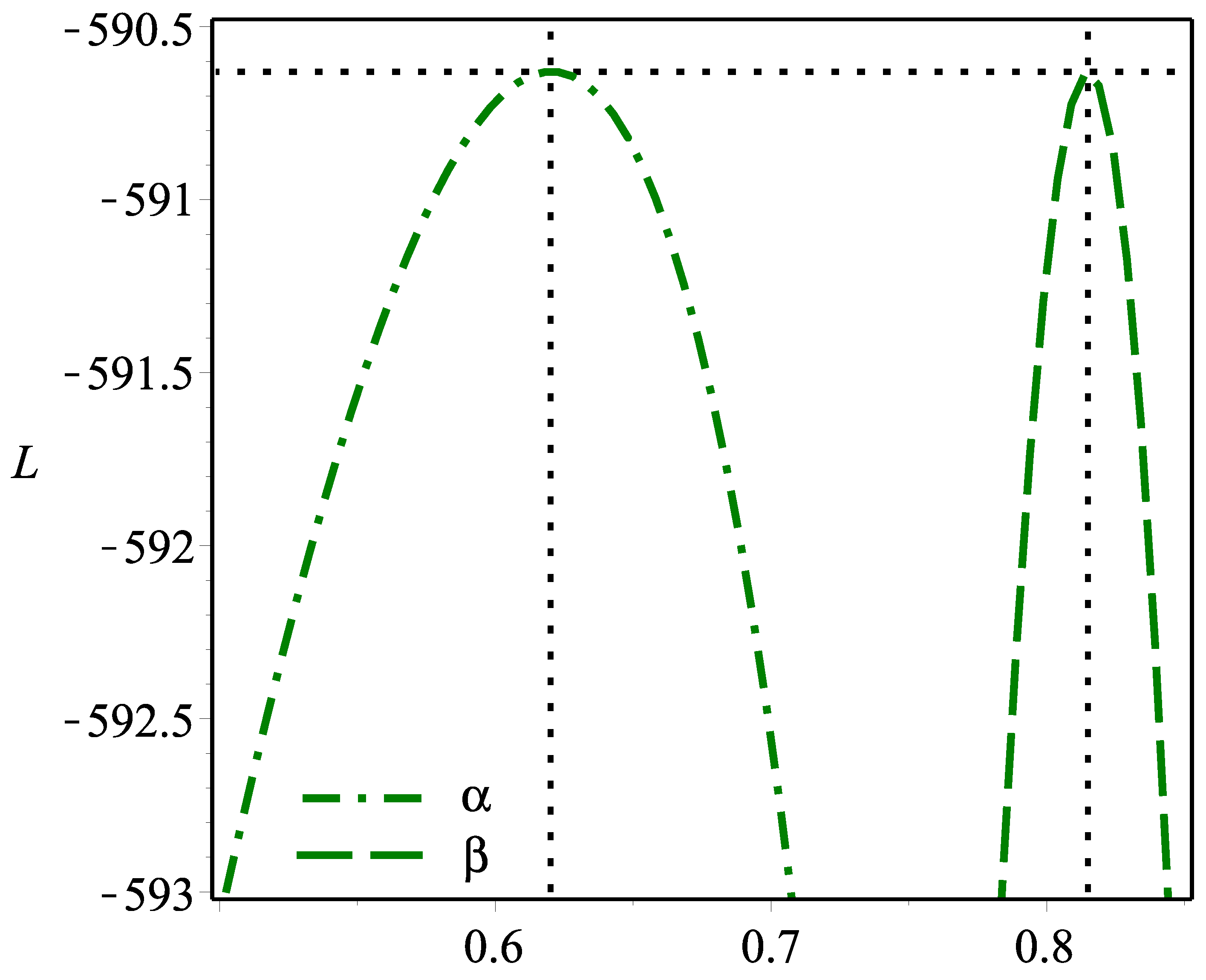
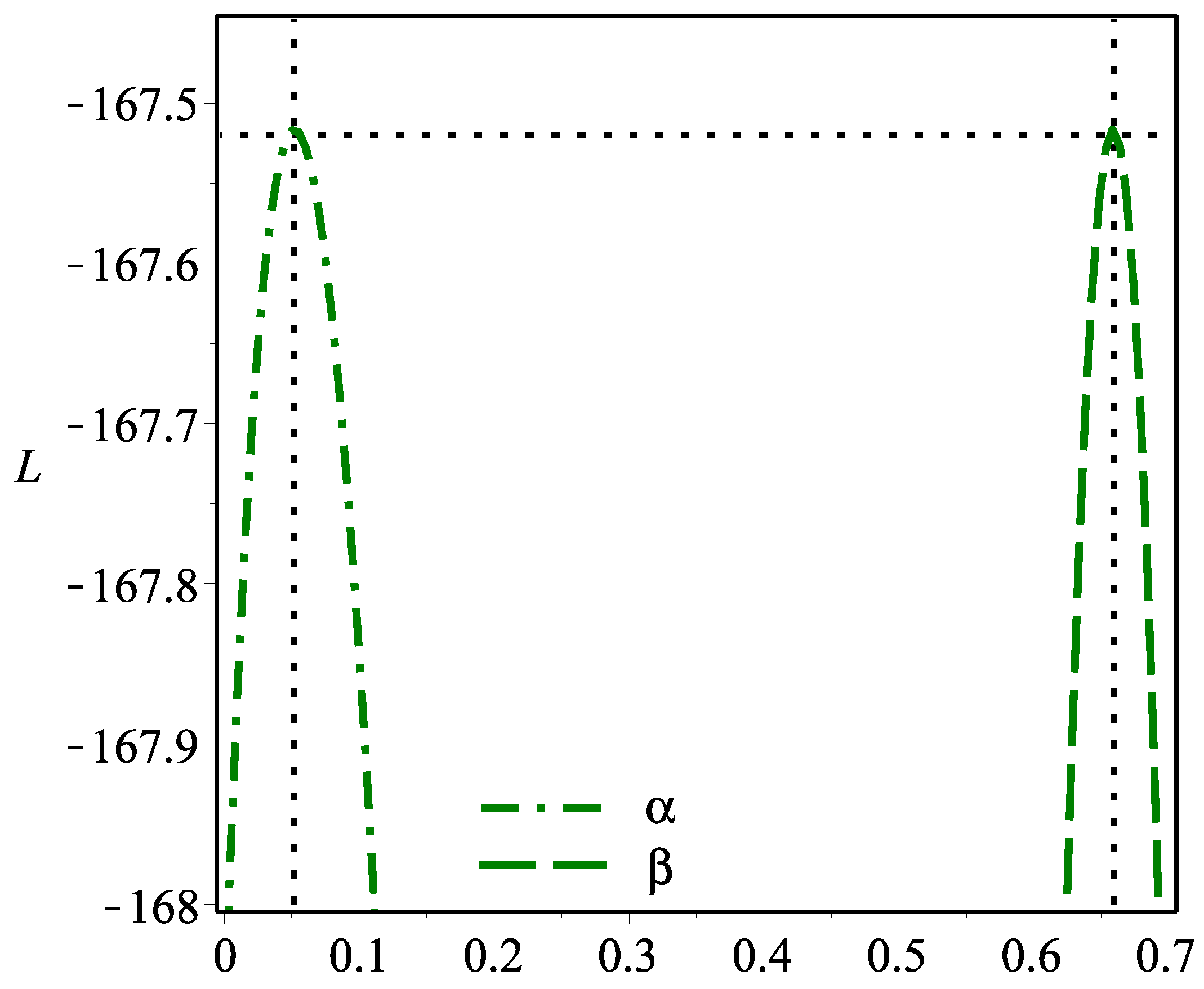
Figure 5 shows that the MLEs are unique because the
L profiles have only unimodal shapes.
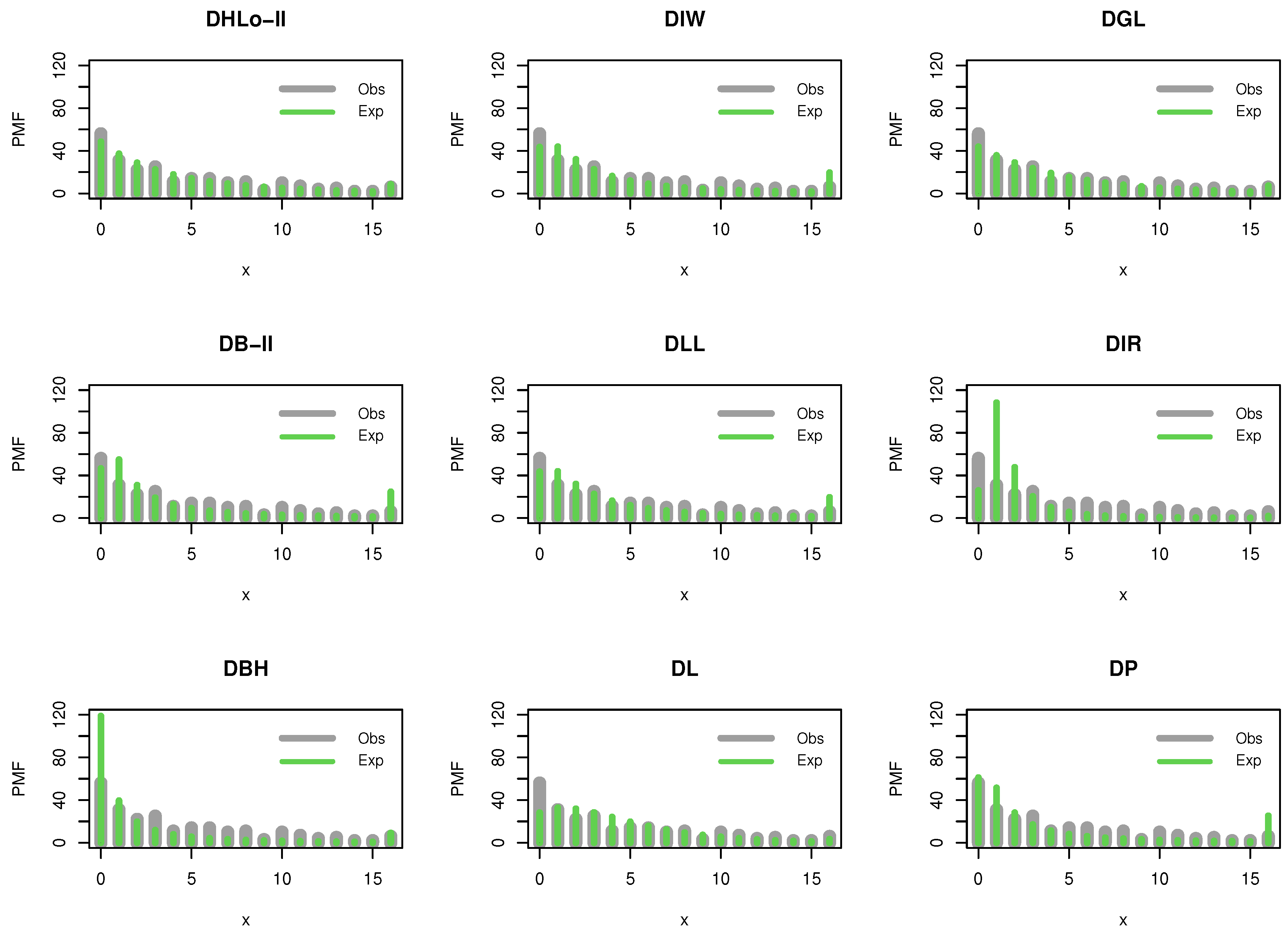
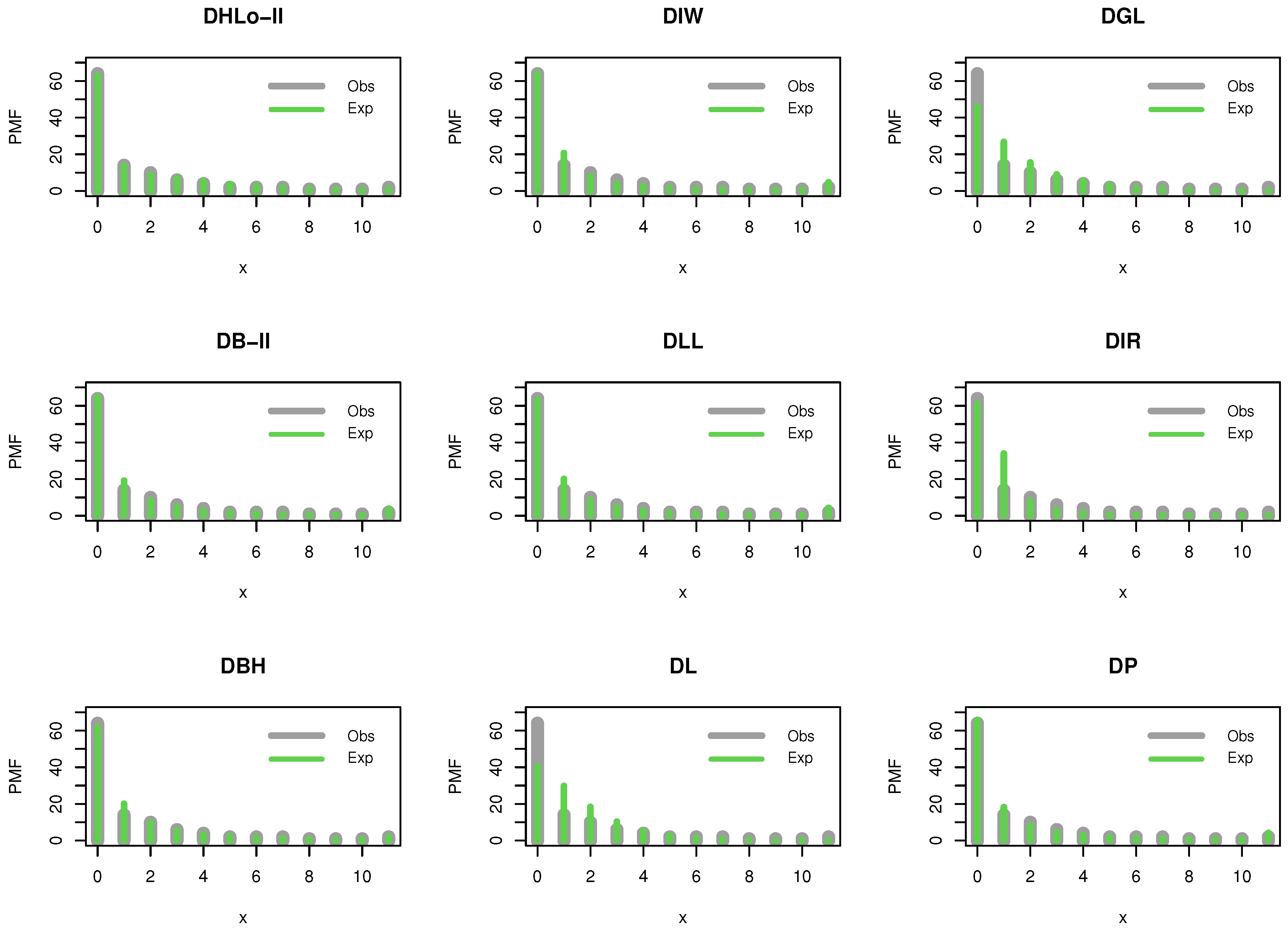
Figure 6 supports our empirical results where the DHLo-II is more fit to analyze these data, whereas
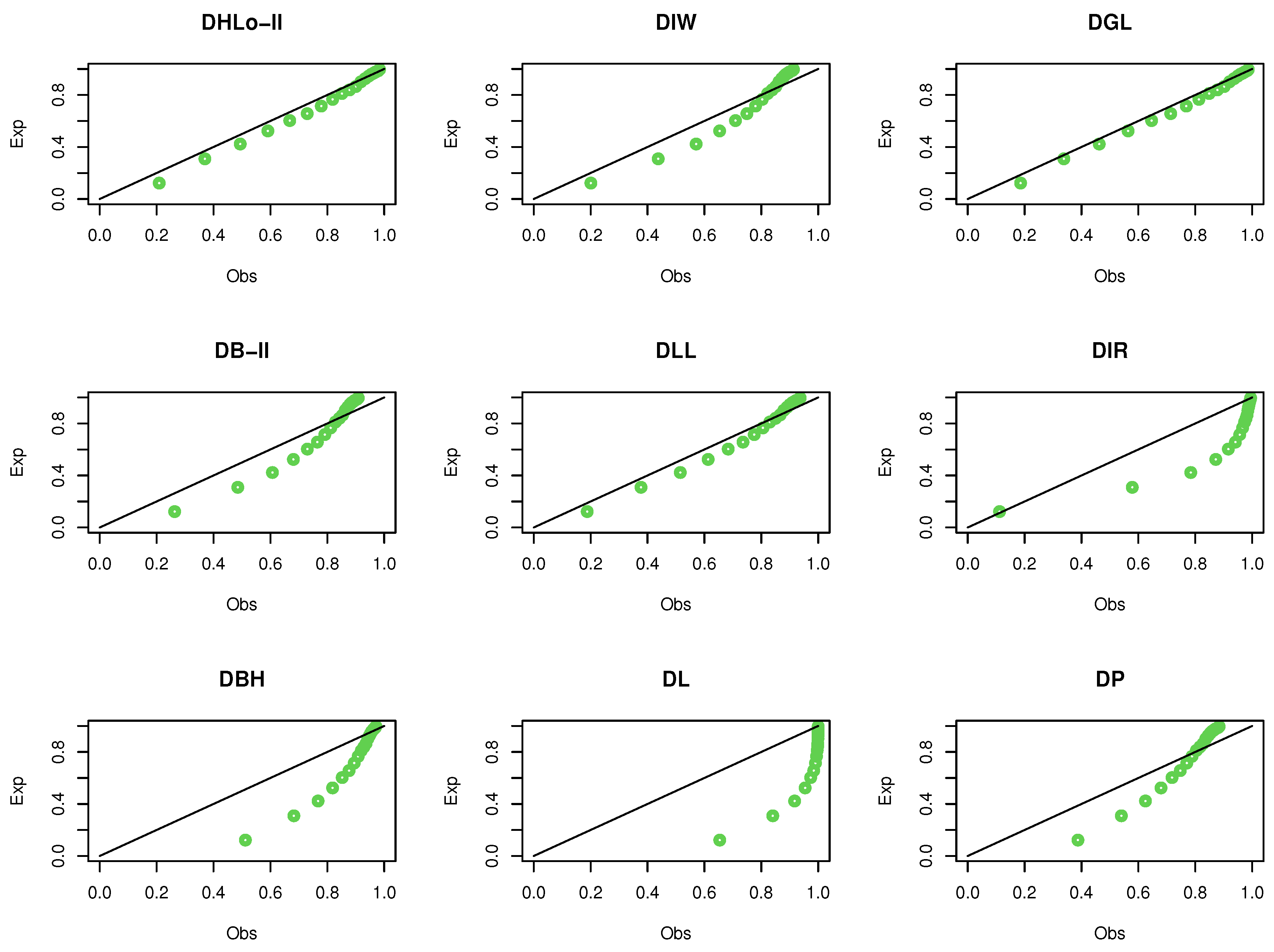
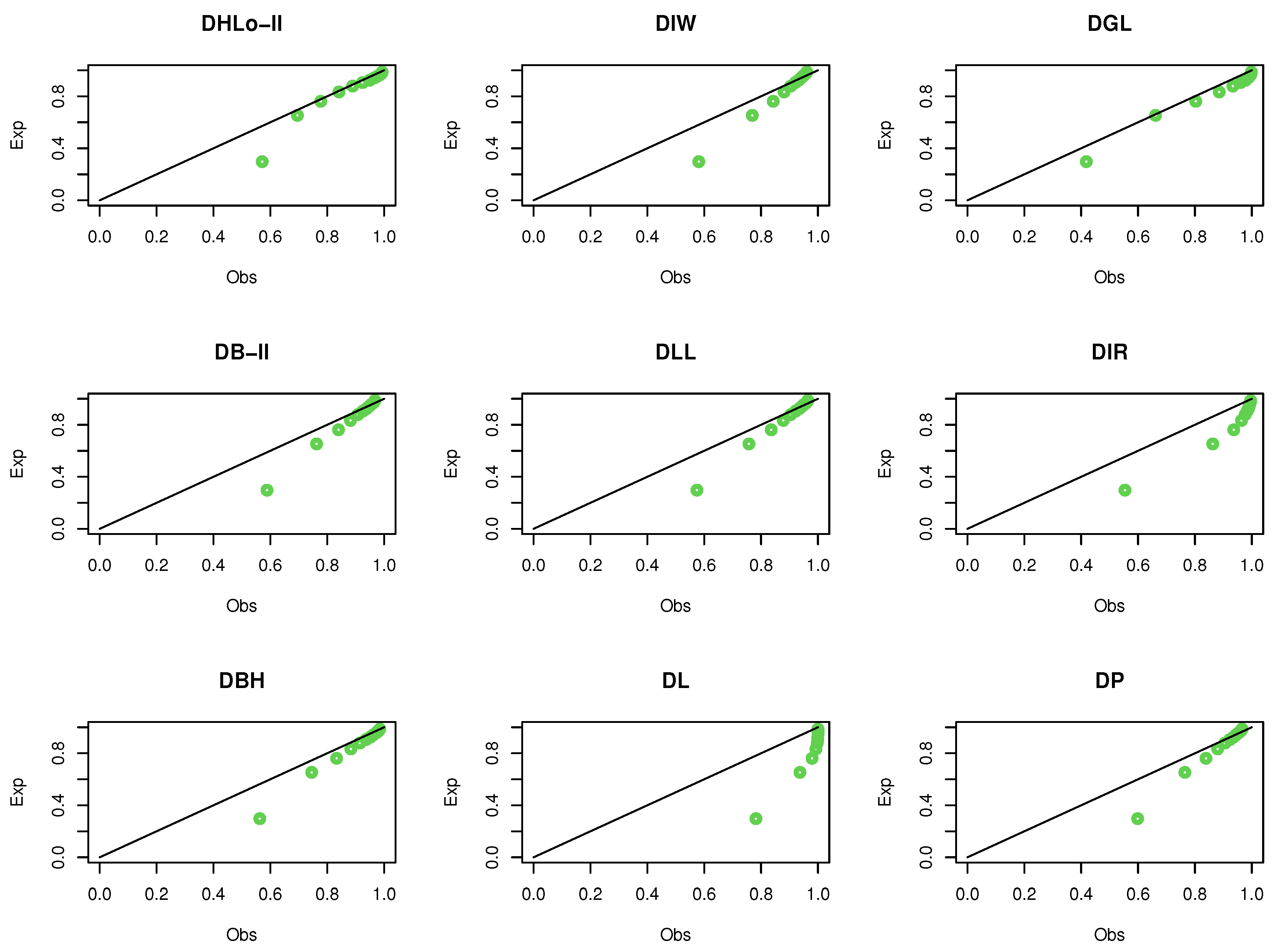
Figure 7 shows the probability–probability (Pr–Pr) plot for data set I, which proves that the data set plausibly came from the DHLo-II distribution.
According to the MLEs, the empirical descriptive statistics (EDS) for mean, variance, IOD, skewness and kurtosis are , , , and , respectively. The data exhibit over-dispersion. Moreover, they are moderately skewed to the right and leptokurtic.
6.2. Data Set II: Kidney Dysmorphogenesis
This data set is taken from the study of Chan et al. [
40]. Initial mass shape for the kidney data is explored using the nonparametric Kme approach in
Figure 8, and it is noted that the mass is asymmetric and multimodal functions. The Nc is checked via the Qu-Qu plot in
Figure 8. The ExOb are spotted from the box plot in
Figure 8, and it is noted that some ExOb were reported.
Here, we examine the fitting capability of the DHLo-II distribution with some other competitive distributions. The MLEs, Se and CI for the parameter(s) as well as goodness of fit test for this data are reported in
Table 8 and
Table 9.
It is noted that the DIW, DB-II, DLL, DBH and DP distributions work quite well in addition to the DHLo-II distribution. However, the DHLo-II distribution is the best model among all tested models.
Figure 9 shows that the MLEs are unique.
Figure 10 supports our empirical results where the DHLo-II is more fit to analyze data set II, whereas
Figure 11 shows the Pr–Pr plot for the same data.
According to the MLEs, the EDS for mean, variance, IOD, skewness and kurtosis are , , , and , respectively. The data are over-dispersed, skewed to the right and leptokurtic.
7. Conclusions
In this paper, we proposed a flexible discrete probability model with two parameters, in the so-called discrete half-logistic (DHLo-II) distribution. Various statistical properties of the proposed model have been derived. It was found that the DHLo-II model is convenient for modelling skewed data sets, especially those which have very extreme observations. Furthermore, it can be used as a flexible model to analyze equi- and over-dispersed phenomena, especially in medicine, insurance and engineering fields. More advantages of the proposed model are that it provides a wide variation in the shape of the HRF, including decreasing, increasing and bathtub, and consequently this distribution can be used in modelling various kinds of data. The DHLo-II parameters have been estimated via the MLE approach. A simulation has been performed based on different sample sizes, and it was found that the MLE method works quite effectively in estimating the DHLo-II parameters due to the consistency property. Finally, two distinctive data sets “COVID-19 and kidney dysmorphogenesis” have been analyzed to illustrate the flexibility of the DHLo-II model. In our future work, the bivariate and multivariate extensions will be derived for the DHLo-II distribution with its applications in medicine and engineering fields.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}