
Categorizing Diseases from Leaf Images Using a Hybrid Learning Model

 ,
,  ,
,  ,
,  and
and 
Abstract
:1. Introduction
- Development of a hybrid learning model that uses a blend of image processing techniques for detecting and classifying leaf diseases.
- Performance evaluation of the proposed hybrid learning model.
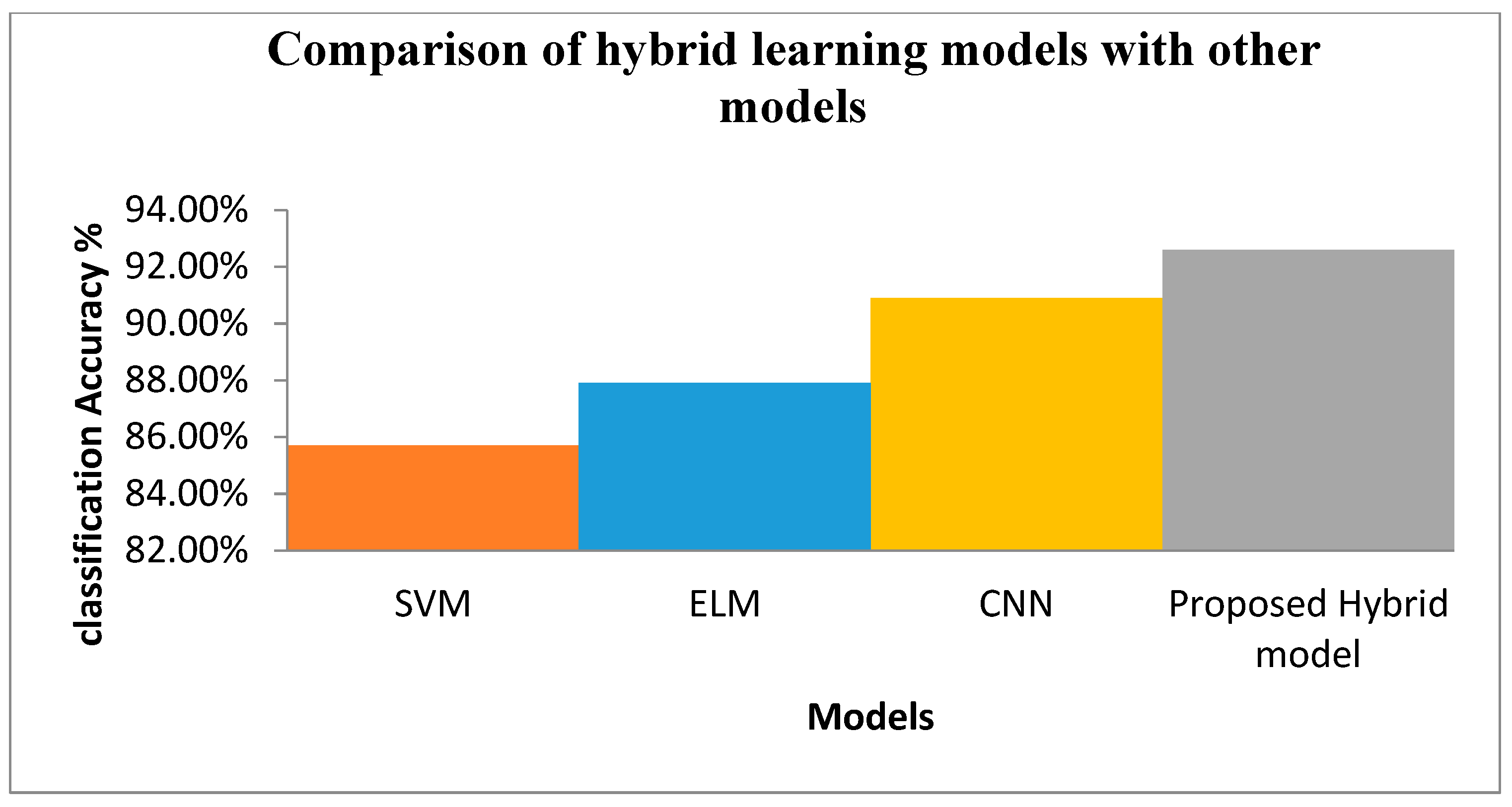
- Comparison of the hybrid model with support vector machine, extreme learning machine-based classification, and CNN.
2. Related Work
3. Methods
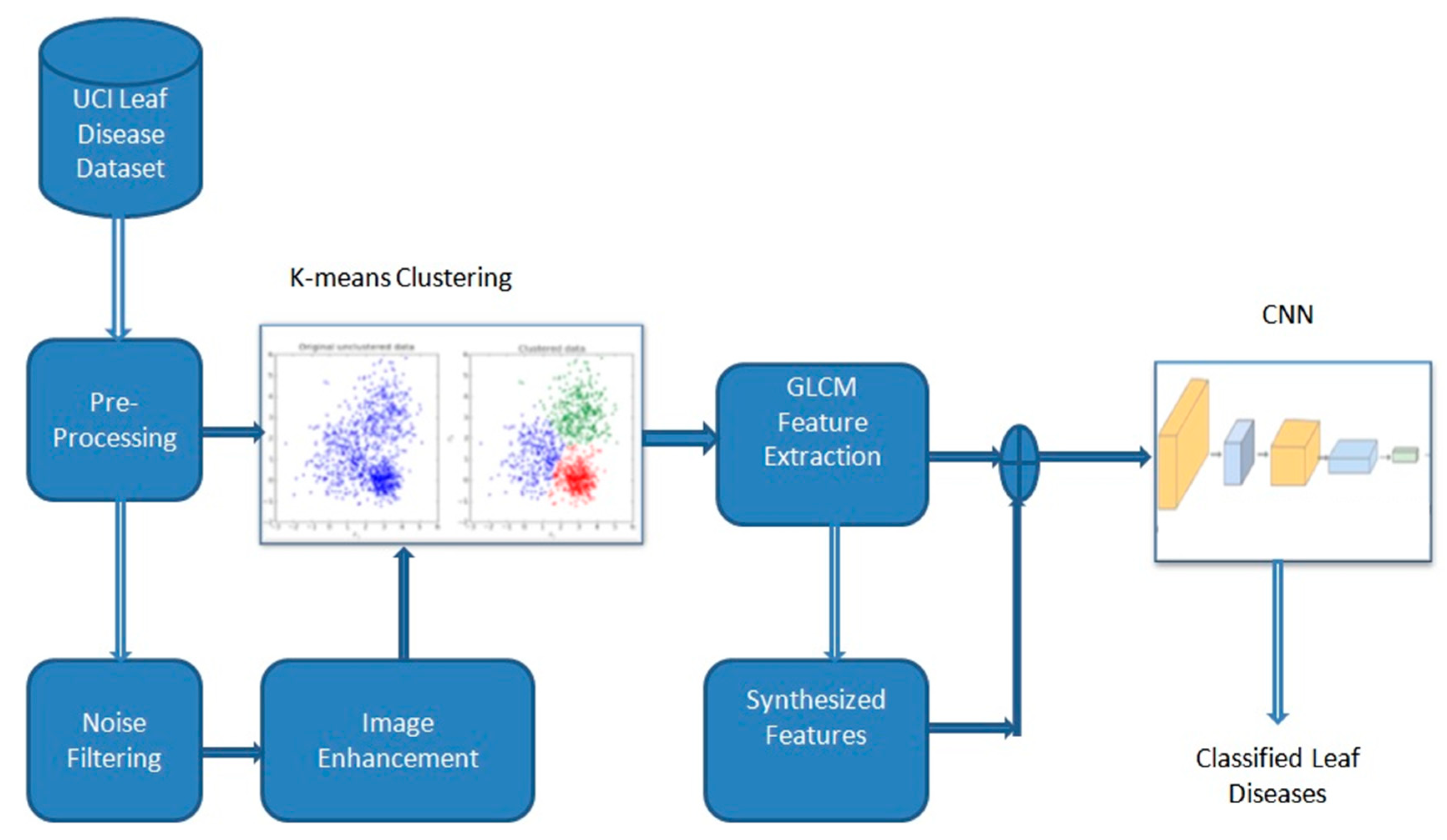
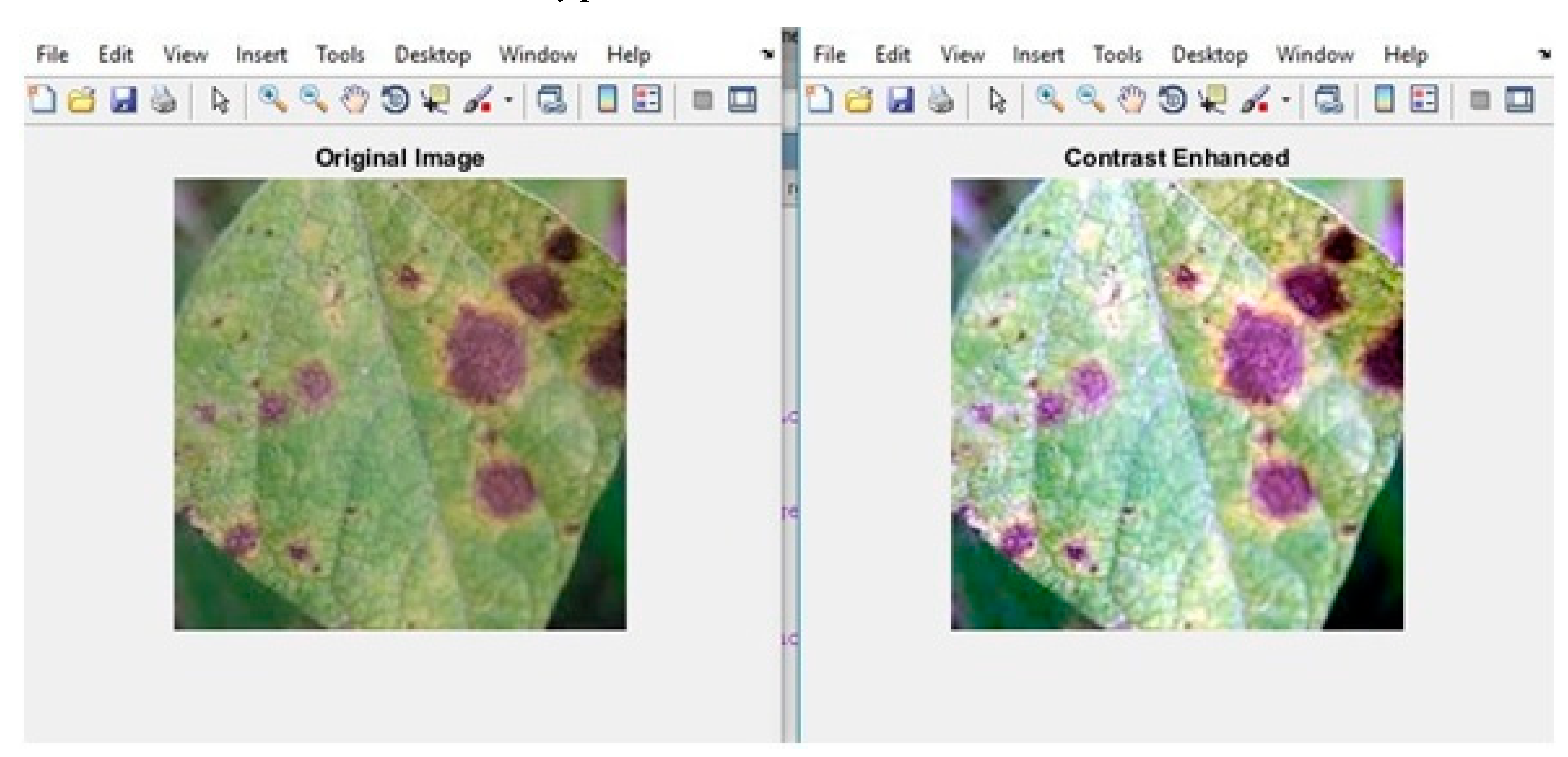
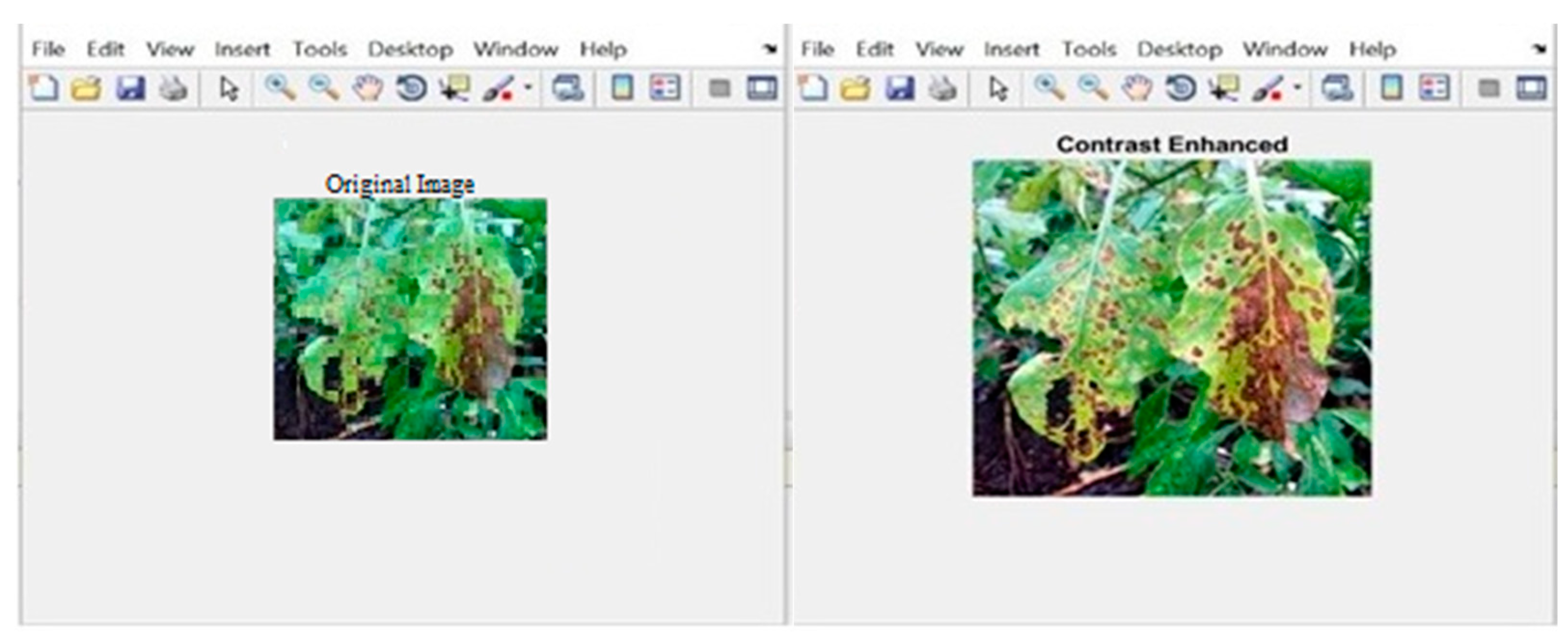
3.1. Hybrid Learning Model for Detecting Leaf Diseases
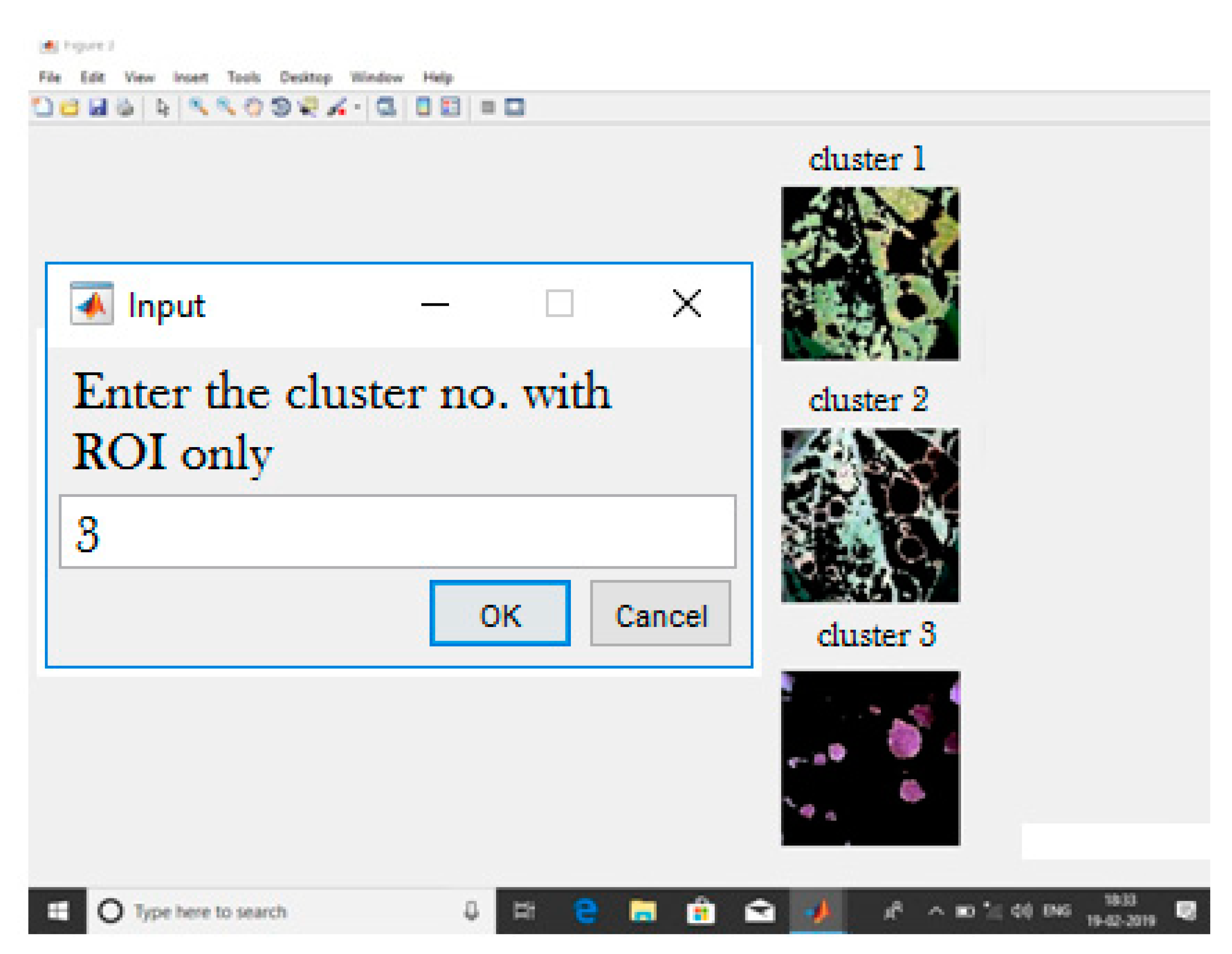
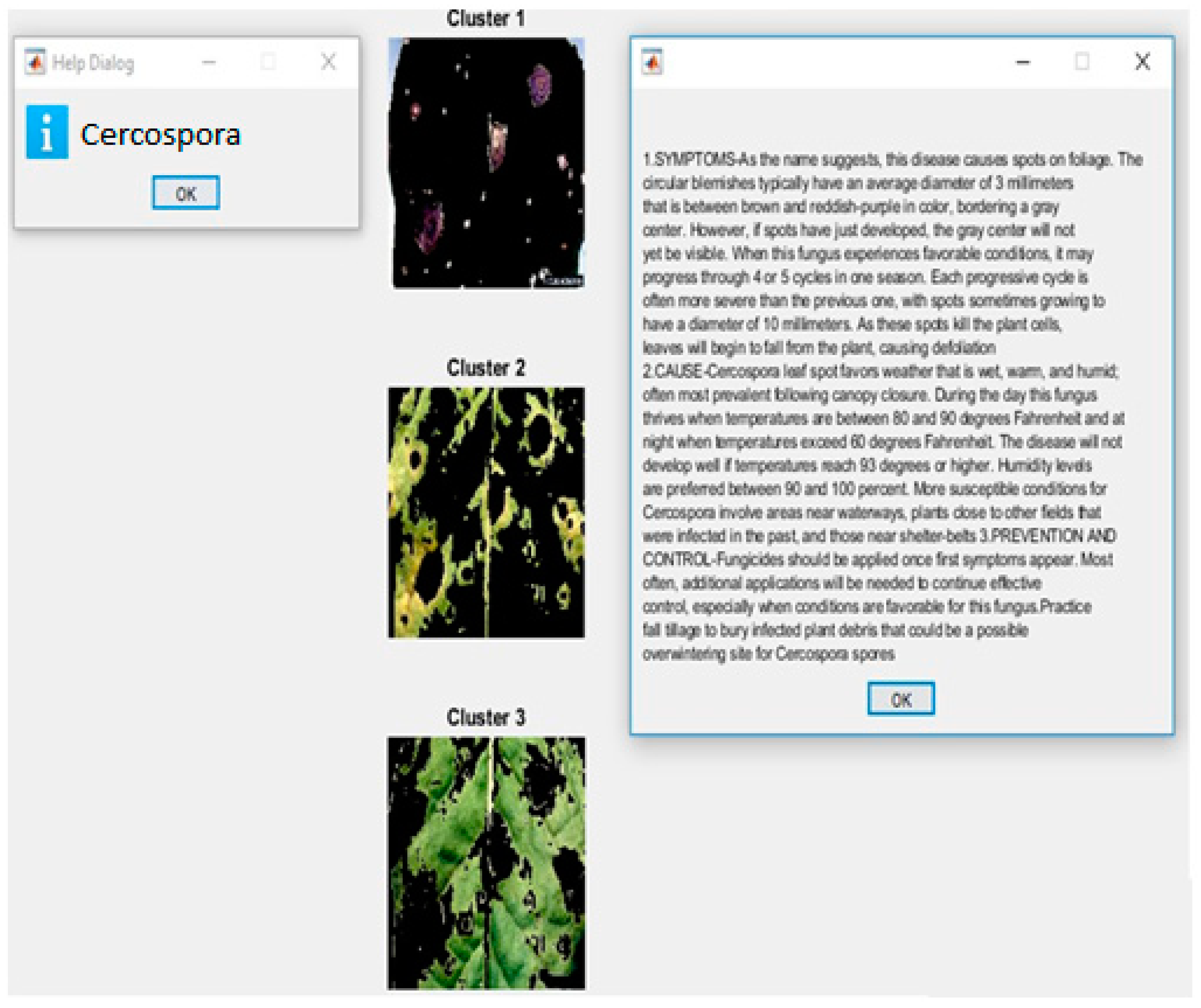
3.2. K-Means Clustering Algorithm for Image Segmentation
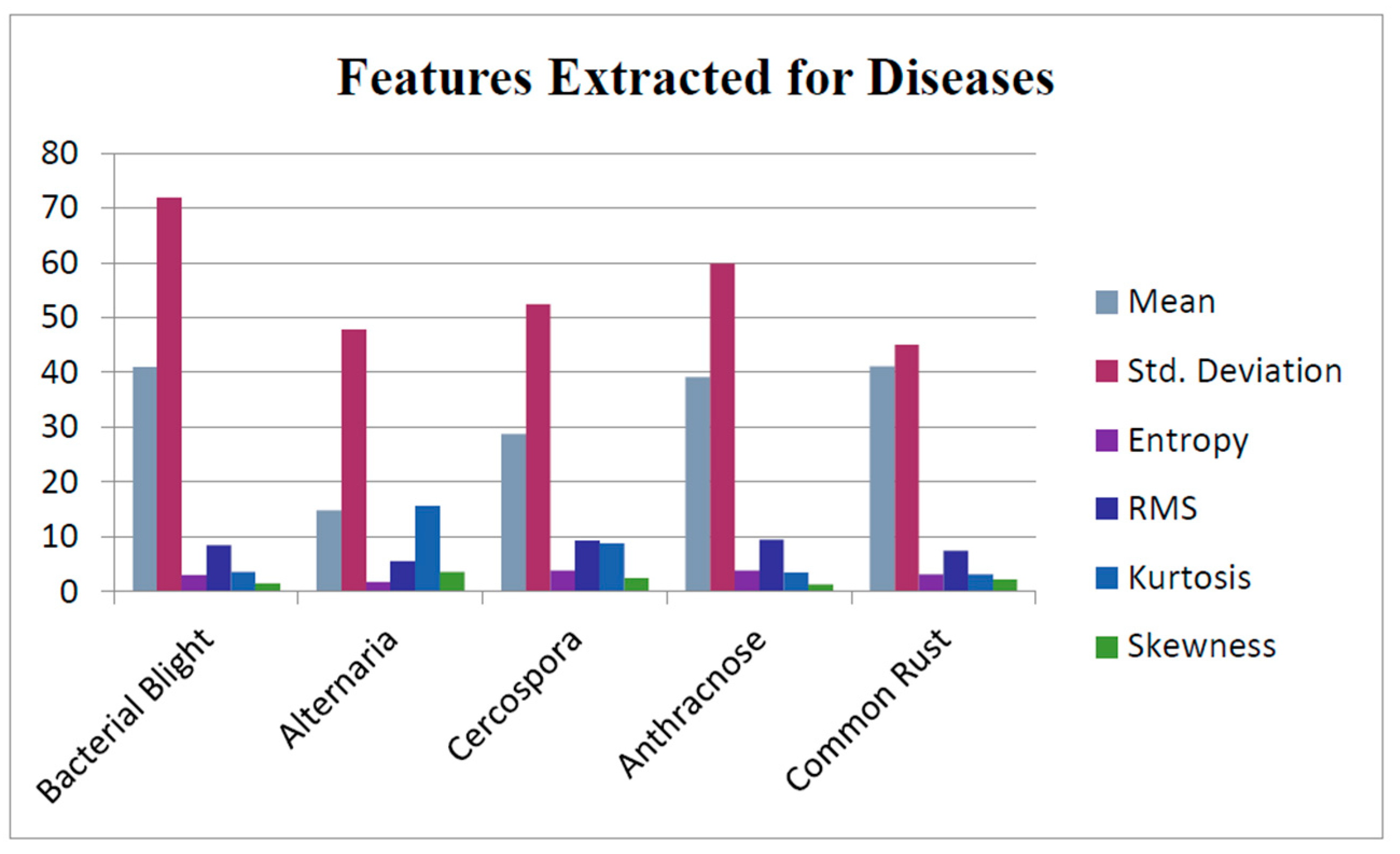
3.3. GLCM Algorithm for Feature Extraction
3.4. Classification of Leaf Diseases
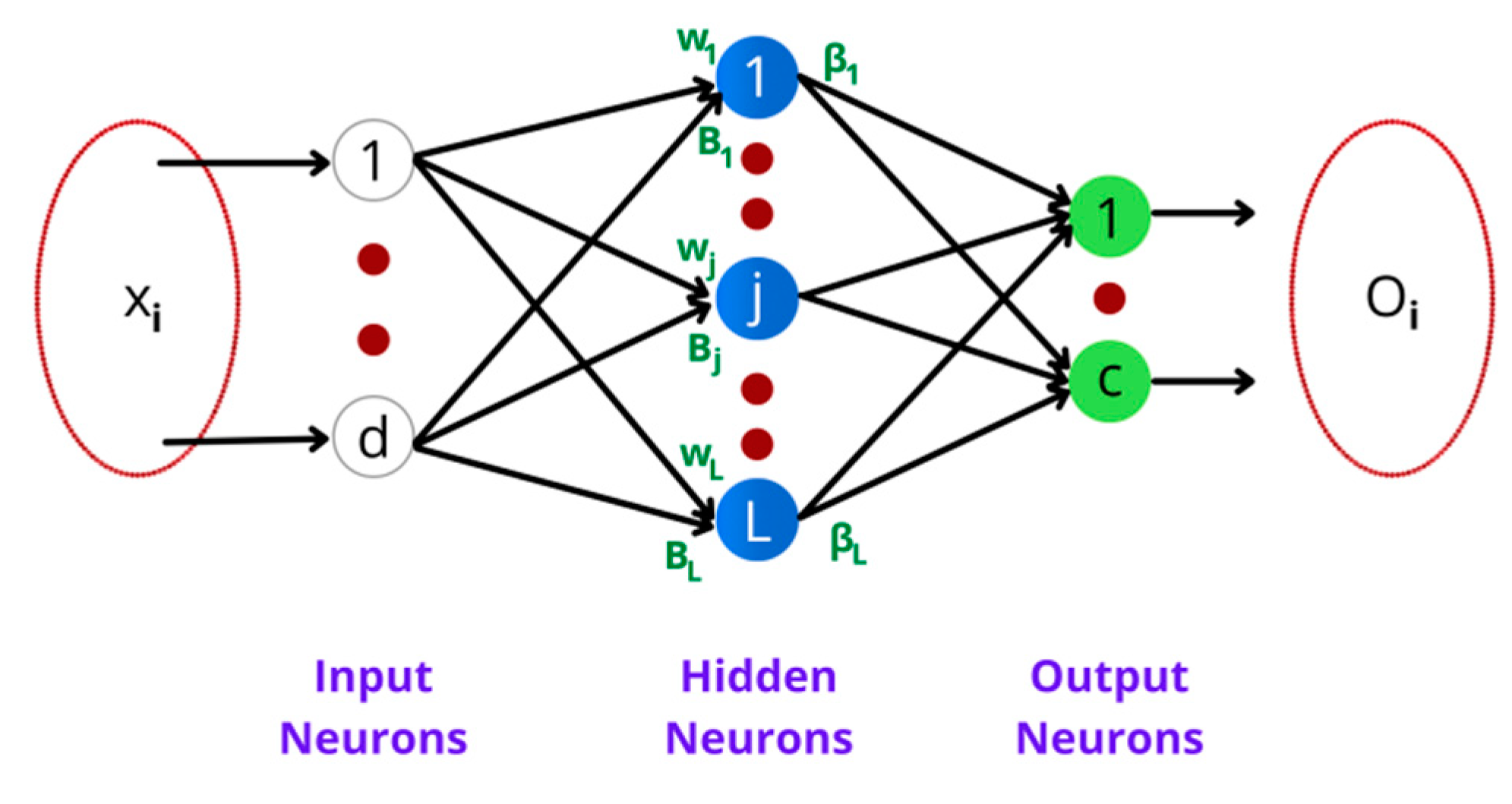
3.4.1. Extreme Learning Machine
3.4.2. Multi-Class SVM
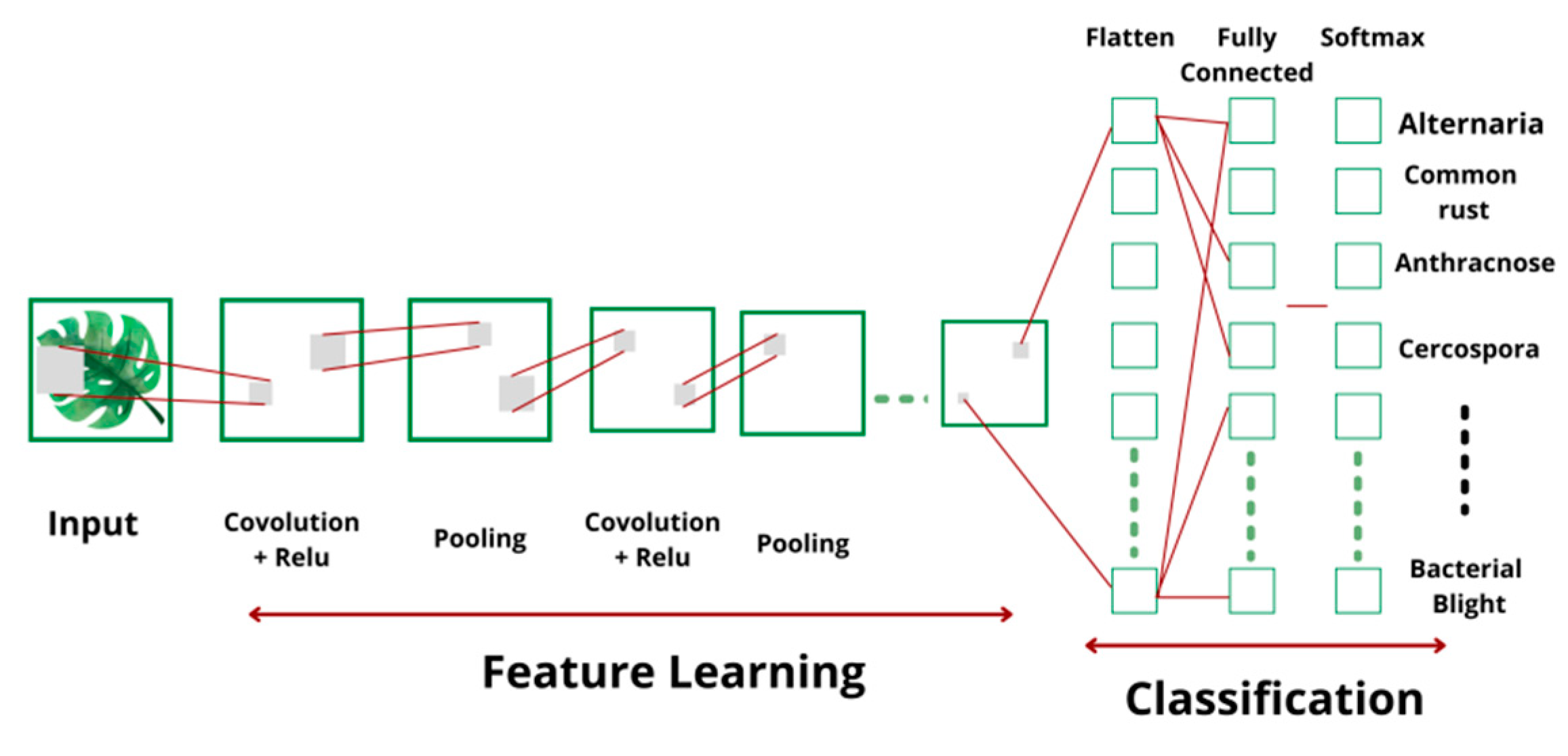
3.4.3. Convolutional Neural Networks
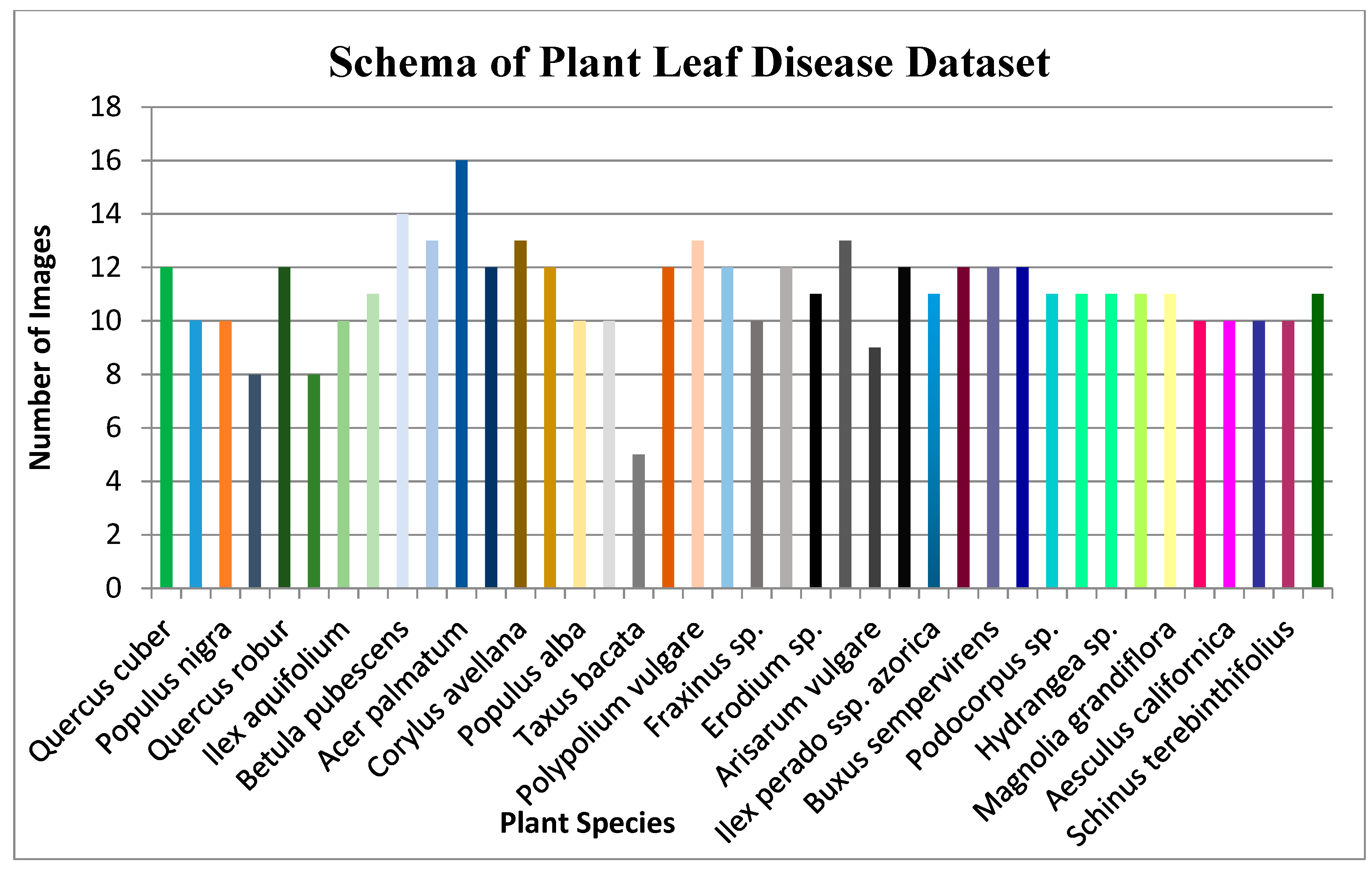
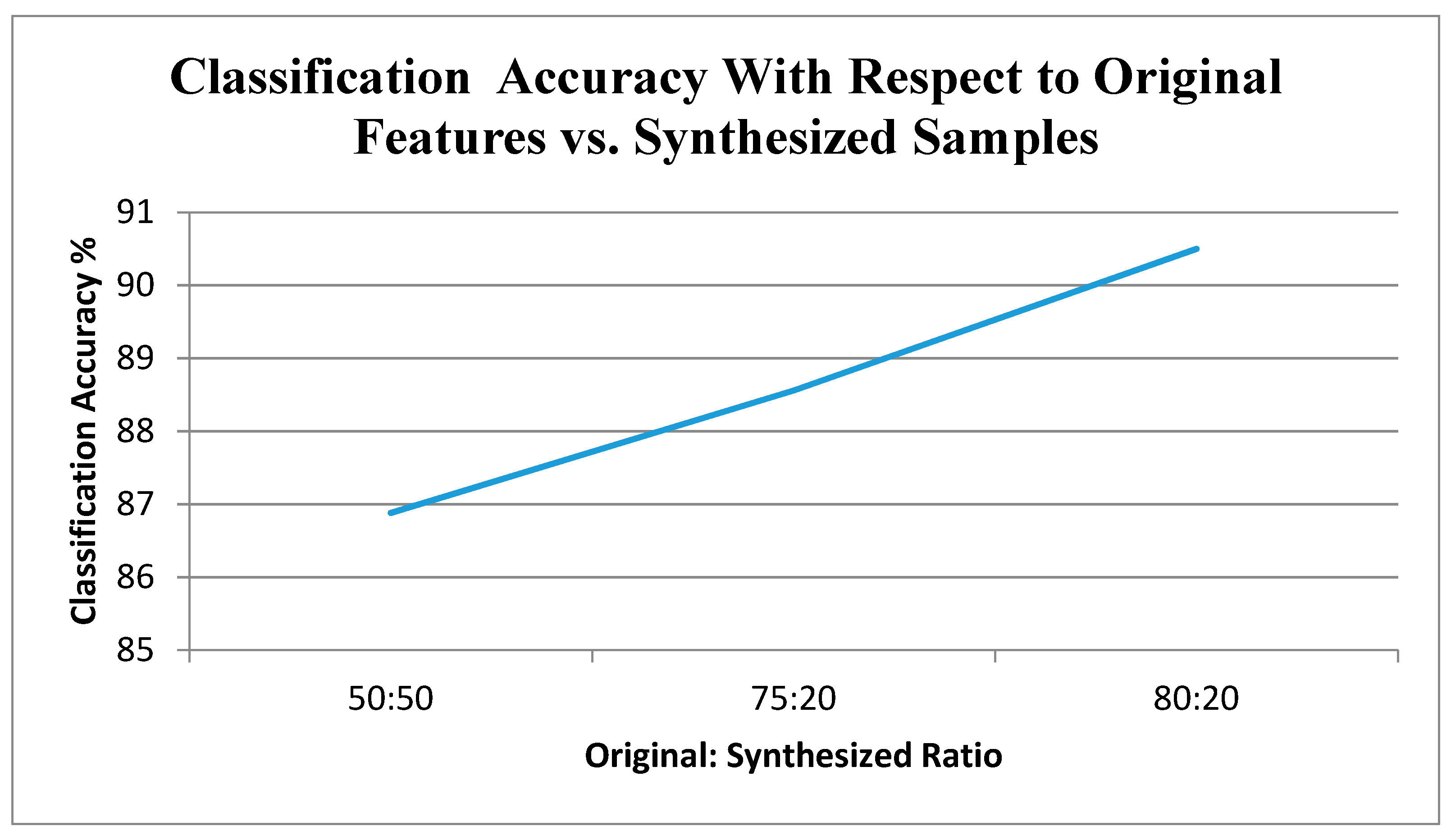
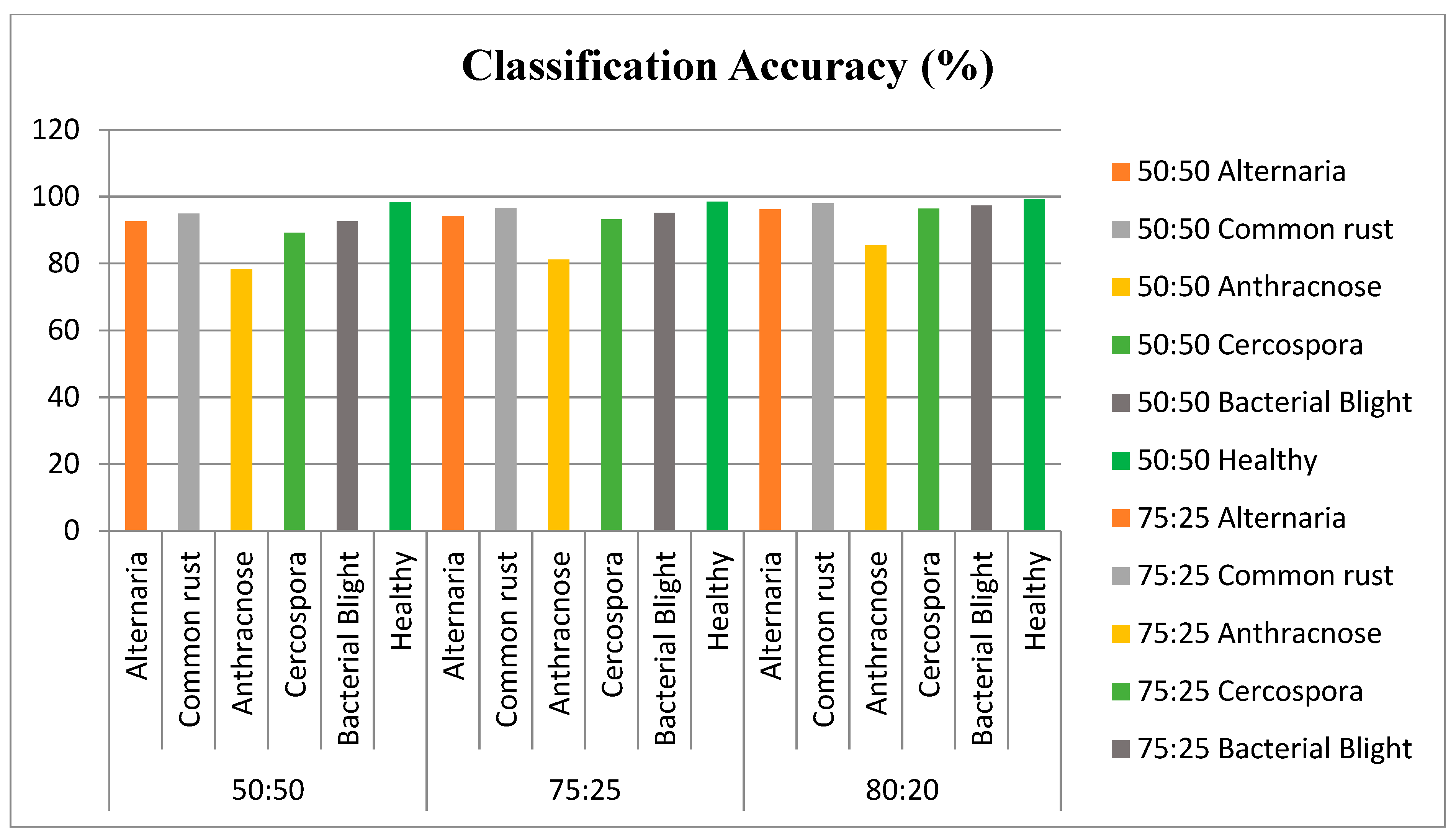
4. Materials and Results
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alsharif, M.H.; Kelechi, A.H.; Yahya, K.; Chaudhry, S.A. Machine learning algorithms for smart data analysis in internet of things environment: Taxonomies and research trends. Symmetry 2020, 12, 88. [Google Scholar] [CrossRef] [Green Version]
- Mainkar, P.M.; Ghorpade, S.; Adawadkar, M. Plant Leaf Disease Detection and Classification Using Image Processing Techniques. Int. J. Innov. Emerg. Res. Eng. 2015, 2, 139–144. [Google Scholar]
- Mitkal, P.; Pawar, P.; Nagane, M.; Bhosale, P.; Padwal, M.; Nagane, P. Leaf Disease Detection and Prevention Using Image processing using Matlab. Int. J. Recent Trends Eng. Res. 2016, 2, 2455–2457. [Google Scholar]
- Landge, P.S.; Patil, S.A.; Khot, D.S. Automatic Detection and Classification of Plant Disease through Image Processing. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 3, 798–801. [Google Scholar]
- Jagtap, S.B.; Hambarde, S.M. Agricultural Plant Leaf Disease Detection and Diagnosis Using Image Processing Based on Morphological Feature Extraction. IOSR J. VLSI Signal Process. 2014, 4, 24–30. [Google Scholar] [CrossRef]
- Naikwadi, S.; Amoda, N. Advances in Image Processing for Detection of Plant Diseases. Int. J. Appl. Innov. Eng. Manag. 2013, 2, 168–175. [Google Scholar]
- Akar, O.; Gungor, O. Integrating multiple texture methods and NDVI to the random forest classification algorithm to detect tea and hazelnut plantation areas in northeast Turkey. Int. J. Remote Sens. 2015, 36, 442–464. [Google Scholar] [CrossRef]
- Halder, M.; Sarkar, A.; Bahar, H. Plant Disease Detection by Image Processing: A Literature Review. SDRP J. Food Sci. Technol. 2019, 3, 534–538. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Golhani, K.; Balasundram, S.K.; Vadamalai, G.; Pradhan, B. A review of neural networks in plant disease detection using hyperspectral data. Inf. Process. Agric. 2018, 5, 354–371. [Google Scholar] [CrossRef]
- Moghimi, A.; Yang, C.; Marchetto, P. Ensemble Feature Selection for Plant Phenotyping: A Journey from Hyperspectral to Multispectral Imaging. IEEE Access 2018, 6, 56870–56884. [Google Scholar] [CrossRef]
- Sharif, M.; Khan, M.A.; Iqbal, Z.; Azam, M.F.; Lali, M.I.U.; Javed, M.Y. Detection and classification of citrus diseases in agriculture based on optimized weighted segmentation and feature selection. Comput. Electron. Agric. 2018, 150, 220–234. [Google Scholar] [CrossRef]
- Gadekallu, T.R.; Rajput, D.S.; Reddy, M.P.K.; Lakshmanna, K.; Bhattacharya, S.; Singh, S.; Jolfaei, A.; Alazab, M. A novel PCA–whale optimization-based deep neural network model for classification of tomato plant diseases using GPU. J. Real Time Image Proc. 2020, 18, 1383–1396. [Google Scholar] [CrossRef]
- Madiwalar, S.C.; Wyawahare, M.V. Plant disease identification: A comparative study. In Proceedings of the 2017 International Conference on Data Management, Analytics and Innovation (ICDMAI), Pune, India, 24–26 February 2017; pp. 13–18. [Google Scholar] [CrossRef]
- Shruthi, U.; Nagaveni, V.; Raghavendra, B.K. A review on machine learning classification techniques for plant disease detection. In Proceedings of the 2019 5th International Conference on Advanced Computing & Communication Systems (ICACCS), Coimbatore, India, 15–16 March 2019; pp. 281–284. [Google Scholar]
- Hlaing, C.S.; Zaw, S.M.M. Plant diseases recognition for smart farming using model-based statistical features. In Proceedings of the 2017 IEEE 6th Global Conference on Consumer Electronics (GCCE), Nagoya, Japan, 24–27 October 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Sankaran, K.S.; Vasudevan, N.; Nagarajan, V. Plant disease detection and recognition using K means clustering. In Proceedings of the 2020 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 28–30 July 2020; pp. 1406–1409. [Google Scholar] [CrossRef]
- Verma, S.; Chug, A.; Singh, A.P. Application of convolutional neural networks for evaluation of disease severity in tomato plant. J. Discret. Math. Sci. Cryptogr. 2020, 23, 273–282. [Google Scholar] [CrossRef]
- Silva, P.F.B.; Marcal, A.; da Silva, R.A. Evaluation of Features for Leaf Discrimination. In Image Analysis and Recognition; ICIAR 2013; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7950, pp. 197–204. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GLCM Properties | ‘S’ | ‘H’ |
|---|---|---|
| Energy | 0.6863 | 0.6949 |
| Homogeneity | 0.9276 | 0.9592 |
| Correlation | 0.7666 | 0.7283 |
| Contrast | 1.7162 | 0.1061 |
| Layer# | Type of Layer | Shape of Output | Parameters |
|---|---|---|---|
| 1 | Conv2d | [−32 224 224] | 896 |
| 2 | ReLU | [−1 32 224 224] | 0 |
| 3 | BatchNorm2d | [−1 32 224 224] | 64 |
| 4 | Conv2d | [−1 32 224 224] | 9248 |
| 5 | ReLU | [−1 32 224 224] | 0 |
| 6 | BatchNorm2d | [−1 32 224 224] | 64 |
| 7 | Maxpool2d | [−1 32 224 224] | 0 |
| 8 | Conv2d | [−1 32 224 224] | 18,496 |
| 9 | ReLU | [−1 32 224 224] | 0 |
| 10 | BatchNorm2d | [−1 32 224 224] | 128 |
| 11 | Conv2d | [−1 32 224 224] | 36,928 |
| 12 | ReLU | [−1 32 224 224] | 0 |
| 13 | BatchNorm2d | [−1 32 224 224] | 128 |
| 14 | Maxpool2d | [−1 64 56 56] | 0 |
| 15 | Conv2d | [−1128 56 56] | 73,856 |
| 16 | ReLU | [−1128 56 56] | 0 |
| 17 | BatchNorm2d | [−1128 56 56] | 256 |
| 18 | Conv2d | [−1128 56 56] | 147,584 |
| 19 | ReLU | [−1128 56 56] | 0 |
| 20 | BatchNorm2d | [−1128 56 56] | 256 |
| 21 | Maxpool2d | [−1128 56 56] | 0 |
| 22 | Conv2d | [−1128 56 56] | 295,168 |
| 23 | ReLU | [−1128 56 56] | 0 |
| 24 | BatchNorm2d | [−1128 56 56] | 512 |
| 25 | Conv2d | [−1128 56 56] | 590,080 |
| 26 | ReLU | [−1128 56 56] | 0 |
| 27 | BatchNorm2d | [−1128 56 56] | 512 |
| 28 | Maxpool2d | [−1128 56 56] | 0 |
| 29 | Dropout | [−1 50716] | 0 |
| 30 | Linear | [−1 1024] | 51,381,248 |
| 31 | ReLU | [−1 1024] | 0 |
| 32 | Dropout | [−1 1024] | 0 |
| 33 | Linear | [−1 39] | 39,975 |
| Total Parameters: 52,595,399 Trainable Parameters: 52,595,399 Non-trainable Parameters: 0 No. of epochs: 25 | |||
| Input size(Mb): 0.62 Forward/Backward pass size: 151.62 Param size (Mb): 200.64 Estimated Total size (Mb): 352.26 | |||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
N., D.; P., L.R.; AR., G.G.; Kannadasan, R.; Alsharif, M.H.; Jahid, A.; Khan, M.A. Categorizing Diseases from Leaf Images Using a Hybrid Learning Model. Symmetry 2021, 13, 2073. https://doi.org/10.3390/sym13112073
N. D, P. LR, AR. GG, Kannadasan R, Alsharif MH, Jahid A, Khan MA. Categorizing Diseases from Leaf Images Using a Hybrid Learning Model. Symmetry. 2021; 13(11):2073. https://doi.org/10.3390/sym13112073
Chicago/Turabian StyleN., Devi, Leela Rani P., Guru Gokul AR., Raju Kannadasan, Mohammed H. Alsharif, Abu Jahid, and Muhammad Asghar Khan. 2021. "Categorizing Diseases from Leaf Images Using a Hybrid Learning Model" Symmetry 13, no. 11: 2073. https://doi.org/10.3390/sym13112073
APA StyleN., D., P., L. R., AR., G. G., Kannadasan, R., Alsharif, M. H., Jahid, A., & Khan, M. A. (2021). Categorizing Diseases from Leaf Images Using a Hybrid Learning Model. Symmetry, 13(11), 2073. https://doi.org/10.3390/sym13112073